
Estimating Growth in Height from Limited Longitudinal Growth Data Using Full-Curves Training Dataset: A Comparison of Two Procedures of Curve Optimization—Functional Principal Component Analysis and SITAR

 , , ,
, , ,
Abstract
:1. Introduction
2. Materials and Methods
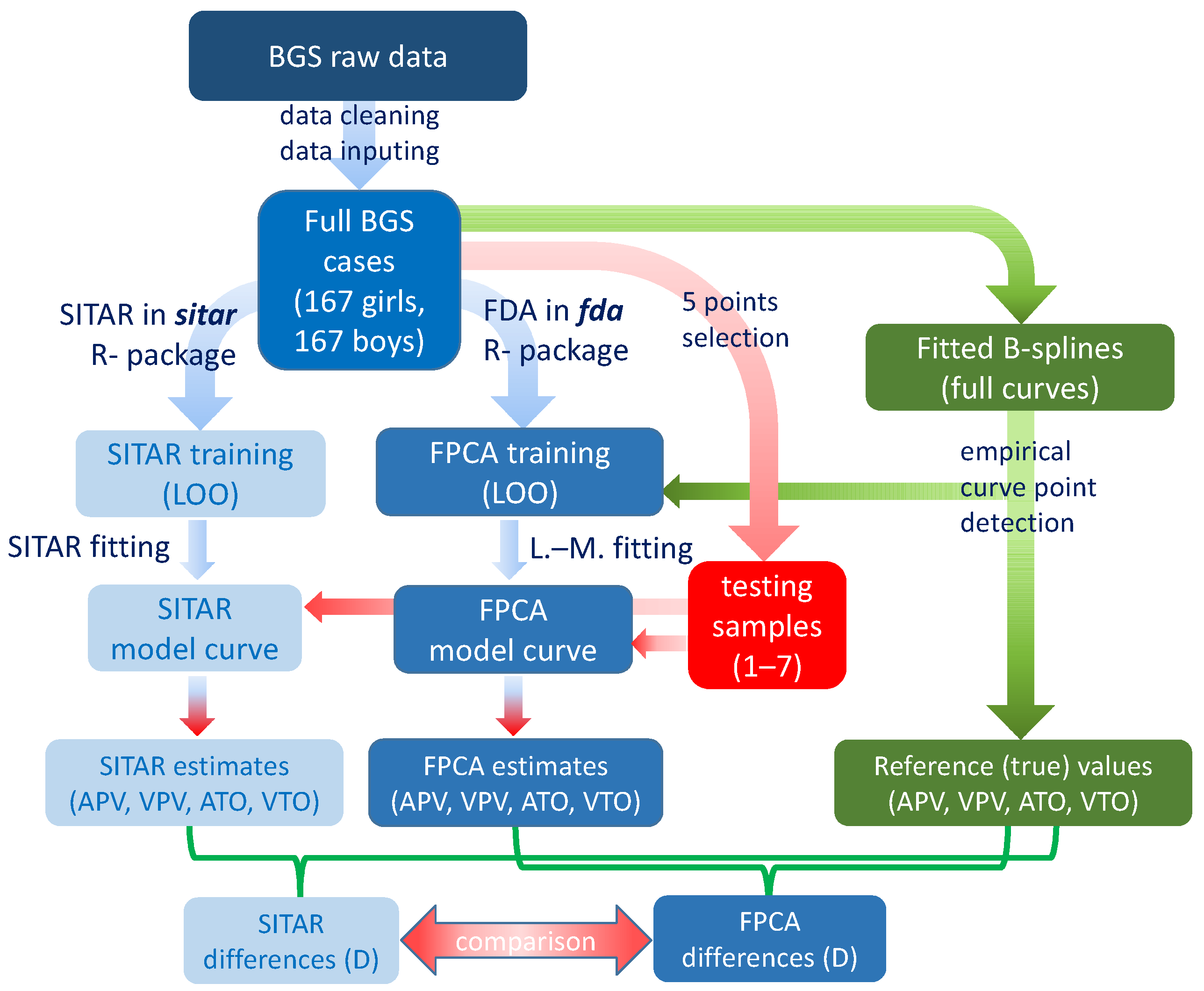
2.1. General Description of the Approach
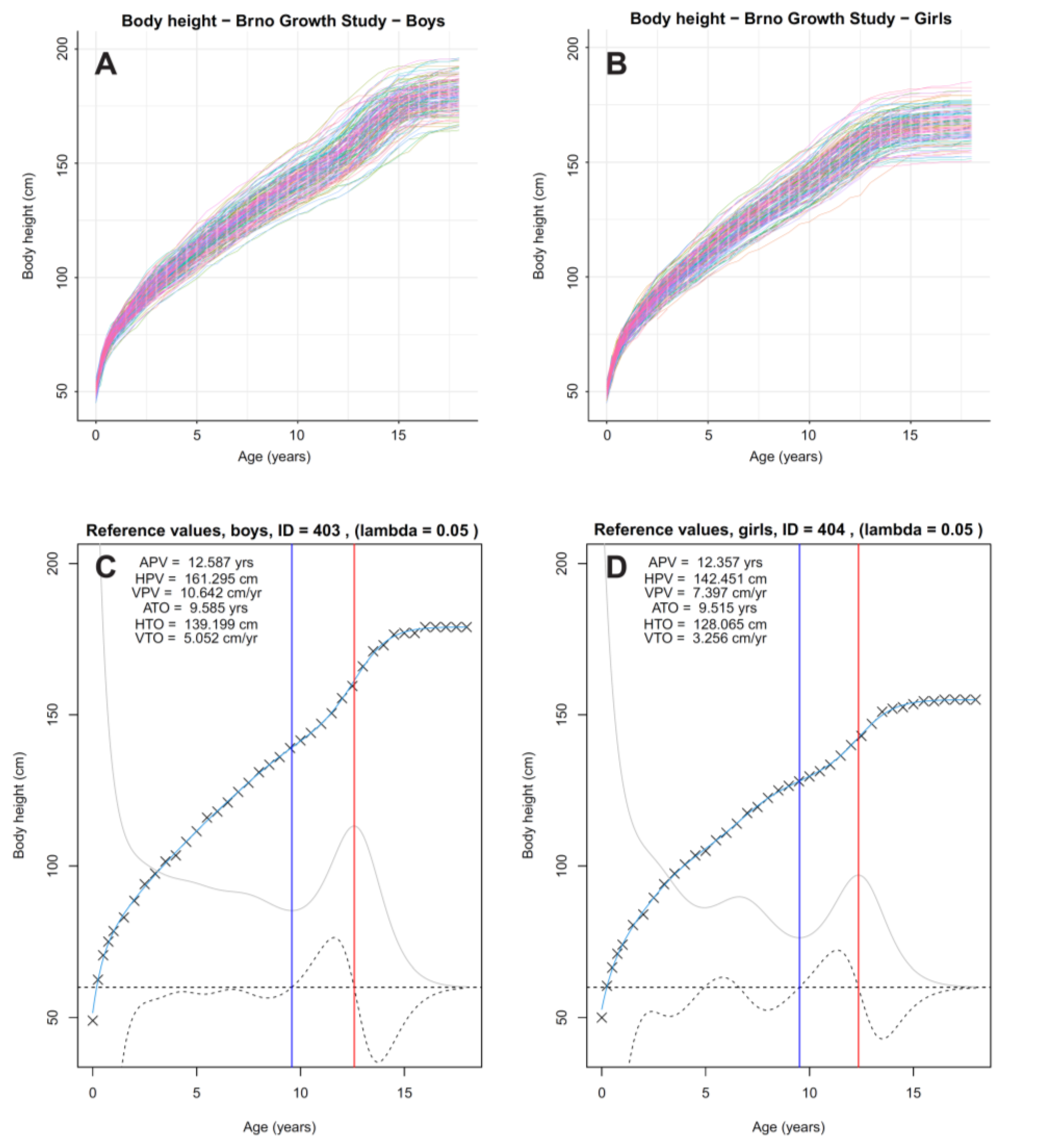
2.2. Reference Sample—The Brno Growth Study
2.3. New Computational Approach
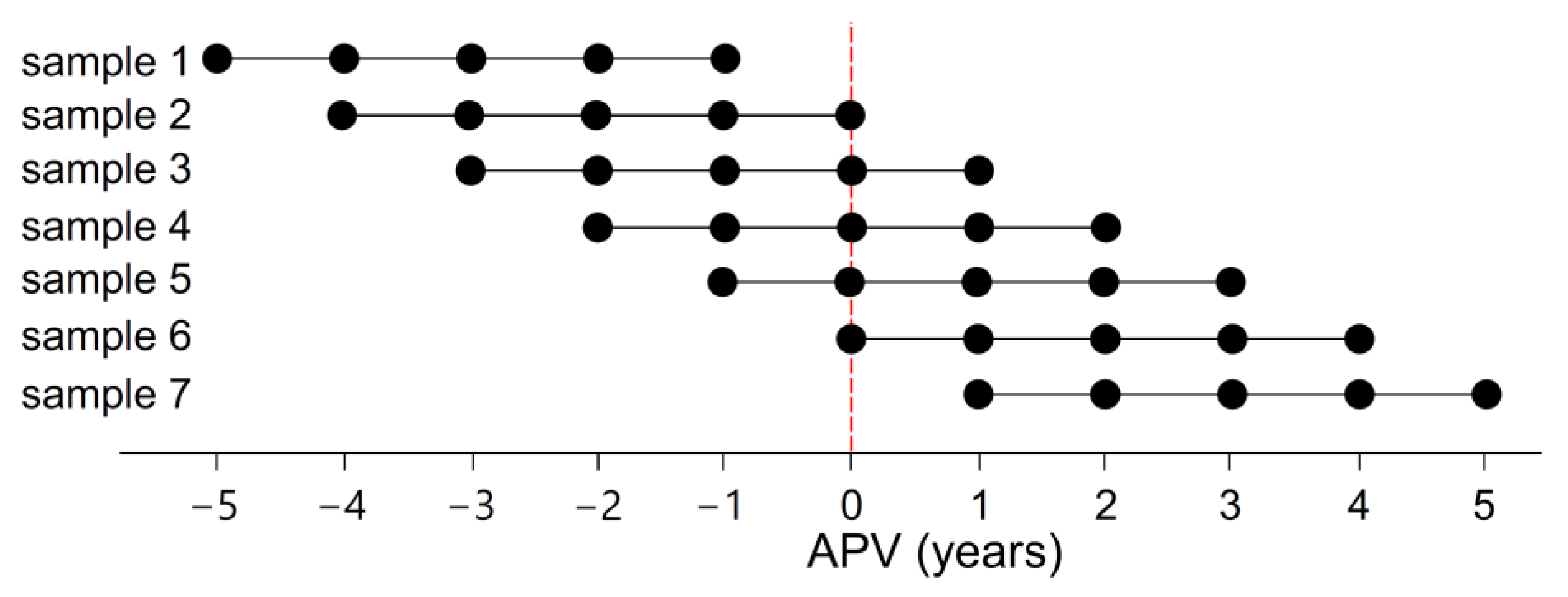
2.4. Application of the Model to Newly Analyzed Cases
2.5. Comparison with an Alternative Fitting Method
3. Results
3.1. Description of the Source Sample
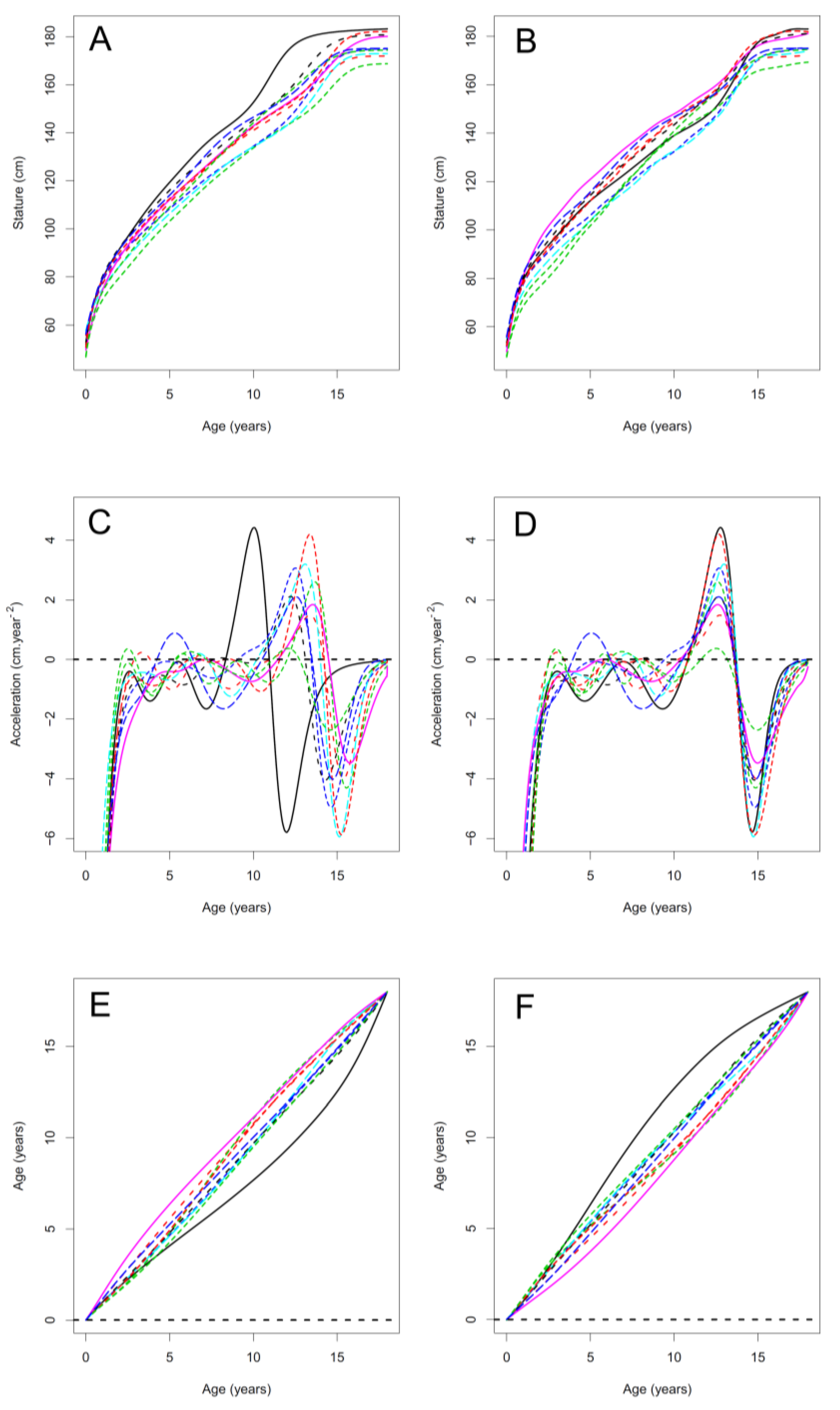
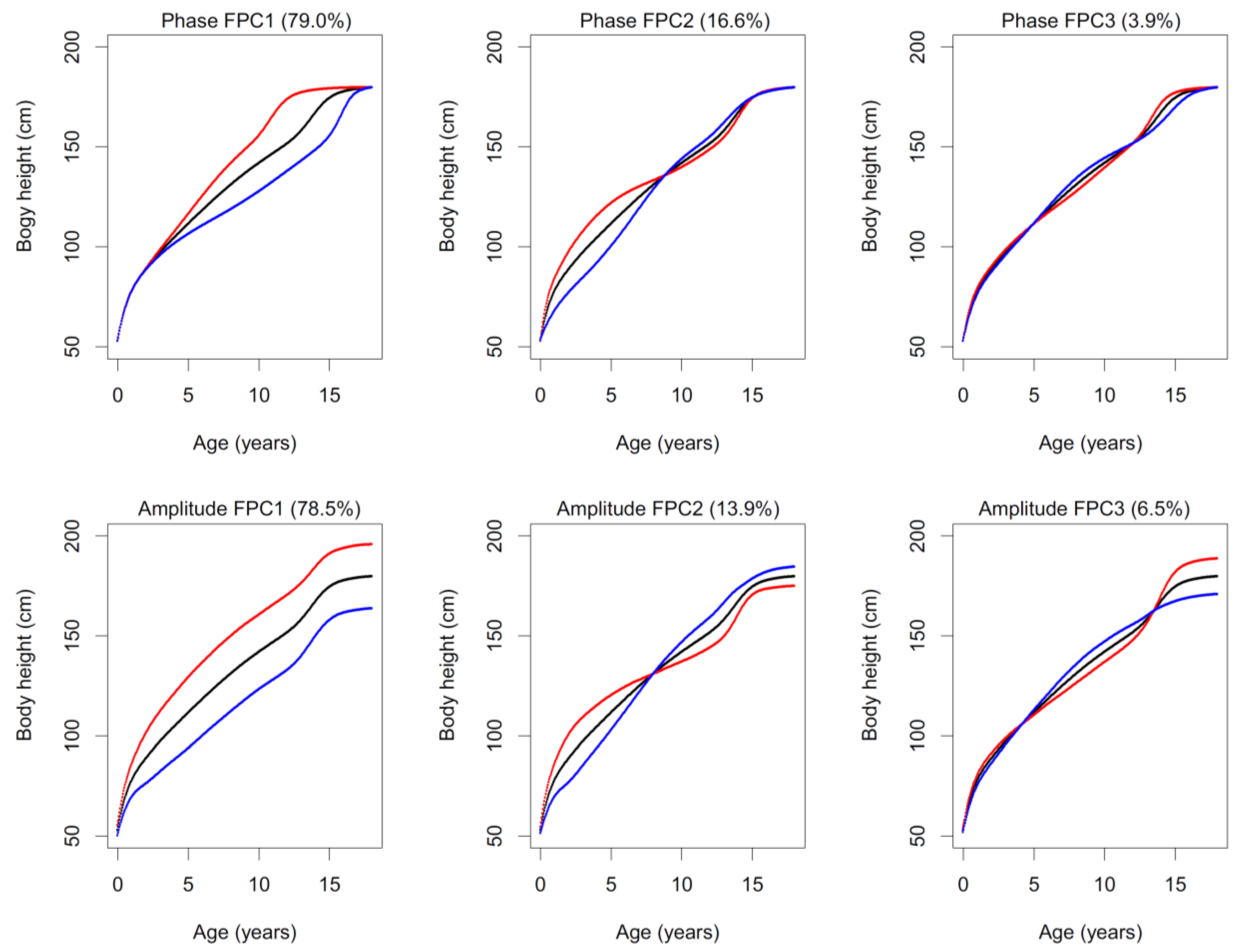
3.2. Functional Principal Component Analysis
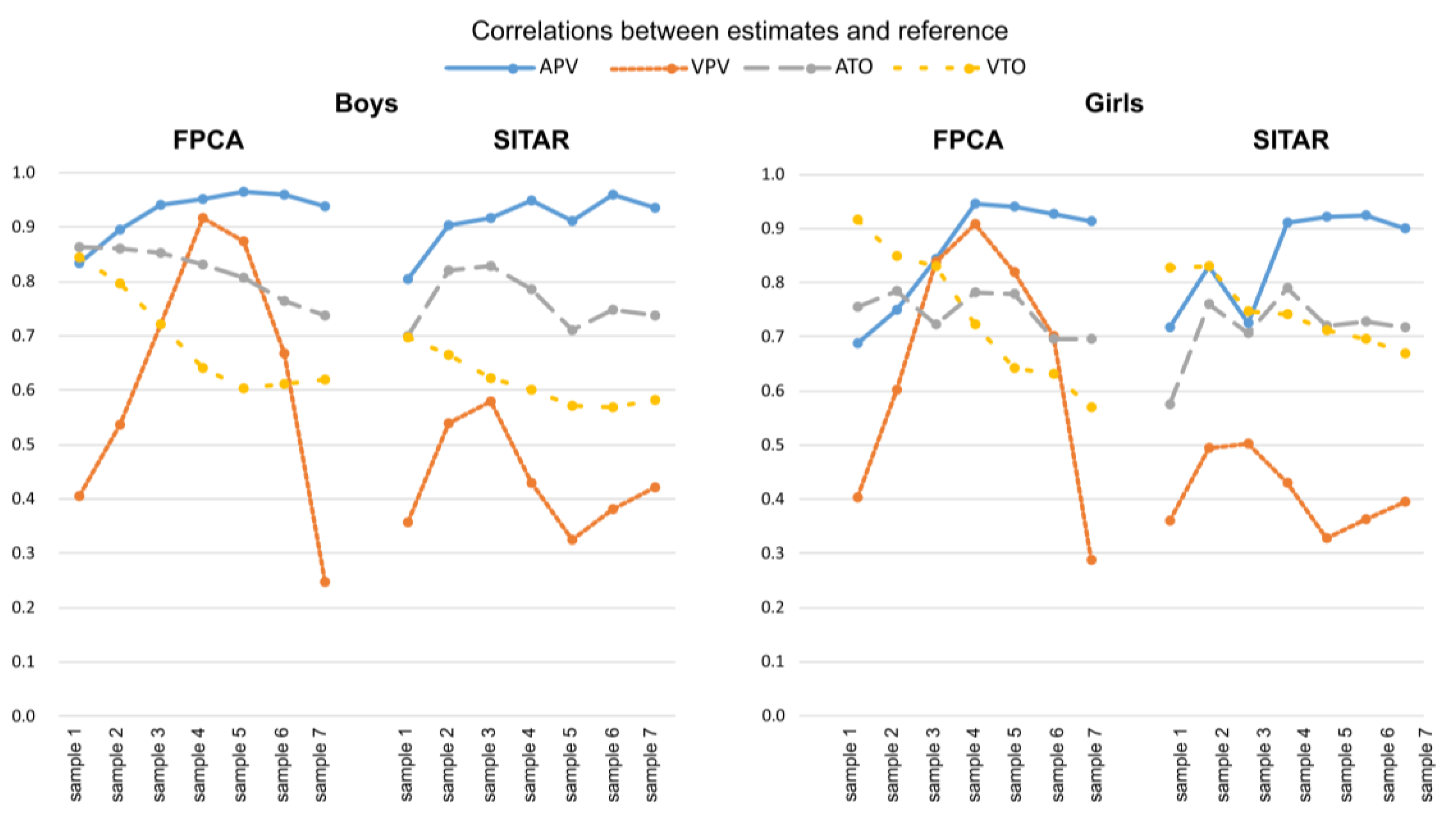
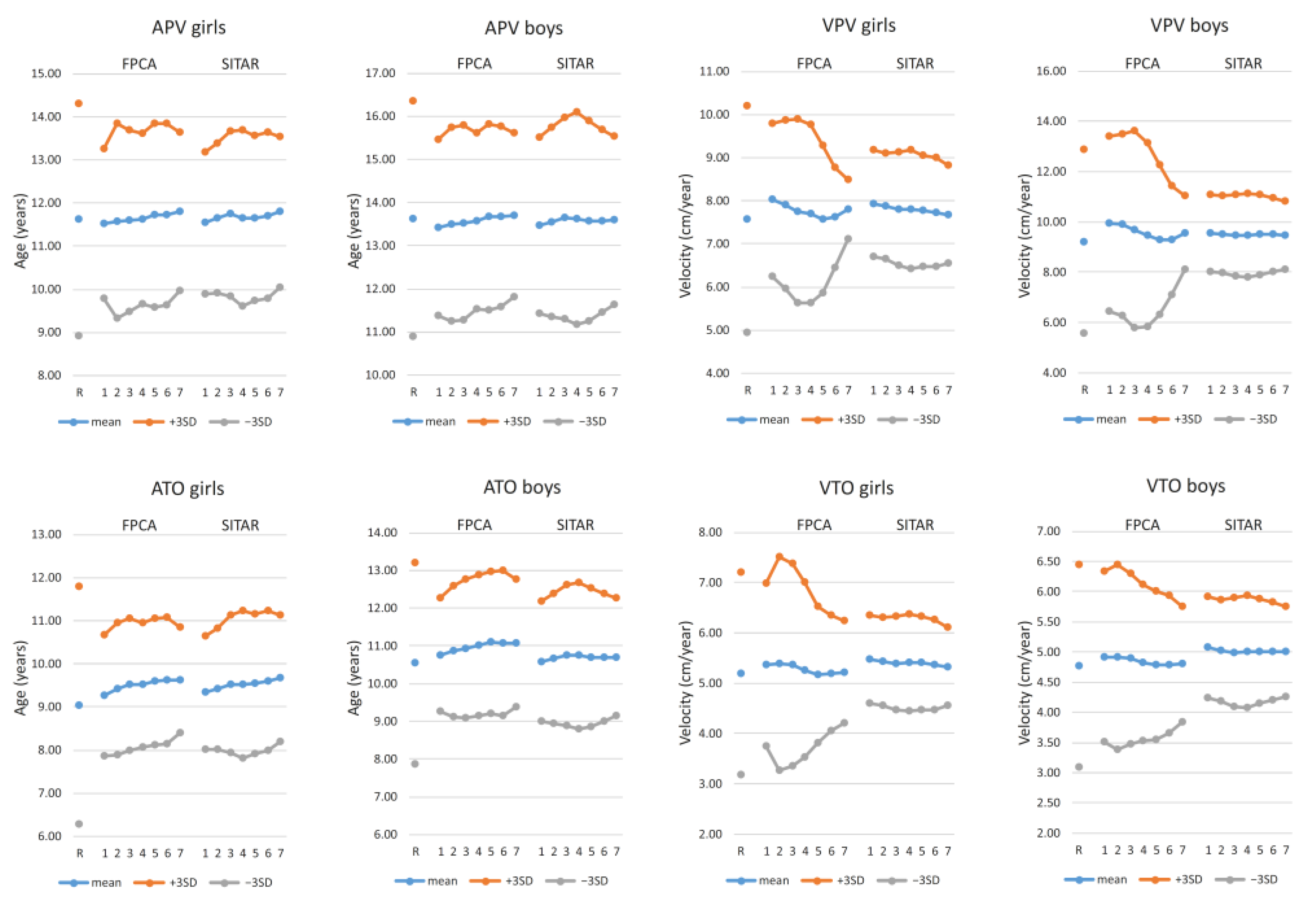
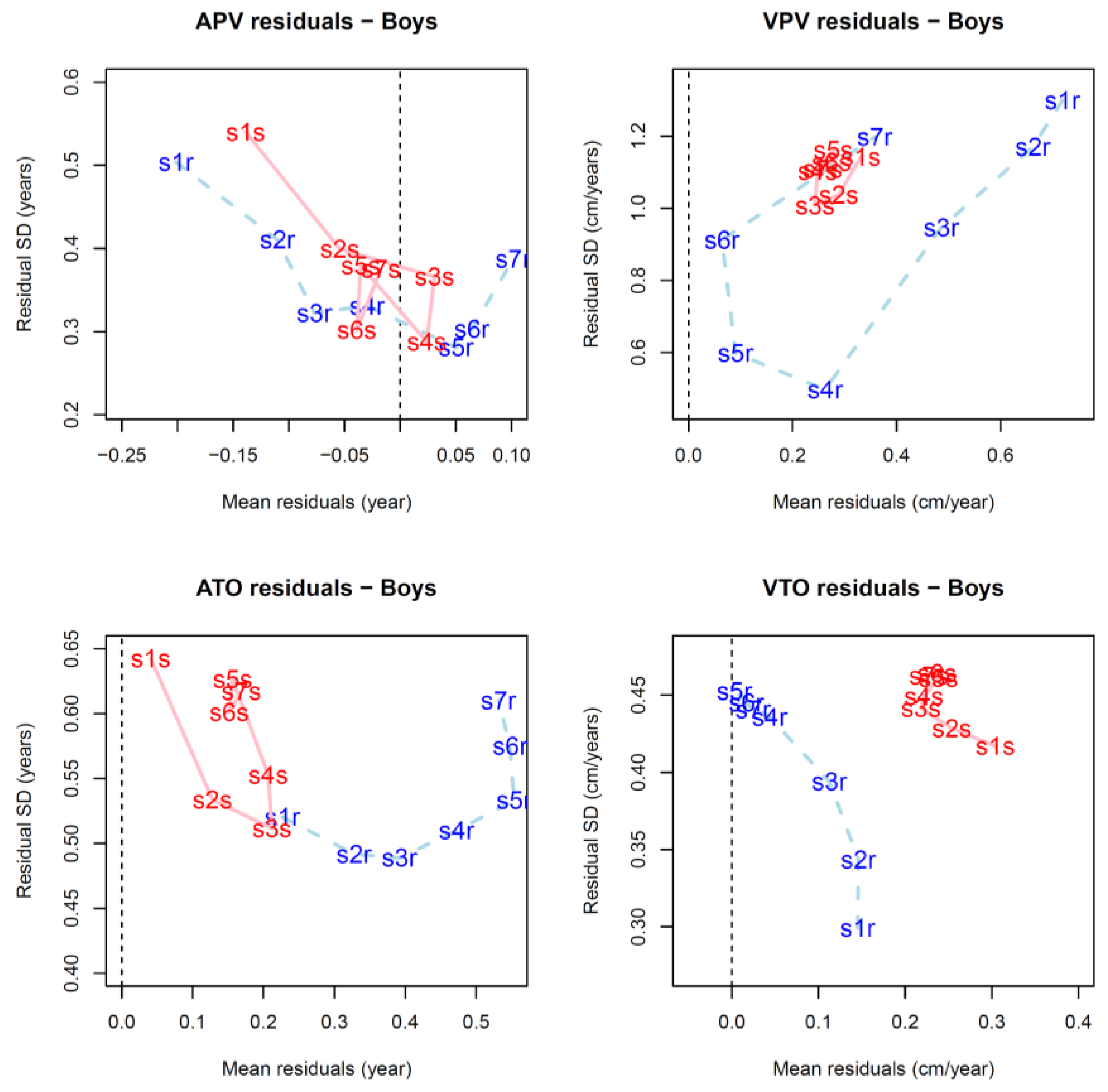
3.3. Testing Results
4. Discussion
4.1. General Aspects of the Approach
