
Multi-Angle Lipreading with Angle Classification-Based Feature Extraction and Its Application to Audio-Visual Speech Recognition †


Abstract
:1. Introduction
2. Related Work
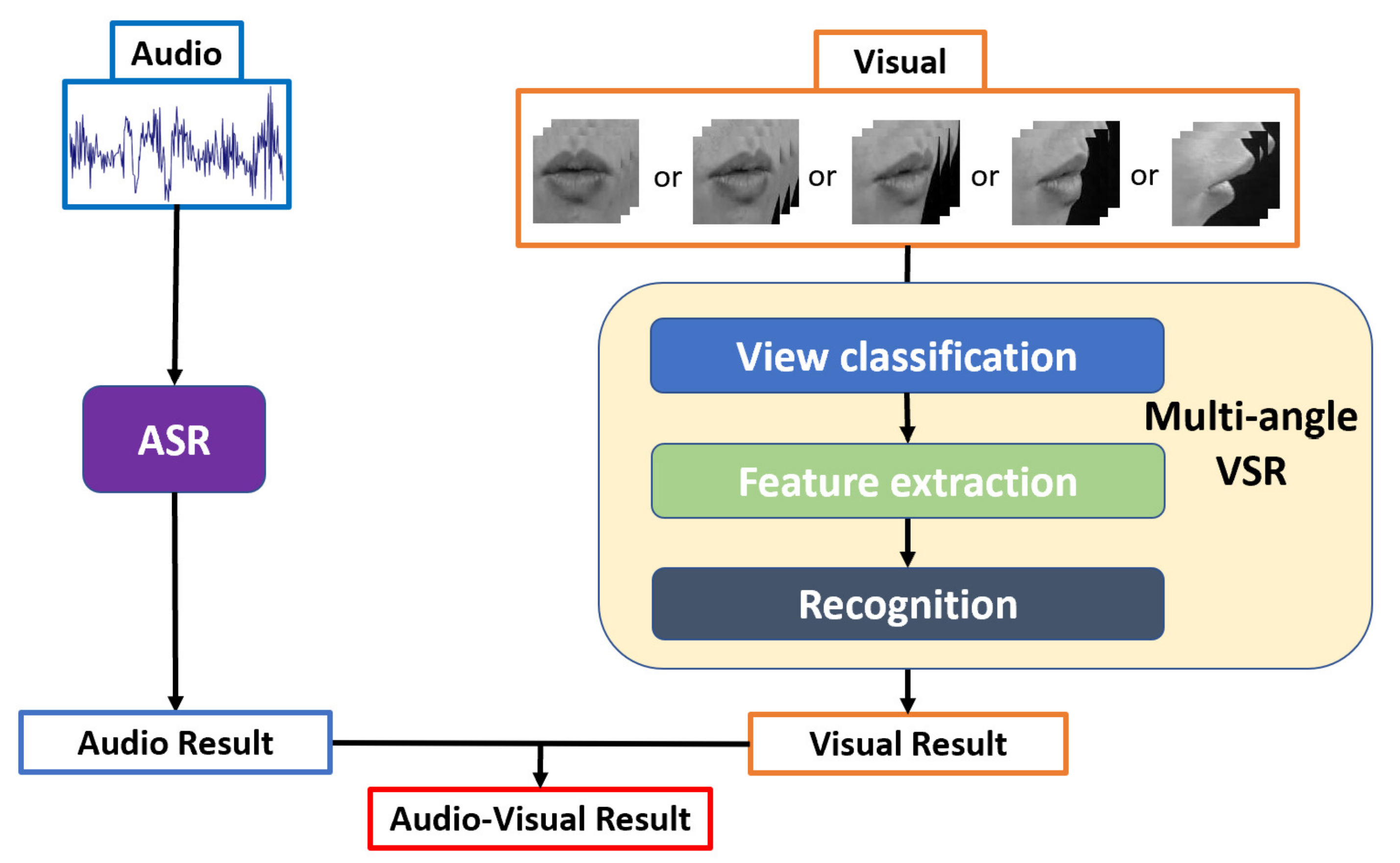
3. Methodology
3.1. Multi-Angle VSR
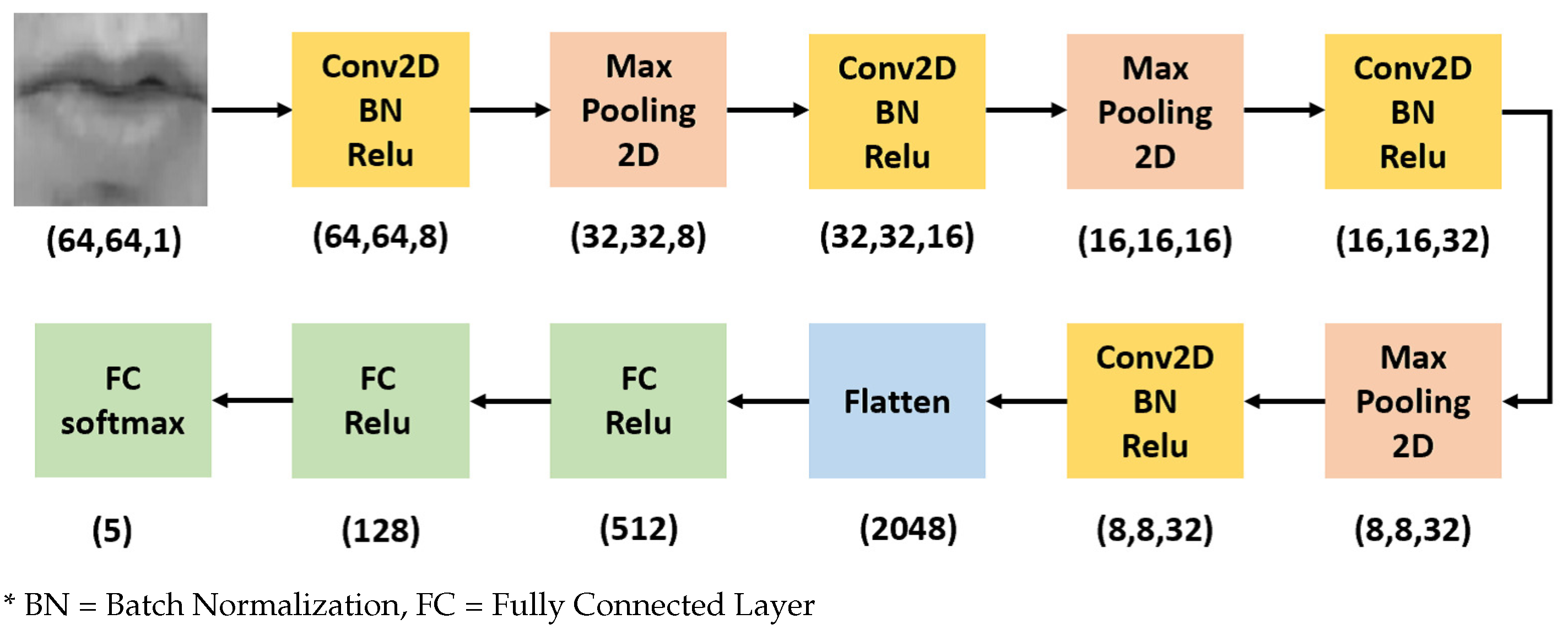
3.1.1. View Classification
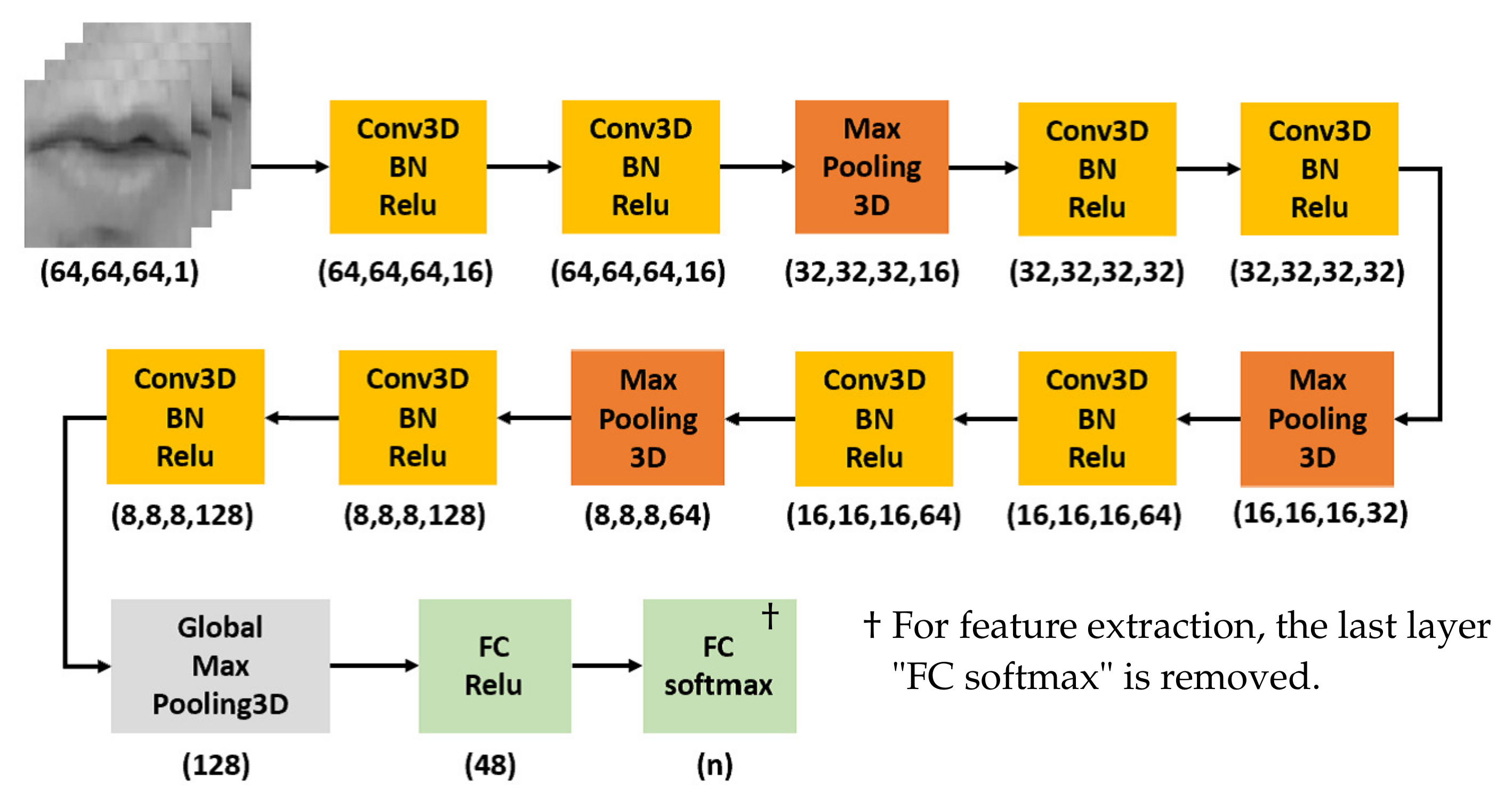
3.1.2. Feature Extraction
3.1.3. Recognition
3.2. ASR
3.2.1. Feature Extraction
3.2.2. Recognition
3.3. AVSR
4. Experiments
4.1. Data Set
4.1.1. OuluVS2
4.1.2. DEMAND
4.1.3. CENSREC-1-AV
4.2. Experimental Setup
4.3. Preprocessing
4.4. Results and Discussion
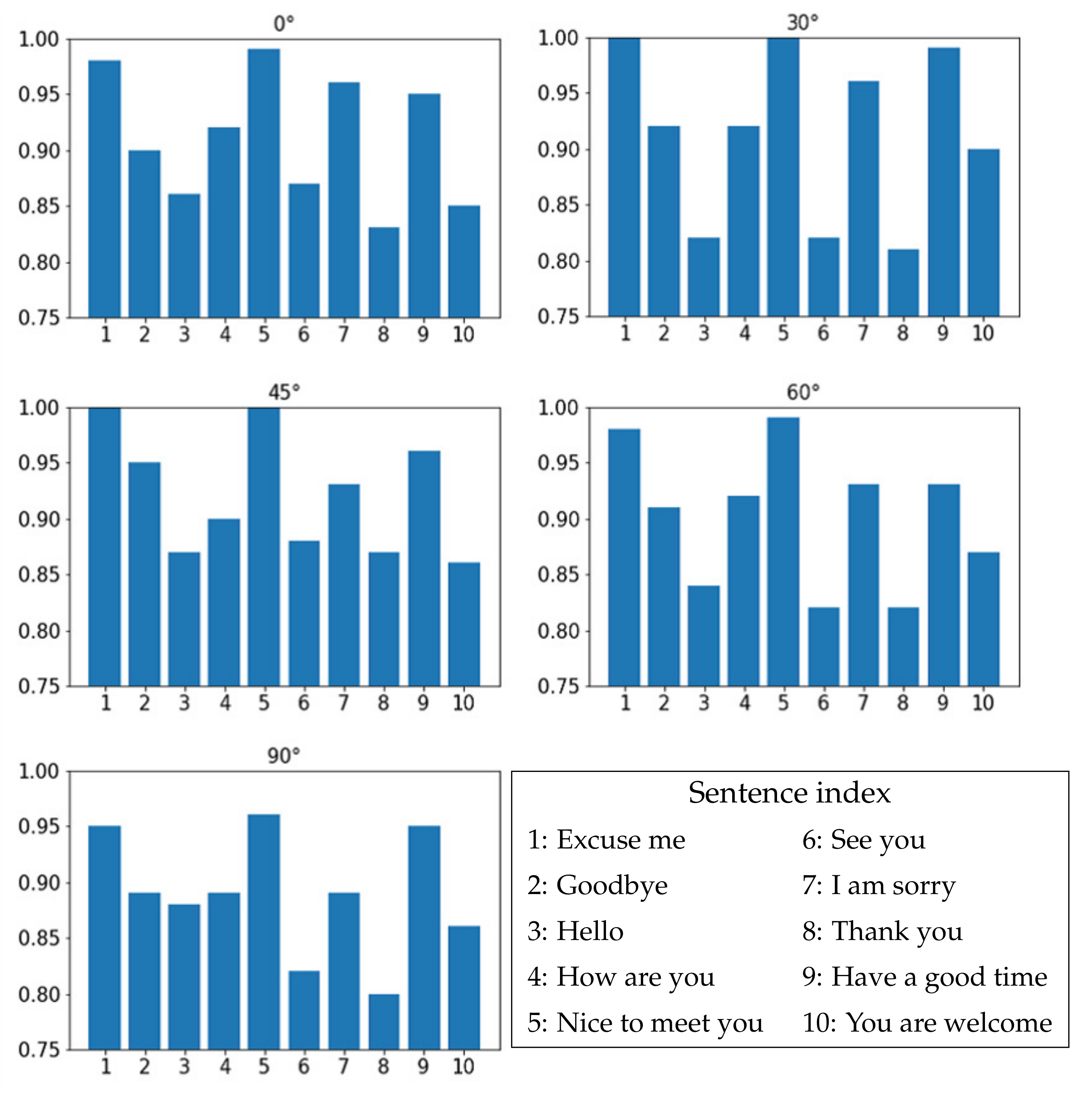
4.4.1. View Classification
4.4.2. VSR
4.4.3. AVSR
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lucey, P.; Potamianos, G. Lipreading using profile versus frontal views. In Proceedings of the MMSP, Victoria, BC, Canada, 3–6 October 2006; pp. 24–28. [Google Scholar]
- Lucey, P.; Sridharan, S.; Dean, D. Continuous pose invariant lipreading. In Proceedings of the INTERSPEECH, Brisbane, Australia, 22–26 September 2008; pp. 2679–2682. [Google Scholar]
- Saitoh, T.; Zhou, Z.; Zhao, G.; Pietikäinen, M. Concatenated frame image based CNN for visual speech recognition. In Proceedings of the ACCV, Taipei, Taiwan, 21–23 November 2016. [Google Scholar]
- Bauman, S.L.; Hambrecht, G. Analysis of view angle used in speech reading training of sentences. Am. J. Audiol. 1995, 4, 67–70. [Google Scholar] [CrossRef]
- Lan, Y.; Theobald, B.J.; Harvey, R. View independent computer lip-reading. In Proceedings of the Multimedia and Expo, Melbourne, Australia, 9–13 July 2012; pp. 432–437. [Google Scholar]
