
Bootstrapping Time-Varying Uncertainty Intervals for Extreme Daily Return Periods



Department of Statistics and Operations Research, North-West University, Mafikeng Campus, Mmabatho 2745, South Africa
*
Author to whom correspondence should be addressed.
Int. J. Financial Stud. 2022, 10(1), 10; https://0-doi-org.brum.beds.ac.uk/10.3390/ijfs10010010
Submission received: 28 September 2021
/
Revised: 6 December 2021
/
Accepted: 14 December 2021
/
Published: 27 January 2022
(This article belongs to the Special Issue Quantitative Finance)
Abstract
:This study aims to overcome the problem of dimensionality, accurate estimation, and forecasting Value-at-Risk (VaR) and Expected Shortfall (ES) uncertainty intervals in high frequency data. A Bayesian bootstrapping and backtest density forecasts, which are based on a weighted threshold and quantile of a continuously ranked probability score, are developed. Developed backtesting procedures revealed that an estimated Seasonal autoregressive integrated moving average-generalized autoregressive score-generalized extreme value distribution (SARIMA–GAS–GEVD) with a skewed student-t distribution had the best prediction performance in forecasting and bootstrapping VaR and ES. Extension of this non-stationary distribution in literature is quite complicated since it requires specifications not only on how the usual Bayesian parameters change over time but also those with bulk distribution components. This implies that the combination of a stochastic econometric model with extreme value theory (EVT) procedures provides a robust basis necessary for the statistical backtesting and bootstrapping density predictions for VaR and ES.
Keywords:
expected shortfall; generalized autoregressive score; extreme value theory; generalized extreme value distribution; stock returns; time-varying; Value-at-RiskJEL Classification:
C10; C40; C59; E441. Introduction
In financial markets, risk refers to the probability distribution of future returns. Uncertainty is a broader concept that encompasses ambiguity about the parameters of this probability distribution Babatunde et al. (2020). There are various types of measures seeking to estimate risk and uncertainty: (1) realized and derivatives-implied distributions of returns across assets, (2) news-based measures of policy and political uncertainty, (3) survey-based indicators, (4) econometric measures, and (5) ambiguity indices. The benefits for macro trading are threefold. First, uncertainty measures provide a basis for comparing the market’s assessment of risk with private information and research. Second, changes in uncertainty indicators often predict near-term flows in and out of risky asset classes. Third, the level of public and market uncertainty is indicative of risk premia offered across asset classes. However, daily return periods involves planning under uncertainty and one has to cope with operational, tactical, and strategic planning. Planning under uncertainty in stock markets involves determining the appropriate location of a stock market, the size of the stock market, transmission, and distribution (returns flow analysis, analysis of the frequency, and occurrence of extreme losses and scheduling of risk factors). Uncertainties in forecasting extreme daily losses may arise due to increased technology making use of financial fraud in online systems, resulting in stock market crash, population growth, and general randomness in the individual participant in stock market, prevailing economic instability and political conditions Sigauke et al. (2014).
To model and predict uncertainties, Mieth et al. (2020) and Zoglat et al. (2013) have indicated that modeling and prediction procedures should be probabilistic because uncertainties are robustly modeled or predicted as quantiles, prediction intervals, or density forecasts, and an asymptotic theory is always applied, while at the same time obscure quantiles are being supplanted by estimated probabilistic quantiles. Probabilistic forecasting of financial uncertainty and risk promotes the management of financial use and planning. The use of VaR and or ES is a measure that aims at lowering risk effects such as that of credit risk, exchange rate risk, and interest rate risk—to mention a few that harm the economic and financial sector. This also gives a positive impact on market values that are associated with the use of other portfolios such as an aggressive portfolio. Short-term forecasting has a superior impact on the safety and financial implication of the financial network. Since the financial sector has a stochastic and uncontrollable nature, the current study uses seasonal autoregressive integrated moving average (SARIMA) combined with a time-varying generalized autoregressive score—generalized extreme value distribution (GAS—GEVD). Application of the SARIMA process requires the computation of independently and identically distributed (i.i.d) residuals and the key element that deeply influences the forecasting results. Hence, it is critical to focus on coming up with a more accurate model. A study by Chandiwana et al. (2021) used a Gaussian process regression coupled with core vector regression for short-term hourly global horizontal irradiance forecasting with uncertainty. On the other hand, Rigotti and Shannon (2005) considered a general equilibrium model in which the distinction between uncertainty and risk is formalized by assuming that agents have incomplete preferences over state-contingent consumption. However, the current study considers a more robust methodology in modeling uncertainty and Beutner et al. (2020) and Rocco (2014) defined this method as a bootstrap to probability forecasting. These authors emphasized that there are different bootstrap procedures that have been studied and are based only on generalized autoregressive conditional heteroscedasticity (GARCH) estimates. Therefore, this study extends the GARCH bootstrap estimates to a SARIMA–GAS–GEVD VaR and ES estimates, and currently, no other study has taken this approach. Bootstrapping of VaR and ES with the combined SARIMA-GAS-GEVD estimates give precise and accurate extreme return periods uncertainty.
Since the number of recent contributions related to forecasting and backtesting ES and VaR is extremely large, the main contribution of this study is the estimation and forecasting of VaR and ES intervals through the use of SARIMA–GAS–GEVD. Nonetheless, Le (2020) used mixed data sampling (MIDAS) framework to forecast VaR and ES. The new methods of this author exploit the serial dependence on short-horizon returns to directly forecast the tail dynamics of the desired horizon. However, the approach of SARIMA–GAS–GEVD in this study takes into consideration real-time system forecasting and this improves the accuracy of the forecasts. This enables one to easily identify changes in the immediate, especially when dealing with economic conditions that are constantly evolving. This is an aspect that is ignored by most researchers when forecasting stock markets indices. To the best of our knowledge, this is the first application of SARIMA–GAS–GEVD with Bayesian methods. This study has adopted the Bayesian approach to estimation because it captures uncertainty as compared to the maximum likelihood estimation (MLE) and also the framework upon which the forecasting is done, is based on Bayesian assumptions, unlike the study of Taylor (2019), which uses the MLE approach to forecasting VaR and ES through a semi-parametric approach. Bayesian estimation makes use of either informative or non-informative priors and it is more attractive than the frequentist MLE technique since it combines prior information to data, allows analysis with small samples, and the forecasting is robust. Moreover, the Bayesian analysis does not depend on asymptotic estimation and it follows the likelihood principle that involves applying a subset of the selected data on the two selected probability models basing on whether they have the same likelihood outcome, producing the same assumptions. The other contribution is the development of threshold and quantile weighted scoring rules to compare the density forecasts of extreme time-varying VaR and ES. Gneiting and Ranjan (2012), typically compared the density forecast through the GARCH model, which currently this improves the GARCH process to the special case for extreme time-varying through the implementation of the GAS-GEVD process. The comparison typically uses a proper scoring rule in order to avoid misguided inferences, and it comes with associated statistical tools that are used to diagnose strengths and weaknesses of a forecasting method. In this case, a test of equal forecast performance is retained and it is based on an appropriate weighted, but proper versions, of a continuous ranked probability score (CRPS). The last contribution is that of a fixed-design residual bootstrap algorithm, tail risk (TR), and dynamic quantile (DQ) backtesting. Siegl and West (2001) used a Monte-Carlo (MC) method while calculating VaR. The approach of these authors is set into resampling towards bootstrapping and this was to refine the computational results in different ways. However, the approach of fixed design bootstraps performs equally well in terms of average coverage, yet leads on average to shorter intervals in smaller samples as compared to recursive bootstrap through the MC procedures.
The sections that follow are arranged as follows: in Section 1.1, a review of relevant literature on this study is presented. In Section 2, methods and procedures followed in the study. This includes the proposed hybrid time-varying model, cross validation, backtesting, and density forecasting of VaR and ES. In Section 3, empirical results are presented while Section 4 concludes the paper.
1.1. Literature Review
Time-varying parameters were firstly introduced in the GAS framework by Creal et al. 2013. When modeling time-varying parameters of stock returns, Eckernkemper (2018) examined a time-varying tail dependence and forecast expected shortfall by modeling a systemic risk. The results of this author indicates a leptokurtic behavior of stock returns. Bernardi and Catania (2019) assesses the co-movement between assets of European countries. These authors allow copular parameters to depend on the realization of the first order Markov process in a Generalized Autoregressive score dynamic of Harvey (2013) by developing regime shifts, and at the same time retaining an appropriate arbitrary specification for the marginals of a conditional distribution dynamics. This empirical investigation of Bernardi shows that their proposed switching GAS models are able to explain and predict the systemic risk contribution of several European countries. These authors also found that their models outperform others when using several VaR backtesting procedures.
