1. Introduction
This paper provides a new approach for the analysis and eventually the classification of dynamical systems. Some classification methods are already known from literature and are now a cornerstone in modern systems theory. For instance, it is possible to classify a linear system as stable, asymptotically stable or unstable, on the basis of the eigenvalues of its transition matrix. The same approach can be extended to nonlinear systems applying a linearisation procedure with respect to some nominal evolution, although now information can only be inferred about the particular evolution. A less conventional method based on the time-frequency plane [
1] is used to distinguish between 5 possible nonlinearities. This method can only be applied to SDOF (Single Degree Of Freedom) nonconservative systems, that is systems that can be described by (
1)
where
c is a small positive parameter and
is a function of the state variable
x identifying the type of nonlinearity. However, an extension of the previous approach to a wider class of nonlinearities still has to come. Alternatively, in [
2], two systems are considered equivalent if any variable of one system may be expressed as a function of the variables of the other system and of a finite number of their derivatives. This is also known as Lie-Bäcklund isomorphism. From this point of view, the class of simplest systems, also called flat systems, includes all systems equivalent to a linear controllable system of any dimension with the same number of inputs. The drawback of this approach from a mathematical point of view is the difficulty of obtaining criteria for checking flatness. Besides, a complete classification of nonlinear systems according to the Lie-Bäcklund isomorphism is still to be done.
Chaotic systems are an important class of nonlinear systems. Chaotic attractors can be recognised by visual inspection of phase space portraits, and numerical quantification of chaos can be computed by several well known methods such as Lyapunov Exponents, auto-correlation functions and the power spectrum [
3,
4]. For instance, Lyapunov Exponents can be used to classify attractors into equilibria, cycles and chaotic sets. However, a drawback of this approach is that this classification makes sense only when the dynamical systems under exam admit attractive sets.
In this paper a novel method for comparing nonlinear systems is proposed and is based on a generalisation of the entropy of a plane curve [
5]. Roughly speaking, the entropy of a curve is 0 when the curve is a straight line, and increases as the curve becomes more “wiggly". Starting from the seminal work of [
5], a new theory, called “thermodynamics of curves", was developed [
6], with some analogies with thermodynamics. However, defining the entropy of a curve only for plane curves has restricted its use to a few applications, as for instance [
7].
In [
8] and [
9] a first attempt to extend the concept to higher dimensions was made leading to a natural application for the analysis of nonlinear systems. The main idea is to study the evolution in time of the entropy of a curve which starts from entropy 0 and consisting of the segments connecting an ordered set of points in the phase space of a dynamical system. As the selected points follow their corresponding trajectories in the phase space, also the curve connecting them evolves and its entropy can be evaluated iteratively. With the proposed method, all curves evolving according to linear dynamics keep their entropy constant and fixed to 0. If the entropy increases, it is a symptom of some nonlinear behaviour. In particular, larger or smaller values of the entropy might discriminate between stronger and milder nonlinearities. This ability is potentially very useful for the analysis and control of dynamical systems. First of all, a class of well-established methods for controlling linear systems is available, but an analogous systematic approach for nonlinear systems is still an open problem. Therefore it is convenient to know how much a nonlinear system can be considered close to a linear one [
10]. Moreover, linear behaviours often imply the capacity of predicting a trajectory in the phase space in the long term. On the other hand, if the straight segment connecting points in the phase space is dynamically bent and folded and its entropy increases, then it can be expected that it is harder to make a reliable prediction of the system [
11].
This paper follows the previous works [
8]-[
11] and provides here a general and systematic approach to the analysis of nonlinear systems in more dimensions; in particular special attention is dedicated to the analysis of chaotic systems and it is shown how the proposed approach is related to the well known Lyapunov exponents and other asymptotic quantities.
The paper is organised as follows: the next section is dedicated to a review of the main concepts from thermodynamics of curves and to its generalisation to higher dimensions.
Section 3 introduces the algorithmic procedure to compute the proposed indicator and in 4 its main properties are listed and proved.
Section 5 describes the behaviour of the proposed indicator when applied to the analysis of chaotic systems and compares it with other known indicators. Simulation results for the analysis of classic benchmark dynamical systems are described and discussed in
section 6. Finally in the last section we summarise our results and conclude the paper.
3. Entropy Based Analysis of Dynamical Systems
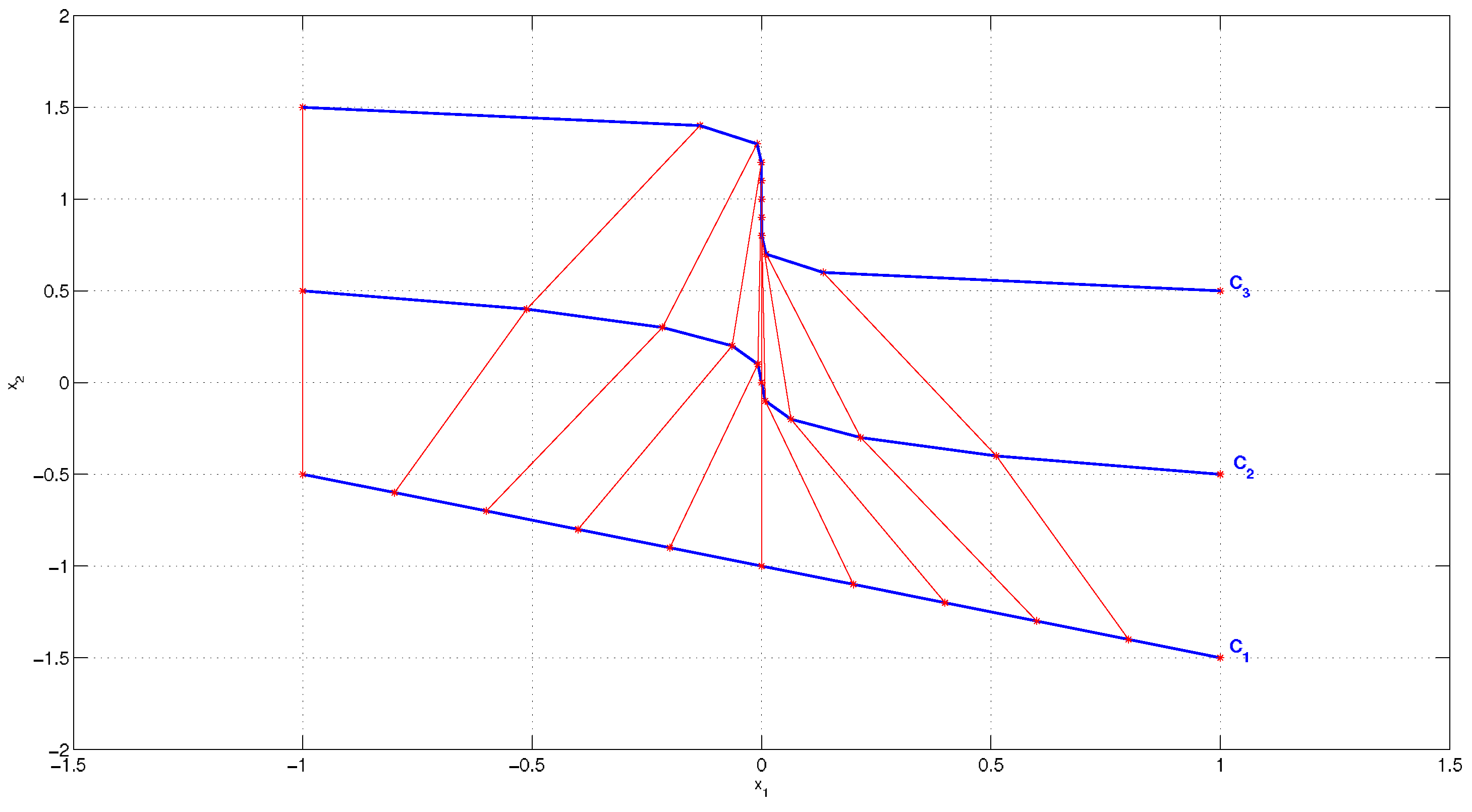
Let us consider a set of sample initial conditions for a dynamical system that are aligned along a straight line in the phase plane (or equivalently in the state space). The straight line connecting all the points has zero entropy, according to definition (
6) in the previous section. As initial conditions evolve in the state space accordingly to the system dynamics, also the curve connecting them evolves, as shown in the example of
figure 1. In particular, if points evolve according to linear dynamics, the entropy of the curve connecting them remains zero because collinearity is preserved under affine transformations. On the other hand, higher values of the entropy are a symptom of nonlinearity.
