
Spatial Prediction of Agrochemical Properties on the Scale of a Single Field Using Machine Learning Methods Based on Remote Sensing Data †


Abstract
:1. Introduction
2. Materials and Methods
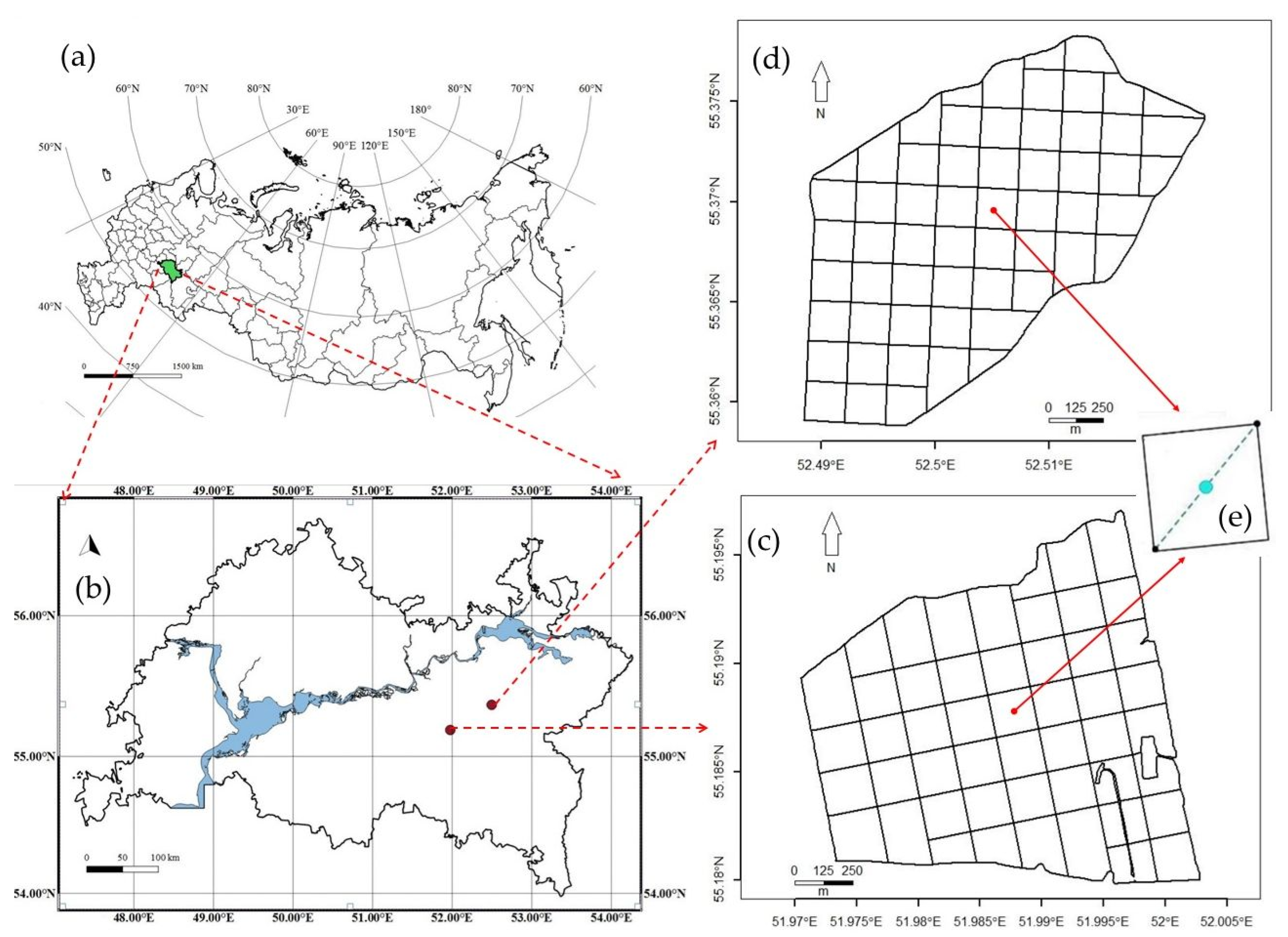
2.1. Study Area and Sampling Design
2.2. Remote Sensing Data and Spectral Indices
2.3. Spatial Prediction Methods
- Fitting the model to the original data and evaluating the performance indicator.
- Getting a bootstrap sample with replacement from the original data.
- Fitting the model to the bootstrap dataset and evaluating the performance indicator.
- Fitting the model from the bootstrap dataset to the original dataset and evaluating the performance indicator.
- Evaluation of optimism by the average value of the difference in the performance indicator of the model from point 3 and the model from point 4.
- Evaluation of the performance indicator adjusted for optimism by subtracting the value of the optimism from the performance indicator of the model from point 1.
