
Effects of Nonlinearity and Network Architecture on the Performance of Supervised Neural Networks

 , , ,
, , ,
Abstract
:1. Introduction
2. Background and Objectives
3. Results and Discussion
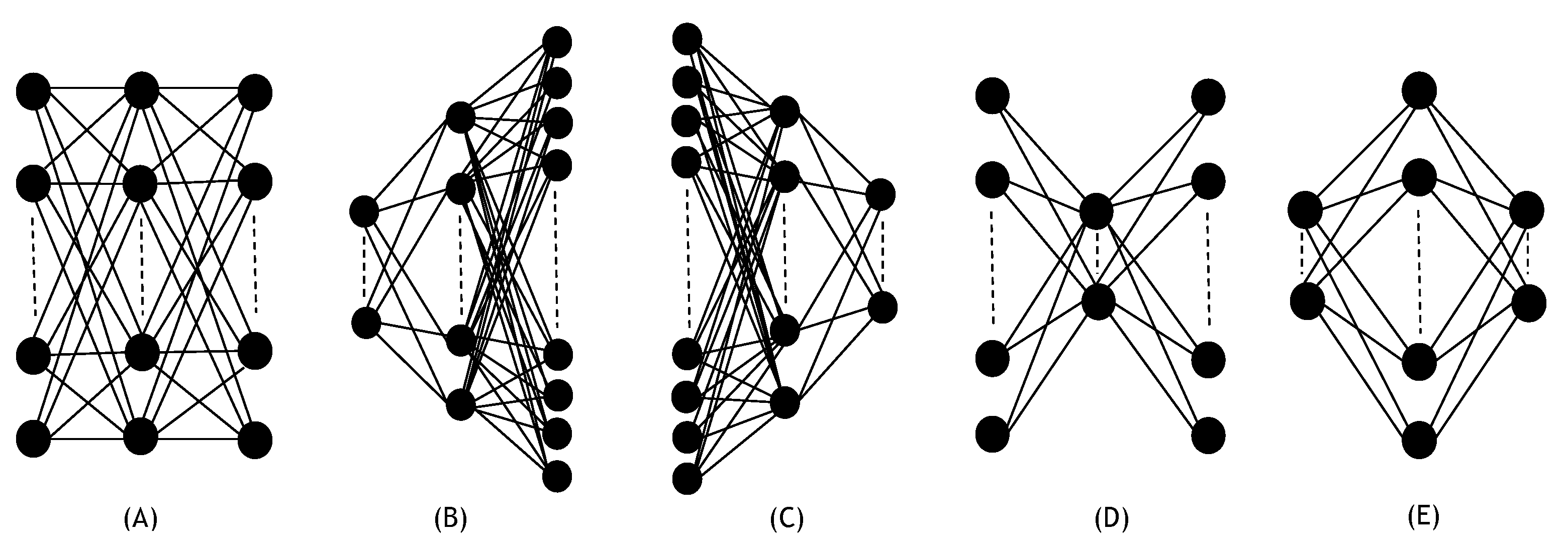
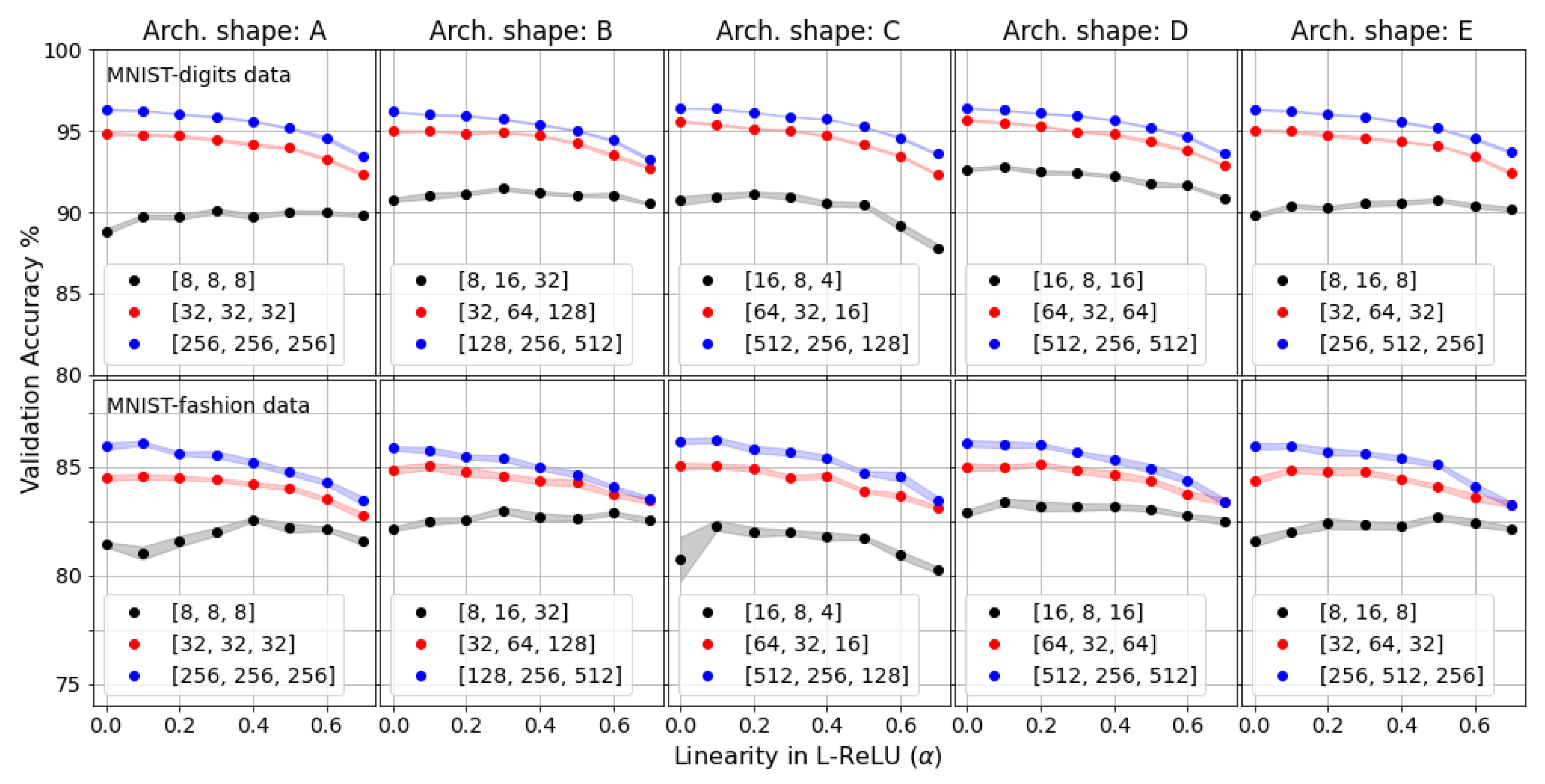
3.1. Effects of Nonlinearity in Different Network Architectures
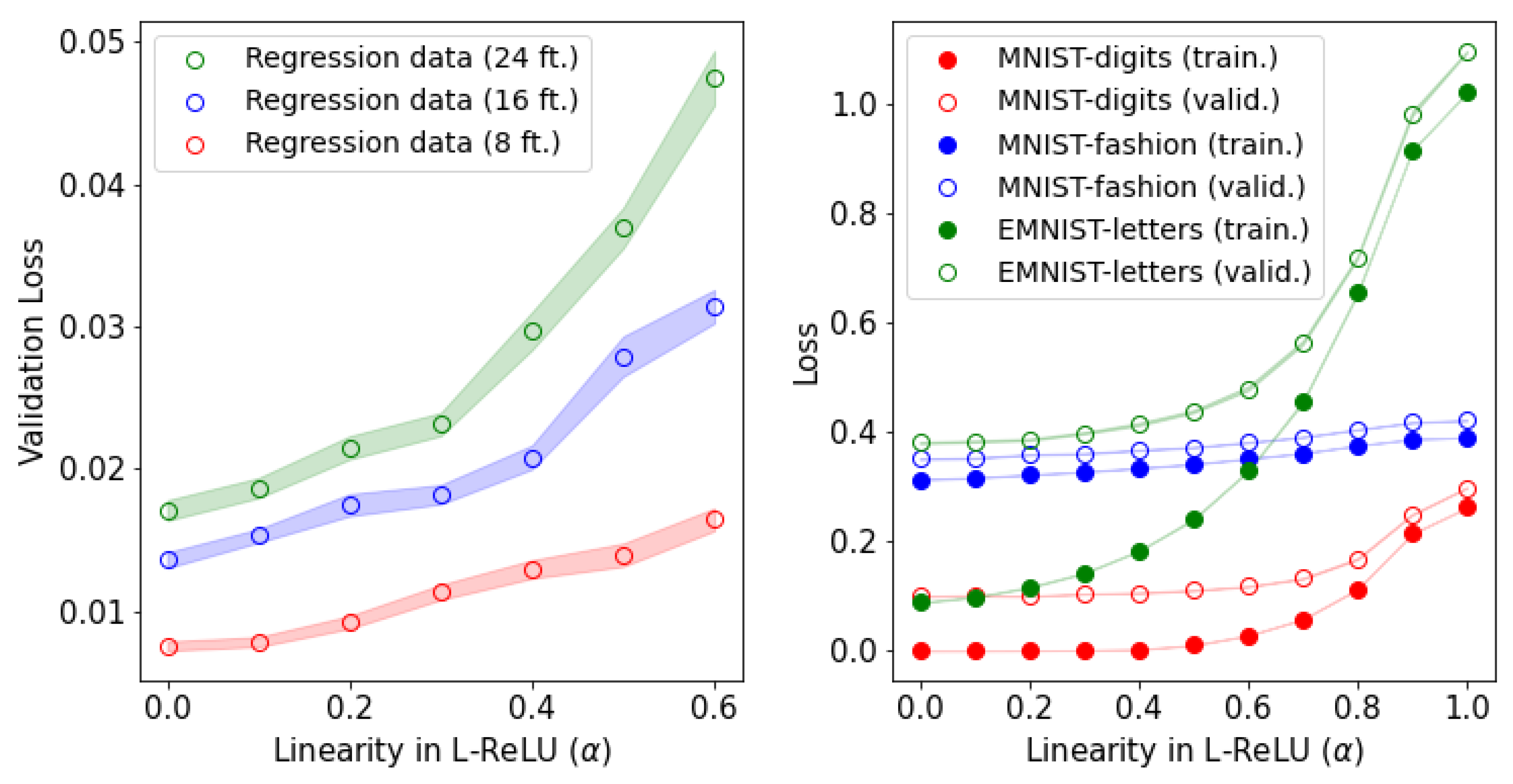
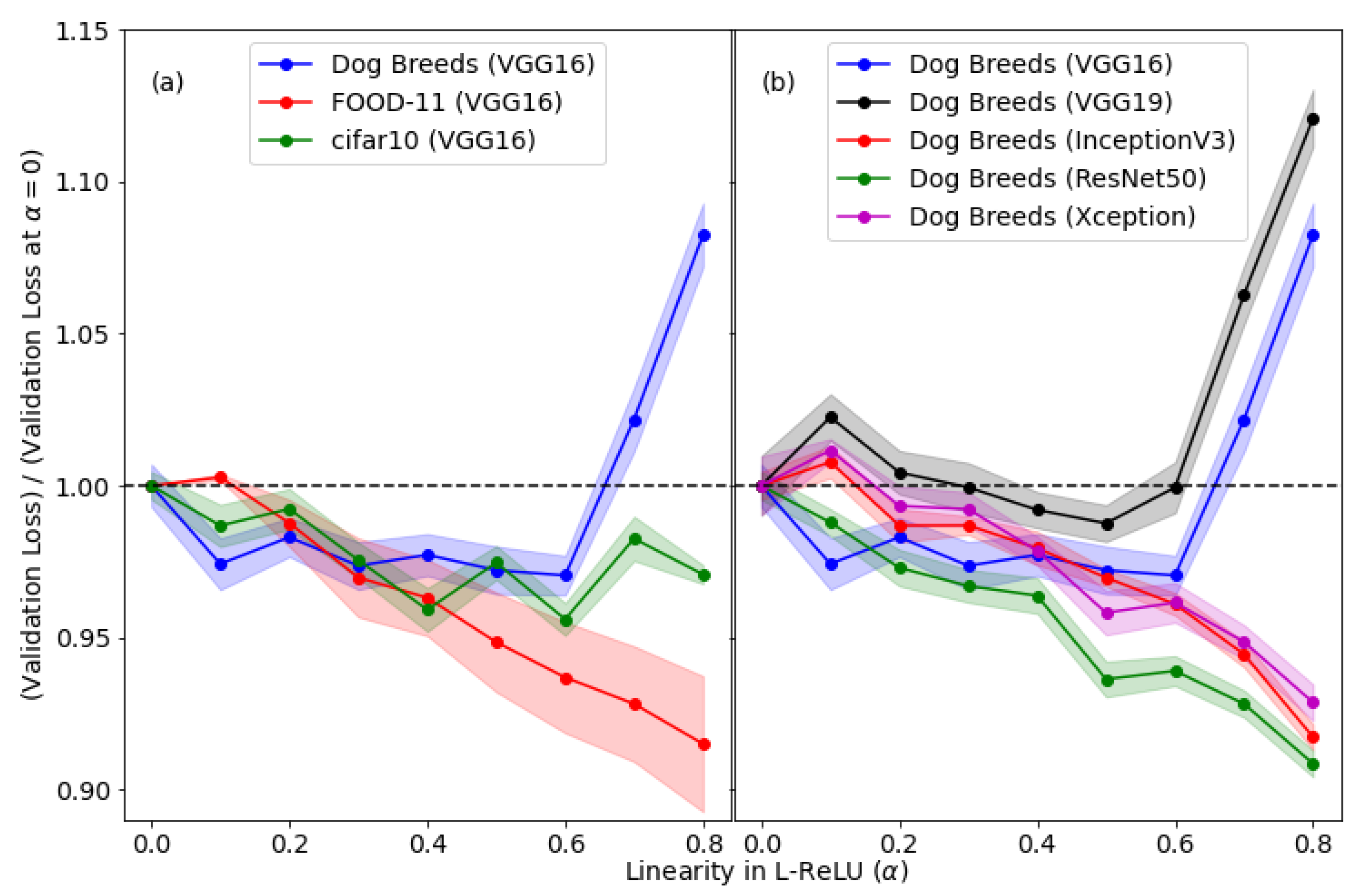
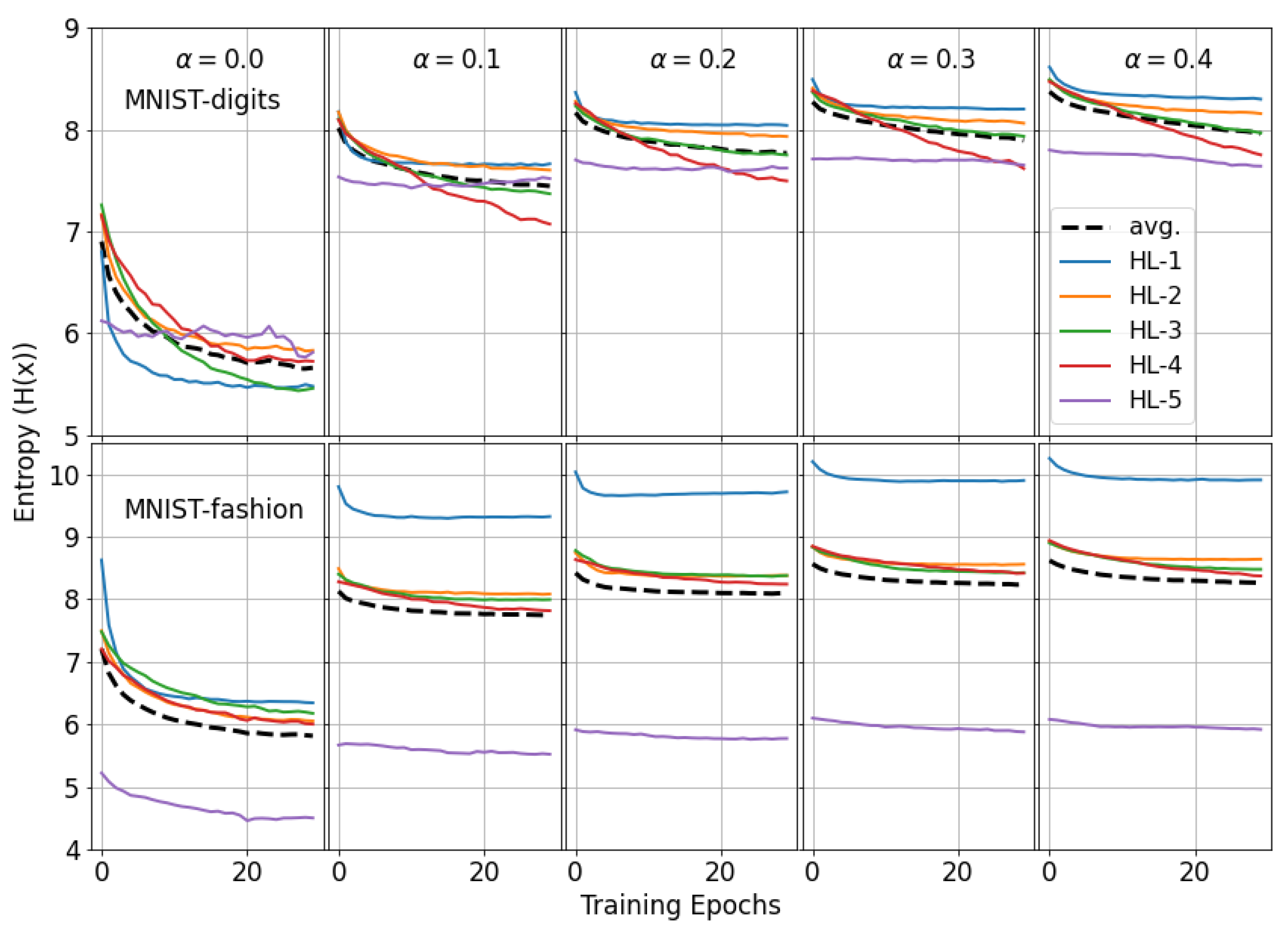
3.2. Effects of Nonlinearity for Different Data Domains
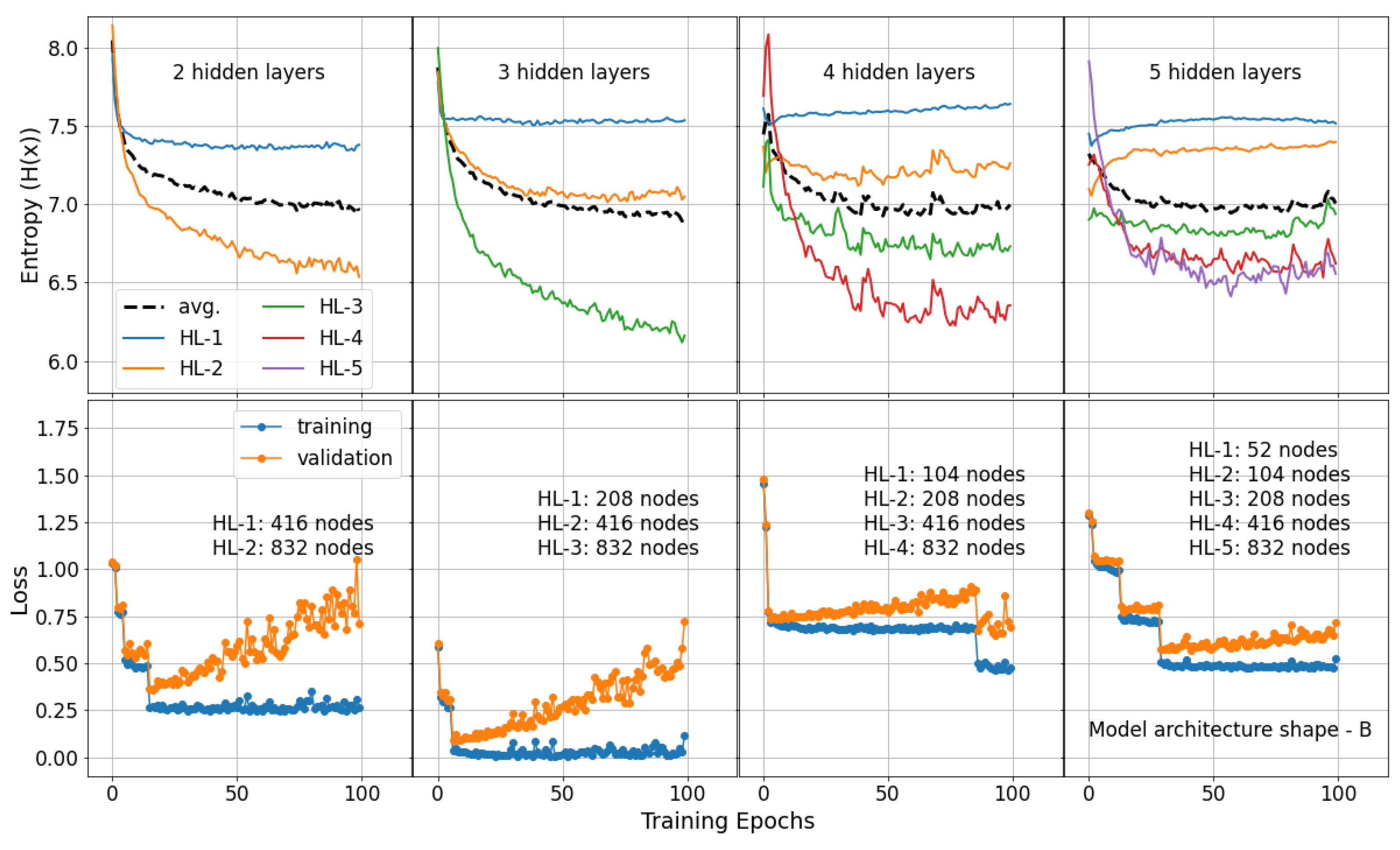
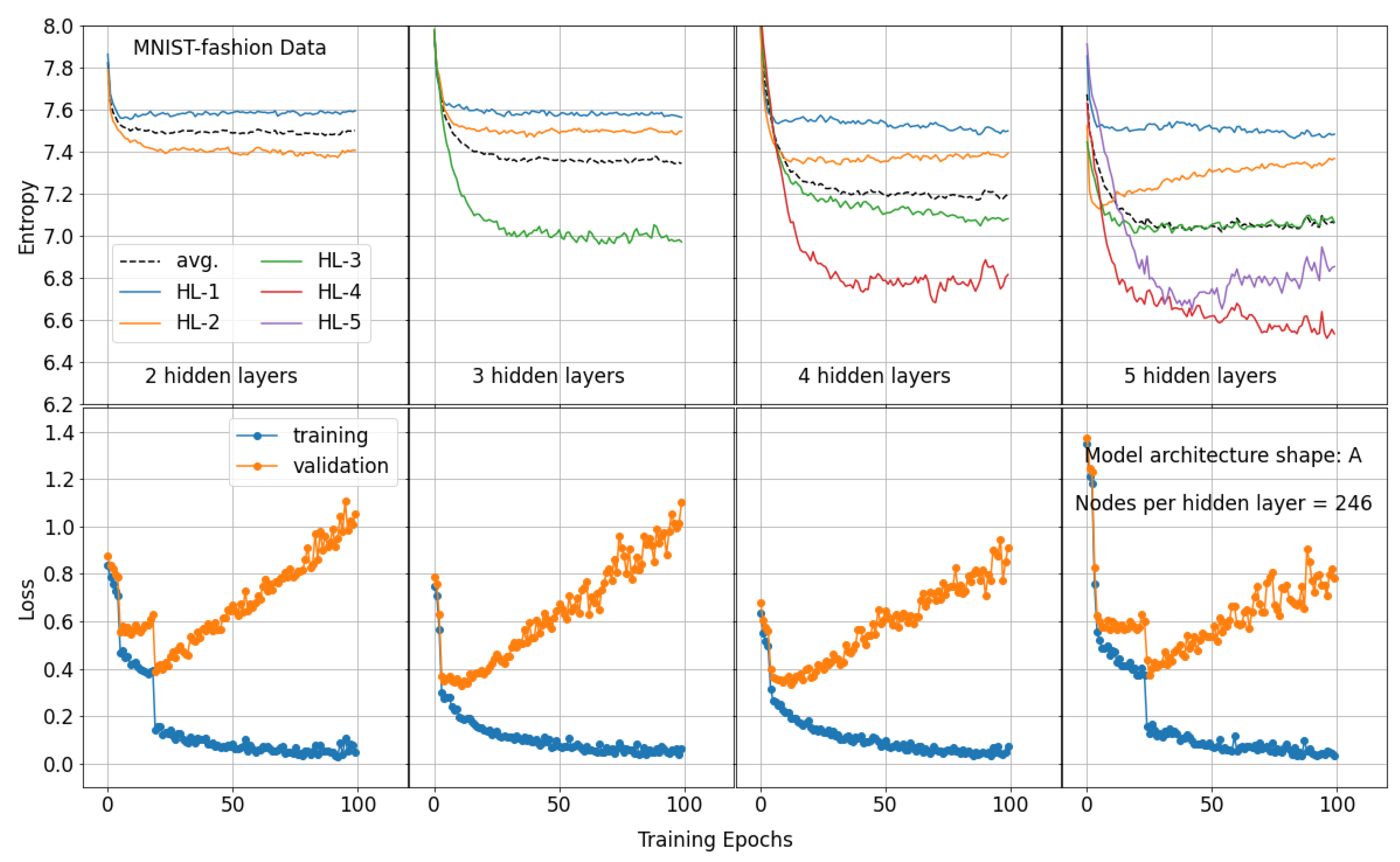
3.3. Entropy Profile of Shallow Neural Networks
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
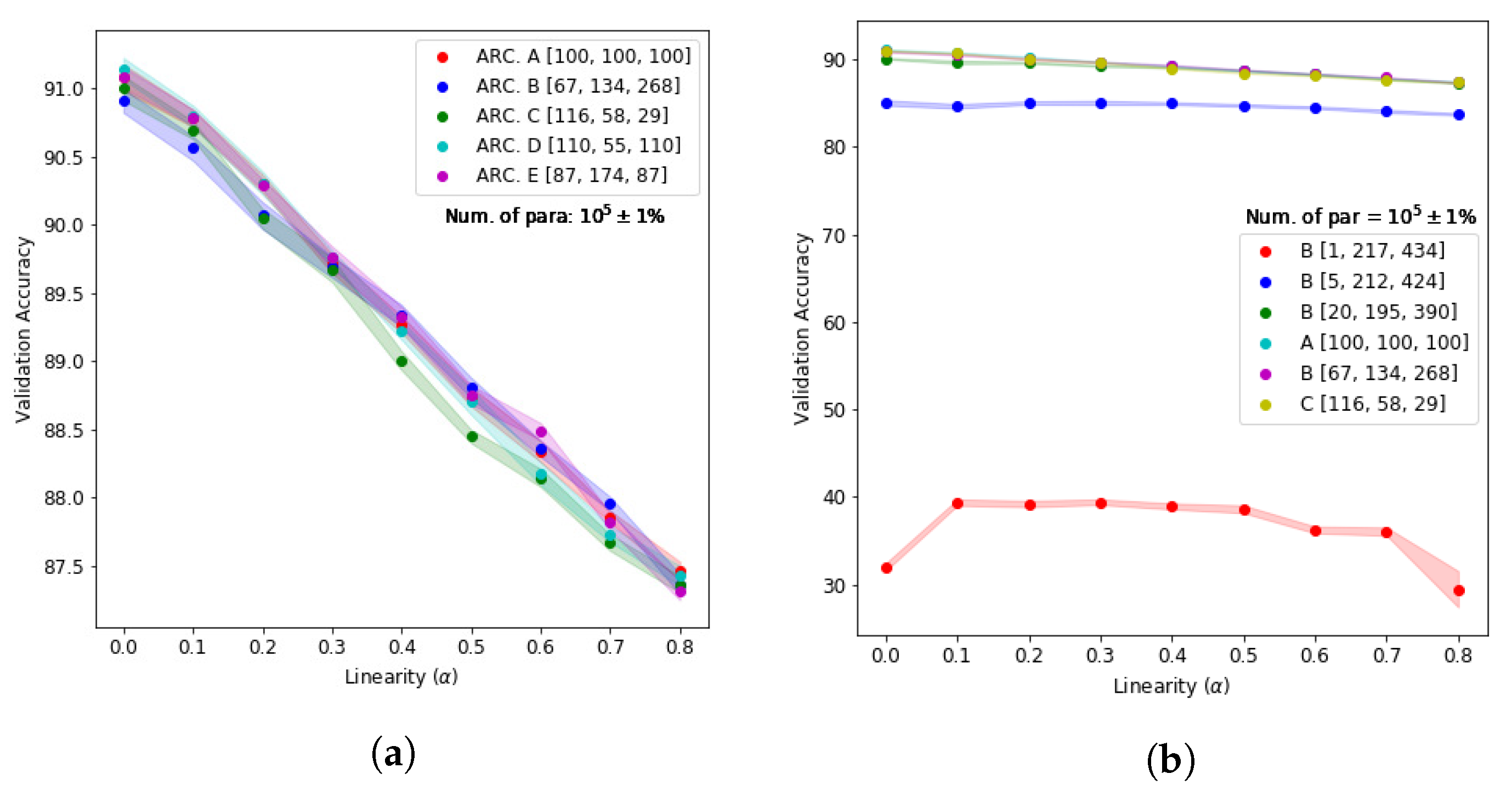
Appendix A.1. Accuracy vs. Linearity Factor for Different Model Architectures with Number of Parameters Fixed

