
Design of Machine Learning Prediction System Based on the Internet of Things Framework for Monitoring Fine PM Concentrations

Abstract
:1. Introduction
2. Problem Statements
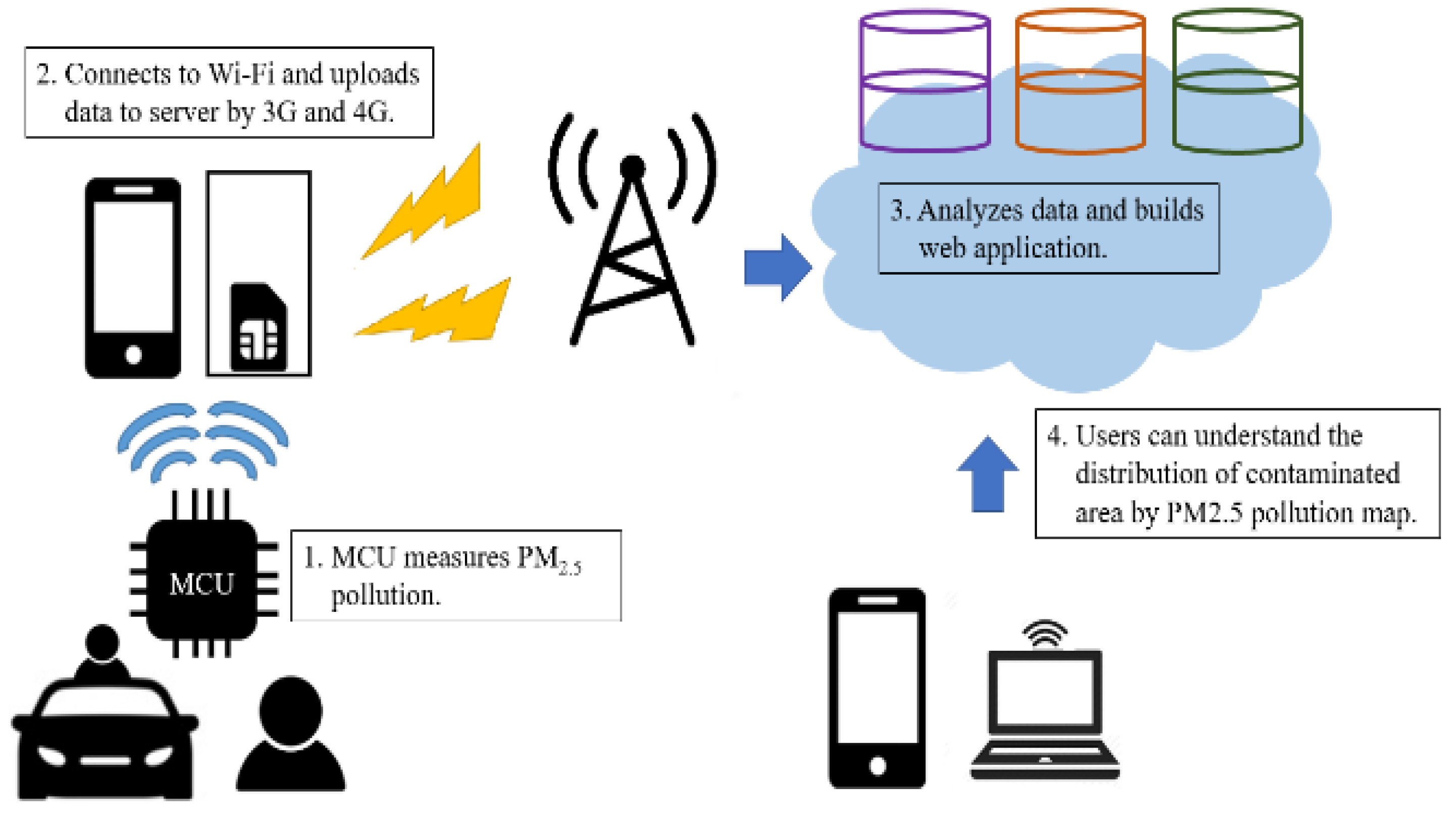
2.1. System Architectures
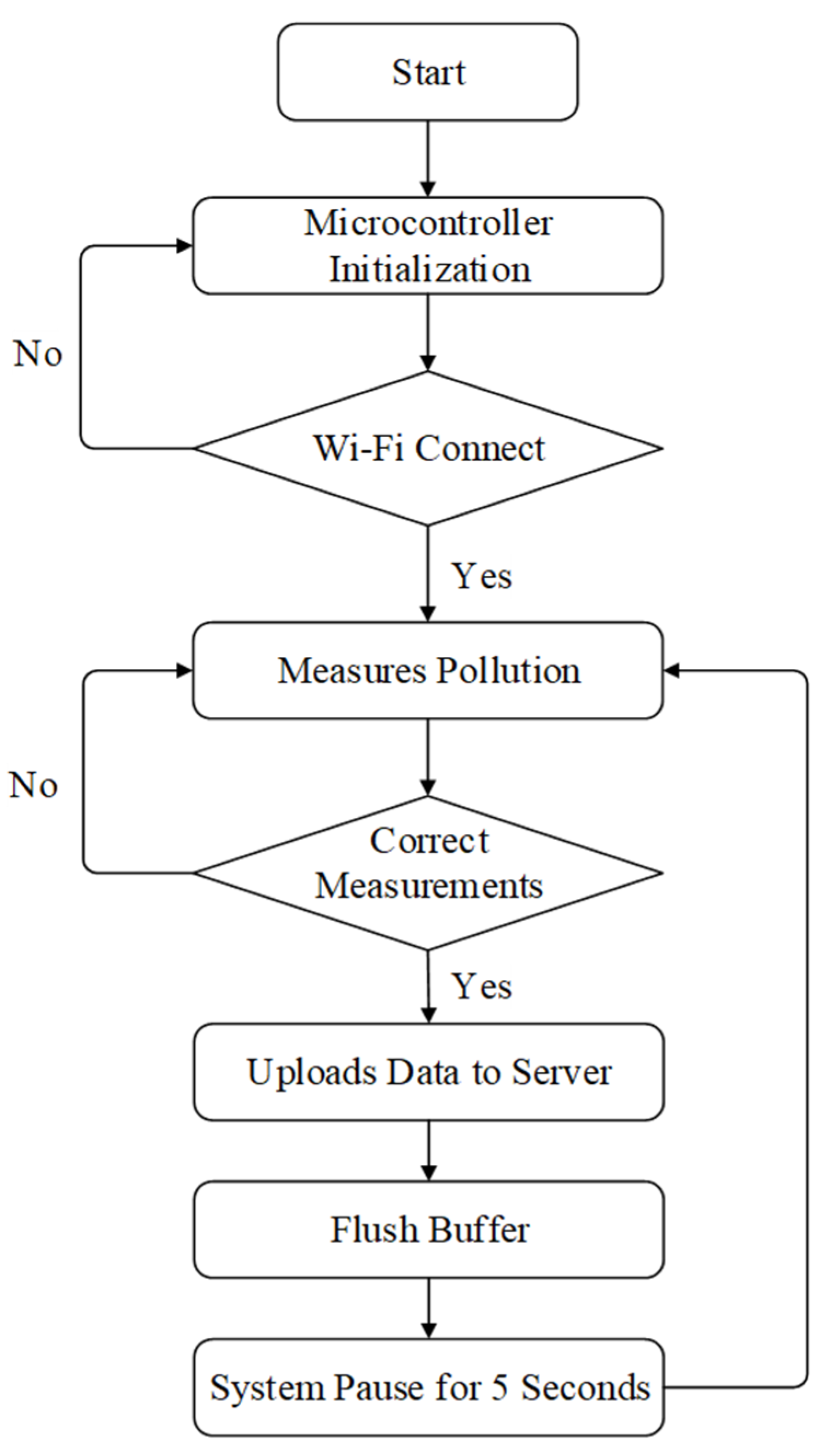
2.2. IoT for Fine Suspended Particulate Monitoring
3. Design of the PM Predictive System
3.1. PM Pollution Dataset
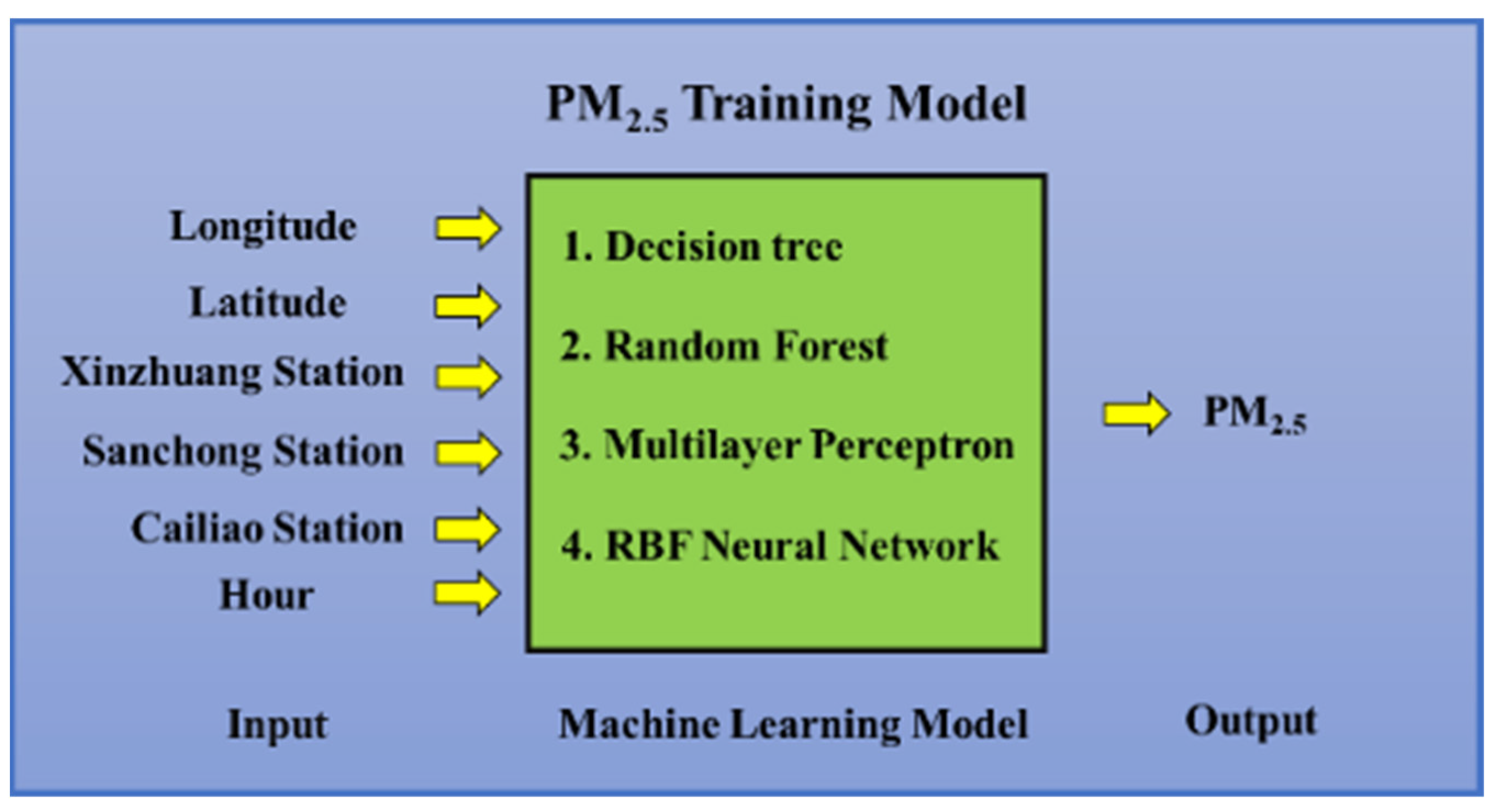
3.2. Structure of the Machine Learning Models
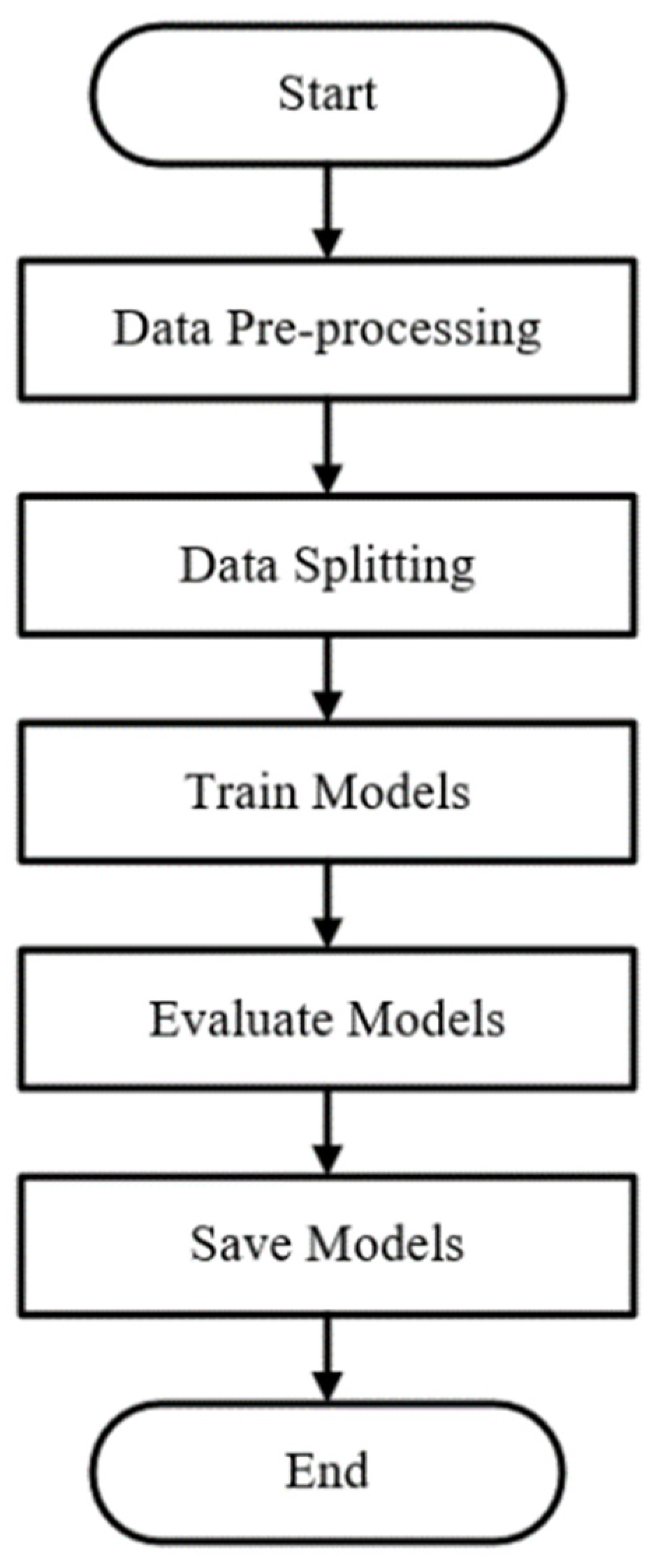
3.3. Model Training Process
3.3.1. Model Training Process
3.3.2. Data Grouping
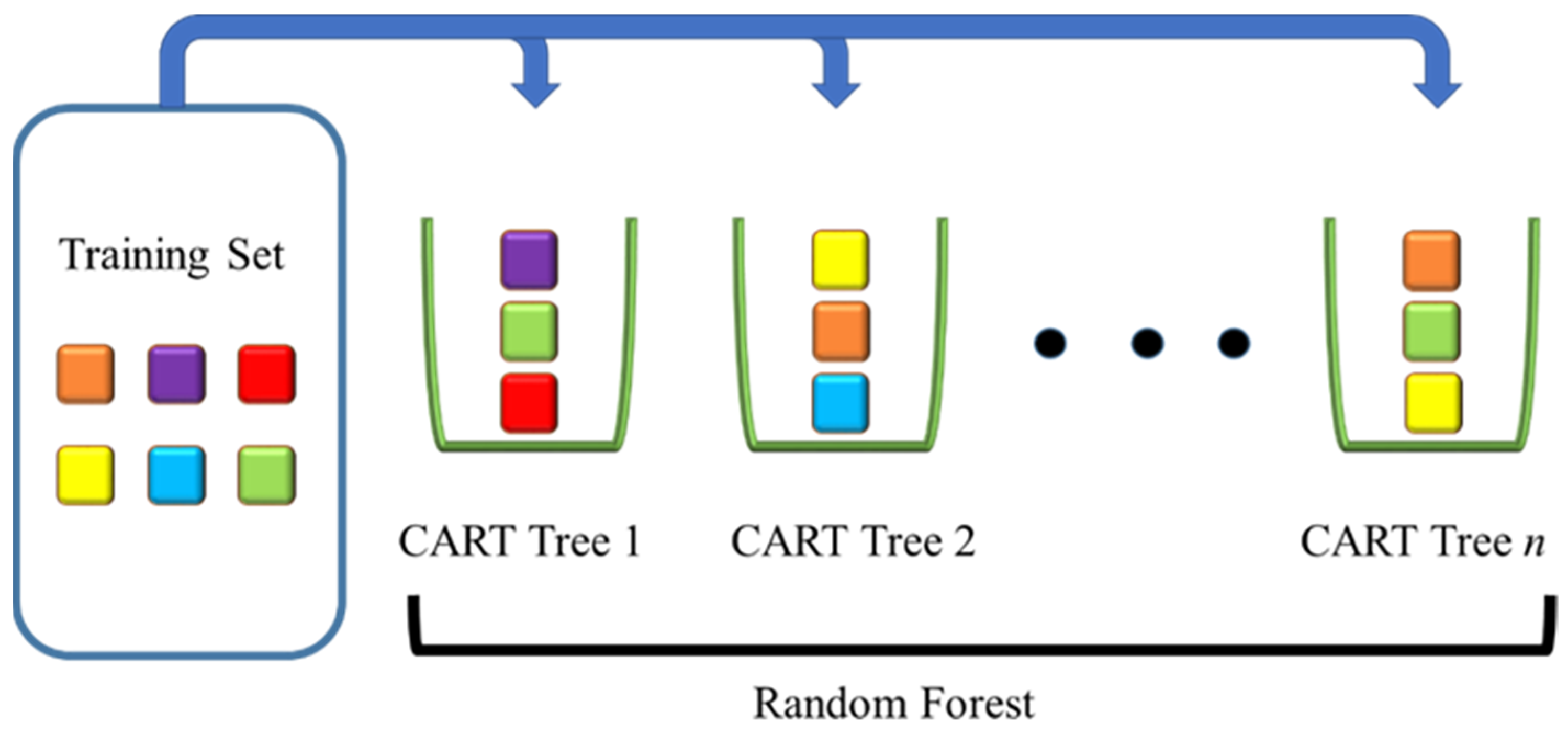
3.3.3. Machine Learning Methods
3.3.4. Model Training
3.4. Model Training Process
3.5. Model Saving
4. Model Training Comparison
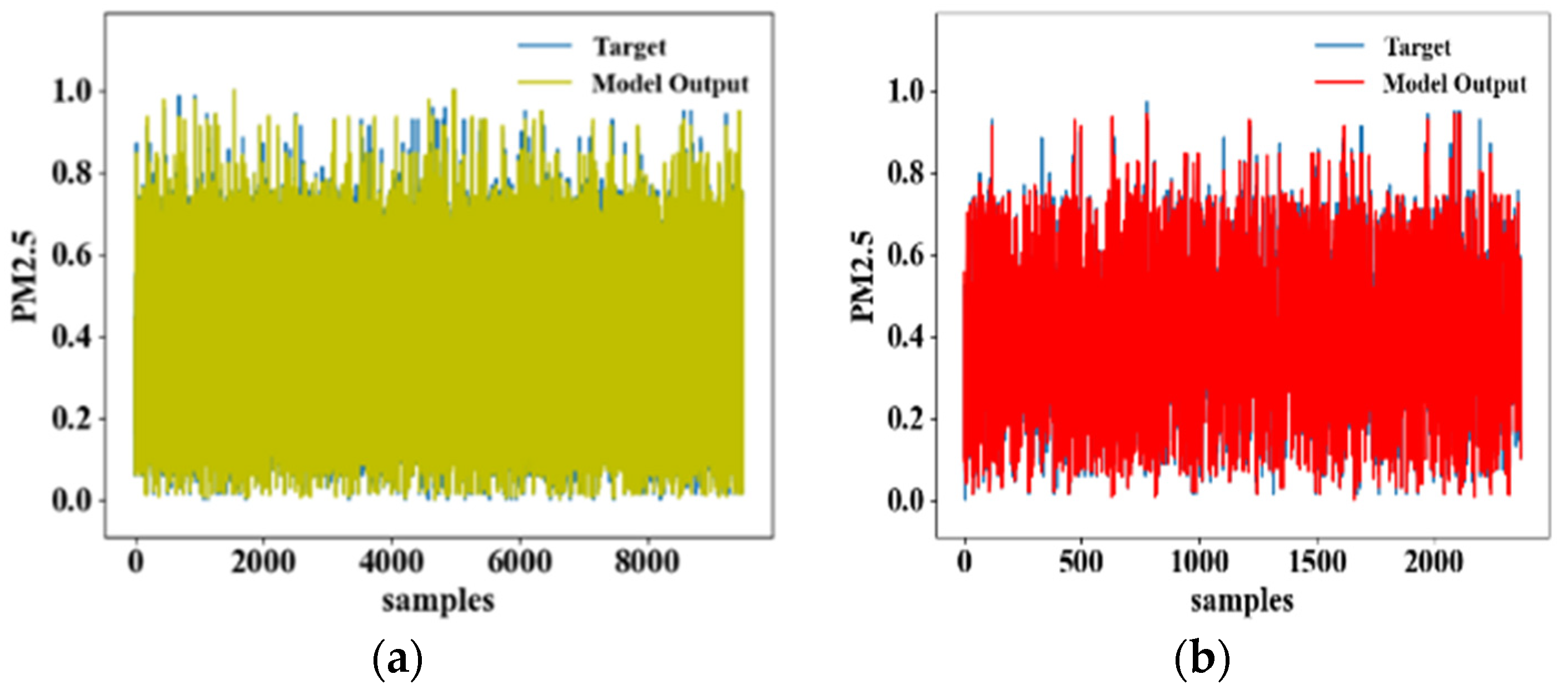
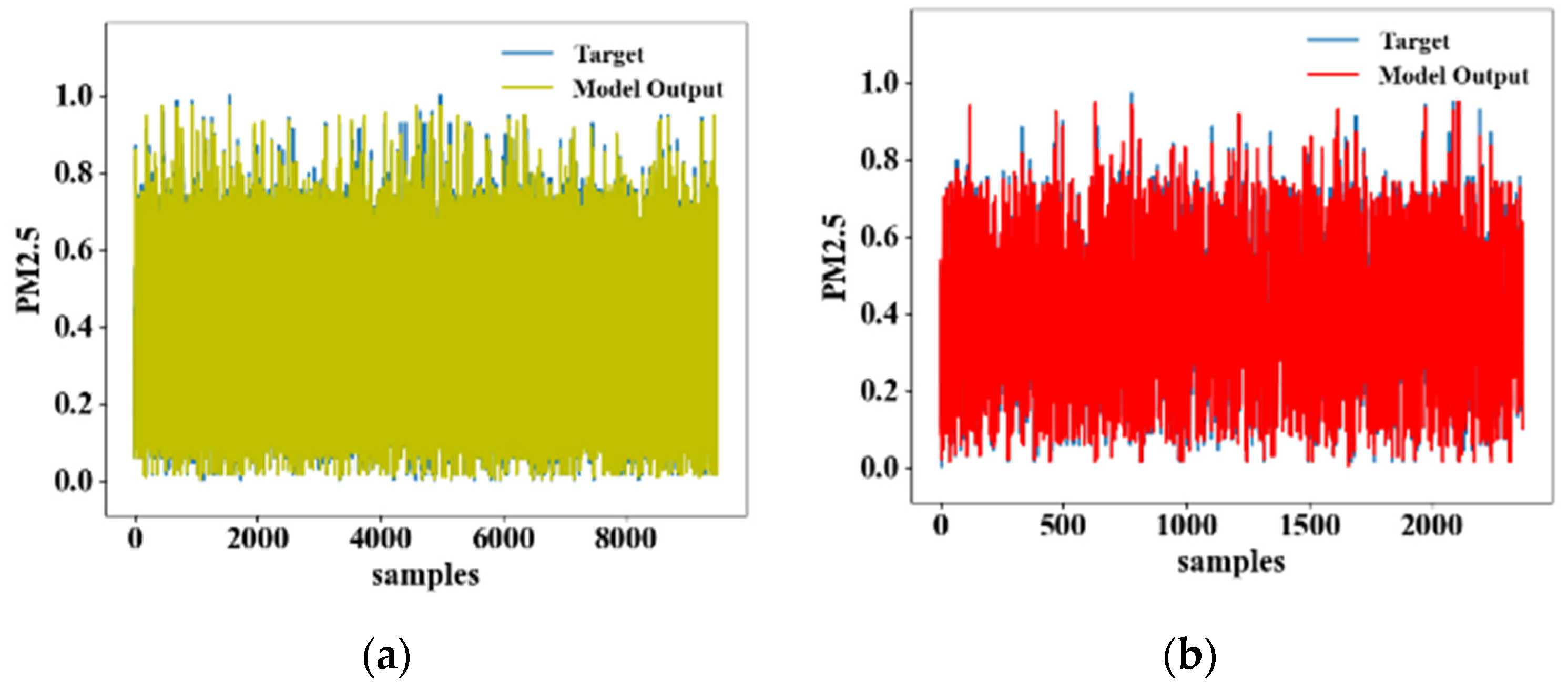
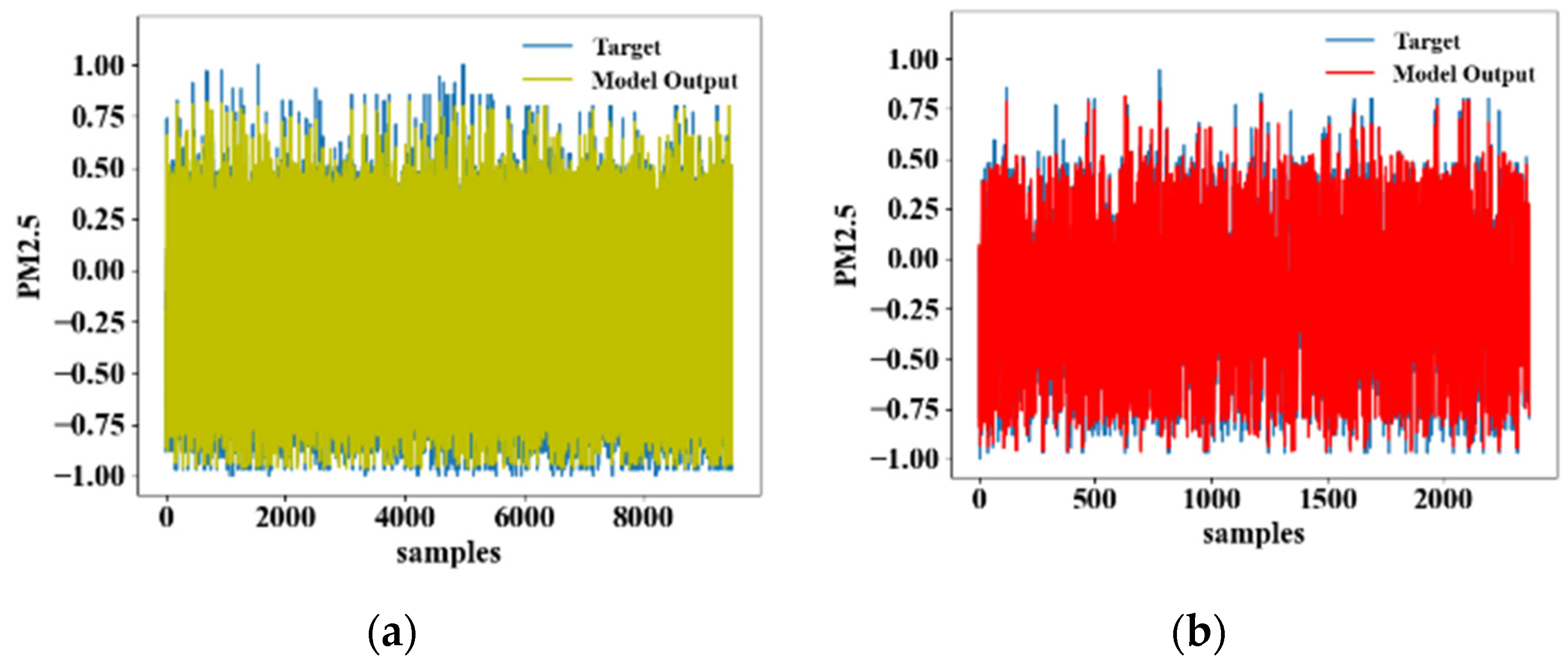
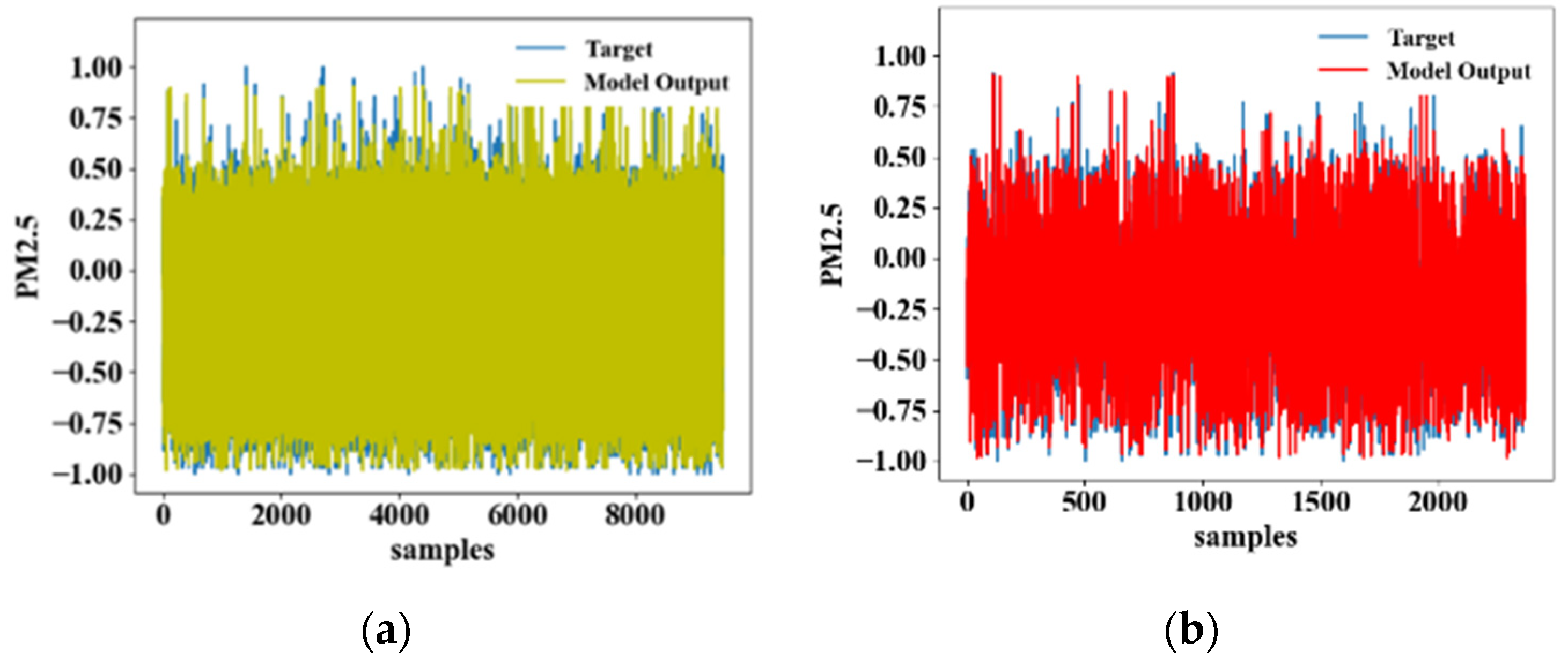
4.1. Comparison of the Model Learning Results
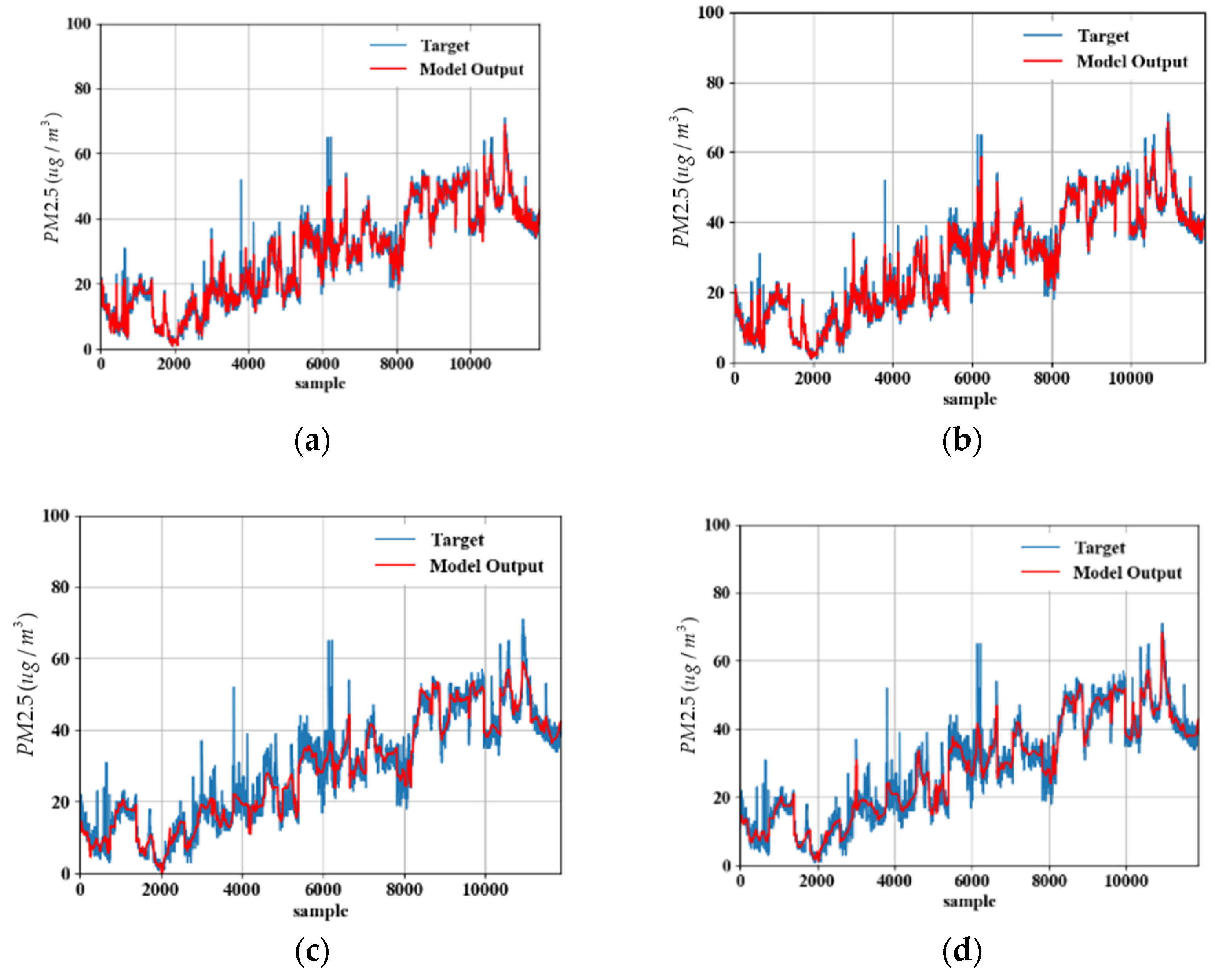
4.2. Comparison of the Model Output Results
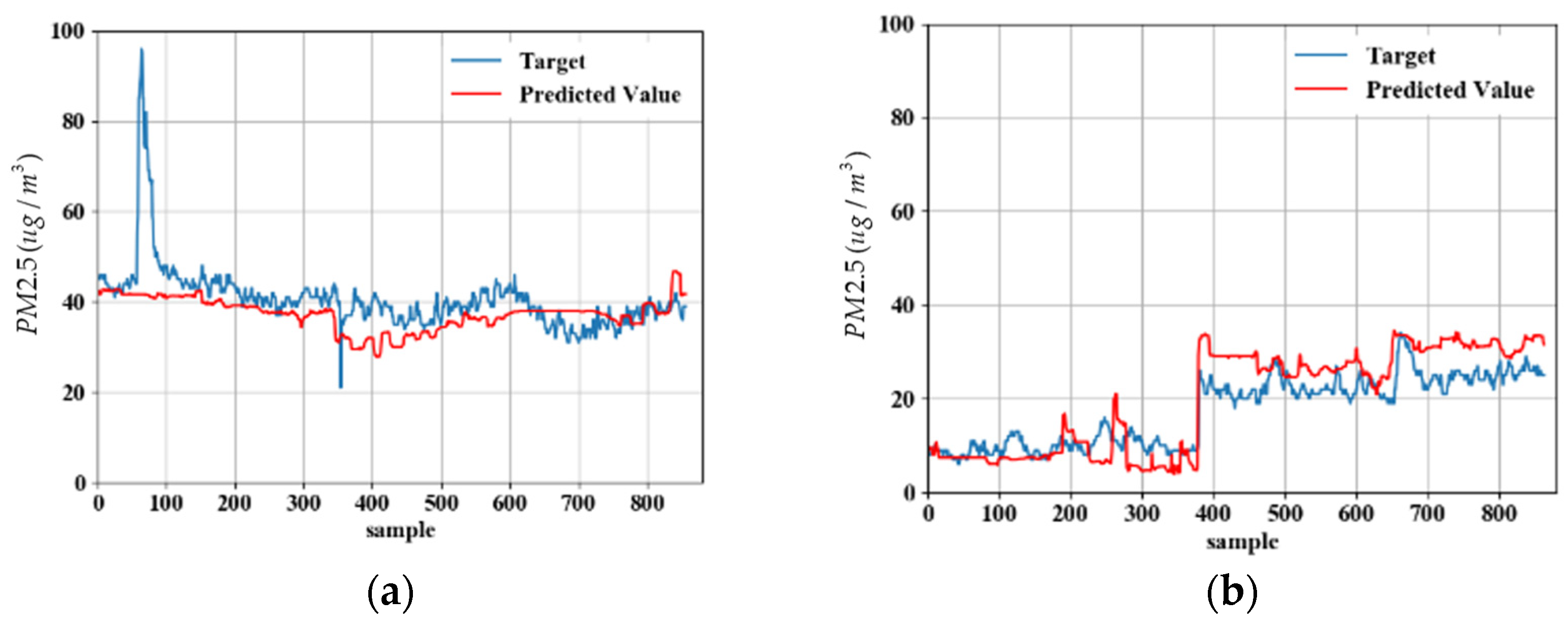
