The Potential of the SP System in Machine Learning and Data Analysis for Image Processing


CognitionResearch.org, 18 Penlon, Menai Bridge, Anglesey LL59 5LR, UK
Big Data Cogn. Comput. 2021, 5(1), 7; https://0-doi-org.brum.beds.ac.uk/10.3390/bdcc5010007
Submission received: 29 November 2020
/
Revised: 14 February 2021
/
Accepted: 18 February 2021
/
Published: 23 February 2021
Abstract
:This paper aims to describe how pattern recognition and scene analysis may with advantage be viewed from the perspective of the SP system (meaning the SP theory of intelligence and its realisation in the SP computer model (SPCM), both described in an appendix), and the strengths and potential of the system in those areas. In keeping with evidence for the importance of information compression (IC) in human learning, perception, and cognition, IC is central in the structure and workings of the SPCM. Most of that IC is achieved via the powerful concept of SP-multiple-alignment, which is largely responsible for the AI-related versatility of the system. With examples from the SPCM, the paper describes: how syntactic parsing and pattern recognition may be achieved, with corresponding potential for visual parsing and scene analysis; how those processes are robust in the face of errors in input data; how in keeping with what people do, the SP system can “see” things in its data that are not objectively present; the system can recognise things at multiple levels of abstraction and via part-whole hierarchies, and via an integration of the two; the system also has potential for the creation of a 3D construct from pictures of a 3D object from different viewpoints, and for the recognition of 3D entities.
{kind=link}
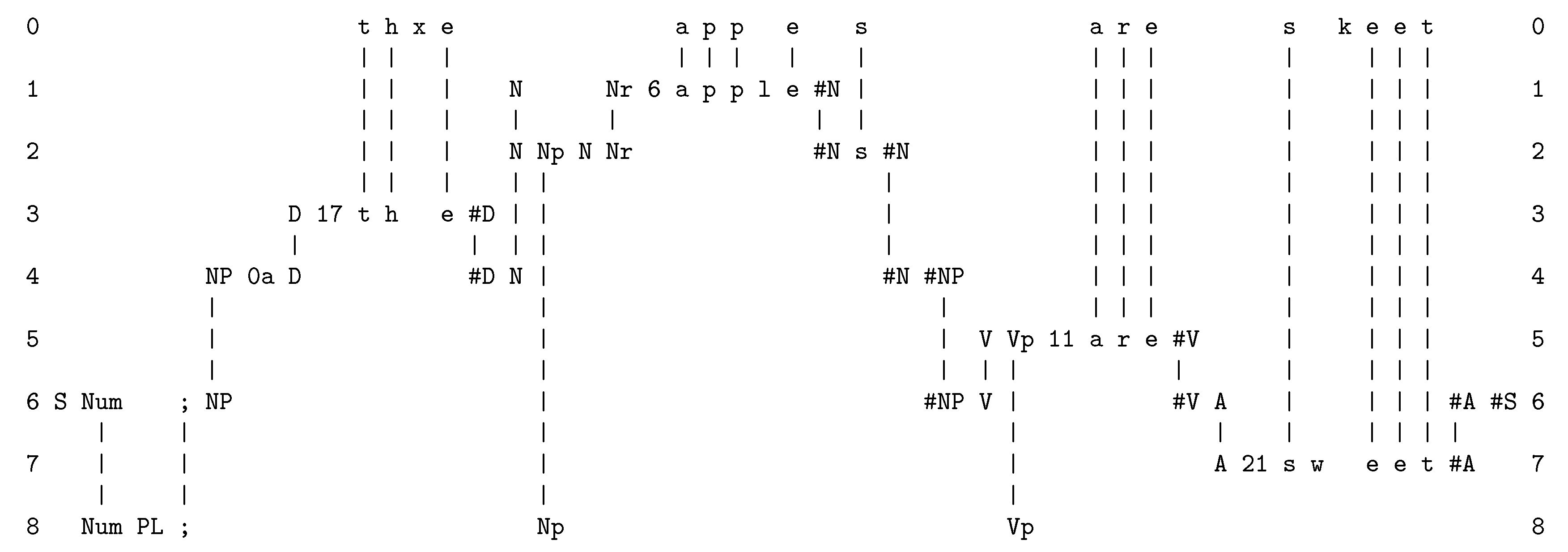{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
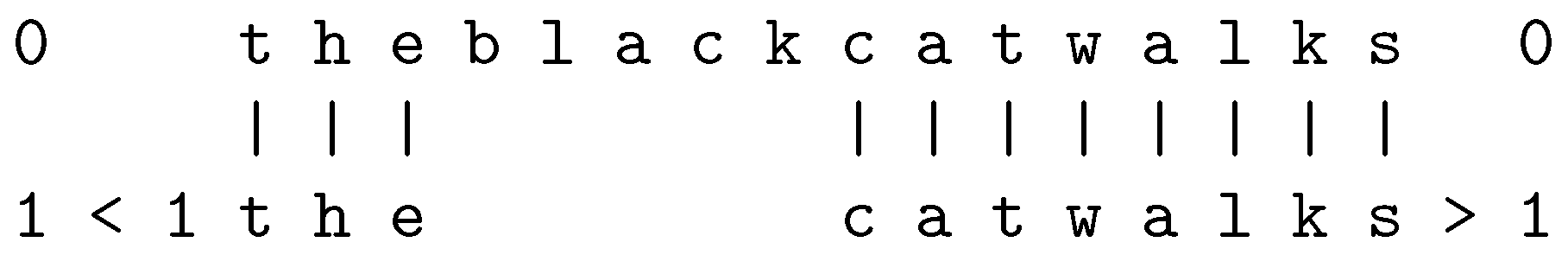{kind=link}
{kind=link}
1. Introduction
The processing of images via machine learning and data analysis is an area of research with many potential applications. Examples include: the recognition of Arab sign language (see, for example, [1]); the analysis of 3D thermal images to facilitate the non-destructive testing of products (e.g., [2]); the recognition of faces [3]; monitoring the formation of ice, or melting, or other changes to ice that may occur on, for example, aeroplane wings (e.g., [4]); the recognition of finger prints (e.g., [5]); and more.
In this paper, the focus is on aspects of image processing that may be seen as pattern recognition, or as scene analysis, or as the inference or recognition of three-dimensional structures. The paper does not address such aspects of image processing as the filtering an image to sharpen it, or transformation of an image such as scaling or rotating it, or creating a mirror or sheared version of it.
In pattern recognition and scene analysis, it is clear that existing techniques for machine learning and data analysis can yield useful results, but it is also clear that, in those tasks, they are generally not as good as people. In particular:
- It is widely acknowledged that, while computer-based techniques for image processing have advantages compared with people in that they do not suffer from boredom, they do not get drunk, and they do not fall asleep, they fall far short of people in terms of the subtlety and intelligence that can be applied.