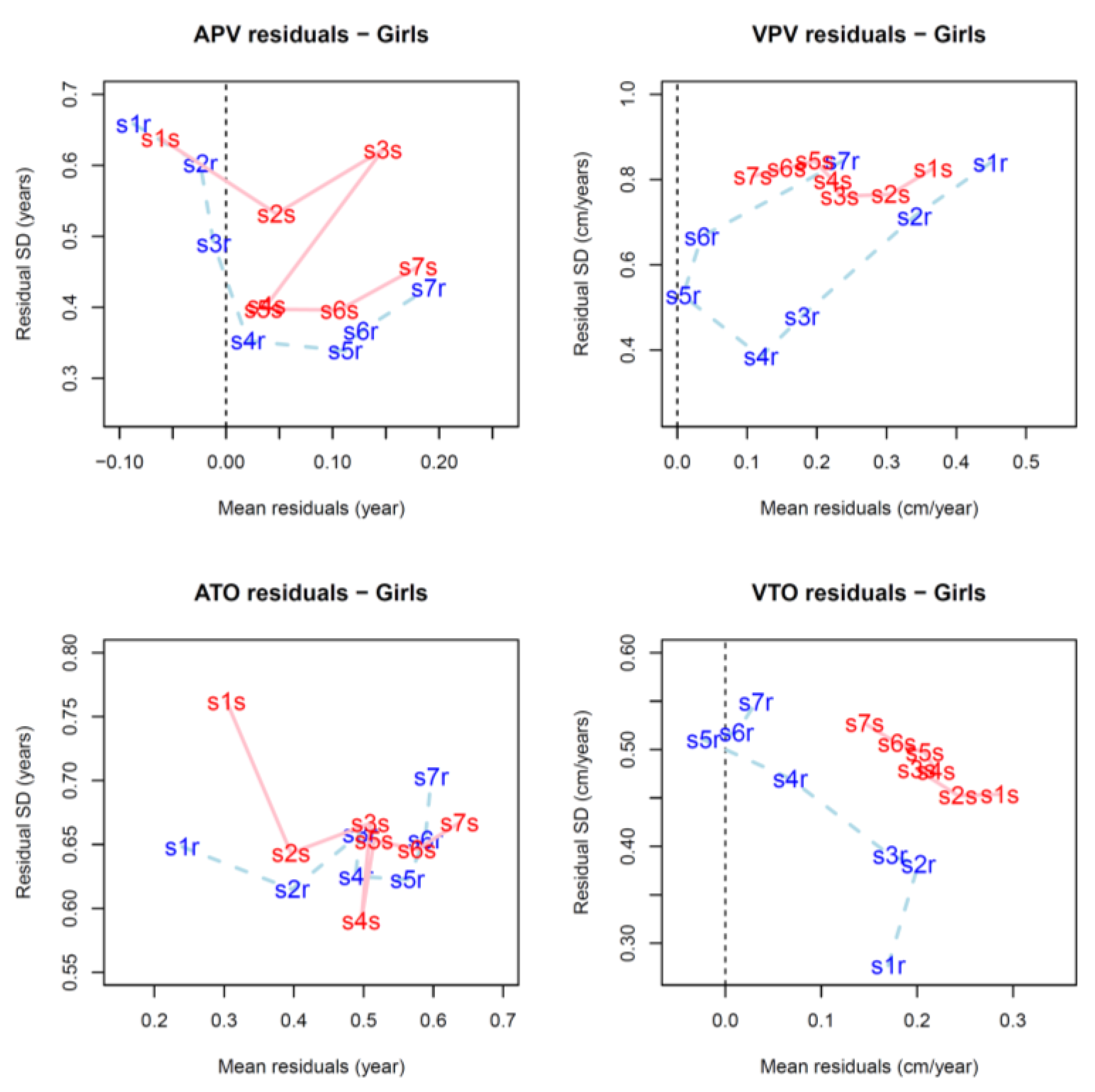
4.2. Comparison between FPCA and SITAR
4.3. Strengths of the Method and Comparisons with Alternative Approaches
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bock, R.D.; Wainer, H.; Petersen, A.; Thissen, D.; Murray, J.; Roche, A. A Parameterization for Individual Human Growth Curves. Hum. Biol. 1973, 45, 63–80. [Google Scholar]
- Preece, M.A.; Baines, M.J. A New Family of Mathematical Models Describing the Human Growth Curve. Ann. Hum. Biol. 1978, 5, 1–24. [Google Scholar] [CrossRef]
- Sayers, A.; Baines, M.; Tilling, K. A New Family of Mathematical Models Describing the Human Growth Curve—Erratum: Direct Calculation of Peak Height Velocity, Age at Take-off and Associated Quantities. Ann. Hum. Biol. 2013, 40, 298–299. [Google Scholar] [CrossRef]
- Čuta, M. Modelování Lidského Růstu. Dynamický Fenotyp; Akademické nakladatelství CERM: Brno, Czech Republic, 2014; ISBN 978-80-7204-893-9. [Google Scholar]