Appendix A.2. Entropy Profile of Model Architecture Shape A Trained Using MNIST-Fashion Data

Appendix A.3. Entropy Profile of Model Architecture Shape B Trained Using MNIST-Fashion Data

Appendix A.4. Model Architectures Used for the Study of the Effects of Nonlinearity on the Model Performance in the Presence of Transfer Learning and Different Data Domains

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LAYER | SHAPE (in, out) | NUM. of PAR. |
|---|---|---|
| Layer-1 | (512, 128) | 65,664 |
| Layer-2 | (128, 512) | 66,048 |
| Layer-3 | (512, 512) | 262,656 |
| Layer-4 | (512, 128) | 65,664 |
| Output | (128, 11) | 1419 |
| LAYER | SHAPE (in, out) | NUM. of PAR. |
|---|---|---|
| Layer-1 | (16, 128) | 2176 |
| Layer-2 | (128, 512) | 66,048 |
| Layer-3 | (512, 512) | 262,656 |
| Layer-4 | (512, 128) | 65,664 |
| Output | (128, 1) | 129 |
| LAYER | SHAPE (in, out) | NUM. of PAR. |
|---|---|---|
| Layer-1 | (784, 128) | 100,480 |
| Layer-2 | (128, 512) | 66,048 |
| Layer-3 | (512, 512) | 262,656 |
| Layer-4 | (512, 128) | 65,664 |
| Output | (128, 10) | 1290 |
References
- Pedamonti, D. Comparison of non-linear activation functions for deep neural networks on MNIST classification task. arXiv 2018, arXiv:1804.02763. [Google Scholar]
- Nwankpa, C.; Ijomah, W.; Gachagan, A.; Marshall, S. Activation Functions: Comparison of trends in Practice and Research for Deep Learning. arXiv 2018, arXiv:1811.03378. [Google Scholar]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical Evaluation of Rectified Activations in Convolutional Network. arXiv 2015, arXiv:1505.00853. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on Machine Learning, ICML’10, Haifa, Israel, 21–24 June 2010; Omnipress: Madison, WI, USA, 2010; pp. 807–814. [Google Scholar]
