Traffic Crash Severity Prediction—A Synergy by Hybrid Principal Component Analysis and Machine Learning Models


Abstract
:1. Introduction
2. Literature Review
3. Methodology
3.1. Dataset Discerption
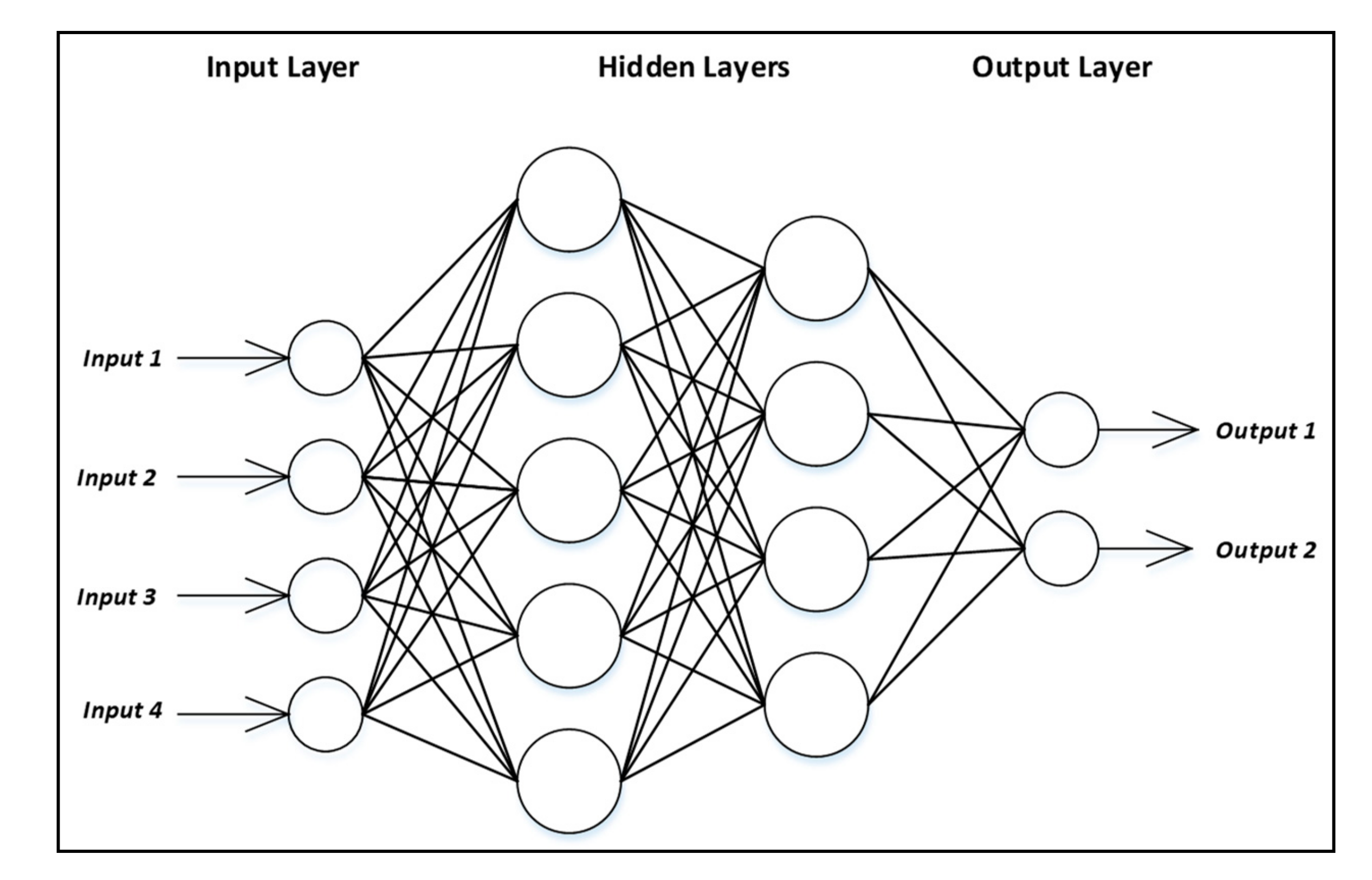
3.2. Multilayer Perceptron Neural Networks
3.3. Support Vector Machine
3.4. Principal Component Analysis
4. Data Processing
4.1. Development of the Multilayer Perceptron Neural Networks Model Using Original Crash Attributes
4.2. Development of the Support Vector Machine Model Using Original Crash Attributes
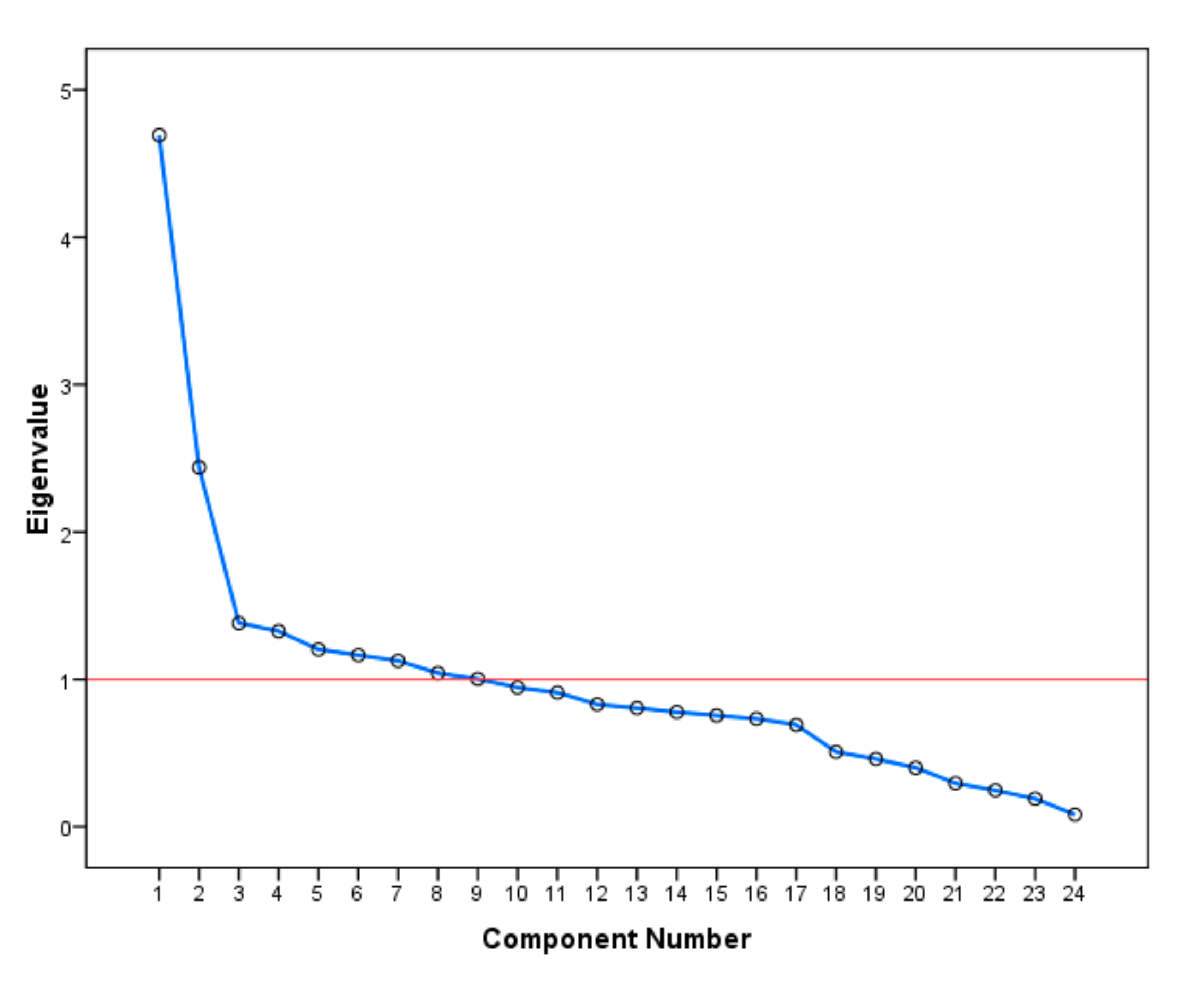
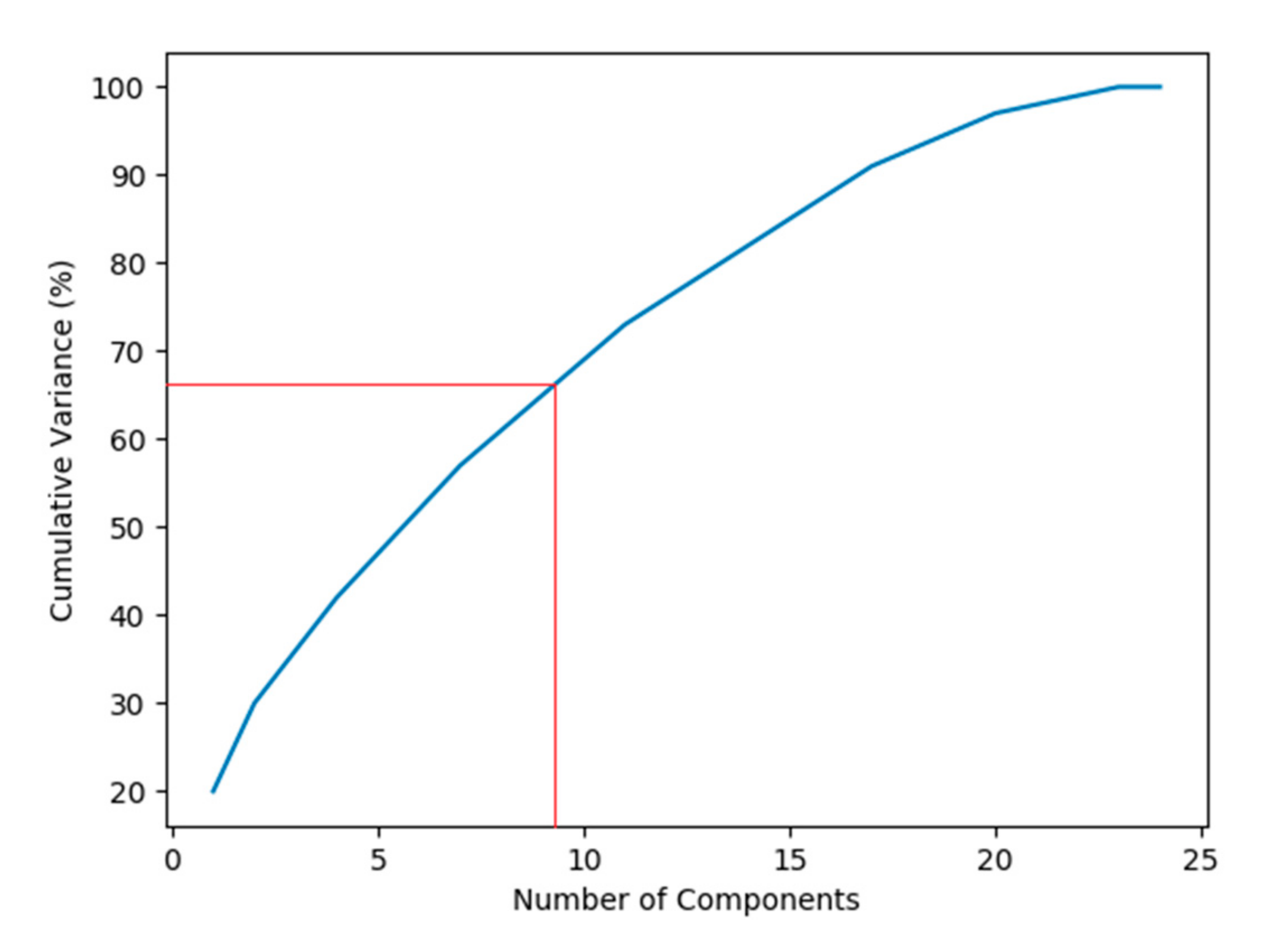
4.3. Principal Component Analysis
4.4. Development of the Multilayer Perceptron Neural Networks and Support Vector Machine Models Using Principal Components
5. Results and Discussion
6. Conclusions
Limitations and Future Work
Funding
Acknowledgments
Conflicts of Interest
References
- Peden, M.; Scurfield, R.; Sleet, D.; Hyder, A.A.; Mathers, C.; Jarawan, E.; Hyder, A.A.; Mohan, D.; Jarawan, E. World Report on Road Traffic Injury Prevention; World Health Organizatio: Geneva, Switzerland, 2004. [Google Scholar]
- World Health Organization. Global Status Report on Road Safety; World Health Organizatio: Geneva, Switzerland, 2018. [Google Scholar]
- Andersson, R.; Menckel, E. On the prevention of accidents and injuries: A comparative analysis of conceptual frameworks. Accid. Anal. Prev. 1995, 27, 757–768. [Google Scholar] [CrossRef]
- Mujalli, R.O.; de Oña, J. Injury severity models for motor vehicle accidents: A review. Proc. Inst. Civ. Eng. Transp. 2013, 166, 255–270. [Google Scholar] [CrossRef]
- Sanguansat, P. Principal Component Analysis: Engineering Applications; BoD–Books on Demand, Intech: Rijeka, Croatia, 2012. [Google Scholar]
