1. Introduction
The development of autonomous vehicles (AVs) and advanced driver assistance systems (ADASs) has prompted the development of high-definition (HD) maps with attributes such as crosswalks, signalized intersections, and bike lanes [
1]. Lane markings are essential elements of these maps and, thus, their extraction is necessary. Lane markings are also vital for road management, providing well-defined lanes for navigating roads safely in day and night conditions [
2]. Traffic accidents have increased in densely populated urban areas with worn-out lane markings [
3]. To mitigate these accidents, it is imperative to provide the current condition of lane markings along the road surface. While several studies have been conducted to detect lane markings through images and videos, light detection and ranging (LiDAR) point clouds have attracted significant attention from the research community due to the availability of reflective properties of lane markings in LiDAR data unlike images, which could be affected by weather and lighting conditions. Additionally, highly accurate, dense point-cloud data can be obtained in a short time interval without being affected by occlusions, lighting, and weather. Moreover, on the basis of the geometric and reflectivity information provided by LiDAR scanners, the intensity information of extracted lane markings can be automatically reported. Such information is valuable for transportation agencies since it will reduce the number of on-site inspections whereby lane marking gaps can be identified, and their causes can be investigated through coacquired imagery visualization, thereby saving manual labor and ensuring personnel safety. Hence, a strategy for generating intensity profiles, as well as investigating the cause of lane marking gaps, is required.
LiDAR-based lane marking extraction approaches are based on either derived 2D intensity images [
4,
5] or original 3D point clouds as input [
6,
7,
8]. Traditionally, these strategies focus on finding an optimum intensity threshold that separates lane marking points from non-lane marking ones. However, LiDAR point-cloud intensity depends on multiple factors such as the sensor-to-object range, laser beam incidence angle, and reflective properties of the scanned surface. Thus, intensity values must be corrected/normalized for determining an effective threshold [
9]. Höfle et al. [
10] proposed two approaches for intensity data correction: (a) data-based correction where homogeneous surfaces were used to empirically estimate parameters for a correction function accounting for range-dependent factors, and (b) model-based correction where intensity values were corrected according to the physical principle of radar systems. Another range-dependent intensity correction was proposed by Tan et al. [
11]. They substituted the theoretical model (intensity dependence on the inverse of squared ranges) with a polynomial function in the range. The degree of the polynomial, together with its coefficients, was determined for each sensor by least-squares adjustment. Krooks et al. [
12] studied the effect of incidence angle on LiDAR intensity and found that such an effect is independent of the sensor-to-object distance and, thus, can be corrected separately. Bolkas et al. [
13] modeled diffused and specular reflection from different colored surfaces through a Torrance–Sparrow model [
14]. They used the specular reflection component and incidence angle to correct the intensity data. However, even after intensity correction through various strategies proposed in the literature, one must have prior information about intensity distribution for LiDAR-based lane marking extraction approaches to be effective. Recently, the focus has shifted to applying deep learning in the form of novel convolutional neural network (CNN) architectures for lane marking extraction that are agnostic to LiDAR intensity correction or prior knowledge about intensity distribution. However, a huge dataset is required to train CNNs, which is often a major bottleneck as manual effort is required for labeling input data [
15,
16]. Cheng et al. [
17], thus, proposed a strategy to automatically label intensity images for lane marking extraction. They first normalized LiDAR point-cloud intensity using the procedure proposed by Levinson [
18]. Thereafter, a fixed intensity threshold was applied, followed by noise removal to extract lane markings. The lane marking point clouds were then rasterized into intensity images to serve as labels for training a U-net model.
In addition to requiring a large number of training samples, another drawback of CNNs is their inability to generalize to patterns that are significantly different from ones encountered during training even after application of techniques such as dropout (a technique where neurons in a neural network are randomly dropped during training to prevent overfitting), weight regularization (set of techniques that prevent the neural network weights from growing too large so that network is not highly sensitive to small changes in input), and data augmentation (set of techniques where training data size is increased by adding modified copies of existing training samples) [
19,
20,
21]. Thus, transfer learning has gained more interest where the current knowledge can be adapted to new conditions for better prediction [
22,
23]. In the geospatial domain, many researchers have utilized a pretrained network to solve their problems of interest. Yuan et al. [
24] first trained a CNN to learn the nonlinear mapping from low-resolution RGB images to high-resolution ones. The same network was then transferred to hyperspectral images by tackling bands individually. Chen et al. [
25] used a Visual Geometry Group-16 model (VGG16) pretrained on the ImageNet dataset (a database of 14 million annotated images over 20,000 miscellaneous categories) for airplane detection in remote sensing images. They replaced the fully connected layers of the model with additional convolutional layers and retrained the model on a small number of manually labeled airplane samples. Nezafat et al. [
26] investigated three networks (AlexNet, VGGNet, and ResNet) pretrained on the ImageNet dataset to classify truck images, generated from LiDAR point-cloud data, according to their body type. Low-level features extracted as output from each pretrained model were fed as input to train a multilayer perceptron (MLP) for truck body type classification.
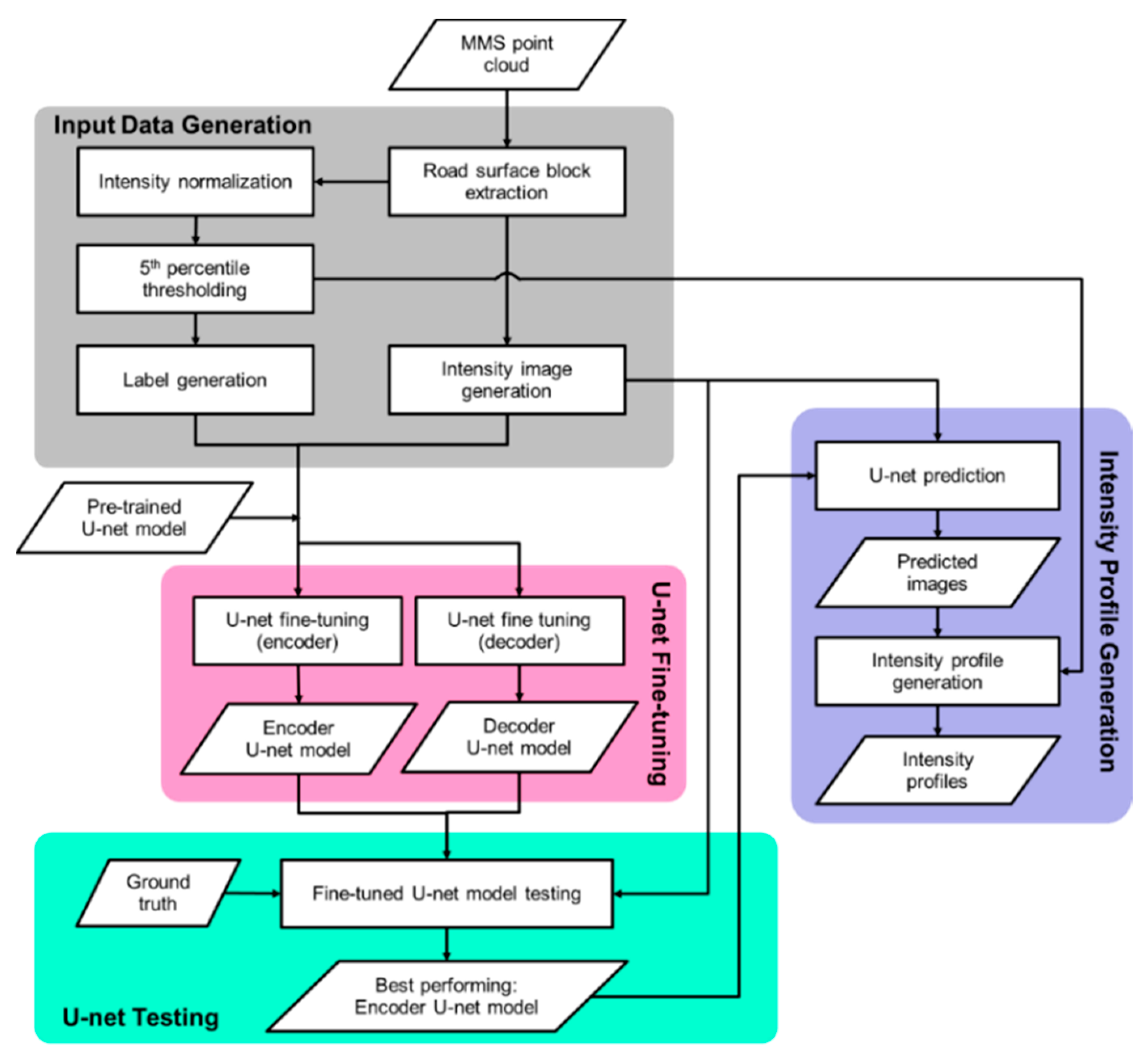
It is, thus, evident that a model trained on a dataset can be adapted to perform predictions on a new dataset through changes in architecture and retraining with few examples. This is significant in the context of deep learning-based lane marking extraction in LiDAR intensity images. Since the intensity of LiDAR data and lane marking patterns vary from one dataset to another, it is not practical and efficient to train a model from scratch for every newly collected dataset, even with an automated labeling procedure. Thus, the objectives of this paper are (1) to study fine-tuning of a pretrained U-net model for knowledge transfer from the source to target domain in the context of lane marking extraction, and (2) to propose an intensity profile generation strategy utilizing the lane marking predictions by the fine-tuned U-net model.
