1. Introduction
There are many uncertainties when conducting research in spatial epidemiology and environmental epidemiology. Two major uncertainties are the location and timing of etiologically relevant environmental exposures that increase disease risk for individuals in a study population. In typical spatial analyses of epidemiologic data, the focus is on the location (e.g., where in space is risk elevated) with less consideration of the timing of the exposures (e.g., when and where in space was risk elevated). This is evident through the common use in risk analysis of spatial information that is related only to the time of study enrollment [
1]. The spatial information is often the residential location, which is used as a surrogate for unknown environmental exposures or is used in environmental epidemiology to assign environmental exposures for potential risk factors of interest. The inherent assumption is that time of study enrollment is the relevant time of environmental exposures, or that the study population is not residentially mobile over time so that the residential location at the time of study enrollment represents the relevant environmental exposures.
However, high levels of population mobility and disease latencies make the use of addresses at study enrollment questionable for many health outcomes. According to the 2013 Annual Social and Economic Supplement (ASEC) of the Current Population Survey (CPS) conducted by the U.S. Census Bureau, 11.7 percent of people aged one year or more living in the United States changed residences between 2012 and 2013 [
2], and the five-year mover rate was 35.4 percent from 2005 to 2010 and 44.1 percent from 1990 to 1995 [
3]. The estimates of the five-year mover rate are underestimates of population mobility, as the five-year mobility survey question only asks if a person lives at the same residential location as five years ago. It has also been estimated based on the 2007 American Community Survey from the U.S. Census Bureau that a person in the United States on average moves 11.7 times in his/her lifetime [
4]. In addition, the median duration of residence in the U.S. in 1996 was only 4.7 years [
5]. Moreover, simulation studies show that the levels of population mobility in the United States are sufficient to obscure the spatial signal related to pertinent, historic environmental exposures for diseases with long latencies [
6,
7]. In addition, the power to detect an area of elevated risk and the spatial sensitivity of detection models both decrease when population mobility is simulated [
8].
When a disease has a long latency, or lag time between exposure to an important risk factor and diagnosis of chronic disease, the relevance of the residential location at time of study enrollment may be minimal. For certain cancers, the latency period can be substantial. For example, the latency for cancers such as lung and bladder has been estimated to be between 20 and 30 years [
9,
10], while the latency for mesothelioma is estimated to be between 20 and 50 years [
11]. For these diseases, and others with long latencies, spatial epidemiologic studies need to consider residential locations over a long time period for study subjects, and allow for the possibility of different environmental exposures at each residential location.
Once residential histories are collected in a study, historic patterns of spatial risk can be assessed [
12,
13] and historic environmental exposures can be assigned in studies [
14,
15,
16]. However, few published epidemiologic studies in the United States have collected residential histories for subjects. An option when address histories have not been collected is to consider purchasing residential histories from public record database providers. Previous work has explored this option and compared residential history data obtained through a survey in a case-control study of bladder cancer to those available from a public-record database sold by LexisNexis using five performance metrics [
17]. The previous study used data for 946 individuals from a case-control study with enrollment limited to subjects living in one of 11 counties in Michigan for at least five consecutive years [
17]. In addition, the previous study limited the address lookup from the LexisNexis database to only up to the three most recent addresses per subject. Our aim in this paper was to expand on previous research and evaluate the ability of a public record database from LexisNexis to replicate address histories recorded during follow-up in a geographically diverse cohort study using a large set of performance metrics and multiple public-record database products, including an address query designed to cover the entire cohort follow-up period.