Figure 1.
Evolution of a line in the phase space at three different time steps.
Figure 1.
Evolution of a line in the phase space at three different time steps.
It should be remarked that the proposed approach does not compute the future trajectory of the initial line, but only the future trajectories of the initial points, and the line is derived consequently by connecting the points. According to this new approach, the upper bound of the indicator (
6) depends now on the number of points that are used, so we normalise (
6)
where
is the number of segments approximating the line, and the proof that the entropy computed according to (
8) is bounded between zero and one is provided in Property 2,
section 4. Also notice that at least two segments should be used, so that
and indicator (
8) has sense. By comparing equations (
6) and (
7) it is possible to obtain equation (
8) to compute directly
Notation
reminds that the entropy of a curve has been normalised, but from now on only the normalised value will be used and therefore the subscript
will be dropped for the sake of simplicity.
Assuming that a dynamical system evolves according to a discrete-time model
where
m represents the dimension of the state vector, then the indicator (
8) can be computed according to the following procedure
Algorithm 1
:Initialisation: - (a)
Choose N points ordered along a straight line
- (b)
is 0
Evolution: step
k- (a)
Compute the next state for each point according to (
9)
- (b)
Consider the line that connects sequentially all the points and take its length
- (c)
Compute the smallest hypersphere that contains all the points, and take its diameter
- (d)
Compute according to (
8)
- (e)
Go to next step ( ).
Deterministic inputs can be included in equation (
9) without significant changes, and have not been considered here for the sake of simplicity. Computation of the minimum covering sphere in point 2.c) is solved here using the approach of [
14], and a brief discussion with the description of the algorithm is reported in the
appendix for the sake of completeness.
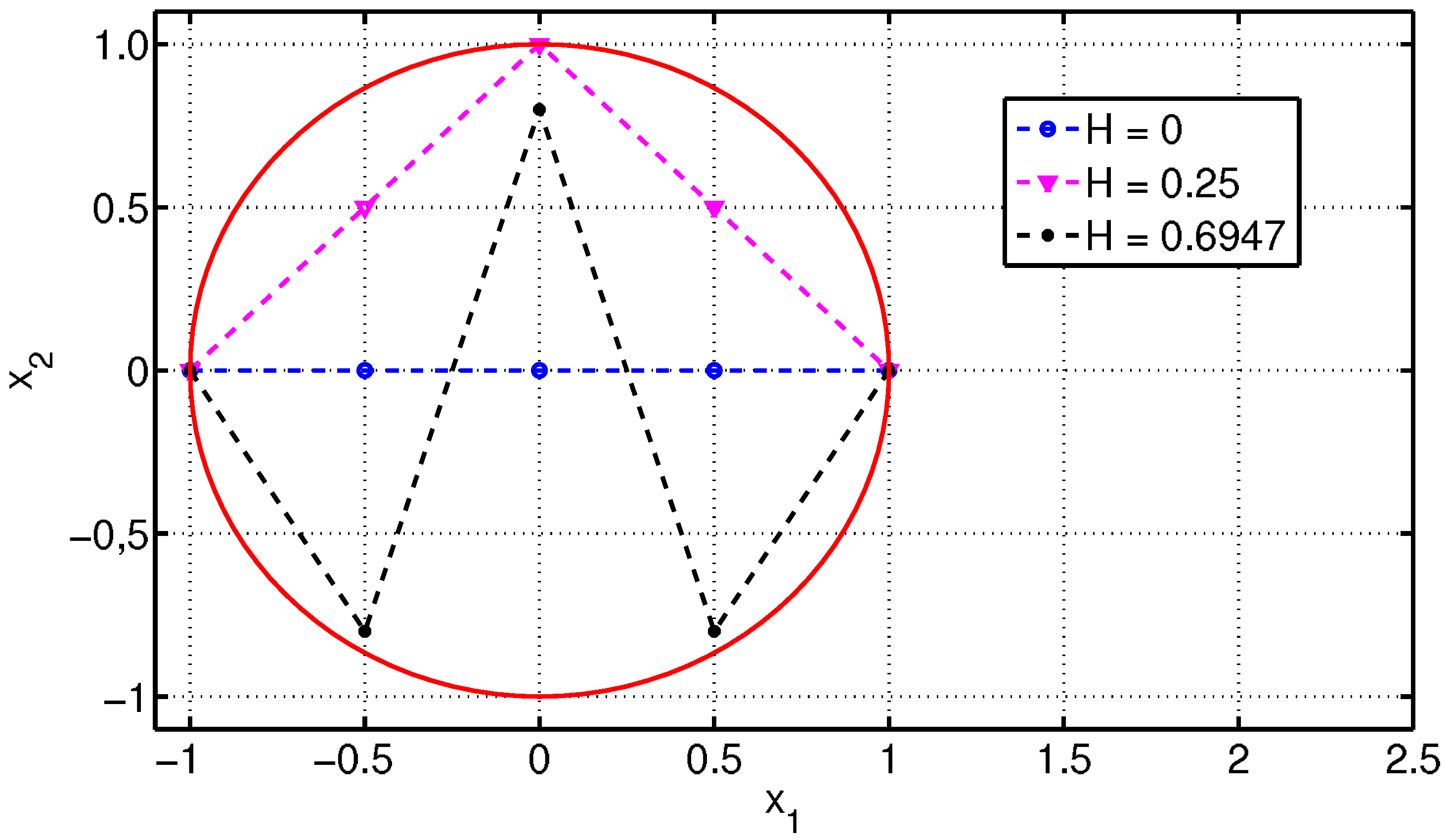
The rationale of indicator (
8) is that it describes the regularity of a line: if all points are aligned sequentially along a straight line, then the segment has entropy 0. On the other hand, more tortuous lines have higher entropies, as illustrated in the example in
figure 2.
Figure 2.
Three plane lines covered by the same circle: more irregular lines have higher entropies.
Figure 2.
Three plane lines covered by the same circle: more irregular lines have higher entropies.
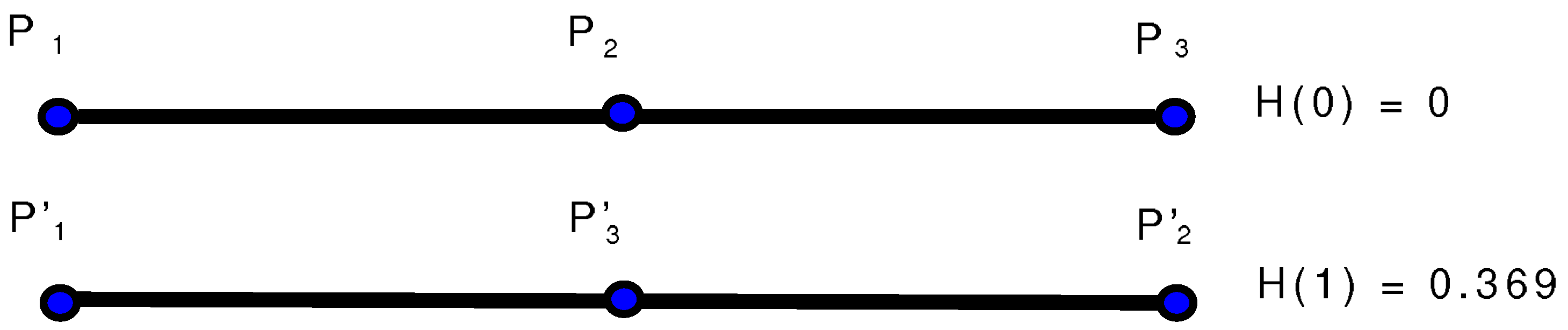
A second property is that the generalised entropy takes into account the ordering of the points in the sequence. This is described in
Figure 3. At the beginning points
,
and
are chosen ordered along a straight line according to the first step of the previous algorithm. In this case
and thus
. If at the next step the system dynamics exchange
and
, then
while
. Therefore
. By taking into account the ordering of the points, the generalised entropy is able to capture if the system dynamics are folding the initial segment over itself, which is clearly a symptom of nonlinearity.
Figure 3.
A straight line turns into another straight line, but if the ordering of the points changes then the entropy changes as well.
Figure 3.
A straight line turns into another straight line, but if the ordering of the points changes then the entropy changes as well.