In detail, a transfer learning strategy is applied for lane marking extraction whereby a pretrained U-net model from a previous study [
17] is fine-tuned with additional training samples from another dataset consisting of new lane marking patterns (not seen earlier during the training phase of the pretrained model). This is an example of domain adaptation where the task in the two settings remains the same (here, the task being lane marking extraction) but input distribution is different. The pretrained U-net model was trained on the past dataset collected over two-lane highways (hereafter referred to as “source domain dataset”). The new dataset (hereafter also referred to as “target domain dataset”) includes other lane marking patterns such as one-lane highways and dual lane markings at the edge of the road surface, in addition to two-lane highways. Specifically, the main contributions of this study are as follows:
A transfer learning approach is successfully applied to fine-tune weights of a pre-trained U-net model with limited training data for lane marking extraction on a target domain dataset under two scenarios:
The predictions of both transfer learning models are compared with each other. In addition, the fine-tuned models are also evaluated upon the source domain dataset with two-lane highways, and their performance is compared with the pretrained model. This helped in assessing the generalization ability of the two models. Moreover, these performance comparisons aided in assessing the preferable modes of fine-tuning U-net for domain adaptation. To the best of authors’ knowledge, most transfer learning strategies deal with networks that are not fully convolutional unlike U-net. Moreover, U-net fine-tuning has only been studied in the biomedical context [
27].
To clearly illustrate the benefits of fine-tuning, another U-net model is trained from scratch on source and target domain datasets, and then its predictions are compared with the fine-tuned models on target domain datasets.
