Robust Estimation for the Single Index Model Using Pseudodistances

1
Department of Applied Mathematics, Bucharest Academy of Economic Studies, 010374 Bucharest, Romania
2
“Gh. Mihoc - C. Iacob” Institute of Mathematical Satistics and Applied Mathematics, Romanian Academy, 010071 Bucharest, Romania
*
Author to whom correspondence should be addressed.
Entropy 2018, 20(5), 374; https://0-doi-org.brum.beds.ac.uk/10.3390/e20050374
Submission received: 31 March 2018
/
Revised: 11 May 2018
/
Accepted: 14 May 2018
/
Published: 17 May 2018
(This article belongs to the Special Issue New Developments in Statistical Information Theory Based on Entropy and Divergence Measures)
Abstract
:For portfolios with a large number of assets, the single index model allows for expressing the large number of covariances between individual asset returns through a significantly smaller number of parameters. This avoids the constraint of having very large samples to estimate the mean and the covariance matrix of the asset returns, which practically would be unrealistic given the dynamic of market conditions. The traditional way to estimate the regression parameters in the single index model is the maximum likelihood method. Although the maximum likelihood estimators have desirable theoretical properties when the model is exactly satisfied, they may give completely erroneous results when outliers are present in the data set. In this paper, we define minimum pseudodistance estimators for the parameters of the single index model and using them we construct new robust optimal portfolios. We prove theoretical properties of the estimators, such as consistency, asymptotic normality, equivariance, robustness, and illustrate the benefits of the new portfolio optimization method for real financial data.
1. Introduction
The problem of portfolio optimization in the mean-variance approach depends on a large number of parameters that need to be estimated on the basis of relatively small samples. Due to the dynamics of market conditions, only a short period of market history can be used for estimation of the model’s parameters. In order to reduce the number of parameters that need to be estimated, the single index model proposed by Sharpe (see [1,2]) can be used. The traditional estimators for parameters of the single index model are based on the maximum likelihood method. These estimators have optimal properties for normally distributed variables, but they may give completely erroneous results in the presence of outlying observations. Since the presence of outliers in financial asset returns is a frequently occurring phenomenon, robust estimates for the parameters of the single index model are necessary in order to provide robust and optimal portfolios.
Our contribution to robust portfolio optimization through the single index model is based on using minimum pseudodistance estimators.
The interest on statistical methods based on information measures and particularly on divergences has grown substantially in recent years. It is a known fact that, for a wide variety of models, statistical methods based on divergence measures have some optimal properties in relation to efficiency, but especially in relation to robustness, representing viable alternatives to the classical methods. We refer to the monographs of Pardo [3] and Basu et al. [4] for an excellent presentation of such methods, for their importance and applications.
We can say that the minimum pseudodistance methods for estimation go to the same category as the minimum divergence methods. The minimum divergence estimators are defined by minimizing some appropriate divergence between the assumed theoretical model and the true model corresponding to the data. Depending on the choice of the divergence, minimum divergence estimators can afford considerable robustness with a minimal loss of efficiency. The classical minimum divergence methods require nonparametric density estimation, which imply some difficulties such as the bandwidth selection. In order to avoid the nonparametric density estimation in minimum divergence estimation methods, some proposals have been made in [5,6,7] and robustness properties of such estimators have been studied in [8,9].
The pseudodistances that we use in the present paper were originally introduced in [6], where they are called "type-0" divergences, and corresponding minimum divergence estimators have been studied. They are also obtained (using a cross entropy argument) and extensively studied in [10] where they are called -divergences. They are also introduced in [11] in the context of decomposable pseudodistances. By its very definition, a pseudodistance satisfies two properties, namely the nonnegativity and the fact that the pseudodistance between two probability measures equals to zero if and only if the two measures are equal. The divergences are moreover characterized by the information processing property, i.e., by the complete invariance with respect to statistically sufficient transformations of the observation space (see [11], p. 617). In general, a pseudodistance may not satisfy this property. We adopted the term pseudodistance for this reason, but in the literature we can also meet the other terms above. The minimum pseudodistance estimators for general parametric models have been presented in [12] and consist of minimization of an empirical version of a pseudodistance between the assumed theoretical model and the true model underlying the data. These estimators have the advantages of not requiring any prior smoothing and conciliate robustness with high efficiency, usually requiring distinct techniques.
In this paper, we define minimum pseudodistance estimators for the parameters of the single index model and using them we construct new robust optimal portfolios. We study properties of the estimators, such as, consistency, asymptotic normality, robustness and equivariance and illustrate the benefits of the proposed portfolio optimization method through examples for real financial data.
We mention that we define minimum pseudodistance estimators, and prove corresponding theoretical properties, for the parameters of the simple linear regression model (35), associated with the single index model. However, in a very similar way, we can define minimum pseudodistance estimators and obtain the same theoretical results for the more general linear regression model , , where the errors are i.i.d. normal variables with mean zero and variance , is the vector of independent variables corresponding to the j-th observation and represents the regression coefficients.
The rest of the paper is organized as follows. In Section 2, we present the problem of robust estimation for some portfolio optimization models. In Section 3, we present the proposed approach. We define minimum pseudodistance estimators for regression parameters corresponding to the single index model and obtain corresponding estimating equations. Some asymptotic properties and equivariance properties of these estimators are studied. The robustness issue for estimators is considered through the influence function analysis. Using minimum pseudodistance estimators, new optimal portfolios are defined. Section 4 presents numerical results illustrating the performance of the proposed methodology. Finally, the proofs of the theorems are provided in the Appendix A.
2. The Single Index Model
Portfolio selection represents the problem of allocating a given capital over a number of available assets in order to maximize the return of the investment while minimizing the risk. We consider a portfolio formed by a collection of N assets. The returns of the assets are given by the random vector . Usually, it is supposed that X follows a multivariate normal distribution , with being the vector containing the mean returns of the assets and the covariance matrix of the assets returns. Let be the vector of weights associated with the portfolio, where is the proportion of capital invested in the asset i. Then, the total return of the portfolio is defined by the random variable
The mean and the variance of the portfolio return are given by
A classical approach for portfolio selection is the mean-variance optimization introduced by Markowitz [13]. For a given investor’s risk aversion , the mean-variance optimization gives the optimal portfolio , solution of the problem
with the constraint , being the N-dimensional vector of ones. The solution of the optimization problem (4) is explicit, the optimal portfolio weights for a given value of being
where
This is the case when short selling is allowed. When short selling is not allowed, we have a supplementary constraint in the optimization problem, namely all the weights are positive.
