Three-Stage Sequential Estimation of the Inverse Coefficient of Variation of the Normal Distribution


1
Department of Mathematics, Kuwait College of Science and Technology, Doha District B. O. Box 27235, Kuwait
2
Faculty of Management Sciences, October University for Modern Sciences and Arts, 6th October City 12566, Cairo, Egypt
*
Author to whom correspondence should be addressed.
Computation 2019, 7(4), 69; https://0-doi-org.brum.beds.ac.uk/10.3390/computation7040069
Submission received: 8 November 2019
/
Revised: 29 November 2019
/
Accepted: 3 December 2019
/
Published: 4 December 2019
Abstract
:This paper sequentially estimates the inverse coefficient of variation of the normal distribution using Hall’s three-stage procedure. We find theorems that facilitate finding a confidence interval for the inverse coefficient of variation that has pre-determined width and coverage probability. We also discuss the sensitivity of the constructed confidence interval to detect a possible shift in the inverse coefficient of variation. Finally, we find the asymptotic regret encountered in point estimation of the inverse coefficient of variation under the squared-error loss function with linear sampling cost. The asymptotic regret provides negative values, which indicate that the three-stage sampling does better than the optimal fixed sample size had the population inverse coefficient of variation been known.
1. Introduction
Let be a sequence of independent and identically distributed IID random variables from a normal distribution with mean and variance , where both parameters are finite but unknown. The population coefficient of variation is the population standard deviation divided by the population mean that is , , mostly presented as a percentage. It is useful when we seek relative variability rather than the absolute variability. It is a dimensionless quantity, which enables researchers to compare different distributions, regardless of their measurable units. Such practicality makes it widely used in different areas of science, such as engineering, finance, economics, medicine, and others. Nairy and Rao [1] conducted a survey of several applications in engineering, business, climatology, and other fields. Ahn [2] used the coefficient of variation to predict the unknown number of flaw trees, while Gong and Li [3] used it to estimate the strength of ceramics. Faber and Korn [4] applied the measure in the mean synaptic response of the central nervous system. Hammer et al. [5] used the measure to test the homogeneity of bone samples in order to determine the effect of external treatments on the properties of bones. Billings et al. [6] used it to study the impact of socioeconomic status on hospital use in New York City. In finance, Brief and Owen [7] used the coefficient of variation to evaluate the project risks considering the rate of return as a random variable. Pyne et al. [8] used the measure to study the variability of the competitive performance of Olympic swimmers. In health sciences, see Kelley [9] and Gulhar et al. [10].
The disadvantage of the measure lies in the singularity point . Therefore, it is preferable to work with the reciprocal of the measure, inverse coefficient of variation, defined over . The inverse coefficient of variation is equal to the signal-to-noise ratio, which measures the signal strength relative to background noise. In quality control, it represents the magnitude of the process mean compared to its variation. In other words, it quantifies how much signal has been corrupted by noise, see McGibney and Smith [11]. In finance, it is called Sharpe’s index, which measures portfolio performance, for example, see Knight and Satchell [12].
Having observed a random sample of size from the normal population, we continue to use both and as the sample mean and the sample standard deviation point estimates of the normal distribution mean and standard deviation , respectively. Consequently, we define the sample inverse coefficient of variation .
Hendricks and Robey [13] studied the sampling distribution of the coefficient of variation. Koopmans et al. [14] showed that without any prior restriction to the range of the population mean, it is impossible to obtain confidence intervals for the population coefficient of variation that have finite length with a probability one, uniformly for all values of except by using purely sequential procedure. Rao and Bhatta [15] approximate the distribution function of the sample coefficient of variation using the Edgeworth series to obtain a more accurate large-sample test for the population coefficient of variation under normality. McKay [16] derived a confidence interval for the population coefficient of variation, which is based on the chi-squared distribution. He found that the constructed confidence interval works well when the coefficient of variation is less than 0.33, see Umphrey [17]. Later Vangel [18] modified McKay’s confidence interval, which shown to be closely related to McKay’s confidence interval, but is more accurate and nearly exact under normality. Miller [19] discussed the approximate distribution function of the sample coefficient of variation and proposed the approximate confidence interval for the coefficient of variation under normality. Lehmann [20] found an exact form for the distribution function of the sample coefficient of variation, which depends mainly on the non-central -distribution (defined over , so it is computationally cumbersome. Curto and Pino [21] studied the distribution of the sample coefficient of variation in the case of non-IID random variables.
Sharma and Krishna [22] mathematically derived an asymptotic confidence interval for the population inverse coefficient of variation without any prior assumption regarding the underline distribution. Albatineh, Kibria, and Zogheib, [23] studied the performance of their constructed confidence interval using Monte Carlo simulation. They used randomly generated data from different distributions—normal, log-normal, (Chi-squared-distribution), Gamma, and Weibull distributions.
Regarding sequential estimation, Chaturvedi and Rani [24] proposed a sequential procedure to construct a fixed-width confidence interval for the population inverse coefficient of variation of a normal distribution with a preassigned coverage probability. They mathematically showed that the proposed procedure attains asymptotic efficiency and consistency in the sense of Chow and Robbins [25]. Chattopadhyay and Kelley [26] used the purely sequential procedure [25] to estimate the population coefficient of variation of the normal distribution under a squared-error loss function using a Nagar-type expansion.
Yousef and Hamdy [27] utilized Hall’s three-stage sampling procedure to estimate the population inverse coefficient of variation of the normal distribution using a Monte Carlo Simulation. They found a unified stopping rule, which is a function of the unknown population variance that tackles both a fixed-width confidence interval for the unknown population mean with a pre-assigned coverage probability and a point estimation problem for the unknown population variance under a squared-error loss function with linear sampling cost. In other words, they found the asymptotic coverage probability for the population mean and the asymptotic regret incurred by estimating the population variance by the sample variance. As an application, they write FORTRAN codes and use Microsoft Developer Studio software to find the simulated coverage probability for the inverse coefficient of variation and the simulated regret. The simulation results showed that the three-stage procedure attains asymptotic efficiency and consistency in the sense of Chow and Robbins [25].
Up to our knowledge, none of the existing papers in the literature discussed the three-stage estimation of the population inverse coefficient of variation theoretically. Here, the procedure is different than in Yousef and Hamdy [27]; the stopping rule depends directly on the sample inverse coefficient of variation. We derive mathematically an asymptotic confidence interval for the population inverse coefficient of variation that has a fixed-width and coverage probability at least .