- Karlberg, J. A Biologically-Oriented Mathematical Model (ICP) for Human Growth. Acta Paediatr. 1989, 78, 70–94. [Google Scholar] [CrossRef] [PubMed]
- Karlberg, J. On the Construction of the Infancy-Childhood-Puberty Growth Standard. Acta Paediatr. 2009, 79, 963–967. [Google Scholar] [CrossRef] [PubMed]
- Novák, L.; Kukla, L.; Čuta, M. Child and Adolescent Longitudinal Growth Data Evaluation Using Logistic Curve Fitting with Use of the Dynamic Phenotype Method. Scr. Med. 2008, 81, 31–46. [Google Scholar]
- Novák, L.; Kukla, L.; Zeman, L. Characteristic Differences between the Growth of Man and the Other Animals. Prague Med. Rep. 2007, 108, 155–166. [Google Scholar]
- Beath, K.J. Infant Growth Modelling Using a Shape Invariant Model with Random Effects. Stat. Med. 2007, 26, 2547–2564. [Google Scholar] [CrossRef]
- Cole, T.J.; Pan, H.; Butler, G.E. A Mixed Effects Model to Estimate Timing and Intensity of Pubertal Growth from Height and Secondary Sexual Characteristics. Ann. Hum. Biol. 2014, 41, 76–83. [Google Scholar] [CrossRef]