The proposed indicator has many other interesting properties that make it suited for the analysis of dynamical systems, and they are described in the next section.
4. Properties of the generalised entropy
This section lists the main properties of the generalised entropy.
Property 1: Let Γ be a curve in , then the entropy of Γ is 0 if and only if Γ is a straight line.
Proof: The sufficient condition, i.e. a straight line has zero entropy according to (
8) is easily verified. The necessary condition to be proved is that if
, and thus the diameter of the smallest hypersphere covering the curve Γ is equal to the length of Γ, then the only possibility is that the curve Γ is straight. To prove the necessary condition it should be noted that
, being
A the hypersphere centered in the mid-point of Γ and diameter
L equal to the lenght of Γ. Therefore, being the Minimum Covering Sphere (MCS) minimal, its diameter is always smaller or equal than
L and, as a consequence of the fact that the MCS is unique, if
then
A must be the MCS. The curve Γ has at least two distinct points on the sphere surface, otherwise a smaller hypersphere can always be found. So,
implies that Γ must have a point in the centre of the MCS and at least two on the surface. Now, since the overall length of Γ is
d, then Γ must be formed by the two segments connecting the centre with the two points on the surface, otherwise it would be longer than just
d by triangle inequality. In this case, the only possibility is that Γ is the diameter itself, otherwise the centre would not be a convex combination of the two points on the hypersphere surface, which is a necessary condition for the MCS [
15]. Therefore the curve Γ corresponds to the diameter and it is a straight line.
Remark: This was the main property of the entropy of a plane curve and it still holds also for our generalised indicator.
Property 2: Let Γ be a curve in , then the entropy of Γ is always between 0 and 1.
Proof: As a consequence of the proof of property 1, the entropy of a curve Γ is bounded from below by 0. Besides, the maximum distance between two points within a hypersphere can not exceed the diameter. Thus, and so .
Remark: This property is guaranteed by the choice of the normalisation factor
in equation (
8). The introduction of a normalising constant might not seem a proper choice because it affects the computation of the entropy of a curve. For instance, two identical curves described by a different number of points have now different entropies. However, from the point of view of dynamical systems analysis, it is convenient to have a fixed full scale range, although some care is required in providing the value of the entropy always accompanied with the information about the number of used points. Extensive simulations have been performed to investigate the sensitivity of equation (
8) to the choice of the number of initial points and they showed that the asymptotic value of the entropy increases of one unit if the number of points doubles (i.e. it is proportional to the logarithm of the number of points). This result is in accordance with general intuition, for instance it directly follows from equation (
8) if one assumes that the asymptotic distance between points does not depend on the number of considered points, and it is obviously true for the upper bound of the entropy as a consequence of property 2. Another important consequence of property 2 is that
Algorithm 1 can be used consistently also to analyse unstable dynamical systems where the length of the curve tends to infinity. Finally, the normalisation step paves the way to a probabilistic approach.
Property 3: Let be the curve in at time step k generated by a dynamical system according to Algorithm 1. Then, if then , if the dynamical system is linear.
Proof: A linear system is described by the transition state function
where
A is a matrix and
b is a vector of opportune dimensions, and (
10) corresponds to an affine transformation of the vector
. Collinearity and ordering of points are preserved under affine transformations, therefore a straight line remains a straight line and its entropy is constantly zero.
Remark: This property still holds for the approximation of the curve with arbitrary points, and it is the main reason why the entropy of curves is a valid tool for the analysis of dynamical systems. It should also be noted that the property is true even if the linear dynamical system (
10) is time variant and includes deterministic inputs
u (i.e. it is described by the more general equation
). This more general case includes typical dynamical systems like for instance switching linear systems (provided that the switching condition is a function of time and not a function of the current state).
Property 4: Let Γ be a curve in , then the entropy of Γ is insensitive to scale changes, rotations and translations.
Proof: Entropy of a curve is defined as a ratio of lengths and therefore is not affected by scale changes. Furthermore, rotations and translations do not change lengths.
Property 5: Let be the curve in at time step k generated by a dynamical system according to Algorithm 1. If the dynamical system is one-dimensional, the state transition function is monotone and , then ,
Proof: The proposed entropy indicator is based on the alignment or misalignment of a sequence of points. The case when the state space dimension is 1 is a degenerate situation in the sense that all the points remain necessarily aligned along the only (available) dimension. Therefore the proposed indicator only perceives the change of ordering of the points along the line, which is the only possibility for the entropy to be larger than 0, as it was shown in
figure 3. The sequence of points does never change ordering if and only if
implies
(monotonically increasing) or implies
(monotonically decreasing) for each choice of the points
and
. Therefore, when the dynamical system has only one dimension the proposed entropy approach measures some way the monotonicity of the state transition function.
Remark: Even if the state function is not monotonic, the indicator might still be 0 if the initial segment is chosen in a region of the state space where the state function is monotonic. For instance, if an initial segment of ordered positive numbers is chosen and the state function is , the non-monotonic behaviour of this system is missed.
Note 1: Following from the previous properties, one may think that nonlinear systems defined over dimensions greater than one always provide values of the entropy which are greater than zero. However, as already mentioned in property 3 the value of the entropy is constantly equal to zero for whatever choice of the initial line if the state transition function is such that transforms all straight lines into straight lines without affecting the ordering. The most famous class of transformations that preserve collinearity and ordering is indeed that of affine functions, which corresponds to the notion of linear dynamical systems. However degenerate dynamical systems that do not correspond to affine transformation can still be built
ad hoc such that collinearity and ordering are preserved, as can be obviously seen in the next two-dimensional example:
It could be argued however that dynamical systems like the previous one are intrinsically one-dimensional just the same.
Note 2: In this paper, we present an indicator that aims at evaluating the nonlinearity of dynamical systems. The indicator computes the entropy of a curve associated to a dynamical system (where the association comes into play because the curve evolves according to the system dynamics as described in
Algorithm 1). Sometimes, for brevity, it is tempting to associate the entropy directly to the dynamical system. This shorter notation can however be misinterpreted with dramatic consequences because it conceals the fact that entropy is computed only of a curve. On the contrary, in our paper we never compute the entropy of the dynamical system, which is something completely different, and the entropy of curves does not inherit automatically the properties of the entropy as in the classic Boltzmann notion. As an example, one could expect that the entropy we compute here can never decrease, while this is not true because the entropy of curves evaluates the irregularity of a curve that, at least in principle, can decrease in time according to particular dynamic equations. Here, the term
entropy is maintained for uniformity with the original notation [
5,
6].
The value of the proposed indicator can be computed either theoretically exploiting the previous properties and theorems, or by
Algorithm 1. The theoretical approach can be used if the dynamical system is linear to infer that the entropy will be constantly zero, or if the dynamical system has symmetric properties that lead to a geometrical solution. For instance, if the nonlinear system is
, then an initial line symmetric with respect to the origin will fold up on itself so that (
8) will be
.
If the dynamical system does not have particular symmetries or properties, it will be generally very hard to predict the behaviour of the indicator and it is necessary to use the algorithmic procedure. On the other hand, a drawback of Algorithm 1 is that it might be numerically unstable if the points converge all to an equilibrium or diverge. In the first case, all distances among the points go to zero, while in the second case they go to infinity. For this reason, the algorithmic procedure gives the best results in the case that the norms of the state points remain bounded and do not converge to one only value. A possible application is therefore the analysis of chaotic systems, when the states evolve within attractors. Besides, literature of chaotic systems is rich of indicators that are used to quantify the amount of chaoticity, starting from the well-known Lyapunov exponents. It is therefore of interest to investigate how the proposed indicator is related with the other approaches.
5. Analysis of Chaotic Behaviours
The generalised entropy indicator introduced in this work can be computed in an algorithmic way which is particularly convenient for the evaluation of chaotic behaviours. Chaotic behaviours have been widely studied in the recent years, and methods like the Lyapunov Exponents (LEs), the auto-correlation function and the power spectrum have become classic tools of chaos theory [
4]. Other less conventional indicators have been introduced in the last few years, as for instance [
16,
17,
18] and the very recent [
19]. However, no approach has prevailed over the others yet, since depending on the particular dynamical system, or on the particular aspect of interest, one method can be more convenient and more informative than the others.
The different indexes try to quantify the amount of chaos by observing the evolution of different quantities. In this framework the entropy approach proposed here is closely related to LEs and to the
parameter introduced in [
20,
21], since they are both concerned on the evaluation of some distances, as will be clarified in the following.
