
Genome-Wide Identification, Characterization and Expression Analysis of the Chalcone Synthase Family in Maize

Abstract
:1. Introduction
2. Results
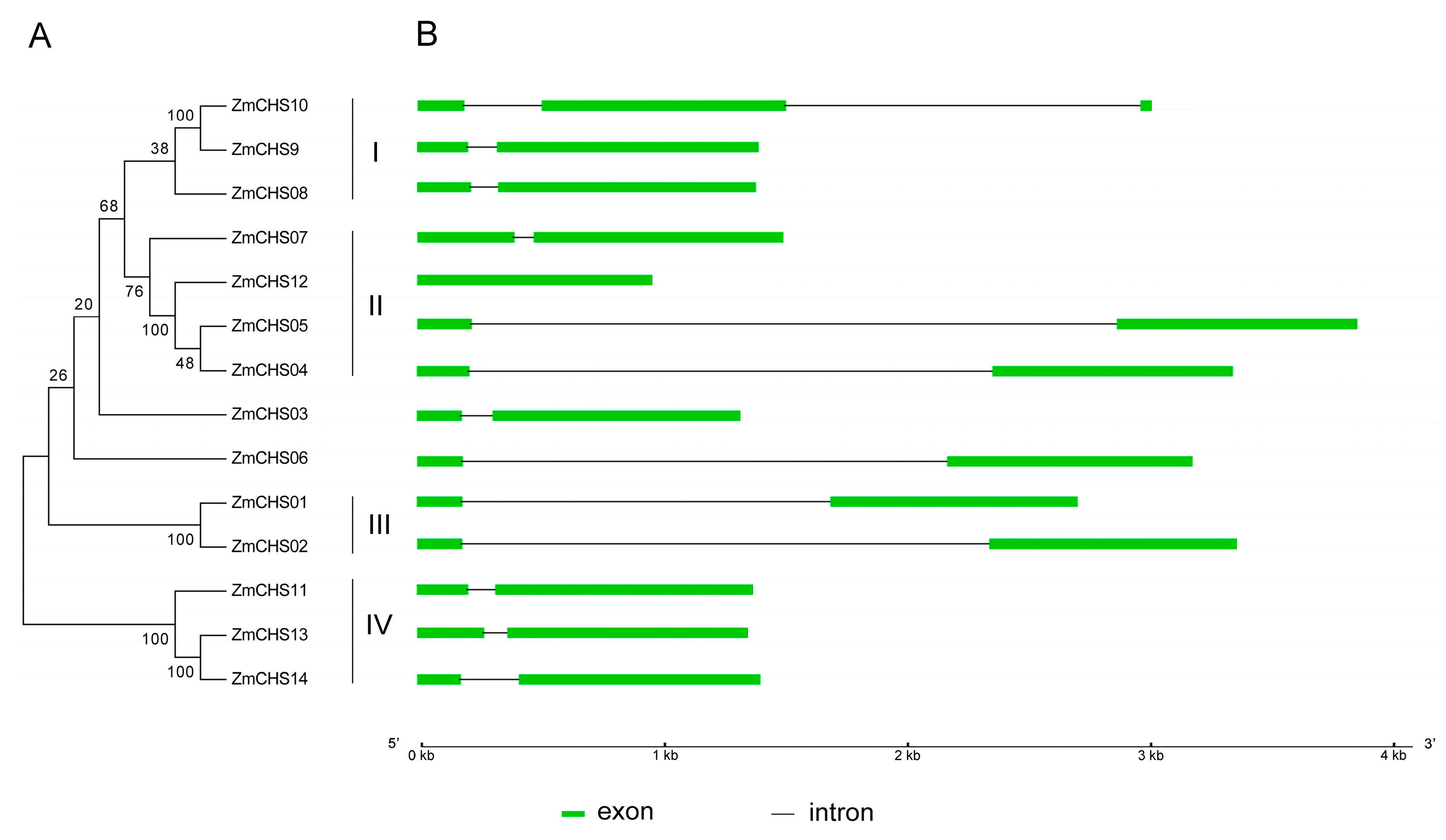
2.1. Identification and Annotation of Chalcone Synthase (CHS) Genes in Maize

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Gene Name | Translation Product | Mw (Da) | Size (aa) | pI | Chromosome |
|---|---|---|---|---|---|---|
| 1 | ZmCHS01 | GRMZM2G422750_P03 | 43195.59 | 400 | 6.33 | 4 |
| 2 | ZmCHS02 | GRMZM2G151227_P01 | 43325.61 | 401 | 6.02 | 2 |
| 3 | ZmCHS03 | GRMZM2G175812_P01 | 43006.2 | 402 | 5.74 | 7 |
| 4 | ZmCHS04 | AC191551.3_FGP003 | 43065.52 | 396 | 5.98 | 3 |
| 6 | ZmCHS05 | GRMZM2G435393_P01 | 43425.83 | 398 | 6.28 | 3 |
| 7 | ZmCHS06 | GRMZM2G346095_P01 | 42391.54 | 397 | 6.19 | 5 |
| 8 | ZmCHS07 | GRMZM2G009348_P01 | 49692.84 | 472 | 8.9 | 4 |
| 9 | ZmCHS08 | GRMZM2G009510_P01 | 44829.17 | 420 | 6.08 | 4 |
| 10 | ZmCHS09 | GRMZM2G027130_P01 | 44136.6 | 420 | 5.83 | 2 |
| 11 | ZmCHS10 | GRMZM2G114471_P01 | 43556.78 | 405 | 5.46 | 4 |
| 12 | ZmCHS11 | GRMZM2G108894_P01 | 45994.51 | 427 | 5.35 | 7 |
| 13 | ZmCHS12 | GRMZM2G131529_P01 | 35275.5 | 326 | 5.77 | 3 |
| 14 | ZmCHS13 | GRMZM2G477683_P01 | 45574.27 | 421 | 8.08 | 5 |
| 15 | ZmCHS14 | GRMZM2G380650_P02 | 42110.41 | 390 | 6.92 | 1 |
2.2. Phylogenetic and Structural Analysis of the Putative Maize CHS Proteins

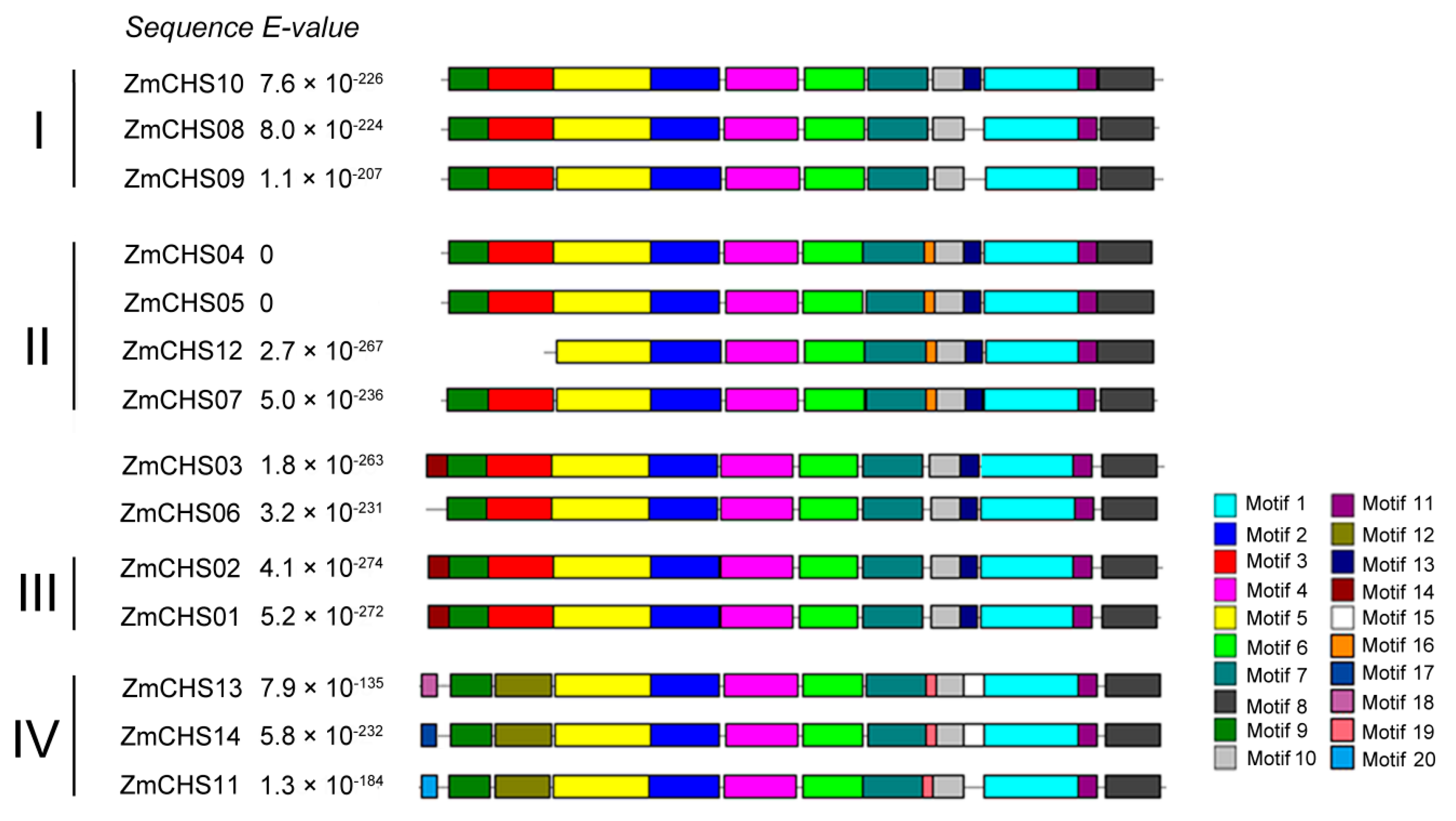
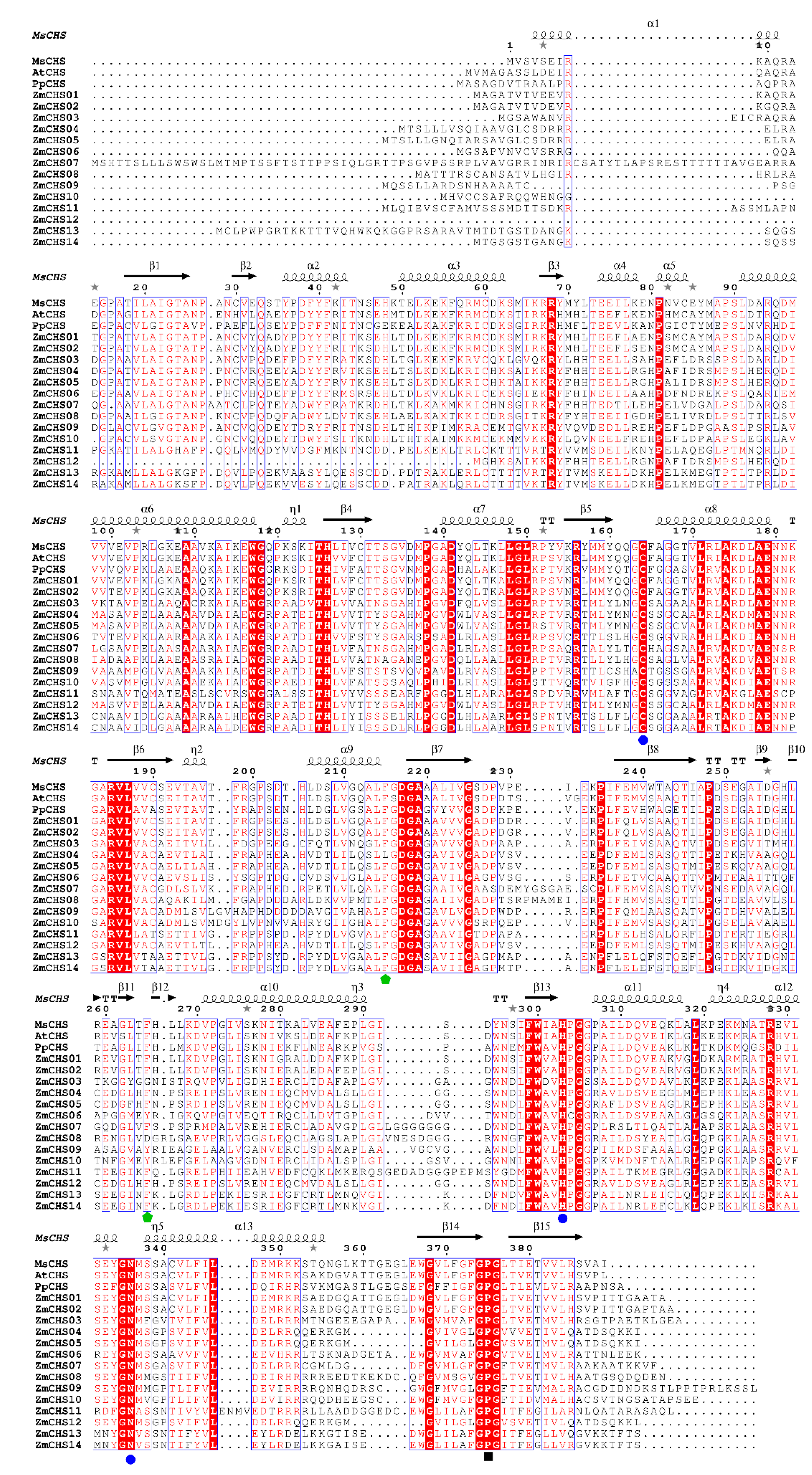
2.3. Conserved Motifs of the Putative ZmCHS Proteins and Sequence Alignment against Other Plant CHSs

| Motif | Width | Best Possible Match | Domain |
|---|---|---|---|
| 1 | 50 | WNDLFWAVHPGGPAILDQVEACLKLQPHKLKASRHVLSEYGNMSSPTVIF | Chal_sti_synt_C |
| 2 | 36 | EWGRPATDITHLVFCTYSGAHMPGVDWQLASLLGLR | Chal_sti_synt_N |
| 3 | 34 | NCVYQDEYPDYYFRITKSEHLTDLKEKFKRICHK | Chal_sti_synt_N |
| 4 | 38 | RTMLYMNGCSGGCAALRVAKDMAENNRGARVLVACAEM | Chal_sti_synt_N |
| 5 | 50 | IKKRYFHHTEELLREHPEFIDYSMPSLHERQDIMNSAVPELAAAAAQKAI | Chal_sti_synt_N |
| 6 | 31 | FRPPHEDHPYTLIGQALFGDGAGAVIVGADP | Chal_sti_synt_N |
| 7 | 31 | VERPIFEMVSASQTMIPDSEHVIDGQLCEDG | * |
| 8 | 28 | CEWGVMVGFGPGFTVETMVLHACKKTKK | Chal_sti_synt_C |
| 9 | 21 | RKWQRADGPATVLAIGTANPP | Chal_sti_synt_N |
| 10 | 15 | REIPSLIEENIEQCM | * |
| 11 | 9 | VLDELRRRQ | * |
| 12 | 29 | PQEKVVDSYLQESSCDDPDTRAKLQRLCT | * |
| 13 | 8 | DAFSPLGI | * |
| 14 | 11 | MAGATVTVEEV | * |
| 15 | 11 | RTLMNKVGIKD | * |
| 16 | 6 | LHFNPS | * |
| 17 | 6 | IDQFIN | * |
| 18 | 6 | VQHWKK | * |
| 19 | 6 | INFKLG | * |
| 20 | 7 | QIEYSCF | * |

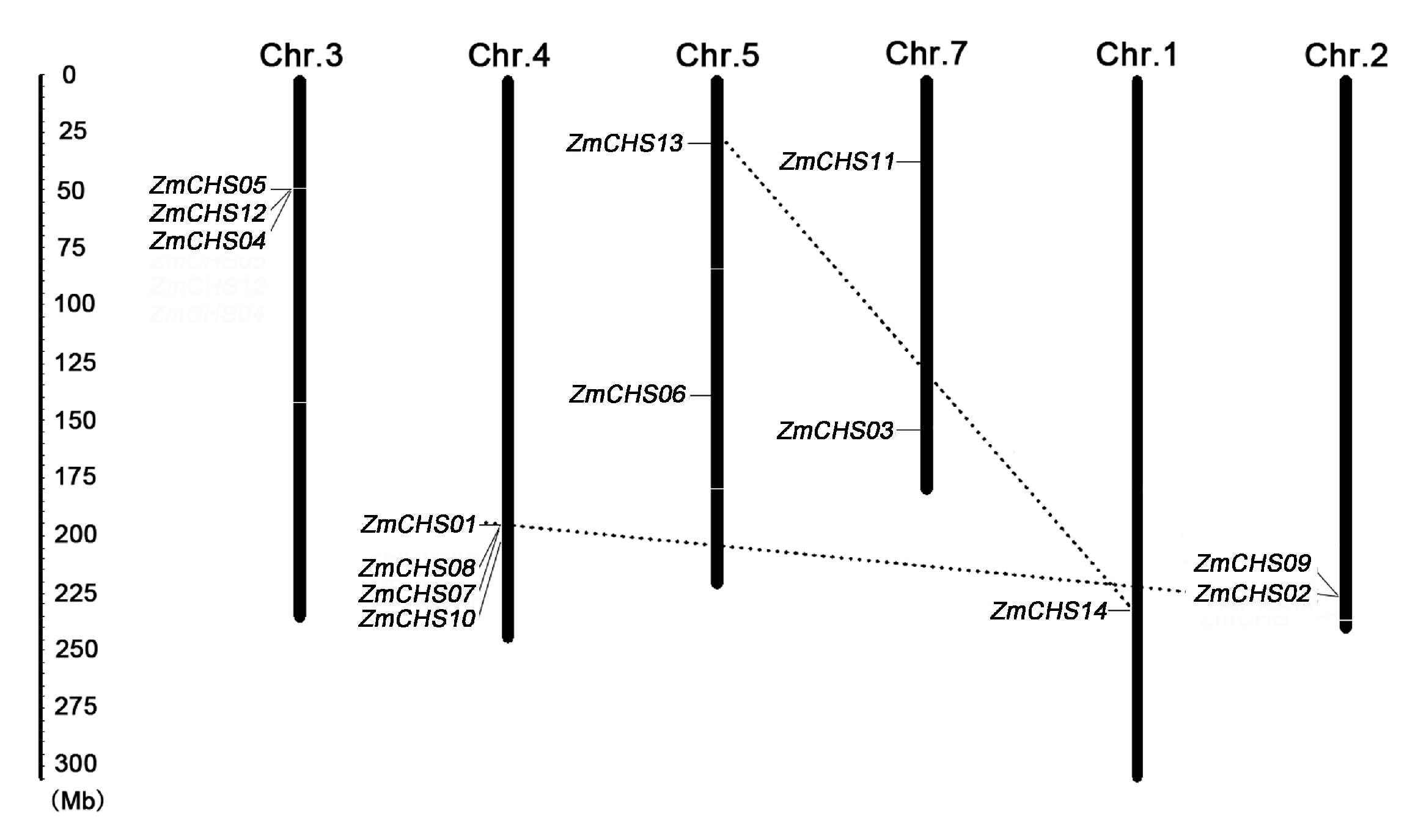
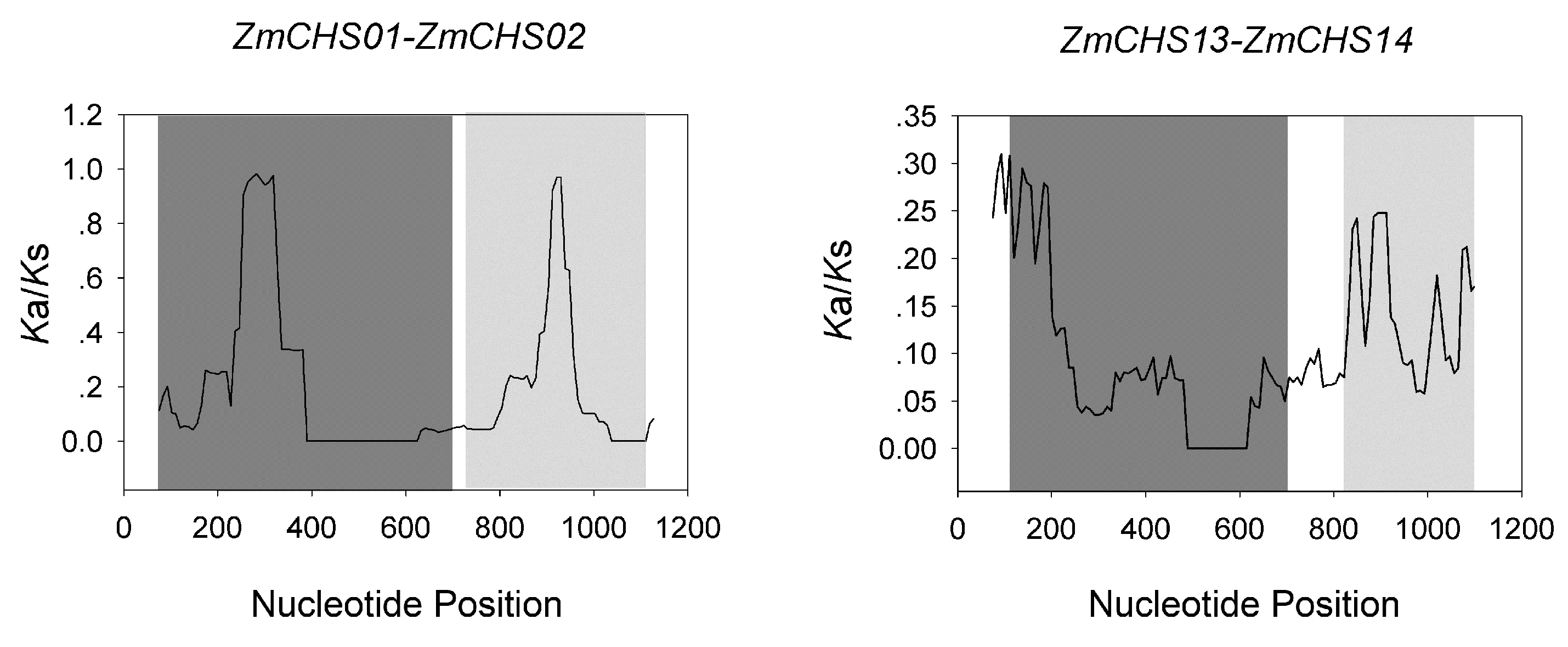
2.4. Chromosomal Location, Gene Duplication

