4.2. Evaluation
The proposed method models the named entity recognition problem as a multi-classification problem. There are five categories in the CCKS-2017 dataset and three in the CHIP-2018 dataset. In the evaluation, they were converted into a two-category problem, and the specific conversion method is explained as follows.
According to the tagging pattern described in
Section 4.1, each kind of entity recognition can be regarded as a five-category problem BIESO. We regard the complete recognition of a named entity as a correct recognition, and record it as the positive class of the two classifications, while only a part of the identified entity is regarded as an incorrect recognition, as the negative class, and the recognition result as O is also recorded as the negative class.
TP (True Positive) is the total number of entities matched with the entity in the labels. FP (False Positive) is the number of recognized labels that do not match the annotated corpus dataset. FN (False Negative) is the number of entity terms that do not match the predicted label entity.
where P indicates precision measurement that defines the capability of a model to represent only related entities [
38] and R (recall) computes the aptness to refer all corresponding entities. F is the harmonic average of P and R, which expresses the comprehensive effect of both.
4.3. Experimental Results
Our experiments were mainly divided into two parts. First, we carried out entity extraction model experiments on CCKS-2017 and CHIP-2018 datasets. Second, experiments were conducted for CHIP-2018-specific tasks.
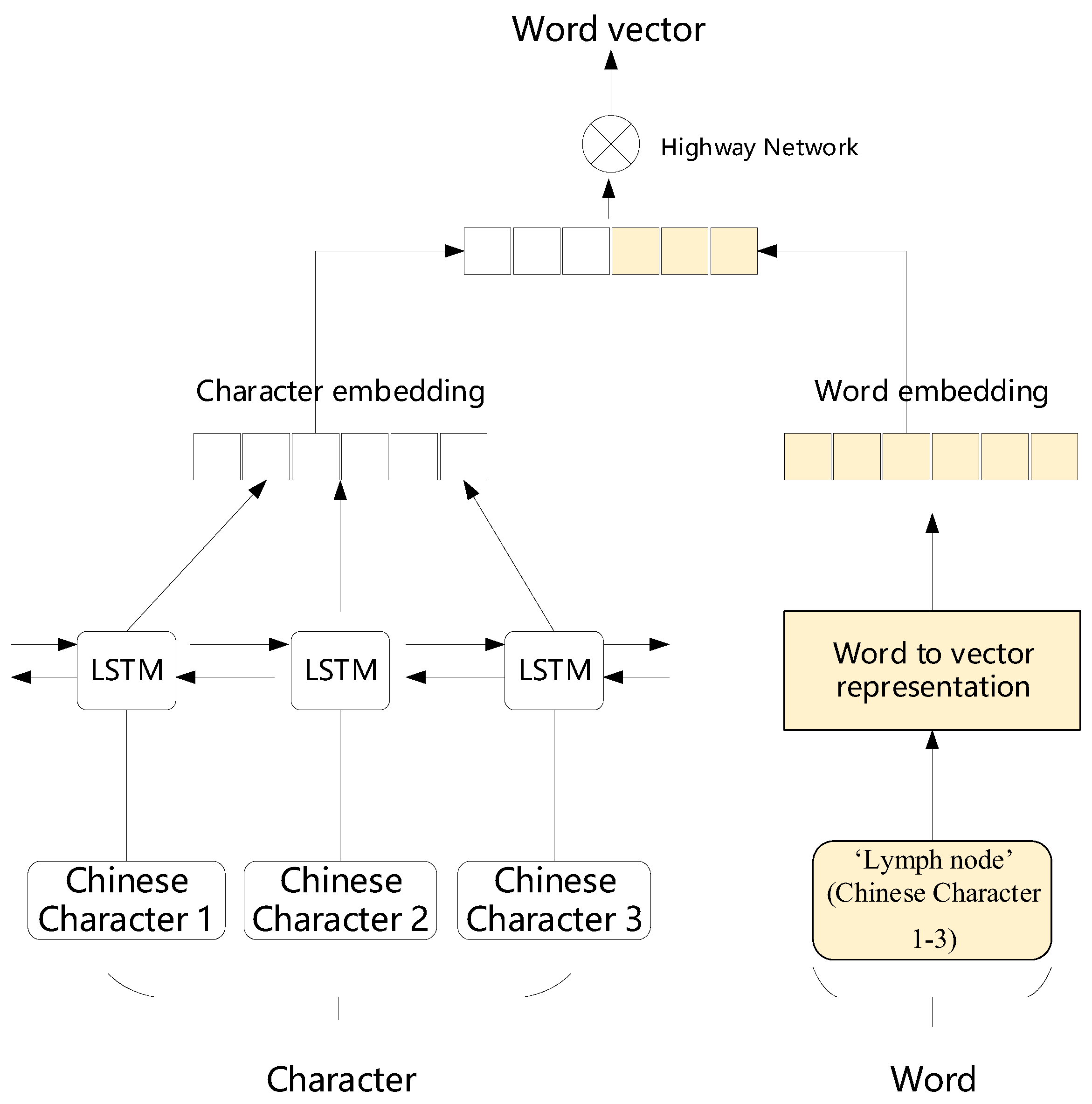
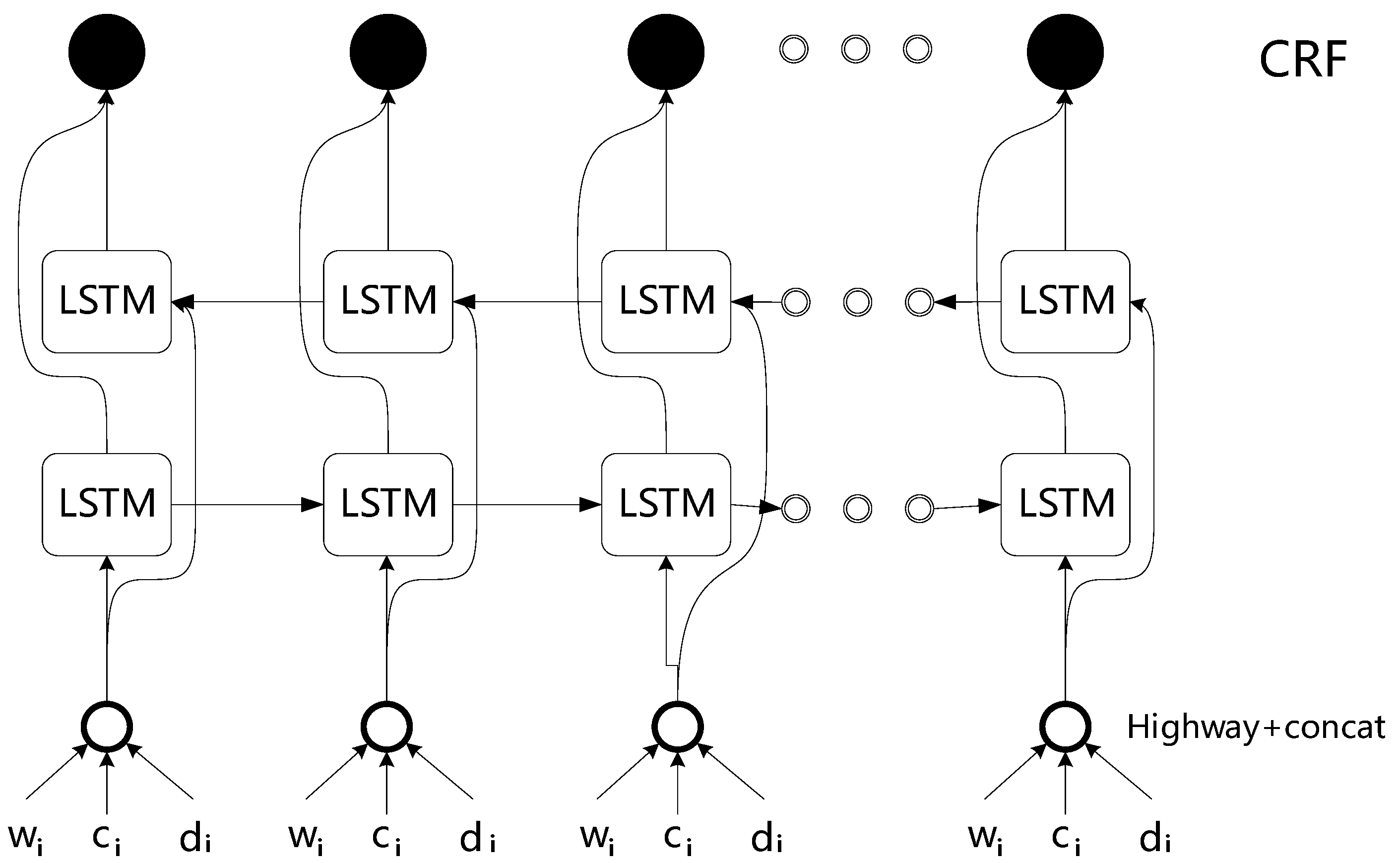
In order to verify the effectiveness of the entity extraction model, we did several sets of experiments. Firstly, we compared with the basic Bi-LSTM-CRF model. Gridach [
11], Habibi et al. [
39], and Zeng et al. [
40] successfully employed Bi-LSTM-CRF models with no additional features for English EMR. We compared the proposed (CWD-Bi-LSTM-CRF) model with the Char-Bi-LSTM-CRF models. We implemented five models with different features and various combinations. These models were test on two datasets (2017 CCKS Task 2 on body category and 2018 CHIP Task 1 on anatomic site.). All comparative results are summarized in
Table 6.