The maximum LE [
22] gives a quantitative characterization of the exponential divergence of initially nearby trajectories. Similarly to the entropy approach, it is not generally possible to compute LEs in an analytic way, but one has to resort to numerical methods. LEs are computed evaluating the evolution of some points in the phase space, and two recent references for computation in continuous time systems and discrete time can be found in [
23] and [
24] respectively. A recent survey of the theory of Lyapunov exponents is also available from [
25]. A drawback of LEs is that two dynamical systems having the same LEs can behave in a very different way [
26]. In particular, if a chaotic system in
is characterised by LEs
, then a linear continuous dynamical system with state transition matrix
has the same LEs. Although it is still true that two trajectories arbitrarily close diverge in the long term if the dynamical system is linear and unstable, yet the behaviour is far from chaotic. This is a major difference with respect to the proposed generalised entropy indicator. A second drawback of LEs is that it is not clear how to compute them for dynamical systems defined over a discrete state space. In this case, it is not straightforward how to define the distance between two states and whether two trajectories converge or not. On the contrary, the proposed generalised indicator provides a nice extension for the investigation of unusual dynamical systems defined on a discrete state space, as for instance the Kaprekar routine [
27] addressed in the next section.
The parameter
was first introduced in [
20] and measures the asymptotic distance between trajectories. An iterative procedure to compute the value of
starts from the choice of several pairs of initial conditions. The mean distance
between two trajectories after
j iterations can be computed as
where, using the same notation of [
21],
and
are the pair
i (out of the total of
N) of points at iteration
j. Finally
is computed by averaging
after
n iterations, when
n tends to
∞. The previous approach can be used for the analysis of chaotic dynamical systems, where the distance reaches a characteristic asymptotic value [
21] that has lost memory of the initial conditions [
28]. In [
21] it is not outlined how the initial points of a pair should be chosen, apart from being very close one to the other. If it were possible to choose all of them along a line, then the asymptotic entropy according to the equation (
8), here called for analogy
, would be
where, to avoid confusion with the mean distance
(
12), we call
the diameter of the smallest hypersphere that encloses all the points (which in equation (
8) had been called
d). It should be noted that also
reaches an asymptotic value, since after the first steps, the points get spread enough to cover the whole attractor. Therefore a proportional relationship between the logarithm of
and the entropy indicator proposed here gets established. In [
21], a relationship between
and the maximum LE is computed according to the equation
where
is the maximum Lyapunov exponent, and Ψ represents the folding action. Therefore, asymptotically, apart from the simple solution
, the fixed point is
. The previous relationship emphasises the fact that the maximum LE measures the stretching effect, while
takes into account also the folding aspects through the term Ψ. However, during the first steps the stretching effect is dominant over the folding one, and thus the rate of growth of the initially small distance
is directly related to the maximum LE. In [
29] an empirical way of estimating the maximum LE from the evolution of
is suggested, although results are not very accurate. However this is important to remind, because it points out that not only the asymptotic value of the entropy of curves is an interesting parameter, but also the entropy rate provides significative information of the underlying dynamics.
Finally, it is remarked that the previous relationships between LEs, and the entropy indicator only hold when the dynamical system is chaotic.
6. Results and Discussion
Extensive simulations have been performed to study the behaviour of the proposed index in many benchmark problems. In the following, some of the most significant results that have been obtained are presented and compared.
Figure 4.
Comparison of the entropy of curves computed for a two-state dynamical system as a function of the probability of changing the state.
Figure 4.
Comparison of the entropy of curves computed for a two-state dynamical system as a function of the probability of changing the state.
An interesting example is the case when the state can either be 0 or 1. At each time step the state remains the same or changes as according to the outcome of a Bernoulli experiment. The generalised entropy computed in this situation is larger when the two probabilities of remaining in the same state and switching to the second one are close one to each other, as shown in
figure 4. This is in analogy with the entropy as in information theory, [
13] and [
30], and emphasises that the proposed indicator takes into account the predictability of a dynamical system. Indeed, a probability of
of switching the state represents the most unpredictable situation and is characterised by the highest entropy.
Figure 5.
Comparison of the entropy of curves associated to some probability distributions. Highest entropies are reached respectively by the exponential, the Gaussian and then the uniform distribution.
Figure 5.
Comparison of the entropy of curves associated to some probability distributions. Highest entropies are reached respectively by the exponential, the Gaussian and then the uniform distribution.
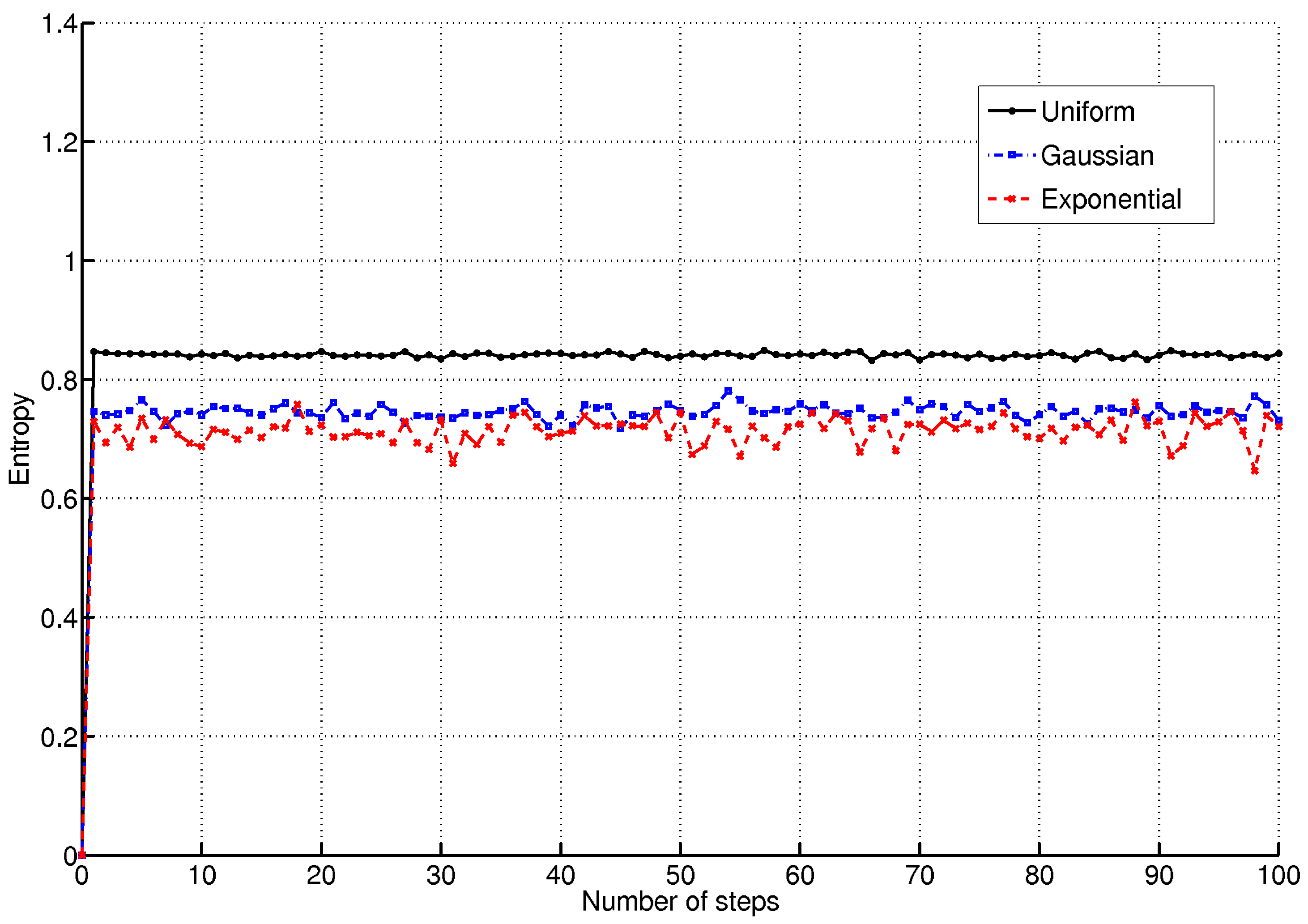
A similar example is shown in
figure 5, where entropies of curves associated to several probability distributions are compared. In this case the dynamical system is described by the equation
where ’
’ means that the state is sampled according to the probability distribution
. In the comparison three different simulations have been performed, where the state is sampled according to a uniform, Gaussian and exponential probability distribution respectively. It should be noted that it is possible to associate an entropy of curves to a distribution without specifying the typical values characterising a distribution. This implies for instance that it is not necessary to specify the bounds of the uniform distribution, because the entropy is insensitive to translations or changes of scales, according to property 4 in the previous section. Similarly, in the Gaussian case, the entropy does not depend on the mean or on the variance and in the exponential case it does not depend on the mean or on the value of the parameter
μ. Dynamical systems (
15) are characterized by the loss of memory of the previous state, but in the Gaussian and in the exponential cases lower entropies are achieved since samples have higher probabilities the closer they are to the mean value. On the other hand, the uniform case represents the least predictable dynamical system.