Moreover, we tackle a point estimation problem for the population inverse coefficient of variation using a squared-error loss function with linear sampling cost. Then we examine the capability of the constructed confidence interval to detect any potential shift that occurs in the population inverse coefficient of variation. Here, the stopping rule depends on the asymptotic distribution of the sample inverse coefficient of variation.
The Layout of the Paper
In Section 2, we present preliminary asymptotic results that facilitate finding the asymptotic distribution of the sample inverse coefficient of variation. In Section 3, we present Hall’s three-stage procedure and find the asymptotic characteristics for both the main-study phase and the fine-tuning phase. In Section 4, we find the asymptotic coverage probability for the population inverse coefficient of variation. In Section 5, we discuss the capability of the constructed interval to detect any shift in the inverse coefficient of variation. In Section 6, we find the asymptotic regret.
2. Preliminary Results
The following Corollaries are necessary to find the asymptotic distribution of the sample inverse coefficient of variation .
Corollary 1.
Letbe a random sample from. Let,andfor. Then for allwe have
- (i)
- (ii)
- (iii)
- (iv)
- (v)
Proof.
By using the fact we get
, , , , and
, where . The asymptotic expansion of , the asymptotic expansion of , , while the asymptotic expansion of . By direct substitution, we get the results. The proof is complete. □
The next corollary provides the asymptotic characteristics of in the case of fixed sample size as shown in Chaturvedi and Rani [24].
Corollary 2.
For all as we have
- (i)
- (ii)
- (iii)
- (iv)
- (v)
- .
Proof.
The proof follows from Lemma 1 and Lemma 2 in Chaturvedi and Rani [24]. □
For simplicity, let us consider , then from the central limit theorem as in distribution. To satisfy the requirement of having a confidence interval for that has a fixed-width and coverage probability with at least , we need
From which we get,
where is the upper cut off point of the .
Since is unknown, then no fixed sample size procedure can achieve the above confidence interval uniformly for all and , see Dantzig [28]. Therefore, we resort to the three-stage procedure to estimate the unknown population inverse coefficient of variation via estimation of .
3. Three-Stage Sequential Estimation
Hall [29,30] introduced the idea of sampling in three-stages for constructing a confidence interval for the mean of the normal distribution that has prescribed width and coverage probability. His findings motivated many researchers to utilize the procedure to generate inference for other distributions; for a complete list of research, see Ghosh, Mukhopadhyay, and Sen [31]. Others have introduced point estimation under some error loss functions or tried to improve the quality of inference like protecting the inference against type II error probability, studying the operating characteristic curve, or/and discussing the sensitivity of the three-stage sampling when the underline distribution departs away from normality. For details, see Costanzo et al. [32], Hamdy et al. [33], Son et al. [34], Yousef et al. [35], Hamdy et al. [36], and Yousef [37,38].
In the following lines, we present Hall’s three-stage procedure, as described by Hall [29,30]. The procedure based on three phases: The pilot phase, the main-study phase, and the fine-tuning phase.
The Pilot Phase: In the pilot study phase a random sample of size () is taken from the normal distribution say, to initiate sample measure, for the population mean and for the population standard deviation . Hence, we propose to estimate the inverse coefficient of variation by the corresponding sample measure .
The Main Study Phase: We estimate only a portion of to avoid possible oversampling. In literature, is known as the design factor.
where, means the largest integer function.
If , then we stop at this stage; otherwise, we continue to sample an extra sample of size , say , then we update the sampling measures and for the unknown population parameters, and respectively.
The Fine-Tuning Phase: In the fine-tuning phase, the decision to stop sampling or continue based on the following stopping rule
If , sampling is terminated, else we continue to sample and an additional sample of size , say Hence, we augment the previously collected samples with the new to update the sample estimates to and for the unknown parameters and . Upon terminating the sampling process, we propose to estimate the unknown inverse coefficient of variation with the fixed confidence interval .
The following asymptotic results are developed under the general assumptions set forward by Hall [28] to develop a theory for the three-stage procedure, condition (A) by definition, , and , .
The following Helmert’s transformation is necessary to obtain asymptotic results regarding and for any real number . We need to express the sample variance as an average of IID random variables. To do so let
where . It follows that is IID . If we set then for From Lemma 2 of Robbins [39], it follows that and are identically distributed. So, in all the proofs we use instead of , to develop asymptotic results regarding and .
Under condition (A),
From Anscombe’s [40] central limit Theorem, we have as ,
- (i)
- in distribution
- (ii)
- in distribution
Now, , except possibly on a set of measure zero. Therefore, for real , we have
Provided that the moment exists and as .
3.1. The Asymptotic Characteristics of the Main-Study Phase
The following theorem gives a second-order approximation regarding the moment of the sample average of the main-study phase.
Theorem 1.
For the three-stage sampling rule in Equation (2), if condition (A) holds then, as,
Proof.
We write
Then, we expand the above expression in infinite series while conditioning on the –field generated by , where are standard normal variates. Notice also that,
Thus
Consider the first three terms in the infinite Binomial series and expand in Taylor series around and taking the expectation all through, the statement of Theorem 1 is immediate. □
Special cases of Theorem 1, when and , provide
It follows from Equations (4) and (5),
Theorem 2 below gives the moment of the three-stage sample variance of the main-study phase.
Theorem 2.
For the three-stage sampling rule in Equation (2), if condition (A) holds then, for real k and as
Proof.
First, write ). Hence, we condition on the field generated by , , ,…, write
Then we expand the binomial term as an infinite series as
where , when and for
Conditioning on , ,…, the random variable ( is distributed according to and therefore Thus,
where , with and .
Consider the first three terms in the infinite expansion of the above expression in addition to a remainder term, and then we have
Recall = , where is a generic constant. Since , we have
Consider the second term , and expand ( in Taylor series
where is a random variable lies between and . It is not hard to show that
We omit details for brevity.
Likewise, we recall the third term and expand ( in Taylor series we get
Finally, collect terms, and the statement of Theorem 2 is complete. □
A particular case for Theorem 2 at and are as follows
and
Asymptotic results of the sample inverse coefficient of variation of the main-study phase Theorems 1, and 2, above provided the following approximate upper bound estimates
Corollary 3.
For the three-stage sampling rule in Equation (2), if condition (A) holds, then as we have
- (i)
- (ii)
- (iii)
Proof.
