
An Enhanced Photonic Quantum Finite Automaton
by
 , , , , and
, , , , and
Alessandro Candeloro
1,† ,
,
Carlo Mereghetti
1,†,
Beatrice Palano
2,†,
Simone Cialdi
1,3,†,
Matteo G. A. Paris
1,3,† and
Stefano Olivares
1,3,*,† 1
Dipartimento di Fisica “Aldo Pontremoli”, Università degli Studi di Milano, via Celoria 16, I-20133 Milano, Italy
2
Dipartimento di Informatica “Giovanni Degli Antoni”, Università degli Studi di Milano, via Celoria 18, I-20133 Milano, Italy
3
INFN, Sezione di Milano, via Celoria 16, I-20133 Milano, Italy
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Appl. Sci. 2021, 11(18), 8768; https://0-doi-org.brum.beds.ac.uk/10.3390/app11188768
Submission received: 10 August 2021
/
Revised: 16 September 2021
/
Accepted: 18 September 2021
/
Published: 21 September 2021
(This article belongs to the Special Issue Basics and Applications in Quantum Optics)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
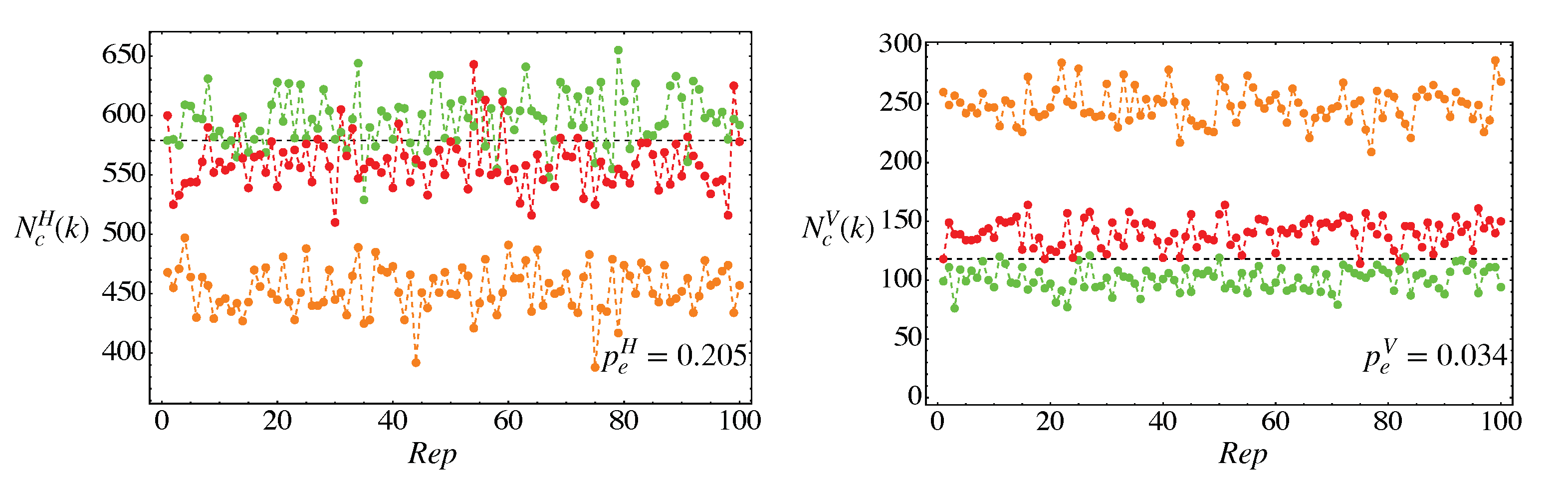{kind=link}
Abstract
:In a recent paper we have described an optical implementation of a measure-once one-way quantum finite automaton recognizing a well-known family of unary periodic languages, accepting words not in the language with a given error probability. To process input words, the automaton exploits the degree of polarization of single photons and, to reduce the acceptance error probability, a technique of confidence amplification using the photon counts is implemented. In this paper, we show that the performance of this automaton may be further improved by using strategies that suitably consider both the orthogonal output polarizations of the photon. In our analysis, we also take into account how detector dark counts may affect the performance of the automaton.
1. Introduction
In the recent years, quantum computers have eventually leaped out of the laboratories [1] and become accessible to a still growing community interested in investigating their actual potentialities. Nevertheless, a full-featured quantum computer is still far from being built. However, it is reasonable to think of classical computers exploiting some quantum components. In this framework, quantum finite automata [2,3]—theoretical models for quantum machines with finite memory—may play a key role, as they model small-size quantum computational devices that can be embedded in classical ones. Among possible models, the so-called measure-once one-way quantum finite automaton [4,5] is the simplest, and it has been shown to be the most promising for a physical realization [6]. In fact, restricted models of computation, such as quantum versions of finite automata, have been theoretically studied [7,8,9] and, very recently, experimentally investigated [6,10].
In [6], a measure-once one-way quantum finite automaton recognizing a well-known family of unary periodic languages [4], namely, languages , has been implemented using quantum optical technology [11,12]. In our implementation, a given input word is accepted by the automaton, with a given error probability, whenever a single photon arrives at the output of the device with a specific polarization. In particular, the experimental realization, based on the manipulation of single-photon polarization and photodetection, has demonstrated the possibility of building small quantum computational component to be embedded in more sophisticated and precise quantum finite automata or also in other computational systems and approaches [13,14,15]. Albeit the photonic automaton realized in [6] is fed with single photons, it works in a regime where polarized laser pulses (coherent states) are enough, up to detecting the intensity of the output signals instead of counting the number of photons successfully passing through the device with a given polarization (see in [6] for details).
