1. Introduction
Under the minimal mean square error criteria, the KF is the optimal estimator for the linear Gaussian state-space model [
1,
2]. KF has been widely employed in a variety of applications [
3,
4,
5]. Unfortunately, in many practical applications, when the sensor produces intermittent faults, the actual measurement of the sensors may not be accurately represented by the KF measurement model [
6,
7]. If the random measurement loss occurs, the measurement of the sensors contains only pure noise. In this situation, the estimation accuracy of a typical KF will drop significantly or even diverge. Various filtering methods have been developed to address the measurement loss filtering issue, such as the intermittent KF (IKF) [
8,
9]. However, IKF has an important assumption: the measurement loss probability is known. In practical applications, the measurement loss probability is usually unknown and the IKF is no longer applicable in this case [
7].
In order to address the filtering issues of the unknown measurement loss probability of the linear system, the first Bayesian Kalman filter and the second Bayesian Kalman filter were designed by estimating the process and posterior distribution of the measurement loss, respectively [
10]. The above two filters, however, are no longer valid if the unknown measurement loss probability is time-varying. Recently, the variational Bayesian-based adaptive KF (VBAKF) was derived for a linear system with unknown time-varying measurement loss probability (UTVMLP) and both the system vector and UTVMLP are jointly estimated by introducing the variational Bayesian technique [
7]. Additionally, VBAKF shows excellent performance in the context of white Gaussian measurement noise with known statistical characteristics. Unfortunately, in realistic engineering applications, measurement outliers may occur at various periods due to environmental changes and unreliable sensors, resulting in NSHTMN, i.e., when the system runs healthily, the measurement noise is the Gaussian-distributed, and when the time-varying measurement outliers erode the system, the measurement noise is heavy-tail-distributed [
11,
12]. In the scenario of NSHTMN, the estimation accuracy of VBAKF will drop sharply.
Recently, some mixture distribution-based algorithms have been presented to address NSHTMN, such as the Gaussian-Student’s
t-mixture distribution-based KF (GSTKF) [
13,
14]. However, the filtering problem with UTVMLP and NSHTMN cannot directly solved by employing a mixture distribution, that is, under the scenario of UTVMLP and NSHTMN, the current likelihood function is a weighted sum of double-mixture distributions, which is an unclosed and unconjugated distribution that makes the Bayesian inference difficult to employ directly.
In this paper, a new variational Bayesian-based KF is presented to settle the filtering issue for linear discrete-time systems with UTVMLP and NSHTMN. Firstly, the Gaussian-Student’s t-mixture distribution with BM is employed to model the NSHTMN. Secondly, the form of the likelihood function is converted to an exponential product and constructs a new hierarchical Gaussian state-space model by utilizing BL. Thirdly, the variational Bayesian method is introduced to simultaneously estimate the system state vector, BM, BL, the intermediate random variables, the mixing probability, and the UTVMLP. Finally, a numerical simulation experiment reveals that the proposed filter has better estimation accuracy but is more time-consuming than existing filtering algorithms in the scenarios of NSHTMN and UTVMLP.
The contributions of this paper are as follows:
- (a)
By employing a Bernoulli-distributed variable, the NSHTMN is modelled as a Gaussian-Student’s t-mixture distribution;
- (b)
The measurement likelihood function is converted from the weight sum of two mixture distributions to an exponential product and a new hierarchical Gaussian state-space model is therefore derived;
- (c)
The system state vector, UTVMLP, and the unknown variables are simultaneously estimated by utilizing the variational Bayesian technique;
- (d)
Numerical simulation results indicate that the proposed filter has better performance than that of existing algorithms in the scenarios of NSHTMN and UTVMLP
2. Problem Formulation
Consider the linear stochastic system with the following state and measurement equations:
where
denotes the system state vector;
denotes the state transition matrix;
represents the Gaussian-distributed white process noise vector with a zero mean value and covariance matrix
;
represents the measurement vector;
is the measurement matrix;
is the white NSHTMN vector; and
represents the index of discrete time. The phenomenon of measurement loss is described by introducing the identically distributed and mutually uncorrelated measurement loss defined as the Bernoulli random variable (BL)
, which is expressed by the following equations.
where
denotes the time-varying measurement loss probability. Note that the value of
is unknown in this paper. The initial Gaussian-distributed system state vector
is the random vector with mean
and covariance matrix
. Additionally, it is assumed that the initial system state vector
, the noise vectors
and
, and the Bernoulli random variable
are mutually independent.
