
CGK4PM: Towards a Methodology for the Systematic Generation of Clinical Guideline Process Models and the Utilization of Conformance Checking


Abstract
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. Materials and Methods
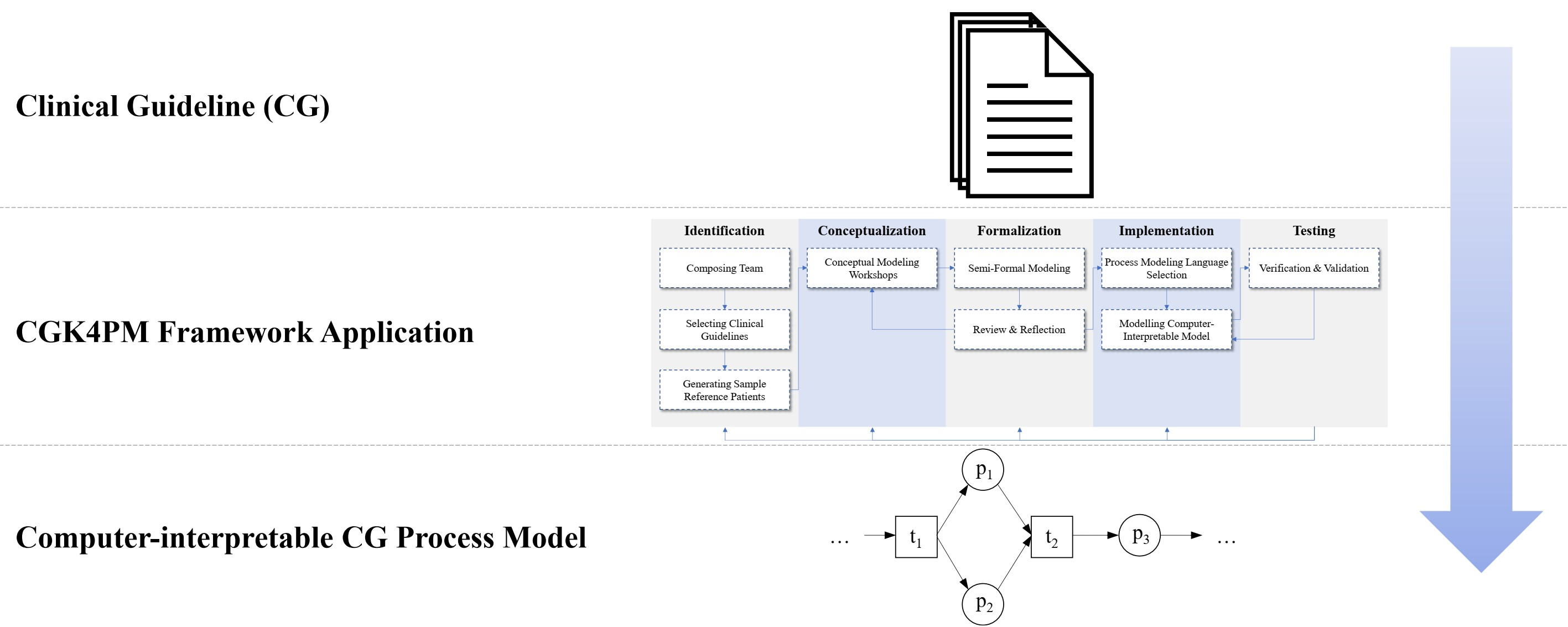
2.1. The CGK4PM Framework
2.1.1. Identification Stage
- (1)
- Composing team. This activity involves the identification of participants and roles. Previous case studies [17] and the Process Mining Project Methodology (PM2) [18] recommend team members with diverse backgrounds [15,19]. Based on this fact and the fact that process engineers have little knowledge of the medical domain and medical staff typically have limited experience with process engineering and modeling [15,20], we define the following roles that need to be filled: domain experts (usually physicians of the domain in question) and process engineers (who have experience in transforming the knowledge into a procedural representation and to prepare it for the application of process mining).