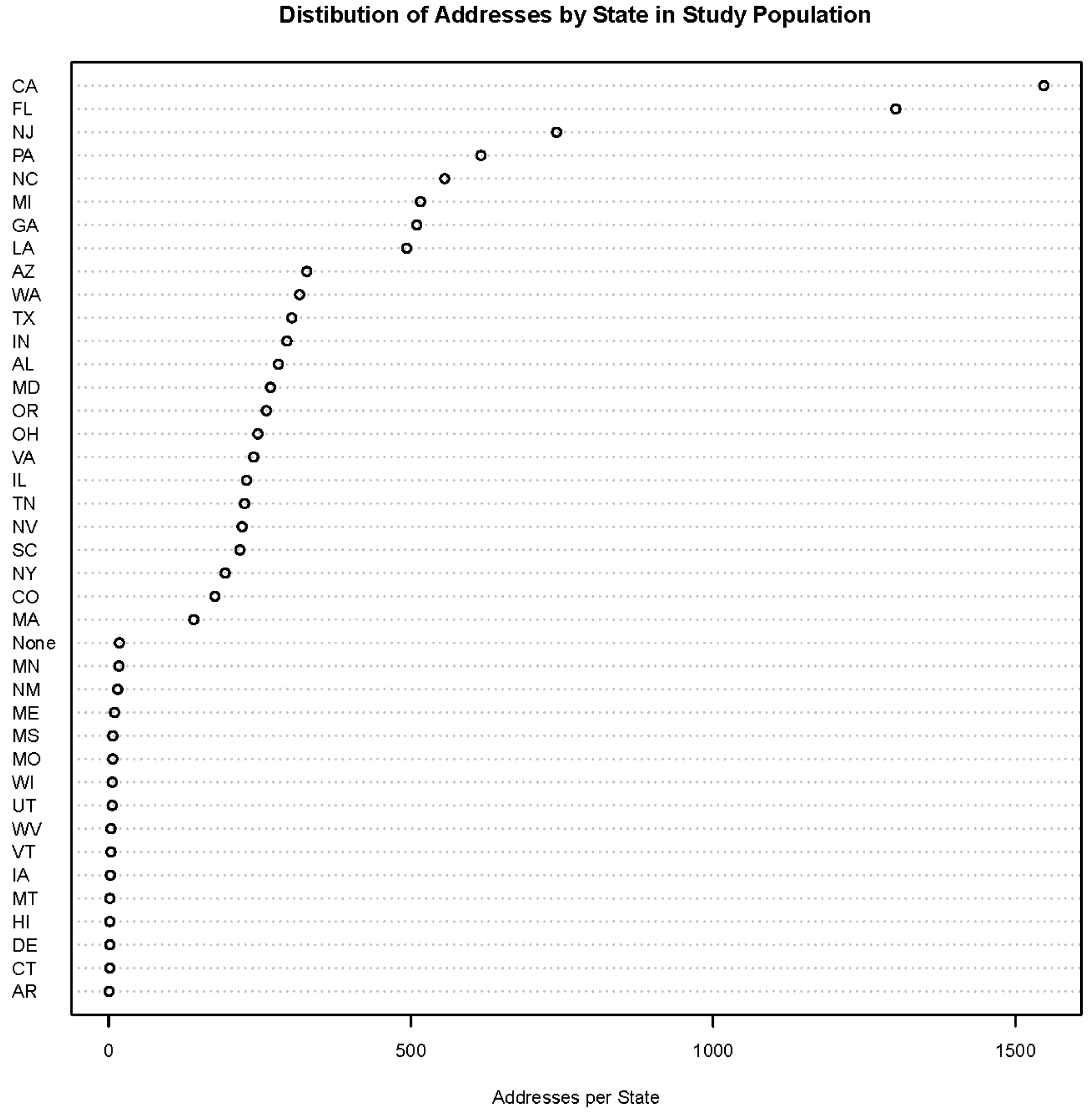
Figure 1.
Distribution of study population addresses by state.
Figure 1.
Distribution of study population addresses by state.