- There are now many studies that demonstrate that, although deep neural networks (DNNs) can be quite good at recognising things, they can make surprisingly silly mistakes (see, for example, [6,7,8]). Mistakes like these can be a serious problem when there is a risk of death or injury to people, or when expensive equipment may be damaged or destroyed.
- It is sometimes simpler and more effective for recognition tasks to be done by human “clickworkers”, earning money for skills which currently exceed what computers can do (see, for example, item 24 in https://tinyurl.com/y6yfrkqp, accessed on 22 February 2021).
- Some websites aim to exclude web-crawling bots by setting recognition tasks which require human knowledge and intelligence. Examples include such tasks as identifying all the pictures within a set which show all or part of a shop front, or of a car, and so on.
- In a similar way, “captcha” tasks—such as the recognition of highly irregular and obscured letters and numbers—are used with the aim of separating humans from bots.
The aim in this paper is to describe how image processing may with advantage be viewed from the perspective of the SP system (to be described), and the potential of the SP system as a foundation for further development towards human-like capabilities.
As it stands now, the computer model in the SP system is limited to a shrink-wrapped widget that can be applied directly to all kinds of pattern recognition or scene analysis. However, as described below, it has strengths and potential which may cast useful light on issues in the processing of images, and it has potential as a powerful system for pattern recognition and related kinds of image processing.
In the sections that follow, the SP system is described with enough detail for the present purposes, and with pointers to where fuller information may be found. The rest of the paper describes how the SP concepts may prove useful in pattern recognition and related processes.
Abbreviations
Abbreviations used in this paper are detailed below, with, for each one, a reference to where it first appears.
- Artificial intelligence: AI.
- Information compression: IC.
- SP computer model: SPCM.
- SP-multiple-alignment: SPMA.
It is intended that “SP” should be treated as a name. This because:
- The SP system is intended, in itself, to combine simplicity with descriptive and explanatory power.
- Additionally, because the SP system works entirely by compression of information, which may be seen as a process that creates structures that combine conceptual simplicity with descriptive and explanatory power.
2. Preamble
This section describes some preliminaries needed in the rest of the paper.
2.1. Introduction to the SP System
The SP system, meaning the SP theory of intelligence and its realisation in the SPCM, is the product of a lengthy programme of research, seeking to simplify and integrate observations and concepts across AI, mainstream computing, mathematics, and human learning, perception, and cognition (HLPC).
Appendix A describes the SP system with enough detail to ensure that, for readers who are not otherwise familiar with the SP system, the rest of the paper makes sense. For that reason, an appendix like this is necessary in most papers about the SP system, something that may wrongly be interpreted as self-plagiarism.
Much more detail may be found in the book “Unifying Computing and Cognition: the SP Theory and Its Applications” [9], and the system is described more briefly but quite fully in [10]. Key publications relating to the SP programme of research are detailed with download links in https://tinyurl.com/ybo2r7g9, accessed on 22 February 2021, and more comprehensive information is available at https://tinyurl.com/y8v368og, accessed on 22 February 2021.
A key feature of the SP system is that, for reasons outlined in Appendix A.2, it works entirely via the compression of information. Although it may seem unlikely, information compression (IC) in the SP system, as described in Appendix A.3, Appendix A.4 and Appendix A.5, is largely responsible for the SP system’s strengths and potential in AI-related structures and functions, as summarised in Appendix A.6.
2.2. The SP Computer Model
It is important to stress that the SP theory of intelligence has been developed largely in conjunction with the development of the SPCM. The whole process of discovering a framework that could simplify and integrate concepts across a broad canvass (Section 2.1), and then developing that framework via the development and testing of a large number of versions of the SPCM, took about 17 years.
That long process of research, development, and testing has been extremely important in weeding out bad ideas and blind alleys in the SP theory.
Although many problems have been solved, and the SPCM as it is now is vastly superior to early versions, there is still a lot to be done. It is envisaged that the SPCM will be developed into a much more robust SP machine, as outlined in Appendix A.8.
For readers who feel that there is no rigour without mathematics, it must be stressed that the SPCM contains mathematics in key areas, and, in addition, it provides a rigorous expression of important concepts that would be difficult to express in mathematics—and those important concepts have survived the afore-mentioned lengthy period of development and testing. The SPCM also provides the means to demonstrate or test how the SP concepts work with varied kinds of data.
A summary of the mathematics incorporated in the SPCM or otherwise contributing to its development may be found in the open-access paper [11], Appendix A.
The source code and Windows executable code for the SPCM may be downloaded via links from http://www.cognitionresearch.org/sp.htm#SOURCE-CODE, accessed on 22 February 2021.
2.3. The SP System as a Foundation for the Development of Artificial General Intelligence
For two main reasons, the SP system appears to be a promising foundation for the development of artificial general intelligence (AGI):
- There is good evidence, described in [12], that the SP system may help to solve 20 significant problems in AI research. There appears to be no other system with this potential.
- Although the SP system is conceptually simple, it demonstrates strengths and potential across several different aspects of intelligence, as described in [9,10]. Those strengths and that potential are summarised in Appendix A.6.
3. Pattern Recognition and Scene Analysis
The SPCM is not yet ready to be applied in the processing of 2D images. This is because the program has not yet been generalised to process two-dimensional SP-patterns, and one-dimensional SP-patterns. However, much of the potential of the system in image processing can be seen in several aspects of how it works, as described in this and following main sections.