2.4. Software
3. Results and Discussion
3.1. Descriptive Statistics
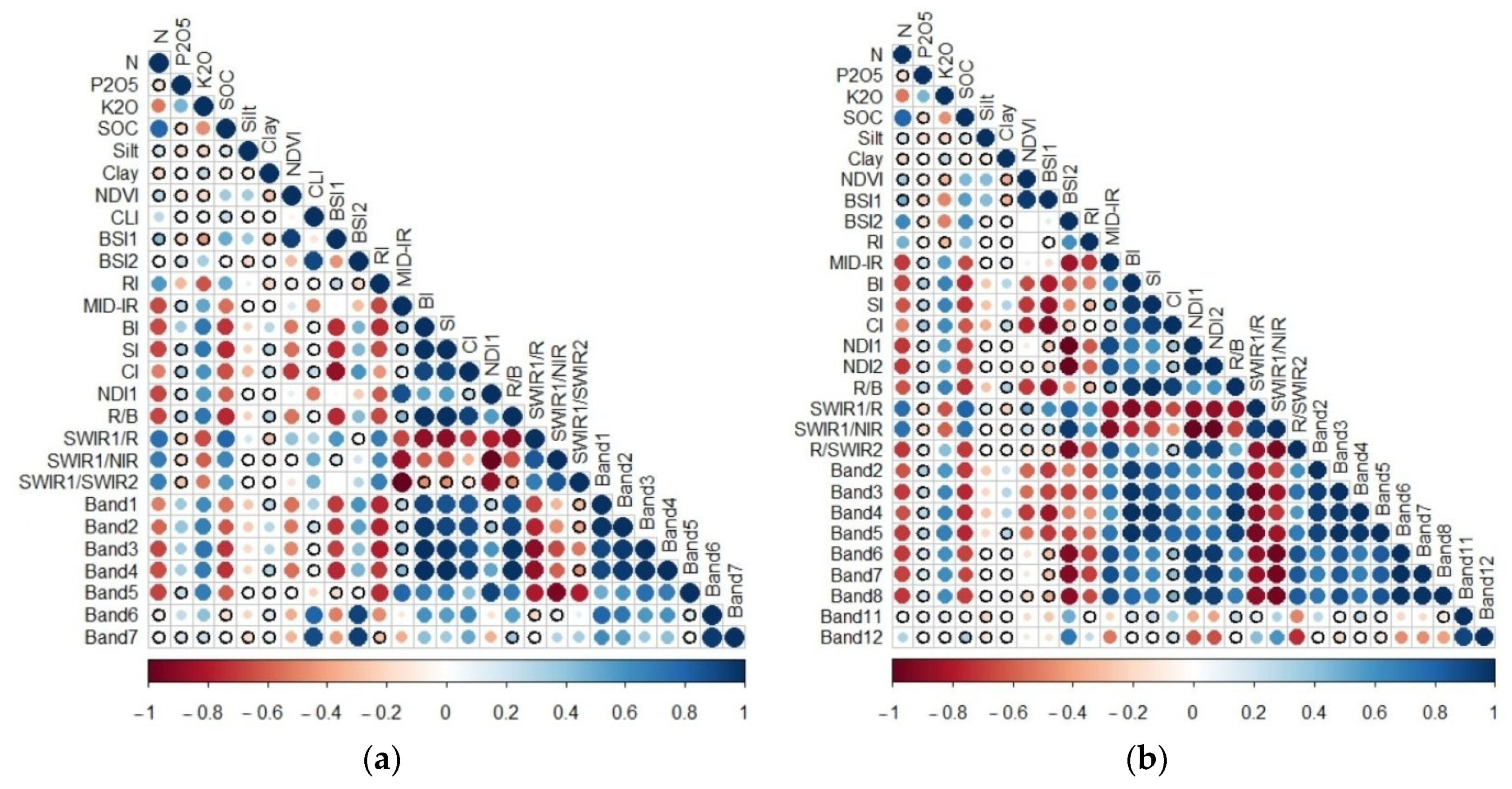
3.2. Correlation Relations
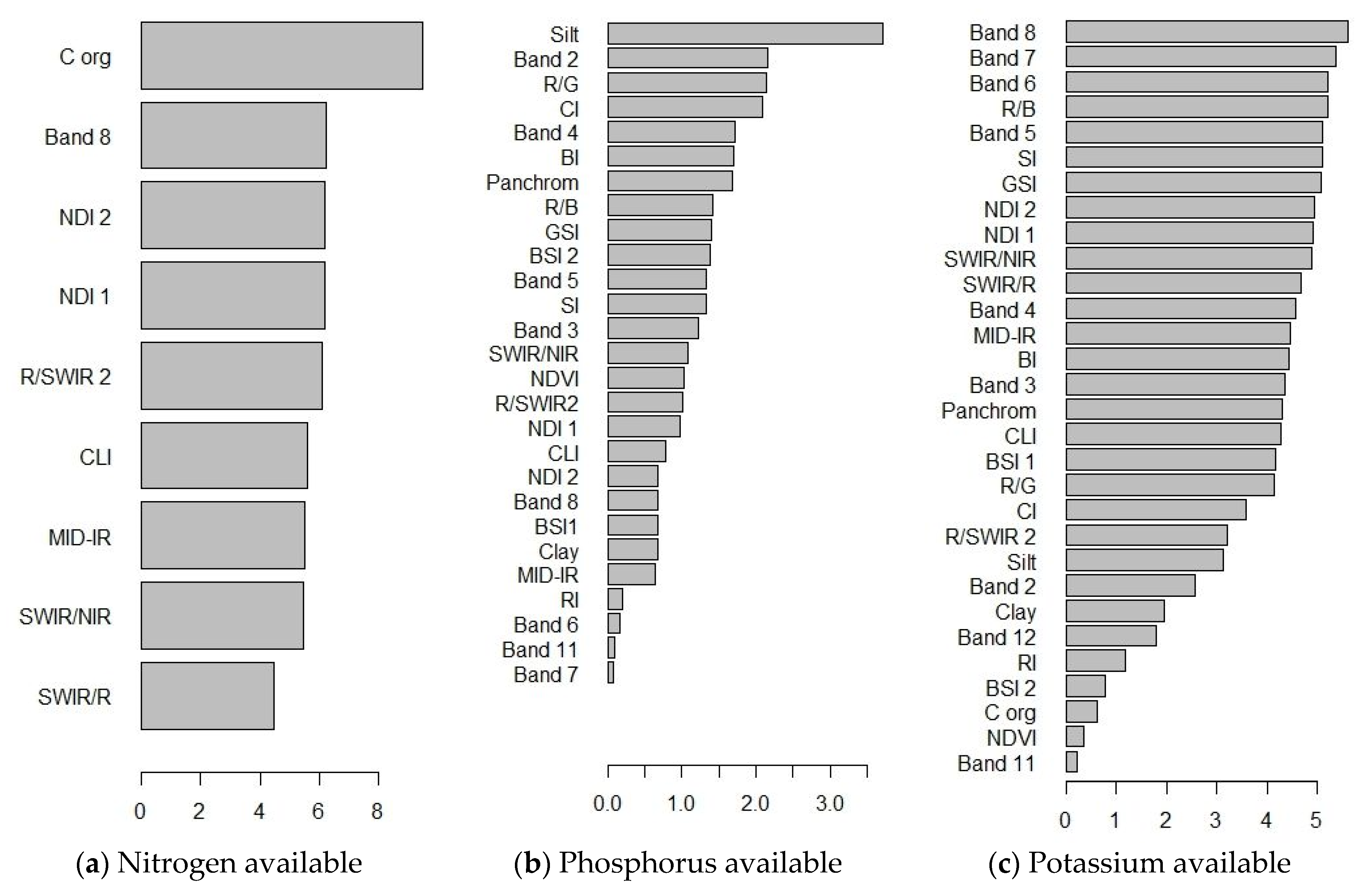
3.3. Accuracy of Remote Sensing-Based Models
3.4. Accuracy of Models Based on Remote Sensing and Soil Properties
3.5. Validation of the Models Based on an Independent Data Sample
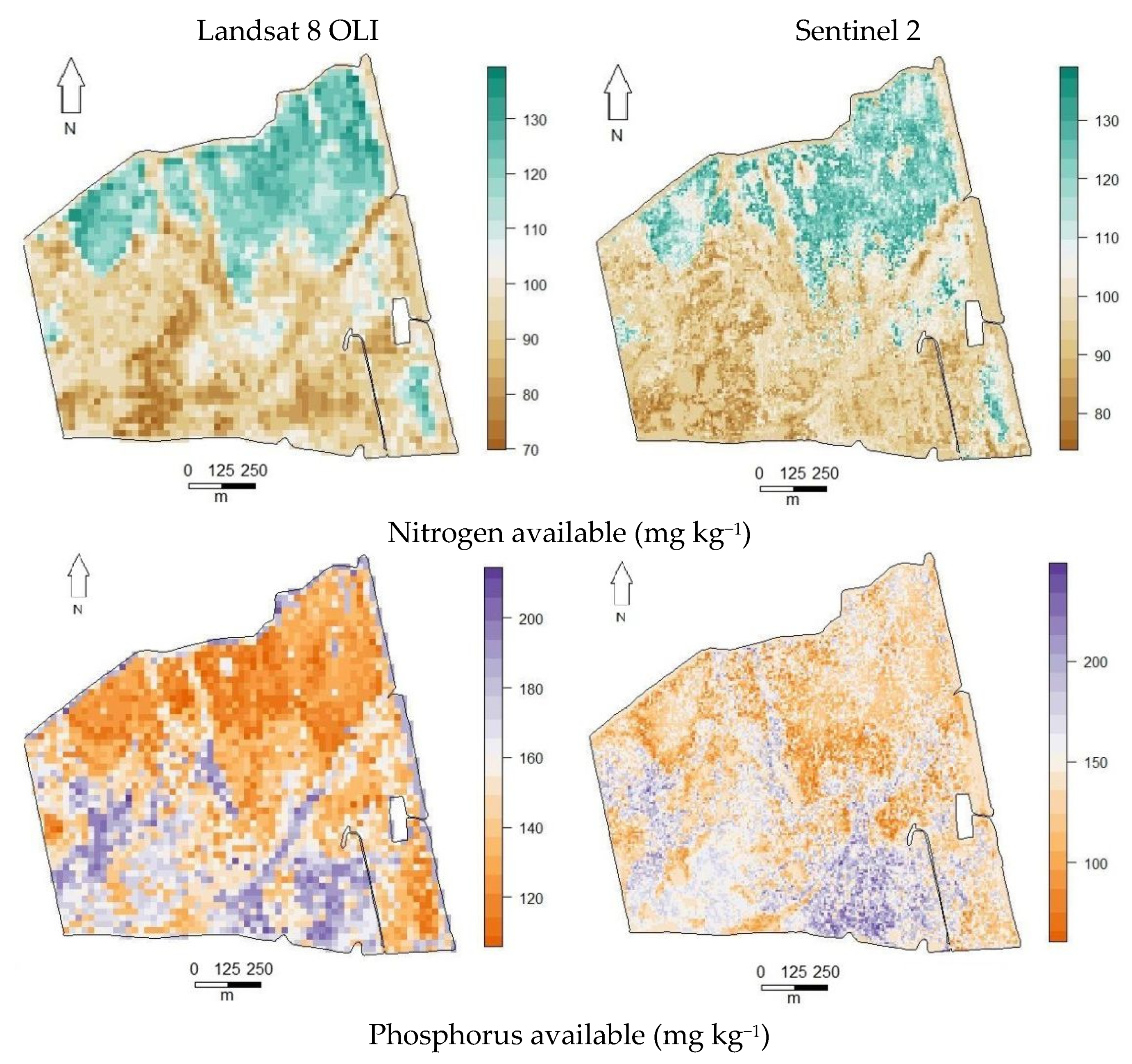
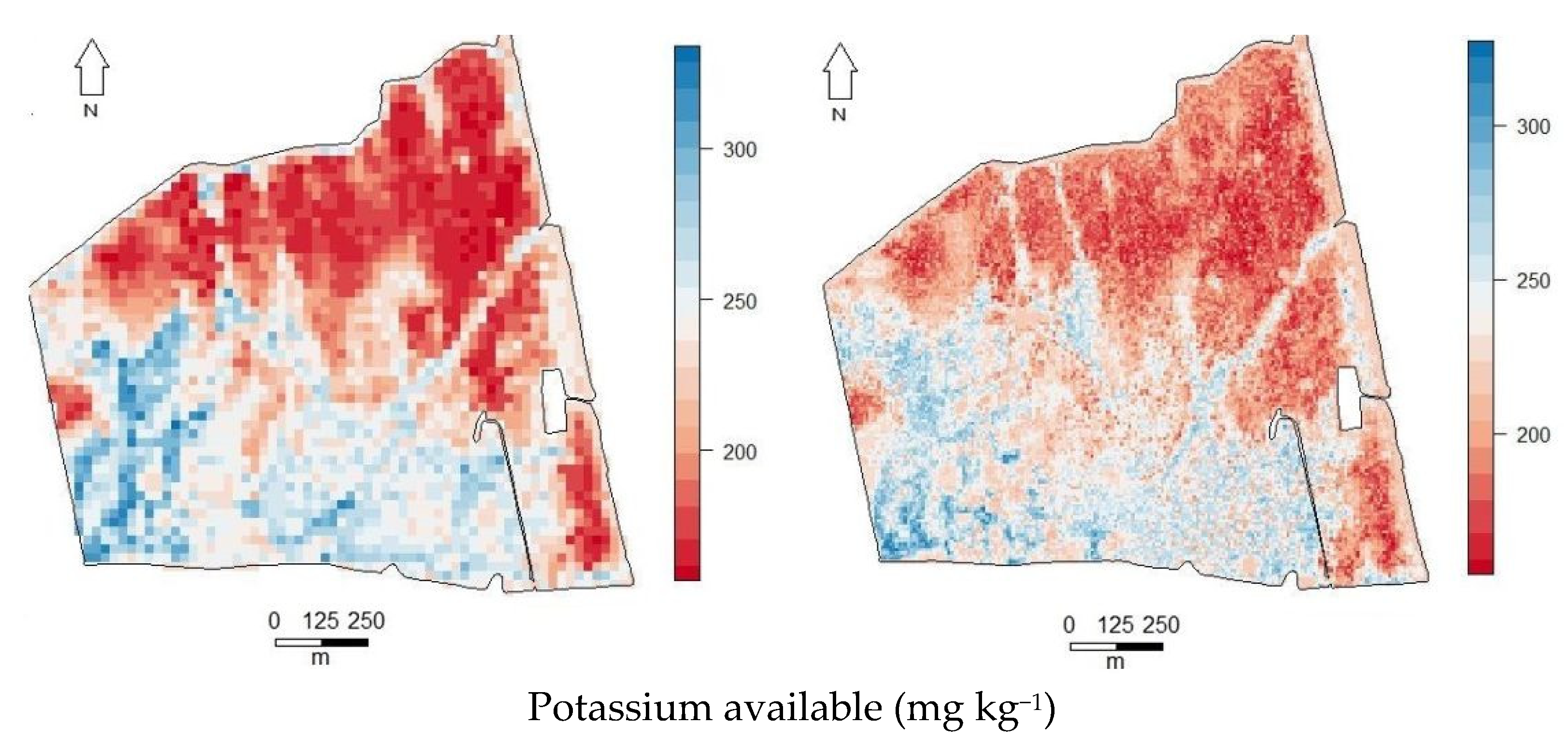
3.6. Final Spatial Prediction Maps
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Oliver, M.A. An Overview of Geostatistics and Precision Agriculture. In Geostatistical Applications for Precision Agriculture; Oliver, M.A., Ed.; Springer: Dordrecht, The Netherlands, 2010; pp. 1–34. [Google Scholar] [CrossRef]
- Sozzi, M.; Bernardi, E.; Kayad, A.; Marinello, F.; Boscaro, D.; Cogato, A.; Gasparini, F.; Tomasi, D. On-the-Go Variable Rate Fertilizer Application on Vineyard Using a Proximal Spectral Sensor. In Proceedings of the 2020 IEEE International Workshop on Metrology for Agriculture and Forestry (MetroAgriFor), Trento, Italy, 4–6 November 2020; pp. 343–347. [Google Scholar]
- Wiesmeier, M.; Barthold, F.; Blank, B.; Kögel-Knabner, I. Digital Mapping of Soil Organic Matter Stocks Using Random Forest Modeling in a Semi-Arid Steppe Ecosystem. Plant Soil 2011, 340, 7–24. [Google Scholar] [CrossRef]
- Kerry, R.; Goovaerts, P.; Rawlins, B.G.; Marchant, B.P. Disaggregation of Legacy Soil Data Using Area to Point Kriging for Mapping Soil Organic Carbon at the Regional Scale. Geoderma 2012, 170, 347–358. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dai, F.; Zhou, Q.; Lv, Z.; Wang, X.; Liu, G. Spatial Prediction of Soil Organic Matter Content Integrating Artificial Neural Network and Ordinary Kriging in Tibetan Plateau. Ecol. Indic. 2014, 45, 184–194. [Google Scholar] [CrossRef]
- Martin, M.P.; Orton, T.G.; Lacarce, E.; Meersmans, J.; Saby, N.P.A.; Paroissien, J.B.; Jolivet, C.; Boulonne, L.; Arrouays, D. Evaluation of Modelling Approaches for Predicting the Spatial Distribution of Soil Organic Carbon Stocks at the National Scale. Geoderma 2014, 223–225, 97–107. [Google Scholar] [CrossRef] [Green Version]
