
Block-Iterative Reconstruction from Dynamically Selected Sparse Projection Views Using Extended Power-Divergence Measure

 , , and
, , and
Abstract
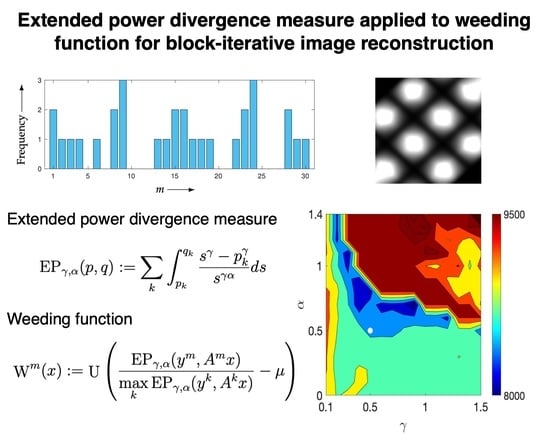
:
1. Introduction
2. Problem Description
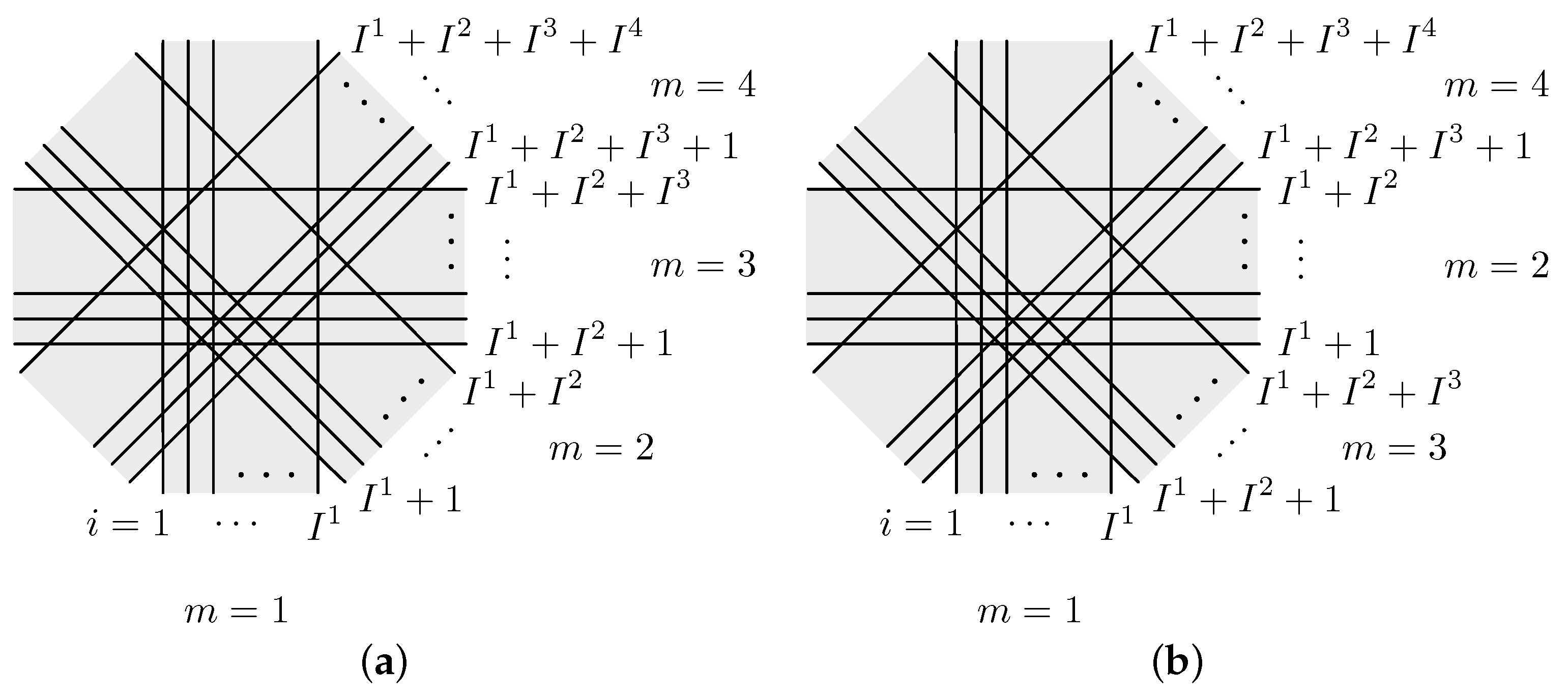
2.1. Block Iterative Reconstruction
2.2. Preliminaries
3. Results
3.1. Proposed Method
3.2. Theory
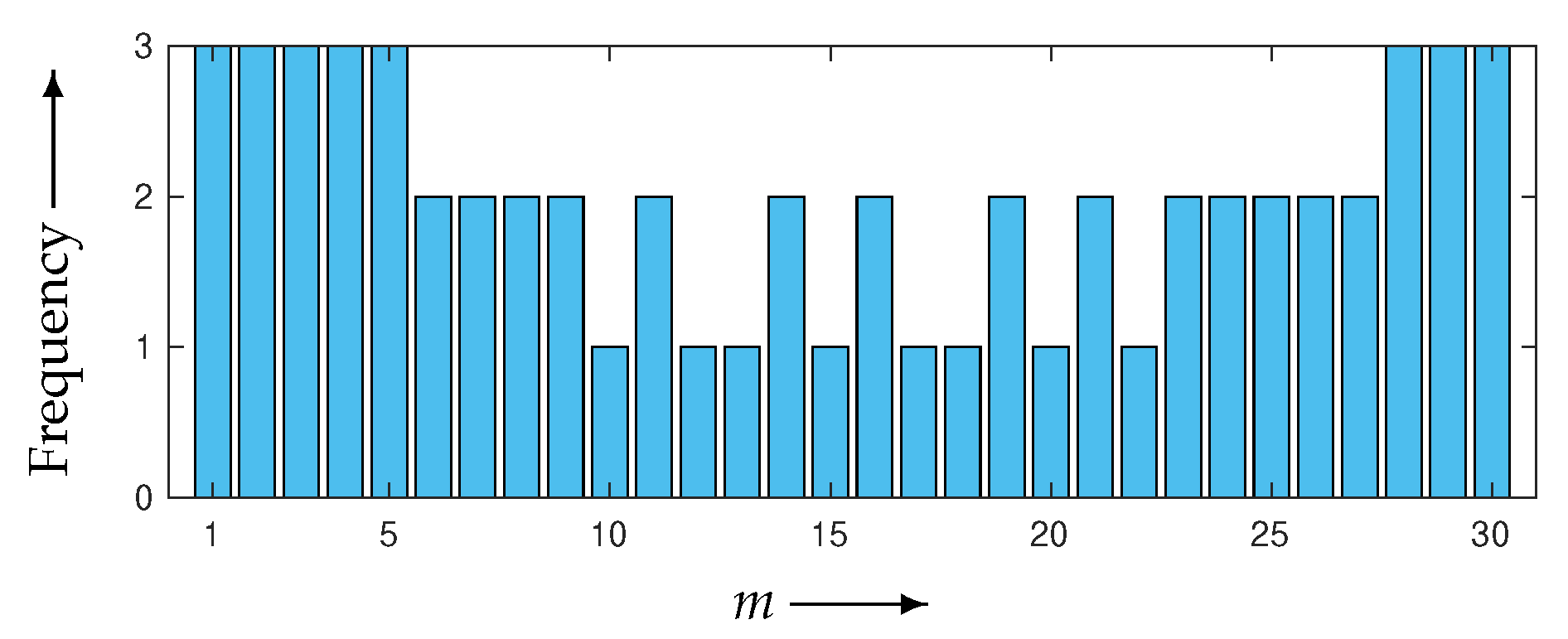
3.3. Optimization Strategy
4. Experiments and Discussion
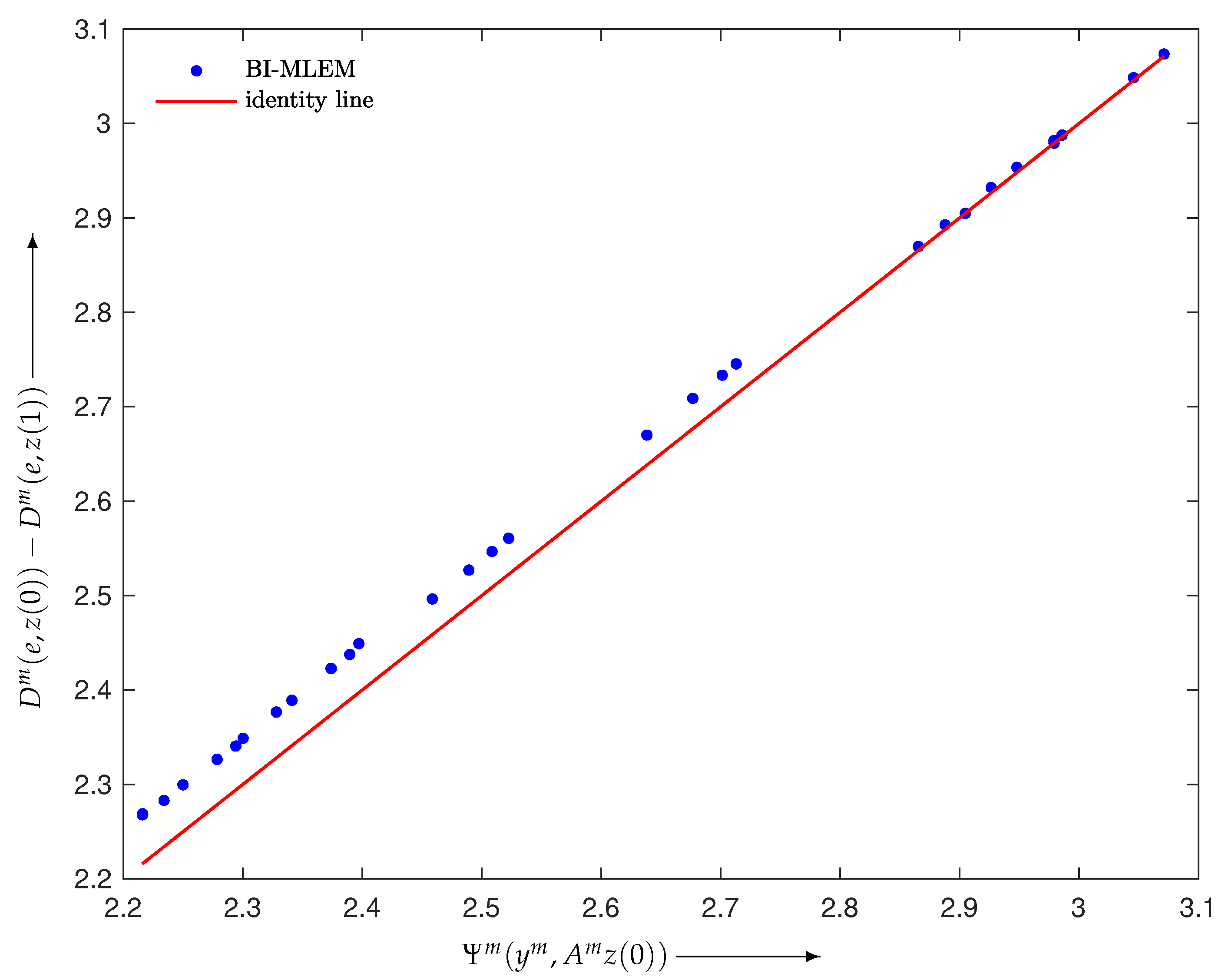
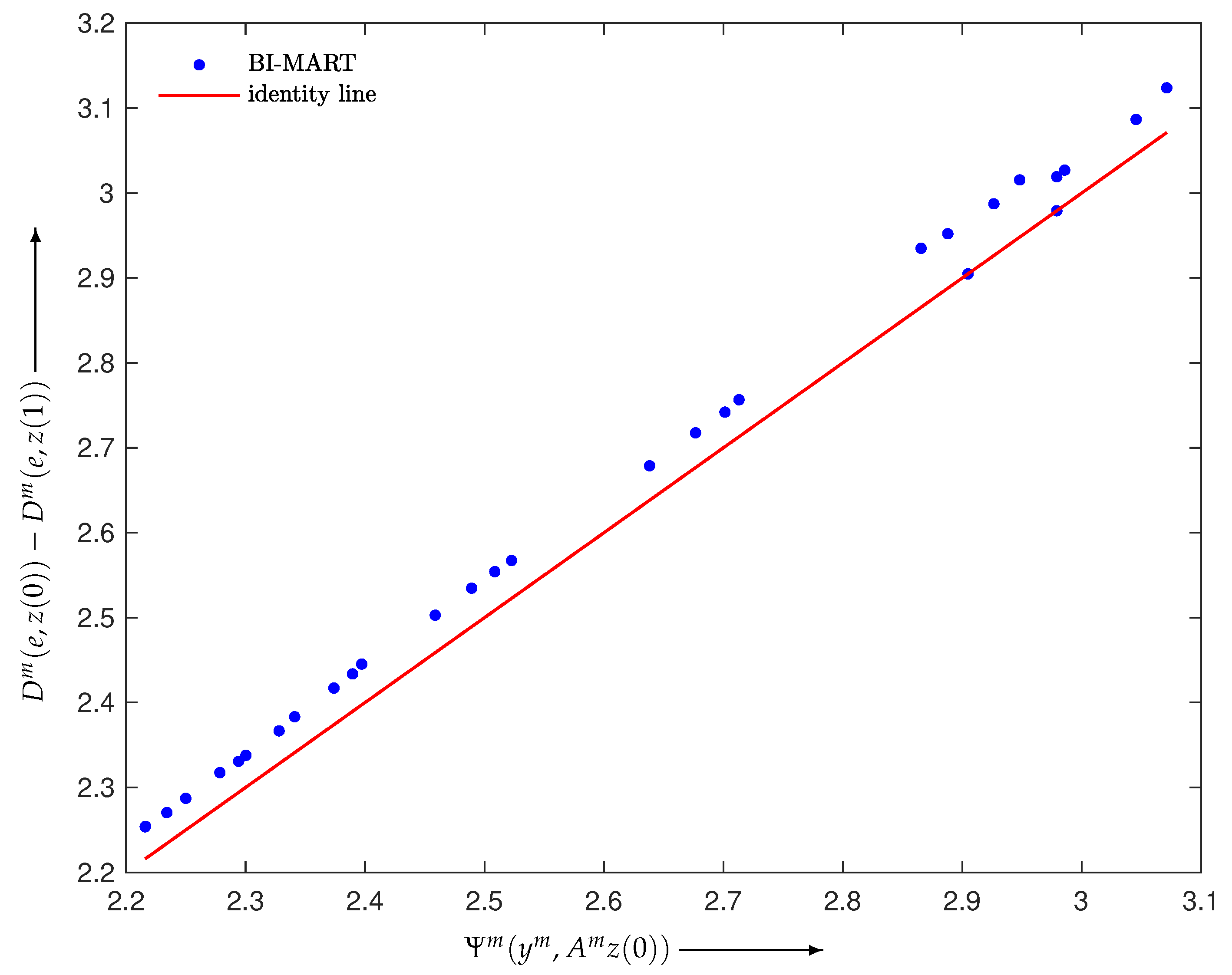
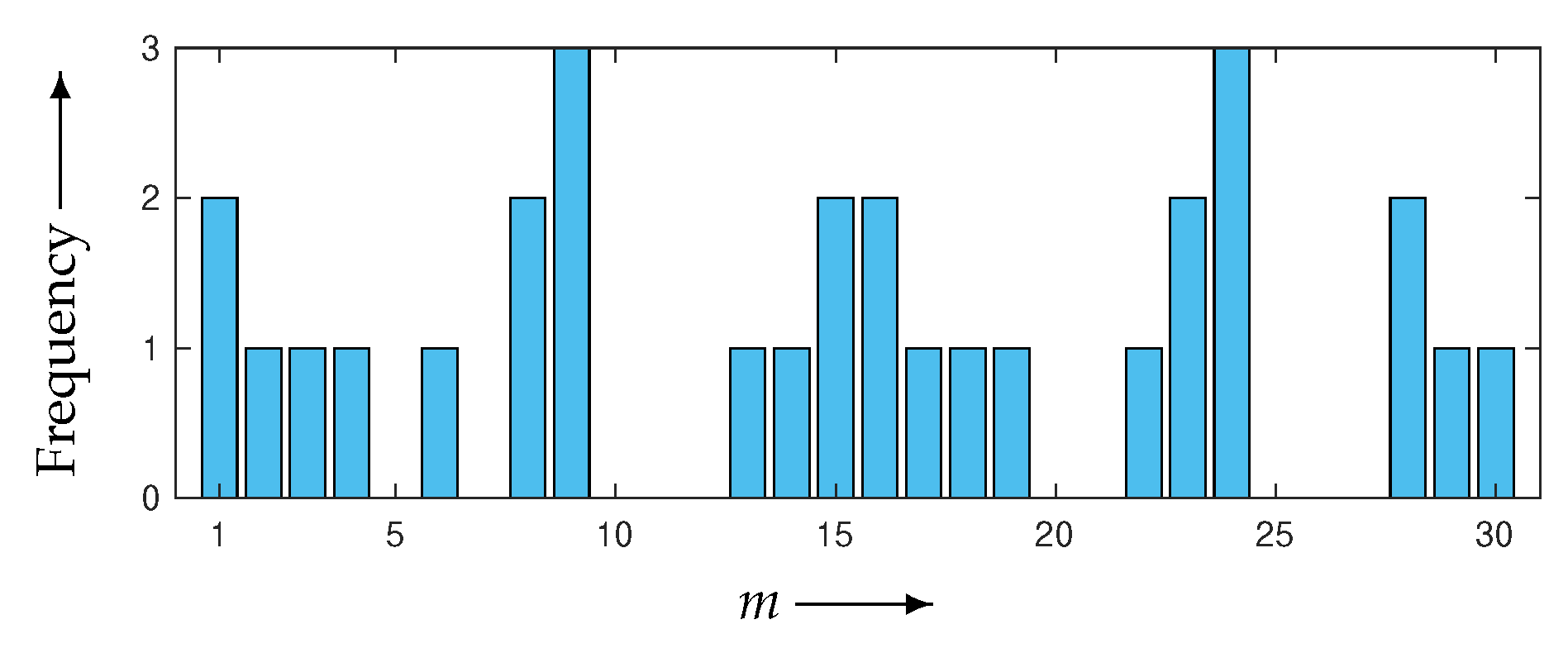
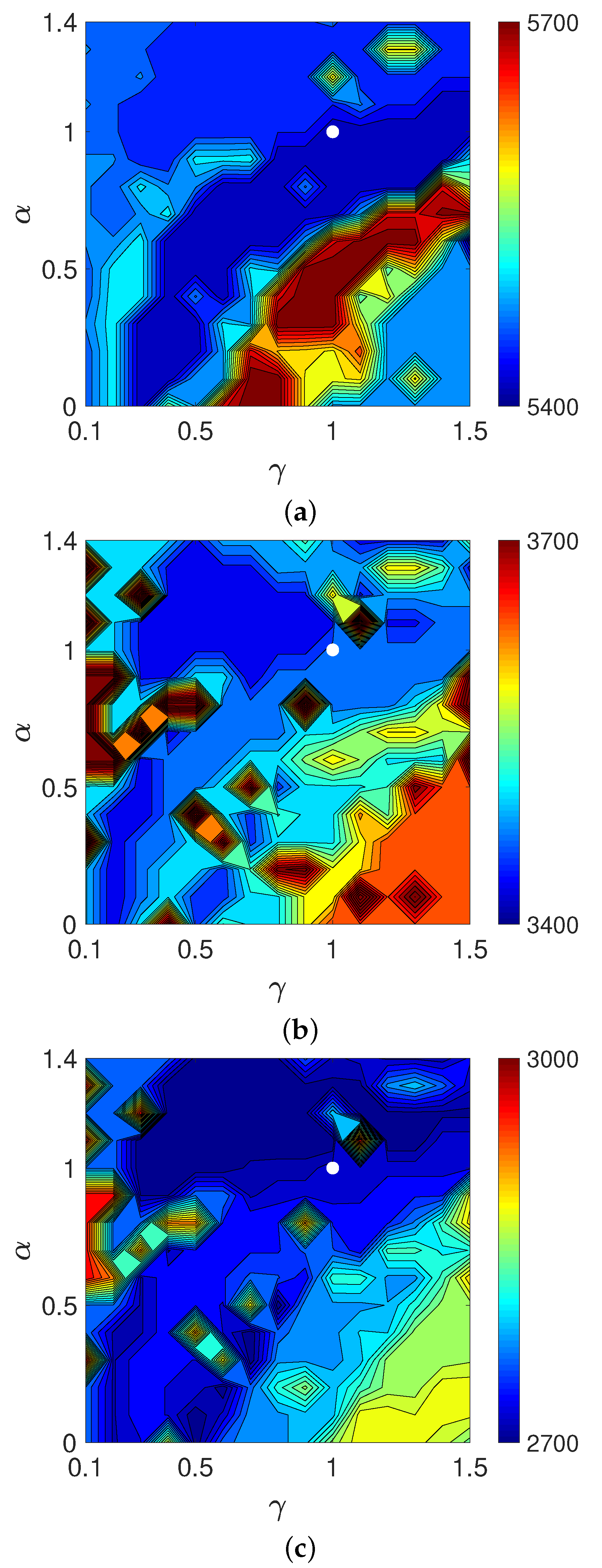
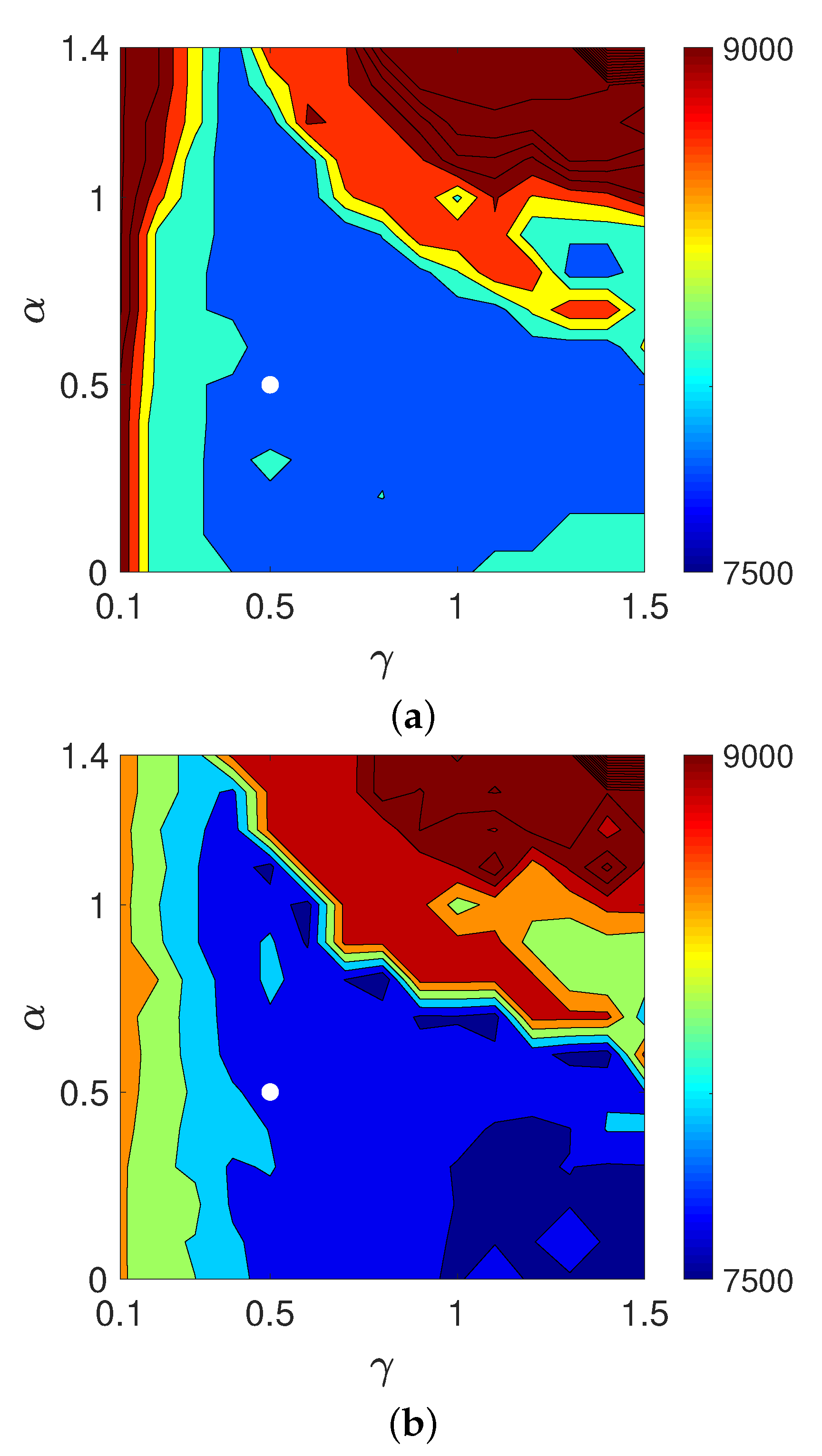
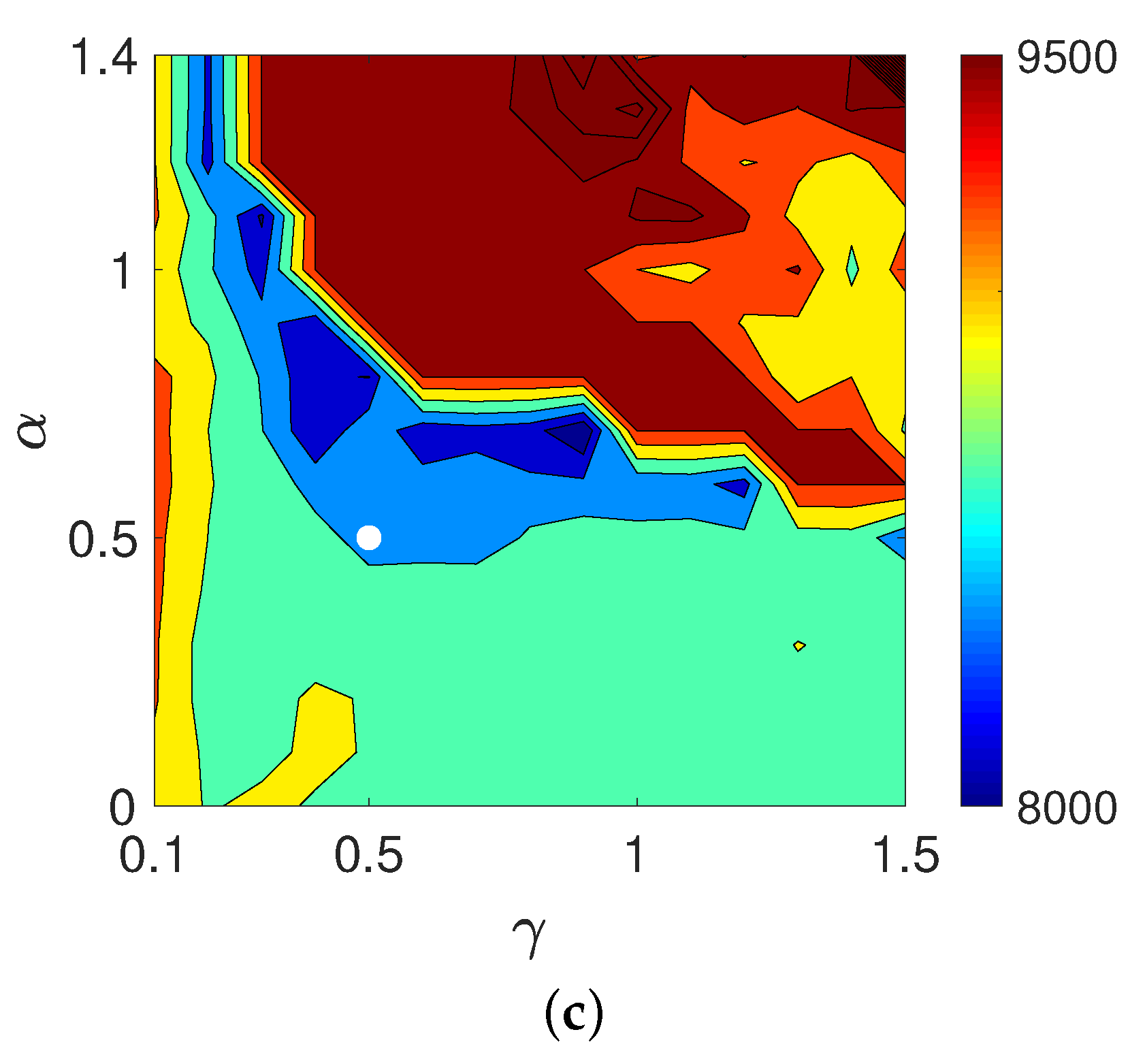
4.1. Verification of Theory
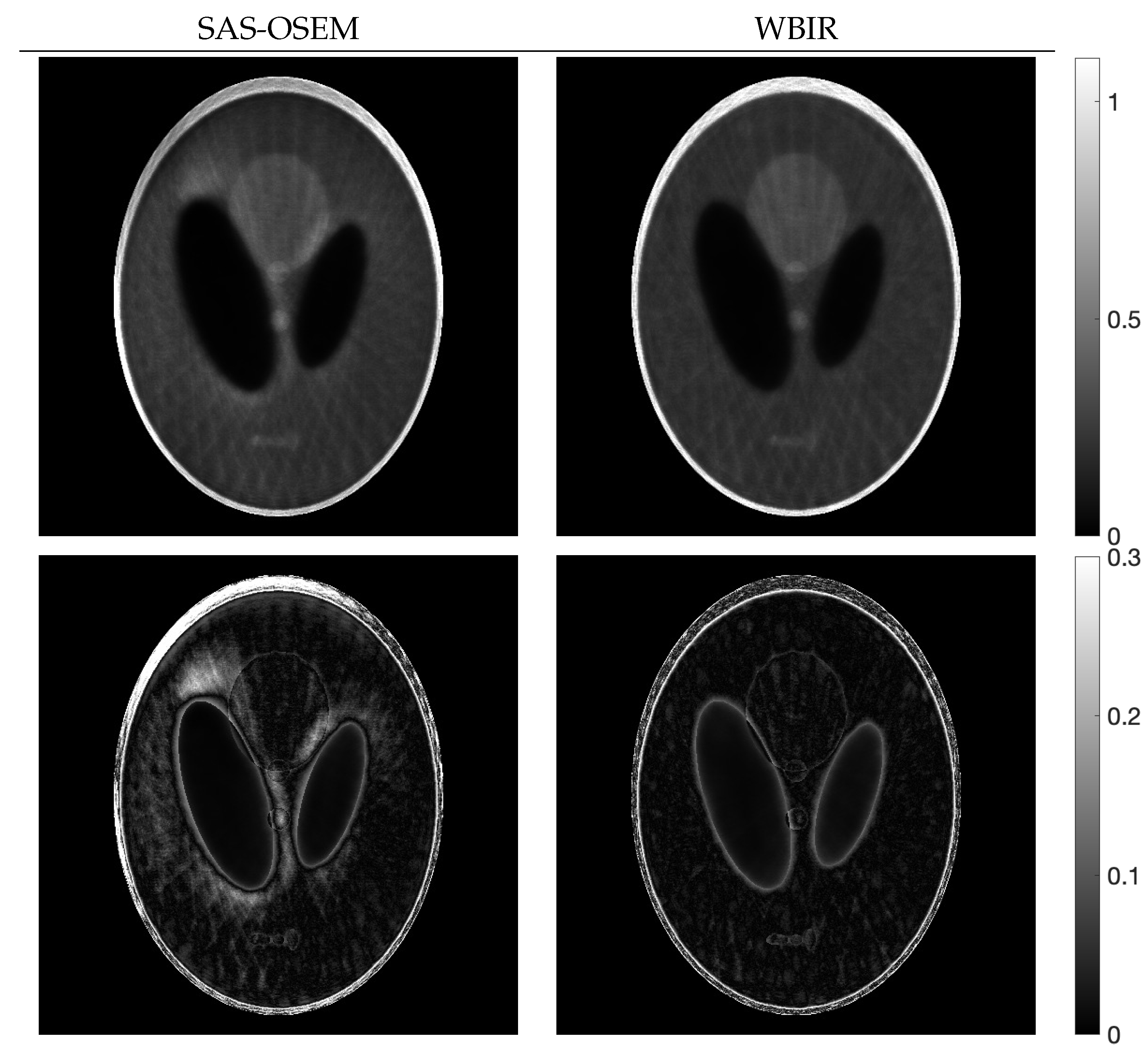
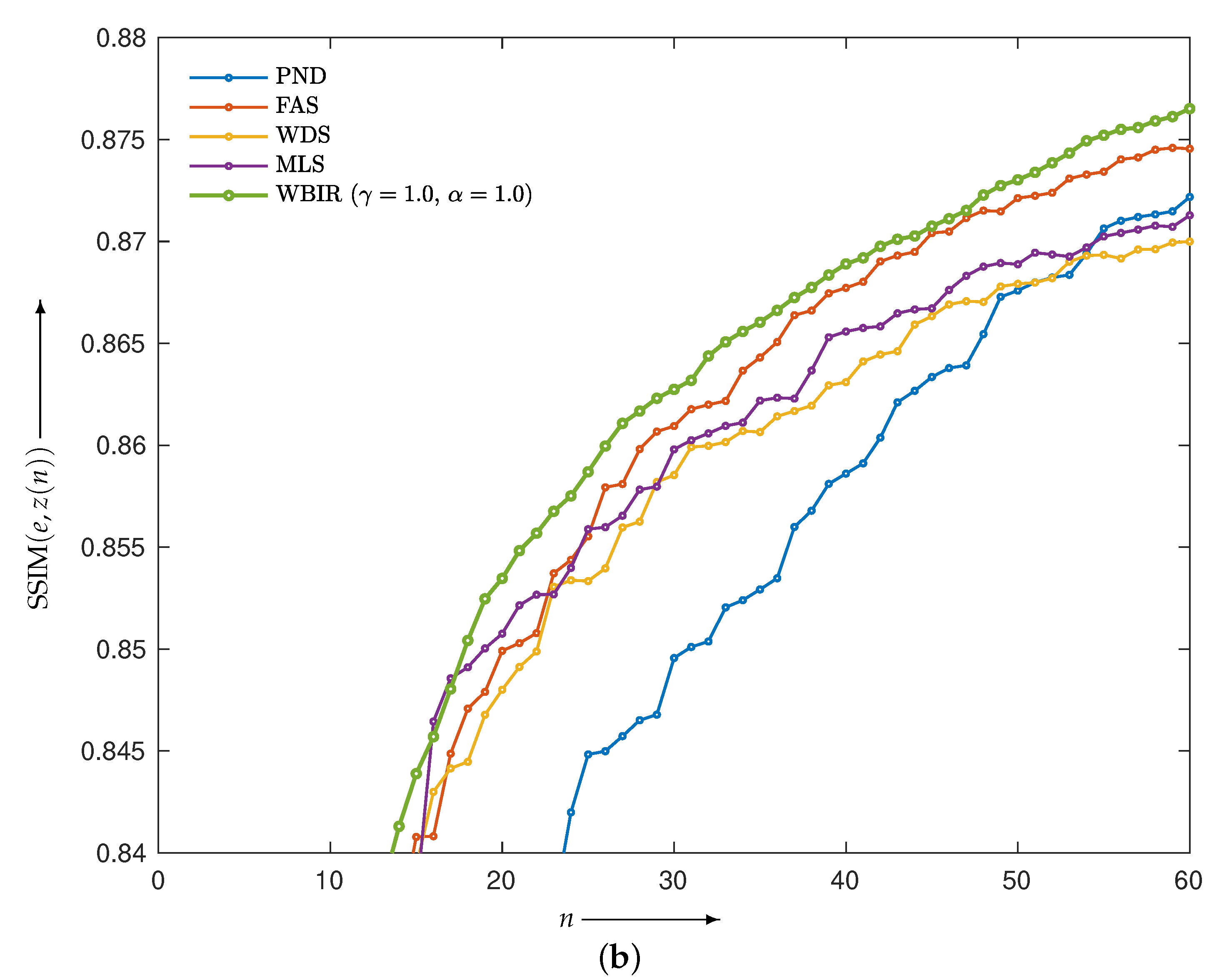
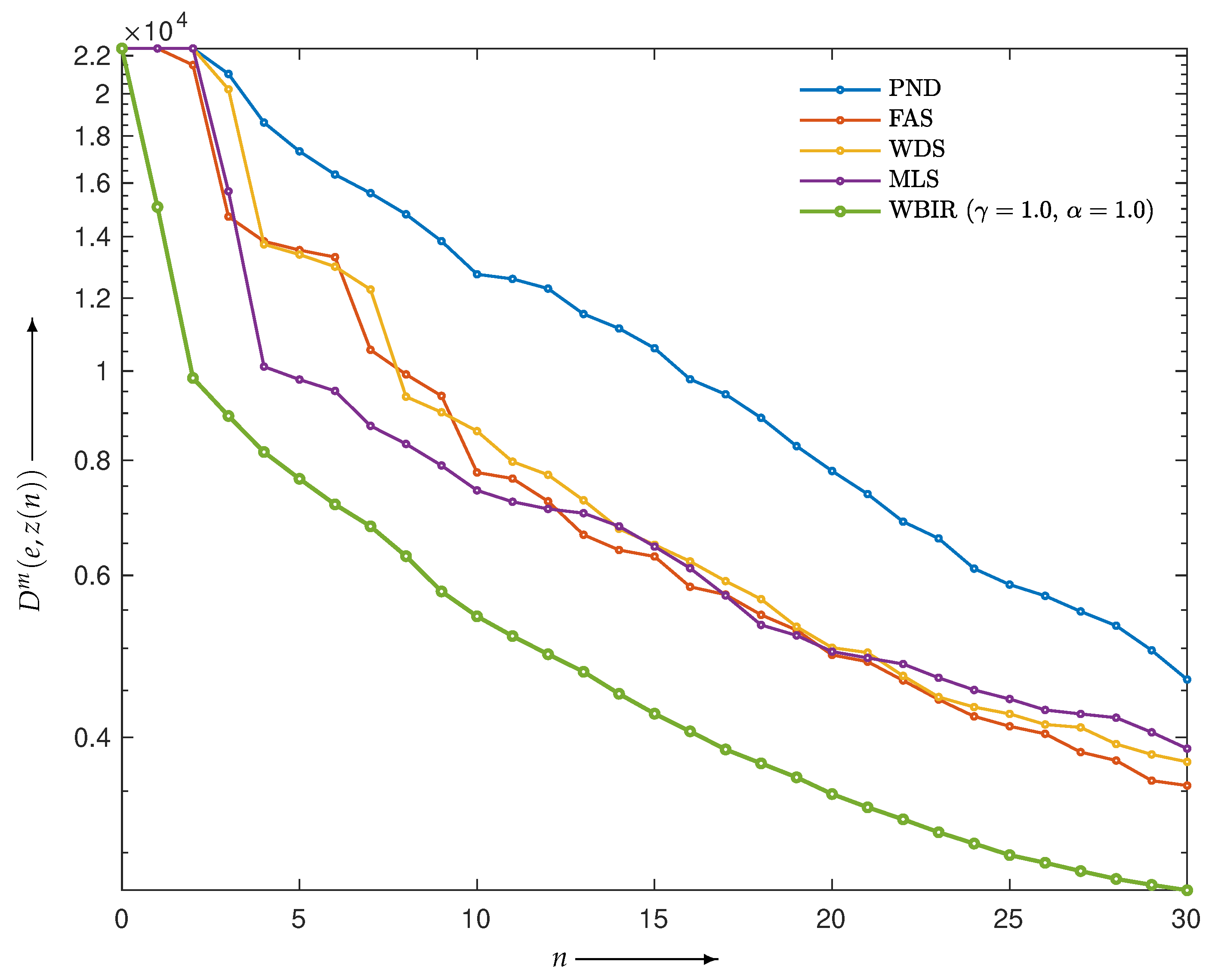
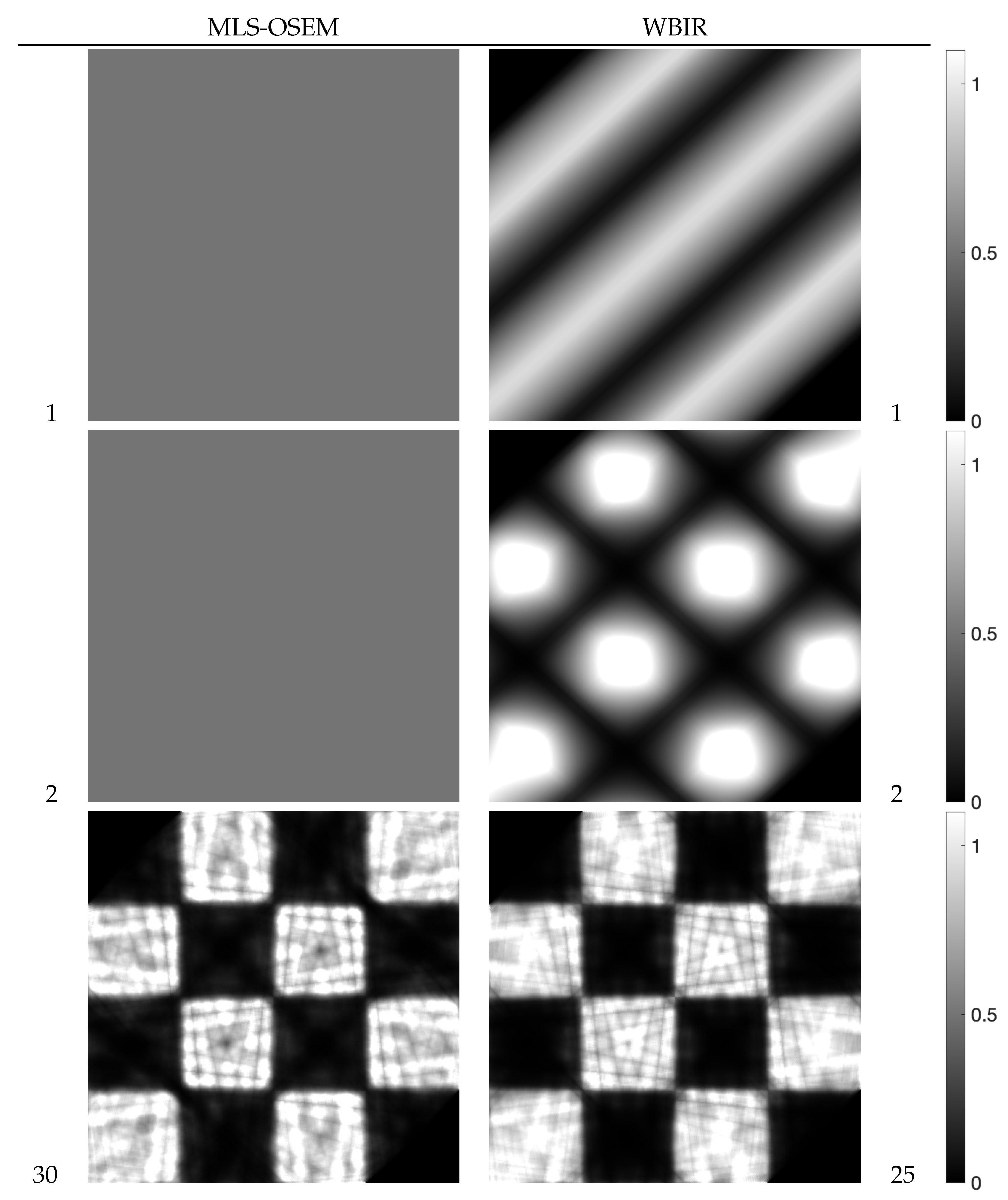
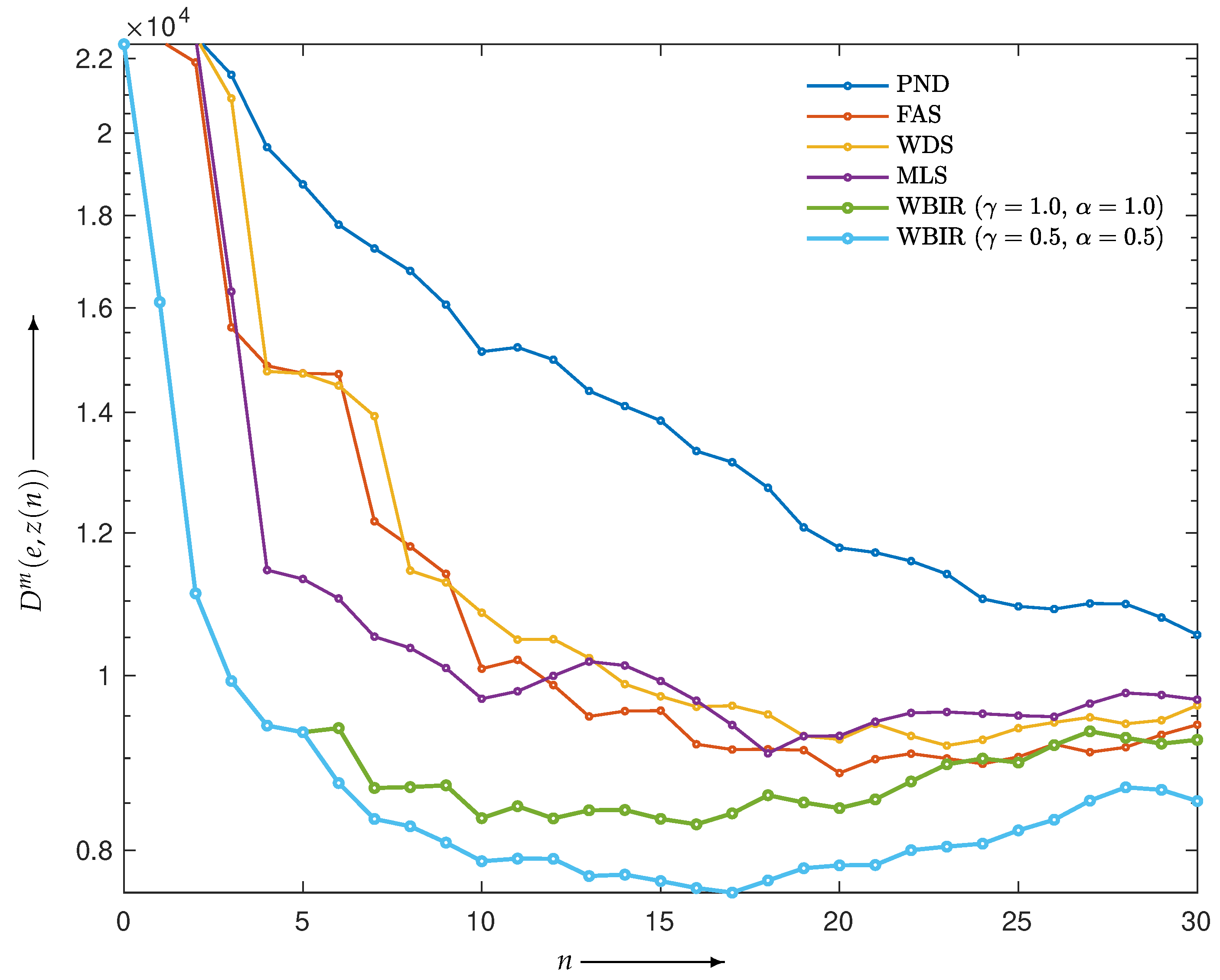
4.2. Evaluation of Reconstructed Images
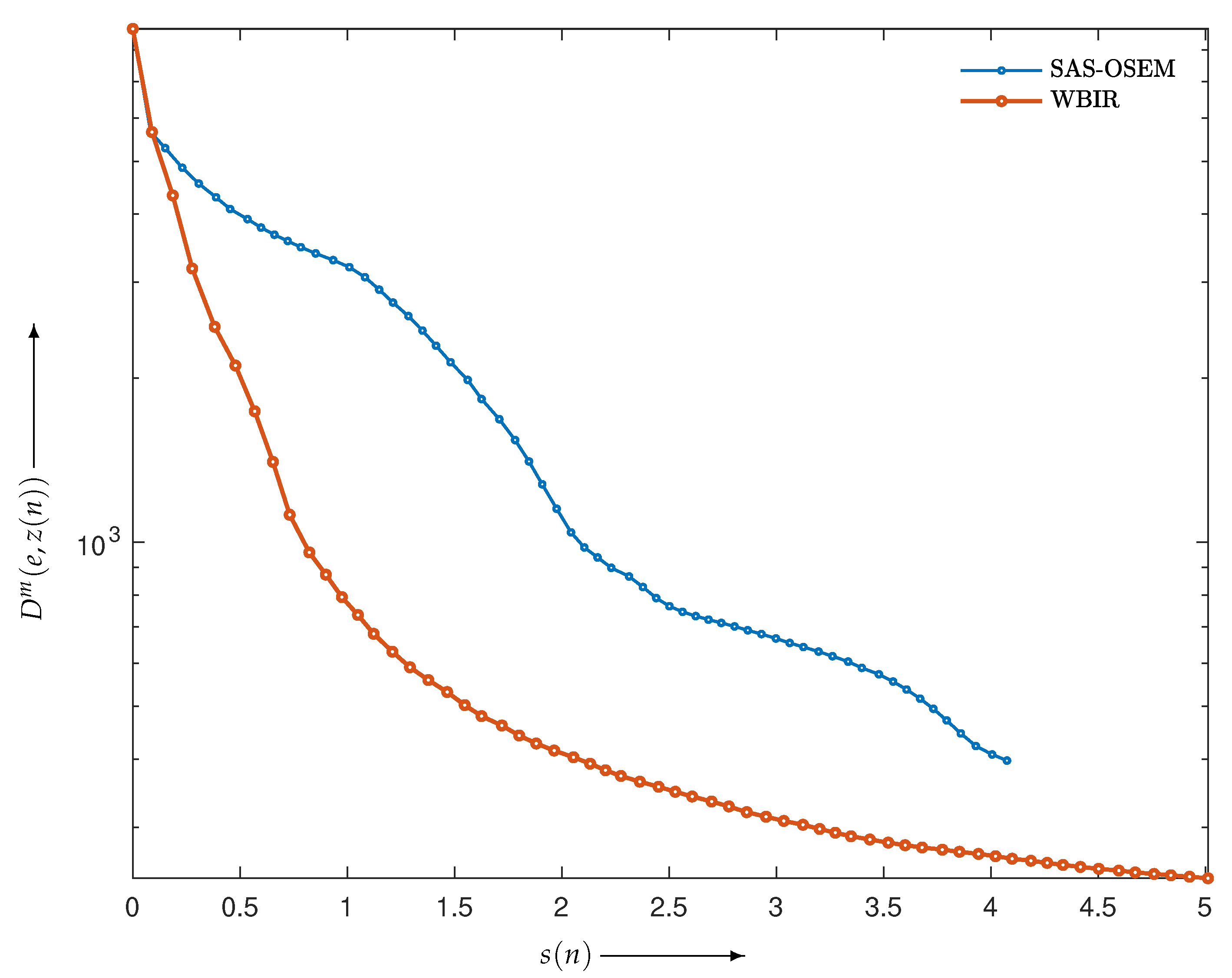
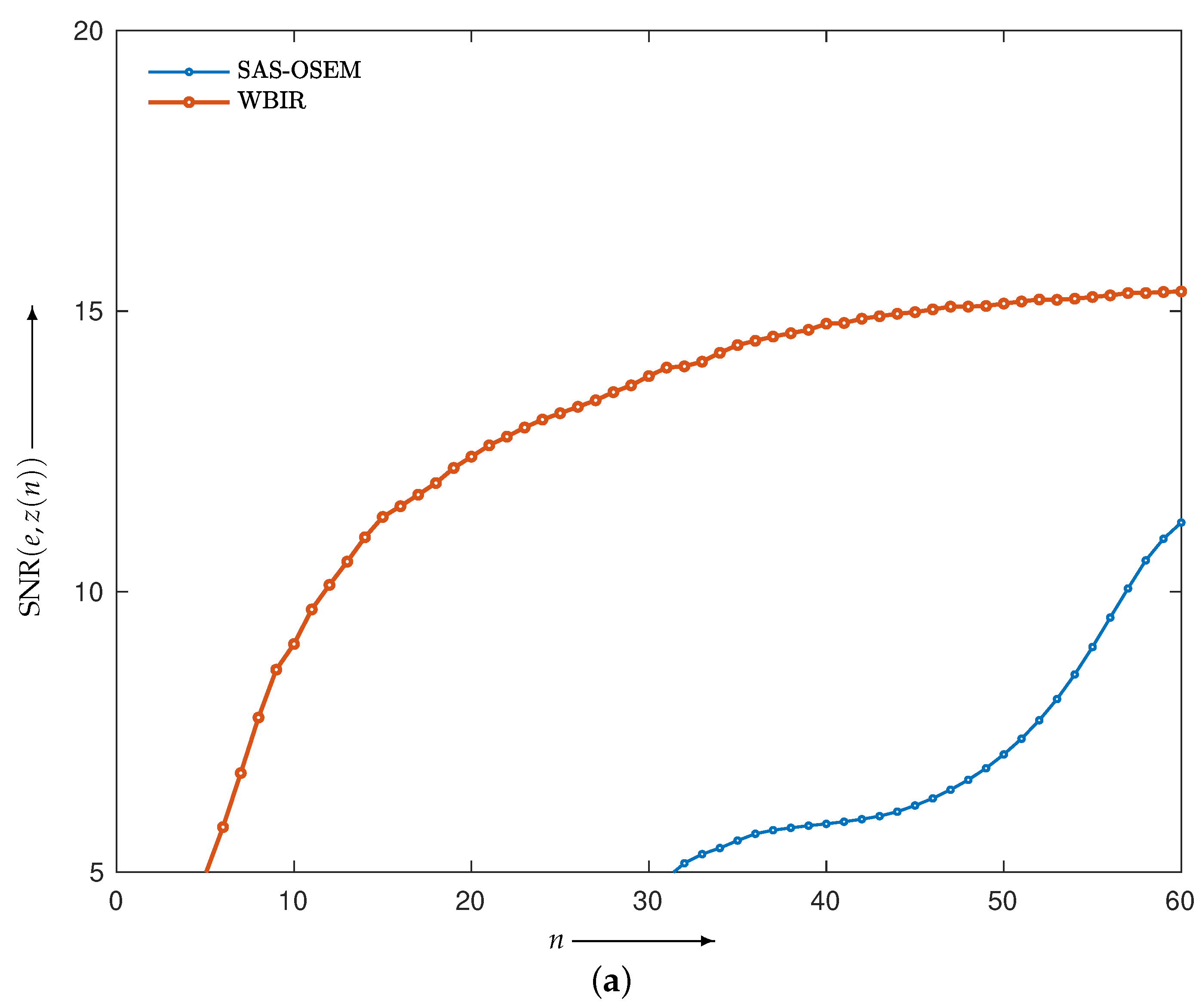
