

Regression with Highly Correlated Predictors: Variable Omission Is Not the Solution

Abstract
:1. Introduction
2. Methods
2.1. The Problem of Collinearity
2.2. Diagnostics for Collinearity
2.3. Remedial Measures for Collinearity
3. Examples
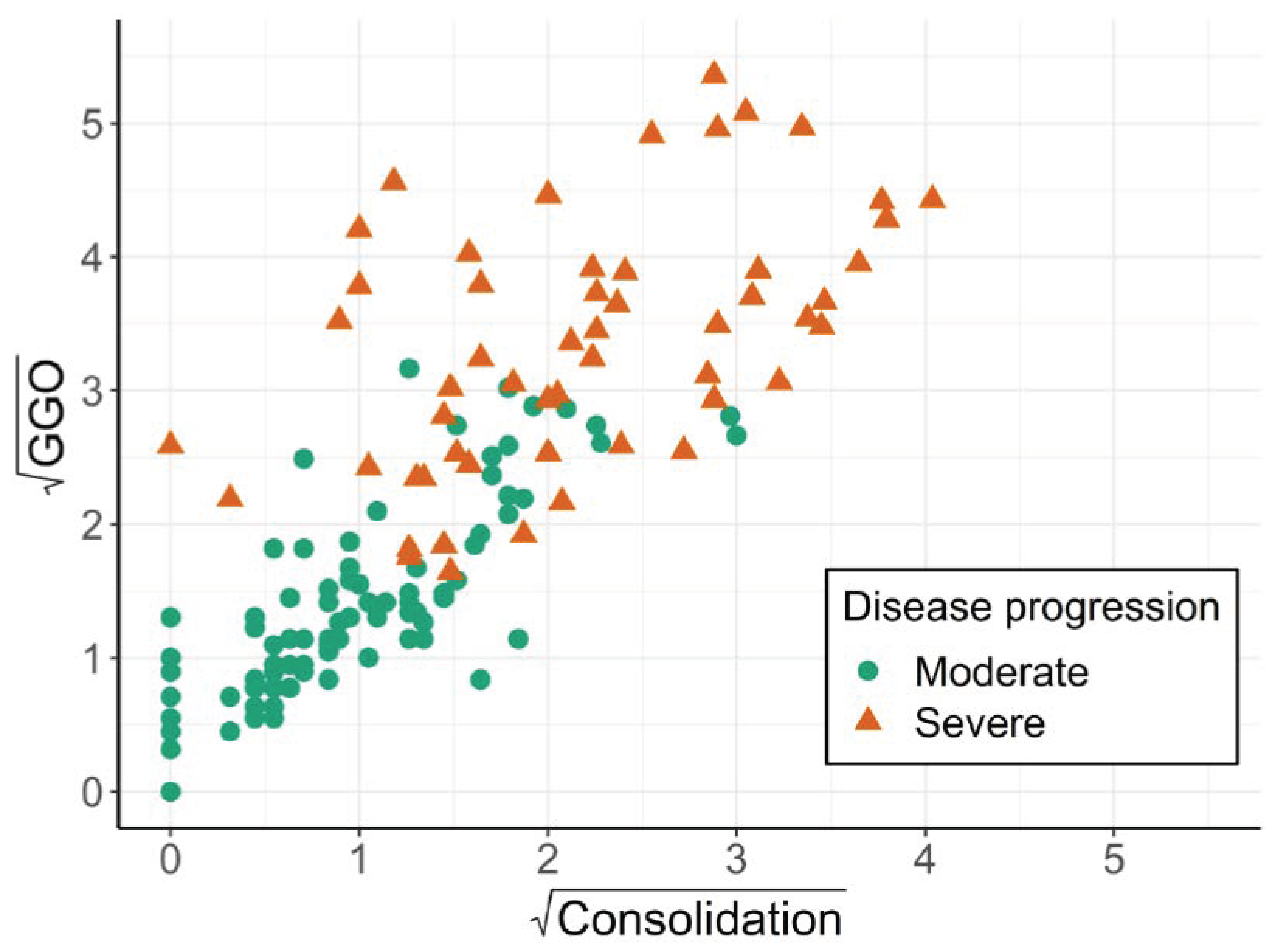
3.1. Worked Example: COVID-19 Study
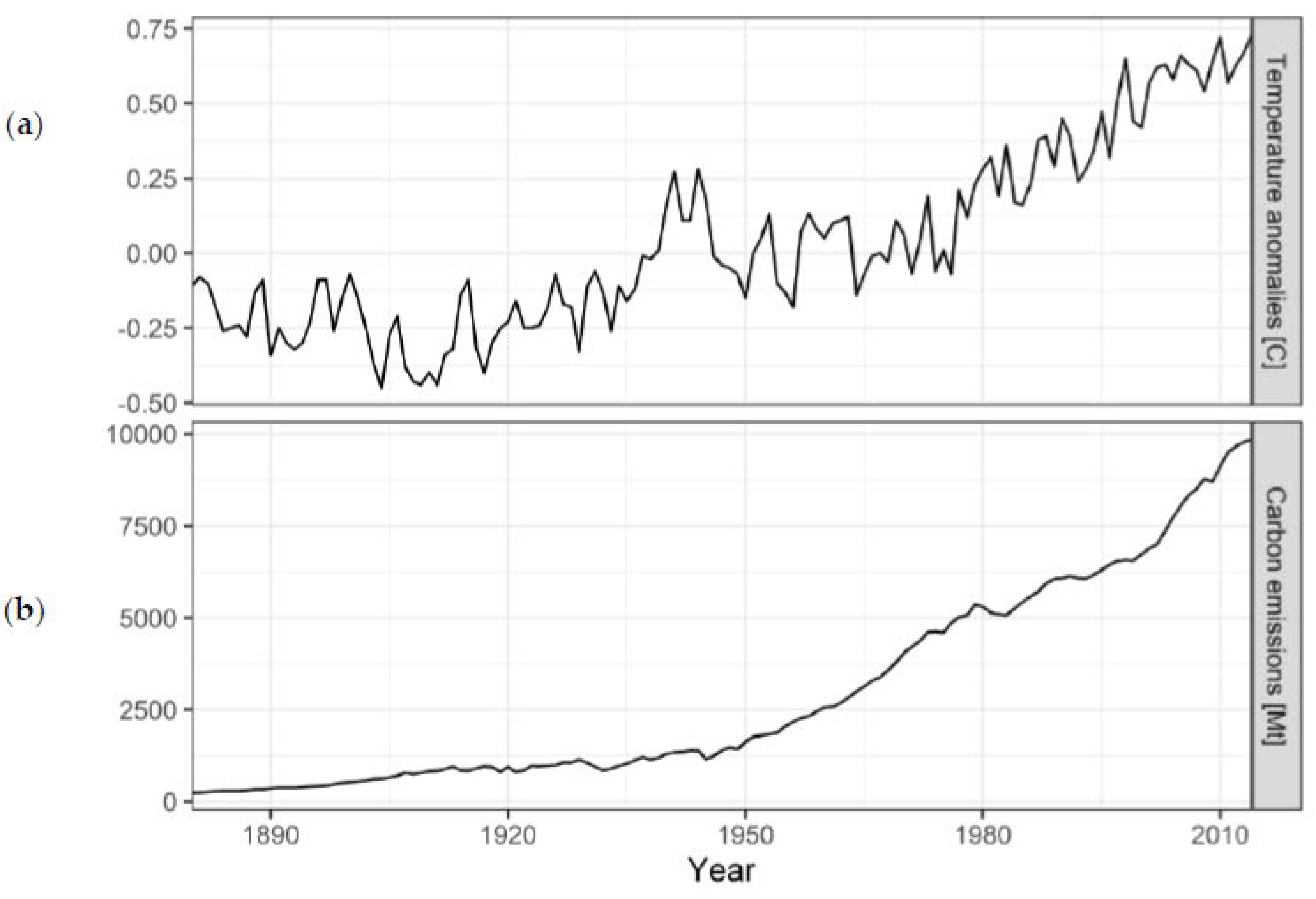
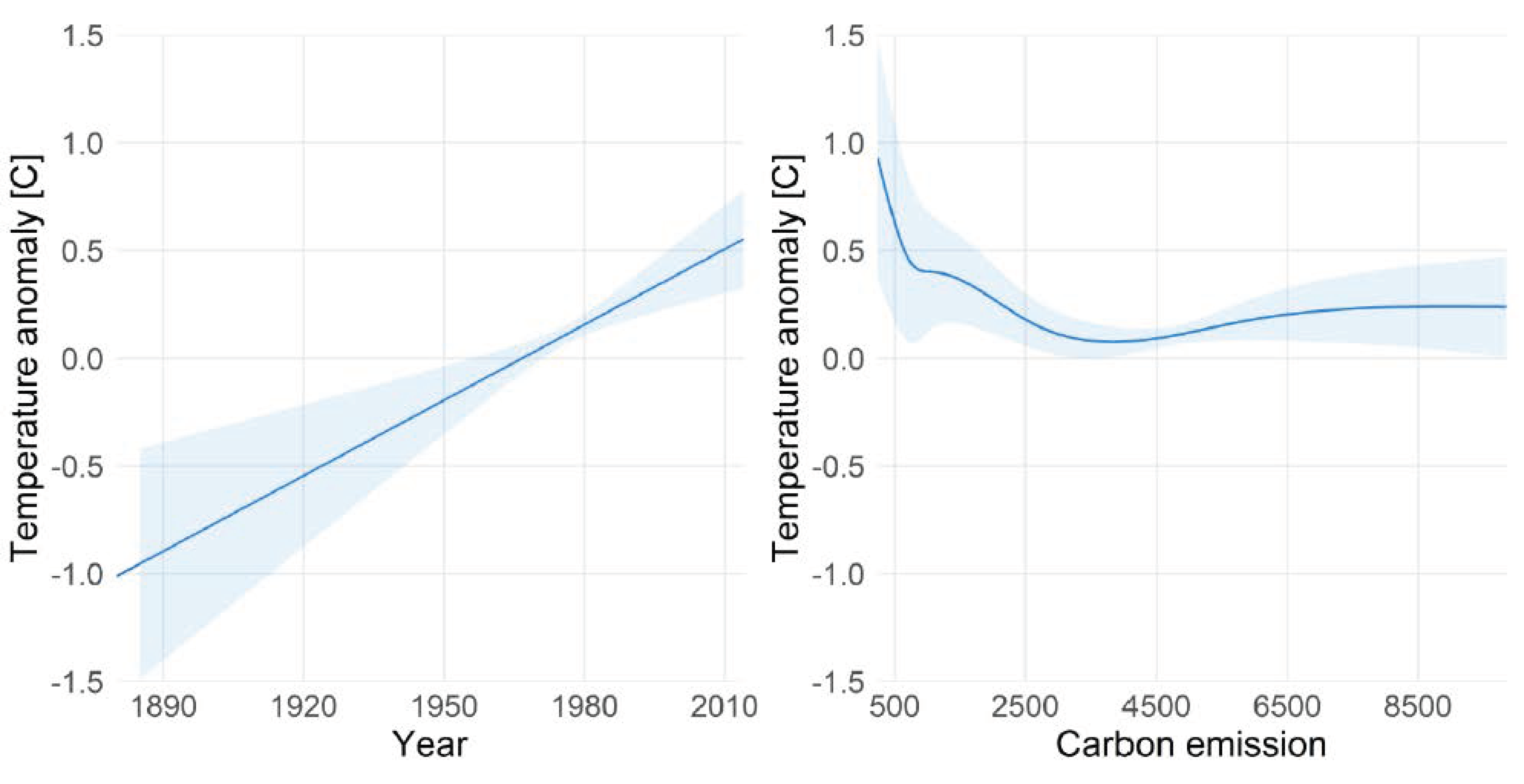
3.2. Worked Example: Carbon Emissions and Temperature Anomalies
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Belsley, D.A.; Kuh, E.; Welsch, R.E. Regression Diagnostics: Identifying Influential Data and Sources of Collinearity; John Wiley & Sons: New York, NY, USA, 2005. [Google Scholar]