In this paper, we propose an enhanced version of our photonic automaton mentioned above, where, to further reduce the acceptance error probability, we consider not only the photons with the “correct” polarization, but also the other ones. To achieve this goal, the use of single-photon techniques turns out to be crucial, such as the detection of coincidence count to reduce the dark-count rate of the photodetectors [16]. Analytical and numerical results, supported by simulated experiments, show that the enhanced version allows to reduce the error probability by orders of magnitude compared to the previous version, or, analogously, to drastically reduce the mean number of photons needed to achieve the same performance.
The paper is structured as follows. As our work requires some previous knowledge from Theoretical Computer Science about formal languages and finite automata, Section 2 is devoted to introduce the reader to these topics, providing the relevant motivations. In Section 3, we briefly review basics of formal language theory and the definition of a measure-once one-way quantum finite automaton. Section 4 describes the implementation of the measure-once one-way quantum finite automaton based on the polarization of single photons, linear optical elements, and photodetectors. In Section 5, we explain how to improve the confidence of the obtained measure-once one-way quantum finite automaton by processing the number of counts at the detectors. We also introduce new strategies that reduce the error probability, namely, the probability that a “wrong” word is accepted by the automaton or a “correct” word is rejected. The numerical results and the simulated experiments are reported in Section 6. We close the paper with some concluding remarks in Section 7.
2. Formal Languages, Finite Automata, and Quantum Computing
In this section, we would like to expand on motivations that have been driving our research covered by the present contribution and the previous one in [6]. The aim of our work, that bridges between Theoretical Computer Science and Experimental Quantum Optics, has been and is to show that a quantum computing device with finite memory is physically realizable by means of photonics, using a very limited amount of “quantum hardware”. To the best of our knowledge, our physical implementation, described here and in [6], of a quantum finite automaton for language acceptation is the first proposed in the literature. Thus, we have shown how the quantum behaviour of microscopic systems can actually represent a computational resource, as theoretically established within the discipline of Quantum Computing. From this perspective, the simple language , introduced in the next section and for which we build our photonic quantum finite automaton, is not really the point here. Instead, the point is the concrete creation of a programmable fully quantum computer with finite memory.
With this being said, we would also like to quickly comment on the language from a Theoretical Computer Science viewpoint. Notwithstanding its simplicity, the language plays a crucial role in Descriptional Complexity Theory (see, e.g., in [17,18,19,20,21]), the area of Formal Language Theory in which the size of computational models is investigated. In particular, a well-consolidated trend in Descriptional Complexity is devoted to study the size of several types of finite automata. The reader is referred to, e.g., the work in [22] for extensive presentations of automata theory. Very roughly speaking, the hardware of a (one-way) finite automaton A features a read-only input tape consisting of a sequence of cells, each one being able to store an input symbol. The tape is scanned by an input head always moving one position right at each step. At each time during the computation of A, a finite state control is in a state from a finite set Q. Some of the states in Q are designated as accepting states, while a state is a designated initial state. The computation of A on a word (i.e., a finite sequence of symbols) from a given input alphabet begins by having (i) stored symbol by symbol, left to right, in the cells of the input tape; (ii) the input head scanning the leftmost tape cell; and (iii) the finite state control being in the state . In a move, A reads the symbol below the input head and, depending on such a symbol and the state of the finite state control, it switches to the next state according to a fixed transition function and moves the input head one position forward. We say that A accepts whenever it enters an accepting state after scanning the rightmost symbol of ; otherwise, A rejects . The language accepted by A consists of all the input words accepted by A.
The one described so far is the original model of a finite automaton, called deterministic. Several variants of such an original model have been introduced and studied in the literature, sharing the same hardware but different dynamics. Therefore, we have nondeterministic, probabilistic and, recently, quantum finite automata (see, e.g., in [23,24,25]). Furthermore, two-way automata are studied, where the input head can move back and forth on the input tape.
Finite automata represent a formidable theoretical model used in the design and analysis of several devices such as the control units for vending machines, elevators, traffic lights, combination locks, etc. Particularly important is the use of finite automata in very large-scale integration (VLSI) design, namely, in the project of sequential networks which are the building blocks of modern computers and digital systems. Very roughly speaking, a sequential network is a boolean circuit equipped with memory. Engineering a sequential network typically requires modeling its behaviour with a finite automaton whose number of states directly influences the amount of hardware (i.e., the number of logic gates) employed in the electronic realization of the sequential network. From this point of view, having fewer states in the modeling finite automaton directly results in employing smaller hardware which, in turn, means having less energy absorption and fewer cooling problems. These “physical” considerations, that are of paramount importance given the current level of digital device miniaturization, have led to define the size of a finite automaton as the number of its states. In particular, reducing or increasing the number of states is studied, when using different computational paradigms (e.g., deterministic, nondeterministic, probabilistic, quantum, one-way, and two-way) on a finite automaton to perform a given task. Here, is where our simple language comes into play. In fact, this language is universally used as a benchmark to emphasize the succinctness of several types of automata. Several results in the literature shows that accepting on classical models of finite state automata is particularly size-consuming (i.e., it requires a great number of states), while only two basis states are enough on quantum finite automata, as we will see in the next section.
