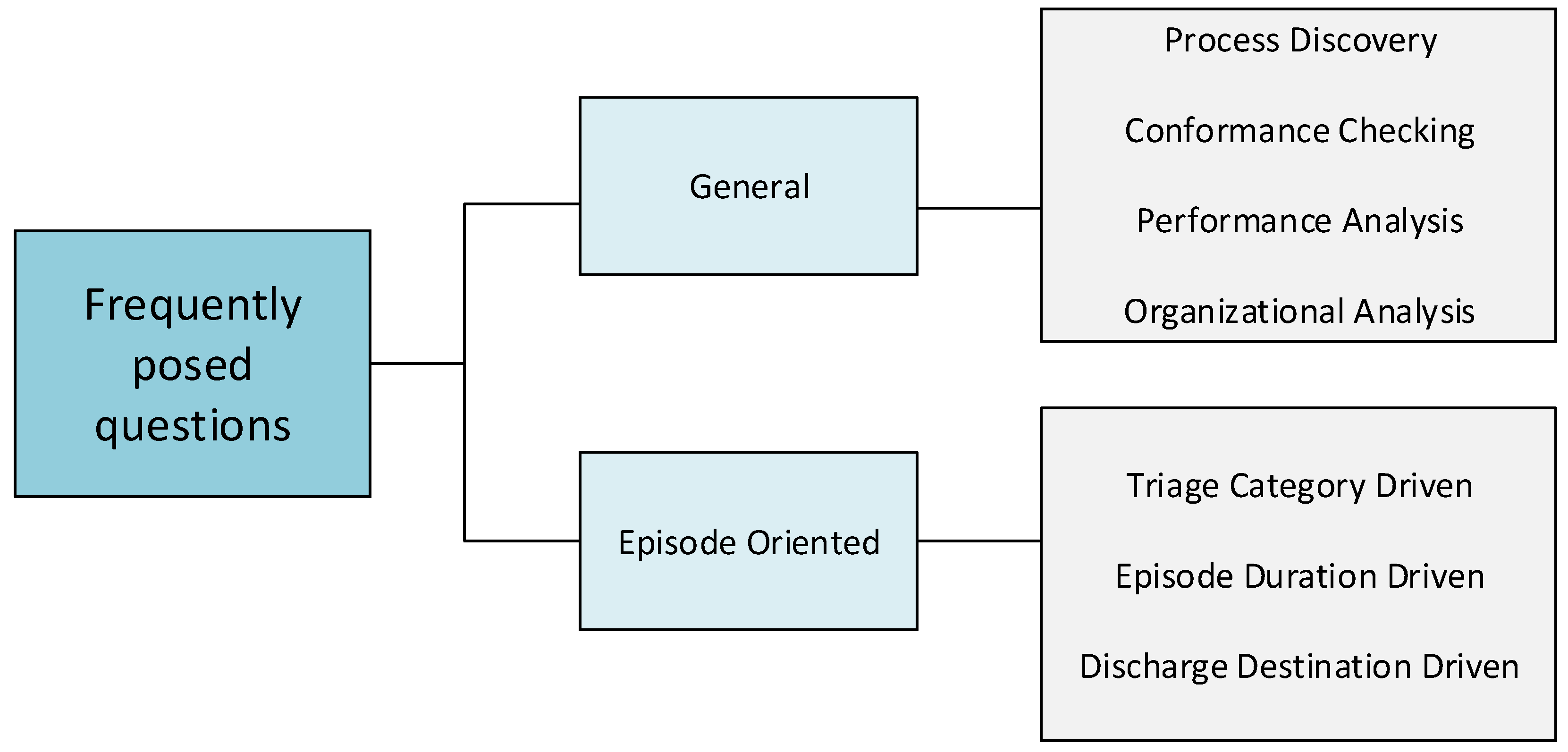
3.1. Data Reference Model for ER
This section provides information on how to build a data model, in order to apply process mining techniques to answer FPQs. First the data sources are discussed, followed by the definition of a data model for ER data.
