Strong Secrecy on a Class of Degraded Broadcast Channels Using Polar Codes



Departament de Teoria del Senyal i Communications (TSC), Universitat Politècnica de Catalunya, Barcelona 08034, Spain
*
Author to whom correspondence should be addressed.
Entropy 2018, 20(6), 467; https://0-doi-org.brum.beds.ac.uk/10.3390/e20060467
Submission received: 15 May 2018
/
Revised: 8 June 2018
/
Accepted: 12 June 2018
/
Published: 15 June 2018
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Asymptotic secrecy-capacity achieving polar coding schemes are proposed for the memoryless degraded broadcast channel under different reliability and secrecy requirements: layered decoding or layered secrecy. In these settings, the transmitter wishes to send multiple messages to a set of legitimate receivers keeping them masked from a set of eavesdroppers. The layered decoding structure requires receivers with better channel quality to reliably decode more messages, while the layered secrecy structure requires eavesdroppers with worse channel quality to be kept ignorant of more messages. Practical constructions for the proposed polar coding schemes are discussed and their performance evaluated by means of simulations.
1. Introduction
Information-theoretic security over noisy channels was introduced by Wyner in [1], which characterized the (secrecy-)capacity of the degraded wiretap channel. Later, Csiszár and Körner in [2] generalized Wyner’s results to the general wiretap channel. In these settings, one transmitter wishes to reliably send one message to a legitimate receiver, while keeping it secret from an eavesdropper, where secrecy is defined based on a condition on some information-theoretic measure that is fully quantifiable. One of these measures is the information leakage, defined as the mutual information between a uniformly-distributed random message W and the channel observations at the eavesdropper, n being the number of uses of the channel. Based on this measure, the most common secrecy conditions required to be satisfied by channel codes are the weak secrecy, which requires , and the strong secrecy, requiring . Although the second notion of security is stronger, surprisingly, both secrecy conditions result in the same secrecy-capacity region [3].
In the last decade, information-theoretic security has been extended to a large variety of contexts, and this paper focuses on two different classes of discrete memoryless Degraded Broadcast Channels (DBC) surveyed in [4]: (a) with Non-Layered Decoding and Layered Secrecy (DBC-NLD-LS) and (b) with Layered Decoding and Non-Layered Secrecy (DBC-LD-NLS). In these models, the transmitter wishes to send a set of messages through the DBC, and each message must be reliably decoded by a particular set of receivers and kept masked from a particular set of eavesdroppers. The degradedness condition of the channel implies that individual channels can be ordered based on the quality of their received signals. The layered decoding structure requires receivers with better channel quality to reliably decode more messages, while the layered secrecy requires eavesdroppers with worse channel quality to be kept ignorant of more messages.
The capacity region of these models was first characterized in [4,5,6]. However, the achievable schemes used by these works rely on random coding arguments that are nonconstructive in practice. In this sense, the purpose of this paper is to provide coding schemes based on polar codes, which were originally proposed by Arikan [7] to achieve the capacity of binary-input, symmetric, point-to-point channels under Successive Cancellation (SC) decoding. Capacity achieving polar codes for the binary symmetric degraded wiretap channel were introduced in [8,9], satisfying the weak and the strong secrecy condition, respectively. Recently, polar coding has been extended to the general wiretap channel in [10,11,12,13]. Indeed, [12,13] generalize their results providing polar coding schemes for the broadcast channel with confidential messages, and [11] also proposes polar coding strategies to achieve the best-known inner bounds on the secrecy-capacity region of some multi-user settings.
Although recent literature has proven the existence of different secrecy-capacity achieving polar coding schemes for multi-user scenarios (for instance, see [11,12,13,14,15,16,17,18]), polar codes for the two models on which this paper is focused have, as far as we know, not been analyzed yet. As mentioned in [4], these settings capture practical scenarios in wireless systems, in which channels can be ordered based on the quality of the received signals (for example, Gaussian channels are degraded). Hence, the ultimate goal of this work is not only to prove the existence of two asymptotic secrecy-capacity achieving polar coding schemes for these models under the strong secrecy condition, but also to discuss their practical construction and evaluate their performance for a finite blocklength by means of simulations.
1.1. Relation to Prior Work
A good overview of the similarities and differences between the polar codes proposed in [10,11,12,13] for the general wiretap channel can be found in [13] (Figure 1). The polar coding schemes proposed in this paper are based mainly on those introduced by [13] because of the following reasons:
- To provide strong secrecy. Despite both weak and strong secrecy conditions resulting in the same secrecy-capacity region, the weak secrecy requirement in practical applications can result in important system vulnerabilities [19] (Section 3.3).
- To provide polar coding schemes that are implementable in practice. Notice in [13] (Figure 1) that the coding scheme presented in [10] relies on a construction for which no efficient code is presently known. Moreover, the polar coding scheme in [12] relies on the existence, through averaging, of certain deterministic mappings for the encoding/decoding process.
As in [13], our polar coding schemes are totally explicit. However, to provide strong secrecy and reliability simultaneously, the transmitter and the legitimate receivers need to share a secret key of negligible size in terms of rate, and the distribution induced by the encoder must be close in terms of statistical distance to the original one considered for the code construction. Moreover, we adapt the deterministic SC encoder of [20] to our channel models, and we show that it can perform well in practice. As concluded in [20], this deterministic SC encoder will avoid the need to draw large sequences according to specific distributions at the encoder, which can be useful in communication systems requiring low complexity at the transmitter.
In [13] (Remark 3), the authors highlight the connection between polar code constructions and random binning proofs that allows them to apply their designs to different problems in network information theory. Nevertheless, in our polar coding schemes, the chaining construction used in [13] is not needed because of the degradedness condition of the channels, and consequently, we can introduce small changes in the design in order to make our proposed coding schemes more practical. In this sense, we assume that a source of common randomness is accessible to all parties, which allows the transmitter to send secret information in just one block of size n by only using a secret key with negligible size in terms of rate. Despite this common randomness being available to the eavesdroppers, no information will be leaked about the messages. Moreover, if we consider a communication system requiring transmissions over several blocks of size n, the same realization of this source of common randomness can be used at each block without compromising the strong secrecy condition.
1.2. Overview of Novel Contributions
The main novelties of this paper can be summarized as follows:
- Scenario. This paper focuses on two different models of the DBC with an arbitrary number of legitimate receivers and an arbitrary number of eavesdroppers for which polar codes have not yet been proposed. These two models arise very commonly in wireless communications.
- Existence of the polar coding schemes. We prove the existence for sufficiently large n of two secrecy-capacity achieving polar coding schemes under the strong secrecy condition.
- Practical implementation. We provide polar codes that are implementable in real communication systems, and we discuss further how to construct them in practice. As far as we know, although the construction of polar codes has been covered in a large number of references (for instance, see [21,22,23]), they only focus on polar code constructions under reliability constraints.
- Performance evaluation. Simulations results are provided in order to evaluate the reliability and secrecy performance of the polar coding schemes. The performance is evaluated according to different design parameters of the practical code construction. As far as we know, this paper is the first to evaluate the secrecy performance in terms of the strong secrecy, which is done by upper-bounding the information leakage at the eavesdroppers.
1.3. Notation
Through this paper, let for , denote a row vector . We write for to denote the subvector . Let , then we write to denote the sequence , and we use to denote the set complement with respect to the universal set , that is . If denotes an event, then also denotes its complement. We use ln to denote the natural logarithm, whereas log denotes the logarithm base two. Let X be a random variable taking values in , and let and be two different distributions with support , then and denote the Kullback-Leibler divergence and the total variation distance, respectively. Finally, denotes the binary entropy function, i.e., , and we define the indicator function such that it equals one if the predicate u is true and zero otherwise.
1.4. Organization
The remainder of this paper is organized as follows. In Section 2, the channel models DBC-NLD-LS and DBC-LD-NLS are introduced formally, and their secrecy-capacity regions are characterized. In Section 3, the fundamentals theorems of polar codes are revisited. In Section 4 and Section 5, two polar coding schemes are proposed for the DBC-NLD-LS and DBC-LD-NLS, respectively, and we prove that both are asymptotic secrecy-capacity achieving. In Section 6, practical polar code constructions are discussed for both models, and the performances of the polar codes are evaluated by means of simulations. Finally, the concluding remarks are presented in Section 7.
2. System Model and Secrecy-Capacity Region
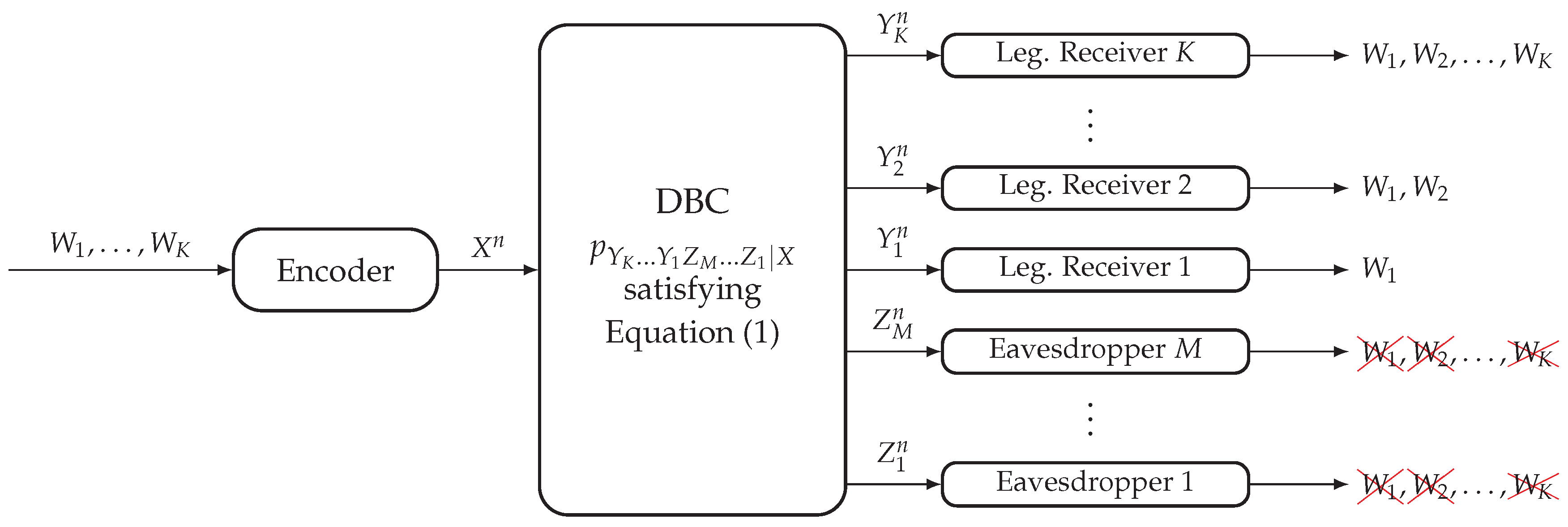
Formally, a DBC with K legitimate receivers and M eavesdroppers is characterized by the probability transition function , where denotes the channel input, denotes the channel output corresponding to the legitimate receiver and denotes the channel output corresponding to the eavesdropper . The broadcast channel is assumed to gradually degrade in such a way that each legitimate receiver has a better channel than any eavesdropper, that is:
forms a Markov chain. Although we consider physically degradation, the polar coding schemes proposed in this paper are also suitable for stochastically degraded channels (see Remark 2).
2.1. Degraded Broadcast Channel with Non-Layered Decoding and Layered Secrecy
In this model (see Figure 1), the transmitter wishes to send M messages to the K legitimate receivers. The non-layered decoding structure requires the legitimate receiver to reliably decode all M messages, and the layered secrecy structure requires the eavesdropper to be kept ignorant about messages . Consider a code for the DBC-NLD-LS, where for any . The reliability condition to be satisfied by this code is measured in terms of the average probability of error at each legitimate receiver and is given by:
On the other hand, the strong secrecy condition to be satisfied by the code is measured in terms of the information leakage at each eavesdropper and is given by:
A tuple of rates is achievable for the DBC-NLD-LS if there exists a sequence of codes satisfying Equations (2) and (3).