The proof of (i), and (ii) follows immediately from Equations (4), (5), (7) and (8). Part (iii) follows from (i) and (ii). The proof is complete. □
3.2. The Asymptotic Characteristics of the Fine-Tuning Phase
Recall the representation of and write
and
Theorem 3 gives a second-order approximation of a continuously differentiable and bounded real-valued function of
Theorem 3.
If condition (A) holds and ( 0) be a real-valued continuously differentiable and bounded function, such that , then
Proof.
The proof follows by expanding around using the Taylor series. Then utilizing Equations (9) and (10) in the expansion, we get the result. □
Theorem 4.
For the three-stage sampling rule in Equation (3), if Condition A holds then, as ,
Proof.
First, write
then write down the binomial expression as an infinite series as
where, , when and for
Now, conditioning on the field generated by and we write the conditional sum as a binomial expansion, then take the conditional expectation we get
where are standard normal variates.
|, is distributed
Therefore, | is distributed as . Hence,
as and finally, we have , where are standard normal variates.
Consider the first three terms and the remainder in the infinite series, expand , and and take the expectation through, then the statement of Theorem 4 is proved. It is not hard to prove the remainder term is of order . We omit any further details. □
Special cases of Theorem 4, for are particularly important
Theorem 5 gives a second-order approximation for the moment of the fine-tuning sample variance.
Theorem 5.
For the three-stage sampling rule in Equation (3), if condition (A) holds then, for real k as
Proof.
The proof of Theorem 5 can be justified along the lines of the proof of Theorem 4 if we condition on the field generated by and expand as an infinite series, to get,
where, , when and for
The random sum is distributed as a and
