
Dense Matrix Multiplication Algorithms and Performance Evaluation of HPCC in 81 Nodes IBM Power 8 Architecture

 ,
,  ,
,  and
and
Abstract
:1. Introduction
- Estimate the average runtime for a single job.
- Reduce the waiting time to start a job.
- To set a proper size for the jobs.
- Improve the customization process on a given application for accessing large centers such as Edinburgh Parallel Computing Center (EPCC) [14].
- We demonstrate HPL performance on our HPC “Quinde I”, which is equipped with high technology with the following features: a cluster with IBM Power 8 processors, 1760 cores, RAM 11 TB, parallel memory 350 TB, NVIDIA K80 Tesla GPU and InfiniBand technology. Based on the official linpack results, “Quinde I” achieves 231.9 teraflops, we discuss two different linpacks to measure the performance of CPUs and GPUs independently.
- We show how appropriate microarchitectural benchmarking can be used to reveal the cache performance characteristics of modern Tesla K80 by NVIDIA processors between CPU and GPU’s, specifically parameterizing the performance of possible multiple layers of cache present on and off the processor, we detailed the Cache-Bench which contains eight different sub-benchmarks, related to raw bandwidth in floating point workloads and compared the performance characteristics of CPU and GPU’s.
- We show how the optimization problem can be parallelized on both traditional CPU based systems and GPU and compare their performance