- Arora, R.; Basu, A.; Mianjy, P.; Mukherjee, A. Understanding Deep Neural Networks with Rectified Linear Units. arXiv 2016, arXiv:1611.01491. [Google Scholar]
- Javid, A.M.; Das, S.; Skoglund, M.; Chatterjee, S. A ReLU Dense Layer to Improve the Performance of Neural Networks. arXiv 2020, arXiv:2010.13572. [Google Scholar]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the Difficulty of Training Recurrent Neural Networks. In Proceedings of the 30th International Conference on Machine Learning, ICML, Atlanta, GA, USA, 17–19 June 2013. [Google Scholar]
- Maas, A.L. Rectifier Nonlinearities Improve Neural Network Acoustic Models. In Proceedings of the 30th International Conference on Machine Learning (ICML), Atlanta, GA, USA, 17–19 June 2013. [Google Scholar]
- D’Souza, R.N.; Huang, P.Y.; Yeh, F.C. Structural Analysis and Optimization of Convolutional Neural Networks with a Small Sample Size. Sci. Rep. 2020, 10, 834. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; Volume 15, pp. 315–323. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Panigrahi, A.; Shetty, A.; Goyal, N. Effect of Activation Functions on the Training of Overparametrized Neural Nets. arXiv 2020, arXiv:1908.05660. [Google Scholar]
- Hahnloser, R.; Sarpeshkar, R.; Mahowald, M.; Douglas, R.; Seung, S. Digital selection and analogue amplification coexist in a cortex-inspired silicon circuit. Nature 2000, 405, 947–951. [Google Scholar] [CrossRef] [PubMed]
- Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.; Blum, M.; Hutter, F. Efficient and Robust Automated Machine Learning. In Advances in Neural Information Processing Systems; Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015; Volume 28, pp. 2962–2970. [Google Scholar]