3.1.1. Data Sources
Data from ER processes are stored in Hospital Information Systems (HIS), i.e., information systems designed to manage all aspects of a hospital’s operation, including its medical, administrative, financial and legal issues, and the corresponding processing of services. As in general healthcare, the architecture of HIS in ER can be as follows: integrated [
14], in which all data are in the same system; distributed [
22], in which a specific system provides support for episodes; and the remaining data, such as medication data or medical staff data, are stored on different systems; or any intermediate point between the two extreme cases. Data extraction is challenging because the systems have heterogeneous architectures, including legacy systems developed ad hoc for the needs of each particular hospital. The disadvantage of the systems and repositories is that, despite them being able to store large quantities of data, they are not geared towards recording information regarding processes, which in turn, results in great difficulty when analyzing hospital processes. Accordingly and based on the concept of integrated HIS, we propose a data reference model that allows data to be stored and used for analysis on the process perspective.
3.1.2. Data Reference Model
Data reference models are common across a wide range of areas [
23]. For example, in [
20,
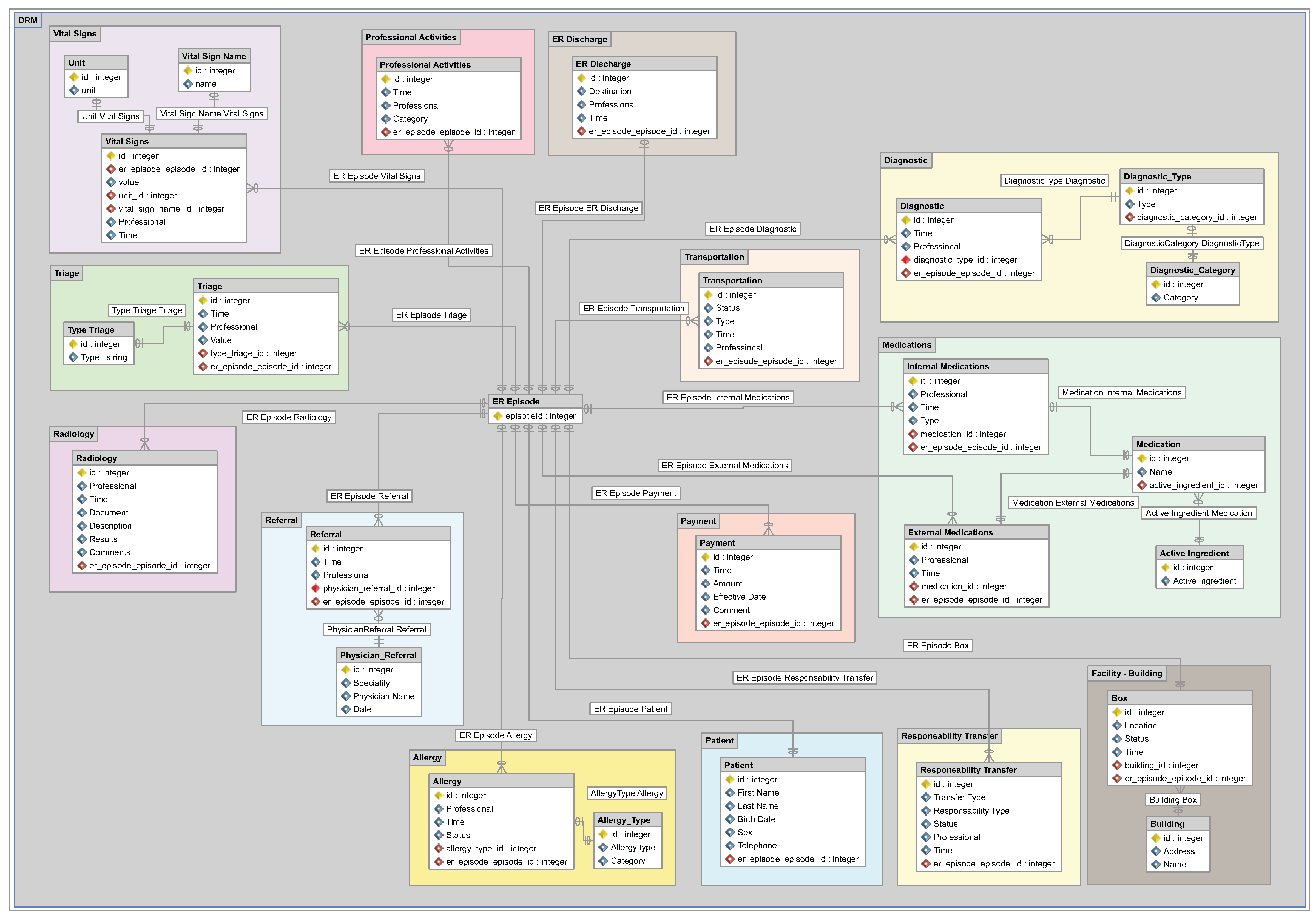
23], the authors propose a general model for HC. However, a model for ER has not yet been proposed. The ER model proposed in this section, as shown in
Figure 2, extends the aforementioned HC model, including specific dimensions of ER, such as consultation rooms (boxes) or triage, obtained from the analysis of previous ER case studies and information provided by ER experts. The data model proposed for ER is a model that specifies the data structures and their relationships for representing ER episodes. The data types included in the proposed data reference model were defined or identified from the original HC model and from the HIS studied during the case study. The model does not aim to fit any specific system, but rather to provide a framework that represents, in a generic manner, the data extracted from any ER system.
