
Task Offloading Strategy Based on Mobile Edge Computing in UAV Network

1
Department of Information Technology, Jiangsu Union Technical Institute, Xuzhou 221000, China
2
School of Computer Sciences and Technology, China University of Mining and Technology, Xuzhou 221000, China
3
School of Sciences, Xi’an Jiaotong-Liverpool University, Suzhou 215123, China
*
Author to whom correspondence should be addressed.
Entropy 2022, 24(5), 736; https://0-doi-org.brum.beds.ac.uk/10.3390/e24050736
Submission received: 18 April 2022
/
Revised: 20 May 2022
/
Accepted: 20 May 2022
/
Published: 22 May 2022
(This article belongs to the Special Issue Wireless Sensor Networks and Their Applications)
Abstract
:When an unmanned aerial vehicle (UAV) performs tasks such as power patrol inspection, water quality detection, field scientific observation, etc., due to the limitations of the computing capacity and battery power, it cannot complete the tasks efficiently. Therefore, an effective method is to deploy edge servers near the UAV. The UAV can offload some of the computationally intensive and real-time tasks to edge servers. In this paper, a mobile edge computing offloading strategy based on reinforcement learning is proposed. Firstly, the Stackelberg game model is introduced to model the UAV and edge nodes in the network, and the utility function is used to calculate the maximization of offloading revenue. Secondly, as the problem is a mixed-integer non-linear programming (MINLP) problem, we introduce the multi-agent deep deterministic policy gradient (MADDPG) to solve it. Finally, the effects of the number of UAVs and the summation of computing resources on the total revenue of the UAVs were simulated through simulation experiments. The experimental results show that compared with other algorithms, the algorithm proposed in this paper can more effectively improve the total benefit of UAVs.
1. Introduction
Power patrol inspection includes calculation-intensive tasks such as fault identification and foreign-object detection. However, such tasks require UAVs to carry out complex calculations in a limited time [1]. Due to the limited battery energy and storage space, the efficiency of UAVs is low. To solve this problem, some researchers have proposed transmitting the computing tasks or data from mobile devices to the remote cloud for execution [2]. However, traditional cloud computing usually connects the remote cloud center with a large transmission delay and an unstable wireless connection, which cannot meet the real-time needs of users [3]. Different from traditional cloud computing technology, mobile edge computing is a new technology. This offloads the computing tasks from mobile devices to the network edge cloud for real-time data transmission and computing, thus expanding the capabilities of mobile devices [4,5]. In this paper, the MEC task offloading part is added to the UAV patrol system, and the distributed computing method is adopted to sink the computing task to the edge of the network, so as to reduce the demand for equipment to offload data to the cloud server and effectively reduce network congestion and delay [6,7].
In research on UAV-aided wireless communication systems with edge computing, the optimization problems and constraints change with the change in the UAV application scenario. For example, Li et al. [8] considered a scenario where a UAV with edge computing functions assists ground IOT equipment in data acquisition and calculation and jointly optimizes UAV trajectory, communication bandwidth allocation, and calculation offloading strategy based on the goal of minimizing the total energy consumption of IOT equipment. In [9], Liu et al. studied a scenario in which multiple UAVs assist ground IOT equipment in computing and offloading. The authors also took UAV energy consumption into account to minimize the total energy consumption of UAVs and ground equipment. In research on UAV-assisted ground mobile users in computing offloading, Jeong [10], Hu [11], and Xiong [12] carried out UAV trajectory planning and computing offloading strategy allocation from the perspective of system energy consumption optimization. Different from the above research studies, Hu Q et al. assumed that the ground user can calculate some tasks locally and then offload the remaining tasks to the UAV in the scenario where the ground user uses the UAV to perform remote computing, and the optimization goal is to minimize the maximum transmission delay of all users [13]. In the study [14], Wang et al. proposed a heuristic-calculation offloading algorithm.
Zhou [15] studied a new system whereby a UAV assists wireless power transmission with edge computing, in which UAVs can not only transmit energy signals to ground mobile users but can also provide users with computing offloading. The author optimized a UAV trajectory and computing offloading strategy based on the goal of maximizing the total energy of users considering fairness; in [16], the author further studied the system from the perspective of minimizing UAV energy consumption. In addition, some intelligent optimization algorithms have also been introduced into research on wireless communication systems aided by UAVs. For example, Wan et al. [17] proposed a new online computing offloading algorithm based on Lyapunov optimization in research on multi-UAV-assisted computing offloading of ground IOT equipment. Wang et al. [18] proposed a user scheduling and computing offloading algorithm based on reinforcement learning in research on multi-UAVs as a relay to provide computing offloading for ground mobile users.
Research on the networked UAV communication system with edge computing usually focuses on the differences among the offloading modes of UAVs. Cao et al. [19] creatively proposed a new scheme whereby networked UAVs can enhance their own computing performance by using edge computing technology by studying the application scenario where multiple ground base stations assist networked UAVs to perform computing offloading. Aiming at minimizing the task completion time of UAVs, the UAV trajectory and offloading strategy are jointly optimized. Based on the consideration of transmission delay and energy constraints, Ateya et al. [20] studied a scenario where networked UAVs can choose to offload computing-intensive tasks to ground base stations or other UAVs nearby. In [21], Chen et al. proposed an intelligent UAV computing offloading algorithm based on a deep Monte Carlo tree search in the study of ground base stations assisting multiple UAVs to perform computing task offloading.
As the ground base station has the advantages of sufficient computing resources and convenient energy supply, authors usually focus on the optimization of UAV energy consumption in research on the energy consumption of networked UAV communication systems with edge computing. For example, Fan et al. [22] considered a scenario where a simple UAV offloads to a ground base station. Assuming that the UAV itself could complete some local calculations, the authors minimized the flight energy consumption of the UAV by optimizing the UAV trajectory. Hua et al. [23] studied a scenario in which a ground base station assists multi-vehicle UAVs to perform computing offloading. With various UAV access schemes, such as time-division multiple access, orthogonal-frequency-division multiple access, and nonorthogonal-frequency-division multiple access, the authors jointly optimized the UAV trajectory, transmit power, and computing offloading strategy with the goal of minimizing the total energy consumption of UAVs. It is worth noting that, in practical applications, when the networked UAV offloads some confidential computing tasks to the ground base station, some important information is likely to be intercepted by the ground eavesdropper. Therefore, research on secure-communication-oriented networked UAV communication systems with edge computing is also very important. Bai et al. [24] considered a scenario where a fixed UAV offloads some computing tasks to the ground base station in the presence of ground eavesdroppers. The authors optimized the computing offloading strategy with the goal of minimizing the total energy consumption of UAVs.
In [25], Avgeris et al. presented a three-level cyber-physical social system (CPSS) for early fire detection to assist public authorities in promptly identifying and acting on emergency situations; they designed a dynamic resource scaling mechanism for the edge computing infrastructure, which can address the demanding Quality of Service (QoS) requirements of this IoT-enabled time and mission-critical application.
To sum up, in existing research on UAV-aided wireless communication systems with edge computing, authors have mainly focused on the optimization of system energy consumption and constraints on transmission delay caused by computing offloading. For the networked UAV communication system with edge computing, the computing power of the ground base station is generally much greater than that of the UAV or other equipment, and the transmission delay problem can usually be ignored. Therefore, existing research studies have mainly focused on optimizing the total task time or total energy consumption of the UAV.
In this article, to balance the delay and consumption of UAVs and optimize the process of computing offloading in UAV networks, we utilize the Stackelberg game model to model the UAV network. Then, based on the game model, to deal with the complex UAV-MEC task offloading problem, the Markov Decision Process (MDP) and the MADDPG algorithm are introduced to solve the resource allocation interaction model of the UAV and MEC. Extensive experiments are performed to evaluate and compare the performance of the MADDPG and related algorithms, and the results verify the effectiveness of the proposed algorithm in reducing the delay and energy consumption of UAVs and maximizing the utility of UAV networks.
