
Dynamic Model of Collaboration in Multi-Agent System Based on Evolutionary Game Theory

Key Laboratory of Electronic Information of State Ethnic Affairs Commission, Southwest Minzu University, Chengdu 610041, China
*
Author to whom correspondence should be addressed.
Games 2021, 12(4), 75; https://0-doi-org.brum.beds.ac.uk/10.3390/g12040075
Submission received: 21 July 2021
/
Revised: 28 September 2021
/
Accepted: 29 September 2021
/
Published: 3 October 2021
(This article belongs to the Section Behavioral and Experimental Game Theory)
Abstract
:Multi-agent collaboration is greatly important in order to reduce the frequency of errors in message communication and enhance the consistency of exchanging information. This study explores the process of evolutionary decision and stable strategies among multi-agent systems, including followers, leaders, and loners, involved in collaboration based on evolutionary game theory (EGT). The main elements that affected the strategies are discussed, and a 3D evolution model is established. The evolutionary stability strategy (ESS) and stable conditions were analyzed subsequently. Numerical simulation results were obtained through MATLAB simulation, and they manifested that leaders play an important role in exchanging information with other agents, accepting agents’ state information, and sending messages to agents. Then, with the positivity of receiving and feeding back messages for followers, implementing message communication is profitable for the system, and the high positivity can accelerate the exchange of information. At the behavior level, reducing costs can strengthen the punishment of impeding the exchange of information and improve the positivity of collaboration to facilitate the evolutionary convergence toward the ideal state. Finally, the EGT results revealed that the possibility of collaboration between loners and others is improved, and the rewards are increased, thereby promoting the implementation of message communication that encourages leaders to send all messages, improve the feedback positivity of followers, and reduce the hindering degree of loners.
1. Introduction
A multi-agent system is an important branch of distributed artificial intelligence, and several independent agents are adopted to achieve common goals in this system. These agents have an autonomous ability to coordinate with each other. In multi-agent systems, the research on the system’s collaboration control has mainly involved tracking [1,2,3,4], formation [5,6,7], swarm [8,9,10], rendezvous [11], distributed filtering [12], and consistency [13,14]. Collaboration consistency elucidates that the state of all agents tends toward the same tendency, and it illustrates the rule of interacting and transmitting information when agents cooperate with other agents; additionally, it describes the process of information exchange between each agent and other agents. When agents are able to deal with various unpredictable situations and suddenly variable environments, the effectiveness of collaboration is reflected in reaching consensus on goals as the environment changes. Therefore, the agreement of multi-agents to achieve common goals is a primary condition for collaborative control.
In previous works, collaboration consistency was first applied to solve the problem of fusion under uncertain information in multi-sensors in 1974 [15]. In the subsequent few years, Borkar et al. [16,17] studied synchronous asymptotic consistency, which was adopted to investigate the decision of a distributed system in the field of control theory. In 1995 [18], Vicsek et al. proposed a classical model, that is, the dispersion system of multi-agents moving in a plane to simulate the phenomenon of particles presenting coherent behavior. Through the introduction of graph theory and matrix theory in 2003 [19], Jadbabaie explained the theory of consistency and found that the sets of agents’ neighbors varied over time in the system. Subsequently, R. Olfati et al. [20,21,22] described a framework of theory to figure out a consistency problem for dynamic systems. In 2010 [23], researchers observed the problem of consistency and synchronization of multi-agent systems in complex networks. Over the last few decades, researchers have explored this collaboration from different aspects. Some researchers focused on controlling groups of autonomous mobile vehicles to implement concentrated and decentralized collaboration control [24]. Two basic controllers of leader–follower control were proposed to allow the followers to maintain a relative position and avoid collisions in front of the obstacles. Different from other studies on leader–follower approaches, a recent article has suggested that the orientation deviations of leader–followers be explicitly expressed in the model to successfully solve collaboration controls when the agents move backward [25].
In previous studies, the agents’ consistency has been investigated in simple integrators, whereas agents are complex in practical engineering applications. In addition, it is not in line with the conditions of actual applications under complex and changeable environments.
In recent years, with the continuous efforts of researchers, the consistency of static and dynamic networks has been adopted in various fields to satisfy practical applications. In terms of the consistency of collaboration in formation control, leadership–follow strategy [26,27] indicates that some agents are leaders and others are followers who track the position and direction of the leaders at a certain distance. Some researchers [28] investigated the leader–follower formation control model based on uncertain nonholonomic-wheeled mobile robots. They also expressed that the leaders’ signal can be smooth, feasible, or nonfeasible. Adopting the estimated states of a leader, they transform formation errors into external oscillator states in an augmented system that presents additional control parameters that overcome actuation difficulties and reduce formation errors. One article [29] manifested the problem of formation control based on the leader–follower model in 3D space, which explores the persistent excitation of the desired formation to achieve the exponential stabilization of actual formation in terms of shape and scale. In general, designing these controllers to realize and describe the collaboration of agents is easy. However, considering the operating capability of different agents is difficult. Ignoring the perspective of global programming limits the effectiveness of the collaboration, which can be resolved in a distributed coordination approach. Then, for the consistency of collaboration, researchers [30,31] have investigated swarming motility in various networks. Tanner and Jadbabaie [32] proved the stability of swarm control and proposed a new protocol of consistency to analyze the stable properties of mobile agents and stabilize their inter-agent distances, adopting the rules of decentralized and nearest-neighbor interaction with exchanging information. The discontinuities of control laws are introduced via these changes. Nonsmooth analysis is used to accommodate arbitrary switching based on the network of interactions. The main result shows that regardless of switching, a common velocity vector is guaranteed to reach a convergence state when the network remains connected all along. Moreover, the collaboration based on the evolutionary game is analyzed thoroughly in small-world and scale-free networks [33,34,35]. Meanwhile, researchers described the consistency of fixed and switched topology in a multi-agent system [36,37,38], where each agent is a universal linear dynamic system and a linear model of nonlinear networks. Thus, a unified framework for complex networks is set up.
In summary, the existing studies only consider the interactions of leaders–followers. In reality, environmental factors play an indispensable role in the exchange of information. Therefore, the interactions of three stakeholders involved in the collaboration should be investigated.
Hence, in response to this discussion, the process of evolutionary decision and stable strategies among three stakeholders, such as followers, leaders, and loners, involved in the collaboration of a multi-agent system based on evolutionary game theory (EGT) is demonstrated. The main elements that affected the strategies of the agents are discussed, and the 3D replicator evolution equation is established to obtain the evolutionary stability strategy (ESS). Stable conditions are acquired through the theory of Lyapunov stability. The reasonability of the proposed mechanism is confirmed by simulation experiments. This research may help the agents to make optimal decisions and may provide theoretical guidance to agents to implement collaboration and adapt to complex environments. The contributions of this study are presented as follows:
(1) We establish a tripartite dynamic evolution model of followers, leaders, and loners for collaboration. Different from the previous game model, which involved only two stakeholders of leadership–followers, this model investigates the influence of factors and the exchange of information among the three stakeholders effectively.
(2) The main parameters of the strategies are involved in feedback, sending, and receiving messages for three parties, namely, the followers, leaders, and loners, respectively; these parameters are analyzed in the simulation discussion. Moreover, other influential factors, including the degree of positivity and the possibility of interaction, are discussed in the game model. We figure out the evolutionary stable strategies (ESS) of agents under different stability conditions and scenarios.
(3) The simulation results indicate that when the possibility of collaboration between loners and others is improved and when the rewards are increased, the implementation of message communication can be promoted to encourage leaders to send all messages, improve the positivity of feedback for followers, and reduce the hindering degree of loners.
(4) Finally, conclusions are obtained and policy implementation is put forward to offer suggestive guidance of actual application.
The remainder of this paper is presented as follows: We describe the evolution of the game model in Section 2. Then, Section 3 illustrates the equilibrium points and stability analysis. In Section 4, the simulation results and discussion are confirmed. Finally, our conclusions and policy enlightenment are figured out in Section 5.
2. Model
In this section, the dynamic collaboration model based on evolutionary game theory is proposed. Then, the payoff matrix of the agents is obtained according to the parameters of the agents’ behavior. In addition, the tripartite replication dynamic equation is derived.
2.1. Descriptions and Notes of the Parameters in a Multi-Agent System
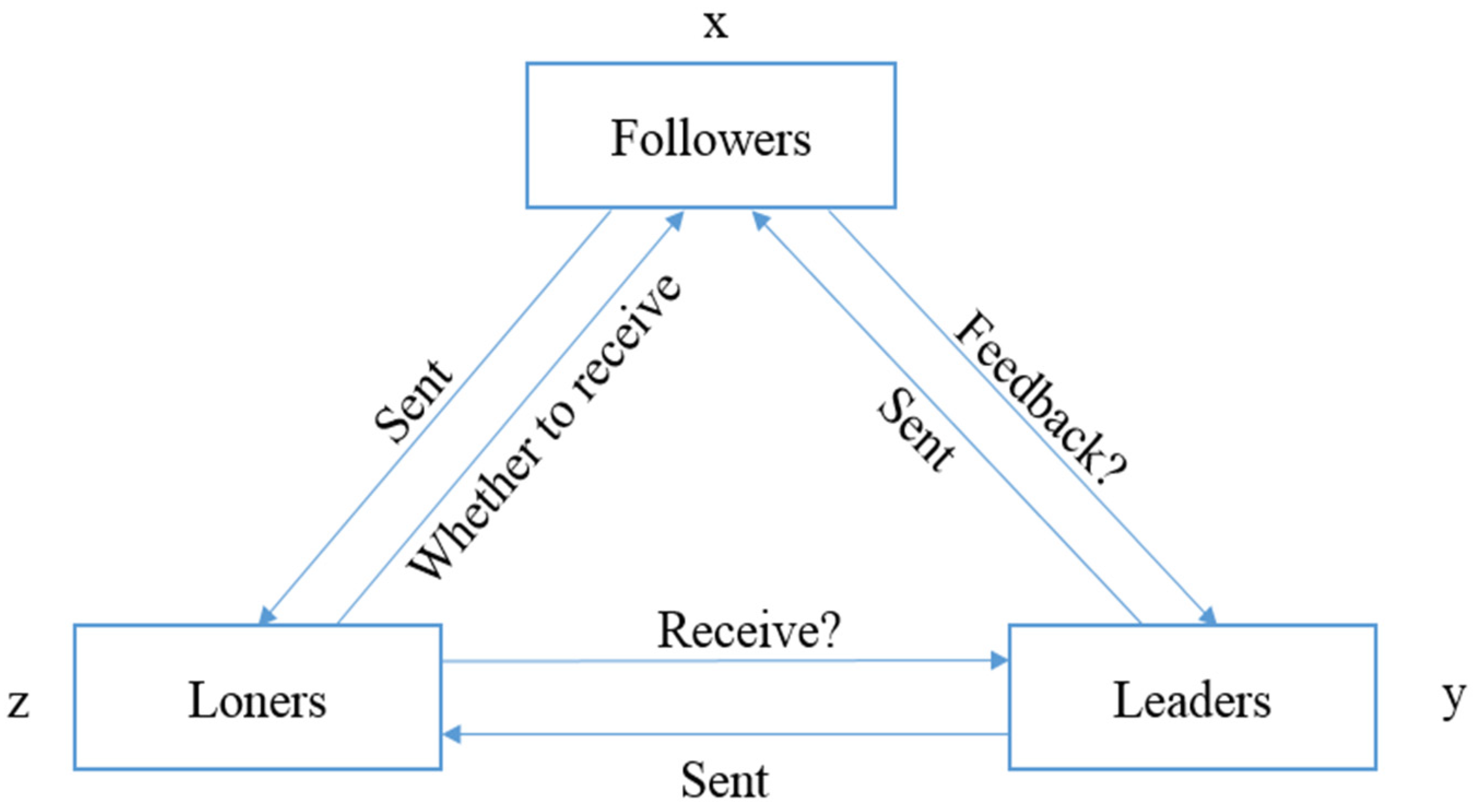
In a multi-agent system, each agent can work by itself or in an environment and interact with other agents. Thus, mutually independent agents deal with complex problems in the coordinated approach to achieve a common goal. However, agents may be disturbed by external factors in a hostile environment when completing tasks, thereby resulting in the failure of normal communication. We assume that the interferential factors are described by the loners’ behavior. As shown in Figure 1, in the multi-agent system model, different agents perform their own various tasks. Initially, leaders send messages to followers and loners. Then, the followers decide whether to provide feedback to the leaders after receiving messages while sending messages to the loners. Subsequently, the loners can select whether or not to receive messages. If the loners receive messages, then the destructive power of the loner decreases when they communicate with each other. Otherwise, the destructive power of the loner increases in the exchange of information in a changing environment.