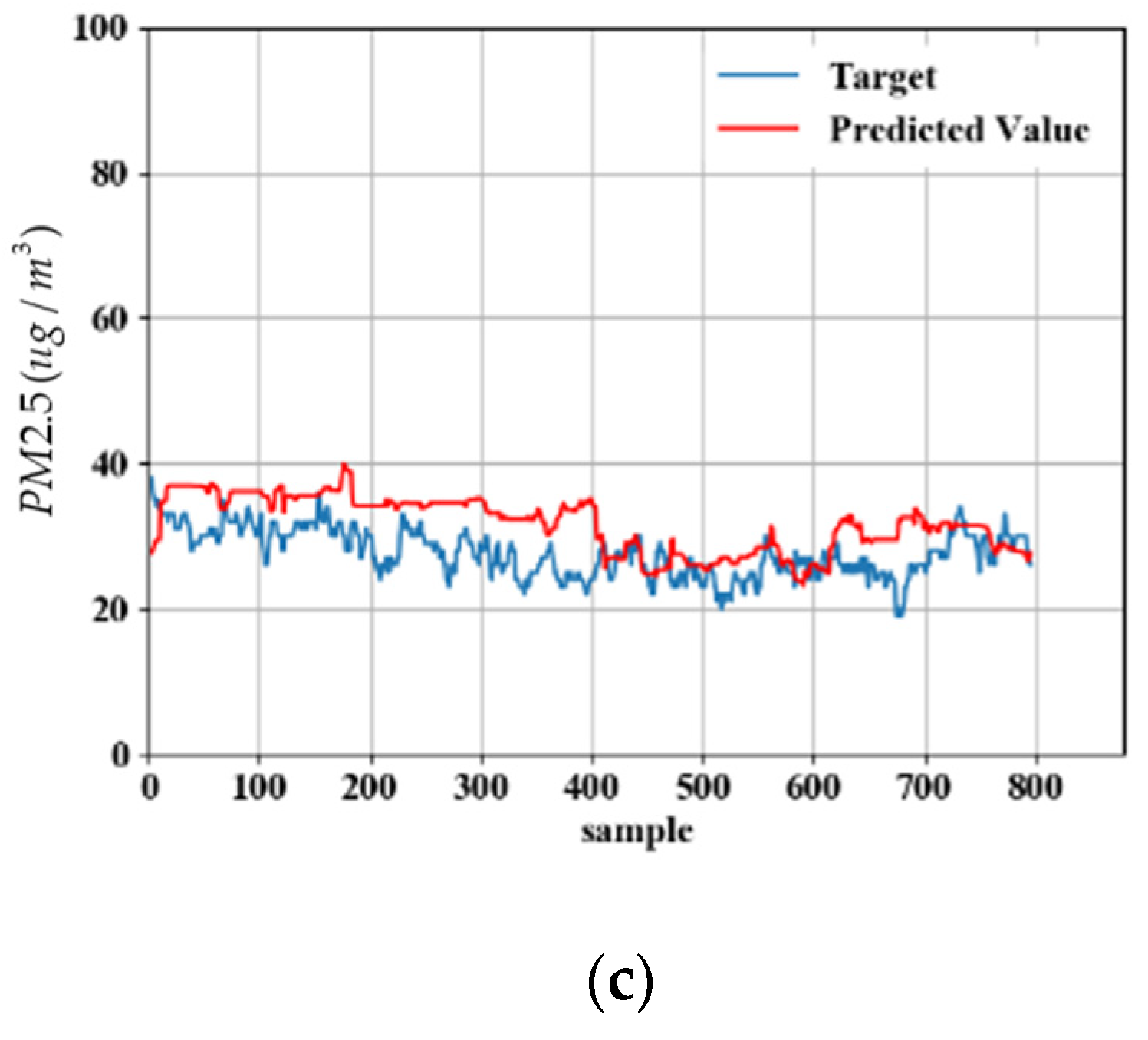
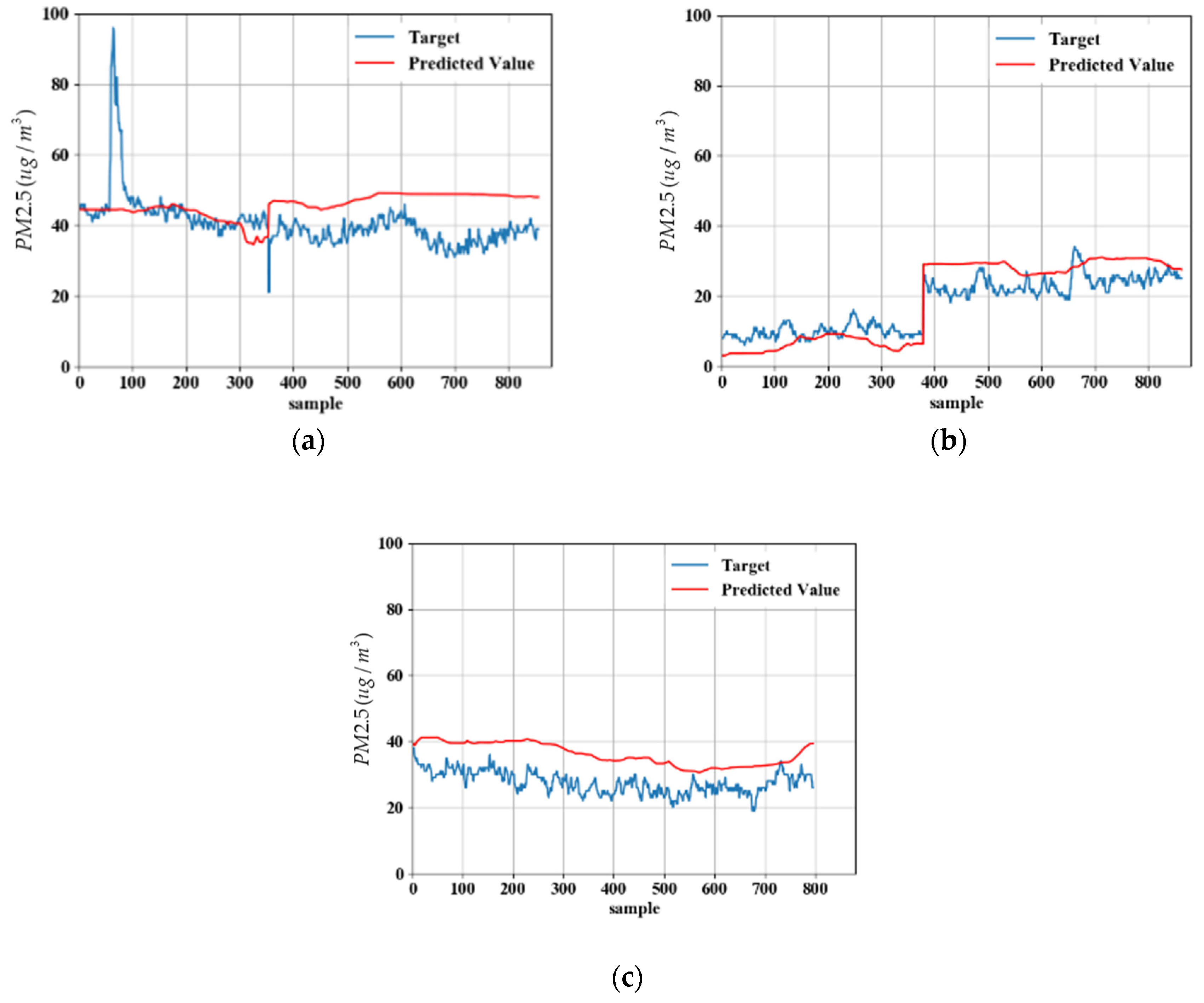
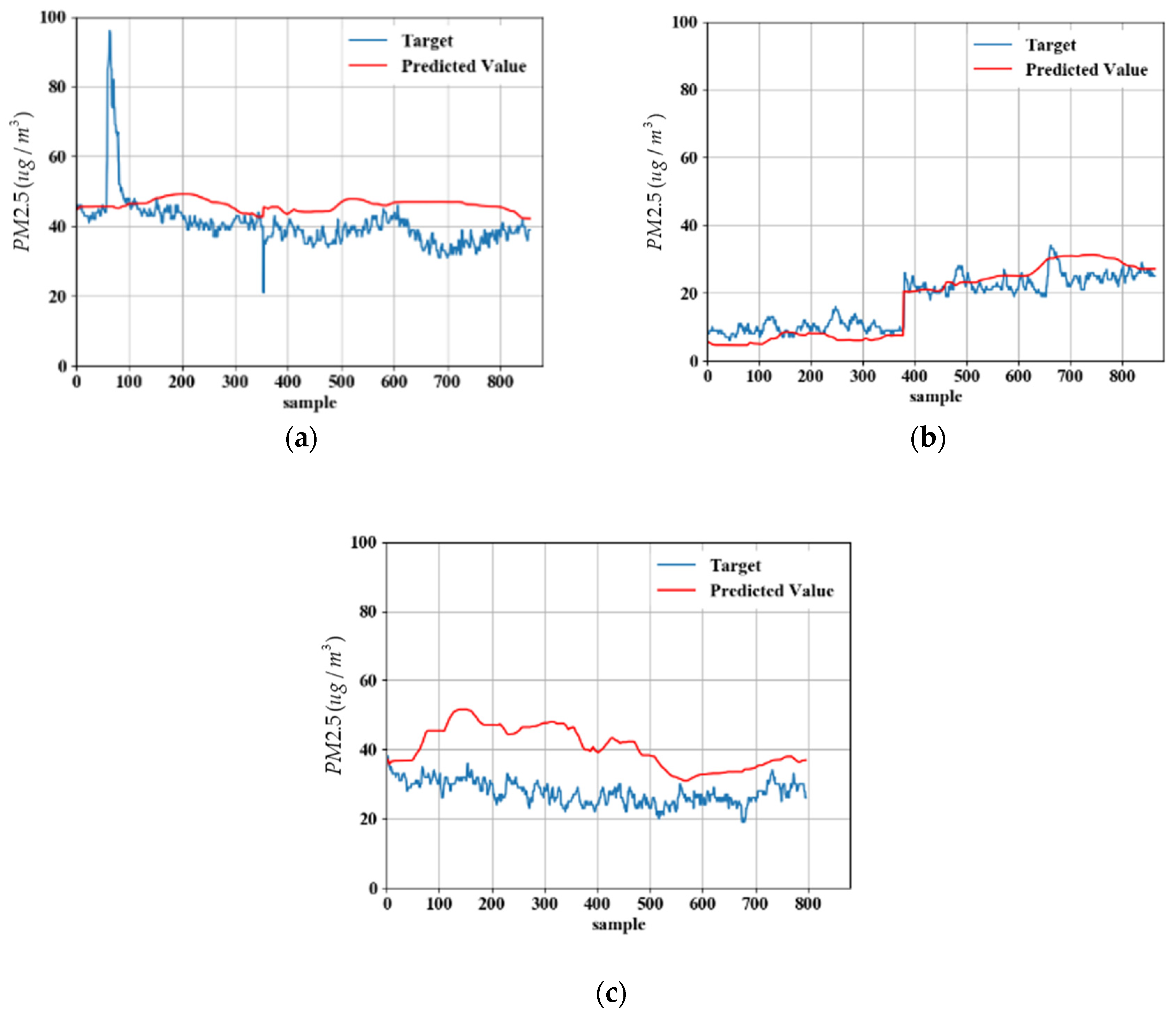
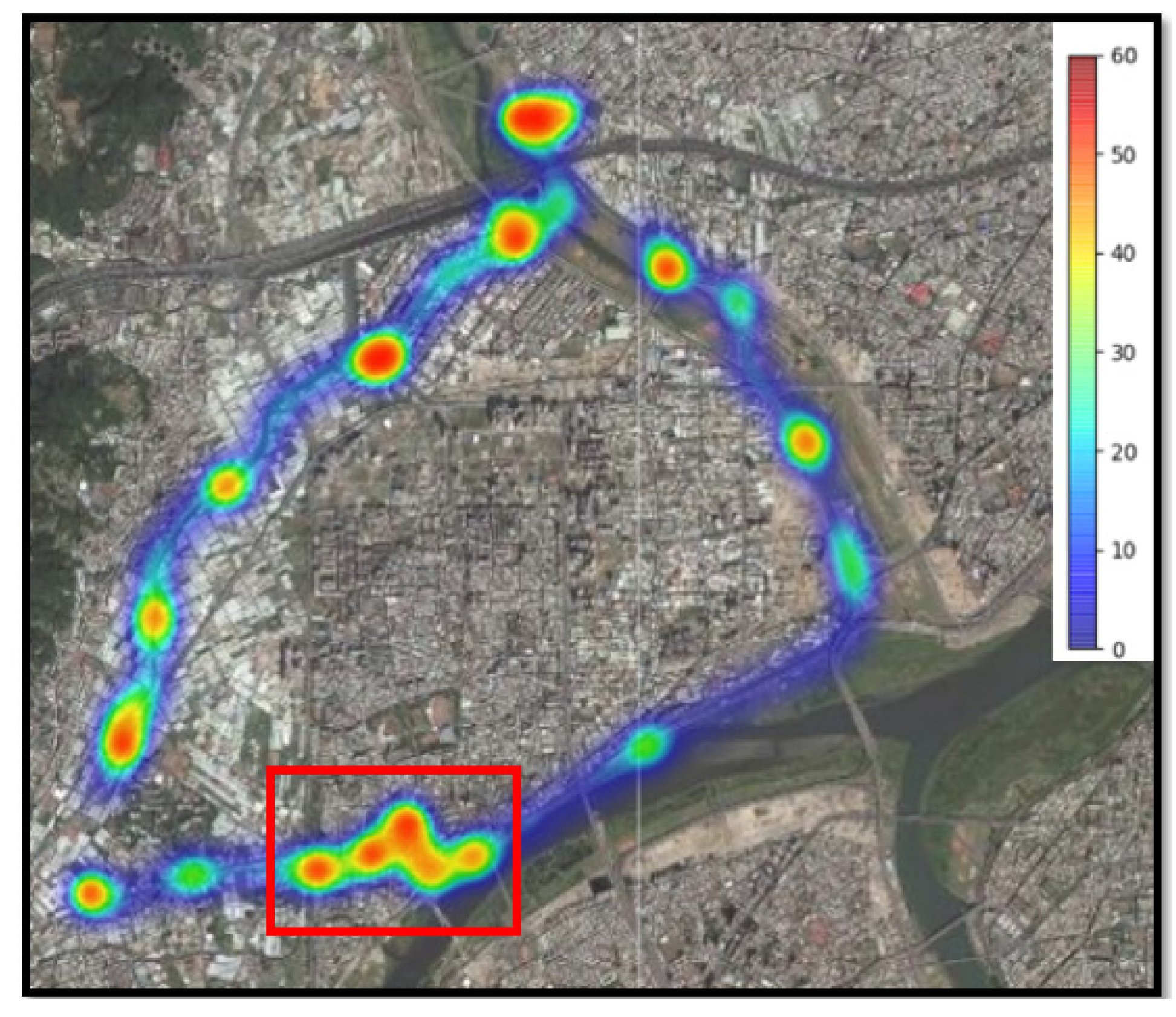
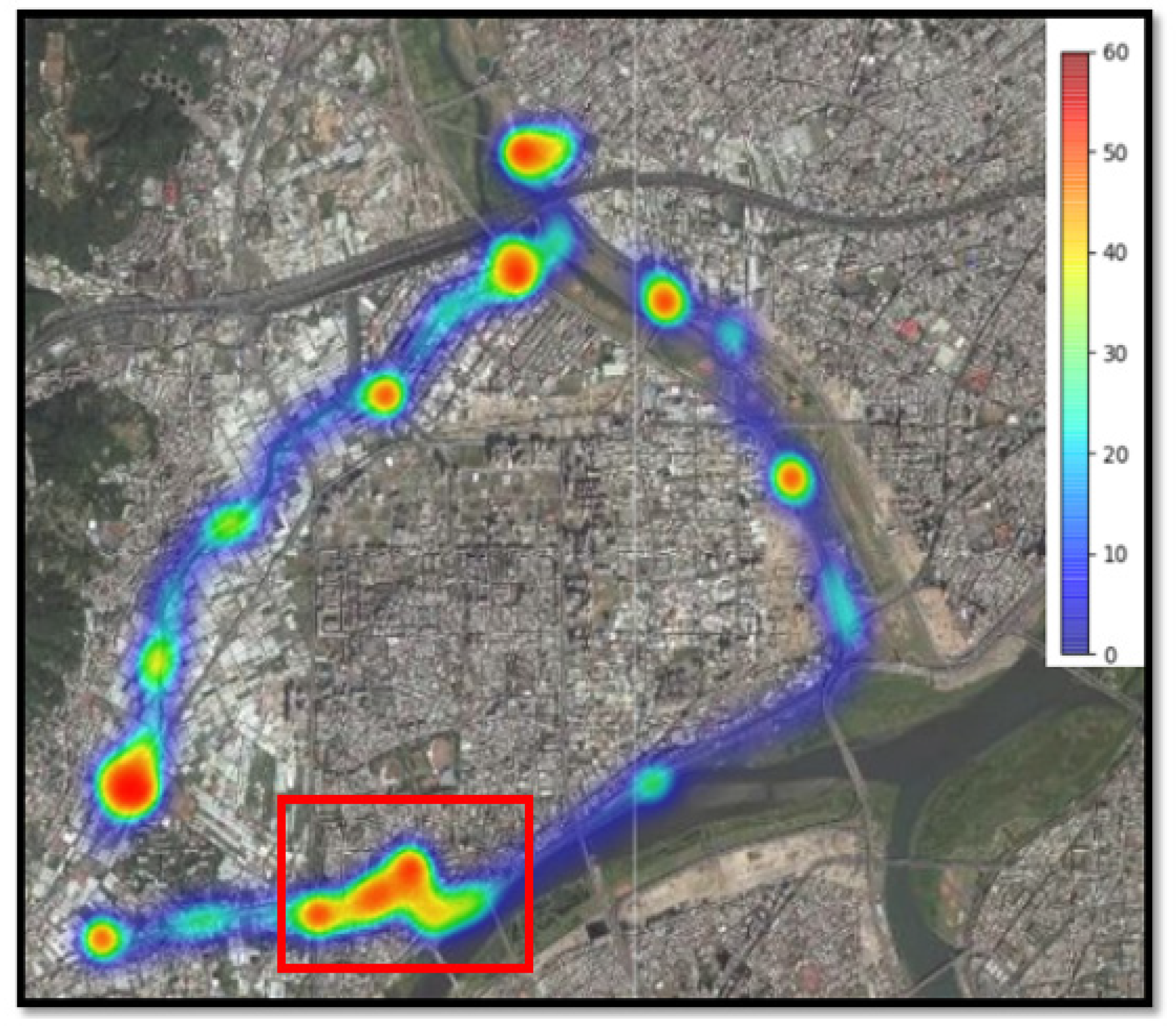
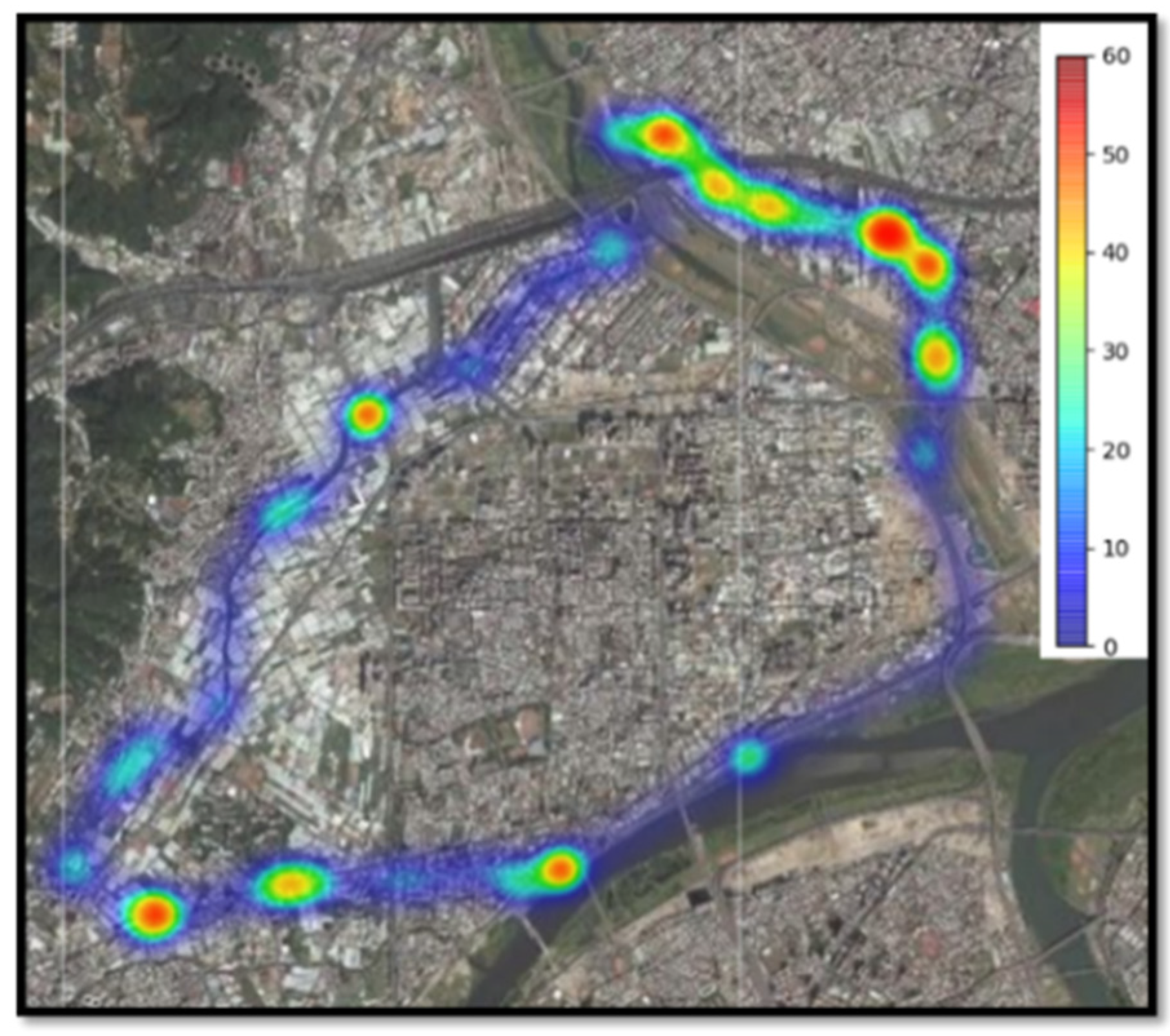
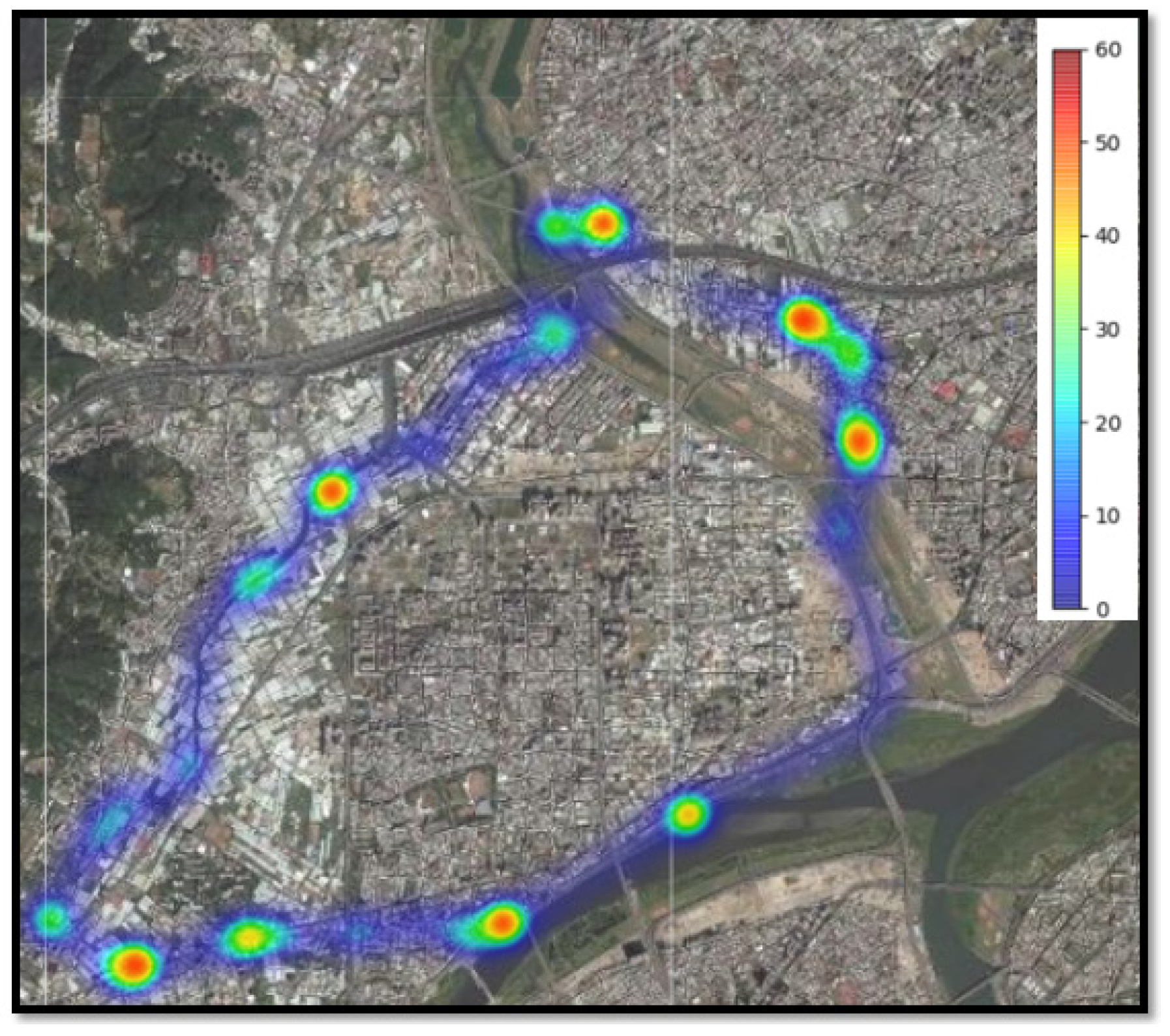
5. Experimental Results
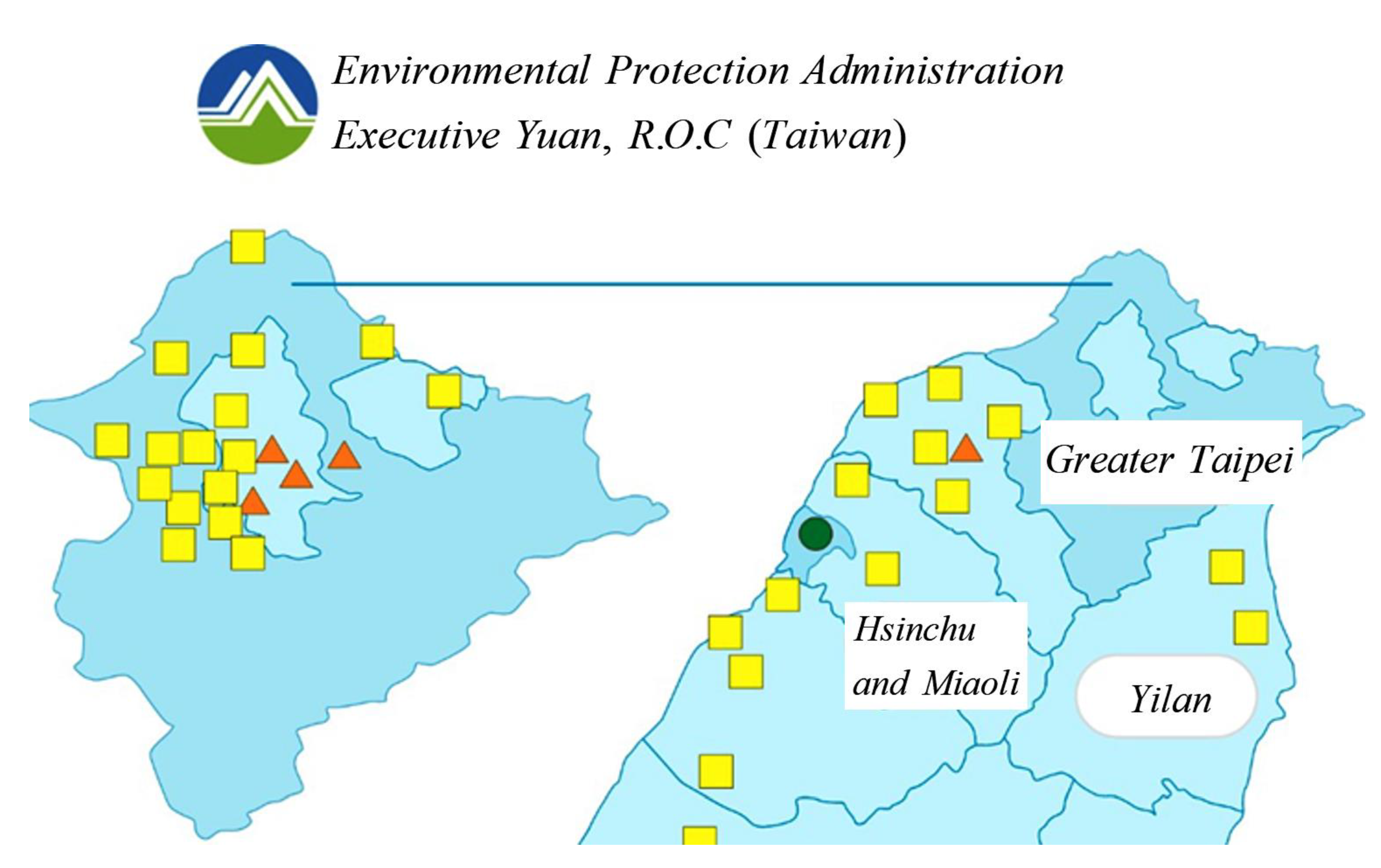
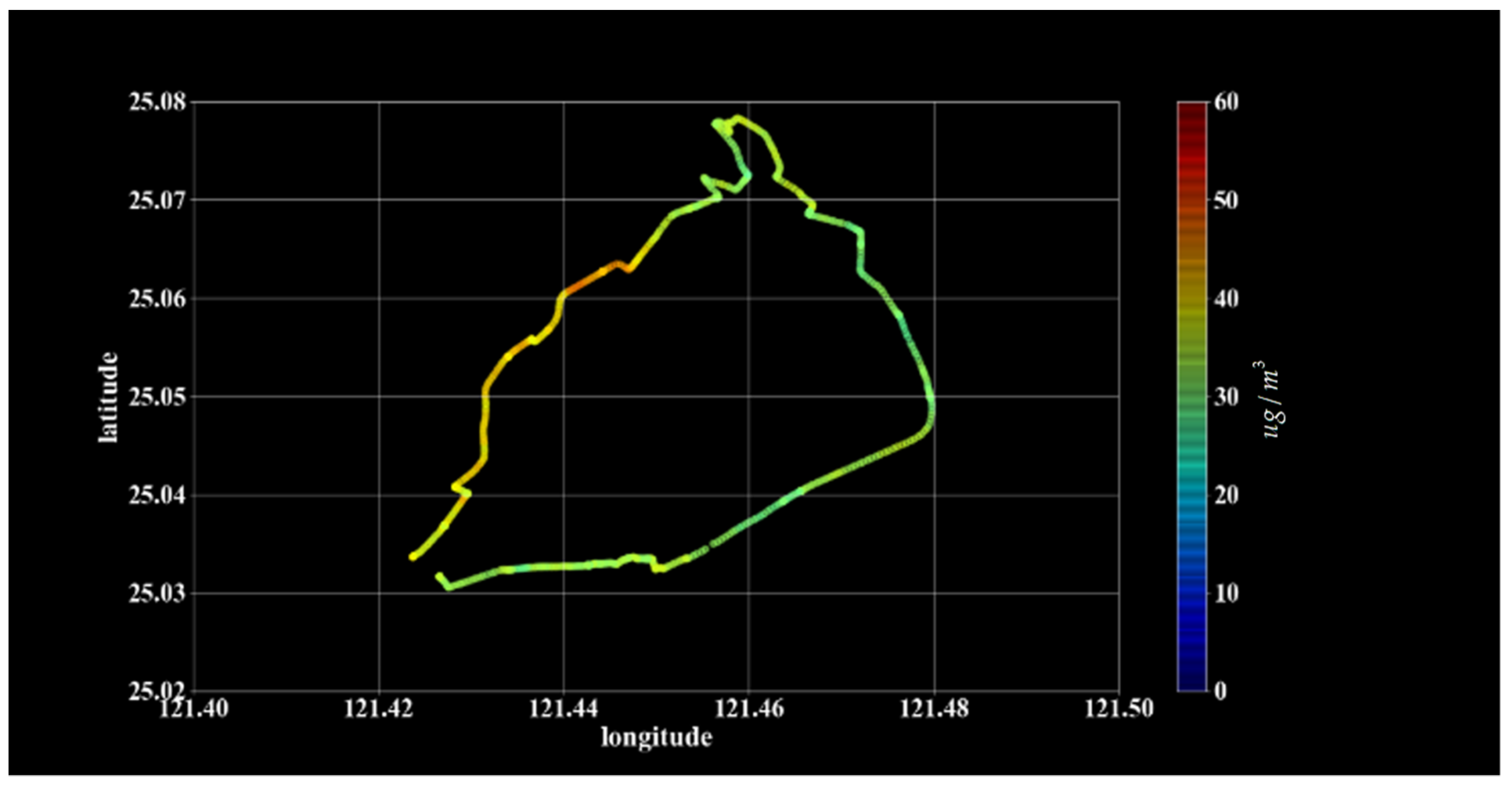
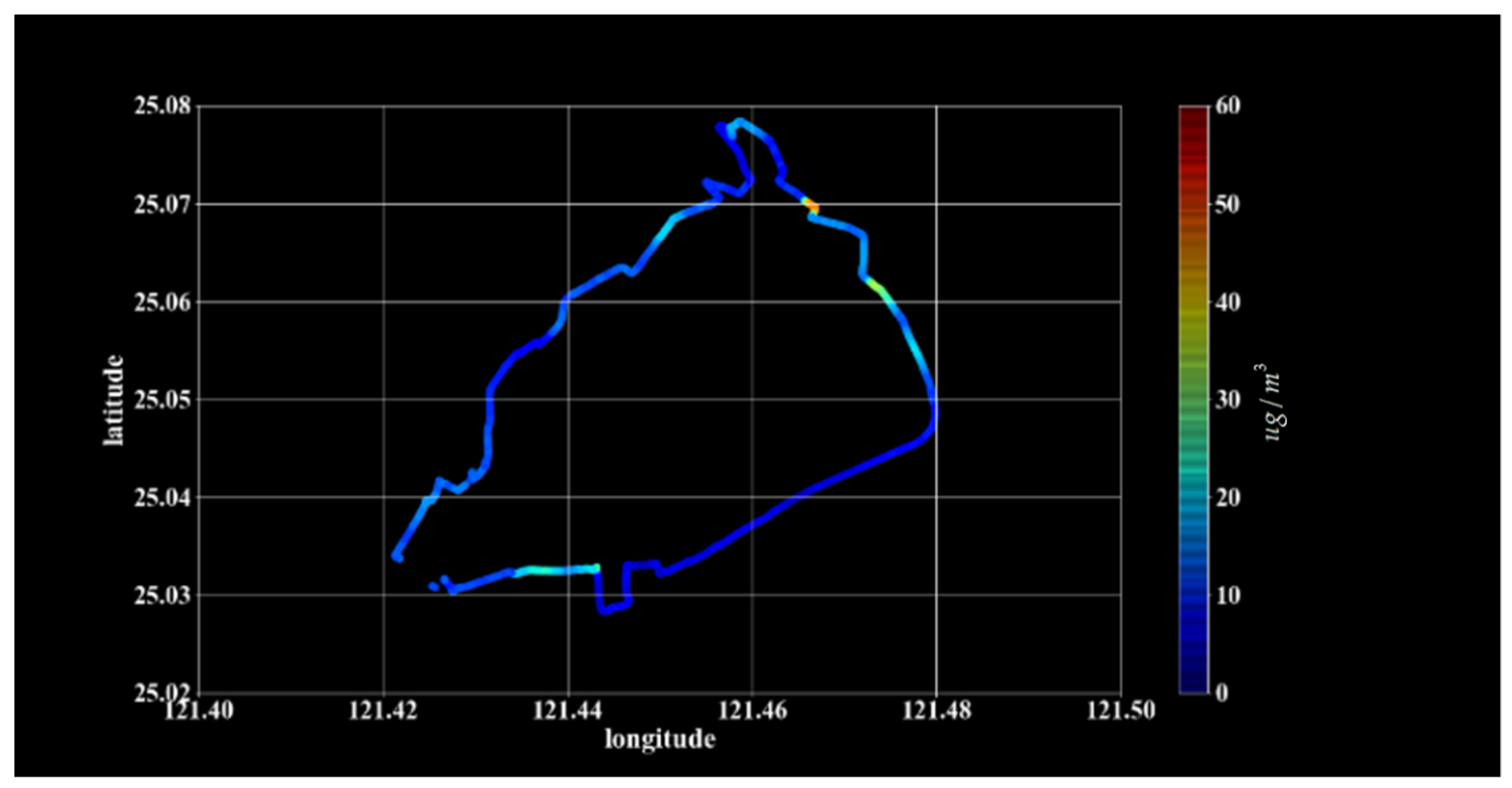
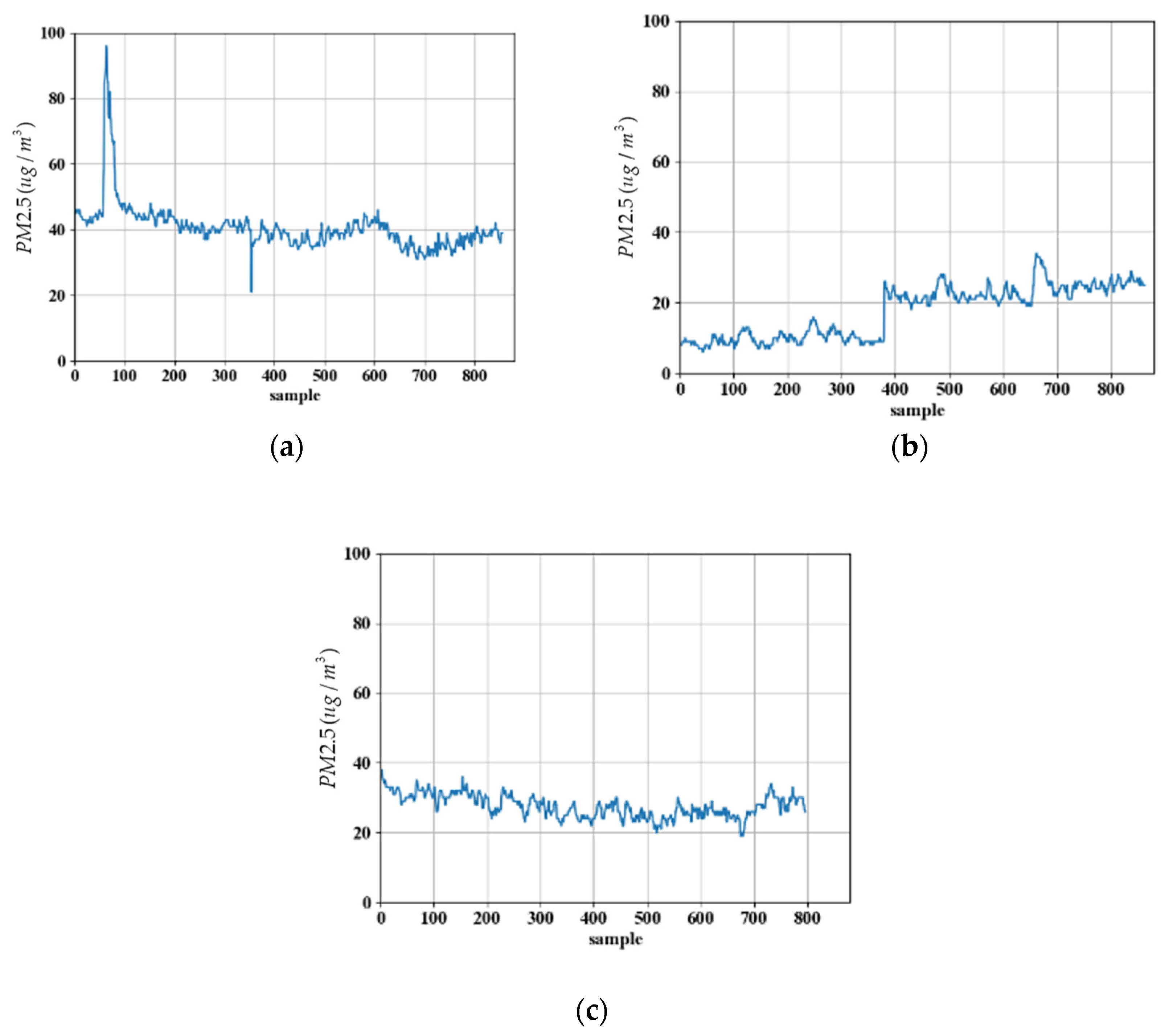
5.1. Measurement Data
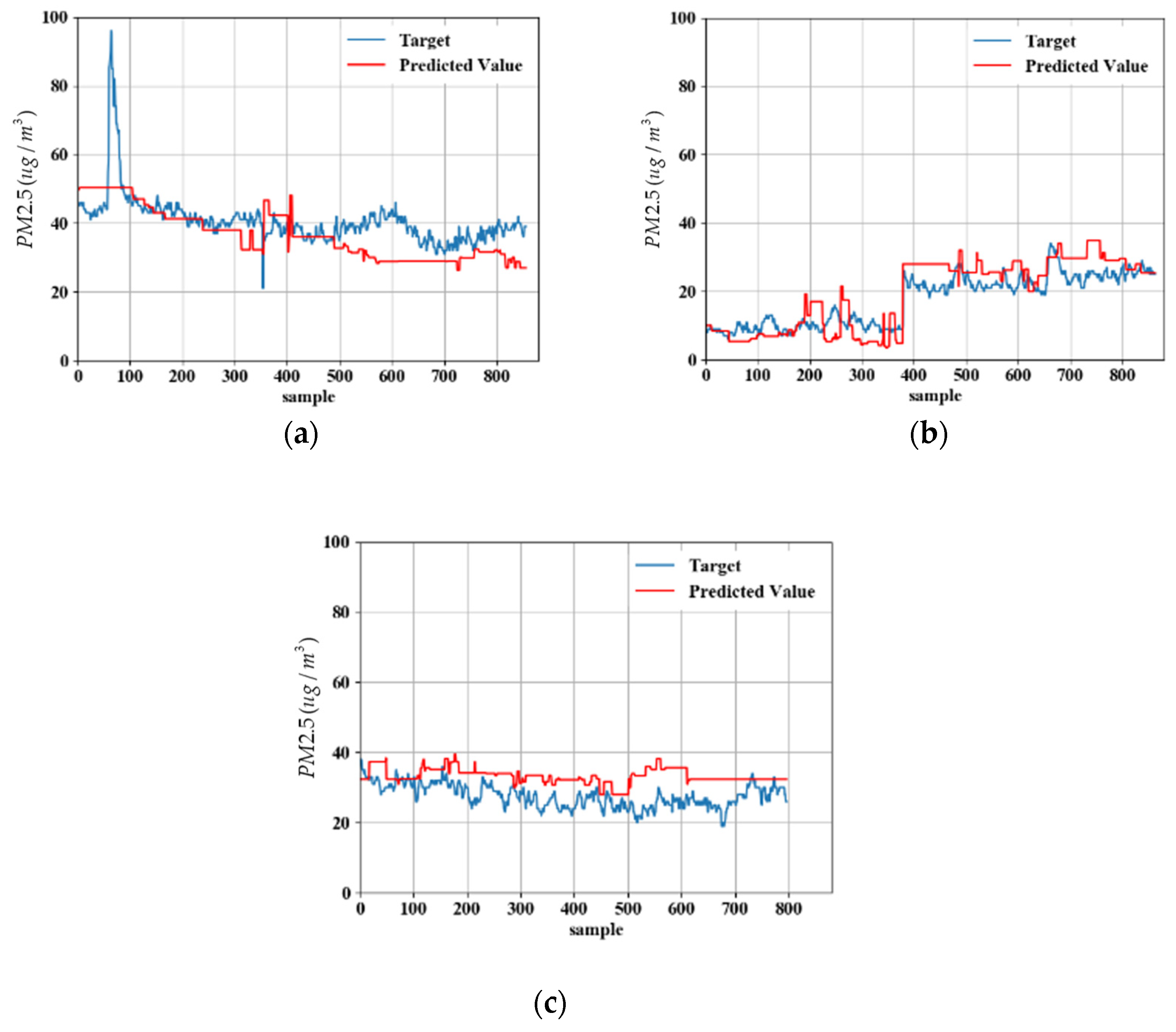
5.2. Model Predicted Data
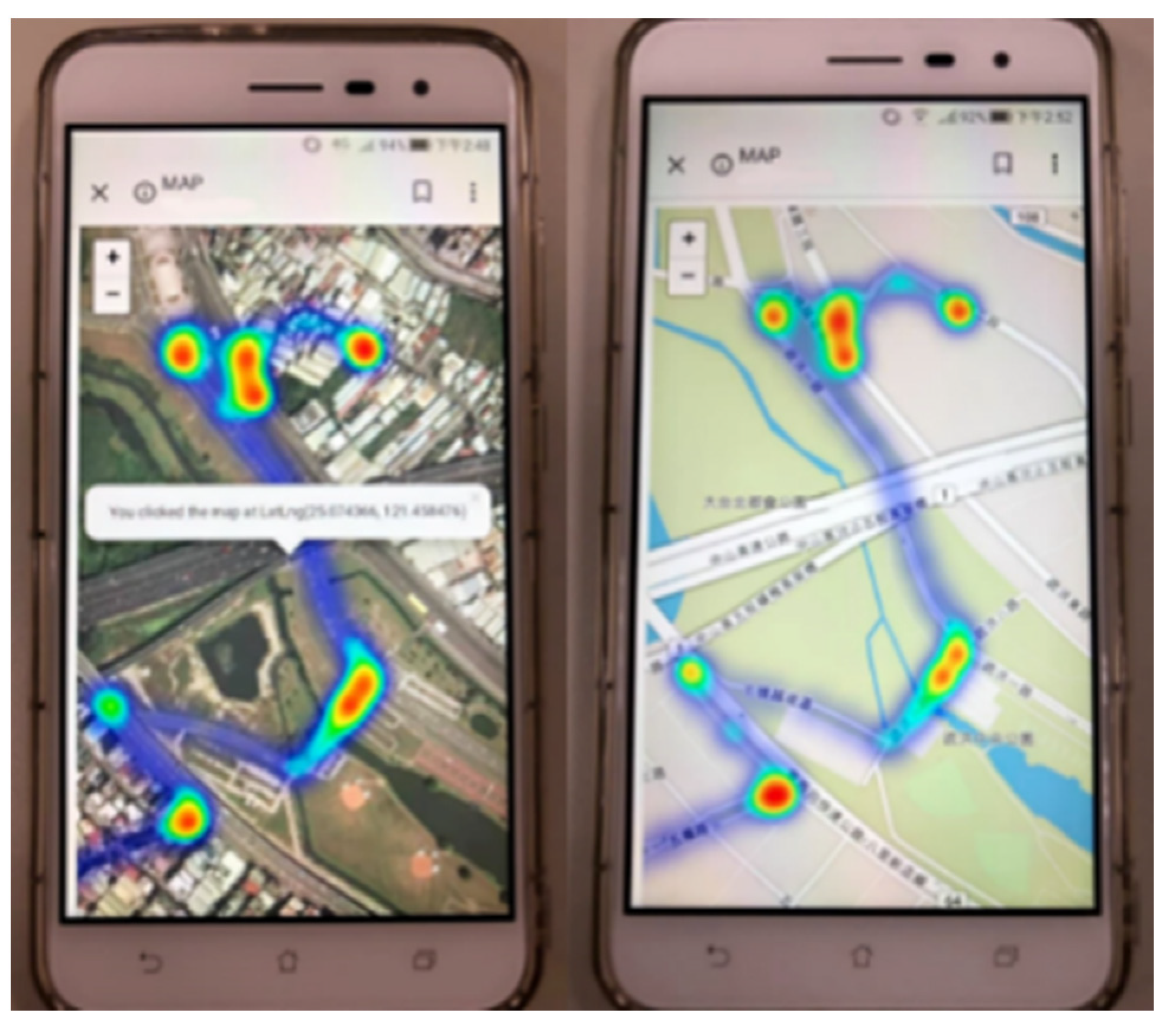
5.3. Web Application
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Fazziki, A.; Benslimane, D.; Sadiq, A.; Ouarzazi, J.; Sadgal, M. An Agent Based Traffic Regulation System for The Roadside Air Quality Control. IEEE Access 2017, 5, 13192–13201. [Google Scholar] [CrossRef]
- Hu, K.; Rahman, A.; Bhrugubanda, H.; Sivaraman, V. Hazeest: Machine Learning Based Metropolitan Air Pollution Estimation from Fixed and Mobile Sensors. IEEE Sens. J. 2017, 17, 3517–3525. [Google Scholar] [CrossRef]