| Duplicated Pairs | Ka | Ks | Ka/Ks | Purifying Selection |
|---|---|---|---|---|
| ZmCHS01-ZmCHS02 | 0.015 | 0.155 | 0.095 | Yes |
| ZmCHS13-ZmCHS14 | 0.027 | 0.22 | 0.123 | Yes |

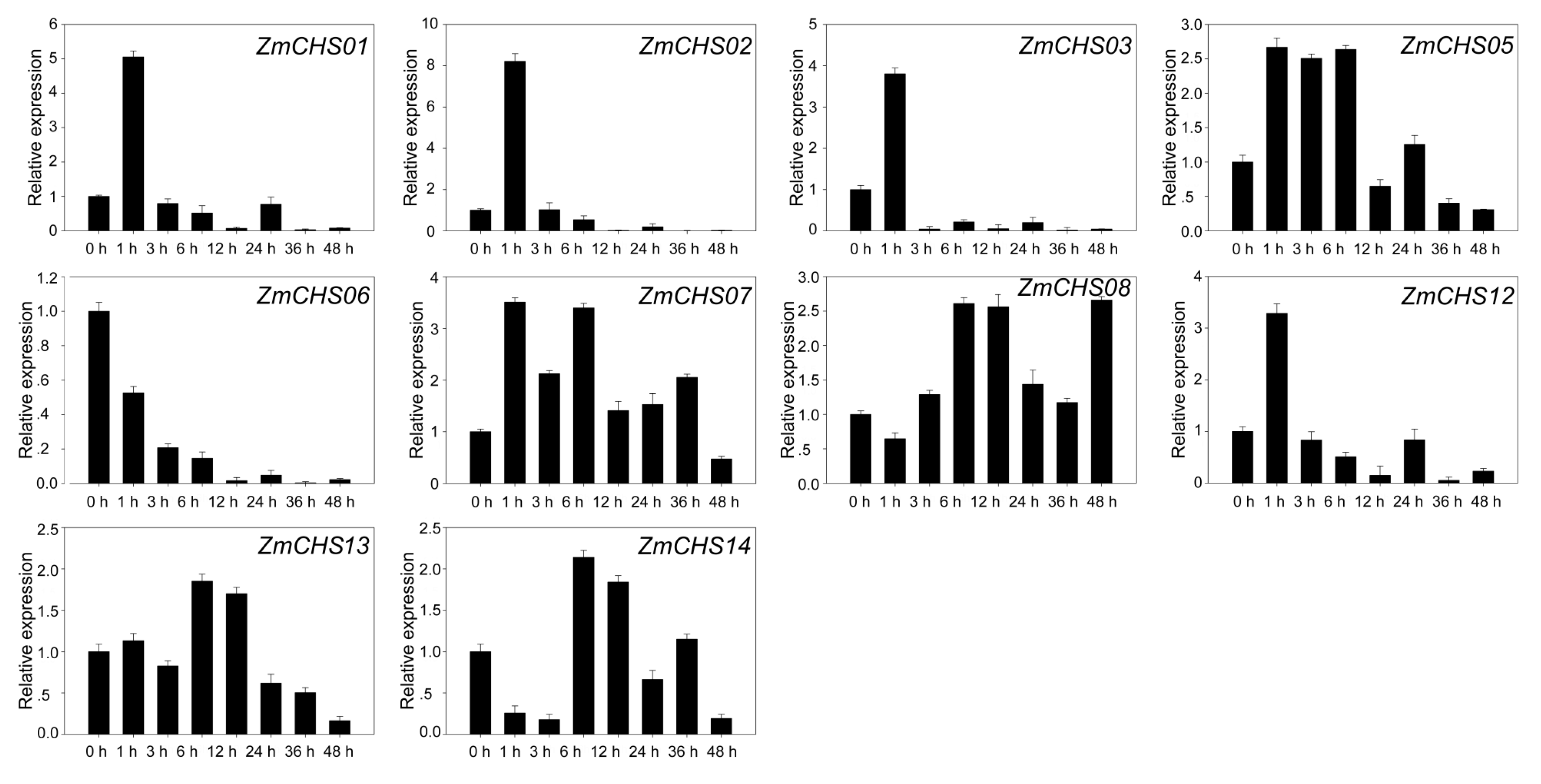
2.5. Microarray Analysis of CHS Expression during Maize Development

2.6. Expression Levels of Maize CHS Genes in Response to Salicylic Acid Treatment

3. Discussion
4. Materials and Methods
4.1. Identification and Sequence Analysis of CHS Proteins in Maize
4.2. Phylogenetic Analysis
4.3. Analysis of Conserved Motifs, Gene Structure and Sequence Alignment
4.4. Chromosomal Locations and Gene Duplication
4.5. Microarray Analysis of CHSs in Maize
4.6. Plant Material and Salicylic Acid Stress Treatment
4.7. RNA Isolation and Quantitative Real-Time PCR (qPCR) Analysis
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Martinez-Perez, C.; Ward, C.; Cook, G.; Mullen, P.; McPhail, D.; Harrison, D.J.; Langdon, S.P. Novel flavonoids as anti-cancer agents: Mechanisms of action and promise for their potential application in breast cancer. Biochem. Soc. Trans. 2014, 42, 1017–1023. [Google Scholar] [CrossRef] [PubMed]
- Jiang, C.; Kim, S.Y.; Suh, D.-Y. Divergent evolution of the thiolase superfamily and chalcone synthase family. Mol. Phylogenet. Evol. 2008, 49, 691–701. [Google Scholar] [CrossRef] [PubMed]
- Austin, M.B.; Noel, J.P. The chalcone synthase superfamily of type III polyketide synthases. Nat. Prod. Rep. 2003, 20, 79–110. [Google Scholar] [CrossRef] [PubMed]
- Schröder, J. A family of plant-specific polyketide synthases: Facts and predictions. Trends Plant Sci. 1997, 2, 373–378. [Google Scholar] [CrossRef]
- Liu, B.; Raeth, T.; Beuerle, T.; Beerhues, L. Biphenyl synthase, a novel type III polyketide synthase. Planta 2007, 225, 1495–1503. [Google Scholar] [CrossRef] [PubMed]
- Jez, J.M.; Austin, M.B.; Ferrer, J.-L.; Bowman, M.E.; Schröder, J.; Noel, J.P. Structural control of polyketide formation in plant-specific polyketide synthases. Chem. Biol. 2000, 7, 919–930. [Google Scholar] [CrossRef]
- Lu, H.; Yang, M.; Liu, C.; Lu, P.; Cang, H.; Ma, L. Protein preparation, crystallization and preliminary X-ray analysis of polygonum cuspidatum bifunctional chalcone synthase/benzalacetone synthase. Acta Crystallogr. Sect. F Struct. Biol. Cryst. Commun. 2013, 69, 871–875. [Google Scholar] [CrossRef] [PubMed]
- Parage, C.; Tavares, R.; Réty, S.; Baltenweck-Guyot, R.; Poutaraud, A.; Renault, L.; Heintz, D.; Lugan, R.; Marais, G.A.; Aubourg, S. Structural, functional, and evolutionary analysis of the unusually large stilbene synthase gene family in grapevine. Plant Physiol. 2012, 160, 1407–1419. [Google Scholar] [CrossRef] [PubMed]