All agents have the right to select their own decisions in the communication process. Therefore, the set of strategies for followers is {feedback, not feedback}. Regardless of sending all or partial messages to the leaders, the followers receive messages and obtain payoffs. Then, the followers decide whether or not the processed information is fed back to the leaders. They can obtain rewards when feeding back to the leaders. Otherwise, they obtain nothing and do not involve cost.
For leaders, the set of strategies is {all messages, partial messages}. They obtain payoffs with the cost of when sending all messages. When sending partial messages, they obtain payoffs under the cost of . Leaders can gain rewards as the feedback messages are received. We assume that is greater than , and is more than .
In terms of loners, the strategy set is {receive, not receive}. represents the payoff of loners receiving messages from followers with the cost of . The loners obtain payoffs when messages from the leaders are received under the cost of . represents the payoff of unsuccessfully receiving messages. Interactive rewards and can be obtained as loners interact with the followers and leaders, respectively.
Other parameters and notes are described as follows: represents the payoffs of receiving messages for followers at the cost of . indicates the payoffs that followers obtain as they send messages to loners with the cost of . We adopt parameters and to describe the degree of positivity for feedback and receiving, respectively, to define the positivity. represents the probability of successful sending. is the interactive possibility of agents communicating with others. For interactive rewards, we stipulate that the value of is the same as that of . Specific parameters and notes can be represented in Table 1.
2.2. Payoff Matrix of Agents
The proportion of strategies in the agents’ population can be denoted as follows. is the probability of followers feeding back messages. On the contrary, the probability of nonfeedback is . For leaders, represents the proportion of sending all messages. indicates the proportion of sending partial messages. In terms of loners, assuming that the probability of receiving messages is denotes the proportion of nonreceiving messages. The corresponding payoff matrix is shown in Table 2.
In accordance with the different strategies decided by agents, the corresponding payoffs can be obtained. Fop, Lep, and Lop represent the payoffs of followers, leaders, and loners, respectively. The specific expression is shown in the following equations:
2.3. Replication Dynamic Equation of Agents
The expected revenue can be obtained according to the payoff matrix. Let represent the expected payoffs of followers when they feedback messages. Similarly, represents the expected payoffs of nonfeedback, as shown in the equation where is the average of expected payoffs for followers. and can be shown as follows:
Hence, we can obtain the dynamic equation of followers as follows:
They obtain the expected payoffs when the leaders send all messages. Similarly, is the expected payoffs of sending partial messages, as shown in the equation where is the average of the expected payoffs.
Therefore, the dynamic equation of the leaders can be expressed as follows:
As loners receive messages, they obtain the expected payoffs . Similarly, indicates the expected payoffs of nonreceiving, as shown in the equation where is the average of the expected payoffs.
The dynamic equation of loners can be expressed as follows:
Finally, the 3D dynamic equations of the system are expressed by the replicated dynamic equations of the followers, leaders, and loners, as follows:
3. Equilibrium Point and Stability Analysis
To simplify the calculation, complex formulas of these dynamic equations can be expressed by simple letters as follows:
