The Hybridization of Ensemble Empirical Mode Decomposition with Forecasting Models: Application of Short-Term Wind Speed and Power Modeling

 ,
,  ,
,  ,
, 
Abstract
:1. Introduction
2. State-of-the-Art Methods
2.1. Empirical Mode Decomposition (EMD) Method
- mean of both envelopes (lower and upper) approaches zero
- count of minima and maxima, and zero crossings differs at most by one
2.2. Ensemble Empirical Mode Decomposition (EEMD) Method
2.3. Pattern Sequence based Forecasting (PSF) Method
2.4. Autoregressive Integrated Moving Average (ARIMA) Method
3. Proposed Methods
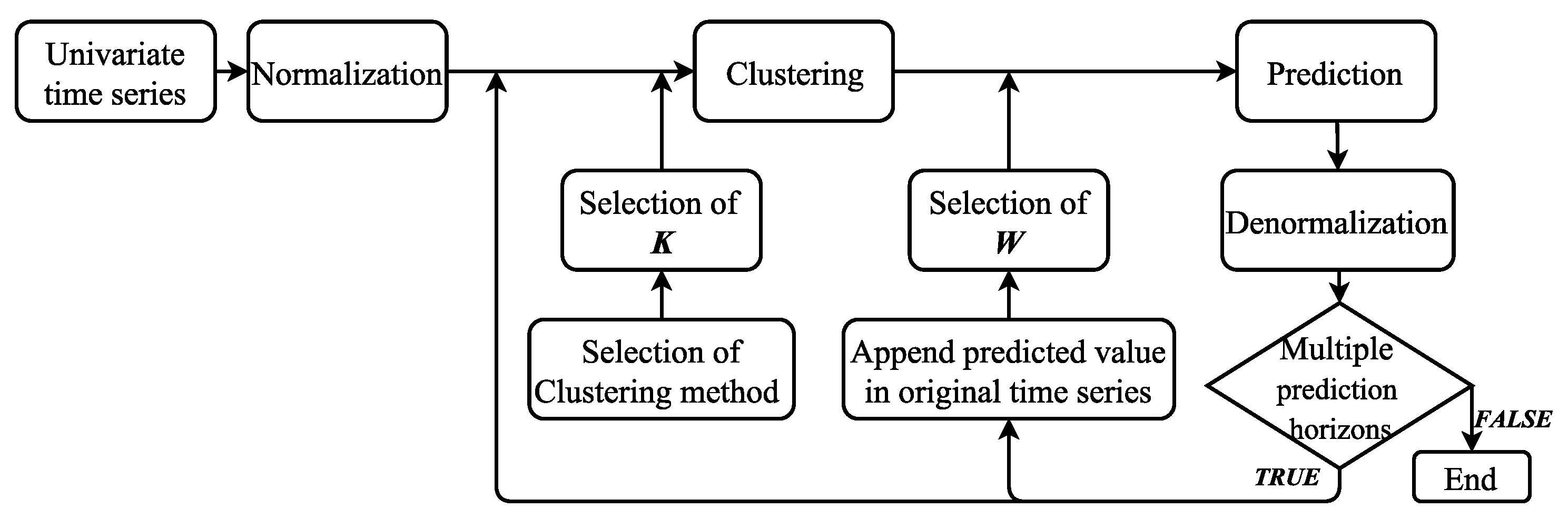
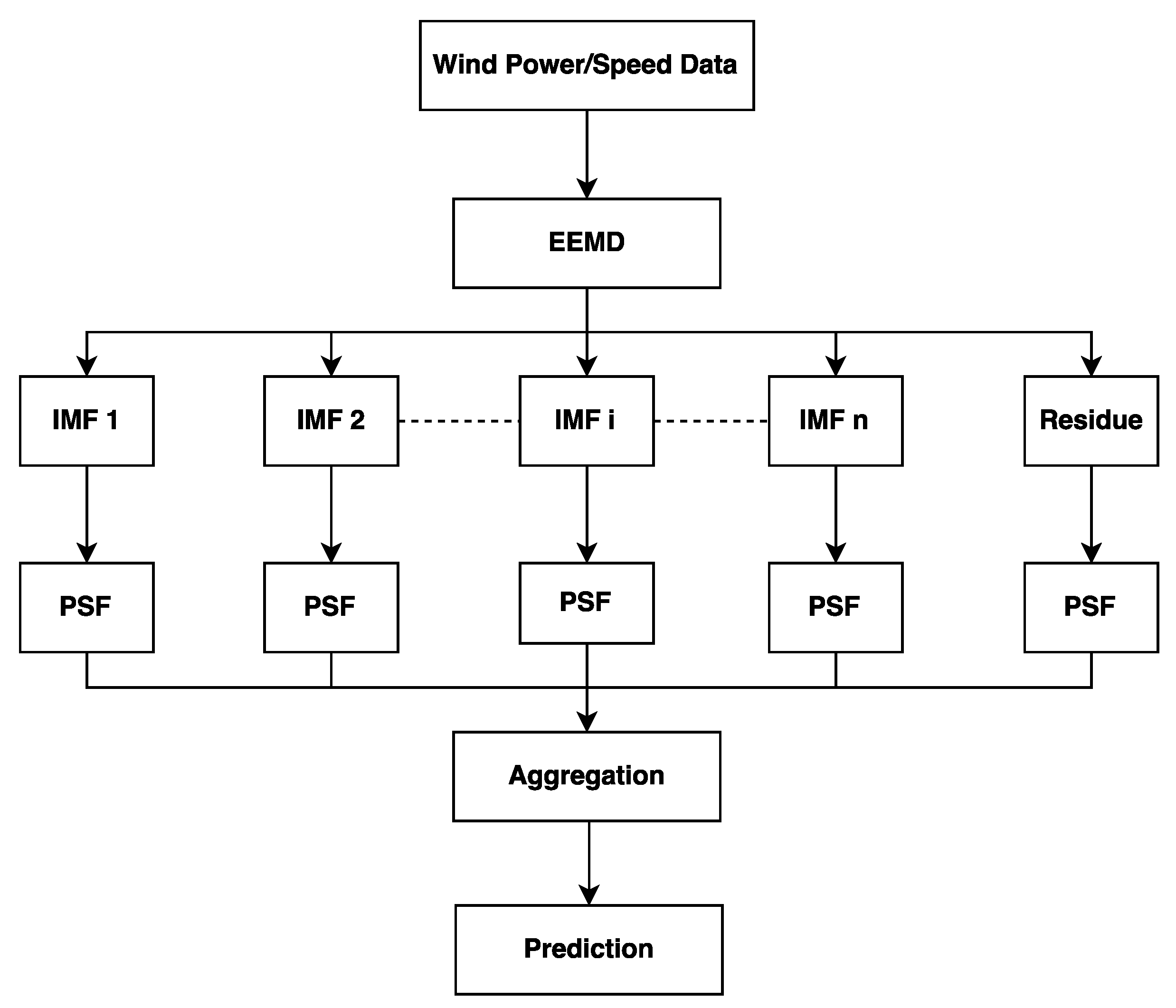
3.1. Hybrid EEMD-PSF Model
- Step 1: Apply EEMD method to transform a time-series in to a set of sub-series (IMFs and a residue).