Modular design frameworks have been theoretically proposed [7,8,9], where more reliable and sophisticated quantum automata can be built by suitably composing (see, e.g., in [26]) easy-to-obtain variants of the quantum automaton for . Hence, our work provides crucial and concrete quantum components for such frameworks, and suggest investigating a physical implementation of some automata composition laws. More generally, the Krohn–Rhodes decomposition theorem [27] states that any classical finite automaton can be simulated by composing very “simple” finite automata: one of these simple automata is exactly the one for . From this perspective, our photonic quantum automaton could be hardwired into “hybrid” architectures joining classical and quantum components to build very succinct finite state devices operating in environments where dimension and energy absorption are particularly critical issues (e.g., drone or robot-based systems [28]).
3. Measure-Once One-Way Quantum Finite Automaton
Here, we briefly overview the main concepts on automata and formal language theory. We refer the interested reader to any of the standard books on these subjects (see, e.g., in [22]), as well as to our contribution [6].
An alphabet is any finite set of elements called symbols. A word on is any sequence with . The set of all words on is denoted by . A language L on is any subset of , i.e., . If , we say that is a unary alphabet, and languages on unary alphabets are called unary languages. In case of unary alphabets, we customarily let so that a unary language is any set . We let be the unary word obtained by concatenating k times the symbol a.
In what follows, we will be interested in the unary language defined as
This language is rather famous in the realm of automata theory, since it has proven particularly “size-consuming” to be accepted by several models of classical automata, as the number of needed states increases with m [6]. The reader may find a deep investigation on this fact in the literature [22,29,30,31]. On the other hand, as presented in [6], very succinct measure-once one-way quantum finite automata (1qfa’s, from now on) may be designed and physically realized for . Let us now sketch the main ingredients for a 1qfa accepting .
If we consider the two orthogonal states and , the 1qfa is defined as (here we use the formalism based on the Dirac’s notation; the analysis based on a more general formalism can be found in [6])
where represents the initial state, the unitary operation applied by the automaton upon processing any input symbol a is defined as
with and the Pauli matrix, while is the projector onto the mono-dimensional accepting subspace spanned by . The probability that the 1qfa accepts the word writes as
Therefore, the 1qfa perfectly recognizes the word , as we can set a cut point and an isolation to the following values (see in [6] for details on accepting languages with isolated cut point)
However, may also recognize an input word not in with a non-null probability. In the following, we let with any of the word with the highest probability of erroneously being accepted, i.e., , which tends to 1 as m gets large. This can be seen also by the fact that as m increases.
As matter of fact, we can also introduce the following 1qft, where we still consider the initial state , but, at the output, we focus on the final projection involving the state , namely
where . Indeed, is formally equivalent to , as . In fact, the probability of accepting a word is now given by
that is the same as in Equation (6), as one may expect. Nevertheless, we show in the next section that the two are not equivalent in a photonic implementation for reasons that will be clear soon.
4. Photonic Implementation of the 1qfa
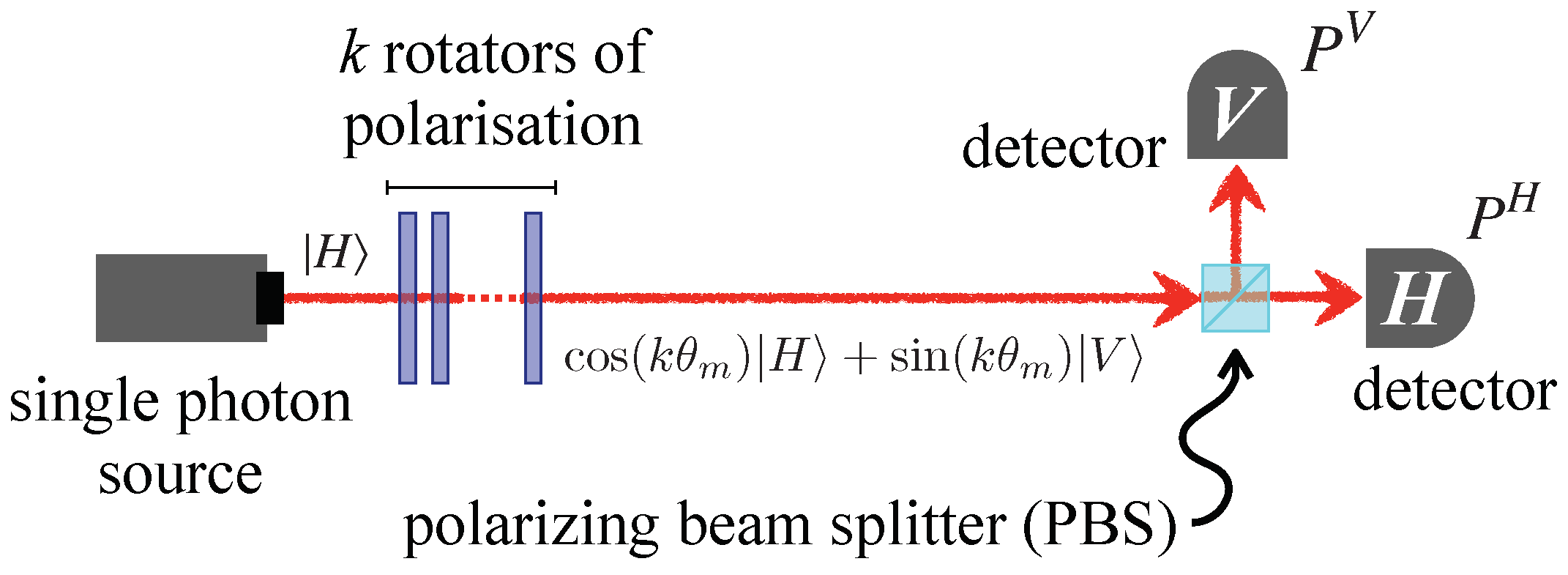
A photonic implementation of the 1qfa described in the previous section was proposed and demonstrated in [6]. Figure 1 depicts the main elements of the enhanced version of the automata we will describe in the following.