- We show the CUDA implementation of the assembly step in NVIDIA 80, which is straightforward.
- For DGEMM, we show the effect of varying core and detail problem size in terms of node performance after testing and speed up of each node of “Quinde I”.
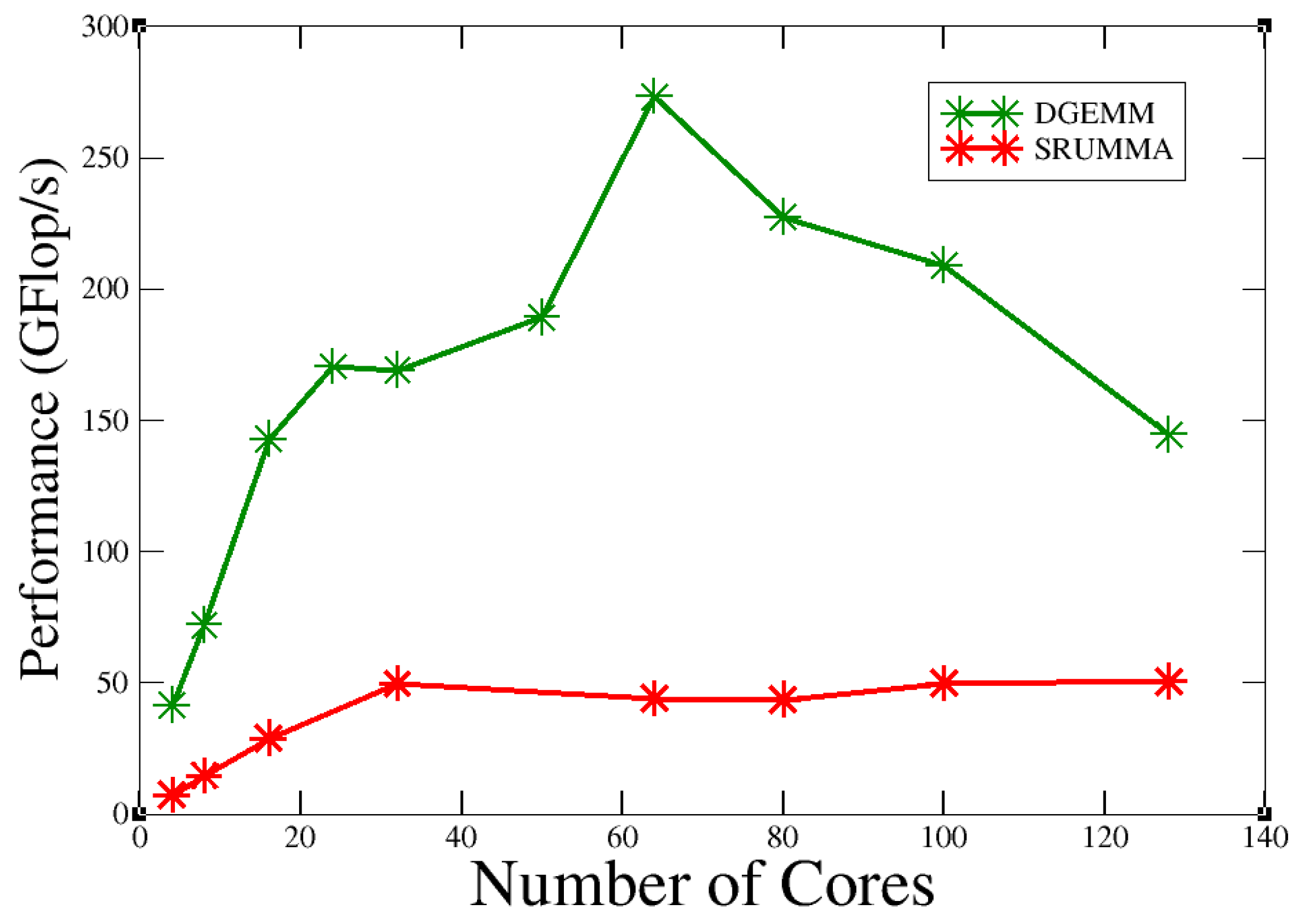
- For Shared and Remote-memory based Universal Matrix Multiplication Algorithm (SRUMMA) [15], a parallel algorithm implementing dense matrix multiplication with algorithmic efficiency, experimental results on clusters (16-way IBM SP and 2-way Linux/Xeon nodes) and shared-memory systems confirm SGI Altix, Cray X1 with its partitioned shared memory hardware SUMMA [16] that with reference to previous studies, SRUMMA demonstrates consistent performance advantages over the pdgemm routine from the ScaLAPACK/PBBLAS suite [17,18], the leading implementation of the parallel matrix multiplication algorithms used today. Considering such factors and the impact of SRUMMA on various such clusters, we evaluated the performance of SRUMMA on the IBM power 8 architecture.
2. Materials and Methods
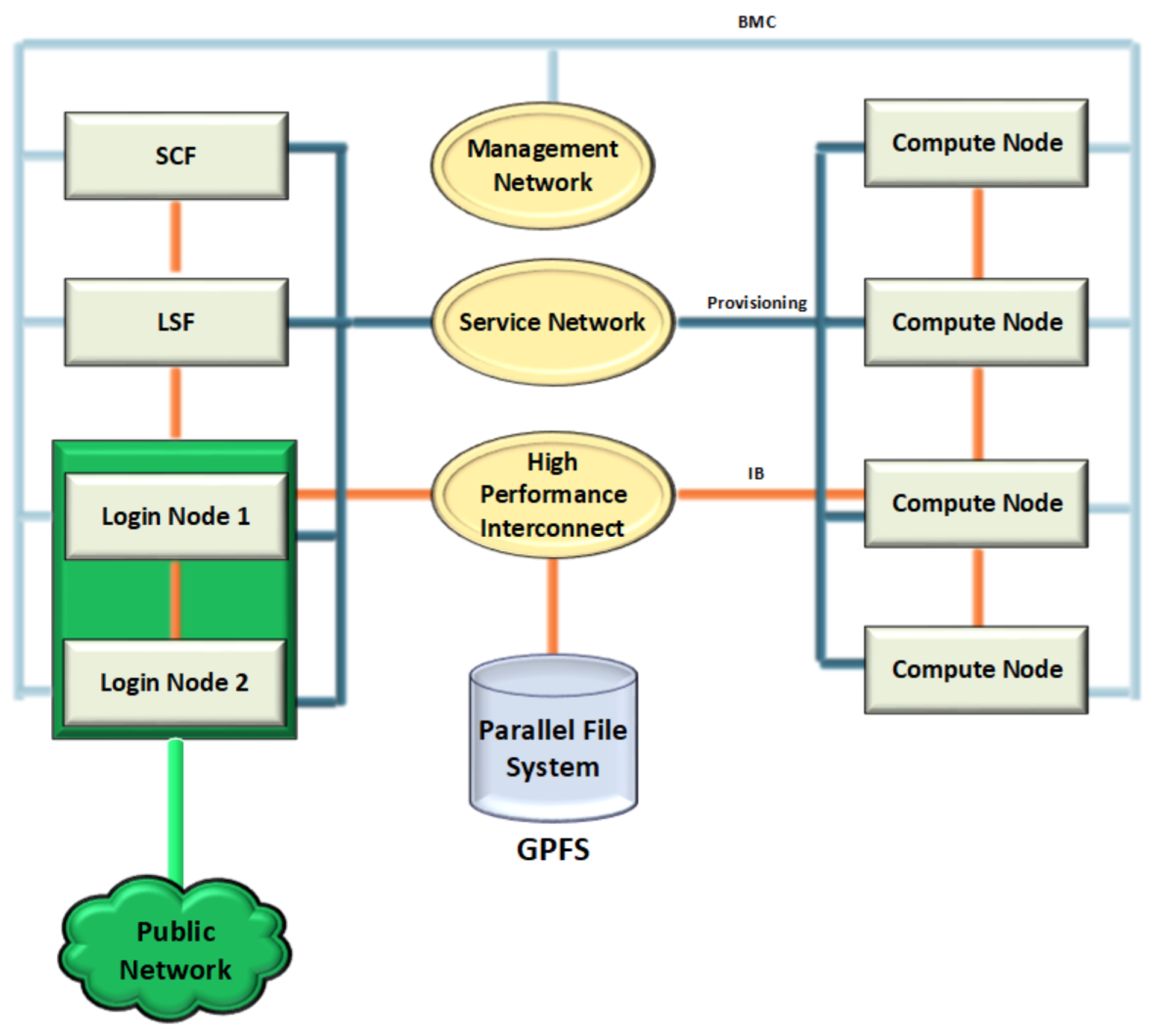
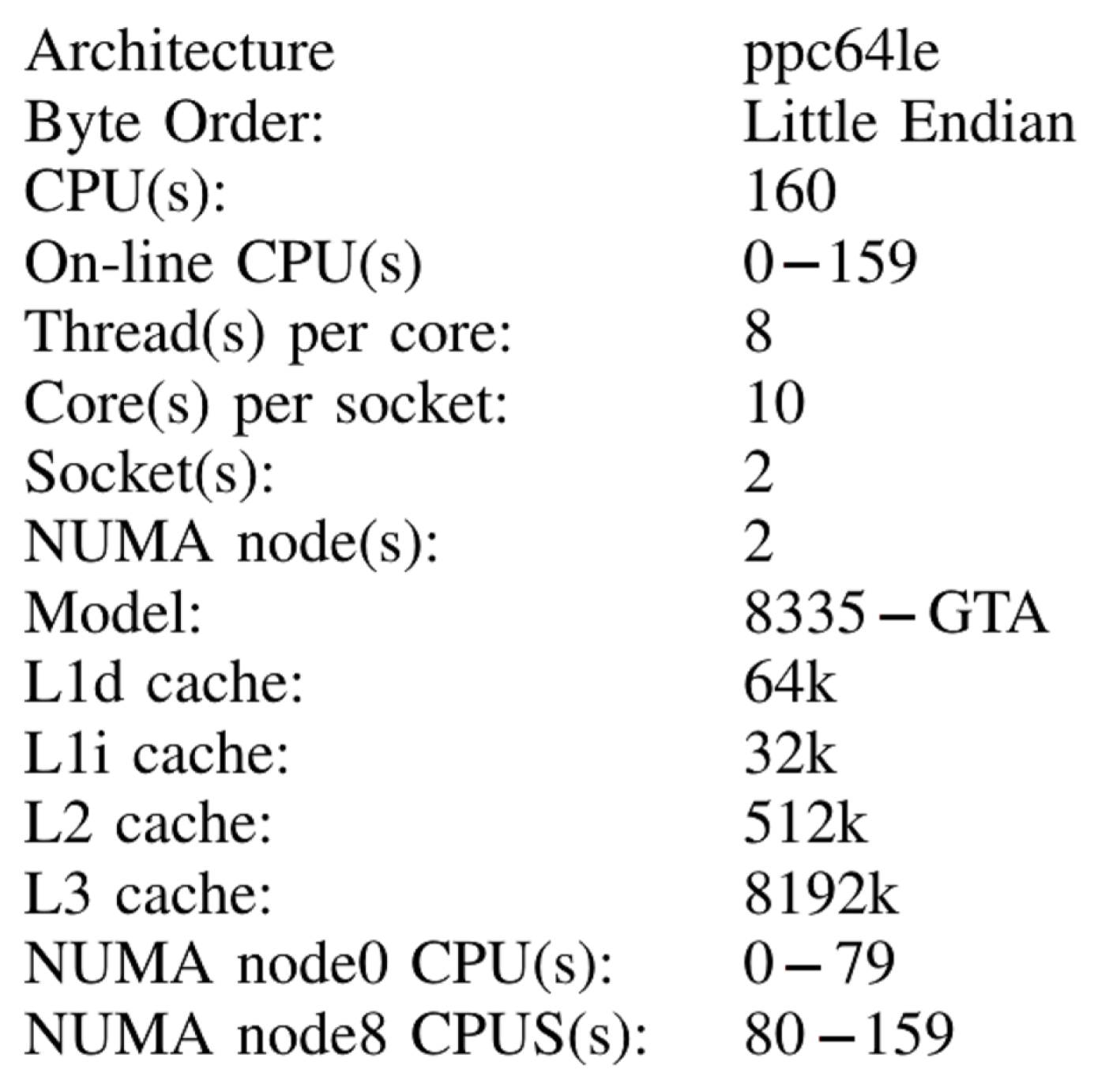
2.1. Experimental Platform
2.2. High Performance Linpack (HPL)
2.3. Stream Benchmark
2.4. DGEMM Benchmark
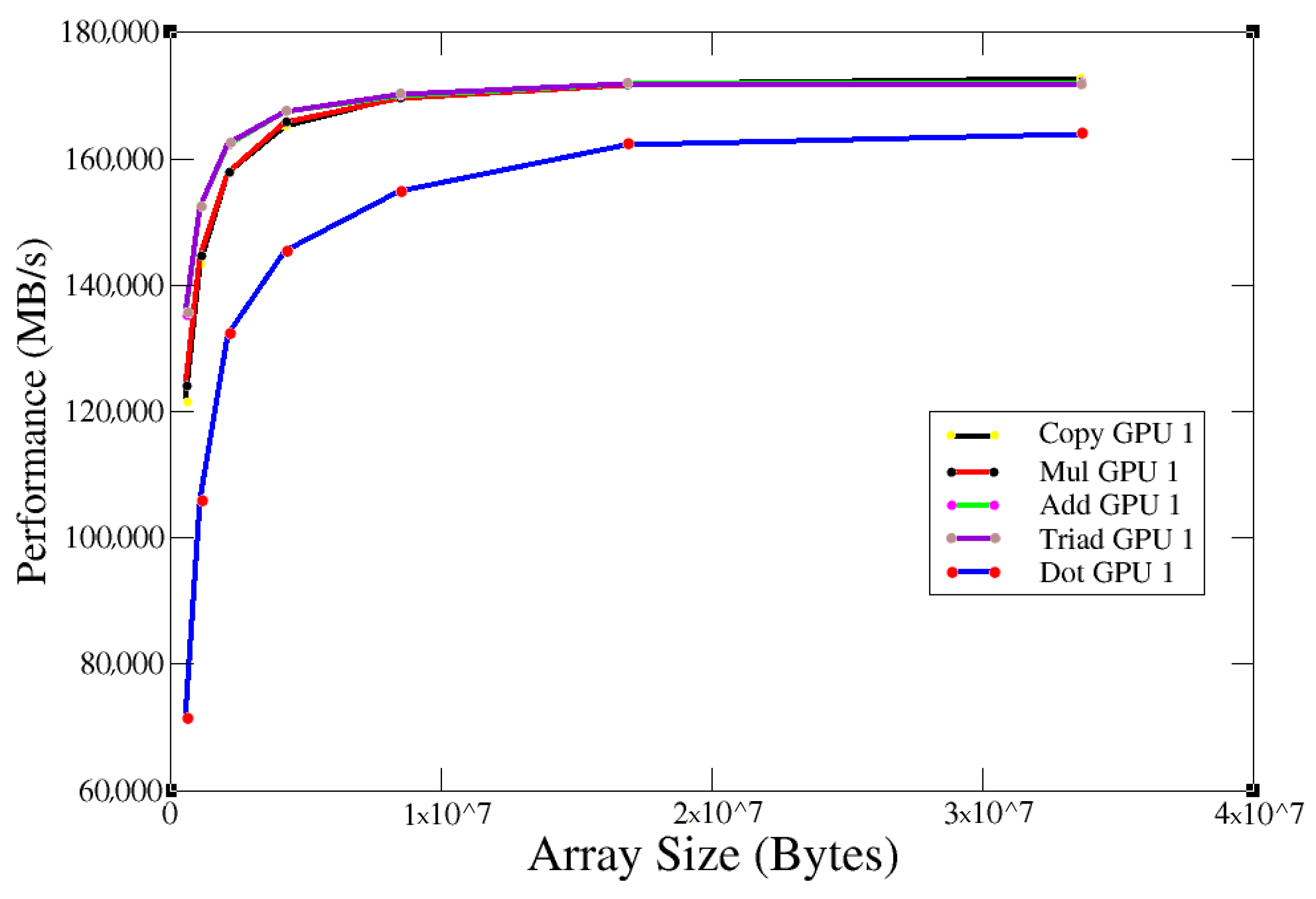
2.5. Babel Stream
- OpenCL
- CUDA
- OpenACC
- OpenMP 3 and 4.5
- Kokkos
- RAJA
- SYCL
2.6. Cache Bench
- Cache Read: This benchmark is designed to give us the read bandwidth for different vector lengths in a compiler optimized loop.