Another classical approach for portfolio selection is to minimize the portfolio risk defined by the portfolio variance, under given constraints. This means determining the optimal portfolio as a solution of the optimization problem
subject to , for a given value of the portfolio return.
However, the mean-variance analysis has been criticized for being sensitive to estimation errors of the mean and the covariance of the assets returns. For both optimization problems above, estimations of the input parameters and are necessary. The quality and hence the usefulness of the results of the portfolio optimization problem critically depend on the quality of the statistical estimates for these input parameters. The mean vector and the covariance matrix of the returns are in practice estimated by the maximum likelihood estimators under the multivariate normal assumption. When the model is exactly satisfied, the maximum likelihood estimators have optimal properties, being the most efficient. On the other hand, in the presence of outlying observations, these estimators may give completely erroneous results and consequently the weights of the corresponding optimal portfolio may be completely misleading. It is a known fact that outliers frequently occur in asset returns, where an outlier is defined to be an unusually large value well separated from the bulk of the returns. Therefore, robust alternatives to the classical approaches need to be carefully analyzed.
For an overview on the robust methods for portfolio optimization, using robust estimators of the mean and covariance matrix in the Markowitz’s model, we refer to [14]. We also cite the methods proposed by Vaz-de Melo and Camara [15], Perret-Gentil and Victoria-Feser [16], Welsch and Zhou [17], DeMiguel and Nogales [18], and Toma and Leoni-Aubin [19].
On the other hand, in portfolio analysis, one is sometimes faced with two conflicting demands. Good quality statistical estimates require a large sample size. When estimating the covariance matrix, the sample size must be larger than the number of different elements of the matrix. For example, for a portfolio involving 100 securities, this would mean observations from 5050 trading days, which is about 20 years. From a practical point of view, considering such large samples is not adequate for the considered problem. Since the market conditions change rapidly, very old observations would lead to irrelevant estimates for the current or future market conditions. In addition, in some situations, the number of assets could even be much larger than the sample size of exploitable historical data. Therefore, estimating the covariance matrix of asset returns is challenging due to the high dimensionality and also to the heavy-tailedness of asset return data. It is a known fact that extreme events are typical in financial asset prices, leading to heavy-tailed asset returns. One way to treat these problems is to use the single index model.
The single index model (see [1]) allows us to express the large number of covariances between the returns of the individual assets through a significantly smaller number of parameters. This is possible under the hypothesis that the correlation between two assets is strictly given by their dependence on a common market index. The return of each asset i is expressed under the form
where is the random variable representing the return of the market index, are zero mean random variables representing error terms and are new parameters to be estimated. It is supposed that the ’s are independent and also that the s are independent of . Thus, , and for all i and all .
The intercept in Equation (35) represents the asset’s expected return when the market index return is zero. The slope coefficient represents the asset’s sensitivity to the index, namely the impact of a unit change in the return of the index. The error is the return variation that cannot be explained by the index.
The following notations are also used:
Both variances and covariances are determined by the assets’ betas and sigmas and by the standard deviation of the market index. Thus, the different elements of the covariance matrix can be expressed by parameters , . This is a significant reduction of the number of parameters that need to be estimated.
The traditional estimators for parameters of the single index model are based on the maximum likelihood method. These estimators have optimal properties for normally distributed variables, but they may give completely erroneous results in the presence of outlying observations. Therefore, robust estimates for the parameters of the single index model are necessary in order to provide robust and optimal portfolios.
3. Robust Estimators for the Single Index Model and Robust Portfolios
3.1. Definitions of the Estimators
Consider the linear regression model
Suppose we have i.i.d. two-dimensional random vectors , , such that . The random variables , , are i.i.d. with and independent on the , .
The classical estimators for the unknown parameters of the linear regression model are the maximum likelihood estimators (MLE). The classical MLE estimators perform well if the model hypotheses are satisfied exactly and may otherwise perform poorly. It is well known that the MLE are not robust, since a small fraction of outliers, even one outlier may have an important effect inducing significant errors on the estimates. Therefore, robust alternatives of the MLE should be considered, in order to propose robust estimates for the single index model, leading then to robust portfolio weights.
In order to robustly estimate the unknown parameters , suppressing the outsized effects of outliers, we use the approach based on pseudodistance minimization.
For two probability measures admitting densities p, respectively, q with respect to the Lebesgue measure, we consider the following family of pseudodistances (also called -divergences in some articles) of orders
satisfying the limit relation
Note that is the well-known modified Kullback–Leibler divergence. Minimum pseudodistance estimators for parametric models, using the family (13), have been studied by [6,10,11]. We also mention that pseudodistances (13) have also been used for defining optimal robust M-estimators with the Hampel’s infinitesimal approach in [20].
For the linear regression model, we consider the joint distribution of the entire data, the explanatory variable being random together with the response variable X, and write a pseudodistance between a theoretical model and the data. Let , with , be the probability measure associated with the theoretical model given by the random vector , where with , e independent on , and Q the probability measure associated with the data. Denote by , respectively, q, the corresponding densities. For , the pseudodistance between and Q is defined by
Using the change of variables and taking into account that is the density of , since and e are independent, we can write
where is the density of and is the density of the random variable . Then,
Notice that the first and the third terms in the pseudodistance do not depend on and hence are not included in the minimization process. The parameter of interest is then given by
Suppose now that an i.i.d. sample is available from the true model. For a given , we define a minimum pseudodistance estimator of by minimizing an empirical version of the objective function in Equation (17). This empirical version is obtained by replacing with the empirical density function , where is the Dirac delta function, and Q with the empirical measure corresponding to the sample. More precisely, we define
or equivalently
Differentiating with respect to , the estimators are solutions of the system
Note that, for , the solution of this system is nothing but the maximum likelihood estimator of . Therefore, the estimating Equations (19)–(21) are generalizations of the maximum likelihood score equations. The tuning parameter associated with the pseudodistance controls the trade-off between robustness and efficiency of the minimum pseudodistance estimators.