- Han, Y.-Y.; Ming, F.; Wang, W.; Wang, J.-W.; Ye, M.-M.; Shen, D.-L. Molecular evolution and functional specialization of chalcone synthase superfamily from phalaenopsis orchid. Genetica 2006, 128, 429–438. [Google Scholar] [CrossRef] [PubMed]
- Huang, L.; Wang, H.; Ye, H.; Du, Z.; Zhang, Y.; Beerhues, L.; Liu, B. Differential expression of benzophenone synthase and chalcone synthase in hypericum sampsonii. Nat. Prod. Commun. 2012, 7, 1615–1618. [Google Scholar] [PubMed]
- Morita, H.; Kondo, S.; Oguro, S.; Noguchi, H.; Sugio, S.; Abe, I.; Kohno, T. Structural insight into chain-length control and product specificity of pentaketide chromone synthase from aloe arborescens. Chem. Biol. 2007, 14, 359–369. [Google Scholar] [CrossRef] [PubMed]
- Watanabe, K.; Praseuth, A.P.; Wang, C.C. A comprehensive and engaging overview of the type III family of polyketide synthases. Curr. Opin. Chem. Biol. 2007, 11, 279–286. [Google Scholar] [CrossRef] [PubMed]
- Akiyama, T.; Shibuya, M.; Liu, H.M.; Ebizuka, Y. p-Coumaroyltriacetic acid synthase, a new homologue of chalcone synthase, from Hydrangea macrophylla var. Thunbergii. Eur. J. Biochem. 1999, 263, 834–839. [Google Scholar] [CrossRef] [PubMed]
- Eckermann, S.; Schröder, G.; Schmidt, J.; Strack, D.; Edrada, R.A.; Helariutta, Y.; Elomaa, P.; Kotilainen, M.; Kilpeläinen, I.; Proksch, P. New pathway to polyketides in plants. Nature 1998, 396, 387–390. [Google Scholar] [CrossRef]
- Harris, N.; Luczo, J.; Robinson, S.; Walker, A. Transcriptional regulation of the three grapevine chalcone synthase genes and their role in flavonoid synthesis in shiraz. Aust. J. Grape Wine Res. 2013, 19, 221–229. [Google Scholar] [CrossRef]
- Deng, X.; Bashandy, H.; Ainasoja, M.; Kontturi, J.; Pietiäinen, M.; Laitinen, R.A.; Albert, V.A.; Valkonen, J.; Elomaa, P.; Teeri, T.H. Functional diversification of duplicated chalcone synthase genes in anthocyanin biosynthesis of gerbera hybrida. New Phytol. 2014, 201, 1469–1483. [Google Scholar] [CrossRef] [PubMed]
- Dare, A.P.; Tomes, S.; Jones, M.; McGhie, T.K.; Stevenson, D.E.; Johnson, R.A.; Greenwood, D.R.; Hellens, R.P. Phenotypic changes associated with rna interference silencing of chalcone synthase in apple (Malus × domestica). Plant J. 2013, 74, 398–410. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.-J.; Chuang, Y.-N.; Chiou, C.-Y.; Chin, D.-C.; Shen, F.-Q.; Yeh, K.-W. Methylation effect on chalcone synthase gene expression determines anthocyanin pigmentation in floral tissues of two oncidium orchid cultivars. Planta 2012, 236, 401–409. [Google Scholar] [CrossRef] [PubMed]