- Step 2: Calculate the cluster size (K) and optimum window size (W) for the IMFs and residue.
- Step 3: Use PSF method to forecast all sub-series (IMFs and residue).
- Step 4: Add forecasted outcomes corresponding to all sub-series to achieve the ultimate forecasting results.
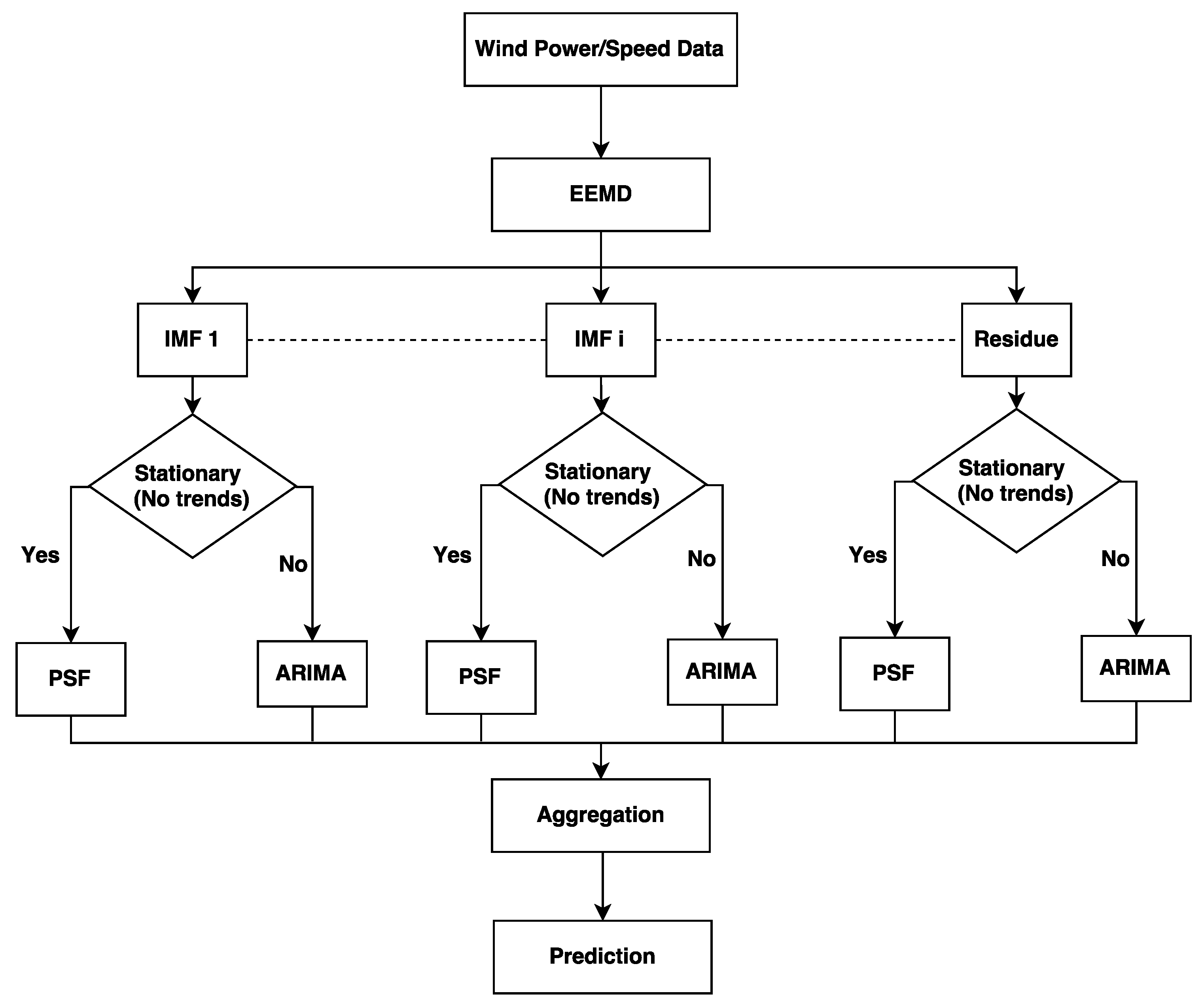
3.2. Hybrid EEMD-PSF-ARIMA Model
- Step 1: Apply EEMD method to transform a time-series in to a set of sub-series (IMFs and a residue).
- Step 2: Execute the KPSS test on all IMFs and the residue to differentiate them in stationary and non-stationary groups.
- Step 3: Apply the PSF method on stationary IMFs and the ARIMA method on non-stationary IMFs.
- Step 4: Add forecasted outcomes corresponding to all sub-series to achieve the ultimate forecasting results.
4. Case Study
- 24 h-ahead prediction with iterated strategy, and
- multiple step ahead prediction with direct strategy (12 and 24 h).
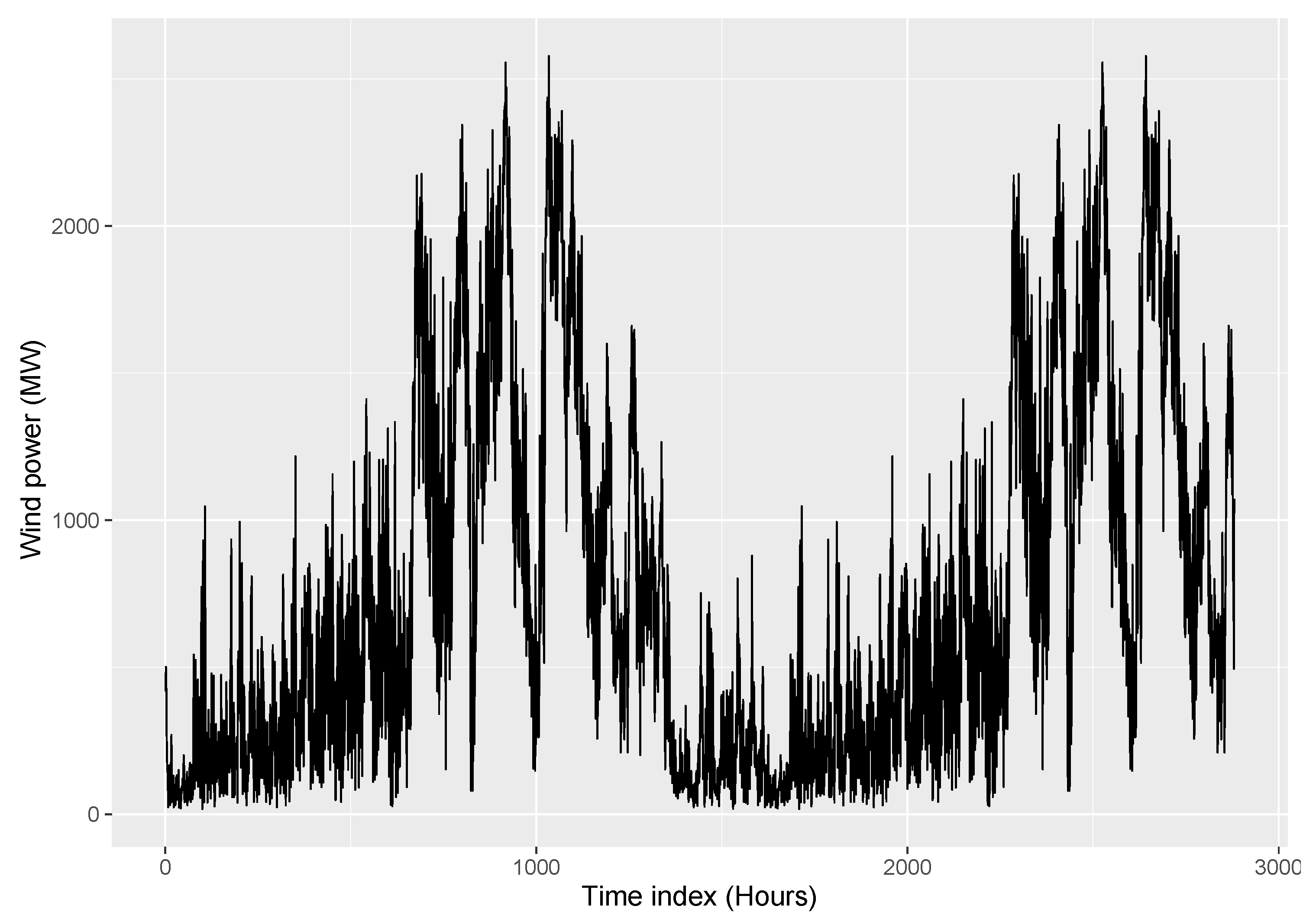
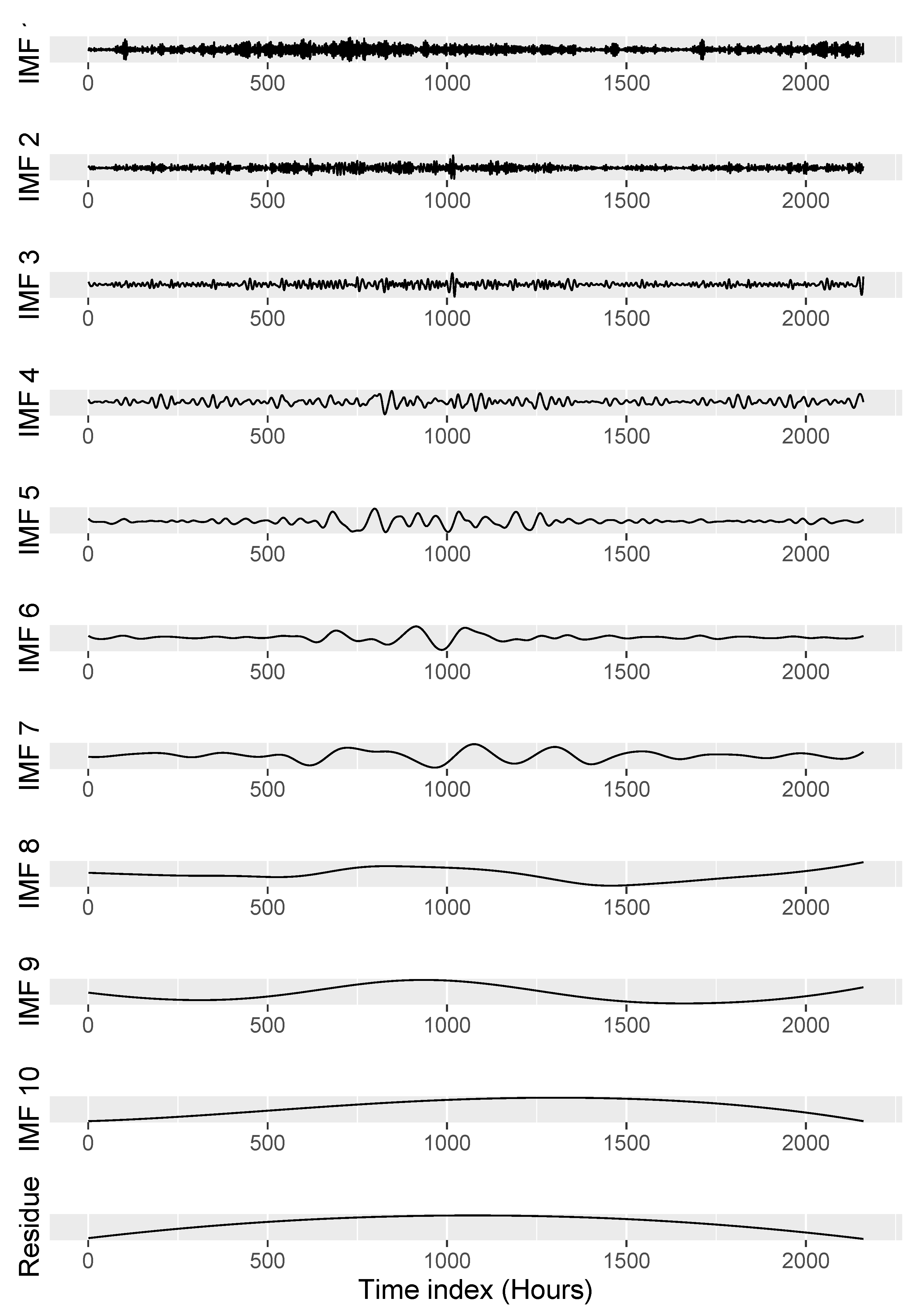
4.1. Case Study 1 - Wind Power Data
4.1.1. Simulation
4.1.2. Comparison and Discussion
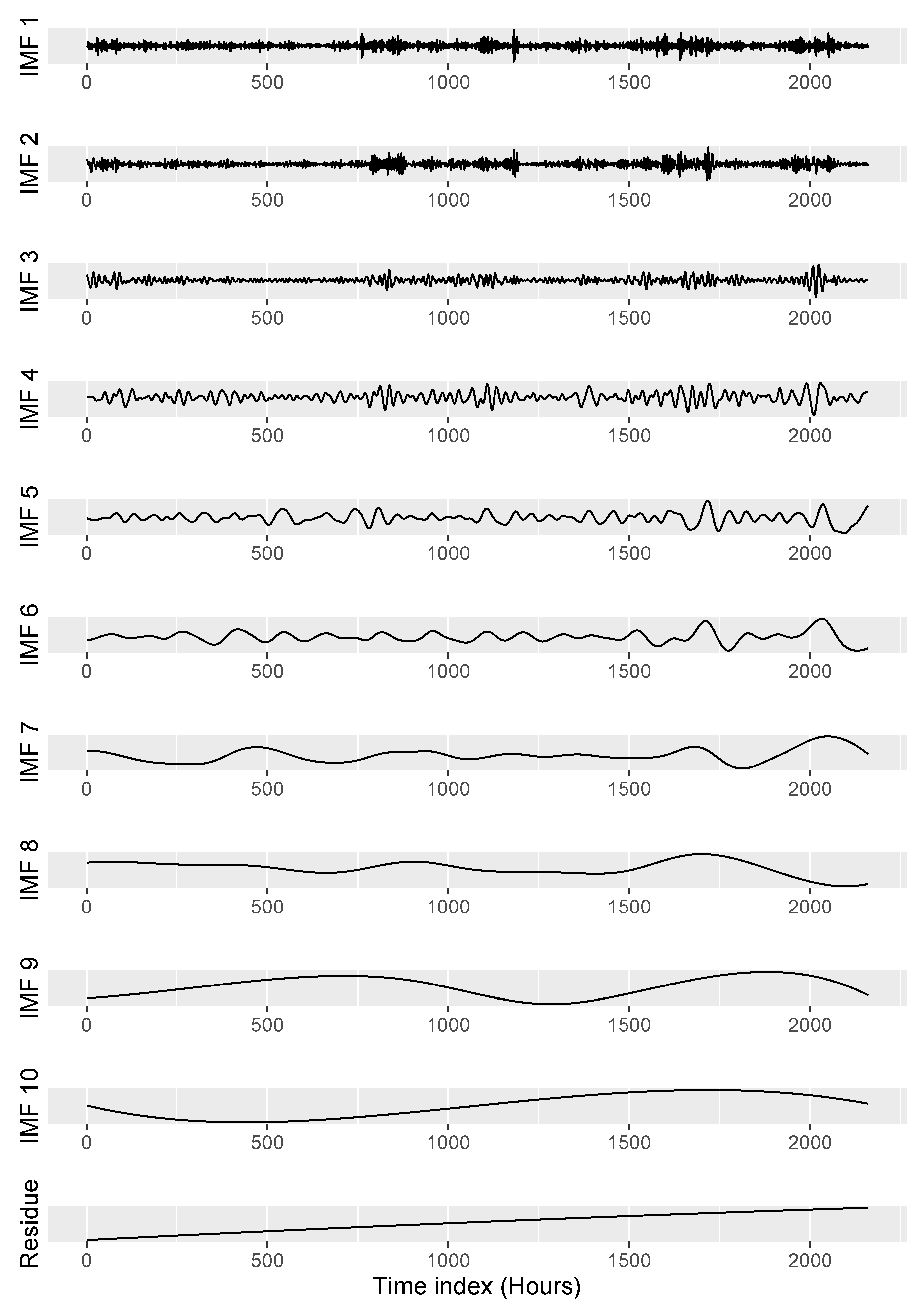
4.2. Case Study 2—Wind Speed Data
4.2.1. Simulation
4.2.2. Comparison and Discussion
- Prediction with the proposed models (EEMD-PSF and EEMD-PSF-ARIMA) is more accurate as compared to other methods.
- The hybridization with EMD and EEMD methods with PSF, ARIMA, and LSSVM methods lead to more accurate predictions as compared to their original forms.
- Similar to case 1, the trade-off between accuracy in prediction and computation time consumption is observed in case 2. For example, EEMD-ARIMA and EMD-ARIMA show more prediction accuracy at the cost of excess in computation delays.
- While discussing computation time, there are a few different things from case 1:
- (a)
- the performance of the PSF model is better than that of the EMD-PSF model in terms of prediction accuracy as well as computation time, and
- (b)
- the computation time for models hybridized with the EEMD method noted longer than the models hybridized with the EMD method. For example, the EEMD-PSF consumed 11.41 s, whereas the EMD-PSF completed the task in 9.75 s.
- In Table 6, the ANOVA test results are shown. The EEMD-PSF-ARIMA model prediction results show one-sided p-values significant at and show statistical significance of the proposed comparison.
5. Conclusions
- In case of short-term wind power time-series prediction, both proposed methods have shown at least 18.03 and 14.78 percentage improvement in forecast accuracy as compared to contemporary methods considered in this study for direct and iterated strategies, respectively. Similarly, for wind speed data, those improvement observed to be 20.00 and 23.80 percentages, respectively.
- In all cases, EEMD-PSF-ARIMA has outperformed in terms of prediction accuracy improvements by at least 10.03 and 8.33 percentages in wind power and speed data, respectively. In wind power data, this achievement is attained at the cost of minute computation delay in the EEMD-PSF-ARIMA model better than EEMD-PSF model by merely few seconds. Conversely, in wind time-series, the EEMD-PSF-ARIMA model takes lesser computation delay as compared to the EEMD-PSF model. Hence, it can be stated that the forecasting accuracy benefits are much greater than the harm produced by the time delay.
- Furthermore, the hybridization of a prediction method with the EEMD method has improved the prediction accuracy significantly. For example, in wind power time-series, EEMD-PSF, EEMD-ARIMA, and EEMD-LSSVM models have shown 23.56, 29.34 and 6.76 percentage improvements in prediction accuracy, better than simple PSF, ARIMA, and LSSVM models, respectively.
Author Contributions
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| AIC | Akaike’s Information Criterion |
