Improvement of an Online Education Model with the Integration of Machine Learning and Data Analysis in an LMS


Abstract
:1. Introduction
2. Related Works
3. Preliminary Concepts
3.1. Analysis of Data
- Marketing: Data analysis has been used primarily to predict consumer behavior, including to classify it.
- Human resources: Data analysis is also very useful within companies to maintain a good work environment, identifying potential employees.
- Academics: Data analysis is also present in education; it serves to select new students and to measure student performance.
3.2. Artificial Intelligence
- Siri works as a personal assistant as it uses natural language processing.
- Facebook and Google Photos suggest tagging and grouping of photos based on image recognition.
- Amazon offers product recommendations based on shopping basket models.
- Waze provides optimized traffic information and real-time navigation.
- Machine learning is a type of artificial intelligence that gives computers the ability to learn. It is based on data analysis, through which new patterns are identified that allow modification of your behavior [7]. That is, it analyzes and processes information, discovers patterns, and acts accordingly.
- Knowledge engineering is based on the use of the necessary techniques to create expert systems. It is a computational area that is used to store important information and uses it for strategic purposes [25]. The deeper the layers of information, the better the strategies applied.
- Fuzzy logic is one of the most trending mathematical theories currently. It is based on the use of appreciations that are not totally true or false but occupy all the intermediate positions between the absolute truth and total falsehood [26].
- Artificial neural networks is a technique whose behavior is inspired by the functioning of human neural networks. As in the human being, they are independent systems that are interconnected with each other [13]. Each artificial neuron receives a certain number of inputs, to which it gives a certain “weight”. Depending on the number of inputs and your weight, it will receive a certain “nervous impulse”, which translates into an output value [21].
- Rule-based systems work by applying different rules for a given situation and comparing the results obtained. This task can be carried out by different methods. On the one hand, they can start from initial evidence or a situation and find their possible solution [27]. On the other hand, they can start from hypotheses with possible solutions and carry out the inverse journey to find the premise or evidence.
- Expert systems are computer systems that function as a human expert in a specific subject. Its operation is based on learning, memorizing, and communicating information [28]. Normally, the information has been provided by human experts, and the system performs the processes based on standards to use its knowledge in particular situations. In turn, this expert system can learn and improve with future additions.