The state of the automaton is encoded in the polarization of single photons, and the Hilbert space is . A single photon source generates a horizontal-polarized state, , which is sent to k rotators of polarization, being the input word to be processed. Each rotator corresponds to a unitary rotation of an amount , which is thus language-dependent. After the rotators, the single photon state reads
and it is sent to a polarizing beam splitter (PBS; see Figure 1) that reflects the vertical polarization component and transmits the horizontal one. Finally, two photodetectors placed after the PBS realize the projective measure of and . As the reader can see, the scheme is almost the same of that proposed in [6], but here we will implement a new inference strategy exploiting the outcomes from both the detectors.
As we observed in the previous section, the automata and accept with certainty a word that belongs to . However, there is a high probability that an incorrect word, such as with can be accepted, as we can see from Equations (6) and (9). Therefore, strategies based on a single-photon shot may not be the optimal way to recognize an arbitrary word .
5. Confidence Amplification: An Enhanced Strategy
To reduce the probability of error, we can adopt a technique of confidence amplification as also proposed in [6], namely, we sent a mean number of photons and we count the number of click at the photodetector , see Figure 1. Therefore, the observed detection frequency at detector for an input word will be
Thereafter, we turn our problem into that of discriminating among the corresponding detection frequencies and, in particular, we can focus on those related to (or, equivalently, ) and (or, more in general, ), since if one has (). To implement this strategy, we set a threshold frequency as
where () is the highest (lowest) frequency of erroneously accepted words , while () is the frequency corresponding to the correct word. In this formula, we have distinguished the two different strategies: for the H detector, , as the corresponding photon will always be detected; instead, for the V detector, , as no photon is detected when the word belongs to . Therefore, the strategy is to accept the word if () and reject it if (). From now on, we will refer to these strategies as “H strategy” and “V strategy”, respectively.
In an ideal scenario, namely, without fluctuations in the sent number of photons, it is clear that the two approaches are complementary and yield to the same conclusion, as the single detections in H and V are perfectly correlated. Moreover, given that only the words satisfy the condition , with this strategy we have a zero error probability, provided that is large enough such that the integer part of () is strictly positive (negative) than (), i.e., we have the conditions
In Figure 2 (black lines and dots), we report the minimum values of such that the last two inequalities hold.
In a realistic scenario, the photo-detection is influenced by two distinct noisy effects that can affect the error probability. The first is that the number of detected photons follows a Poisson distribution [32], that is, we have
that is, the probability of detect n photons depends on the average number of detected photons . How this affects the error probability has been thoroughly addressed both theoretically and experimentally in [6].
The second effect that we should consider in order to apply our enhanced strategy is due to the dark counts, namely, the random counts registered by the detector without any incident light on it. Being still related to the detection process, also the dark counts follow a Poissonian distribution, whose mean depends on the particular detector one choose to use. In a typical quantum optics experiment, the dark-count rate ranges from tens to hundreds of photons per second, but this number can be drastically reduced by using coincidence counting techniques [16], up to making this effect negligible. For instance, in the implementation in [6] the dark counts where only 0.001% of the effective coincidence counts. As the dark counts occurs randomly, we cannot distinguish between a dark count and signal one. Therefore, the probability of detecting N photon in the H or V photodetector for a word is finally given by
where and , while we have defined the overall mean number of detected photons as
As we noticed above, the dark count rate is usually very small with respect to the detected count rate of the signal. Therefore, for the H detector which detects the higher number of photons, see Equation (18), they are relevant only when . On the contrary, for the V detector, detecting the lower number of photons, their role is fundamental in determining the performance of the photonic automaton, as . This is the main difference between the two strategies: in the first, we need to distinguish between two finite mean numbers of photon and , while in the second case, we need to distinguish between the noise due to dark counts, being , and . However, to assess the performance of second strategy with respect the first one, we need to evaluate the probability of errors in the two cases.