It can be seen from Equations (1)–(4) that the ideal measurement was received by the sensor when and the measurement loss with UTVMLP occurred when . Meanwhile, the measurement noise is NSHTMN due to measurement outliers, that is, when the system runs healthily, the measurement noise is Gaussian-distributed, and when measurement outliers erode the system, the measurement noise is heavy-tail-distributed. The NSHTMN and UTVMLP can result in estimation errors or even in filtering divergence. Therefore, a new variational Bayesian-based Kalman filter with NSHTMN and UTVMLP will be proposed.
3. Proposed Variational Bayesian-Based Kalman Filter
In this section, a new variational Bayesian-based Kalman filter is proposed to address the filtering issue for a linear system with NSHTMN and UTVMLP. Firstly, the Gaussian-Student’s t-mixture distribution is utilized to model the NSHTMN and the hierarchical form is derived. Secondly, by converting the measurement likelihood function into an exponential multiplication, a new hierarchical Gaussian state-space model is established. Thirdly, by using the variational Bayesian method, the system state and unknown variables are simultaneously estimated. Finally, the required mathematical expectations are given.
3.1. Gaussian-Student’s t-Mixture Distribution
The NSHTMN vector can be modeled as the Gaussian-Student’s
t-mixture distribution by employing another mixing-defined Bernoulli random variable (BM),
, and the probability density function (PDF),
is given as
where
represents the Gaussian PDF with a zero mean vector and covariance matrix
, and
represents the student’s
t-PDF with a zero mean vector, covariance matrix
, and degree of freedom (dof) parameter
.
represents the covariance matrix of the nominal measurement noise. The PDF of the mixing probability
and the probability mass function (PMF) of
are defined as follows, respectively.
where
represents the Beta PDF with shape parameters
and
.
Due to the hierarchical properties of the student’s
t-distribution, Equation (5) can be rewritten as such:
where
represents the Gamma PDF with shape parameter
and rate parameter
, and
represents the intermediate random variable.
3.2. New Hierarchical Gaussian State-Space Model (HGSSM)
According to Equations (2)–(4), the measurement likelihood PDF is derived as Based on Equation (2), the following equation can be obtained.
where
represents the measurement noise PD. Substituting Equations (11) and (12) in Equation (10) results in
Remark 1. The measurement likelihood PDF in Equation (13) is an unclosed and unconjugated weighted sum form, and it is impossible to infer the system state vector and unknown parameters directly by utilizing the variational Bayesian. The weighted sum will then be converted into an exponential multiplication form to address this problem.
The PMF of BL
is given as
Exploiting Equations (13) and (14), the measurement likelihood PDF is reformulated as
According Equation (15), the exponential multiplication-formed likelihood PDF
is given as follows.
Remark 2. The variational Bayesian method must select the suitable conjugate-prior distributions for unknown variables. Therefore, the appropriate prior PDFs to construct a new HGSSM are selected.
The one-step predicted PDF
of system state vector
is assumed as being Gaussian distributed as follows.
where
represents the mean vector and
represents the covariance matrix. Both
and
can be updated by the typical Kalman filter, which is given as
In employing Equations (8), (9) and (16), the conditional likelihood PDF
is derived as
It can be seen from Equations (6)–(9), (13) and (20) that the measurement vector
depends on system state vector
, intermediate random variable
, BM
, BL
, mixing probability
, and measurement loss probability
. The following joint-prior PDF must be calculated, i.e.,
where the definitions of
,
,
,
, and
are given in Equations (6), (7), (9), (14) and (17), respectively. Additionally,
denotes the prior PDF of the time-varying measurement loss probability, which can be assumed as the following Beta distribution.
where the shape parameters
and
can be calculated by introducing the forgetting factor
as follows.
where
and
represent posterior shape parameters.
The proposed new HGSSM is comprised of Equations (14) and (17)–(24). System state vector , intermediate random variable , BM , BL , mixing probability , and measurement loss probability will be simultaneously estimated by utilizing the variational Bayesian method.