- Shankar, V.; Mannering, F.; Barfield, W. Statistical analysis of accident severity on rural freeways. Accid. Anal. Prev. 1996, 28, 391–401. [Google Scholar] [CrossRef]
- Garrido, R.; Bastos, A.; de Almeida, A.; Elvas, J.P. Prediction of road accident severity using the ordered probit model. Transp. Res. Procedia 2014, 3, 214–223. [Google Scholar] [CrossRef] [Green Version]
- Kashani, A.T.; Mohaymany, A.S. Analysis of the traffic injury severity on two-lane, two-way rural roads based on classification tree models. Saf. Sci. 2011, 49, 1314–1320. [Google Scholar] [CrossRef]
- de Oña, J.; Mujalli, R.O.; Calvo, F.J. Analysis of traffic accident injury severity on Spanish rural highways using Bayesian networks. Accid. Anal. Prev. 2011, 43, 402–411. [Google Scholar] [CrossRef]
- Zong, F.; Xu, H.; Zhang, H. Prediction for traffic accident severity: Comparing the Bayesian network and regression models. Math. Probl. Eng. 2013, 2013, 475194. [Google Scholar] [CrossRef] [Green Version]
- Abdelwahab, H.T.; Abdel-Aty, M.A. Development of artificial neural network models to predict driver injury severity in traffic accidents at signalized intersections. Transp. Res. Rec. 2001, 1746, 6–13. [Google Scholar] [CrossRef]
- Alkheder, S.; Taamneh, M.; Taamneh, S. Severity prediction of traffic accident using an artificial neural network. J. Forecast. 2017, 36, 100–108. [Google Scholar] [CrossRef]
- Zheng, M.; Li, T.; Zhu, R.; Chen, J.; Ma, Z.; Tang, M.; Cui, Z.; Wang, Z. Traffic Accident’s Severity Prediction: A Deep-Learning Approach-Based CNN Network. IEEE Access 2019, 7, 39897–39910. [Google Scholar] [CrossRef]
- Hashmienejad, S.H.-A.; Hasheminejad, S.M.H. Traffic accident severity prediction using a novel multi-objective genetic algorithm. Int. J. Crashworthiness 2017, 22, 425–440. [Google Scholar] [CrossRef]