The proposed data reference model is designed to contain all of the data required to answer any FPQs about ER processes using data mining and process mining techniques. However, not all data are necessary for all questions. In fact, having all data is unusual in real scenarios. Therefore, at the moment of creating the actual data model, we should try to include as much information available as possible, according to the reference data model, but we must be aware that not all data will be available. Then, at the moment of addressing one of the FPQs, we should check whether the available data are sufficient to answer the question.
The data reference model consists of 15 data types used in ER linked by an episode ID. The episode ID is an identification number unique for each episode, in which each episode may be linked to the following: only one patient, one or more payments and zero or more values in the remaining data types. It should be noted that this model can be extended with additional data, which is not included herein, according to the specific characteristics of each ER.
The proposed data reference model retains certain data structures, extends others and adds new ones that are specific to ER. It retains the data structures for payment, patient, referral and radiology, since they already relate to activities generally carried out in all medical centers. It extends the data structures for transportation, internal medication, external medication and facility or building, including additional information, such as the status of a particular transportation, the active ingredient for a medication or information about each consultation room (box) of the ER facility. Finally, the model includes new general structures for all hospital facilities, as well as ones specific to ER. The new structures relate to vital signs, responsibility transfer, detailed professional activity, allergy, diagnosis, triage and ER discharge. Of the included dimensions, those specific to ER are the following: data from the consultation room (box) that form part of the facilities or buildings, triage data and data from the final ER discharge.
3.2. New Methodology
This section proposes a methodology based on process mining to analyze ER processes. The methodology is based on the guidelines for process mining projects proposed in [
19] and has adapted them to be question driven.
The proposed methodology deals with the flexible nature of ER processes as follows:
- -
FPQs are established. For each of them, it is possible to identify from the beginning the data in which the analysis should be focused.
- -
From these data, an event log is extracted that includes only the information required for the analysis of the selected FPQ.
- -
A list of ad hoc methods is provided to address each FPQ.
- -
The process can be decomposed into subprocesses, and episodes can be clustered in groups that can be analyzed independently, allowing more comprehensible models to be obtained.
- -
Moreover, process mining provides a set of tools to deal with unstructured processes: trace clustering gathers episodes into similar groups; identifying more frequent variants of how the process can be performed; and the ability of process mining algorithms, such as fuzzy miner or the one used by Disco, to ignore less frequent behaviors [
19].
The proposed methodology is intended to guide a team formed by a domain expert and a process mining expert, so that they have a clear roadmap of how to apply process mining to analysis ER processes. The domain expert contributes with his/her knowledge about and insights about how ER processes are performed. The process mining expert contributes with his/her understanding of how to use the process mining techniques and how to correctly interpret their results.
The methodology consists of six stages (as shown in
Figure 3), as follows: (1) extracting data from HIS; (2) creating an event log (main input for process mining techniques) based on the FPQ; (3) filtering the log for any given clinical context; (4) applying data analysis; (5) applying process mining (PM) techniques; and (6) analyzing the results with the experts. Each of the stages is explained below:
Activity 1.1. Identify available data in HIS and build the data model:
The data may be centralized in a single HIS or distributed across different information systems. A data model should be constructed, based on the reference model proposed in
Section 3.1.2, while always identifying each episode with a unique episode ID. Storing data based on a data reference model facilitates data extraction and the use thereof when answering the questions of the experts. It is important at this point to bear in mind a number of challenges when constructing the data reference model, as the quality of the data is not usually optimal, and actions are required as a result.