Thus, + , where are as defined before.
Consider the first three terms in the infinite series and the remainder, then write down , In the Taylor series, then take the expectation all through while applying Wald’s first and second equations [41], and then the statement of Theorem 5 is justified. □
Special cases of Theorem 5, at are particularly among our interest to obtain the moments of .
Corollary 4.
For the three-stage sampling rule in Equation (3), If condition (A) holds, then as we have
- (i)
- (ii)
- (iii)
- (iv)
- .
Proof.
Part (i) and Part (ii) follow from Equations (11), (12), (14) and (15). Part (iii) follows from (i) and (ii) while part (iv) follows from Equations (13) and (16). The proof is complete. □
3.3. The Asymptotic Coverage Probability of the Inverse Coefficient of Variation
Recall the three-stage sampling confidence interval of the inverse coefficient variation, the coverage probability is given by
From Anscombe [39], we have as (0, 1) which is independent of the random variable , thus
Utilizing Theorem 3, we get
where, and are the cumulative and the density functions of the standard normal distribution, respectively.
The asymptotic coverage probability in Equation (17) depends on the choice of and . If we choose the design factor then ; otherwise, it exceeds the desired .
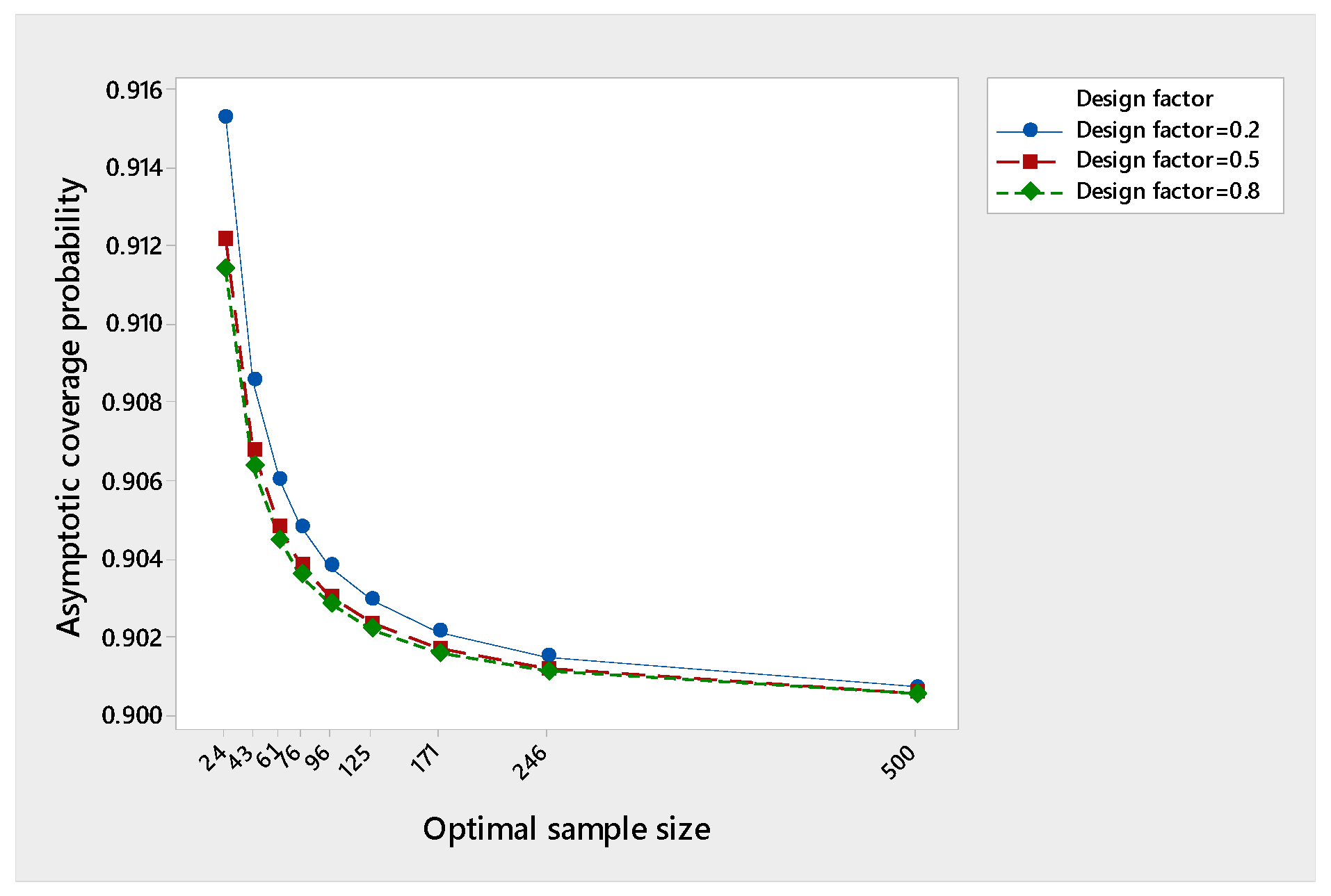
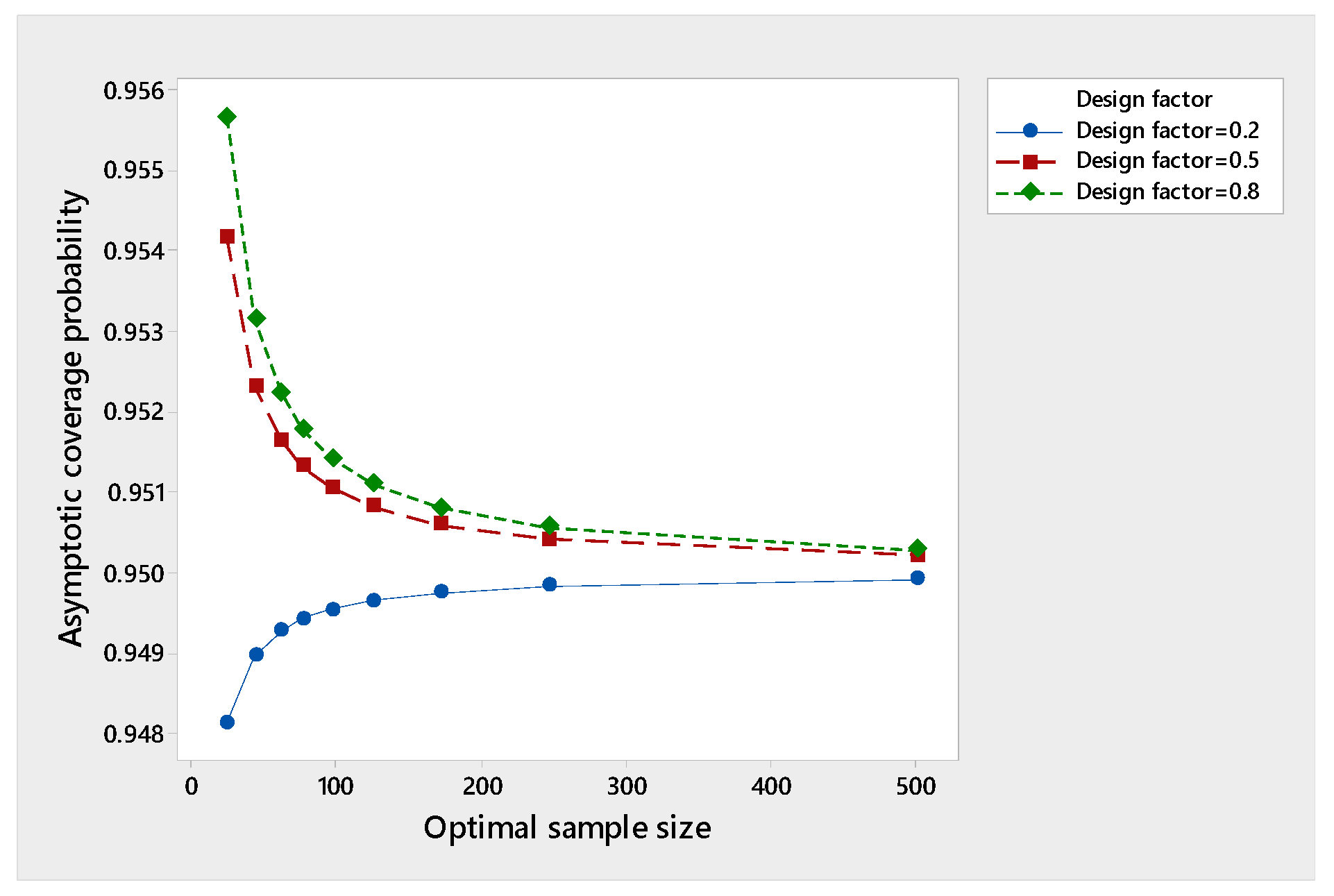
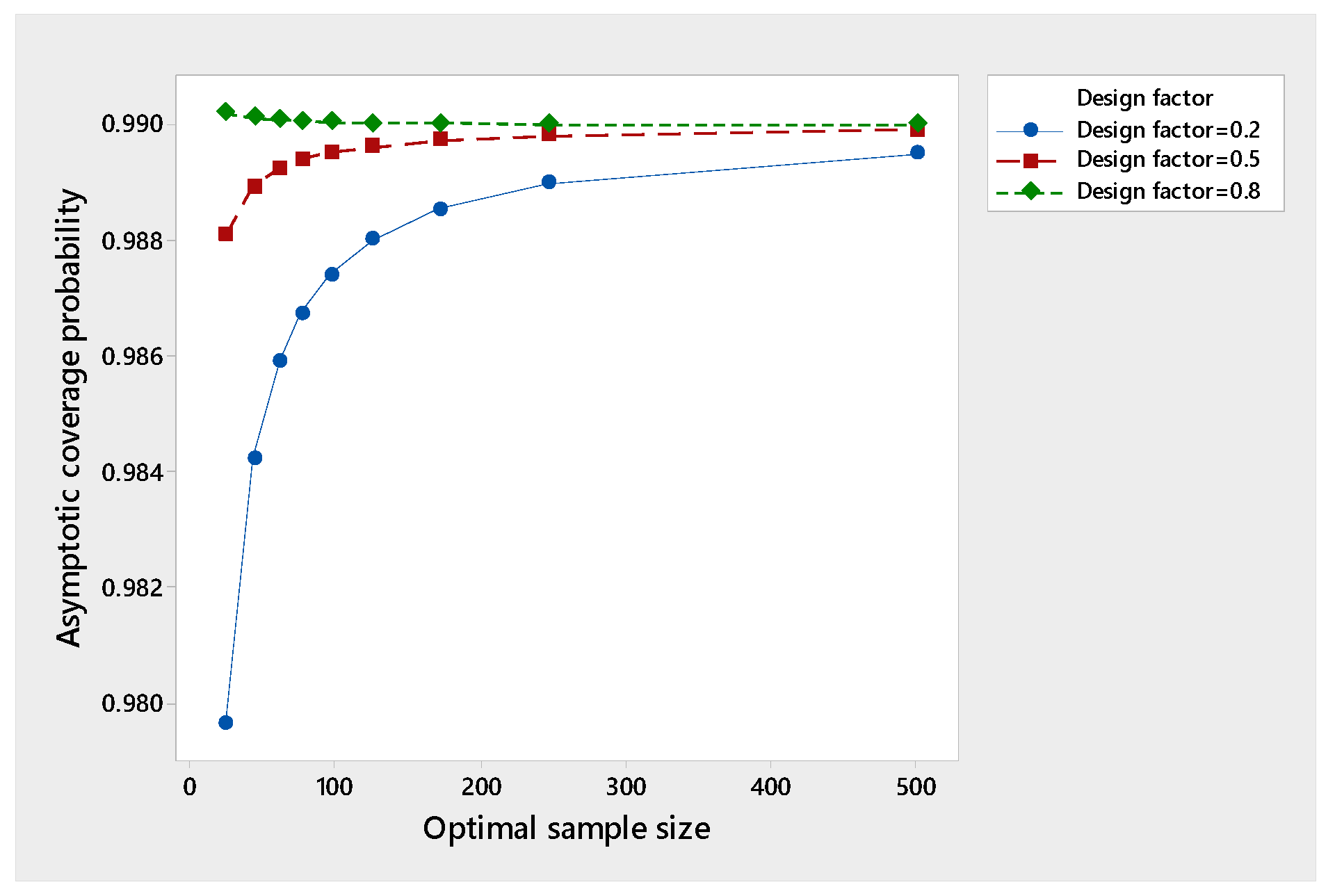
To study the effect of changing on the performance of the asymptotic coverage probability in Equation (17) as the optimal sample size increases, we take and as preferred by Hall [29] and take and . Table 1 below shows the results for and confidence coefficients. We noticed that at 90%, the asymptotic coverage probability exceeds for all chosen , while at 95%, the asymptotic coverage probability exceeds 0.95 only at and . At 99%, the asymptotic coverage probability exceeds 0.99 only at .