2. System Model
2.1. System Architecture
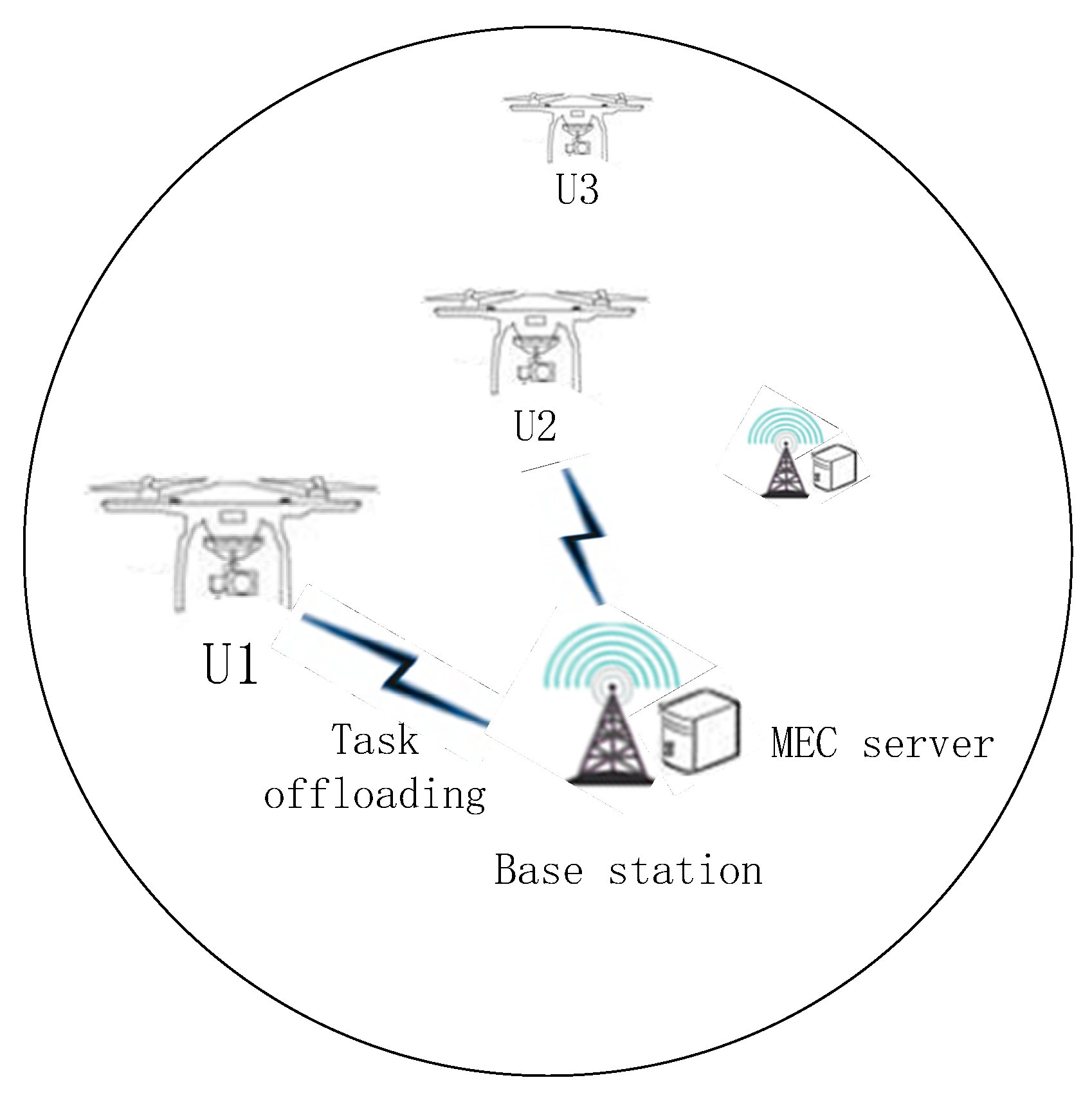
As shown in Figure 1, we consider a scenario where the edge node is composed of a base station (BS) responsible for communication and a MEC server that can provide computing services serves multiple patrol UAVs; the communication between UAVs and edge nodes adopts an orthogonal-frequency-division multiple access system, whereby each channel is orthogonal to the others. Each UAV can only be assigned to one channel, so interference can be avoided.
It is assumed that there are UAVs in the system, the set of which is , and the UAVs are randomly distributed around the edge node along the line. There are edge nodes in the system, and the set of edge nodes is . Each UAV generates tasks randomly and can purchase computing resources from edge nodes. The computing resource that edge nodes can provide is . We consider a quasi-static scenario, that is, the UAV moves in different periods, and its position remains unchanged for a period of time [26].
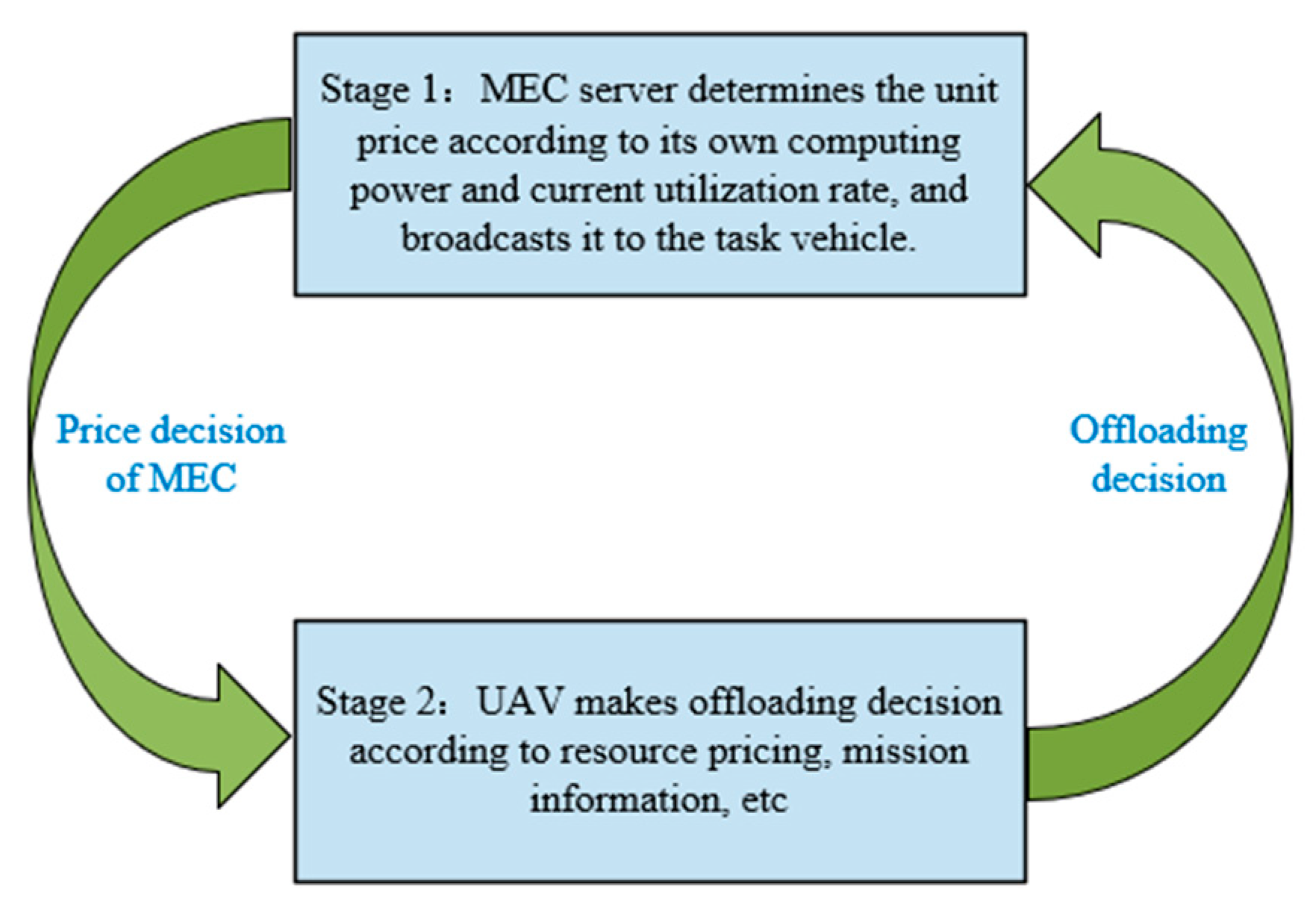
2.2. Two-Stage Stackelberg Game Model
We construct a two-stage Stackelberg game model, as shown in Figure 2. In the first stage of the game, the MEC server determines the unit price of its computing resources according to its own computing resources and current utilization rate and broadcasts it to the UAV. In the second stage, the UAV decides which edge nodes to offload to and how much computing resources to purchase, as well as what proportion to offload according to its own price-sensitive factor; delay-sensitive factor; task priority-, task success-, or failure-sensitive factor; task information.
2.3. Communication Model
The transmission rate [27] from UAV to MEC server can be expressed as follows:
where represents the bandwidth, due to the total bandwidth being divided into channels, so . indicates the transmission power of UAV . The Rayleigh channel model with shadow fading coefficient and noise power is adopted. The parameters in the channel model represent the signal-to-noise ratio to ensure the minimum bit error rate. It is assumed that the channel coefficient is perfectly estimated, and the channel fading is constant throughout the transmission cycle. is the path loss index. represents the distance between UAV and edge node .
2.4. Task Model
The task in the system is recorded as . It is assumed that the task can be divided and offloaded to different edge nodes for parallel computing. The data volume of the task is bits. Generally, the index to measure the amount of computation of a task is the number of CPU cycles, which can be calculated by , where represents the number of CPU cycles required when calculating one-bit data, which is determined by the task type. For complex tasks, is usually large. Usually, the return result of the task is much smaller than the input data of the task. Task can be represented by a triple .
2.5. Computation Model
This section proposes a computational model to represent the execution time of tasks on local and MEC servers. Each UAV can be represented as a quad ; and represent the position of the UAV in the system; is the time of the UAV in the system; is the computing power of the UAV.
Local execution time can be expressed as follows:
The process of offloading tasks to edge nodes can be divided into the following three stages: offloading, execution, and return. The time of offloading can be expressed as follows:
where is the proportion of tasks offloaded to edge nodes.
represents the computing resources allocated to UAV by edge node . The execution time can be expressed as follows:
The calculation results are transmitted back to the UAV through the downlink channel of the OFDMA system. It is assumed that the return result of the task is very small compared with the input data, and the return time can be ignored [28]. Therefore, completion time can be represented as follows:
The completion time of the task, , depends on the latest completion time in the edge node, which can be expressed as follows:
When the task is offloaded to the edge node for calculation, the energy consumption only considers the consumption during transmission, so the energy consumption [28] can be expressed as follows:
where indicates the transmission power of UAV .