- (2)
- Selecting clinical guidelines. The guideline selection is based on [21,22] and addresses the fact that there are different guidelines from different publishers on the same topic. In addition, depending on the guidelines and national requirements, there may be one aggregated guideline that addresses a specific topic or many guidelines that together form the evidence-based body of knowledge for the treatment of a disease. Therefore, the selection of the guidelines to be implemented is an important step that can significantly influence the quality of the result. Suggested decision criteria include validity and level of the guidelines’ evidence, the applicability in a clinical context, institutional recommendations, local practice variations, and the ease of operationalization [22]. When using multiple guidelines, it is important to cross-check them for conflicting recommendations [23]. In the following, the set of selected guidelines is denoted by G.
- (3)
- Generating sample reference patients. It is important that the acquired knowledge is checked for consistency and correctness in relation to the guidelines at all stages of the framework. For this purpose, reference patients are presented. Reference patients are synthetically generated patients with guideline-compliant or non-compliant treatment courses. Therefore, a set of compliant and a set of non-compliant reference patients for the set of guidelines G is generated by the stakeholders. It is recommended to describe patients that cover both special and standard cases and that cover as many possible pathways in treatment. At the same time, it must be considered that the chosen amount of reference patients is still manageable for manual evaluation.
2.1.2. Conceptualization Stage
- The initial workshop includes a segmentation of the guidelines into n segments. The segmentation process shall facilitate addressing and focusing on a specific segment in future workshops. The resulting number and size of segments depends on the complexity of the guidelines and the duration of the workshops. Confirming the state of the science, however, it was found that shorter workshops in which smaller segments were discussed produced better results [28]. Once the segmentation is complete and a focus segment has been selected, the workshop can proceed with the second step of the follow-up workshop.
- For the follow-up workshops a three-step approach is recommended: (1) discussion of the reviews (see Section 2.1.3), (2) discussion of the previously defined focus segment, derivation and collection of concepts from it, and conceptual modeling of these using the brown paper method, (3) definition of a new focus segment for the next workshop. It is important that the relation between guideline statements and the concepts can be established, e.g., through annotation of the concepts or documentation. This enables efficient maintenance of the model in case of guideline updates. During the workshop, it is the process engineers’ job to guide the discussions as a moderator and outline the discussions’ outcomes in the conceptual model.
2.1.3. Formalization Stage
- Do the changes to the semi-formal representation exactly match the results from the last workshop?
- Does the representation correctly reflect the guidelines content of the modeled segment?
- Does the representation cover the set of patients defined in the planning stage? Furthermore, would the representation classify patient set as non-compliant?
- Are there any suggested changes to the representation, and in particular to the section under consideration?
2.1.4. Implementation Stage
- Criteria definition. The criteria definition is based on Luo & Tung [36] and divides PML requirements into modeling objectives. The identified objectives are desired characteristics that can be the degree of formalization of the language, the scalability of the language via the possibility of multilevel modeling, the ease of use of modeling [36], the intelligibility of the PML, software support, the portability of the format and the spread of the language [35]. Additional objectives include requirements for specific process mining perspectives (e.g., data, control flow, time, resource, case) [32,37,38] and the availability of required process mining algorithms. Each requirement is categorized as a mandatory requirement or an optional requirement. Optional requirements are weighted according to the importance of the requirement. For determining the weights, the weighted score method is used [39,40]. The development of the requirements is conducted in workshops with the stakeholders and documented on the basis of the IEEE 830-1998 standard [41].
- Candidate subset. Based on the current literature, a subset of candidate PMLs is identified. In particular, the experience of the process engineers can be drawn upon. For a basic pre-selection of modeling languages, we recommend considering the quality properties that provide a good basis for the evaluation of modeling techniques [42,43]:
- Expressiveness. The degree to which a given modeling technique is capable of denoting the models of any number and kinds of application domains.
- Arbitrariness. The degree of freedom one has when modeling one and the same domain.
- Suitability. The degree to which a given modeling technique is specifically tailored for a specific kind of application domain.