This means that the three-stage procedure attains consistency or asymptotic consistency in the sense of Chow and Robbins [25], depending on the choice of the design factor and the confidence coefficient. It looks like the three-stage procedure loses consistency as increases. Figure 1, Figure 2, and Figure 3 show the results of the tables as graphs for clarification.
The quantity known as the cost of ignorance (the cost of not knowing the variance ), see Simons [42] for details.
4. The Sensitivity of Three-Stage Sampling to Shift in the Population Inverse Coefficient of Variation
The word sensitivity of sequential procedures means either sensitivity to departure from the underline distribution or sensitivity to shifting in the true parameter value. Bhattacharjee [43], Blumenthal and Govindarajulu [44], Ramkaran [45], Sook and DasGupta [46] were the first who examined the robustness of Stein’s two-stage sampling procedure [47] to departure from normality. Costanza et al. [32] and Son et al. [34], were the first to address the issue of the sensitivity of the three-stage confidence interval against the type II error probability while estimating the mean of the normal distribution. Hamdy [33] studied the same problem for the exponential distribution. However, Hamdy et al. [36] provided a more comprehensive analysis of the departure of both the underline distribution and the shift in the true parameter.
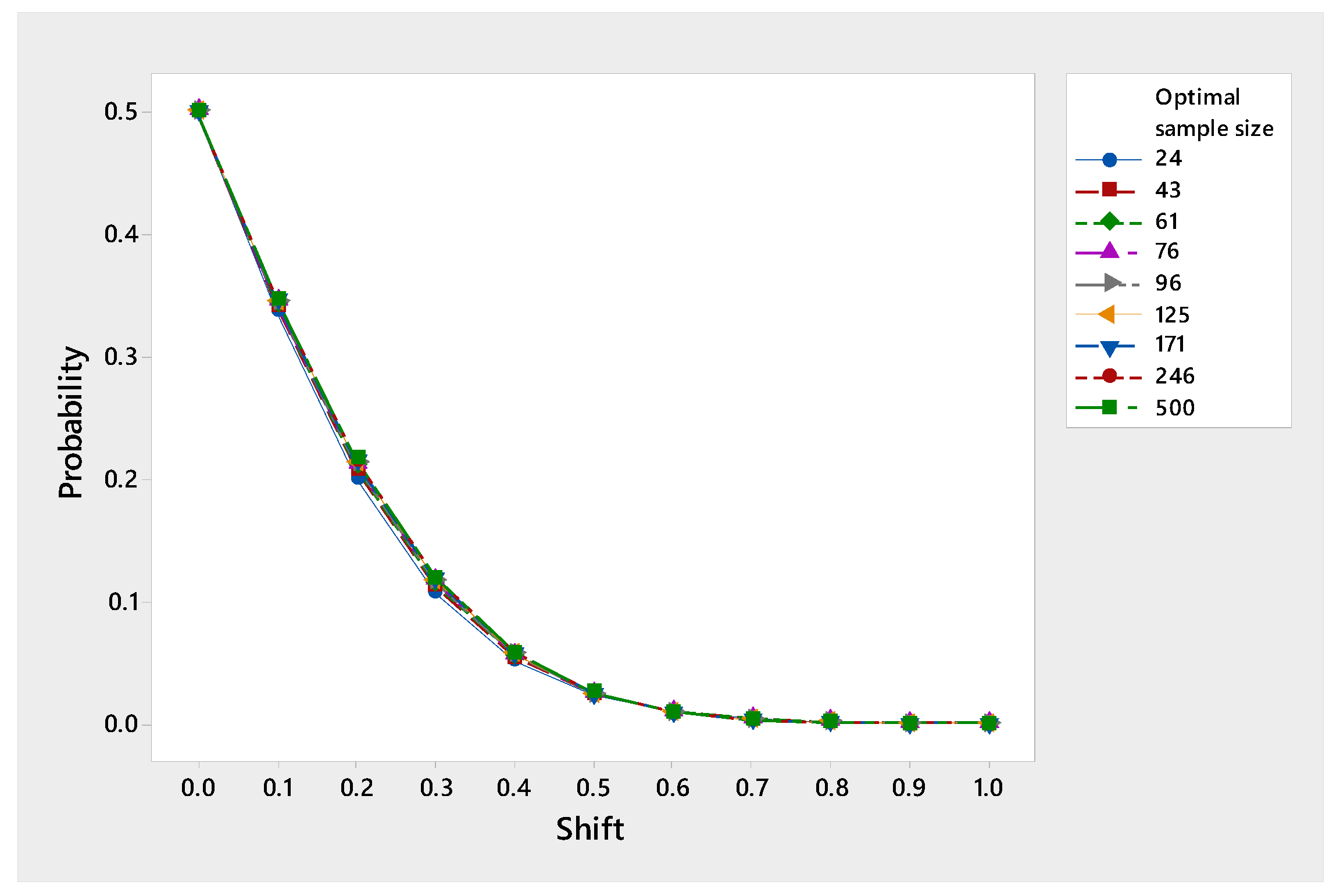
Suppose we need to investigate the capability of the constructed fixed-width confidence interval to signify potential shifts in the true population inverse coefficient of variation of distance occurring outside the interval when it is incorrectly thought that such shifts never took place. In some applications, like in quality control, it is a matter of concern to closely monitor the sensitivity of the interval to depict any departure from the centerline in order to ensure the creditability of the interval. In this regard, we derive both the null and alternative hypotheses as follows:
where , claims that no departure of the true parameter has taken place, against the alternative hypotheses which alleges that the parameter value differs from by a distance measured in units of the precision .