- Draper, N.R.; Smith, H. Applied Regression Analysis; John Wiley & Sons: New York, NY, USA, 1998. [Google Scholar]
- Fox, J. Applied Regression Analysis and Generalized Linear Models; Sage Publications: Los Angeles, CA, USA, 2015. [Google Scholar]
- Vatcheva, K.P.; Lee, M.; McCormick, J.B.; Rahbar, M.H. Multicollinearity in regression analyses conducted in epidemiologic studies. Epidemiol. Sunnyvale Calif. 2016, 6, 227. [Google Scholar] [CrossRef] [Green Version]
- Graham, M.H. Confronting multicollinearity in ecological multiple regression. Ecology 2003, 84, 2809–2815. [Google Scholar] [CrossRef] [Green Version]
- Tu, Y.K.; Clerehugh, V.; Gilthorpe, M.S. Collinearity in linear regression is a serious problem in oral health research. Eur. J. Oral Sci. 2004, 112, 389–397. [Google Scholar] [CrossRef]
- Dormann, C.F.; Elith, J.; Bacher, S.; Buchmann, C.; Carl, G.; Carré, G.; Marquéz, J.R.G.; Gruber, B.; Lafourcade, B.; Leitao, P.J.; et al. Collinearity: A review of methods to deal with it and a simulation study evaluating their performance. Ecography 2013, 36, 27–46. [Google Scholar] [CrossRef]
- Leeuwenberg, A.M.; van Smeden, M.; Langendijk, J.A.; van der Schaaf, A.; Mauer, M.E.; Moons, K.G.; Reitsma, J.B.; Schuit, E. Comparing methods addressing multi-collinearity when developing prediction models. arXiv 2021, arXiv:210101603. Available online: https://arxiv.org/abs/2101.01603 (accessed on 15 April 2021).
- Hernán, M.A.; Hsu, J.; Healy, B. A second chance to get causal inference right: A classification of data science tasks. Chance 2019, 32, 42–49. [Google Scholar] [CrossRef] [Green Version]
- Shmueli, G. To explain or to predict? Stat. Sci. 2010, 25, 289–310. [Google Scholar] [CrossRef]
- Ratzinger, F.; Dedeyan, M.; Rammerstorfer, M.; Perkmann, T.; Burgmann, H.; Makristathis, A.; Dorffner, G.; Lötsch, F.; Blacky, A.; Ramharter, M. A risk prediction model for screening bacteremic patients: A cross sectional study. PLoS ONE 2014, 9, e106765. [Google Scholar] [CrossRef]
- Tang, Z.; Zhao, W.; Xie, X.; Zhong, Z.; Shi, F.; Liu, J.; Shen, D. Severity assessment of coronavirus disease 2019 (COVID-19) using quantitative features from chest CT images. arXiv 2020, arXiv:200311988. Available online: https://arxiv.org/abs/2003.11988 (accessed on 15 April 2021).