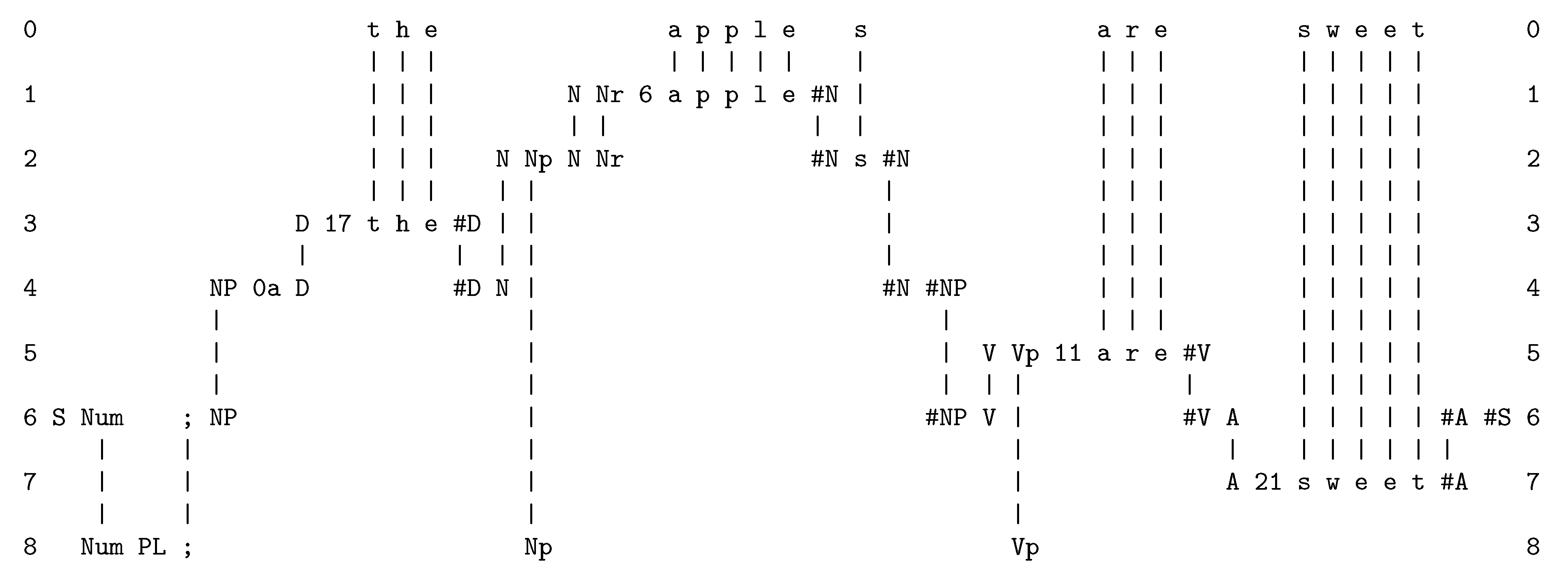
Figure A2 in Appendix A.4 shows how, with the SPCM, the sentence “t h e a p p l e s a r e s w e e t” in row 0 may be analysed or parsed in terms of grammatical structures shown in rows 1 to 8. With the generalisation of SP-patterns to two dimensions, this kind of parsing may be seen as the analysis of a scene into its parts and sub-parts, together with the recognition of entities such as the words “t h e”, “a p p l e s”, and so on. The similarity of linguistic parsing and scene analysis is widely recognised (see, for example, [13,14,15]).
4. Robust Analysis in the Face of Errors
A nice feature of the SP system is that it can accommodate errors in a way that is broadly similar to what people can do, and is a desirable feature of any AI system that aspires to human-like capabilities.
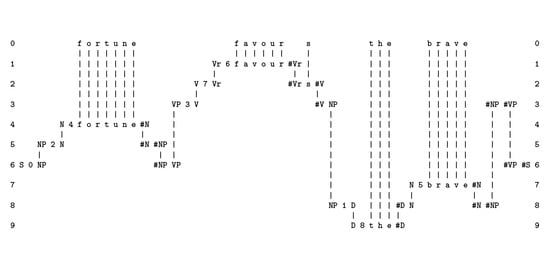
This capability can be seen in Figure 1, which is similar to Figure A2 except that the sentence to be parsed contains errors of addition (“t h x e” instead of “t h e”), omission (“a p p e s” instead of “a p p l e s”), and substitution (“s k e e t” instead of “s w e e t”).
A noteworthy feature of this feature of the SP system is that it has not required any special mechanism for processing errors. It is a direct result of the central role of IC in the design of the SP system, and it provides indirect evidence for the importance of IC in AI, in accordance with the importance of IC in HLPC (Appendix A.2).
5. Seeing Things That Are Not Objectively There
A prominent feature of human vision is that, very often, we see things that are not objectively there. An example described by David Marr (Figure 4-1 (a) in [17]) is a photograph of a leaf which is overlapping another leaf. As we view the picture, we can “see” the edge of the upper leaf as it crosses the lower leaf, but if we look closely, there is no physical line of any kind. The reason we feel as if the line is there is because we have analysed the whole picture and we infer that, because the picture is of one leaf overlapping another leaf, the edge of the upper leaf must be there.
This phenomenon may be interpreted in two ways, both of which may be valid:
- Interpolation via parsing. In Figure A2, the new SP-pattern in row 0 does not contain anything to mark the boundary between any pair of neighbouring words. However, the process of parsing has the effect of splitting up the sentence into its constituent words, and it also marks the morpheme boundary between “a p p l e” and “s”.
- Interpolation via error correction. It appears that, in the same way that the SPCM has interpolated the missing “l” in the sequence “a p p e s” within the new SP-pattern; as described in Section 4, the human brain interpolates part of the edge of the upper leaf in Marr’s photo, although in a literal interpretation of the photo, that part of the edge is missing.
More generally, the SPCM can model at least some of what people can do in making inferences in vision and other aspects of intelligence. For example, if we see a nut with an unbroken shell, we infer that there is a tasty kernel inside. If we see a red-hot poker, we infer that it will burn us if we touch it, and so on.
A large part of human intelligence, and the intelligence of other animals, is the ability to make these kinds of inferences. Over millions of years of evolution, it has given us great survival value.
A simple example is shown in Figure 2. Here, the new SP-pattern in row 0 corresponds to us seeing “black clouds”, and the old SP-pattern in row 1, “black clouds rain”, may be seen to represent stored knowledge of the association between black clouds and rain.
The unmatched SP-symbol “rain” in the figure is the inference that may be drawn from the SPMA. In a more fully-developed example, there would be alternative inferences that snow or hail might follow and there would be a probability value for each alternative.
6. Recognition at Multiple Levels of Abstraction
A prominent feature of HLPC is the way we organise our knowledge into classes and subclasses—often with cross-classification—and how accordingly, we may recognise things at several different levels of abstraction.
The SPCM is not yet able to learn such structures for itself but, with user-supplied knowledge, it is able to demonstrate recognition at multiple levels of abstraction.