- Hutter, F.; Hoos, H.; Leyton-Brown, K. An Efficient Approach for Assessing Hyperparameter Importance. In Proceedings of the 31st International Conference on Machine Learning ICML, Beijing, China, 21–26 June 2014. [Google Scholar]
- Probst, P.; Bischl, B.; Boulesteix, A.L. Tunability: Importance of Hyperparameters of Machine Learning Algorithms. arXiv 2018, arXiv:1802.09596. [Google Scholar]
- van Rijn, J.N.; Hutter, F. Hyperparameter Importance Across Datasets. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.; Zhang, K.; Ou, L.; Ba, C.; Wang, H.; Wang, C. Automatic Hyper-Parameter Optimization Based on Mapping Discovery from Data to Hyper-Parameters. arXiv 2020, arXiv:2003.01751. [Google Scholar]
- Lee, A.; Xin, D.; Lee, D.; Parameswaran, A. Demystifying a Dark Art: Understanding Real-World Machine Learning Model Development. arXiv 2020, arXiv:2005.01520. [Google Scholar]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef] [Green Version]
- Lu, L.; Shin, Y.; Su, Y.; Karniadakis, G.E. Dying ReLU and Initialization: Theory and Numerical Examples. arXiv 2019, arXiv:1903.06733. [Google Scholar] [CrossRef]
- Sperl, P.; Böttinger, K. Optimizing Information Loss Towards Robust Neural Networks. arXiv 2020, arXiv:2008.03072. [Google Scholar]
- Foggo, B.; Yu, N.; Shi, J.; Gao, Y. Information Losses in Neural Classifiers From Sampling. IEEE Trans. Neural Networks Learn. Syst. 2020, 31, 4073–4083. [Google Scholar] [CrossRef]
- LeCun, Y.; Cortes, C. MNIST Handwritten Digit Database. 2010. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 10 October 2020).