Hence, 3D dynamic equations can also be expressed as follows:
Theorem 1.
To gain equilibrium points, let,, andshould be equal to 0 in Equations (41)–(43). Under the condition of pure strategies, we can obtain eight equilibrium points(0,0,0),(0,0,1),(1,0,0),(1,1,0),(1,0,1),(0,1,0),(0,1,1), and(1,1,1). According to dynamic equations, the loners use two equilibrium points for pure strategies, such as(,,0) and(,,1). Among them, 0 << 1, 0 << 1.
Proof of Theorem 1.
Substituting the value of = 0 or 1, = 0 or 1, = 0 or 1 into Equations (41)–(43), equations , , and equal to 0 are satisfied. As a result, ,,,,,,, and are equilibrium points of the system model. As , if and , that is, , is plugged into Equations (41)–(43), where , and = 0 can be obtained. Therefore, and are also equilibrium points. The multi-agent system model has no mixed strategy equilibrium point. □
According to the method of Frideman [39,40], is an evolutionary stable strategy as and . Jacobian matrix analyses of the stability of the system should be adopted for convenient calculation. The Jacobian matrix for the system can be described as follows:
The specific matrix representation is shown in the following equation:
Initially, the equilibrium points are carried out into the Jacobian matrix to obtain the eigenvalues. Then, whether the equilibrium points are stable or not is judged according to the eigenvalues and limiting conditions; the results are shown in Table 3. Specifically, the eigenvalue of and is shown as follows:
4. Simulation Results and Discussion
The replication dynamic equation (RD) and the evolutionary stable strategy (ESS) constitute the core concepts of evolutionary game theory. They describe the dynamic convergence process to the steady-state of the evolutionary game. In RD, the time step of represents the derivative of the dynamic system of followers, leaders, and loners as follows:
Simulation experiments are carried out with different parameters to demonstrate the influence of the parameters on the convergence rate under the restricted condition of ESS. The length of time is set to 30.
4.1. Scenarios of Different Parameters with Constraint Conditions in the Equilibrium Points
4.1.1. Scenario 1
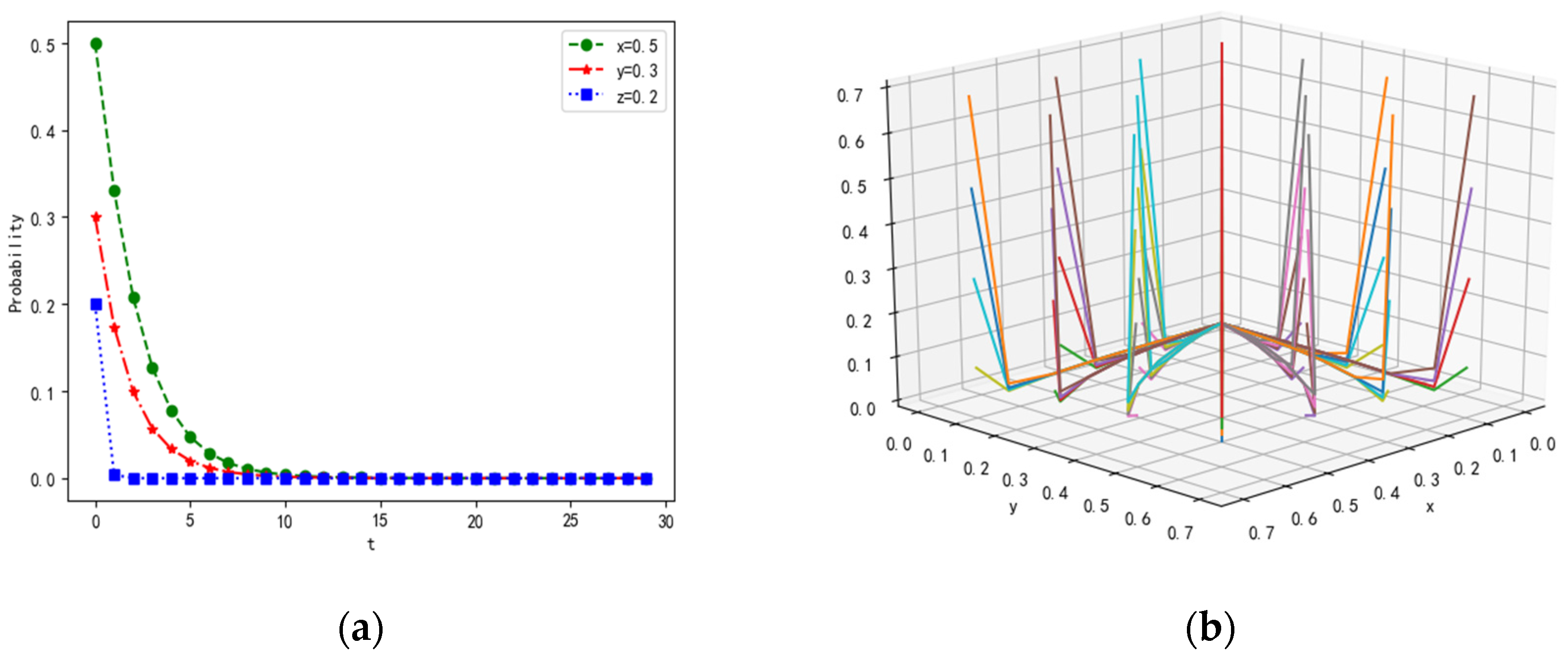
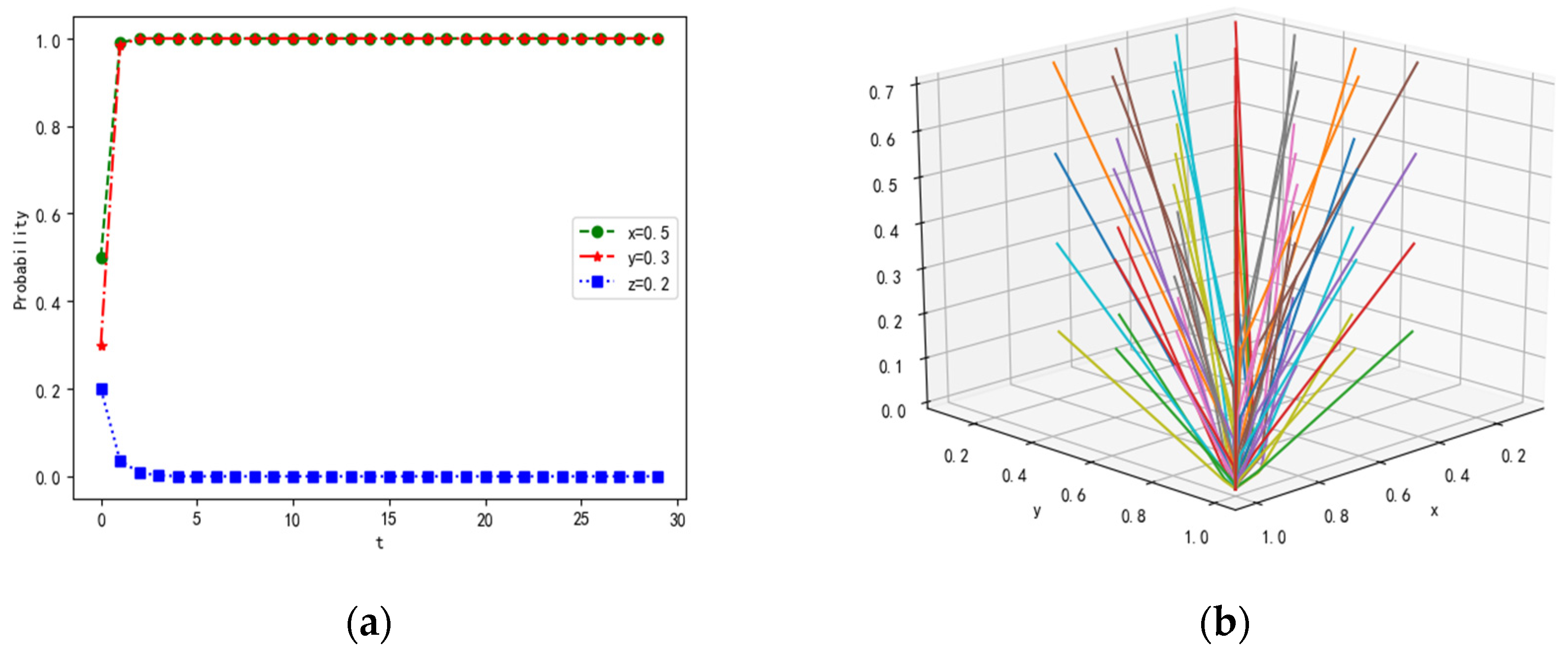
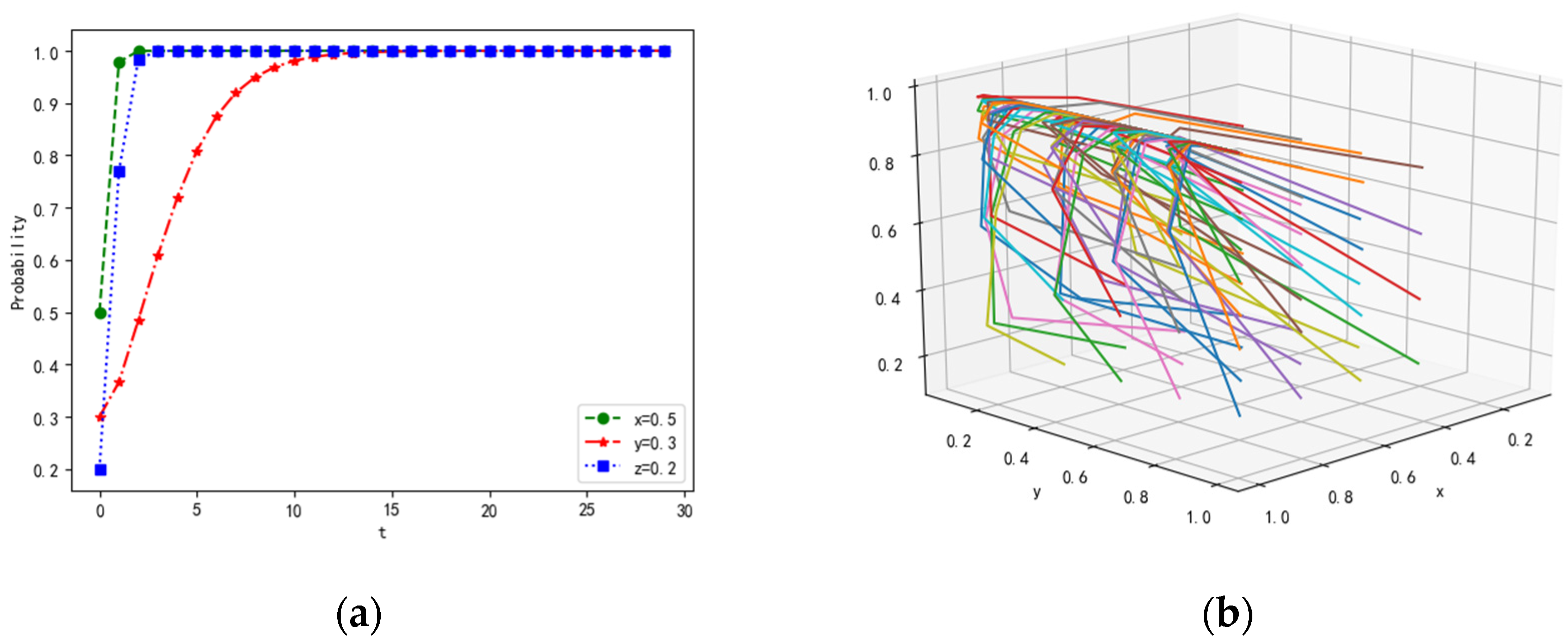
In point , we can set the initial values of parameters λ = 0.5, α = 0.2, β = 0.2, γ = 0.1, p = 0.3, Rf = 20, Cf = 5, PL1 = 15, PL2 = 10, CL1 = 3, CL2 = 1, RL = 20, CL = 5, Pz1 = 15, Pz2 = 15, Cz1 = 1,Cz2 = 1, If = 15, IL = 15, R = 10. The number of leaders with high comprehensive ability and loners with weak cooperation ability is in the minority due to the agents’ different abilities. At the initial time of dynamic evolution, that is, , we assume that the proportion of followers equals 0.5, the proportion of leaders equals 0.3, and the proportion of loners equals 0.2. The evolutionary results are denoted in Figure 2.
For , that is, and , we find that the cost of tasks completed together is higher than the payoffs in the multi-agent system, thereby leading to the probability of feedback, sending, and receiving tending to zero over time. If the leaders do not send messages, then the followers and loners will not receive and feedback messages. This phenomenon is not conducive to the collaboration and interaction of the system.
4.1.2. Scenario 2
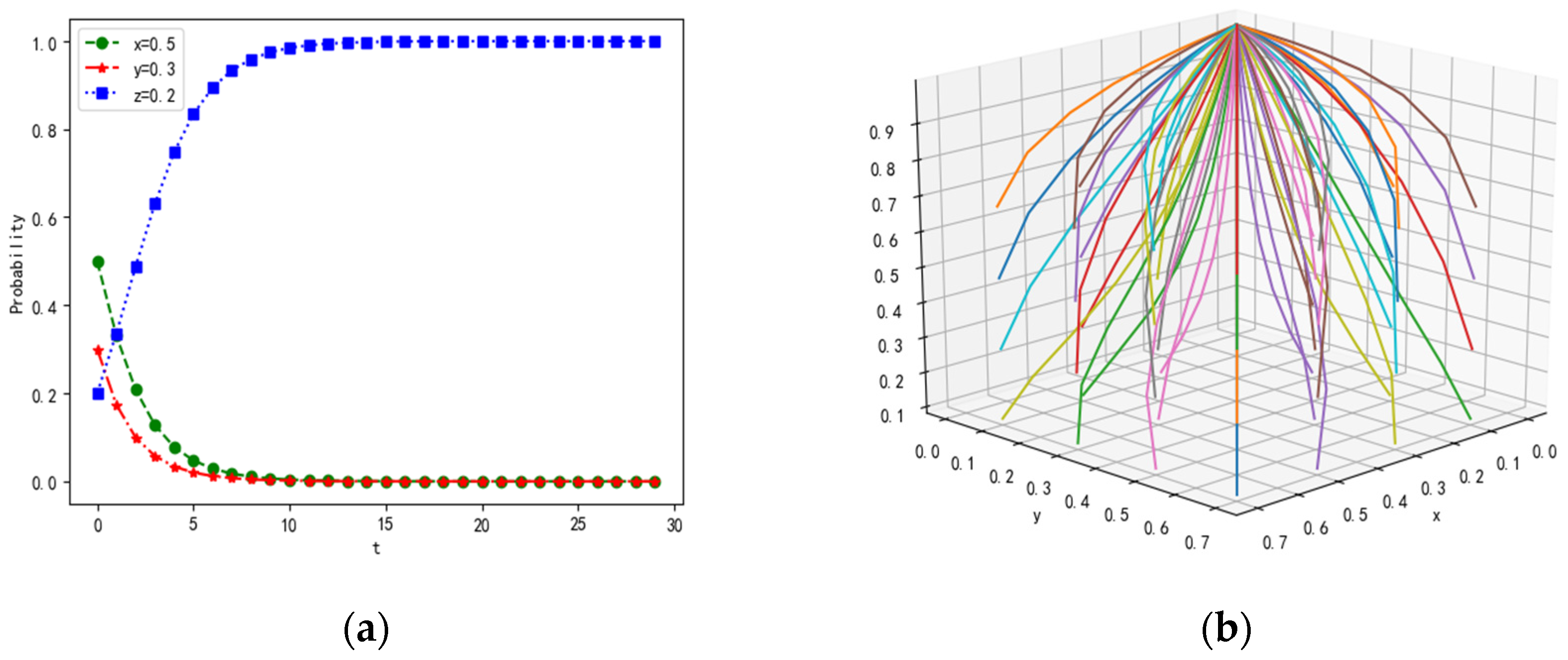
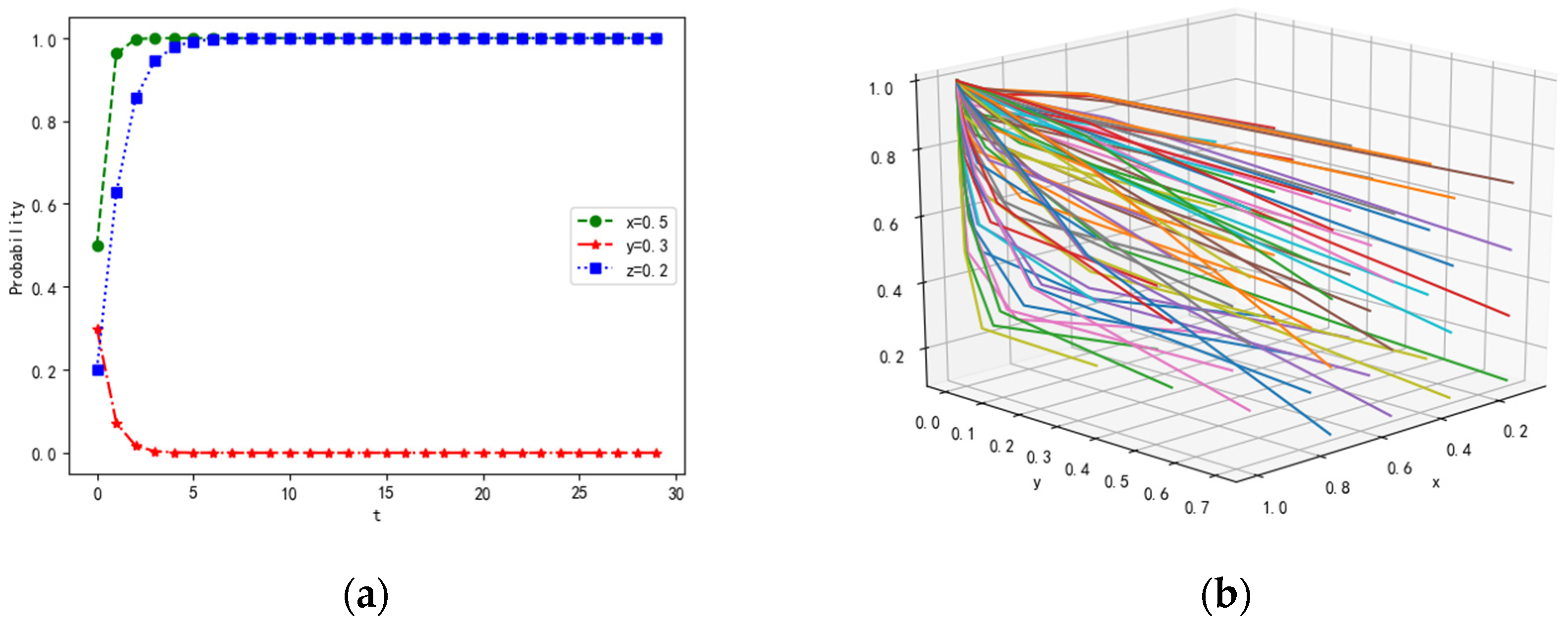
According to the stability conditions of , the parameter values are set as follows: λ = 0.5, α = 0.2, β = 0.2, γ = 0.3, p = 0.3, Rf = 20, Cf = 5, PL1 = 15, PL2 = 10, CL1 = 3, CL2 = 1, RL = 20, CL = 5, Pz1 = 20, Pz2 = 20, Cz1 = 1,Cz2 = 1, If = 15, IL = 15, R = 10. The probability of strategies remains unchanged. The simulation results are shown in Figure 3.
