
The Complete Chloroplast Genome Sequences of the Medicinal Plant Pogostemon cablin

Abstract
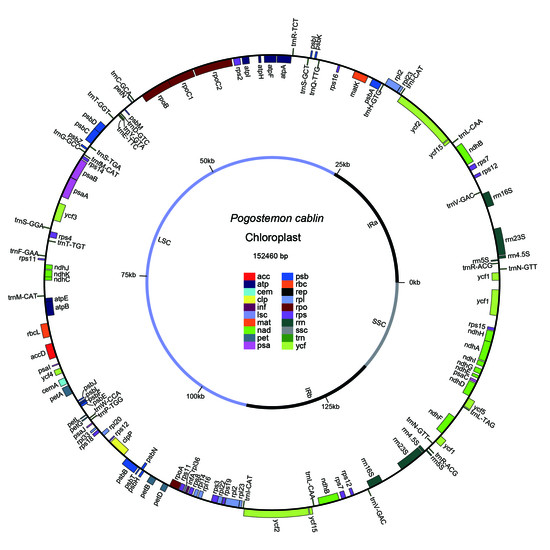
:
1. Introduction
2. Results and Discussions
2.1. Genome Features
List 1. Summary of contigs.
| Contig Number | 40 |
| Total size | 150,312 |
| Average length | 3757.8 |
| GC Number | 57,886 |
| AT number | 92,426 |
| N50 length | 25,662 |
| Minimum contig length | 515 |
