Q-Cell Glioblastoma Resource: Proteomics Analysis Reveals Unique Cell-States Are Maintained in 3D Culture

 , , , , , ,
, , , , , , {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
2.1. Cell Culture
2.2. Proteome Sample Preparation
2.3. Liquid Chromatography (LC) and Mass Spectrometry (MS) Analysis
2.4. Data Processing and Analysis
2.5. Bioinformatics and Statistical Analysis
2.6. Cell-State ssGSEA
2.7. Cytoscape-Based Data Visualisation
3. Results
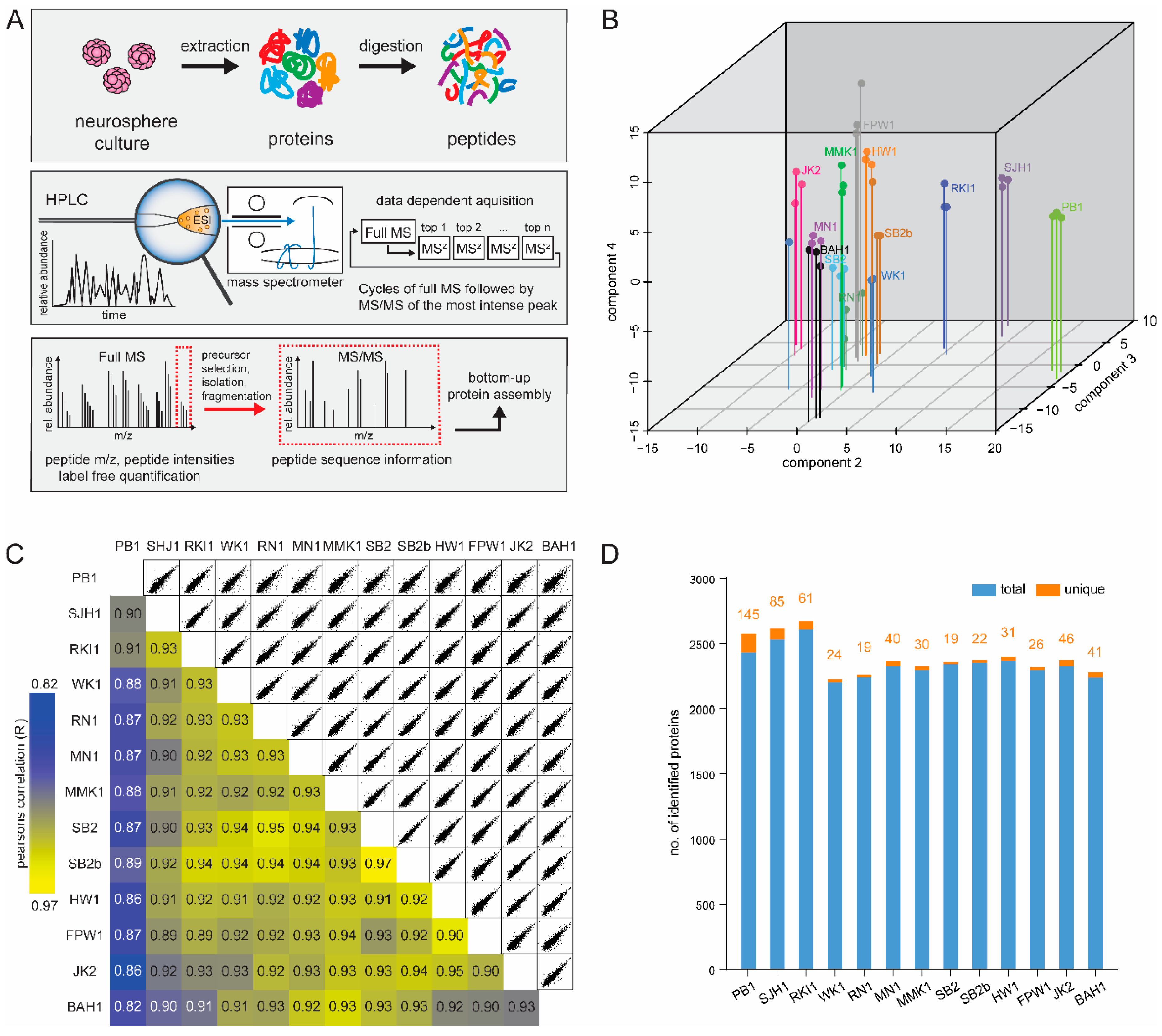
3.1. Q-Cell Proteomics Analysis
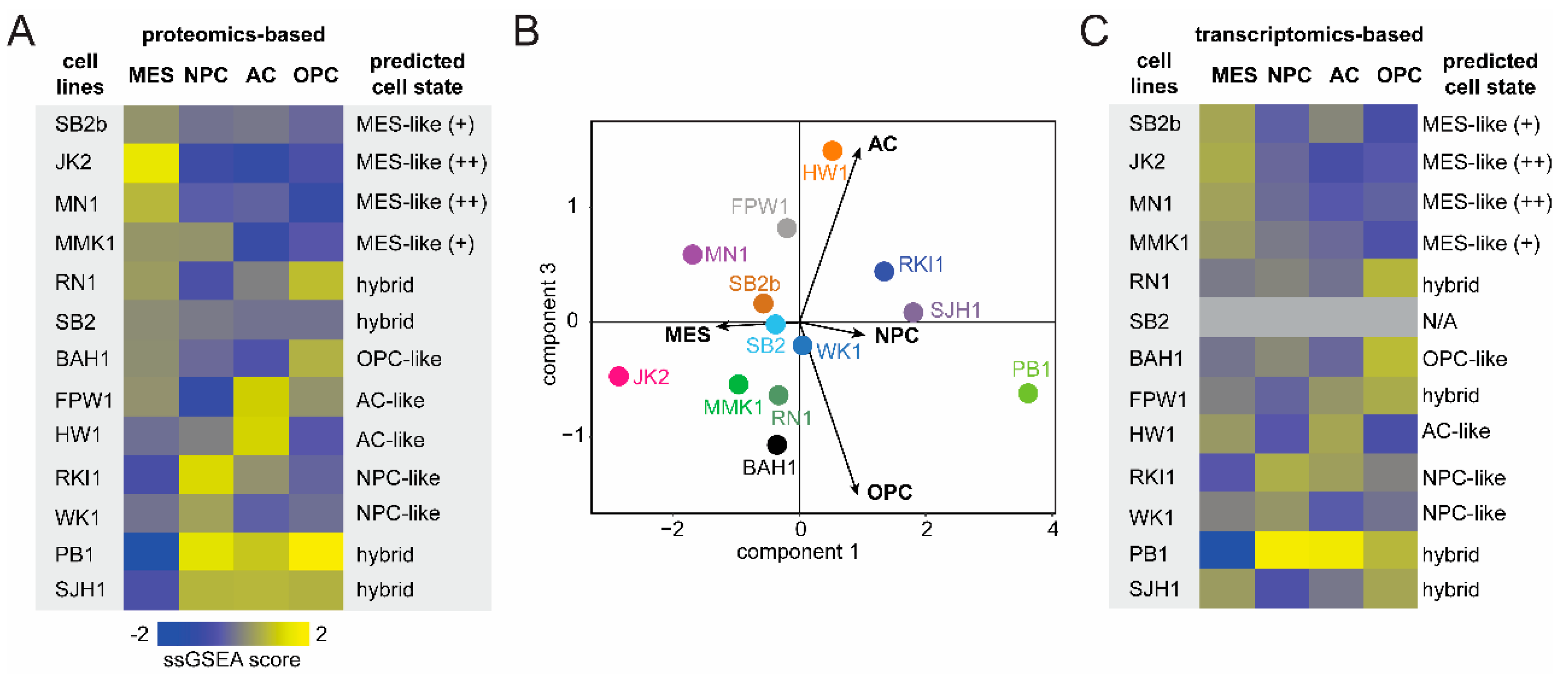
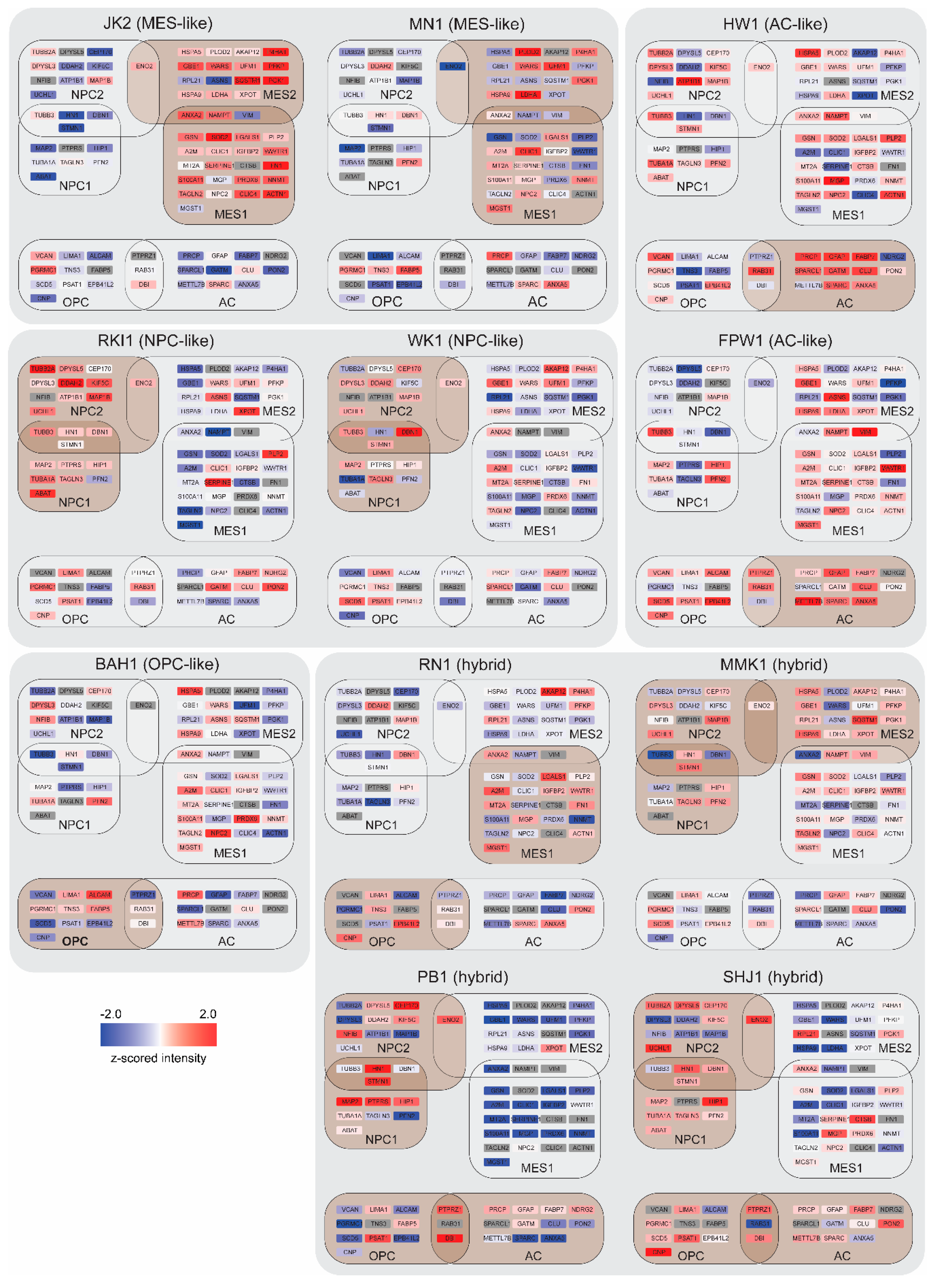
3.2. GBM Cell-State Analysis
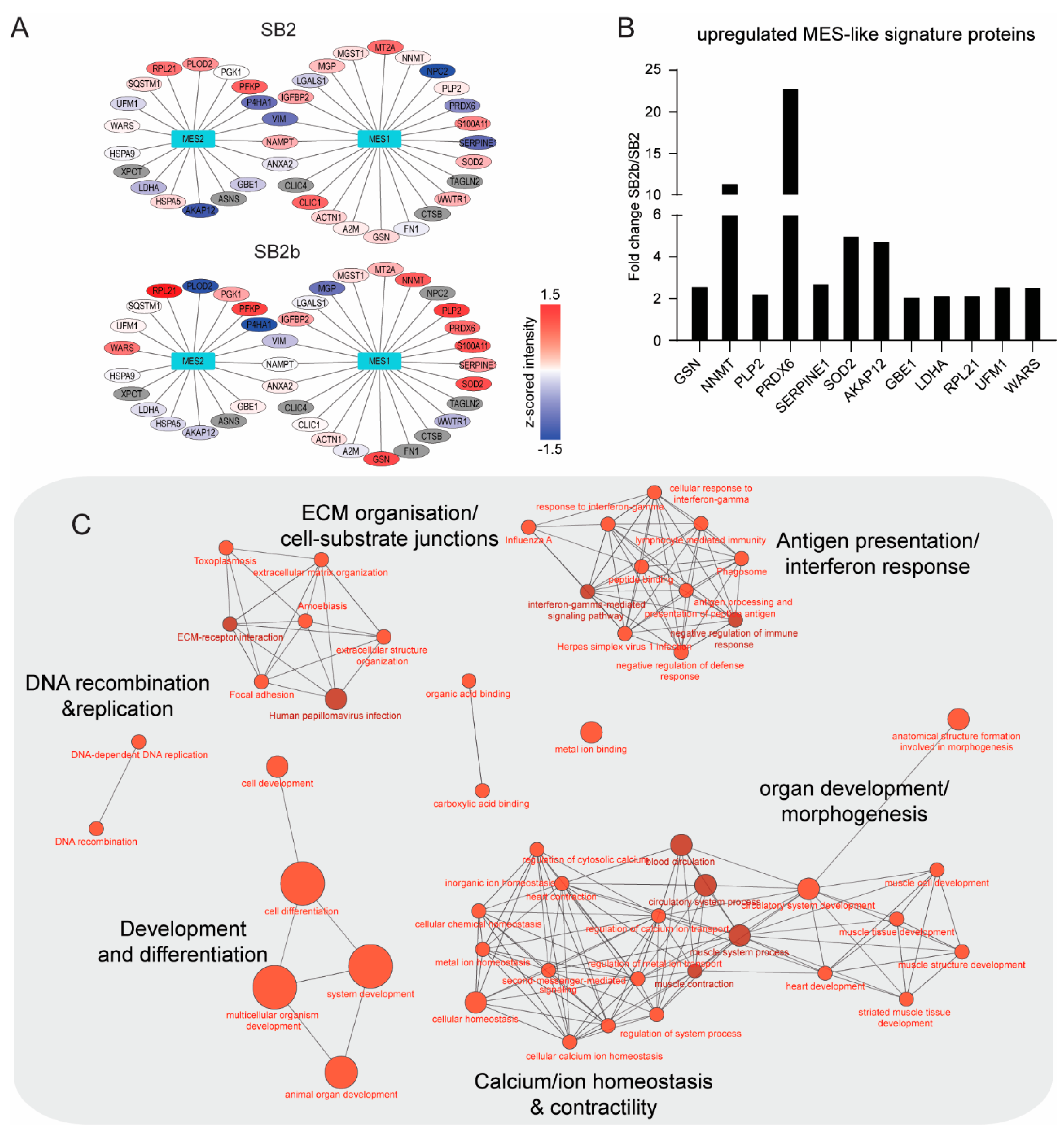
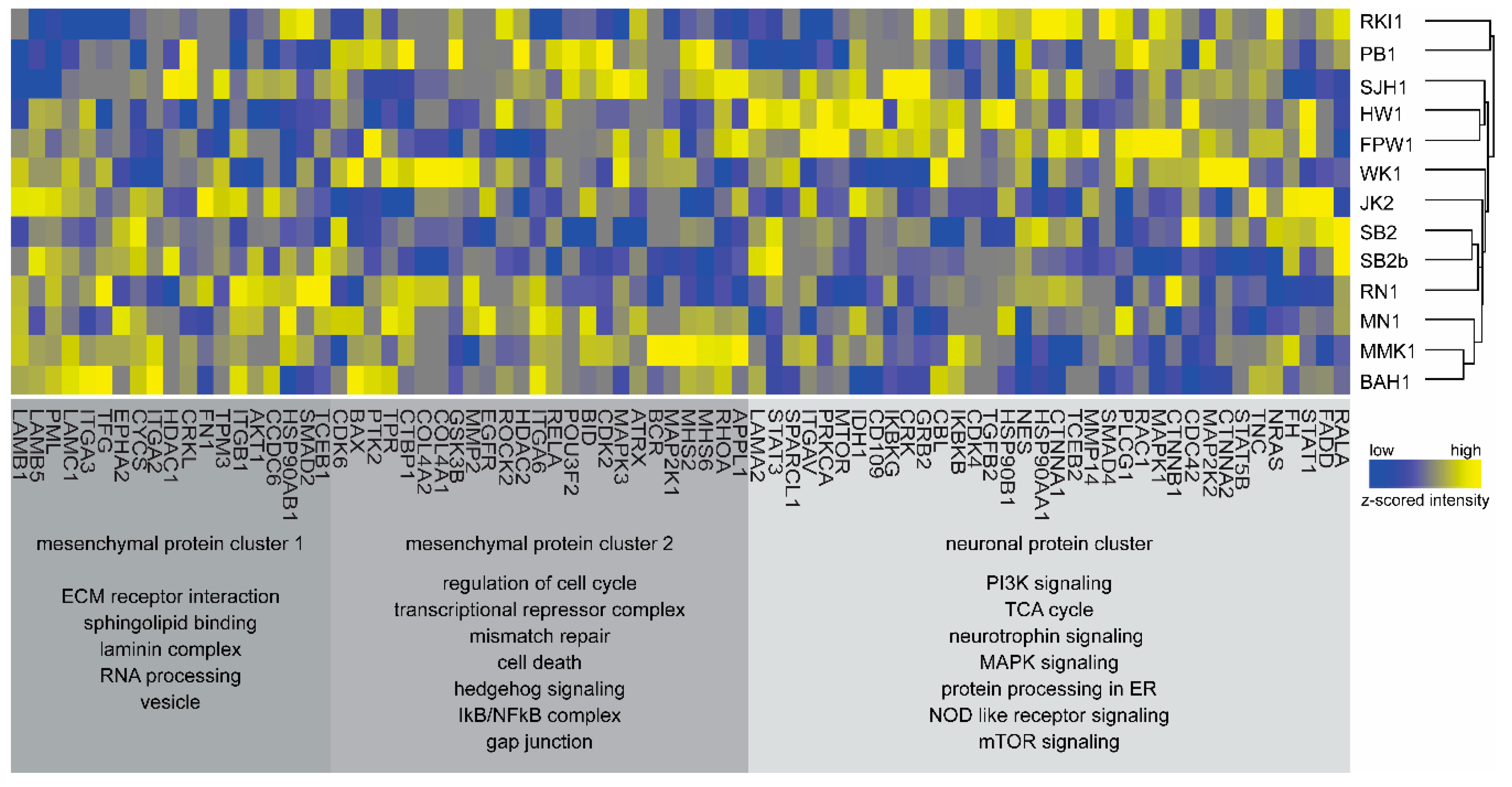
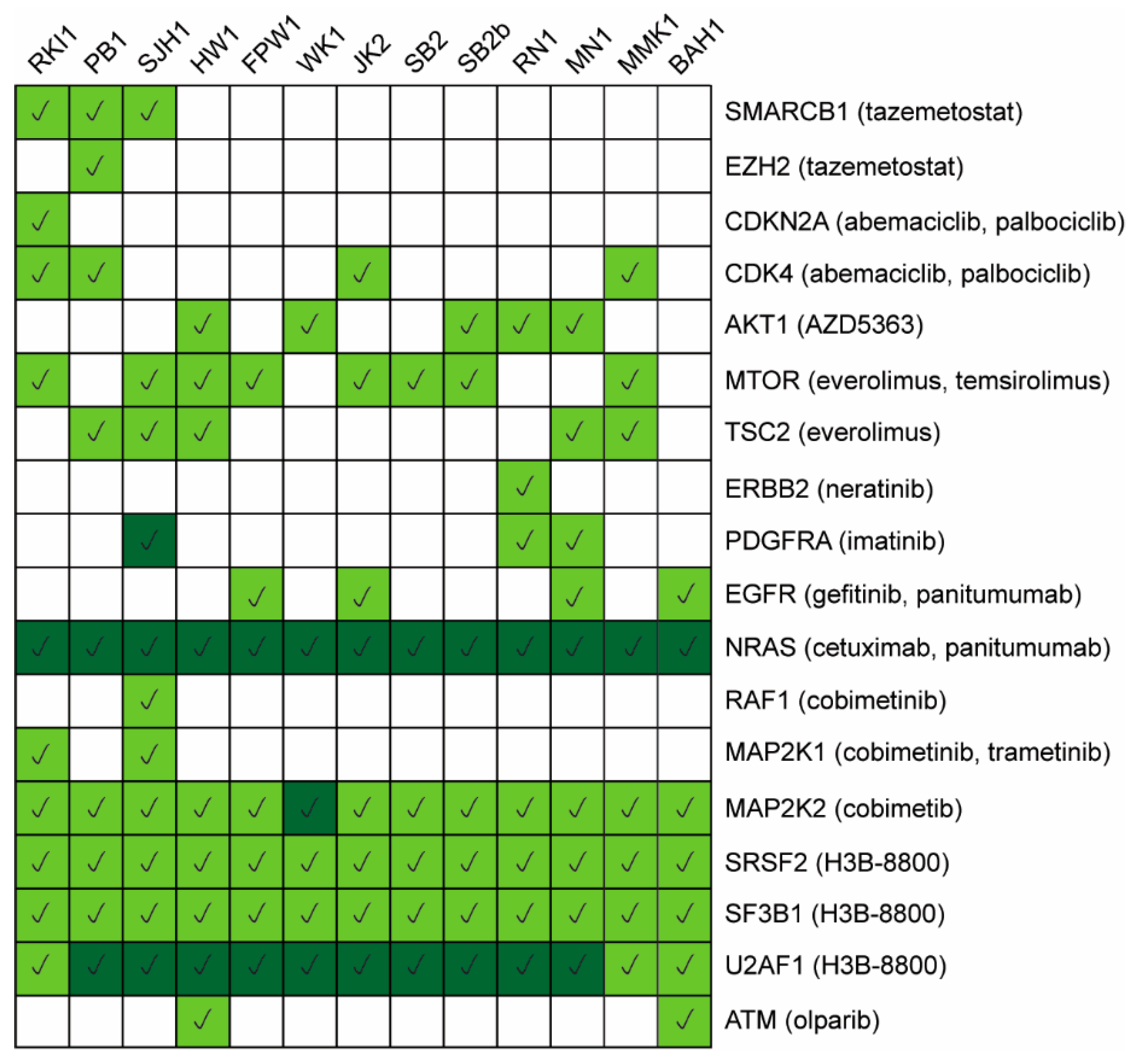
3.3. Bioinformatics and Gene-Ontology-Based Protein Analysis
4. Discussion
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Furnari, F.B.; Fenton, T.; Bachoo, R.M.; Mukasa, A.; Stommel, J.M.; Stegh, A.; Hahn, W.C.; Ligon, K.L.; Louis, D.N.; Brennan, C.; et al. Malignant astrocytic glioma: Genetics, biology, and paths to treatment. Genes Dev. 2007, 21, 2683–2710. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stupp, R.; Mason, W.P.; van den Bent, M.J.; Weller, M.; Fisher, B.; Taphoorn, M.J.; Belanger, K.; Brandes, A.A.; Marosi, C.; Bogdahn, U.; et al. Radiotherapy plus concomitant and adjuvant temozolomide for glioblastoma. N. Engl. J. Med. 2005, 352, 987–996. [Google Scholar] [CrossRef] [PubMed]