Under the condition of and , the payoffs of receiving and the possibility of interaction are improved for loners, compared with their initial values. Hence, the probability of receiving tends to 1 for loners. Therefore, the willingness to receive messages is enhanced as the payoffs of receiving and the possibility of interaction are improved. When the loners are willing to receive messages, their damage is reduced; thus, the ability to collaborate is enhanced in the multi-agent system.
4.1.3. Scenario 3
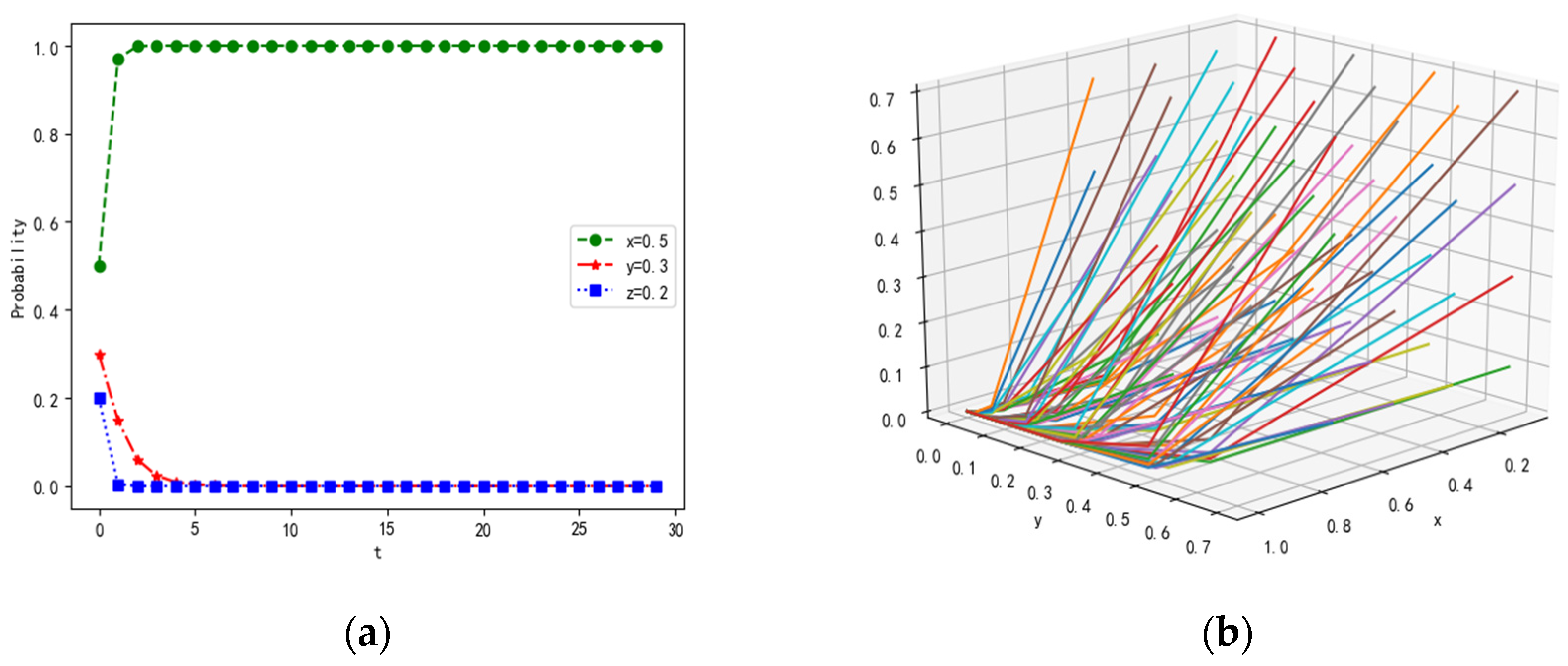
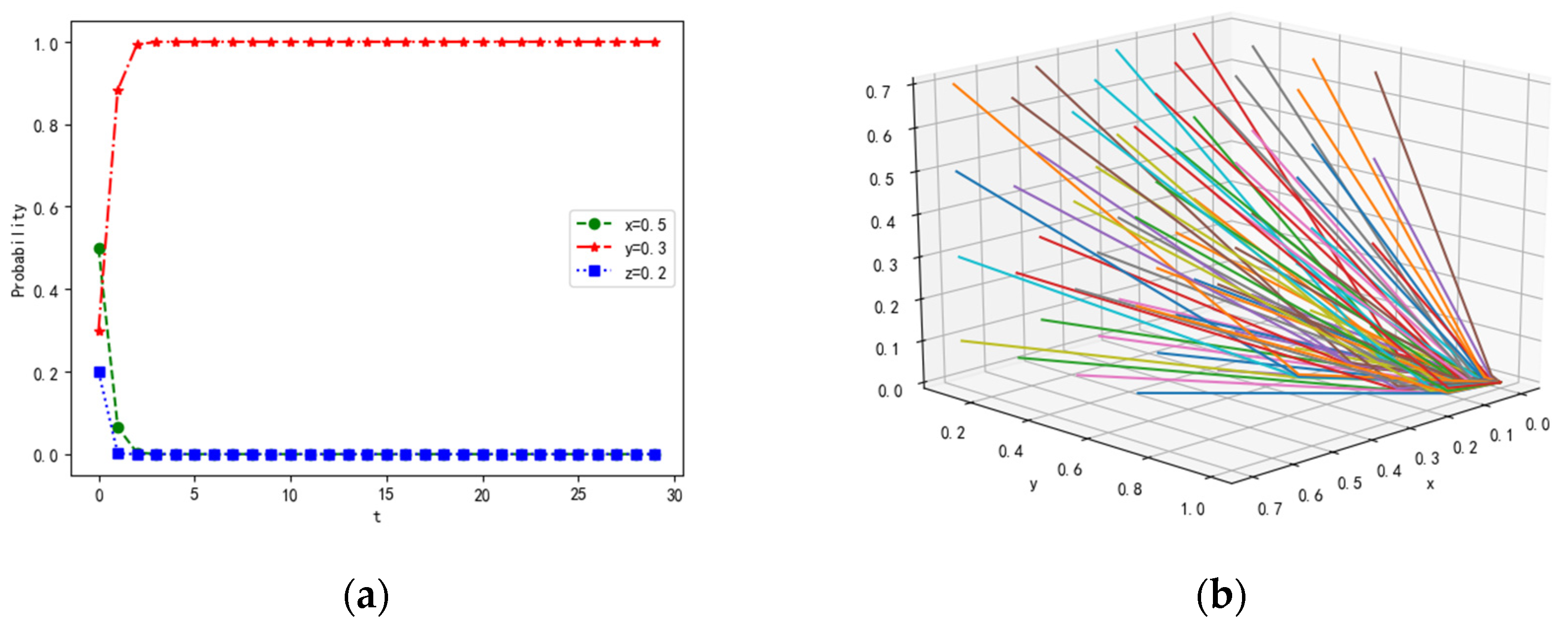
In terms of the stability conditions of , the parameter values are assumed as follows: λ = 0.5, α = 0.5, β = 0.2, γ = 0.1, p = 0.3, Rf = 20, Cf = 5, PL1 = 15, PL2 = 10, CL1 = 3, CL2 = 1, RL = 20, CL = 5, Pz1 = 15, Pz2 = 15, Cz1 = 1,Cz2 = 1, If = 15, IL = 15, R = 10. The probability of strategies remains unchanged. The simulation results are shown in Figure 4.
For the condition of and , the positivity of feedback is improved for followers, compared with initial values. Hence, the probability of the strategies of feedback tends to 1 for followers. That is, the followers can track leaders and share information with each other in real-time, strengthening their ability to cooperate with each other in the multi-agent system. The possibility that agents are influenced by others with the power to destroy collaboration is reduced; thus, the ability to collaborate is enhanced in the system.