The energy consumption [29] of the edge server when calculating tasks can be expressed as follows:
where represents the coefficient of the CPU energy structure, which is used to calculate the energy consumption of task computing.
2.6. Utility Function
The utility function of edge nodes can be expressed as follows:
where represents the price of unit electricity, and denotes the resource price of edge node .
If the price of the edge node is too low, even if all computing resources are sold, it does not obtain satisfactory income and disrupts the market, resulting in other edge nodes following suit and reducing prices, such that none of the edge nodes obtains high income. If the price is too high, most UAVs tend to buy other low-cost computing resources instead of the edge node’s computing resources, which leads to low benefits for this edge node. Therefore, edge nodes should set an appropriate price to obtain satisfactory income. In order to obtain the optimal utility of edge node , the optimal pricing strategy is , where represents the optimal strategy of edge nodes other than edge node , and is the optimal purchasing strategy of computing power for each UAV. The goal of the edge node is to maximize its utility function, that is, .
The benefit of UAVs brought by time can be measured by time . When a task is calculated locally, the task completion time is . When UAV offloads a task to edge server for calculation, the task completion time can be expressed as . Local execution time minus the average completion time of each offloaded subtask represents the average time that can be saved after offloading, which is as follows:
Obviously, in order to increase , UAVs have to continue to purchase computing resources, which causes a waste of resources. To avoid this, we take , representing the benefit of UAVs brought by time. increases with the increase in . With the continuous purchase of resources by UAVs, conforms to the law of diminishing marginal utility; even if more time is saved, does not increase much.
The resource consumption of each UAV includes energy consumption during data transmission and MEC calculation resource consumption. Therefore, the total resource consumption can be expressed as follows:
where represents the cost coefficient of energy consumption during transmission.
Therefore, the utility function of any UAV can be formulated as follows:
where is the expenditure-sensitive factor; is the time-sensitive factor; is the mission-success-sensitive factor; represents the utility brought by the saved time when the UAV offloads a task to the MEC servers. represents the reward for task completion, which is a constant greater than . The UAV formulates its own optimal demand strategy according to the price strategy sent by the edge node. Due to the limited computing power of each edge node, the demand strategies among UAVs affect each other. The strategy set of all UAVs can be expressed as ; the resource purchase strategy of UAV is , while the optimal strategy can be expressed as , where represents the optimal strategy of UAVs other than UAV . The objective of each UAV is to maximize the utility function, that is, .
3. Problem Formulation
In this section, for task offloading in a UAV network, we model the maximizing utility problem in and as an MDP by defining state space , action space , and reward function . The agents are divided into the following two layers: leader and follower, in which the leader is the edge node, and the follower is the UAV. It is assumed that the two-tier agents in the game process are asymmetric; that is, the follower agent observes the behavior of the leader agent so as to solve the two-tier optimization problem of the Markov game.
Therefore, the game problem in this paper can be described as follows:
where indicate the actions of leaders and followers, respectively. represent the rewards of leaders and followers, respectively. represents the reward discount rate of the agent, which is used to measure the importance of future rewards and current rewards, and its value range is . The closer is to 1, the more important the future reward is. The whole game can be represented by octets . In an environment with agents, represents the strategies of all agents; represents the strategy parameters of agents; represents the deterministic strategies of agents.
3.1. State Space
The state space of each leader agent and follower agent at time is defined respectively as follows:
where represents the available computing resources of the computing node at time ; represents the resource utilization of each UAV at time ; represents edge node information; is the decision set of leaders at time , and is the concurrent task information set at time , including task size, latest completion time, time-sensitive factor, price-sensitive factor, etc. is the set of data transmission rate at time .
3.2. Action Space
The action spaces of the leader and follower are as follows:
where represents the price of unit computing resources of the edge node at time ; represents the collection of computing resources purchased by the UAV from each edge node.
3.3. Reward Function
The reward functions of the leader and follower are as follows:
The goal of the system is to obtain the offloading strategy to maximize the cumulative leader utility under the condition of maximizing the cumulative follower utility. The cumulative reward of each agent, that is, the objective function is as follows:
4. Task Offloading Based on RL
In this section, we first review the basic theoretical knowledge of reinforcement learning (RL). Then we introduce the MADDPG algorithm model. Finally, the training process of the agent based on the MADDPG algorithm for task offloading is introduced, and the corresponding pseudo-code is shown.
4.1. Reinforcement Learning
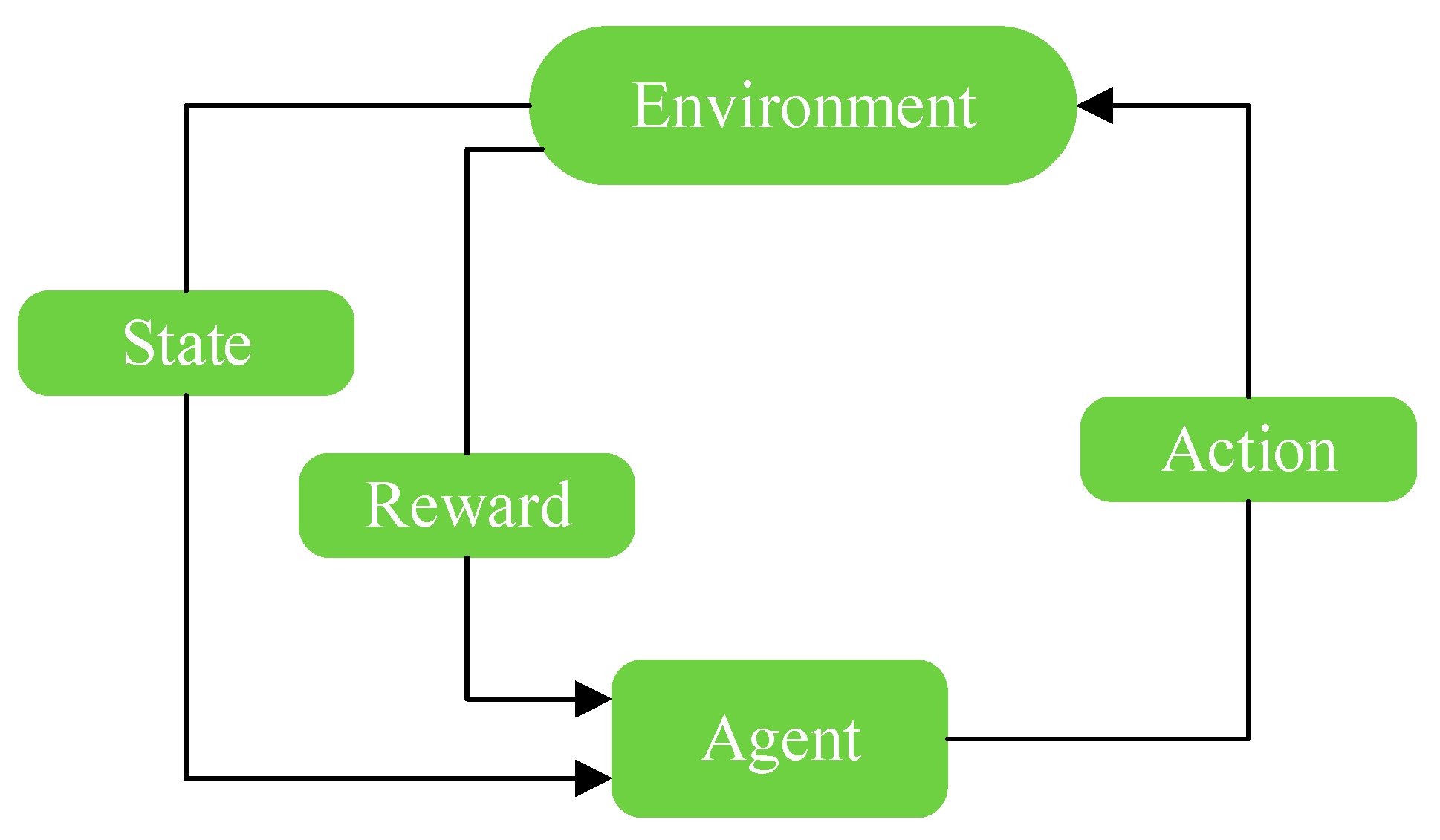
RL is the third learning method in machine learning, besides supervised learning and unsupervised learning. The characteristic of reinforcement learning is that, without given training data in advance, it uses environmental feedback as input to learn by constantly trying and correcting its own strategies in the environment, and it makes the agent learn the best or approximate the optimal solution in the environment by maximizing the cumulative reward expectation.
As shown in Figure 3, the agent executes an action in the environment according to the current state at time ; after-action occurs, the environment changes, the current state shifts to the next state, , and the agent obtains reward from the environment. According to the new environmental state, , the agent executes action and obtains reward . This loop runs until the end state of the environment, and the agent completes a complete interaction process in the environment. The purpose of the agent is to find a strategy that can maximize the cumulative reward function.