The probability of not detecting a shift in the true parameter can statistically measure by the corresponding type II error probability (-risk), which is, in fact, the conditional probability of not depicting a departure from , when, in fact, the departure actually occurred. In quality assurance (-risk), is known as the operating characteristic function
Since the process has an equal probability of committing a type II error probability above the centerline or below the centerline, we, therefore, consider only the probability of committing a positive shift from the true parameter value .
Let be the probability of committing a type II error probability, which is the probability of no shift occurring given that an actual shift occurred. Our objective is to control the probability of committing a type II error probability. We do so by finding the characteristic operating curve that gives the probability of acceptance of various possible values of . The minimum sample size required to control both is
where is the upper point of . For more details, see Nelson [48,49], Hamdy [33], and Son et al. [34].
The second-order approximation of the characteristic operating function under Equations (18) and (19) as
Utilizing Theorem 3, we obtain
Similarly for .
Hence,
where
and
and
5. The Asymptotic Regret Encountered in Point Estimation of the Inverse Coefficient of Variation
In this section, we aim to find the asymptotic regret that occurs when we use the sample inverse coefficient of variation rather than the population inverse coefficient of variation. We use squared-error loss function with linear sampling cost. A typical situation is in constructing a quality control chart to the inverse coefficient of variation where both estimation of control limits (the upper and the lower control limits) and the centerline are required.
What if we want to utilize the available data to provide a point estimate of (the centerline) under the squared-error loss function with linear sampling cost. Therefore, we assume that the cost incurred in estimating is given by
where is the cost per unit sample. Regarding , the literature in sequential point estimation customarily assumes that is a known constant, which reflects the cost of estimation and can be permitted to approach . However, here, we try to give a better understanding of the nature of in this context. First, the risk associated with the above loss function is given by
Minimizing the risk associated with the loss function provides the optimal sample size . If we have to use the optimal sample size used to construct a fixed confidence interval for , where the coverage probability is at least the nominal value, to propose for under the squared error loss function, the constant should be chosen such that
Clearly as where
In this case, the optimal risk is given by . The asymptotic regret, which is defined as the difference between the risk of using the three-stage procedure minus the optimal risk see, Robbins [38] would be
where
The risk of the three-stage sampling can be approximated by the upper bound
Hence, the asymptotic regret is
Which provides negative regret. This means that the three-stage procedure does better than the optimal fixed sample size had been known. Martinsek [50] discussed the issue of negative regret in sequential point estimation.
6. Conclusions
This paper theoretically tackles three estimation problems for the population inverse coefficient of variation of the normal distribution under Hall’s three-stage procedure. We obtain asymptotic mathematical forms for the population inverse coefficient of variation, the asymptotic coverage probability, the characteristics operating function, and the asymptotic regret. We find the range of the design factor that makes the three-stage procedure achieve consistency or asymptotic consistency as the width of the interval approaches zero. The asymptotic regret has negative values for all possible values of the design factor.
Author Contributions
Conceptualization, A.Y.; Methodology, A.Y. and H.H.; software, A.Y.; Validation, A.Y. and H.H.; formal analysis, A.Y.; investigation, A.Y. and H.H.; resources, A.Y.; data curation, A.Y. and H.H.; writing original draft, A.Y.; Preparation, A.Y.; Writing review and editing, A.Y.; Visualization, A.Y. and H.H.; Supervision, A.Y.; Project administrator, A.Y.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conlict of interest.
References
- Nairy, K.S.; Rao, K.A. Tests of Coefficients of Variation of Normal Population. Commun. Stat. Simul. Comput. 2003, 3, 641–661. [Google Scholar] [CrossRef]
- Ahn, K. On the use of coefficient of variation for uncertainty analysis in fault tree analysis. Reliab. Eng. Syst. Saf. 1995, 47, 229–230. [Google Scholar] [CrossRef]
- Gong, J.; Li, Y. Relationship between the Estimated Weibull Modulus and the Coefficient of Variation of the Measured Strength for Ceramics. J. Am. Ceram. Soc. 1999, 82, 449–452. [Google Scholar] [CrossRef]
- Faber, D.S.; Korn, H. Applicability of the coefficient of variation method for analyzing synaptic plasticity. Biophys. J. 1991, 60, 1288–1294. [Google Scholar] [CrossRef] [Green Version]
- Hammer, A.J.; Strachan, J.J.; Black, M.M.; Ibbotson, C.; Elson, R.A. A new method of comparative bone strength measurement. J. Med. Eng. Technol. 1995, 19, 1–5. [Google Scholar] [CrossRef] [PubMed]
- Billings, J.; Zeitel, L.; Lukomnik, J.; Carey, T.S.; Blank, A.E.; Newman, L. Impact of socioeconomic status on hospital use in New York City. Health Aff. 1993, 12, 162–173. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brief, R.P.; Owen, J. A Note on earnings risk and the coefficient of variation. J. Financ. 1969, 24, 901–904. [Google Scholar] [CrossRef]
- Pyne, D.B.; Trewin, C.B.; Hopkins, W.G. Progression and variability of competitive performance of Olympic swimmers. J. Sports Sci. 2004, 22, 613–620. [Google Scholar] [CrossRef]
- Kelly, K. Sample size planning for the coefficient of variation from the accuracy in parameter estimation approach. Behav. Res. Methods 2007, 39, 755–766. [Google Scholar] [CrossRef] [Green Version]
- Gulhar, M.; Kibria, B.M.; Albatineh, A.N.; Ahmed, N.U. A Comparison of some confidence intervals for estimating the population coefficient of variation: A simulation study. SORT Stat. Oper. Res. Trans. 2012, 36, 45–68. [Google Scholar]
- McGibney, G.; Smith, M.R. An unbiased signal to noise ratio measure for magnetic resonance images. Med. Phys. 1993, 20, 1077–1079. [Google Scholar] [CrossRef] [PubMed]