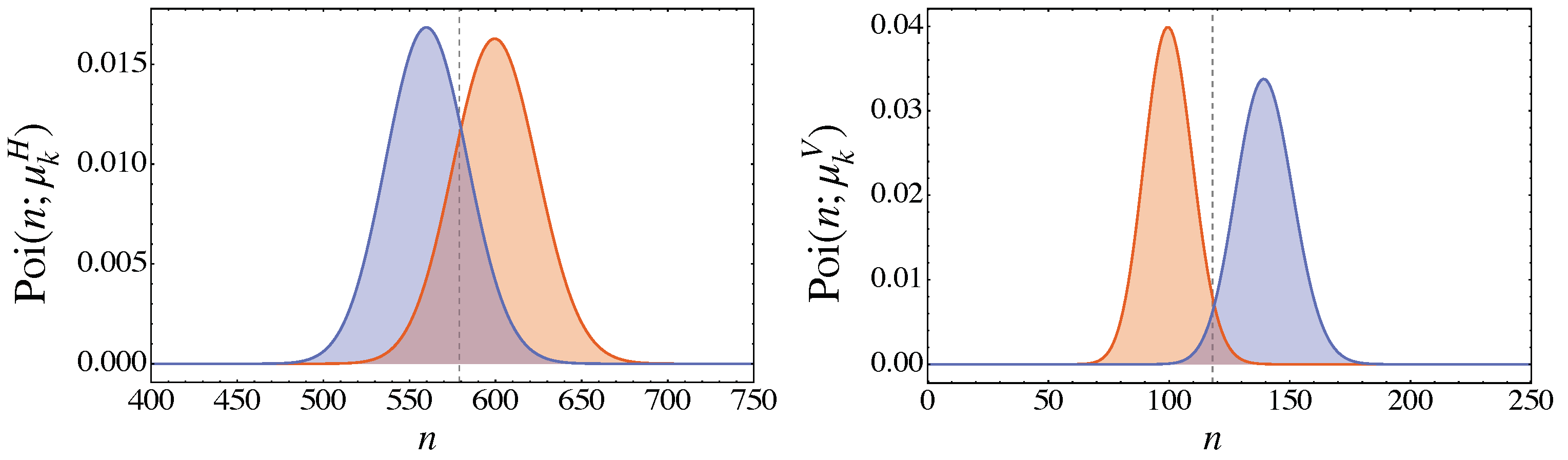
Let us first find the threshold values in the two different strategy. We need to find the intersection between two Poissonian distributions for a word belong to and a word with highest probability of being erroneously being accepted, as show in Figure 3. By imposing , where , we find an exact solution for given by (see the vertical dashed line in Figure 3)
To highlight the dark counts effects, we introduce the ratio , and we have
In our framework, the accepting problem is introduced as binary discrimination between the correct word and the word with the highest probability of error. However, in the photonic realization of the automata [6], when the number of input photons is small and m is large, also word with larger may contribute to the error. For this reason, like in the ideal case, we establish the minimum number of input photon which are necessary to faithfully consider the problem as binary discrimination.
To have faithfully binary discrimination the fluctuations due to the word with the second-largest probability of error, i.e., a word with , must be much larger than the fluctuations due to the correct word, where here for “large” we mean at least two standard deviations. In this way, the discrimination can be considered only between the words and . In the case of a Poissonian random variable, the standard deviation is the square root of the mean for Poissonian random variables. Hence, we have the two conditions, respectively, for the H and V detector
In the first one we ask that the fluctuations due to the word with the second largest probability of error, i.e., a word with are much larger than the fluctuations due to dark counts. In a similar way, we define the threshold for the horizontal detector. These equations can be solved for and set a lower bounds for it such that the probability of error can be evaluated in term of a binary discrimination problem, as shown in Figure 2 (red and blue lines and points).
Now, we can evaluate the probability of error for the two strategies. Indeed, this is equal to
where we have denoted as the probability of detecting the word as by the detector . As we have no a priori knowledge on the input word we set the prior probabilities , and for the V detector we obtain
where is the incomplete Gamma function
Analogously, we may evaluate the probability of error for the detection of a horizontally polarized photon, i.e.,
Eventually, we can introduce a third strategy that combines the two described so far: for each beam of photon, we propose to measure both the H and V polarization and to combine the results so obtained. From a theoretical point of view, this is equivalent to the automata presented before, as in the ideal case the two detectors perfectly agree, i.e., one sees the photon and the other one does not see it. However, in the non-ideal case, noisy fluctuations affect photodetection. As the fluctuations in the H detector are independent from the one in the V detector, the probability of erroneously accepting it by looking at both H and V is given as
where J here stands for joint.
6. Numerical Results and Simulations
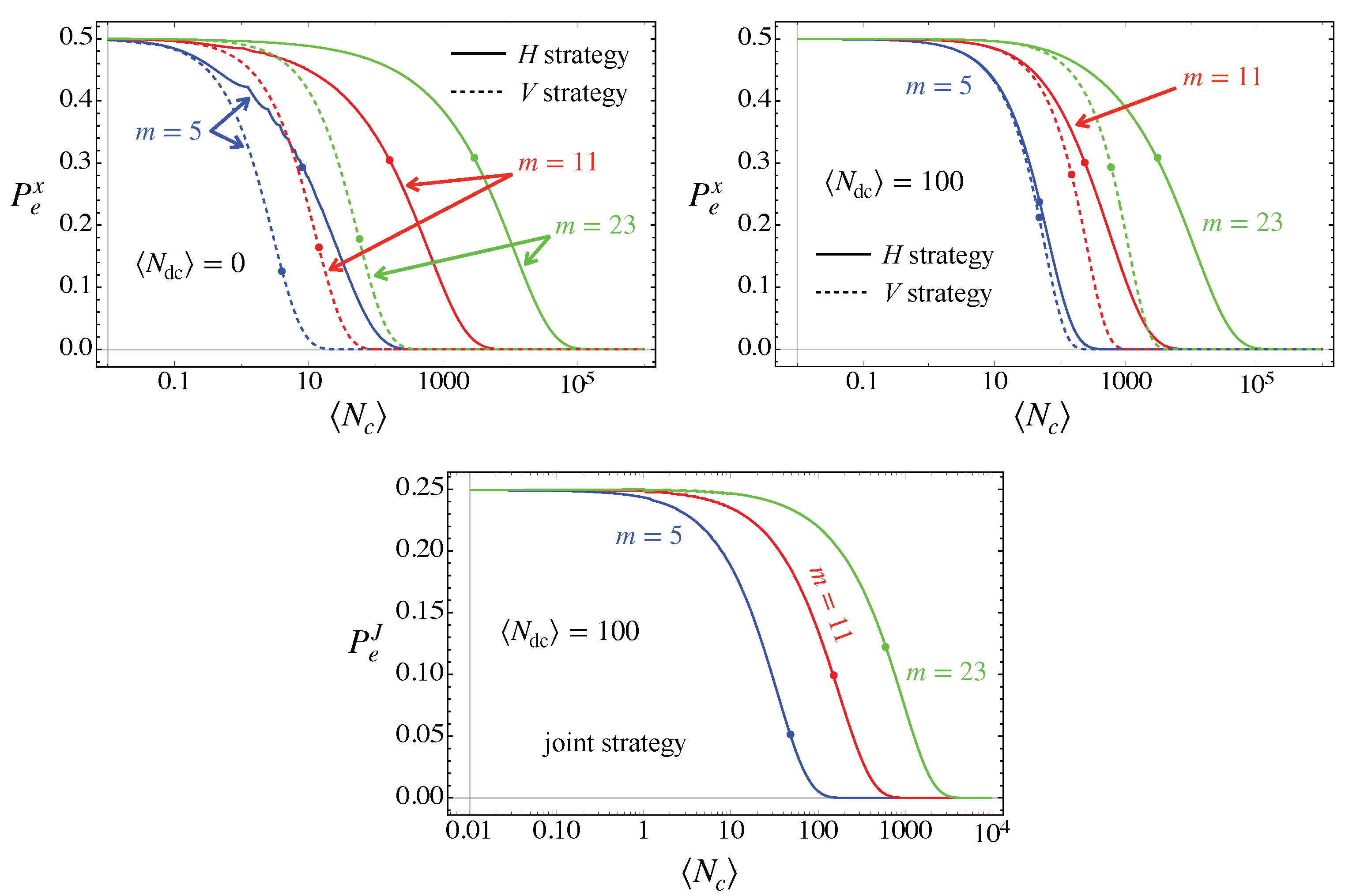