- Mahmoudzadeh, H.; Matinfar, H.R.; Taghizadeh-Mehrjardi, R.; Kerry, R. Spatial Prediction of Soil Organic Carbon Using Machine Learning Techniques in Western Iran. Geoderma Reg. 2020, 21, e00260. [Google Scholar] [CrossRef]
- Ward, K.J.; Chabrillat, S.; Brell, M.; Castaldi, F.; Spengler, D.; Foerster, S. Mapping Soil Organic Carbon for Airborne and Simulated EnMAP Imagery Using the LUCAS Soil Database and a Local PLSR. Remote Sens. 2020, 12, 3451. [Google Scholar] [CrossRef]
- Sakizadeh, M.; Rodríguez Martín, J.A. Spatial Methods to Analyze the Relationship between Spanish Soil Properties and Cadmium Content. Chemosphere 2021, 268, 129347. [Google Scholar] [CrossRef]
- Jafari, A.; Khademi, H.; Finke, P.A.; Van de Wauw, J.; Ayoubi, S. Spatial Prediction of Soil Great Groups by Boosted Regression Trees Using a Limited Point Dataset in an Arid Region, Southeastern Iran. Geoderma 2014, 232–234, 148–163. [Google Scholar] [CrossRef]
- Matinfar, H.R.; Maghsodi, Z.; Mousavi, S.R.; Rahmani, A. Evaluation and Prediction of Topsoil Organic Carbon Using Machine Learning and Hybrid Models at a Field-Scale. CATENA 2021, 202, 105258. [Google Scholar] [CrossRef]
- Grunwald, S.; Yu, C.; Xiong, X. Transferability and Scalability of Soil Total Carbon Prediction Models in Florida, USA. Pedosphere 2018, 28, 856–872. [Google Scholar] [CrossRef]
- Webster, R.; Oliver, M.A. Sample Adequately to Estimate Variograms of Soil Properties. J. Soil Sci. 1992, 43, 177–192. [Google Scholar] [CrossRef]
- Kerry, R.; Oliver, M.; Frogbrook, Z. Sampling in Precision Agriculture. In Geostatistical Applications for Precision Agriculture; Oliver, M.A., Ed.; Springer: Dordrecht, The Netherlands, 2010; pp. 35–63. [Google Scholar] [CrossRef]
- Saito, H.; Goovaerts, P. Geostatistical Interpolation of Positively Skewed and Censored Data in a Dioxin-Contaminated Site. Environ. Sci. Technol. 2000, 34, 4228–4235. [Google Scholar] [CrossRef]