Proposition 1
The proof for the case of only one legitimate receiver in the context of the fading wiretap channel is provided in [5], where the information-theoretic achievable scheme is based on embedded coding, stochastic encoding and rate sharing. Due to the degradedness condition of Equation (1), by applying the data processing inequality and Fano’s inequality, an achievable scheme ensuring the reliability condition in Equation (2) for the legitimate Receiver 1 will satisfy it for any legitimate receiver .
Corollary 1.
The achievable subregion of the DBC-NLD-LS without considering rate sharing is a K-orthotope defined by the closure of all K-tuples of rates satisfying:
2.2. Degraded Broadcast Channel with Layered Decoding and Non-Layered Secrecy
In this model (see Figure 2), the transmitter wishes to send K messages to the K legitimate receivers. The layered decoding structure requires the legitimate receiver to reliably decode the messages , and the non-layered secrecy structure requires the eavesdropper to be kept ignorant of all K messages. Consider a code for the DBC-LD-NLS, where for any . The reliability condition to be satisfied by this code is:
and the strong secrecy condition is given by:
A tuple of rates is achievable for the DBC-LD-NLS if there exists a sequence of codes such that they satisfy Equations (4) and (5).
Proposition 2
The proof for the case of only one eavesdropper is provided in [6], where the information-theoretic achievable scheme is based on superposition coding, stochastic encoding and rate sharing. Due to the degradedness condition of Equation (1), note that any achievable scheme ensuring the strong secrecy condition in Equation (5) for the eavesdropper M will also satisfy it for any eavesdropper .
Corollary 2.
The achievable subregion of the DBC-LD-NLS without considering rate sharing is a K-orthotope defined by the closure of all K-tuples of rates satisfying:
3. Review of Polar Codes
Let be a Discrete Memoryless Source (DMS), where (see Endnote [24]—which refers to References [25,26]) and . The polar transform over the n-sequence , n being any power of two, is defined as , where is the source polarization matrix [27]. Since , then .
The polarization theorem for source coding with side information [27] (Theorem 1) states that the polar transform extracts the randomness of in the sense that, as , the set of indices can be divided practically into two disjoint sets, namely and , such that for is practically independent of and uniformly distributed, i.e., , and for is almost determined by , i.e., . Formally, let:
where for some . Then, by [27] (Theorem 1), we have and , which imply that , i.e., the number of elements that have not been polarized is asymptotically negligible in terms of rate. Furthermore, [27] (Theorem 2) states that given and , can be reconstructed using SC decoding with error probability in . Alternatively, the previous sets can be defined based on the Bhattacharyya parameters because both parameters polarize simultaneously [27] (Proposition 2). It is worth mentioning that both the entropy terms and the Bhattacharyya parameters required to define these sets can be obtained deterministically from and the algebraic properties of [21,22,23].
Similarly to and , the sets and can be defined by considering that observations are absent. A discrete memoryless channel with some arbitrary can be seen as a DMS . In channel polar coding, first, we define , , and from the target distribution (polar construction). Then, based on the previous sets, the encoder somehow constructs and applies the inverse polar transform , with distribution (since the polar-based encoder will construct random variables that must approach the target distribution of the DMS, throughout this paper, we use a tilde above the random variables to emphasize this purpose). Afterwards, the transmitter sends over the channel, which induces . If , then the receiver can reliably reconstruct from and by using SC decoding [28].
To conclude this part, the following lemma provides a useful property of polar codes for the DBC.
Lemma 1
(Subset property, adapted from [14] (Lemma 4)). Let be random variables such that forms a Markov chain. Then, the following property holds for the polar transform ,
Remark 1.
The subset property also holds if the sets are defined based on the Bhattacharyya parameters because, under the previous Markov chain condition, .
Remark 2.
According to [14] (Lemma 4), the subset property also holds if the channels are stochastically degraded. Therefore, since the construction of the polar codes proposed in the following sections is based basically on Lemma 1, the polar coding schemes are suitable for physically- and stochastically-degraded channels.
4. Polar Coding Scheme For the DBC-NLD-LS
The polar coding scheme provided in this section is designed to achieve the supremum of the achievable rates given in Corollary 1 (secrecy-capacity without rate sharing). Thus, consider the DMS that represents the input and output random variables involved in the achievable subregion of Corollary 1, where . Let be an i.i.d. n-sequence of this source. We define the polar transform , whose distribution is (due to the invertibility of ), and we write:
4.1. Polar Code Construction
Let , where . Based on , we define:
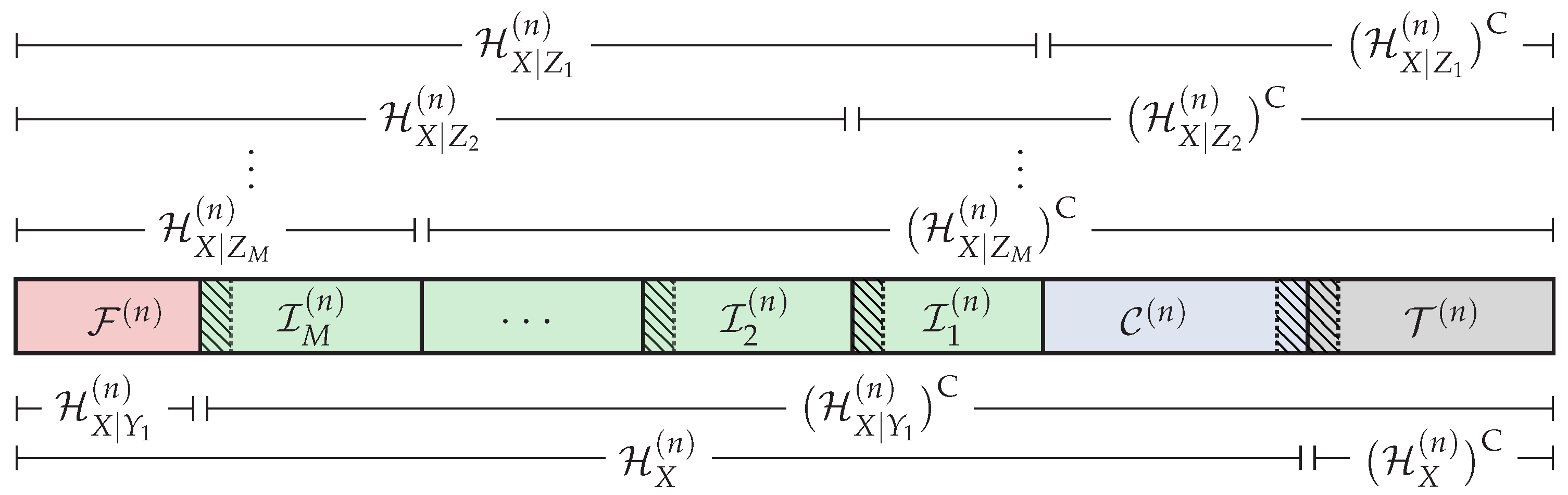
Then, based on the previous sets, we define the following partition of the universal set ,
which is graphically represented in Figure 3. Roughly speaking, in order to ensure reliability and strong secrecy, the distribution of after the encoding process must be close in terms of statistical distance to the distribution given in Equation (6) corresponding to the original DMS. Hence, the elements such that will be suitable for storing uniformly-distributed random sequences. On the other hand, will not, and the elements such that will be constructed somehow from and the distribution . The set () belongs to , and by Lemma 1, we have for any . Thus, will be suitable for storing information to be secured from Eavesdroppers 1–m. Since for any , the sequence cannot contain information to be secured from any eavesdropper, and it will be used to store the local randomness [8] required to confuse the eavesdroppers (the local randomness in polar codes plays the same role as the stochastic encoding used in [1,2]). According to [27] (Theorem 2), the legitimate Receiver 1 will be able to reliably infer given and . Hence, if the polar coding scheme somehow make the entries such that j belongs to and (hatched areas in Figure 3) available to the legitimate Receiver 1, this receiver will be able to reliably infer the entire sequence . In this sense, will be used to store the uniformly-distributed random sequence provided by a source of common randomness that will be available to all parties. Since for any , the knowledge of of the eavesdroppers will not compromise the strong secrecy condition. On the other hand, will contain secret information or elements that cannot be known directly by all the eavesdroppers. Therefore, the transmitter somehow will secretly send it to the legitimate receivers. Nevertheless, as will be seen, this additional transmission will incur an asymptotically negligible rate penalty. Finally, by Lemma 1, we have for any . Hence, given , all the legitimate receivers will be able to reliably infer the entire sequence from their own channel observations.
Remark 3.
The goal of the polar code construction is to obtain the entropy terms , and for all required to define the sets in Equations (7)–(11) and, consequently, to obtain the partition of given in Equations (12)–(16). In Section 6, we discuss further how to construct polar codes under both reliability and secrecy constraints.
4.2. Polar Encoding
The polarization-based encoder aims to construct the sequence and, consequently, . Let for all and C be uniformly-distributed random vectors of size and , respectively, where C represents the local randomness required to confuse the eavesdroppers, and recall that represents the message m that is intended for all legitimate receivers. Let F be a given uniformly-distributed random -sequence, which represents the source of common randomness that is available to all parties. The encoder constructs the sequence as follows. Consider the realizations for all , c and f, whose elements have been indexed by the set of indices , and , respectively. The encoder draws from the distribution:
where:
being the distribution induced by the original DMS. Note that , and according to Equation (17), is constructed deterministically by adapting the SC encoding algorithm in [20], while is constructed randomly. By [27] (Theorem 1), we have that the amount of randomness for SC encoding will be asymptotically negligible in terms of rate. Then, the encoder computes and transmits it over the DBC, inducing .
Finally, besides the sequence , the encoder outputs the following additional secret sequence,
This sequence must be additionally transmitted to all legitimate receivers keeping it masked from the eavesdroppers. To do so, the transmitter can perform a modulo-two addition between and a uniformly-distributed secret key that is privately shared with the legitimate receivers and somehow additionally send it to them. Nevertheless, by [27] (Theorem 1), we know that this additional transmission is asymptotically negligible in terms of rate.
Remark 4.
The additional secret sequence Φ can be divided into two parts: , which will be uniformly distributed according to Equation (17), and the remaining part that will not. The transmitter could make the uniformly-distributed part available to the legitimate receivers by using a chaining structure as the one presented in [9]. However, such a scheme requires the transmission to take place over several blocks of size n. Moreover, it requires having a large memory capacity on either the transmitter or the legitimate receivers, which can make the polar coding scheme unpractical in communication systems.
4.3. Polar Decoding
Before the decoding process, consider that the realization of the source of common randomness F is available to all parties and the sequence has been successfully received by the legitimate receivers.
The legitimate receiver forms an estimate of the sequence as follows. Given that and F are available, notice that it knows . Moreover, by Lemma 1, for any . Thus, the k-th legitimate receiver performs SC decoding for source coding with side information [27] to construct from and its channel output observations . In Section 4.5.3, we show formally that the reliability condition in Equation (2) is satisfied at each legitimate receiver .
4.4. Information Leakage
Besides the observations , the eavesdropper has access to the common randomness . Thus, the information about the messages leaked to this eavesdropper is:
In Section 4.5.4, we prove that is asymptotically statistically independent of .
4.5. Performance of the Polar Coding Scheme
The analysis of the polar coding scheme described previously leads to the following theorem.
Theorem 1.
Consider an arbitrary DBC such that and satisfies the Markov chain condition . The polar coding scheme described in Section 4.1, Section 4.2, Section 4.3 and Section 4.4 achieves any rate tuple of the region defined in Corollary 1, satisfying the reliability and strong secrecy conditions given in Equations (2) and (3), respectively.
Corollary 3.
Since for some can contain information to be secured from Eavesdroppers 1–m, the polar coding scheme described in Section 4.1, Section 4.2, Section 4.3 and Section 4.4 can achieve the entire region considering rate sharing of Proposition 1 by storing part of any message such that into instead of part of .
Corollary 4.
If we consider a communication scenario requiring transmissions over several blocks of size n, the same realization of the source of common randomness F that is known by all parties could be used at each block, and the reliability and the strong secrecy conditions would still be ensured.