- Artificial vision is the combination of hardware and software that allows devices to process and recognize images captured in the real world based on numerical or symbolic concepts [4].
3.3. Online Education Model
- Interactive model allows the student to interact with the content, their teachers, and fellow students.
- Accessible, no matter the place or time, and works anywhere with Internet access.
- Synchronous and asynchronous, allowing the student to participate in tasks or activities at the same time as others.
- Online resources allow access to resources without the need to have them physically at any time that is necessary.
4. Method
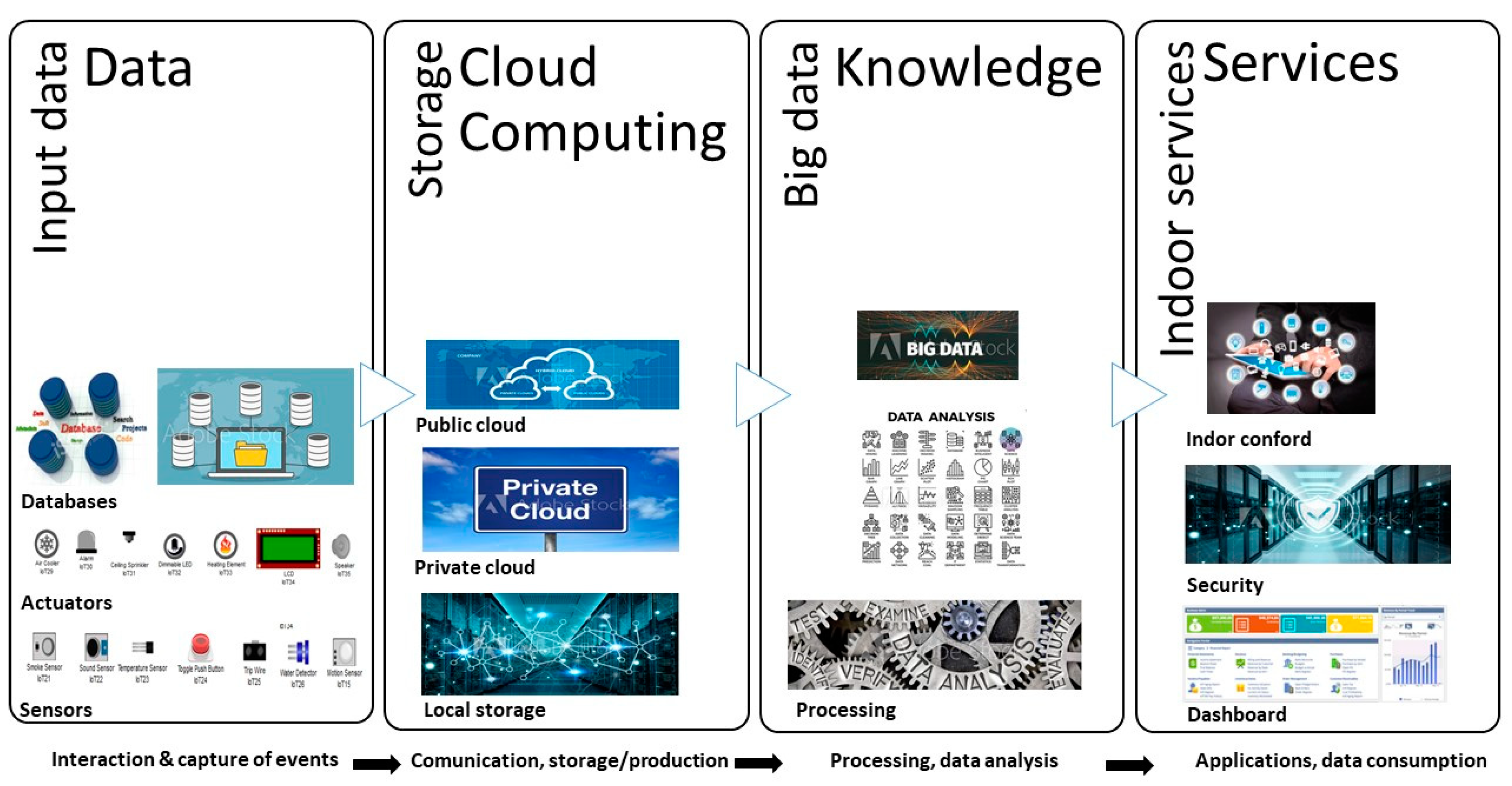
4.1. Identification of the Environment
4.2. Analysis of Data
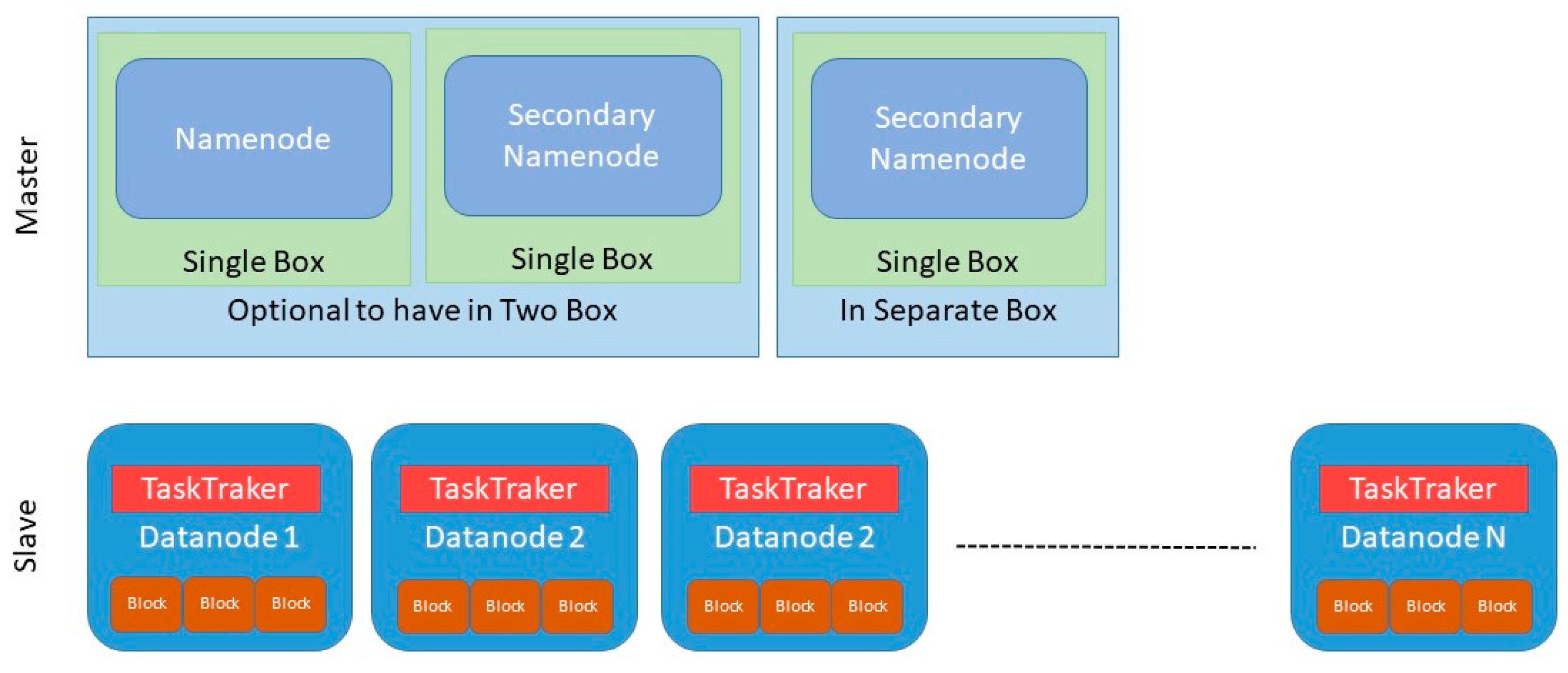
4.2.1. Hadoop Operation
- Map.
- Reduce: shuffle data and reduce.
4.2.2. Phases in Hadoop MapReduce
- The map phase runs on subtasks called mappers. These components are responsible for generating key-value pairs by filtering, grouping, ordering, or transforming the original data. Intermediate data pairs are not stored in HDFS.
- The shuffle sort phase may not be necessary. It is the intermediate step between map and reduce that helps to collect data and sort them conveniently for processing. With this phase, the repeated occurrences in each of the mappers are added.
- The reduce phase manages the aggregation of the values produced by all the mappers in the system or by the key-value-type shuffle phase based on their key. Finally, each reducer generates its output file independently, generally written in HDFS.
4.3. Artificial Intelligence
- Expert systems are systems highly trained in a specific intellectual activity, based on the knowledge of experts in the field. A classic example is that of systems that play chess.
- Chatbots are systems that make an interesting use of natural language processing and improve with each experience, allowing coherent two-way communication with humans, either oral or written.
- Virtual assistants are the closest thing to a movie AI that we can interact with today. It recognizes our voice, adapts to the way we ask for things, and is able to recommend entertainment according to our tastes. One of the strengths of these technologies is that they have an immense number of users who feed them constantly and help reinforce their learning algorithms.
- Machine learning are computer programs that try to learn from previous experience and examples, and have a specific and predetermined purpose that is generally modeling, predicting, understanding patterns in the data, or controlling some system.