4.1.4. Scenario 4
On the basis of the stability conditions of , the parameters values are λ = 0.5, α = 0.5, β = 0.2, γ = 0.1, p = 0.5, Rf = 20, Cf = 5, PL1 = 25, PL2 = 15, CL1 = 3, CL2 = 1, RL = 20, CL = 5, Pz1 = 15, Pz2 = 15, Cz1 = 1,Cz2 = 1, If = 15, IL = 15, R = 10. The probability of the strategies remains unchanged. The simulation results are shown in Figure 5.
For the condition of and , the probability of successful sending and payoffs is improved for leaders, compared with the parameter values at point . Hence, the probability of the strategies to send also tends to 1; that is, sending accurate messages is a prerequisite of successful communication in the multi-agent system.
4.1.5. Scenario 5
According to the stability conditions of , the parameter values are set to λ = 0.5, α = 0.5, β = 0.2, γ = 0.3, p = 0.3, Rf = 20, Cf = 5, PL1 = 15, PL2 = 10, CL1 = 5, CL2 = 1, RL = 15, CL = 1, Pz1 = 20, Pz2 = 20, Cz1 = 1,Cz2 = 1, If = 15, IL = 15, R = 5. The probability of strategies remains unchanged. The simulation results are shown in Figure 6.
For the condition of and , the positivity of feedback is improved for followers, and the payoffs of unreceiving decreases, compared with the parameters’ values in . Hence, the probability of the strategies of feedback also tends to 1 for the followers; that is, the followers can track leaders and share information with each other in real time, strengthening the ability of agents to cooperate with each other. The damage of loners is reduced due to the decrease in ; thus, the ability to collaborate is enhanced in the multi-agent system. Figure 6 shows the difference in graphs.
4.1.6. Scenario 6
On the basis of the stability conditions of , the parameter values are λ = 0.5, α = 0.2, β = 0.2, γ = 0.1, p = 0.5, Rf = 10, Cf = 5, PL1 = 20, PL2 = 20, CL1 = 3, CL2 = 1, RL = 20, CL = 5, Pz1 = 15, Pz2 = 15, Cz1 = 1, Cz2 = 1, If = 15, IL = 15, R = 10. The probability of strategies remains unchanged. The simulation results are shown in Figure 7.
For the condition of and , the positivity of feedback and rewards decreased for the followers, compared with the parameter values in point . Meanwhile, the payoffs of sending reduce for leaders. Hence, the probability of the strategies of feedback tends to 0. The convergence speed of the strategy of receiving declines. In this scenario, loners do not send messages on time, and the followers are inactive to feedback, resulting in delayed collaboration and tracking errors in the multi-agent system.
4.1.7. Scenario 7
For the stability conditions of , the parameter values are λ = 0.5, α = 0.2, β = 0.2, γ = 0.1, p = 0.5, Rf = 10, Cf = 5, PL1 = 20, PL2 = 10, CL1 = 3, CL2 = 1, RL = 20, CL = 5, Pz1 = 20, Pz2 = 20, Cz1 = 1, Cz2 = 1, If = 15, IL = 15, R = 10. The probability of strategies remains unchanged. The simulation results are shown in Figure 8.
For the condition of and , the payoffs of receiving are improved for the loners, compared with the parameter values at point . Hence, the probability of the strategies of receiving also tends to 1. In this scenario, the loners can receive messages and promote the probability of interaction, reducing the destructive possibility of tracking to cooperate in the multi-agent system.
4.1.8. Scenario 8
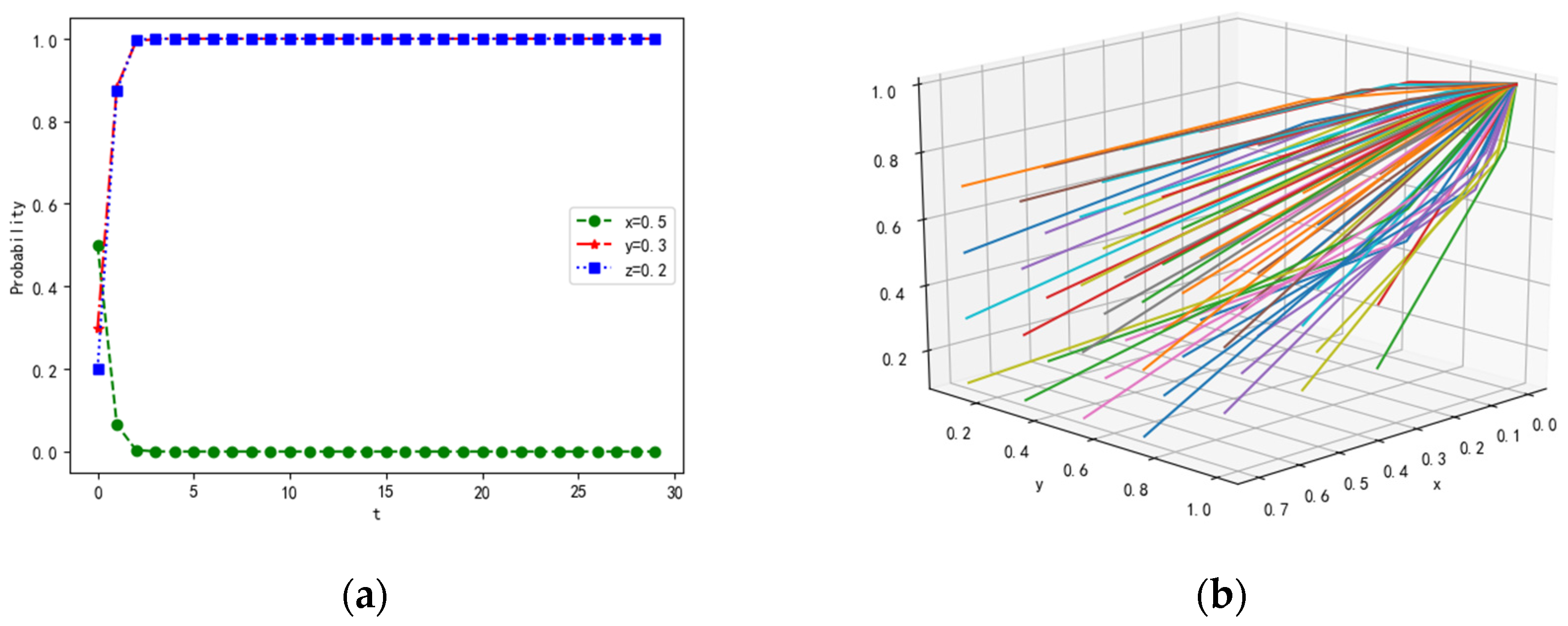
In terms of the stability conditions of , the parameter values are λ = 0.5, α = 0.5, β = 0.2, γ = 0.1, p = 0.5, Rf = 20, Cf = 5, PL1 = 20, PL2 = 10, CL1 = 3, CL2 = 1, RL = 20, CL = 5, Pz1 = 20, Pz2 = 20, Cz1 = 1, Cz2 = 1, If = 15, IL = 15, R = 10. The probability of strategies remains unchanged. The simulation results are shown in Figure 9.
Under the conditions of and , the payoffs of feedback and the positivity of feedback are improved for the followers, compared with the parameter values at point . Hence, the probability of the strategies of feedback also tends to 1. In this scenario, the convergence speed of the loners decreases and that of the followers and leaders increases, enhancing the communication and cooperation capabilities of target tracking in the multi-agent system.
4.2. Impacts of Different Parameters on the Evolutionary Results
This analysis indicates that point is an ideal ESS at eight equilibrium points. Though the initial values of the parameters do not affect the evolutionary results, they can affect the speed of convergence. Subsequently, we investigate the effect of parameters, such as the proportion of messages , the positivity of feedback and receiving , the possibility of interaction , and the probability of successful sending p on mutual cooperation. The evolutionary results of and p are shown in the following section.