The comparison of the three strategies is reported in Figure 4. We see that the V strategy outperforms the H strategy for all the possible values of input photon, reaching almost a negligible error for approximately an order of magnitude less than the H strategy. The joint strategy realizes a further enhancement, even though the approaches 0 with the same order of magnitude of as . We have also reported the solution for the inequalities (22) and (23) as a point along the corresponding line: for smaller value, the probabilities of error are not reliable as the contribution of the words with larger is not negligible. In addition, increasing the average number of dark counts slightly increases the probability of error for all the strategies considered, even though no significant effects are detected for the considered range of values of .
In Figure 5, we show the number of counts at the H and V detectors from a simulated experiment. We can see a significant reduction of the fluctuations in the V detector, which is also marked by the significant difference in the probability of error and . The main reason is that the counts in the V detector are affected only by the randomness due to the dark counts (if present), while in the H detector the expected number of photons contributes to the randomness of the outcomes as well. We have also reported the results for words of length , which are are significantly separated from and as the value of considered is much larger than the threshold given in (22) and (23).
7. Conclusions
In this work, we have presented an enhanced photonic implementation of 1qfa for the recognition of unary language that significantly improves the performance obtained by the one originally proposed in [6]. The protocol uses the polarization degree of freedom of single photons, and exploits the possibility of detecting not only the horizontal polarization, as in [6], but also the vertical one. The resulting scheme largely outperforms the original automaton for smaller values of the mean number of sent photon . In addition, we have extended the results previously found with a detailed analysis of the conditions for which such 1qfa can work with high reliability. We have evaluated the minimum number of photons that must be sent in order to solve faithfully the inherent binary discrimination problem. As one would expect, the minimum is smaller for the automaton that relies on the new strategy based on the V detector.
In our analysis, we have discussed the presence of dark counts in the detection of both strategies, and we have evaluated their effects both on the probability of error and on the minimum . Eventually, we also examined a joint strategy in which we combine both the H and the V detection, which can indeed be used at no additional cost. We have therefore proved that when the number of sent photon is constrained to small values, the V detection version of the 1qfa should be preferred.
Our results pave the way to the effective implementation of 1qfa using quantum optical platform, thus opening the possibility of processing strings of input symbols using feasible devices and, in turn, to introduce quantum languages and compare the complexity of classes of languages in classical and quantum cases. More generally, as the assessment of the actual power of quantum computers is one of the most significant challenges of quantum technology, implementing quantum automata provides a relevant arena to better understand the computing capabilities offered by quantum devices.