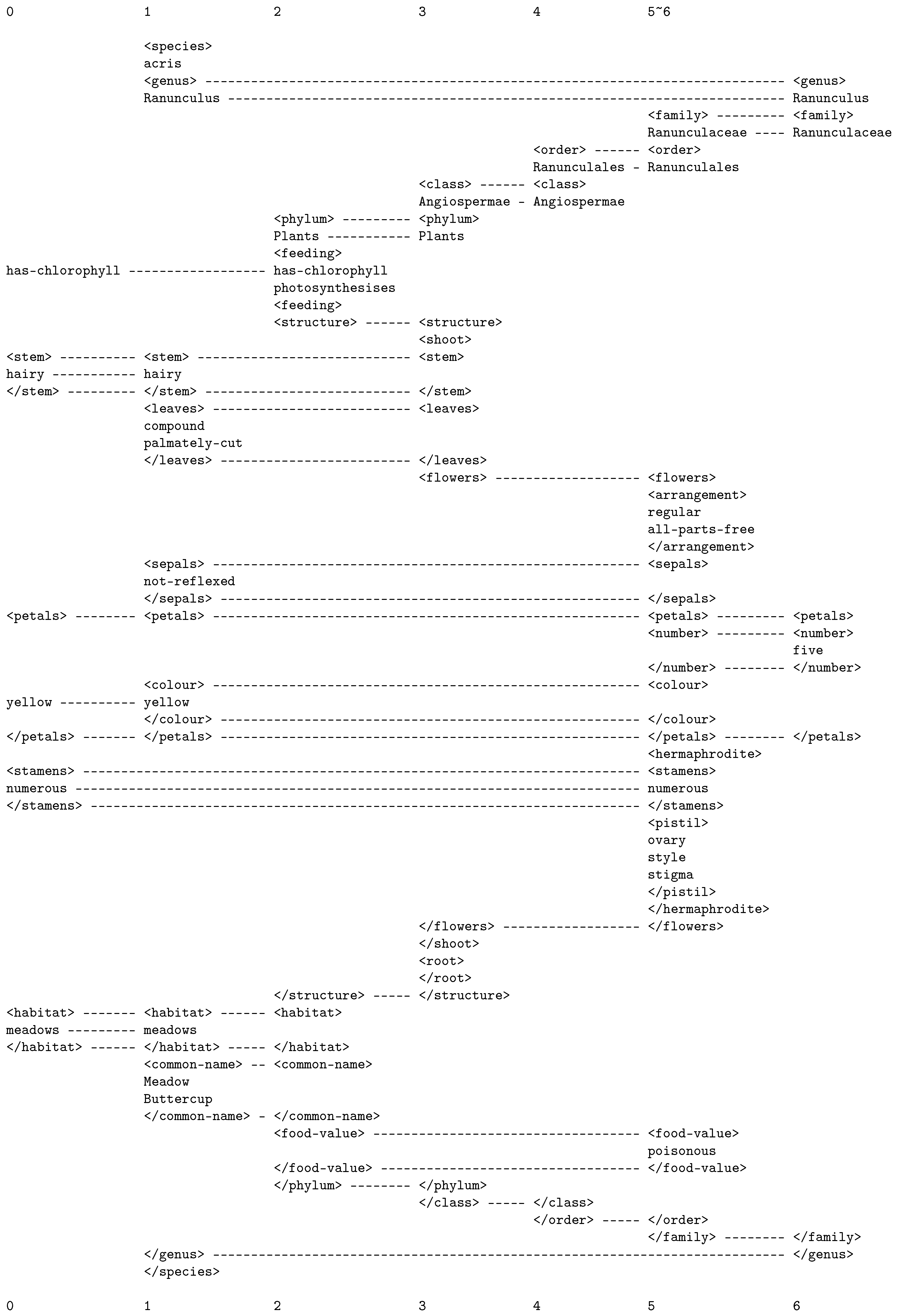
An example is shown in Figure 3. (Unlike other SP-multiple-alignments shown in this paper, the SPMA shown here has SP-patterns arranged in columns instead of rows. The choice between these alternatives depends entirely on what fits best on the page.)
As noted in the caption to Figure 3, it shows the best SPMA created by the SPCM with new information (shown in column 0) that describe features of some unknown plant, and a collection of old SP-patterns, such as those shown in columns 1 to 6, one SP-pattern per column, which describe a variety of features of plants.
The SPMA in the figure shows that the unknown plant has been recognised as a meadow buttercup (column 1), which belongs to the genus Ranunculus (column 6), which is in the family Ranunculaceae (column 5), which is in the order Ranunculales (column 4), and so on. Of course, people who are not experts in botany would recognise plants in terms of less formal categories.
7. Recognition in Terms of Part-Whole Categories, and Hybrid Recognition
In addition to recognition in terms of class-inclusion hierarchies, the SP system may recognise things in terms of part-whole hierarchies (Section 6.4 in [9], Section 9.1 in [10]). For example, a person may be recognised at the general level of “person” in terms of their head (including such parts as eyes, nose, and mouth), their body (including the chest and abdomen), their arms (each one with a hand with five fingers), and their legs (each one with a foot with five toes).
Due to the generality of representing all kinds of knowledge with SP-patterns (Appendix A.1), and performing all kinds of processing (except for some parts of unsupervised learning) via the building of sp-multiple-alignments (Appendix A.4), there can be seamless integration of recognition at multiple levels of abstraction (Section 6) with recognition in terms of part-whole categories (this section).
Although the SPMA in Figure 3 was presented as an example of recognition at multiple levels of abstraction, it actually illustrates the integration just described. This is because, in addition to class-inclusion relations, it shows such part-whole relations as the division of a flower into sepals, petals, stamens, and so on.
8. Learning and Perception of Three-Dimensional Structures
The discussion so far has assumed that everything we see is flat, but of course our visual world is filled with structures in three dimensions.
Although the SPCM cannot at present learn 3D structures, or perceive them, it is reasonably clear how such capabilities may be developed.
Figure 4 shows a plan view of a 3D object, with each of the five lines with arrows around it representing a view of the object from one side, seen from above, with the line showing the lateral extent of the view, and the arrow showing which way the viewer or camera is facing.
Provided the several views overlap each other, processes for detecting alignments can stitch the several views together into a coherent representation of the 3D structure. This is much like the way that, in digital photography, several overlapping photos of a scene may be stitched together to create a panorama. With regard to 3D models, there are now several commercial companies offering facilities for the creation of 3D models of real-world objects from a set of photographs taken from several different view points as shown in Figure 4.
Much the same kind of capability is part of the Google Streetview system that builds 3D models of streets from many overlapping photographs.
Since the discovery of alignments between SP-patterns is bread-and-butter for the SPCM, it should be relatively straightforward to develop the system for the learning of 3D structures.
Without much further development, the SPCM should be able to recognise 3D objects, since recognition in those cases is likely to be similar to the system’s existing capabilities for recognition.
9. Conclusions
The SP system, meaning the SP theory of intelligence and its realisation in the SP computer model (SPCM), is the product of a lengthy programme of research, seeking to simplify and integrate observations and concepts across AI; mainstream computing; mathematics; and human learning, perception, and cognition. The organisation and workings of the SP system are introduced in Section 2.1, and described more fully in Appendix A.
On the strength of empirical evidence for the importance of information compression (IC) in human learning, perception, and cognition [11], IC is central in the workings of the SPCM. More specifically, the model achieves IC via a search for patterns that match each other and the merging or “unification” of patterns that are the same. Even more specifically, IC is achieved via the powerful concept of SPMA, borrowed and adapted from the concept of “multiple sequence alignment” in bioinformatics.
The main sections of the paper describes with examples how this framework provides for the modelling of pattern recognition and scene analysis; robust analysis of patterns in the face of errors; seeing things that are not objectively there; recognition at multiple levels of abstraction; recognition in terms of part-whole hierarchies and hybrid hierarchies; and the learning and perception of three-dimensional structures.
Taking account of these features of the SP system, and others described in other publications, the SP system has potential as a foundation for the development of human-like general AI or “artificial general intelligence”. The realisation of that potential (via a possible scenario outlined in [19]) is likely to yield further benefits in the recognition of entities, in scene analysis, and in the inference and recognition of three-dimensional structures.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Details of the examples presented in this study are available on request from the corresponding author. The source code and Windows executable code for the SPCM may be downloaded via links from http://www.cognitionresearch.org/sp.htm#SOURCE-CODE, accessed on 22 February 2021.