3. Results
The mean match rate and overall match rate for Metrics 1, 2, 3 and 5 for the basic and enhanced address services are shown in
Table 2. The mean match rate over subjects was higher than overall match rate over all records for each service for Metrics 1–3. For the basic service, the mean match rate over subjects of city and state names was 77.1%, while the overall match rate of city and state names was lower at 73.4%. As expected, the mean street match (72.5%) and detailed match (72.0%) metrics had lower match rates than the mean city and state match metric. For Metric 5, the mean match rate of subject reported time for detailed matched addresses covered by LexisNexis was 89.2% and the overall match rate of subject reported time for detailed matched addresses covered by LexisNexis was 91.0%. The enhanced service improved on all the match rates for Metrics 1–3. The overall match rate increased from 73.4% to 88.1% (difference = 14.7) for Metric 1, from 68.5% to 86.4% (difference = 17.9) for Metric 2, and from 67.9% to 85.9% (difference = 18.0) for Metric 3. For Metric 5, the enhanced service yielded slightly lower mean (88.4%) and overall (89.0%) match rates for subject reported time than the basic service.
Table 2.
Mean subject match rate and overall match rate for Metric 1 of city and state match, Metric 2 of street match, Metric 3 of detailed match, and Metric 5 of years spent at matched address.
Table 2.
Mean subject match rate and overall match rate for Metric 1 of city and state match, Metric 2 of street match, Metric 3 of detailed match, and Metric 5 of years spent at matched address.
| Metric | Title | Basic Service | Enhanced Service |
|---|
| Mean Match Rate | Overall Match Rate | Mean Match Rate | Overall Match Rate |
|---|
| 1 | City and state match | 77.1% | 73.4% | 90.0% | 88.1% |
| 2 | Street match | 72.5% | 68.5% | 87.7% | 86.4% |
| 3 | Detailed match | 72.0% | 67.9% | 87.3% | 85.9% |
| 5 | Years at matched address | 89.2% | 91.0% | 88.4% | 89.0% |
The results for Metric 4 of the distribution of time spent at each address from each data source are shown in
Table 3. The length of time spent at each address from the basic LexisNexis service was longer than that from the study. The mean time spent at each address from the basic LexisNexis was 9.2 years, while the mean time was 7.2 years for the study. The median (9 years) and third quartile (14 years) of time reported by the basic LexisNexis service were three years longer than those from the study. The enhanced LexisNexis service better matched the distribution of time recorded in the study, as evidenced by the mean time of 8.5 years and median time of 8 years, which was closer to the study median of 6 years. Both LexisNexis services had a minimum time of one year and a maximum time of 19 years, where the maximum time matches the restricted the time frame of the study (1995 to 2013).
Table 3.
Results for Metric 4 of distribution of time spent in years at each address from each data source.
Table 3.
Results for Metric 4 of distribution of time spent in years at each address from each data source.
| Data Source | Percentiles | Mean |
|---|
| Min | 25% | 50% | 75% | Max |
|---|
| Basic LexisNexis | 1 | 3 | 9 | 14 | 19 | 9.2 |
| Enhanced LexisNexis | 1 | 3 | 8 | 13 | 19 | 8.5 |
| Study | 0.3 | 3 | 6 | 11 | 18.5 | 7.2 |
The results for Metric 6 of the difference in time spent at each detailed matched address for LexisNexis and the study data are shown in
Table 4. The distributions of differences in time spent at each detailed matched address were similar for the basic and enhanced LexisNexis services. The mean time spent at each matched detailed address from basic LexisNexis was 2.8 years longer than that from the study, while the mean difference for the enhanced LexisNexis was 2.9 years. The first quartile (0 years), median (2 years), and third quartile (5 years) of the distribution of time differences were the same for the basic and enhanced LexisNexis services. The histogram of the differences in time spent at each detailed matched address for the enhanced LexisNexis and the study data is shown in
Figure 2. The mass of the distribution lies between 0 and 5 years.
Table 4.
Results for Metric 6 of the differences in time spent in years at each detailed matched address .
Table 4.
Results for Metric 6 of the differences in time spent in years at each detailed matched address .
| Data Source | Min | 25% | 50% | 75% | Max | Mean |
|---|
| Basic LexisNexis | −16 | 0 | 2 | 5 | 18 | 2.8 |
| Enhanced LexisNexis | −16 | 0 | 2 | 5 | 18 | 2.9 |
Figure 2.