- Zeng, Q.; Huang, H. A stable and optimized neural network model for crash injury severity prediction. Accid. Anal. Prev. 2014, 73, 351–358. [Google Scholar] [CrossRef]
- Arhin, S.A.; Gatiba, A. Predicting injury severity of angle crashes involving two vehicles at unsignalized intersections using artificial neural networks. Eng. Technol. Appl. Sci. Res. 2019, 9, 3871–3880. [Google Scholar]
- Abdel-Aty, M.A.; Abdelwahab, H.T. Predicting injury severity levels in traffic crashes: A modeling comparison. J. Transp. Eng. 2004, 130, 204–210. [Google Scholar] [CrossRef]
- Iranitalab, A.; Khattak, A. Comparison of four statistical and machine learning methods for crash severity prediction. Accid. Anal. Prev. 2017, 108, 27–36. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Li, Z.; Pu, Z.; Xu, C. Comparing Prediction Performance for Crash Injury Severity Among Various Machine Learning and Statistical Methods. IEEE Access 2018, 6, 60079–60087. [Google Scholar] [CrossRef]
- Wang, X.; Kim, S.H. Prediction and factor identification for crash severity: Comparison of discrete choice and tree-based models. Transp. Res. Rec. 2019, 2673, 640–653. [Google Scholar] [CrossRef]
- Cuenca, L.G.; Puertas, E.; Aliane, N.; Andres, J.F. Traffic accidents classification and injury severity prediction. In Proceedings of the 2018 3rd IEEE International Conference on Intelligent Transportation Engineering (ICITE), Singapore, 3–5 September 2018; pp. 52–57. [Google Scholar]
- Sohn, S.Y.; Shin, H. Pattern recognition for road traffic accident severity in Korea. Ergonomics 2010, 44, 107–117. [Google Scholar] [CrossRef]
- Li, Z.; Liu, P.; Wang, W.; Xu, C. Using support vector machine models for crash injury severity analysis. Accid. Anal. Prev. 2012, 45, 478–486. [Google Scholar] [CrossRef]
