
Adapting Data-Driven Research to the Fields of Social Sciences and the Humanities

 , , , and
, , , and
Abstract
:
1. Introduction
2. Related Work
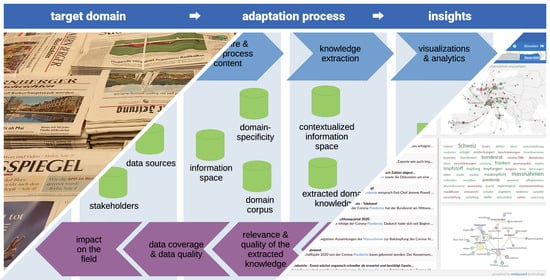
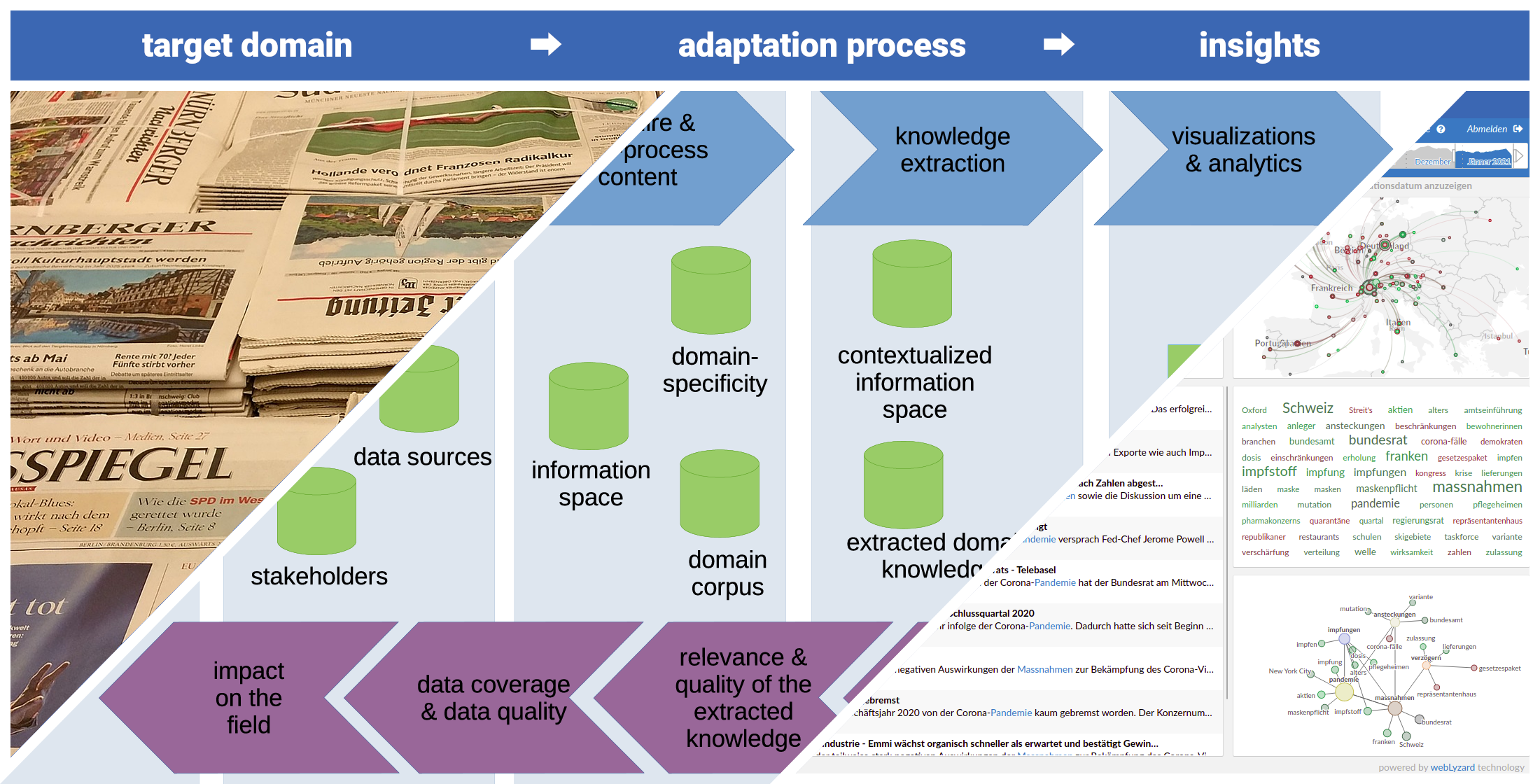
3. Method
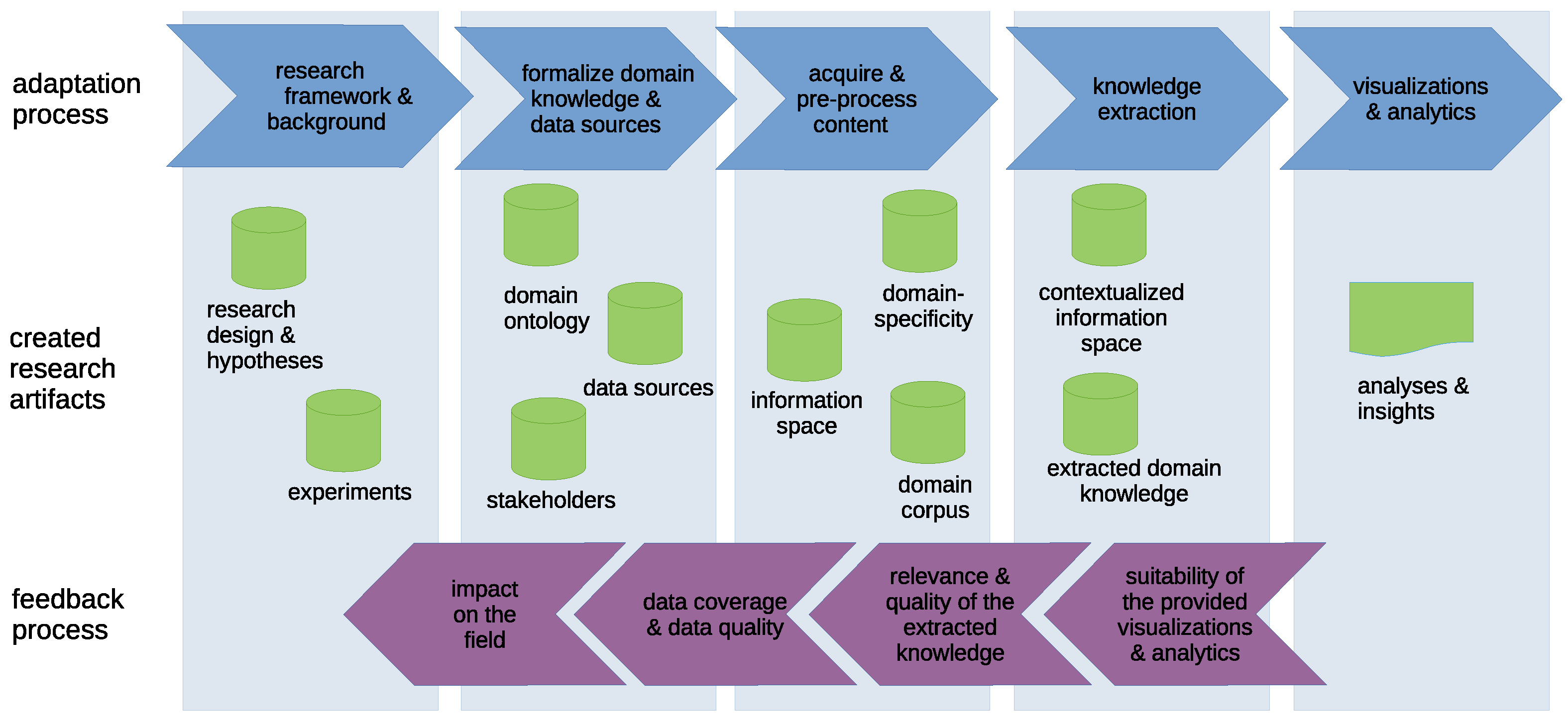
3.1. Adaptation to the Research Framework and Background of the Target Domain
- The required domain knowledge on stakeholders and sources (Section 5), which, in turn, influenced:
- The sources and source groupings considered by data acquisition components (Section 6) and
- The types and kinds of entities supported in the named entity-linking process (Section 7.1);
- Whether a domain-specific affective model or standard sentiment should be used in the knowledge extraction pipeline (Section 7.2);
- The approach used for data analytics, i.e., investing considerable effort into building the Swiss Media Criticism portal and analytics dashboard, which supports real-time tracking of emerging issues in addition to historical analyses (Section 8).
3.2. Formalization of Domain Knowledge and Selection of Relevant Data Sources
- Domain knowledge, such as ontological knowledge on entities (e.g., relevant stakeholders, locations, events, etc.) and their relations to each other, which is well suited for supporting data acquisition and knowledge extraction processes. Approaches for computing the domain specificity (Section 6), named entity linking (Section 7.1), and sentiment analysis (Section 7.2) also benefit heavily from domain knowledge.
- Data sources, such as (i) links to relevant web resources (e.g., news media sites), (ii) search terms, and (iii) social media accounts of major stakeholders.
3.3. Acquiring and Preprocessing Textual Data
3.4. Knowledge Extraction