- Supervised learning: For this methodology, a previous training phase (datasets) is required, where hundreds of labels are introduced. If a machine is required to be able to recognize between dogs and cats in a photo, then we have to show the program thousands of images where it becomes clear what is a cat? What is a dog? After this training phase, the program would be able to identify each of the animals in different circumstances. This method is called classification. Another type of supervised learning would be regression, which is the same as following a continuous value. It is somewhat similar to the machine being able to follow logical values, such as if there is a numerical series of 2, 4, 6 that the machine is able to follow it as 8, 10, 12. This is used especially for prediction.
- Unsupervised learning: In this procedure, a training phase is not required, and the machine must be able to understand and find patterns in the information itself directly. An example is to group students into homogeneous groups. If the information from thousands of clients with unstructured data is disclosed to the system, the computer system would be able to recognize the characteristics of the students, and segment it into profiles with similar criteria. This problem is called clustering or data agglomeration. This is useful to reduce the number of total variables to 2 or 3 maximums, so that there is no loss of information, and thus the data can be visualized, visually facilitating its understanding.
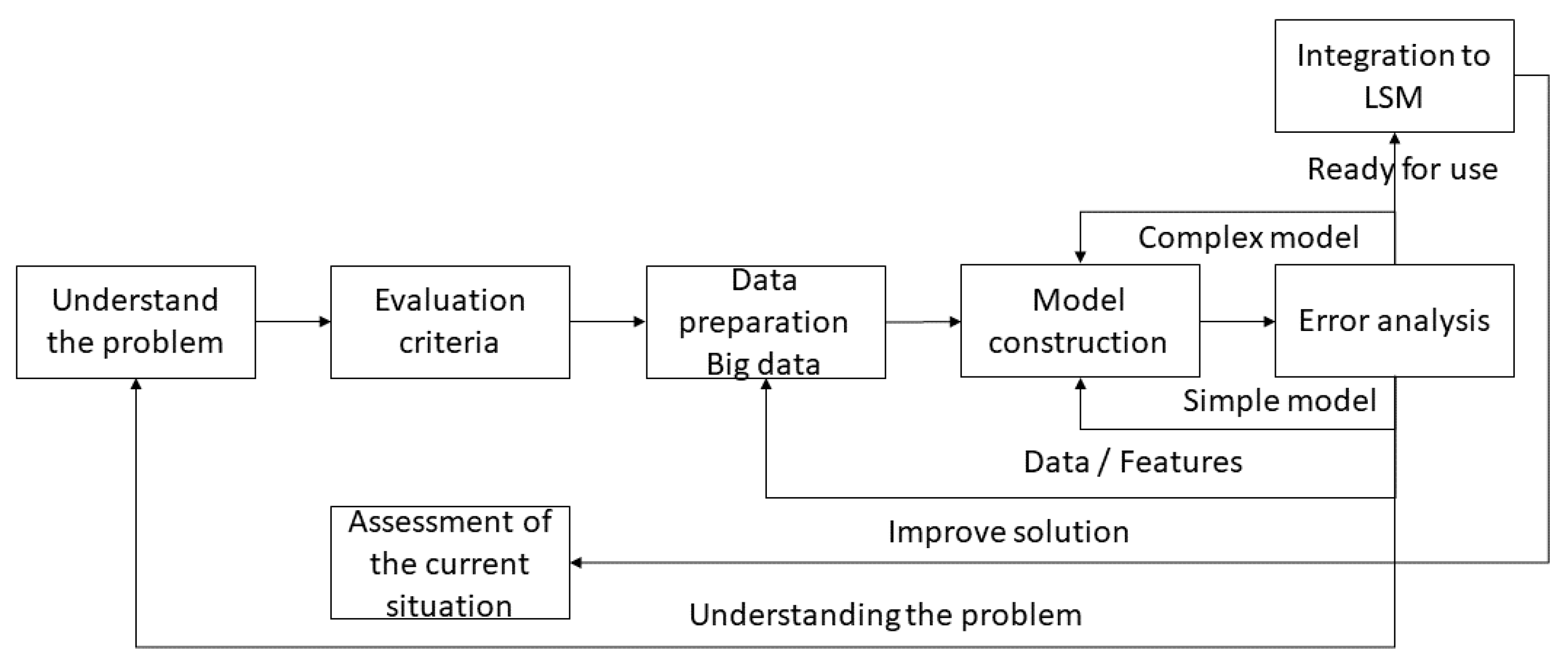
Phases for the Implementation of Machine Learning
- To understand the problem, it is important to understand the problem that we have to solve. Normally, this takes a long time, especially if the problem comes from a sector in which knowledge is poor. In this phase, it is necessary to create collaborative environments with people who know a lot about the problem.
- To understand the data, it is common to do an exploratory analysis of the data to become familiar with it. Descriptive statistics, correlations, and graphs are performed in exploratory analysis to better understand the story the data is telling. Furthermore, it helps to estimate if the available data is sufficient, and relevant, to build a model.
- Defining an evaluation criterion is usually an error measure. Typically, the root-mean-square error is used for regression problems and the cross entropy is used for classification problems. For classification problems with two classes that are common, other measures, such as accuracy and completeness, are used.
- Evaluation of the current solution: Probably, the problem to be solved with machine learning, is already being solved in another way. Surely, the motivation to use machine learning to solve this problem is to get better results. Another common motivation is to get similar results automatically, replacing boring manual work. By measuring the performance of the current solution, it can be compared to the performance of the machine learning model. In this way, the feasibility of using the machine learning model is identified. If there is no current solution, a simple solution can bee defined that is very easy to implement. For example, predicting a student’s grade in a course with automatic learning is comparable to a simple solution (the average value of their qualifications during an academic period). Only in this way, when the machine learning model is implemented, is it possible to define if it is good enough, if it needs to be improved, or if it is not worth implementing. If in the end it turns out that the current solution or a simple solution is similar to the machine learning solution, it is probably better to use the simple solution.