- Zimmermann, M.; Ghazi, M.M.; Ekenel, H.K.; Thiran, J.-P. Visual speech recognition Using PCA networks and LSTMs in a tandem GMM-HMM system. In Proceedings of the ACCV, Taipei, Taiwan, 21–23 November 2016. [Google Scholar]
- Kumar, K.; Chen, T.; Stern, R. Profile view lip reading. In Proceedings of the ICASSP, Honolulu, HI, USA, 15–20 April 2007; pp. 429–432. [Google Scholar]
- Komai, Y.; Yang, N.; Takiguchi, T.; Ariki, Y. Robust AAM based audio-visual speech recognition against face direction changes. In Proceedings of the ACM Multimedia, Nara, Japan, 29 October–2 November 2012; pp. 1161–1164. [Google Scholar]
- Koumparoulis, A.; Potamianos, G. Deep view2view mapping for view-invariant lipreading. In Proceedings of the SLT, Athens, Greece, 18–21 December 2018; pp. 588–594. [Google Scholar]
- Estellers, V.; Thiran, J.-P. Multipose audio-visual speech recognition. In Proceedings of the EUSIPCO, Barcelona, Spain, 29 August–2 September 2011; pp. 1065–1069. [Google Scholar]
- Petridis, S.; Stafylakis, T.; Ma, P.; Cai, F.; Tzimiropoulos, G.; Pantic, M. End-to-end multiview lip reading. In Proceedings of the ICASSP, Calgary, AB, Canada, 15–20 April 2018; pp. 6548–6552. [Google Scholar]
- Zimmermann, M.; MehdipourGhazi, M.; Ekenel, H.K.; Thiran, J.-P. Combining multiple views for visual speech recognition. In Proceedings of the AVSP, Stockholm, Sweden, 25–26 August 2017. [Google Scholar]
- Sahrawat, D.; Kumar, Y.; Aggarwal, S.; Yin, Y.; Shah, R.R.; Zimmermann, R. “Notic My Speech”—Blending Speech Patterns with Multimedia. arXiv 2020, arXiv:2006.08599. [Google Scholar]