On the other hand, Babatunde et al. (2020) investigates the volatility of exchange rates in Nigeria and the authors uses the United States (U.S) dollar, Pound Sterling, and Euro against the Naira. Variants of the GAS model are applied by these authors and studies exchange rate volatility by assuming three different probability distributions. Utilising Akaike information criterion (AIC) and Bayesian information criterion (BIC), the GAS model with a t distribution (GAS–T), exponential GAS with t distribution (EGAS–T) and exponential GAS with student-t distribution (EGAS–ST) are being selected for US dollar/Naira, Pound sterling/Naira, and Euro/Naira exchange rates as the best fitted models. Based on mean absolute error (MAE) and root mean square error (RMSE), the GAS-T, EGAS-T, and EGAS-SKT respectively are selected for forecasting the volatility of US dollar/Naira, Pound sterling/Naira, and Euro/Naira exchange rates. With the current study, a skewed student distribution of SARIMA–GAS–GEVD is applied to FTSE/JSE-ALSI. Moreover, Kamika (2019) uses different statistical techniques to estimate unconditional and conditional risk measures. The former is computed using three traditional Value-at-Risk procedures, namely the Historical Simulation (HS), Variance-Covariance (VC), and Monte Carlo simulation (MCS). This author solved unrealistic assumption, which is regularly used in empirical studies1 through the GAS framework. The assumption is relaxed, and a score of an empirical distribution is set to evolve over time. Tafakori et al. (2018) proposes a class observation-driven time series model referred to as an asymmetric exponential generalized autoregressive score (AEGAS) model in order to evaluate the accuracy of VaR forecasts for Australian electricity returns. The mechanism to update the parameters over time is provided by a scaled score of a likelihood function of the proposed model. Based on this new approach, the results provided a unified and consistent framework for introducing time-varying parameters in a wide class of non-linear models.
Le (2020) develops a mixing data sampling (MIDAS) framework for forecasting VaR and ES. The methods of this author exploit the serial dependence on short-horizon returns, to directly forecast the tail dynamics of the desired horizon. A comprehensive comparison and backtest is performed. The MIDAS-based models significantly outperform the traditional GARCH-based forecasts and the alternative conditional quantile specifications of multi-day forecast horizons. The analysis of Le (2020) advocates asymmetric conditional quantiles and the use of asymmetric Laplace density to jointly estimate Value-at-Risk and expected shortfall. Additionally, Lazar and Xue (2019) used a new framework for a joint estimation and forecasting the dynamics of VaR and ES. The authors incorporated an intra-day information into a GAS model in order to estimate the risk measures in a quantile regression set-up. Four intra-day measures, which are realized volatility at 5-min and 10-min sampling frequencies, were considered. Furthermore, an overnight return was also incorporated into these two realized volatilities. In a forecasting study, a set of newly developed semi-parametric models are applied to four international stock market indices (S&P 500, Dow Jones Industrial Average, Nikkei 225, and FTSE 100) which are further compared with a range of parametric, non-parametric, and semi-parametric models. The procedure included historical simulations, the GARCH, and the original GAS models. The backtesting procedure for both VaR and ES was individually established and, the joint loss function was used for comparisons. Their results showed that the enhanced GAS models with realized volatility measures outperform the benchmark models consistently across all indices and various probability levels.
In a study of dynamic semi-parametric models for expected shortfall and Value-at-Risk, Patton et al. (2019) used recent results from statistical decision theory to overcome the problem of “elicitability” for ES by jointly modeling ES and VaR; and further develops a new dynamic model for these risk measures. The authors provided an estimation and inference methods for established models. Simulation studies were used to confirm that the new dynamic model have good finite-sample properties. Applying these models to daily returns, on four international equity indices, the results of Patton et al. (2019) indicated that the new ES–VaR model outperform forecasts that are based on GARCH or rolling window models. Christoffersen and Gonçalves (2005) looked at different quantile estimators and develops some intervals for the conditional VaR by utilizing a recursive-design residual bootstrap approach. On that note, Hartz et al. (2006) presumed an advanced distribution to be a standard normal with an end goal that a quantile parameter is known. These authors further propose a resampling procedure that is dependent on a residual bootstrap and a bias-correction step to represent deviations from the assumption of normality. Interestingly, Spierdijk (2016) fosters the m-out-of-n without-replacement bootstrap to develop confidence intervals for autoregressive-moving average-generalized autoregressive-conditional-heteroscedasticity (ARMA-GARCH) VaR. However, this study develops a Bayesian approach to bootstrapping the Seasonal Autoregressive Integrated Moving Average-Generalized autoregressive score-Generalized extreme value distribution.
The literature on forecasting and backtesting of risk measures largely assumes that the appropriate data are used. However, Frésard et al. (2011), using information from the annual reports of the 200 largest US and international commercial banks, document that a large fraction of them boost the performances of their models artificially by polluting their returns with extraneous profits such as intra-day revenues, fees, commissions, net interest income, and revenues from market making or underwriting activities. They find that over the period of 2005–2008, fewer than 6% of the largest commercial banks in the world evaluated their VaR models using the appropriate uncontaminated data. They also show that all of the available backtesting procedures are highly sensitive to data contamination. For example, using the “traffic light” approach developed by the Basel Committee, 23.5% of the VaR models are rejected when tested with uncontaminated data, whereas only 10.8% are rejected when tested with returns that include both fees and intra-day trading revenues. Therefore, data contamination has dramatic implications for model validation and can lead to the acceptance of misspecified VaR models, and therefore significantly reduced the regulatory capital.
2. Methodology
Let be stock returns at time t, Bee and Trapin (2018) showed that can be modeled by
where is the time-varying mean; is the error term that can be modeled by
In model (2), is the time-varying dynamic, while is the i.i.d residuals from model (1). The proposed SARIMA model has the following multiplicative form
where , S is the seasonal length while L is the lag operator. A multiplicative representation of the SARIMA model allows no common factors between the polynomials of seasonal autoregressive (SAR) and seasonal moving average (SMA) and the SAR polynomials acquaints with the characteristic a SARMA model. Moreover, the SMA term adhere to remove serial correlation in the returns. The next step is to fit a time-varying GAS–GEVD to these i.i.d residuals obtained from model (3). The GAS–GEVD is presented in a manner that the mapping function shows how extreme time-varying parameters can be modeled in a restricted parameter space. Therefore, Creal et al. (2013) specified the GAS model by first letting to be the N-dimensional random vector at time t where the conditional distribution of model (3) is given by
where holds the past values of and a vector of time-varying parameters is given by . The fruition in this vector is the main feature of a GAS model and it is driven by the score of a conditional distribution defined in model (3). A completed description of the GAS in model (3) is given by
Note that and in model (5) are the coefficient matrices. A vector that is proportional to a score of model (5) is as follows
Here, scaling matrix that is known at time t; is the score of model (6) that is appraised at . In order to account for the variance of , a scaling matrix is set to the power and according to Ardia et al. (2019), this simplifies to where is fixed at and gives
Finally, the generalized extreme value distribution according to Masingi and Maposa (2021) and Gagaza et al. (2019) is given by
This distribution is valid for where , and are the location, scale, and shape parameters. The GEVD uses a block minima or block maxima approach to model the extreme losses or gains. This procedure with respect to Nemukula (2018) usually sets the block size to one year and from each block; the extreme losses or gains are selected. Additionally, Maposa et al. (2016) showed that at period t, while Taylor (2019) emphasized that for the linear variation of a location parameter; model (8) should have the intercept as and a slope as which can also be expressed as and further indicates the rate of change in daily losses or gains.
2.1. Bayesian Inferences to Parameter Estimates
In the Bayesian methodology, all obscure quantiles are considered as irregular factors and vulnerabilities over those quantiles that are addressed utilizing the likelihood contingent of the accessible data. When estimating any parameter using classical/frequentist methods, the sampling distribution of a parameter is most likely assumed to be normal or Gaussian. This methodology is very unrefined in the sense that in real situations the sampling distributions of parameters can deviate from normality. With Bayesian analysis, reasonable approximations to the sampling distribution are thought of; and their inferences are arrived at utilizing non-exclusive procedures and observed data. The fundamental standard behind Bayesian statistics is as follows. Some prior thoughts regarding any parameter or data set can neither be acquired from prolonged, some detailed observations, nor by comparing them with similar conditions Ghosh et al. (2007).
The Bayesian approach also allows for an additional source of variation, which implies that the parameters now have probability distributions with hyper-parameters giving small standard errors. This is achieved through the naive standard errors, which are computed by dividing the actual standard deviation by the number of iterations just as Maposa (2016) has suggested. Furthermore, Droumaguet (2012) also emphasized that Bayesian methods provide densities of the model parameters, which solves the problem of confidence interval, and finally Bayesian shrinkage techniques allow models to be estimated with higher dimensions and these would have complex shapes of the likelihood function and be more difficult to estimate with classical algorithms. Sigauke et al. (2012) declared that ambiguity about the parameters is very minimal.
The Likelihood Function
For both frequentist (maximum likelihood) and Bayesian estimations, the likelihood function that follows a skewed distribution of the vector , is given by . The likelihood function of the n-th sample for is then given by
where Y is a vector of n observations, and are the functions of that are computed based on the inverse of a covariance matrix of denoted by . To ease the complexity of computing , the history of observed data and the errors are incorporated. The observations for this study are and respectively. The n variate skewed distribution of the SARIMA–GAS process is represented by
The moving average part in model (3) is as follows
and the observations are assumed to follow skewed density as
which is simplified to
The mean vector , and . The parameter that describes a degree of asymmetry ranges between and is a symmetric density with mean zero and unit variance. Hence, the likelihood function of the SARIMA–GAS is finally given by
Applying SARIMA–GAS to model (14) and considering a simplified as , this leads to model (15) as
that is further simplified to expression (16) through partial differentiation
Here, , and . For the priors, there are some restrictions on the range of . The invertibility region of the model, which is required by a condition that the roots of should lie outside the unit circle. This is defined by and to ensure stationarity, this condition is required. The considered priors for , and are of a uniform distribution at the range of . Note that and . The non-informative prior for , is
and the posterior is given by
When integrating the marginal (posterior) distribution that is denoted by ; all unknown parameters are found and in order to get the marginal distribution for each unknown parameters, the other two unknowns are integrated out. So, to find the marginal distribution of the three unknown parameters; integration(s) (19)–(21) are performed as follows
From the posterior distribution, a predictive distribution is obtained through
and for the generalised extreme value distribution, a parameter vector and its Bayes estimates are given by
and
where and are the prior, posterior, likelihood, and normalization constant respectively. In addition to that, Vidal (2014) have indicated that a posterior information is a combined sum of prior and sample information. With these computations, model (24) is further modified to
where is the vector parameters of the generalized extreme value distribution, is the posterior distribution, x is a vector of observations is the space parameter, is the prior distribution, and is the likelihood function of the GEVD.