- Kadri, A.; Yaacoub, E.; Mushtaha, M.; Abu-Dayya, A. Wireless Sensor Network for Real time Air Pollution Monitoring. In Proceedings of the IEEE International Conference on Communications, Signal Processing and Their Applications, Sharjah, United Arab Emirates, 12–14 February 2013; pp. 1–5. [Google Scholar]
- Mead, M.; Popoola, O.; Stewart, G.; Landshoff, P.; Calleja, M.; Hayes, M.; Baldovi, J.; McLeod, M.; Hodgson, T.; Dicks, J.; et al. The Use of Electrochemical Sensors for Monitoring Urban Air Quality in Low-cost, High density Networks. Atmos. Environ. 2013, 70, 186–203. [Google Scholar] [CrossRef] [Green Version]
- Predić, B.; Yan, Z.; Eberle, J.; Stojanovic, D.; Aberer, K. Exposuresense: Integrating Daily Activities with Air Quality Using Mobile Participatory Sensing. In Proceedings of the IEEE International Conference on Pervasive Computing Communications Workshops, San Diego, CA, USA, 18–22 March 2013; pp. 303–305. [Google Scholar]
- Shaban, K.; Kadri, A.; Rezk, E. Urban Air Pollution Monitoring System with Forecasting Models. IEEE Sens. J. 2016, 16, 2598–2606. [Google Scholar] [CrossRef]