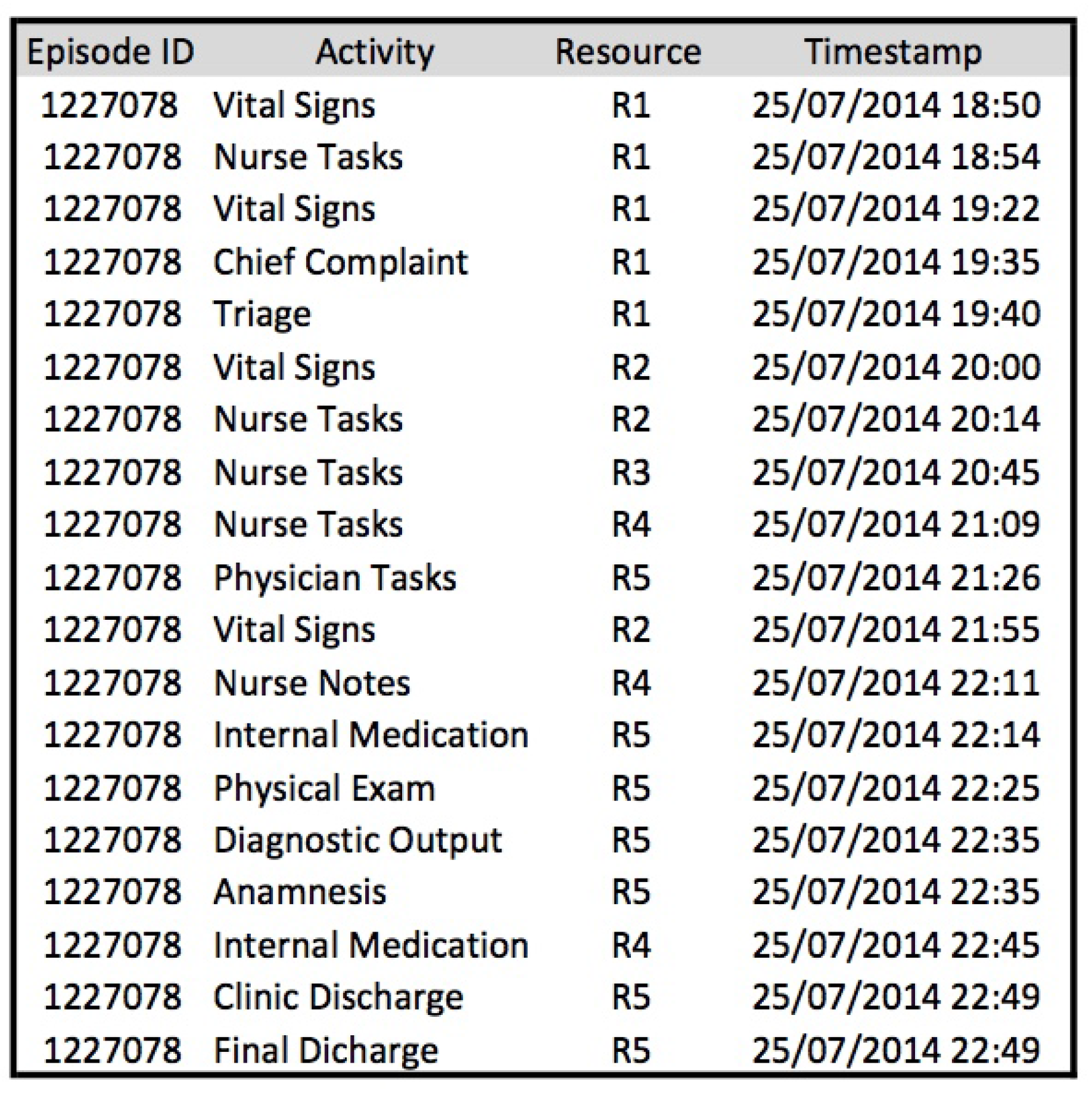
Activity 1.2. Ensure the availability of a timestamp for each event:
The first challenge is to ensure that a timestamp is present for each event of an episode. Each timestamp shows the moment in which a relevant event takes place. In addition to verifying the presence of a timestamp, the granularity of the timestamp must also be checked, since some timestamps have a high degree of accuracy (e.g., with a precision up to seconds), whereas others have a low level of accuracy (e.g., with a precision up to hours). As a result, it is necessary to decide the desired level in order to conduct the analysis. Ideally, the timestamp with the highest level of accuracy will be used. If different levels of accuracy are present, the highest one present in all of the data is recommended, just to have the same level across all of the examined data. If some data do not have a timestamp, they cannot be used for the analysis. Check that for each event or activity included in the data model, a correct timestamp is included. This will allow the use of the event or activity in the desired analysis.
