
A Novel Low-Area Point Multiplication Architecture for Elliptic-Curve Cryptography

 ,
,  ,
,  , ,
, ,
Abstract
:1. Introduction
1.1. State-of-the-Art PM Architectures
1.2. Contributions
- Elliptic-curve PM architecture: We present a low-area Elliptic-curve PM architecture over with (descriptions are available in Section 3).
- Bit-serial polynomial multiplier architecture: For two m-bit polynomial multiplications over , we propose a bit serial multiplier architecture for the schoolbook multiplication method, which eventually reduces the hardware resources (see Section 3.2.3).
- Inclusion of pipelining: To shorten the critical path and to maximize the clock frequency, we employ a two-stage pipelining.
- Proposed scheduling for PA and PD operations: In order to cope with the pipelined architecture, we propose rescheduling the PA and PD instructions for the computation of the PM operation in ECC (details are shown in Section 3.2.1).
- Controller: A dedicated finite state machine (FSM)-based controller is incorporated for various control activities (see Section 3.3).
2. Background for PM Computation
| Algorithm 1: Montgomery PM Algorithm [14,19,21,24] |
 |
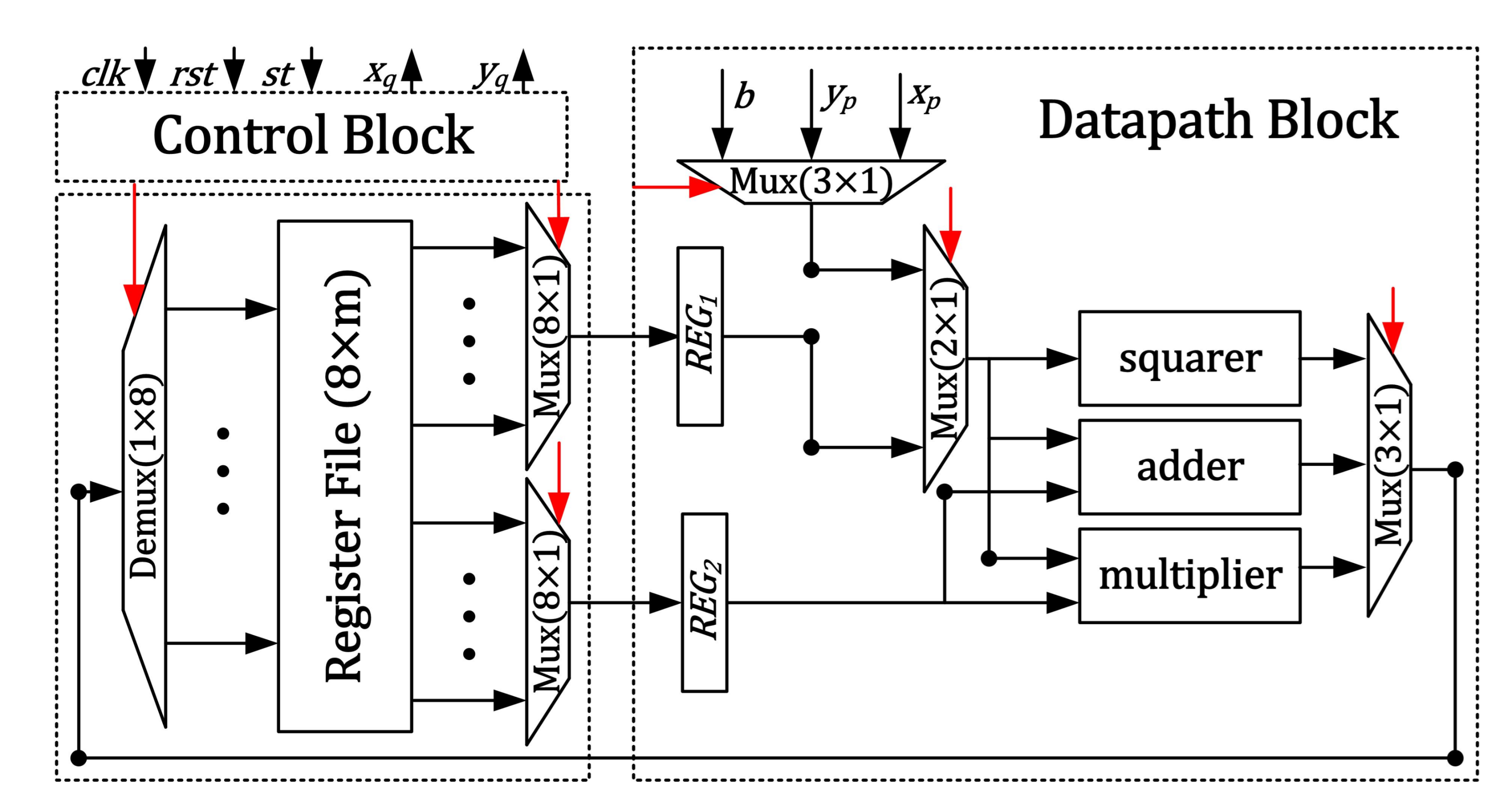
3. Proposed PM Architecture
3.1. Register File
3.2. Data Path Block
3.2.1. Pipelined Registers and Proposed Scheduling of PA and PD Operations
3.2.2. Routing Multiplexers
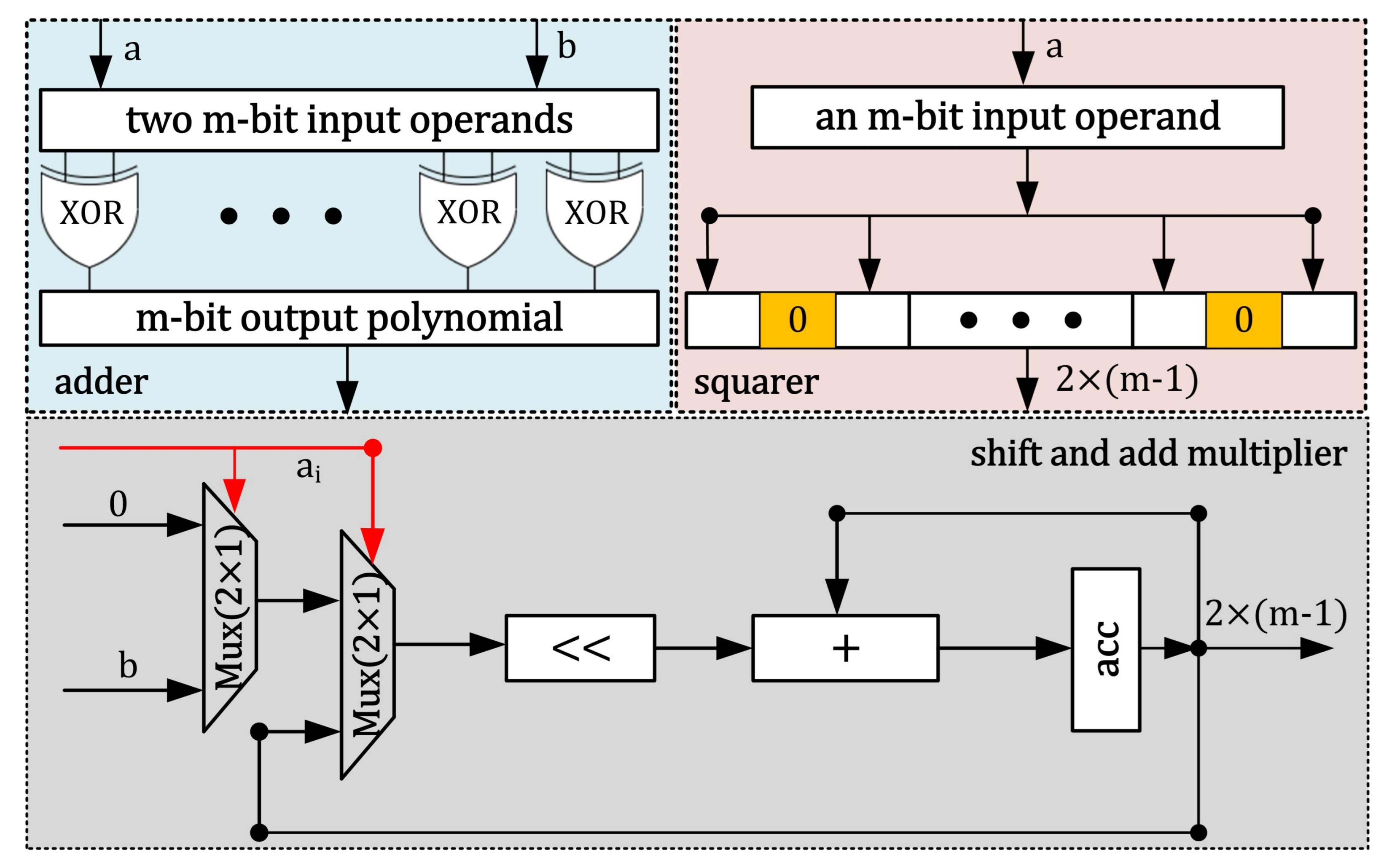
3.2.3. Adder, Squarer, and Multiplier
3.3. Control Block
- Idle state: It represents the start of overall operation. Consequently, State 0 is used for this purpose.