3.5. Visualizations and Analytics
4. Use Case—Analyzing Media Criticism
4.1. Research Background
4.2. Research Framework
4.3. Conclusions
5. Collecting Domain Knowledge and Data Sources
5.1. Domain Knowledge on Stakeholders
5.2. Formalizing Domain Knowledge
5.3. Selecting Relevant Data Sources
- A total of 185 mass media sources were identified by the experts, comprising web pages of radio stations, TV stations, and printed media with an edition of at least 15,000 copies, as well as online only media. In addition to editions, crucial factors concerning printed media were timeliness, universality, and periodicity. This category also contained well-established TV and radio programs (i.e., programs that have been broadcasted for at least five years).
- The professional public category gathered articles from 100 Swiss German media-critical agents participating in the public discourse related to media criticism and the corresponding press releases. It included a heterogeneous range of organizations that are either part of the media system (intra-media agents) or belong to another societal system (extra-media agents) [27]. The resulting list contains 170 agents with approximately 100 harvestable URLs.
- Based on the domain experts’ assessment, our research considered two different types of social media accounts: The first one collected tweets from mass media sources, and the second one collected tweets from media- and journalism-related persons. For inclusion in the Twitter sample, profiles needed to fulfill the following three criteria: (i) at least 100 followers, (ii) a relation to Swiss media criticism, and (iii) the majority of the tweets must be written in German. The system monitored 180 Twitter accounts of mass media and 740 accounts of Swiss journalists and media-related persons.