- Fiorentini, N.; Losa, M. Handling imbalanced data in road crash severity prediction by machine learning algorithms. Infrastructures 2020, 5, 61. [Google Scholar] [CrossRef]
- Zhang, C.; He, J.; Wang, Y.; Yan, X.; Zhang, C.; Chen, Y.; Liu, Z.; Zhou, B. A crash severity prediction method based on improved neural network and factor Analysis. Discret. Dyn. Nat. Soc. 2020, 2020, 4013185. [Google Scholar] [CrossRef]
- Hasheminejad, S.H.-A.; Zahedi, M.; Hasheminejad, S.M.H. A hybrid clustering and classification approach for predicting crash injury severity on rural roads. Int. J. Inj. Control Saf. Promot. 2018, 25, 85–101. [Google Scholar] [CrossRef] [PubMed]
- Assi, K.; Rahman, S.M.; Mansoor, U.; Ratrout, N. Predicting crash injury severity with machine learning algorithm synergized with clustering technique: A promising protocol. Int. J. Environ. Res. Public Health 2020, 17, 5497. [Google Scholar] [CrossRef] [PubMed]
- Kassu, A.; Hasan, M. Identifying the principal factors influencing traffic safety on interstate highways. SN Appl. Sci. 2019, 1, 1729. [Google Scholar] [CrossRef] [Green Version]
- Mussone, L.; Bassani, M.; Masci, P. Analysis of factors affecting the severity of crashes in urban road intersections. Accid. Anal. Prev. 2017, 103, 112–122. [Google Scholar] [CrossRef]
- Xiao-Duan, H.S.; Qi-Hua, H.Y. Relationships between Crash Severity and Traffic Flow Characteristics on Freeways. China Saf. Sci. J. 2011, 9. [Google Scholar] [CrossRef]
- Haykin, S.; Network, N. A comprehensive foundation. Neural Netw. 2004, 2, 41. [Google Scholar]
- Sun, K.; Huang, S.-H.; Wong, D.S.-H.; Jang, S.-S. Design and application of a variable selection method for multilayer perceptron neural network with LASSO. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 1386–1396. [Google Scholar] [CrossRef]