| Maximum contig length | 26,687 |
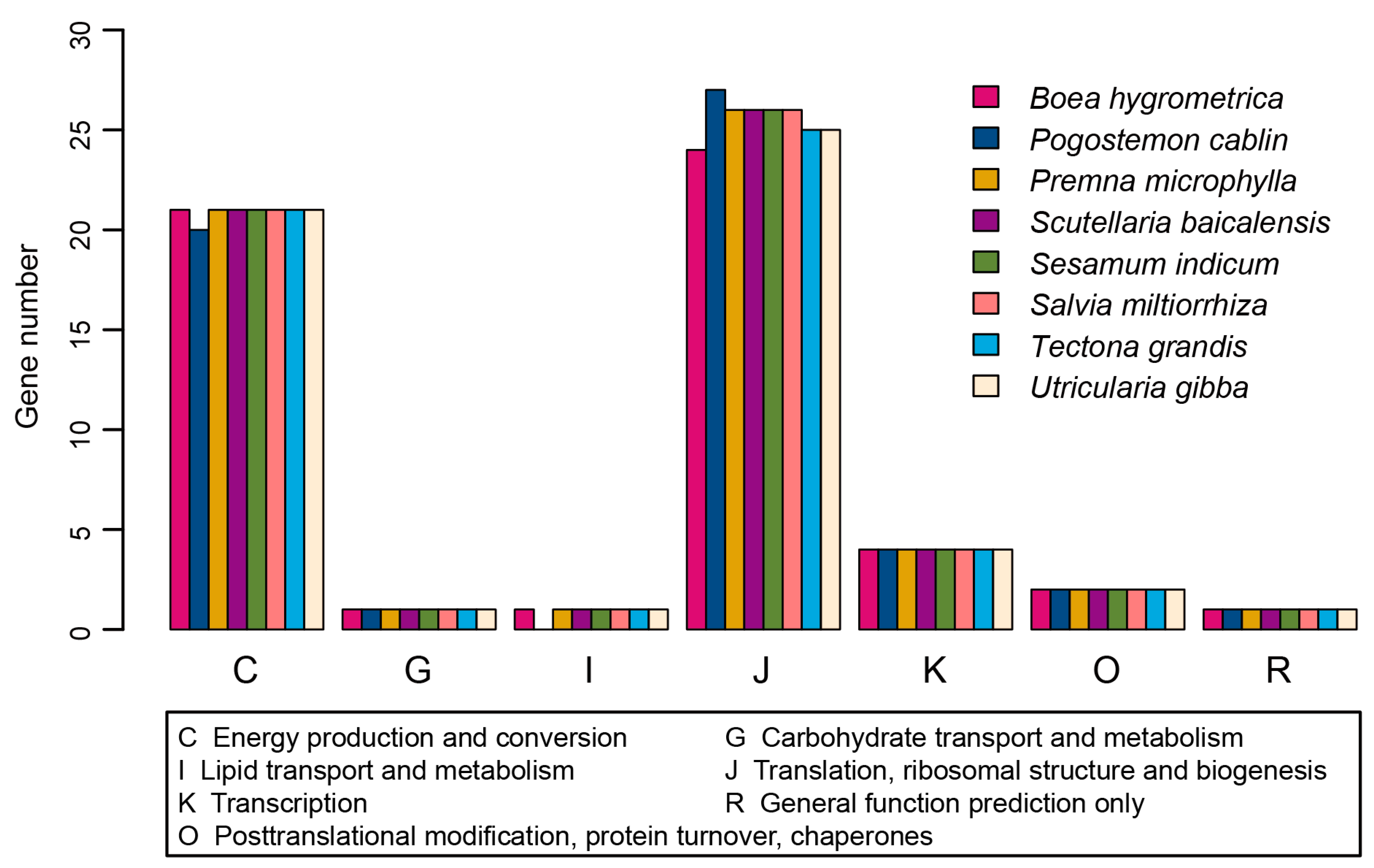
2.2. Genome Annotations
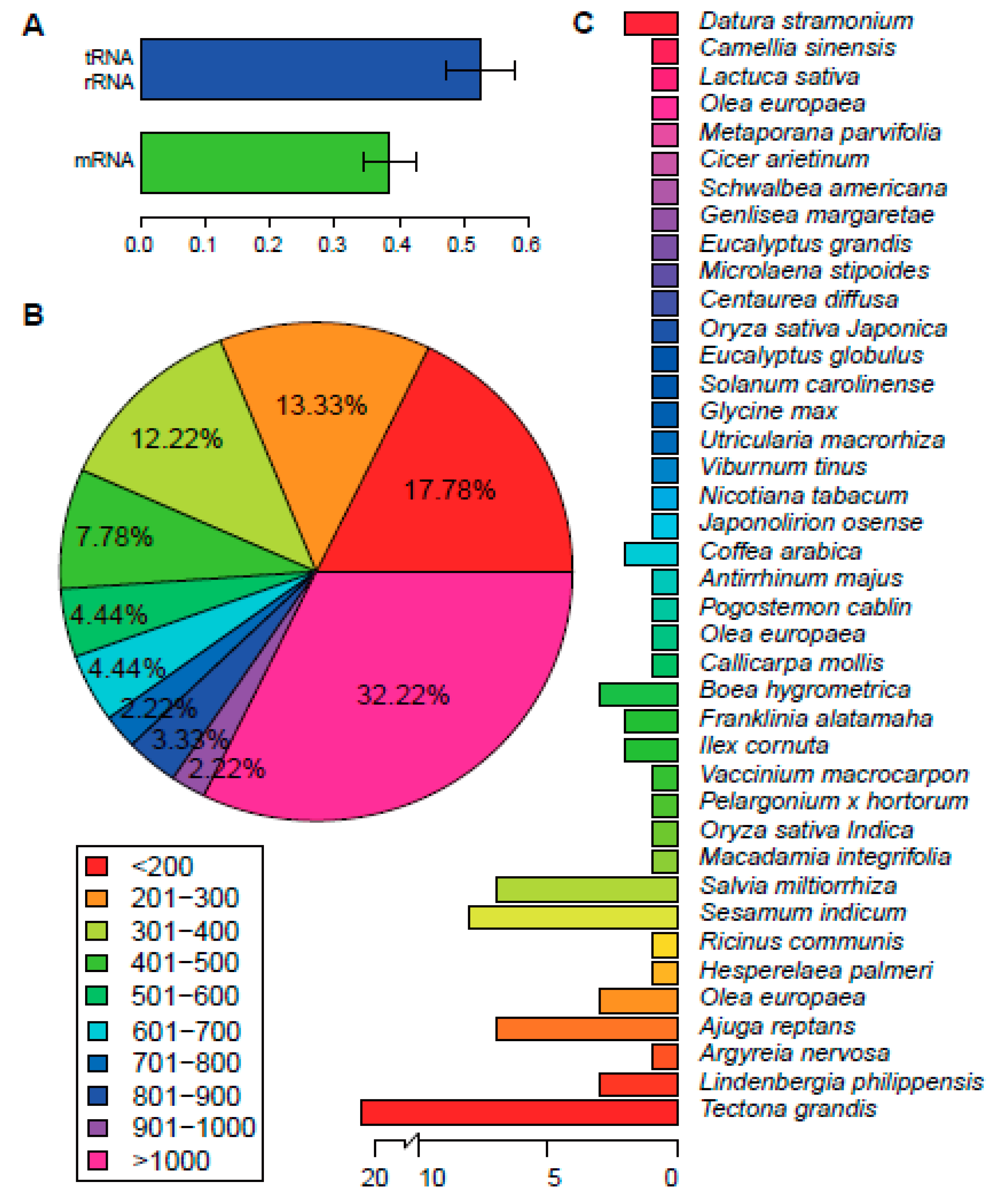
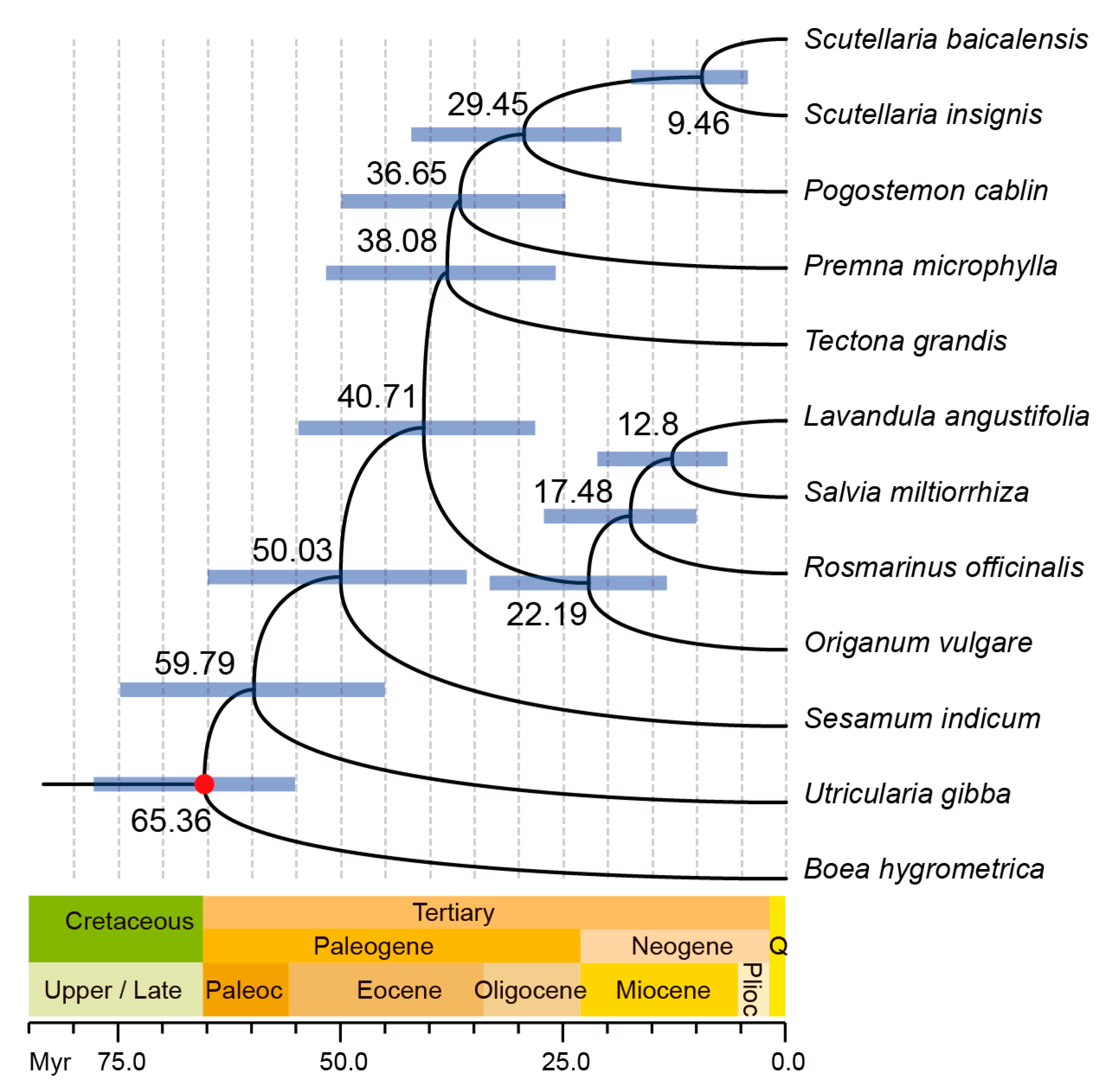
2.3. Phylogenetic Analysis and Divergence Time Estimation
2.4. SSRs (Simple Sequence Repeats) Analysis
3. Materials and Methods
3.1. Plant Material and Library Preparation
3.2. DNA Sequencing, Data Preprocessing and Genome Assembly
3.3. Genome Annotation and Comparative Genomics
3.4. Phylogenetic Tree Reconstruction and Divergence Time Estimation
3.5. SSR Identification
4. Conclusions
Supplementary Information
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lamiaceae plant family Britannica.com. Available online: http://global.britannica.com/plant/Lamiaceae (accessed on 12 May 2016).