| ANN | Artificial Neural Networks |
| ANOVA | Analysis of Variance |
| AR | Autoregression |
| ARMA | Autoregressive Moving Average |
| ARIMA | Autoregressive Integrated Moving Average |
| BIC | Schwartz Bayesian Information Criterion |
| EEMD | Ensemble Empirical Mode Decomposition |
| EMD | Empirical Mode Decomposition |
| ENN | Elman Neural Network |
| f-ARIMA | Fractional Autoregressive Integrated Moving Average |
| GABP | Genetic Algorithm Back Propagation |
| GARCH | Generalized Autoregressive Conditional Heteroskedasticity |
| IMF | Intrinsic Mode Function |
| kNN | k - Nearest Neighbors |
| KPSS test | Kwiatkowski Phillips Schmidt Shin test |
| LSSVM | Least Squares Support Vector Machine |
| MAE | Mean Absolute Error |
| MAPE | Mean Absolute Percentage Error |
| NARX | Nonlinear Autoregressive Exogenous |
| NN | Neural Networks |
| PSF | Pattern Sequence based Forecasting |
| RMSE | Root Mean Square Error |
| SSA | Singular Spectrum Analysis |
| SVM | Support Vector Machine |
| WNN | Weighted Neural Network |
| WRF | Weather Research and Forecasting |
| WT | Wavelet Transform |
Appendix A. ‘decomposedPSF’—An R Package

| Models | Functions |
|---|---|
| EMD-PSF | emdpsf(data, n.ahead) |
| EEMD-PSF | eemdpsf(data, n.ahead) |
| EMD-ARIMA | emdarima(data, n.ahead) |
| EEMD-ARIMA | eemdarima(data, n.ahead) |
| EMD-PSF-ARIMA | emdpsfarima(data, n.ahead) |
| EEMD-PSF-ARIMA | eemdpsfarima(data, n.ahead) |
References
- Kisi, O.; Heddam, S.; Yaseen, Z.M. The implementation of univariable scheme-based air temperature for solar radiation prediction: New development of dynamic evolving neural-fuzzy inference system model. Appl. Energy 2019, 241, 184–195. [Google Scholar] [CrossRef]
- Maroufpoor, S.; Sanikhani, H.; Kisi, O.; Deo, R.C.; Yaseen, Z.M. Long-term modelling of wind speeds using six different heuristic artificial intelligence approaches. Int. J. Climatol. 2019, 39, 3543–3557. [Google Scholar] [CrossRef]
- Yuan, X.; Chen, C.; Yuan, Y.; Huang, Y.; Tan, Q. Short-term wind power prediction based on LSSVM–GSA model. Energy Convers. Manag. 2015, 101, 393–401. [Google Scholar] [CrossRef]
- Zhu, X.; Genton, M.G. Short-Term Wind Speed Forecasting for Power System Operations. Int. Stat. Rev. 2012, 80, 2–23. [Google Scholar] [CrossRef]
- Bokde, N.D.; Feijóo, A.; Al-Ansari, N.; Yaseen, Z.M. A comparison between reconstruction methods for generation of synthetic time series applied to wind speed simulation. IEEE Access 2019, 7, 135386–135398. [Google Scholar] [CrossRef]
- Erdem, E.; Shi, J. ARMA based approaches for forecasting the tuple of wind speed and direction. Appl. Energy 2011, 88, 1405–1414. [Google Scholar] [CrossRef]
- Xu, Q.; He, D.; Zhang, N.; Kang, C.; Xia, Q.; Bai, J.; Huang, J. A short-term wind power forecasting approach with adjustment of numerical weather prediction input by data mining. IEEE Trans. Sustain. Energy 2015, 6, 1283–1291. [Google Scholar] [CrossRef]
- Carvalho, D.; Rocha, A.; Gómez-Gesteira, M.; Santos, C. A sensitivity study of the WRF model in wind simulation for an area of high wind energy. Environ. Model. Softw. 2012, 33, 23–34. [Google Scholar] [CrossRef] [Green Version]
- Treiber, N.A.; Heinermann, J.; Kramer, O. Wind Power Prediction with Machine Learning. In Computational Sustainability; Springer: Berlin/Heidelberg, Germany, 2016; pp. 13–29. [Google Scholar]
- Bludszuweit, H.; Domínguez-Navarro, J.A.; Llombart, A. Statistical analysis of wind power forecast error. IEEE Trans. Power Syst. 2008, 23, 983–991. [Google Scholar] [CrossRef]
- Zhou, J.; Shi, J.; Li, G. Fine tuning support vector machines for short-term wind speed forecasting. Energy Convers. Manag. 2011, 52, 1990–1998. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Ortiz-Garcı, E.G.; Pérez-Bellido, Á.M.; Portilla-Figueras, A.; Prieto, L. Short term wind speed prediction based on evolutionary support vector regression algorithms. Expert Syst. Appl. 2011, 38, 4052–4057. [Google Scholar] [CrossRef]