- Candidate review. Candidates are reviewed in detail. For this purpose, each PML is examined to determine whether it meets the specified requirements. In addition to Boolean values, free text answers can also be given in case of ambiguity. The review results are documented in PML profiles.
- PML comparison. The PMLs are compared on the basis of the candidate review. For this purpose, the PML profiles are aggregated in a table. The overview is used to identify all PMLs that fulfill all mandatory requirements.
- PML selection. Finally, the PML is selected based on the results of the PML comparison. If several PMLs fulfill all mandatory requirements, the optional requirements and their weightings are used for decision-making.
- (1)
- Preparation— Identification of the segment’s requirements (e.g., in terms of data) and specification of the segment’s dependencies between segment activities and with predecessor and successor segments (e.g., edge conditions).
- (2)
- Modeling—Translation of the semi-formal representation into the computer- interpretable model.
- (3)
- Check—Verification of the modeled segment to ensure that it actually reflects the intended medical procedure and that all contingencies and possibilities have been integrated by the semi-formal representation.
2.1.5. Testing Stage
- Verification: As the complexity of the models often leads to deadlocks or lack of synchronization, verification is important in process modeling [46]. Therefore, the focus of verification is on identifying undesirable behaviors in the process model and syntactic errors [49]. Since the framework provides flexibility regarding the PML choice and verification approaches depend on the PML used, no specific approaches are described here. Following [48] the evaluation step is aborted if it fails and the model has to be revised in the implementation step. Only if the verification is successful, the model is validated.
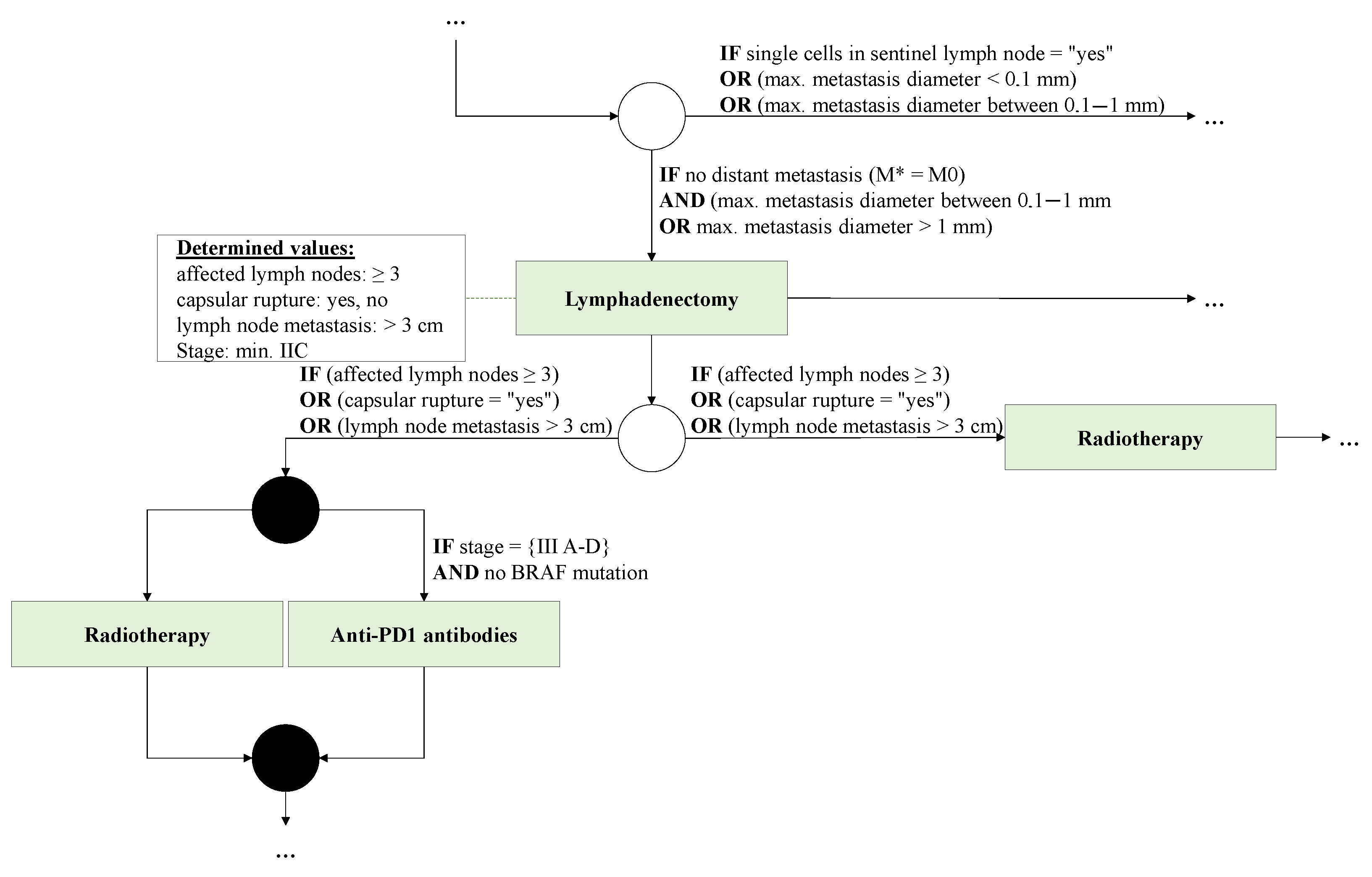
- Validation: Validation deals with the correct translation of the guidelines recommendations into a process model. The validation is done in two steps. In the first step, the validation is carried out against the sample data set of reference patients. Using a conformance checking algorithm, these can be automatically validated against the process model. This is carried out by the process engineers and is intended to detect initial errors. In the second step, the model is tested using a facilitated model walkthrough, a method for checking the adequacy in representing the actual process [50]. In such walkthroughs, the process model is presented to the domain experts by the moderator. Based on this, the validity of the model is examined collaboratively and stakeholders point out errors. The moderator summarizes the results of the walkthrough and mediates the discussion between the stakeholders. Usually, several iterations are needed to reach a common result [51]. If errors are found, they have to be fixed by a backward step in the framework and verified and validated again.