- Cole, T.J.; Donaldson, M.D.C.; Ben-Shlomo, Y. SITAR—A Useful Instrument for Growth Curve Analysis. Int. J. Epidemiol. 2010, 39, 1558–1566. [Google Scholar] [CrossRef]
- Ramsay, J.O.; Silverman, B.W. Functional Data Analysis, 2nd ed.; Springer Science+Business Media, Inc.: New York, NY, USA, 2005. [Google Scholar]
- Ramsay, J.O.; Hooker, G.; Graves, S. Functional Data Analysis with R and MATLAB; Springer: Dordrecht, The Netherlands; Heidelberg, Germany; London, UK; New York, NY, USA, 2009; ISBN 978-0-387-98184-0. [Google Scholar]
- Ramsay, J.O.; Silverman, B.W. Applied Functional Data Analysis: Methods and Case Studies, 1st ed.; Springer: Berlin/Heidelberg, Germany; New York, NY, USA, 2002; ISBN 0-387-95414-7. [Google Scholar]
- Malina, R.M.; Claessens, A.L.; Van Aken, K.; Thomis, M.; Lefevre, J.; Philippaerts, R.; Beunen, G.P. Maturity Offset in Gymnasts: Application of a Prediction Equation. Med. Sci. Sports Exerc. 2006, 38, 1342–1347. [Google Scholar] [CrossRef] [PubMed]