The proof of Theorem 1 follows in four steps with similar reasoning as in [13] and is provided in Section 4.5.1, Section 4.5.2, Section 4.5.3 and Section 4.5.4. The proof of Corollary 3 is immediate, and the proof of Corollary 4 is provided in Section 4.5.5.
4.5.1. Transmission Rates
In this step, we prove that the polar coding scheme approaches the corner point of the subregion defined in Corollary 1. For any , the rate corresponding to the message satisfies:
where follows from the definition of the set in Equation (13), holds because, by Lemma 1, , and follows from [27] (Theorem 1). Similarly, according to Equation (12), we obtain:
4.5.2. Distribution of the DMS after the Polar Encoding
Let be the distribution of after the encoding in Section 4.2. The following lemma shows that and the distribution in Equation (6) of the original DMS are nearly statistically indistinguishable for sufficiently large n and, consequently, so are the overall distributions and .
Lemma 2.
Let for some . Then,
where .
Proof.
See Appendix A, setting . □
Remark 5.
The first term of bounds the impact on the total variation distance of using the deterministic SC encoding in Equation (18) for the entries , while the second term bounds the impact of storing uniformly-distributed random sequences (messages, local randomness and common randomness) into the entries .
As will be seen in the following subsections, an encoding process satisfying Lemma 2 is crucial for the reliability and the secrecy performance of the polar code.
4.5.3. Reliability Performance
Consider the probability of incorrectly decoding all messages at the legitimate receiver . Let and be the marginal distributions of and , respectively. Consider an optimal coupling [29] (Proposition 4.7) between and such that:
where or, equivalently, because of the invertibility of . Thus, for the legitimate receiver , we obtain:
where holds by [27] (Theorem 2) because is available to all receivers, holds by Lemma 1, that is, for any , and by the definition of in Equation (9) and [27] (Proposition 2), that is , and holds by the optimal coupling and Lemma 2 because . Therefore, the polar coding scheme satisfies the reliability condition given in Equation (2).
4.5.4. Secrecy Performance
Consider the information leakage at the eavesdropper given in Equation (20). We obtain:
Now, we provide a lower-bound for the conditional entropy term of Equation (22). First, for large enough n,
where holds by the chain rule of entropy and the triangle inequality, holds by [30] (Lemma 2.9) and holds because the function is decreasing for small enough and by Lemma 2 because , as well as by the invertibility of , . Hence, we have:
where holds because conditioning does not increase the entropy and holds because, according to Equations (12)–(14) and Lemma 1, , as well as by the definition of in Equation (11).
Finally, by substituting Equation (24) into Equation (22), for n sufficiently large, we obtain:
Hence, the polar code satisfies the strong secrecy condition in Equation (3), and the proof of Theorem 1 is concluded.
4.5.5. Reuse of the Source of Common Randomness
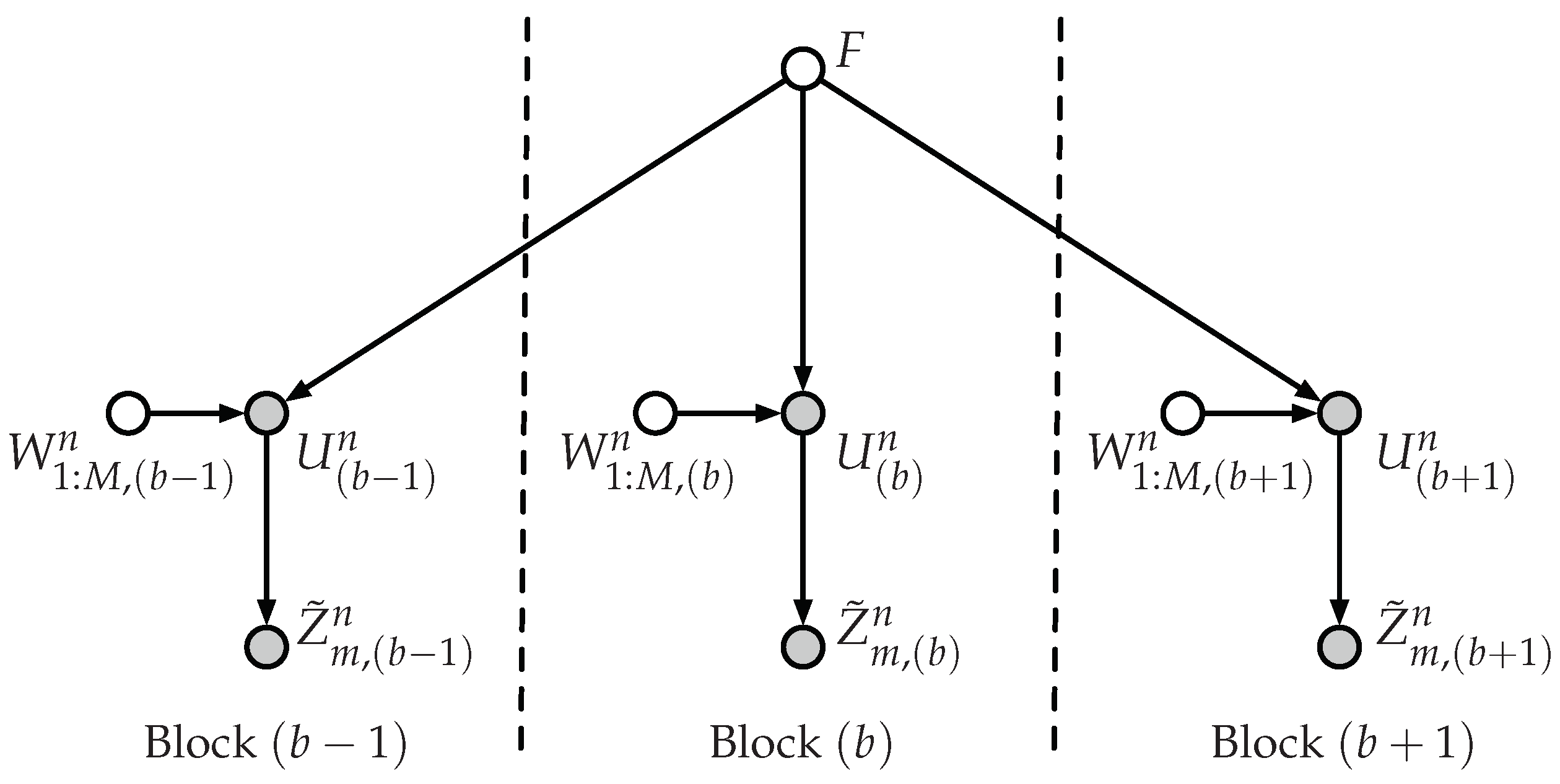
Consider that the transmission takes place over B blocks of size n. We use the subscript between parentheses to denote random variables associated with the block b. From Lemma 2, we have for any because we use the same encoding of Equation (17) at each block. Hence, by the union bound, the polar code satisfies the reliability condition given in Equation (2) because:
where the last inequality follows from the fact that, since F and are perfectly known, only depends on the decoding at block b and, consequently, can be bounded as in Equation (21).
With a slight abuse of notation, let , where , denote the messages . It remains to show that is asymptotically statistically independent of . Since F is reused at each block, we have to consider the dependencies between the random variables of different blocks that are involved in the secrecy analysis. According to these dependencies, which are represented in the Bayesian graph of Figure 4, we obtain:
where follows from the independence between and F, and holds because:
where holds because the messages at blocks –B are independent of F and all the random variables of the previous blocks, follows from Equation (25) and holds by applying d-separation [31] over the graph of Figure 4 because forms a common cause and, consequently, and are independent given F.
5. Polar Coding Scheme for the DBC-LD-NLS
The polar coding scheme provided in this section is designed to achieve the supremum of the achievable rates given in Corollary 2 (secrecy-capacity without rate sharing). In this model, there are K input random variables (where ), each one corresponding to a different superposition layer. Consider the DMS that represents the input and output random variables involved in the achievable subregion of Corollary 2, where for any . Let be an i.i.d. n-sequence of this source. Then, we define the K polar transforms , where . Since and, consequently, (by the invertibility of ) form a Markov chain, the joint distribution of satisfies”
5.1. Polar Code Construction
Based on , the construction is carried out similarly at each superposition layer. Consider the polar construction at layer . Let , where . For the polar transform associated with the ℓ-th layer, we define the sets:
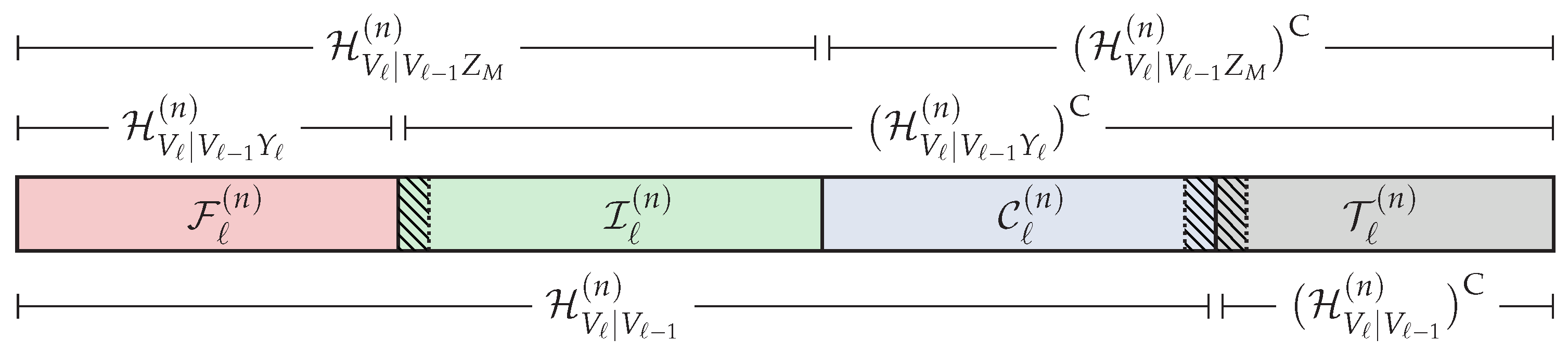
where we recall that when and when . At each layer , based on these previous sets, we define the following partition of the universal set ,
which is graphically represented in Figure 5. The way we define this partition at the ℓ-th layer follows similar reasoning as the one to define the partition in Section 4.1 for the DBC-NLD-LS. In this sense, will be suitable for storing uniformly-distributed random sequences. Otherwise, will not and such that will be constructed somehow from and the distribution . Now, will be suitable for storing information to be secured from all eavesdroppers because belongs to , and by Lemma 1, for any . Since , will be used to store the local randomness required to confuse all eavesdroppers about the secret information carried on this layer. According to [27] (Theorem 2), the legitimate receiver will be able to reliably infer given and . By Lemma 1, we have for any . Therefore, given , the legitimate receivers ℓ–K will be able to reliably reconstruct from its own channel observations. In this sense, will be used to store the random sequence provided by the source of common randomness. Since , the strong secrecy condition will not be compromised. On the other hand, (hatched areas in Figure 5) will contain secret information or elements that cannot be known directly by the eavesdroppers. Therefore, the transmitter somehow will make those elements available to the legitimate receivers ℓ–K keeping them masked from all eavesdroppers by incurring an asymptotically-negligible rate penalty.
As mentioned in Remark 3, the goal of the polar construction is to obtain the entropy terms associated with the sets in Equations (27)–(31) and then define the partition of given in Equations (32)–(35).
5.2. Polar Encoding
The superposition-based polar encoder will consist of K encoding blocks operating sequentially at each superposition layer, the block at layer being responsible for the construction of . In order to construct for some , the encoder block needs , which have been constructed previously by the encoding block operating at the -th layer.