Lastly, intensity profiles are generated along the road datasets utilized in this study. Regions with lane marking gaps are reported along with the corresponding RGB image visualization. This procedure assists in lane marking inspection, and it removes the possibility of missed problematic areas during manual inspection.
The rest of this paper is structured as follows: first, the mobile mapping system and collected LiDAR point clouds used in this study are described in
Section 2. The motivation for U-net fine-tuning is presented in
Section 3, followed by
Section 4 that introduces the proposed strategies. Lastly, the results are reported and discussed in
Section 5, while the conclusions and scope for future work are summarized in
Section 6.
3. Motivation for U-Net Fine-Tuning
In the previous study [
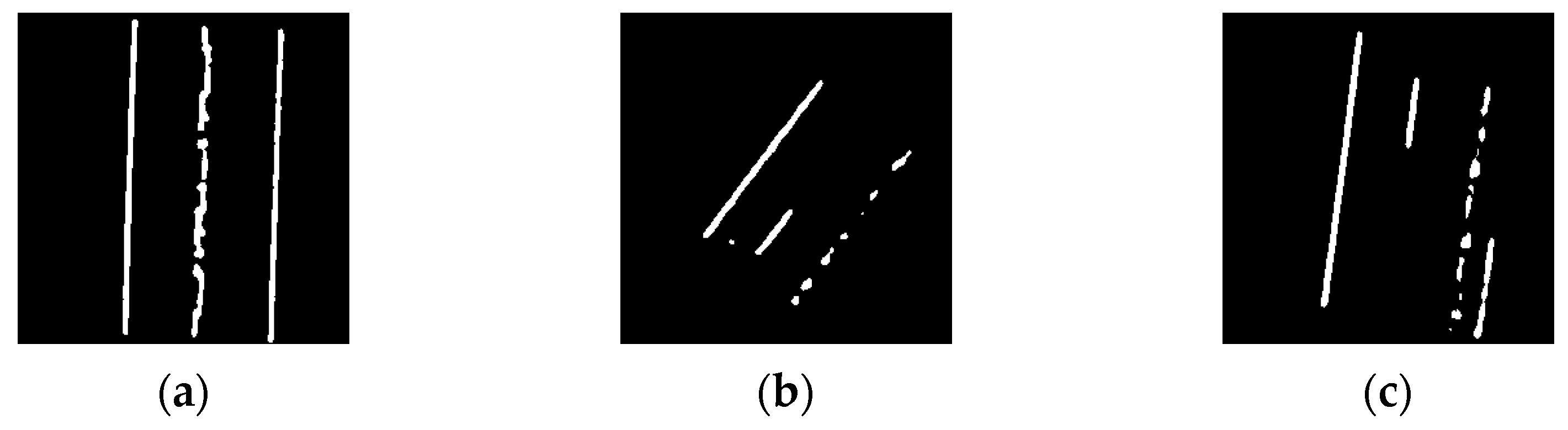
17], a fully convolutional neural network (FCNN), denoted as U-net, was trained for lane marking extraction on two-lane highways. Typical LiDAR intensity images for such regions are shown in
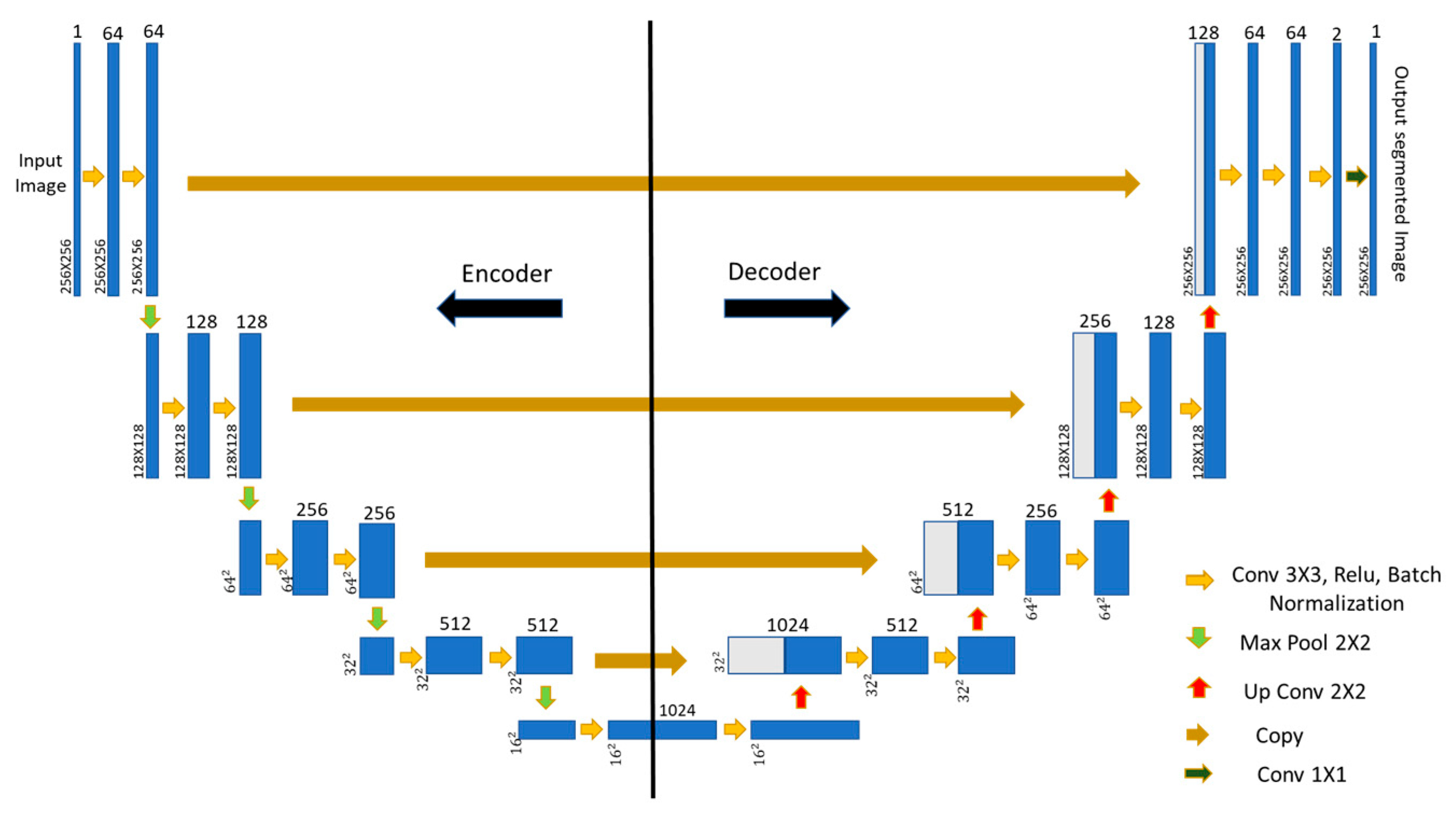
Figure 8. The network architecture consisted of two salient paths, as shown in
Figure 9—an encoder (on the left in
Figure 9) and a decoder (on the right in
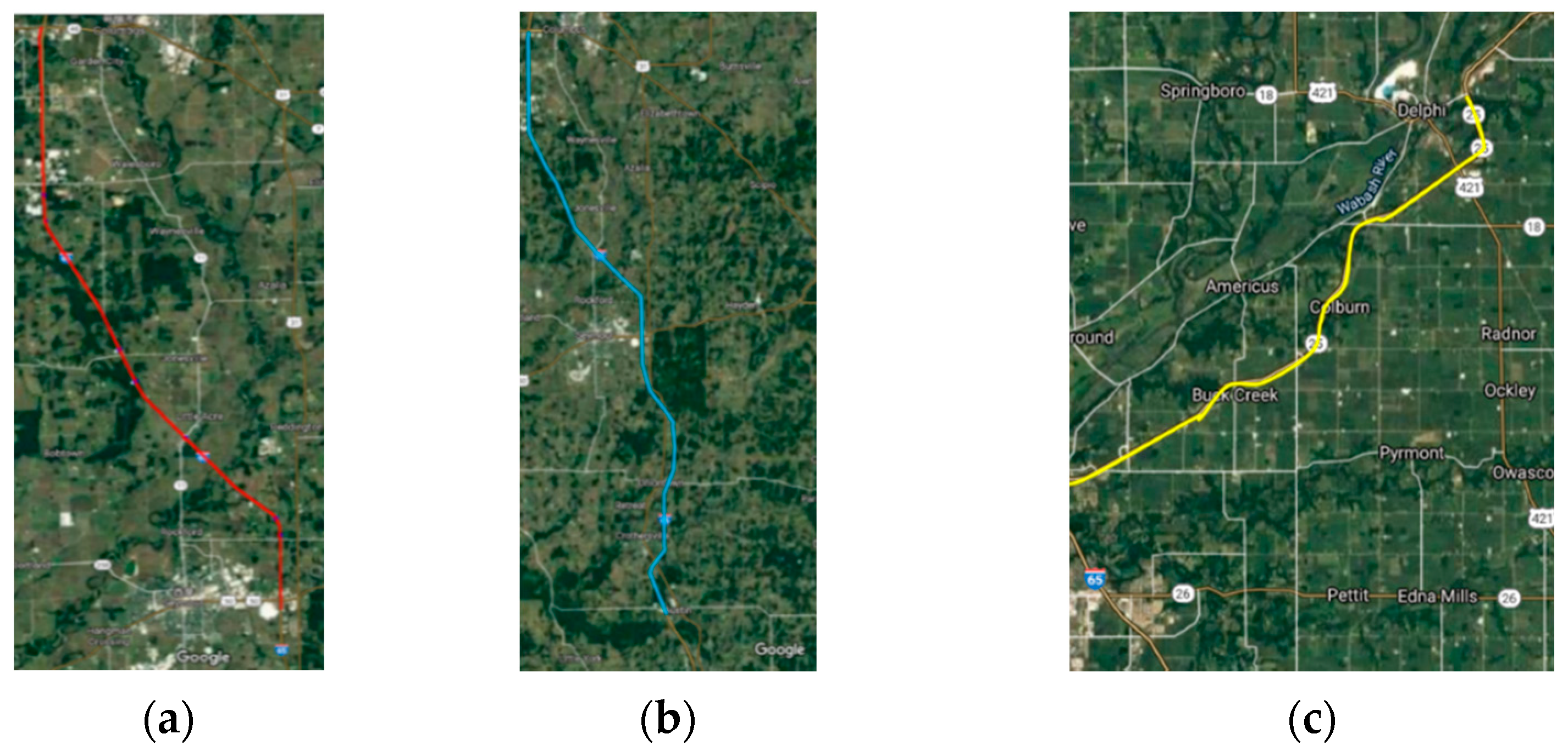
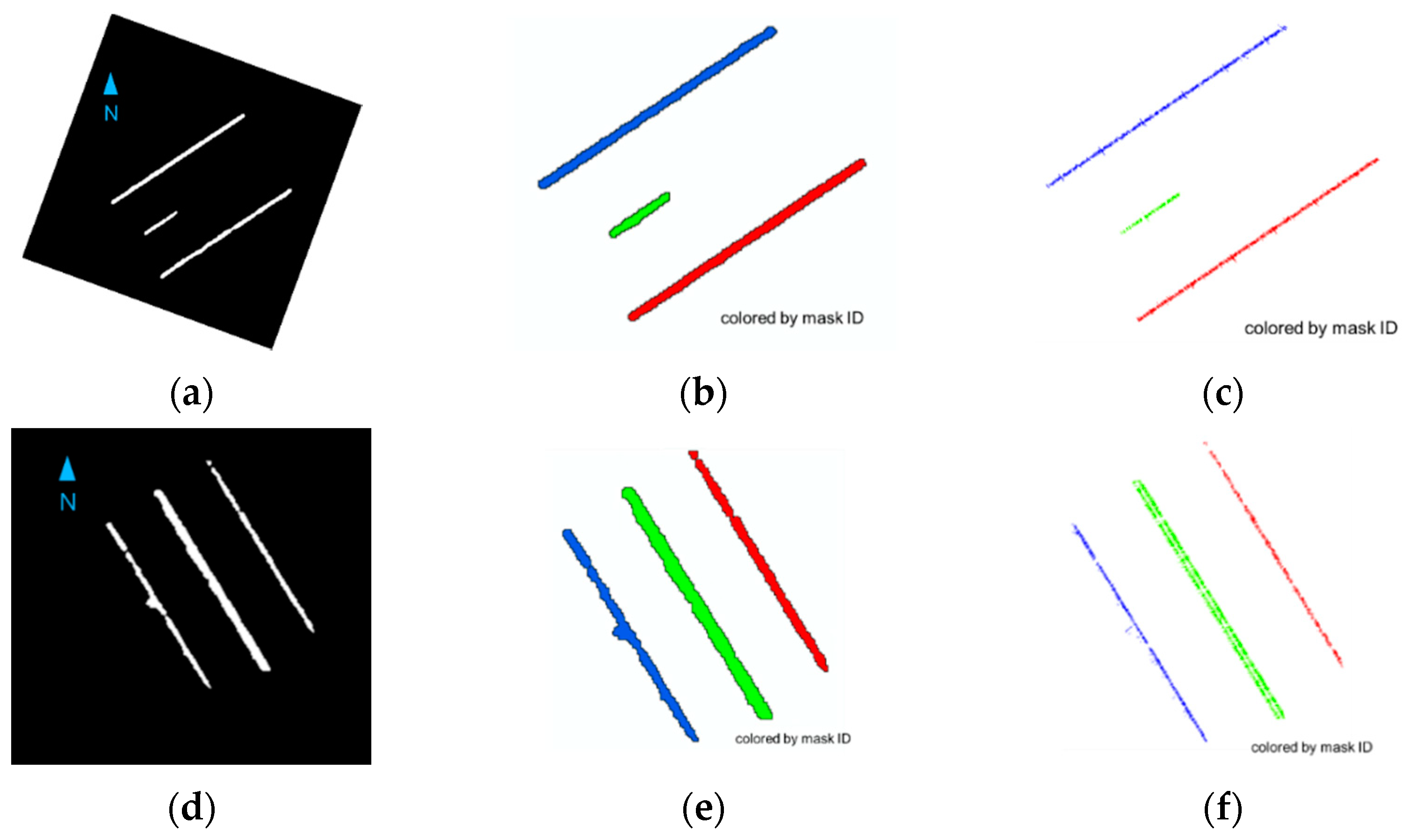
Figure 9). In this paper, these two paths of the pretrained U-net model were fine-tuned separately to obtain better predictions for different lane marking patterns that were not encountered earlier. As mentioned previously, such new patterns included (a) a one-lane highway with dual lane marking at the center, (b) dual lane markings at the road edge, and (c) a pair of dual lane markings at the road edge; their corresponding LiDAR intensity images are shown in
Figure 10. The results of the pretrained model on these new patterns showed significant misdetection, as illustrated in
Figure 11.