Author Contributions
Conceptualization, A.C., C.M., B.P., S.C., M.G.A.P. and S.O.; Data curation, A.C., S.C. and S.O.; Investigation, A.C., C.M., B.P., S.C., M.G.A.P. and S.O.; Methodology, A.C., C.M., B.P., S.C., M.G.A.P. and S.O.; Supervision, S.O.; Writing—original draft, A.C., C.M., B.P., S.C., M.G.A.P. and S.O.; Writing—review and editing, A.C., C.M., B.P., S.C., M.G.A.P. and S.O. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Acknowledgments
M. G. A. Paris is member of GNFM-INdAM. C. Mereghetti and B. Palano are members of GNCS-INdAM. We thank V. Vento for useful discussion.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| 1qfa | measure-once one-way quantum finite automaton |
| PBS | polarizing beam splitter |
| dc | dark counts |
References
- Castelvecchi, D. Quantum computers ready to leap out of the lab in 2017. Nature 2017, 541, 9–10. [Google Scholar] [CrossRef]
- Ambainis, A.; Yakaryılmaz, A. Automata and Quantum Computing. arXiv 2018, arXiv:cs.FL/1507.01988. [Google Scholar]
- Bhatia, A.S.; Kumar, A. Quantum finite automata: Survey, status and research directions. arXiv 2019, arXiv:cs.FL/1901.07992. [Google Scholar]
- Bertoni, A.; Carpentieri, M. Regular Languages Accepted by Quantum Automata. Inf. Comp. 2001, 165, 174–182. [Google Scholar] [CrossRef] [Green Version]
- Brodsky, A.; Pippenger, N. Characterizations of 1-Way Quantum Finite Automata. SIAM J. Comput. 2002, 31, 1456–1478. [Google Scholar] [CrossRef] [Green Version]
- Mereghetti, C.; Palano, B.; Cialdi, S.; Vento, V.; Paris, M.G.A.; Olivares, S. Photonic realization of a quantum finite automaton. Phys. Rev. Res. 2020, 2, 013089. [Google Scholar] [CrossRef] [Green Version]
- Bertoni, A.; Mereghetti, C.; Palano, B. Small size quantum automata recognizing some regular languages. Theor. Comput. Sci. 2005, 340, 394–407. [Google Scholar] [CrossRef] [Green Version]
- Mereghetti, C.; Palano, B. Quantum automata for some multiperiodic languages. Theor. Comput. Sci. 2007, 387, 177–186. [Google Scholar] [CrossRef] [Green Version]
- Ambainis, A.; Nahimovs, N. Improved constructions of quantum automata. Theor. Comput. Sci. 2009, 410, 1916–1922. [Google Scholar] [CrossRef] [Green Version]
- Birkan, U.; Salehi, Ö.; Olejar, V.; Nurlu, C.; Yakaryılmaz, A. Implementing Quantum Finite Automata Algorithms on Noisy Devices. In Computational Science—ICCS 2021; Paszynski, M., Kranzlmüller, D., Krzhizhanovskaya, V.V., Dongarra, J.J., Sloot, P.M.A., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 3–16. [Google Scholar]
- Cialdi, S.; Rossi, M.A.C.; Benedetti, C.; Vacchini, B.; Tamascelli, D.; Olivares, S.; Paris, M.G.A. All-optical quantum simulator of qubit noisy channels. App. Phys. Lett. 2017, 110, 081107. [Google Scholar] [CrossRef] [Green Version]
- Olivares, S. Introduction to generation, manipulation and characterization of optical quantum states. arXiv 2021, arXiv:quant-ph/2107.02519. to appear in Phys. Lett. A. [Google Scholar]
- de Falco, D.; Tamascelli, D. Noise-assisted quantum transport and computation. J. Phys. A Math. Theor. 2013, 46, 225301. [Google Scholar] [CrossRef] [Green Version]
- Tamascelli, D.; Zanetti, L. A quantum-walk-inspired adiabatic algorithm for solving graph isomorphism problems. J. Phys. A Math. Theor. 2014, 47, 325302. [Google Scholar] [CrossRef] [Green Version]
- Rossi, M.A.C.; Benedetti, C.; Borrelli, M.; Maniscalco, S.; Paris, M.G.A. Continuous-time quantum walks on spatially correlated noisy lattices. Phys. Rev. A 2017, 96, 040301. [Google Scholar] [CrossRef] [Green Version]
- Bachor, H.A.; Ralph, T.C. A Guide to Experiments in Quantum Optics; Wiley-VCH: Hoboken, NJ, USA, 2004. [Google Scholar]
- Bednárová, Z.; Geffert, V.; Mereghetti, C.; Palano, B. Removing nondeterminism in constant height pushdown automata. Inf. Comput. 2014, 237, 257–267. [Google Scholar] [CrossRef]
- Bianchi, M.P.; Mereghetti, C.; Palano, B.; Pighizzini, G. On the size of unary probabilistic and nondeterministic automata. Fundam. Inform. 2011, 112, 119–135. [Google Scholar] [CrossRef]
- Choffrut, C.; Malcher, A.; Mereghetti, C.; Palano, B. First-order logics: Some characterizations and closure properties. Acta Inform. 2012, 49, 225–248. [Google Scholar] [CrossRef] [Green Version]
- Jakobi, S.; Meckel, K.; Mereghetti, C.; Palano, B. Queue automata of constant length. In Lecture Notes in Computer Science, Volume 8031, Proceedings of the International Workshop on Descriptional Complexity of Formal Systems, London, ON, Canada, 22–25 July 2013; Jürgensen, H., Reis, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 124–135. [Google Scholar]
- Kutrib, M.; Malcher, A.; Mereghetti, C.; Palano, B. Descriptional Complexity of Iterated Uniform Finite-State Transducers. In Lecture Notes in Computer Science, Volume 11612, Proceedings of the International Conference on Descriptional Complexity of Formal Systems, Košice, Slovakia, 17–19 July 2019; Hospodár, M., Jirásková, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; pp. 223–234. [Google Scholar]
- Hopcroft, J.E.; Ullman, J.D. Introduction to Automata Theory, Languages, and Computation; Addison-Wesley: New York, NY, USA, 1979. [Google Scholar]
- Bertoni, A.; Mereghetti, C.; Palano, B. Trace monoids with idempotent generators and measure-only quantum automata. Nat. Comput. 2010, 9, 383–395. [Google Scholar] [CrossRef]
- Bianchi, M.P.; Mereghetti, C.; Palano, B. Quantum finite automata: Advances on Bertoni’s ideas. Theor. Comput. Sci. 2017, 664, 39–53. [Google Scholar] [CrossRef]
- Bianchi, M.P.; Palano, B. Behaviours of unary quantum automata. Fundam. Inform. 2010, 104, 1–15. [Google Scholar] [CrossRef]
- Bednárová, Z.; Geffert, V.; Mereghetti, C.; Palano, B. Boolean language operations on nondeterministic automata with a pushdown of constant height. In Lecture Notes in Computer Science, Volume 7913, Proceedings of the International Computer Science Symposium in Russia, Ekaterinburg, Russia, 25–29 June 2013; Bulatov, A.A., Shur, A.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 100–111. [Google Scholar]
- Ginzburg, A. Algebraic Theory of Automata; Academic Press: Cambridge, MA, USA, 1968. [Google Scholar]
- Feletti, C.; Mereghetti, C.; Palano, B. Uniform circle formation for swarms of opaque robots with lights. In Lecture Notes in Computer Science, Volume 11201, Proceedings of the International Symposium on Stabilizing, Safety, and Security of Distributed Systems, Tokyo, Japan, 4–7 November 2018; Izumi, T., Kuznetsov, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; pp. 317–332. [Google Scholar]
- Paz, A. Introduction to Probabilistic Automata; Academic Press: New York, NY, USA, 1971. [Google Scholar]
- Mereghetti, C.; Pighizzini, G. Two-Way Automata Simulations and Unary Languages. J. Autom. Lang. Comb. 2000, 5, 287–300. [Google Scholar]
- Mereghetti, C.; Palano, B.; Pighizzini, G. Note on the Succinctness of Deterministic, Nondeterministic, Probabilistic and Quantum Finite Automata. RAIRO-Theor. Inf. Appl. 2001, 35, 477–490. [Google Scholar] [CrossRef] [Green Version]
- Loudon, R. The Quantum Theory of Light; OUP Oxford: Oxford, UK, 2000. [Google Scholar]
Figure 1.