Consider the encoding procedure at layer . Let and be uniformly-distributed random vectors of size and , respectively, where represents the message intended for receivers ℓ–K and the local randomness required at the ℓ-th layer to confuse all eavesdroppers about this message. Let be a given uniformly-distributed random -sequence, which represents the source of common randomness that is available to all parties. The ℓ-th encoding block constructs the sequence as follows. Given the realizations , and , whose elements have been indexed by the set of indices , and , respectively, and given provided by the previous encoding block (recall that at the first layer), the ℓ-th encoding block draws from:
where:
being the distribution induced by the original DMS. Notice that , and similarly to the previous model, is constructed in a deterministic way by adapting the SC encoding algorithm in [20]; and is constructed randomly. By [27] (Theorem 1), the rate of the amount of randomness for SC encoding will be asymptotically negligible. After constructing , the ℓ-th encoding block computes the sequence and delivers it to the next encoding block. If , then , and the encoder transmits it over the DBC, which induces the channel outputs .
Finally, besides the sequence , the encoder outputs the following additional secret sequences,
The sequence corresponding to the layer must be additionally transmitted to the legitimate receivers ℓ–K keeping it masked from the eavesdroppers. To do so, the transmitter can perform a modulo-two addition between and a uniformly-distributed secret key privately shared with the legitimate receivers and somehow additionally send it to them. If , by [27] (Theorem 1), we have that the overall rate required to transmit these additional secret sequences is asymptotically negligible, i.e., . As for the previous model, the uniformly-distributed part of any could be made available to the corresponding legitimate receivers by using a chaining structure as in [9]. However, this approach will present the same disadvantages as those mentioned in Remark 4.
5.3. Polar Decoding
Consider that the realizations of are available to all parties, and the sequences have been successfully received by the corresponding legitimate receivers before the decoding process.
Consider the decoding at the legitimate receiver . This receiver forms the estimates of the sequences in a successive manner from -, and the procedure to estimate for some is as follows. First, given that and are available, the receiver knows . Moreover, by Lemma 1, for any . Thus, given , the k-th legitimate receiver performs SC decoding for source coding with side information [27] to construct from , and from estimated previously. In Section 5.5.3, we show formally that the polar coding scheme satisfies the reliability condition in Equation (4).
5.4. Information Leakage
Besides the observations , the eavesdropper has access to the common randomness . Therefore, the information about all messages leaked to the m-th eavesdropper is:
In Section 5.5.4, we prove that is asymptotically statistically independent of .
5.5. Performance of the Polar Coding Scheme
The analysis of the polar coding scheme leads to the following theorem.
Theorem 2.
Consider an arbitrary DBC such that and satisfies the Markov chain condition . The polar coding scheme described in Section 5.1, Section 5.2, Section 5.3 and Section 5.4 achieves any rate tuple of the achievable region defined in Corollary 2, satisfying the reliability and strong secrecy conditions in Equations (4) and (5), respectively.
Corollary 5.
Since for some can contain any information to be reliably decoded by the legitimate receivers ℓ–K, the coding scheme in Section 5.1, Section 5.2, Section 5.3 and Section 5.4 can achieve the entire region considering the rate sharing of Proposition 2 by storing part of any message such that into instead of part of .
Corollary 6.
If we consider a communication scenario requiring transmissions over several blocks of size n, the same realization of the source of common randomness that is known by all parties could be used at each block, and the reliability and the strong secrecy conditions would still be ensured.
As in Theorem 1, the proof of Theorem 2 follows in four steps and is provided in Section 4.5.1, Section 4.5.2, Section 4.5.3 and Section 4.5.4. The proof of Corollary 5 is immediate. The proof of Corollary 6 is omitted because it follows similar reasoning as in Corollary 4. Despite that in this model, we have different superposition layers, the dependencies between the random variables at different blocks have the same structure of those graphically represented in Figure 4.
5.5.1. Transmission Rates
We prove that the polar coding scheme approaches the corner point of the subregion defined in Corollary 2. For any , the transmission rate corresponding to the message satisfies:
where follows from the definition of the set in Equation (32), holds because, by Lemma 1, , and holds by [27] (Theorem 1).
5.5.2. Distribution of the DMS after the Polar Encoding
Let be the distribution of after the encoding in Section 5.2. The following lemma shows that and of the DMS are nearly statistically indistinguishable for sufficiently large n and, consequently, so are the overall distributions and .
Lemma 3.
Let for some . Then,
where .
Proof.
See Appendix A setting . □
Remark 6.
The first term of bounds the impact on the total variation distance of using the deterministic SC encoding in Equation (37) for at each layer . The second term bounds the impact of storing uniformly-distributed random sequences that are independent of into .
5.5.3. Reliability Performance
Consider the probability of incorrectly decoding at the legitimate receiver . Let and for any be marginals of and , respectively. Consider an optimal coupling [29] (Proposition 4.7) between and such that:
where or, equivalently, due to the invertibility of . Furthermore, for all , we define the error events or, equivalently, ; and we define . Hence, for any , the average probability of incorrectly decoding the message at the k-th receiver can be upper-bounded as:
where holds by [27] (Theorem 2) because for any is available to the k-th receiver, holds by Lemma 1, by the definition of the set in Equation (29) and by applying [27] (Proposition 2) and holds by the optimal coupling and Lemma 3 because . Thus, by induction, we obtain:
Consequently, if , the polar coding scheme satisfies the reliability condition in Equation (4).
5.5.4. Secrecy Performance
Consider the leakage at the eavesdropper given in Equation (39). As in Equation (22), we obtain:
Following similar reasoning as in Equation (23), for n large enough, we have:
where holds by defining and [30] (Lemma 2.9) and follows from Lemma 2 by using similar reasoning as in Equation (23) and because the function is decreasing for small enough. Hence, we obtain:
where holds because conditioning does not increase the entropy and because forms a Markov chain and the invertibility of and holds because, according to Equations (32) and (33), for all , because by Lemma 1, we have for any , and by the definition of the set given in Equation (31).
Finally, by substituting Equation (45) into Equation (43), we obtain:
Hence, if , the polar code satisfies the secrecy condition in Equation (5), and the proof is concluded.
6. Polar Construction and Performance Evaluation
In this section, we discuss further how to construct the polar codes for the DBC-NLD-LS and DBC-LD-NLS proposed in Section 4 and Section 5, respectively. Moreover, we evaluate the reliability and the secrecy performance of both polar coding schemes according to different parameters involved in the polar code construction. Although the construction of polar codes has been covered in a large number of references (see, for instance, [21,22,23]), they only focus on polar codes under reliability constraints.
For the DBC-NLD-LS, we consider the Binary Erasure Broadcast Channel (BE-BC), where each individual channel of the DBC is a Binary Erasure Channel (BEC). For this model, we propose a construction of the polar code that is based on the Bhattacharyya parameters instead of the corresponding entropy terms. The reason is that, for the BE-BC, the Bhattacharyya parameters associated with the sets in Equations (7)–(11) can be computed exactly [7] (Proposition 5). Then, we evaluate the reliability and the secrecy performance of the code, and we focus on how different parameters involved in the proposed polar code construction impact its performance.
On the other hand, for the DBC-LD-NLS, we consider the Binary Symmetric Broadcast Channel (BS-BC), where each individual channel is a Binary Symmetric Channel (BSC). From [7] (Proposition 5), we know that the method to compute the exact values of the Bhattacharyya parameters for a BEC provides an upper-bound on the Bhattacharyya parameters of the BSC. Although this method can be useful to construct polar codes under reliability constraints [21,22,23], it fails when the code must guarantee some secrecy condition based on the information leakage. Indeed, in order to upper-bound the information leakage in Equation (39), according to Equation (45), notice that we need a lower-bound on the entropy terms (or Bhattacharyya parameters). Hence, for this model, we focus more on proposing a new polar code construction that is based directly on the entropy terms associated with the sets in Equations (27)–(31).
Throughout this section, as in [7], we say that a channel or a conditional distribution with and is symmetric if the columns of the probability transition matrix can be grouped into sub-matrices such that for each sub-matrix, each row is a permutation of each other row and each column is a permutation of each other column. Therefore, the individual channels of both BE-BC and the BS-BC are symmetric.
Due to the symmetry of BE-BC, we will see that the distribution induced by the encoding described in Section 4.2 for the DBC-NLD-LS will approach exactly the optimum distribution of the original DMS used in the polar code construction. Consequently, the performance of the polar code will depend only on the parameters involved in the construction. On the other hand, despite the symmetry of the BS-BC, due to its superposition-based structure, the encoding described in Section 5.2 for the DBC-NLD-LS only approaches the target distribution asymptotically. Hence, this encoding will impact the reliability and secrecy performance of the polar code when we consider a finite blocklength.
6.1. DBC-NLD-LS
For this model, we consider BE-BC with two legitimate receivers () and two eavesdroppers (). Therefore, each individual channel is a BEC with and , E being the erasure symbol and . The individual channels are defined simply by their erasure probability, which is denoted by for the corresponding legitimate receiver k () and for the eavesdropper m (). Due to the degradedness condition of the broadcast channel given in Equation (1), we have . By properly applying [19] (Proposition 3.2), it is easy to shown that the secrecy-capacity achieving distribution for this model is the uniform, i.e., . For the simulations, we consider a BE-BC such that , , and . According to Corollary 1 and since is uniform, we obtain that the capacity without considering rate sharing is and .
6.1.1. Practical Polar Code Construction
Given the blocklength n and the distribution , the goal of the polar code construction is to obtain the partition of the universal set defined in Equations (12)–(16) and graphically represented in Figure 3. Hence, we need to define first the required sets of Equations (7)–(11), which means having to compute the entropy terms , and associated with the polar transform . Alternatively, as mentioned in Section 3, we can define the sets in Equations (7)–(11) from the corresponding Bhattacharyya parameters. Indeed, since each individual channel is a BEC, by [7] (Proposition 5), we can compute with very low complexity the exact values of , and . To do so, we use the recursive algorithm [22] (PCC-0) adapted to the BEC, which, for instance, will obtain from the initial value (the entire code in MATLAB used for this section is provided as Supplementary Material—see Endnote [32]). Regarding , since is uniform, it is clear that for all , which means . Consequently, the set , and according to Equation (17), neither random, nor deterministic SC encoding will be needed.
In order to compare the performance of the polar coding scheme according to different parameters and to provide more flexibility in the design, instead of using only to define the sets in Equations (7)–(11), we introduce the pair , where and for some . Let and denote the target rates that the polar coding scheme must approach. We obtain the partition defined in Equations (12)–(16) as follows. First, we define , where one can notice that we have used . Then, we choose by taking the indices that correspond to the highest Bhattacharyya parameters for Eavesdropper 2. Second, we choose by taking the indices that correspond to the highest Bhattacharyya parameters for Eavesdropper 1. Finally, we obtain and . Furthermore, in order to evaluate the reliability performance of the code, we define , where one can notice that we have used . Since the additional secret sequence corresponds to those entries belonging to , its length will depend on . According to the polar code construction proposed in this section, notice that must be small enough to guarantee that .
6.1.2. Performance Evaluation
First, notice that the encoding of Section 4.2 will induce a distribution because (we do not use SC encoding), and the encoder will store uniformly-distributed sequences into the entries that satisfy for all . Hence, , and the performance will only depend on the code construction.
To evaluate the reliability performance, we obtain an upper-bound on the average bit error probability at the legitimate Receiver 1. Since , from Equation (21), we have:
Due to the degradedness condition of the BE-BC and, consequently, by Lemma 1, the average bit error probability at the legitimate Receiver 2 will be always less than the one at the legitimate Receiver 1. Since the legitimate receivers must estimate the entries belonging to regardless of and the target rates , the reliability performance only depends on the pair .
In order to evaluate the secrecy performance, we compute an upper-bound on the information leakage and an upper-bound on the information leakage . Since , from Equations (22) and (24), we obtain:
where we have used [27] (Proposition 2) to express the information leakage in terms of the Bhattacharyya parameters because . According to the proposed polar code construction, the secrecy performance will depend on and the rates , but not on .
Additionally, we evaluate the rate of the additional sequence simply by computing:
which will depend on the triple , but not on .