- Hunter, D.; Yu, H.; Pukish, M.S., III; Kolbusz, J.; Wilamowski, B.M. Selection of proper neural network sizes and architectures—A comparative study. IEEE Trans. Ind. Inform. 2012, 8, 228–240. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin, Germany, 2013. [Google Scholar]
- Richhariya, B.; Tanveer, M. EEG signal classification using universum support vector machine. Expert Syst. Appl. 2018, 106, 169–182. [Google Scholar] [CrossRef]
- Shafiullah, M.; Ijaz, M.; Abido, M.; Al-Hamouz, Z. Optimized support vector machine & wavelet transform for distribution grid fault location. In Proceedings of the 2017 11th IEEE International Conference on Compatibility, Power Electronics and Power Engineering (CPE-POWERENG), Cadiz, Spain, 4–6 April 2017; pp. 77–82. [Google Scholar]
- Shahriar, M.S.; Shafiullah, M.; Rana, M.J. Stability enhancement of PSS-UPFC installed power system by support vector regression. Electr. Eng. 2018, 100, 1601–1612. [Google Scholar] [CrossRef]
- Canedo, E.D.; Mendes, B.C. Software Requirements Classification Using Machine Learning Algorithms. Entropy 2020, 22, 1057. [Google Scholar] [CrossRef]
- Cecati, C.; Kolbusz, J.; Różycki, P.; Siano, P.; Wilamowski, B.M. A novel RBF training algorithm for short-term electric load forecasting and comparative studies. IEEE Trans. Ind. Electron. 2015, 62, 6519–6529. [Google Scholar] [CrossRef]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417. [Google Scholar] [CrossRef]
- Hair, J.F.; Black, W.C.; Babin, B.J.; Anderson, R.E.; Tatham, R.L. Multivariate Data Analysis; Pearson Prentice Hall: Englewood Cliffs, NJ, USA, 2006. [Google Scholar]
- Johnson, R.A.; Wichern, D.W. Applied Multivariate Statistical Analysis; Pearson Prentice Hall: Englewood Cliffs, NJ, USA, 1982. [Google Scholar]