Scheme of the photonic implementation of the 1qfa highlighting the main involved optical elements. See the text for details.
Figure 1.
Scheme of the photonic implementation of the 1qfa highlighting the main involved optical elements. See the text for details.

Figure 2.
Black line and dots: minimum value such that Equation (13) (left plot) and Equation (14) (right plot) are satisfied as a function of m in the absence of dark counts (). Red line and dots (), blue line and dot (): minimum vale such that Equation (22) (left plot) and Equation (23) (right plot) are satisfied. Notice the different scaling for the y-axis.
Figure 2.
Black line and dots: minimum value such that Equation (13) (left plot) and Equation (14) (right plot) are satisfied as a function of m in the absence of dark counts (). Red line and dots (), blue line and dot (): minimum vale such that Equation (22) (left plot) and Equation (23) (right plot) are satisfied. Notice the different scaling for the y-axis.

Figure 3.
Probability density function of the Poissonian distribution in Equation (17) for the H detector (left plot) and the V detector (right plot) for , and . The probability of error in Equations (25) and (29) are, respectively, (V detector) and (H detector). The gray dashed line is the threshold values in Equation (19). The values of the involved parameters have been chosen to better highlight the investigated effect.
Figure 3.
Probability density function of the Poissonian distribution in Equation (17) for the H detector (left plot) and the V detector (right plot) for , and . The probability of error in Equations (25) and (29) are, respectively, (V detector) and (H detector). The gray dashed line is the threshold values in Equation (19). The values of the involved parameters have been chosen to better highlight the investigated effect.

Figure 4.
Probability of error for the different strategies as functions of the average number of input photon in a semi-log plot. Red line: ; blue line: ; green line . (Top panels): H (solid lines) and V (dashed lines) strategies in the absence of dark counts (left) and for (right). (Bottom panel): joint strategy in the case . The dots on the lines refer to the threshold values evaluated according to (22) and (23). See the text for details.
Figure 4.
Probability of error for the different strategies as functions of the average number of input photon in a semi-log plot. Red line: ; blue line: ; green line . (Top panels): H (solid lines) and V (dashed lines) strategies in the absence of dark counts (left) and for (right). (Bottom panel): joint strategy in the case . The dots on the lines refer to the threshold values evaluated according to (22) and (23). See the text for details.

Figure 5.
Simulation of for the horizontal (left) and vertical (right) automata as a function of the experimental run number (). Green dot: , i.e., ; red dot: , i.e., ; orange dot: , i.e., ; black dashed line: . We considered and (the same parameters of Figure 3). The probabilities of error given in Equations (25) and (29) are respectively and . The minimum number of input for the H detector, solution of (22), is , while for V, solution of (23), is .
Figure 5.
Simulation of for the horizontal (left) and vertical (right) automata as a function of the experimental run number (). Green dot: , i.e., ; red dot: , i.e., ; orange dot: , i.e., ; black dashed line: . We considered and (the same parameters of Figure 3). The probabilities of error given in Equations (25) and (29) are respectively and . The minimum number of input for the H detector, solution of (22), is , while for V, solution of (23), is .

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Candeloro, A.; Mereghetti, C.; Palano, B.; Cialdi, S.; Paris, M.G.A.; Olivares, S. An Enhanced Photonic Quantum Finite Automaton. Appl. Sci. 2021, 11, 8768. https://0-doi-org.brum.beds.ac.uk/10.3390/app11188768
AMA Style
Candeloro A, Mereghetti C, Palano B, Cialdi S, Paris MGA, Olivares S. An Enhanced Photonic Quantum Finite Automaton. Applied Sciences. 2021; 11(18):8768. https://0-doi-org.brum.beds.ac.uk/10.3390/app11188768
Chicago/Turabian StyleCandeloro, Alessandro, Carlo Mereghetti, Beatrice Palano, Simone Cialdi, Matteo G. A. Paris, and Stefano Olivares. 2021. "An Enhanced Photonic Quantum Finite Automaton" Applied Sciences 11, no. 18: 8768. https://0-doi-org.brum.beds.ac.uk/10.3390/app11188768
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.