Predicting Fire Propagation across Heterogeneous Landscapes Using WyoFire: A Monte Carlo-Driven Wildfire Model


 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Overview
2.2. Model Description
2.3. Data
2.4. Wildfire Simulation
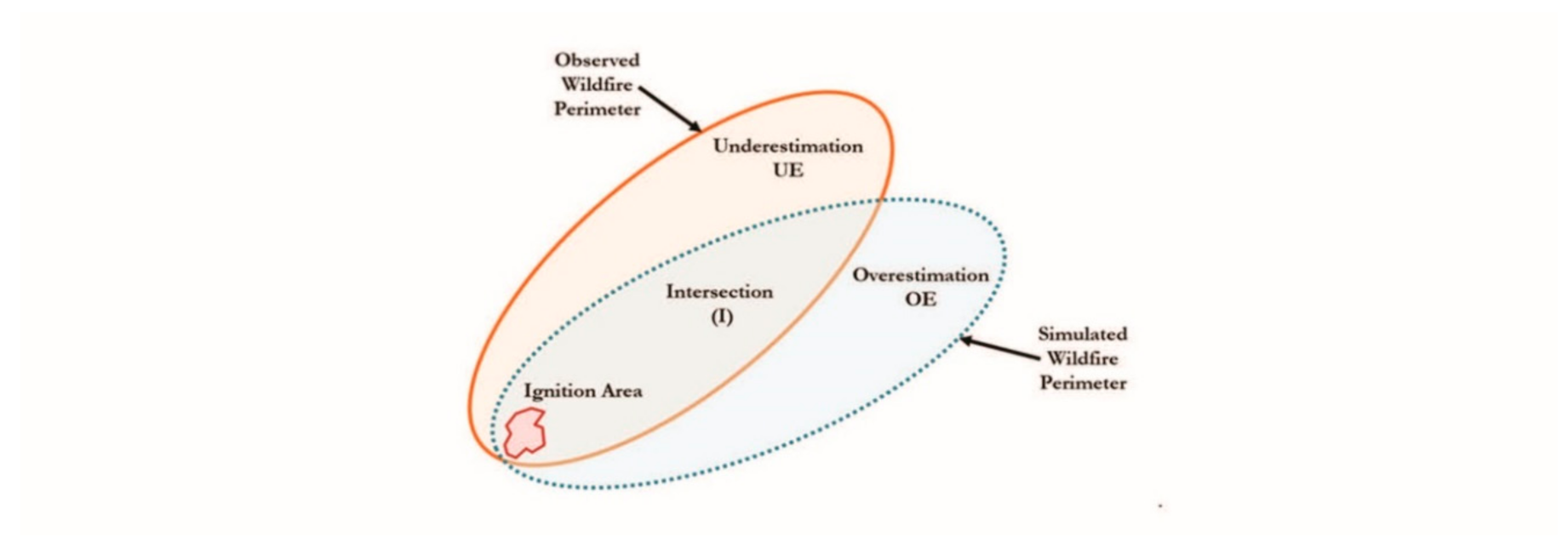
2.5. Assessing Model Performance
2.6. Principle Components Analysis
3. Results
3.1. Statistical Performance
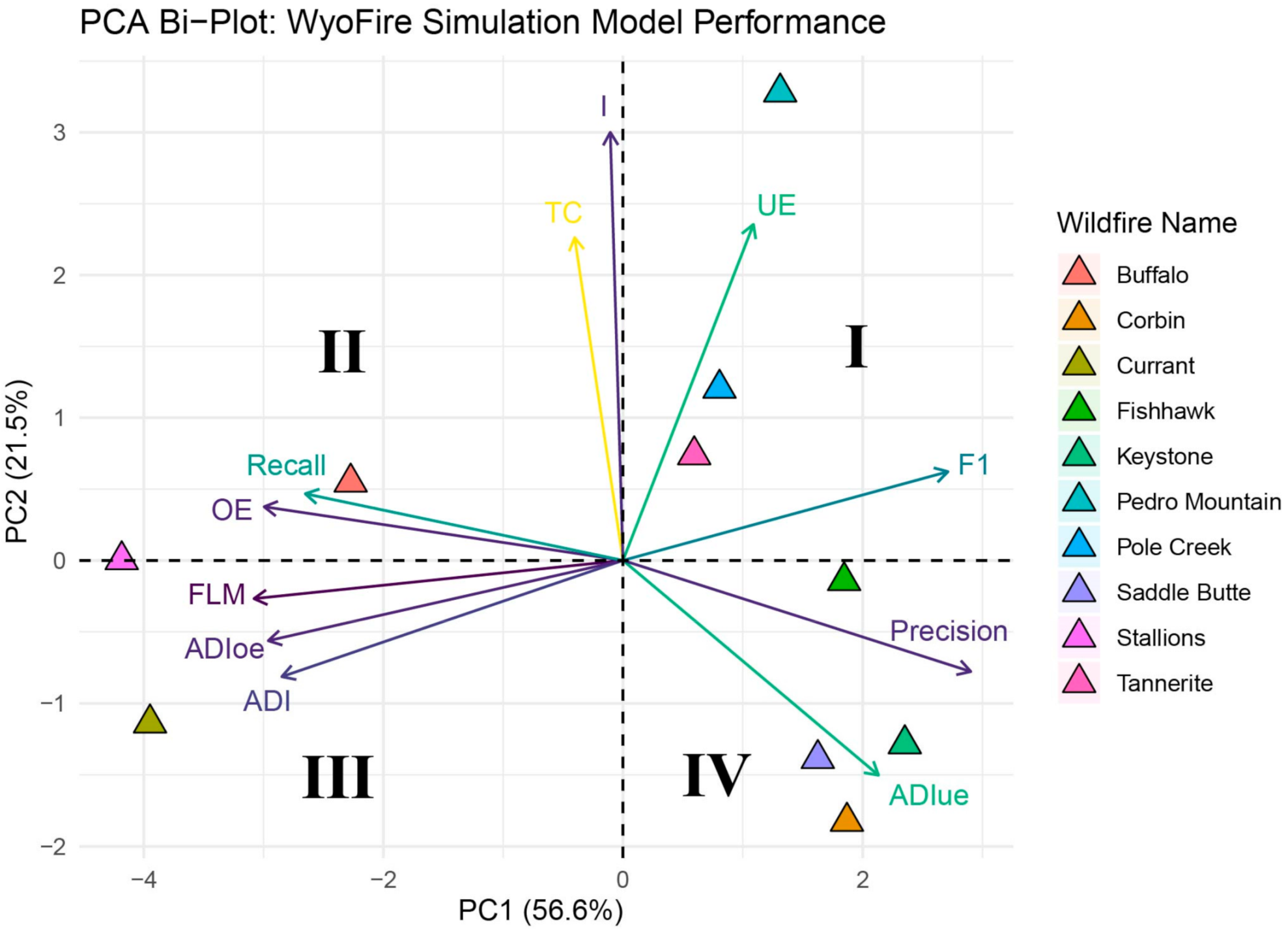
3.2. Principle Components Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Garfin, G.; Gonzalez, P.; Breshears, D.; Brooks, K.; Brown, H.; Elias, E.; Gunasekara, A.; Huntly, N.; Maldonado, J.; Mantua, N. Southwest. In Impacts, Risks, and Adaptation in the United States: Fourth National Climate Assessment; Reidmiller, D.R., Avery, C.W., Easterling, D.R., Kunkel, K.E., Lewis, K.L.M., Maycock, T.K., Stewart, B.C., Eds.; U.S. Global Change Research Program: Washington, DC, USA, 2018; Volume II, pp. 1101–1184. [Google Scholar]
- Westerling, A.L. Increasing western US forest wildfire activity: Sensitivity to changes in the timing of spring. Philos. Trans. R. Soc. B Biol. Sci. 2016, 371, 20150178. [Google Scholar] [CrossRef] [PubMed]