- Gholamy, A.; Kreinovich, V.; Kosheleva, O. Why 70/30 or 80/20 Relation Between Training and Testing Sets: A Pedagogical Explanation. Int. J. Intell. Technol. Appl. Stat. 2018, 11, 105–111. [Google Scholar]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. (TIST) 2011, 2, 27. [Google Scholar] [CrossRef]
- Kaiser, H.F. The application of electronic computers to factor analysis. Educ. Psychol. Meas. 1960, 20, 141–151. [Google Scholar] [CrossRef]
- Abdel-Aty, M. Analysis of driver injury severity levels at multiple locations using ordered probit models. J. Saf. Res. 2003, 34, 597–603. [Google Scholar] [CrossRef] [PubMed]
- Chang, L.-Y.; Wang, H.-W. Analysis of traffic injury severity: An application of non-parametric classification tree techniques. Accid. Anal. Prev. 2006, 38, 1019–1027. [Google Scholar] [CrossRef]
- Bedard, M.; Guyatt, G.H.; Stones, M.J.; Hirdes, J.P. The independent contribution of driver, crash, and vehicle characteristics to driver fatalities. Accid. Anal. Prev. 2002, 34, 717–727. [Google Scholar] [CrossRef]
- Huang, H.; Xu, H.; Wang, X.; Silamu, W. Maximum F1-score discriminative training criterion for automatic mispronunciation detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 787–797. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Variable | Description |
|---|---|---|
| Crash Characteristics | Crash type | 1. Collision with a vehicle; 2. Struck pedestrian; 3. Struck animal; 4. Collision with a fixed object; 5. Collision with some other object; 6. The vehicle overturned; 7. Fall from or in moving vehicle; 8. Other crash. |
| Day of the week | 1. Monday; 2. Tuesday; 3. Wednesday; 4. Thursday; 5. Friday; 6. Saturday; 7. Sunday | |
| Number of vehicles involved | Integer value (with a maximum of two vehicles) | |
| Number of persons involved | Integer value | |
| Roadway Characteristics | Roadway median separation | 0. Undivided, 1. Divided |