The Bayesian credible set C (or in particular credible interval) is a subset of the space parameter such that . The quantile-based credible interval is such that if is ; a posterior quantile for and is while is the credible interval for .
2.2. Value-at-Risk and Expected Shortfall
Having obtained estimators for and the conditional VaR and ES for a one-period ahead are estimated at level. Employing the proposed SARIMA(p,d,q)(P,D,Q)–GAS(p)–GEVD, the conditional VaR according to Anjum and Malik (2020) and Bernard et al. (2017) is estimated as
n is the length of the sub-period, , and are Bayesian parameter estimates.
Expected shortfall considers a loss beyond Value-at-Risk level and is shown to be sub-additive, while VaR disregards a loss beyond the percentile and is not sub-additive. The measure is related to in such a way that
The second term in model (27) is the mean excess distribution over threshold of .
2.3. Cross-Validation on Prediction and Uncertainty Problems
There is a peculiarity between test error rate and the training error rate. The former is defined by Gareth et al. (2013) as the average error that results for the use of statistical learning procedure that predicts the response on a new observation. For a performance of the proposed hybrid model, some frequent metrics like accuracy and error rate, are not used but; the following five classification metrics are used. These are Precision, recall, F1-score, Matthews correlation coefficient (MCC), and balanced classification rate (BCR). The extreme financial loss is considered as a positive class and legal as negative class; hence, TP (true positive) and TN (true negative) are the number of losses that are correctly classified, and FP (false positive) and FN (false negative) are the numbers of losses incorrectly classified.
Lastly, the Balanced classification rate combines the specificity and sensitivity metrics as follows
2.4. Fixed-Design Residual Bootstrap
A fixed-design residual bootstrap procedure, described in Algorithm 1, is used to approximate the distribution of a conditional Value-at-Risk and expected shortfall.
Remark 1.
The term ’fixed-design’ refers to the fact that bootstrap observations are generated with . In contrast, the recursive design duplicates the dynamic structure of the model; i.e., with and which is computationally more demanding. For a complete description on recursive-design residual bootstrap, the reader is refereed to Appendix B of Beutner et al. (2020).
2.5. Backtesting Value-at-Risk and Expected Shortfall Forecasts
Once a series of VaR predictions is available, forecasts adequacy is assessed through backtesting procedures. VaR backtesting procedures usually check the correct coverage of the unconditional and conditional left-tail of the log-returns distribution. Correct unconditional coverage (UC) was first considered by Kupiec (1995), while correct conditional coverage (CC) by Christoffersen (1998). The main difference between UC and CC concerns the distribution that one focuses onto. For instance, UC considers correct coverage of the left-tail of the unconditional log-return distribution while CC deals with the conditional density . From an inferential perspective, UC looks at the ratio between the number of realized VaR violations observed from the data and the expected number of VaR violations implied by the chosen risk level, , during the forecast period, that is, . In order to investigate CC, Christoffersen (1998) proposed a test on the series of VaR exceedance where or , usually referred to as the hitting series. Specifically, if correct conditional coverage is achieved by the model, VaR exceedances should be independently distributed over time. For more readings on backtesting VaR and ES, the reader is referred to Bayer and Dimitriadis (2020).
Furthermore, Escanciano and Olmo (2010) show that the use of standard unconditional and independence backtesting procedures can be misleading, because they do not take into account the uncertainty associated with parameter estimation. They quantify this risk in a very general class of dynamic parametric VaR models and propose a correction of the standard backtests that takes it into account. They show that one of the main determinants of the corrected asymptotic variance is the forecasting scheme used to generate the VaR forecasts, i.e., whether one uses recursive, rolling, or fixed parameter estimates. The backtesting methodologies described above focus only on the number of VaR and ES exceptions, and totally disregard their magnitudes. Nieto and Ruiz (2016) criticizes the statistics proposed by Christoffersen (1998) because they are two-tailed, and, as a consequence, can reject a risk model for being over conservative. However, note that, as was mentioned above, risk models can also be rejected for being over conservative because this is not desirable for financial institutions. Alternatively, the tail risk statistic is proposed and is defined as
| Algorithm 1: Fixed-design Residual Bootstrap |
 |
The TR statistic in model (33) tells risk managers the size of the aggregate tail losses that a portfolio may incur over the period considered. The asymptotic distribution of the TR statistic is derived under the assumption of normal returns.
The DQ test by Engle and Manganelli (2004) assesses the joint hypothesis that and the hit variables are independently distributed. The implementation of the test involves the de-meaned process . Under correct model specification, unconditionally and conditionally, has zero mean and is serially uncorrelated. The DQ test is then the traditional Wald test of the joint nullity of all coefficients in the following linear regressions
Under the null hypothesis of correct unconditional and conditional coverage, we have that the Wald test statistic is asymptotically chi-square distributed with degrees of freedom. Engle and Manganelli (2004) set lags, which has become the standard choice.
2.6. Density Forecasts Using Threshold and Quantile-Weighted Scoring Rules for VaR and ES
For the density forecasts of the conditional VaR and ES, the study considers density forecasts in a time series context, in which a rolling window consisting of the past b observations is used to fit a density forecast for a future observation that lies at k time steps ahead. Distinctively, let be a stochastic process that can be divided into where is the vector of predictors and is the variable of interest and in the case of this study is the return series on FTSE/JSE-ALSI. Let ; at time the density forecast and are generated and they all rely of . In this context, the only requirement for creating a forecast is that the forecast is a measurable function of the data in the rolling estimation window. Coroneo and Iacone (2020) insisted that the ideal predictor should be preferred by rational users, regardless of the cost-loss structure. Therefore, it is vital to set the evaluation rule within the following sense
for all density function f and g. The scoring rule is strictly proper if model (35) holds; if and only if . Additionally, the density forecast procedures are then ranked by comparing their average scores hence,
and
where f is preferred if and prefer g otherwise. Amisano and Giacomini (2007) considered tests of equal forecast performance based on the test statistic
where
and as proposed by Coroneo and Iacone (2020). What scoring rule should be considered? Amisano and Giacomini (2007) employed model (40) as the weighted logarithmic scoring rule
where w is a fixed non-negative weight function, and estimates the unconditional mean and standard deviation of the predictand. These non-negative functions are based on the past m observations, and is the logarithmic scoring rule, . The weight function emphasizes regions of interest, such as tails or the center of a variable’s range. Denoting a standard normal probability density and cumulative distribution functions with and , respectively, the weight functions , , , emphasize the center, the tails, the right tail, and the left tail.
The weighting approach seems appealing; however, it corresponds to the use of an improper scoring rule and incurs misguided inferences. Instead of employing the GARCH(1,1), process as in the work of Gneiting and Ranjan (2012), the SARIMA–GAS–GEVD is used in this study. The goal of this article proposes a test that adopts the weighting approach of Amisano and Giacomini (2007), this is to avoid misguided inferences, and comes with associated graphical tools that can be used to diagnose strengths and weaknesses of a forecasting method. The test statistic in model (38) is retained but it is based on appropriately weighted versions of a continuous ranked probability score (CRPS). Any density forecast f induces a probability forecast for the binary event passing through the value of the corresponding cumulative distribution function (CDF),
at the threshold . Similarly, this induces the quantile forecast as at the level . The continuous ranked probability score is then defined by
that can simplified to
where is the Brier likelihood score for the probability forecast of a binary event at the threshold and is the quantile score for the quantile forecast at the level . Here, the symbol stands for an indicator function. Following Gneiting and Ranjan (2012), a threshold weighted version of the continuous ranked probability score is obtained as
where u is a non-negative weight function on the real line. In the same way, a quantile weighted version is obtained by
where v is a non-negative weight function on the unit interval. Table 1 displays the proposed weight functions for threshold and quantile weighted versions of the continuous ranked probability score. The threshold weight functions are specified in terms of the probability density function and the cumulative distribution function , of the normal distribution with mean a and standard deviation b.
2.7. Data and Software
The data used in this study are five business day FTSE/JSE-ALSI for the period 4 January 2010 to 30 June 2021. The index used has been kept in its original currency to avoid exchange rates fluctuations. The data has been collected from the South African Stock Exchange and it was accessed on 15 July 2021. Data for the period 4 January 2010 to 3 April 2020 are used for training the models, while the remaining data (6 April 2020 to 30 June 2021) are used for testing the models. R version 4.0.2 is the statistical packages that is used in this study. Several package used to execute the analysis in this study, which includes, among others, the GAS package for the GAS model, timeseries and ismive for SARIMA and GEVD, respectively.
3. Empirical Results
Results of bootstrapping and backtesting time-varying VaR and ES uncertainty intervals for extreme daily periods are done on datasets. The results are presented in tables and figures.