- Azad, H.B.; Mekhilef, S.; Ganapathy, V.G. Long-term wind speed forecasting and general pattern recognition using neural networks. IEEE Trans. Sustain. Energy 2014, 5, 546–553. [Google Scholar] [CrossRef]
- Ata, R.; Çetin, N.S. Analysis of height affect on average wind speed by ANN. Math. Comput. Appl. 2011, 16, 556–564. [Google Scholar] [CrossRef] [Green Version]
- Rajagopalan, S.; Santoso, S. Wind power forecasting and error analysis using the autoregressive moving average modeling. In Proceedings of the Power & Energy Society General Meeting, Calgary, AB, Canada, 26–30 July 2009; pp. 1–6. [Google Scholar]
- Zhang, W.; Su, Z.; Zhang, H.; Zhao, Y.; Zhao, Z. Hybrid wind speed forecasting model study based on SSA and intelligent optimized algorithm. Abstr. Appl. Anal. 2014, 2014. [Google Scholar] [CrossRef]
- Shi, J.; Ding, Z.; Lee, W.J.; Yang, Y.; Liu, Y.; Zhang, M. Hybrid forecasting model for very-short term wind power forecasting based on grey relational analysis and wind speed distribution features. IEEE Trans. Smart Grid 2014, 5, 521–526. [Google Scholar] [CrossRef]
- Kavasseri, R.G.; Seetharaman, K. Day-ahead wind speed forecasting using f-ARIMA models. Renew. Energy 2009, 34, 1388–1393. [Google Scholar] [CrossRef]
- Eymen, A.; Köylü, Ü. Seasonal trend analysis and ARIMA modeling of relative humidity and wind speed time series around Yamula Dam. Meteorol. Atmos. Phys. 2019, 131, 601–612. [Google Scholar] [CrossRef]
- Cadenas, E.; Rivera, W. Wind speed forecasting in three different regions of Mexico, using a hybrid ARIMA–ANN model. Renew. Energy 2010, 35, 2732–2738. [Google Scholar] [CrossRef]
- Liu, H.; Erdem, E.; Shi, J. Comprehensive evaluation of ARMA–GARCH (-M) approaches for modeling the mean and volatility of wind speed. Appl. Energy 2011, 88, 724–732. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.Q.; Li, Y.F. Comparison of two new ARIMA-ANN and ARIMA-Kalman hybrid methods for wind speed prediction. Appl. Energy 2012, 98, 415–424. [Google Scholar] [CrossRef]
- Cadenas, E.; Rivera, W.; Campos-Amezcua, R.; Heard, C. Wind speed prediction using a univariate ARIMA model and a multivariate NARX model. Energies 2016, 9, 109. [Google Scholar] [CrossRef] [Green Version]
- Cai, H.; Jia, X.; Feng, J.; Yang, Q.; Hsu, Y.M.; Chen, Y.; Lee, J. A combined filtering strategy for short term and long term wind speed prediction with improved accuracy. Renew. Energy 2019, 136, 1082–1090. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; Mohtar, W.H.M.W.; Ameen, A.M.S.; Ebtehaj, I.; Razali, S.F.M.; Bonakdari, H.; Salih, S.Q.; Al-Ansari, N.; Shahid, S. Implementation of univariate paradigm for streamflow simulation using hybrid data-driven model: Case study in tropical region. IEEE Access 2019, 7, 74471–74481. [Google Scholar] [CrossRef]
- Jiang, P.; Wang, Y.; Wang, J. Short-term wind speed forecasting using a hybrid model. Energy 2017, 119, 561–577. [Google Scholar] [CrossRef]
- Taswell, C.; McGill, K.C. Algorithm 735: Wavelet transform algorithms for finite-duration discrete-time signals. ACM Trans. Math. Softw. (TOMS) 1994, 20, 398–412. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. In Proceedings of the Royal Society of London A: Mathematical, Physical and Engineering Sciences; The Royal Society: London, UK, 1998; Volume 454, pp. 903–995. [Google Scholar]
- Liu, H.; Chen, C.; Tian, H.q.; Li, Y.F. A hybrid model for wind speed prediction using empirical mode decomposition and artificial neural networks. Renew. Energy 2012, 48, 545–556. [Google Scholar] [CrossRef]
- Ren, Y.; Suganthan, P.; Srikanth, N. A comparative study of empirical mode decomposition-based short-term wind speed forecasting methods. IEEE Trans. Sustain. Energy 2015, 6, 236–244. [Google Scholar] [CrossRef]