- Knight, J.L.; Satchell, S. A Re-Examination of Sharpe’s Ratio for Log-Normal Prices. Appl. Math. Financ. 2005, 12, 87–100. [Google Scholar] [CrossRef]
- Hendricks, W.A.; Robey, K.W. The Sampling Distribution of the Coefficient of Variation. Ann. Math. Stat. 1936, 7, 129–139. [Google Scholar] [CrossRef]
- Koopmans, L.H.; Owen, D.B.; Rosenblatt, J.I. Confidence intervals for the coefficient of variation for the normal and log-normal distribution. Biometrika 1964, 51, 25–32. [Google Scholar] [CrossRef]
- Rao, K.A.; Bhatta, A.R. A note on test for coefficient of variation. Calcutta Stat. Assoc. Bull. 1989, 38, 225–229. [Google Scholar] [CrossRef]
- McKay, A.T. Distribution of the coefficient of variation and the extended t distribution. J. R. Stat. Soc. 1932, 95, 695–698. [Google Scholar] [CrossRef]
- Umphrey, G.J. A comment on McKay’s approximation for the coefficient of variation. Commun. Stat. Simul. Comput. 1983, 12, 629–635. [Google Scholar] [CrossRef]
- Vangel, M.G. Confidence intervals for a normal coefficient of variation. Am. Stat. 1996, 50, 21–26. [Google Scholar]
- Miller, E.G. Asymptotic test statistics for coefficient of variation. Commun. Stat. Theory Methods 1991, 20, 3351–3363. [Google Scholar] [CrossRef]
- Lehmann, E.L. Theory of Point Estimation, 2nd ed.; Wiley: New York, NY, USA, 1983. [Google Scholar]
- Curto, J.D.; Pinto, J.C. The coefficient of variation asymptotic distribution in the case of non-iid random variables. J. Appl. Stat. 2009, 36, 21–32. [Google Scholar] [CrossRef]
- Sharma, K.K.; Krishna, H. Asymptotic sampling distribution of inverse coefficient-of variation and its applications. IEEE Trans. Reliab. 1994, 43, 630–633. [Google Scholar] [CrossRef]
- Albatineh, A.; Kibria, B.M.; Zogheib, B. Asymptotic sampling distribution of inverse coefficient of variation and its applications: Revisited. Int. J. Adv. Stat. Probab. 2014, 2, 15–20. [Google Scholar] [CrossRef]
- Chaturvedi, A.; Rani, U. Fixed-width confidence interval estimation of the inverse coefficient of variation in a normal population. Microelectron. Reliab. 1996, 36, 1305–1308. [Google Scholar] [CrossRef]
- Chow, Y.S.; Robbins, H. On the asymptotic theory of fixed width confidence intervals for the mean. Ann. Math. Stat. 1965, 36, 457–462. [Google Scholar] [CrossRef]
- Chattopadhyay, B.; Kelley, K. Estimation of the Coefficient of Variation with Minimum Risk: A Sequential Method for Minimizing Sampling Error and Study Cost. Multivar. Behav. Res. 2016, 51, 627–648. [Google Scholar] [CrossRef] [PubMed]
- Yousef, A.; Hamdy, H. Three-stage estimation for the mean and variance of the normal distribution with application to inverse coefficient of variation. Mathematics 2019, 7, 831. [Google Scholar] [CrossRef] [Green Version]
- Dantzig, G.B. On the Non-Existence of Tests of Student’s Hypothesis Having Power Function Independent of σ. Ann. Math. Stat. 1940, 11, 186–192. [Google Scholar] [CrossRef]
- Hall, P. Asymptotic Theory and Triple Sampling of Sequential Estimation of a Mean. Ann. Stat. 1981, 9, 1229–1238. [Google Scholar] [CrossRef]
- Hall, P. Sequential Estimation Saving Sampling Operations. J. R. Stat. Soc. 1983, 45, 1229–1238. [Google Scholar] [CrossRef]
- Ghosh, M.; Mukhopadhyay, N.; Sen, P. Sequential Estimation; Wiley: New York, NY, USA, 1997. [Google Scholar]
- Costanza, M.C.; Hamdy, H.I.; Haugh, L.D.; Son, M.S. Type II Error Performance of Triple Sampling Fixed Precision Confidence Intervals for the Normal Mean. Metron 1995, 53, 69–82. [Google Scholar]
- Hamdy, H.I. Performance of Fixed Width Confidence Intervals under Type II Errors: The Exponential Case. South African. J. Stat. 1997, 31, 259–269. [Google Scholar]
- Son, M.S.; Haugh, L.D.; Hamdy, H.I.; Costanza, M.C. Controlling Type II Error while Constructing Triple Sampling Fixed Precision Confidence Intervals for the Normal Mean. Ann. Inst. Stat. Math. 1997, 49, 681–692. [Google Scholar] [CrossRef]
- Yousef, A.; Kimber, A.; Hamdy, H.I. Sensitivity of Normal-Based Triple Sampling Sequential Point Estimation to the Normality Assumption. J. Stat. Plan. Inference 2013, 143, 1606–1618. [Google Scholar] [CrossRef] [Green Version]
- Hamdy, H.I.; Son, S.M.; Yousef, S.A. Sensitivity Analysis of Multi-Stage Sampling to Departure of an underlying Distribution from Normality with Computer Simulations. J. Seq. Anal. 2015, 34, 532–558. [Google Scholar] [CrossRef]
- Yousef, A. Construction a Three-Stage Asymptotic Coverage Probability for the Mean Using Edgeworth Second-Order Approximation. In International Conference on Mathematical Sciences and Statistics; Springer: Singapore, 2014; pp. 53–67. [Google Scholar] [CrossRef]
- Yousef, A. A Note on a Three-Stage Sequential Confidence Interval for the Mean When the Underlying Distribution Departs away from Normality. Int. J. Appl. Math. Stat. 2018, 57, 57–69. [Google Scholar]
- Robbins, H. Sequential Estimation of the Mean of a Normal Population. In Probability, and Statistics; Almquist and Wicksell: Uppsala, Sweden, 1959; pp. 235–245. [Google Scholar]
- Anscombe, F.J. Large-sample theory of sequential estimation. In Mathematical Proceedings of the Cambridge Philosophical Society; Cambridge University Press: Cambridge, UK, 1952; Volume 48, pp. 600–607. [Google Scholar]
- Wald, A. Sequential Analysis; Wiley: New York, NY, USA, 1947. [Google Scholar]
- Simons, G. On the cost of not knowing the variance when making a fixed-width interval estimation of the mean. Ann. Math. Stat. 1968, 39, 1946–1952. [Google Scholar] [CrossRef]
- Bhattacharjee, G.P. Effect of non-normality on Stein’s two-sample test. Ann. Math. Stat. 1965, 36, 651–663. [Google Scholar] [CrossRef]
- Blumenthal, S.; Govindarajulu, Z. Robustness of Stein’s two-stage procedure for mixtures of normal populations. J. Am. Stat. Assoc. 1977, 72, 192–196. [Google Scholar] [CrossRef]
- Ramkaran. The robustness of Stein’s two-stage procedure. J. Seq. Anal. 1983, 5, 139–168. [Google Scholar] [CrossRef]
- Oh, H.S.; Dasgupta, A. Robustness of Stein’s two-stage procedure. Seq. Anal. 1995, 14, 321–334. [Google Scholar]
- Stein, C.A. Two-sample test for a linear hypothesis whose power is independent of the variance. Ann. Math. Stat. 1945, 16, 243–258. [Google Scholar] [CrossRef]
- Nelson, L.S. Comments on significant tests and confidence intervals. J. Qual. Technol. 1990, 22, 328–330. [Google Scholar] [CrossRef]
- Nelson, L.S. Sample sizes for confidence intervals with specified length and tolerances. J. Qual. Technol. 1994, 26, 54–63. [Google Scholar] [CrossRef]
- Martinsek, A.T. Negative regret, optimal stopping, and the elimination of outliers. J. Am. Stat. Assoc. 1988, 10, 65–80. [Google Scholar]
Figure 1.