- Prepare the data: Although this process is carried out by the big data section, it is necessary to detail certain factors in the machine learning phases. Data preparation is one of the phases of machine learning that involves more effort. The main challenges are incomplete data. It is normal that the ideal data for the machine learning process is not available. For example, to predict which students are more likely to enter an online educational model, the data we have comes from an online survey. There will be many people who have not filled in all the fields. However, incomplete data is better than having no data at all, and there are several actions that can be used to prepare the data, such as deleting it, imputing it with a reasonable value, imputing it with a machine learning model, or doing nothing and using some machine learning technique that handles incomplete data. When combining data from various sources, some data may come from a database, others from a spreadsheet, from files, etc. It is necessary to combine the data so that the machine learning algorithms can consider all the information. Calculating the relevant features (machine learning algorithms) works much better with relevant features instead of pure data [47]. As an example, it is much easier for people to know the temperature in degrees Celsius than to know how many milligrams of mercury have been dilated in a traditional thermometer.
- Building the model: The phase of building a machine learning model, once the data is ready, surprisingly requires little effort. This is because there are already several machine learning libraries available. Many of them are free and open source. During this phase, which type of machine learning technique to use it chosen. The machine learning algorithm will automatically learn to get the right results with the historical data that has been prepared.
- Error analysis: This phase is important to understand what needs to be done to improve machine learning results. In particular, the options will be use a more complex model, use a simpler model, identify the need to include more data and/or more characteristics, develop a better understanding of the problem, etc. In the error analysis phase, it is important to ensure that the model is capable of generalization. Generalization is the ability of machine learning models to produce good results when they use new data. In general, it is not difficult to achieve acceptable results using this process. However, to get excellent results, we have to iterate over the previous phases several times. With each iteration, the understanding of the problem and the data will grow. This allows the design of better relevant features and reduces the generalization error. A greater understanding also offers the possibility of choosing with more criteria the machine learning technique that best suits the problem.
- Model integrated into a system. Once the model has been adjusted based on error, the machine learning model is integrated into the LMS. The phase of integrating a machine learning model into a system requires a greater relative effort. It is necessary to be able to automatically repeat the data preparation phases, which requires that the machine learning model communicates with other parts of the system and that the results of the model are used in the system. Furthermore, errors must be automatically monitored. The model warns if model errors grow over time to rebuild the machine learning model with new data, either manually or automatically. The construction of interfaces for the data is necessary so that the model can obtain data automatically and so that the system can use its prediction automatically.