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Cohen, G.; Afshar, S.; Tapson, J.; Schaik, A.V. EMNIST: Extending MNIST to handwritten letters. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Chollet, F. Keras: The Python Deep Learning API. 2015. Available online: https://github.com/fchollet/keras (accessed on 10 January 2021).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Nystrom, N.A.; Levine, M.J.; Roskies, R.Z.; Scott, J.R. Bridges: A Uniquely Flexible HPC Resource for New Communities and Data Analytics. In Proceedings of the 2015 XSEDE Conference: Scientific Advancements Enabled by Enhanced Cyberinfrastructure, XSEDE ’15, St. Louis, MO, USA, 26–30 July 2015; ACM: New York, NY, USA, 2015; pp. 30:1–30:8. [Google Scholar] [CrossRef]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Mannor, S.; Peleg, D.; Rubinstein, R. The cross entropy method for classification. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 561–568. [Google Scholar] [CrossRef] [Green Version]
- Singla, A.; Yuan, L.; Ebrahimi, T. Food/Non-food Image Classification and Food Categorization using Pre-Trained GoogLeNet Model. In Proceedings of the 2nd International Workshop on MADiMa, Amsterdam, The Netherlands, 16 October 2016; pp. 3–11. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://www.cs.toronto.edu/~kriz/cifar.html (accessed on 15 January 2021).
- Liu, J.; Kanazawa, A.; Jacobs, D.; Belhumeur, P. Dog Breed Classification Using Part Localization. In Computer Vision—ECCV; Springer: Berlin/Heidelberg, Germany, 2012; pp. 172–185. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. IJCV 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv 2015, arXiv:1512.00567. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. arXiv 2017, arXiv:1610.02357. [Google Scholar]
- The Negative Log Likelihood Loss. Available online: https://pytorch.org/docs/stable/generated/torch.nn.NLLLoss.html (accessed on 10 December 2020).
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Statist. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Joyce, J.M. Kullback-Leibler Divergence. In International Encyclopedia of Statistical Science; Lovric, M., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 720–722. [Google Scholar] [CrossRef]







| Width | Arch. A | Arch. B | Arch. C | Arch. D | Arch. E |
|---|---|---|---|---|---|
| width-1 | (8, 8, 8) | (8, 16, 32) | (16, 8, 4) | (16, 8, 16) | (8, 16, 8) |
| width-2 | (32, 32, 32) | (32, 64, 128) | (64, 32, 16) | (64, 32, 64) | (32, 64, 32) |
| width-3 | (256, 256, 256) | (128, 256, 512) | (512, 256, 128) | (512, 256, 512) | (256, 512, 256) |
| Training | Width | Optimal Valve of the Linearity () in the Network | ||||
|---|---|---|---|---|---|---|
| Data Set | per Layer | Arch. A | Arch. B | Arch. C | Arch. D | Arch. E |
| MNIST- | width-1 | 0.3 | 0.3 | 0.2 | 0.1 | 0.5 |
| digits | width-2 | 0.0 | 0.1 | 0.0 | 0.0 | 0.0 |
| width-3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | |
| MNIST- | width-1 | 0.4 | 0.3 | 0.1 | 0.1 | 0.5 |
| fashion | width-2 | 0.1 | 0.1 | 0.1 | 0.0 | 0.1 |
| width-3 | 0.1 | 0.0 | 0.1 | 0.0 | 0.0 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kulathunga, N.; Ranasinghe, N.R.; Vrinceanu, D.; Kinsman, Z.; Huang, L.; Wang, Y. Effects of Nonlinearity and Network Architecture on the Performance of Supervised Neural Networks. Algorithms 2021, 14, 51. https://0-doi-org.brum.beds.ac.uk/10.3390/a14020051
Kulathunga N, Ranasinghe NR, Vrinceanu D, Kinsman Z, Huang L, Wang Y. Effects of Nonlinearity and Network Architecture on the Performance of Supervised Neural Networks. Algorithms. 2021; 14(2):51. https://0-doi-org.brum.beds.ac.uk/10.3390/a14020051
Chicago/Turabian StyleKulathunga, Nalinda, Nishath Rajiv Ranasinghe, Daniel Vrinceanu, Zackary Kinsman, Lei Huang, and Yunjiao Wang. 2021. "Effects of Nonlinearity and Network Architecture on the Performance of Supervised Neural Networks" Algorithms 14, no. 2: 51. https://0-doi-org.brum.beds.ac.uk/10.3390/a14020051