As per the misdetections in
Figure 11, the pretrained model needs to be fine-tuned. One could also argue for training a new model from scratch using LiDAR intensity images with the new lane marking patterns shown in
Figure 10. However, since the target domain dataset is small and, thus, less representative of different possible variants of lane marking patterns, this would lead to significant overfitting [
34], whereby the model would perform well on new lane marking patterns but obtain poor results in two-lane highway areas. Another overfitting case could also arise if the whole pretrained model was fine-tuned where all network parameters could change to perform well on a small training dataset [
35]. Therefore, only the encoder or decoder part of the pre-trained U-net model was fine-tuned in this study.
5. Results and Discussion
For U-net fine-tuning, an original U-net model, which was trained on two-lane highways (source domain dataset), was fine-tuned to make predictions on datasets with new lane marking patterns such as one-lane highways and dual lane markings at the edge of the road (target domain dataset). Two experiments were conducted: (a) in the first, only encoder weights could change; (b) in the second, only decoder weights could change. Another experiment was also conducted where another U-net model was trained from scratch on both source and target domain datasets. The performance comparison of this model with fine-tuned models helped in analyzing the effectiveness of transfer learning for lane marking extraction in new patterns. Additionally, both encoder- and decoder-trained U-net models were also evaluated using the past test dataset to assess if fine-tuning negatively affected their performance on two-lane highways due to overfitting to new lane marking patterns. Furthermore, all four U-net models were evaluated on the independent test dataset (not belonging to either source or target domain dataset locations) to obtain another assessment of their generalization capability. Once the U-net models were evaluated on various test datasets, all the intensity images (4682 images) from the target domain dataset were fed to the best-performing model for intensity profile generation. The description of used datasets for training or fine-tuning, validation, testing, and intensity profile generation are summarized in
Table 1. The model fine-tuning/training was executed on the Google Collaboratory platform that provides free K-80 GPU access. The Keras deep learning framework was used to implement U-net.
Table 2 lists the time taken by each step in the adopted methodology.
In this study, 1421 pairs (1183 for training and 238 for validation) of intensity image and corresponding label from the source domain dataset were used, while, for the target domain dataset, a total of 336 such pairs were generated. Both encoder- and decoder-trained U-net models utilized 267 images for training and the remaining 69 images for validation. The model trained from scratch used 1450 (1183 + 267) and 307 (238 + 69) images for training and validation, respectively. For testing, lane marking extraction results from the target domain dataset (122 intensity images) for various U-net models—pretrained, encoder-trained, decoder-trained, and one trained from scratch—are presented in
Table 3. Additionally, to gauge the generalization ability of newly trained models (fine-tuned and trained from scratch), they were also evaluated on source domain datasets (174 intensity images), and their performance was compared with the pretrained one, as listed in
Table 4. Lastly, performance measures on independent test data (100 intensity images) are provided in
Table 5.
As evident from
Table 3, the pretrained model showed substandard performance on the new test dataset with an F1-score of only 65.7%, which was due to poor predictions in new lane marking patterns. On the other hand, the encoder- and decoder-trained models obtained better F1-scores of 86.9% and 82.1%, respectively.
Figure 19 shows the superior performance of fine-tuned models over the pretrained one, whereby the latter showed misdetection in areas with new lane marking patterns. Furthermore, the encoder-trained model performed better than the decoder-trained one as evident by the respective F1-score values. Specifically, the former was able to eliminate false positives and false negatives to a larger extent than the latter, as illustrated in
Figure 20.
The better performance of the encoder-trained model is owed to the fact that, in deep learning models, the shallow layers (the encoder path) learn low-level features [
27]. In the context of lane marking extraction, such features include speckle pattern and distribution of high-intensity non-lane marking points, which vary from dataset to dataset depending upon lane marking patterns and are critical for accurate prediction. While freezing the encoder and training decoder, we did not allow the network to learn such low-level features in the new training dataset leading to worse performance. Lastly, the model trained from scratch, while performing better than the pretrained model, was outperformed by both fine-tuned models, as evident by the F1-scores in
Table 3. The inferior performance of the model trained from scratch compared to fine-tuned models was expected since the combined training dataset was still dominated by previous lane marking samples, and the number of new training samples was not enough to adapt network parameters for better performance in new lane marking patterns. This is visualized in
Figure 21 where the model trained from scratch showed partial detections in areas with pair of dual lane markings at the edge. In addition, another demerit of the model trained from scratch was its fivefold longer training time compared to fine-tuning, as mentioned in
Table 2. A large number of training samples and random initial weights (no prior knowledge embedded) increased the training time.
As far as the performance on the source domain dataset is concerned, the encoder-trained model with F1-score of 84.7% again outperformed the decoder trained one with an F1-score of just 79.4% and the model trained from scratch with an F1-score of 82.9%, as listed in
Table 4. In addition, the encoder-trained model’s performance was comparable to the pretrained U-net model (F1-score 85.9%), which shows that the encoder-trained model generalized well on the source domain dataset in addition to robust predictions on the target domain dataset. Lastly, as can be seen from
Table 5, once again, the encoder-trained model outperformed all other models with an F1-score of 90.1%. In summary, the encoder-trained U-net model obtained by fine-tuning a pretrained model with only a few hundred images not only performed better on the target domain test dataset but also generalized well to the source domain and independent test datasets.