- Louis, D.N.; Perry, A.; Reifenberger, G.; von Deimling, A.; Figarella-Branger, D.; Cavenee, W.K.; Ohgaki, H.; Wiestler, O.D.; Kleihues, P.; Ellison, D.W. The 2016 World Health Organization Classification of Tumors of the Central Nervous System: A summary. Acta Neuropathol. 2016, 131, 803–820. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Phillips, H.S.; Kharbanda, S.; Chen, R.; Forrest, W.F.; Soriano, R.H.; Wu, T.D.; Misra, A.; Nigro, J.M.; Colman, H.; Soroceanu, L.; et al. Molecular subclasses of high-grade glioma predict prognosis, delineate a pattern of disease progression, and resemble stages in neurogenesis. Cancer Cell 2006, 9, 157–173. [Google Scholar] [CrossRef] [Green Version]
- Verhaak, R.G.; Hoadley, K.A.; Purdom, E.; Wang, V.; Qi, Y.; Wilkerson, M.D.; Miller, C.R.; Ding, L.; Golub, T.; Mesirov, J.P.; et al. Integrated genomic analysis identifies clinically relevant subtypes of glioblastoma characterized by abnormalities in PDGFRA, IDH1, EGFR, and NF1. Cancer Cell 2010, 17, 98–110. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Hu, B.; Hu, X.; Kim, H.; Squatrito, M.; Scarpace, L.; deCarvalho, A.C.; Lyu, S.; Li, P.; Li, Y.; et al. Tumor Evolution of Glioma-Intrinsic Gene Expression Subtypes Associates with Immunological Changes in the Microenvironment. Cancer Cell 2017, 32, 42–56.e46. [Google Scholar] [CrossRef] [Green Version]
- Akgul, S.; Patch, A.M.; D’Souza, R.C.J.; Mukhopadhyay, P.; Nones, K.; Kempe, S.; Kazakoff, S.H.; Jeffree, R.L.; Stringer, B.W.; Pearson, J.V.; et al. Intratumoural Heterogeneity Underlies Distinct Therapy Responses and Treatment Resistance in Glioblastoma. Cancers 2019, 11, 190. [Google Scholar] [CrossRef] [Green Version]