Distribution of the differences in time spent in years at each detailed matched address as reported in the enhanced LexisNexis and the study .
Figure 2.
Distribution of the differences in time spent in years at each detailed matched address as reported in the enhanced LexisNexis and the study .
Table 5.
Mean match rate for Metric 7 of time covered rate, Metric 8 of most recent address match, and Metric 9 of baseline address match for the basic and enhanced LexisNexis products.
Table 5.
Mean match rate for Metric 7 of time covered rate, Metric 8 of most recent address match, and Metric 9 of baseline address match for the basic and enhanced LexisNexis products.
| Metric | Description | Basic LexisNexis Rate | Enhanced LexisNexis Rate |
|---|
| 7 | Time covered rate | 73.8% | 86.3% |
| 8 | Most recent address match | 85.3% | 90.5% |
| 9 | Baseline address match | 53.3% | 78.3% |
The match rates for Metrics 7, 8, and 9 are shown in
Table 5. The mean proportion of subject time covered by LexisNexis (metric 7) was 73.8% for the basic service and 86.3% for the enhanced service. The match rate for the most recent address recorded for each subject was 85.3% for the basic service and 90.5% for the enhanced service. Study baseline addresses (1995/1996) were matched by LexisNexis at 53.3% for the basic service and 78.3% for the enhanced service.
The percentage of study addresses with matches in the basic and enhanced LexisNexis by year of follow-up for Metric 10 is shown in
Table 6. The match rates were above 80% for year 2004 through 2013 for the basic LexisNexis service. There was a substantial dip in the match rate from 2002 to 2001 (74.5% to 55.8%), and the match rate more gradually decreased until 1995 (40.0%). With the enhanced service, the match rate remained above 78% for all years, and the match rate was higher than the basic service match rate for every year. The annual match rate with the enhanced service was at least 20 percentage points higher than with the basic service during 1995–2001.
Table 6.
Percent of detailed study addresses that matched basic and enhanced LexisNexis by year of follow-up (Metric 10).
Table 6.
Percent of detailed study addresses that matched basic and enhanced LexisNexis by year of follow-up (Metric 10).
| Year | Count | Basic LexisNexis Match | Enhanced LexisNexis Match |
|---|
| 1995 | 30 | 40.0% | 83.3% |
| 1996 | 1024 | 53.0% | 78.3% |
| 1997 | 1005 | 53.5% | 78.5% |
| 1998 | 1012 | 53.9% | 79.3% |
| 1999 | 1009 | 54.5% | 79.4% |
| 2000 | 1011 | 54.8% | 79.8% |
| 2001 | 1017 | 55.8% | 79.9% |
| 2002 | 1098 | 74.5% | 86.2% |
| 2003 | 1053 | 78.0% | 85.9% |
| 2004 | 1116 | 80.8% | 87.4% |
| 2005 | 1157 | 83.1% | 88.9% |
| 2006 | 1108 | 81.9% | 87.6% |
| 2007 | 1167 | 84.6% | 89.8% |
| 2008 | 1025 | 80.4% | 86.2% |
| 2009 | 1067 | 83.5% | 89.1% |
| 2010 | 830 | 84.0% | 89.8% |
| 2011 | 827 | 84.3% | 90.0% |
| 2012 | 897 | 85.7% | 90.6% |
| 2013 | 825 | 88.4% | 93.3% |
For Metric 11, the overall record match rate and mean subject match rate based on the spatial distance threshold of 100 feet (match based on presence of LexisNexis point within distance threshold of study point) were 68.2% and 72.0%, respectively, with the basic LexisNexis service. With the enhanced LexisNexis service, the overall record match rate and mean subject match rate were 86.6% and 88.2%, respectively.