- Hasenfratz, D.; Saukh, O.; Walser, C.; Hueglin, C.; Fierz, M.; Thiele, L. Pushing The Spatio temporal Resolution Limit of Urban Air Pollution Maps. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications, Budapest, Hungary, 24–28 March 2014; pp. 69–77. [Google Scholar]
- Bacco, M.; Delmastro, F.; Ferro, E.; Gotta, A. Environmental Monitoring for Smart Cities. IEEE Sens. J. 2017, 17, 7767–7774. [Google Scholar] [CrossRef]
- Chen, L.J.; Ho, Y.H.; Hsieh, H.H.; Huang, S.T.; Lee, H.C.; Mahajan, S. ADF: An Anomaly Detection Framework for Large scale PM2.5 Sensing Systems. IEEE Internet Things J. 2018, 52, 559–570. [Google Scholar] [CrossRef]
- Singh, V.; Carnevale, C.; Finzi, G.; Pisoni, E.; Volta, M. A Cokriging Based Approach to Reconstruct Air Pollution Maps Processing Measurement Station Concentrations and Deterministic Model Simulations. Environ. Model. Softw. 2011, 26, 778–786. [Google Scholar] [CrossRef]
- Sivaraman, V.; Carrapetta, J.; Hu, K.; Luxan, B.G. HazeWatch: A Participatory Sensor System for Monitoring Air Pollution in Sydney. In Proceedings of the IEEE Conference on Local Computer Networks Workshops, Sydney, Australia, 21–24 October 2013; pp. 56–64. [Google Scholar]