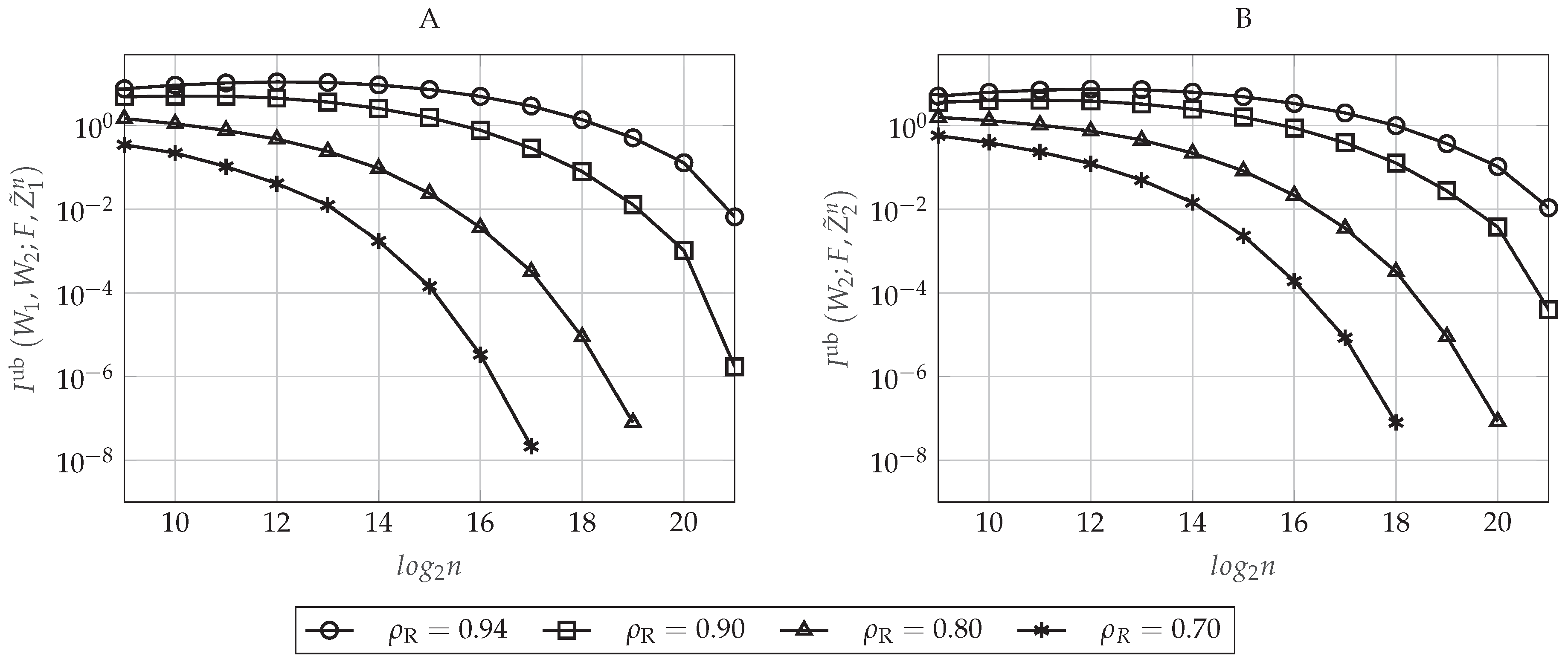
Let be the normalized target rate in which the polar coding scheme operates, that is . In Figure 6A,B, we evaluate the upper-bounds on the information leakage defined in Equations (48) and (49), respectively, as a function of the blocklength n for different values of . To do so, we set and , which defines a particular pair for each value of n (recall that does not impact on the secrecy performance of the polar code). As we proved in Section 4.5.4, for large enough n, the secrecy performance improves as n increases. Moreover, to achieve a particular secrecy performance level, the polar code will require a larger blocklength n as the rates approach the capacity. This happens because, given and, consequently, , the parameter only determines the amount of indices that will belong to . Since, by construction, we take those indices corresponding to the highest Bhattacharyya parameters associated with the eavesdroppers, taking more elements always increases the corresponding leakage. For rates approaching the capacity and small values of n, notice that we obtain a secrecy performance that is getting worse as n increases (for instance, for , we obtain that the information leakage is increasing from to ). This behavior is mainly explained because the elements of have not been polarized enough for small values of n. Consequently, for a given value of , not all the Bhattacharyya parameters associated with the eavesdroppers corresponding to the sets and are sufficiently close to one. Since, for a given , the cardinality of and increases with n, then the information leakage can increase with n when n is not large enough. Moreover, since operating at lower rates means taking a fewer number of indices in and , but taking those that are closest to one, this behavior appears only for large values of .
The impact of on the secrecy performance is graphically represented in Figure 7A,B, where the former plots the upper-bound defined in Equation (48) and the latter the upper-bound in Equation (49) as a function of the blocklength n for different values of . Now, we set and . As can be seen in Figure 7, the secrecy performance improves as the value of increases (or equivalently, as decreases). This behavior is as expected because notice that defines the value of the highest Bhattacharyya parameter that will belong to , that is the set containing the possible candidates for . Since the polar construction chooses the indices that will belong to and by taking the ones corresponding to the highest Bhattacharyya parameters associated with the eavesdroppers and since, by Lemma 1, for any , the sums in Equations (48) and (49) over the indices will be larger as increases (as decreases), while their cardinality remains the same for a given . Furthermore, notice that also defines . Thus, the larger is the value of (the lower is ), the smaller is the cardinality of and the higher are the Bhattacharyya parameters associated with the eavesdroppers that belong to this set.
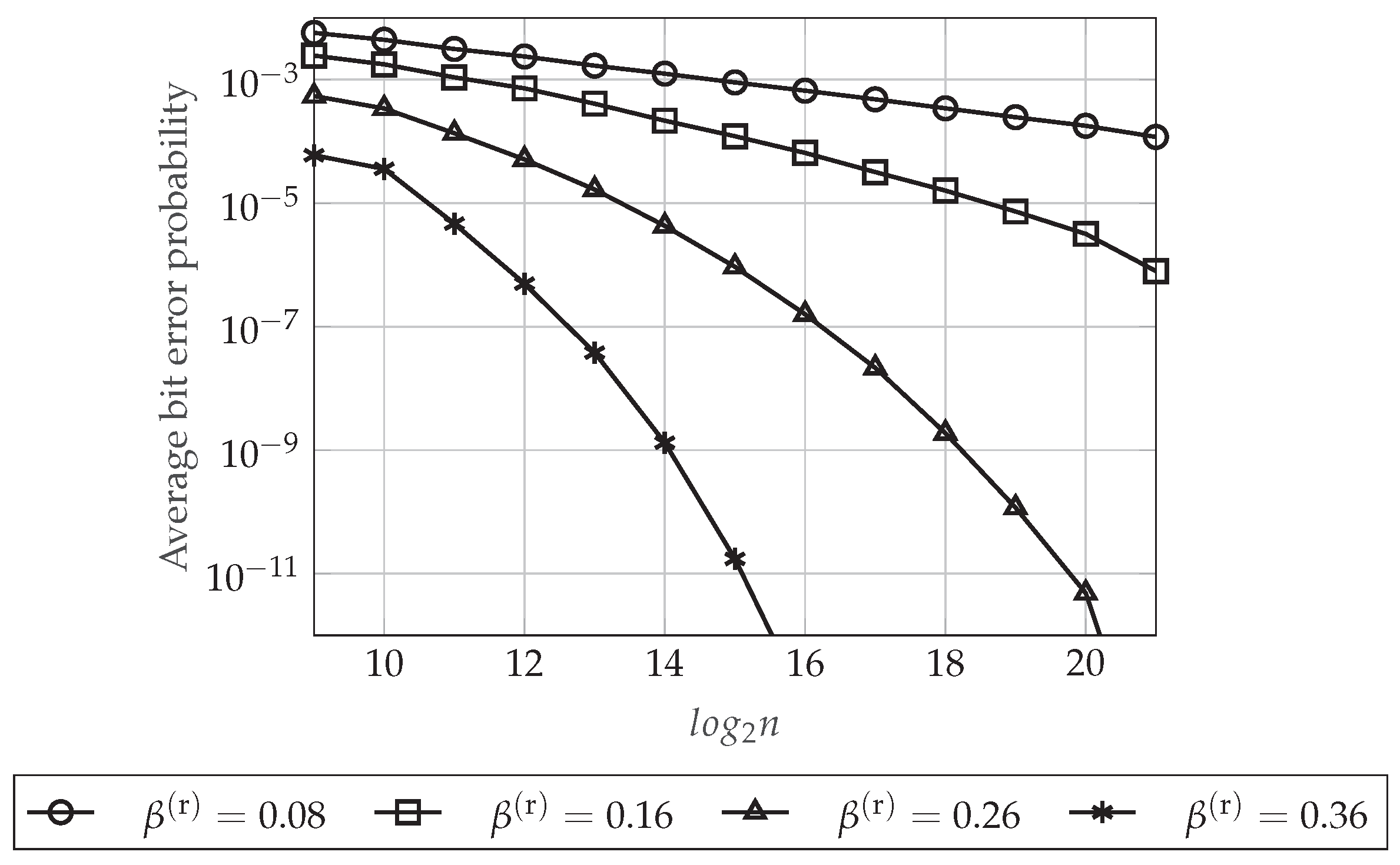
Figure 8 plots the upper-bound on the average bit error probability at the legitimate Receiver 1 defined in Equation (47) as a function of the blocklength n for different values of (which defines a particular for each n). For this figure, we set and . As can be seen in Figure 8, the higher is the value of (the smaller is the value of ), the better is the reliability performance of the polar code. This is because defines the higher Bhattacharyya parameter associated with the legitimate Receiver 1 whose corresponding index will belong to the set (recall that this set contains the indices of those entries that the legitimate receivers have to estimate). Hence, it is clear that the upper-bound in Equation (47) is decreasing as decreases (as increases). Moreover, as we have proven in Section 4.5.3, we can see that the reliability performance is always improving as n increases.
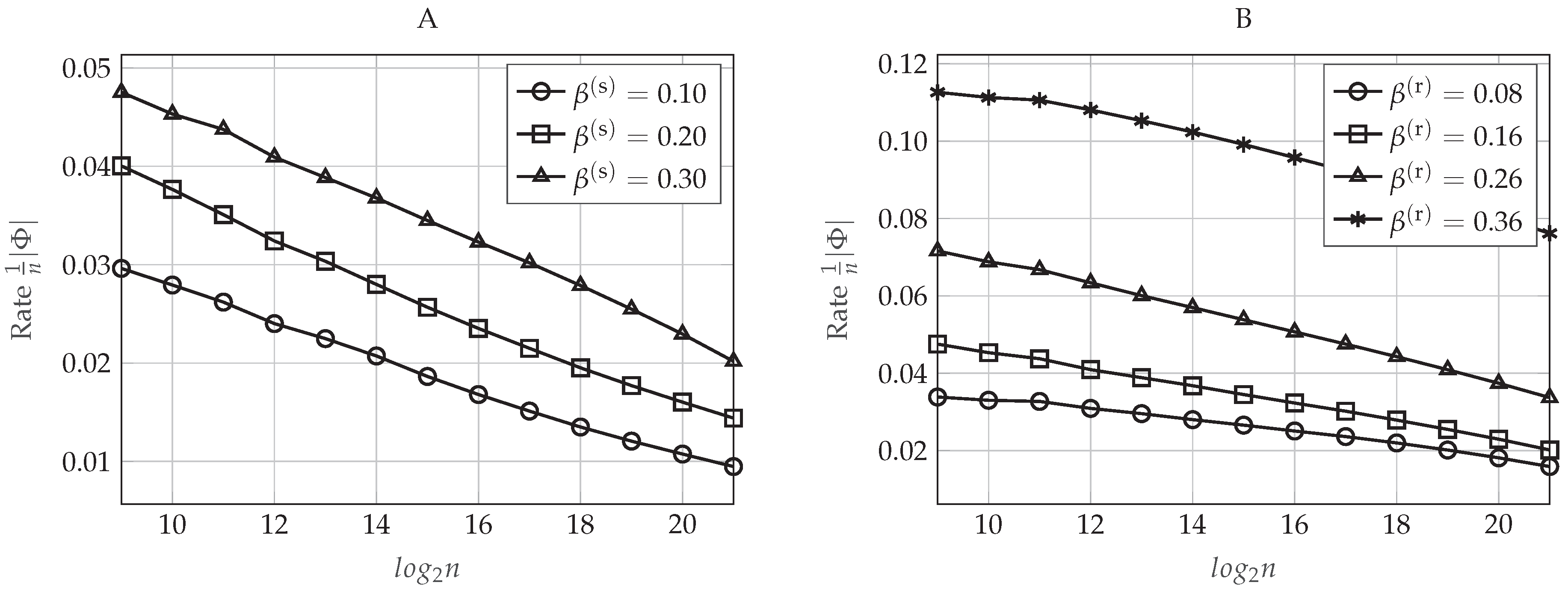
Finally, how the values of the pair , or equivalently, the values of , impact the rate of the additional secret sequence given in Equation (50) is represented graphically in Figure 9. In Figure 9A, we set and , and we represent the rate of as a function of the blocklength n for different values of . Otherwise, in Figure 9B, we evaluate the rate of as a function of n for different values of when and . As mentioned in Section 4.2, this rate tends to be negligible for sufficiently large n. Moreover, according to the polar code construction proposed previously, for a fixed n, the cardinality of the set will be higher for larger values of , or equivalently, smaller values of . Therefore, as can be seen in Figure 9, it is clear that higher values of mean also higher rate of the additional secret sequence.