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CGK4PM | Clinical Guideline Knowledge for Process Mining |
| 7PMG | Seven Process Modeling Guidelines |
| BPM | Business Process Modeling |
| DPN | Data Petri Net |
| PML | Process Modeling Language |
| CG | Clinical Guideline |
References
- Lohr, K.N.; Field, M.J. Clinical Practice Guidelines: Directions for a New Program; Publication IOM; National Academy Press: Washington, DC, USA, 1990; Volume 90, No. 8. [Google Scholar]
- Graham, R. Clinical Practice Guidelines We Can Trust; National Academies Press: Washington, DC, USA, 2011. [Google Scholar]
- McGowan, J.; Muratov, S.; Tsepke, A.; Issina, A.; Slawecki, E.; Lang, E.S. Clinical practice guidelines were adapted and implemented meeting country-specific requirements—the example of Kazakhstan. J. Clin. Epidemiol. 2016, 69, 8–15. [Google Scholar] [CrossRef] [PubMed]
- Peleg, M.; Tu, S.; Bury, J.; Ciccarese, P.; Fox, J.; Greenes, R.A.; Hall, R.; Johnson, P.D.; Jones, N.; Kumar, A.; et al. Comparing computer-interpretable guideline models: A case-study approach. J. Am. Med. Inform. Assoc. JAMIA 2003, 10, 52–68. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Peleg, M. Computer-interpretable clinical guidelines: A methodological review. J. Biomed. Inform. 2013, 46, 744–763. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aalst, W.V.D. Process mining. Commun. ACM 2012, 55, 76–83. [Google Scholar] [CrossRef]
- van der Aalst, W.M.P. Process Mining: Discovery, Conformance and Enhancement of Business Processes; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Grüger, J.; Geyer, T.; Kuhn, M.; Braun, S.; Bergmann, R. Verifying Guideline Compliance in Clinical Treatment Using Multi-perspective Conformance Checking: A Case Study. In Process Mining Workshops; Munoz-Gama, J., Lu, X., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 301–313. [Google Scholar]
- Gatta, R.; Vallati, M.; Fernandez-Llatas, C.; Martinez-Millana, A.; Orini, S.; Sacchi, L.; Lenkowicz, J.; Marcos, M.; Munoz-Gama, J.; Cuendet, M.; et al. Clinical Guidelines: A Crossroad of Many Research Areas. Challenges and Opportunities in Process Mining for Healthcare. In Business Process Management Workshops; Di Francescomarino, C., Dijkman, R., Zdun, U., Eds.; Lecture Notes in Business Information Processing; Springer International Publishing: Cham, Switzerland, 2019; Volume 362, pp. 545–556. [Google Scholar]
- Grimshaw, J.M.; Russell, I.T. Effect of clinical guidelines on medical practice: A systematic review of rigorous evaluations. Lancet 1993, 342, 1317–1322. [Google Scholar] [CrossRef]
- American Society of Clinical Oncology. Good clinical practice research guidelines reviewed, emphasis given to responsibilities of investigators: Second article in a series. J. Oncol. Pract. 2008, 4, 233–235. [Google Scholar] [CrossRef] [Green Version]
- Lenz, R.; Reichert, M. IT support for healthcare processes—Premises, challenges, perspectives. Data Knowl. Eng. 2007, 61, 39–58. [Google Scholar] [CrossRef]