6. Data Acquisition and Preprocessing
6.1. Keyword-Based Approach
6.2. Knowledge-Aware Text Classification
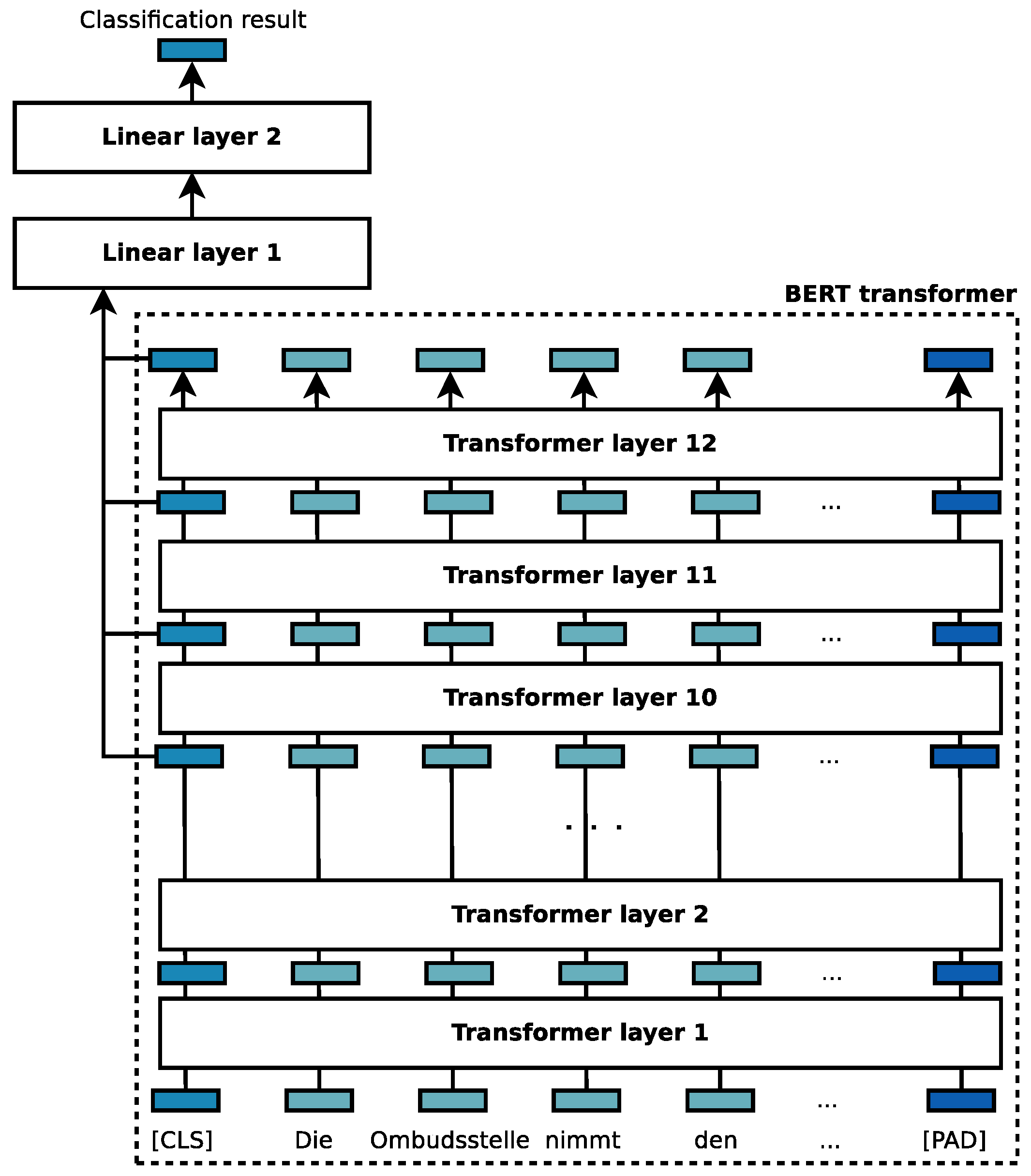
6.3. Deep Learning for Text Classification
- German BERT base (https://huggingface.co/bert-base-german-cased, accessed on 21 February 2021): A case-sensitive BERT transformer that has been trained on over 10 GB of textual data comprising the German Wikipedia dump (6 GB), the OpenLegalData dump (2.4 GB), and 3.6 GB of news articles.
- Multilingual BERT (https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment, accessed on 21 February 2021): A case-insensitive, multilingual BERT model that has been fine-tuned for sentiment analysis on product reviews in English, Dutch, German, French, Spanish, and Italian.
7. Knowledge Extraction
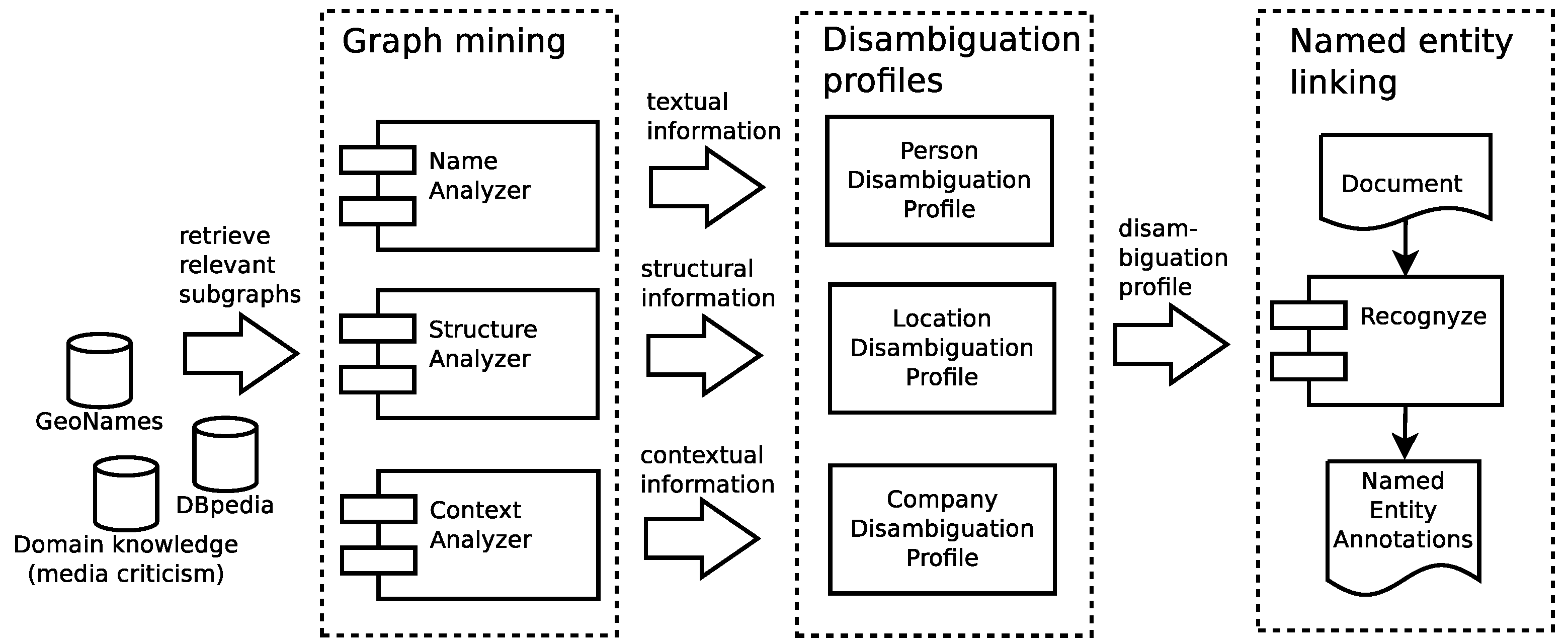
7.1. Named Entity Linking
7.2. Sentiment Analysis
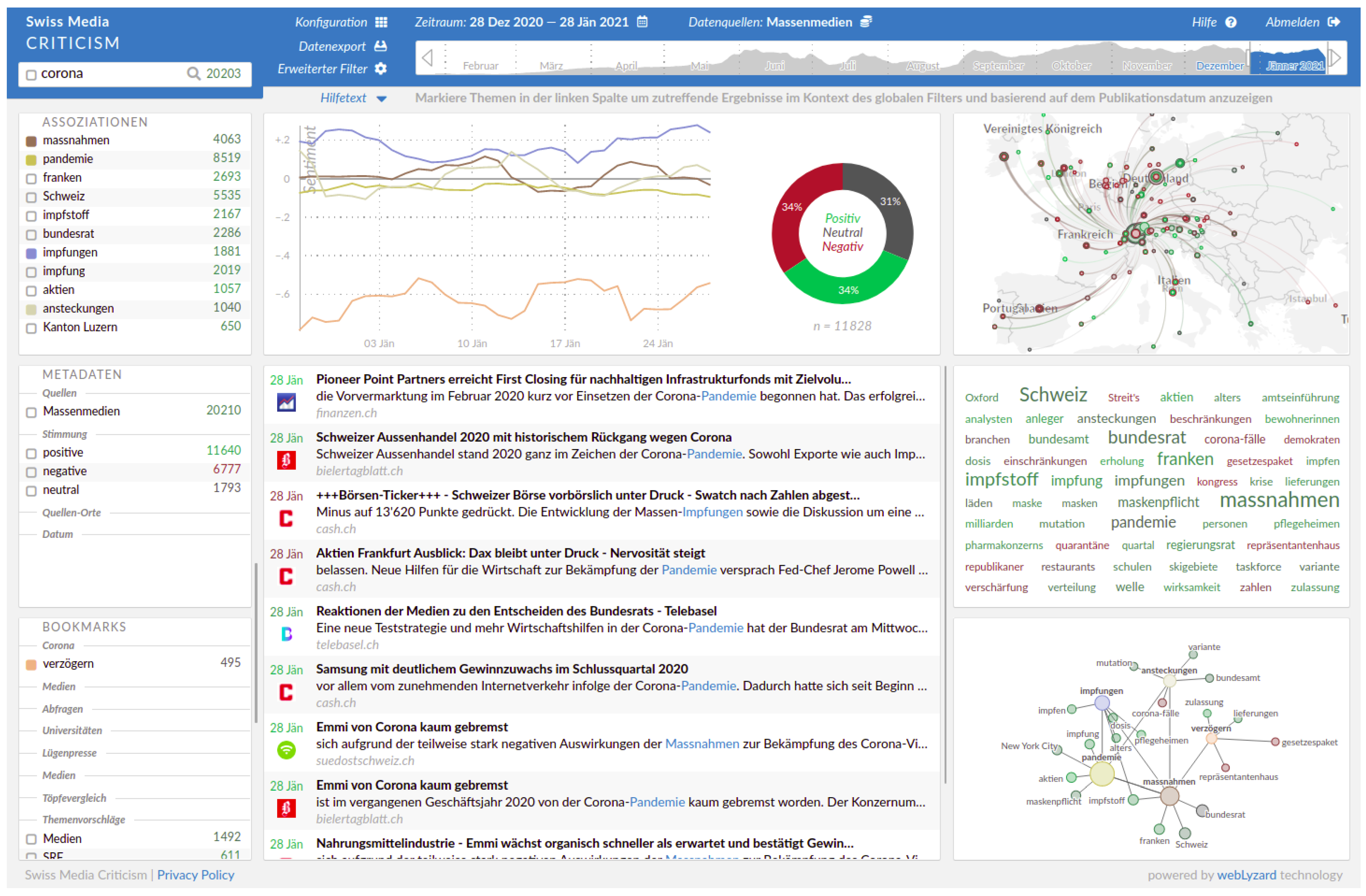
8. Visualizations and Analytics—The Swiss Media Criticism Portal
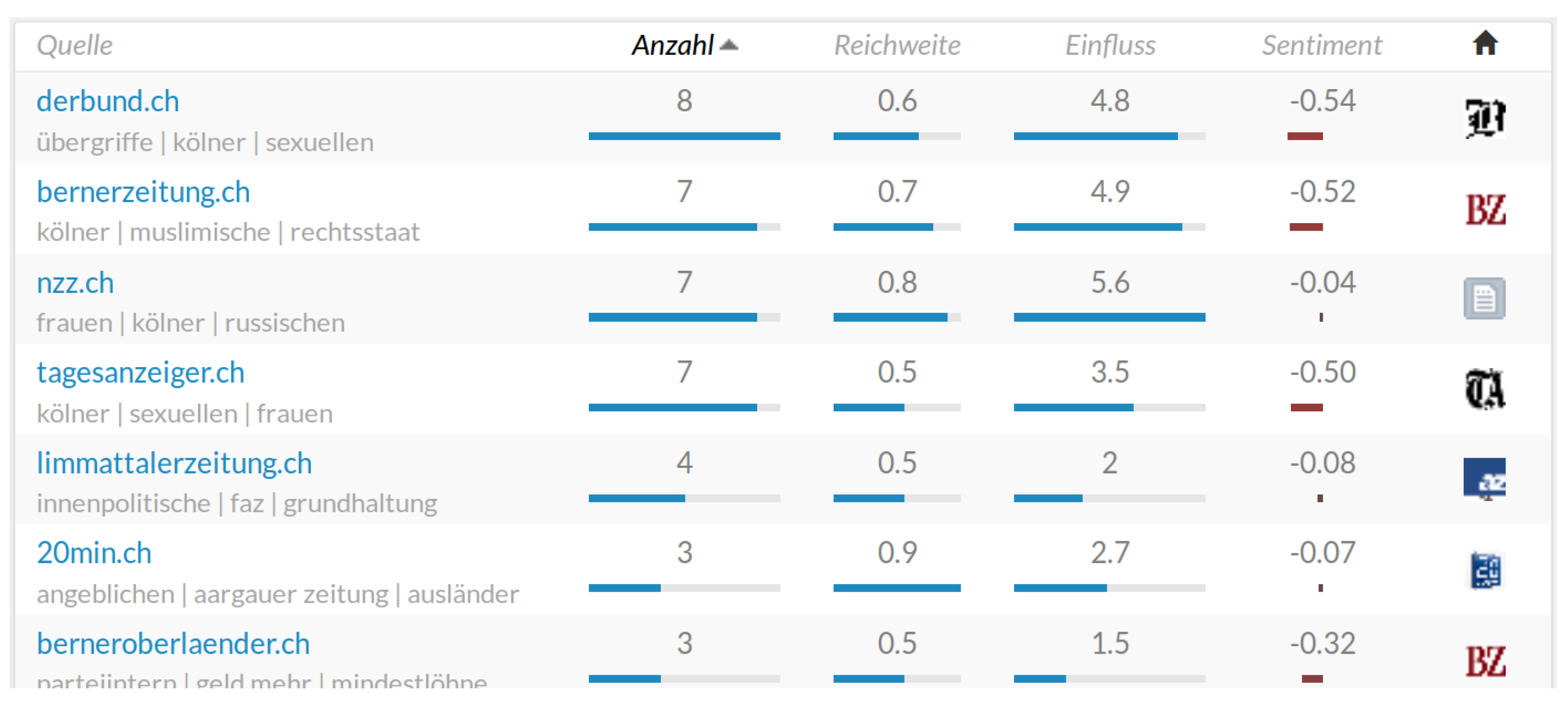
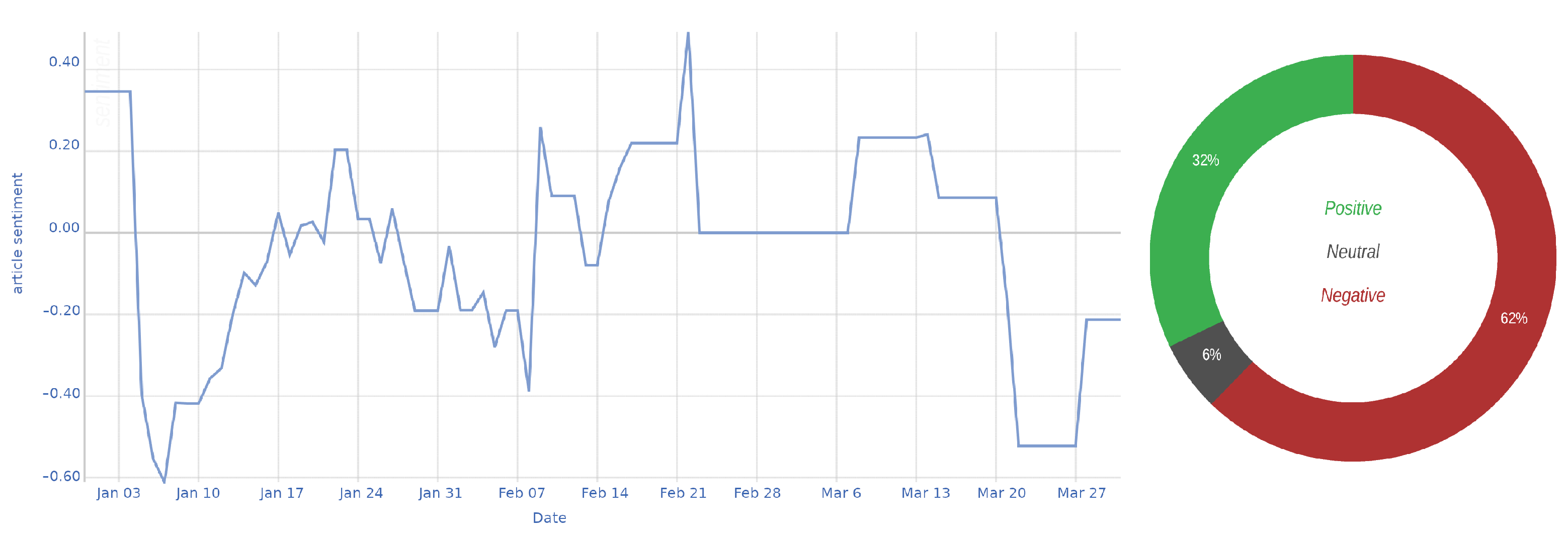
- The platform provides real-time coverage of current (e.g., Figure 4) and past (e.g., Section 8.1) issues, thus enabling experts to analyze the dynamics of both current and past issues and to participate in the discourse with data-driven insights.
- Stakeholder groups (i.e., mass media, professional public, and social media) are organized in different samples, allowing domain experts to analyze and contrast the output and impact of these groups.
- Named entity linking enables analyses that focus on the stakeholder groups that have been defined by the domain experts (Section 5).