4.2. MADDPG Algorithm Model
The MADDPG algorithm is a natural extension of the DDPG algorithm under the multi-agent system. It belongs to centralized training and has an algorithm framework for decentralized execution. The MADDPG algorithm has made a series of improvements based on the Actor-Critic algorithm and the DDPG algorithm; it adopts the principle of centralized learning and distributed application, which makes it suitable for the complex multi-agent environment that the traditional reinforcement learning algorithm cannot deal with. Traditional reinforcement learning algorithms must use the same information data in learning and application, while the MADDPG algorithm allows some additional information (i.e., global information) to be used in learning, but only local information is used in application decisions. Compared with the traditional actor-critical algorithm, there are agents in the MADDPG algorithm environment. The strategy of agent is represented by , and its strategy parameter is ; then, the strategy set of agents is , and the set of strategy parameters and actions are and . The cumulative expected return of agent is as follows:
where represents the reward obtained by agent at time . In the multi-agent environment, we mainly consider the rewards of different agents at the same time, so we replaced with . is the state distribution under strategy . is a random strategy function used to map the probability distribution from state to action. represents the time in the environment.
represents the observation value of agent , and represents the observation vector. is a centralized state action function, which includes not only the observed states and actions, but also , which represent the actions of other agents. Then, in the random strategy, the strategy gradient formula can be obtained as follows:
Therefore, the critical network of each agent knows not only the changes of its own agent but also the action strategies of all other agents.
In order to improve the problem of low convergence efficiency when selecting actions according to probability, MADDPG algorithm was extended to deterministic strategy. Let the continuous deterministic strategy of agents be , and its return expectation gradient is as follows:
where is the experience pool, which stores the experience of all agents. Each sample datum is composed of . is the action value function. establishes a value function for each agent, which greatly solves the shortcomings of the traditional reinforcement learning algorithm in the field of multi-agent environments. The updated formula of is as follows:
where is obtained from the following formula:
where represents the target network, represents the predicted action by the target actor network and is the parameter of the target strategy with lag update.
represents the approximation function of agent to deterministic strategy of agent . The approximation cost is a logarithmic cost function, and with the entropy of the strategy, the cost function can be written as follows:
As long as the above cost function is minimized, the approximation of other agent strategies can be obtained. Therefore, can be changed to the following:
Before updating , a sampling batch of experience reply is used to update the approximation function of agent to deterministic strategy of agent . In this way, the purpose of other agent strategies can be obtained by fitting the approximation without communicating with each other. The core idea of the algorithm is that each agent has its own strategy network. The evaluation network uses the experience of each agent and combines state actions as input. For the strategy network, only the observation value and state information of the agent are used in the training. For the evaluation network, it is only used in the network training. The information used includes the states and actions of all agents, and the corresponding value is output.
In the process of updating the network, a batch of data at the same time are randomly extracted from the experience pool of each agent and spliced to obtain new experience , where and are the state combinations of all agents at the same time; is the set of actions made by all agents at the same time; selects the return value of agent . Finally, input into the target strategy network of agent to obtain action ; then, we input and together into the target evaluation network of agent to obtain the value of target estimated for the next time, and calculate the value of target at the current time according to the following formula:
The actual value of is obtained by using the evaluation network; then, the TD deviation [30] is used to update the evaluation network, and the strategy gradient of is used to update the strategy network. All agents update their networks in the same way, but the input of each agent is different, and the update process is the same under other aspects.
4.3. Task Offloading Algorithm Based on MADDPG
To balance the delay and consumption of the UAV and achieve the goal of maximizing the overall system utility, we propose an experience-driven offloading strategy based on multi-agent reinforcement learning. The algorithm can make effective offloading decisions without solving complex mathematical models, so as to make efficient use of computing resources. The algorithm is centrally trained on the task controller and then deployed to UAVs and edge nodes for distributed execution.
In this UAV network, there are distributed deployment agents. Each agent independently observes its environment in parallel and interacts with the environment to obtain different states, selecting corresponding actions based on the state. For a single agent, first, we input its state into its own strategy network, obtain an action output, and then act on the environment. Then, a new state and return value are obtained. Finally, the agent stores the state transfer data into the agent’s own experience pool. All agents constantly interact with the environment and constantly generate data and store them in their own experience pool.
The specific description of the MADDPG task offloading algorithm based on the Stackelberg model is shown in Algorithm 1.
| Algorithm 1. MADDPG task offloading algorithm based on Stackelberg model |
| . Steps of each episode and number of episodes; |
| Output: Total utility function value of each UAV and system at each episode; |
| 1. Initialize the edge node environment and UAV environment according to the edge network environment parameters; |
| 2. Initialize parameters in leader_network and follower_network; initialize the space of |
| 3. for episode=1: n_episode do |
| 4. for step=1: steps do |
| 5. Calculate the uplink rate of UAV according to formula (1); # Obtain leader state and follower state; |
| 7. Update position of UAV; # Get leader action and follower action, and add noise to the action to ensure the exploration rate; |
| # Storage experience; |
| 11. |
| 12. |
| 13. Update network parameters; |
| 14. |
| 15. end |
| 16. end |
5. Performance Evaluation
5.1. Experiment Environment
In this section, the offloading algorithm based on reinforcement learning proposed in this paper is simulated, and the performance of the algorithm is analyzed. The simulation environment was Python 3 8.5. The length of the system site was 100 m; the UAVs were distributed near the edge calculation nodes; the altitude of the UAVs was h = 20 m; the UAVs were randomly distributed. There were five evenly distributed edge nodes in the system environment. The price sensitivity coefficient, delay sensitivity coefficient, mission-success or -failure sensitivity coefficient, initial position, and speed of each UAV were generated randomly. The channel parameters were the following: the bandwidth was 100 MHz, and the Gaussian white noise power was 2.5 × 10 −13 w. For the UAV, its computing power was 1.5 GHz. The volume of each task was a random value in the range of 100~150 MB. The computing power of the edge nodes was 10 GHz.
The parameters, definitions, and values of the simulation experiment are shown in the Table 1.
5.2. Simulation Results and Analysis
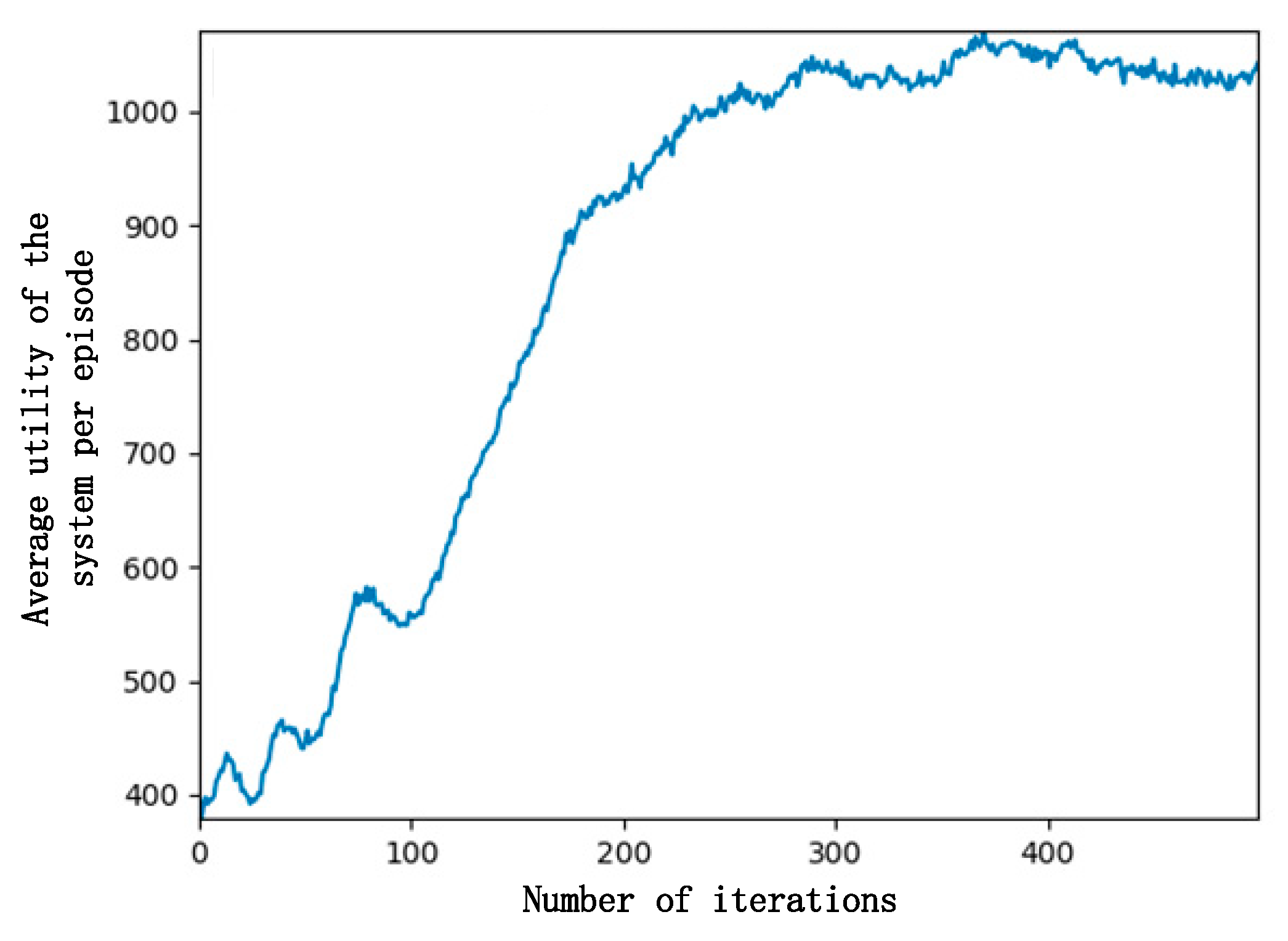
Figure 4 demonstrates how the number of iterations affects the total utility of the system. The total utility of the system is defined as the weighted sum of the standardized rewards of leaders and followers. It can be seen from the figure that in about 80 iterations, the total utility of the system reached a maximum, but the leader utility and follower utility were not balanced, and neither accepted such a result, so both sides learned from previous experience and then adjusted the strategy.