Acknowledgments
I’m grateful to anonymous reviewers for constructive comments on earlier versions of this paper.
Conflicts of Interest
The author declares no conflict of interest.
Appendix A. Outline of the SP System
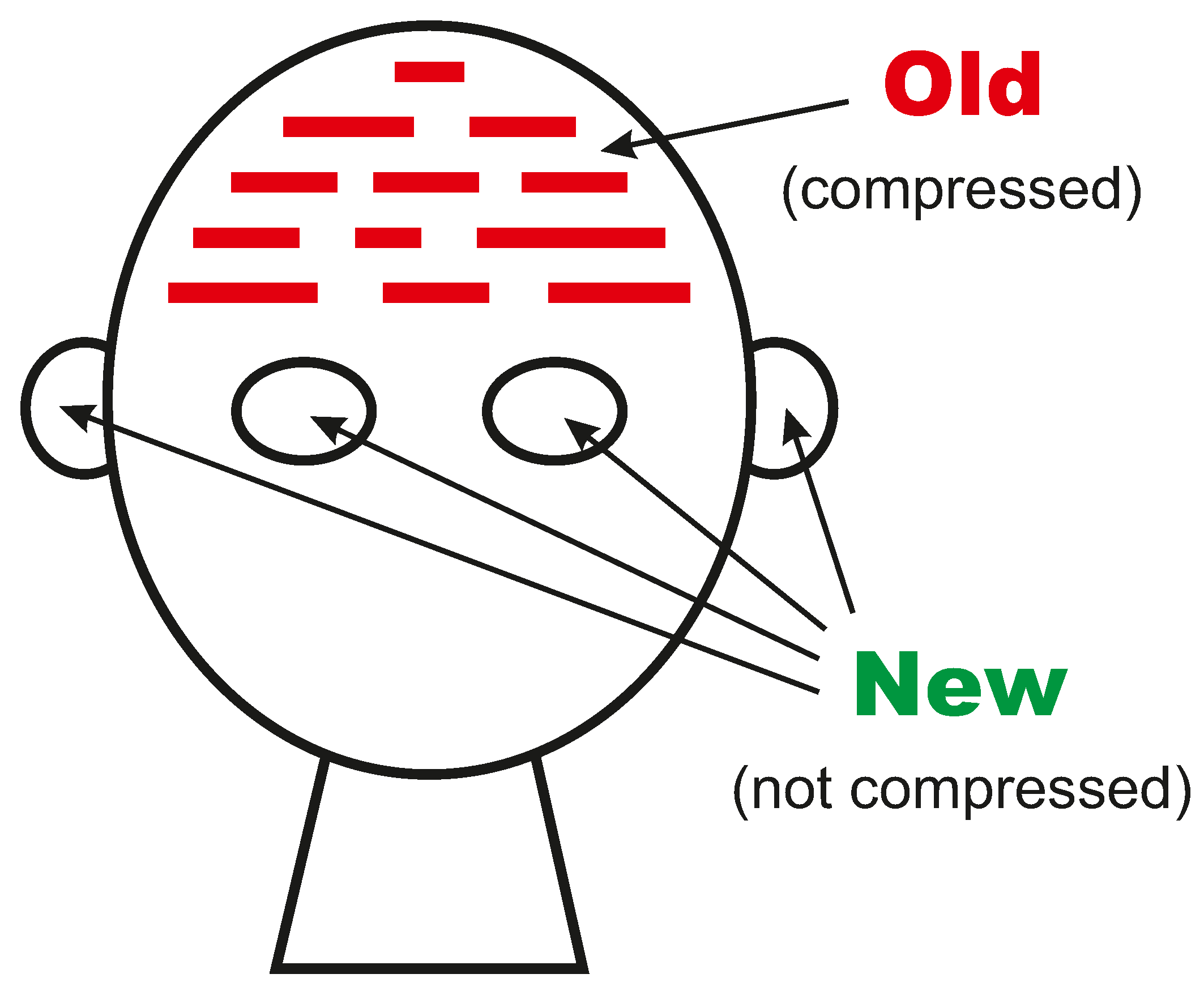
The SP system is conceived as a brain-like system as shown in Figure A1, with new information (green) coming in via the senses (eyes and ears in the figure), and with some or all of that information stored as old information (red), stored in the brain.
Figure A1.
Schematic representation of the SP system from an “input” perspective. Reproduced, with permission, from Figure 1 in [10].

Appendix A.1. SP-Patterns and SP-Symbols
In the SP system, all information is represented by SP-patterns, where an SP-pattern is array of SP-symbols in one or two dimensions. Here, an SP-symbol is simply a mark from an alphabet of alternative that can be matched in a yes/no manner with other SP-symbols.
At present, the SPCM works only with one-dimensional SP-patterns, but it is envisaged that, at some stage, the SPCM will be generalised to work with two-dimensional SP-patterns and one-dimensional SP-patterns.
Appendix A.2. Biology, Psychology, and Compression of Information
Since, as described above, the SP programme of research aims, inter alia, to simplify and integrate observations and concepts from HLPC, there is potential for the SP system to benefit from important ideas and insights from biology.
Chief amongst the ideas that have illuminated and still illuminate the design and development of the SP system is that IC can be a key in understanding the workings of brains and nervous systems.
This strand of research was pioneered by Fred Attneave (see, for example, ref. [20] and Horace Barlow (see, for example, [21,22]) and has been developed by many other researchers up to the present. A review of evidence for the importance of IC in HLPC is in [11].
In this connection, an important strand of evidence is that IC can be an important driver for the evolution people and other animals by natural selection, by introducing advantages in both the transmission and storage of information (Section 4 in [11]). Much the same can be said about the design of artificial systems, including AI systems.
Appendix A.3. IC via the Matching and Unification of Patterns
By contrast with techniques for IC such as arithmetic coding or wavelet compression, IC in the SP system is achieved by searching for patterns that match each other and merging or “unifying” patterns that are the same. The expression “information compression via the matching and unification of patterns” may be abbreviated as “ICMUP”.
An important point in this connection is that there can be good matches between patterns that are not exactly the same. For example, there can be a successful match between two patterns such as “t h e b l a c k c a t w a l k s” and “t h e c a t w a l k s”. As described in Appendix A.5, this capability is important in the unsupervised learning of new structures.
Appendix A.4. IC via SP-Multiple-Alignment
As noted above, a major part of the SP system is IC via the concept of SPMA. This incorporates ICMUP but super-drives it in the way that the matching and unification of patterns is done. An example of an SPMA shown in Figure A2.
Figure A2.
The best SPMA created by the SPCM that achieves the effect of parsing a sentence (“t h e a p p l e s a r e s w e e t”), as described in the text.
Figure A2.