- Alharbi, R.F.; Berri, J.; El-Masri, S. Ontology based clinical decision support system for diabetes diagnostic. In Proceedings of the Science and Information Conference (SAI), London, UK, 28–30 July 2015; pp. 597–602. [Google Scholar]
- Rebuge, Á.; Ferreira, D.R. Business process analysis in healthcare environments: A methodology based on process mining. Inf. Syst. 2012, 37, 99–116. [Google Scholar] [CrossRef] [Green Version]
- Patel, V.L.; Allen, V.G.; Arocha, J.F.; Shortliffe, E.H. Representing clinical guidelines in GLIF: Individual and collaborative expertise. J. Am. Med. Inform. Assoc. JAMIA 1998, 5, 467–483. [Google Scholar] [CrossRef] [Green Version]
- Buchanan, B.G.; Barstow, D.; Bechtal, R.; Bennett, J.; Clancey, W.; Kulowski, C.; Mitchell, T. Constructing an expert system. Build. Expert Syst. 1983, 127–167. [Google Scholar]
- Rick, U.; Vossen, R.; Richert, A.; Henning, K. Designing agile processes in information management. In Proceedings of the 2010 2nd IEEE International Conference on Information Management and Engineering, Chengdu, China, 16–18 April 2010. [Google Scholar] [CrossRef]
- van Eck, M.L.; Lu, X.; Leemans, S.J.J.; van der Aalst, W.M.P. PM2: A Process Mining Project Methodology. In Advanced Information Systems Engineering; Zdravkovic, J., Kirikova, M., Johannesson, P., Eds.; Lecture Notes in Computer Science Information Systems and Applications, Incl. Internet/Web and HCI; Springer: Cham, Switzerland, 2015; Volume 9097, pp. 297–313. [Google Scholar]
- Huckman, R.S.; Staats, B.R. Variation in Experience and Team Familiarity: Addressing the Knowledge Acquisition-Application Problem: Harvard Business School Working Papers; Harvard Business School: Boston, MA, USA, 2008. [Google Scholar]
- Kirchner, K.; Malessa, C.; Scheuerlein, H.; Settmacher, U. Experience from collaborative modeling of clinical pathways. In ICB Research Report, No. 57; Universität Duisburg-Essen, Institut für Informatik und Wirtschaftsinformatik (ICB): Essen, Germany, 2014; pp. 13–24. [Google Scholar]
- Shiffman, R.N.; Michel, G.; Essaihi, A.; Thornquist, E. Bridging the guideline implementation gap: A systematic, document-centered approach to guideline implementation. J. Am. Med. Inform. Assoc. JAMIA 2004, 11, 418–426. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tso, G.J.; Tu, S.W.; Oshiro, C.; Martins, S.; Ashcraft, M.; Yuen, K.W.; Wang, D.; Robinson, A.; Heidenreich, P.A.; Goldstein, M.K. Automating Guidelines for Clinical Decision Support: Knowledge Engineering and Implementation. Amia Annu. Symp. Proc. 2017, 2016, 1189–1198. [Google Scholar] [PubMed]
- Hing, M.M.; Michalowski, M.; Wilk, S.; Michalowski, W.; Farion, K. Identifying inconsistencies in multiple clinical practice guidelines for a patient with co-morbidity. In Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine workshops (BIBMW), Hong Kong, China, 18 December 2010; Di Bernardo, D., Ed.; IEEE: Piscataway, NJ, USA, 2010; pp. 447–452. [Google Scholar]
- Rittgen, P. Collaborative Modeling. Int. J. Inf. Syst. Model. Des. 2010, 1, 1–19. [Google Scholar] [CrossRef]