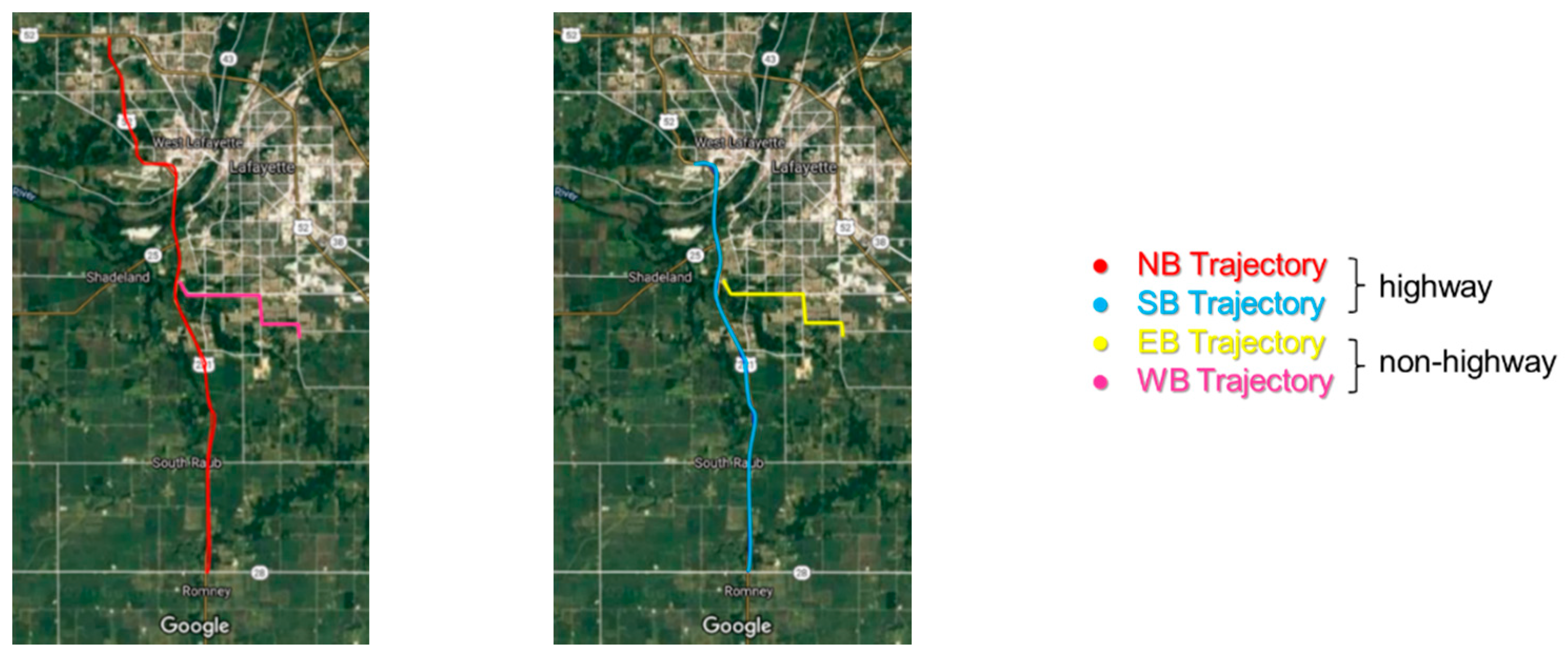
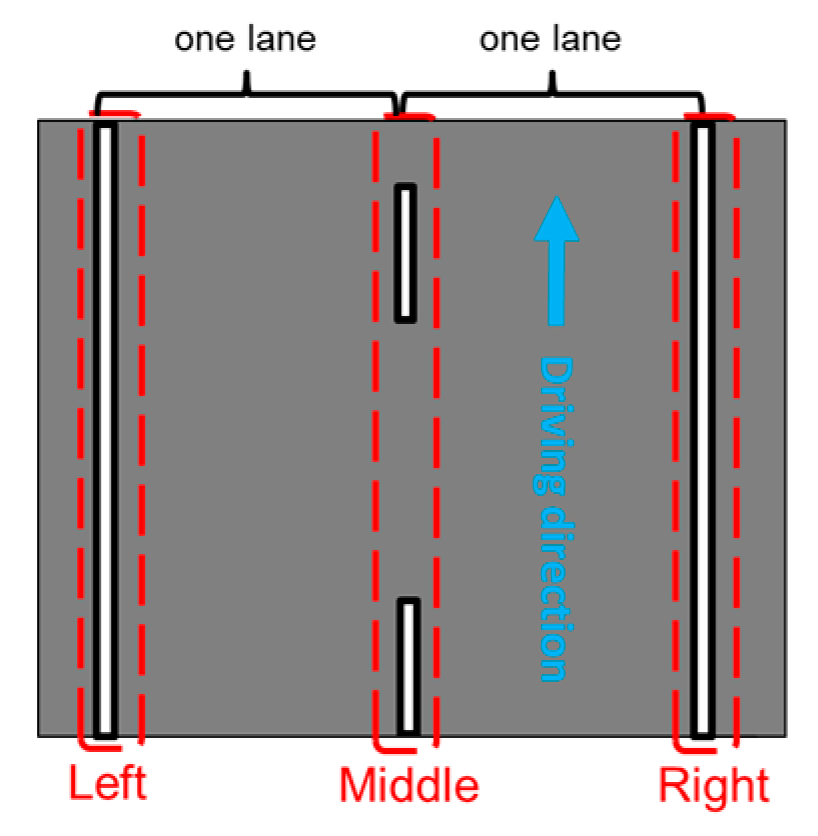
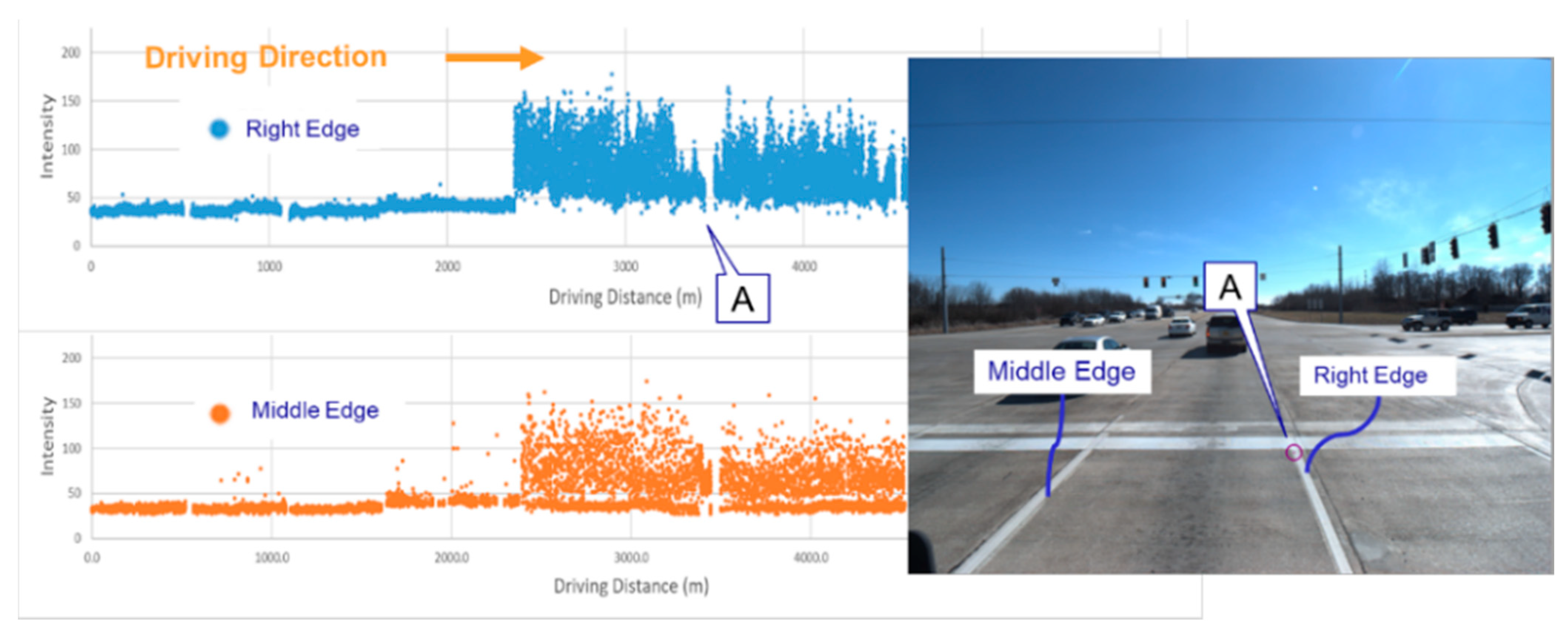
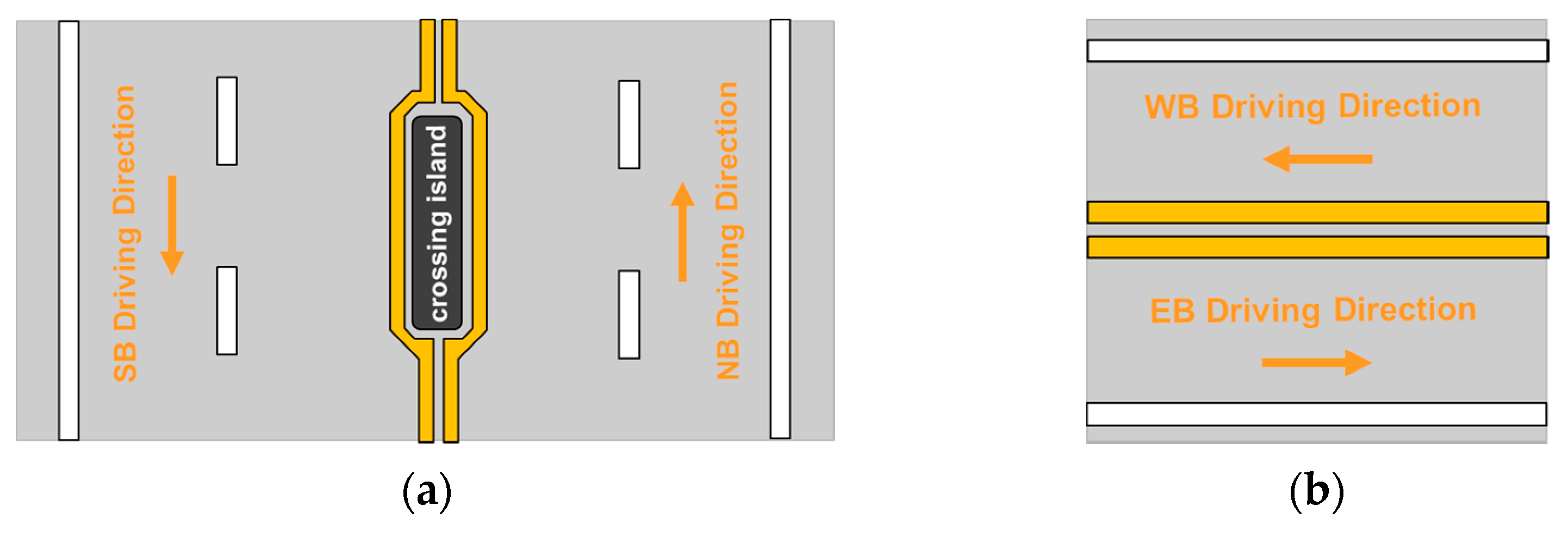
The intensity profiles for lane marking predictions by the encoder-trained U-net (the best-performing model) in the whole target domain dataset (a total of 4682 intensity images for NB, SB, WB, and EB segments) were derived for the right, middle, and left edges of the roadway. The NB and SB segments were surveyed on the outer lane of a two-lane highway whose common lane markings were center dual yellow lines, as shown in
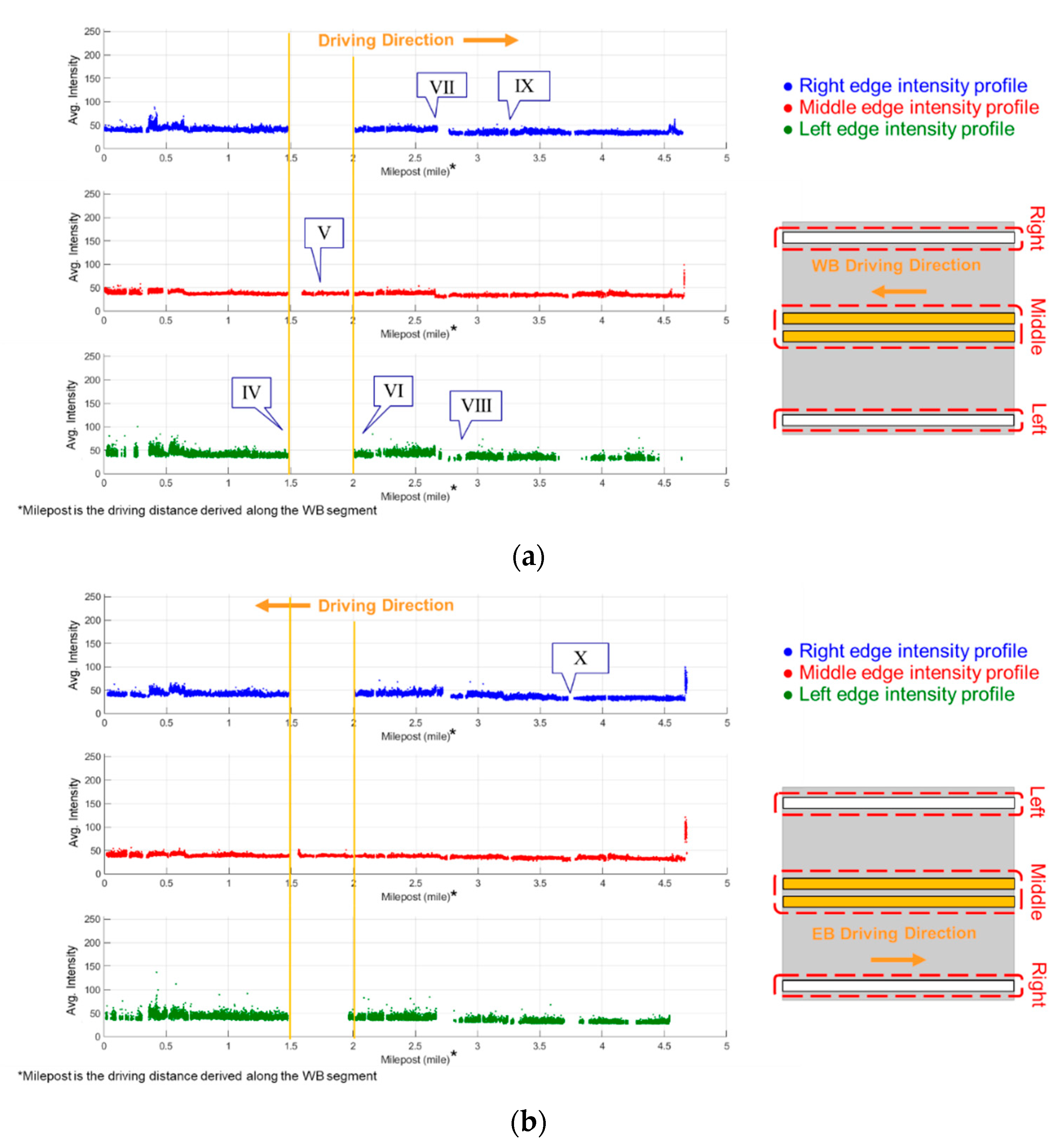
Figure 22a. Hence, only the left-edge profiles from NB and SB segments corresponded (note: in some regions, the dual lane markings were temporarily separated by a crossing island). On the other hand, WB and EB segments were collected in opposite driving directions, as shown in
Figure 22b, on the same rural road divided by the center dual yellow lines. The intensity profiles derived from the WB segment could be related to those from the EB segment. For example, the right-edge profile from the WB segment could correspond to the left-edge profile from EB segment. For NB and SB segments, the intensity profiles and the corresponding RGB images are visualized in
Figure 23 and
Figure 24, while those for WB and EB segments are displayed in
Figure 25 and
Figure 26.