Table 6 shows that the fifth model with char embedding, word embedding, and dictionary feature vector achieves the best performance: on 2018 CHIP Task 1 on anatomic site, it achieved a precision of 93.58%, a recall 94.20%, and a F1-score of 93.89%, while, on the 2017 CCKS Task 2 on body category, it achieved a precision of 91.38%, a recall 89.93%, and a F1-score of 90.65%. Because of the ambiguity of Chinese word boundaries, we found that word+Bi-LSTM model has the worst effect in all respects. Combining with char and word embedding, the F1 values of the two datasets were increased by 0.51% and 0.62%, respectively, compared with the first method; on CHIP dataset, the precision achieved the best results. In addition, the dictionary feature could bring benefit on the CHIP and CCKS datasets with improvement of 2.68% and 1.46% in term of F1-score, respectively. Finally, we tried the combination method of highway network and obtained the best result.
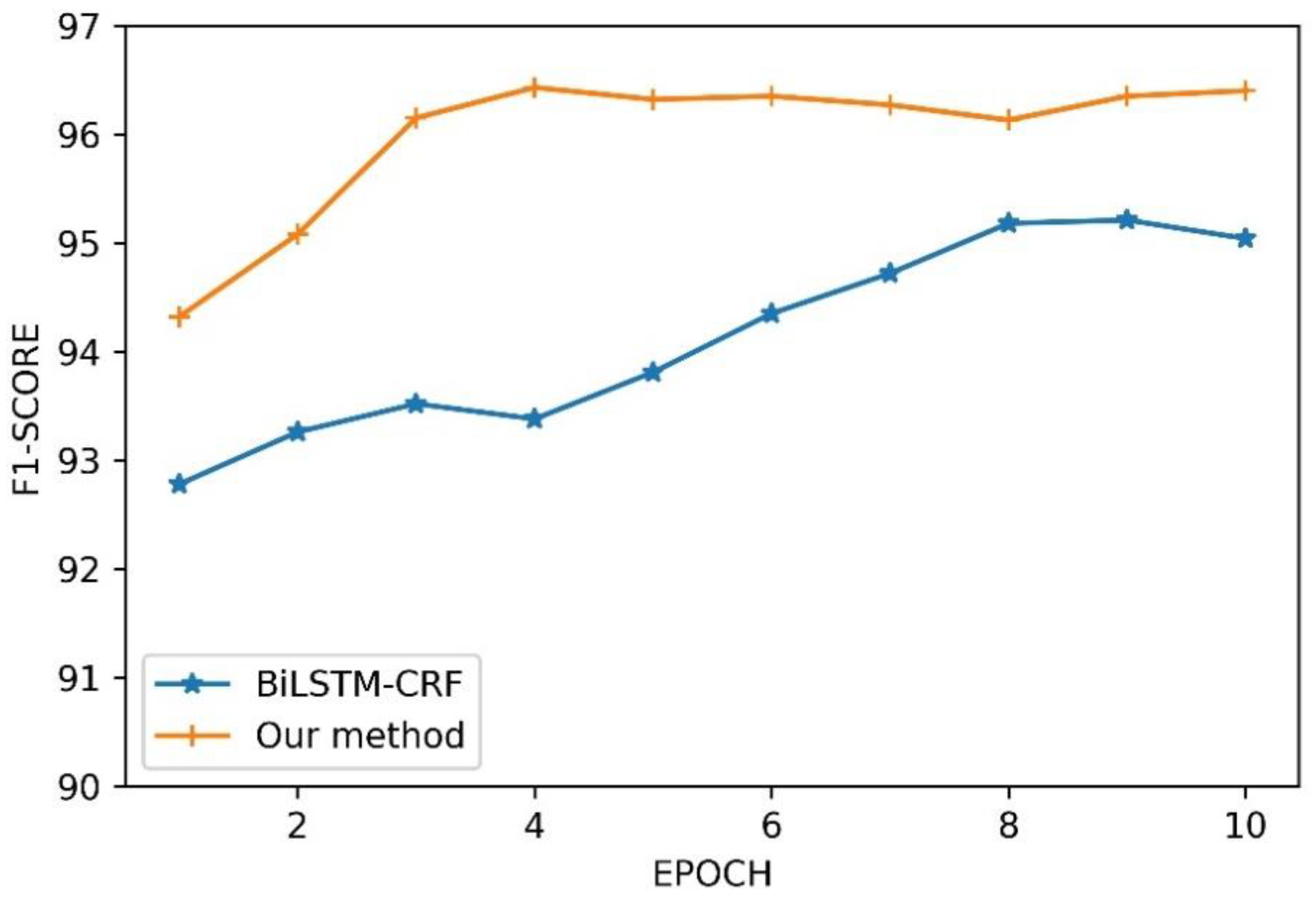
To investigate training speed, we compared our method with the basic Bi-LSTM-CRF in F1-score on the CHIP-2018 training dataset. As shown in
Figure 4, our method converged at the fourth epoch, while the basic Bi-LSTM-CRF model did not converge until the eighth epoch. The convergence rate of the basic Bi-LSTM-CRF model is about twice that of our method. It is reasonable because our method includes dictionary vector features that facilitate the convergence of the model.