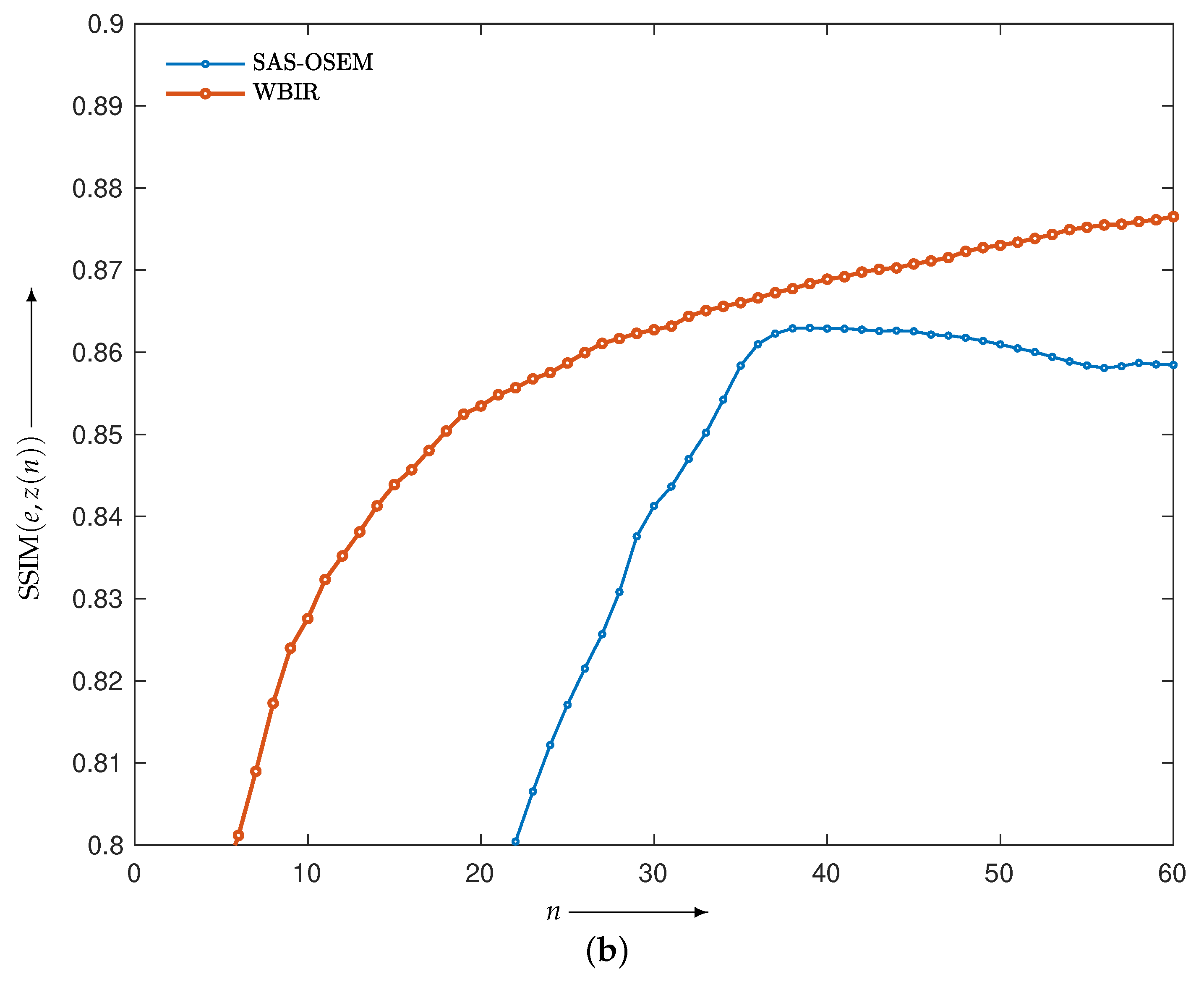
4.2.1. Comparison with SAS-OSEM
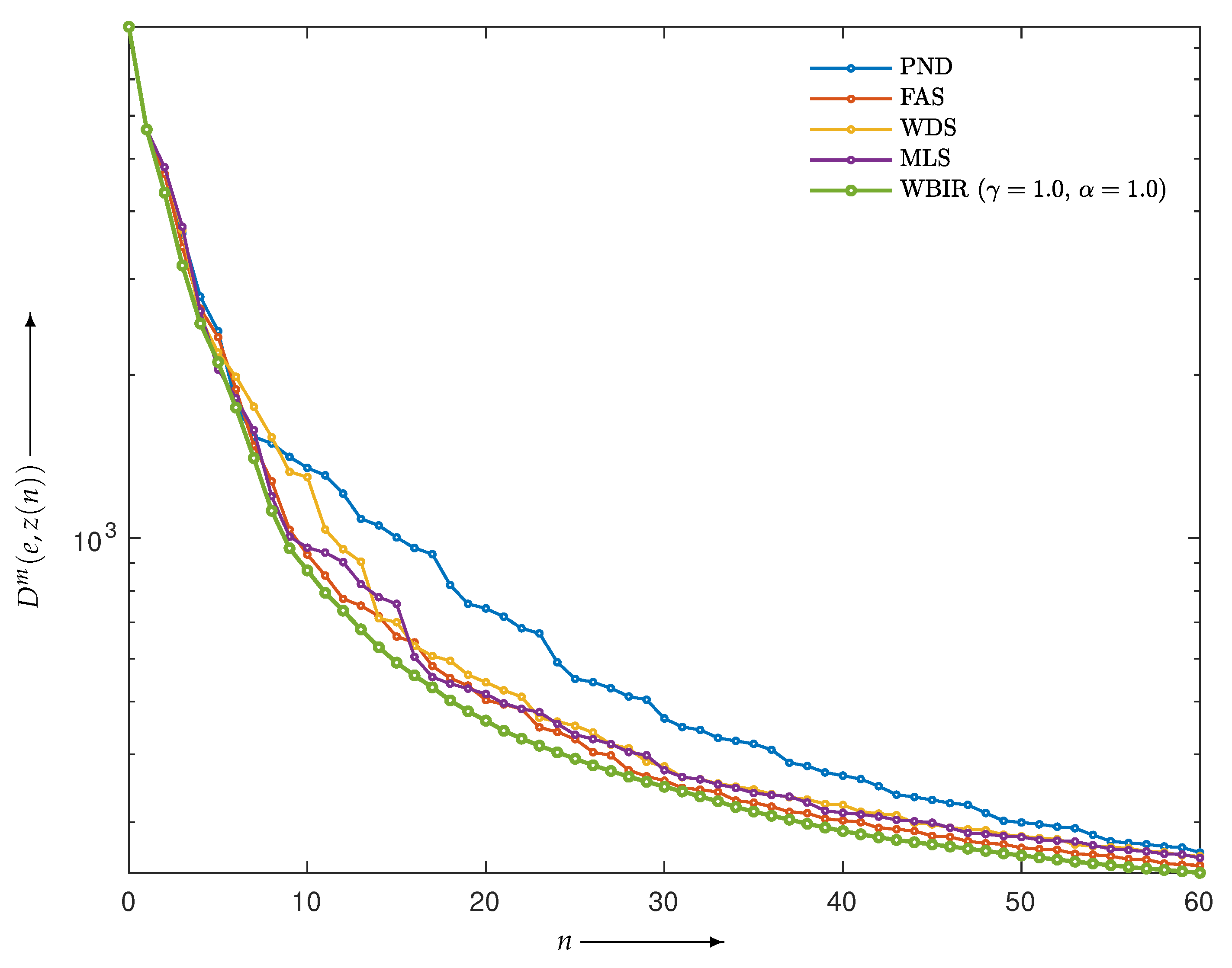
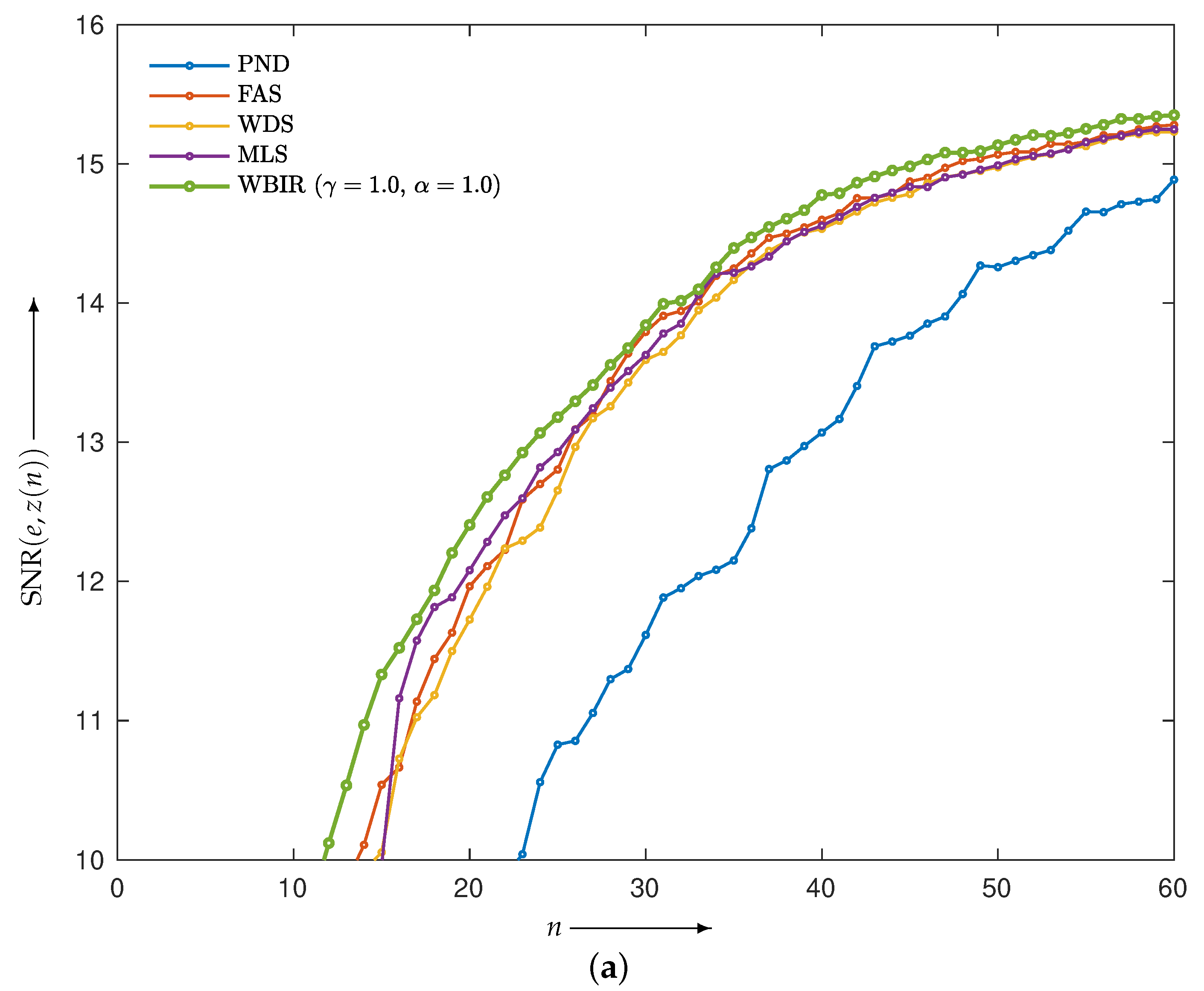
4.2.2. Comparison with OSEM with Non-SAS
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gordon, R.; Bender, R.; Herman, G.T. Algebraic reconstruction techniques (ART) for three-dimensional electron microscopy and X-ray photography. J. Theor. Biol. 1970, 29, 471–481. [Google Scholar] [CrossRef]
- Badea, C.; Gordon, R. Experiments with the nonlinear and chaotic behaviour of the multiplicative algebraic reconstruction technique (MART) algorithm for computed tomography. Phys. Med. Biol. 2004, 49, 1455–1474. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Prakash, P.; Kalra, M.K.; Kambadakone, A.K.; Pien, H.; Hsieh, J.; Blake, M.A.; Sahani, D.V. Reducing abdominal CT radiation dose with adaptive statistical iterative reconstruction technique. Investig. Radiol. 2010, 45, 202–210. [Google Scholar] [CrossRef] [PubMed]