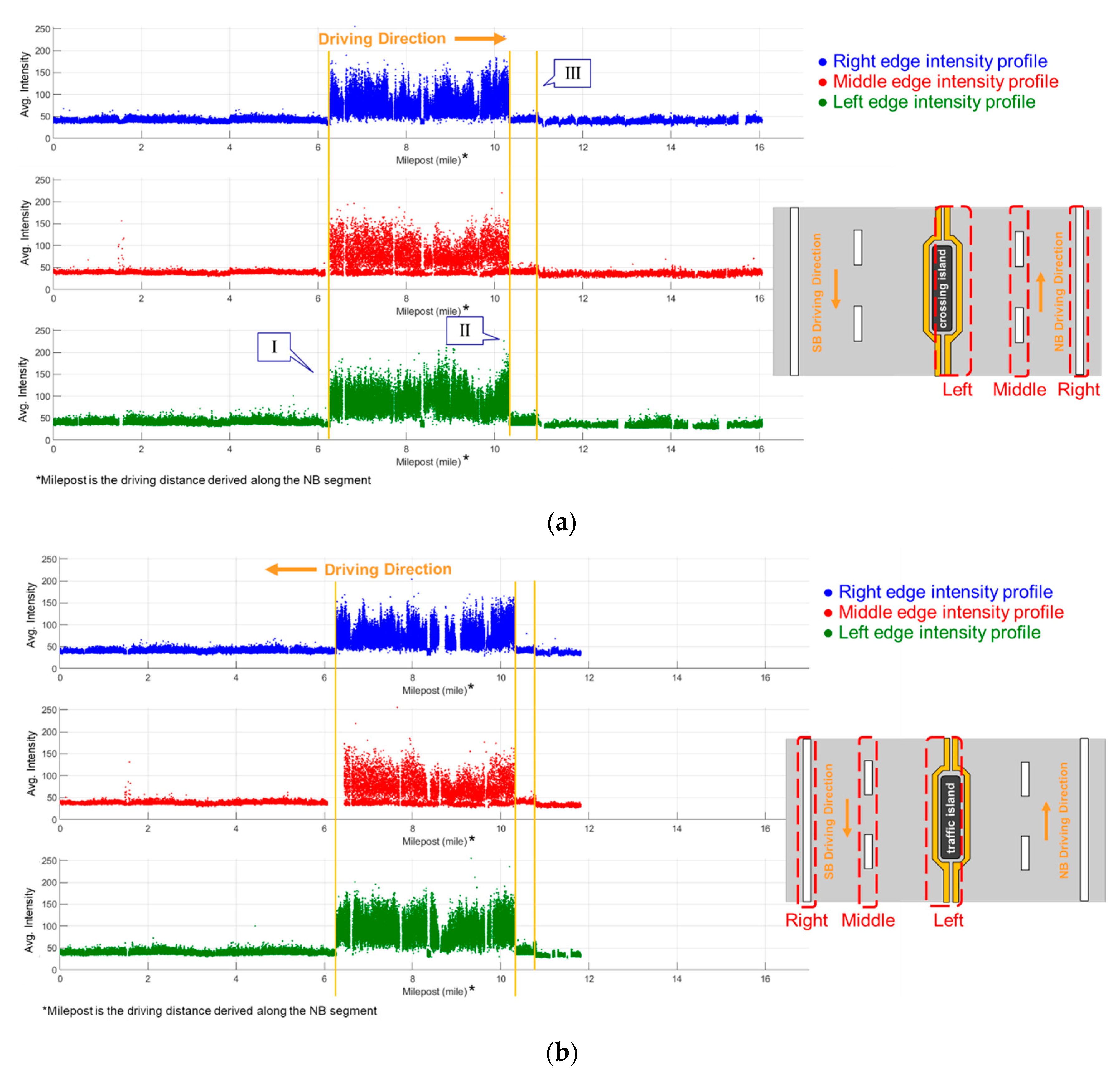
Using the corresponding nature of profiles in different dataset segments, the repeatability of the proposed strategies for detecting lane markings and generating intensity profiles could be demonstrated. As can be seen in
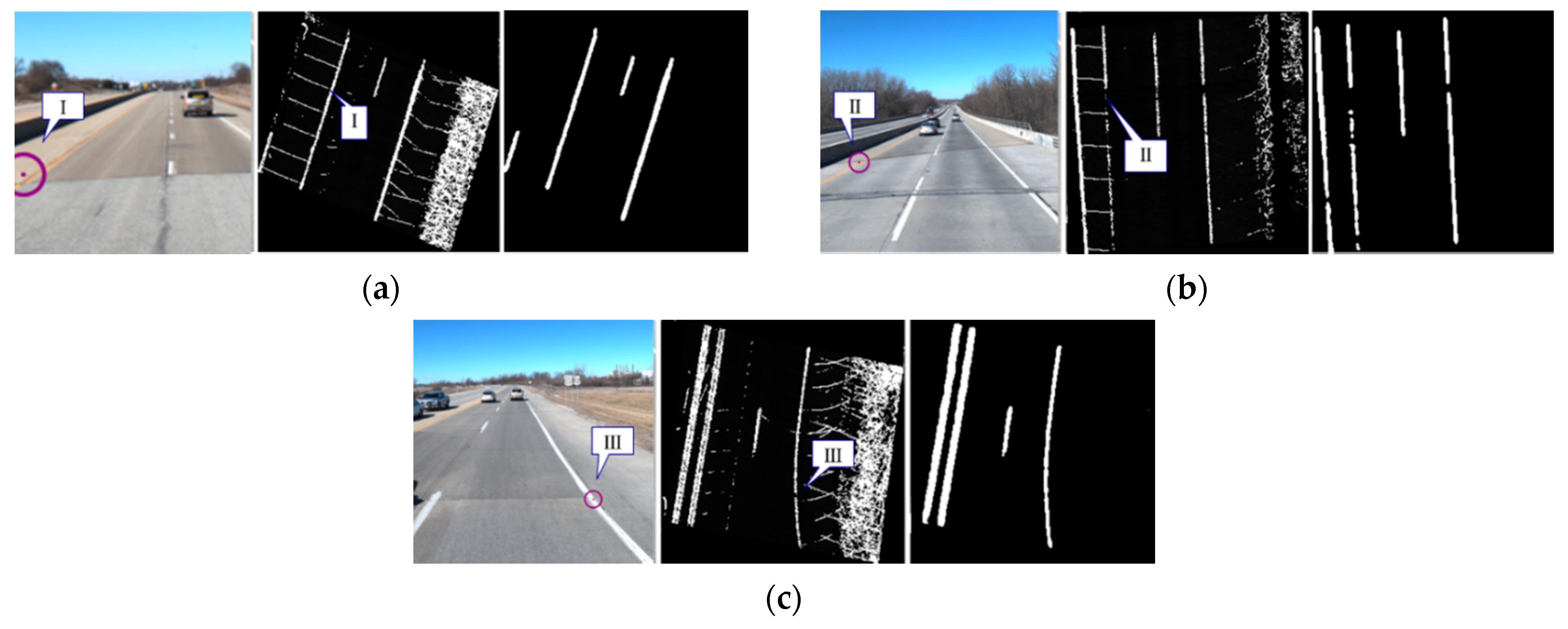
Figure 23a,b, sudden intensity changes in the profiles for both NB and SB segments could be observed at locations I, II, and III within milepost range 6–10. The cause behind these sudden intensity changes was a transition of pavement from asphalt to concrete, shown in
Figure 24a,b, where it is known that the average luminance of concrete pavements is 1.77 times that of asphalt pavements [
39]. Another area with different asphalt pavements can be seen in
Figure 24c. Next, as displayed in
Figure 25, the right-, middle-, and left-edge intensity profiles from the WB segment were almost the same as the left, middle, and right ones, respectively, from the EB segment. At locations IV, V, and VI in
Figure 25, the missing lane marking regions could be identified and visualized through the corresponding images, as shown in
Figure 26a–c. A roundabout and its merging region led to the long gap for locations IV, V, and VI in
Figure 25.
Furthermore, the agreement of intensity profiles derived from NB/SB and WB/EB segments was estimated by comparing the average intensity values at the same location.
Table 6 and
Table 7 list the difference statistics for the intensity profiles from NB/SB and WB/EB segments, respectively. The results show that the root-mean-squared error (RMSE) of the NB/SB intensity profiles (left-edge common lane markings) was around 3.2 (note: PWMMS-HA provided intensity as an integer number within 0–255). The average intensity values from WB and EB segments (three edges lane markings) were in agreement within the range of 4.2 to 4.4. Lastly, RGB image visualization identified the following four primary causes behind the intensity profile gaps: (a) misdetection by the U-net model in spite of high intensity of lane marking points, (b) adequately visible lane markings in RGB images but not reflective enough to be detected as high-intensity points in LiDAR point cloud, (c) worn-out lane markings leading to poor reflectivity, and (d) absence of lane markings. An example location for each of the above conditions is marked in the intensity profiles in
Figure 25 (locations VII, VIII, IX, and X), and they are further illustrated in
Figure 26c–f by the RGB images, intensity image, and lane marking predictions by the encoder-trained U-net model. One should note that the datasets used for intensity profile generation were collected on highway and non-highway regions at different speed limits (25–60 mph), which resulted in road surface blocks with varying point density (ranging from 2500 to 7500 points per m
2). Accurate lane predictions, as shown in
Figure 24 (highway region) and
Figure 26 (non-highway region), prove that the lane marking extraction by the U-net model was agnostic to point density.