- Godwin, R.J.; Miller, P.C.H. A Review of the Technologies for Mapping Within-Field Variability. Biosyst. Eng. 2003, 84, 393–407. [Google Scholar] [CrossRef] [Green Version]
- Goovaerts, P.; Kerry, R. Using Ancillary Data to Improve Prediction of Soil and Crop Attributes in Precision Agriculture. In Geostatistical Applications for Precision Agriculture; Oliver, M.A., Ed.; Springer: Dordrecht, The Netherlands, 2010; pp. 167–194. [Google Scholar] [CrossRef]
- Hengl, T.; Heuvelink, G.B.M.; Stein, A. A Generic Framework for Spatial Prediction of Soil Variables Based on Regression-Kriging. Geoderma 2004, 120, 75–93. [Google Scholar] [CrossRef] [Green Version]
- Hengl, T.; Heuvelink, G.B.M.; Rossiter, D.G. About Regression-Kriging: From Equations to Case Studies. Comput. Geosci. 2007, 33, 1301–1315. [Google Scholar] [CrossRef]
- Keskin, H.; Grunwald, S. Regression Kriging as a Workhorse in the Digital Soil Mapper’s Toolbox. Geoderma 2018, 326, 22–41. [Google Scholar] [CrossRef]
- Lin, Y.-P.; Cheng, B.-Y.; Chu, H.-J.; Chang, T.-K.; Yu, H.-L. Assessing How Heavy Metal Pollution and Human Activity Are Related by Using Logistic Regression and Kriging Methods. Geoderma 2011, 163, 275–282. [Google Scholar] [CrossRef]
- Sahabiev, I.A.; Ryazanov, S.S.; Kolcova, T.G.; Grigoryan, B.R. Selection of a Geostatistical Method to Interpolate Soil Properties of the State Crop Testing Fields Using Attributes of a Digital Terrain Model. Eurasian Soil Sci. 2018, 51, 255–267. [Google Scholar] [CrossRef]
- Wadoux, A.; Minasny, B.; Mcbratney, A. Machine learning for digital soil mapping: Applications, challenges and suggested solutions. Earth-Sci. Rev. 2020, 210, 103359. [Google Scholar] [CrossRef]
- Tarasov, D.A.; Buevich, A.G.; Sergeev, A.P.; Shichkin, A.V. High Variation Topsoil Pollution Forecasting in the Russian Subarctic: Using Artificial Neural Networks Combined with Residual Kriging. Appl. Geochem. 2018, 88, 188–197. [Google Scholar] [CrossRef]