At the 80th–100th iterations, the strategy began to be adjusted, and the total utility of the system decreased. This is because the leader started to raise the selling price, and the follower fine-tuned the purchase decision; then, the follower utility decreased, and the leader utility increased too much. After the first 300 iterations, the average utility of the system continued to increase and then gradually stabilized at about 1000 after 300 iterations, almost reaching convergence and better completing the task of maximizing the utility of the system.
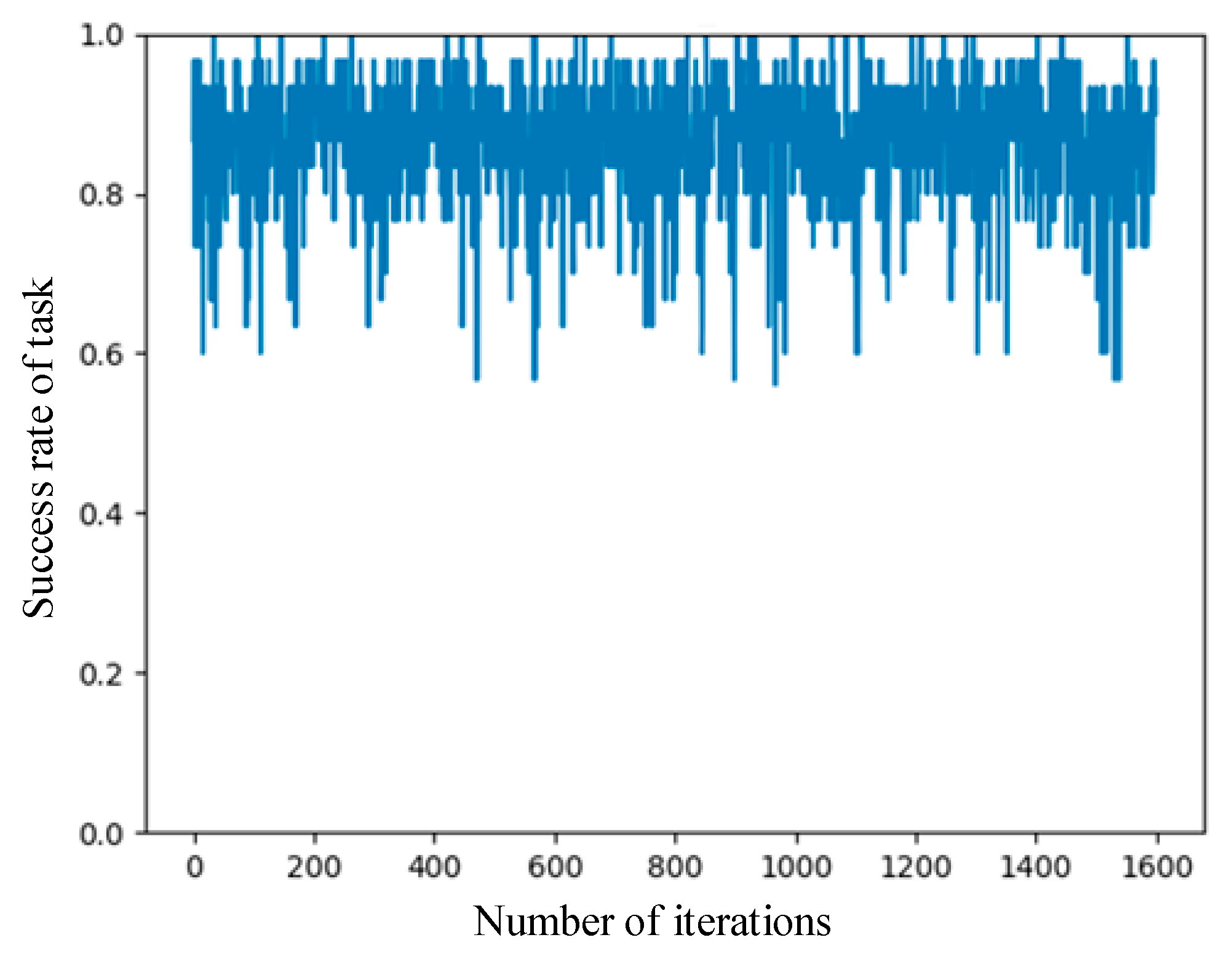
Figure 5 shows the curve of the success rate of the UAV mission with respect to the number of episode iterations when the numbers of leaders and followers are 5 and 15, respectively. It can be seen from the figure that the UAV mission success rate was unstable; it fluctuated back and forth between 80% and 90%, with the lowest success rate being about 60% and the highest success rate being 100%. The main reason for the fluctuation in the mission success rate is that the mission-success-sensitive factor of the UAV was generated randomly.
Some UAVs were not sensitive to whether the task could be completed on time, so the value of was low. Even if the task completion time exceeded the delay, UAVs could still obtain high utility. Moreover, the volume of the task was 100~150 MB, and the task completion delay was 1–5 s. Assuming that the data size of the task is 150 MB, and the task completion delay is less than 1 s, if UAVs purchase too many computational resources to compute tasks, the utility of the UAVs is reduced. The experiments show that the offloading algorithm proposed in this paper can maintain a high task success rate.
In order to verify the effectiveness of the MADDPG in the UAV network, the proposed algorithm was compared with the following typical strategies:
- (1)
- NSGA (non-dominated sorting genetic algorithms) multi-objective genetic algorithm: The decisions of purchase power and fix price are made simultaneously by the algorithm, and the Pareto optimal solution of purchase power decision and fix price decision is obtained;
- (2)
- Random algorithm: The purchasing decision of computing power is generated randomly, and the offloading proportion is generated randomly;
- (3)
- QoS priority algorithm: It distributes all tasks equally to all edge nodes and minimizes task delay as much as possible.
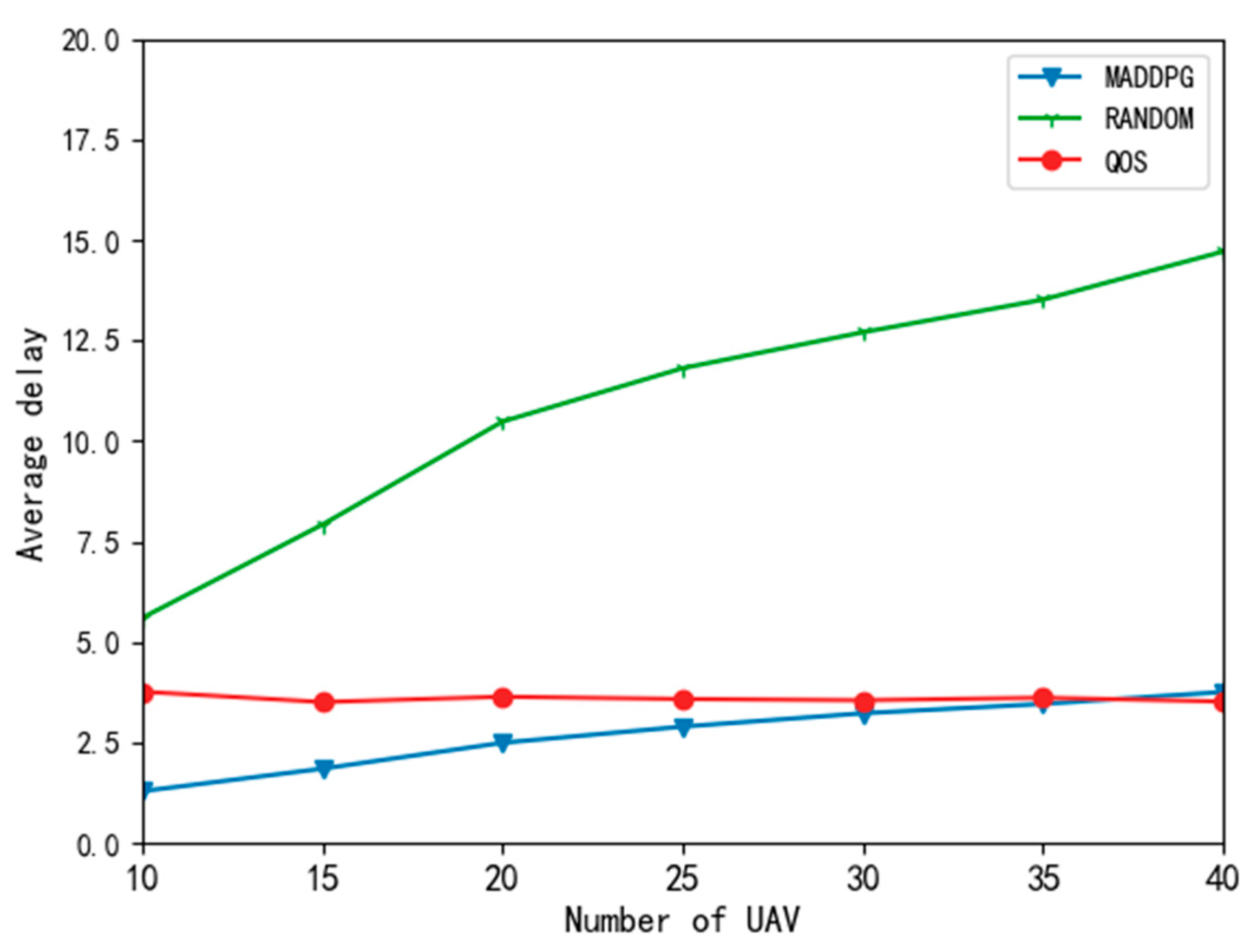
Figure 6 compares the impact of the different algorithms on task delay when changing the number of UAVs. It can be seen from the simulation diagram that the MADDPG algorithm could significantly reduce the task delay. The main reason is that the random algorithm randomly offloads the tasks of the UAV to the edge node, does not consider the resource state of the edge node and UAV in the system, and cannot make full use of the computing resources of local and edge nodes. This also leads to other UAVs being unable to obtain the offloading decision with the best utility, so the average delay of the task is the highest. With the increase in the number of UAVs, the average resource decreased, resulting in an increase in the average delay. When the number of UAVs grows larger than 35, the average delay of the MADDPG exceeds that of the QoS priority algorithm. The reason is that the QoS priority algorithm offloads all tasks equal to the edge nodes and does not consider utility. Moreover, the edge nodes have enough computing resources to compute these tasks, so the average delay of the QoS priority algorithm could be kept low. Although its average delay was lower than that of the MADDPG algorithm, the QoS priority algorithm could not make rational use of the computing resources of local and edge nodes. Still, the MADDPG algorithm could obtain a low average delay.