3.1. Exploratory Data Analysis
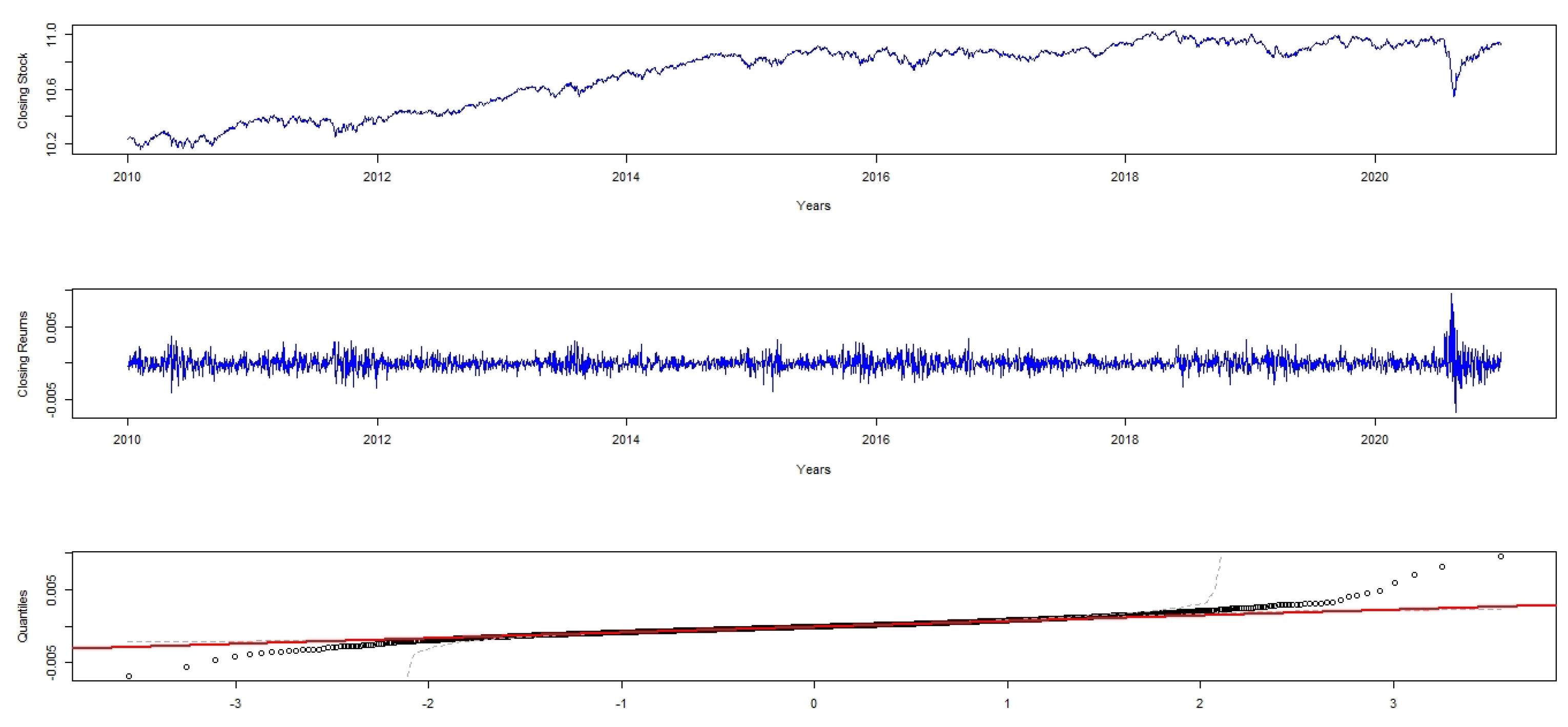
Figure 1 displays intra-day returns on FTSE/JSE-ALSI. The visual inspection of this reveals that the distribution of FTSE/JSE-ALSI is not normally distributed. The quantile-quantile (Q-Q) plot in the last panel reveals a strong departure of linearity in the tails of returns on FTSE/JSE-ALSI. This departure is also evident from Table 2, which gives a descriptive statistics for intra-day returns on FTSE/JSE-ALSI. The reported kurtosis in Table 2 is greater than three and the skewness is less than zero, making the returns to be asymmetric with one heavy, and one semi-heavy tails. Two significant issues are uncovered by these charts; these are the weight easing cause and steady unpredictability. The latter infers that individual shocks often have a long effect on subsequent volatility. The former state that shocks are followed by periods of low volatility rather than high volatility. Similar results were obtained by Musunuru et al. (2013).
3.2. SARIMA–GAS–GEVD Framework
To begin the main analysis, a SARIMA in model (3) is fitted to the training data. This model is used to filter the returns on FTSE/JSE-ALSI in order to obtain independent and identically distributed residuals. Moreover, in order to accommodate the Box-Jenkins methodology, the Augmented Dickey Fuller (ADF) test is applied and the ADF model with intercept and trend is selected because its . To test for a long-term trend, a Mann-Kendall test statistics is used and the results of this test statistic revealed a significant monotonic increasing long-term trend in FTSE/JSE-ALSI returns. Finally, ARIMA is selected as the final model and it is formulated as
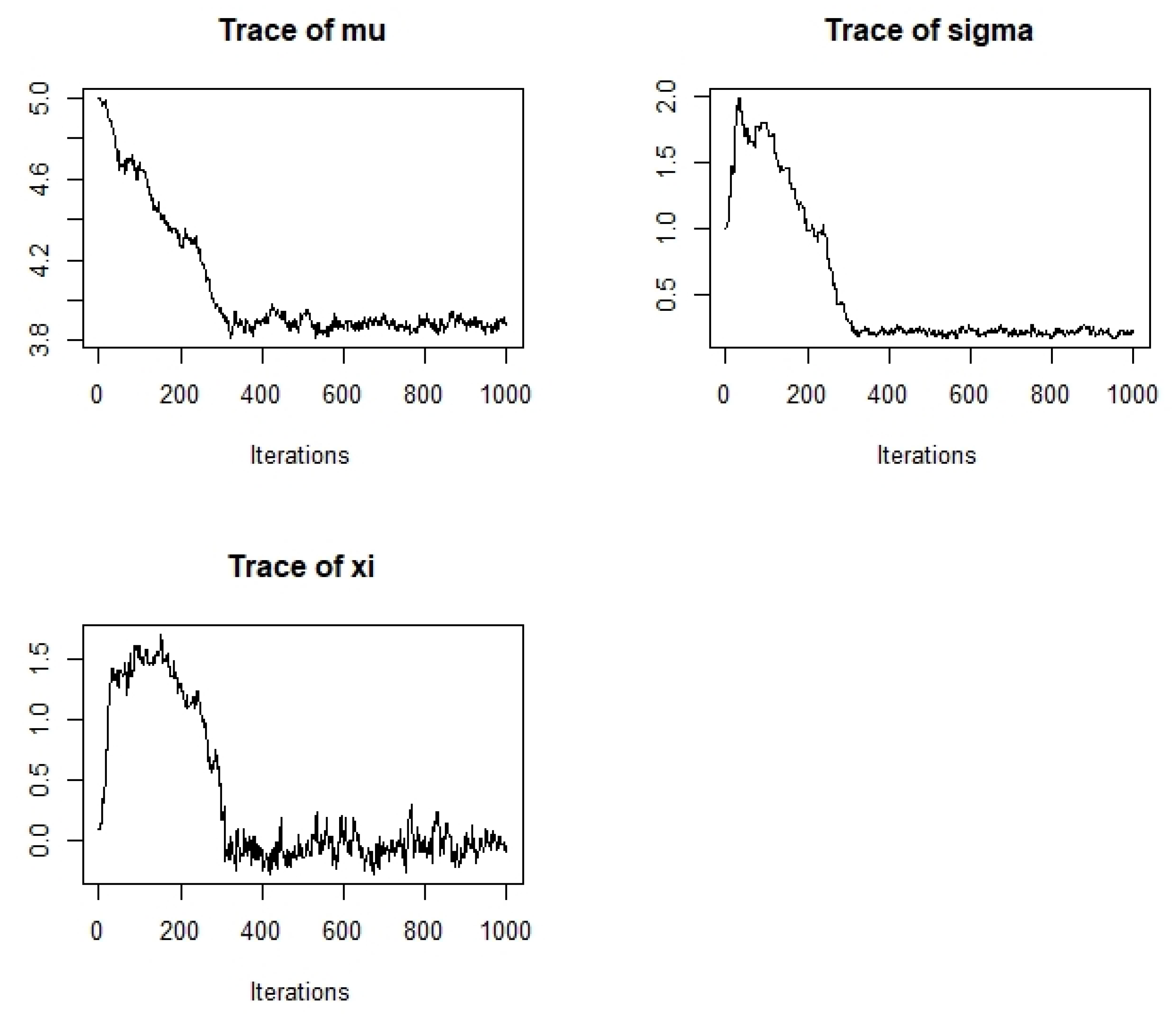
The model diagnosis indicated that the estimated SARIMA model is a white noise process. Using obtained i.i.d residuals and the block size of 2400, the GAS-GEVD is fitted with a total minimas of 482. Estimates of targeted parameters in a skewed student-t distribution are reported in Table 3, which reports parameter estimates of the proposed generalized autoregressive-generalized extreme value distribution. Figure 2 shows the traces of and , which are produced by running a Markov-chain-Monte-Carlo (MCMC) on the Bayesian estimates of SARIMA . Results in this figure shows those properties that are found in financial econometric literature. These are, but not limited to, strong persistence in volatility and positive reaction of conditional variance to negatively skewed innovations. The choice of a skewed student-t is justified by its significant parameter estimate denoted by . The same results found in this study were also found by Bernardi and Catania (2019) in their study of Switching-GAS copula model for systemic risk assessment. The parameter of excess kurtosis denoted by is also significant and it is greater than three. This signifies heavy tails (i.e., leptokurtic) features that have been reported in Table 2. See for instance Gródek-Szostak et al. (2019) and Guégan and Hassani (2019) who also found similar results. In their study on application of the GAS model to stock returns, Makatjane et al. (2017) use the maximum likelihood method to estimate the parameters of the model and these authors also found a leptokurtic behavior in stock returns.