- Al-Ruzouq, R.; Gibril, M.B.A.; Shanableh, A.; Kais, A.; Hamed, O.; Al-Mansoori, S.; Khalil, M.A. Sensors, Features, and Machine Learning for Oil Spill Detection and Monitoring: A Review. Remote Sens. 2020, 12, 3338. [Google Scholar] [CrossRef]
- Shi, T.; Yang, C.; Liu, H.; Wu, C.; Wang, Z.; Li, H.; Zhang, H.; Guo, L.; Wu, G.; Su, F. Mapping Lead Concentrations in Urban Topsoil Using Proximal and Remote Sensing Data and Hybrid Statistical Approaches. Environ. Pollut. 2021, 272, 116041. [Google Scholar] [CrossRef]
- Were, K.; Bui, D.T.; Dick, Ø.B.; Singh, B.R. A Comparative Assessment of Support Vector Regression, Artificial Neural Networks, and Random Forests for Predicting and Mapping Soil Organic Carbon Stocks across an Afromontane Landscape. Ecol. Indic. 2015, 52, 394–403. [Google Scholar] [CrossRef]
- Chen, L.; Ren, C.; Li, L.; Wang, Y.; Zhang, B.; Wang, Z.; Li, L. A Comparative Assessment of Geostatistical, Machine Learning, and Hybrid Approaches for Mapping Topsoil Organic Carbon Content. ISPRS Int. J. Geo-Inf. 2019, 8, 174. [Google Scholar] [CrossRef] [Green Version]
- Vågen, T.-G.; Winowiecki, L.A.; Tondoh, J.E.; Desta, L.T.; Gumbricht, T. Mapping of Soil Properties and Land Degradation Risk in Africa Using MODIS Reflectance. Geoderma 2016, 263, 216–225. [Google Scholar] [CrossRef] [Green Version]
- Deiss, L.; Margenot, A.J.; Culman, S.W.; Demyan, M.S. Tuning Support Vector Machines Regression Models Improves Prediction Accuracy of Soil Properties in MIR Spectroscopy. Geoderma 2020, 365, 114227. [Google Scholar] [CrossRef]
- Lo Seen, D.; Ramesh, B.R.; Nair, K.M.; Martin, M.; Arrouays, D.; Bourgeon, G. Soil carbon stocks, deforestation and land-cover changes in the Western Ghats biodiversity hotspot (India). Glob. Chang. Biol. 2010, 16, 1777–1792. [Google Scholar] [CrossRef]
- Kovačević, M.; Bajat, B.; Gajić, B. Soil Type Classification and Estimation of Soil Properties Using Support Vector Machines. Geoderma 2010, 154, 340–347. [Google Scholar] [CrossRef]