The best SPMA created by the SPCM that achieves the effect of parsing a sentence (“t h e a p p l e s a r e s w e e t”), as described in the text.

Here is a summary of how SP-multiple-alignments like the one shown in the figure are formed:
- At the beginning of processing, the SPCM has a store of old SP-patterns including those shown in rows 1 to 8 (one SP-pattern per row), and many others. When the SPCM is more fully developed, those old SP-patterns would have been learned from raw data as outlined in Appendix A.5, but for now they are supplied to the program by the user.
- The next step is to read in the new SP-pattern, “t h e a p p l e s a r e s w e e t”.
- Then the program searches for “good” matches between SP-patterns, where “good” means matches that yield relatively high levels of compression of the new SP-pattern in terms of old SP-patterns with which it has been unified. The details of relevant calculations are given in ([10], Section 4.1) and ([9], Section 3.5).
- As can be seen in the figure, matches are identified at early stages between (parts of) the new SP-pattern and (parts of) the old SP-patterns “D 17 t h e #D”, “N Nr 6 a p p l e #N”, “V Vp 11 a r e #V”, and “A 21 s w e e t #A”.
- Each of these matches may be seen as a partial SPMA. For example, the match between “t h e” in the new SP-pattern and the old SP-pattern “D 17 t h e #D” may be seen as an SPMA between the SP-pattern in row 0 and the SP-pattern in row 3.
- After unification of the matching symbols, each such SPMA may be seen as a single SP-pattern. So the unification of “t h e” with “D 17 t h e #D” yields the unified SP-pattern “D 17 t h e #D”, with exactly the same sequence of SP-symbols as the second of the two SP-patterns from which it was derived.
- As processing proceeds, similar pair-wise matches and unifications eventually lead to the creation of SP-multiple-alignments like that shown in Figure A2. At every stage, all the SP-multiple-alignments that have been created are evaluated in terms of IC, and then the best SP-multiple-alignments are retained and the remainder are discarded. In this case, the overall “winner” is the SPMA shown in Figure A2.
- This process of searching for good SP-multiple-alignments in stages, with selection of good partial solutions at each stage, is an example of heuristic search. This kind of search is necessary because there are too many possibilities for anything useful to be achieved by exhaustive search. By contrast, heuristic search can normally deliver results that are reasonably good within a reasonable time, but it cannot guarantee that the best possible solution has been found.
As noted in the caption to Figure A2, the SPMA in the figure achieves the effect of parsing the sentence into its parts and sub-parts. However, the beauty of the SPMA construct is that it can model many more aspects of intelligence besides the parsing of a sentence. These are summarised in Appendix A.6, although unsupervised learning (Appendix A.5) is a little different from the others.
Appendix A.5. IC via Unsupervised Learning
“Unsupervised learning represents one of the most promising avenues for progress in AI. [...] However, it is also one of the most difficult challenges facing the field. A breakthrough that allowed machines to efficiently learn in a truly unsupervised way would likely be considered one of the biggest events in AI so far, and an important waypoint on the road to AGI.”Martin Ford ([23], pp. 11–12), emphasis added.
Unsupervised learning in the SP system is intimately combined with processes of interpretation, as outlined in Appendix A.4. For the sake of clarity, unsupervised learning in the SP system will be described in the following two subsections.
Appendix A.5.1. Learning with a Tabula Rasa
When the SPCM is a tabula rasa, with no stored old SP-patterns, the system learns by taking in new SP-patterns via it “senses” and storing them directly as received, except that “ID” SP-symbols are added at the beginning and end, like the SP-symbols “A”, “21”, and “#A”, in the SP-pattern “A 21 s w e e t #A” in Figure A2. Those added SP-symbols provide the means of identifying and classifying SP-patterns, and they may be modified or added to by later processing.
This kind of direct learning of new information reflects the way that people may learn from a single event or experience. One experience of getting burned may teach a child to take care with hot things, and the lesson may stay with him or her for life. However, we may remember quite incidental things from one experience that have no great significance in terms of pain or pleasure—such as a glimpse we may have had of a red squirrel climbing a tree.
Any or all of this one-shot learning may go into service immediately without the need for repetition, as for example: when we ask for directions in a place that we have not been to before; or how, in a discussion, we normally take account of what other people are saying.
These kinds of one-shot learning contrast sharply with learning in DNNs which requires large volumes of data and many repetitions before anything useful is learned.
“We can imagine systems that can learn by themselves without the need for huge volumes of labeled training data.”Martin Ford ([23], p. 12).
“... the first time you train a convolutional network you train it with thousands, possibly even millions of images of various categories.”Yann LeCun ([23], p. 124).
Appendix A.5.2. Learning with Previously-Stored Knowledge
Of course, with people, the closest we come to learning as a tabular rasa is when we are babies. At all other times, learning occurs when we already have some knowledge. In people, and in the SP system, two kinds of things can happen:
- The new information is interpreted via SPMA in terms of the old information, as described in Appendix A.4. The example illustrated in Figure A2 is of a purely syntactic analysis, but with the SPCM, semantic analysis is feasible too (Section 5.7 in [9]).
- Partial matches between new and old SP-patterns may lead to the creation of additional old SP-patterns, as outlined next.
As an example, Figure A3 shows an SPMA between new and old SP-patterns—the “cat” examples mentioned earlier.
Figure A3.
The best SPMA created by the SPCM with a new SP-pattern “t h e b l a c k c a t w a l k s” and an old SP-pattern “< 1 t h e c a t w a l k s >”.
Figure A3.
The best SPMA created by the SPCM with a new SP-pattern “t h e b l a c k c a t w a l k s” and an old SP-pattern “< 1 t h e c a t w a l k s >”.

From a partial matching like this, the SPCM derives SP-patterns that reflect coherent sequences of matched and unmatched SP-symbols, and it stores the newly-created SP-patterns in its repository of old SP-patterns, each SP-pattern with added “ID” SP-symbols. The results in this case are the SP-patterns “< 13 t h e >”, “< 19 b l a c k >”, and “< 20 c a t w a l k s >”.
With this small amount of information, the SP-pattern “< 20 c a t w a l k s >” is a “word”. However, with more information such as “c a t r u n s” or “d o g w a l k s”, the SP-patterns “c a t” and “w a l k s” would become separate words.
Even with simple examples like these, there is a lot of complexity in the many alternative structures that the program considers. However, with the IC heuristic, the structures that are intuitively “bad” are normally weeded out, leaving behind the structures that people regard intuitively as “good”.
Appendix A.5.3. Unsupervised Learning of SP-Grammars
In the SPCM, processes like those just described provide the foundation for the unsupervised learning of SP-grammars, where an SP-grammar is simply a set of old SP-patterns that is relatively good at compressing a given set of new SP-patterns.
To create “good” SP-grammars requires step-wise processes of selection, very much like processes of that kind in the creation of “good” SP-multiple-alignments (Appendix A.4).