- Feinbaum, R.; Ausubel, F. Transcriptional regulation of the Arabidopsis thaliana chalcone synthase gene. Mol. Cell. Biol. 1988, 8, 1985–1992. [Google Scholar] [CrossRef] [PubMed]
- Van der Meer, I.M.; Spelt, C.E.; Mol, J.N.; Stuitje, A.R. Promoter analysis of the chalcone synthase (chsA) gene of Petunia hybrida: A 67 bp promoter region directs flower-specific expression. Plant Mol. Biol. 1990, 15, 95–109. [Google Scholar] [CrossRef] [PubMed]
- Schmid, J.; Doerner, P.W.; Clouse, S.D.; Dixon, R.A.; Lamb, C.J. Developmental and environmental regulation of a bean chalcone synthase promoter in transgenic tobacco. Plant Cell Online 1990, 2, 619–631. [Google Scholar] [CrossRef] [PubMed]
- Della Vedova, C.B.; Lorbiecke, R.; Kirsch, H.; Schulte, M.B.; Scheets, K.; Borchert, L.M.; Scheffler, B.E.; Wienand, U.; Cone, K.C.; Birchler, J.A. The dominant inhibitory chalcone synthase allele C2-Idf (Inhibitor diffuse) from Zea mays (L.) acts via an endogenous RNA silencing mechanism. Genetics 2005, 170, 1989–2002. [Google Scholar] [CrossRef] [PubMed]
- Franken, P.; Niesbach-Klösgen, U.; Weydemann, U.; Marechal-Drouard, L.; Saedler, H.; Wienand, U. The duplicated chalcone synthase genes C2 and Whp (white pollen) of Zea mays are independently regulated; evidence for translational control of Whp expression by the anthocyanin intensifying gene in. EMBO J. 1991, 10, 2605–2612. [Google Scholar] [PubMed]
- Jepson, C.; Karppinen, K.; Daku, R.M.; Sterenberg, B.T.; Suh, D.Y. Hypericum perforatum hydroxyalkylpyrone synthase involved in sporopollenin biosynthesis–phylogeny, site-directed mutagenesis, and expression in nonanther tissues. FEBS J. 2014, 281, 3855–3868. [Google Scholar] [CrossRef] [PubMed]
- Wienand, U.; Weydemann, U.; Niesbach-Klösgen, U.; Peterson, P.A.; Saedler, H. Molecular cloning of the C2 locus of Zea mays, the gene coding for chalcone synthase. Mol. Gen. Genet. MGG 1986, 203, 202–207. [Google Scholar] [CrossRef]
- Dooner, H.K.; Nelson, O.E. Interaction among C, R and Vp in the control of the Bz glucosyltransferase during endosperm development in maize. Genetics 1979, 91, 309–315. [Google Scholar] [PubMed]
- Dooner, H.K. Coordinate genetic regulation of flavonoid biosynthetic enzymes in maize. Mol. Gen. Genet. MGG 1983, 189, 136–141. [Google Scholar] [CrossRef]
- Koduri, P.H.; Gordon, G.S.; Barker, E.I.; Colpitts, C.C.; Ashton, N.W.; Suh, D.-Y. Genome-wide analysis of the chalcone synthase superfamily genes of physcomitrella patens. Plant Mol. Biol. 2010, 72, 247–263. [Google Scholar] [CrossRef] [PubMed]