3.3. Variational Bayesian Approximation of the Joint Posterior PDFs
Aiming at the estimation of the unknown variables of the new HGSSM, the joint posterior PDF
with
is required to be solved. However, the analytical solution of
is not accessible. The variational Bayesian approach is therefore employed to determine an approximate PDF for
and to compute an approximate solution [
15,
16,
17], i.e.,
where
represents an arbitrary element of
and
denotes the approximate PDF or PMF. By minimizing the Kullback–Leibler divergence (KLD) between
and
,
can be obtained as follows.
where
represents the KLD between
and
, and the optimal solution of Equation (26) can be calculated via the following formula [
15,
17].
where
denotes the mathematical expectation operation,
signifies a grouping of all the components in
apart from
, and the constant with regard to
is denoted by
. Additionally, the fixed-point iteration technique is utilized to derive the approximate formation of
due to the fact that estimated parameters are mutually coupled.
The joint PDF
in Equation (26) can be derived as
Proposition 1. Let
and by using Equation (29) in (28),
can be updated as Gaussian, i.e.,
where
represents the approximate PDF in the
iteration, while the mean vector
and the covariance matrix
are assumed to be updated in accordance with the traditional Kalman filter as follows.
where
represents the Kalman gain matrix. The modified measurement noise covariance matrix at
iteration
is formulated as
where
represents the mathematical expectation of variables in the
iteration.
Proposition 2. Let
and by using Equation (29) in Equation (28),
can be updated as Gamma, i.e.,
where the shape parameter
and rate parameter
are formulated as
where
represents the dimension of the measurement vector,
represents the trace operation, and
is defined as
Proposition 3. Let
and by using Equation (29) in Equation (28),
can be updated as the Bernoulli distribution. The posterior probabilities
and
of BL
are given as
where
represents the normalizing constant and the parameters
and
are, respectively, defined as
Proposition 4. Let
and by using Equation (29) in (28),
can be also updated as the Bernoulli distribution. The posterior probabilities
and
of BM
are given as
where
also represents the normalizing constant and the definitions of parameters
and
are, respectively, given as
Proposition 5. Let
and by using Equation (29) in (28),
can be updated as the Beta distribution, i.e.,
where the shape parameters
and
are formulated as
Proposition 6. Let
and by using Equation (29) in Equation (28),
can be also updated as the Beta distribution, i.e.,
where the definitions of shape parameters
and
are given as
3.4. Calculation of the Required Mathematical Expectations
The required mathematical expectations
,
,
,
,
,
,
,
,
and
in
Section 3.3 are defined, respectively, as follows:
where
represents the digamma function [
18].
The presented variational Bayesian-based Kalman filter with UTVMLP and NSHTMN consists of Equations (18), (19) and (30)–(62).
Table 1 describes the implementation of the proposed new KF.
4. Simulations
Aimed at demonstrating the superiority of the presented filter in the scenario with UTVMLP and NSHTMN, a numerical example is simulated. The process and measurement equations of the stochastic system are, respectively, given as [
7]
where the Gaussian process noise
and the NSHTMN
are given as [
12]
where
represents “with probability”. The true process noise covariance matrix
with parameter
and the nominal measurement noise covariance matrix
with parameter
are set as
The real UTVMLP is set as
From Equations (66)–(69), it can be seen that the measurement noise and UTVMLP are divided into four stages, as shown in
Table 2. The remaining system parameters are as follows: the sampling interval
and the total simulation time
. The proposed filter is compared with the typical Kalman filter (KF) [
2]; the existing variational Bayesian-based adaptive KF with UTVMLP (VBAKF) [
7]; the existing Gaussian-Student’s
t-mixture distribution-based KF (GSTKF) with Gaussian process noise [
14]; and the existing IKF with known real measurement loss probability [
8]. The parameters of VBAKF are selected as
,
,
,
, and
. The parameters of GSTKF are selected as
and
. The parameters of the proposed filter are given as
,
,
,
,
, and
,
. All filters are programmed with MATLAB R2018a and run on a computer with Intel Core i5-6300HQ CPU at 2.30 GHz and 8 GB of RAM.
Aimed at evaluating the performances in the estimation of the system state vector of all the algorithms, the root-mean square error (RMSE) and the averaged root-mean square error (AGRMSE) are utilized as performance indicators. The definitions of RMSE and AGRMSE of the system state are given as
where
and
denote the actual and estimated system state at the
Monte Carlo run and discrete-time
, respectively.
represents the total Monte Carlo run time.
Different from the proposed algorithm and VBAKF, the KF, IKF and GSTKF do not estimate UTVMLP. Although IKF can also address the filtering problem with measurement loss, IKF is based on the assumption that the measurement loss probability is known. Therefore, only VBAKF and the proposed algorithm participate in the comparison of the UTVMLP estimation performance.