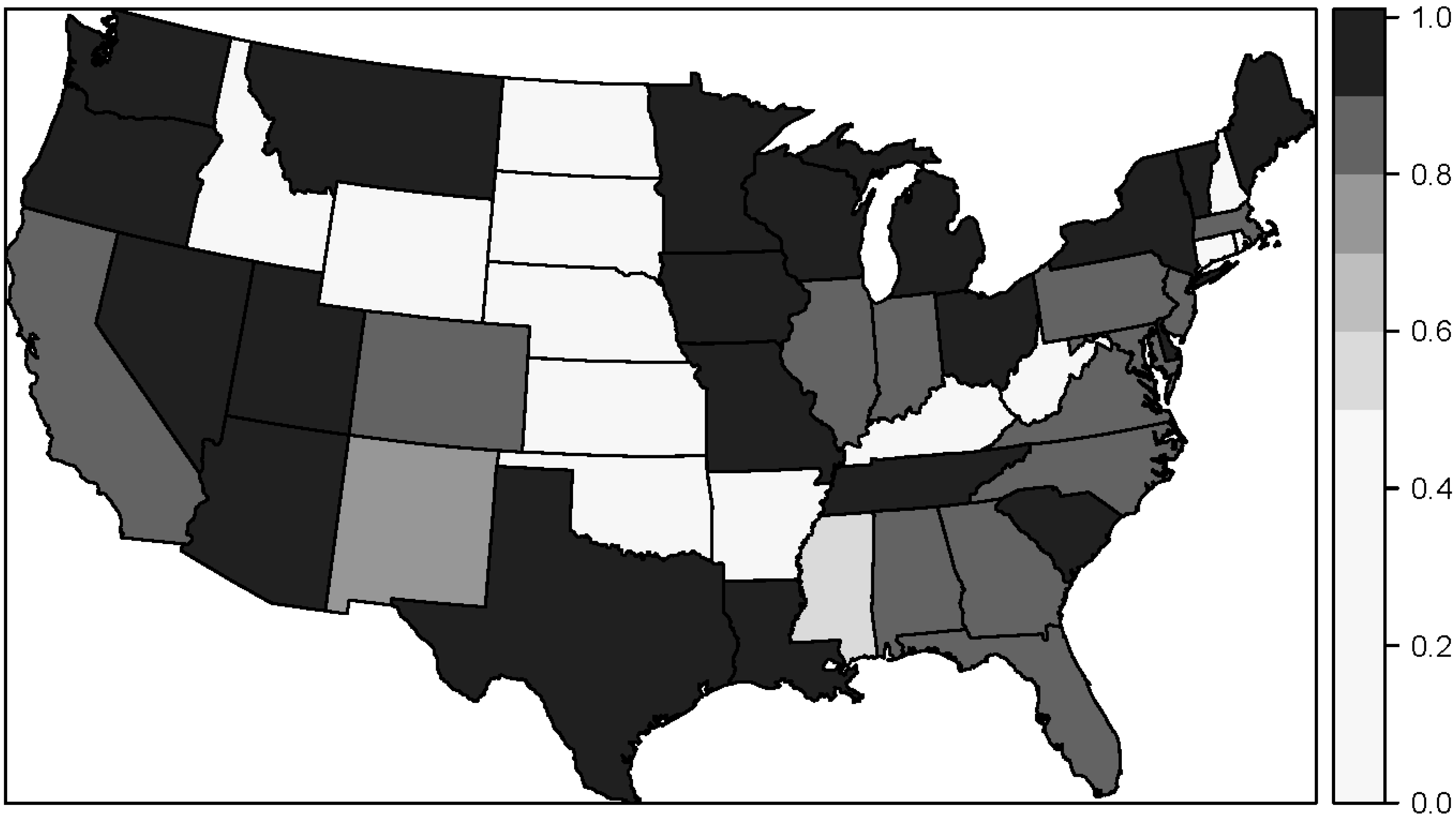
To assess the spatial dimension of the agreement between the study and LexisNexis addresses, we plotted the mean match rate by state for Metric 3 using the enhanced LexisNexis service (
Figure 3). The spatial pattern of Metric 3 reveals that Midwestern states generally had higher match rates than southeastern states. For example, Ohio (91.2%) and Michigan (90.5%) had higher match rates than Alabama (84.4%) and Georgia (86.0%). Many western states, such as Washington (96.8%) and Oregon (98.4%) also had high match rates. States with a match rate of 0% had no or very few study addresses. In addition to the visual variation in match rates, the stratified analysis by California and Los Angeles showed unequal match rates among the strata. For example, with the basic service the mean match rate for Metric 3 was 58.8% for California and 74.8% outside California, and it was 62.5% for Los Angeles and 72.4% outside Los Angeles. Using the enhanced LexisNexis service the differences between strata were smaller, with a mean match rate for Metric 3 of 84.2% for California and 87.8% outside California and 85.5% for Los Angeles and 87.5% outside Los Angeles.