- Philippaerts, R.M.; Vaeyens, R.; Janssens, M.; Van Renterghem, B.; Matthys, D.; Craen, R.; Bourgois, J.; Vrijens, J.; Beunen, G.; Malina, R.M. The Relationship between Peak Height Velocity and Physical Performance in Youth Soccer Players. J. Sports Sci. 2006, 24, 221–230. [Google Scholar] [CrossRef] [PubMed]
- Mirwald, R.L.; Baxter-Jones, A.D.G.; Bailey, D.A.; Beunen, G.P. An Assessment of Maturity from Anthropometric Measurements. Med. Sci. Sports Exerc. 2002, 34, 689–694. [Google Scholar] [CrossRef] [PubMed]
- Moore, S.A.; McKay, H.A.; Macdonald, H.; Nettlefold, L.; Baxter-Jones, A.D.G.; Cameron, N.; Brasher, P.M.A. Enhancing a Somatic Maturity Prediction Model. Med. Sci. Sports Exerc. 2015, 47, 1755–1764. [Google Scholar] [CrossRef]
- Malina, R.M.; Kozieł, S.M.; Králik, M.; Chrzanowska, M.; Suder, A. Prediction of Maturity Offset and Age at Peak Height Velocity in a Longitudinal Series of Boys and Girls. Am. J. Hum. Biol. 2020, e23551. [Google Scholar] [CrossRef]