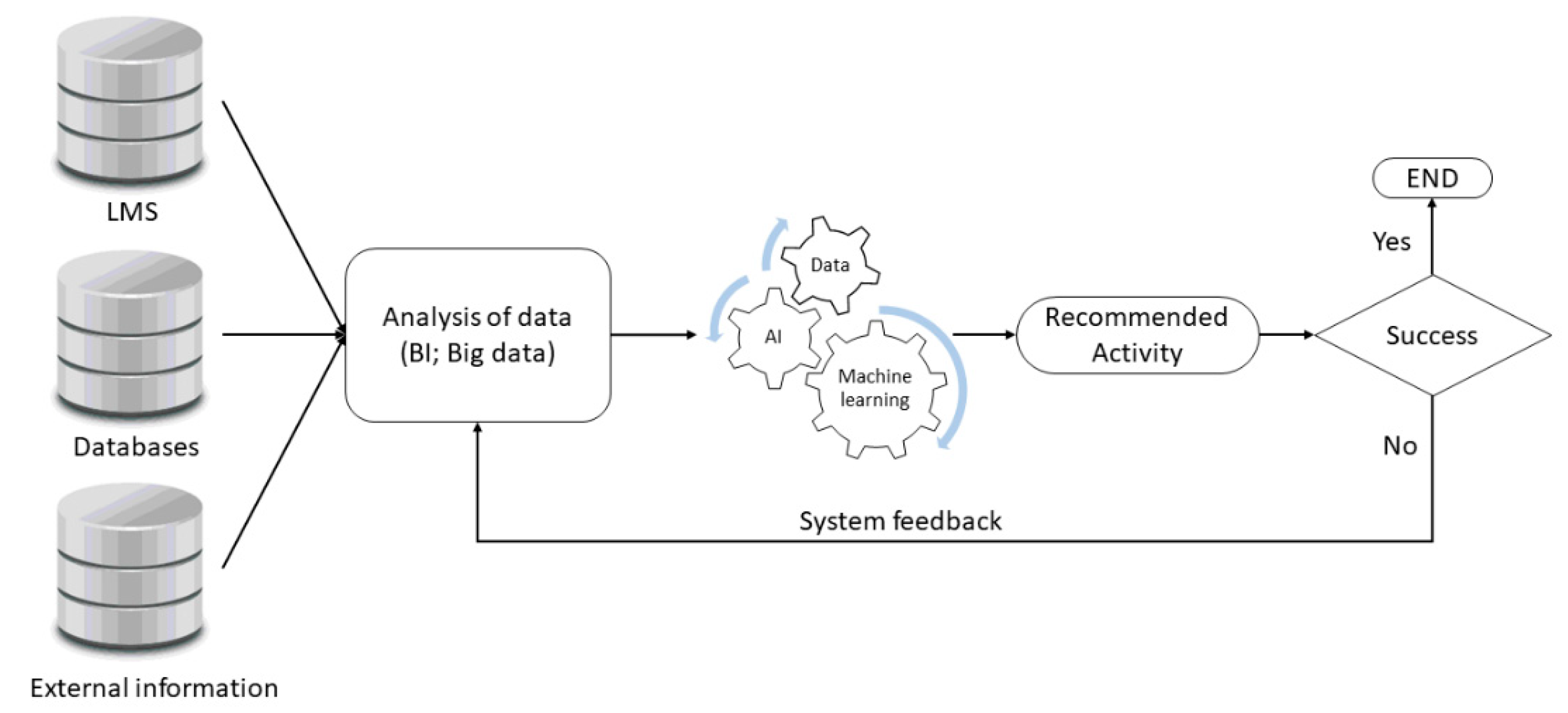
4.4. Integration of Big Data, Machine Learning, and LMS
5. Discussion and Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Li, H.; Liu, S.M.; Yu, X.H.; Tang, S.L.; Tang, C.K. Coronavirus disease 2019 (COVID-19): Current status and future perspectives. Int. J. Antimicrob. Agents 2020, 55, 105951. [Google Scholar] [CrossRef]
- Riofrio, G.; Encalada, E.; Guaman, D.; Aguilar, J. Business intelligence applied to learning analytics in student-centered learning processes. In Proceedings of the Latin American Computing Conference, Arequipa, Peru, 19−23 October 2015; pp. 1–10. [Google Scholar]
- Beldarrain, Y. Distance education trends: Integrating new technologies to foster student interaction and collaboration. Distance Educ. 2006, 27, 139–153. [Google Scholar] [CrossRef]
- Hssina, B.; Bouikhalene, B.; Merbouha, A. Europe and MENA Cooperation Advances in Information and Communication Technologies; Rocha, A., Mohammed, S., Felgueiras, C., Eds.; Springer International Publishing: Saidia, Marocco, 2017; Volume 520, ISBN 978-3-319-46567-8. [Google Scholar]
- Villegas-Ch, W.; Lujan-Mora, S.; Buenano-Fernandez, D. Application of a Data Mining Method in to LMS for the Improvement of Engineering Courses in Networks. In Proceedings of the 10th International Conference of Education, Research and Innovation (Iceri2017), Seville, Spain, 16–18 November 2017; pp. 6374–6381. [Google Scholar]
- Comendador, B.E.V.; Rabago, L.W.; Tanguilig, B.T. An educational model based on Knowledge Discovery in Databases (KDD) to predict learner’s behavior using classification techniques. In Proceedings of the IEEE International Conference on Signal Processing, Communications and Computing, Shanghai, China, 20–25 March 2016; pp. 1–6. [Google Scholar]
- Kim, T.; Lim, J. Designing an Efficient Cloud Management Architecture for Sustainable Online Lifelong Education. Sustainability 2019, 11, 1523. [Google Scholar] [CrossRef] [Green Version]
- Ferguson, R. Learning analytics: Drivers, developments and challenges. Int. J. Technol. Enhanc. Learn. 2013, 4, 304–317. [Google Scholar] [CrossRef]
- Lee, S.J.; Lee, H.; Kim, T.T. A study on the instructor role in dealing with mixed contents: How it affects learner satisfaction and retention in e-learning. Sustainability 2018, 10, 850. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.; Song, H.D.; Hong, A.J. Exploring factors, and indicators for measuring students’ sustainable engagement in e-learning. Sustainability 2019, 11, 985. [Google Scholar] [CrossRef] [Green Version]
- Villegas-Ch, W.; Palacios-Pacheco, X.; Buenaño-Fernandez, D.; Luján-Mora, S. Comprehensive learning system based on the analysis of data and the recommendation of activities in a distance education environment. Int. J. Eng. Educ. 2019, 35, 1316–1325. [Google Scholar]
- Darcy, A.M.; Louie, A.K.; Roberts, L.W. Machine learning and the profession of medicine. JAMA J. Am. Med. Assoc. 2016, 315, 551–552. [Google Scholar] [CrossRef] [PubMed]