It is worth noting that the fitted skewed student-t distribution follows an extreme distribution that is well known as the Weibull class. This is because the estimated shape parameter denoted as is negative. Gagaza et al. (2019) and Sigauke et al. (2014) also reported a negative shape parameter estimates. The contrast is in an empirical analysis of Chan (2017). These author reported a positive shape parameter in their study, which indicates a Fréchet distribution. Additionally, a 95% confidence interval for the shape parameter is estimated by 2 . It can be seen that the interval limits encloses the estimated parameter and therefore conclude that a Weibull is an appropriate distribution for FTSE/JSE-ALSI returns. Finally, the right endpoint is computed as and it implies that for any degree losses above 5%, the likelihood of any further degrease in FTSE/JSE-ALSI is minimal.
3.3. Comparative Analysis
The purpose of this section is to determine the model that best mimics the data and produces less error forecasts. The Akaike information criterion (AIC), Bayesian information criterion (BIC), mean absolute error (MAE), log-likelihood (LL), mean absolute percentage error (MAPE) which are defined in literature as statistical loss function, are used. Table 4 shows the statistical loss functions used to compare the estimated models. This helps in selecting the best model that mimic the FTSE/JSE-ALSI returns. Looking at the results of these statistics in Table 4, the log-likelihood and AIC selects a SARIMA–GAS–GEVD as the best performing model. However, the mean absolute error selects the GEVD. Using the rank of 1 to 5, where rank 1 denotes the best model and rank 5 denotes the poorest model, Table 4 gives much evidence that the SARIMA model has the poorest performance because the frequency of rank 4 is higher than the other three models. The final conclusion made here is that SARIMA–GAS–GEVD model outperformed all the models.
3.4. Evaluation of the Prediction Experiment
To reduce variability, a 10-fold cross-validation method is used. This approach partitions the training set into 10 subsets and averages validation results over 10 rounds. Table 5 gives the results of cross-validations metrics, which are discussed in Section 2.3. The cross-validations are done on both training and validation data. The SARIMA–GAS–GEVD is evaluated in both training set and validation set, respectively. The classification performance of the model indicates a reasonable goodness-of-fit in the training and validation sets. The average classification on the training set is estimated at 0.9226 while on the validation set it is estimated at 0.92798.
Table 6 shows the pairwise comparison using Wilcoxon signed-rank test and power test using model power prediction. A pair-wise comparison is done to establish the statistical significance of the selected SARIMA–GAS–GEVD model. Chen et al. (2017) and Bui et al. (2016) employed the former, while Karsten et al. (2020) utilized the latter in their empirical analysis in 2020. At 95% confidence level, the null hypothesis is that the model is not statistically different from zero. The relevance of the model is further evaluated by the use of z statistic and p-values. In relation to the actual prediction capacity, the mean difference of the model in both training and validation sets is established and used to complete this assignment. Reject the null hypothesis when z values exceeds the critical value of and when p-values are less than the significant level of . The results of a Wilcoxon signed-rank and power tests are shown in Table 6. Since the (p-value = 0.001, z value = 8.67), the model is significantly different from zero, implying a good fit of the SARIMA–GAS–GEVD model. Therefore, this model passes the power test with a score of 82.41%, suggesting that it fits the data well.
3.5. Forecasting and Backtesting Procedure
The forecasting exercise is performed in pseudo real-time and the information that is not accessed is never utilized at the time the forecast is made. Table 7 shows the comparisons of the threshold and quantile weights forecasting of time-varying VaR and ES. The comparison is based on predicting time-varying VaR and ES at days head, for a test period ranging from the 1 July 2021 to 31 December 2021 for a total density forecast cases. The ES forecast has a clear edge at almost all thresholds and quantiles, with a mean continuous ranked probability score of 0.112%, as opposed to 0.1106% for the VaR forecast. The superiority of ES forecast is corroborated by Table 7, which reports the results of weighted CRPS tests, using the weight functions of Table 1.
Table 8 shows results on backtesting one-step ahead density forecasts for VaR and ES. The established tail risk statistic suggest that the null hypothesis is not rejected and conclude that the forecasts of VaR and ES produced reliable, efficient, and unbiased estimates at 1% confidence levels. Under the null hypothesis, there is a correct model specification for the chosen risk level. DQ test statistic p-values for the FTSE/JSE-ALSI returns constituents one-step ahead VaR and ES forecasts at the two downside risk levels . For long-time periods, the model would produce suitable risk estimates and, according to Bee and Trapin (2018), these long periods are indicated by high probability values of losses at all selected confidence levels for all the tests used. As it is seen in Table 8, none of the tests reject the null hypothesis of vanishing expected score differentials. However, the methods that consider the extreme time-varying volatility show lower violation rates. This is also confirmed by the absolute error loss function.
3.6. Return Level Periods and Bootstrapping Uncertainty Intervals
Table 9 shows returns level periods and extreme uncertainty interval bootstraps. The bootstrap procedure is developed on the fixed-design residual bootstrap algorithm, which is discussed in Section 2.4. A performance of two distributions as a function of the return period T is explored. It is not phenomenal to calculate return periods as high as 10,000 years relating to a small risk. Ten years, three years and five years, as in Nemukula (2018), are used in the current paper and the results are reported in Table 9. The return levels are obtained by applying a fixed-design residual bootstrap with replications. As reported in Table 9, a three year return period is 4.376, emphasizing that a daily loss as high as 4.4% would be observed once in three years. The same interpretation can be used for 5-year and 10-year return periods. The estimated bootstrap intervals are not wide, indicating that the MCMC estimates of SARIMA –GAS–GEVD are accurate with a forecasting power of 89.6%.
3.7. Discussion of Results
Financial risk is any of the various types of risk associated with financing, including financial transactions of a company loans. Risk analysts can use the proposed loss distributions in this study to predict their financial loss and further estimate the risk associated with their losses. Associated risk factors should be taken into consideration while predicting the loss risk with these loss distributions. Duration of returns on losses could also be increased, as the study used only 3, 5, and 10 year return periods. Insurance companies may also use the estimated time-varying Value-at-Risk and expected shortfall to draw their risk management policy towards their loss on investment and return levels on their losses.
This paper makes use of a stochastic time-varying econometric model and extreme value theory procedures to bootstrap and backtest time varying Value-at-Risk and expected shortfall uncertainty intervals for extreme intra-day return periods. Few studies aim to backtest a one-step-ahead density prediction using time-varying parameters and extreme value distribution. To our knowledge, this is the first use of such a model to produce a map characterizing time-varying and extreme density predictions of VaR ES. To achieve this objective, a three stage procedure is set up. In the first, a SARIMA-GAS-GEVD is estimated and the second stage uncertainty intervals for both ES and the conditional VaR are being bootstrapped by the established fixed-design residual bootstrap procedure. Finally, a 10-fold cross validation and backtesting of the density forecasts that are based on a weighted continuous ranked probability score with the established threshold and quantile weights are used. Robust parameter estimates are achieved by the use of MCMC procedures and setting the number of burns (nburn) and of MCMC replicate to nburn = 1,000,000 L and nmcmc = 810,000 L. This estimation approach produced an overall acceptance sampling rate of 85%, the acceptance rate of the location and a shape parameters at 76.3% and 91.61%, respectively. Estimation of this hybrid has delivered an enhanced understanding for the use of the Bayesian approach to model estimation, bootstrapping, and backtesting time-varying VaR and ES uncertainty intervals for extreme daily return periods. In particular, the study is unique in terms of uniting univariate methods in bootstrapping uncertainty intervals for extreme daily returns. Due to studying a specific sector in the economy, the approach taken in this study best treats the SARMA–GAS(1)–GEVD shape parameter in a simple manner. This has established a significant Weibull distribution in the FTSE/JSE-ALSI returns.
Taking a local density score step as a driving mechanism, time-varying parameters increased and produced a clear indication of a leptokurtic performance in which the empirical properties revealed the same behavior with the volatility of 55.995%. Nevertheless, Anjum and Malik (2020) used a GARCH model with volatility shifts to forecast the conditional VaR. Their approach produced the most accurate VaR forecast relative to several benchmark methods they have used. In this study, the special case of the GARCH model is used, which is the GAS model in collaboration with SARIMA and GEVD. According to Makatjane et al. (2017), the GAS model serves as an extension of the GARCH family models, which assume that the conditional distribution does not vary over time. A vibrant advantage of the GAS model is that it exploits the full likelihood of information. Taking a local density score step as a driving mechanism, the time-varying parameters increase and produced a clear indication of a leptokurtic behavior, in which the empirical properties revealed the same behavior with a skewness of 1.091 in the unconditional parameters. The same behavior of the leptokurtic was also realized in the study of Kamika (2019). When backtesting one-step-ahead density predictions of Value-at-Risk and expected shortfall, no violations were met. All the backtesting tests accepted the null hypothesis, implying that computed risk measures and their uncertainty intervals are reliable and correct future uncertainty signals are given out by these risk measures to the risk managers.