- Suuster, E.; Ritz, C.; Roostalu, H.; Kõlli, R.; Astover, A. Modelling Soil Organic Carbon Concentration of Mineral Soils in Arable Land Using Legacy Soil Data. Eur. J. Soil Sci. 2012, 63, 351–359. [Google Scholar] [CrossRef]
- Taghizadeh-Mehrjardi, R.; Nabiollahi, K.; Kerry, R. Digital Mapping of Soil Organic Carbon at Multiple Depths Using Different Data Mining Techniques in Baneh Region, Iran. Geoderma 2016, 266, 98–110. [Google Scholar] [CrossRef]
- Pouladi, N.; Møller, A.B.; Tabatabai, S.; Greve, M.H. Mapping Soil Organic Matter Contents at Field Level with Cubist, Random Forest and Kriging. Geoderma 2019, 342, 85–92. [Google Scholar] [CrossRef]
- Mirzaee, S.; Ghorbani-Dashtaki, S.; Mohammadi, J.; Asadi, H.; Asadzadeh, F. Spatial Variability of Soil Organic Matter Using Remote Sensing Data. CATENA 2016, 145, 118–127. [Google Scholar] [CrossRef]
- Pahlavan-Rad, M.R.; Akbarimoghaddam, A. Spatial Variability of Soil Texture Fractions and PH in a Flood Plain (Case Study from Eastern Iran). CATENA 2018, 160, 275–281. [Google Scholar] [CrossRef]
- Vågen, T.-G.; Winowiecki, L.; Abegaz, A.; Hadgu, K. Landsat-Based Approaches for Mapping of Land Degradation Prevalence and Soil Functional Properties in Ethiopia. Remote Sens. Environ. 2013, 134, 266–275. [Google Scholar] [CrossRef]
- Žížala, D.; Minařík, R.; Zádorová, T. Soil Organic Carbon Mapping Using Multispectral Remote Sensing Data: Prediction Ability of Data with Different Spatial and Spectral Resolutions. Remote Sens. 2019, 11, 2947. [Google Scholar] [CrossRef]
- Chen, L.; Ren, C.; Zhang, B.; Wang, Z. Multi-Sensor Prediction of Stand Volume by a Hybrid Model of Support Vector Machine for Regression Kriging. Forests 2020, 11, 296. [Google Scholar] [CrossRef] [Green Version]
- Chavez, P.S., Jr. An Improved Dark-Object Subtraction Technique for Atmospheric Scattering Correction of Multispectral Data. Remote Sens. Environ. 1988, 24, 459–479. [Google Scholar] [CrossRef]
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Third Earth Resources Technology Satellite-1 Symposium—Volume I: Technical Presentations; NASA SP-351; NASA: Washington, DC, USA, 1974; p. 309.