- Arpana, J.; Bagyaraj, D.; Prakasa Rao, E.; Parameswaran, T.; Abdul Rahiman, B. Symbiotic response of patchouli [Pogostemon cablin (Blanco) Benth.] to different arbuscular mycorrhizal fungi. Adv. Environ. Biol. 2008, 2, 20–24. [Google Scholar]
- Wu, Y.G.; Guo, Q.S.; He, J.C.; Lin, Y.F.; Luo, l.J.; Liu, G.D. Genetic diversity analysis among and within populations of Pogostemon cablin from China with ISSR and SRAP markers. Biochem. Syst. Ecol. 2010, 38, 63–72. [Google Scholar] [CrossRef]
- Kiuchi, F.; Matsuo, K.; Ito, M.; Qui, T.K.; Honda, G. New sesquiterpene hydroperoxides with trypanocidal activity from Pogostemon cablin. Chem. Pharm. Bull. 2004, 52, 1495–1496. [Google Scholar] [CrossRef] [PubMed]
- Guan, L.; Quan, L.; Xu, L.; Cong, P. Chemical constituents of Pogostemon cablin (Blanco) Benth. China J. Chin. Mater. Med. 1994, 19, 355–356, 383. [Google Scholar]
- Miyazawa, M.; Okuno, Y.; Nakamura, S.I.; Kosaka, H. Antimutagenic activity of flavonoids from Pogostemon cablin. J. Agr. Food Chem. 2000, 48, 642–647. [Google Scholar] [CrossRef]
- Li, P.; Yin, Z.Q.; Li, S.L.; Huang, X.J.; Ye, W.C.; Zhang, Q.W. Simultaneous determination of eight flavonoids and pogostone in Pogostemon cablin by high performance liquid chromatography. J. Liq. Chromatogr. Relat. Technol. 2014, 37, 1771–1784. [Google Scholar] [CrossRef]
- Albert, T.L.; Steven, F.B. Encyclopedia of Common Natural Ingredients Used in Food, Drugs, and Cosmetics, 1st ed.; John Wiley & Sons: New York, NY, USA, 1996. [Google Scholar]
- Bauer, K.; Garbe, D.; Surburg, H. Common Fragrance and Flavor Materials: Preparation, Properties and Uses; John Wiley & Sons: New York, NY, USA, 2008. [Google Scholar]
- Hsu, H.C.; Yang, W.C.; Tsai, W.J.; Chen, C.C.; Huang, H.Y.; Tsai, Y.C. α-Bulnesene, a novel PAF receptor antagonist isolated from Pogostemon cablin. Biochem. Bioph. Res. Commun. 2006, 345, 1033–1038. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Li, B.; Wang, X.; Jin, M.; Wang, G. Inhibitory effect and possible mechanism of action of patchouli alcohol against influenza A (H2N2) virus. Molecules 2011, 16, 6489–6501. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; Zhang, J.; Lai, Y.; Wang, S.; Li, P.; Xiao, J.; Hu, C.; Hu, H.; Wang, Y. Analysis of Pogostemon cablin from pharmaceutical research to market performances. Expert Opin. Inv. Drug. 2013, 22, 245–257. [Google Scholar] [CrossRef] [PubMed]
- Committee, N.P. Chinese Pharmacopoeia; China Medical Science Press: Beijing, China, 2010; pp. 70–71. [Google Scholar]