- Stavros, E.N.; Abatzoglou, J.T.; McKenzie, D.; Larkin, N.K. Regional projections of the likelihood of very large wildland fires under a changing climate in the contiguous Western United States. Clim. Chang. 2014, 126, 455–468. [Google Scholar] [CrossRef]
- Higuera, P.E.; Abatzoglou, J.T. Record-setting climate enabled the extraordinary 2020 fire season in the western United States. Glob. Chang. Biol. 2020. [Google Scholar] [CrossRef] [PubMed]
- McWethy, D.B.; Schoennagel, T.; Higuera, P.E.; Krawchuk, M.; Harvey, B.J.; Metcalf, E.C.; Schultz, C.; Miller, C.; Metcalf, A.L.; Buma, B. Rethinking resilience to wildfire. Nat. Sustain. 2019, 2, 797–804. [Google Scholar] [CrossRef]
- Duff, T.J.; Chong, D.M.; Tolhurst, K.G. Indices for the evaluation of wildfire spread simulations using contemporaneous predictions and observations of burnt area. Environ. Model. Softw. 2016, 83, 276–285. [Google Scholar] [CrossRef]
- Rothermal, R. A Mathematical Model for Predicting Fire Spread in Wildland Fuels; Intermountain Forest & Range Experiment Station, Forest Service, US Department of Agriculture: Ogden, UT, USA, 1972; 40p. [Google Scholar]
- Adhikari, B.; Xu, C.; Hodza, P.; Minckley, T.A. Developing a geospatial data-driven solution for rapid natural wildfire risk assessment. J. Appl. Geogr. In Revision.