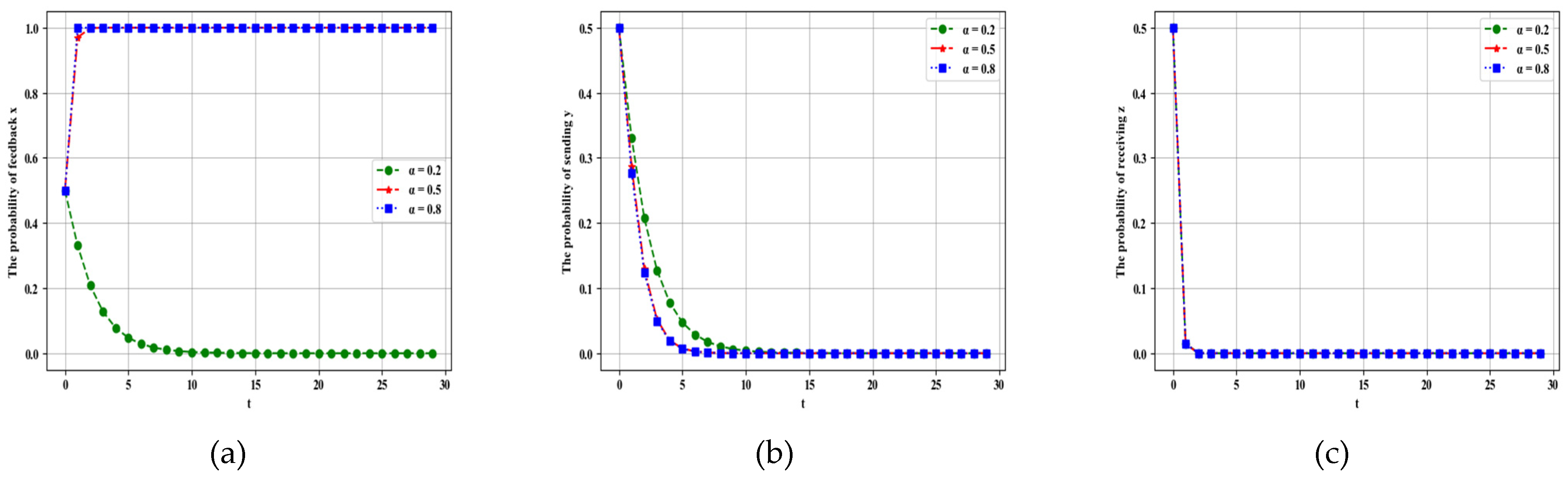
4.2.1. Influence of Parameter on Dynamic Evolution
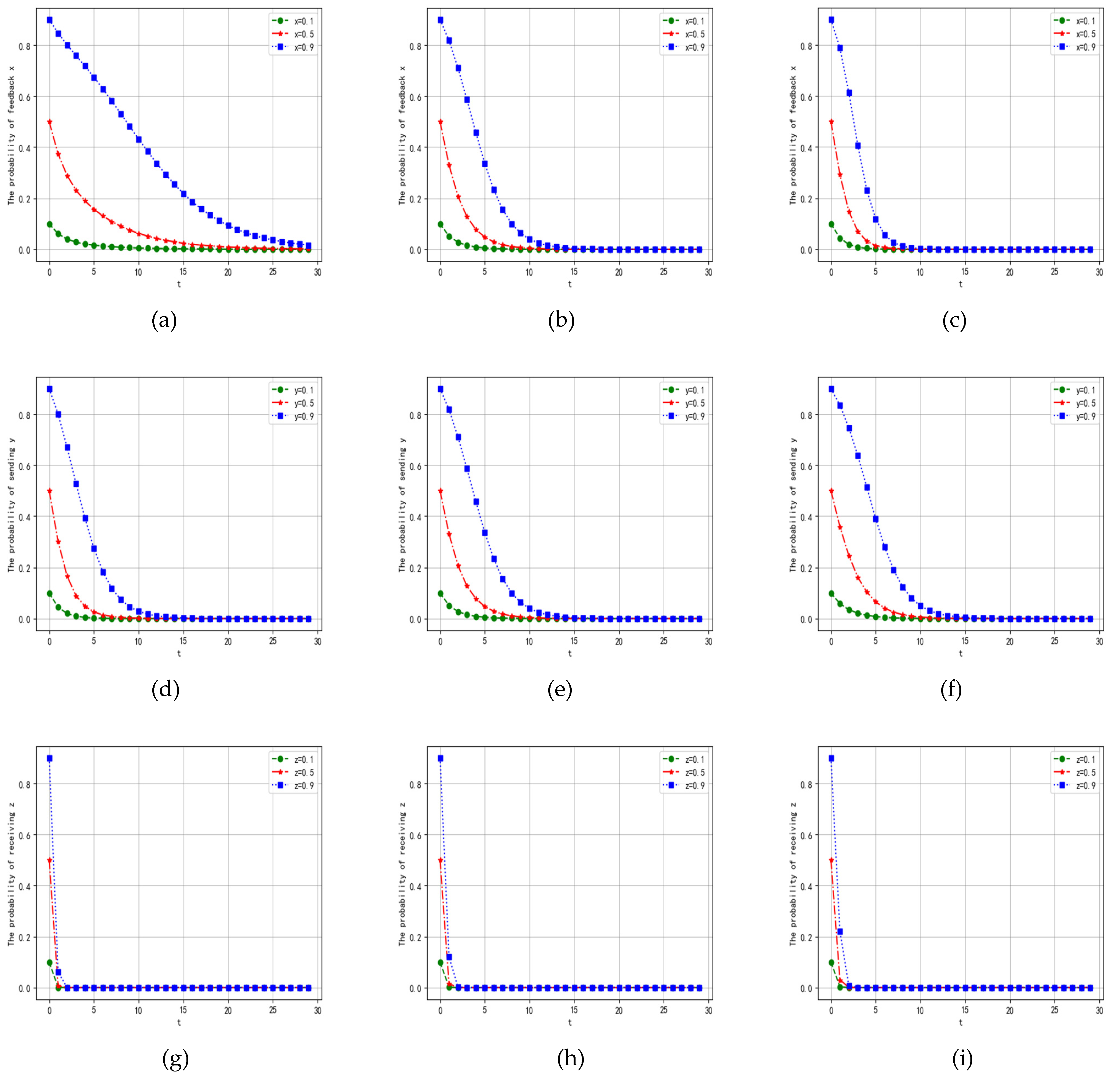
Leaders send messages with a certain proportion, which can affect the accuracy of communication throughout the system. Sending all messages provides the basic guarantee for target tracking. On the contrary, lack of information leads to the deviation in tracking and affects the feedback of followers. Hence, exploring the effect of parameter on followers, leaders, and loners is necessary. The other parameters are set as follows: α = 0.5, β = 0.2, γ = 0.1, p = 0.5, Rf = 20, Cf = 5, PL1 = 20, PL2 = 10, CL1 = 3, CL2 = 1, RL = 20, CL = 5, Pz1 = 20, Pz2 = 20, Cz1 = 1, Cz2 = 1, If = 15, IL = 15, R = 10. When is 0.2, 0.5, and 0.8, the simulation results are as shown in Figure 10.
For the followers, as increases, the probability of feedback remains unchanged, but the convergence speed increases with different proportions of feedback. Sending all messages can enhance leaders’ performance to motivate the effectiveness of followers’ feedback. With the increase in , the probability and convergence speed of sending are unchanged. does not affect the probability and convergence speed of receiving of the loners.
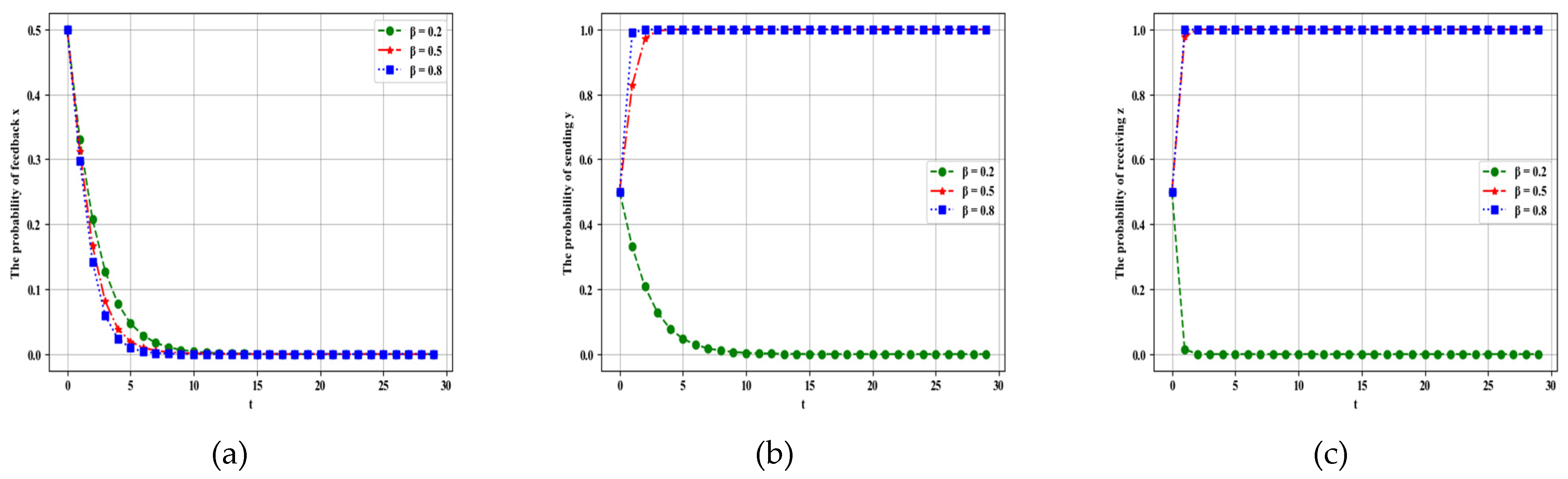
4.2.2. Influence of Parameter on Dynamic Evolution
Figure 11 elucidates the impact of parameter on evolutionary results under different agents in the multi-agent system. The other parameters are assumed as follows: λ = 0.5, β = 0.2, γ = 0.1, p = 0.5, Rf = 20, Cf = 5, PL1 = 20, PL2 = 10, CL1 = 3, CL2 = 1, RL = 20, CL = 5, Pz1 = 20, Pz2 = 20, Cz1 = 1, Cz2 = 1, If = 15, IL = 15, R = 10. The values of are set to 0.2, 0.5, and 0.8, and the simulation results are shown in the following section.
When the positivity of feedback of the followers increases, the probability of feedback builds up from 0 to 1; thus, can affect the selection of strategy of the followers. However, the probability of sending is not affected by the increase in as it approaches 0. The convergence speed of sending is improved when the value of increases. For the loners, with the increase in , the probability of receiving remains unchanged, and tends to 0 under different . Thus, the feedback’s positivity evidently affects dynamic evolution.
4.2.3. Influence of Parameter on Dynamic Evolution
The positivity of receiving messages of a certain proportion can affect the accuracy of communication throughout the system. In fact, if messages are received by the leaders and loners, then this provides the basic guarantee for target tracking. On the contrary, lack of receiving information leads to deviation in tracking and affects the feedback for followers. Hence, exploring the effect of parameter on followers, leaders, and loners is necessary. Other parameters are λ = 0.5, α = 0.2, γ = 0.1, p = 0.5, Rf = 20, Cf = 5, PL1 = 20, PL2 = 10, CL1 = 3, CL2 = 1, RL = 20, CL = 5, Pz1 = 20, Pz2 = 20, Cz1 = 1, Cz2 = 1, If = 15, IL = 15, R = 10. When is 0.2, 0.5, and 0.8, the simulation results are as shown in Figure 12.
As increases, the probability of feedback remains unchanged, but the probability of sending y and receiving increases from 0 to 1. Receiving feedback messages and transmitting messages can enhance the system’s performance to motivate the effectiveness of feedback, sending, and receiving. With the increase in , the probability and the convergence speed of sending of the followers are unchanged. In terms of loners and leaders, does not affect the convergence and the speed of receiving and sending.
4.2.4. Influence of Parameter on Dynamic Evolution
Figure 13 illustrates the impact of parameter on the evolutionary results under different agents in the multi-agent system. Other parameters are assumed as follows: λ = 0.5, α = 0.5, β = 0.2, p = 0.5, Rf = 20, Cf = 5, PL1 = 20, PL2 = 10, CL1 = 3, CL2 = 1, RL = 20, CL = 5, Pz1 = 20, Pz2 = 20, Cz1 = 1, Cz2 = 1, If = 15, IL = 15, R = 10. The values of are set to 0.2, 0.5, and 0.8, and the simulation results are shown in the following section.
When the possibility of interaction increases, the probability of feedback and sending remains unchanged. We found that can affect the selection of strategy for loners. The probability of receiving increases from 0 to 1 with the increase in , and its convergence speed also increases. The dynamic evolution of collaboration is enhanced with the increase in interactive possibilities in multi-agent systems. In summary, the possibility of interaction increases, thereby enhancing the positivity of receiving messages. Therefore, this condition is favorable when communicating with each other.