- Villegas-Ch, W.; Arias-navarrete, A.; Palacios-pacheco, X. Proposal of an Architecture for the Integration of a Chatbot with Artificial Intelligence in a Smart Campus for the Improvement of Learning. Sustainability 2020, 12, 1500. [Google Scholar] [CrossRef] [Green Version]
- Villegas-Ch, W.; Palacios-Pacheco, X.; Luján-Mora, S. Artificial intelligence as a support technique for university learning. In Proceedings of the IEEE World Conference on Engineering Education (EDUNINE), Lima, Peru, 26 May 2019; pp. 1–6. [Google Scholar]
- Villegas-Ch, W.; Luján-Mora, S. Analysis of data mining techniques applied to LMS for personalized education. In Proceedings of the IEEE World Engineering Education Conference (EDUNINE), Santos, Brazil, 19–22 March 2017; pp. 85–89. [Google Scholar]
- Villegas-Ch, W.; Palacios-Pacheco, X.; Ortiz-Garcés, I.; Luján-Mora, S. Management of educative data in university students with the use of big data techniques. Rev. Iberica Sist. Tecnol. Inf. 2019, E19, 227–238. [Google Scholar]
- Villegas-Ch, W.; Luján-Mora, S.; Buenaño-Fernandez, D. Data mining toolkit for extraction of knowledge from LMS. In Proceedings of the ACM International Conference Proceeding Series, Moscow, Russia, 18–21 April 2017; Volume 1346, pp. 31–35. [Google Scholar]
- Hill, J.; Ford, W.R.; Farreras, I.G. Computers in Human Behavior Real conversations with artificial intelligence: A comparison between human—Human online conversations and human—Chatbot conversations. Comput. Hum. Behav. 2015, 49, 245–250. [Google Scholar] [CrossRef]
- Boran, A.; Bedini, I.; Matheus, C.J.; Patel-Schneider, P.F.; Keeney, J. A smart campus prototype for demonstrating the semantic integration of heterogeneous data. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2011; Volume 6902, pp. 238–243. [Google Scholar]
- Zhou, J.; Zhou, Y.; Wang, B.; Zang, J. Human–Cyber–Physical Systems (HCPSs) in the Context of New-Generation Intelligent Manufacturing. Engineering 2019, 5, 624–636. [Google Scholar] [CrossRef]
- Sultan Mahmud, M.; Zhexue Huang, J.; Salloum, S.; Emara, T.Z.; Sadatdiynov, K. A Survey of Data Partitioning and Sampling Methods to Support Big Data Analysis. Big Data Min. Anal. 2020, 3, 85–101. [Google Scholar] [CrossRef]
- Popoola, S.I.; Atayero, A.A.; Badejo, J.A.; John, T.M.; Odukoya, J.A.; Omole, D.O. Learning analytics for smart campus: Data on academic performances of engineering undergraduates in Nigerian private university. Data BR 2018, 17, 76–94. [Google Scholar] [CrossRef] [PubMed]
- Peng, M.Y.-P.; Tuan, S.-H.; Liu, F.-C. Establishment of Business Intelligence and Big Data Analysis for Higher Education. In Proceedings of the International Conference on Business and Information Management, Beijing, China, 23–25 July 2017; pp. 121–125. [Google Scholar]
- Colin, H.; Donnelly, I.A. Ambient intelligence: Technologies, applications, and opportunities. Proc. Annu. Meet. ISSS 2017, 91, 399–404. [Google Scholar]
- Syeda Farha Shazmeen, S.F.S. Performance Evaluation of Different Data Mining Classification Algorithm and Predictive Analysis. J. Comput. Eng. 2013, 10, 1–6. [Google Scholar] [CrossRef]
- Lee, C.K.M.; Na, C.M.; Kit, N.C. IoT-based asset management system for healthcare-related industries. Int. J. Eng. Bus. Manag. 2015, 7, 7–19. [Google Scholar]