- Patel, A.P.; Tirosh, I.; Trombetta, J.J.; Shalek, A.K.; Gillespie, S.M.; Wakimoto, H.; Cahill, D.P.; Nahed, B.V.; Curry, W.T.; Martuza, R.L.; et al. Single-cell RNA-seq highlights intratumoral heterogeneity in primary glioblastoma. Science 2014, 344, 1396–1401. [Google Scholar] [CrossRef] [Green Version]
- Neftel, C.; Laffy, J.; Filbin, M.G.; Hara, T.; Shore, M.E.; Rahme, G.J.; Richman, A.R.; Silverbush, D.; Shaw, M.L.; Hebert, C.M.; et al. An Integrative Model of Cellular States, Plasticity, and Genetics for Glioblastoma. Cell 2019, 178, 835–849.e821. [Google Scholar] [CrossRef]
- Day, B.W.; Stringer, B.W.; Wilson, J.; Jeffree, R.L.; Jamieson, P.J.; Ensbey, K.S.; Bruce, Z.C.; Inglis, P.; Allan, S.; Winter, C.; et al. Glioma Surgical Aspirate: A Viable Source of Tumor Tissue for Experimental Research. Cancers 2013, 5, 357–371. [Google Scholar] [CrossRef] [Green Version]
- Stringer, B.W.; Day, B.W.; D’Souza, R.C.J.; Jamieson, P.R.; Ensbey, K.S.; Bruce, Z.C.; Lim, Y.C.; Goasdoue, K.; Offenhauser, C.; Akgul, S.; et al. A reference collection of patient-derived cell line and xenograft models of proneural, classical and mesenchymal glioblastoma. Sci. Rep. 2019, 9, 4902. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bhat, K.P.; Balasubramaniyan, V.; Vaillant, B.; Ezhilarasan, R.; Hummelink, K.; Hollingsworth, F.; Wani, K.; Heathcock, L.; James, J.D.; Goodman, L.D.; et al. Mesenchymal differentiation mediated by NF-kappaB promotes radiation resistance in glioblastoma. Cancer Cell 2013, 24, 331–346. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Day, B.W.; Stringer, B.W.; Al-Ejeh, F.; Ting, M.J.; Wilson, J.; Ensbey, K.S.; Jamieson, P.R.; Bruce, Z.C.; Lim, Y.C.; Offenhauser, C.; et al. EphA3 maintains tumorigenicity and is a therapeutic target in glioblastoma multiforme. Cancer Cell 2013, 23, 238–248. [Google Scholar] [CrossRef] [Green Version]
- Pollard, S.M.; Yoshikawa, K.; Clarke, I.D.; Danovi, D.; Stricker, S.; Russell, R.; Bayani, J.; Head, R.; Lee, M.; Bernstein, M.; et al. Glioma stem cell lines expanded in adherent culture have tumor-specific phenotypes and are suitable for chemical and genetic screens. Cell Stem Cell 2009, 4, 568–580. [Google Scholar] [CrossRef] [Green Version]
- Reynolds, B.A.; Weiss, S. Generation of neurons and astrocytes from isolated cells of the adult mammalian central nervous system. Science 1992, 255, 1707–1710. [Google Scholar] [CrossRef] [Green Version]
- Wisniewski, J.R.; Zougman, A.; Nagaraj, N.; Mann, M. Universal sample preparation method for proteome analysis. Nat. Methods 2009, 6, 359–362. [Google Scholar] [CrossRef]
- Rappsilber, J.; Ishihama, Y.; Mann, M. Stop and go extraction tips for matrix-assisted laser desorption/ionization, nanoelectrospray, and LC/MS sample pretreatment in proteomics. Anal. Chem. 2003, 75, 663–670. [Google Scholar] [CrossRef]
- Cox, J.; Mann, M. MaxQuant enables high peptide identification rates, individualized p.p.b.-range mass accuracies and proteome-wide protein quantification. Nat. Biotechnol. 2008, 26, 1367–1372. [Google Scholar] [CrossRef]