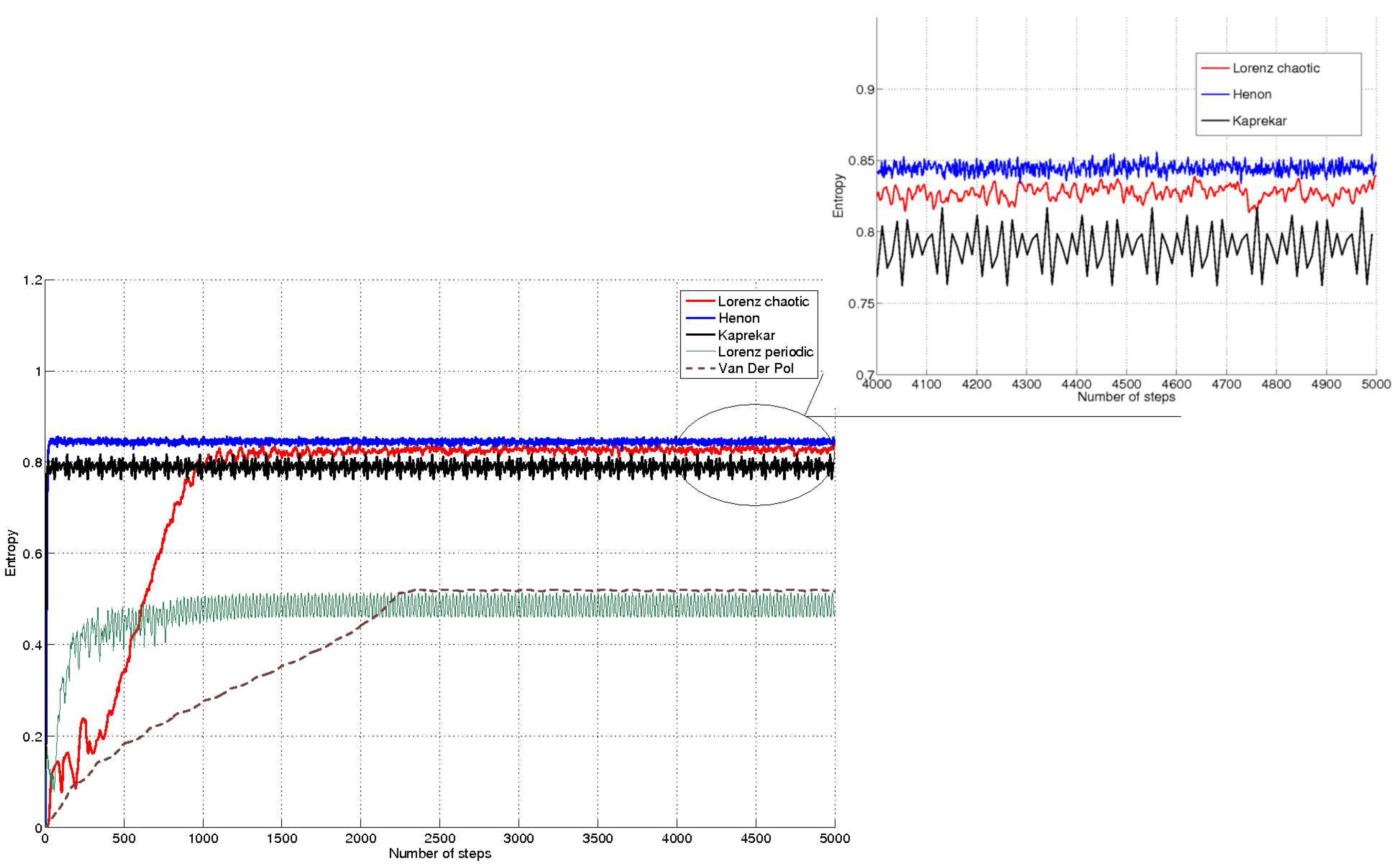
Figure 6 compares several dynamical systems, such as Lorenz attractor, Hénon map, Van Der Pol oscillator and Kaprekar routine. Lorenz equations are described by
and have been discretised with a sampling time of
s. In a first example the chaotic behaviour of the equations was obtained by choosing the classic values
,
and
. In a second example a periodic solution of the Lorenz equations is obtained by choosing
. Hénon map is described by
where the typical values
and
have been used. Van Der Pol oscillator is described by:
where a discretisation step of
has been used again.
Figure 6.
Comparison of the entropy of curves for some dynamical systems. Higher entropies are achieved respectively by the chaotic Hénon map, Lorenz equations in the chaotic case and Kaprekar routine. Lower entropy values are reached by the Van Der Pol oscillator and Lorenz equations in the periodic case.
Figure 6.
Comparison of the entropy of curves for some dynamical systems. Higher entropies are achieved respectively by the chaotic Hénon map, Lorenz equations in the chaotic case and Kaprekar routine. Lower entropy values are reached by the Van Der Pol oscillator and Lorenz equations in the periodic case.
The same notation of [
4] was used to describe the previous dynamical systems. Finally, Kaprekar routine [
27] consists of an algorithm that can be applied to integer numbers and works performing alternately the following steps:
- Step 1
Rearrange the digits of a number in ascending and descending order so to obtain two new numbers and respectively.
- Step 2
Compute . Increase time index k and go back to step 1
In the example, Kaprekar routine has been applied to ten digit numbers. All the previous examples are compared in
figure 6, where
points have been used in all the examples.
Remark: It might be argued that a comparison among so different dynamical systems is somewhat artificial. For instance, Lorenz equations have three states, the Hénon map and the Van Der Pol oscillator have two states and Kaprekar routine has one only dimension. Two of them are continuous time dynamical systems (although discretisation is performed) and two of them are discrete time. Moreover the Kaprekar routine is described by non-continuous equations and its domain is a discrete set. What is meant to show here is the flexibility of the proposed algorithm, which can be used efficiently to describe the nonlinear behaviour of classic continuous dynamical systems as well as less conventional dynamics like the Kaprekar routine. Not the same holds for other approaches like Lyapunov exponents.