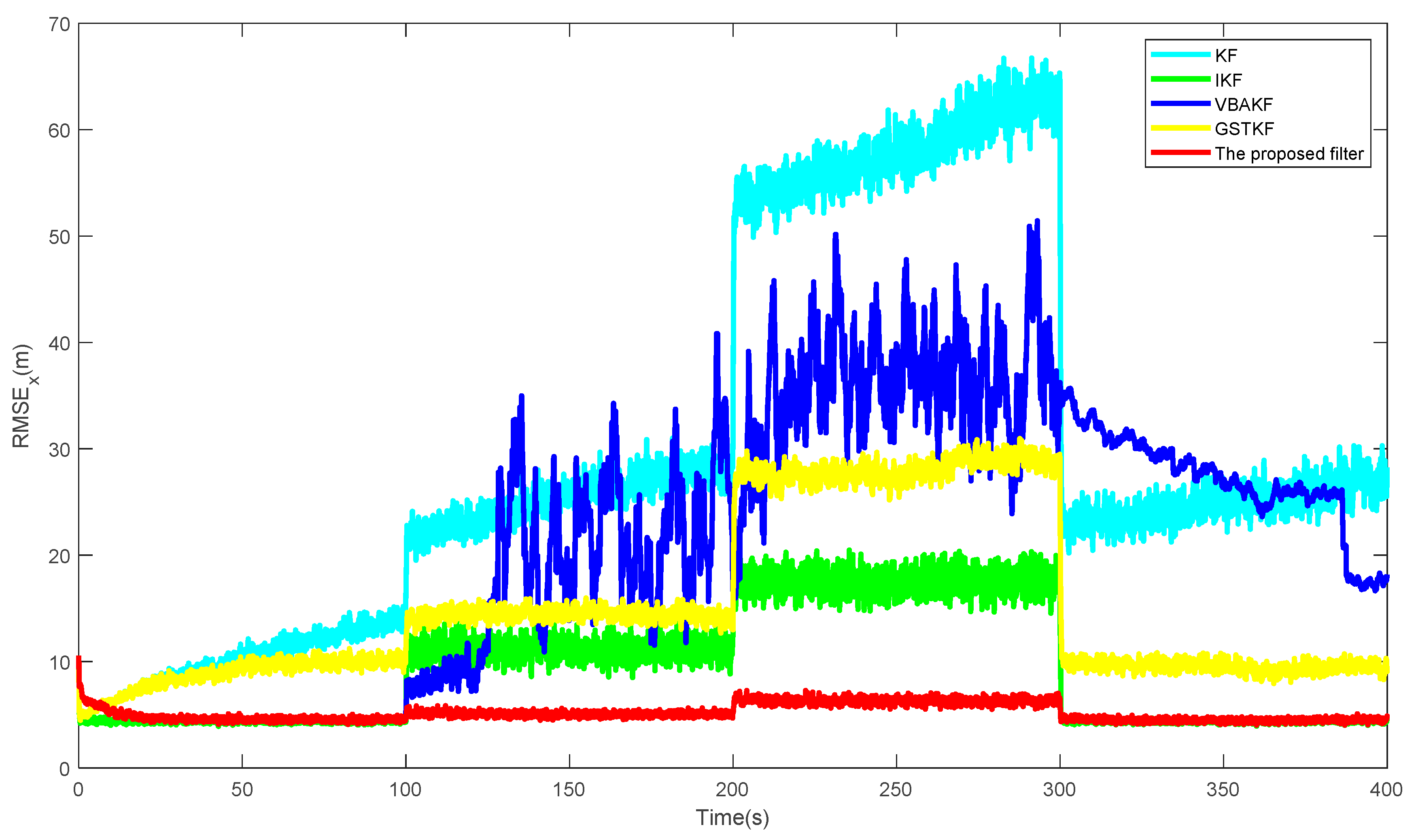
Figure 1 shows the
s of the proposed filter and the existing filters over 500 times of the Monte Carlo run. Additionally, the
s and SSRTs of different filters are listed in
Table 2. It can be seen from
Figure 1 and
Table 3 that in the contexts of UTVMLP and NSHTMN, when the measurement is the Gaussian measurement noise and there is slight loss probability, as shown in stages 1 and 4, the estimation accuracy of the proposed filter is close to the IKF with true loss probability and the performance of the proposed algorithm is better than the other algorithms. We can also find that the proposed algorithm still has better performance than the existing algorithms when the measurement has heavy-tailed measurement noise and larger measurement loss probability, as shown in stages 2 and 4. In addition, the proposed algorithm has longer SSRT and higher computational complexity than the existing filters, which can be observed from
Table 3.