- Phrase extraction automatically identifies terms and concepts that are associated with stakeholders, locations, and queries, supporting domain experts in uncovering important topics, dominant issues, and their framing.
- Sentiment analysis provides insights into the perception of stakeholders and issues.
- Drill-down analyses ensure that aggregated results and trends presented in the portal are valid and help in understanding the underlying reasons for the observed effects.
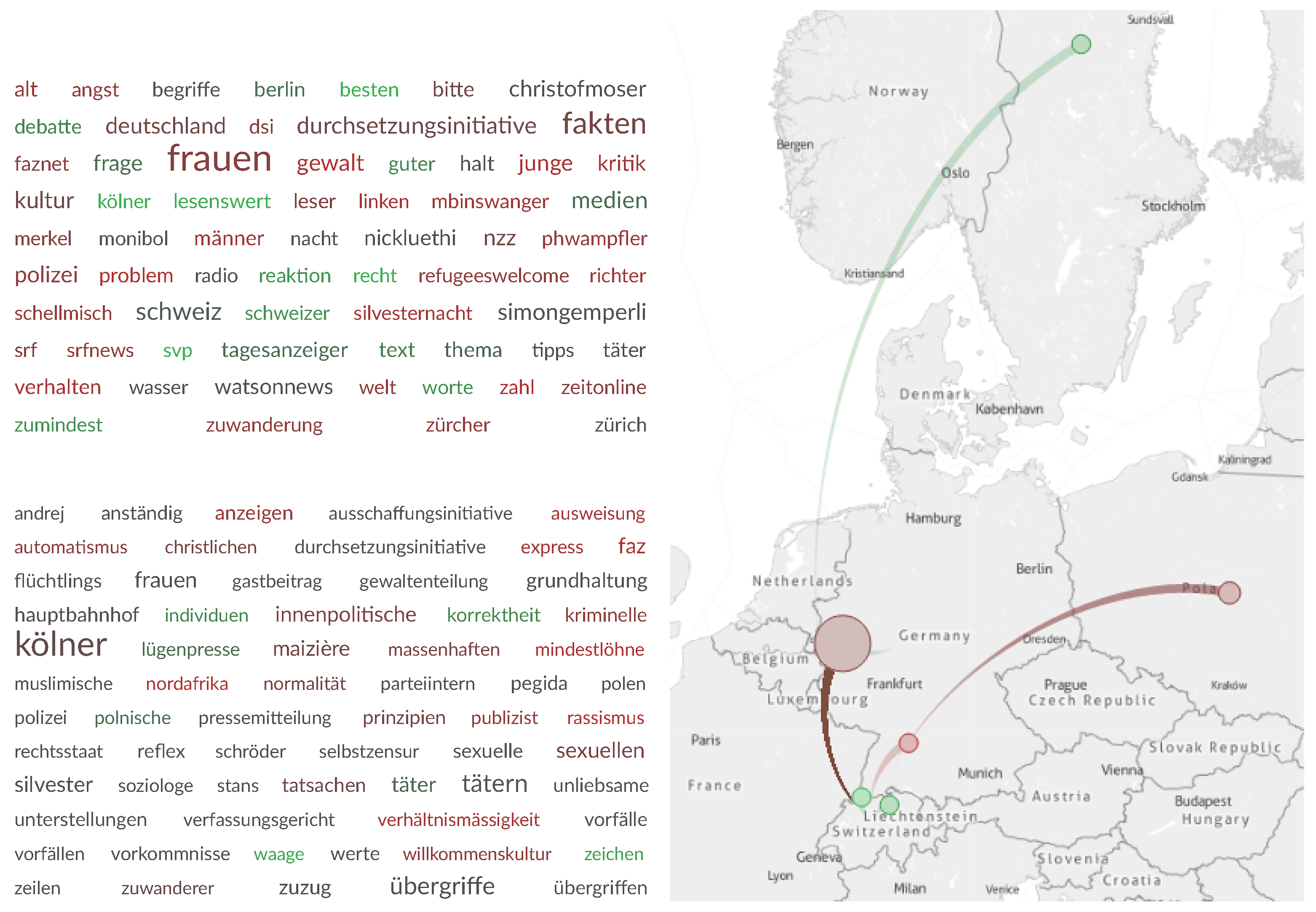
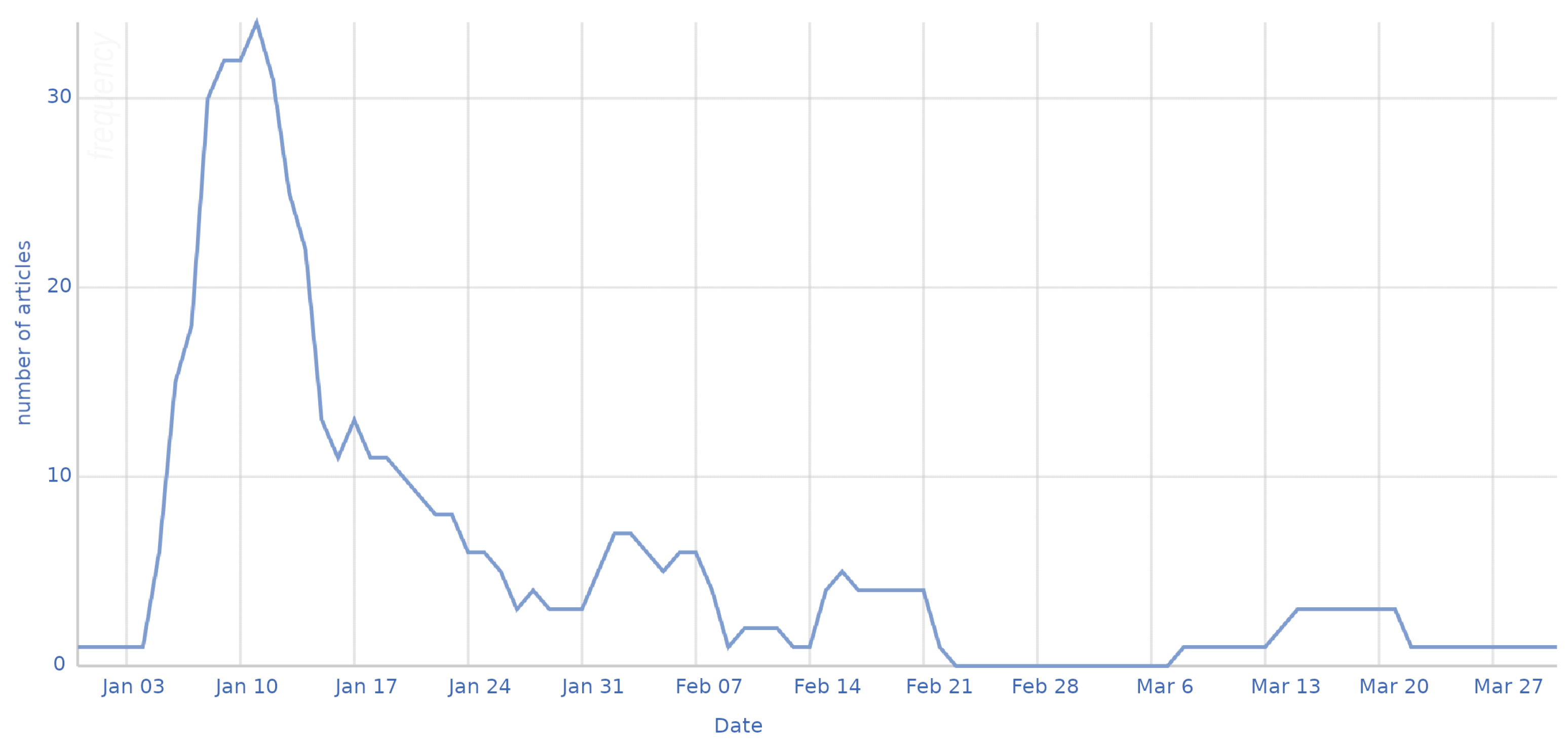
8.1. Case Study: New Year’s Eve Sexual Assaults in Cologne
8.2. Validation of the Results
8.3. Discussion of the Case Study
9. Conclusions
- Aligning their research design and hypotheses with the target discipline’s research framework and background to ensure that the envisioned research has a real impact on that discipline;
- Leveraging theories and concepts from the target domain in the design of indicators and metrics;
- Considering the target domain’s research framework in the development of the entire data acquisition, processing, and analytics process and integrating domain expert input (e.g., on formalized domain knowledge and data sources) into their development;
- Organizing the collaboration between the groups by defining interfaces and feedback loops.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Connolly, R. Why computing belongs within the social sciences. Commun. ACM 2020, 63, 54–59. [Google Scholar] [CrossRef]
- Susanto, Y.; Livingstone, A.; Ng, B.C.; Cambria, E. The Hourglass model revisited. IEEE Intell. Syst. 2020, 35, 96–102. [Google Scholar] [CrossRef]
- Ekman, P. An Argument for Basic Emotions. Cogn. Emot. 1992, 6, 169–200. [Google Scholar] [CrossRef]