We can also write that is a solution of
where
with , , and .
When the measure Q corresponding to the data pertain to the theoretical model, hence , it holds that
Thus, we can consider as a Z-estimator of , which allows for adapting in the present context asymptotic results from the general theory of Z-estimators (see [21]).
Remark 1.
In the case when the density is known, by replacing Q with the empirical measure in Equation (17), a new class of estimators of can be obtained. These estimators can also be written under the form of Z-estimators, using the same reasoning as above. The results of Theorems 1–4 below could be adapted for these new estimators, and moreover all the influence functions of these estimators would be redescending bounded. However, in practice, the density of the index return is not known. Therefore, we will work with the class of minimum pseudodistance estimators as defined above.
3.2. Asymptotic Properties
In order to prove the consistency of the estimators, we use their definition (22) as Z-estimators.
3.2.1. Consistency
Theorem 1.
Assume that, for any , the following condition for the separability of solution holds
where . Then, converges in probability to .
3.2.2. Asymptotic Normality
Assume that are i.i.d. two-dimensional random vectors having the common probability distribution . For fixed, let be a sequence of estimators of the unknown parameter , solution of
where
with , , and . Note that the estimators defined by Equations (19)–(21), or equivalently by (22), are also solutions of the system (26). Using the function (27) for defining the estimators allows for obtaining the asymptotic normality, only imposing the consistency condition of the estimators, without other supplementary assumptions that are usually imposed in the case of Z-estimators.
Theorem 2.
Assume that in probability. Then,
in distribution, where and , with Ψ defined by (27), being the matrix with elements .
After some calculations, we obtain the asymptotic covariance matrix of having the form
It follows that and are asymptotically independent; in addition, and are asymptotically independent.
3.3. Influence Functions
In order to describe stability properties of the estimators, we use the following well-known concepts from the theory of robust statistics. A map T, defined on a set of probability measures and parameter space valued, is a statistical functional corresponding to an estimator of the parameter , if , being the empirical measure pertaining to the sample. The influence function of T at is defined by
where being the Dirac measure putting all mass at z. As a consequence, the influence function describes the linearized asymptotic bias of a statistic under a single point contamination of the model . An unbounded influence function implies an unbounded asymptotic bias of a statistic under single point contamination of the model. Therefore, a natural robustness requirement on a statistical functional is the boundedness of its influence function.
For fixed and a given probability measure P, the statistical functionals , and , corresponding to the minimum pseudodistance estimators , and , are defined by the solution of the system
with defined by (23) and , whenever this solution exists.
When corresponds to the considered theoretical model, the solution of system (29) is .
Theorem 3.
The influence functions corresponding to the estimators and are respectively given by
Since is redescending, has a bounded influence function and hence it is a redescending B-robust estimator. On the other hand, and will tend to infinity only when tends to infinity and , for some k. Hence, these influence functions are bounded with respect to partial outliers or leverage points (outlying values of the independent variable). This means that large outliers with respect to , or with respect to x, will have a reduced influence on the estimates. However, the influence functions are clearly unbounded for , which corresponds to the non-robust maximum likelihood estimators.
3.4. Equivariance of the Regression Coefficients’ Estimators
If an estimator is equivariant, it means that it transforms "properly" in some sense. Rousseeuw and Leroy [22] (p. 116) discuss three important equivariance properties for a regression estimator: regression equivariance, scale equivariance and affine equivariance. These are desirable properties since they allow one to know how the estimates change under different types of transformations of the data. Regression equivariance means that any additional linear dependence is reflected in the regression vector accordingly. The regression equivariance is routinely used when studying regression estimators. It allows for assuming, without loss generality, any value for the parameter for proving asymptotic properties or describing Monte-Carlo studies. An estimator being scale equivariant means that the fit produced by it is independent of the choice of measurement unit for the response variable. The affine equivariance is useful because it means that changing to a different co-ordinate system for the explanatory variable will not affect the estimate. It is known that the maximum likelihood estimator of the regression coefficients satisfies all these three properties. We show that the minimum pseudodistance estimators of the regression coefficients satisfy all the three equivariance properties, for all .
Theorem 4.
For all , the minimum pseudodistance estimators of the regression coefficients are regression equivariant, scale equivariant and affine equivariant.
On the other hand, the objective function in the definition of the estimators depends on data only through the summation
which is permutation invariant. Thus, the corresponding estimators of the regression coefficients and of the error standard deviation are permutation invariant, therefore the ordering of data does not affect the estimators.
The minimum pseudodistance estimators are also equivariant with respect to reparametrizations. If and the model is reparametrized to with a one-to-one transformation, then the minimum pseudodistance estimator of is simply , in terms of the minimum pseudodistance estimator of , for the same .
3.5. Robust Portfolios Using Minimum Pseudodistance Estimators
The robust estimation of the parameters from the single index model given by (35), using minimum pseudodistance estimators, together with the robust estimation of and lead to robust estimates of and , on the basis of relations (9)–(11). Since we do not model the explanatory variable in a specific way, we estimate and the standard deviation using as robust estimators the median, respectively the median absolute deviation. Then, the portfolio weights, obtained as solutions of the optimization problems (4) or (7) with input parameters robustly estimated, will also be robust. This methodology leads to new optimal robust portfolios. In the next section, on the basis of real financial data, we illustrate this new methodology and compare it with the traditional method based on maximum likelihood estimators.
4. Applications
4.1. Comparisons of the Minimum Pseudodistance Estimators with Other Robust Estimators for the Linear Regression Model
In order to illustrate the performance of the minimum pseudodistance estimators for the simple linear regression model, we compare them with the least median of squares (LMS) estimator (see [22,23]), with S-estimators (SE) (see [24]) and with the minimum density power divergence (MDPD) estimators (see [25]), estimators that are known to have a good behavior from the robustness point of view.