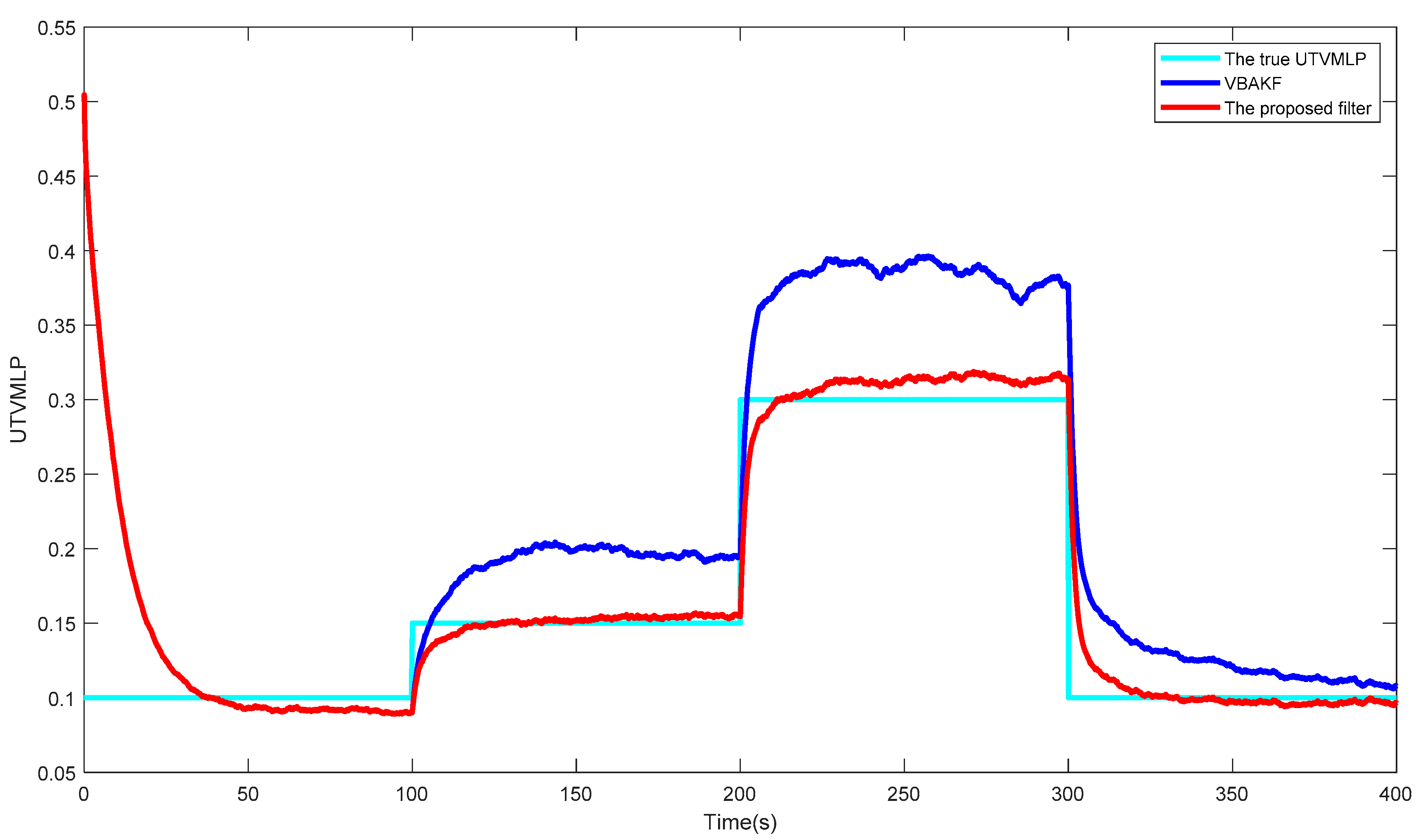
Figure 2 shows the curves of the true and estimated UTVMLPs of VBAKF and the proposed filter over 500 times of the Monte Carlo run. Obviously, the NSHTMN has a great influence on the filtering performance of VBAKF and the proposed filter has better UTVMLP estimation accuracy than VBAKF in the scenario of NSHTMN.