- Schnable, P.S.; Ware, D.; Fulton, R.S.; Stein, J.C.; Wei, F.; Pasternak, S.; Liang, C.; Zhang, J.; Fulton, L.; Graves, T.A. The B73 maize genome: Complexity, diversity, and dynamics. Science 2009, 326, 1112–1115. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.-N.; Wang, L.; Sun, B.; Gao, S.; Cheng, A.-X.; Lou, H.-X. Functional characterization of a chalcone synthase from the liverwort plagiochasma appendiculatum. Plant Cell Rep. 2015, 34, 233–245. [Google Scholar] [CrossRef] [PubMed]
- Finn, R.D.; Mistry, J.; Schuster-Böckler, B.; Griffiths-Jones, S.; Hollich, V.; Lassmann, T.; Moxon, S.; Marshall, M.; Khanna, A.; Durbin, R. Pfam: Clans, web tools and services. Nucleic Acids Res. 2006, 34, D247–D251. [Google Scholar] [CrossRef] [PubMed]
- Götz, S.; García-Gómez, J.M.; Terol, J.; Williams, T.D.; Nagaraj, S.H.; Nueda, M.J.; Robles, M.; Talón, M.; Dopazo, J.; Conesa, A. High-throughput functional annotation and data mining with the Blast2GO suite. Nucleic Acids Res. 2008, 36, 3420–3435. [Google Scholar] [CrossRef] [PubMed]
- Cannon, S.B.; Mitra, A.; Baumgarten, A.; Young, N.D.; May, G. The roles of segmental and tandem gene duplication in the evolution of large gene families in Arabidopsis thaliana. BMC Plant Biol. 2004, 4. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mehan, M.R.; Freimer, N.B.; Ophoff, R.A. A genome-wide survey of segmental duplications that mediate common human genetic variation of chromosomal architecture. Hum. Genom. 2004, 1. [Google Scholar] [CrossRef]
- Sekhon, R.S.; Lin, H.; Childs, K.L.; Hansey, C.N.; Buell, C.R.; de Leon, N.; Kaeppler, S.M. Genome-wide atlas of transcription during maize development. Plant J. 2011, 66, 553–563. [Google Scholar] [CrossRef] [PubMed]
- Harashima, S.; Takano, H.; Ono, K.; Takio, S. Chalcone synthase-like gene in the liverwort, Marchantia paleacea var. diptera. Plant Cell Rep. 2004, 23, 167–173. [Google Scholar] [CrossRef] [PubMed]
- Jeong, S.T.; Goto-Yamamoto, N.; Kobayashi, S.; Esaka, M. Effects of plant hormones and shading on the accumulation of anthocyanins and the expression of anthocyanin biosynthetic genes in grape berry skins. Plant Sci. 2004, 167, 247–252. [Google Scholar] [CrossRef]
- Junghans, H.; Dalkin, K.; Dixon, R.A. Stress responses in alfalfa (Medicago sativa L.). 15. Characterization and expression patterns of members of a subset of the chalcone synthase multigene family. Plant Mol. Biol. 1993, 22, 239–253. [Google Scholar] [CrossRef] [PubMed]
- Koes, R.E.; Spelt, C.E.; Mol, J.N. The chalcone synthase multigene family of Petunia hybrida (V30): Differential, light-regulated expression during flower development and UV light induction. Plant Mol. Biol. 1989, 12, 213–225. [Google Scholar] [CrossRef] [PubMed]