- Bartlett, A.; Lewis, J.; Reyes-Galindo, L.; Stephens, N. The locus of legitimate interpretation in Big Data sciences: Lessons for computational social science from -omic biology and high-energy physics. Big Data Soc. 2018, 5, 2053951718768831. [Google Scholar] [CrossRef] [Green Version]
- Ranganath, S.; Hu, X.; Tang, J.; Liu, H. Understanding and Identifying Advocates for Political Campaigns on Social Media. In Proceedings of the Ninth ACM International Conference on Web Search and Data Mining (WSDM’16), San Francisco, CA, USA, 22–25 February 2016; ACM: New York, NY, USA, 2016; pp. 43–52. [Google Scholar] [CrossRef]
- Scharl, A.; Herring, D.; Rafelsberger, W.; Hubmann-Haidvogel, A.; Kamolov, R.; Fischl, D.; Föls, M.; Weichselbraun, A. Semantic Systems and Visual Tools to Support Environmental Communication. IEEE Syst. J. 2017, 11, 762–771. [Google Scholar] [CrossRef] [Green Version]
- Khatua, A.; Cambria, E.; Ho, S.S.; Na, J.C. Deciphering Public Opinion of Nuclear Energy on Twitter. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Cavalcante, R.C.; Brasileiro, R.C.; Souza, V.L.F.; Nobrega, J.P.; Oliveira, A.L.I. Computational Intelligence and Financial Markets: A Survey and Future Directions. Expert Syst. Appl. 2016, 55, 194–211. [Google Scholar] [CrossRef]
- Xing, F.Z.; Cambria, E.; Welsch, R.E. Natural language based financial forecasting: A survey. Artif. Intell. Rev. 2018, 50, 49–73. [Google Scholar] [CrossRef] [Green Version]
- Yang, D.; Huang, C.; Wang, M. A social recommender system by combining social network and sentiment similarity: A case study of healthcare. J. Inf. Sci. 2017, 43, 635–648. [Google Scholar] [CrossRef]
- Xiao, S.; Wei, C.P.; Dong, M. Crowd intelligence: Analyzing online product reviews for preference measurement. Inf. Manag. 2016, 53, 169–182. [Google Scholar] [CrossRef]