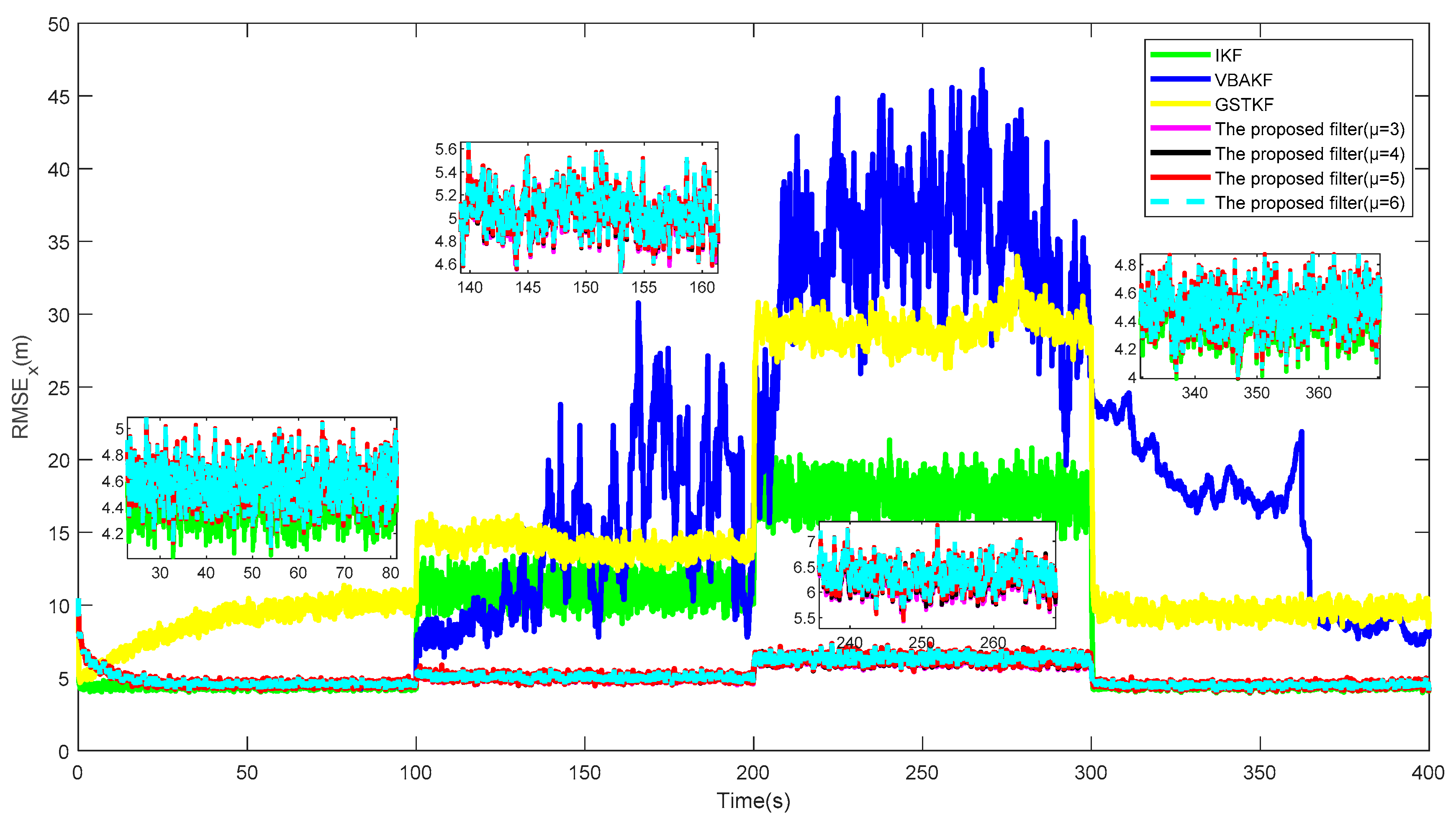
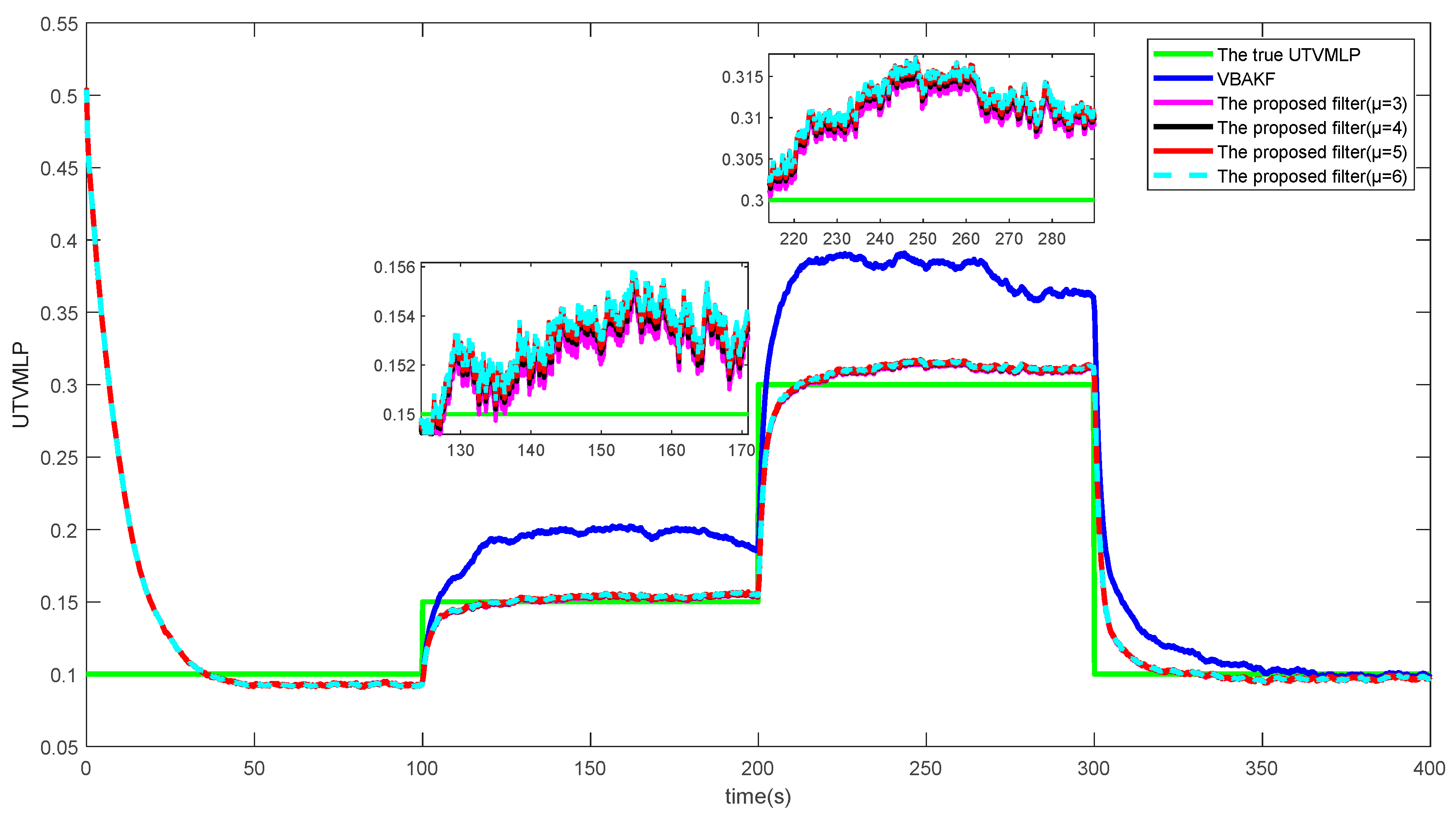
Figure 3 and
Figure 4 show the
s and the estimated UTVMLPs of the proposed filter with shape parameter
over the 500 Monte Carlo run, respectively. The corresponding SSRTs of the proposed filter with
are 0.2991, 0.2983, 0.2993, and 0.2989. It can be seen that the proposed filter with different shape parameters has better performance than current algorithms in the system state and UTVMLP estimations. Moreover, the degree of freedom parameter
has little influence on the estimation accuracy and time complexity of the proposed algorithm, and the recommended value of
is therefore set as 5.