Appendix A.5.4. Future Developments
The SPCM can learn plausible grammars from examples of an English-like artificial language but at present it cannot learn intermediate levels of structure such as phrases and clauses (Section 3.3 in [10]). It appears that this problem is soluble and solving it will greatly enhance the capabilities of the system.
It is envisaged that similar principles may apply to the learning of non-syntactic “semantic” structures, and to the integration of syntax with semantics. Such developments are likely to be facilitated by generality in the way in which the SPCM represents and processes all kinds of knowledge.
With generalisation of the concept of SP-pattern to include two-dimensional SP-patterns, there is potential for the SPCM to learn 3D structures, as described in (Sections 6.1 and 6.2 in [18]).
Appendix A.5.5. The DONSVIC Principle
A general principle in the workings of the SPCM, and the earlier SNPR and MK10 computer models of language learning [24], is the discovery of natural structures via information compression (DONSVIC) (Section 5.2 in [10]), where “natural” structures are things that people recognise naturally such as words and objects.
Why is this principle not recognised in processes for IC such as LV, JPEG, and MPEG? It seems that this is probably because such processes have been designed to achieve speed on relatively low-powered computers, with corresponding sacrifices in IC efficiency. The DONSVIC principle is likely to become more important with computers that can achieve higher levels of efficiency in IC.
Appendix A.6. Strengths and Potential of the SP System in AI-Related Functions
Appendix A.7. SP-Neural
The SP system has been developed primarily in terms of abstract concepts such as the SPMA construct. However, a version of the SP system called SP-Neural has also been proposed, expressed in terms of neurons and their inter-connections and inter-communications. Current thinking in that area is described in [26].
Appendix A.8. Development of an “SP Machine”
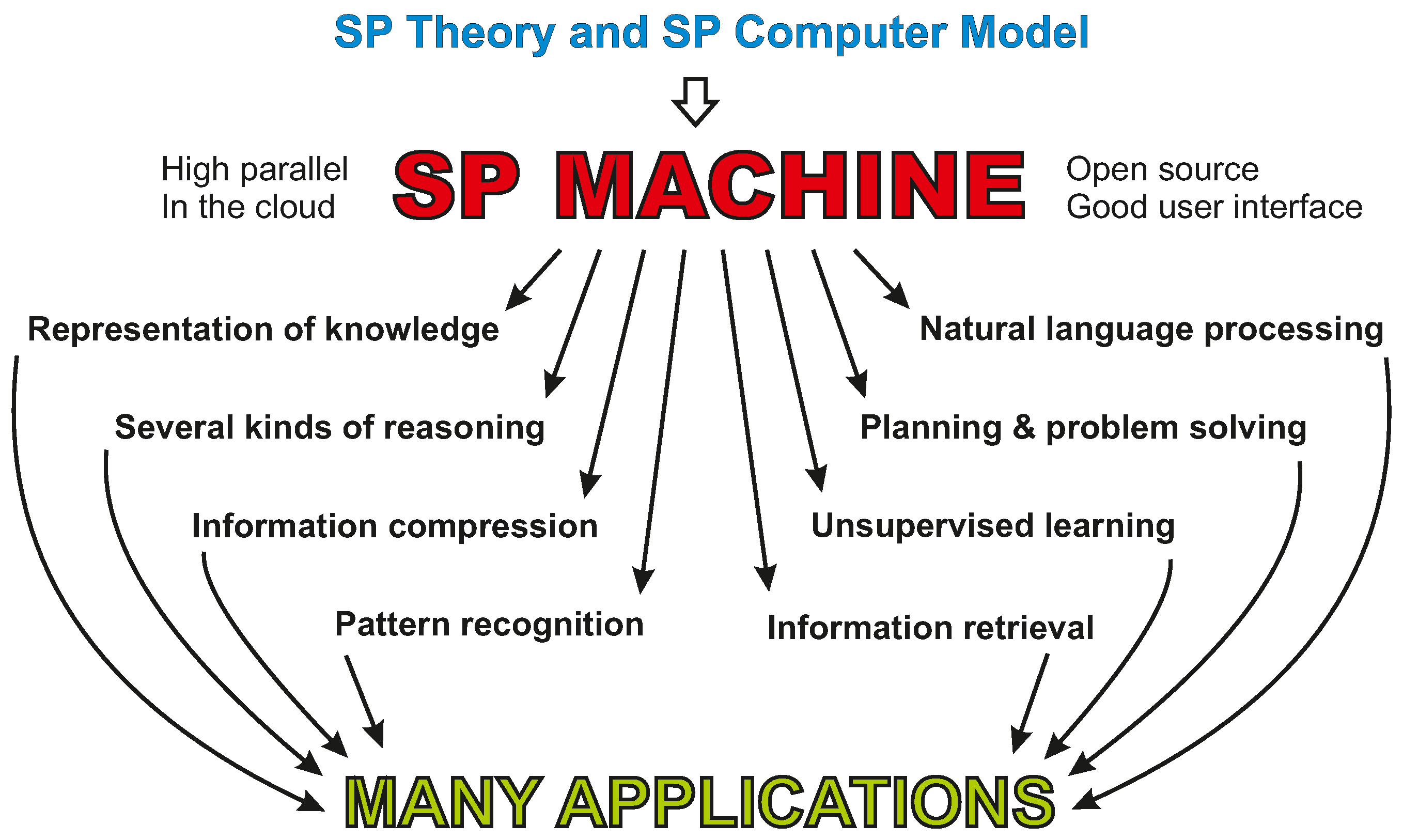
In view of the strengths and potential of the SP system (Appendix A.6), the SPCM appears to have promise as the foundation for the development of an SP machine, as mentioned in Appendix A.2, and described in [19].
It is envisaged that the SP machine wills feature high levels of parallel processing and a good user interface. It may serve as a vehicle for further development of the SP system by researchers anywhere. Eventually, it should become a system with industrial strength that may be applied to the solution of many problems in government, commerce, and industry. A schematic view of this development is shown in Figure A4.
Figure A4.
Schematic representation of the development and application of the SP machine. Reproduced from Figure 2 in [10], with permission.
Figure A4.
Schematic representation of the development and application of the SP machine. Reproduced from Figure 2 in [10], with permission.