- Lee, D.; Lee, J.; Kim, K.E. Multi-view automatic lip-reading using neural network. In Proceedings of the ACCV, Taipei, Taiwan, 21–23 November 2016. [Google Scholar]
- Makino, T.; Liao, H.; Assael, Y.; Shillingford, B.; Garcia, B.; Braga, O.; Siohan, O. Recurrent Neural Network Transducer for Audio-Visual Speech Recognition. arXiv 2019, arXiv:1911.04890v1. [Google Scholar]
- Zhou, P.; Yang, W.; Chen, W.; Wang, Y.; Jia, J. Modality Attention for End-to-End Audio-visual Speech Recognition. arXiv 2019, arXiv:1811.05250v2. [Google Scholar]
- Paraskevopoulos, G.; Parthasarathy, S.; Khare, A.; Sundaram, S. Multiresolution and Multimodal Speech Recognition with Transformers. arXiv 2020, arXiv:2004.14840v1. [Google Scholar]
- Isobe, S.; Tamura, S.; Hayamizu, S. Speech Recognition using Deep Canonical Correlation Analysis in Noisy Environments. In Proceedings of the ICPRAM, Online. 4–6 February 2021; pp. 63–70. [Google Scholar]
- Petridis, S.; Wang, Y.; Li, Z.; Pantic, M. End-to-End Audiovisual Fusion with LSTMs. In Proceedings of the ICASSP, Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Lee, Y.H.; Jang, D.W.; Kim, J.B.; Park, R.H.; Park, H.M. Audio–visual speech recognition based on dual cross-modality attentions with the transformer model. Appl. Sci. 2020, 10, 7263. [Google Scholar] [CrossRef]
- Bear, H.L.; Harvey, R. Alternative visual units for an optimized phoneme-based lipreading system. Appl. Sci. 2019, 9, 2019. [Google Scholar] [CrossRef] [Green Version]