- Qu, H.; Chan, W.I.; Xu, A.; Chug, K.L.; Lau, K.H.; Guo, P. Visual Analysis of the Air Pollution Problem in Hong Kong. IEEE Trans. Vis. Comput. Graph. 2007, 13, 1408–1415. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gu, K.; Qiao, J.; Lin, W. Recurrent Air Quality Predictor Based on Meteorology and Pollution Related Factors. IEEE Trans. Ind. Inform. 2018, 14, 3946–3955. [Google Scholar] [CrossRef]
- Boubrima, A.; Bechkit, W.; Rivano, H. Optimal WSN Deployment Models for Air Pollution Monitoring. IEEE Trans. Wirel. Commun. 2017, 16, 2723–2735. [Google Scholar] [CrossRef] [Green Version]
- Al-Ali, R.A.; Zualkernan, I.; Aloul, F. A Mobile GPRS Sensors Array for Air Pollution Monitoring. IEEE Sens. J. 2010, 10, 1666–1671. [Google Scholar] [CrossRef]
- Xiaojun, C.; Xianpeng, L.; Peng, X. IoT Based Air Pollution Monitoring and Forecasting System. In Proceedings of the International Conference on Computer and Computational Sciences, Las Vegas, NV, USA, 7–9 December 2015; pp. 257–260. [Google Scholar]