- Shawar, B.A.; Atwell, E.S. Using corpora in machine-learning chatbot systems. Int. J. Corpus Linguist. 2005, 10, 489–516. [Google Scholar] [CrossRef]
- Chen, C. Personalized E-learning system with self-regulated learning assisted mechanisms for promoting learning performance. Expert Syst. Appl. 2009, 36, 8816–8829. [Google Scholar] [CrossRef]
- D’Adamo, I.; Falcone, P.M.; Ferella, F. A socio-economic analysis of biomethane in the transport sector: The case of Italy. Waste Manag. 2019, 95, 102–115. [Google Scholar] [CrossRef]
- Riquelme, J.C.; Ruiz, R.; Gilbert, K. Minería de datos: Conceptos y tendencias. Intel. Artif. 2006, 10, 11–18. [Google Scholar]
- Shukla, V.K.; Verma, A. Enhancing LMS Experience through AIML Base and Retrieval Base Chatbot using R Language. In Proceedings of the International Conference on Automation, Computational and Technology Management, London, UK, 24–26 April 2019; pp. 561–567. [Google Scholar]
- Villegas-Ch, W.; Luján-Mora, S. Systematic Review of Evidence on Data Mining Applied to LMS Platforms for Improving E-Learning. In Proceedings of the International Technology, Education and Development Conference, Valencia, Spain, 6–8 March 2017; pp. 6537–6545. [Google Scholar]
- Villegas-Ch, W.; Molina-Enriquez, J.; Chicaiza-Tamayo, C.; Ortiz-Garcés, I.; Luján-Mora, S. Application of a Big Data Framework for Data Monitoring on a Smart Campus. Sustainability 2019, 11, 5552. [Google Scholar] [CrossRef] [Green Version]
- Pacheco, J.; Hariri, S. Anomaly behavior analysis for IoT sensors. Trans. Emerg. Telecommun. Technol. 2018, 29, 1–15. [Google Scholar] [CrossRef]
- Aazam, M.; Khan, I.; Alsaffar, A.A.; Huh, E.N. Cloud of Things: Integrating Internet of Things and cloud computing and the issues involved. In Proceedings of the 2014 11th International Bhurban Conference on Applied Sciences and Technology, Islamabad, Pakistan, 14–18 January 2014; pp. 414–419. [Google Scholar]
- Taleb, I.; Serhani, M.A. Big Data Pre-Processing: Closing the Data Quality Enforcement Loop. In Proceedings of the IEEE International Congress on Big Data (BigData Congress), Boston, MA, USA, 11–14 December 2017; pp. 498–501. [Google Scholar]
- Shah, S.; Soriano, C.B.; Coutroubis, A.D. Is big data for everyone? The challenges of big data adoption in SMEs. In Proceedings of the 2017 IEEE International Conference on Industrial Engineering and Engineering Management (IEEM), Singapore, 11–13 December 2017; pp. 803–807. [Google Scholar]
- Mohammed, A.F.; Humbe, V.T.; Chowhan, S.S. A review of big data environment and its related technologies. In Proceedings of the 2016 International Conference on Information Communication and Embedded Systems (ICICES), Chennai, India, 23–24 February 2016; pp. 1–5. [Google Scholar]
- Merla, P.; Liang, Y. Data analysis using hadoop MapReduce environment. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Chennai, India, 23–24 February 2017; pp. 4783–4785. [Google Scholar]
- McHugh, J.; Cuddihy, P.E.; Williams, J.W.; Aggour, K.S.; Vijay, S.K.; Mulwad, V. Integrated access to big data polystores through a knowledge-driven framework. Proc. IEEE Int. Conf. Big Data 2018, 2018, 1494–1503. [Google Scholar]
- Saraladevi, B.; Pazhaniraja, N.; Paul, P.V.; Basha, M.S.S.; Dhavachelvan, P. Big data and Hadoop—A study in security perspective. Procedia Comput. Sci. 2015, 50, 596–601. [Google Scholar] [CrossRef] [Green Version]