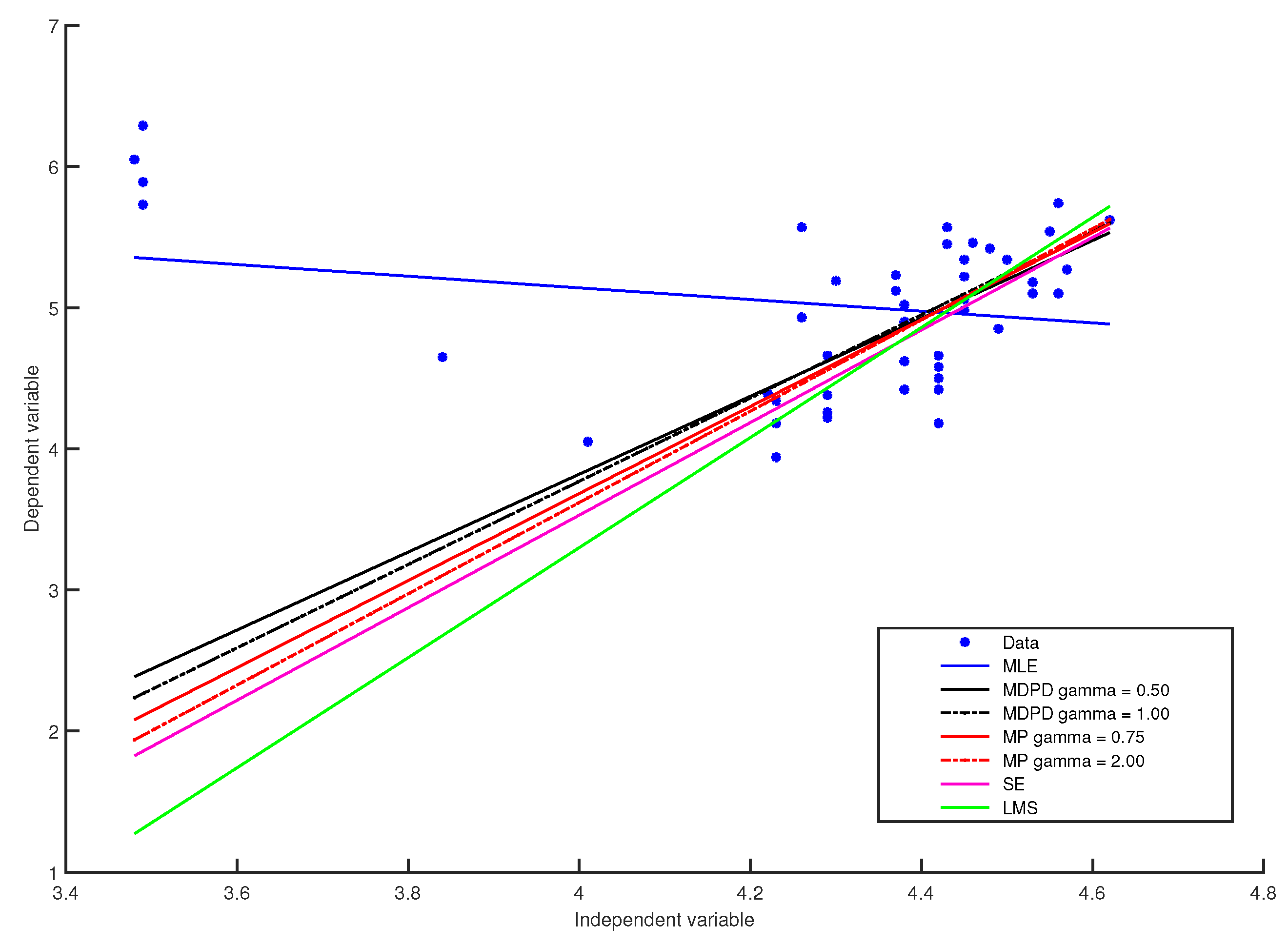
We considered a data set that comes from astronomy, namely the data from the Hertzsprung–Russell diagram of the star clusters CYG OB1 containing 47 stars in the direction of Cygnus. For these data, the independent variable is the logarithm of the effective temperature at the surface of the star and the dependent variable is the logarithm of its light intensity. The data are given in Rousseeuw and Leroy [22] (p. 27), who underlined that there are two groups of points: the majority, following a steep band, and four stars clearly forming a separate group from the rest of the data. These four stars are known as giants in astronomy. Thus, these outliers are not recording errors, but represents leverage points coming from a different group.
The estimates of the regression coefficients and of error standard deviation obtained with minimum pseudodistance estimators for several values of are given in Table 1 and some of the fitted models are plotted in Figure 1. For comparison, in Table 1, we also give estimates obtained with S-estimators based on the Tukey biweighted function, these estimates being taken from [24], as well as estimations obtained with minimum density power divergence methods for several values of the tuning parameter, and estimates obtained with the least median of squares method, all these estimates being taken from [25]. The MLE estimates, given on the first line of Table 1, are significantly affected by the four leverage points. On the other hand, like the robust least median of squares estimator, the robust S-estimators and some minimum density power divergence estimators, the minimum pseudodistance estimators with can successfully ignore outliers. In addition, the minimum pseudodistance estimators with give robust fits that are closer to the fits generated by the least median of squares estimates or by the S-estimates than the fits generated by the minimum density power divergence estimates.
4.2. Robust Portfolios Using Minimum Pseudodistance Estimators
In order to illustrate the performance of the proposed robust portfolio optimization method, we considered real data sets for the Russell 2000 index and for 50 stocks from its components. The stocks are listed in Appendix B. We selected daily return data for the Russell 2000 index and for all these stocks from 2 January 2013 to 30 June 2016. The data were retrieved from Yahoo Finance.
The data has been divided by quarter, in total 14 quarters for index and each stock. For each quarter, on the basis of data corresponding to the index, we estimated and the standard deviation using as robust estimators the median (MED), respectively the median absolute deviation (MAD) defined by
We also estimated and classically, using sample mean and sample variance. Then, for each quarter and each of the 50 stocks, we estimated , and from the regression model using robust minimum pseudodistance estimators, respectively the classical MLE estimators. Then, on the basis of relations (9), (10) and (11), we estimated and first using the robust estimates and then the classical estimates, all being previously computed.