- Xiao, J.; Shen, Y.; Tateishi, R.; Bayaer, W. Development of Topsoil Grain Size Index for Monitoring Desertification in Arid Land Using Remote Sensing. Int. J. Remote Sens. 2006, 27, 2411–2422. [Google Scholar] [CrossRef]
- Hengl, T. A Practical Guide to Geostatistical Mapping of Environmental Variables; Office for Official Publications of the European Communities: Luxembourg, 2007; 165p. [Google Scholar]
- Banerjee, K.; Panda, S.; Bandyopadhyay, J.; Jain, M. Forest Canopy Density Mapping Using Advance Geospatial Technique. Int. J. Innov. Sci. Technol. 2014, 7, 358–363. [Google Scholar]
- Rikimaru, A.; Roy, P.S.; Miyatake, S. Tropical forest cover density mapping. Trop. Ecol. 2002, 43, 39–47. [Google Scholar]
- Houssa, R.; Pion, J.-C.; Yésou, H. Effects of Granulometric and Mineralogical Composition on Spectral Reflectance of Soils in a Sahelian Area. ISPRS J. Photogramm. Remote Sens. 1996, 51, 284–298. [Google Scholar] [CrossRef]
- Scull, P.; Franklin, J.; Chadwick, O.A. The Application of Classification Tree Analysis to Soil Type Prediction in a Desert Landscape. Ecol. Model. 2005, 181, 1–15. [Google Scholar] [CrossRef]
- Mathieu, R.; Pouget, M. Relationships between satellite-based radiometric indices simulated using laboratory reflectance data and typic soil colour of an arid environment. Remote Sens. Environ. 1998, 66, 17–28. [Google Scholar] [CrossRef]
- McNairn, H.; Protz, R. Mapping corn residue cover on agricultural fields in Oxford County, Ontario, using Thematic Mapper. Can. J. Remote Sens. 1993, 19, 152–159. [Google Scholar] [CrossRef]
- Daughtry, C.S.T.; Doraiswamy, P.C.; Hunt, E.R., Jr.; Stern, A.J.; McMurtrey, J.E., III; Prueger, J.H. Remote sensing of crop residue cover and soil tillage intensity. Soil Tillage Res. 2006, 91, 101–108. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Smola, A.J.; Schölkopf, B. A Tutorial on Support Vector Regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Pasolli, L.; Notarnicola, C.; Bruzzone, L. Estimating Soil Moisture with the Support Vector Regression Technique. IEEE Geosci. Remote Sens. Lett. 2011, 8, 1080–1084. [Google Scholar] [CrossRef]
- Taghizadeh-Mehrjardi, R.; Schmidt, K.; Toomanian, N.; Heung, B.; Behrens, T.; Mosavi, A.; Band, S.S.; Amirian-Chakan, A.; Fathabadi, A.; Scholten, T. Improving the Spatial Prediction of Soil Salinity in Arid Regions Using Wavelet Transformation and Support Vector Regression Models. Geoderma 2021, 383, 114793. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Hengl, T.; Nussbaum, M.; Wright, M.N.; Heuvelink, G.B.M.; Gräler, B. Random forest as a generic framework for predictive modeling of spatial and spatio-temporal variables. PeerJ 2018, 6, e5518. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Biau, G.; Scornet, E. A Random Forest Guided Tour. TEST 2016, 25, 197–227. [Google Scholar] [CrossRef] [Green Version]
- Kuhn, M. Applied Predictive Modeling; Springer: New York, NY, USA, 2013; 443p. [Google Scholar] [CrossRef]
- Harrell, F. Regression Modeling Strategies: With Applications to Linear Models, Logistic and Ordinal Regression, and Survival Analysis; Springer: Cham, Switzerland, 2015; 507p. [Google Scholar] [CrossRef]
- Congedo, L. Semi-Automatic Classification Plugin: A Python Tool for the Download and Processing of Remote Sensing Images in QGIS. J. Open Source Softw. 2021, 6, 3172. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021; Available online: https://www.R-project.org/ (accessed on 7 November 2021).