| Roadway geometry | 1. Cross intersection; 2. T intersection; 3. Y intersection; 4. Multiple intersections; 5. Not at an intersection; 6. Dead end; 7. Road closure | |
| Roadway speed | Integer value | |
| Roadway surface condition | 1. Dry; 2. Wet; 3. Muddy; 4. Snowy; 5. Icy | |
| Roadway surface type | 1. Paved; 2. Unpaved; 3. Gravel | |
| Traffic control | 0. No control; 1. Stop-go lights; 2. Pedestrian lights; 3. Pedestrian crossing; 4. Roundabout; 5. Stop sign; 6. Give Way sign; 7. other | |
| Environmental Characteristics | Weather condition | 1. Clear; 2. Raining; 3. Snowing; 4. Fog; 5. Smoke; 6. Dust; 7. Strong wind |
| Light condition | 1. Day; 2. Dusk/Dawn; 3. Dark: streetlight on; 4. Dark: streetlight off; 5. Dark/no streetlights; 6. Dark/street lights unknown | |
| Driver Characteristics * | Driver’s gender | 0. Female; 1. Male |
| Driver’s age | Integer value | |
| Vehicle Characteristics * | Vehicle’s age | Integer value |
| Vehicle type | 1. Car; 2. A station wagon; 3. Utility vehicle; 4. Panel van; 5. Bus; 6. Motorcycle; 7. Moped, 8. Bicycle; 9. Quad bike |
| Principle Component No. | The Highly Correlated Original Feature |
|---|---|
| 1 | Crash Type [9] |
| 2 | Road Surface Condition |
| 3 | Traffic Control Type |
| 4 | Drivers’ Gender [47] |
| 5 | Vehicle Type [47,48] |
| 6 | Road Surface Type |
| 7 | Roadway Speed [47,48] |
| 8 | Road Geometry [47] |
| 9 | Driver’s Age [9,47,49] |
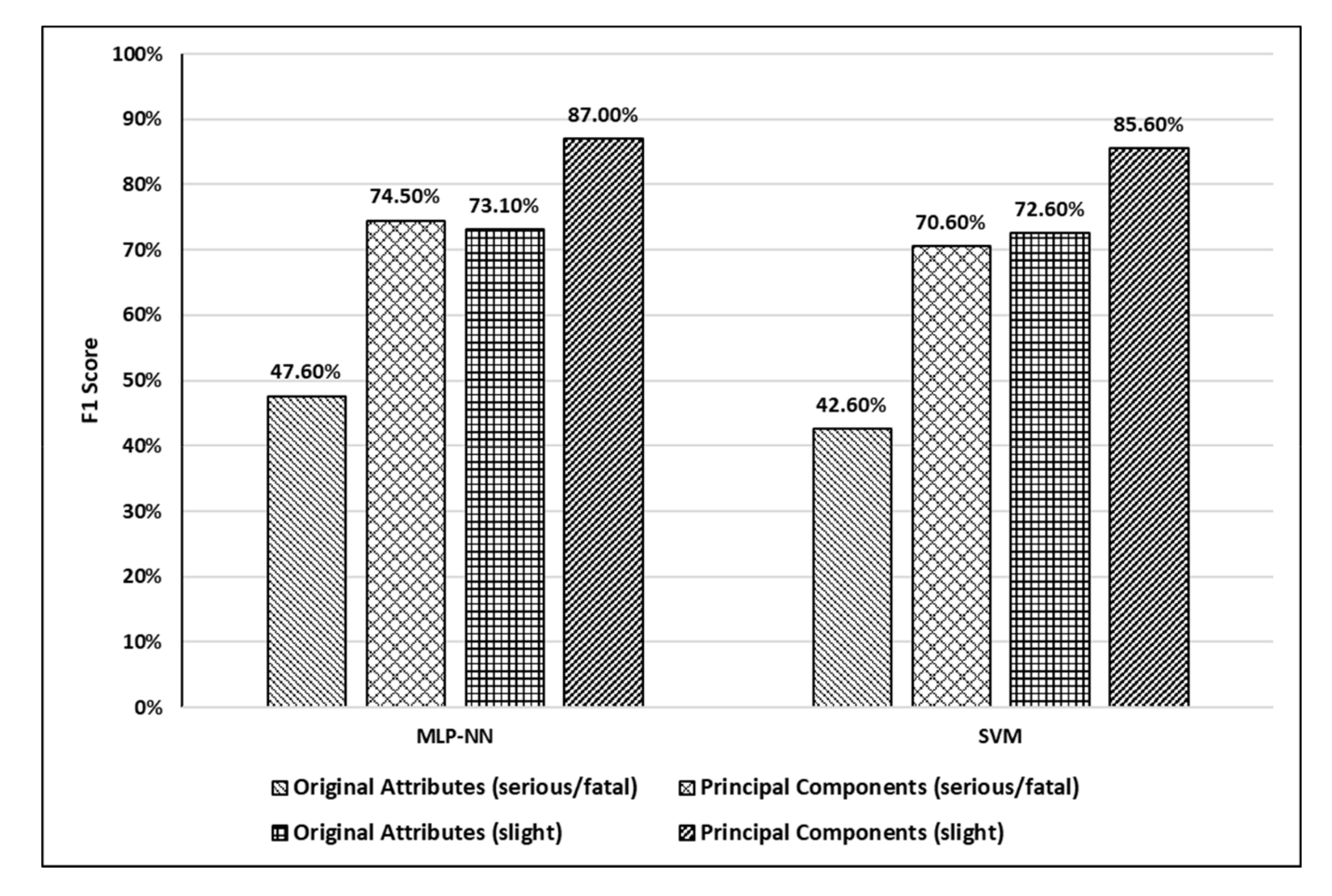
| Model | Training Accuracy | Testing Accuracy | Sensitivity | Precision | F1 Score |
|---|---|---|---|---|---|
| MLP-NN with original attributes | 65.5% | 64.5% | 41.1% | 56.6% | 47.6% |
| SVM with original attributes | 65.9% | 62.7% | 34.7% | 55.0% | 42.6% |
| MLP-NN with principal components | 82.7% | 82.7% | 65.1% | 87.10% | 74.5% |