- Ren, Y.; Suganthan, P.N.; Srikanth, N. A novel empirical mode decomposition with support vector regression for wind speed forecasting. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 1793–1798. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, N.E. Ensemble empirical mode decomposition: A noise-assisted data analysis method. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, N.; Wu, L.; Wang, Y. Wind speed forecasting based on the hybrid ensemble empirical mode decomposition and GA-BP neural network method. Renew. Energy 2016, 94, 629–636. [Google Scholar] [CrossRef]
- Hu, J.; Wang, J.; Zeng, G. A hybrid forecasting approach applied to wind speed time series. Renew. Energy 2013, 60, 185–194. [Google Scholar] [CrossRef]
- Yu, C.; Li, Y.; Zhang, M. Comparative study on three new hybrid models using Elman Neural Network and Empirical Mode Decomposition based technologies improved by Singular Spectrum Analysis for hour-ahead wind speed forecasting. Energy Convers. Manag. 2017, 147, 75–85. [Google Scholar] [CrossRef]
- Bokde, N.; Feijóo, A.; Villanueva, D.; Kulat, K. A Review on Hybrid Empirical Mode Decomposition Models for Wind Speed and Wind Power Prediction. Energies 2019, 12, 254. [Google Scholar] [CrossRef] [Green Version]
- Qin, Q.; Lai, X.; Zou, J. Direct Multistep Wind Speed Forecasting Using LSTM Neural Network Combining EEMD and Fuzzy Entropy. Appl. Sci. 2019, 9, 126. [Google Scholar] [CrossRef] [Green Version]
- Wu, Q.; Lin, H. Short-term wind speed forecasting based on hybrid variational mode decomposition and least squares support vector machine optimized by bat algorithm model. Sustainability 2019, 11, 652. [Google Scholar] [CrossRef] [Green Version]
- Lu, P.; Ye, L.; Sun, B.; Zhang, C.; Zhao, Y.; Teng, J. A new hybrid prediction method of ultra-short-term wind power forecasting based on EEMD-PE and LSSVM optimized by the GSA. Energies 2018, 11, 697. [Google Scholar] [CrossRef] [Green Version]
- Santhosh, M.; Venkaiah, C.; Kumar, D.V. Ensemble empirical mode decomposition based adaptive wavelet neural network method for wind speed prediction. Energy Convers. Manag. 2018, 168, 482–493. [Google Scholar] [CrossRef]
- Young, I.R.; Ribal, A. Multiplatform evaluation of global trends in wind speed and wave height. Science 2019, 364, 548–552. [Google Scholar] [CrossRef]
- Hong, D.; Ji, T.; Zhang, L.; Li, M.; Wu, Q. An indirect short-term wind power forecast approach with multi-variable inputs. In Proceedings of the Innovative Smart Grid Technologies-Asia, Melbourne, VIC, Australia, 28 November–1 December 2016; pp. 793–798. [Google Scholar]
- Sohoni, V.; Gupta, S.; Nema, R. A Critical Review on Wind Turbine Power Curve Modelling Techniques and Their Applications in Wind Based Energy Systems. J. Energy 2016, 2016. [Google Scholar] [CrossRef] [Green Version]
- Tian, J.; Zhou, D.; Su, C.; Soltani, M.; Chen, Z.; Blaabjerg, F. Wind turbine power curve design for optimal power generation in wind farms considering wake effect. Energies 2017, 10, 395. [Google Scholar] [CrossRef] [Green Version]
- Bokde, N.; Feijóo, A.; Villanueva, D. Wind Turbine Power Curves Based on the Weibull Cumulative Distribution Function. Appl. Sci. 2018, 8, 1757. [Google Scholar] [CrossRef] [Green Version]
- Bokde, N.; Feijóo, A.; Villanueva, D.; Kulat, K. A Novel and Alternative Approach for Direct and Indirect Wind-Power Prediction Methods. Energies 2018, 11, 2923. [Google Scholar] [CrossRef] [Green Version]
- Martínez-Álvarez, F.; Troncoso, A.; Riquelme, J.C.; Aguilar-Ruiz, J.S. LBF: A labeled-based forecasting algorithm and its application to electricity price time series. In Proceedings of the International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 453–461. [Google Scholar]