Once the input parameters for the portfolio optimization procedure were estimated, for each quarter, we determined efficient frontiers, for both robust estimates and classical estimates. In both cases, the efficient frontier is determined as follows. Firstly, the range of returns is determined as the interval comprised between the return of the portfolio of global minimum risk (variance) and the maximum value of the return of a feasible portfolio, where the feasible region is
and . We trace each efficient frontier in 100 points; therefore, the range of returns is divided, in each case, in ninety-nine sub-intervals with
where is the return of the portfolio of global minimum variance and is the maximum return for the feasible region X. We determined and using robust estimates of and (for the robust frontier) and then using classical estimates (for the classical frontier). In each case, 100 optimization problems are solved:
where .
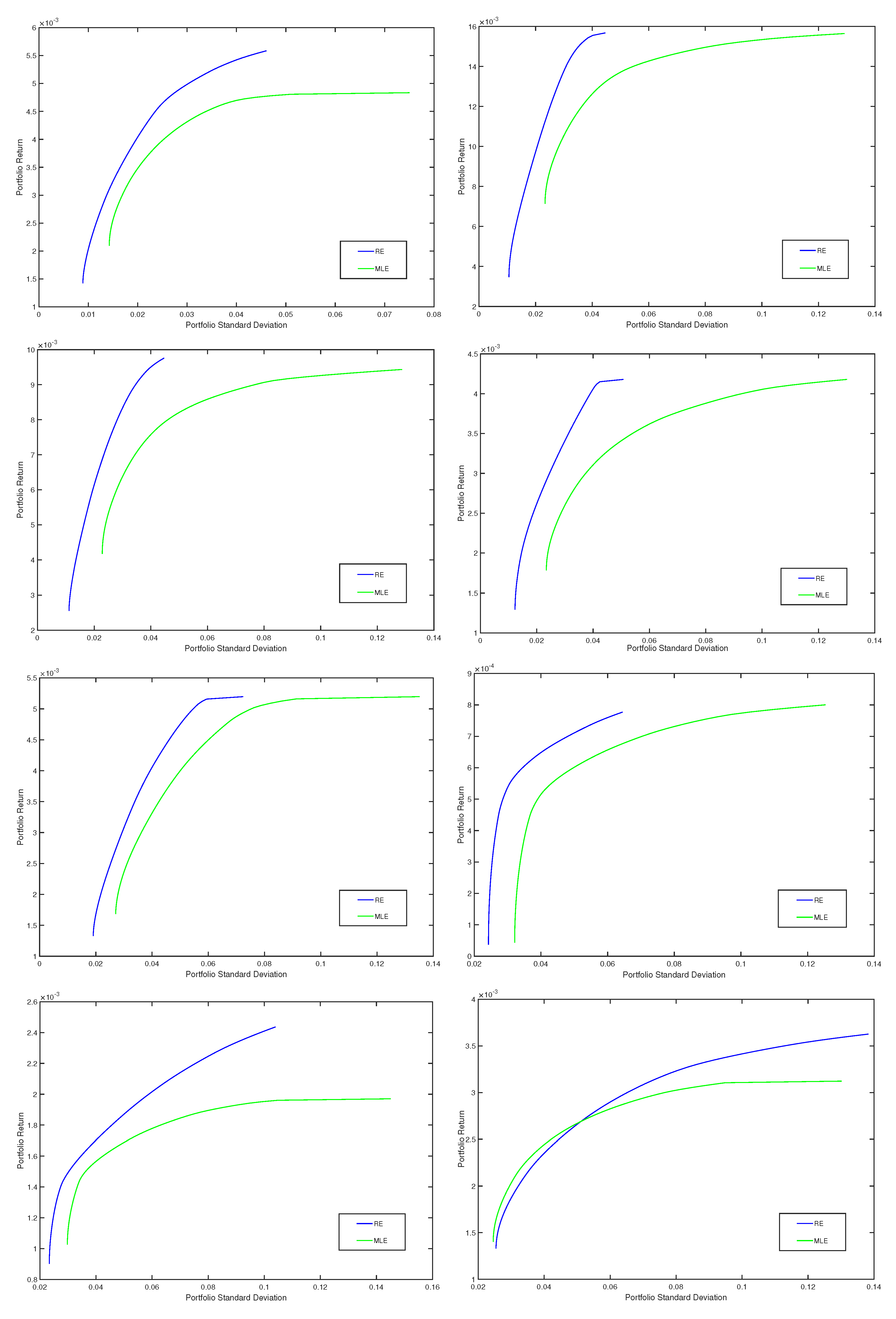
In Figure 2, for eight quarters (the first four quarters and the last four quarters), we present efficient frontiers corresponding to the optimal minimum variance portfolios based on the robust minimum pseudodistance estimates with , respectively based on the classical estimates. Thus, on the -axis, we consider the portfolio risk (given by the portfolio standard deviation) and, on the -axis, we represent the portfolio return. We notice that, in comparison with the classical method based on MLE, the proposed robust method provides optimal portfolios that have higher returns for the same level of risk (standard deviation). Indeed, for each quarter, the robust frontier is situated above the classical one, the standard deviations of the robust portfolios being smaller compared with those of the classical portfolios. We obtained similar results for the other quarters and for other choices of the tuning parameter , corresponding to the minimum pseudodistance estimators, too.
We also illustrate the empirical performance of the proposed optimal portfolios through an out-of-sample analysis, by using the Sharpe ratio as out-of-sample measure. For this analysis, we apply a “rolling-horizon” procedure as presented in [18]. First, we choose a window over which to perform the estimation. We denote the length of the estimation window by , where T is the size of the entire data set. Then, using the data in the first estimation window, we compute the weights for the considered portfolios. We repeat this procedure for the next window, by including the data for the next day and dropping the data for the earliest day. We continue doing this until the end of the data set is reached. At the end of this process, we have generated portfolio weight vectors for each strategy, which are the vectors for , k denoting the strategy. For a strategy k, has the components , where denotes the portfolio weight in asset j chosen at the time t.