4. Conclusions and Recommendations
The current study aims to empirically investigate the behavior of time-varying uncertainty intervals of ES and VaR by estimating the SARIMA–GAS–GEVD model to the FTSE/JSE-ALSI. The literature on bootstrapping and backtesting uncertainty intervals for extreme return periods while utilizing the SARIMA model combined with GAS–GEVD. No study on the subject are published, and as a result, very few sources are available. The SARIMA(1, 0, 0)(1, 0, 0)–GAS(1)–GEVD is estimated using the Bayesian algorithms in which a non-linear modeling approach with higher dimensions such as GAS-GEVD becomes more complicated, because it has positive semi-definiteness constraints for covariance matrices.
The findings of this study diverge from other previous studies when predicting financial risk. Studies such as Chinhamu et al. (2015) for instance, used only VaR and ES, which is the case in this study. In order to avoid biases that may be caused by using only two risk measures, researchers and scholars should engage more risk measures and avoid using ES and VaR, but use risk measures such as Tail conditional median, expected proportional shortfall, and Wang’s risk measure among others, as these measures and many others are available in the work of Chan and Nadarajah (2019). Additionally, future studies should add one more backtesting procedure known as quantile dynamic test, which was not considered in this study. Moreover, multivariate loss distributions should also be adopted together with multivariate copular methods to test the interdependence and extreme relationships. It would be interesting to see what sort of results would be available when using a machine learning approach to filter the series and quantify one-step-ahead densities for extreme losses and do a comparative analysis with time-varying parameters, extreme value distribution, and bootstrap the credible confidence interval for risk measures. Another area that requires future research is a probabilistic description and modeling of extreme risk loads using the Poison point process. This approach helps in estimating the frequency of the occurrence of peak risks. A sensitivity analysis for daily risk performed and the development of a two-stage stochastic integer recourse models to optimize returns’ distribution is an interesting future research direction.
Banks and stock market participants can use these results to optimist their daily operational one head prediction losses and further predict the probability of future default in their daily operations. Regarding credit risk, the findings can also be useful for banks. Financial risk is any of the various types of risk associated with financing, including financial transactions that include company loans in risk of default. Therefore, risk analysts can use the proposed loss distributions in this study to predict their financial loss and further estimate the risk associated with the losses. Associated risk factors should be taken into consideration while predicting the loss risk with this loss distribution. Duration of returns on losses could also be increased, as the study used only 3-year, 5-year, and 10-year return periods. Insurance companies may also use this model to draw their risk management policy towards their loss on investment and return levels on their losses.
Author Contributions
All authors contributed equally to the conception and design of this empirical analysis. K.M. has developed the introduction, methodology and he also did data analysis of this manuscript. T.T. has written the literature, conclusion and the abstract and proof read the final draft of the paper. T.T. has also acquired the data used in the study from Johannesburg Stock exchange. All in all, the authors have read and agreed to the published version of the manuscript.
Funding
This study received no specific financial support.
Institutional Review Board Statement
Not Applicable.
Informed Consent Statement
No informed consent for this study because the study is not involed with humans or animals. The study used secondary data.
Data Availability Statement
The data used in this study is available from South African Stock Market upon request to them to get the latest dataset. An it can also be available from the author upon request.
Acknowledgments
The author is grateful to the Johannesburg stock exchange (JSE) for provision of a high frequency five-day data.
Conflicts of Interest
The author declares that there is no competing interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AE | Absolute Error |
| ADF | Augmented Dickey Fuller |
| AIC | Akaike Information Criterion |
| ARMA-GARCH | Autoregressive-Moving Average-Generalized Autoregressive-Conditional–Heteroscedasticity |
| BCR | Balanced Classification Rate |
| BM | Block Minima |
| CC | Conditional Coverage |
| CDF | Cumulative Distribution Function |
| CRPS | Continuous Ranked Probability Score |
| DQ | Dynamic Quantile |
| ES | Expected Shortfall |
| EVT | Extreme Value Theory |
| FN | False Negative |
| FP | False Positive |
| FTSE/JSE-ALSI | Financial Time Series exchange/Johannesburg Stock Exchange–All Share Index |
| GARCH | Generalized Autoregressive Conditional Heteroscedasticity |
| GAS | Generalised Autoregressive Score |
| GAS-GEVD | Generalised Autoregressive Score–Generalised Extreme Value Distribution |
| GEVD | Generalised Extreme Value Distribution |
| i.i.d | Independent and Identically Distributed |
| JSE-ALSI | Johannesburg Stock Exchange–All Share Index |
| MAE | Mean Absolute Error |
| MAPE | Mean Absolute Percentage Error |
| MCMC | Markov-chain-Monte-Carlo |
| MCC | Matthews Correlation Coefficient |
| MLE | Maximum Likelihood Estimation |
| MIDAS | Mixing Data Sampling |
| MC | Monte Carlo |
| Q-Q | Quantile-Quantile |
| SARIMA | Seasonal Autoregressive Integrated Moving Average |
| SARIMA-GAS-GEVD | Seasonal Autoregressive Integrated Moving Average–Generalised Autoregressive Score–Generalised Extreme Value Distribution |
| TN | True Negative |
| TR | Tail Risk |
| TP | True Positive |
| UC | Unconditional Coverage |
| VaR | Value-at-Risk |
| wCRPS | Weighted Continuous Ranked Probability Score |
| 1 | This assumption states that a score of the empirical distribution when computing the conditional Value at Risk measures is constant over time. |
| 2 | se herein referenced standard error of ξ. |
References
- Amisano, Gianni, and Raffaella Giacomini. 2007. Comparing Density Forecasts via Weighted Likelihood Ratio Tests. Journal of Business and Economic Statistics 25: 177–90. [Google Scholar] [CrossRef]
- Anjum, Hassan, and Farooq Malik. 2020. Forecasting Risk in the US Dollar Exchange Rate under Volatility Shifts. The North American Journal of Economics and Finance 54: 101257. [Google Scholar] [CrossRef]
- Ardia, David, Kris Boudt, and Leopoldo Catania. 2019. Generalised Autoregressive Score Models in R: The GAS Package. Journal of Statistical Software 88: 1–28. [Google Scholar] [CrossRef] [Green Version]
- Babatunde, Oluwagbenga Tobi, Henrietta Ebele Oranye, and Cynthia Ndidiamaka Nwafor. 2020. Volatility of Some Selected Currencies Against the Naira Using Generalized Autoregressive Score Models. International Journal of Statistical Distributions and Applications 6: 42–46. [Google Scholar] [CrossRef]
- Bayer, Sebastian, and Timo Dimitriadis. 2020. Regression based expected shortfall backtesting. Journal of Financial Econometrics 18: nbaa013. [Google Scholar] [CrossRef]
- Bee, Marco, and Luca Trapin. 2018. Estimating and Forecasting Conditional Risk Measures with Extreme Value Theory: A Review. Risks 6: 45. [Google Scholar] [CrossRef] [Green Version]
- Bernard, Carole, Ludger Rüschendorf, and Steven Vanduffel. 2017. Value-at-risk Bounds with Variance Constraints. Journal of Risk and Insurance 84: 923–59. [Google Scholar] [CrossRef]
- Bernardi, Mauro, and Leopoldo Catania. 2019. Switching-GAS Copula Models for Systemic Risk Assessment. Journal of Applied Econometrics 34: 43–65. [Google Scholar] [CrossRef] [Green Version]
- Beutner, Eric, Alexander Heinemann, and Stephan Smeekes. 2020. A Residual Bootstrap for Conditional Value-at-Risk. arXiv arXiv:1808.09125. [Google Scholar]
- Bui, Dieu Tien, Tran Anh Tuan, Harald Klempe, Biswajeet Pradhan, and Inge Revhaug. 2016. Spatial Prediction Model for shallow Landslide Hazards: A Comparative Assessment of the Efficacy of Support Vector Machines, Artificial Neural Networks, Kernel Logistic Regression, and Logistic Model Tree. Landslides 13: 361–78. [Google Scholar] [CrossRef]
- Chan, Joshua C. C. 2017. The Stochastic Volatility in Mean Model With Time-Varying Parameters: An Application to Inflation Modeling. Journal of Business and Economic Statistics 35: 17–28. [Google Scholar] [CrossRef]
- Chan, Stephen, and Saralees Nadarajah. 2019. Risk: An R package for Financial Risk Measures. Computational Economics 53: 1337–51. [Google Scholar] [CrossRef] [Green Version]
- Chandiwana, Edina, Caston Sigauke, and Alphonce Bere. 2021. Twenty-Four-Hour Ahead Probabilistic Global Horizontal Irradiance Forecasting Using Gaussian Process Regression. Algorithms 14: 177. [Google Scholar] [CrossRef]
- Chen, Wei, Xiaoshen Xie, Jiale Wang, Biswajeet Pradhan, Haoyuan Hong, Dieu Tien Bui, Zhao Duan, and Jianquan Ma. 2017. A Comparative Study of Logistic Model Tree, Random Forest, and Classification and Regression tree Models for Spatial Prediction of Landslide Susceptibility. Catena 51: 147–60. [Google Scholar] [CrossRef] [Green Version]
- Chinhamu, Knowledge, Chun-Kai Huang, Chun-Sung Huang, and Delson Chikobvu. 2015. Extreme Risk, Value-at-Risk and Expected Shortfall in the Gold Market. The International Business and Economics Research Journal 14: 109–22. [Google Scholar] [CrossRef]
- Christoffersen, Peter F. 1998. Evaluating Interval Forecasts. International Economic Review 39: 841–62. [Google Scholar] [CrossRef]
- Christoffersen, Peter, and Sílvia Gonçalves. 2005. Estimation Risk in Financial Risk Management. The Journal of Risk 7: 1–28. [Google Scholar] [CrossRef] [Green Version]
- Coroneo, Laura, and Fabrizio Iacone. 2020. Comparing Predictive Accuracy in Small Samples using Fixed-smoothing Asymptotics. Journal of Applied Econometrics 35: 391–409. [Google Scholar] [CrossRef]
- Creal, Drew, Siem Jan Koopman, and André Lucas. 2013. Generalized Autoregressive Score Models with Applications. Journal of Applied Econometrics 28: 777–95. [Google Scholar] [CrossRef] [Green Version]
- Droumaguet, Matthieu. 2012. Markov-Switching Vector Autoregressive Models: Monte Carlo Experiment, Impulse Response Analysis, and Granger-Causal. Ph.D. thesis, European University Institute, Europe, Department of Economics, Fiesole, Italy. Available online: http://hdl.handle.net/1814/25135 (accessed on 13 August 2021).