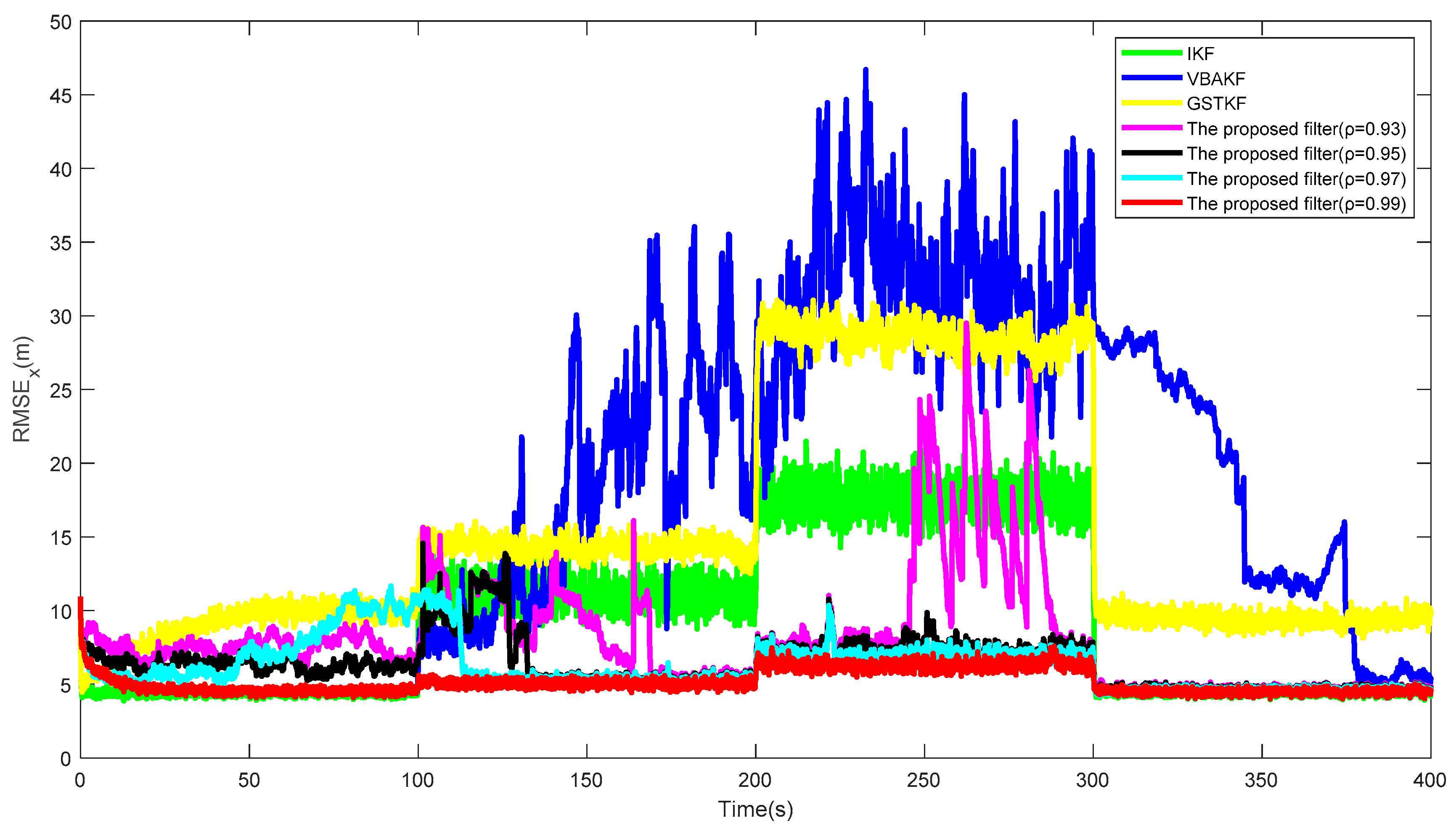
Figure 5 and
Figure 6 show the
s and the estimated UTVMLPs of the proposed filter with forgetting factor
over the 500 Monte Carlo run, respectively. The corresponding SSRT of the proposed filter with
is approximately equal to 0.2990. We can find that the proposed filter with
has the best performance in the system state and UTVMLP estimations, and the value of
has little effect on calculation complexity. Therefore, the recommended value of
is 0.99.
Figure 7 shows the
s of the proposed filter and the current algorithms with the iteration number
. We can see from
Figure 7 that the proposed filter has a smaller
than the existing filters when
and the proposed filter converges faster than the existing filters. However,
Table 4 shows that the setting of
has a huge impact on the time consumption of the proposed filter and the SSRT increases with the increase of
. Therefore, considering time consumption and estimation accuracy, the recommended value of
ranges from 4 to 10.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}