- Cox, J.; Neuhauser, N.; Michalski, A.; Scheltema, R.A.; Olsen, J.V.; Mann, M. Andromeda: A peptide search engine integrated into the MaxQuant environment. J. Proteome Res. 2011, 10, 1794–1805. [Google Scholar] [CrossRef]
- Geiger, T.; Wehner, A.; Schaab, C.; Cox, J.; Mann, M. Comparative proteomic analysis of eleven common cell lines reveals ubiquitous but varying expression of most proteins. Mol. Cell. Proteom. 2012, 11, M111.014050. [Google Scholar] [CrossRef] [Green Version]
- Cox, J.; Hein, M.Y.; Luber, C.A.; Paron, I.; Nagaraj, N.; Mann, M. Accurate proteome-wide label-free quantification by delayed normalization and maximal peptide ratio extraction, termed MaxLFQ. Mol. Cell. Proteom. 2014, 13, 2513–2526. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tyanova, S.; Temu, T.; Sinitcyn, P.; Carlson, A.; Hein, M.Y.; Geiger, T.; Mann, M.; Cox, J. The Perseus computational platform for comprehensive analysis of (prote)omics data. Nat. Methods 2016, 13, 731–740. [Google Scholar] [CrossRef] [PubMed]
- Ashburner, M.; Ball, C.A.; Blake, J.A.; Botstein, D.; Butler, H.; Cherry, J.M.; Davis, A.P.; Dolinski, K.; Dwight, S.S.; Eppig, J.T.; et al. Gene ontology: Tool for the unification of biology. The Gene Ontology Consortium. Nat. Genet. 2000, 25, 25–29. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kanehisa, M.; Goto, S.; Kawashima, S.; Nakaya, A. The KEGG databases at GenomeNet. Nucleic Acids Res. 2002, 30, 42–46. [Google Scholar] [CrossRef] [PubMed]