Activity 1.3. Name events:
The second challenge is to decide the explicit name used to identify each of the activities included in the event log. In the reference models, data structures are identified for each of the activities undertaken. However, at the precise moment of creating the event log, it is necessary to define a particular name for each of them, in case they do not have one already established. For example, if we decide to include the events outlined in the vital signs data structure, each event must have a particular name, such as “record vital signs” or “taking vital signs”. In case any activity or event does not have an appropriate name, one should be assigned to it. The name should be establish according to the knowledge of the domain and taking into consideration the ER expert.
Activity 1.4. Create specific-fields:
Create specific fields based on the required needs. According to the available data and their level of granularity, we can build specific fields to help us through the analysis. This may involve grouping activities into subprocesses or splitting activities into more specific ones, in order to obtain more details of the process. This can be done manually or automatically according to the information provided by the domain expert. Specific fields may be significant for a specific analysis, but not for another, so this task may not apply to all FPQ.
Activity 1.5. Verify data quality:
In addition to the explained challenges, further general issues have been identified from the literature review that must be tackled when generating an event log for process mining purposes in healthcare.
Some of the most significant ones that should be studied and considered are:
The definition of 11 patterns that describe the event log quality issues, such as incorrect inputs from UI forms, incorrect time stamps, incorrect format of the data, missing episode IDs related to the characteristics, missing events or activities, repeated events, and others. They should be considered when extracting, building a data reference model and generating an event log. More details can be found in [
24].
The identification of 27 quality issues regarding the quality of the event log, classified into 4 categories, including process characteristics (amount of data, different types of traces and event granularity) and the quality of the event log (missing, imprecise, incorrect and irrelevant data). The details of the 27 quality issues are described in [
20,
25].
If the data contain incorrect or inaccurate values, they should be verified and checked with the HIS data owners to see if they are useful or not. If the data can be fixed by the experts to obtain the correct values, they still can be used. In case this is not reliable, the data should not be included in the analysis. It is important to overcome these challenges in the first stage, since it is in this stage that the data model is constructed. This model will facilitate data extraction and filtering processes for the subsequent stage of creating the event log.
Stage 2. Event log creation:
The event log creation stage considers the FPQ, establishes a specific data model and builds an event log to use in the following stages.
Table 2 sums up the main activities of this stage and provides a series of guidelines to be considered during this stage.
Activity 2.2. Create the event log:
Once the data stored in the specific data reference model are available, a specific event log must be created each time a question requires a response. Every event log is guided by the question that requires an answer. Event logs are the input for all process mining techniques and represent the actual execution of a process. An event log is composed of traces (i.e., process instances or episodes in this context), and each trace is represented by the ordered sequence of events that have occurred during the execution of that particular episode. Each event may contain additional information about its execution, such as its performer.
Activity 2.3. Include specific characteristics for each event or activity according to the specific analysis:
According to the characteristics of the data and the question that requires an answer, certain data types must be included in the event log for later use in the discovery or improvement of the process model. For example, in the case of wanting to discover the executed process, it is necessary to have the executed activities and their timestamps for each episode. In the case of wishing to conduct an organizational analysis, information about the health professionals that execute the activities must be included. In the case of wanting greater detail for certain activities, additional information to complement the activity must be included, for example when the requirement is to understand the characteristics of vital signs, including units of measurement and instruments used. Creating the event log is no trivial task, and it is necessary to undertake the process with due caution in order to include all required information. If such caution is lacking, results may be inaccurate and incorrect, meaning that this stage will have to be revisited at a later moment in order to include all missing data.
Stage 3. Filtering stage:
The filtering log stage consists of generating a specific event log for each question based on the filtering capacity of the different tools. It includes doing an analysis of the desired filters and the execution of them.
Once the event log has been created, data can be filtered according to the requirements of the question that requires an answer. This stage enables the event log to be refined in line with detailed characteristics in accordance with the analysis sought, for example establishing ranges of hours or days, clinical characteristics specific to the episodes or patient type. Undertaking this type of filtering is important since it reduces the quantity of episodes in the event log to those that are strictly necessary. This facilitates the application of the techniques and algorithms and the analysis of the data and models obtained. Normally, filters are included in the tools used to apply the process mining methods or techniques. These filter algorithms work by including/excluding episodes from the event log, based on the characteristics or values established in the filtering criteria options [
26,
27]. Three types of filtering are outlined: basic filtering, clinical domain filtering and question-driven filtering.