- Yang, M.; Zhang, X.; Liu, G.; Yin, Y.; Chen, K.; Yun, Q.; Zhao, D.; Al-Mssallem, I.S.; Yu, J. The complete chloroplast genome sequence of date palm (Phoenix dactylifera L.). PLoS ONE 2010, 5, e12762. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Kong, W. The complete chloroplast genome sequence of Premna microphylla Turcz. Mitochond. DNA 2015. [Google Scholar] [CrossRef]
- Qian, J.; Song, J.; Gao, H.; Zhu, Y.; Xu, J.; Pang, X.; Yao, H.; Sun, C.; Li, X.; Li, C.; et al. The complete chloroplast genome sequence of the medicinal plant Salvia miltiorrhiza. PLoS ONE 2013, 8, e57607. [Google Scholar] [CrossRef] [PubMed]
- Lukas, B.; Novak, J. The complete chloroplast genome of Origanum vulgare L. (Lamiaceae). Gene 2013, 528, 163–169. [Google Scholar] [CrossRef] [PubMed]
- Yi, D.K.; Kim, K.J. Complete chloroplast genome sequences of important oilseed crop Sesamum indicum L. PLoS ONE 2012, 7, e35872. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Fang, Y.; Wang, X.; Deng, X.; Zhang, X.; Hu, S.; Yu, J. The complete chloroplast and mitochondrial genome sequences of Boea hygrometrica: Insights into the evolution of plant organellar genomes. PLoS ONE 2012, 7, e30531. [Google Scholar] [CrossRef] [PubMed]
- Shinozaki, K.; Ohme, M.; Tanaka, M.; Wakasugi, T.; Hayashida, N.; Matsubayashi, T.; Zaita, N.; Chunwongse, J.; Obokata, J.; Yamaguchi-Shinozaki, K.; et al. The complete nucleotide sequence of the tobacco chloroplast genome: Its gene organization and expression. EMBO J. 1986, 5, 2043–2049. [Google Scholar] [CrossRef] [PubMed]
- Hedges, S.B.; Dudley, J.; Kumar, S. TimeTree: A public knowledge-base of divergence times among organisms. Bioinformatics 2006, 22, 2971–2972. [Google Scholar] [CrossRef] [PubMed]
- Barchi, L.; Lanteri, S.; Portis, E.; Acquadro, A.; Valè, G.; Toppino, L.; Rotino, G.L. Identification of SNP and SSR markers in eggplant using RAD tag sequencing. BMC Genom. 2011, 12, 304. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Gui, S.; Zhu, Z.; Wang, X.; Ke, W.; Ding, Y. Genome-wide identification of SSR and SNP markers based on whole-genome re-sequencing of a Thailand wild sacred lotus (Nelumbo nucifera). PLoS ONE 2015, 10, e0143765. [Google Scholar] [CrossRef] [PubMed]
- Kuang, D.Y.; Wu, H.; Wang, Y.L.; Gao, L.M.; Zhang, S.Z.; Lu, L. Complete chloroplast genome sequence of Magnolia kwangsiensis (Magnoliaceae): Implication for DNA barcoding and population genetics. Genome 2011, 54, 663–673. [Google Scholar] [CrossRef] [PubMed]
- FASTX—Toolkit. Available online: http://hannonlab.cshl.edu/fastx_toolkit/ (accessed on 12 May 2016).