- Bennett, N.D.; Croke, B.F.; Guariso, G.; Guillaume, J.H.; Hamilton, S.H.; Jakeman, A.J.; Marsili-Libelli, S.; Newham, L.T.; Norton, J.P.; Perrin, C. Characterising performance of environmental models. Environ. Model. Softw. 2013, 40, 1–20. [Google Scholar] [CrossRef]
- Kelso, J.K.; Mellor, D.; Murphy, M.E.; Milne, G.J. Techniques for evaluating wildfire simulators via the simulation of historical fires using the Australis simulator. Int. J. Wildland Fire 2015, 24, 784–797. [Google Scholar] [CrossRef] [Green Version]
- Adhikari, B. A Web GIS Portal for Modeling Wildfire Spread in Near Realtime and Assessing Associated Risk; University of Wyoming: Laramie, WY, USA, 2018. [Google Scholar]
- Filippi, J.B.; Mallet, V.; Nader, B. Representation and evaluation of wildfire propagation simulations. Int. J. Wildland Fire 2014, 23, 46–57. [Google Scholar] [CrossRef]
- Wagner, C.V. Conditions for the start and spread of crown fire. Can. J. For. Res. 1977, 7, 23–34. [Google Scholar] [CrossRef]
- Finney, M.A. FARSITE: Fire Area Simulator—Model Development and Evaluation; Research Paper RMRS-RP-4 Revised; USDA Forest Service, Rocky Mountain Research Station: Ogden, UT, USA, 2004; 47p. [Google Scholar]
- Ott, C.W. Performance Evaluation of a Monte Carlo Driven Wildfire Simulation Model: Assessing Model Performance to Advance Education and Improve Human Safety; University of Wyoming: Laramie, WY, USA, 2020. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Pugnet, L.; Chong, D.; Duff, T.; Tolhurst, K. Wildland–urban interface (WUI) fire modelling using PHOENIX Rapidfire: A case study in Cavaillon, France. In Proceedings of the 20th International Congress on Modelling and Simulation, Adelaide, Australia, 1–6 December 2013; pp. 1–6. [Google Scholar]
- Duff, T.J.; Cawson, J.G.; Cirulis, B.; Nyman, P.; Sheridan, G.J.; Tolhurst, K.G. Conditional performance evaluation: Using wildfire observations for systematic fire simulator development. Forests 2018, 9, 189. [Google Scholar] [CrossRef] [Green Version]
- Moon, K.; Duff, T.; Tolhurst, K. Sub-canopy forest winds: Understanding wind profiles for fire behaviour simulation. Fire Saf. J. 2019, 105, 320–329. [Google Scholar] [CrossRef]
- Andrews, P.L.; Cruz, M.G.; Rothermel, R.C. Examination of the wind speed limit function in the Rothermel surface fire spread model. Int. J. Wildland Fire 2013, 22, 959–969. [Google Scholar] [CrossRef]
- Loehle, C. Applying landscape principles to fire hazard reduction. Forest Ecol. Manag. 2004, 198, 261–267. [Google Scholar] [CrossRef] [Green Version]
- Kerby, J.D.; Fuhlendorf, S.D.; Engle, D.M. Landscape heterogeneity and fire behavior: Scale-dependent feedback between fire and grazing processes. Landsc. Ecol. 2007, 22, 507–516. [Google Scholar] [CrossRef]
- Coen, J.L.; Schroeder, W. Use of spatially refined satellite remote sensing fire detection data to initialize and evaluate coupled weather-wildfire growth model simulations. Geophys. Res. Lett. 2013, 40, 5536–5541. [Google Scholar] [CrossRef]
- Salis, M.; Arca, B.; Alcasena, F.; Arianoutsou, M.; Bacciu, V.; Duce, P.; Duguy, B.; Koutsias, N.; Mallinis, G.; Mitsopoulos, I. Predicting wildfire spread and behaviour in Mediterranean landscapes. Int. J. Wildland Fire 2016, 25, 1015–1032. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resolution | ||||