- Koes, R.E.; Spelt, C.E.; van den Elzen, P.J.; Mol, J.N. Cloning and molecular characterization of the chalcone synthase multigene family of petunia hybrida. Gene 1989, 81, 245–257. [Google Scholar] [CrossRef]
- Durbin, M.L.; McCaig, B.; Clegg, M.T. Molecular evolution of the chalcone synthase multigene family in the morning glory genome. In Plant Molecular Evolution; Springer: Riverside, CA, USA, 2000; pp. 79–92. [Google Scholar]
- Ito, M.; Ichinose, Y.; Kato, H.; Shiraishi, T.; Yamada, T. Molecular evolution and functional relevance of the chalcone synthase genes of pea. Mol. Gen. Genet. MGG 1997, 255, 28–37. [Google Scholar] [CrossRef] [PubMed]
- Paterson, A.; Bowers, J.; Chapman, B. Ancient polyploidization predating divergence of the cereals, and its consequences for comparative genomics. Proc. Natl. Acad. Sci. USA 2004, 101, 9903–9908. [Google Scholar] [CrossRef] [PubMed]
- Swigoňová, Z.; Lai, J.; Ma, J.; Ramakrishna, W.; Llaca, V.; Bennetzen, J.L.; Messing, J. Close split of sorghum and maize genome progenitors. Genome Res. 2004, 14, 1916–1923. [Google Scholar] [CrossRef] [PubMed]
- Pang, Y.; Shen, G.; Wu, W.; Liu, X.; Lin, J.; Tan, F.; Sun, X.; Tang, K. Characterization and expression of chalcone synthase gene from Ginkgo biloba. Plant Sci. 2005, 168, 1525–1531. [Google Scholar] [CrossRef]
- Wei, F.; Coe, E.; Nelson, W.; Bharti, A.K.; Engler, F.; Butler, E.; Kim, H.; Goicoechea, J.L.; Chen, M.; Lee, S. Physical and genetic structure of the maize genome reflects its complex evolutionary history. PLoS Genet. 2007, 3, e123. [Google Scholar] [CrossRef] [PubMed]
- Salse, J.; Bolot, S.; Throude, M.; Jouffe, V.; Piegu, B.; Quraishi, U.M.; Calcagno, T.; Cooke, R.; Delseny, M.; Feuillet, C. Identification and characterization of shared duplications between rice and wheat provide new insight into grass genome evolution. Plant Cell Online 2008, 20, 11–24. [Google Scholar] [CrossRef] [PubMed]
- Murat, F.; Xu, J.-H.; Tannier, E.; Abrouk, M.; Guilhot, N.; Pont, C.; Messing, J.; Salse, J. Ancestral grass karyotype reconstruction unravels new mechanisms of genome shuffling as a source of plant evolution. Genome Res. 2010, 20, 1545–1557. [Google Scholar] [CrossRef] [PubMed]
- Baumgarten, A.; Cannon, S.; Spangler, R.; May, G. Genome-level evolution of resistance genes in Arabidopsis thaliana. Genetics 2003, 165, 309–319. [Google Scholar] [PubMed]
- Jiang, C.; Gu, X.; Peterson, T. Identification of conserved gene structures and carboxy-terminal motifs in the Myb gene family of Arabidopsis and Oryza sativa L. ssp. Indica. Genome Biol. 2004, 5. [Google Scholar] [CrossRef] [Green Version]
- Oakley, T.H.; Østman, B.; Wilson, A.C. Repression and loss of gene expression outpaces activation and gain in recently duplicated fly genes. Proc. Natl. Acad. Sci. USA 2006, 103, 11637–11641. [Google Scholar] [CrossRef] [PubMed]