Performance of the asymptotic coverage probability at 90%.

Figure 2.
Performance of the asymptotic coverage probability at 95%.

Figure 3.
Performance of the asymptotic coverage probability at 99%.

Figure 4.
Performance of the characteristic operating curve as the shift increases.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Asymptotic coverage probabilities for different values of as the optimal sample size increases.
Table 1.
Asymptotic coverage probabilities for different values of as the optimal sample size increases.
| n* | |||||||||
| 24 | 0.91528 | 0.91216 | 0.91138 | 0.94812 | 0.95415 | 0.95565 | 0.97964 | 0.98810 | 0.99021 |
| 43 | 0.90853 | 0.90679 | 0.90635 | 0.94895 | 0.95231 | 0.95315 | 0.98422 | 0.98894 | 0.99012 |
| 61 | 0.90601 | 0.90478 | 0.90448 | 0.94926 | 0.95163 | 0.95222 | 0.98592 | 0.98925 | 0.99008 |
| 76 | 0.90482 | 0.90384 | 0.90359 | 0.94941 | 0.95131 | 0.95178 | 0.98673 | 0.98940 | 0.99007 |
| 96 | 0.90382 | 0.90304 | 0.90285 | 0.94953 | 0.95104 | 0.95141 | 0.98741 | 0.98952 | 0.99005 |
| 125 | 0.90293 | 0.90233 | 0.90218 | 0.94964 | 0.95080 | 0.95109 | 0.98801 | 0.98962 | 0.99004 |
| 171 | 0.90214 | 0.90171 | 0.90160 | 0.94974 | 0.95058 | 0.95079 | 0.98855 | 0.98973 | 0.99003 |
| 246 | 0.90149 | 0.90119 | 0.90111 | 0.94982 | 0.95040 | 0.95055 | 0.98899 | 0.98981 | 0.99002 |
| 500 | 0.90073 | 0.90058 | 0.90055 | 0.94991 | 0.95020 | 0.95027 | 0.98950 | 0.98991 | 0.99001 |
Table 2.
The sensitivity of the three-stage procedure as the shift and the optimal sample size increases
Table 2.
The sensitivity of the three-stage procedure as the shift and the optimal sample size increases
| Shift | 24 | 43 | 61 | 76 | 96 | 125 | 171 | 246 | 500 |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 |
| 0.1 | 0.3366 | 0.3414 | 0.3432 | 0.3441 | 0.3448 | 0.3454 | 0.3460 | 0.3465 | 0.3470 |
| 0.2 | 0.2008 | 0.2077 | 0.2103 | 0.2115 | 0.2126 | 0.2135 | 0.2143 | 0.2150 | 0.2158 |
| 0.3 | 0.1065 | 0.1124 | 0.1146 | 0.1156 | 0.1165 | 0.1172 | 0.1179 | 0.1185 | 0.1192 |
| 0.4 | 0.0512 | 0.0544 | 0.0556 | 0.0561 | 0.0566 | 0.0570 | 0.0574 | 0.0577 | 0.0581 |
| 0.5 | 0.0229 | 0.0238 | 0.0242 | 0.0243 | 0.0245 | 0.0246 | 0.0247 | 0.0248 | 0.0249 |
| 0.6 | 0.0098 | 0.0096 | 0.0095 | 0.0095 | 0.0095 | 0.0094 | 0.0094 | 0.0094 | 0.0094 |
| 0.7 | 0.0040 | 0.0036 | 0.0034 | 0.0034 | 0.0033 | 0.0032 | 0.0032 | 0.0031 | 0.0031 |
| 0.8 | 0.0015 | 0.0012 | 0.0011 | 0.0011 | 0.0010 | 0.0010 | 0.0010 | 0.0009 | 0.0009 |
| 0.9 | 0.0005 | 0.0004 | 0.0003 | 0.0003 | 0.0003 | 0.0003 | 0.0003 | 0.0002 | 0.0002 |
| 1.0 | 0.0002 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Yousef, A.; Hamdy, H. Three-Stage Sequential Estimation of the Inverse Coefficient of Variation of the Normal Distribution. Computation 2019, 7, 69. https://0-doi-org.brum.beds.ac.uk/10.3390/computation7040069
AMA Style
Yousef A, Hamdy H. Three-Stage Sequential Estimation of the Inverse Coefficient of Variation of the Normal Distribution. Computation. 2019; 7(4):69. https://0-doi-org.brum.beds.ac.uk/10.3390/computation7040069
Chicago/Turabian StyleYousef, Ali, and Hosny Hamdy. 2019. "Three-Stage Sequential Estimation of the Inverse Coefficient of Variation of the Normal Distribution" Computation 7, no. 4: 69. https://0-doi-org.brum.beds.ac.uk/10.3390/computation7040069
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.