The out-of-sample return at the time , corresponding to the strategy k, is defined as , representing the data at the time . For each strategy k, using these out-of-sample returns, the out-of-sample mean and the out-of-sample variance are defined by
and the out-of-sample Sharpe ratio is defined by
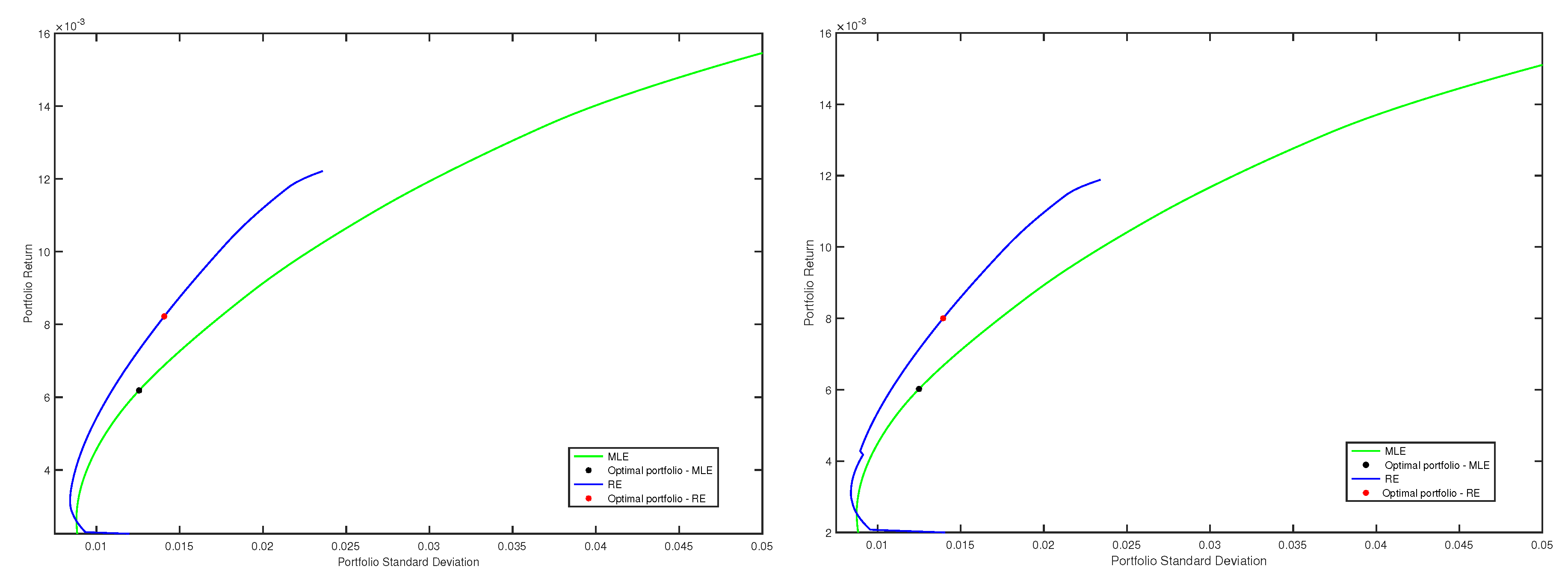
In this example, we considered the data set corresponding to the quarters 13 and 14. The size of the entire data set was and the length of the estimation window was points. For the data from the first window, classical and robust efficient frontiers were traced, following all the steps that we explained in the first part of this subsection. More precisely, we considered the classical efficient frontier corresponding to the optimal minimum variance portfolios based on MLE and three robust frontiers, corresponding to the optimal minimum variance portfolios using robust minimum pseudodistance estimations with , and , respectively. Then, on each frontier, we chose the optimal portfolio associated with the maximal value of the ratio between the portfolio return and portfolio standard deviation. These four optimal portfolios represent the strategies that we compared in the out-of-sample analysis. For each of these portfolios, we computed the out-of-sample returns for the next time (next day). Then, we repeated all these procedures for the next window, and so on until the end of the data set has been reached. In the spirit of [18] Section 5, using (35) and (36), we computed out-of-sample means, out-of-sample variances and out-of-sample Sharpe ratios for each strategy. The out-of-sample means and out-of-sample variances were annualized, and we also considered a benchmark rate of 1.5 %. In this way, we obtained the following values for the out-of-sample Sharpe ratio: for the optimal portfolio based on MLE, for the optimal portfolio based on minimum pseudodistance estimations with , for the optimal portfolio based on minimum pseudodistance estimations with and for the optimal portfolio based on minimum pseudodistance estimations with . In Figure 3, we illustrate efficient frontiers for the windows 7 and 8, as well as the optimal portfolios chosen on each frontier.
This example shows that the optimal minimum variance portfolios based on robust minimum pseudodistance estimations in the single index model may attain higher Sharpe ratios than the traditional optimal minimum variance portfolios given by the single index model using MLE.
The obtained numerical results show that, for the single index model, the presented robust technique for portfolio optimization yields better results than the classical method based on MLE, in the sense that it leads to larger returns for the same value of risk in the case when outliers or atypical observations are present in the data set. The considered data sets contain such outliers. This is often the case for the considered problem, since outliers frequently occur in asset returns data. However, when there are no outliers in the data set, the classical method based on MLE is more efficient than the robust ones and therefore may lead to better results.
5. Conclusions
When outliers or atypical observations are present in the data set, the new portfolio optimization method based on robust minimum pseudodistance estimates yields better results than the classical single index method based on MLE estimates, in the sense that it leads to larger returns for smaller risks. In literature, there exist various methods for robust estimation in regression models. In the present paper, we proposed the method based on the minimum pseudodistance approach, which suppose to solve a simple optimization problem. In addition, from a theoretical point of view, these estimators have attractive properties, such as being redescending robust, consistent, equivariant and asymptotically normally distributed. The comparison with other known robust estimators of the regression parameters, such as the least median of squares estimators, the S-estimators or the minimum density power divergence estimators, shows that the minimum pseudodistance estimators represent an attractive alternative that may be considered in other applications too.