Besides the basic Bi-LSTM-CRF model, some existing methods incorporate additional features or approaches into Bi-LSTM-CRF models [
29,
30,
31]. We also compared or method to a rule-based model and a machine learning model.
The comparative results are shown in
Table 7. Because the corresponding reference method utilizes external resources that are not provided, we could not reproduce their model, thus some blank parts are reserved in the experiment results of CHIP-2018 dataset. Entities in both datasets can be considered as body parts, thus they can also be trained together. “Overall” indicates that both datasets were simultaneously used as training data. As shown in the table. The Bi-LSTM-CRF model achieved good results, increasing the F1 value by 0.63% compared to the model of Hu et al. [
29]. Although the model of Hu et al. [
30] had a better overall effect in the extraction of five types of entities, the F1 value being 91.08%, the entity extraction effect for the body category was not good. According to the evaluation results, our proposed model showed better performance on recognizing medical entity terms compared with the other models including CRF and rule-based model.
To further verify the experimental effect of the model on low-frequency entities and unknown entities, we first combined the 2017 CCKS Task 2 and 2018 CHIP Task 1 datasets. Then, we randomly selected 50% of the data as the training set, and the remaining 50% as the test set. The division was based on the number of times the entity appears in the training set. The criteria were:
- (1)
Unknown entity test set: The entities in the sample have never appeared in the training set.
- (2)
Low-frequency entity test set: The entities in the sample appear fewer than five times in the training set.
- (3)
High-frequency entity test set: Entities in the sample appear more than five times in the training set.
As shown in
Table 8, in the high-frequency entity test set, since the entities in the test set appear more times in the training set, the model could learn more features, thus all three algorithms achieved good results, and our method’s F1 score reached 98.08%. In the low-frequency entity and unknown entity test set, because there are too few samples for learning in the training set, fewer features could be learned. Compared with the other two methods, our method had the best results under these two types of test sets. Compared with Bi-LSTM-CRF, our method’s F1 score was improved by 30%, and our method was 20% higher than Bi-LSTM-Attention. Experiments proved that our method has greater advantages in low-frequency entities and unknown entity datasets.
Three entities were extracted from the CHIP-2018 dataset (600 training data and 200 test data), namely the primary site of the tumor, the size of the lesion, and the tumor metastasis site. The size of the lesion refers specifically to the size of the primary site of the tumor. Not all entities contained in EMRs belong to these entity categories, thus we only needed to extract some of the entities from EMRs. We used the rules to locate the candidate sentences of the three entities and obtained the entities from the sentences through the entity extraction method. The tumor origin site entity and tumor metastasis site entity could be directly obtained, while the size of the lesion needed to determine whether the primary site of the tumor is included in the sentence. In
Table 9, we list the F1 values of the local test (using 10% of the training data as test data, and results obtained on a local computer) and the submitted results (using the test data given by the evaluation organization, and the results obtained on the evaluation organization’s server).
The method submitted to CHIP-2018 is to use rules to extract entity candidate sentences and char+Bi-LSTM-CRF model to extract entities. In the table, we can see that the local test and submission results are quite different: the gaps in F1 values are above 10%, and the gap in the metastasis site reached 23.36%. This shows that the generalization ability of the first method we submitted is not good.