- Harrell, F.E., Jr. Regression Modeling Strategies: With Applications to Linear Models, Logistic and Ordinal Regression, and Survival Analysis; Springer: New York, NY, USA, 2015. [Google Scholar]
- Chatterjee, S.; Hadi, A.S. Regression Analysis by Example; John Wiley & Sons: New York, NY, USA, 2015. [Google Scholar]
- O’Brien, R.M. A caution regarding rules of thumb for variance inflation factors. Qual. Quant. 2007, 41, 673–690. [Google Scholar] [CrossRef]
- Huebner, M.; le Cessie, S.; Schmidt, C.O.; Vach, W. A contemporary conceptual framework for initial data analysis. Obs. Stud. 2018, 4, 171–192. [Google Scholar]
- Dohoo, I.R.; Ducrot, C.; Fourichon, C.; Donald, A.; Hurnik, D. An overview of techniques for dealing with large numbers of independent variables in epidemiologic studies. Prev. Vet. Med. 1997, 29, 221–239. [Google Scholar] [CrossRef]
- Marquaridt, D.W. Generalized inverses, ridge regression, biased linear estimation, and nonlinear estimation. Technometrics 1970, 12, 591–612. [Google Scholar] [CrossRef]
- Hair, J.F.; Black, W.C.; Babin, B.J.; Anderson, R.E.; Tatham, R.L. Multivariate Data Analysis; Prentice Hall: Upper Saddle River, NJ, USA, 1998. [Google Scholar]
- Rawlings, J.O.; Pantula, S.G.; Dickey, D.A. Applied Regression Analysis: A Research Tool; Springer Science & Business Media: Berlin, Germany, 2001. [Google Scholar]
- Hastie, T.; Tibshirani, R. Generalized additive models: Some applications. J. Am. Stat. Assoc. 1987, 82, 371–386. [Google Scholar] [CrossRef]
- Harrell, F.E., Jr.; Harrell, M.F.E., Jr. Package ‘Hmisc’; CRAN2018; The R Foundation: Vienna, Australia, 2019; pp. 235–236. [Google Scholar]
- Tabachnick, B.G.; Fidell, L.S.; Ullman, J.B. Using Multivariate Statistics; Pearson: Boston, MA, USA, 2007. [Google Scholar]
- Hernán, M.A.; Robins, J.M. Causal Inference: What If; Chapman & Hall/CRC: Boca Raton, FL, USA, 2020. [Google Scholar]
- Manabe, S.; Wetherald, R.T. Thermal equilibrium of the atmosphere with a given distribution of relative humidity. J. Atmos. Sci. 1967, 24, 241–259. [Google Scholar] [CrossRef] [Green Version]
- Masson-Delmotte, V.; Zhai, P.; Pörtner, H.O.; Roberts, D.; Skea, J.; Shukla, P.R.; Pirani, A.; Moufouma-Okia, W.; Péan, C.; Pidcock, R.; et al. Summary for Policymakers. In Global Warming of 1.5 °C; An IPCC Special Report on the impacts of global warming of 1.5 °C above pre-industrial levels and related global greenhouse gas emission pathways, in the context of strengthening the global; World Meteorological Organization: Geneva, Switzerland, 2018. [Google Scholar]
- NOAA. National Centers for Environmental Information, Climate at a Glance: Divisional Time Series; NOAA: Washington, DC, USA, 2018. [Google Scholar]
- Boden, T.; Andres, R.; Marland, G. Global, Regional, and National Fossil-Fuel CO2 Emissions (1751-2014)(v. 2017). Environmental System Science Data Infrastructure for a Virtual Ecosystem; Oak Ridge National Laboratory (ORNL): Oak Ridge, TN, USA, 2017. [Google Scholar]
- Andrews, D.W. Heteroskedasticity and autocorrelation consistent covariance matrix estimation. Econom. J. Econom. Soc. 1991, 59, 817–858. [Google Scholar] [CrossRef]
- Zeileis, A. Econometric computing with HC and HAC covariance matrix estimators. J. Stat. Softw. 2004, 11, 1–17. [Google Scholar] [CrossRef]
- Perperoglou, A.; Sauerbrei, W.; Abrahamowicz, M.; Schmid, M. A review of spline function procedures in R. BMC Med Res. Methodol. 2019, 19, 46. [Google Scholar] [CrossRef] [Green Version]