- Gu, X. Statistical framework for phylogenomic analysis of gene family expression profiles. Genetics 2004, 167, 531–542. [Google Scholar] [CrossRef] [PubMed]
- Albrecht, V.; Weinl, S.; Blazevic, D.; D’Angelo, C.; Batistic, O.; Kolukisaoglu, Ü.; Bock, R.; Schulz, B.; Harter, K.; Kudla, J. The calcium sensor CBL1 integrates plant responses to abiotic stresses. Plant J. 2003, 36, 457–470. [Google Scholar] [CrossRef] [PubMed]
- Kasuga, M.; Liu, Q.; Miura, S.; Yamaguchi-Shinozaki, K.; Shinozaki, K. Improving plant drought, salt, and freezing tolerance by gene transfer of a single stress-inducible transcription factor. Nat. Biotechnol. 1999, 17, 287–291. [Google Scholar] [PubMed]
- Coram, T.E.; Pang, E.C. Transcriptional profiling of chickpea genes differentially regulated by salicylic acid, methyl jasmonate and aminocyclopropane carboxylic acid to reveal pathways of defence-related gene regulation. Funct. Plant Biol. 2007, 34, 52–64. [Google Scholar] [CrossRef]
- Duan, Y.; Jiang, Y.; Ye, S.; Karim, A.; Ling, Z.; He, Y.; Yang, S.; Luo, K. PtrWRKY73, a salicylic acid-inducible poplar WRKY transcription factor, is involved in disease resistance in Arabidopsis thaliana. Plant Cell Rep. 2015, 34, 831–841. [Google Scholar] [CrossRef] [PubMed]
- Häffner, E.; Karlovsky, P.; Splivallo, R.; Traczewska, A.; Diederichsen, E. ERECTA, salicylic acid, abscisic acid, and jasmonic acid modulate quantitative disease resistance of Arabidopsis thaliana to Verticillium longisporum. BMC Plant Biol. 2014, 14. [Google Scholar] [CrossRef] [PubMed]
- Goodstein, D.M.; Shu, S.; Howson, R.; Neupane, R.; Hayes, R.D.; Fazo, J.; Mitros, T.; Dirks, W.; Hellsten, U.; Putnam, N. Phytozome: A comparative platform for green plant genomics. Nucleic Acids Res. 2012, 40, D1178–D1186. [Google Scholar] [CrossRef] [PubMed]
- Letunic, I.; Doerks, T.; Bork, P. Smart 6: Recent updates and new developments. Nucleic Acids Res. 2009, 37, D229–D232. [Google Scholar] [CrossRef] [PubMed]
- Thompson, J.D.; Higgins, D.G.; Gibson, T.J. Clustal w: Improving the sensitivity of progressive multiple sequence alignment through sequence weighting, position-specific gap penalties and weight matrix choice. Nucleic Acids Res. 1994, 22, 4673–4680. [Google Scholar] [CrossRef] [PubMed]
- Tamura, K.; Dudley, J.; Nei, M.; Kumar, S. MEGA4: Molecular evolutionary genetics analysis (MEGA) software version 4.0. Mol. Biol. Evol. 2007, 24, 1596–1599. [Google Scholar] [CrossRef] [PubMed]
- Bailey, T.L.; Elkan, C. The Value of Prior Knowledge in Discovering Motifs with Meme; Ismb: La Jolla, CA, USA, 1995; pp. 21–29. [Google Scholar]