- Cache Write: This benchmark is designed to give us the write bandwidth for different vector lengths in a compiler optimized loop.
- Cache Read/Modify/Write: This benchmark is designed to provide us with read/modify/write bandwidth for varying vector lengths in a compiler optimized loop. This benchmark generates twice as much memory traffic, as each data item must be first read from memory/cache to register and then back to cache.
- Hand tuned Cache Read: This benchmark is a modification of Cache Read. The modifications reflect what a minimally good compiler should do for these simple loops.
- Hand tuned Cache Write: This benchmark is a modification of Cache Write. The modifications reflect what a minimally good compiler should do on these simple loops.
- Hand tuned Cache Read/Modify/Write: This benchmark is a modification of Cache Read/Modify/Write. The modifications reflect what a minimally good compiler should do with these simple loops.
- memset() from the C library: The C library has the memset() function to initialize memory areas. With this benchmark, we can compare the performance of the two formulations for writing the memory.
- memcpy() from the C library: The C library has the memcpy() function for copying memory areas. With this benchmark, we can compare the performance of the two versions of memory read/modify/write with this version.
2.7. Effective Bandwidth
| Algorithm 1 The algorithm of |
| = logavg ( logavgcartesian pattern (sumL (maxmthd (maxrep ( b(cartes.pat.,L,mthd,rep) )))/21 ), logavg-random pattern(sumL (maxmthd (maxrep ( b(random pat.,L,mthd,rep) )))/21 )) |
- Effective Bandwith Benchmark () Version 3.5
- High-Performance Computing
- Mon March 9 22:42:00 2020 on Linux it01-r10-cn-36.yachay.ep 3.10.0-327.el7.ppc64le Number 1 SMP Thu Oct 29 17:31:13 EDT 2015 ppc64le
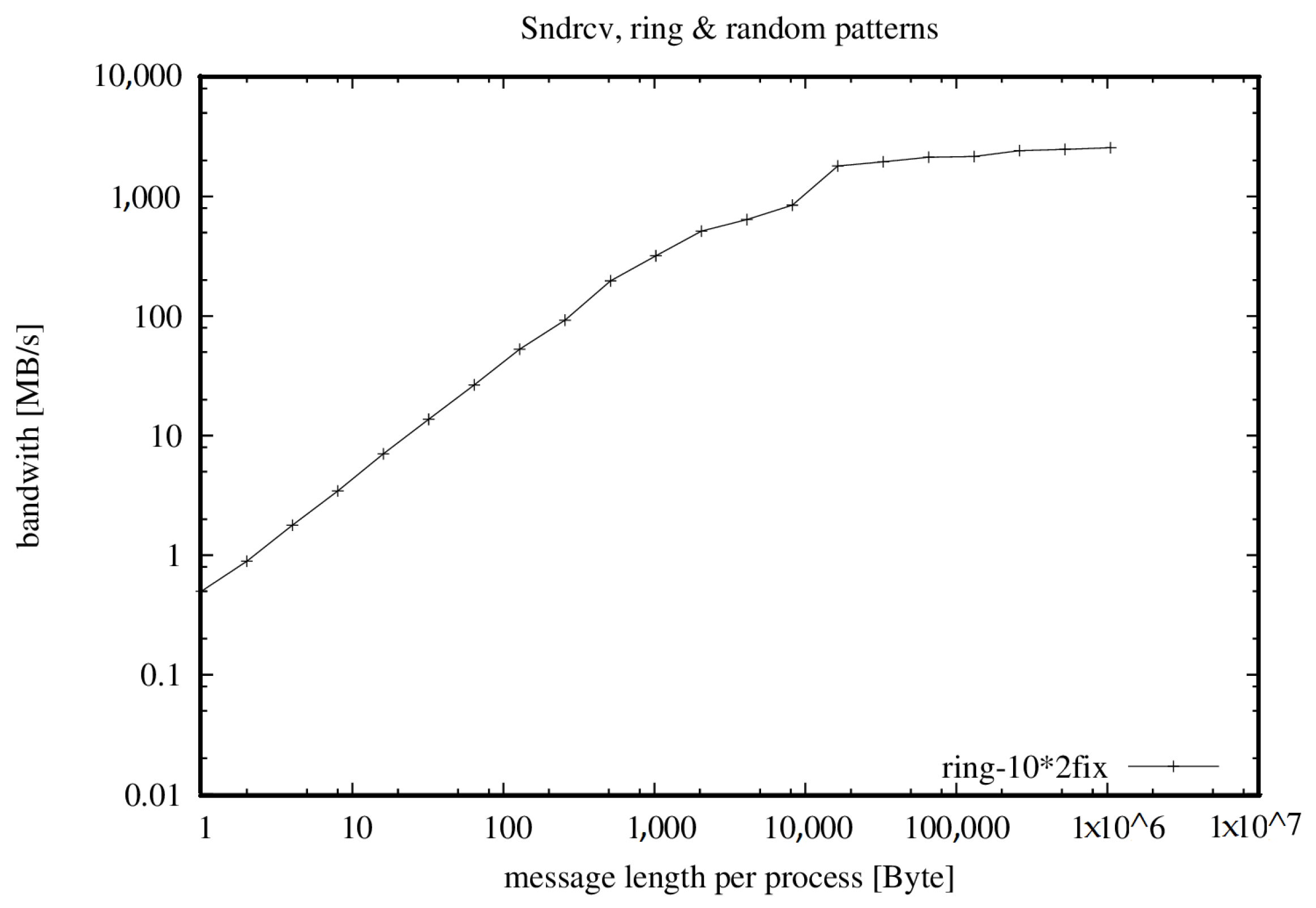
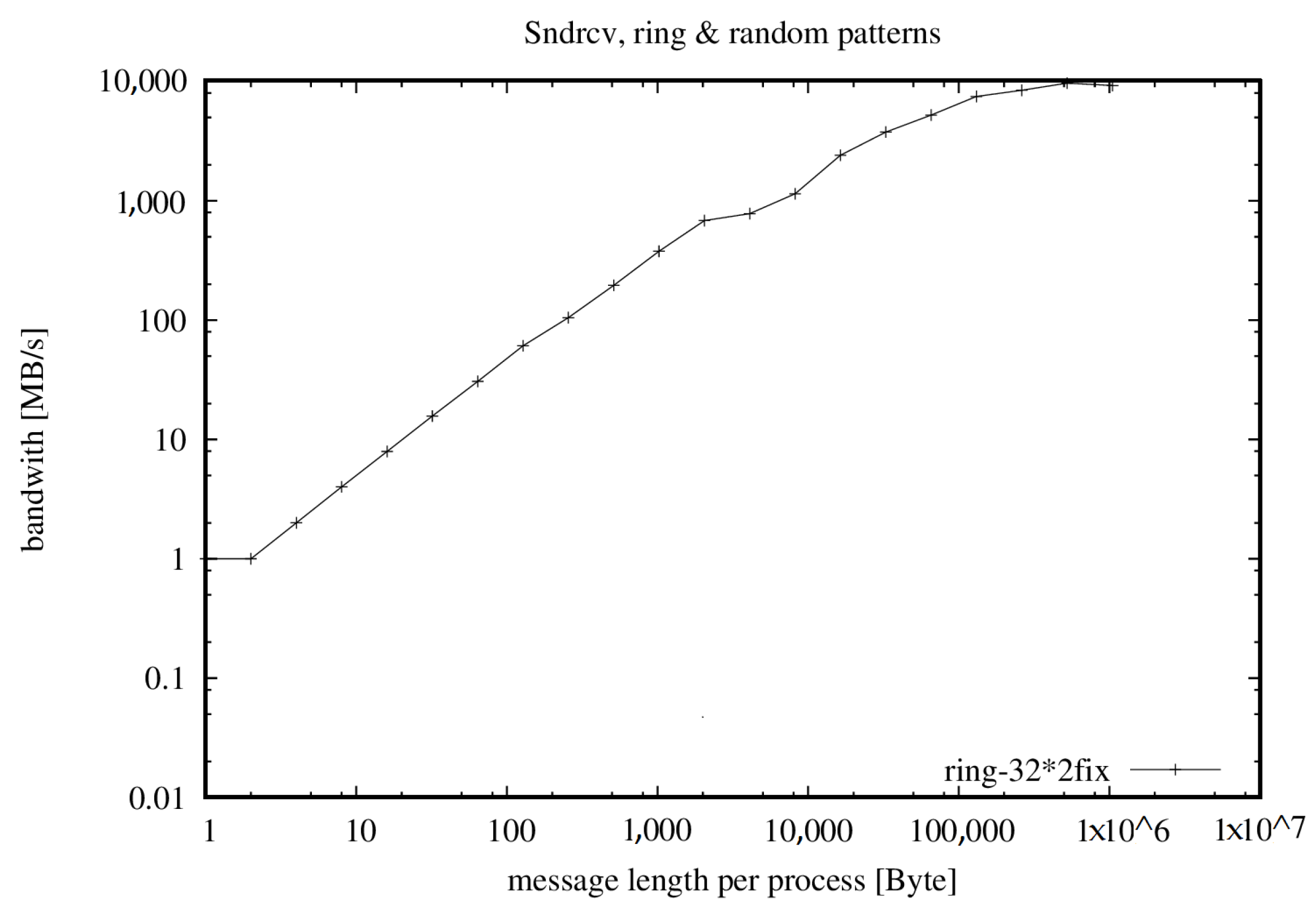
- = 17,556.798 MB/s = 877.840 ∗ 20 PEs with 128 MB/PE
- Sun March 15 23:31:05 2020 on Linux it01-r14-cn-63.yachay.e3.10.0-327.el7.ppc64le #1 SMP Thu Oct 29 17:31:13 EDT 2015 ppc64le
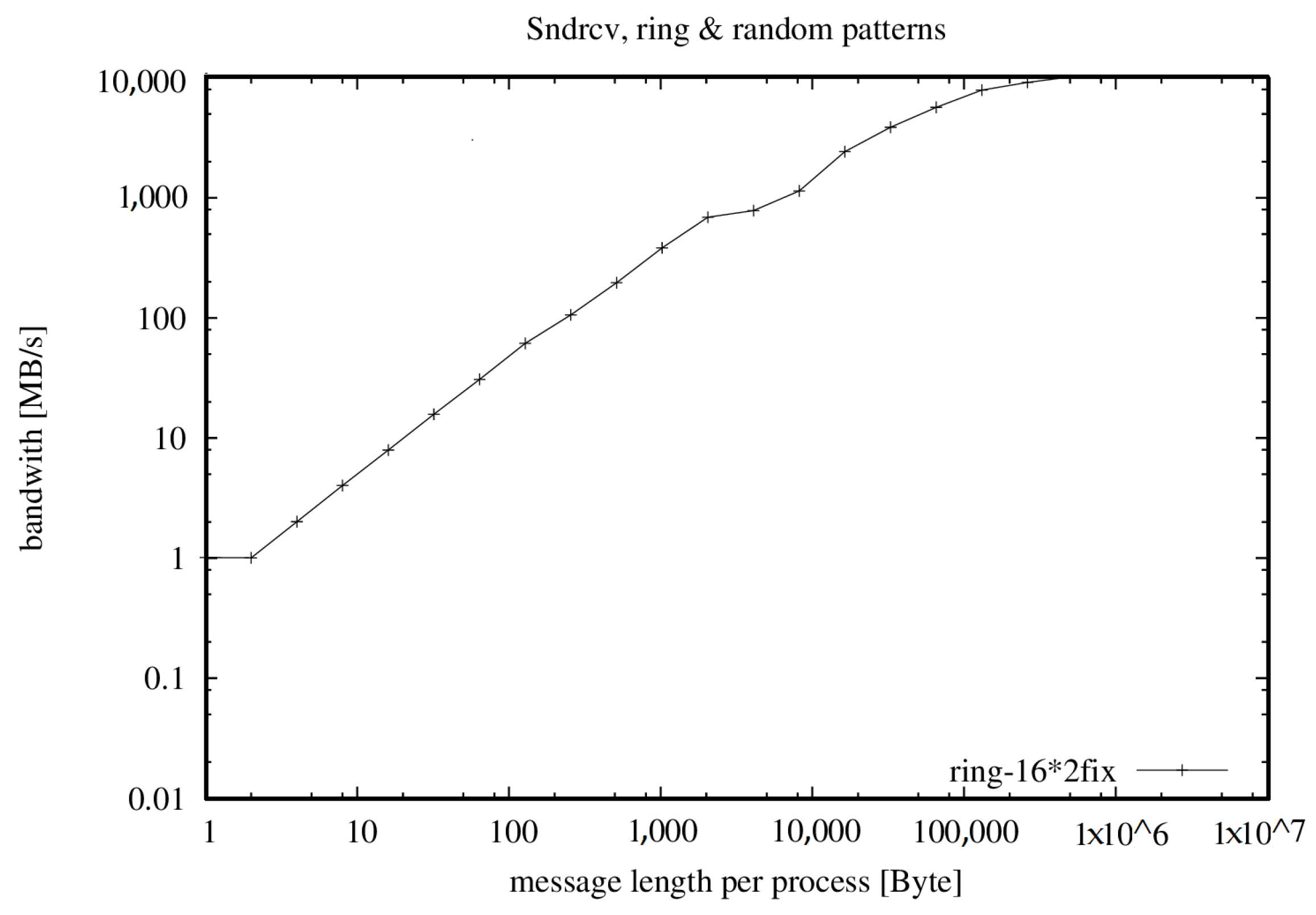