- Zerbino, D.R.; Birney, E. Velvet: Algorithms for de novo short read assembly using de Bruijn graphs. Genome Res. 2008, 18, 821–829. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Shi, L.; Zhu, Y.; Chen, H.; Zhang, J.; Lin, X.; Guan, X. CpGAVAS, an integrated web server for the annotation, visualization, analysis, and GenBank submission of completely sequenced chloroplast genome sequences. BMC Genom. 2012, 13, 715. [Google Scholar] [CrossRef] [PubMed]
- Kanehisa, M.; Sato, Y.; Kawashima, M.; Furumichi, M.; Tanabe, M. KEGG as a reference resource for gene and protein annotation. Nucleic Acids Res. 2016, 44, D457–D462. [Google Scholar] [CrossRef] [PubMed]
- Tatusov, R.L.; Fedorova, N.D.; Jackson, J.D.; Jacobs, A.R.; Kiryutin, D.; Koonin, E.V.; Mekhedov, S.L.; Nikolskaya, A.N.; Rao, B.S.; Smirnov, S.; et al. The COG database: An updated version includes eukaryotes. BMC Bioinform. 2003, 4, 41. [Google Scholar] [CrossRef] [PubMed]
- Kurtz, S.; Phillippy, A.; Delcher, A.L.; Smoot, M.; Shumway, M.; Antonescu, C.; Salzberg, S.L. Versatile and open software for comparing large genomes. Genome Biol. 2004, 5, R12. [Google Scholar] [CrossRef] [PubMed]
- Conant, G.C.; Wolfe, K.H. GenomeVx: Simple web-based creation of editable circular chromosome maps. Bioinformatics 2008, 24, 861–862. [Google Scholar] [CrossRef] [PubMed]
- Wyman, S.K.; Jansen, R.K.; Boore, J.L. Automatic annotation of organellar genomes with DOGMA. Bioinformatics 2004, 20, 3252–3255. [Google Scholar] [CrossRef] [PubMed]
- Guindon, S.; Delsuc, F.; Dufayard, J.F.; Gascuel, O. Estimating maximum likelihood phylogenies with PhyML. Methods Mol. Biol. 2009, 537, 113–137. [Google Scholar] [PubMed]
- Tsai, Y.C.; Hsu, H.C.; Yang, W.C.; Tsai, W.J.; Chen, C.C.; Watanabe, T. α-Bulnesene, a PAF inhibitor isolated from the essential oil of Pogostemon cablin. Fitoterapia 2007, 78, 7–11. [Google Scholar] [CrossRef] [PubMed]
- MISA—Microsatellite searching tool. Available online: http://pgrc.ipk-gatersleben.de/misa/ (accessed on 12 May 2016).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gene | Strand | Start | End | Exon I | Intron I | Exon II | Intron II | Exon III |
|---|---|---|---|---|---|---|---|---|
| ndhB | + | 13,161 | 15,372 | 867 | 589 | 756 | ||
| rpl2 | + | 24,040 | 25,529 | 391 | 631 | 468 | ||
| atpF | − | 37,673 | 38,945 | 150 | 664 | 459 | ||
| rpoC1 | − | 46,797 | 49,641 | 454 | 769 | 1622 | ||
| ycf3 | − | 67,542 | 69,472 | 134 | 696 | 235 | 720 | 146 |
| clpP | − | 95,175 | 97,129 | 74 | 726 | 294 | 638 | 223 |
| rpl2 | − | 109,281 | 110,769 | 394 | 628 | 467 | ||
| ndhB | − | 119,440 | 121,648 | 870 | 586 | 753 | ||
| ndhA | − | 143,869 | 146,015 | 556 | 1055 | 536 |
| AA | Codon | No. | Total | AA Frequency | AA | Codon | No. | Total | AA Frequency |
|---|---|---|---|---|---|---|---|---|---|
| A | GCA | 399 | 1418 | 5.25% | P | CCA | 318 | 1139 | 4.22% |
| GCC | 251 | CCC | 246 | ||||||
| GCG | 176 | CCG | 178 | ||||||
| GCT | 592 | CCT | 397 | ||||||