- States from affine to projective conversions: Based on the start (i.e., ) signal, the FSM switches from the idle state to the next state (i.e., state 1). Subsequently, the control signals for projective to affine conversions are generated from state 1 to state 6.
- PM states: As shown in Algorithm 1, the PM step consists of 14 instructions (6 are for multiplications, 3 are for additions, and 5 are for squares). Out of these 14 instructions, 7 are for PA while the remaining 7 are for PD computations. To implement these 14 instructions, FSM requires 17 states (state 7 to state 23). Moreover, each state from 7 to 23 is responsible for checking the inspected key bit, i.e., . Once the value for becomes 1, the part from Algorithm 1 is implemented. Otherwise, the part is implemented. These states (7 to 23) are repeated until the condition for the statement of Algorithm 1 becomes true. Once the loop condition becomes true, the next state is state 24.
- States from projective to affine conversions: The PAC step requires two inversion operations, as depicted in Algorithm 1. Therefore, each inversion is computed during states 24 to 69. The remaining states from 70 to 108 are responsible for implementing additional instructions of the PAC step.
4. Results and Comparisons
4.1. Implementation Results
4.2. Comparison with Existing PM Solutions
4.3. Possible Leakages and Countermeasures
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Verri Lucca, A.; Mariano Sborz, G.A.; Leithardt, V.R.Q.; Beko, M.; Albenes Zeferino, C.; Parreira, W.D. A Review of Techniques for Implementing Elliptic Curve Point Multiplication on Hardware. J. Sens. Actuator Netw. 2021, 10, 3. [Google Scholar] [CrossRef]
- Rashid, M.; Imran, M.; Jafri, A.R.; Al-Somani, T.F. Flexible Architectures for Cryptographic Algorithms — A Systematic Literature Review. J. Circuits Syst. Comput. 2019, 28, 1930003. [Google Scholar] [CrossRef]
- Mallouli, F.; Hellal, A.; Sharief Saeed, N.; Abdulraheem Alzahrani, F. A Survey on Cryptography: Comparative Study between RSA vs. ECC Algorithms, and RSA vs El-Gamal Algorithms. In Proceedings of the 2019 6th IEEE International Conference on Cyber Security and Cloud Computing (CSCloud)/2019 5th IEEE International Conference on Edge Computing and Scalable Cloud (EdgeCom), Paris, France, 21–23 June 2019; pp. 173–176. [Google Scholar] [CrossRef]
- Yadav, A.K. Significance of Elliptic Curve Cryptography in Blockchain IoT with Comparative Analysis of RSA Algorithm. In Proceedings of the 2021 International Conference on Computing, Communication, and Intelligent Systems (ICCCIS), Greater Noida, India, 19–20 February 2021; pp. 256–262. [Google Scholar] [CrossRef]
- Suárez-Albela, M.; Fernández-Caramés, T.M.; Fraga-Lamas, P.; Castedo, L. A Practical Performance Comparison of ECC and RSA for Resource-Constrained IoT Devices. In Proceedings of the 2018 Global Internet of Things Summit (GIoTS), Bilbao, Spain, 4–7 June 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Käsper, E. Fast Elliptic Curve Cryptography in OpenSSL. In Financial Cryptography and Data Security; Danezis, G., Dietrich, S., Sako, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 27–39. [Google Scholar] [CrossRef] [Green Version]
- Kikwai, B.K. Elliptic Curve Digital Signatures and Their Application in the Bitcoin Crypto-currency Transactions. Int. J. Sci. Res. Publ. 2017. Available online: http://www.ijsrp.org/research-paper-1117.php?rp=P716921 (accessed on 26 August 2021).