- Eckernkemper, Tobias. 2018. Modelling systemic Risk: Time-varying Tail Dependence when Forecasting Marginal Expected Shortfall. Journal of Financial Economics 16: 63–117. [Google Scholar] [CrossRef]
- Engle, Robert F., and Simone Manganelli. 2004. CAViaR: Conditional Autoregressive Value-at-Risk by Regression Quantiles. Journal of Business and Economic Statistics 22: 412–15. [Google Scholar] [CrossRef]
- Escanciano, J. Carlos, and Jose Olmo. 2010. Backtesting Parametric Value-at-Risk with Estimation Risk. Journal of Business and Economic Statistics 28: 36–51. [Google Scholar] [CrossRef]
- Frésard, Laurent, Christophe Pérignon, and Anders Wilhelmsson. 2011. The Pernicious Effects of Contaminated Data in Risk Management. Journal of Banking and Finance 35: 2569–83. [Google Scholar] [CrossRef]
- Gagaza, Nceba, Murendeni Maurel Nemukula, Retius Chifurira, and Danielle Jade Roberts. 2019. Modelling Non-stationary Temperature Extremes in KwaZulu-Natal using the Generalised Extreme Value Distribution. In Annual Proceedings of the South African Statistical Association Conference. Number Congress 2. Centurion: South African Statistical Association (SASA), pp. 1–8. Available online: https://hdl.handle.net/10520/EJC-19ea5a8642 (accessed on 3 July 2021).
- Gareth, James, Witten Daniela, Hastie Trevor, and Tibshirani Robert. 2013. An Introduction to Statistical Learning with Application in R. New York: Springer, vol. 112, Available online: https://d1wqtxts1xzle7.cloudfront.net/ (accessed on 3 March 2021).
- Ghosh, Bidisha, Biswajit Basu, and Margaret O’Mahony. 2007. Bayesian Time-Series Model for Short-term Traffic Flow Forecasting. Journal of Transportation Engineering 133: 180–89. [Google Scholar] [CrossRef]
- Gneiting, Tilmann, and Roopesh Ranjan. 2012. Comparing Density Forecasts using Threshold-and Quantile-Weighted Scoring Rules. Journal of Business and Economic Statistics 29: 411–22. [Google Scholar] [CrossRef] [Green Version]
- Gródek-Szostak, Zofia, Gabriela Malik, Danuta Kajrunajtys, Anna Szeląg-Sikora, Jakub Sikora, Maciej Kuboń, Marcin Niemiec, and Joanna Kapusta-Duch. 2019. Modelling the Dependency Between Extreme Prices of Selected Agricultural Products on the Derivatives Market using the Linkage Function. Sustainability 11: 4144. [Google Scholar] [CrossRef] [Green Version]
- Guégan, Dominique, and Bertrand K. Hassani. 2019. Risk Measurement: From Quantitative Measures to Management Decisions. Berlin: Springer. [Google Scholar] [CrossRef]
- Hartz, Christoph, Stefan Mittnik, and Marc Paolella. 2006. Accurate Value-at-Risk Forecasting Based on the Normal-GARCH Model. Computational Statistics and Data Analysis 51: 2295–312. [Google Scholar] [CrossRef]
- Harvey, Andrew C. 2013. Dynamic Models for Volatility and Heavy Tails: With Applications to Financial and Economic Time Series. Cambridge: Cambridge University Press, Available online: hppts://www.cambridge.org/9781107630024 (accessed on 27 September 2021).
- Kamika, Mbuaya Grace. 2019. An Application of the Generalised Autoregressive Score Model to Market Risk Modelling. Ph.D. thesis, University of Johannesburg, School of Economics and Econometrics, Johannesburg, South Africa. Available online: http://hdl.handle.net/102000/0002 (accessed on 27 September 2021).
- Karsten, Bettina, Luca Petrigna, Andreas Klose, Antonino Bianco, Nathan Townsend, and Christoph Triska. 2020. Relationship between the critical power test and a 20-min functional threshold power test in cycling. Frontiers in Physiology 11: 613151. [Google Scholar] [CrossRef]
- Kupiec, Paul. 1995. Techniques for Verifying the Accuracy of Risk Measurement Models. The Journal of Derivatives 3: 73–84. Available online: https://ssrn.com/abstract=7065 (accessed on 27 September 2021). [CrossRef]
- Lazar, Emese, and Xiaohan Xue. 2019. Forecasting Risk Measures using Intra-day Data in a Generalized Autoregressive Score Framework. International Journal of Forecasting 36: 1–16. [Google Scholar] [CrossRef]
- Le, Trung H. 2020. Forecasting Value at Risk and Expected Shortfall with Mixed Data Sampling. International Journal of Forecasting 36: 1362–79. [Google Scholar] [CrossRef]
- Makatjane, Katleho, Diteboho Xaba, and Ntebogang Moroke. 2017. Application of Generalized Autoregressive Score Model to Stock Returns. International Journal of Economics and Management Engineering 11: 2714–17. [Google Scholar] [CrossRef]
- Maposa, Daniel. 2016. Statistics of Extremes with Applications to Extreme Flood Heights in the Lower Limpopo River Basin of Mozambique. Ph.D. thesis, University of Limpopo, School of Mathematical and Computer Sciences, Mankweng, South Africa. Available online: http://hdl.handle.net/10386/1695 (accessed on 27 September 2021).
- Maposa, Daniel, Maseka Lesaoana, and James J. Cochran. 2016. Modelling Non-stationary Annual Maximum Flood Heights in the Lower Limpopo River Basin of Mozambique. Jàmbá Journal of Disaster Risk Studies 8: 1–9. [Google Scholar] [CrossRef] [PubMed]
- Masingi, Vusi Ntiyiso, and Daniel Maposa. 2021. Modelling Long-term Monthly Rainfall Variability in Selected Provinces of South Africa: Trend and Extreme Value Analysis Approaches. Hydrology 8: 70. [Google Scholar] [CrossRef]
- Mieth, Robert, Matt Roveto, and Yury Dvorkin. 2002. Risk Trading in a Chance-constrained Stochastic Electricity Market. IEEE Control Systems Letters 5: 199–204. [Google Scholar] [CrossRef]
- Musunuru, Naveen, Mark Yu, and Arley Larson. 2013. Forecasting Volatility of Returns for Corn using GARCH Models. Texas Journal of Agriculture and Natural Resources 26: 42–55. Available online: https://txjanr.agintexas.org/index.php/txjanr/article/view/33/21 (accessed on 27 September 2021).
- Nemukula, Murendeni Maurel. 2018. Modelling Temperature in South Africa using Extreme Value Theory. Ph.D. thesis, University of the Witwatersrand, School of Statistics and Actuarial Science, Johannesburg, South Africa. Available online: https://core.ac.uk/download/pdf/188769682.pdf (accessed on 27 September 2021).
- Nieto, Maria Rosa, and Esther Ruiz. 2016. Frontiers in VaR Forecasting and Backtesting. International Journal of Forecasting 32: 475–50. [Google Scholar] [CrossRef]
- Patton, Andrew J., Johanna F. Ziegel, and Rui Chen. 2019. Dynamic Semi–parametric Models for Expected Shortfall and Value-at-Risk. Journal of Econometrics 211: 388–413. [Google Scholar] [CrossRef] [Green Version]
- Rigotti, Luca, and Chris Shannon. 2005. Uncertainty and Risk in Financial Markets. Econometrica 73: 203–43. [Google Scholar] [CrossRef] [Green Version]
- Rocco, Marco. 2014. Extreme value theory in Finance: A Survey. Journal of Economic Surveys 28: 82–108. [Google Scholar] [CrossRef] [Green Version]
- Siegl, Thomas, and Ansgar West. 2001. Statistical Bootstrapping Methods in VaR Calculation. Applied Mathematical Finance 8: 67–181. [Google Scholar] [CrossRef]
- Sigauke, Caston, Andréhette Verster, and Delson Chikobvu. 2012. Tail Quantile Estimation of Heteroscedastic Intra-day Increases in Peak Electricity Demand. African Review of Economics and Finance 2: 435. [Google Scholar] [CrossRef] [Green Version]
- Sigauke, Caston, Rhoda M. Makhwiting, and Maseka Lesaoana. 2014. Modelling Conditional Heteroscedasticity in JSE Stock Returns using the Generalised Pareto Distribution. African Review of Economics and Finance 6: 41–55. Available online: https://hdl.handle.net/10520/EJC155586 (accessed on 27 September 2021).