- Bouchalová, M. Vývoj Během Dětství a Jeho Ovlivnění. Brněnská Růstová Studie; Avicenum, Zdravotnické nakladatelství: Praha, Czech Republic, 1987. [Google Scholar]
- Bouchalová, M. Sociální Poměry a Pořadí Dětí v Rodině Jako Činitelé Působící v Růstu Kojenců. Českoslov. Zdr. 1968, 16, 116–124. [Google Scholar]
- Bouchalová, M. Růst Dětí Za Růszných Sociálních a Biologických Podmínek. Českoslov. Pediatr. 1980, 35, 437–443. [Google Scholar]
- Bouchalová, M.; Omelka, F. Vývoj v Útlém Věku Podle Doby Kojení. Českoslov. Pediatr. 1970, 25, 545–547. [Google Scholar]
- Moritz, S.; Bartz-Beielstein, T. ImputeTS: Time Series Missing Value Imputation in R. R J. 2017, 9, 207–218. [Google Scholar] [CrossRef] [Green Version]
- Johannesson, T.; Bjornsson, H.; Icelandic Met. Office; Grothendieck, G. Stinepack: Stineman, a Consistently Well Behaved Method of Interpolation. 2018. Available online: https://CRAN.R-project.org/package=stinepack (accessed on 25 June 2020).