- Rittgen, P. Success Factors of e-Collaboration in Business Process Modeling. In Active Flow and Combustion Control 2018; Notes on Numerical Fluid Mechanics and Multidisciplinary Design; King, R., Ed.; Springer International Publishing: Cham, Switzerland, 2019; Volume 141, pp. 24–37. [Google Scholar]
- Larman, C. Applying UML and Patterns: An Introduction to Object-Oriented Analysis and Design and Iterative Development, 3rd ed.; 12th print ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2009. [Google Scholar]
- Dandekar, A.; Perry, D.E.; Votta, L.G. Studies in process simplification. Softw. Process Improv. Pract. 1997, 3, 87–104. [Google Scholar] [CrossRef]
- Molloy, K.; Moore, D.R.; Sohoglu, E.; Amitay, S. Less Is More: Latent Learning Is Maximized by Shorter Training Sessions in Auditory Perceptual Learning. PLoS ONE 2012, 7, e36929. [Google Scholar] [CrossRef]
- Mendling, J.; Reijers, H.A.; van der Aalst, W. Seven process modeling guidelines (7PMG). Inf. Softw. Technol. 2010, 52, 127–136. [Google Scholar] [CrossRef] [Green Version]
- Havey, M. Essential Business Process Modeling; O’Reilly Media, Inc.: Newton, MA, USA, 2005. [Google Scholar]
- Curtis, B.; Kellner, M.I.; Over, J. Process Modeling. Commun. ACM 1992, 35, 75–90. [Google Scholar] [CrossRef]
- Mannhardt, F. Multi-perspective Process Mining. In Proceedings of the Dissertation Award, Demonstration, and Industrial Track at BPM 2018 Co-Located with 16th International Conference on Business Process Management (BPM 2018), Sydney, Australia, 9–14 September 2018; van der Aalst, W.M.P., Casati, F., Conforti, R., de Leoni, M., Dumas, M., Kumar, A., Mendling, J., Nepal, S., Pentland, B.T., Weber, B., Eds.; CEUR Workshop Proceedings. CEUR-WS.org: Aachen, Germany, 2018; Volume 2196, pp. 41–45. [Google Scholar]
- Goedertier, S.; Vanthienen, J. Declarative Process Modeling with Business Vocabulary and Business Rules. In Proceedings of the On the Move to Meaningful Internet Systems: OTM, Vilamoura, Portugal, 25–30 November 2007; Volume 4805, pp. 603–612. [Google Scholar]
- Maggi, F.M.; Mooij, A.J.; van der Aalst, W.M. User-guided discovery of declarative process models. In Proceedings of the 2011 IEEE Symposium on Computational Intelligence and Data Mining (CIDM), Paris, France, 11–15 April 2011; pp. 192–199. [Google Scholar]
- Kelemen, Z.D.; Kusters, R.; Trienekens, J.; Balla, K. Selecting a Process Modeling Language for Process Based Unification of Multiple Standards and Models; Technical Report TR201304; Project Multimodel SPI: Budapest, Hungary, 2013. [Google Scholar]
- Luo, W.; Alex Tung, Y. A framework for selecting business process modeling methods. Ind. Manag. Data Syst. 1999, 99, 312–319. [Google Scholar] [CrossRef]
- van der Aalst, W.; Adriansyah, A.; de Medeiros, A.K.A.; Arcieri, F.; Baier, T.; Blickle, T.; Bose, J.C.; van den Brand, P.; Brandtjen, R.; Buijs, J.; et al. Process Mining Manifesto. In Business Process Management Workshops; Daniel, F., Barkaoui, K., Dustdar, S., Eds.; Lecture Notes in Business Information Processing; Springer: Berlin/Heidelberg, Germany, 2012; Volume 99, pp. 169–194. [Google Scholar]