- Chung, W.; Zeng, D. Social-media-based public policy informatics: Sentiment and network analyses of U.S. Immigration and border security. J. Assoc. Inf. Sci. Technol. 2016, 67, 1588–1606. [Google Scholar] [CrossRef]
- Scharl, A.; Herring, D.D. Extracting Knowledge from the Web and Social Media for Progress Monitoring in Public Outreach and Science Communication. In Proceedings of the 19th Brazilian Symposium on Multimedia and the Web (WebMedia’13), Salvador, Brazil, 5–8 November 2013; ACM: New York, NY, USA, 2013; pp. 121–124. [Google Scholar] [CrossRef] [Green Version]
- Napoli, P.M. Social TV Engagement Metrics: An Exploratory Comparative Analysis of Competing (Aspiring) Market Information Regimes. SSRN Electron. J. 2013. [Google Scholar] [CrossRef]
- Wakamiya, S.; Lee, R.; Sumiya, K. Towards Better TV Viewing Rates: Exploiting Crowd’s Media Life Logs over Twitter for TV Rating. In Proceedings of the 5th International Conference on Ubiquitous Information Management and Communication (ICUIMC’11), Seoul, Korea, 21–23 February 2011; ACM: New York, NY, USA, 2011; pp. 39:1–39:10. [Google Scholar] [CrossRef]
- Scharl, A.; Hubmann-Haidvogel, A.; Jones, A.; Fischl, D.; Kamolov, R.; Weichselbraun, A.; Rafelsberger, W. Analyzing the Public Discourse on Works of Fiction—Automatic Emotion Detection in Online Media Coverage about HBO’s Game of Thrones. Inf. Process. Manag. 2016, 52, 129–138. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Q.; Wang, T.; Li, P.; Liu, L.; Gong, Q.; Chen, Y. The effect of news and public mood on stock movements. Inf. Sci. 2014, 278, 826–840. [Google Scholar] [CrossRef]
- Xing, F.; Malandri, L.; Zhang, Y.; Cambria, E. Financial Sentiment Analysis: An Investigation into Common Mistakes and Silver Bullets. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain (Online), 8–13 December 2020; International Committee on Computational Linguistics: Barcelona, Spain (Online), 2020; pp. 978–987. [Google Scholar]