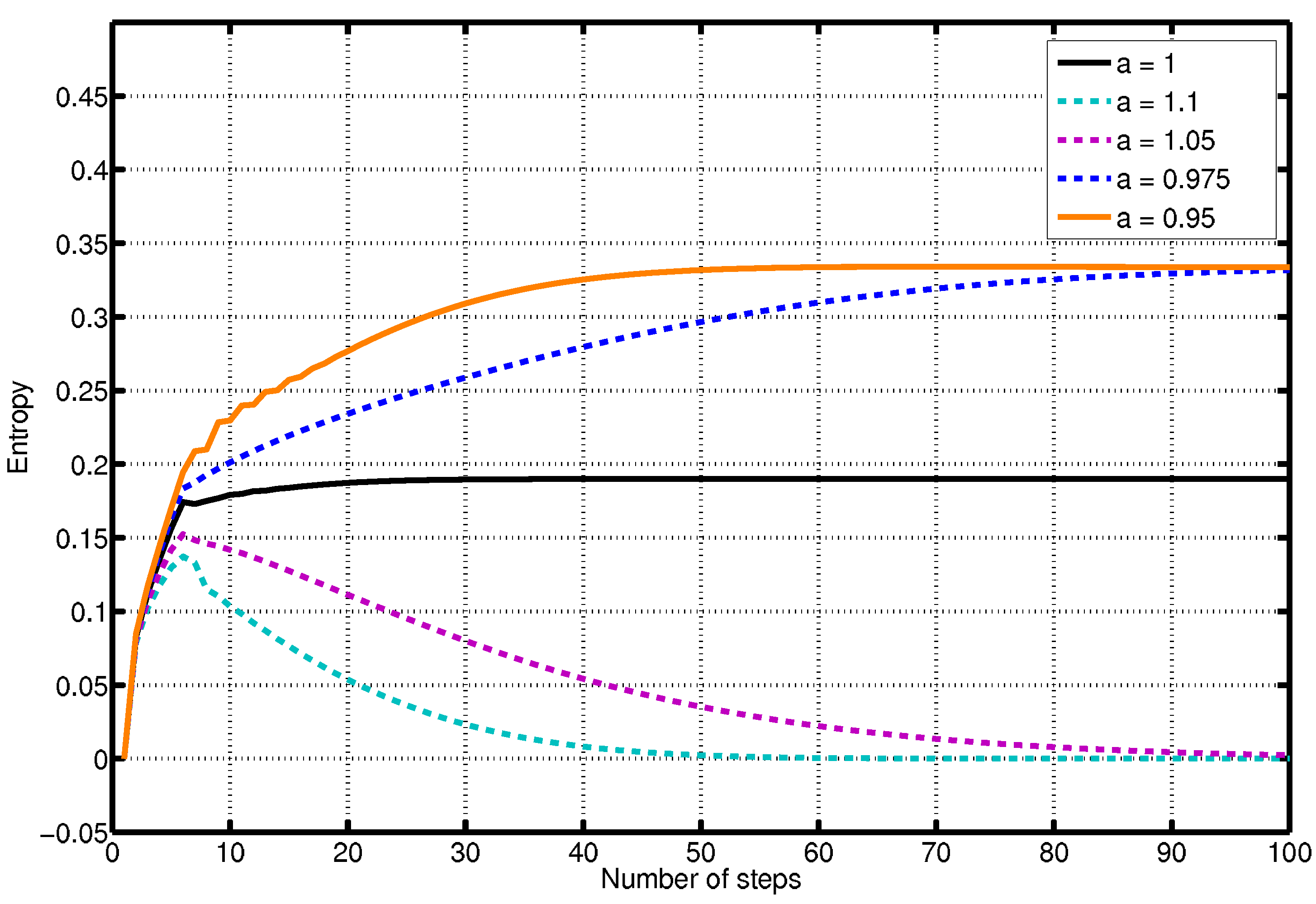
The next example is dedicated to the comparison of the entropy indicator for a dynamical system where a parameter
a is used to tune the amount of nonlinearity. The investigated dynamical system evolves according to the equations:
The first component of the system (
19) evolves with linear dynamics, so its expected entropy is 0. The second component evolves according to a logistic equation, which is a function that can be used to represent demographic models, where the multiplicative parameter is a positive number representing a combined rate for reproduction and starvation [
3]. In the example here the value of the parameter is
, and the equation has two equilibrium points. In the example, when
, the linear component goes to zero and the dynamical system reduces to the nonlinear part. On the contrary, when
, the linear component overrides the nonlinear one. Finally when
the two components have comparable values. The entropy of the system reflects this situation, and it either assumes the value of the dominant component or an intermediate value in the last case.
The simulation results are shown in
figure 7, where the higher entropies are reached when
a has values
and
(nonlinear dominance). The curves converging to 0 entropy are due to values of
a equal to
and
(linear dominance). The curve in the centre is obtained when
. In addition, it can be noted that the value of
a affects the time that is necessary before the linear component becomes dominant or can be neglected, therefore affecting the transient behaviour of the entropy. Also notice that in the case that the linear component prevails over the nonlinear one the entropy recognises the nonlinearity (the entropy indicator is not constantly zero), and then it decreases to zero. The fact that the entropy decreases implies that the curve in the phase space after the first few steps becomes more regular.
Figure 7.
Comparison of the entropy of curves indicator applied to a dynamical system in function of a parameter that weighs the contributions of the linear and nonlinear components
Figure 7.
Comparison of the entropy of curves indicator applied to a dynamical system in function of a parameter that weighs the contributions of the linear and nonlinear components
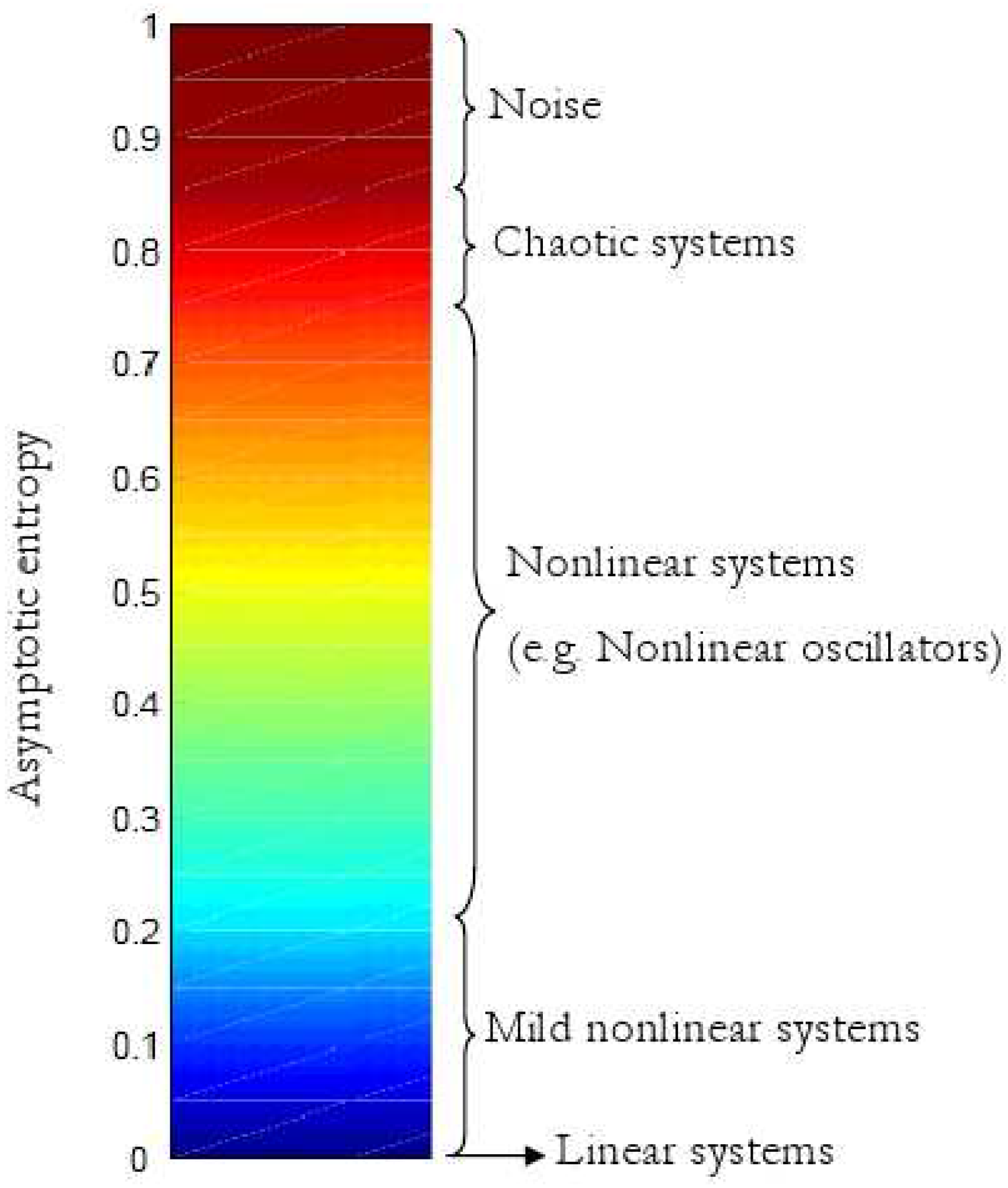
Figure 8.
A thermometer is used to classify dynamical systems according to the asymptotic value of the associated entropy of curves.
Figure 8.
A thermometer is used to classify dynamical systems according to the asymptotic value of the associated entropy of curves.
The results shown so far associated a particular value of the entropy of curves to a dynamical system without specifying the choice of the initial line. Extensive simulations have been performed to prove that dependence on the initial conditions, for instance the direction or the length of initial line is not relevant. This is the case of many nonlinear systems, as those previously investigated, provided that the initial condition is chosen within the state space region of interest, for instance the attractor set for chaotic systems. In such situations, the entropy indicator manages to describe some nonlinearity properties of the dynamical system in exam, and simulation results were used to build up a thermometer with several degrees of nonlinearity associated to nonlinear behaviours, as shown in
figure 8.