|---|---|---|---|---|
| Dataset | Source | Data Volume (Gigabyte/Iteration) | Spatial (m) | Temporal (h) |
| High-Resolution Rapid Refresh (HRRR) | NOAA | 11.5 | 3000 | 1 |
| VIIIRS Active Fire Hotspot | NASA | 0.02 | 375 | 12 |
| Dead Fuel Moisture | WSFD/USFS | 1 | 2500 | 24 |
| Digital Elevation Model | USGS | 26 | 10 | Updated: January 2017 |
| Vegetation and Fuels | LANDFIRE | 3.5 | 30 | Updated: January 2014 |
| Historical Wildfire Perimeter (Observed) | USGS GeoMAC | 0.1 | N/A | 24 |
| Historical HRRR Data | Uni. Of Utah | 9 | 3000 | 24 |
| Wildfire | Total Size (Acres) | Simulation Duration (h) | Observed Perimeter Source | Total Simulations (n) |
|---|---|---|---|---|
| Keystone, 2017 | 1102 | 13 | VIIRS | 600 |
| Pole Creek, 2017 | 2139 | 12 | GeoMAC and VIIRS | 600 |
| Buffalo, 2017 | 3515 | 12 | GeoMAC and VIIRS | 600 |
| Stallions, 2017 | 1111 | 12 | VIIRS | 600 |
| Tannerite, 2019 | 1349 | 18 | GeoMAC | 600 |
| Pedro Mountain, 2019 | 9388 | 18 | GeoMAC and VIIRS | 600 |
| Currant, 2019 | 381 | 12 | GeoMAC | 600 |
| Corbin, 2019 | 164 | 8 | GeoMAC | 600 |
| Fishhawk, 2019 | 2359 | 18 | GeoMAC and VIIRS | 600 |
| Saddle Butte, 2019 | 252 | 12 | GeoMAC | 600 |
| Total Simulations | 6000 |
| Wildfire | Existing Vegetation Type(s) | Terrain Roughness | ADIoe–ADIue | Fuel Loading |
|---|---|---|---|---|
| Currant | Grassland, Shrubland | 3 | 37.940 | Med—High |
| Stallions | Northwestern Great Plains Grassland, Ponderosa-Pine Forest | 6 | 32.430 | Med–High |
| Buffalo | Northwestern Great Plains Grassland, Sage Brush Steppe | 3 | 8.479 | Low–Med |
| Tannerite | Sage Brush Steppe, Montane–Foothill–Valley Grassland | 5 | 1.481 | Low–High |
| Pole Creek | Spruce-Fir Woodland, Aspen and Mixed-Conifers | 7 | 1.031 | Low–Med |
| Pedro Mountain | Sage Brush Shrubland, Limber Pine-Juniper Forest | 6 | −0.093 | Low–Med |
| Keystone | Lodgepole Forest, Spruce-Fire Woodland, Aspen and Mixed Conifers | 1 | −1.733 | Low–Med |
| Fishhawk | Subalpine Woodland, Spruce-Fir Woodland, Douglas-Fir Forest | 5 | −2.450 | Low |
| Saddle Butte | Sage Brush Shrubland, Sage Brush Steppe, Montane Meadow | 4 | −2.789 | Low |
| Corbin | Sage Brush Steppe, Sage Brush Shrubland, Semi-Desert Shrub Steppe | 2 | −4.248 | Low |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ott, C.W.; Adhikari, B.; Alexander, S.P.; Hodza, P.; Xu, C.; Minckley, T.A. Predicting Fire Propagation across Heterogeneous Landscapes Using WyoFire: A Monte Carlo-Driven Wildfire Model. Fire 2020, 3, 71. https://0-doi-org.brum.beds.ac.uk/10.3390/fire3040071
Ott CW, Adhikari B, Alexander SP, Hodza P, Xu C, Minckley TA. Predicting Fire Propagation across Heterogeneous Landscapes Using WyoFire: A Monte Carlo-Driven Wildfire Model. Fire. 2020; 3(4):71. https://0-doi-org.brum.beds.ac.uk/10.3390/fire3040071
Chicago/Turabian StyleOtt, Cory W., Bishrant Adhikari, Simon P. Alexander, Paddington Hodza, Chen Xu, and Thomas A. Minckley. 2020. "Predicting Fire Propagation across Heterogeneous Landscapes Using WyoFire: A Monte Carlo-Driven Wildfire Model" Fire 3, no. 4: 71. https://0-doi-org.brum.beds.ac.uk/10.3390/fire3040071