- = 28,590.215 MB/s = 893.444 ∗ 32 PEs with 128 MB/PE
- Sun March 15 23:34:36 2020 on Linux it01-r10-cn-39.yachay.ep 3.10.0-327.el7.ppc64le #1 SMP Thu Oct 29 17:31:13 EDT 2015 ppc64le
- = 62,367.350 MB/s = 974.490 ∗ 64 PEs with 128 MB/PE
3. Results and Discussion
3.1. Linpack Results
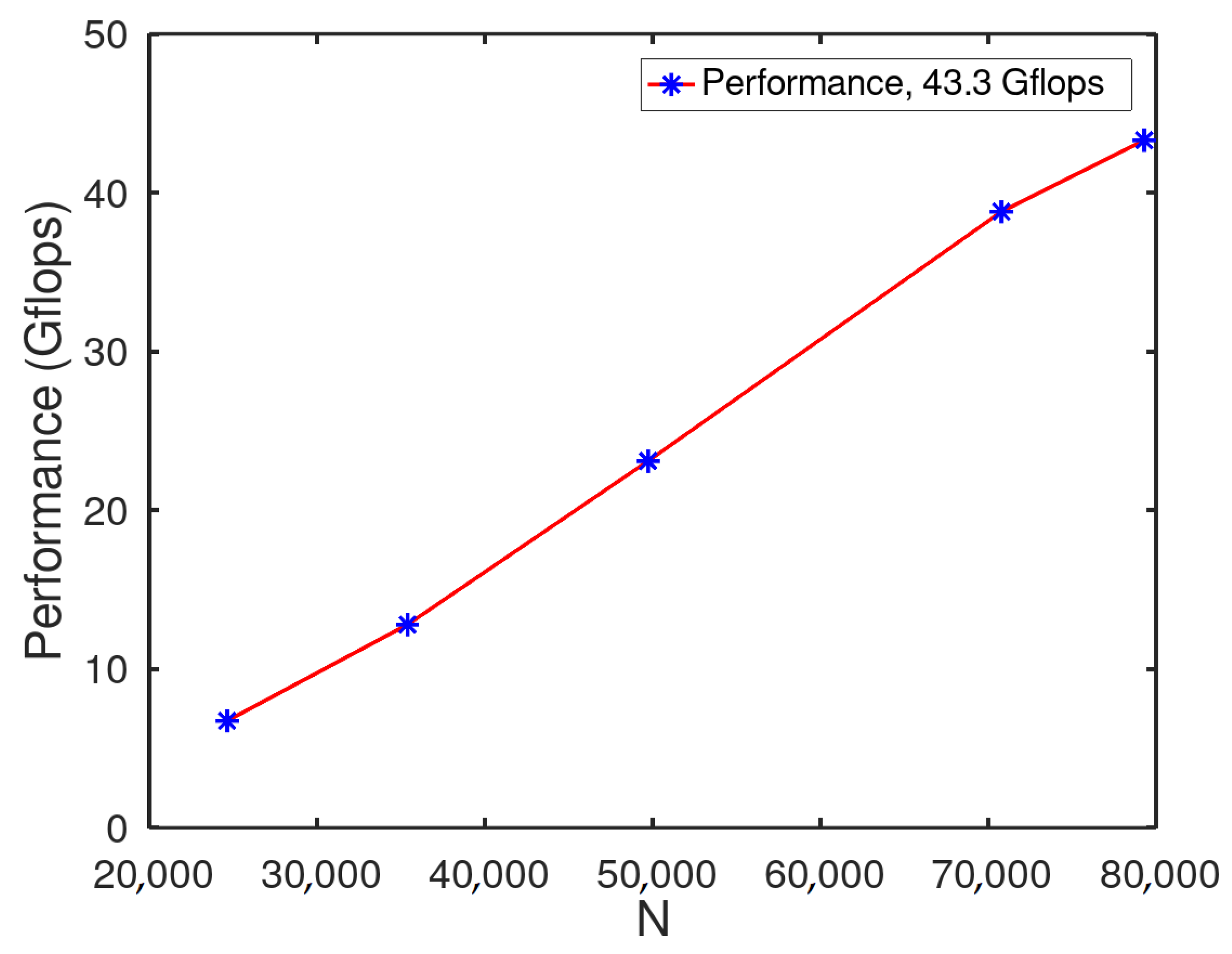
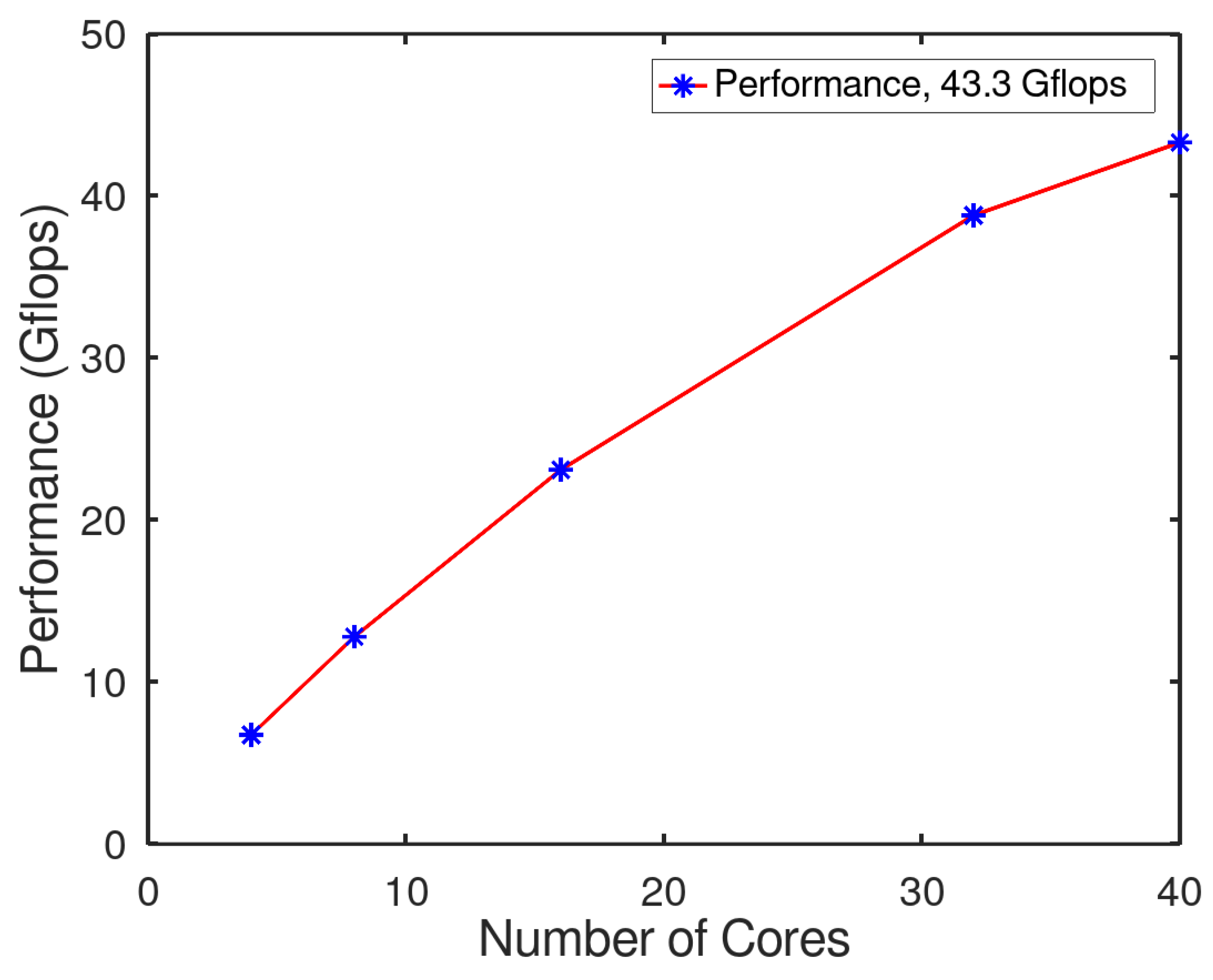
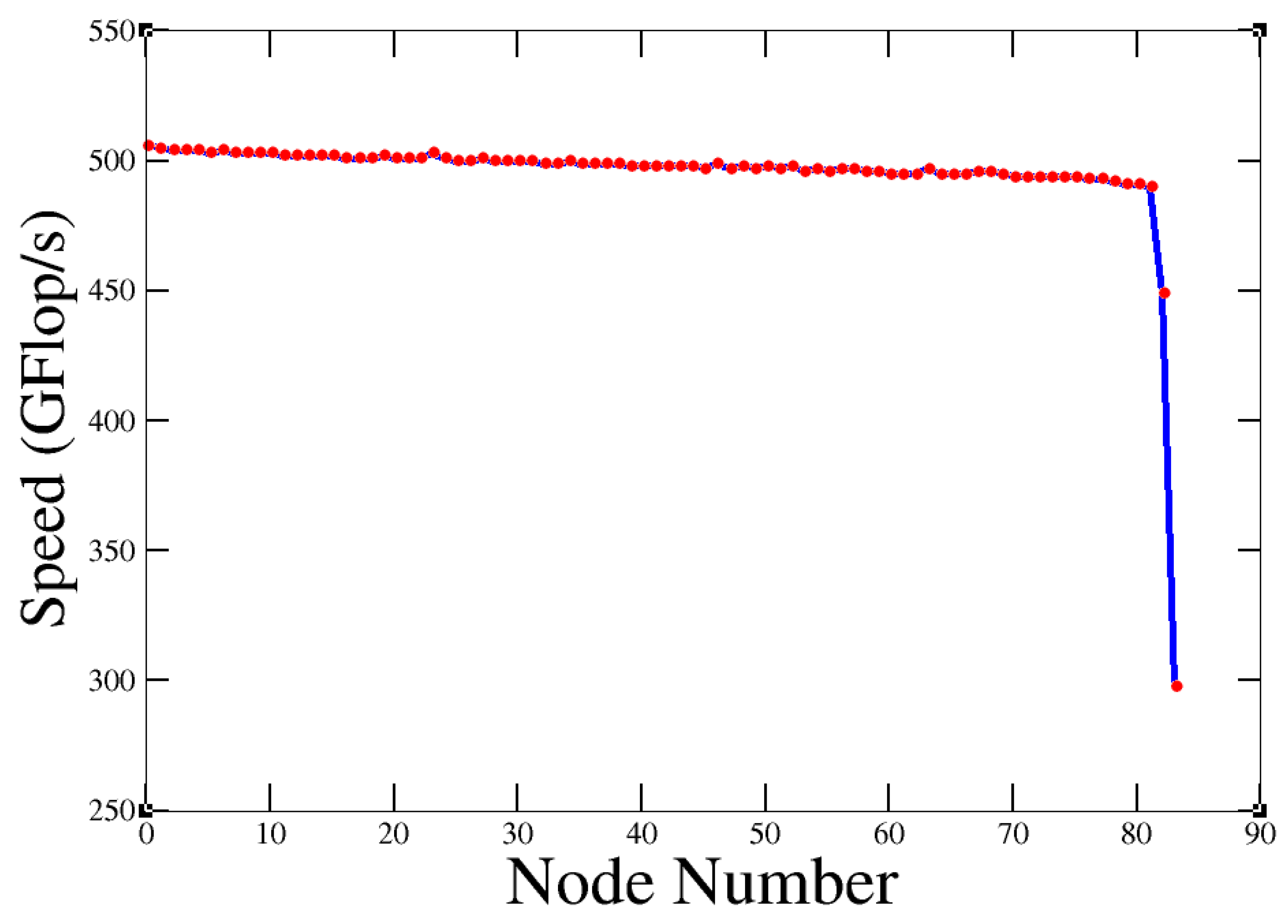
3.1.1. HPL with CPUs
- MP PROCS = 4
- CPU CORES PER GPU = 5
3.1.2. HPL Analysis
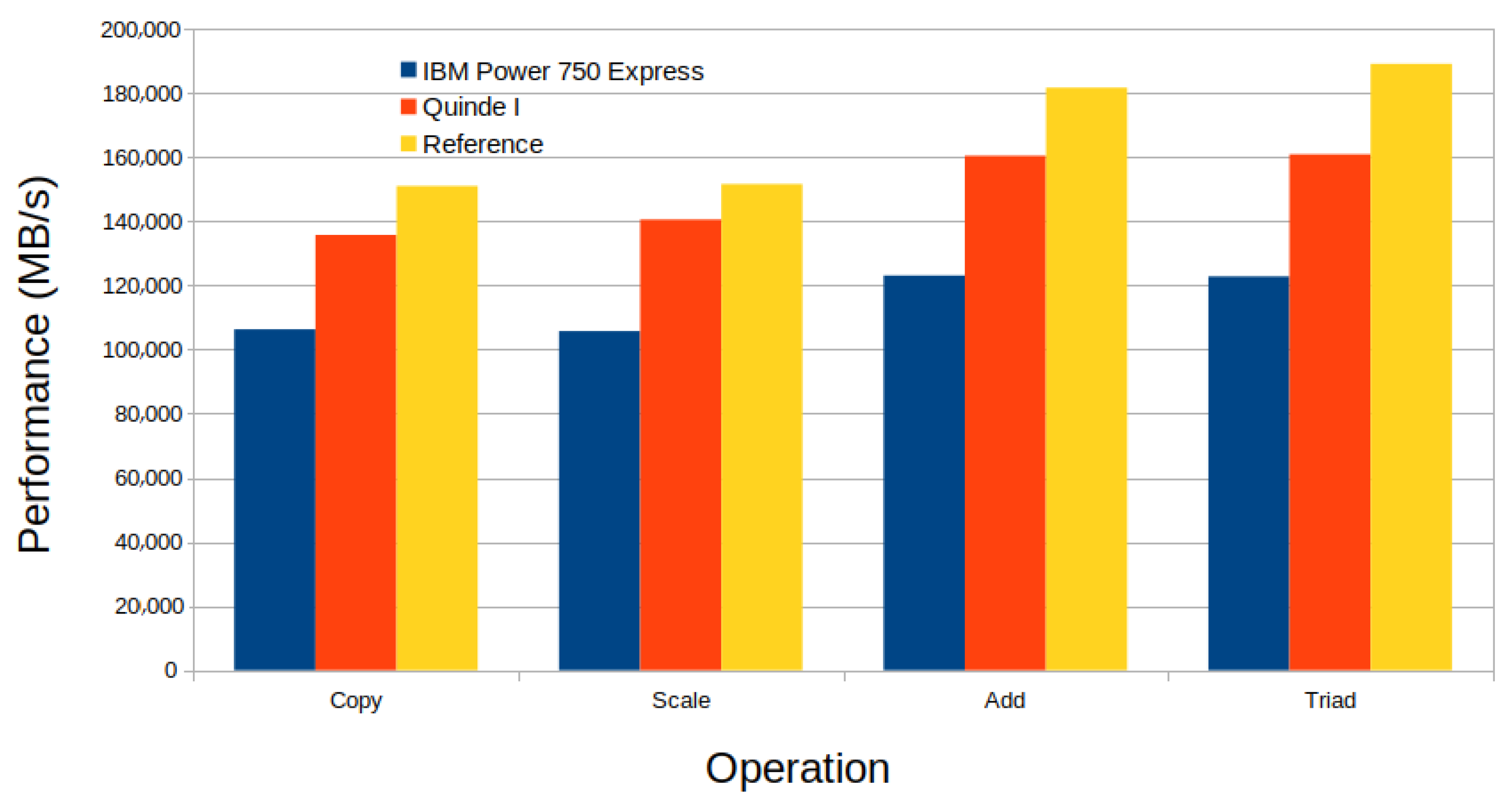
3.2. Stream Benchmark
3.3. Babel Stream Results
- nvidia-smi-application-clocks = memory clock speed, clock speed
- nvidia-smi-application-clocks = 2505 MHz, 705 MHz
- nvidia-smi-application-clocks = 2505 MHz, 810 MHz
- nvidia-smi-application-clocks = 2505 MHz, 875 MHz
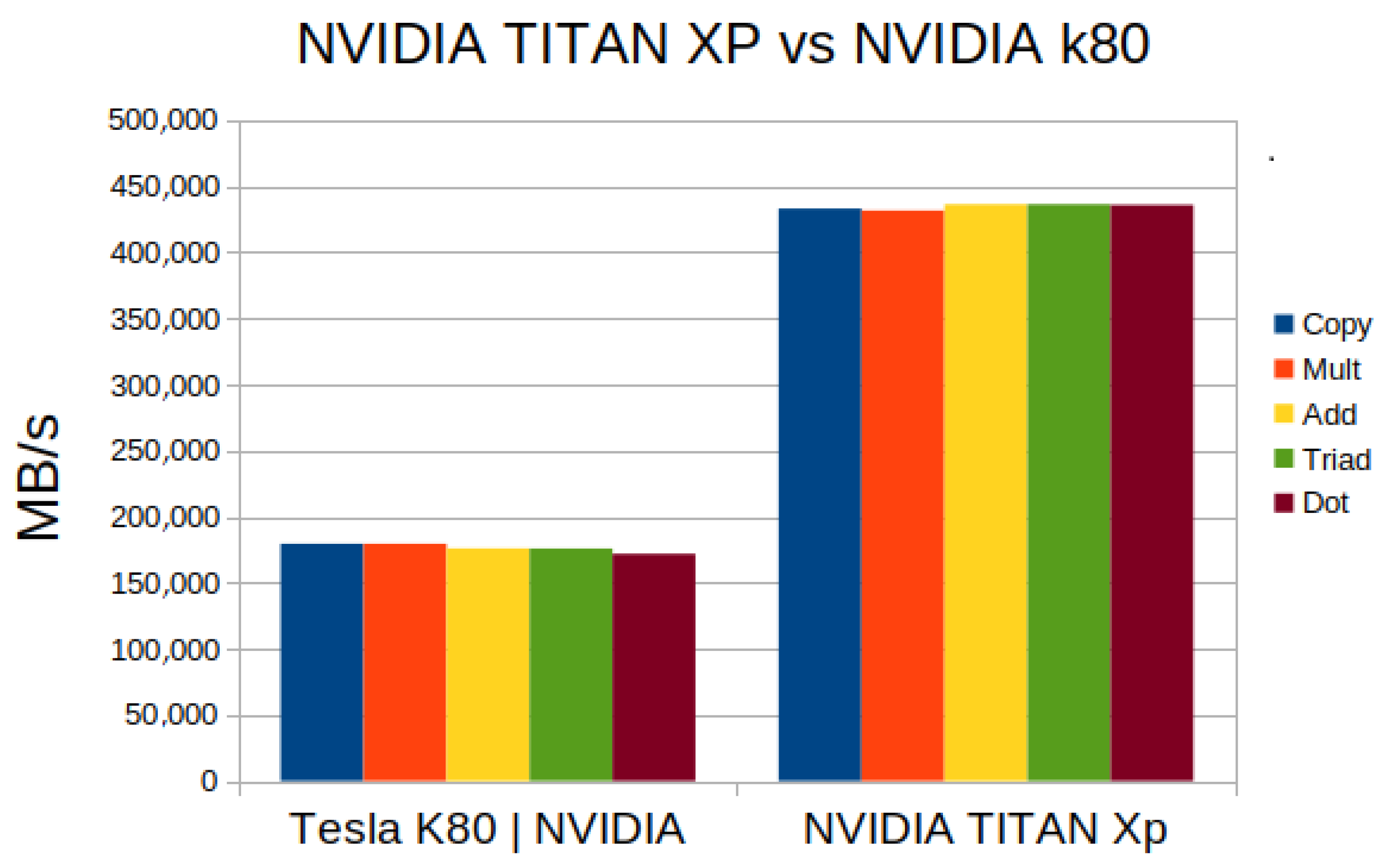
NVIDIA TITAN XP vs. NVIDIA K80
- NVIDIA K80: 0.137855579868709
- NVIDIA TITAN xp: 1.16064362964917
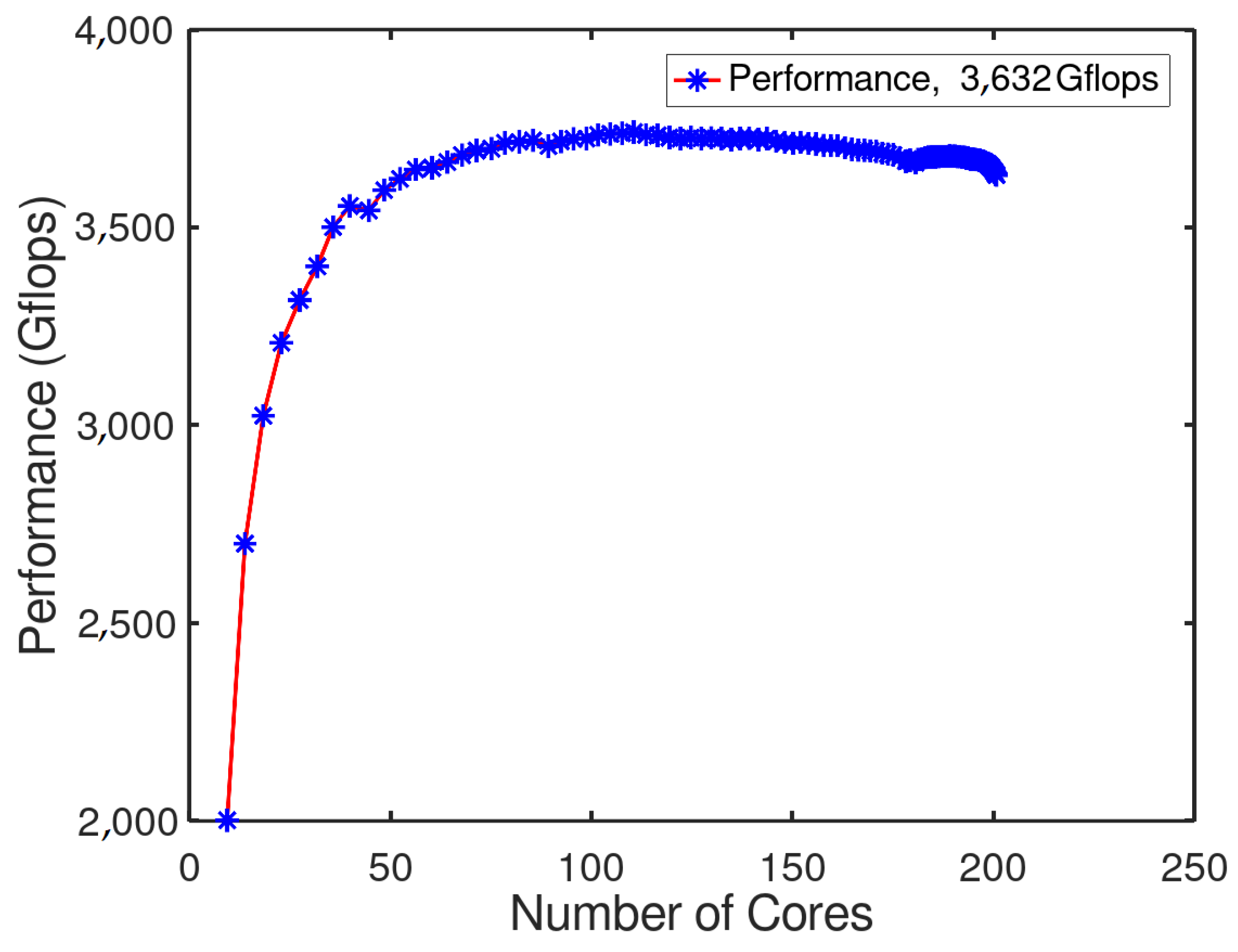
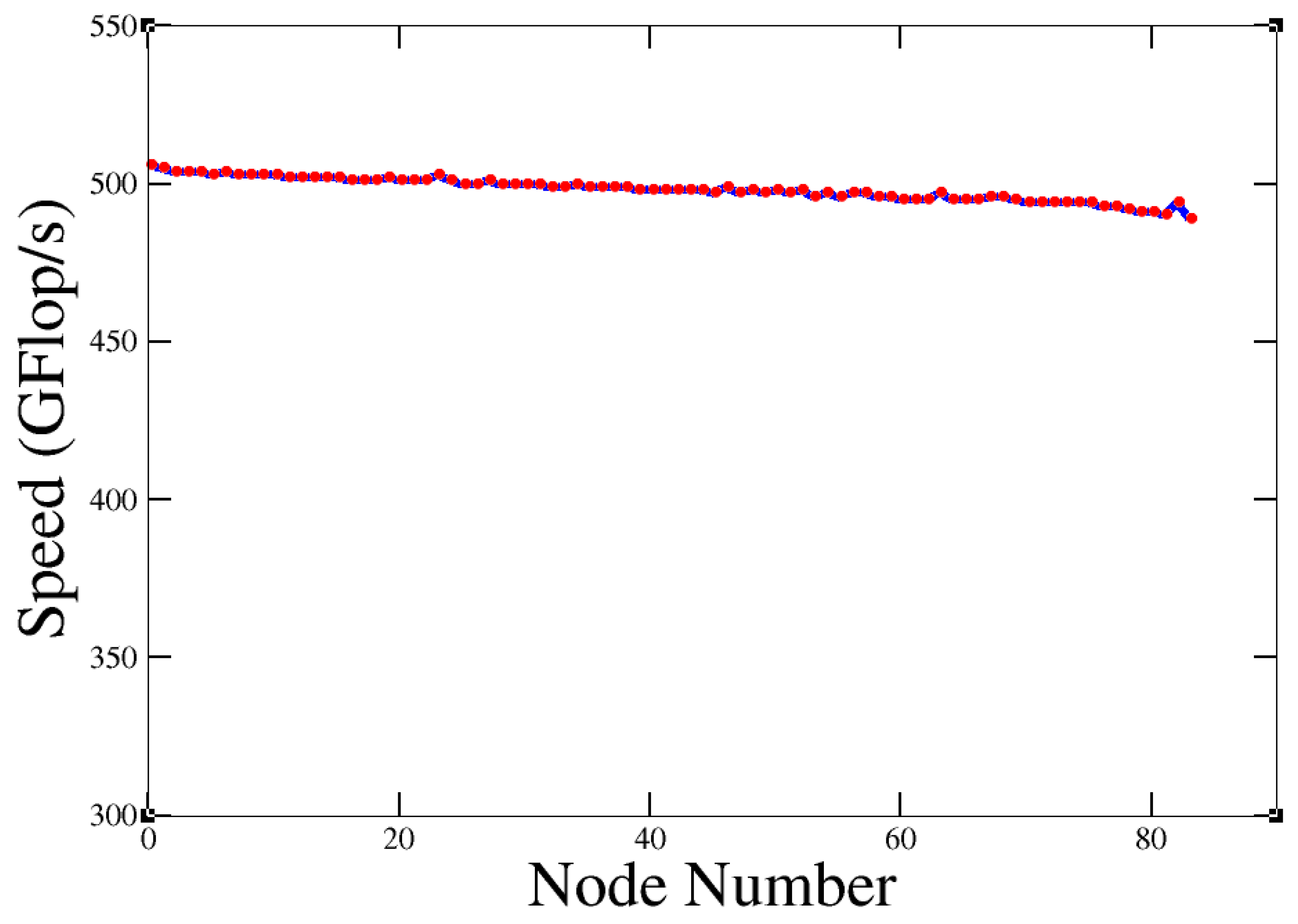
3.4. DEGMM Results