4.2.5. Influence of Parameter on Dynamic Evolution
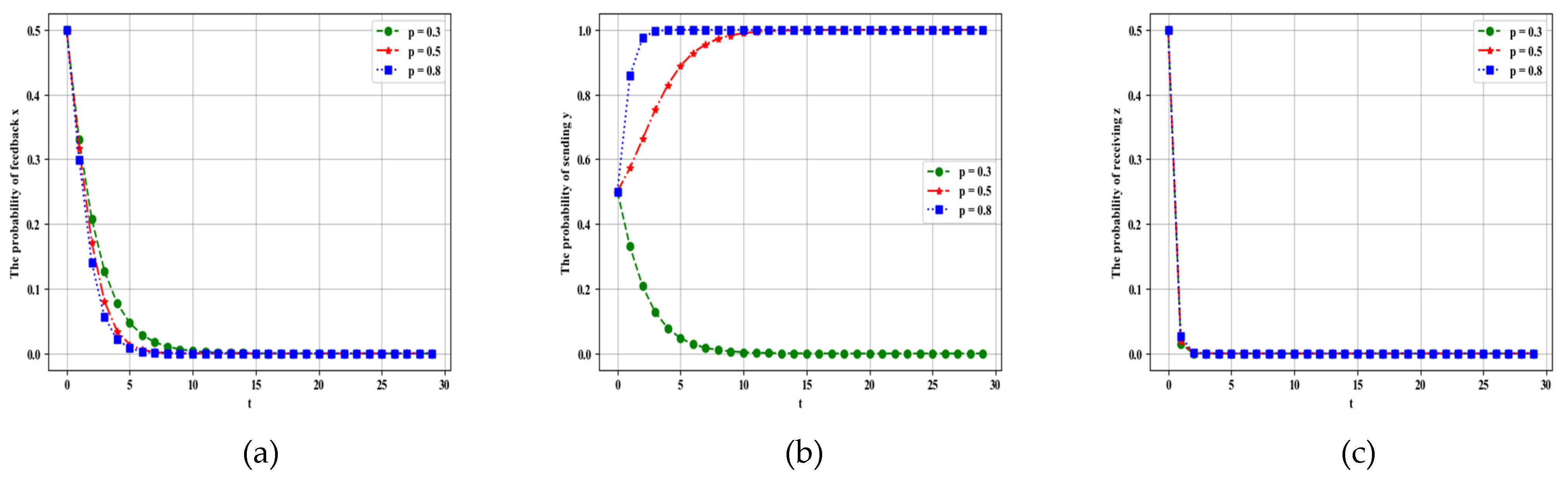
The probability of successful sending with different proportions can affect the accuracy of communication throughout the system. Hence, exploring the effect of parameter on the system is necessary. Other parameters are λ = 0.5, α = 0.5, β = 0.2, γ = 0.1, Rf = 20, Cf = 5, PL1 = 20, PL2 = 10, CL1 = 3, CL2 = 1, RL = 20, CL = 5, Pz1 = 20, Pz2 = 20, Cz1 = 1, Cz2 = 1, If = 15, IL = 15, R = 10. When is 0.2, 0.5, and 0.8, the simulation results are shown in Figure 14.
With the increase in , the probability of receiving remains unchanged, but the probability of sending increases from 0 to 1. The convergence speed of feedback and sending is improved. In fact, if the messages are sent by leaders successfully, then the basic guarantee for target tracking is provided. On the contrary, lack of sending information leads to deviation in tracking and affects the feedback. As increases, the convergence speed of feedback increases for the followers. In terms of loners, does not affect the convergence speed of receiving. In summary, the probability of successful sending p increases, thereby enhancing the positivity of feedback and sending messages to communicate with each other.
5. Conclusions and Policy Enlightenment
In summary, we have demonstrated the evolution of collaboration based on evolutionary games. This study initially develops the model of different strategies, different parameters, and interaction in a multi-agent system of followers, leaders, and loners. Subsequently, after setting up the replication dynamic equation of different roles, equilibrium points are obtained to confirm the constraint conditions of the evolutionary stable strategy. Then, the research focuses on the influence of strategies and parameters on the dynamic evolutionary results of collaboration in different scenarios. The simulation results indicate that to gain the optimal results, followers should feedback messages to leaders positively while receiving messages from the leaders and transmitting messages to the loners. The leaders send all messages to the followers and loners; the loners receive the messages from the followers and leaders. In fact, the results have shown that the leaders played an important role in the collaboration. If all messages are sent by the leaders successfully, then they provide a basic guarantee for the accurate exchange of information. On the contrary, the lack of sending all information leads to a deviation in tracking and an impact on feedback. In terms of a multi-agent system, collaboration is key to ensure that all agents harmoniously form a unified entirety in an expectant approach.
In addition, according to the simulation results, we found that the consistency of collaboration is in an optimal state when the stakeholders agree to achieve a common goal of exchanging information. That is, leaders send all messages, followers feedback messages to leaders on time, and loners receive messages positively, as shown in Figure 9. This result demonstrates that the effectiveness of our proposed model is reasonable.
This study elucidates some policy implementations of the model realized by the followers, leaders, and loners for collaboration in evolutionary games. The probability of strategies is affected by their obtained payoffs and costs in the system. Therefore, promoting their payoffs is necessary to enhance the positivity of interaction while decreasing costs of communication with each other. For the followers, the payoffs of receiving and transmitting are increased to motivate the positivity of feedback messages. Then, improving the rewards of feedback in the communication process between followers and leaders is reasonable. For the leaders, sending all messages is necessary to provide the basis of mutual communication. On the contrary, if partial messages are sent, then integral communication is affected in the multi-agent system. Meanwhile, reducing the costs of sending can enhance interaction with agents. The probability of the successful sending of messages should be improved to provide a basic guarantee for collaboration, which can ensure that all agents receive messages. For the loners, increasing the possibility of interaction with followers and leaders is the most important to reduce hindrance to the system. That is, as much interaction as possible between loners and others is a good decision, thereby ensuring that all agents harmoniously form a unified entirety in an expectant approach. Then, through cooperation between agents, the basic capabilities of each agent are improved, and their social behavior can be further understood from the interaction of the agents. In summary, in a dynamic and open environment, agents with different goals must coordinate their goals and resources. During conflicts between resources and goals, if the coordination of agents fails to reach a better situation, then a deadlock occurs. This condition causes the agents to be unable to carry out their next step of work. On the contrary, if all agents can reach an agreement of collaboration in a multi-agent system, then the exchange of information is enhanced to improve cooperation.
Author Contributions
Z.G.: methodology, visualization, and writing of the original draft. Y.D.: review. Z.G. and Y.D.: preliminary investigations. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Science Foundation (62073270, 61673016, 61703353), Innovation Research Team of the Education Department of Sichuan province (15TD0050), and the Graduate Innovative Research Project of Southwest Minzu University, Project number: CX2020SZ99.
Acknowledgments
We really appreciate the support from the National Science Foundation (62073270, 61673016, 61703353), Innovation Research Team of the Education Department of Sichuan province (15TD0050), and the Graduate Innovative Research Project of Southwest Minzu University, Project number: CX2020SZ99.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Harmati, I.; Skrzypczyk, K. Robot team coordination for target tracking using fuzzy logic controller in game theoretic framework. Robot. Auton. Syst. 2009, 57, 75–86. [Google Scholar] [CrossRef]
- Zhang, M.; Liu, H.H. Cooperative tracking a moving target using multiple fixed-wing uavs. J. Intell. Robot. Syst. 2016, 81, 505–529. [Google Scholar] [CrossRef]
- Cheng, Y.; Wang, S.; Yu, D. Improved fast compressive tracking for low-altitude flying target tracking. Multi-Media Tools Appl. 2021, 80, 11239–11254. [Google Scholar] [CrossRef]
- Cheng, Y.; Wang, S.A.; Yu, D. García-Martínez, Target tracking with dynamically adaptive correlation. Opt. Commun. 2016, 365, 140–149. [Google Scholar]
- Zhang, L.; Feng, J.E. Mix-valued logic-based formation control. Int. J. Control. 2013, 86, 1191–1199. [Google Scholar] [CrossRef]
- Zhao, S. Affine formation maneuver control of multi-agent systems. IEEE Trans. Autom. Control. 2018, 63, 4140–4155. [Google Scholar] [CrossRef] [Green Version]
- Qian, M.; Jiang, B.; Xu, D. Fault tolerant control scheme design for the formation control system of unmanned aerial vehicles. Proc. Inst. Mech. Eng. Part I J. Syst. Control. Eng. 2013, 227, 626–634. [Google Scholar] [CrossRef]
- Chen, Y.H. Adaptive robust control of artificial swarm systems. Appl. Math. Comput. 2010, 217, 980–987. [Google Scholar] [CrossRef]
- Liang, X.; Qu, X.; Wang, N.; Li, Y.; Zhang, R. A novel distributed and self-organized swarm control framework for under-actuated unmanned marine vehicles. IEEE Access 2019, 7, 112703–112712. [Google Scholar] [CrossRef]
- Han, K.; Lee, J.; Kim, Y. Unmanned aerial vehicle swarm control using potential functions and sliding mode control. Proc. Inst. Mech. Eng. Part G J. Aerosp. Eng. 2008, 222, 721–730. [Google Scholar] [CrossRef]
- Parasuraman, R.; Kim, J.; Luo, S.; Min, B.C. Multipoint rendezvous in multi-robot systems. IEEE Trans. Cybern. 2019, 50, 310–323. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.; Huang, C.; Peng, L. Distributed consensus strong tracking filter for wireless sensor networks with model mismatches. Int. J. Distrib. Sens. Netw. 2017, 13, 1550147717741576. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.M.; Lin, T.E.; Lee, L.W. Group decision making using incomplete fuzzy preference relations based on the additive consistency and the order consistency. Inf. Sci. 2014, 259, 1–15. [Google Scholar] [CrossRef]
- Yao, Q.; Hu, Y.; Chen, Z.; Liu, J.Z.; Meng, H. Active power dispatch strategy of the wind farm based on improved multi-agent consistency algorithm. IET Renew. Power Gener. 2019, 13, 2693–2704. [Google Scholar] [CrossRef]
- Degroot, M.H. Reaching a consensus. J. Am. Stat. Assoc. 1974, 69, 118–121. [Google Scholar] [CrossRef]
- Borkar, V.; Varaiya, P. Asymptotic agreement in distributed estimation. IEEE Trans. Autom. Control. 1982, 27, 650–655. [Google Scholar] [CrossRef] [Green Version]
- Tsitsiklis, J.; Athans, M. Convergence and asymptotic agreement in distributed decision problems. IEEE Trans. Autom. Control. 1984, 29, 42–50. [Google Scholar] [CrossRef] [Green Version]
- Vicsek, T.; Czirók, A.; Ben-Jacob, E.; Cohen, I.; Shochet, O. Novel type of phase transition in a system of self-driven particles. Phys. Rev. Lett. 1995, 75, 1226–1229. [Google Scholar] [CrossRef] [Green Version]
- Jadbabaie, A.; Lin, J.; Morse, A. Coordination of groups of mobile autonomous agents using nearest neighbor rules. IEEE Trans. Autom. Control. 2003, 48, 988–1001. [Google Scholar] [CrossRef] [Green Version]
- Olfati-Saber, R.; Murray, R. Consensus problems in networks of agents with switching topology and time-delays. IEEE Trans. Autom. Control. 2004, 49, 1520–1533. [Google Scholar] [CrossRef] [Green Version]
- Olfati-Saber, R.; Fax, J.A.; Murray, R.M. Consensus and cooperation in networked multi-agent systems. Proc. IEEE 2007, 95, 215–233. [Google Scholar] [CrossRef] [Green Version]
- Xiao, F.; Wang, L.; Wang, A. Consensus problems in discrete-time multiagent systems with fixed topology. J. Math. Anal. Appl. 2006, 322, 587–598. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Duan, Z.; Chen, G.; Huang, L. Consensus of multiagent systems and synchronization of complex networks: A unified viewpoint. IEEE Trans. Circuits Syst. I Regul. Pap. 2010, 57, 213–224. [Google Scholar]
- Wang, J.; Tan, Y.; Mareels, I. Robustness analysis of leader-follower consensus. J. Syst. Sci. Complex. 2009, 22, 186–206. [Google Scholar] [CrossRef]