- Guo, A.; Zhu, Q.; Chen, X.; Luo, J. GSDS: A gene structure display server. Yi chuan = Hereditas/Zhongguo Yi Chuan Xue Hui Bian Ji 2007, 29, 1023–1026. [Google Scholar] [CrossRef] [PubMed]
- Ferrer, J.-L.; Jez, J.M.; Bowman, M.E.; Dixon, R.A.; Noel, J.P. Structure of chalcone synthase and the molecular basis of plant polyketide biosynthesis. Nat. Struct. Mol. Biol. 1999, 6, 775–784. [Google Scholar]
- Berman, H.; Henrick, K.; Nakamura, H.; Markley, J.L. The worldwide Protein Data Bank (wwPDB): Ensuring a single, uniform archive of PDB data. Nucleic Acids Res. 2007, 35, D301–D303. [Google Scholar] [CrossRef] [PubMed]
- Robert, X.; Gouet, P. Deciphering key features in protein structures with the new endscript server. Nucleic Acids Res. 2014, 42, W320–W324. [Google Scholar] [CrossRef] [PubMed]
- MapInspect. Available online: http://www.softsea.com/review/MapInspect.html (accessed on 5 September 2015).
- Tang, H.; Bowers, J.E.; Wang, X.; Ming, R.; Alam, M.; Paterson, A.H. Synteny and collinearity in plant genomes. Science 2008, 320, 486–488. [Google Scholar] [CrossRef] [PubMed]
- Gentleman, R.C.; Carey, V.J.; Bates, D.M.; Bolstad, B.; Dettling, M.; Dudoit, S.; Ellis, B.; Gautier, L.; Ge, Y.; Gentry, J. Bioconductor: Open software development for computational biology and bioinformatics. Genome Biol. 2004, 5. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gasic, K.; Hernandez, A.; Korban, S.S. RNA extraction from different apple tissues rich in polyphenols and polysaccharides for cDNA library construction. Plant Mol. Biol. Rep. 2004, 22, 437–438. [Google Scholar] [CrossRef]
- Livak, K.J.; Schmittgen, T.D. Analysis of relative gene expression data using real-time quantitative PCR and the 2−ΔΔCt method. Methods 2001, 25, 402–408. [Google Scholar] [CrossRef] [PubMed]
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, Y.; Ding, T.; Su, B.; Jiang, H. Genome-Wide Identification, Characterization and Expression Analysis of the Chalcone Synthase Family in Maize. Int. J. Mol. Sci. 2016, 17, 161. https://0-doi-org.brum.beds.ac.uk/10.3390/ijms17020161
Han Y, Ding T, Su B, Jiang H. Genome-Wide Identification, Characterization and Expression Analysis of the Chalcone Synthase Family in Maize. International Journal of Molecular Sciences. 2016; 17(2):161. https://0-doi-org.brum.beds.ac.uk/10.3390/ijms17020161
Chicago/Turabian StyleHan, Yahui, Ting Ding, Bo Su, and Haiyang Jiang. 2016. "Genome-Wide Identification, Characterization and Expression Analysis of the Chalcone Synthase Family in Maize" International Journal of Molecular Sciences 17, no. 2: 161. https://0-doi-org.brum.beds.ac.uk/10.3390/ijms17020161