- Dam, N.; Ricketts, A.; Catlett, B.; Henriques, J. Wearable Sensors for Analyzing Personal Exposure to Air Pollution. In Proceedings of the System and Information Engineering Design Symposium, Charlottesville, VA, USA, 28 April 2017; pp. 1–4. [Google Scholar]
- Qin, D.; Yu, J.; Zou, G.; Yong, R.; Zhao, Q. A Novel Combined Prediction Scheme Based on CNN and LSTM for Urban PM2.5 Concentration. IEEE Access 2019, 7, 20050–20059. [Google Scholar] [CrossRef]
- Duangsuwan, S.; Takarn, A.; Nujankaew, R.; Jamjareegulgarn, P. A Study of Air Pollution Smart Sensors LPWAN via NB-IoT for Thailand Smart Cities 4.0. In Proceedings of the IEEE International Conference on Knowledge and Smart Technology, Chiangmai, Thailand, 31 January–3 February 2018. [Google Scholar]
- Florence, G.; Jason, S.; Martin, W. A machine learning approach to investigating the effects of mathematics dispositions on mathematical literacy. Int. J. Res. Method Educ. 2017, 41, 306–327. [Google Scholar]
- AFath, H.; Madanifar, F.; Abbasi, M. Implementation of multilayer perceptron (MLP) and radial basis function (RBF) neural networks to predict solution gasoil ratio of crude oil systems. Petroleum 2020, 6, 80–91. [Google Scholar]



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Decision tree | max_depth | 15 |
| min_samples_split | 11 | |
| splitter | Random | |
| Random Forest | max_depth | 15 |
| min_samples_split | 11 | |
| n_estimators | 20 | |
| Multilayer Perceptron | Hidden Layers | 3 |
| Nodes | 29 | |
| Activation Function | ReLU | |
| Optimizer | AdamOptimizer | |
| RBF Neural Network | Nodes Optimizer | 120 AdamOptimizer |
| Model | Data Pre Processing | Training | Testing |
|---|---|---|---|
| Decision tree | MinMaxScaler (0~1) | 0.0242 | 0.0296 |
| Random forest | MinMaxScaler (0~1) | 0.0168 | 0.0236 |
| Multilayer perceptron | MinMaxScaler (−1~1) | 0.0892 | 0.0899 |
| RBF neural network | MinMaxScaler (−1~1) | 0.0830 | 0.0872 |
| Model | MAE (μg/m3) |
|---|---|
| Decision tree | 1.0680 |
| Random forest | 0.8099 |
| Multilayer perceptron | 2.2612 |
| RBF neural network | 2.1642 |
| Estimation Models MAE (μg/m3) | |||