In conclusion, Figure 6, Figure 7, Figure 8 and Figure 9 show that, for a particular value of the blocklength n, there is a trade-off between the reliability or the secrecy performance of the polar code and the length of the additional secret sequence , which can be controlled by the value of or , respectively, in the polar code construction. Moreover, for sufficiently large n, the performance of the polar coding scheme always is improving as n increases. Indeed, these figures show that we can transmit at rates very close to the capacity, providing good reliability and secrecy performance levels.
6.2. DBC-LD-NLS
For this model, we consider BS-BC with two legitimate receivers () and two eavesdroppers (). Hence, each individual channel is a BSC where , and . The individual channels are defined simply by their crossover probability, which is denoted by for the corresponding legitimate receiver k () and for the corresponding eavesdropper m (). Due to the degradedness condition of the broadcast channel given in Equation (1), we have . Due to the symmetry of the channel, it is easy to prove by using similar reasoning as in [33] (Ex. 15.6.5) and by properly applying [19] (Proposition 3.2) that the secrecy-capacity achieving distribution satisfies , and consequently, is symmetric. Thus, the distribution can be characterized simply by the crossover probability , where . Indeed, the overall rate in Proposition 2 is maximized when , which implies that . Then, by taking , we can transfer part of the rate associated with the message to the rate , and being maximum if . For the simulations, we consider a BS-BC with , , and . We set , which corresponds to the distribution that maximizes for this particular channel (proportional fair allocation). Thus, according to Corollary 2, the maximum achievable rates are and .
6.2.1. Practical Polar Code Construction
Given the blocklength n and the distribution , the goal of the polar code construction is to obtain the partition of the universal set defined in Equations (32)–(35) and graphically represented in Figure 5. Hence, we need to define first the sets in Equations (27)–(31), which means having to compute the entropy terms , and associated with the polar transform for the first superposition layer and , and associated with the polar transform for the second layer. In the following, we propose an adaptation of the Monte Carlo method [22] (PCC-1), which is based on the butterfly algorithm described in [7] for SC decoding, to directly estimate these entropy terms.
Monte-Carlo method to estimate the entropy terms. First, consider the entropy terms associated with to the first layer. As for the previous model, since , we have for all . In order to compute and for some , we run the Monte Carlo simulation as follows. First, due to the symmetry of the channel and the symmetry of , as in [22] (PCC-1), we can set at each iteration. For the realization , being the number of realizations, we randomly generate and from and , respectively (by abuse of notation, we use in any sequence to emphasize that it is generated at the iteration ). Next, we obtain the log-likelihood ratios and by using the algorithm [22] (PCC-1). For instance, consider . From the initial values , the algorithm recursively computes:
for all , where follows from the fact that because for all . Hence, we can obtain from , and since:
after realizations, we can estimate by computing the empirical mean, that is,
Now, consider the Monte Carlo method to estimate , and for any associated with the second layer. To obtain , we can see X and V as the input and output random variables, respectively, of a symmetric channel with distribution . Now, although is uniform and, consequently, for all , notice that and because and its complementary set depend on . On the other hand, to obtain or , we can see or as the output of a symmetric channel with distribution or , respectively, where notice that and because forms a Markov chain. Hence, due to the symmetry of the previous distributions, we can set at each iteration. Then, for the realization , we draw , and from the distributions , and , respectively. Next, we obtain the log-likelihood ratios , and by using [22] (PCC-1). Since for all , we have for all , and we can compute , and from the corresponding log-likelihood ratios. Finally, after realizations, we can estimate the corresponding entropy terms by computing the empirical mean.
Partition of the universal set. In order to provide more flexibility on the design, now we introduce for the first layer, where and for some . For the second layer, we introduce and , where , , and for some .
Consider the partition of for the first layer ( in Equations (32)–(35)). As mentioned previously, since , we have and . Let denote the target rate corresponding to the message that the polar coding scheme must approach. We obtain the partition in Equations (32)–(35) as follows. First, we define . Then, we choose by taking the indices that correspond to the highest entropy terms associated with Eavesdropper 2. Notice that must guarantee . Finally, we obtain and . Furthermore, in order to evaluate the reliability performance, we define .
Consider the partition of for the second layer ( in Equations (32)–(35)). Since and , we define and , where we have used and , respectively. Let denote the target rate corresponding to . We define . Then, we choose by taking the indices that correspond to the highest entropy terms associated with Eavesdropper 2. Thus, notice that and must guarantee . Then, we obtain and . Finally, in order to evaluate the reliability performance, we define .
6.2.2. Performance Evaluation
First, notice that the encoding at the first layer induces a distribution . For the second layer, the entries of the original DMS only are almost independent of because for . Nevertheless, the encoding will construct by storing uniformly-distributed sequences that are totally independent of . On the other hand, since , the encoder will use the deterministic SC encoding in Equation (37) to construct . Therefore, according to Lemma 3 and Remark 6, we will have for finite n. Since, as seen in Section 5.5, this total variation distance impacts the performance, we obtain first an upper-bound on , which is defined as:
where will measure the impact of using the deterministic SC encoding in Equation (37) for the entries , and is the contribution on the total variation distance of storing uniformly-distributed random sequences into that are totally independent of .
Consider , which corresponds to the analytic bound found in Lemma A2. For the simulations, we can use the Monte Carlo method to directly estimate Equation (A4) by computing the empirical mean,
where must be drawn at each iteration according to Equation (A2), has been obtained previously in the polar code construction and, according to Equation (A4), . Due to the symmetry of , the probabilities can be obtained with low complexity using the butterfly algorithm described in [7].
Consider now , which corresponds to the analytic bound found in Lemma A1. We can compute exactly the Kullback-Leibler divergence as in Equation (A3) by using the corresponding entropy terms obtained in the polar code construction. Thus, by applying Pinsker’s inequality, we have:
According to the polar code construction, and will depend only on the values of and , respectively, for a particular n. Hence, the value of can be controlled by adjusting . It is clear that higher values of mean lower cardinalities of the sets and and, consequently, lower . However, increases with , and the encoder in Equation (36) requires more randomness to form .
To evaluate the reliability performance, we obtain the upper-bounds and on the average bit error probability at Receivers 1 and 2, respectively. From Equations (41) and (42) and by applying [27] (Proposition 2) to upper-bound the Bhattacharyya parameters from the entropy terms, we have:
To evaluate the secrecy performance, we compute an upper-bound on the information leakage for Eavesdropper 2. From Equation (45) we obtain:
Due to the degradedness condition of BS-BC and, consequently, by Lemma 1, the information leakage at Eavesdropper 1 will be always less than the one at Eavesdropper 2.
Finally, we evaluate the overall rate of the additional sequences by computing:
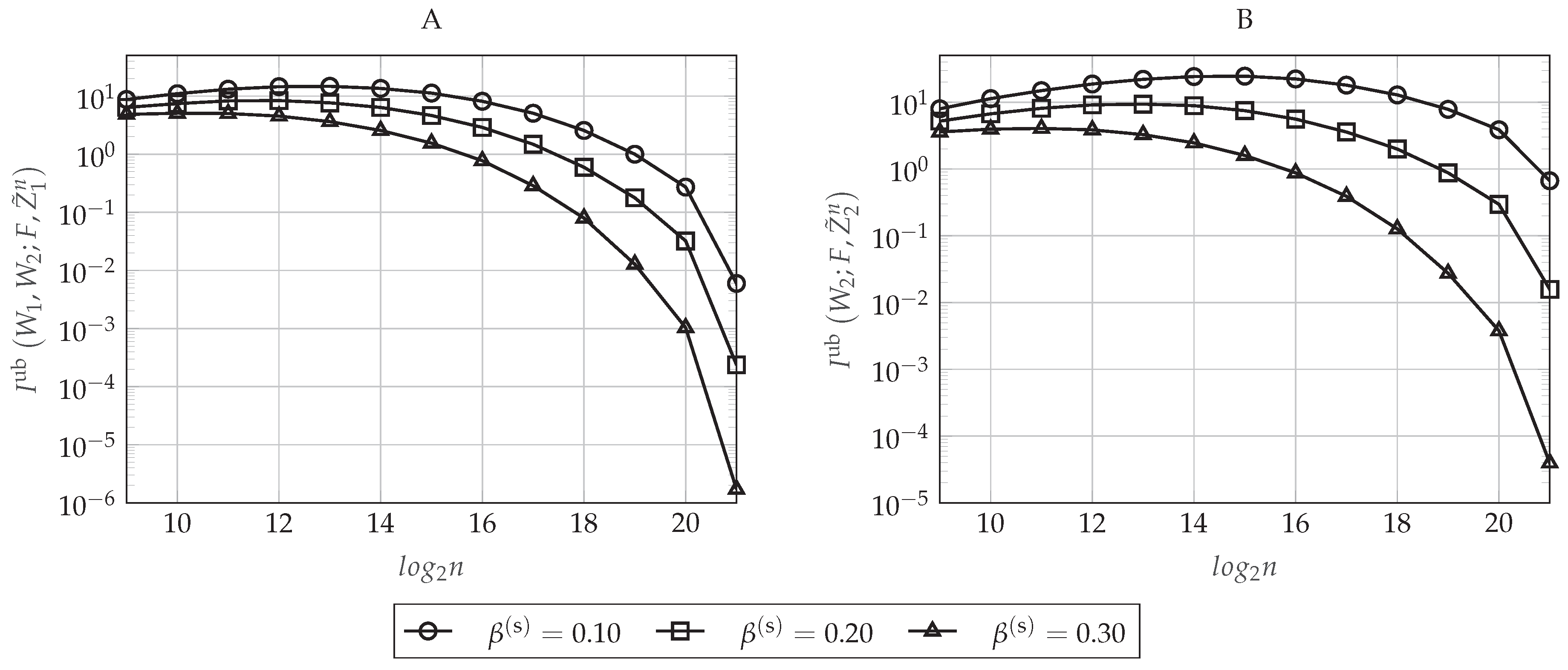
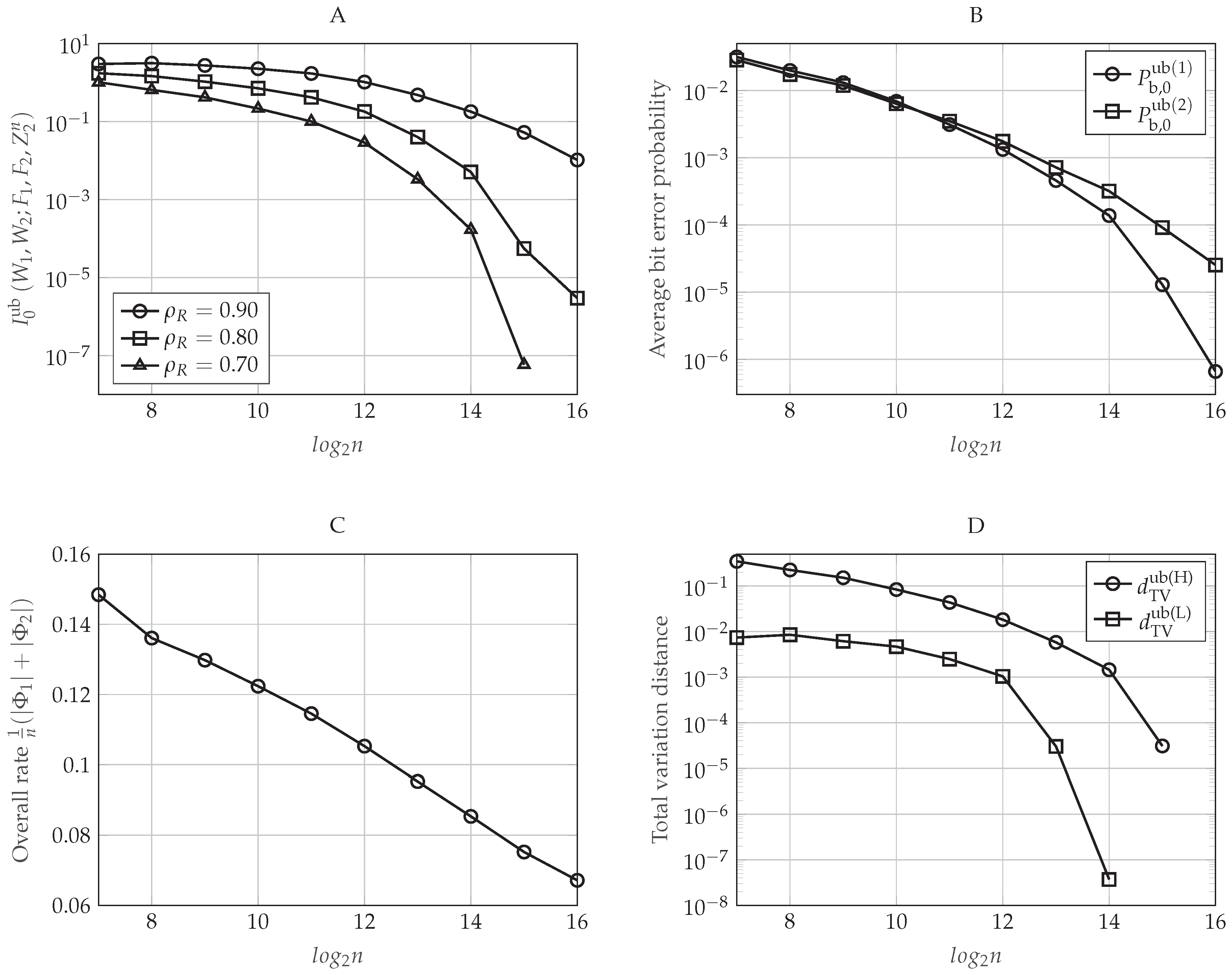
The performance of the polar coding scheme is graphically shown in Figure 10. As for the previous model, let be the normalized target rate in which the polar coding scheme operates, that is . In Figure 10A, we evaluate the upper-bound , which corresponds to the upper-bound on the information leakage defined in Equation (55) when we consider , as a function of the blocklength n for different values of . For this plot, we set and . Notice that and if we set will not impact the information leakage. As we have proven in Section 5.5.4, the secrecy performance is improving as n increases. Moreover, to satisfy a particular secrecy performance level, the polar code will need higher values of n as the target rates approach the capacity.