- Singh, S.; Kalra, M.K.; Gilman, M.D.; Hsieh, J.; Pien, H.H.; Digumarthy, S.R.; Shepard, J.O. Adaptive statistical iterative reconstruction technique for radiation dose reduction in chest CT: A pilot study. Radiology 2011, 259, 565–573. [Google Scholar] [CrossRef] [PubMed]
- Singh, S.; Kalra, M.K.; Do, S.; Thibault, J.B.; Pien, H.; O’Connor, O.J.; Blake, M.A. Comparison of hybrid and pure iterative reconstruction techniques with conventional filtered back projection: Dose reduction potential in the abdomen. J. Comput. Assist. Tomogr. 2012, 36, 347–353. [Google Scholar] [CrossRef] [PubMed]
- Beister, M.; Kolditz, D.; Kalender, W.A. Iterative reconstruction methods in X-ray CT. Phys. Med. 2012, 28, 94–108. [Google Scholar] [CrossRef]
- Huang, H.M.; Hsiao, I.T. Accelerating an Ordered-Subset Low-Dose X-ray Cone Beam Computed Tomography Image Reconstruction with a Power Factor and Total Variation Minimization. PLoS ONE 2016, 11, e0153421. [Google Scholar] [CrossRef] [Green Version]
- Kak, A.C.; Slaney, M. Principles of Computerized Tomographic Imaging; IEEE Press: Piscataway, NJ, USA, 1988. [Google Scholar]