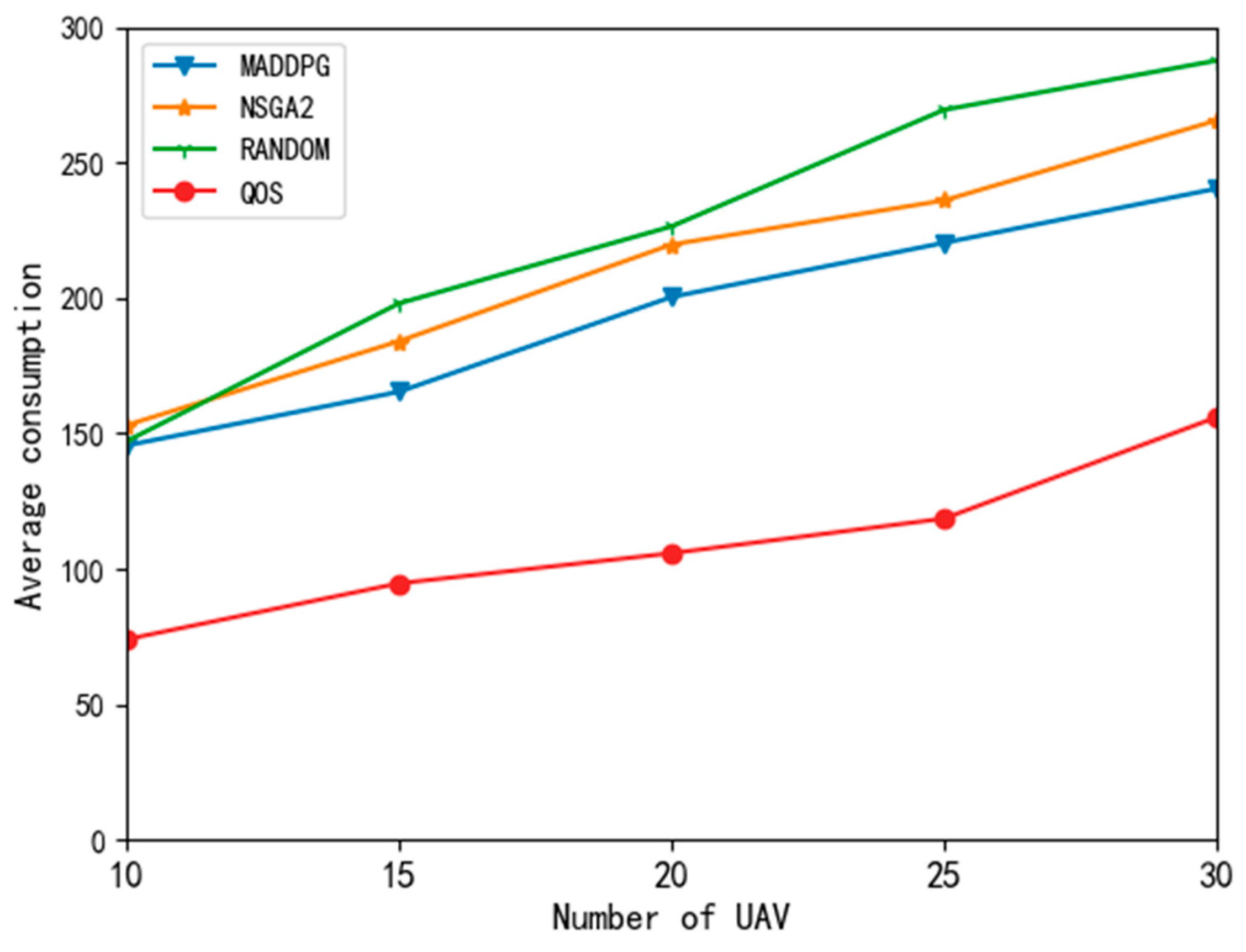
Figure 7 shows the energy consumption curves of different algorithms. Because the QoS algorithm offloads all tasks to the edge nodes, the UAV does not need to calculate tasks and only considers transmission energy consumption, so the energy consumption is quite low. The volume of edge node resources remains unchanged; with the increase in the number of UAVs, edge nodes increase the price of the resource, and UAVs begin to change their strategies and execute more tasks locally, so the average energy consumption also begins to increase.
When the number of UAVs was 10, the average energy consumption of the random algorithm, NSGA2 algorithm, and MADDPG algorithm was similar. When the number of UAVs exceeded 15, the average energy consumption of the MADDPG algorithm was significantly lower than that of the other two algorithms. It can be seen that the MADDPG algorithm could better reduce the average energy consumption of UAVs compared with the random algorithm and the NSGA2 algorithm.
Figure 8 shows the comparison results of average utility with different algorithms. The results show that the MADDPG algorithm proposed in this paper could maximize the average utility of the system. The total system utility in this paper is the weighted sum of the average utility of the UAVs and the average utility of the edge nodes. It can be seen from the figure that the QoS and random algorithms performed poorly, mainly because they do not comprehensively consider delay, expenditure, and task timeout penalties.
The MADDPG algorithm obtained a high total system utility. The increase in the number of UAVs allowed it to make better use of the resources in the system, so the system utility was improved. When the number of UAVs is 10, the utility value of the MADDPG algorithm is lower than that of the NSGA2 algorithm, which evolved over 2000 generations. When the number of UAVs increased to 15 or above, the MADDPG algorithm performed better than the NSGA2 algorithm.