In Figure 10B, we evaluate the upper-bounds and , which correspond to the bounds on the average bit error probability at the legitimate Receivers 1 and 2, respectively, when we set , as a function of the blocklength n. For this plot, we set and notice that the reliability performance will not depend on the values of and . If we set , then it is clear that it will not depend on either. As shown theoretically in Section 5.5.3, the error probability becomes lower as the blocklength n increases.
Figure 10C plots the overall rate of the additional secret sequences computed as in Equation (56) when we set , and . As mentioned in Section 5.2, we can see that this rate tends to be negligible for n sufficiently large.
Finally, Figure 10D plots the upper-bounds and defined in Equations (51) and (52), respectively, when we set . As we have proven theoretically in Lemma 3, notice that the total variation distance decays with the blocklength n. Precisely, notice that is lower than , and therefore, the bound on the total variation distance is practically governed by (). This happens because although we can compute exactly the Kullback–Leibler divergence as in Equation (A3) from the entropy terms estimated in the polar code construction, Pinsker’s inequality to obtain as in Equation (52) can be too loose for n not sufficiently large. Consider the impact of on the reliability performance of the code. The average error probability bounds in Equations (53) and (54) are modeled as the sum of two terms, one depending directly on and the other depending on the polar construction (which has been plotted in Figure 10B). Since is too loose, what we obtain is that the reliability performance of the code will be governed practically by the bound for small values of the blocklength n. Now, consider the impact of on the secrecy performance of the code. The bound on the information leakage in Equation (55) is modeled as the sum of two terms, one also depending only on the polar code construction (which has been plotted in Figure 10A) and the other depending on . However, in this situation, impacts the information leakage approximately as , which means that this term will totally govern the secrecy performance. Recall that this term follows from Equation (44), which bounds the impact of the encoding in Equation (36) on the conditional entropy term of the information leakage as a function of the total variation distance. Hence, we can conclude that this bound, which follows from applying [30] (Lemma 2.9), can be too loose for n not sufficiently large.
7. Conclusions
We have described two polar coding schemes for two different models over the degraded broadcast channel: DBC-NLD-LS and DBC-LD-NLS. For both models, we have proven that the proposed polar coding schemes are asymptotically secrecy-capacity achieving, providing reliability and strong secrecy simultaneously. Then, we have discussed how to construct these polar codes in practice, and we have evaluated their performance for a finite blocklength by means of simulations. Although several polar code constructions methods have been proposed in the literature, this paper, as far as we know, is the first to discuss practical constructions when the polar code must satisfy both reliability and secrecy constraints. In addition, we have evaluated the secrecy performance of the polar code in terms of the strong secrecy performance, which has been possible by obtaining an upper-bound on the corresponding information leakage at the eavesdroppers. Indeed, we have shown that the proposed polar coding schemes can perform well in practice for a finite blocklength.
The criteria we have chosen for designing the polar codes are: to provide reliability and strong secrecy in one block of size n by using only a secret key that is negligible in terms of rate and to minimize the amount of random decisions for the SC encoding. For the first purpose, we have introduced the source of common randomness, and we have avoided the use of the chaining construction given in [9] (which is possible due to the degraded nature of the broadcast channel); for the second one, we have adapted the deterministic SC encoding given in [20]. These two types of randomness have different implications on the practical design: while the common randomness is uniformly distributed and can be provided by the communication system, the randomness for SC encoding is not and must be drawn by the encoder. In communication scenarios requiring several transmissions of size n, we have shown that one realization of the common randomness can be reused without worsening the performance.
Despite the good performance of the polar coding schemes, some issues still persist. How to avoid the transmissions of the additional secret sequences is a problem that remains open. Despite the length of the required secret key being asymptotically negligible in terms of rate, these additional transmissions can be problematic in practical scenarios. As pointed out in Remark 4, one can adopt the chaining construction in [9] to further reduce the length of these sequences, but this requires the transmission to take place over several blocks of size n and a very large memory capacity at the transmitter or receiver side. Furthermore, despite the rate of the amount of randomness required for SC encoding being negligible, how to replace the random decisions entirely by deterministic ones is a problem that still remains unsolved. Another problem that remains open is how to avoid the use of the common randomness, which allows keyless secret communication over a single block of size n (keyless in the sense that the rate of the required secret key is negligible). Finally, to design polar codes based on the proposed performance evaluation, it seems necessary to find tighter upper-bounds on the total variation distance between the distribution induced by the encoder and the original distribution used in the code construction, particularly for the term that models the impact of storing uniformly-distributed sequences. Also, for the secrecy performance, it would be interesting to find a tighter upper-bound to evaluate the impact of the total variation distance on the information leakage.
Lastly, it is worth mentioning that having to know the statistics of the eavesdropper channels for the polar code construction may seem problematic. Nevertheless, for the polar code construction, one can consider virtual eavesdroppers with some target channel qualities. For DBC-LD-NLS, we can design a polar code according to the statistics of this virtual eavesdropper, and due to the degradedness condition of the channel, this code will perform well if the real eavesdroppers have worse channel quality (worst-case design). On the other hand, for the DBC-NLD-LS, one can simply consider different levels of secrecy depending on different target channel qualities. Depending on the channel quality of the real eavesdropper with respect to the virtual ones considered for the design, the polar coding scheme will provide a particular secrecy performance level.
Supplementary Materials
The MATLAB code used in this paper for Section 6 is available at https://0-www-mdpi-com.brum.beds.ac.uk/1099-4300/20/6/467/s1.
Author Contributions
Conceptualization, J.d.O.A. and J.R.F. Formal analysis, J.d.O.A. Funding acquisition, J.R.F. Investigation, J.d.O.A. and J.R.F. Methodology, J.d.O.A. and J.R.F. Software, J.d.O.A. Supervision, J.R.F. Validation, J.R.F. Writing, original draft, J.d.O.A.
Funding
This work is supported by the “Ministerio de Ciencia, Innovación y Universidades” and the “Agencia Estatal de Investigación” of the Spanish Government, ERDF funds (TEC2013-41315-R, TEC2015-69648-REDC, TEC2016-75067-C4-2-R) and the Catalan Government (2017 SGR 578 AGAUR).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| DBC | Degraded Broadcast Channel |
| DBC-NLD-LS | Degraded Broadcast Channel with Non-Layered Decoding and Layered Secrecy |
| DBC-LD-NLS | Degraded Broadcast Channel with Layered Decoding and Non-Layered Secrecy |
| SC | Successive Cancellation |
| DMS | Discrete Memoryless Source |
| BEC | Binary Erasure Channel |
| BSC | Binary Symmetric Channel |
| BE-BC | Binary Erasure Broadcast Channel |
| BS-BC | Binary Symmetric Broadcast Channel |
Appendix A. Proof of Lemmas 2 and 3
Consider a DMS , the joint distribution of which satisfies the Markov chain condition . Consider an i.i.d. n-sequence of this DMS, n being any power of two. We define the polar transforms , where for each , with joint distribution . Then, define and as in Equations (27) and (28), where . Let ; if , notice that this DMS is the one considered for the code construction of DBC-NLD-LS. Otherwise, if , it is the one considered for DBC-LD-NLS.
Now, consider the polar encoding procedures described for both models in Section 4.2 and Section 5.2. Let be the joint distribution of after the encoding. For both models, we have:
where, for all ,
being the distribution induced by the original DMS and being the deterministic arg max function given in Equation (18) for DBC-NLD-LS or given in Equation (37) for DBC-LD-NLS.
Additionally, consider another encoding process that constructs by omitting the use of the deterministic arg max function, but samples from the distribution:
First, the following lemma shows that the joint distributions and are nearly statistically indistinguishable for sufficiently large n.
Lemma A1.
Let for some , and define . Then,
Proof.
The Kullback-Leibler distance between and is:
where holds by the chain rule, the invertibility of and the fact that (and ) forms a Markov chain, follows from Equation (A2) and by applying [14] (Lemma 10), and holds by the definition of in Equation (27). Finally, since and by using Pinsker’s inequality, we obtain . □
Now, we show that and are nearly indistinguishable for n large enough.
Lemma A2.
Let for some . Then,
where and defined as in Lemma A1.
Proof.
The proof follows similar reasoning as the one for [20] (Lemma 2). Hence, define a coupling [29] for and such that . Thus, we have:
where follows from the coupling lemma [29] (Proposition 4.7), holds by the union bound, the invertibility of and the fact that (and ) forms a Markov chain, also holds by the union bound and follows from Equations (A1) and (A2) given that and from defining .
Next, for any and , for sufficiently large n, we have:
where holds by the chain rule of entropy and the triangle inequality, follows from applying [30] (Lemma 2.9), the invertibility of and because , and holds because (by using Lemma A1 and taking ) and because the function is monotonically decreasing for small enough.