- Anina, I.; Zhou, Z.; Zhao, G.; Pietikäinen, M. OuluVS2: A multi-view audiovisual database for non-rigid mouth motion analysis. In Proceedings of the 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015. [Google Scholar]
- Tuasikal, D.A.A.; Nugraha, M.B.; Yudhatama, E.; Muharom, A.S.; Pura, M. Word Recognition for Color Classification Using Convolutional Neural Network. In Proceedings of the CONMEDIA, Bali, Indonesia, 9–11 October 2019. [Google Scholar]
- Petridis, S.; Stafylakis, T.; Ma, P.; Cai, F.; Tzimiropoulos, G.; Pantic, M. End-to-End Audiovisual Speech Recognition. In Proceedings of the ICASSP, Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Mahmood, A.; Köse, U. Speech recognition based on convolutional neural networks and MFCC algorithm. In Proceedings of the AAIR, Uttar Pradesh, India, 30 June–4 July 2021; Volume 1, pp. 6–12. [Google Scholar]
- Kathania, H.K.; Shahnawazuddin, S.; Adiga, N.; Ahmad, W. Role of Prosodic Features on Children’s Speech Recognition. In Proceedings of the ICASSP, Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Bountourakis, V.; Vrysis, L.; Konstantoudakis, K.; Vryzas, N. An Enhanced Temporal Feature Integration Method for Environmental Sound Recognition. Acoustics 2019, 1, 23. [Google Scholar] [CrossRef] [Green Version]
- Vrysis, L.; Hadjileontiadis, L.; Thoidis, I.; Dimoulas, C.; Papanikolaou, G. Enhanced Temporal Feature Integration in Audio Semantics via Alpha-Stable Modeling. J. Audio Eng. Soc. 2021, 69, 227–237. [Google Scholar] [CrossRef]
- Thiemann, J.; Ito, N.; Vincent, E. DEMAND: A collection of multichannel recordings of acoustic noise in diverse environments. In Proceedings of the ICA, Montreal, QC, Canada, 2–7 June 2013; Available online: https://zenodo.org/record/1227121#.YNS2p3X7Q5k (accessed on 14 July 2021).