References
- Hayani, S.; Benaddy, M.; Meslouhi, O.E.; Kardouchi, M. Arab sign language recognition with convolutional neural networks. In Proceedings of the International Conference of Computer Science and Renewable Energies, Agadir, Morocco, 22–24 July 2019; pp. 1–4. [Google Scholar]
- Akhloufi, M.; Guyon, Y.; Ibarra-Castanedo, C.; Bendada, A.H. Three-dimensional thermography for nondestructive testing and evaluation. Quant. Infrared Thermogr. J. 2017, 14, 79–106. [Google Scholar] [CrossRef]
- Elgarrai, Z.; Elmeslouhi, O.; Kardouchi, M.; Allali, H.; Selouani, S.-A. Offline face recognition system based on gabor-fisher descriptors and hidden markov models. Int. J. Interact. Multimed. Artif. Intell. 2016, 4, 11–14. [Google Scholar] [CrossRef] [Green Version]
- Wadham-Gagnon, M.; Bolduc, D.; Akhloufi, M.; Petersen, J.; Friedrich, H.; Camion, A. Monitoring icing events with remote cameras and image analysis. In Proceedings of the International Wind Energy Conference in Winterwind, Barcelona, Spain, 10–13 March 2014. [Google Scholar]
- Yoon, S.; Jain, A.K. Longitudinal study of fingerprint recognition. Proc. Natl. Acad. Sci. USA 2015, 112, 8555–8560. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Heaven, D. Why deep-learning AIs are so easy to fool. Nature 2019, 574, 163–166. [Google Scholar] [CrossRef]
- Nguyen, A.; Yosinski, J.; Clune, J. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015; pp. 427–436. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2014, arXiv:1312.6199v4. [Google Scholar]
- Wolff, J.G. Unifying Computing and Cognition: The SP Theory and Its Applications; CognitionResearch.org: Menai Bridge, UK, 2006. [Google Scholar]
- Wolff, J.G. The SP Theory of Intelligence: An overview. Information 2013, 4, 283–341. [Google Scholar] [CrossRef] [Green Version]
- Wolff, J.G. Information compression as a unifying principle in human learning, perception, and cognition. Complexity 2019, 38. [Google Scholar] [CrossRef]
- Wolff, J.G. Problems in AI research and how the SP System may help to solve them. arXiv 2009, arXiv:2009.09079. [Google Scholar]
- Jeong, C.Y.; Yang, S.H.; Moon, K.D. Horizon detection in maritime images using scene parsing network. Electron. Lett. 2018, 54, 760–762. [Google Scholar] [CrossRef]
- Shi, Q.Y.; Fu, K.-S. Parsing and translation of (attributed) expansive graph languages for scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1983. [Google Scholar] [CrossRef] [PubMed]
- Zellers, R.; Yatskar, M.; Thomson, S.; Choi, Y. Neural motifs: Scene graph parsing with global context. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5831–5840. [Google Scholar]
- Wolff, J.G. Big data and the SP Theory of Intelligence. IEEE Access 2014, 2, 301–315. [Google Scholar] [CrossRef] [Green Version]
- Marr, D. Vision: A Computational Investigation into the Human Representation and Processing of Visual Information; W.H. Freeman: San Francisco, CA, USA, 1982. [Google Scholar]
- Wolff, J.G. Application of the SP Theory of Intelligence to the understanding of natural vision and the development of computer vision. SpringerPlus 2014, 3, 552–570. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Palade, V.; Wolff, J.G. A roadmap for the development of the ‘SP Machine’ for artificial intelligence. Comput. J. 2019, 62, 1584–1604. [Google Scholar] [CrossRef]
- Attneave, F. Some informational aspects of visual perception. Psychol. Rev. 1954, 61, 183–193. [Google Scholar] [CrossRef] [PubMed]
- Barlow, H.B. Sensory mechanisms, the reduction of redundancy, and intelligence. In The Mechanisation of Thought Processes; HMSO, Ed.; Her Majesty’s Stationery Office: London, UK, 1959; pp. 535–559. [Google Scholar]
- Barlow, H.B. Trigger features, adaptation and economy of impulses. In Information Processes in the Nervous System; Leibovic, K.N., Ed.; Springer: New York, NY, USA, 1969; pp. 209–230. [Google Scholar]
- Ford, M. Architects of Intelligence: The Truth About AI From the People Building It, Kindle ed.; Packt Publishing: Birmingham, UK, 2018. [Google Scholar]
- Wolff, J.G. Learning syntax and meanings through optimization and distributional analysis. In Categories and Processes in Language Acquisition; Levy, Y., Schlesinger, I.M., Braine, M.D.S., Eds.; Lawrence Erlbaum: Hillsdale, NJ, USA, 1988; pp. 179–215. [Google Scholar]
- Wolff, J.G. The SP Theory of Intelligence: Its distinctive features and advantages. IEEE Access 2016, 4, 216–246. [Google Scholar] [CrossRef]
- Wolff, J.G. Information compression, multiple alignment, and the representation and processing of knowledge in the brain. Front. Psychol. 2016, 7, 1584. [Google Scholar] [CrossRef] [PubMed] [Green Version]
Figure 1.
The best SP-multiple-alignment created by the SP computer model (SPCM) that achieves the effect of parsing a sentence (“t h e a p p l e s a r e s w e e t”), as described in the text. Reproduced from Figure 4 in [16], with permission.
Figure 1.
The best SP-multiple-alignment created by the SP computer model (SPCM) that achieves the effect of parsing a sentence (“t h e a p p l e s a r e s w e e t”), as described in the text. Reproduced from Figure 4 in [16], with permission.

Figure 2.
The best SPMA created by the SPCM that achieves the effect of parsing a sentence (“t h e a p p l e s a r e s w e e t”), as described in the text.
Figure 2.
The best SPMA created by the SPCM that achieves the effect of parsing a sentence (“t h e a p p l e s a r e s w e e t”), as described in the text.

Figure 3.
The best SPMA created by the SPCM, with a set of new SP-patterns (in column 0) that describe some features of an unknown plant, and a set of old SP-patterns, including those shown in columns 1 to 6, that describe different categories of plant, with their parts and sub-parts, and other attributes. Reproduced with permission from Figure 16 in [10].
Figure 3.
The best SPMA created by the SPCM, with a set of new SP-patterns (in column 0) that describe some features of an unknown plant, and a set of old SP-patterns, including those shown in columns 1 to 6, that describe different categories of plant, with their parts and sub-parts, and other attributes. Reproduced with permission from Figure 16 in [10].

Figure 4.
Plan view of a 3D object, with five views of it as seen from above, as described in the text. Adapted from Figure 11 in [18], with permission.
Figure 4.
Plan view of a 3D object, with five views of it as seen from above, as described in the text. Adapted from Figure 11 in [18], with permission.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Wolff, J.G. The Potential of the SP System in Machine Learning and Data Analysis for Image Processing. Big Data Cogn. Comput. 2021, 5, 7. https://0-doi-org.brum.beds.ac.uk/10.3390/bdcc5010007
AMA Style
Wolff JG. The Potential of the SP System in Machine Learning and Data Analysis for Image Processing. Big Data and Cognitive Computing. 2021; 5(1):7. https://0-doi-org.brum.beds.ac.uk/10.3390/bdcc5010007
Chicago/Turabian StyleWolff, J. Gerard. 2021. "The Potential of the SP System in Machine Learning and Data Analysis for Image Processing" Big Data and Cognitive Computing 5, no. 1: 7. https://0-doi-org.brum.beds.ac.uk/10.3390/bdcc5010007