- Stark, H. Image Recovery: Theory and Applications; Academic Press: New York, NY, USA, 1987. [Google Scholar]
- Hudson, H.M.; Larkin, R.S. Accelerated image reconstruction using ordered subsets of projection data. IEEE Trans. Med. Imaging 1994, 13, 601–609. [Google Scholar] [CrossRef] [Green Version]
- Fessler, J.A.; Hero, A.O. Penalized maximum-likelihood image reconstruction using space-alternating generalized EM algorithms. IEEE Trans. Image Process. 1995, 4, 1417–1429. [Google Scholar] [CrossRef]
- Byrne, C. Accelerating the EMML algorithm and related iterative algorithms by rescaled block-iterative methods. IEEE Trans. Image Process. 1998, 7, 100–109. [Google Scholar] [CrossRef]
- Hwang, D.; Zeng, G.L. Convergence study of an accelerated ML-EM algorithm using bigger step size. Phys. Med. Biol. 2006, 51, 237–252. [Google Scholar] [CrossRef] [PubMed]
- Byrne, C. Block-iterative methods for image reconstruction from projections. IEEE Trans. Image Process. 1996, 5, 792–794. [Google Scholar] [CrossRef] [PubMed]
- Byrne, C. Block-iterative algorithms. Int. Trans. Oper. Res. 2009, 16, 427–463. [Google Scholar] [CrossRef]
- Herman, G.; Meyer, L. Algebraic reconstruction techniques can be made computationally efficient (positron emission tomography application). IEEE Trans. Med. Imaging 1993, 12, 600–609. [Google Scholar] [CrossRef] [Green Version]
- van Dijke, M.C. Iterative Methods in Image Reconstruction. Ph.D. Thesis, Rijksuniversiteit, Utrecht, The Netherlands, 1992. [Google Scholar]
- Kazantsev, I.G.; Matej, S.; Lewitt, R.M. Optimal Ordering of Projections using Permutation Matrices and Angles between Projection Subspaces. Electron. Notes Discret. Math. 2005, 20, 205–216. [Google Scholar] [CrossRef]
- Guan, H.; Gordon, R. A projection access order for speedy convergence of ART (algebraic reconstruction technique): A multilevel scheme for computed tomography. Phys. Med. Biol. 1994, 39, 2005–2022. [Google Scholar] [CrossRef]
- Mueller, K.; Yagel, R.; Cornhill, J. The weighted-distance scheme: A globally optimizing projection ordering method for ART. IEEE Trans. Med. Imaging 1997, 16, 223–230. [Google Scholar] [CrossRef]