- Barbie, D.A.; Tamayo, P.; Boehm, J.S.; Kim, S.Y.; Moody, S.E.; Dunn, I.F.; Schinzel, A.C.; Sandy, P.; Meylan, E.; Scholl, C.; et al. Systematic RNA interference reveals that oncogenic KRAS-driven cancers require TBK1. Nature 2009, 462, 108–112. [Google Scholar] [CrossRef]
- Shannon, P.; Markiel, A.; Ozier, O.; Baliga, N.S.; Wang, J.T.; Ramage, D.; Amin, N.; Schwikowski, B.; Ideker, T. Cytoscape: A software environment for integrated models of biomolecular interaction networks. Genome Res. 2003, 13, 2498–2504. [Google Scholar] [CrossRef] [PubMed]
- Bindea, G.; Mlecnik, B.; Hackl, H.; Charoentong, P.; Tosolini, M.; Kirilovsky, A.; Fridman, W.H.; Pages, F.; Trajanoski, Z.; Galon, J. ClueGO: A Cytoscape plug-in to decipher functionally grouped gene ontology and pathway annotation networks. Bioinformatics 2009, 25, 1091–1093. [Google Scholar] [CrossRef] [Green Version]
- Rahman, M.; Reyner, K.; Deleyrolle, L.; Millette, S.; Azari, H.; Day, B.W.; Stringer, B.W.; Boyd, A.W.; Johns, T.G.; Blot, V.; et al. Neurosphere and adherent culture conditions are equivalent for malignant glioma stem cell lines. Anat. Cell Biol. 2015, 48, 25–35. [Google Scholar] [CrossRef] [Green Version]
- Yu, Q.; Xue, Y.; Liu, J.; Xi, Z.; Li, Z.; Liu, Y. Fibronectin Promotes the Malignancy of Glioma Stem-Like Cells Via Modulation of Cell Adhesion, Differentiation, Proliferation and Chemoresistance. Front. Mol. Neurosci. 2018, 11, 130. [Google Scholar] [CrossRef]
- Jung, C.S.; Foerch, C.; Schanzer, A.; Heck, A.; Plate, K.H.; Seifert, V.; Steinmetz, H.; Raabe, A.; Sitzer, M. Serum GFAP is a diagnostic marker for glioblastoma multiforme. Brain 2007, 130, 3336–3341. [Google Scholar] [CrossRef]