- Stineman, R.W. A Consistently Well Behaved Method of Interpolation. Creat. Comput. 1980, 6, 54–57. [Google Scholar]
- Ramsay, J.O.; Graves, S.; Hooker, G. fda: Functional Data Analysis. 2020. Available online: https://cran.r-project.org/web/packages/fda/index.html (accessed on 25 September 2020).
- Kelley, C.T. Iterative Methods for Optimization; Frontiers in Applied Mathematics; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1999; ISBN 978-0-89871-433-3. [Google Scholar]
- Cole, T. sitar: Super Imposition by Translation and Rotation Growth Curve Analysis. 2020. Available online: https://CRAN.R-project.org/package=sitar (accessed on 20 June 2020).
- Lehnert, B. BlandAltmanLeh: Plots (Slightly Extended) Bland-Altman Plots. R Package Version 0.3.1. 2015. Available online: https://CRAN.R-project.org/package=BlandAltmanLeh (accessed on 30 March 2021).
- Pinheiro, J.; Bates, D.; DebRoy, S.; Sarkar, D.; R Core Team. nlme: Linear and Nonlinear Mixed Effects Models. R Package Version 3.1-148. 2020. Available online: https://CRAN.R-project.org/package=nlme (accessed on 30 August 2020).
- Hermanussen, M.; Meigen, C. Phase Variation in Child and Adolescent Growth. Int. J. Biostat. 2007, 3. [Google Scholar] [CrossRef]
- Ramsay, J.; Bock, R. Functional Data Analysis for Human Growth. Unpublished Manuscript. 2002.
- Ramsay, J.O.; Silverman, B.W. Functional Data Analysis; Springer: New York, NY, USA; Berlin/Heidelberg, Germany, 1997; ISBN 0-387-95414-7. [Google Scholar]
- Bronstein, I.; Semendjajew, K. Taschenbuch Der Mathematik; Teubner: Leipzig, Germany, 1991. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GIRLS | BOYS | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| n | Mean | sd | min | Max | n | Mean | sd | Min | Max | ||
| APV | 167 | 11.61 | 0.90 | 9.09 | 13.75 | 167 | 13.61 | 0.91 | 10.95 | 16.57 | |
| VPV | 167 | 7.57 | 0.88 | 5.19 | 10.80 | 167 | 9.21 | 1.22 | 6.15 | 11.96 | |
| ATO | 167 | 9.03 | 0.92 | 6.4 | 11.23 | 167 | 10.54 | 0.89 | 7.99 | 13.02 | |
| VTO | 167 | 5.19 | 0.67 | 3.26 | 7.23 | 167 | 4.77 | 0.56 | 3.49 | 6.31 |
| GIRLS | BOYS | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FPCA | SITAR | FPCA | SITAR | ||||||||||||||
| Mean | sd | Median | Mean | sd | Median | Mean | sd | Median | Mean | sd | Median | ||||||
| sample 1 | −0.09 | 0.66 | −0.06 | −0.06 | 0.64 | −0.05 | −0.20 | 0.50 | −0.10 | −0.14 | 0.54 | −0.08 | |||||
| sample 2 | −0.02 | 0.60 | −0.01 | 0.05 | 0.53 | 0.04 | −0.11 | 0.41 | −0.01 | −0.05 | 0.40 | −0.02 | |||||
| sample 3 | −0.01 | 0.49 | 0.03 | 0.15 | 0.62 | 0.07 | −0.08 | 0.32 | 0.01 | 0.03 | 0.37 | 0.06 | |||||
| APV | sample 4 | 0.02 | 0.35 | 0.05 | 0.04 | 0.40 | 0.03 | −0.03 | 0.33 | 0.03 | 0.02 | 0.29 | 0.04 | ||||
| sample 5 | 0.11 | 0.34 | 0.09 | 0.04 | 0.40 | 0.05 | 0.05 | 0.28 | 0.08 | −0.04 | 0.38 | 0.00 | |||||
| sample 6 | 0.13 | 0.37 | 0.11 | 0.11 | 0.40 | 0.11 | 0.06 | 0.30 | 0.09 | −0.04 | 0.30 | −0.02 | |||||
| sample 7 | 0.19 | 0.43 | 0.14 | 0.18 | 0.46 | 0.14 | 0.10 | 0.39 | 0.10 | −0.02 | 0.37 | −0.05 | |||||
| sample 1 | 0.45 | 0.84 | 0.42 | 0.37 | 0.83 | 0.30 | 0.72 | 1.30 | 0.59 | 0.33 | 1.14 | 0.38 | |||||
| sample 2 | 0.34 | 0.71 | 0.25 | 0.31 | 0.77 | 0.31 | 0.66 | 1.17 | 0.45 | 0.29 | 1.04 | 0.34 | |||||
| sample 3 | 0.18 | 0.48 | 0.18 | 0.23 | 0.76 | 0.25 | 0.49 | 0.95 | 0.37 | 0.24 | 1.01 | 0.24 | |||||
| VPV | sample 4 | 0.12 | 0.38 | 0.15 | 0.22 | 0.80 | 0.25 | 0.26 | 0.50 | 0.30 | 0.25 | 1.10 | 0.19 | ||||
| sample 5 | 0.01 | 0.53 | 0.11 | 0.20 | 0.84 | 0.18 | 0.09 | 0.60 | 0.27 | 0.28 | 1.16 | 0.24 | |||||
| sample 6 | 0.03 | 0.67 | 0.15 | 0.16 | 0.83 | 0.15 | 0.06 | 0.91 | 0.27 | 0.28 | 1.13 | 0.23 | |||||
| sample 7 | 0.24 | 0.84 | 0.29 | 0.11 | 0.81 | 0.14 | 0.36 | 1.20 | 0.51 | 0.26 | 1.11 | 0.26 | |||||
| sample 1 | 0.24 | 0.65 | 0.28 | 0.30 | 0.76 | 0.31 | 0.23 | 0.52 | 0.23 | 0.04 | 0.64 | 0.06 | |||||
| sample 2 | 0.40 | 0.61 | 0.29 | 0.40 | 0.64 | 0.38 | 0.33 | 0.49 | 0.27 | 0.13 | 0.53 | 0.09 | |||||
| sample 3 | 0.49 | 0.66 | 0.42 | 0.51 | 0.67 | 0.45 | 0.39 | 0.49 | 0.33 | 0.21 | 0.51 | 0.13 | |||||