- Shepp, L.A.; Vardi, Y. Maximum likelihood reconstruction for emission tomography. IEEE Trans. Med. Imaging 1982, 1, 113–122. [Google Scholar] [CrossRef]
- Darroch, J.; Ratcliff, D. Generalized iterative scaling for log-linear models. Ann. Math. Stat. 1972, 43, 1470–1480. [Google Scholar] [CrossRef]
- Schmidlin, P. Iterative separation of sections in tomographic scintigrams. J. Nucl. Med. 1972, 11, 1–16. [Google Scholar] [CrossRef]
- Read, T.R.C.; Cressie, N.A.C. Goodness-of-Fit Statistics for Discrete Multivariate Data; Springer: New York, NY, USA, 1988. [Google Scholar]
- Pardo, L. Statistical Inference Based on Divergence Measures; Chapman and Hall/CRC: London, UK, 2005; pp. 1–492. [Google Scholar]
- Liese, F.; Vajda, I. On Divergences and Informations in Statistics and Information Theory. IEEE Trans. Inf. Theory 2006, 52, 4394–4412. [Google Scholar] [CrossRef]
- Pardo, L. New Developments in Statistical Information Theory Based on Entropy and Divergence Measures. Entropy 2019, 21, 391. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Csiszár, I. Why least squares and maximum entropy? An axiomatic approach to inference for linear inverse problems. Ann. Stat. 1991, 19, 2032–2066. [Google Scholar] [CrossRef]
- Kasai, R.; Yamaguchi, Y.; Kojima, T.; Abou Al-Ola, O.; Yoshinaga, T. Noise-Robust Image Reconstruction Based on Minimizing Extended Class of Power-Divergence Measures. Entropy 2021, 23, 1005. [Google Scholar] [CrossRef] [PubMed]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Subset Indices | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BI-SART | 17 | 15 | 30 | 2 | 18 | 14 | 29 | 3 | 16 | 19 |
| 17 | 15 | 30 | 2 | 18 | 14 | 29 | 3 | 19 | 13 | |
| BI-MLEM | 17 | 15 | 2 | 30 | 16 | 18 | 14 | 1 | 29 | 3 |
| 17 | 15 | 2 | 16 | 30 | 18 | 14 | 1 | 29 | 3 | |
| BI-MART | 17 | 15 | 2 | 30 | 18 | 14 | 16 | 29 | 3 | 1 |
| 17 | 15 | 2 | 16 | 30 | 18 | 14 | 1 | 29 | 3 | |
| Method | Subset Indices and Angles | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MLS-OSEM | 1 | 16 | 9 | 24 | 5 | 20 | 12 | 27 | 3 | 18 |