Thus, for any and , we have:
where holds because, by definition, if , holds by Equation (A5), holds because and if and follows from Jensen’s inequality.
Finally, by combining Equations (A4) and (A6) and because , we have . □
Hence, by Lemma A1, Lemma A2 and by applying the triangle inequality, we obtain:
Consequently, since and the invertibility of , we obtain , and this concludes the proof.
References and Notes
- Wyner, A. The wire-tap channel. Bell Syst. Tech. J. 1975, 54, 1355–1387. [Google Scholar] [CrossRef]
- Csiszár, I.; Körner, J. Broadcast channels with confidential messages. IEEE Trans. Inf. Theory 1978, 24, 339–348. [Google Scholar] [CrossRef]
- Maurer, U.; Wolf, S. Information-theoretic key agreement: From weak to strong secrecy for free. In Advances in Cryptology—EUROCRYPT 2000; Springer: Berlin/Heidelberg, Germany, 2000; pp. 351–368. [Google Scholar]
- Zou, S.; Liang, Y.; Lai, L.; Poor, H.; Shamai, S. Broadcast networks with layered decoding and layered secrecy: Theory and applications. Proc. IEEE 2015, 103, 1841–1856. [Google Scholar] [CrossRef]
- Liang, Y.; Lai, L.; Poor, H.V.; Shamai, S. A broadcast approach for fading wiretap channels. IEEE Trans. Inf. Theory 2014, 60, 842–858. [Google Scholar] [CrossRef]
- Ekrem, E.; Ulukus, S. Secrecy capacity of a class of broadcast channels with an eavesdropper. EURASIP J. Wirel. Commun. Netw. 2009, 2009. [Google Scholar] [CrossRef]
- Arikan, E. Channel polarization: A method for constructing capacity-achieving codes for symmetric binary-input memoryless channels. IEEE Trans. Inf. Theory 2009, 55, 3051–3073. [Google Scholar] [CrossRef] [Green Version]
- Mahdavifar, H.; Vardy, A. Achieving the secrecy capacity of wiretap channels using polar codes. IEEE Trans. Inf. Theory 2011, 57, 6428–6443. [Google Scholar] [CrossRef]
- Şaşoğlu, E.; Vardy, A. A new polar coding scheme for strong security on wiretap channels. In Proceedings of the IEEE International Symposium on Information Theory Proceedings (ISIT), Istanbul, Turkey, 7–12 July 2013; pp. 1117–1121. [Google Scholar] [CrossRef]
- Renes, J.M.; Renner, R.; Sutter, D. Efficient one-way secret key agreement and private channel coding via polarization. In Advances in Cryptology-ASIACRYPT; Springer: Berlin/Heidelberg, Germany, 2013; pp. 194–213. [Google Scholar]
- Wei, Y.; Ulukus, S. Polar coding for the general wiretap channel with extensions to multiuser scenarios. IEEE J. Sel. Areas Commun. 2016, 34, 278–291. [Google Scholar] [CrossRef]
- Cihad Gulcu, T.; Barg, A. Achieving secrecy capacity of the wiretap channel and broadcast channel with a confidential component. arXiv, 2014; arXiv:1410.3422. [Google Scholar]
- Chou, R.A.; Bloch, M.R. Polar coding for the broadcast channel with confidential messages: A random binning analogy. IEEE Trans. Inf. Theory 2016, 62, 2410–2429. [Google Scholar] [CrossRef]
- Goela, N.; Abbe, E.; Gastpar, M. Polar codes for broadcast channels. IEEE Trans. Inf. Theory 2015, 61, 758–782. [Google Scholar] [CrossRef]
- Chou, R.A.; Bloch, M.R.; Abbe, E. Polar coding for secret-key generation. IEEE Trans. Inf. Theory 2015, 61, 6213–6237. [Google Scholar] [CrossRef]
- Wang, L.; Sasoglu, E. Polar coding for interference networks. In Proceedings of the 2014 IEEE International Symposium on Information Theory, Honolulu, HI, USA, 29 June–4 July 2014; pp. 311–315. [Google Scholar] [CrossRef]
- Chou, R.A.; Yener, A. Polar coding for the multiple access wiretap channel via rate-splitting and cooperative jamming. In Proceedings of the 2016 IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 983–987. [Google Scholar] [CrossRef]
- Hirche, C.; Morgan, C.; Wilde, M.M. Polar codes in network quantum information theory. IEEE Trans. Inf. Theory 2016, 62, 915–924. [Google Scholar] [CrossRef]
- Bloch, M.; Barros, J. Physical-Layer Security: From Information Theory to Security Engineering; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Chou, R.A.; Bloch, M.R. Using deterministic decisions for low-entropy bits in the encoding and decoding of polar codes. In Proceedings of the 2015 53rd Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 29 September–2 October 2015; pp. 1380–1385. [Google Scholar] [CrossRef]
- Tal, I.; Vardy, A. How to construct polar codes. IEEE Trans. Inf. Theory 2013, 59, 6562–6582. [Google Scholar] [CrossRef]
- Vangala, H.; Viterbo, E.; Hong, Y. A comparative study of polar code constructions for the AWGN channel. arXiv, 2015; arXiv:1501.02473. [Google Scholar]
- Honda, J.; Yamamoto, H. Polar coding without alphabet extension for asymmetric models. IEEE Trans. Inf. Theory 2013, 59, 7829–7838. [Google Scholar] [CrossRef]
- Throughout this paper, we assume binary polarization. An extension to q-ary alphabets is possible [25,26].
- Karzand, M.; Telatar, E. Polar codes for q-ary source coding. In Proceedings of the 2010 IEEE International Symposium on Information Theory, Austin, TX, USA, 12–18 June 2010; pp. 909–912. [Google Scholar] [CrossRef]
- Şasoğlu, E.; Telatar, E.; Arikan, E. Polarization for arbitrary discrete memoryless channels. In Proceedings of the IEEE Information Theory Workshop, Sicily, Italy, 11–16 October 2009; pp. 144–148. [Google Scholar]
- Arikan, E. Source polarization. In Proceedings of the 2010 IEEE International Symposium on Information Theory, Austin, TX, USA, 12–18 June 2010; pp. 899–903. [Google Scholar]
- Korada, S.B.; Urbanke, R.L. Polar codes are optimal for lossy source coding. IEEE Trans. Inf. Theory 2010, 56, 1751–1768. [Google Scholar] [CrossRef]
- Levin, D.A.; Peres, Y.; Wilmer, E.L. Markov Chains and Mixing Times; American Mathematical Society: Providence, RI, USA, 2009. [Google Scholar]
- Csiszar, I.; Körner, J. Information Theory: Coding Theorems for Discrete Memoryless Systems; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Pearl, J. Causality; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Most of the code in MATLAB is adapted from https://ecse.monash.edu/staff/eviterbo/polarcodes.html.
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
Figure 1.
DBC with Non-Layered Decoding and Layered Secrecy (DBC-NLD-LS).

Figure 2.
DBC with Layered Decoding and Non-Layered Secrecy (DBC-LD-NLS).

Figure 3.
Polar code construction for DBC-NLD-LS. The hatched area represents those indices , which can belong to the sets (), , or .
Figure 3.
Polar code construction for DBC-NLD-LS. The hatched area represents those indices , which can belong to the sets (), , or .

Figure 4.
Bayesian graph plotting the dependencies between the random variables of different blocks that are involved in the secrecy analysis when we consider a transmission over several blocks of size n.
Figure 4.
Bayesian graph plotting the dependencies between the random variables of different blocks that are involved in the secrecy analysis when we consider a transmission over several blocks of size n.

Figure 5.
Polar code construction for the DBC-LD-NLS at the ℓ-th layer. The hatched area represents those indices , which can belong to the sets , or .
Figure 5.
Polar code construction for the DBC-LD-NLS at the ℓ-th layer. The hatched area represents those indices , which can belong to the sets , or .

Figure 6.
Secrecy performance of the polar coding scheme for DBC-NLD-LS over BE-BC as a function of the blocklength n and the normalized target rate when we set and . (A) Upper-bound on the information about leaked to Eavesdropper 1 defined as in Equation (48). (B) Upper-bound on the information about leaked to Eavesdropper 2 defined as in Equation (49).
Figure 6.
Secrecy performance of the polar coding scheme for DBC-NLD-LS over BE-BC as a function of the blocklength n and the normalized target rate when we set and . (A) Upper-bound on the information about leaked to Eavesdropper 1 defined as in Equation (48). (B) Upper-bound on the information about leaked to Eavesdropper 2 defined as in Equation (49).

Figure 7.
Secrecy performance of the polar coding scheme for DBC-NLD-LS over BE-BC as a function of n and , which defines for each n, when we set and . (A) Upper-bound on the information about leaked to Eavesdropper 1 defined as in Equation (48). (B) Upper-bound on the information about leaked to Eavesdropper 2 defined as in Equation (49).
Figure 7.
Secrecy performance of the polar coding scheme for DBC-NLD-LS over BE-BC as a function of n and , which defines for each n, when we set and . (A) Upper-bound on the information about leaked to Eavesdropper 1 defined as in Equation (48). (B) Upper-bound on the information about leaked to Eavesdropper 2 defined as in Equation (49).

Figure 8.
Reliability performance of the polar coding scheme for DBC-NLD-LS over BE-BC as a function of n and , which defines for each n, when we set and . That is, the bound on the average bit error probability at the legitimate Receiver 1 is defined as in Equation (47).
Figure 8.
Reliability performance of the polar coding scheme for DBC-NLD-LS over BE-BC as a function of n and , which defines for each n, when we set and . That is, the bound on the average bit error probability at the legitimate Receiver 1 is defined as in Equation (47).

Figure 9.
Rate of the additional secret sequence computed as in Equation (50) for DBC-NLD-LS over BE-BC as a function of the blocklength n for different values of , which defines for each n. (A) Rate of for different values of when and . (B) Rate of for different values of when and .
Figure 9.
Rate of the additional secret sequence computed as in Equation (50) for DBC-NLD-LS over BE-BC as a function of the blocklength n for different values of , which defines for each n. (A) Rate of for different values of when and . (B) Rate of for different values of when and .

Figure 10.
Performance of the polar coding scheme for DBC-LD-NLS over BS-BC as a function of the blocklength n when , , and . (A) Upper-bound on the information about leaked to Eavesdropper 2 defined as in Equation (55) for different normalized target rates when we set . (B) Upper-bounds on the average error probability at legitimate Receivers 1 and 2 defined as in Equations (53) and (54), respectively, when . (C) Overall rate of the sequences computed as in Equation (56). (D) terms and that contribute to the bound on the total variation distance defined as in Equations (51) and (52), respectively.
Figure 10.
Performance of the polar coding scheme for DBC-LD-NLS over BS-BC as a function of the blocklength n when , , and . (A) Upper-bound on the information about leaked to Eavesdropper 2 defined as in Equation (55) for different normalized target rates when we set . (B) Upper-bounds on the average error probability at legitimate Receivers 1 and 2 defined as in Equations (53) and (54), respectively, when . (C) Overall rate of the sequences computed as in Equation (56). (D) terms and that contribute to the bound on the total variation distance defined as in Equations (51) and (52), respectively.

© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Del Olmo Alos, J.; Rodríguez Fonollosa, J. Strong Secrecy on a Class of Degraded Broadcast Channels Using Polar Codes. Entropy 2018, 20, 467. https://0-doi-org.brum.beds.ac.uk/10.3390/e20060467
AMA Style
Del Olmo Alos J, Rodríguez Fonollosa J. Strong Secrecy on a Class of Degraded Broadcast Channels Using Polar Codes. Entropy. 2018; 20(6):467. https://0-doi-org.brum.beds.ac.uk/10.3390/e20060467
Chicago/Turabian StyleDel Olmo Alos, Jaume, and Javier Rodríguez Fonollosa. 2018. "Strong Secrecy on a Class of Degraded Broadcast Channels Using Polar Codes" Entropy 20, no. 6: 467. https://0-doi-org.brum.beds.ac.uk/10.3390/e20060467
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.