- Martínez-Álvarez, F.; Troncoso, A.; Riquelme, J.C.; Aguilar-Ruiz, J.S. Energy time series forecasting based on pattern sequence similarity. IEEE Trans. Knowl. Data Eng. 2011, 23, 1230–1243. [Google Scholar] [CrossRef]
- Majidpour, M.; Qiu, C.; Chu, P.; Gadh, R.; Pota, H.R. Modified pattern sequence-based forecasting for electric vehicle charging stations. In Proceedings of the International Conference on Smart Grid Communications (SmartGridComm), Venice, Italy, 3–6 November 2014; pp. 710–715. [Google Scholar]
- Koprinska, I.; Rana, M.; Troncoso, A.; Martínez-Álvarez, F. Combining pattern sequence similarity with neural networks for forecasting electricity demand time series. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; pp. 1–8. [Google Scholar]
- Fujimoto, Y.; Hayashi, Y. Pattern sequence-based energy demand forecast using photovoltaic energy records. In Proceedings of the International Conference on Renewable Energy Research and Applications (ICRERA), Nagasaki, Japan, 11–14 November 2012; pp. 1–6. [Google Scholar]
- Bokde, N.; Wakpanjar, A.; Kulat, K.; Feijoo, A.E. Robust performance of PSF method over outliers and random patterns in univariate time series forecasting. In Proceedings of the International Technology Congress, Pune, India, 28–29 December 2017. [Google Scholar]
- Bokde, N.; Troncoso, A.; Asencio-Cortés, G.; Kulat, K.; Martínez-Álvarez, F. Pattern sequence similarity based techniques for wind speed forecasting. In International Work-Conference on Time Series; Universidad de Granada: Granada, Spain, 2017. [Google Scholar]
- Wang, Y.; Wang, S.; Zhang, N. A novel wind speed forecasting method based on ensemble empirical mode decomposition and GA-BP neural network. In Proceedings of the Power and Energy Society General Meeting, Vancouver, BC, Canada, 21–25 July 2013; pp. 1–5. [Google Scholar]
- Flandrin, P.; Rilling, G.; Goncalves, P. Empirical mode decomposition as a filter bank. IEEE Signal Process. Lett. 2004, 11, 112–114. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Huang, N.E. A study of the characteristics of white noise using the empirical mode decomposition method. In Proceedings of the Royal Society of London A: Mathematical, Physical and Engineering Sciences; The Royal Society: London, UK, 2004; Volume 460, pp. 1597–1611. [Google Scholar]
- Dunn, J.C. Well-separated clusters and optimal fuzzy partitions. J. Cybern. 1974, 4, 95–104. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 344. [Google Scholar]
- Davies, D.L.; Bouldin, D.W. A cluster separation measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 2, 224–227. [Google Scholar] [CrossRef]
- Jin, C.H.; Pok, G.; Park, H.W.; Ryu, K.H. Improved pattern sequence-based forecasting method for electricity load. IEEJ Trans. Electr. Electron. Eng. 2014, 9, 670–674. [Google Scholar] [CrossRef]
- Bokde, N.; Asencio-Cortes, G.; Martinez-Alvarez, F.; Kulat, K. PSF: Introduction to R Package for Pattern Sequence Based Forecasting Algorithm. R J. 2017, 9, 324–333. [Google Scholar] [CrossRef] [Green Version]
- Bokde, N.; Asencio-Cortes, G.; Martinez-Alvarez, F. PSF: Forecasting of Univariate Time Series Using the Pattern Sequence-Based Forecasting (PSF) Algorithm; R Package Version 0.4; 2017. [Google Scholar]
- Box, G.; Jenkins, G. Some comments on a paper by Chatfield and Prothero and on a review by Kendall. J. R. Stat. Society. Ser. A (General) 1973, 136, 337–352. [Google Scholar] [CrossRef]
- Bokde, N.; Feijóo, A.; Kulat, K. Analysis of differencing and decomposition preprocessing methods for wind speed prediction. Appl. Soft Comput. 2018, 71, 926–938. [Google Scholar] [CrossRef]
- Kwiatkowski, D.; Phillips, P.C.; Schmidt, P.; Shin, Y. Testing the null hypothesis of stationarity against the alternative of a unit root: How sure are we that economic time series have a unit root? J. Econom. 1992, 54, 159–178. [Google Scholar] [CrossRef]