According to simulations, noise and chaotic systems often have similar asymptotic entropy, and therefore are assumed to have comparable degrees of nonlinearity. However uniform noise and Bernoulli experiments with equal probabilities have higher entropy than chaotic systems. Entropies higher than
are not usually reached, although dynamical systems can be designed on purpose so that values of the entropy close to the limit of 1 can be achieved. Finally it is reminded that 0 entropy is achieved by all possible linear (arbitrarily time variant and unstable) dynamical systems. However, this thermometer is far from encompassing all possible nonlinear behaviours. For instance, in many situations the initial conditions (i.e. the first straight line) can affect the generalised entropy indicator and its final value, and therefore it does not make sense to associate the indicator to a dynamical system, since it depends on some initial choices. This can be unavoidable if the behaviour of the nonlinear system depends on the initial conditions as well. In this case Monte Carlo choices of the initial conditions might be necessary to distinguish among different behaviours of the same nonlinear system. As an example of this situation the logistic equation is considered in the case that the state is extended to include the fixed rate parameter:
It might sound misleading to describe a one dimensional system as the logistic map as a two dimensional one as in (
20) (although please note that this is artificial because the second state does not evolve). This is done here to propose a well-known example where the behaviour of the dynamical system depends on the initial conditions in the phase space. This is not true in the conventional notation where the parameter is not considered as a state. It is known from literature [
3] that the logistic function presents both stable and chaotic behaviours depending on the initial value of the parameter (
according to the notation of (
20)). Namely, system (
20) has one equilibrium when
is smaller than 3, it oscillates for parameter values between 3 and
(approximately), and shows a chaotic behaviour for values greater than
and smaller than 4. There is a so-called “island of stability" for values around
and finally it diverges for almost all initial conditions when the parameter is greater than 4. Therefore it is not very sensible to evaluate the dynamical system (
20) with one only indicator, but it is reasonable to compute the entropy indicator as a function of the initial condition of the second component. The graph of the entropy indicator so obtained is summarised in
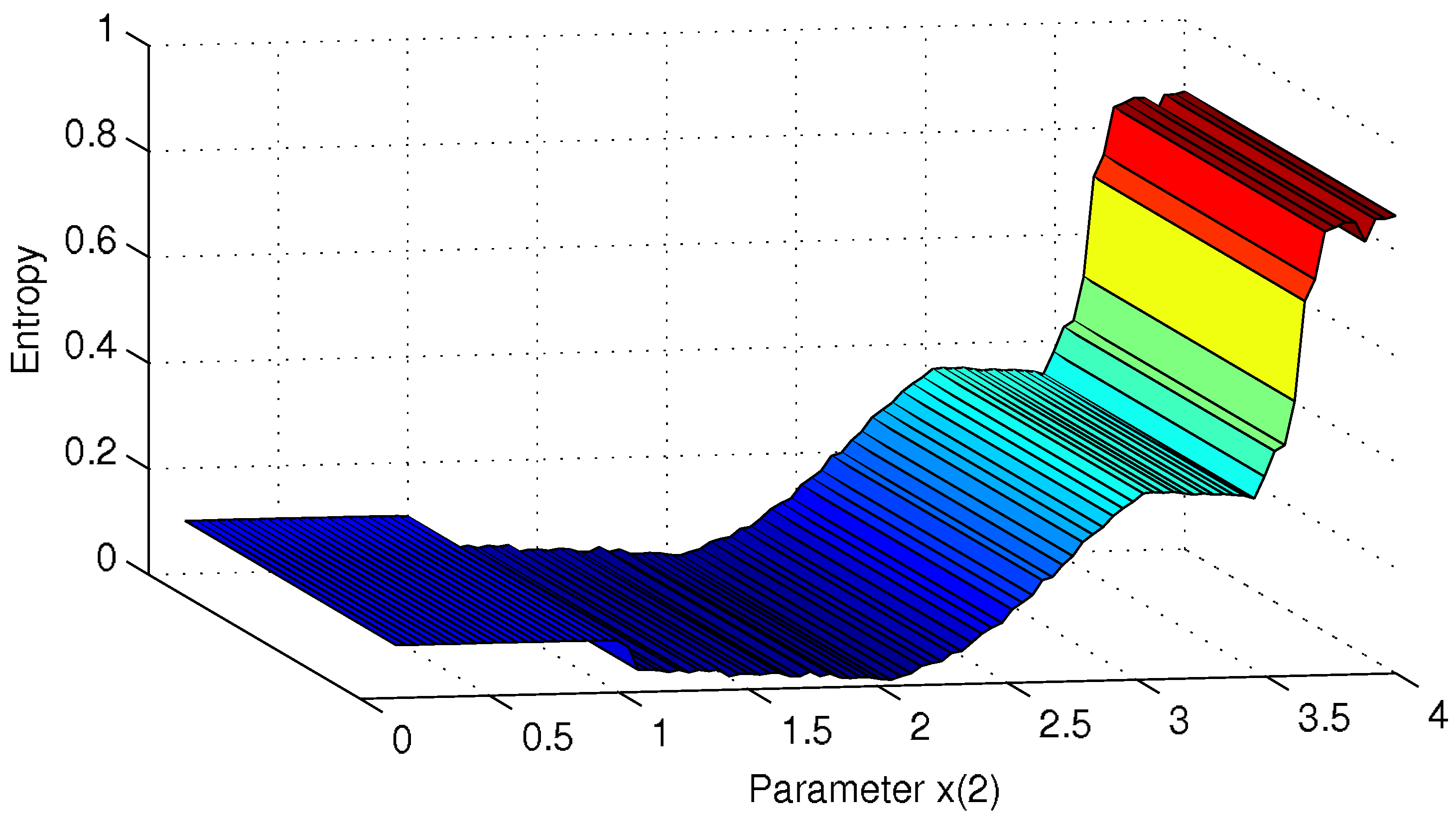
figure 9 and reproduces realistically the known behaviour of the logistic function.
Figure 9 shows the linear interpolation of the values of the asymptotic entropies computed for values of the parameter from
to 4 with a
interval step.
Following the same motivations of the previous example, a last problem is presented now where the behaviour of the dynamical system depends again on the special region of the phase space. This example is known as the standard map, and it is of particular interest in the nonlinear science and it corresponds to a conservative system where both order and chaos coexist. In fact, the phase space is composed at the same time of one large island of stability and a large connected chaotic domain [
31]. Dynamical equations are
where here
is used, so to discuss the example of [
31] with the same value of the parameter. In this case, we choose 20 random initial segments inside the unit square, and 1000 random points within each segment.