Figure 3.
Detailed street match rate (Metric 3) by state using the enhanced LexisNexis service.
Figure 3.
Detailed street match rate (Metric 3) by state using the enhanced LexisNexis service.
4. Discussion
In this study, we evaluated the ability of a public-records database from LexisNexis to provide residential histories for subjects in a geographically diverse cohort study. We calculated 11 performance metrics to assess the agreement between addresses collected in the study and addresses from two LexisNexis services. We found match rates of 77% and 90% for city and state together and match rates of 72% and 87% for detailed addresses with the basic and enhanced LexisNexis services, respectively. The basic and enhanced LexisNexis services were able to account for 74% and 86%, respectively, of the time at residential addresses recorded in the study. The enhanced LexisNexis product better matched the distribution of time spent at each study address than did the basic product. In addition, the enhanced product had much higher annual match rates (20 percentage points or more) of detailed addresses for years 1995–2001.
The overall better performance of the enhanced LexisNexis service compared with the basic service was expected. As the enhanced LexisNexis service was specified to provide addresses going back in time until at least 1995 and the basic service included only the three most recent addresses, we anticipated that the annual match rate for the enhanced service would be better for earlier years. Given the level of population mobility in the U.S., with a median duration of residence of 4.7 years in 1996, the three most recent addresses will not provide all the actual addresses over a 19-year period for many study subjects. The implication of this is that an enhanced service should be preferred when a project budget allows it, particularly for studies of a long duration. However, the results also suggest that the basic LexisNexis service may be adequate for studies of a short duration, as mean subject match rates for city and state and detailed addresses were respectable and the match rates by year were similar for the basic and enhanced services for more recent years (2005–2013). There were, however, relatively larger gaps between the two services for overall record match rates for Metrics 1–3. Hence, how good a substitute the basic service is for the enhanced service also depends on the type of the metric considered and if it is deemed more important to match all address records equally or maximize the average match rate per subject.
In addition to the variation observed in match rates by year, there was variation in match rates over space. The mean match rate for detailed address matches varied spatially over states, where states in the West and Midwest generally had higher match rates than states in the Southeast. Results comparing the match rates in California vs. out of California showed that the match rate was substantially worse in California than elsewhere in the study. The same was true for Los Angeles vs. outside Los Angeles. The implication of these findings is that the ability of a public records database to recreate study addresses will depend on the geographic definition of the study.
There are several strengths and limitations of this study. A strength of this study is that it includes geographically diverse addresses that cover a large portion of the United States. Enrollment into the study cohort took place in eight states, which is considerably larger than a previous study that had enrollment limited to 11 counties in Michigan [
17]. In addition to the eight enrollment states, there were many other states with hundreds of addresses (
Figure 1). Another strength is that our study determined how well a public-record database would recreate addresses collected in a cohort study, which more reflects how one might use the service from LexisNexis in the absence of collected residential histories. A previous study determined how well study addresses matched the LexisNexis addresses [
17]. A limitation of this study is that our reported match rates may not represent those found in other studies. The cohort addresses were collected through the USPS change-of-address program. Studies based on subject recall may have lower match rates. In addition, we used approximate string matching and studies that use exact string matching may have lower match rates. While our study was geographically diverse, studies with larger sample sizes are possible with appropriate budgets.




{kind=link}
{kind=link}
{kind=link}