- Tamura, S.; Miyajima, C.; Kitaoka, N.; Yamada, T.; Tsuge, S.; Takiguchi, T.; Yamamoto, K.; Nishiura, T.; Nakayama, M.; Denda, Y.; et al. CENSREC-1-AV: An audio-visual corpus for noisy bimodal speech recognition. In Proceedings of the AVSP, Kanagawa, Japan, 30 September–3 October 2010; pp. 85–88. Available online: http://research.nii.ac.jp/src/en/CENSREC-1-AV.html (accessed on 14 July 2021).
- Isobe, S.; Tamura, S.; Hayamizu, S.; Gotoh, Y.; Nose, M. Multi-angle lipreading using angle classification and angle-specific feature integration. In Proceedings of the ICCSPA, Sharjah, United Arab Emirates, 16–18 March 2020. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | ||||||
|---|---|---|---|---|---|---|
| Model | ||||||
| 95.33 | 93.33 | 89.78 | 69.22 | 42.78 | ||
| 93.78 | 95.89 | 94.67 | 87.55 | 69.00 | ||
| 88.22 | 91.89 | 95.00 | 93.78 | 76.89 | ||
| 66.00 | 80.11 | 88.22 | 95.89 | 90.89 | ||
| 47.44 | 56.55 | 69.44 | 93.56 | 94.67 | ||
| + | 96.00 | 96.56 | 96.22 | 88.67 | 66.56 | |
| + | 94.78 | 95.78 | 95.78 | 93.67 | 79.34 | |
| + | 92.78 | 94.00 | 93.55 | 95.44 | 88.22 | |
| + | 96.33 | 96.67 | 94.67 | 96.56 | 93.56 | |
| + | 93.56 | 95.56 | 95.22 | 90.89 | 79.00 | |
| + | 93.78 | 96.89 | 96.44 | 97.11 | 87.33 | |
| + | 94.67 | 97.22 | 96.78 | 95.78 | 95.11 | |
| + | 88.33 | 92.22 | 96.00 | 96.11 | 89.56 | |
| + | 89.11 | 93.67 | 94.67 | 96.78 | 94.67 | |
| + | 75.11 | 83.56 | 88.00 | 96.89 | 94.45 | |