- Jian, C.; Sun, D.; Yang, J.; Chen, H. Leader-Follower Formation Control of Multiple Non-holonomic Mobile Robots Incorporating a Receding-horizon Scheme. Int. J. Robot. Res. 2010, 29, 727–747. [Google Scholar] [CrossRef]
- Shao, J.; Xie, G.; Wang, L. Leader-following formation control of multiple mobile vehicles. IET Control. Theory Appl. 2007, 1, 545–552. [Google Scholar] [CrossRef]
- Tang, Q.; Cheng, Y.; Hu, X.; Chen, C.; Song, Y.; Qin, R. Evaluation Methodology of Leader-Follower Autonomous Vehicle System for Work Zone Maintenance. Transp. Res. Rec. J. Transp. Res. Board 2021, 2675, 107–119. [Google Scholar] [CrossRef]
- Yan, L.; Ma, B. Adaptive practical leader-following formation control of multiple non-holonomic wheeled mobile robots. Int. J. Robust Nonlinear Control. 2020, 30, 7216–7237. [Google Scholar] [CrossRef]
- Tang, Z.; Cunha, R.; Hamel, T.; Silvestre, C. Formation control of a leader–follower structure in three dimensional space using bearing measurements. Automatica 2021, 128, 109567. [Google Scholar] [CrossRef]
- Saber, R.; Murray, R. Consensus protocols for networks of dynamic agents. In Proceedings of the 2003 American Control Conference, Denver, CO, USA, 4–6 June 2003; Volume 2, pp. 951–956. [Google Scholar]
- Moreau, L. Stability of multiagent systems with time-dependent communication links. IEEE Trans. Autom. Control. 2005, 50, 169–182. [Google Scholar] [CrossRef]
- Tanner, H.G.; Jadbabaie, A.; Pappas, G.J. Flocking in fixed and switching networks. IEEE Trans. Autom. Control. 2007, 52, 863–868. [Google Scholar] [CrossRef]
- Duan, Z.; Chen, G.; Huang, L. Disconnected synchronized regions of complex dynamical networks. IEEE Trans. Autom. Control. 2009, 54, 845–849. [Google Scholar] [CrossRef] [Green Version]
- Porfiri, M.; Stilwell, D.J.; Bollt, E.M. Synchronization in random weighted directed networks. IEEE Trans. Circuits Syst. I Regul. Pap. 2008, 55, 3170–3177. [Google Scholar] [CrossRef]
- Wu, W.; Zhou, W.; Chen, T. Cluster synchronization of linearly coupled complex networks under pinning control. IEEE Trans. Circuits Syst. I Regul. Pap. 2009, 56, 829–839. [Google Scholar] [CrossRef]
- Papachristodoulou, A.; Jadbabaie, A.; Münz, U. Effects of delay in multi-agent consensus and oscillator synchronization. IEEE Trans. Autom. Control. 2010, 55, 1471–1477. [Google Scholar] [CrossRef] [Green Version]
- Jiang, F.; Wang, L. Finite-time information consensus for multi-agent systems with fixed and switching topologies. Phys. D Nonlinear Phenom. 2009, 238, 1550–1560. [Google Scholar] [CrossRef]
- Liu, S.; Xie, L.; Lewis, F.L. Synchronization of multi-agent systems with delayed control input information from neighbors. Automatica 2011, 47, 2152–2164. [Google Scholar] [CrossRef]
- Friedman, D. Evolutionary game in economics. Econometrica 1991, 59, 637–666. [Google Scholar] [CrossRef] [Green Version]
- Friedman, D. On economic application of evolutionary game theory. J. Evol. Econ. 1998, 8, 15–43. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
Multi-agent system model.

Figure 2.
Evolutionary results of are shown under a corresponding constraint condition, (a) represents the convergence of probability with time, and (b) shows the results of dynamic simulation in three dimensions.
Figure 2.
Evolutionary results of are shown under a corresponding constraint condition, (a) represents the convergence of probability with time, and (b) shows the results of dynamic simulation in three dimensions.

Figure 3.
Evolutionary results of shown under a corresponding constraint condition, (a) represents the convergence of probability with time, and (b) shows the results of dynamic simulation in three dimensions.
Figure 3.
Evolutionary results of shown under a corresponding constraint condition, (a) represents the convergence of probability with time, and (b) shows the results of dynamic simulation in three dimensions.

Figure 4.
Evolutionary results of shown under a corresponding constraint condition, (a) represents the convergence of probability with time, and (b) shows the results of dynamic simulation in three dimensions.
Figure 4.
Evolutionary results of shown under a corresponding constraint condition, (a) represents the convergence of probability with time, and (b) shows the results of dynamic simulation in three dimensions.

Figure 5.
Evolutionary results of shown under a corresponding constraint condition, (a) represents the convergence of probability with time, and (b) shows the results of dynamic simulation in three dimensions.
Figure 5.
Evolutionary results of shown under a corresponding constraint condition, (a) represents the convergence of probability with time, and (b) shows the results of dynamic simulation in three dimensions.

Figure 6.
Evolutionary results of shown under a corresponding constraint condition, (a) represents the convergence of probability with time, and (b) shows the results of dynamic simulation in three dimensions.
Figure 6.
Evolutionary results of shown under a corresponding constraint condition, (a) represents the convergence of probability with time, and (b) shows the results of dynamic simulation in three dimensions.

Figure 7.
Evolutionary results of shown under a corresponding constraint condition, (a) represents the convergence of probability with time, and (b) shows the results of dynamic simulation in three dimensions.
Figure 7.
Evolutionary results of shown under a corresponding constraint condition, (a) represents the convergence of probability with time, and (b) shows the results of dynamic simulation in three dimensions.

Figure 8.
Evolutionary results of shown a corresponding under a constraint condition, (a) represents the convergence of probability with time, and (b) shows the results of dynamic simulation in three dimensions.
Figure 8.
Evolutionary results of shown a corresponding under a constraint condition, (a) represents the convergence of probability with time, and (b) shows the results of dynamic simulation in three dimensions.

Figure 9.
Evolutionary results of shown under a corresponding constraint condition, (a) represents the convergence of probability with time, and (b) shows the results of dynamic simulation in three dimensions.
Figure 9.
Evolutionary results of shown under a corresponding constraint condition, (a) represents the convergence of probability with time, and (b) shows the results of dynamic simulation in three dimensions.

Figure 10.
Evolutionary results of λ shown under different probabilities of strategy. λ is 0.2, 0.5, and 0.8, from left to right. (a–c) show that the probability of strategy changes when time is under the different conditions of . (d–f) show that the probability of strategy y changes when time is under the different conditions of . (g–i) show that the probability of strategy changes when time t is under the different conditions of = 0.2, 0.5, and 0.8.
Figure 10.
Evolutionary results of λ shown under different probabilities of strategy. λ is 0.2, 0.5, and 0.8, from left to right. (a–c) show that the probability of strategy changes when time is under the different conditions of . (d–f) show that the probability of strategy y changes when time is under the different conditions of . (g–i) show that the probability of strategy changes when time t is under the different conditions of = 0.2, 0.5, and 0.8.

Figure 11.
Evolutionary results of shown under different probabilities of strategies in (a), (b), and (c), respectively.
Figure 11.
Evolutionary results of shown under different probabilities of strategies in (a), (b), and (c), respectively.

Figure 12.
Evolutionary results of shown under different probabilities of strategies in (a), (b), and (c), respectively.
Figure 12.
Evolutionary results of shown under different probabilities of strategies in (a), (b), and (c), respectively.

Figure 13.
Evolutionary results of shown under different probabilities of strategies in (a), (b), and (c), respectively.
Figure 13.
Evolutionary results of shown under different probabilities of strategies in (a), (b), and (c), respectively.

Figure 14.
Evolutionary results of shown under different probabilities of strategies in (a), (b), and (c), respectively.
Figure 14.
Evolutionary results of shown under different probabilities of strategies in (a), (b), and (c), respectively.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Parameter descriptions and notes.
| Parameters | Descriptions | Notes |
|---|---|---|
| Profits and costs of followers receiving messages, respectively. | ||
| Profits and costs of sending messages to loners, respectively. | ||
| Rewards and costs of followers sending feedback messages to leaders. | ||
| Positive degree of feedback to leaders. | ||
| Positive degree of reception. | ||
| Profits and costs of leaders sending all messages, respectively. | ||
| Profits and costs of leaders sending partial messages, respectively. | ||
| Rewards and costs of receiving messages from followers, respectively. | ||
| Probability of sending messages successfully. | ||
| indicates all messages, represents partial messages. | ||
| Profits and costs of loners receiving messages from followers. | ||
| Profits and costs of receiving messages from leaders, respectively. | ||
| Profits of receiving messages unsuccessfully. | ||
| Possibility of interaction when loners receive messages successfully. | ||
| Rewards of interacting with followers and leaders respectively. |
Table 2.
Payoff matrix of followers, leaders, and loners.
| Feedback () | ||||
| Not feedback () | ||||
Table 3.
Stability analysis of equilibrium points.
| Equilibrium Points | Stability Condition | |||
|---|---|---|---|---|
| . | ||||
| unstable | ||||
| unstable |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Gou, Z.; Deng, Y. Dynamic Model of Collaboration in Multi-Agent System Based on Evolutionary Game Theory. Games 2021, 12, 75. https://0-doi-org.brum.beds.ac.uk/10.3390/g12040075
AMA Style
Gou Z, Deng Y. Dynamic Model of Collaboration in Multi-Agent System Based on Evolutionary Game Theory. Games. 2021; 12(4):75. https://0-doi-org.brum.beds.ac.uk/10.3390/g12040075
Chicago/Turabian StyleGou, Zhuozhuo, and Yansong Deng. 2021. "Dynamic Model of Collaboration in Multi-Agent System Based on Evolutionary Game Theory" Games 12, no. 4: 75. https://0-doi-org.brum.beds.ac.uk/10.3390/g12040075
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.