- Kim, E.H.J.; Jeong, Y.K.; Kim, Y.; Kang, K.Y.; Song, M. Topic-based content and sentiment analysis of Ebola virus on Twitter and in the news. J. Inf. Sci. 2016, 42, 763–781. [Google Scholar] [CrossRef]
- Hubmann-Haidvogel, A.; Scharl, A.; Weichselbraun, A. Multiple Coordinated Views for Searching and Navigating Web Content Repositories. Inf. Sci. 2009, 179, 1813–1821. [Google Scholar] [CrossRef] [Green Version]
- Malik, M. Journalismusjournalismus. Funktion, Strukturen und Strategien der journalistischen Berichterstattung; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Wyss, V.; Keel, G. Media Governance and Media Quality Management: Theoretical Concepts and an Empirical Example from Switzerland. In Press Freedom and Pluralism in Europe: Concepts and Conditions; Intellect: Bristol, TN, USA; Chicago, IL, USA, 2009; pp. 115–128. [Google Scholar]
- Sutter, T. Medienanalyse und Medienkritik. Forschungsfelder einer Konstruktivistischen Soziologie der Medien; VS Verlag: Wiesbaden, Germany, 2010. [Google Scholar]
- Schmidt, S.J. Zur Grundlegung einer Medienkritik. In Neue Kritik der Medienkritik. Werkanalyse, Nutzerservice, Sales Promotion oder Kulturkritik; Herbert von Halem Verlag: Köln, Germany, 2005; pp. 21–40. [Google Scholar]
- Scodari, C.; Thorpe, J. Media Criticism. Journeys in Interpretation; Kendall Hunt Publishing: Dubuque, IA, USA, 1993. [Google Scholar]
- Meier, C.; Weichert, S. Basiswissen für die Medienpraxis. Journalismus Bibliothek 8. 2012. Available online: https://www.halem-verlag.de/wp-content/uploads/2012/09/9783869620237_inhalt.pdf (accessed on 21 February 2021).