| + + | 96.89 | 97.55 | 97.89 | 96.78 | 76.44 | |
| + + | 96.11 | 97.78 | 96.89 | 96.67 | 87.56 | |
| + + | 95.11 | 97.89 | 96.78 | 95.89 | 94.45 | |
| + + | 96.11 | 96.89 | 96.00 | 97.22 | 85.67 | |
| + + | 94.33 | 95.78 | 95.44 | 95.44 | 93.56 | |
| + + | 96.22 | 96.78 | 95.56 | 97.55 | 94.78 | |
| + + | 93.78 | 96.89 | 97.44 | 96.55 | 84.11 | |
| + + | 95.78 | 97.11 | 97.22 | 97.22 | 94.78 | |
| + + | 95.67 | 97.78 | 97.33 | 97.56 | 94.56 | |
| + + | 89.89 | 92.89 | 95.33 | 96.55 | 94.66 | |
| + + + | 96.67 | 96.89 | 97.78 | 97.11 | 86.33 | |
| + + + | 97.44 | 98.33 | 97.89 | 97.67 | 95.00 | |
| + + + | 96.44 | 98.11 | 97.00 | 98.11 | 94.22 | |
| + + + | 97.67 | 98.22 | 97.45 | 98.22 | 93.89 | |
| + + + | 95.22 | 96.78 | 97.11 | 97.22 | 96.45 | |
| + + + + | 96.89 | 97.89 | 97.00 | 97.55 | 95.89 | |
| SNR | 0 dB | 5 dB | 10 dB | 15 dB | 20 dB | |
|---|---|---|---|---|---|---|
| Noise | ||||||
| Kitchen | 1050 | - | 1050 | - | 1050 | |
| Park | - | 1050 | - | 1050 | - | |
| Office | 1050 | - | 1050 | - | 1050 | |
| Station | - | 1050 | - | 1050 | - | |
| Car | 1050 | - | 1050 | - | 1050 | |
| SNR | ||||||
|---|---|---|---|---|---|---|
| Noise | ||||||
| 360 | 0 | 0 | 0 | 0 | ||
| 0 | 324 | 18 | 0 | 0 | ||
| 0 | 36 | 242 | 0 | 0 | ||
| 0 | 0 | 100 | 359 | 0 | ||
| 0 | 0 | 0 | 1 | 360 | ||
| Data | Mean | ||||||
|---|---|---|---|---|---|---|---|
| Method | |||||||
| CNN + Data Augmentation [3] | 85.6 | 82.5 | 82.5 | 83.3 | 80.3 | 82.84 | |
| PCA + LSTM + GMM–HMM [6] | 73.1 | 75.6 | 67.2 | 63.3 | 59.3 | 67.7 | |
| View2View [9] | - | 86.11 | 83.33 | 81.94 | 78.89 | 82.57 | |