3.5. LLCBench—Cache Bench Results
Cache-Bench on a Node of “Quinde I”
4. SRUMMA vs. DGEMM Algorithm on “Quinde I”
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dongarra, J.; Heroux, M. Toward a New Metric for Ranking High-Performance Computing Systems; Technical Reports; Sandia National Laboratory: Albuquerque, NM, USA, 2013; p. 4744.
- Dongarra, J.; Heroux, M.; Luszczek, P. The HPCG Benchmark. 2016. Available online: http://www.hpcg-benchmark.org (accessed on 21 July 2021).
- Luszczek, P.; Dongarra, J.J.; Koester, D.; Rabenseifner, R.; Lucas, B.; Kepner, J.; Mccalpin, J.; Bailey, D.; Takahashi, D. Introduction to the HPC Challenge Benchmark Suite; Technical Reports; Sandia National Laboratory: Albuquerque, NM, USA, 2005.
- Dongarra, J.J.; Luszczek, P.; Petitet, A. The LINPACK benchmark: Past, present, and future. Concurr. Comput. 2003, 15, 803–820. [Google Scholar] [CrossRef]
- Pfeiffer, W.; Wright, N.J. Modeling and predicting application performance on parallel computers using HPC challenge benchmarks. In Proceedings of the 2008 IEEE International Symposium on Parallel and Distributed Processing, Miami, FL, USA, 14–18 April 2008; pp. 1–12. [Google Scholar] [CrossRef]
- Xing, F.; You, H.; Lu, C. HPC benchmark assessment with statistical analysis. Procedia Comput. Sci. 2014, 29, 210–219. [Google Scholar] [CrossRef] [Green Version]
- Sayeed, M.; Bae, H.; Zheng, Y.; Armstrong, B.; Eigenmann, R.; Saied, F. Measuring High-Performance Computing with Real Applications. Comput. Sci. Eng. 2008, 10, 60–70. [Google Scholar] [CrossRef]
- Marjanović, V.; Gracia, J.; Glass, C.W. HPC Benchmarking: Problem Size Matters. In Proceedings of the 7th International Workshop on Performance Modeling, Benchmarking and Simulation of High Performance Computer Systems (PMBS), Salt Lake City, UT, USA, 13–18 November 2016; pp. 1–10. [Google Scholar] [CrossRef]
- El Supercomputador Quinde I ya Está al Servicio de la Academia. 2017. Available online: https://ecuadoruniversitario.com/noticias_destacadas/supercomputador-quinde-i-ya-esta-al-servicio-la-academia/ (accessed on 21 July 2021).