- Khoirom, M.S.; Laiphrakpam, D.S.; Themrichon, T. Cryptanalysis of multimedia encryption using elliptic curve cryptography. Optik 2018, 168, 370–375. [Google Scholar] [CrossRef]
- Li, C.; Zhang, Y.; Xie, E.Y. When an attacker meets a cipher-image in 2018: A Year in Review. arXiv 2019, arXiv:cs.CR/1903.11764. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Li, B.; Liu, B.; Hu, Y.; Zheng, H. A Privacy-Aware PUFs-Based Multi-Server Authentication Protocol in Cloud-Edge IoT Systems Using Blockchain. IEEE Internet Things J. 2021, 8, 13958–13974. [Google Scholar] [CrossRef]
- Liu, Z.; Liu, D.; Zou, X.; Lin, H.; Cheng, J. Design of an Elliptic Curve Cryptography Processor for RFID Tag Chips. Sensors 2014, 14, 17883–17904. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Noori, D.; Shakeri, H.; Niazi, T.M. Scalable, efficient, and secure RFID with elliptic curve cryptosystem for Internet of Things in healthcare environment. Eurasip J. Inf. Secur. 2020, 2020, 13. [Google Scholar] [CrossRef]
- Zhan, L.; Yong, X.; Weibin, L.; Yun, Z.; Chao, C.; Ziwen, C. A High-Speed Elliptic Curve Cryptography Processor for Teleoperated Systems Security. Math. Probl. Eng. 2021, 2021, 6633925. [Google Scholar] [CrossRef]
- Rashid, M.; Imran, M.; Sajid, A. An Efficient Elliptic-Curve Point Multiplication Architecture for High-Speed Cryptographic Applications. Electronics 2020, 9, 2126. [Google Scholar] [CrossRef]
- Li, L.; Li, S. High-Performance Pipelined Architecture of Point Multiplication on Koblitz Curves. IEEE Trans. Circuits Syst. II Express Briefs 2018, 65, 1723–1727. [Google Scholar] [CrossRef]
- Awaludin, A.M.; Larasati, H.T.; Kim, H. High-Speed and Unified ECC Processor for Generic Weierstrass Curves over GF(p) on FPGA. Sensors 2021, 21, 1451. [Google Scholar] [CrossRef] [PubMed]
- Hossain, M.S.; Saeedi, E.; Kong, Y. High-Performance FPGA Implementation of Elliptic Curve Cryptography Processor over Binary Field GF(2163). In Proceedings of the 2nd International Conference on Information Systems Security and Privacy, Rome, Italy, 19–21 February 2016. [Google Scholar] [CrossRef] [Green Version]
- Imran, M.; Rashid, M.; Shafi, I. Lopez Dahab based elliptic crypto processor (ECP) over GF(2163) for low-area applications on FPGA. In Proceedings of the 2018 International Conference on Engineering and Emerging Technologies (ICEET), Lahore, Pakistan, 22–23 February 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Khan, Z.U.A.; Benaissa, M. Low area ECC implementation on FPGA. In Proceedings of the 2013 IEEE 20th International Conference on Electronics, Circuits, and Systems (ICECS), Abu Dhabi, United Arab Emirates, 8–11 December 2013; pp. 581–584. [Google Scholar] [CrossRef]
- Rashidi, B. Low-Cost and Fast Hardware Implementations of Point Multiplication on Binary Edwards Curves. In Proceedings of the Electrical Engineering (ICEE), Iranian Conference on, Mashhad, Iran, 8–10 May 2018; pp. 17–22. [Google Scholar] [CrossRef]
- Imran, M.; Pagliarini, S.; Rashid, M. An Area Aware Accelerator for Elliptic Curve Point Multiplication. In Proceedings of the 2020 27th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Glasgow, UK, 23–25 November 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Imran, M.; Rashid, M.; Jafri, A.R.; Kashif, M. Throughput/area optimised pipelined architecture for elliptic curve crypto processor. Iet Comput. Digit. Tech. 2019, 13, 361–368. [Google Scholar] [CrossRef] [Green Version]
- Islam, M.M.; Hossain, M.S.; Shahjalal, M.; Hasan, M.K.; Jang, Y.M. Area-Time Efficient Hardware Implementation of Modular Multiplication for Elliptic Curve Cryptography. IEEE Access 2020, 8, 73898–73906. [Google Scholar] [CrossRef]
- Khan, Z.U.A.; Benaissa, M. Throughput/Area-efficient ECC Processor Using Montgomery Point Multiplication on FPGA. IEEE Trans. Circuits Syst. II Express Briefs 2015, 62, 1078–1082. [Google Scholar] [CrossRef]
- Bisheh-Niasar, M.; Azarderakhsh, R.; Mozaffari-Kermani, M. Cryptographic Accelerators for Digital Signature Based on Ed25519. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2021, 29, 1297–1305. [Google Scholar] [CrossRef]
- Bisheh Niasar, M.; Azarderakhsh, R.; Kermani, M.M. Efficient Hardware Implementations for Elliptic Curve Cryptography over Curve448. In Progress in Cryptology—INDOCRYPT 2020; Bhargavan, K., Oswald, E., Prabhakaran, M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 228–247. [Google Scholar]
- Sajid, A.; Rashid, M.; Imran, M.; Jafri, A.R. A Low-Complexity Edward-Curve Point Multiplication Architecture. Electronics 2021, 10, 1080. [Google Scholar] [CrossRef]
- NIST. Recommended Elliptic Curves for Federal Government Use (1999). Available online: https://csrc.nist.gov/csrc/media/publications/fips/186/2/archive/2000-01-27/documents/fips186-2.pdf (accessed on 19 September 2021).