Table 3 sums up the main activities of this stage and provides a series of guidelines to be considered during this stage.
Activity 3.1. Basic filtering:
Basic filtering relates to filters that can be applied to any data characteristic, for example filtering by date or time (e.g., data between June and August 2015), filtering by location, clinical facilities or buildings (e.g., only data from the main hospital and not from its branches) and filtering by specific resources (e.g., specialist data or those relating to a specific role), among others.
Activity 3.2. Clinical filtering:
Clinical filtering (based on expert knowledge) relates to filters that can be applied according to the clinical characteristics of the data and which help to specify the data used in an improved manner. Examples of this type of filtering are to filter by diagnostic type (e.g., episodes with a diagnosis of bronchitis or appendicitis) or by medication type (e.g., ibuprofen).
Activity 3.3. Question-driven filtering:
Question-driven filtering relates to the filtering of data according to the characteristics of the question requiring an answer. If a response is required to a question based on triage values, data must be filtered in line with these values. For example, if the question relates to yellow triaged cases, with a diagnosis of bronchitis and with a final discharge to hospital, data must be filtered according to those particular values.
Stage 4. Data analysis stage:
The data analysis stage includes the analysis of data about how the process has been performed, as stored in the different event logs. This stage includes the selection of the data analysis techniques and the corresponding tools and the application of statistical analysis and data mining.
Table 4 sums up the main activities of this stage and provides a series of guidelines to be considered during this stage.
Activity 4.1. Select data analysis techniques:
The data analysis stage includes two possible types of analysis: statistical analysis and data mining analysis. These analyses are executed according to the relevant requirements for answering the specific question posed by the experts. There are types of analysis for specific questions in which only an exploratory statistical analysis is needed using tools, such as Excel (
products.office.com/en-us/excel) or Disco (
fluxicon.com/disco), and questions that require the use of both statistical analysis and data mining tools.
First, it is required to select the analysis techniques based on the expected outcomes. Outcomes may include a graphical model with data and information about the episodes, or an event log clustered into several sub-event logs. Second, it is required to identify the tools that allow one to perform the chosen techniques.
Activity 4.2. Statistical analysis:
Statistical analysis is used to characterize an event log, identifying the frequency of activities, the distribution of cases over time and variants of process execution, among others. It provides a holistic view of the process from a quantitative perspective and acts as a first step to answering any question. No specific algorithms are associated with this analysis; however, it can be performed using a variety of tools. For example, Disco is more process-oriented, while Excel is more data-oriented. Excel can be useful when the size and amount of data are manageable; but more complex big data solutions may be needed when the size grows, and this is not supported by Excel.
Activity 4.3. Data mining analysis:
Data mining analysis relates to the process of discovering different patterns and knowledge on datasets. There are multiple techniques taken from diverse domains that are applied in data mining in order to obtain the desired results, including, for example, visualization techniques, machine learning, classification algorithms and clustering, among others [
28]. Data mining helps to ensure, by means of different techniques and algorithms, diverse types of analysis, including, among others: identifying associations between data; data classification; data clustering; prediction of patterns; and so on. Data mining techniques previously used with process mining include the use of decision mining algorithms in Petri nets and decisions trees to determine the routing of different cases [
29], the use of clustering techniques and classification analyses to deconstruct different patient cohorts [
30], the use of temporal data mining techniques to analyze clinical time series data and search for patterns in them [
31] and the use of association rule mining and sequence mining techniques to discover associations between risk factors and specific outcomes [
32]. A wide range of commercial and non-commercial tools are available in data mining that enable the application of the aforementioned analyses, including Rapid Miner (
rapidminer.com/products/studio), GNUOctave (
www.gnu.org/software/octave), Weka (
www.cs.waikato.ac.nz/ml/weka), or R (
www.r-project.org).
Stage 5. Process mining stage:
The process mining stage includes all of the steps related to the application of process mining techniques and algorithms, including selecting the appropriate tool and identifying and applying the adequate methods.
Table 5 sums up the main activities of this stage and provides a series of guidelines to be considered during this stage.