- van der Aalst, W. Process Mining: Data Science in Action, 2nd ed.; Springer: New York, NY, USA, 2016. [Google Scholar]
- Alfares, H.K.; Duffuaa, S.O. Determining aggregate criteria weights from criteria rankings by a group of decision makers. Int. J. Inf. Technol. Decis. Mak. 2008, 7, 769–781. [Google Scholar] [CrossRef]
- Odu, G.O. Weighting methods for multi-criteria decision making technique. J. Appl. Sci. Environ. Manag. 2019, 23, 1449. [Google Scholar] [CrossRef] [Green Version]
- IEEE Std 830-1998; IEEE Recommended Practice for Software Requirements Specifications. IEEE: Piscataway, NJ, USA, 1998; pp. 1–40.
- Hommes, B.J.; van Reijswoud, V. Assessing the quality of business process modelling techniques. In Proceedings of the 33rd Annual Hawaii International Conference on System Sciences, Maui, HI, USA, 7 January 2000; p. 10. [Google Scholar]
- Falkenberg, E.D. A Framework of Information System Concepts: The FRISCO Report (Web Edition); University of Leiden, Department of Computer Science: Leiden, The Netherlands, 1998. [Google Scholar]
- Mendling, J.; Neumann, G.; van der Aalst, W. Understanding the Occurrence of Errors in Process Models Based on Metrics. In Proceedings of the On the Move to Meaningful Internet Systems 2007: CoopIS, DOA, ODBASE, GADA, and IS, Vilamoura, Portugal, 25–30 November 2007; Hutchison, D., Kanade, T., Kittler, J., Kleinberg, J.M., Mattern, F., Mitchell, J.C., Naor, M., Nierstrasz, O., Pandu Rangan, C., Steffen, B., et al., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2007; Volume 4803, pp. 113–130. [Google Scholar]
- Desel, J. Model Validation—A Theoretical Issue? In Application and Theory of Petri Nets 2002; Goos, G., Hartmanis, J., van Leeuwen, J., Esparza, J., Lakos, C., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2002; Volume 2360, pp. 23–43. [Google Scholar]
- Mendling, J. Empirical Studies in Process Model Verification. In Special Issue on Concurrency in Process-Aware Information Systems; Lecture Notes in Computer Science; Jensen, K., van der Aalst, W.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5460, pp. 208–224. [Google Scholar]
- Fellmann, M.; Hogrebe, F.; Thomas, O.; Nüttgens, M. How to Ensure Correct Process Models? A Semantic Approach to Deal with Resource Problems. In INFORMATIK 2010. Service Science—Neue Perspektiven für die Informatik. Band 1; GI-Edition Lecture Notes in Informatics Proceedings; Gesellschaft für Informatik e.V.: Bonn, Germany, 2010; pp. 280–285. [Google Scholar]
- van Hee, K.; Sidorova, N.; Somers, L.; Voorhoeve, M. Consistency in model integration. Data Knowl. Eng. 2006, 56, 4–22. [Google Scholar] [CrossRef]
- Wynn, M.T.; Verbeek, H.; van der Aalst, W.; ter Hofstede, A.; Edmond, D. Business Process Verification—Finally a Reality! Bus. Process Manag. J. 2009, 15, 74–92. [Google Scholar] [CrossRef] [Green Version]