- VanderWeele, T.J. Marginal structural models for the estimation of direct and indirect effects. Epidemiology 2009, 20, 18–26. [Google Scholar] [CrossRef] [PubMed]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning; Springer Series in Statistics; Springer: New York, NY, USA, 2001; Volume 1. [Google Scholar]
- Witte, J.; Didelez, V. Covariate selection strategies for causal inference: Classification and comparison. Biomed. J. 2019, 61, 1270–1289. [Google Scholar] [CrossRef]
- Sun, D.-Z.; Bryan, F. Climate Dynamics: Why Does Climate Vary? John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- O’Brien, R.M. Dropping highly collinear variables from a model: Why it typically is not a good idea. Soc. Sci. Q. 2017, 98, 360–375. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Observation | Neutrophils (G/L) | Eosinophils (G/L) | Basophils (G/L) | Lymphocytes (G/L) | Monocytes (G/L) | White Blood Cell Count (G/L) | C-Reactive Protein (mg/dL) |
|---|---|---|---|---|---|---|---|
| 1 | 11.5 | 0.0 | 0.1 | 0.6 | 1.1 | 13.3 | 15.99 |
| 2 | 13.9 | 0.0 | 0.0 | 3.0 | 3.3 | 20.2 | 13.27 |
| 3 | 13.0 | 0.2 | 0.0 | 0.2 | 1.1 | 14.5 | 14.99 |
| 4 | 11.0 | 0.1 | 0.0 | 0.6 | 0.8 | 12.5 | 9.93 |
| 5 | 10.1 | 0.0 | 0.0 | 0.6 | 0.8 | 11.5 | 16.70 |
| Model for Disease Severity | Independent Variable(s) | Odds Ratio | Model Performance | ||
|---|---|---|---|---|---|
| Estimate | 95% CI | AIC | C-Index | ||
| Univariable model 1 | GGO | 1.82 | (1.55, 2.22) | 88.6 | 0.96 |
| Univariable model 2 | Consolidation | 1.94 | (1.59, 2.47) | 142.8 | 0.89 |
| Multivariable model | GGO Consolidation | 1.83 0.99 | (1.48, 2.38) (0.74, 1.33) | 90.6 | 0.96 |
| Method | Explanation | Remark |
|---|---|---|
| Descriptive research aim | ||
| Variable omission | Omit one of the variables involved in the collinearity | Removes the symptoms, but leads to different interpretation of the model |
| Summary score | Combine several nearly collinear variables into a summary score and include only the summary score in the regression model | Removes the symptoms, retains most of the predictive value of the model, but leads to different interpretation of the model |
| Predictive research aim | ||
| Use information criteria | Information criteria such as Akaike’s can be used to guide model building | Information criteria guide the analyst in a search for the most predictive model |
| Explanatory research aim | ||
| Use causal reasoning | Specification of variables (exposure of interest, confounders) is necessitated by causal reasoning | Neither exposure nor confounders should be omitted as this violates assumptions needed to identify the causal estimand of interest |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gregorich, M.; Strohmaier, S.; Dunkler, D.; Heinze, G. Regression with Highly Correlated Predictors: Variable Omission Is Not the Solution. Int. J. Environ. Res. Public Health 2021, 18, 4259. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18084259
Gregorich M, Strohmaier S, Dunkler D, Heinze G. Regression with Highly Correlated Predictors: Variable Omission Is Not the Solution. International Journal of Environmental Research and Public Health. 2021; 18(8):4259. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18084259
Chicago/Turabian StyleGregorich, Mariella, Susanne Strohmaier, Daniela Dunkler, and Georg Heinze. 2021. "Regression with Highly Correlated Predictors: Variable Omission Is Not the Solution" International Journal of Environmental Research and Public Health 18, no. 8: 4259. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18084259