- Bazzoni, R.; Bentivegna, A. Role of Notch Signaling Pathway in Glioblastoma Pathogenesis. Cancers 2019, 11, 292. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wilson, J.J.; Malakhova, M.; Zhang, R.; Joachimiak, A.; Hegde, R.S. Crystal structure of the dachshund homology domain of human SKI. Structure 2004, 12, 785–792. [Google Scholar] [CrossRef] [PubMed]
- Vignais, M.L. Ski and SnoN: Antagonistic proteins of TGFbeta signaling. Bull. Cancer 2000, 87, 135–137. [Google Scholar] [PubMed]
- Behnan, J.; Finocchiaro, G.; Hanna, G. The landscape of the mesenchymal signature in brain tumours. Brain 2019, 142, 847–866. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Greenall, S.A.; McKenzie, M.; Seminova, E.; Dolezal, O.; Pearce, L.; Bentley, J.; Kuchibhotla, M.; Chen, S.C.; McDonald, K.L.; Kornblum, H.; et al. Most clinical anti-EGFR antibodies do not neutralize both wtEGFR and EGFRvIII activation in glioma. Neuro Oncol. 2019, 21, 1016–1027. [Google Scholar] [CrossRef]
- Baker, K.E.; Coller, J. The many routes to regulating mRNA translation. Genome Biol. 2006, 7, 332. [Google Scholar] [CrossRef] [Green Version]
- Okawa, S.; Gagrica, S.; Blin, C.; Ender, C.; Pollard, S.M.; Krijgsveld, J. Proteome and Secretome Characterization of Glioblastoma-Derived Neural Stem Cells. Stem Cells 2017, 35, 967–980. [Google Scholar] [CrossRef]