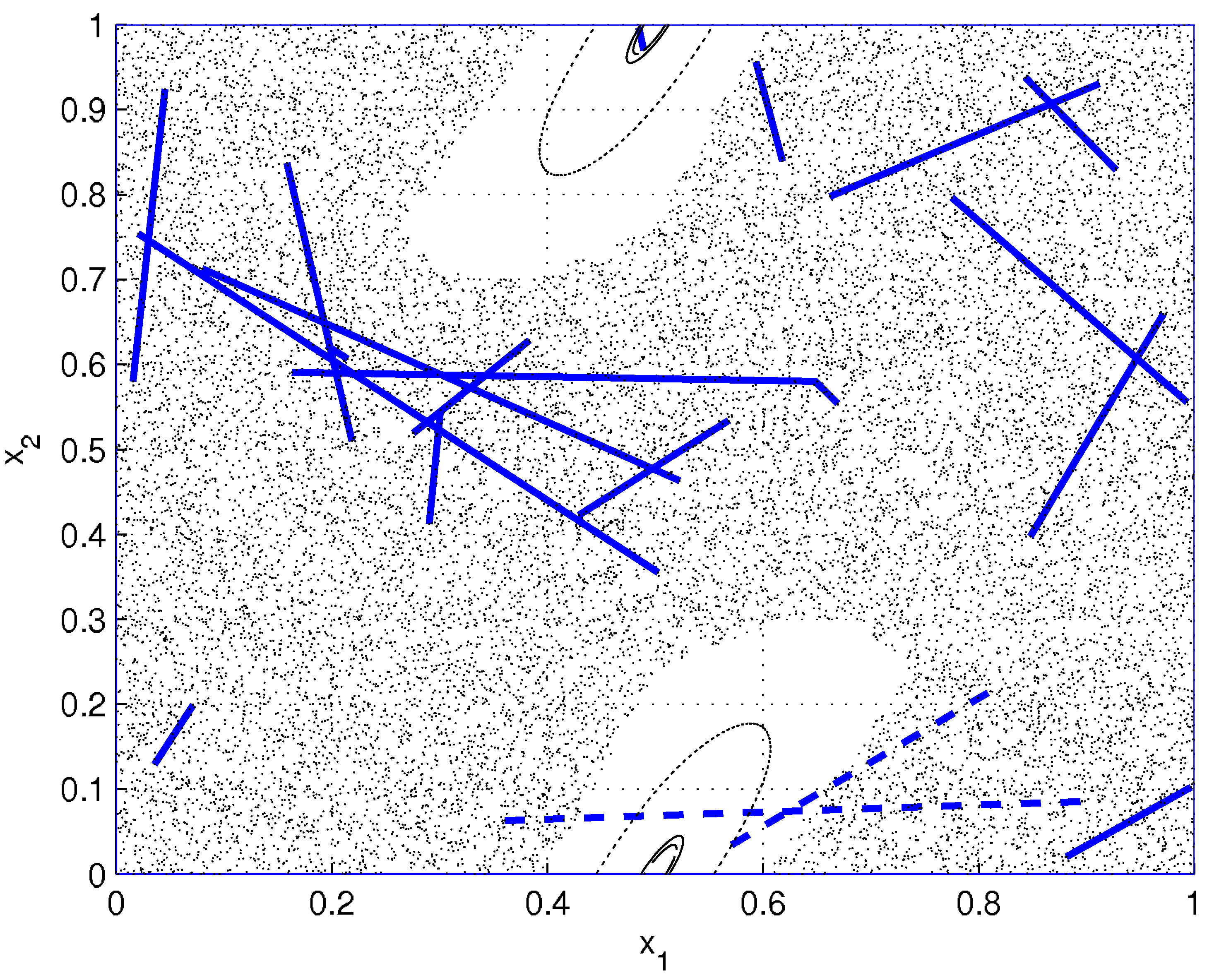
Figure 10 shows the initial segments, and the trajectories followed by the end-points of the segments. The trajectories followed by the end-points of the segments lying initially inside the island of stability can be followed easily by inspection, while points evolving in the chaotic region fill the region apparently homogeneously without following distinguishable orbits.
Figure 9.
Comparison of the entropy indicator of the logistic equation as a function of the parameter.
Figure 9.
Comparison of the entropy indicator of the logistic equation as a function of the parameter.
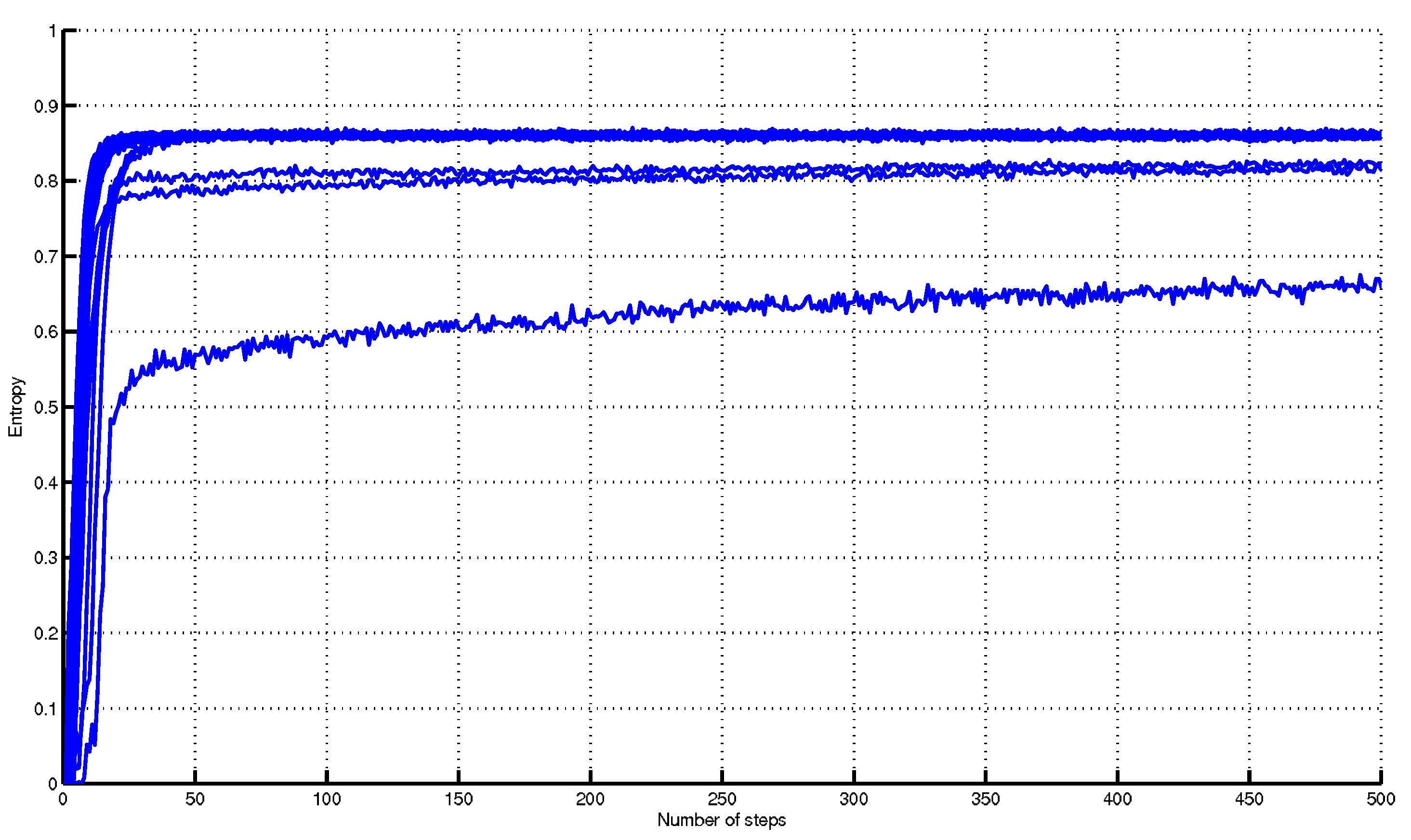
The 20 evolutions of the entropy are recorded and shown in
figure 11, where one entropy graph is clearly different from the others. As one might imagine, it corresponds to the initial condition of the segment inside the island of stability (in
figure 10 it corresponds to the small segment on top of the figure).
Moreover, there are other two entropy graphs slightly different from the others, and they correspond to the two dashed segments that partially cross the island of stability. While it is straightforward to classify the initial conditions from
figure 11, the same does not occur if one just compares the values of the asymptotic entropies as a function of the initial conditions. In fact, it might be surprising to find that all entropy graphs saturate to the same final value, corresponding to that of the other 17 initial segments of
figure 11 if a longer observation time range is chosen. Differently from all the previously studied examples, the information of the rate of growth of the generalised entropy (or alternatively the whole generalised entropy curves) should here be considered together with the asymptotic values to distinguish the initial conditions. Simulations show that the reason why entropy keeps increasing is that although trajectories associated to each initial point inside ordered regions look very regular, points progressively exchange their relative positions, also due to the
functions appearing in equations (
21), and thereby affect the value of the generalised entropy. Also notice that generalised entropy saturates to an asymptotic value and therefore its rate of growth can not be constant, as it is expected because the H index is bounded from above as previously proved in Property 2. A final observation to say that the final value of convergence is very close to the one that is obtained in the case of uniform noise in example 5, so it suggests that in the end the motion of the points is as nonlinear as if driven by a random motion with uniform distribution, independently from the initial conditions.
Figure 10.
Evolution of trajectories of points according to the standard map. Initial segments and the trajectories followed by one of their endpoints are also shown.
Figure 10.
Evolution of trajectories of points according to the standard map. Initial segments and the trajectories followed by one of their endpoints are also shown.
Figure 11.
Evolutions of the entropy for the 20 segments randomly chosen inside the unit square. The initial choice of the segments (whether inside or outside (or even crossing) the island of stability) clearly affects the entropy.
Figure 11.
Evolutions of the entropy for the 20 segments randomly chosen inside the unit square. The initial choice of the segments (whether inside or outside (or even crossing) the island of stability) clearly affects the entropy.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