We found that the previous method was not very effective on the CHIP-2018 task. Hence, we modified the method as: (1) Entity extraction is performed using the CWD-Bi-LSTM-CRF model with the same rules. (2) An external dictionary is used to correct the extracted entities. (3) The rules are redefined to extract candidate sentences. The experimental comparison results are shown in
Table 9. The table uses the final criteria for the task, with weighted P, R, and F1. The weight of the primary site was 0.2, the weight of the lesion was 0.3, and the weight of the metastatic site was 0.5.
In
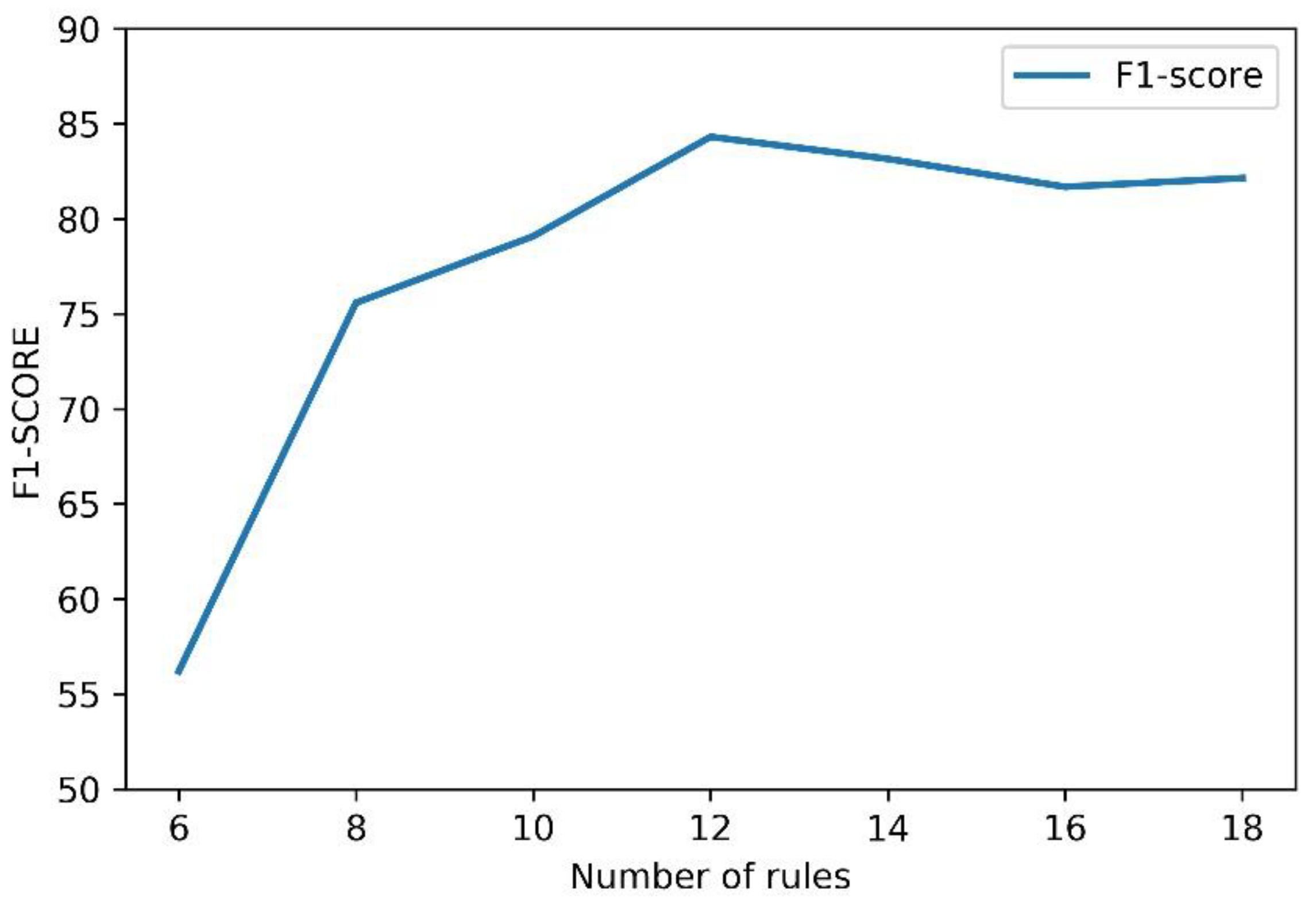
Table 10, we can see that the F1 value was improved in the case of changing the entity extraction model and adding an external dictionary. The F1 value increased by 5.26% when we adopted the CWD-Bi-LSTM model, and it increased by 8.46% after we added the external dictionary. Finally, we redefined the rules, using 12 rules, and the F1 value reached 84.36%. The results demonstrate the necessity of adding rules and external dictionaries to the task.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}