| ATO | sample 4 | 0.49 | 0.63 | 0.45 | 0.50 | 0.59 | 0.46 | 0.47 | 0.51 | 0.40 | 0.21 | 0.55 | 0.17 | ||||
| sample 5 | 0.56 | 0.62 | 0.49 | 0.51 | 0.65 | 0.51 | 0.55 | 0.53 | 0.48 | 0.16 | 0.63 | 0.15 | |||||
| sample 6 | 0.59 | 0.65 | 0.54 | 0.58 | 0.65 | 0.58 | 0.55 | 0.58 | 0.46 | 0.15 | 0.60 | 0.11 | |||||
| sample 7 | 0.60 | 0.70 | 0.55 | 0.64 | 0.67 | 0.61 | 0.53 | 0.61 | 0.44 | 0.17 | 0.62 | 0.09 | |||||
| sample 1 | 0.17 | 0.28 | 0.16 | 0.29 | 0.45 | 0.33 | 0.15 | 0.30 | 0.12 | 0.30 | 0.42 | 0.27 | |||||
| sample 2 | 0.20 | 0.38 | 0.16 | 0.24 | 0.45 | 0.33 | 0.15 | 0.34 | 0.11 | 0.25 | 0.43 | 0.24 | |||||
| sample 3 | 0.17 | 0.39 | 0.11 | 0.20 | 0.48 | 0.30 | 0.11 | 0.39 | 0.08 | 0.22 | 0.44 | 0.21 | |||||
| VTO | sample 4 | 0.07 | 0.47 | 0.07 | 0.22 | 0.48 | 0.28 | 0.04 | 0.44 | 0.02 | 0.22 | 0.45 | 0.24 | ||||
| sample 5 | −0.02 | 0.51 | −0.01 | 0.21 | 0.50 | 0.28 | 0.00 | 0.45 | 0.00 | 0.24 | 0.46 | 0.29 | |||||
| sample 6 | 0.01 | 0.52 | 0.01 | 0.18 | 0.51 | 0.27 | 0.02 | 0.45 | 0.04 | 0.24 | 0.46 | 0.26 | |||||
| sample 7 | 0.03 | 0.55 | 0.05 | 0.15 | 0.53 | 0.22 | 0.02 | 0.44 | 0.05 | 0.23 | 0.46 | 0.26 |
| numDF | denDF | F-Value | p-Value | |
|---|---|---|---|---|
| (Intercept) | 1 | 4330 | 17.5932 | <0.0001 |
| samp | 1 | 4330 | 56.6251 | <0.0001 |
| met | 1 | 4330 | 3.2439 | 0.07 |
| sex | 1 | 330 | 20.0942 | <0.0001 |
| apv.ref | 1 | 330 | 735.1555 | <0.0001 |
| samp:met | 1 | 4330 | 103.4955 | <0.0001 |
| samp:sex | 1 | 4330 | 0.3127 | 0.6 |
| met:sex | 1 | 4330 | 6.2683 | 0.012 |
| samp:apv.ref | 1 | 4330 | 11.9666 | 0.0005 |
| met:apv.ref | 1 | 4330 | 9.5817 | 0.002 |
| sex:apv.ref | 1 | 330 | 17.0984 | <0.0001 |
| samp:met:sex | 1 | 4330 | 11.7618 | 0.0006 |
| samp:met:apv.ref | 1 | 4330 | 1.5042 | 0.22 |
| samp:sex:apv.ref | 1 | 4330 | 5.9837 | 0.015 |
| met:sex:apv.ref | 1 | 4330 | 46.0603 | <0.0001 |
| samp:met:sex:apv.ref | 1 | 4330 | 0.7064 | 0.4 |
| numDF | denDF | F-Value | p-Value | |
|---|---|---|---|---|
| (Intercept) | 1 | 4330 | 496.6572 | <0.0001 |
| samp | 1 | 4330 | 159.4303 | <0.0001 |
| met | 1 | 4330 | 676.2191 | <0.0001 |
| sex | 1 | 330 | 31.8098 | <0.0001 |
| ato.ref | 1 | 330 | 1110.021 | <0.0001 |
| samp:met | 1 | 4330 | 76.7323 | <0.0001 |
| samp:sex | 1 | 4330 | 6.9282 | 0.0085 |
| met:sex | 1 | 4330 | 773.0021 | <0.0001 |
| samp:ato.ref | 1 | 4330 | 0.0824 | 0.8 |
| met:ato.ref | 1 | 4330 | 9.1492 | 0.0025 |
| sex:ato.ref | 1 | 330 | 17.4343 | <0.0001 |
| samp:met:sex | 1 | 4330 | 44.7276 | <0.0001 |
| samp:met:ato.ref | 1 | 4330 | 16.5127 | <0.0001 |
| samp:sex:ato.ref | 1 | 4330 | 1.1218 | 0.3 |
| met:sex:ato.ref | 1 | 4330 | 20.0348 | <0.0001 |
| samp:met:sex:ato.ref | 1 | 4330 | 20.7452 | <0.0001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Králík, M.; Klíma, O.; Čuta, M.; Malina, R.M.; Kozieł, S.; Polcerová, L.; Škultétyová, A.; Španěl, M.; Kukla, L.; Zemčík, P. Estimating Growth in Height from Limited Longitudinal Growth Data Using Full-Curves Training Dataset: A Comparison of Two Procedures of Curve Optimization—Functional Principal Component Analysis and SITAR. Children 2021, 8, 934. https://0-doi-org.brum.beds.ac.uk/10.3390/children8100934
Králík M, Klíma O, Čuta M, Malina RM, Kozieł S, Polcerová L, Škultétyová A, Španěl M, Kukla L, Zemčík P. Estimating Growth in Height from Limited Longitudinal Growth Data Using Full-Curves Training Dataset: A Comparison of Two Procedures of Curve Optimization—Functional Principal Component Analysis and SITAR. Children. 2021; 8(10):934. https://0-doi-org.brum.beds.ac.uk/10.3390/children8100934
Chicago/Turabian StyleKrálík, Miroslav, Ondřej Klíma, Martin Čuta, Robert M. Malina, Sławomir Kozieł, Lenka Polcerová, Anna Škultétyová, Michal Španěl, Lubomír Kukla, and Pavel Zemčík. 2021. "Estimating Growth in Height from Limited Longitudinal Growth Data Using Full-Curves Training Dataset: A Comparison of Two Procedures of Curve Optimization—Functional Principal Component Analysis and SITAR" Children 8, no. 10: 934. https://0-doi-org.brum.beds.ac.uk/10.3390/children8100934