Author Contributions
A.T. designed the methodology, obtained the theoretical results and wrote the paper. A.T. and C.F. conceived the application part. C.F. implemented the methods in MATLAB and obtained the numerical results. Both authors have read and approved the final manuscript.
Acknowledgments
This work was supported by a grant of the Romanian National Authority for Scientific Research, CNCS-UEFISCDI, project number PN-II-RU-TE-2012-3-0007.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of the Results
Proof of Theorem 1.
Since the functions and are redescending bounded functions, for a compact neighborhood of , it holds
Since is continuous, by the uniform law of large numbers, (A1) implies
in probability.
Proof of Theorem 2.
First, note that defined by (27) is twice differentiable with respect to with bounded derivatives. The matrix has the form
with and . Since are redescending bounded functions, for , it holds
In addition, a simple calculation shows that each component is a bounded function, since it can be expressed through the functions , which are redescending bounded functions. In addition, bounds that can be established for each component do not depend on the parameter .
For each i, call the matrix with elements and the matrix with its i-th raw equal to . Using a Taylor expansion, we get
Therefore,
with
i.e., is the matrix with its i-th raw equal to , where
which is bounded by a constant that does not depend on , according to the arguments mentioned above. Since in probability, this implies that in probability.
We have
Note that, for , the vectors are i.i.d. with mean zero and the covariance matrix A, and the matrices are i.i.d. with mean B. Hence, when , using (A3), the law of large numbers implies that in probability, which implies in probability, which is nonsingular. Then, the multivariate central limit theorem implies in distribution.
Then,
in distribution, according to the multivariate Slutzki’s Lemma. ☐
Proof of Theorem 3.
The system (29) can be written as
We consider the contaminated model , where is the Dirac measure putting all mass in the point , which we simply denote here by . Then, it holds
Derivating the first equation with respect to and taking the derivatives in , we obtain
After some calculations, we obtain the relation
Proof of Theorem 4.
In the following, we simply denote by the vector . Then,
For any two-dimensional column vector v, we have
which show that is regression equivariant.
For any constant , we have
This implies that the estimator is scale equivariant.
Now, for any two-dimensional square matrix A, we get
which show the affine equivariance of the estimator . ☐
Appendix B. The 50 Stocks and Their Abbreviations
- Asbury Automotive Group, Inc. (ABG)
- Arctic Cat Inc. (ACAT)
- American Eagle Outfitters, Inc. (AEO)
- AK Steel Holding Corporation (AKS)
- Albany Molecular Research, Inc. (AMRI)
- The Andersons, Inc. (ANDE)
- ARMOUR Residential REIT, Inc. (ARR)
- BJ’s Restaurants, Inc. (BJRI)
- Brooks Automation, Inc. (BRKS)
- Caleres, Inc. (CAL)
- Cincinnati Bell Inc. (CBB)
- Calgon Carbon Corporation (CCC)
- Coeur Mining, Inc. (CDE)
- Cohen & Steers, Inc. (CNS)
- Cray Inc. (CRAY)
- Cirrus Logic, Inc. (CRUS)
- Covenant Transportation Group, Inc. (CVTI)
- EarthLink Holdings Corp. (ELNK)
- Gray Television, Inc. (GTN)
- Triple-S Management Corporation (GTS)
- Getty Realty Corp. (GTY)
- Hecla Mining Company (HL)
- Harmonic Inc. (HLIT)
- Ligand Pharmaceuticals Incorporated (LGND)
- Louisiana-Pacific Corporation (LPX)
- Lattice Semiconductor Corporation (LSCC)
- ManTech International Corporation (MANT)
- MiMedx Group, Inc. (MDXG)
- Medifast, Inc. (MED)
- Mentor Graphics Corporation (MENT)
- Mistras Group, Inc. (MG)
- Mesa Laboratories, Inc. (MLAB)
- Meritor, Inc. (MTOR)
- Monster Worldwide, Inc. (MWW)
- Nektar Therapeutics (NKTR)
- Osiris Therapeutics, Inc. (OSIR)
- PennyMac Mortgage Investment Trust (PMT)
- Paratek Pharmaceuticals, Inc. (PRTK)
- Repligen Corporation (RGEN)
- Rigel Pharmaceuticals, Inc. (RIGL)
- Schnitzer Steel Industries, Inc. (SCHN)
- comScore, Inc. (SCOR)
- Safeguard Scientifics, Inc. (SFE)
- Silicon Graphics International (SGI)
- Sagent Pharmaceuticals, Inc. (SGNT)
- Semtech Corporation (SMTC)
- Sapiens International Corporation N.V. (SPNS)
- Sarepta Therapeutics, Inc. (SRPT)
- Take-Two Interactive Software, Inc. (TTWO)
- Park Sterling Corporation (PSTB)
References
- Sharpe, W.F. A simplified model to portfolio analysis. Manag. Sci. 1963, 9, 277–293. [Google Scholar] [CrossRef]
- Alexander, G.J.; Sharpe, W.F.; Bailey, J.V. Fundamentals of Investments; Prentice-Hall: Upper Saddle River, NJ, USA, 2000. [Google Scholar]
- Pardo, L. Statistical Inference Based on Divergence Measures; Chapman & Hall: Boca Raton, FL, USA, 2006. [Google Scholar]
- Basu, A.; Shioya, H.; Park, C. Statistical Inference: the Minimum Pseudodistance Approach; CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- Basu, A.; Harris, I.R.; Hjort, N.L.; Jones, M.C. Robust and efficient estimation by minimizing a density power divergence. Biometrika 1998, 85, 549–559. [Google Scholar] [CrossRef]
- Jones, M.C.; Hjort, N.L.; Harris, I.R.; Basu, A. A comparison of related density-based minimum divergence estimators. Biometrika 2001, 88, 865–873. [Google Scholar] [CrossRef]
- Broniatowski, M.; Keziou, A. Parametric estimation and tests through divergences and the duality technique. J. Multivar. Anal. 2009, 100, 16–36. [Google Scholar] [CrossRef]
- Toma, A.; Leoni-Aubin, S. Robust tests based on dual divergence estimators and saddlepoint approximations. J. Multivar. Anal. 2010, 101, 1143–1155. [Google Scholar] [CrossRef]
- Toma, A.; Broniatowski, M. Dual divergence estimators and tests: Robustness results. J. Multivar. Anal. 2011, 102, 20–36. [Google Scholar] [CrossRef]
- Fujisawa, H.; Eguchi, S. Robust parameter estimation with a small bias against heavy contamination. J. Multivar. Anal. 2008, 99, 2053–2081. [Google Scholar] [CrossRef]
- Broniatowski, M.; Vajda, I. Several applications of divergence criteria in continuous families. Kybernetica 2012, 48, 600–636. [Google Scholar]
- Broniatowski, M.; Toma, A.; Vajda, I. Decomposable pseudodistances and applications in statistical estimation. J. Stat. Plan. Inference 2012, 142, 2574–2585. [Google Scholar] [CrossRef]
- Markowitz, H.M. Mean-variance analysis in portfolio choice and capital markets. J. Finance 1952, 7, 77–91. [Google Scholar]
- Fabozzi, F.J.; Huang, D.; Zhou, G. Robust portfolios: contributions from operations research and finance. Ann. Oper. Res. 2010, 176, 191–220. [Google Scholar] [CrossRef]
- Vaz-de Melo, B.; Camara, R.P. Robust multivariate modeling in finance. Int. J. Manag. Finance 2005, 4, 12–23. [Google Scholar] [CrossRef]
- Perret-Gentil, C.; Victoria-Feser, M.P. Robust Mean-Variance Portfolio Selection. FAME Research Paper, No. 140. 2005. Available online: papers.ssrn.com/sol3/papers.cfm?abstract_id=721509 (accessed on 28 February 2018).