| 0 | 90 | 48 | 138 | 24 | 114 | 66 | 156 | 12 | 102 | |
| WBIR | 23 | 9 | 19 | 2 | 13 | 30 | 16 | 24 | 8 | 1 |
| 132 | 48 | 108 | 6 | 72 | 174 | 90 | 138 | 42 | 0 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ishikawa, K.; Yamaguchi, Y.; Abou Al-Ola, O.M.; Kojima, T.; Yoshinaga, T. Block-Iterative Reconstruction from Dynamically Selected Sparse Projection Views Using Extended Power-Divergence Measure. Entropy 2022, 24, 740. https://0-doi-org.brum.beds.ac.uk/10.3390/e24050740
Ishikawa K, Yamaguchi Y, Abou Al-Ola OM, Kojima T, Yoshinaga T. Block-Iterative Reconstruction from Dynamically Selected Sparse Projection Views Using Extended Power-Divergence Measure. Entropy. 2022; 24(5):740. https://0-doi-org.brum.beds.ac.uk/10.3390/e24050740
Chicago/Turabian StyleIshikawa, Kazuki, Yusaku Yamaguchi, Omar M. Abou Al-Ola, Takeshi Kojima, and Tetsuya Yoshinaga. 2022. "Block-Iterative Reconstruction from Dynamically Selected Sparse Projection Views Using Extended Power-Divergence Measure" Entropy 24, no. 5: 740. https://0-doi-org.brum.beds.ac.uk/10.3390/e24050740