- Ecuador Tras la Supercomputacion. 2018. Available online: https://www.elcomercio.com/guaifai/ecuador-supercomputacion-tecnologia-yachaytech-computacion.html (accessed on 21 July 2021).
- Supercomputador Quinde I Entró al Servicio del Ecuador. 2017. Available online: https://www.eluniverso.com/noticias/2017/12/14/nota/6525277/supercomputador-quinde-i-entro-servicio-pais/ (accessed on 21 July 2021).
- Curnow, H.J.; Wichmann, B.A. A synthetic benchmark. Comput. J. 1976, 19, 43–49. [Google Scholar] [CrossRef] [Green Version]
- Jakub, J. Performance Analysis of IBM POWER8 Processors. Master’s Thesis, Brno University of Technology, Brno, Czech Republic, 2016. [Google Scholar]
- HPCYachay, E.P. 2019. Available online: https://hpc.yachay.gob.ec/ (accessed on 21 July 2021).
- Krishnan, M.; Nieplocha, J. SRUMMA: A Matrix Multiplication Algorithm Suitable for Clusters and Scalable Shared Memory Systems. In Proceedings of the IPDPS’04, Santa Fe, NM, USA, 26–30 April 2004. [Google Scholar]
- Van de Geijn, R.; Watts, J. SUMMA: Scalable Universal Matrix Multiplication Algorithm. Concurr. Pract. Exp. 1997, 9, 255–274. [Google Scholar] [CrossRef]
- Choi, J.; Dongarra, J.; Ostrouchov, S.; Petitet, A.; Walker, D.; Whaley, R.C. A Proposal for a Set of Parallel Basic Linear Algebra Subprograms; Technical Reports; CS-95-292; University of Tennessee: Knoxville, TN, USA, 1995. [Google Scholar]
- Blackford, L.S.; Choi, J.; Cleary, A.; D’Azevedo, E.; Demmel, J.; Dhillon, I.; Dongarra, J.; Hammarling, S.; Henry, G.; Petitet, A.; et al. ScaLAPACK Users’ Guide; SIAM: Philadelphia, PA, USA, 1997. [Google Scholar]
- Valles, D. Development of Load Balancing Algorithm Based on Analysis of Multi-Core Architecture on Beowulf Cluster. Ph.D. Thesis, University of Texas at El Paso, Austin, TX, USA, 2011; p. 2401. [Google Scholar]
- University of Virginia. 2019. Available online: https://www.cs.virginia.edu/stream/ref.html (accessed on 21 July 2021).
- HPC CHALLENGE. 2019. Available online: https://icl.utk.edu/hpcc/ (accessed on 21 July 2021).
- BabelStream. 2019. Available online: https://uob-hpc.github.io/BabelStream/ (accessed on 21 July 2021).
- LLCbench—Low Level Architectural Characterization Benchmark Suite. 2019. Available online: http://icl.cs.utk.edu/llcbench/index.html (accessed on 21 July 2021).
- Effective Bandwidth (beff) Benchmark. 2020. Available online: https://fs.hlrs.de/projects/par/mpi/b_eff/b_eff_3.5/ (accessed on 21 July 2021).
- Nvidia Tesla K80 The World’S Fastest Gpu Accelerator. 2019. Available online: https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/tesla-product-literature/nvidia-tesla-k80-overview.pdf (accessed on 21 July 2021).
- Hong, S.; Oguntebi, T.; Olukotun, K. Efficient Parallel Graph Exploration on Multi-Core CPU and GPU. In Proceedings of the 2011 International Conference on Parallel Architectures and Compilation Techniques, Galveston, TX, USA, 10–14 October 2011; pp. 78–88. [Google Scholar] [CrossRef] [Green Version]
- D’Souza, P. Best Practices and Basic Evaluation Benchmarks: IBM Power System S822LC for High-Performance Computing (HPC). 2017. Available online: https://www.redbooks.ibm.com/redpapers/pdfs/redp5405.pdf (accessed on 21 July 2021).
- Deakin, T.; Price, J.; Martineau, M.; McIntosh-Smith, S. GPU-STREAM: Now in 2D! In Proceedings of the 2016 International Conference for High Performance Computing, Networking, Storage and Analysis, Salt Lake City, UT, USA, 13–18 November 2016. [Google Scholar]
- Dongarra, J.J.; Croz, J.D.; Hammarling, S.; Duff, I.S. A set of level 3 basic linear algebra subprograms. ACM Trans. Math. Softw. 1990, 16, 1–17. [Google Scholar] [CrossRef]
- Tan, G.; Li, L.; Triechle, S.; Phillips, E.; Bao, Y.; Sun, N. Fast implementation of DGEMM on Fermi GPU. In Proceedings of the 2011 International Conference for High Performance Computing, Networking, Storage and Analysis on—SC ’11, Seattle, WA, USA, 12–18 November 2011. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| number | Lmax | ||||
| of pro- | at Lmax | at Lmax | |||
| cessors | rings and | rings | |||
| random | only | ||||
| MByte/s | MByte/s | MByte/s | |||
| accumulated | 20 | 17,557 | 1 MB | 51,010 | 50,013 |
| per process | 878 | 2551 | 2501 | ||
| Latency | Latency | Latency | ping-pong | ||
| rings and | rings | ping- | bandwidth | ||
| random | only | pong | |||
| microsec | microsec | microsec | MByte/s | ||
| accumulated | 1.970 | 1.808 | 0.782 | 14,893 |
| number | Lmax | ||||
| of pro- | at Lmax | at Lmax | |||
| cessors | rings and | rings | |||
| random | only | ||||
| MByte/s | MByte/s | MByte/s | |||
| accumulated | 32 | 28,590 | 1 MB | 77,698 | 90,036 |
| per process | 893 | 2428 | 2814 | ||
| Latency | Latency | Latency | ping-pong | ||
| rings and | rings | ping- | bandwidth | ||
| random | only | pong | |||
| microsec | microsec | microsec | MByte/s | ||
| accumulated | 1.857 | 1.681 | 0.788 | 18,475 |
| number | Lmax | ||||
| of pro- | at Lmax | at Lmax | |||
| cessors | rings and | rings | |||
| random | only | ||||
| MByte/s | MByte/s | MByte/s | |||
| accumulated | 64 | 62,367 | 1 MB | 180,979 | 250,604 |
| per process | 974 | 2828 | 3916 | ||
| Latency | Latency | Latency | ping-pong | ||
| rings and | rings | ping- | bandwidth | ||
| random | only | pong | |||
| microsec | microsec | microsec | MByte/s | ||
| accumulated | 1.918 | 1.699 | 0.787 | 20,682 |
| Function | Best Rate MB/s | Avg Time | Min Time | Max Time |
|---|---|---|---|---|
| Copy: | 67,630.9 | 0.127412 | 0.127018 | 0.127911 |
| Scale: | 70,672.1 | 0.121959 | 0.121552 | 0.122957 |
| Add: | 81,089.9 | 0.159328 | 0.158904 | 0.159597 |
| Triad: | 81,356.5 | 0.158727 | 0.158383 | 0.159373 |
| Function | Best Rate MB/s | Avg Time | Min Time | Max Time |
|---|---|---|---|---|
| Copy: | 135,680.4 | 0.064878 | 0.063313 | 0.069888 |
| Scale: | 140,497.6 | 0.065011 | 0.061142 | 0.073112 |
| Add: | 160,384.9 | 0.083582 | 0.080341 | 0.091937 |
| Triad: | 160,827.3 | 0.085327 | 0.080120 | 0.095353 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Estévez Ruiz, E.P.; Chicaiza, G.E.C.; Patiño, F.R.J.; López Lago, J.C.; Thirumuruganandham, S.P. Dense Matrix Multiplication Algorithms and Performance Evaluation of HPCC in 81 Nodes IBM Power 8 Architecture. Computation 2021, 9, 86. https://0-doi-org.brum.beds.ac.uk/10.3390/computation9080086
Estévez Ruiz EP, Chicaiza GEC, Patiño FRJ, López Lago JC, Thirumuruganandham SP. Dense Matrix Multiplication Algorithms and Performance Evaluation of HPCC in 81 Nodes IBM Power 8 Architecture. Computation. 2021; 9(8):86. https://0-doi-org.brum.beds.ac.uk/10.3390/computation9080086
Chicago/Turabian StyleEstévez Ruiz, Eduardo Patricio, Giovanny Eduardo Caluña Chicaiza, Fabian Rodolfo Jiménez Patiño, Joaquín Cayetano López Lago, and Saravana Prakash Thirumuruganandham. 2021. "Dense Matrix Multiplication Algorithms and Performance Evaluation of HPCC in 81 Nodes IBM Power 8 Architecture" Computation 9, no. 8: 86. https://0-doi-org.brum.beds.ac.uk/10.3390/computation9080086