- Bao, Y.; Xiong, T.; Hu, Z. Multi-step-ahead time series prediction using multiple-output support vector regression. Neurocomputing 2014, 129, 482–493. [Google Scholar] [CrossRef] [Green Version]
- Marcellino, M.; Stock, J.H.; Watson, M.W. A comparison of direct and iterated multistep AR methods for forecasting macroeconomic time series. J. Econom. 2006, 135, 499–526. [Google Scholar] [CrossRef] [Green Version]
- Armstrong, R.A.; Slade, S.; Eperjesi, F. An introduction to analysis of variance (ANOVA) with special reference to data from clinical experiments in optometry. Ophthalmic Physiol. Opt. 2000, 20, 235–241. [Google Scholar] [CrossRef] [PubMed]
- Games, P.; Keselman, H.; Rogan, J. A review of simultaneous painvise multiple comparisons. Stat. Neerl. 1983, 37, 53–58. [Google Scholar] [CrossRef]
- Bokde, N. decomposedPSF: Time Series Prediction with PSF and Decomposition Methods (EMD and EEMD); R Package Version 0.1.3; 2017. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






| Median | Mean | Maximum | Minimum | Standard Deviation |
|---|---|---|---|---|
| 576.50 | 757.20 | 2578.0 | 18.0 | 623.53 |
| IMFs | EEMD-PSF (Method Selection) | EEMD-PSF-ARIMA (Method Selection) | |||
|---|---|---|---|---|---|
| IMF1 | >0.05 | PSF | (K = 3, W = 3) | PSF | (K = 3, W = 3) |
| IMF2 | >0.05 | PSF | (K = 3, W = 9) | PSF | (K = 3, W = 9) |
| IMF3 | >0.05 | PSF | (K = 3, W = 7) | PSF | (K = 3, W = 7) |
| IMF4 | >0.05 | PSF | (K = 3, W = 1) | PSF | (K = 3, W = 1) |
| IMF5 | >0.05 | PSF | (K = 3, W = 1) | PSF | (K = 3, W = 1) |
| IMF6 | >0.05 | PSF | (K = 2, W = 7) | PSF | (K = 2, W = 7) |
| IMF7 | >0.05 | PSF | (K = 4, W = 9) | PSF | (K = 4, W = 9) |
| IMF8 | <0.05 | PSF | (K = 3, W = 10) | ARIMA | (p = 1, d = 2, q = 0) |
| IMF9 | <0.05 | PSF | (K = 2, W = 1) | ARIMA | (p = 1, d = 2, q = 0) |
| IMF10 | <0.05 | PSF | (K = 2, W = 10) | ARIMA | (p = 0, d = 2, q = 5) |
| Residue | <0.05 | PSF | (K = 2, W = 1) | ARIMA | (p = 0, d = 2, q = 0) |
| Error Measures | RMSE | MAE | MAPE | |||
|---|---|---|---|---|---|---|
| Models | 1 Step ahead | 2 Steps ahead | 1 Step ahead | 2 Steps ahead | 1 Step ahead | 2 Steps ahead |
| EEMD-PSF-ARIMA | 30.18 | 117.84 | 25.06 | 117.43 | 6.34 | 17.73 |
| EEMD-PSF | 49.95 | 147.89 | 44.24 | 133.19 | 8.27 | 17.93 |
| EMD-PSF-ARIMA | 98.64 | 175.67 | 92.41 | 143.95 | 16.33 | 22.02 |
| EMD-PSF | 148.14 | 182.69 | 135.88 | 170.64 | 24.83 | 28.38 |
| PSF | 174.73 | 185.21 | 169.02 | 175.43 | 26.92 | 28.91 |
| EEMD-ARIMA | 178.22 | 193.05 | 174.66 | 180.52 | 27.11 | 29.39 |
| EMD-ARIMA | 189.12 | 212.91 | 180.82 | 203.66 | 29.31 | 31.48 |
| ARIMA | 195.21 | 257.8 | 193.13 | 220.98 | 41.98 | 48.82 |
| EEMD-LSSVM | 202.07 | 262.37 | 197.08 | 245.06 | 43.78 | 50.43 |
| LSSVM | 226.92 | 262.76 | 221.28 | 258.31 | 47.28 | 52.27 |
| Horizon | 12 Hours | 24 Hours | ||||
|---|---|---|---|---|---|---|
| Models | RMSE | MAE | MAPE | RMSE | MAE | MAPE |
| EEMD-PSF-ARIMA | 149.78 | 132.93 | 24.97 | 166.33 | 148.25 | 34.34 |
| EEMD-PSF | 152.29 | 137.56 | 25.73 | 184.88 | 167.06 | 38.40 |
| EMS-PSF,ARIMA | 185.8 | 157.48 | 29.3 | 216.96 | 189.85 | 46.72 |
| EMD-PSF | 200.24 | 179.46 | 38.96 | 226.78 | 203.34 | 51.97 |
| PSF | 205.54 | 191.94 | 39.85 | 241.88 | 217.16 | 57.59 |
| EEMD-ARIMA | 299.73 | 213.26 | 54.30 | 317.81 | 282.22 | 62.02 |
| EMD-ARIMA | 354.78 | 305.19 | 57.34 | 385.79 | 330.14 | 66.14 |
| ARIMA | 419.65 | 380.26 | 59.10 | 449.83 | 423.78 | 71.94 |
| EEMD-LSSVM | 434.60 | 406.22 | 60.52 | 482.54 | 436.06 | 74.54 |
| LSSVM | 460.03 | 422.01 | 65.46 | 517.57 | 473.97 | 78.76 |
| Models | Wind Power Data | Wind Speed Data |
|---|---|---|
| EMD-PSF-ARIMA | 9.28 | 10.18 |
| EEMD-PSF-ARIMA | 8.48 | 10.95 |
| EMD-PSF | 7.10 | 9.75 |
| EEMD-PSF | 6.91 | 11.41 |