- Hochleitner, F.; Oppl, S. Validation of Business Process Models through Interactively Enacted Simulation. In Proceedings of the 10th International Conference on Subject-Oriented Business Process Management—S-BPM ONE 2018, Linz, Austria, 5–6 April 2018; Stary, C., Ed.; ACM Press: New York, NY, USA, 2018; pp. 1–12. [Google Scholar]
- Sutcliffe, A.; Thew, S.; Jarvis, P. Experience with user-centred requirements engineering. Requir. Eng. 2011, 16, 267–280. [Google Scholar] [CrossRef]
- Davis, R. The Event-Driven Process Chain. In Business Process Modelling with ARIS: A Practical Guide; Davis, R., Ed.; Springer: London, UK, 2001; pp. 111–139. [Google Scholar]
- de Leoni, M.; van der Aalst, W.M.P. Aligning Event Logs and Process Models for Multi-perspective Conformance Checking: An Approach Based on Integer Linear Programming. In Business Process Management; Daniel, F., Wang, J., Weber, B., Eds.; LNCS Sublibrary: SL 3-Information Systems and Application, Incl. Internet/Web and HCI; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8094, pp. 113–129. [Google Scholar]
- de Leoni, M.; van der Aalst, W.M.P. Data-aware process mining. In SAC ’13: Proceedings of the 28th Annual ACM Symposium on Applied Computing; Shin, S.Y., Maldonado, J.C., Eds.; ACM Digital Library: New York, NY, USA, 2013; p. 1454. [Google Scholar]
- Burattin, A.; Maggi, F.M.; Sperduti, A. Conformance checking based on multi-perspective declarative process models. Expert Syst. Appl. 2016, 65, 194–211. [Google Scholar] [CrossRef] [Green Version]
- van Dongen, B.F.; de Medeiros, A.K.A.; Verbeek, H.M.W.; Weijters, A.J.M.M.; van der Aalst, W.M.P. The ProM Framework: A New Era in Process Mining Tool Support. In Applications and Theory of Petri Nets 2005; Ciardo, G., Darondeau, P., Eds.; Theoretical Computer Science and General Issues; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3536, pp. 444–454. [Google Scholar]
- Mannhardt, F.; De Leoni, M.; Reijers, H.A. The Multi-perspective Process Explorer. BPM 2015, 1418, 130–134. [Google Scholar]
- van Dongen, B.F.; de Smedt, J.; Di Ciccio, C.; Mendling, J. Conformance checking of mixed-paradigm process models. Inf. Syst. 2020, 102, 101685. [Google Scholar] [CrossRef]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Grüger, J.; Geyer, T.; Bergmann, R.; Braun, S.A. CGK4PM: Towards a Methodology for the Systematic Generation of Clinical Guideline Process Models and the Utilization of Conformance Checking. BioMedInformatics 2022, 2, 359-374. https://0-doi-org.brum.beds.ac.uk/10.3390/biomedinformatics2030023
Grüger J, Geyer T, Bergmann R, Braun SA. CGK4PM: Towards a Methodology for the Systematic Generation of Clinical Guideline Process Models and the Utilization of Conformance Checking. BioMedInformatics. 2022; 2(3):359-374. https://0-doi-org.brum.beds.ac.uk/10.3390/biomedinformatics2030023
Chicago/Turabian StyleGrüger, Joscha, Tobias Geyer, Ralph Bergmann, and Stephan A. Braun. 2022. "CGK4PM: Towards a Methodology for the Systematic Generation of Clinical Guideline Process Models and the Utilization of Conformance Checking" BioMedInformatics 2, no. 3: 359-374. https://0-doi-org.brum.beds.ac.uk/10.3390/biomedinformatics2030023