| C | TGC | 88 | 319 | 1.18% | Q | CAA | 702 | 925 | 3.42% |
| TGT | 231 | CAG | 223 | ||||||
| D | GAC | 179 | 1024 | 3.79% | R | AGA | 485 | 1639 | 6.07% |
| GAT | 845 | AGG | 197 | ||||||
| E | GAA | 1002 | 1358 | 5.03% | CGA | 367 | |||
| GAG | 356 | CGC | 121 | ||||||
| F | TTC | 551 | 1539 | 5.70% | CGG | 143 | |||
| TTT | 988 | CGT | 326 | ||||||
| G | GGA | 736 | 1823 | 6.75% | S | AGC | 131 | 2128 | 7.88% |
| GGC | 197 | AGT | 409 | ||||||
| GGG | 327 | TCA | 405 | ||||||
| GGT | 563 | TCC | 370 | ||||||
| H | CAC | 146 | 640 | 2.37% | TCG | 229 | |||
| CAT | 494 | TCT | 584 | ||||||
| I | ATA | 703 | 2319 | 8.58% | T | ACA | 413 | 1388 | 5.14% |
| ATC | 493 | ACC | 274 | ||||||
| ATT | 1123 | ACG | 164 | ||||||
| K | AAA | 1046 | 1440 | 5.33% | ACT | 537 | |||
| AAG | 394 | V | GTA | 557 | 1518 | 5.62% | |||
| L | CTA | 420 | 2916 | 10.79% | GTC | 178 | |||
| CTC | 203 | GTG | 223 | ||||||
| CTG | 213 | GTT | 560 | ||||||
| CTT | 616 | W | TGG | 497 | 497 | 1.84% | |||
| TTA | 881 | Y | TAC | 203 | 978 | 3.62% | |||
| TTG | 583 | TAT | 775 | ||||||
| M | ATG | 619 | 619 | 2.29% | Stop codon | TAA | 60 | 148 | 0.55% |
| N | AAC | 310 | 1245 | 4.61% | TAG | 42 | |||
| AAT | 935 | TGA | 46 |
| Species | Total | c | p2 | p1 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| all | (A)10 | (A)11 | (A)12 | (T)10 | (T)11 | (T)12 | ||||
| Pogostemon cablin | 52 | 6 | 0 | 46 | 11 | 6 | 3 | 10 | 6 | 2 |
| Scutellaria baicalensis | 26 | 3 | 2 | 21 | 2 | 3 | 0 | 5 | 5 | 1 |
| Scutellaria insignis | 26 | 1 | 2 | 23 | 4 | 1 | 0 | 5 | 2 | 0 |
| Premna microphylla | 39 | 4 | 1 | 34 | 8 | 4 | 1 | 8 | 3 | 5 |
| Tectona grandis | 33 | 2 | 2 | 29 | 9 | 1 | 0 | 10 | 1 | 1 |
| Lavandula angustifolia | 27 | 4 | 3 | 20 | 3 | 2 | 0 | 7 | 3 | 0 |
| Salvia miltiorrhiza | 30 | 2 | 1 | 27 | 3 | 3 | 1 | 5 | 3 | 4 |
| Rosmarinus officinalis | 20 | 2 | 2 | 16 | 4 | 1 | 0 | 6 | 3 | 1 |
| Origanum vulgare L. | 29 | 2 | 1 | 26 | 3 | 1 | 3 | 4 | 6 | 2 |
| Sesamum indicum | 23 | 0 | 2 | 21 | 6 | 0 | 0 | 7 | 5 | 0 |
| Utricularia gibba | 28 | 1 | 1 | 26 | 9 | 4 | 0 | 8 | 3 | 0 |
| Boea hygrometrica | 11 | 0 | 2 | 9 | 4 | 0 | 0 | 3 | 0 | 0 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Y.; Xiao, H.; Deng, C.; Xiong, L.; Yang, J.; Peng, C. The Complete Chloroplast Genome Sequences of the Medicinal Plant Pogostemon cablin. Int. J. Mol. Sci. 2016, 17, 820. https://0-doi-org.brum.beds.ac.uk/10.3390/ijms17060820
He Y, Xiao H, Deng C, Xiong L, Yang J, Peng C. The Complete Chloroplast Genome Sequences of the Medicinal Plant Pogostemon cablin. International Journal of Molecular Sciences. 2016; 17(6):820. https://0-doi-org.brum.beds.ac.uk/10.3390/ijms17060820
Chicago/Turabian StyleHe, Yang, Hongtao Xiao, Cao Deng, Liang Xiong, Jian Yang, and Cheng Peng. 2016. "The Complete Chloroplast Genome Sequences of the Medicinal Plant Pogostemon cablin" International Journal of Molecular Sciences 17, no. 6: 820. https://0-doi-org.brum.beds.ac.uk/10.3390/ijms17060820