- Welsch, R.E.; Zhou, X. Application of robust statistics to asset allocation models. Revstat. Stat. J. 2007, 5, 97–114. [Google Scholar]
- DeMiguel, V.; Nogales, F.J. Portfolio selection with robust estimation. Oper. Res. 2009, 57, 560–577. [Google Scholar] [CrossRef]
- Toma, A.; Leoni-Aubin, S. Robust portfolio optimization using pseudodistances. PLoS ONE 2015, 10, 1–26. [Google Scholar] [CrossRef] [PubMed]
- Toma, A.; Leoni-Aubin, S. Optimal robust M-estimators using Renyi pseudodistances. J. Multivar. Anal. 2013, 115, 359–373. [Google Scholar] [CrossRef]
- Van der Vaart, A. Asymptotic Statistics; Cambridge University Press: New York, NY, USA, 1998. [Google Scholar]
- Rousseeuw, P.J.; Leroy, A.M. Robust Regression and Outlier Detection; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- Andersen, R. Modern Methods for Robust Regression; SAGE Publications, Inc.: Los Angeles, CA, USA, 2008. [Google Scholar]
- Rousseeuw, P.J.; Yohai, V. Robust regression by means of S-estimators. In Robust and Nonlinear Time Series Analysis; Franke, J., Hardle, W., Martin, D., Eds.; Springer: New York, NY, USA, 1984; pp. 256–272. ISBN 978-0-387-96102-6. [Google Scholar]
- Ghosh, A.; Basu, A. Robust estimations for independent, non-homogeneous observations using density power divergence with applications to linear regression. Electron. J. Stat. 2013, 7, 2420–2456. [Google Scholar] [CrossRef]
Figure 1.
Plots of the Hertzsprung–Russell data and fitted regression lines using MLE, minimum density power divergence (MDPD) methods for several values of , minimum pseudodistance (MP) methods for several values of , S-estimators (SE) and the least median of squares (LMS) method.
Figure 1.
Plots of the Hertzsprung–Russell data and fitted regression lines using MLE, minimum density power divergence (MDPD) methods for several values of , minimum pseudodistance (MP) methods for several values of , S-estimators (SE) and the least median of squares (LMS) method.

Figure 2.
Efficient frontiers, classical (MLE) vs. robust corresponding to (RE), for eight quarters (the first four quarters and the last four quarters).
Figure 2.
Efficient frontiers, classical (MLE) vs. robust corresponding to (RE), for eight quarters (the first four quarters and the last four quarters).

Figure 3.
Efficient frontiers, classical (MLE) vs. robust corresponding to (RE), and optimal portfolios chosen on frontiers, for the windows 7 (left) and 8 (right).
Figure 3.
Efficient frontiers, classical (MLE) vs. robust corresponding to (RE), and optimal portfolios chosen on frontiers, for the windows 7 (left) and 8 (right).


{kind=link}
{kind=link}
{kind=link}
Table 1.
The parameter estimates for the linear regression model for the Hertzsprung–Russell data using several minimum pseudodistance (MP) methods, several minimum density power divergence (MDPD) methods, the least median of squares (LMS) method, S-estimators and the MLE method. represents tuning parameter.
Table 1.
The parameter estimates for the linear regression model for the Hertzsprung–Russell data using several minimum pseudodistance (MP) methods, several minimum density power divergence (MDPD) methods, the least median of squares (LMS) method, S-estimators and the MLE method. represents tuning parameter.
| MLE Estimates | |||
| 6.79 | −0.41 | 0.55 | |
| MP Estimates | |||
| 1 | |||
| 2 | |||
| MDPD Estimates | |||
| 1 | |||
| S-Estimates | |||
| − | |||
| LMS Estimates | |||
| − | |||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Toma, A.; Fulga, C. Robust Estimation for the Single Index Model Using Pseudodistances. Entropy 2018, 20, 374. https://0-doi-org.brum.beds.ac.uk/10.3390/e20050374
AMA Style
Toma A, Fulga C. Robust Estimation for the Single Index Model Using Pseudodistances. Entropy. 2018; 20(5):374. https://0-doi-org.brum.beds.ac.uk/10.3390/e20050374
Chicago/Turabian StyleToma, Aida, and Cristinca Fulga. 2018. "Robust Estimation for the Single Index Model Using Pseudodistances" Entropy 20, no. 5: 374. https://0-doi-org.brum.beds.ac.uk/10.3390/e20050374
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.