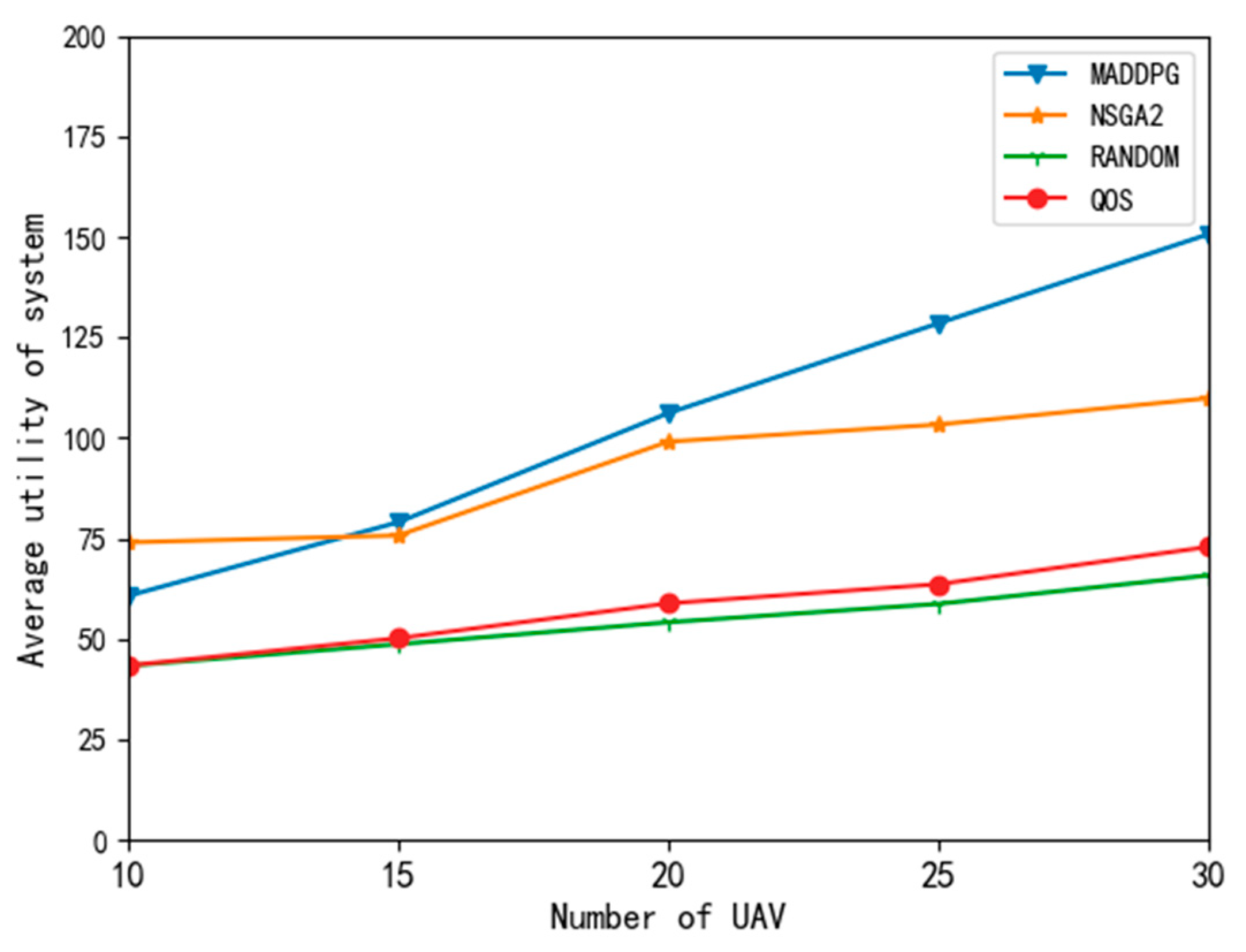
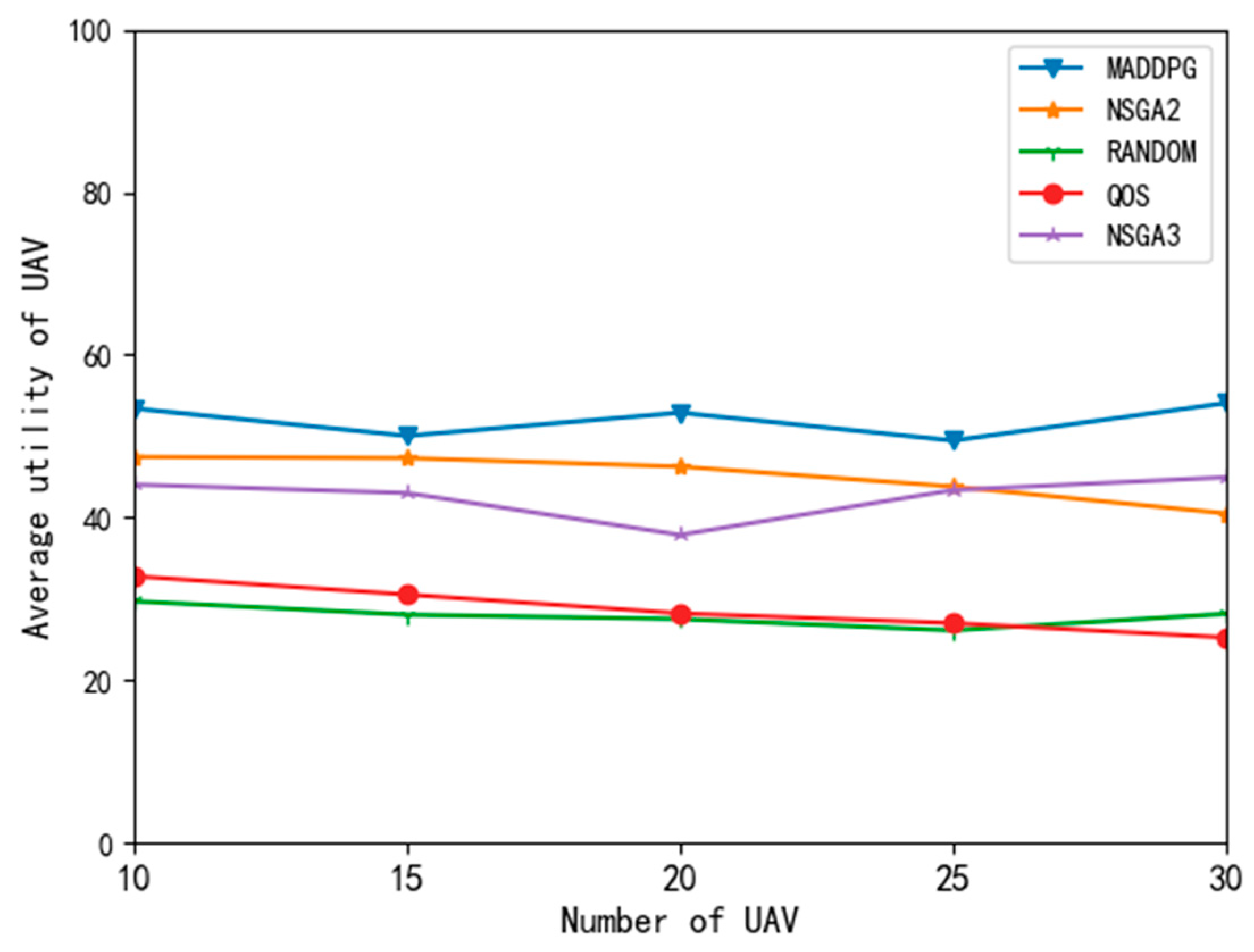
Figure 9 shows the comparison results of UAV average utility with different algorithms. On the average utility curve of UAVs, the QoS and random algorithms performed mediocrely. This is because the QoS algorithm only pays attention to the task processing delay, blindly reduces the task delay, and ignores the impact of expenditure on utility value. These two algorithms are extreme and can not achieve the compromise of delay, energy consumption, and task success or failure reward. The MADDPG algorithm performed well. The average utility of the UAVs with the MADDPG did not decrease with the increase in the UAV number, and the utility was higher than that obtained with the NSGA2 and NSGA3 algorithms.
Because the MADDPG algorithm in this paper is a two-tier structure with sequential actions, the UAV (follower) makes decisions according to the decisions of the edge node (leader) and estimates the strategies of other agents at the same level to make decisions to maximize its own utility. Therefore, this algorithm can achieve a good compromise between delay, energy consumption, and task success rate and obtain a large task utility value.
6. Conclusions
In the UAV network based on MEC, we optimize task offloading by analyzing the delay and energy consumption of UAVs, so as to maximize the total utility of the UAV patrol system. According to the MADDPG algorithm and the Stackelberg game model, this paper proposes the Stackelberg MADDPG algorithm to solve the problem of task offloading. The MADDPG algorithm proposed in this paper relies on historical task information for learning and has low dependence on the optimization model. Not only can it effectively solve the nonconvex optimization problem of the UAV utility function, but it can also meet the requirements of distributed computing. The proposed algorithm was simulated and evaluated. In the simulation experiment, we verified the performance of the algorithm by simulating the change in system utility with the number of UAVs and the number of iterations. The experimental results show that compared with the comparison algorithms, the algorithm proposed in this paper has a high task success rate, can effectively reduce the task delay, balance the delay and consumption of UAVs, and improve the utility of UAVs and the system.