| End-to-end Encoder + BLSTM [11] | 91.8 | 87.3 | 88.8 | 86.4 | 91.2 | 89.1 | |
| End-to-End CNN–LSTM [14] | 82.8 | 81.1 | 85.0 | 83.6 | 86.4 | 83.78 | |
| Ours without view classification | 91.02 | 90.56 | 91.20 | 90.00 | 88.88 | 90.33 | |
| Ours with view classification | 91.02 | 91.38 | 92.21 | 90.09 | 88.88 | 90.65 | |
| Data | Noise | 0 dB | 5 dB | 10 dB | 15 dB | 20 dB | |
|---|---|---|---|---|---|---|---|
| Model | |||||||
| ASR | 95.83 | 99.26 | 99.26 | 99.35 | 99.26 | ||
| VSR | city road | 90.65 | |||||
| AVSR | 98.70 | 99.63 | 99.72 | 99.63 | 99.63 | ||
| ASR | 96.85 | 99.44 | 99.35 | 99.26 | 99.35 | ||
| VSR | expressway | 90.65 | |||||
| AVSR | 99.17 | 99.72 | 99.53 | 99.72 | 99.72 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Isobe, S.; Tamura, S.; Hayamizu, S.; Gotoh, Y.; Nose, M. Multi-Angle Lipreading with Angle Classification-Based Feature Extraction and Its Application to Audio-Visual Speech Recognition. Future Internet 2021, 13, 182. https://0-doi-org.brum.beds.ac.uk/10.3390/fi13070182
Isobe S, Tamura S, Hayamizu S, Gotoh Y, Nose M. Multi-Angle Lipreading with Angle Classification-Based Feature Extraction and Its Application to Audio-Visual Speech Recognition. Future Internet. 2021; 13(7):182. https://0-doi-org.brum.beds.ac.uk/10.3390/fi13070182
Chicago/Turabian StyleIsobe, Shinnosuke, Satoshi Tamura, Satoru Hayamizu, Yuuto Gotoh, and Masaki Nose. 2021. "Multi-Angle Lipreading with Angle Classification-Based Feature Extraction and Its Application to Audio-Visual Speech Recognition" Future Internet 13, no. 7: 182. https://0-doi-org.brum.beds.ac.uk/10.3390/fi13070182