|---|---|---|---|
| Date | 15 February 2019 | 28 February 2019 | 1 March 2019 |
| Decision tree | 5.8774 | 4.3326 | 5.8248 |
| Random forest | 4.6718 | 4.5614 | 4.5789 |
| Multilayer perceptron | 7.5940 | 4.3535 | 8.3501 |
| RBF neural network | 7.0793 | 3.9603 | 15.1626 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.-Y.; Lin, W.-B.; Shu, Y.-C. Design of Machine Learning Prediction System Based on the Internet of Things Framework for Monitoring Fine PM Concentrations. Environments 2021, 8, 99. https://0-doi-org.brum.beds.ac.uk/10.3390/environments8100099
Wang S-Y, Lin W-B, Shu Y-C. Design of Machine Learning Prediction System Based on the Internet of Things Framework for Monitoring Fine PM Concentrations. Environments. 2021; 8(10):99. https://0-doi-org.brum.beds.ac.uk/10.3390/environments8100099
Chicago/Turabian StyleWang, Shun-Yuan, Wen-Bin Lin, and Yu-Chieh Shu. 2021. "Design of Machine Learning Prediction System Based on the Internet of Things Framework for Monitoring Fine PM Concentrations" Environments 8, no. 10: 99. https://0-doi-org.brum.beds.ac.uk/10.3390/environments8100099