| SVM with principal components | 81.1% | 80.7% | 58.4% | 89.1% | 70.6% |
| Model | Training Accuracy | Testing Accuracy | Sensitivity | Precision | F1 Score |
|---|---|---|---|---|---|
| MLP-NN with original attributes | 65.5% | 64.5% | 79.6% | 67.7% | 73.1% |
| SVM with original attributes | 65.9% | 62.7% | 81.8% | 65.2% | 72.6% |
| MLP-NN with principal components | 82.7% | 82.7% | 93.9% | 81.0% | 87.0% |
| SVM with principal components | 81.1% | 80.7% | 95.3% | 77.8% | 85.6% |
| Study | Models | Prediction Accuracy |
|---|---|---|
| Abdelwahab and Abdel-Aty [11] | NN | 60.4% |
| Alkheder et al. [12] | k-means clustering based NN | 74.6% |
| Zeng and Haung [15] | NN trained by the convex combination algorithm | 54.8% |
| Iranitalab and Khattak [18] | SVM | 61.5% |
| Zhang et al. [19] | SVM | 53.9% |
| Li et al. [23] | SVM | 48.8% |
| Assi et al. [27] | Fuzzy c-means clustering-based SVM | 74% |
| Fuzzy c-means clustering-based NN | 71% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Assi, K. Traffic Crash Severity Prediction—A Synergy by Hybrid Principal Component Analysis and Machine Learning Models. Int. J. Environ. Res. Public Health 2020, 17, 7598. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph17207598
Assi K. Traffic Crash Severity Prediction—A Synergy by Hybrid Principal Component Analysis and Machine Learning Models. International Journal of Environmental Research and Public Health. 2020; 17(20):7598. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph17207598
Chicago/Turabian StyleAssi, Khaled. 2020. "Traffic Crash Severity Prediction—A Synergy by Hybrid Principal Component Analysis and Machine Learning Models" International Journal of Environmental Research and Public Health 17, no. 20: 7598. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph17207598