- Spierdijk, Laura. 2016. Confidence Intervals for ARMA–GARCH Value-at-risk: The Case of Heavy Tails and skewness. Computational Statistics and Data Analysis 100: 545–59. [Google Scholar] [CrossRef]
- Tafakori, Laleh, Armin Pourkhanali, and Farzad Alavi Fard. 2018. Forecasting Spikes in Electricity Return Innovations. Energy 150: 508–26. [Google Scholar] [CrossRef]
- Taylor, James W. 2019. Forecasting Value–at–Risk and Expected Shortfall using a Semi-parametric Approach Based on the Asymmetric Laplace Distribution. Journal of Business and Economic Statistics 37: 121–33. [Google Scholar] [CrossRef]
- Vidal, Ignacio. 2014. A Bayesian analysis of the Gumbel Distribution: An Application to Extreme Rainfall Data. Stochastic Environmental Research and Risk Assessment 28: 571–82. [Google Scholar] [CrossRef]
- Zoglat, A., S. El Adlouni, E. Ezzahid, A. Amar, C. G. Okou, and F. Badaoui. 2013. Statistical Methods to Expect Extreme Values: Application of Pot Approach to cac40 Return Index. International Journal of Statistics and Economics 10: 1–13. Available online: http://hdl.handle.net/10625/51488 (accessed on 27 September 2021).
Figure 1.
Presents plots of original FTSE/JSE-ALSI, the logarithm returns on FTSE/JSE–ALSI, and normal Q-Q plot for intra-day returns on FTSE/JSE–ALSI.
Figure 1.
Presents plots of original FTSE/JSE-ALSI, the logarithm returns on FTSE/JSE–ALSI, and normal Q-Q plot for intra-day returns on FTSE/JSE–ALSI.

Figure 2.
Traces of three GEVD for parameters , and showing the maximum iterations used to estimate these parameters.
Figure 2.
Traces of three GEVD for parameters , and showing the maximum iterations used to estimate these parameters.


{kind=link}
{kind=link}
Table 1.
Shows Proposed Threshold and Quantile Weights. These weights are used to compare the density forecasts of both time-varying VaR and ES.
Table 1.
Shows Proposed Threshold and Quantile Weights. These weights are used to compare the density forecasts of both time-varying VaR and ES.
| Threshold Weights | Emphasis | Quantile Weights |
|---|---|---|
| Center | ||
| Tails | ||
| Left Tail | ||
| Right Tail |
Table 2.
Descriptive statistics for intra-day returns with reported skewness and kurtosis of logarithmic returns on FTSE/JSE–ALSI.
Table 2.
Descriptive statistics for intra-day returns with reported skewness and kurtosis of logarithmic returns on FTSE/JSE–ALSI.
| Skewness | Kurtosis | |
|---|---|---|
| Returns on FTSE/JSE-ALSI | −18.83 | 688.84 |
Table 3.
Bayesian parameter estimates of the proposed GAS–GEVD. The estimates are from the i.i.d residuals of the SARIMA model. The GAS–GEVD is fitted using a block minima (BM) with the block size of 2400.
Table 3.
Bayesian parameter estimates of the proposed GAS–GEVD. The estimates are from the i.i.d residuals of the SARIMA model. The GAS–GEVD is fitted using a block minima (BM) with the block size of 2400.
| Parameter | Estimate | Std Error | t-Value | |
|---|---|---|---|---|
| 65.5515 | 0.8782 | 7.4040 | 0.0000 | |
| 0.0702 | 0.0895 | 8.7172 | 0.0000 | |
| 3.7575 | 3.7575 | 1.4740 | 0.0702 | |
| 9.9995 | 0.0005 | 2.0578 | 0.0000 | |
| −1.7119 | 0.1209 | −1.4114 | 0.0000 | |
| −0.9666 | 0.0005 | −2.0670 | 0.0000 | |
| −0.9356 | 0.0065 | −1.5098 | 0.0000 | |
| Unconditional Parameters | ||||
| −0.0046 | 0.00245 | −7.999 | 1.091 | |
Table 4.
Shows a comparative analysis of the SARIMA, GAS, GEVD, and the combined SARIMA-GAS-GEVD models to select the best model that mimic the returns on FTSE/JSE-ALSI.
Table 4.
Shows a comparative analysis of the SARIMA, GAS, GEVD, and the combined SARIMA-GAS-GEVD models to select the best model that mimic the returns on FTSE/JSE-ALSI.
| Test | SARIMA | GAS | GEVD | SARIMA-GAS-GEVD |
|---|---|---|---|---|
| LL | 108 | 110 | 102 | 99 |
| Rank | 3 | 4 | 2 | 1 |
| AIC | −1710 | −1712 | −1719 | −1725 |
| Rank | 4 | 3 | 2 | 1 |
| BIC | −1794 | −1799 | −1802 | −1800 |
| Rank | 4 | 3 | 1 | 2 |
| MAE | 0.9023 | 0.988 | 0.8774 | 0.9930 |
| Rank | 2 | 3 | 1 | 4 |
| MPAE | 1.247 | 1.004 | 1.002 | 0.798 |
| Rank | 4 | 3 | 2 | 1 |
Table 5.
Shows the cross-validation performance of the estimated SARIMA–GAS–GEVD on both the training and validation dataset.
Table 5.
Shows the cross-validation performance of the estimated SARIMA–GAS–GEVD on both the training and validation dataset.
| Metric | Mean | Std Error | Training Set | Validation Set |
|---|---|---|---|---|
| Precision | 0.9514 | 0.0108 | 0.9510 | 0.9701 |
| Recall | 0.9664 | 0.0107 | 0.9645 | 0.9489 |
| F1Score | 0.9580 | 0.0063 | 0.9577 | 0.9594 |
| MCC | 0.8468 | 0.0015 | 0.8489 | 0.8513 |
| BCR | 0.8953 | 0.0076 | 0.8909 | 0.9102 |
Table 6.
Shows a pair-wise comparison and power test to assess the prediction power of SARIMA–GAS–GEVD Model.
Table 6.
Shows a pair-wise comparison and power test to assess the prediction power of SARIMA–GAS–GEVD Model.
| Wilcoxon Signed-Rank Test | Model Power Test | |||
|---|---|---|---|---|
| Parameters | SARIMA–GAS–GEVD | Data | Mean Difference | Actual Power |
| z-value | 8.67 | Training | −0.0194 | 0.8241 |
| p-value | 0.001 | Validation | 0.0298 | 0.8556 |
Table 7.
Weighted CRPS tests for density forecasts for the extreme time-varying process. The density forecast ˆ is estimated under the correct model assumption. Its competitor uses a deliberately misspecified predictive variance. The width of the sliding training window is , and one-step-ahead density forecasts is considered.
Table 7.
Weighted CRPS tests for density forecasts for the extreme time-varying process. The density forecast ˆ is estimated under the correct model assumption. Its competitor uses a deliberately misspecified predictive variance. The width of the sliding training window is , and one-step-ahead density forecasts is considered.
| Threshold Weights | Emphasis | p-Value | Quantile Weights | p-Value |
|---|---|---|---|---|
| Center | 0.1675 | 0.1892 | ||
| Tails | 0.0587 | 0.0774 | ||
| Left Tail | 0.1157 | 0.1422 | ||
| Right Tail | 0.1005 | 0.9911 |
Table 8.
Backtesting one-step ahead Value-at-Risk and wxpected shortfall at risk level using tail risk and dynamic quantile tests. The TR tells how much loss a portfolio can incur while the DQ of the joint hypothesis is at level of significance.
Table 8.
Backtesting one-step ahead Value-at-Risk and wxpected shortfall at risk level using tail risk and dynamic quantile tests. The TR tells how much loss a portfolio can incur while the DQ of the joint hypothesis is at level of significance.
| Risk Measure | TR Test | DQ Test | ADmax | ADMean | AE |
|---|---|---|---|---|---|
| VaR | 0.4816 | 7.3246 | 13.4596 | 0.5664197 | 1.1342 |
| ES | 0.5364 | 0.3958 | 0.48743 | 0.4873 | 1.0982 |
Table 9.
Shows return level periods and posterior distribution with 99% uncertainty interval bootstraps forecasts for VaR and ES.
Table 9.
Shows return level periods and posterior distribution with 99% uncertainty interval bootstraps forecasts for VaR and ES.
| Period | Returns | Bootstrap Replicates | 99% CI |
|---|---|---|---|
| 3 Years | 4.3760 | 15,000 | (4.2996; 4.3977) |
| 5 Years | 5.2416 | 15,000 | (5.166; 5.374) |
| 10 Yeas | 6.3842 | 15,000 | (6.287; 6.439) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Makatjane, K.; Tsoku, T. Bootstrapping Time-Varying Uncertainty Intervals for Extreme Daily Return Periods. Int. J. Financial Stud. 2022, 10, 10. https://0-doi-org.brum.beds.ac.uk/10.3390/ijfs10010010
AMA Style
Makatjane K, Tsoku T. Bootstrapping Time-Varying Uncertainty Intervals for Extreme Daily Return Periods. International Journal of Financial Studies. 2022; 10(1):10. https://0-doi-org.brum.beds.ac.uk/10.3390/ijfs10010010
Chicago/Turabian StyleMakatjane, Katleho, and Tshepiso Tsoku. 2022. "Bootstrapping Time-Varying Uncertainty Intervals for Extreme Daily Return Periods" International Journal of Financial Studies 10, no. 1: 10. https://0-doi-org.brum.beds.ac.uk/10.3390/ijfs10010010
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.