- Kumar, S.; Lal, R. Mapping the Organic Carbon Stocks of Surface Soils Using Local Spatial Interpolator. J. Environ. Monit. 2011, 13, 3128–3135. [Google Scholar] [CrossRef] [PubMed]
- Hengl, T.; Leenaars, J.G.B.; Shepherd, K.D.; Walsh, M.G.; Heuvelink, G.B.M.; Mamo, T.; Tilahun, H.; Berkhout, E.; Cooper, M.; Fegraus, E.; et al. Soil Nutrient Maps of Sub-Saharan Africa: Assessment of Soil Nutrient Content at 250 m Spatial Resolution Using Machine Learning. Nutr. Cycl. Agroecosyst. 2017, 109, 77–102. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mponela, P.; Snapp, S.; Villamor, G.B.; Tamene, L.; Le, Q.B.; Borgemeister, C. Digital Soil Mapping of Nitrogen, Phosphorus, Potassium, Organic Carbon and Their Crop Response Thresholds in Smallholder Managed Escarpments of Malawi. Appl. Geogr. 2020, 124, 102299. [Google Scholar] [CrossRef]
- Wang, J.; Ding, J.; Yu, D.; Teng, D.; He, B.; Chen, X.; Ge, X.; Zhang, Z.; Wang, Y.; Yang, X.; et al. Machine Learning-Based Detection of Soil Salinity in an Arid Desert Region, Northwest China: A Comparison between Landsat-8 OLI and Sentinel-2 MSI. Sci. Total. Environ. 2020, 707, 136092. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spectral Indices | Formula Landsat 8 OLI | Formula Sentinel 2 | References |
|---|---|---|---|
| Normalized differences vegetation Index (NDVI) | [42] | ||
| Grain size index (GSI) | [43] | ||
| Clay index (CLI) | [44] | ||
| Bare soil index (BSI 1, BSI 2) | [45,46] | ||
| Redness index (RI) | [47] | ||
| Panchromatic index (Panchrom) | [48] | ||
| MID-Infrared index (MID-IR) | [47] | ||
| Brightness index (BI) | [49] | ||
| Saturation index (SI) | [49] | ||
| Coloration index (CI) | [49] | ||
| Normalized difference index (NDI 1, NDI 2) | [50,51] | ||
| Bands relations R/B, SWIR1/R, SWIR1/NIR | |||
| Bands relations SWIR1/SWIR2 (Landsat 8 OLI), R/SWIR2 (Sentinel 2) |
| Property | N, mg kg−1 | P2O5, mg kg−1 | K2O, mg kg−1 | SOC, % | Silt, % | Clay, % |
|---|---|---|---|---|---|---|
| Train field | ||||||
| Minimum | 53.8 | 75.3 | 154.6 | 2.7 | 41.1 | 3.5 |
| Maximum | 145.6 | 282.0 | 347.5 | 5.6 | 88.9 | 22.0 |
| Range | 91.8 | 206.7 | 192.9 | 2.9 | 47.8 | 18.5 |
| Mean | 100.4 | 149.4 | 226.5 | 4.0 | 75.2 | 10.1 |
| Coefficient of variation, % | 19 | 34 | 19 | 19 | 10 | 31 |
| Test field | ||||||
| Minimum | 91.8 | 75.1 | 98.9 | 3.1 | 65.77 | 13.73 |
| Maximum | 213.9 | 314.2 | 267.2 | 9.1 | 76.51 | 23.31 |
| Range | 122.1 | 239.1 | 168.3 | 6.0 | 10.74 | 9.58 |
| Mean | 140.0 | 131.3 | 163.3 | 5.1 | 69.35 | 20.72 |
| Coefficient of variation, % | 16 | 42 | 25 | 17 | 4 | 10 |
| Property | Model | RMSE | MAE | R2 | RMSE | MAE | R2 |
|---|---|---|---|---|---|---|---|
| Remote Sensing Data | Remote Sensing + Soil Properties | ||||||
| Sentinel 2 | |||||||
| N | SVMr | 9.06 | 0.55 | 0.79 | 5.78 | 0.24 | 0.92 |
| RF | 10.13 | 1.10 | 0.77 | 8.65 | 1.10 | 0.83 | |
| P2O5 | SVMr | 31.19 | 4.57 | 0.64 | 27.52 | 4.05 | 0.72 |
| RF | 40.47 | 4.91 | 0.45 | 40.90 | 4.57 | 0.45 | |
| K2O | SVMr | 21.86 | 4.02 | 0.77 | 15.04 | 2.16 | 0.88 |
| RF | 28.98 | 2.98 | 0.62 | 28.40 | 2.78 | 0.64 | |
| Landsat 8 OLI | |||||||
| N | SVMr | 6.30 | 0.61 | 0.90 | 4.39 | 0.26 | 0.95 |
| RF | 10.77 | 0.81 | 0.74 | 8.77 | 0.87 | 0.82 | |
| P2O5 | SVMr | 29.53 | 5.90 | 0.68 | 30.60 | 2.33 | 0.65 |
| RF | 39.38 | 3.82 | 0.49 | 39.84 | 4.71 | 0.48 | |
| K2O | SVMr | 19.16 | 1.63 | 0.82 | 14.62 | 2.54 | 0.89 |
| RF | 27.56 | 2.82 | 0.66 | 27.38 | 2.86 | 0.66 | |
| RMSE | MAE | R2 | |
|---|---|---|---|
| Sentinel 2 | |||
| N | 9.19 | 0.39 | 0.85 |
| P2O5 | 31.24 | 7.57 | 0.71 |
| K2O | 25.69 | 5.42 | 0.62 |
| Landsat 8 OLI | |||
| N | 8.35 | 0.44 | 0.88 |
| P2O5 | 46.79 | 12.15 | 0.31 |
| K2O | 24.78 | 3.18 | 0.65 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sahabiev, I.; Smirnova, E.; Giniyatullin, K. Spatial Prediction of Agrochemical Properties on the Scale of a Single Field Using Machine Learning Methods Based on Remote Sensing Data. Agronomy 2021, 11, 2266. https://0-doi-org.brum.beds.ac.uk/10.3390/agronomy11112266
Sahabiev I, Smirnova E, Giniyatullin K. Spatial Prediction of Agrochemical Properties on the Scale of a Single Field Using Machine Learning Methods Based on Remote Sensing Data. Agronomy. 2021; 11(11):2266. https://0-doi-org.brum.beds.ac.uk/10.3390/agronomy11112266
Chicago/Turabian StyleSahabiev, Ilnas, Elena Smirnova, and Kamil Giniyatullin. 2021. "Spatial Prediction of Agrochemical Properties on the Scale of a Single Field Using Machine Learning Methods Based on Remote Sensing Data" Agronomy 11, no. 11: 2266. https://0-doi-org.brum.beds.ac.uk/10.3390/agronomy11112266