- Wyss, V.; Schanne, M.; Stoffel, A. Medienkritik in der Schweiz—Eine Bestandsaufnahme. In Qualität der Medien. Schweiz-Suisse -Svizzera. Jahrbuch 2012; Schwabe: Basel, Switzerland, 2012; pp. 361–376. [Google Scholar]
- Puppis, M.; Schönhagen, P.; Fürst, S.; Hofstetter, B.; Meissner, M. Arbeitsbedingungen und Berichterstattungsfreiheit in Journalistischen Organisationen. Available online: https://www.bakom.admin.ch/dam/bakom/de/dokumente/2014/12/journalistenbefragungimpressum.pdf.download.pdf/journalistenbefragungimpressum.pdf (accessed on 21 February 2021).
- Eberwein, T. Raus aus der Selbstbeobachtungsfalle! Zum medienkritischen Potenzial der Blogosphäre; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Eberwein, T. Typen und Funktionen von Medienblogs; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Eberwein, T. Von “Holzhausen” nach “Blogville”—Und zurück. Medienbeobachtung in Tagespresse und Weblogs. In Journalismus und Öffentlichkeit. Eine Profession und ihr gesellschaftlicher Auftrag; Festschrift für Horst Pöttker; VS Verlag: Wiesbaden, Germany, 2010; pp. 143–165. [Google Scholar]
- Kleiner, M.S. Einleitung; Grundlagentexte zur sozialwissenschaftlichen Medienkritik; VS Verlag: Wiesbaden, Germany, 2010; pp. 13–85. [Google Scholar]
- Russ-Mohl, S.; Fengler, S. Medien auf der Bühne der Medien. Zur Zukunft von Medienjournalismus und Medien-PR; Dahlem University Press: Berlin, Germany, 2000. [Google Scholar]
- Maali, F.; Cyganiak, R.; Peristeras, V. A Publishing Pipeline for Linked Government Data. In Proceedings of the 9th Extended Semantic Web Conference, Heraklion, Greece, 27–31 May 2012. [Google Scholar]
- Lang, H.P.; Wohlgenannt, G.; Weichselbraun, A. TextSweeper—A System for Content Extraction and Overview Page Detection. In Proceedings of the International Conference on Information Resources Management (Conf-IRM), Vienna, Austria, 21–23 May 2012. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Weichselbraun, A.; Steixner, J.; Brasoveanu, A.M.P.; Scharl, A.; Göbel, M.; Nixon, L.J.B. Automatic Expansion of Domain-Specific Affective Models for Web Intelligence Applications. Cogn. Comput. 2021. [Google Scholar] [CrossRef] [PubMed]
- Weichselbraun, A.; Scharl, A.; Gindl, S. Extracting Opini Targets from Environmental Web Coverage and Social Media Streams. In Proceedings of the 49th Hawaii International Conference on System Sciences (HICSS-49), Koloa, HI, USA, 5–8 January 2016; IEEE Computer Society Press: Los Alamitos, CA, USA, 2016. [Google Scholar]
- Weichselbraun, A.; Streiff, D.; Scharl, A. Consolidating Heterogeneous Enterprise Data for Named Entity Linking and Web Intelligence. Int. J. Artif. Intell. Tools 2015, 24, 1540008. [Google Scholar] [CrossRef] [Green Version]
- Scharl, A.; Weichselbraun, A.; Göbel, M.; Rafelsberger, W.; Kamolov, R. Scalable Knowledge Extraction and Visualization for Web Intelligence. In Proceedings of the 49th Hawaii International Conference on System Sciences (HICSS-49), Koloa, HI, USA, 5–8 January 2016; IEEE Computer Society Press: Los Alamitos, CA, USA, 2016. [Google Scholar]
- Wyss, V. Journalismus als duale Struktur. Grundlagen einer strukturationstheoretischen Journalismustheorie. In Theorien des Journalismus; Ein diskursives Handbuch; VS Verlag: Wiesbaden, Germany, 2004; pp. 305–320. [Google Scholar]
- Odoni, F.; Kuntschik, P.; Brasoveanu, A.M.; Rizzo, G.; Weichselbraun, A. On the Importance of Drill-Down Analysis for Assessing Gold Standards and Named Entity Linking Performance. In Proceedings of the 14th International Conference on Semantic Systems (SEMANTICS 2018), Vienna, Austria, 10–13 September 2018; Elsevier: Vienna, Austria, 2018. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Entity Category | Entities |
|---|---|
| Swiss Stakeholders | 1209 |
| Media-critical agents | 65 |
| Mass media (print, radio, TV, online) | 524 |
| Publishing houses and print offices | 85 |
| Publishers, CEOs, and editors in chief | 344 |
| Media events and media awards | 21 |
| Syndicates and associations | 11 |
| Media scholars and (commercial and non-profit) research organizations | 50 |
| Foundations and media schools | 22 |
| Media politicians and federal councillors | 13 |
| Media lawyers | 26 |
| Media journalists | 48 |
| Foreign stakeholders | 39 |
| Selected organizations and persons from foreign countries | 39 |
| Miscellaneous | 462 |
| Information programs of the Swiss Broadcasting Corporation (SRG) | 64 |
| General media-critical keywords (media-relevant terms) | 398 |
| Source Type | Sources |
|---|---|
| Mass media | 185 |
| Professional public | 170 |
| Social Media | |
| Media organizations | 180 |
| Journalists and media stakeholders | 740 |
| Total | 1275 |
| Category | Articles (Agents) | Average per Medium |
|---|---|---|
| Top Categories | ||
| Mass media | 59 (185) | 0.31 |
| Professional public | 13 (100) | 0.13 |
| Sub-Categories | ||
| Quality media | 24 (5) | 4.80 |
| Tabloid press | 5 (5) | 1.00 |
| Institutionalized media criticism | 17 (5) | 3.40 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Weichselbraun, A.; Kuntschik, P.; Francolino, V.; Saner, M.; Dahinden, U.; Wyss, V. Adapting Data-Driven Research to the Fields of Social Sciences and the Humanities. Future Internet 2021, 13, 59. https://0-doi-org.brum.beds.ac.uk/10.3390/fi13030059
Weichselbraun A, Kuntschik P, Francolino V, Saner M, Dahinden U, Wyss V. Adapting Data-Driven Research to the Fields of Social Sciences and the Humanities. Future Internet. 2021; 13(3):59. https://0-doi-org.brum.beds.ac.uk/10.3390/fi13030059
Chicago/Turabian StyleWeichselbraun, Albert, Philipp Kuntschik, Vincenzo Francolino, Mirco Saner, Urs Dahinden, and Vinzenz Wyss. 2021. "Adapting Data-Driven Research to the Fields of Social Sciences and the Humanities" Future Internet 13, no. 3: 59. https://0-doi-org.brum.beds.ac.uk/10.3390/fi13030059