Author Contributions
Conceptualization, W.Q. and S.X.; methodology, W.Q.; software, W.Q.; validation, H.S.; formal analysis, H.S.; resources, S.X.; data curation, H.J.; writing-original draft preparation, H.S.; writing—review and editing, L.Y.; visualization, S.X.; supervision, W.Q.; project administration, H.J.; funding acquisition, L.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the National Natural Science Foundation of China (No. 62071470, No. 61971421, No. 51874300, No. U1510115), Xuzhou science and technology project (KC20167), and the Open Research Fund of Key Laboratory of Wireless Sensor Network and Communication, Shanghai Institute of Microsystem and Information Technology, Chinese Academy of Sciences (No. 20190902, No. 20190913).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Tang, C.; Zhu, C.; Wu, H.; Li, Q.; Rodrigues, J.J.P.C. Toward Response Time Minimization Considering Energy Consumption in Caching-Assisted Vehicular Edge Computing. IEEE Internet Things J. 2022, 9, 5051–5064. [Google Scholar] [CrossRef]
- Tang, C.; Wei, X.; Zhu, C.; Wang, Y.; Jia, W. Mobile Vehicles as Fog Nodes for Latency Optimization in Smart Cities. IEEE Trans. Veh. Technol. 2020, 69, 9364–9375. [Google Scholar] [CrossRef]
- Wang, T.; Gu, Z.; Zhang, W.; Xu, J.; Wei, J.; Zhong, H. Adaptive monitoring based fault detection for cloud computing systems. Chin. J. Comput. 2018, 41, 1332–1345. [Google Scholar] [CrossRef]
- Zhou, Z.; Chen, Y.; Pan, C.; Zhao, X.; Zhang, L.; Wang, Z. Ultra-reliable and low-latency mobile edge computing technology for intelligent power inspection. High Volt. Eng. 2020, 46, 1895–1902. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, Y.; Wang, H.; Gao, C.; Bai, C. Design and application of UAV intelligent inspection system for transmission lines based on cloud and fog-edge heterogeneous collaborative computing architecture. Electr. Power 2020, 53, 161–168. [Google Scholar] [CrossRef]
- Zhang, X.; Zhong, Y.; Liu, P.; Zhou, F.; Wang, Y. Resource Allocation for a UAV-Enabled Mobile-Edge Computing System: Computation Efficiency Maximization. IEEE Access 2019, 7, 113345–113354. [Google Scholar] [CrossRef]
- Sun, H.; Zhang, J.; Wang, P.; Lin, J.; Guo, S.; Chen, L. Edge computation technology based on distribution internet of things. Power Syst. Technol. 2019, 43, 4314–4321. [Google Scholar] [CrossRef]
- Li, W.; Zhao, M.; Wu, Y.; Yu, J.; Bao, L.; Yang, H.; Liu, D. Collaborative offloading for UAV enabled time sensitive MEC networks. EURASIA J. Wirel. Commun. Netw. 2021, 2021, 1–17. [Google Scholar] [CrossRef]
- Liu, M.; Wang, Y.; Li, Z.; Lyu, X.; Chen, Y. Joint Optimization of Resource Allocation and Multi-UAV Trajectory in Space-Air-Ground IoRT Networks. In Proceedings of the 2020 IEEE Wireless Communications and Networking Conference Workshops (WCNCW), Seoul, Korea, 6–9 April 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Jeong, S.; Simeone, O.; Kang, J. Mobile Edge Computing via a UAV-Mounted Cloudlet: Optimization of Bit Allocation and Path Planning. IEEE Trans. Veh. Technol. 2018, 67, 2049–2063. [Google Scholar] [CrossRef] [Green Version]
- Hu, X.; Wong, K.; Yang, K.; Zheng, Z. UAV-Assisted Relaying and Edge Computing: Scheduling and Trajectory Optimization. IEEE Trans. Wirel. Commun. 2019, 18, 4738–4752. [Google Scholar] [CrossRef]
- Xiong, J.; Guo, H.; Liu, J. Task Offloading in UAV-Aided Edge Computing: Bit Allocation and Trajectory Optimization. IEEE Commun. Lett. 2019, 23, 538–541. [Google Scholar] [CrossRef]
- Hu, Q.; Cai, Y.; Yu, G.; Qin, Z.; Zhao, M.; Li, G.Y. Joint Offloading and Trajectory Design for UAV-Enabled Mobile Edge Computing Systems. IEEE Internet Things J. 2019, 6, 1879–1892. [Google Scholar] [CrossRef]
- Wang, Q.; Gao, A.; Hu, Y. Joint Power and QoE Optimization Scheme for Multi-UAV Assisted Offloading in Mobile Computing. IEEE Access 2021, 9, 21206–21217. [Google Scholar] [CrossRef]
- Zhou, F.; Wu, Y.; Hu, R.Q.; Qian, Y. Computation Rate Maximization in UAV-Enabled Wireless-Powered Mobile-Edge Computing Systems. IEEE J. Sel. Areas Commun. 2018, 36, 1927–1941. [Google Scholar] [CrossRef] [Green Version]
- Zhou, F.; Wu, Y.; Sun, H.; Chu, Z. UAV-Enabled Mobile Edge Computing: Offloading Optimization and Trajectory Design. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Wan, S.; Lu, J.; Fan, P.; Letaief, K.B. Toward Big Data Processing in IoT: Path Planning and Resource Management of UAV Base Stations in Mobile-Edge Computing System. IEEE Internet Things J. 2020, 7, 5995–6009. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Huang, P.; Wang, K.; Zhang, G.; Zhang, L.; Aslam, N.; Yang, K. RL-Based User Association and Resource Allocation for Multi-UAV enabled MEC. In Proceedings of the 2019 15th International Wireless Communications & Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; pp. 741–746. [Google Scholar] [CrossRef]
- Cao, X.; Xu, J.; Zhang, R. Mobile Edge Computing for Cellular-Connected UAV: Computation Offloading and Trajectory Optimization. In Proceedings of the 2018 IEEE 19th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Kalamata, Greece, 25–28 June 2018; pp. 1–5. [Google Scholar] [CrossRef] [Green Version]
- Ateya, A.A.A.; Muthanna, A.; Kirichek, R.; Hammoudeh, M.; Koucheryavy, A. Energy- and Latency-Aware Hybrid Offloading Algorithm for UAVs. IEEE Access 2019, 7, 37587–37600. [Google Scholar] [CrossRef]
- Chen, J.; Chen, S.; Luo, S.; Wang, Q.; Cao, B.; Li, X. An intelligent task offloading algorithm (iTOA) for UAV edge computing network. Digit. Commun. Netw. 2020, 6, 433–443. [Google Scholar] [CrossRef]
- Fan, L.; Yan, W.; Chen, X.; Chen, Z.; Shi, Q. An Energy Efficient Design for UAV Communication with Mobile Edge Computing. China Commun. 2019, 16, 26–36. [Google Scholar]
- Hua, M.; Huang, Y.; Wang, Y.; Wu, Q.; Dai, H.; Yang, L. Energy Optimization for Cellular-Connected Multi-UAV Mobile Edge Computing Systems with Multi-Access Schemes. J. Commun. Inf. Netw. 2018, 3, 33–44. [Google Scholar] [CrossRef] [Green Version]
- Bai, T.; Wang, J.; Ren, Y.; Hanzo, L. Energy-Efficient Computation Offloading for Secure UAV-Edge-Computing Systems. IEEE Trans. Veh. Technol. 2019, 68, 6074–6087. [Google Scholar] [CrossRef] [Green Version]
- Avgeris, M.; Spatharakis, D.; Dechouniotis, D.; Kalatzis, N.; Roussaki, I.; Papavassiliou, S. Where There Is Fire There Is SMOKE: A Scalable Edge Computing Framework for Early Fire Detectionin. Sensors 2019, 19, 639. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tang, C.; Zhu, C.; Wu, H.; Liu, C.; Rodrigues, J.J.P.C. Caching Assisted Correlated Task Offloading for IoT Devices in Mobile Edge Computing. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Tan, Z.; Yu, F.R.; Li, X.; Ji, H.; Leung, V.C.M. Virtual Resource Allocation for Heterogeneous Services in Full Duplex-Enabled SCNs With Mobile Edge Computing and Caching. IEEE Trans. Veh. Technol. 2018, 67, 1794–1808. [Google Scholar] [CrossRef]
- Zhang, Y.; Lan, X.; Ren, J.; Cai, L. Efficient Computing Resource Sharing for Mobile Edge-Cloud Computing Networks. IEEE/ACM Trans. Netw. 2020, 28, 1227–1240. [Google Scholar] [CrossRef]
- Yao, D.; Yu, C.; Yang, L.T.; Jin, H. Using Crowdsourcing to Provide QoS for Mobile Cloud Computing. IEEE Trans. Cloud Comput. 2019, 7, 344–356. [Google Scholar] [CrossRef]
- Tesauro, G. Temporal difference learning and TD-Gammon. Commun. ACM 1995, 38, 58–68. [Google Scholar] [CrossRef]
Figure 1.
Task offloading system model in UAV network.

Figure 2.
Two-stage Stackelberg game model.

Figure 3.
Interaction process between agent and environment.

Figure 4.
Curve of system utility and number of iterations.

Figure 5.
Curve of success rate of task.

Figure 6.
Average delay curve of different algorithms.

Figure 7.
Average energy consumption curve of different algorithms.

Figure 8.
Average utility curve of system with different algorithms.

Figure 9.
Average utility curve of UAV with different algorithms.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Experimental parameters of MADDPG task offloading algorithm.
| Parameter | Definition | Setting |
|---|---|---|
| Length of scene | 100 m | |
| Power of communication | 20 W | |
| Bandwidth | 100 MHz | |
| Computing power of UAV | 1.5 GHz | |
| Computing power edge node | 10 GHz | |
| Power of Gaussian white noise | 2.5 × 10 −13 w | |
| Fading factor of transmission channel | 4 | |
| Volume of task data | 100~150 MB | |
| Latest completion time of task | 5~20 s | |
| Coefficient of CPU energy structure | ||
| Expenditure-sensitive factor | 0~0.5 | |
| Time-sensitive factor | 0~0.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Qi, W.; Sun, H.; Yu, L.; Xiao, S.; Jiang, H. Task Offloading Strategy Based on Mobile Edge Computing in UAV Network. Entropy 2022, 24, 736. https://0-doi-org.brum.beds.ac.uk/10.3390/e24050736
AMA Style
Qi W, Sun H, Yu L, Xiao S, Jiang H. Task Offloading Strategy Based on Mobile Edge Computing in UAV Network. Entropy. 2022; 24(5):736. https://0-doi-org.brum.beds.ac.uk/10.3390/e24050736
Chicago/Turabian StyleQi, Wei, Hao Sun, Lichen Yu, Shuo Xiao, and Haifeng Jiang. 2022. "Task Offloading Strategy Based on Mobile Edge Computing in UAV Network" Entropy 24, no. 5: 736. https://0-doi-org.brum.beds.ac.uk/10.3390/e24050736
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.