- Luo, L. Data Acquisition and Analysis of Smart Campus Based on Wireless Sensor. Wirel. Pers. Commun. 2018, 102, 2897–2911. [Google Scholar] [CrossRef]
- Dai, W.; Ji, W. A mapreduce implementation of C4.5 decision tree algorithm. Int. J. Database Theory Appl. 2014, 7, 49–60. [Google Scholar] [CrossRef]
- Thusoo, A.; Sarma, J.; Jain, N.; Shao, Z.; Chakka, P.; Anthony, S.; Liu, H.; Wyckoff, P.; Murthy, R. Hive: A warehousing solution over a map-reduce framework. Proc. VLDB Endow. 2009, 2, 1626–1629. [Google Scholar] [CrossRef]
- Rahman, A.M.; Al Mamun, A.; Islam, A. Programming challenges of chatbot: Current and future prospective. In Proceedings of the 5th IEEE Region 10 Humanitarian Technology Conference 2017, Dhaka, Bangladesh, 21–23 December 2017; Volume 2018, pp. 75–78. [Google Scholar]
- Toutouh, J.; Arellano, J.; Alba, E. BiPred: A Bilevel Evolutionary Algorithm for Prediction in Smart Mobility. Sensors 2018, 18, 4123. [Google Scholar] [CrossRef] [Green Version]
- Arora, R.; Asstt, S.; Cse, D. Comparative Analysis of Classification Algorithms on Different Datasets using WEKA. Int. J. Comput. Appl. 2012, 54, 975–8887. [Google Scholar] [CrossRef]
- Lai, C.-T.; Chang, H.-H.; Lee, K.-T.; Huang, J.-Y.; Lee, W.-P. Predicting Drug Side Effects Using Data Analytics and the Integration of Multiple Data Sources. IEEE Access 2017, 5, 20449–20462. [Google Scholar]
- Chen, Y.S.; Tsai, Y.T. A mobility management using follow-me cloud-cloudlet in fog-computing-based RANs for smart cities. Sensors 2018, 18, 489. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, C.T.; Chen, S.T.; Liu, J.C.; Liu, R.H.; Chang, C.L. On construction of an energy monitoring service using big data technology for the smart campus. Clust. Comput. 2019, 23, 265–288. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
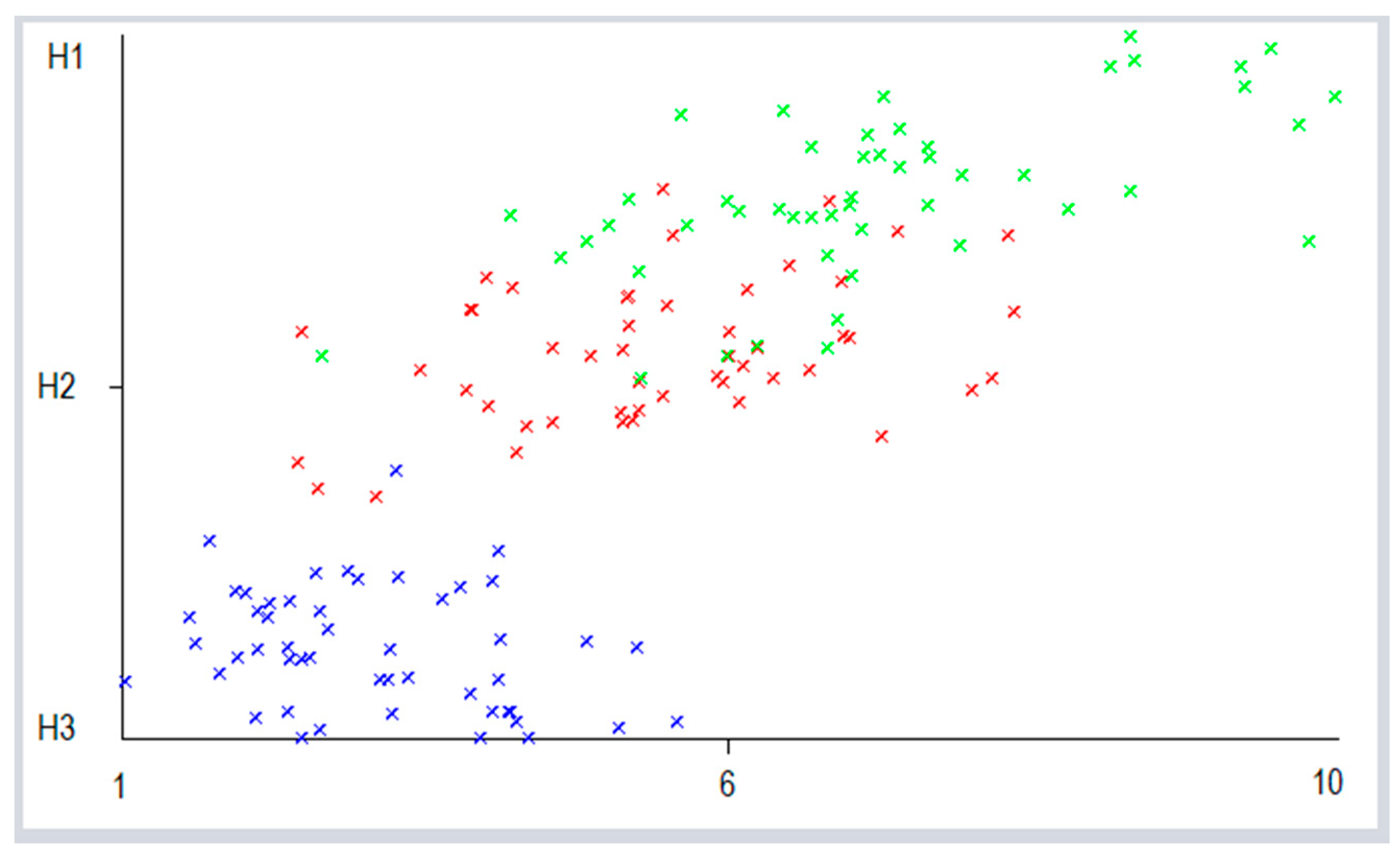{kind=link}
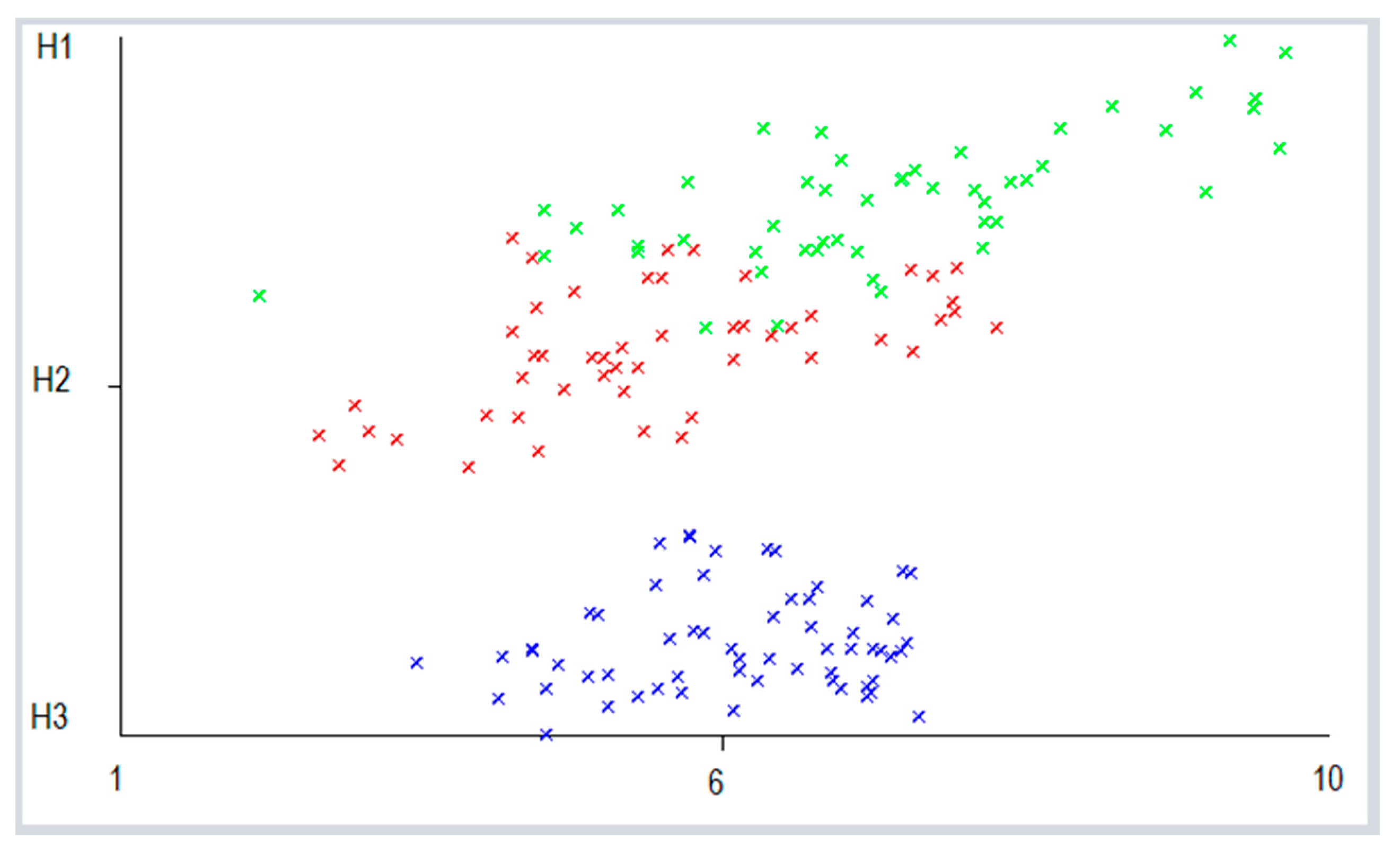{kind=link}
| Correctly Classified Instances | 48 | 94.1176% |
| Incorrectly Classified Instances | 3 | 5.8824% |
| Kappa statistic | 0.9113 | |
| Mean absolute error | 0.0447 | |
| Root mean squared error | 0.1722 | |
| Relative absolute error | 10.0365% | |
| Root relative squared error | 36.4196% | |
| Total Number of Instances | 51 |
| A | B | C | ← Classified as |
|---|---|---|---|
| 15 | 0 | 0 | | a = T. Dedication |
| 0 | 18 | 1 | | b = T. Question |
| 0 | 2 | 15 | | c = Difficulty |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Villegas-Ch, W.; Román-Cañizares, M.; Palacios-Pacheco, X. Improvement of an Online Education Model with the Integration of Machine Learning and Data Analysis in an LMS. Appl. Sci. 2020, 10, 5371. https://0-doi-org.brum.beds.ac.uk/10.3390/app10155371
Villegas-Ch W, Román-Cañizares M, Palacios-Pacheco X. Improvement of an Online Education Model with the Integration of Machine Learning and Data Analysis in an LMS. Applied Sciences. 2020; 10(15):5371. https://0-doi-org.brum.beds.ac.uk/10.3390/app10155371
Chicago/Turabian StyleVillegas-Ch, William, Milton Román-Cañizares, and Xavier Palacios-Pacheco. 2020. "Improvement of an Online Education Model with the Integration of Machine Learning and Data Analysis in an LMS" Applied Sciences 10, no. 15: 5371. https://0-doi-org.brum.beds.ac.uk/10.3390/app10155371