- Hankerson, D.; Menezes, A.J.; Vanstone, S. Guide to Elliptic Curve Cryptography. 2004, pp. 1–311. Available online: https://0-link-springer-com.brum.beds.ac.uk/book/10.1007/b97644 (accessed on 13 August 2021).
- Zode, P.; Deshmukh, R.B.; Samad, A. Fast Architecture of Modular Inversion Using Itoh-Tsujii Algorithm. In VLSI Design and Test; Kaushik, B.K., Dasgupta, S., Singh, V., Eds.; Springer: Singapore, 2017; pp. 48–55. Available online: https://www.springerprofessional.de/fast-architecture-of-modular-inversion-using-itoh-tsujii-algorit/15326436 (accessed on 3 September 2021).
- XILINX. 7 Series FPGAs Data Sheet: Overview. Available online: https://www.mouser.ee/pdfDocs/Virtex-7-ds180_7Series_Overview.pdf (accessed on 17 October 2021).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device | Area Utilization | Timing Information | Throughput | Total Power | |||
|---|---|---|---|---|---|---|---|
| Slices | LUTs | FFs | Freq. ( in MHz) | Latency (in s) | |||
| Virtex-4 | 1880 | 5640 | 1164 | 236 | 690 | 1449.2 | 87 |
| Virtex-5 | 507 | 1521 | 1156 | 321 | 507 | 1972.3 | 79 |
| Virtex-6 | 501 | 1506 | 1149 | 351 | 463 | 2159.8 | 76 |
| Virtex-7 | 491 | 1473 | 1141 | 391 | 416 | 2403.8 | 71 |
| Spartan-7 | 433 | 1391 | 1059 | 314 | 518 | 1930.5 | 67 |
| Artix-7 | 469 | 1421 | 1066 | 325 | 501 | 1996.0 | 56 |
| Kintex-7 | 471 | 1433 | 1069 | 363 | 448 | 2232.1 | 61 |
| Ref #. | ECC Models/PM Algorithm | Platform | Area (FPGA Slices) | Timing Information | |
|---|---|---|---|---|---|
| Freq. (in MHz) | Latency (in s) | ||||
| High-speed architectures | |||||
| [15] | Weierstrass/Right to Left | Virtex-5 | 3670 | 292 | 2.50 |
| [14] | Weierstrass/Montgomery | Virtex-7 | 1593 | 293 | 3.68 |
| [17] | Weierstrass/– | Kintex-7 | 2253 | 306 | – |
| Low-area implementations | |||||
| [19] | Weierstrass/Montgomery | Virtex-5 | 473 | 359 | 110 |
| [20] | BEC/Montgomery | Virtex-5 | 3122 | 288 | 24.52 |
| [18] | Weierstrass/Montgomery | Virtex-7 | 3657 | – | 25.3 |
| [21] | Weierstrass/Montgomery | Virtex-7 | 1529 | 383 | 9.91 |
| Throughput and area improved designs | |||||
| [22] | Weierstrass/Montgomery | Virtex-7 | 2207 | 369 | 10.73 |
| [24] | Weierstrass/Montgomery | Virtex-7 | 1476 | 397 | 10.51 |
| Virtex-5 | 507 | 321 | 507 | ||
| This work | Weierstrass/Montgomery | Virtex-7 | 491 | 391 | 416 |
| Kintex-7 | 471 | 363 | 448 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rashid, M.; Hazzazi, M.M.; Khan, S.Z.; Alharbi, A.R.; Sajid, A.; Aljaedi, A. A Novel Low-Area Point Multiplication Architecture for Elliptic-Curve Cryptography. Electronics 2021, 10, 2698. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics10212698
Rashid M, Hazzazi MM, Khan SZ, Alharbi AR, Sajid A, Aljaedi A. A Novel Low-Area Point Multiplication Architecture for Elliptic-Curve Cryptography. Electronics. 2021; 10(21):2698. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics10212698
Chicago/Turabian StyleRashid, Muhammad, Mohammad Mazyad Hazzazi, Sikandar Zulqarnain Khan, Adel R. Alharbi, Asher Sajid, and Amer Aljaedi. 2021. "A Novel Low-Area Point Multiplication Architecture for Elliptic-Curve Cryptography" Electronics 10, no. 21: 2698. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics10212698