- Bock, T.; Moest, H.; Omasits, U.; Dolski, S.; Lundberg, E.; Frei, A.; Hofmann, A.; Bausch-Fluck, D.; Jacobs, A.; Krayenbuehl, N.; et al. Proteomic analysis reveals drug accessible cell surface N-glycoproteins of primary and established glioblastoma cell lines. J. Proteome Res. 2012, 11, 4885–4893. [Google Scholar] [CrossRef]
- Brennan, C.W.; Verhaak, R.G.; McKenna, A.; Campos, B.; Noushmehr, H.; Salama, S.R.; Zheng, S.; Chakravarty, D.; Sanborn, J.Z.; Berman, S.H.; et al. The somatic genomic landscape of glioblastoma. Cell 2013, 155, 462–477. [Google Scholar] [CrossRef]






© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
D’Souza, R.C.J.; Offenhäuser, C.; Straube, J.; Baumgartner, U.; Kordowski, A.; Li, Y.; Stringer, B.W.; Alexander, H.; Lwin, Z.; Inglis, P.-L.; et al. Q-Cell Glioblastoma Resource: Proteomics Analysis Reveals Unique Cell-States Are Maintained in 3D Culture. Cells 2020, 9, 267. https://0-doi-org.brum.beds.ac.uk/10.3390/cells9020267
D’Souza RCJ, Offenhäuser C, Straube J, Baumgartner U, Kordowski A, Li Y, Stringer BW, Alexander H, Lwin Z, Inglis P-L, et al. Q-Cell Glioblastoma Resource: Proteomics Analysis Reveals Unique Cell-States Are Maintained in 3D Culture. Cells. 2020; 9(2):267. https://0-doi-org.brum.beds.ac.uk/10.3390/cells9020267
Chicago/Turabian StyleD’Souza, Rochelle C. J., Carolin Offenhäuser, Jasmin Straube, Ulrich Baumgartner, Anja Kordowski, Yuchen Li, Brett W. Stringer, Hamish Alexander, Zarnie Lwin, Po-Ling Inglis, and et al. 2020. "Q-Cell Glioblastoma Resource: Proteomics Analysis Reveals Unique Cell-States Are Maintained in 3D Culture" Cells 9, no. 2: 267. https://0-doi-org.brum.beds.ac.uk/10.3390/cells9020267