| EMD-ARIMA | 12.57 | 13.37 |
| EEMD-ARIMA | 10.37 | 7.2 |
| PSF | 1.35 | 1.68 |
| ARIMA | 0.49 | 0.48 |
| LSSVM | 1.11 | 0.26 |
| EEMD-LSSVM | 1.99 | 1.09 |
| Models | Wind Power Data | Wind Speed Data |
|---|---|---|
| EMD-PSF-ARIMA | 1.13 | 3.01 |
| EMD-PSF | 2.53 | 0.003 |
| EEMD-PSF | 1.29 | 1.41 |
| EMD-ARIMA | 0.087 | 4.4 |
| EEMD-ARIMA | 0.009 | 0.007 |
| PSF | 2.83 | 7.9 |
| ARIMA | 0.043 | 5.46 |
| LSSVM | 0.062 | 4.69 |
| EEMD-LSSVM | 0.062 | 4.55 |
| Median | Mean | Maximum | Minimum | Standard Deviation |
|---|---|---|---|---|
| 4.66 | 5.19 | 18.34 | 0.00 | 2.88 |
| IMFs | p-Value | EEMD-PSF (Method Selection) | EEMD-PSF-ARIMA (Method Selection) | ||
|---|---|---|---|---|---|
| IMF1 | >0.05 | PSF | (K = 6, W = 1) | PSF | (K = 6, W = 1) |
| IMF2 | >0.05 | PSF | (K = 10, W = 5) | PSF | (K = 10, W = 5) |
| IMF3 | >0.05 | PSF | (K = 4, W = 10) | PSF | (K = 4, W = 10) |
| IMF4 | >0.05 | PSF | (K = 3, W = 10) | PSF | (K = 3, W = 10) |
| IMF5 | >0.05 | PSF | (K = 6, W = 10) | PSF | (K = 6, W = 10) |
| IMF6 | >0.05 | PSF | (K = 4, W = 10) | PSF | (K = 4, W = 10) |
| IMF7 | <0.05 | PSF | (K = 4, W = 3) | ARIMA | (p = 1, d = 1, q = 0) |
| IMF8 | <0.05 | PSF | (K = 4, W = 1) | ARIMA | (p = 1, d = 2, q = 0) |
| IMF9 | <0.05 | PSF | (K = 2, W = 1) | ARIMA | (p = 1, d = 2, q = 0) |
| IMF10 | <0.05 | PSF | (K = 2, W = 1) | ARIMA | (p = 0, d = 2, q = 2) |
| Residue | <0.05 | PSF | (K = 2, W = 10) | ARIMA | (p = 0, d = 2, q = 5) |
| Error Measures | RMSE | MAE | MAPE | |||
|---|---|---|---|---|---|---|
| Models | 1 Step Ahead | 2 Steps Ahead | 1 Step Ahead | 2 Steps Ahead | 1 Step Ahead | 2 Steps Ahead |
| EEMD-PSF-ARIMA | 0.15 | 0.18 | 0.13 | 0.16 | 4.2 | 6.17 |
| EEMD-PSF | 0.16 | 0.21 | 0.14 | 0.19 | 4.44 | 7.86 |
| PSF | 0.21 | 0.28 | 0.19 | 0.22 | 6.26 | 8.74 |
| EMD-PSF-ARIMA | 0.23 | 0.49 | 0.21 | 0.43 | 6.31 | 12.88 |
| EEMD-ARIMA | 0.23 | 0.47 | 0.21 | 0.32 | 6.29 | 12.07 |
| EMD-PSF | 0.47 | 0.71 | 0.39 | 0.63 | 12.78 | 15.18 |
| EMD-ARIMA | 0.23 | 0.61 | 0.21 | 0.57 | 6.36 | 13.49 |
| EEMD-LSSVM | 0.63 | 0.86 | 0.52 | 0.79 | 18.49 | 19.49 |
| ARIMA | 0.58 | 0.74 | 0.50 | 0.69 | 15.69 | 18.16 |
| LSSVM | 0.72 | 1.07 | 0.77 | 0.94 | 23.01 | 26.74 |
| Horizon | 12 Hours | 24 Hours | ||||
|---|---|---|---|---|---|---|
| Models | RMSE | MAE | MAPE | RMSE | MAE | MAPE |
| EEMD-PSF-ARIMA | 0.23 | 0.19 | 5.48 | 0.33 | 0.28 | 9.42 |
| EEMD-PSF | 0.34 | 0.28 | 8.18 | 0.36 | 0.29 | 11.14 |
| PSF | 0.42 | 0.38 | 11.03 | 0.45 | 0.34 | 15.01 |
| EMD-PSF-ARIMA | 0.66 | 0.58 | 16.61 | 0.84 | 0.76 | 21.88 |
| EEMD-ARIMA | 0.61 | 0.57 | 15.98 | 0.66 | 0.52 | 19.39 |
| EMD-PSF | 1.12 | 0.97 | 26.74 | 1.38 | 1.25 | 34.13 |
| EMD-ARIMA | 0.69 | 0.65 | 18.32 | 1.00 | 0.92 | 26.57 |
| EEMD-LSSVM | 1.20 | 1.10 | 29.37 | 1.61 | 1.42 | 39.42 |
| ARIMA | 1.17 | 1.00 | 27.72 | 1.46 | 1.41 | 38.47 |
| LSSVM | 1.48 | 1.47 | 31.21 | 1.73 | 1.45 | 39.44 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bokde, N.; Feijóo, A.; Al-Ansari, N.; Tao, S.; Yaseen, Z.M. The Hybridization of Ensemble Empirical Mode Decomposition with Forecasting Models: Application of Short-Term Wind Speed and Power Modeling. Energies 2020, 13, 1666. https://0-doi-org.brum.beds.ac.uk/10.3390/en13071666
Bokde N, Feijóo A, Al-Ansari N, Tao S, Yaseen ZM. The Hybridization of Ensemble Empirical Mode Decomposition with Forecasting Models: Application of Short-Term Wind Speed and Power Modeling. Energies. 2020; 13(7):1666. https://0-doi-org.brum.beds.ac.uk/10.3390/en13071666
Chicago/Turabian StyleBokde, Neeraj, Andrés Feijóo, Nadhir Al-Ansari, Siyu Tao, and Zaher Mundher Yaseen. 2020. "The Hybridization of Ensemble Empirical Mode Decomposition with Forecasting Models: Application of Short-Term Wind Speed and Power Modeling" Energies 13, no. 7: 1666. https://0-doi-org.brum.beds.ac.uk/10.3390/en13071666