6. Conclusions and Recommendations for Future Research
Recently, lane marking extraction from LiDAR data using deep learning has gained impetus. However, the requirement of a large number of training samples, which are usually generated manually, is a major bottleneck. Efforts have been made to automate the labeling of intensity images for lane marking extraction; however, curating a new training dataset with many samples for every LiDAR data collection by a different scanner or at different locations with new lane marking patterns is not practical. Hence, this paper presented a transfer learning approach of domain adaptation whereby a U-net model trained on an earlier LiDAR dataset (source domain data collected on two-lane highways) was fine-tuned to make lane marking predictions on another dataset with new lane marking patterns (target domain data collected over one-lane highways, with dual lane markings at the center, and with a pair of dual lane markings at the edge). With this approach, a robust U-net model was trained using only a few training examples from the target domain dataset. To this end, two U-net models were established after fine-tuning either the encoder or decoder path of a pretrained U-net model referred to as encoder-trained and decoder-trained U-net, respectively. Additionally, another U-net model was trained from scratch on combined source and target domain datasets to analyze the benefits of fine-tuning.
On the target domain dataset, the encoder-trained U-net performed the best with an F1-score of 86.9%, while the decoder-trained U-net showed an F-score of 82.1%. Furthermore, the model trained on combined datasets achieved an F1-score of only 75.2% and took nearly fivefold longer to train than the fine-tuned models as a result of a larger training dataset and random initial weights. The fine-tuned models, on the other hand, were trained on a small dataset with initial weights derived from the pretrained model.
On the source dataset, the encoder-trained model obtained an F1-score of 84.7%, while the same metric for the decoder-trained model was 79.4%. The model trained from scratch obtained an F1-score of 82.9%, performing better than the decoder-trained model but not the encoder-trained one. Furthermore, the pretrained model had an F1-score of 85.9% on the same dataset, which was reasonably matched by the encoder-trained model. Additionally, an independent test dataset belonging to neither source nor domain dataset locations was curated to further evaluate the U-net models, where the encoder-trained model outperformed all the other ones with an F1-score of 90.1%. The aforementioned performance results on the target domain, source domain, and independent dataset lead to two conclusions. First, when the target domain dataset is small and different from the source domain dataset, it is preferable to fine-tune a pretrained model than train a model from scratch on combined source and target domain datasets. Secondly, it is preferable to fine-tune encoder weights than decoder ones in a U-net during domain adaptation.
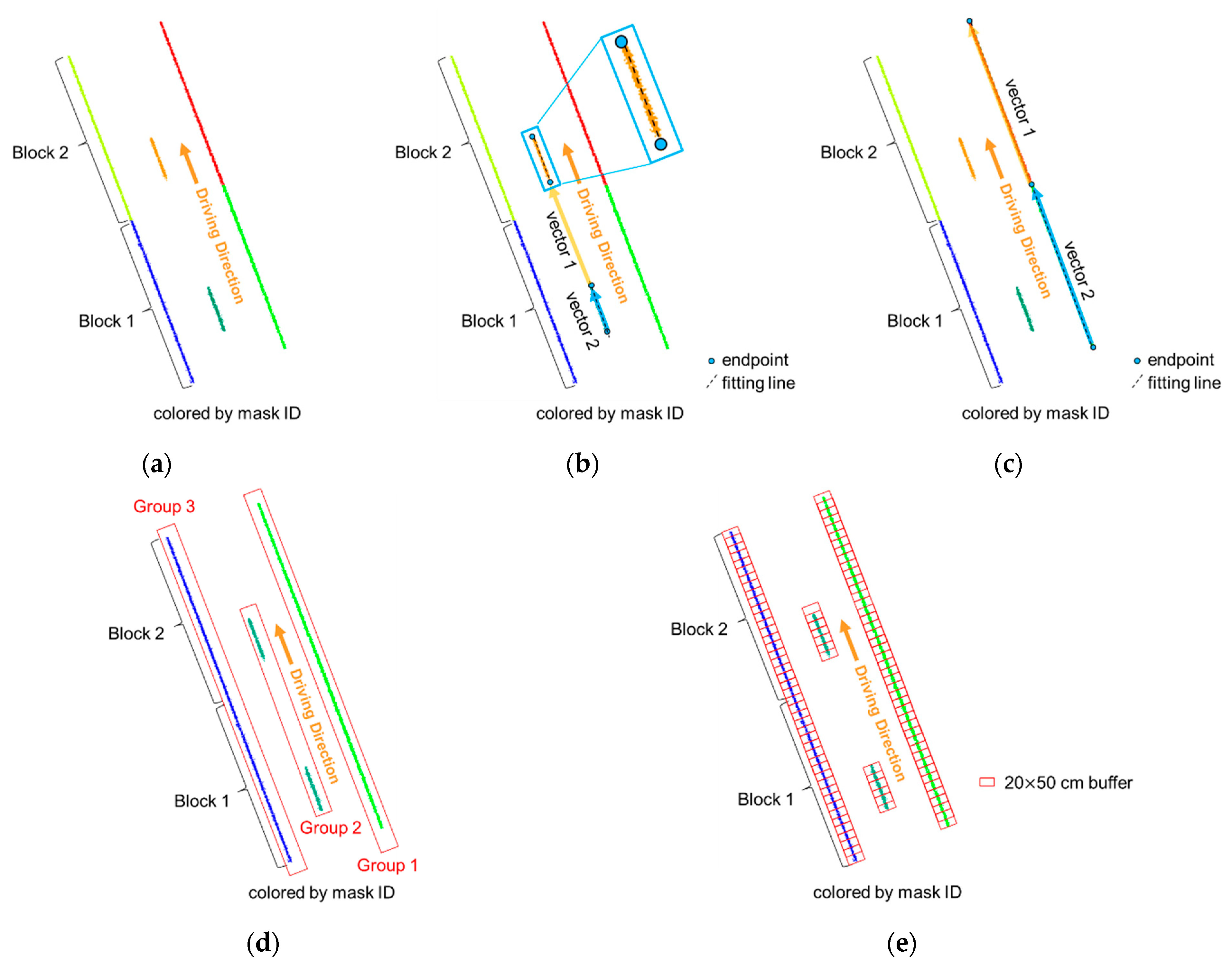
The second part of this paper proposed an intensity profile generation strategy, whereby lane marking intensity variation along the driving direction was reported at regular intervals. First, 3D LiDAR points were extracted by 2D masks generated using the lane marking pixels predicted from the best-performing U-net model (encoder-trained). The extracted lane markings were then clustered into right, middle, and left edges according to the road delineation. Along the driving direction, each group of extracted lane markings was divided by 2D rectangular buffers to estimate the average intensity of the points falling in each buffer. Lastly, the average intensity versus the driving distance (intensity profile) for each edge lane marking was depicted.
For the repeatedly surveyed lane markings, the intensity differences across the derived profiles were within the range of 4.2 to 4.4 (with intensity values registered as integer values within 0 to 255 range), which demonstrated the robustness of the proposed strategies for detecting lane markings and generating intensity profiles. Another benefit of the proposed strategy is the identification of regions with sudden intensity changes due to transition from one pavement type to another, verified by RGB imagery visualization. Moreover, intensity profiling coupled with RGB image visualization can assist departments of transportation in improving and maintaining lane markings while significantly reducing manual labor and mitigating risk associated with in-person inspection.
In the current approach, the proposed strategy cannot predict lane markings in real time. A major bottleneck is the sequential generation of intensity images from road surface point-cloud block, which will be addressed in the future by parallelizing this procedure. Another avenue for future work is testing the encoder-trained U-net model on datasets acquired by different LiDAR units of different models and gauging how well it can generalize. Moreover, in the misdetection regions where lane markings can be observed by the coacquired images, the color and texture information of these images can be utilized to identify undetected points from LiDAR datasets. Through this image-based refinement, the performance of lane marking extraction can be improved.






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}