Activity 5.2. Process discovery:
Process discovery is aimed at discovering a process model based on an event log, in which the resulting model includes the activities and paths taken in different cases. Given the flexible nature of ER processes, in which two episodes are never the same, when dealing with questions related to control-flow analysis, we recommend the use of models with more flexible semantics, such as dependency graphs or fuzzy models, as well as the following discovery algorithms, heuristic miner [
33] and fuzzy miner [
34]. Alternatively, some questions may require models with a more formal semantic (e.g., Petri nets or process trees) and their associated algorithms (e.g., genetic miner [
35] or inductive miner [
36]) in order to verify conformance. Disco focuses on non-formal semantic models, while ProM includes models and algorithms with more formal semantics.
Activity 5.5. Organizational analysis:
Finally, organizational analysis focuses on the resources perspective and how people behave during the execution of process activities. For example, it identifies who performs each task and how resources interact during a case execution. The authors recommend the use of the organizational metrics implemented in ProM (e.g., working together or handover of work) in order to obtain organizational models.
Activity 5.6. Analysis regarding each type of question:
Section 2 provides a classification of FPQ. For each of them, one or several types of techniques can be applied. For example, some FPQs may need to use discovery techniques to obtain process models, while others may need to use conformance checking techniques to verify conformance.
Table 6 provides a general guide of what analysis techniques should be used for each FPQ.
Activity 5.7. Data analysis and process mining cycle:
Data analysis and process mining analysis stages are introduced as a cycle, since, in order to obtain the necessary results for responding to certain questions, a continuous iteration is required for refining the data and the results until the desired answers are obtained. For example, process mining discovery techniques are used at the beginning of an analysis to create a process model with a complete event log that includes all activities. These activities have characteristics (e.g., triage color or diagnosis), which help to undertake statistical analyses of the data and filter the event log, as required. The new event log includes only the desired episodes, and during the process mining stage, it helps to create a new model. By means of this series of iterations, it is possible to filter and analyze the dataset and reduce the spaghetti effect [
19] in the process models discovered. In addition to analyzing the data in order to reduce or filter the event logs, the data analysis stage also enables the use of more advanced data mining techniques to identify trends, prediction rules and decision trees, among other more complex analyses.
Stage 6. Results evaluation stage:
Regardless of the technique used, it is extremely important to gather feedback from the ER experts, not only about the answers provided, but also about the clinical impact of the data and models obtained. In the results evaluation stage, the results are shown to the ER experts in order to know whether they provide the information, data and models to answer their FPQs.
Table 7 sums up the main activities of this stage and provides a series of guidelines to be considered during this stage.
Activity 6.1. Identify ER experts:
The first step is to identify who are the relevant ER experts, those that have the knowledge about the complete process and are able to identify and explain each performed task.
Activity 6.2. Define feedback instruments:
Once the results from the analysis stages have been acquired, it is important to establish the instruments that will be used to verify the results in conjunction with the ER experts by analyzing the models and data obtained from each frequently-posed question. Examples of common instruments that might be considered include questionnaires, interviews and focus groups [
41]. A questionnaire can be used to ask open or closed questions to identify whether the experts encounter the desired answers in the models and the data shown. This type of questionnaire should be used after the introduction and explanation of the obtained results. General questions may include: Do the data and models help to produce answers to the proposed questions? On the other hand, more specific questions might be used, for example: Is the sequence of activities present in the episodes of patients with appendicitis and a yellow triage as expected based on previous experience? Questionnaires do not have to be completed in person; rather, they can be undertaken digitally.
Feedback on the results of the application of process mining can also be obtained by means of interviews with ER experts. The advantage of interviews is that the answers can be broader than ones stemming from more closed questions in a questionnaire. The disadvantage is that they take longer to conduct. On the other hand, through focus groups, multiple experts from the particular field in question can be included simultaneously. In this instance, not only can the experts be asked specific questions, but also a general discussion can be generated regarding the results of the application of process mining in ER.
Activity 6.3. Obtain feedback:
Finally, the results should be shown to the ER experts in order to gather their feedback. It is not necessarily bad that the experts conclude that the outputs obtained are not enough, are not relevant or are not the expected ones. This is part of the process and will imply going back and checking the previous stages. It is usually required to verify whether the data were correct, the filters were made appropriately, the techniques applied were the proper ones and the results were interpreted correctly. This cycle should be repeated as many times as necessary in order to acquire the desired answers.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}