A Note on Universal Bilinear Portfolios


Department of Economics, School of Public and Global Affairs, College of Liberal Arts and Sciences, Northern Illinois University, 514 Zulauf Hall, DeKalb, IL 60115, USA
Int. J. Financial Stud. 2021, 9(1), 11; https://0-doi-org.brum.beds.ac.uk/10.3390/ijfs9010011
Submission received: 8 January 2021
/
Revised: 5 February 2021
/
Accepted: 10 February 2021
/
Published: 24 February 2021
{kind=link}
{kind=link}
Abstract
:This note provides a neat and enjoyable expansion and application of the magnificent Ordentlich-Cover theory of “universal portfolios”. I generalize Cover’s benchmark of the best constant-rebalanced portfolio (or 1-linear trading strategy) in hindsight by considering the best bilinear trading strategy determined in hindsight for the realized sequence of asset prices. A bilinear trading strategy is a mini two-period active strategy whose final capital growth factor is linear separately in each period’s gross return vector for the asset market. I apply Thomas Cover’s ingenious performance-weighted averaging technique to construct a universal bilinear portfolio that is guaranteed (uniformly for all possible market behavior) to compound its money at the same asymptotic rate as the best bilinear trading strategy in hindsight. Thus, the universal bilinear portfolio asymptotically dominates the original (1-linear) universal portfolio in the same technical sense that Cover’s universal portfolios asymptotically dominate all constant-rebalanced portfolios and all buy-and-hold strategies. In fact, like so many Russian dolls, one can get carried away and use these ideas to construct an endless hierarchy of ever more dominant H-linear universal portfolios.
Keywords:
on-line portfolio selection; universal portfolios; robust procedures; model uncertainty; constant-rebalanced portfolios; asymptotic capital growth; kelly criterionJEL Classification:
D81; D83; G11We first investigate what a natural goal might be for the growth of wealth for arbitrary market sequences. For example, a natural goal might be to outperform the best buy-and-hold strategy, thus beating an investor who is given a look at a newspaper n days in the future. We propose a more ambitious goal.—Thomas M. Cover, Universal Portfolios, 1991
In 1988, out of the blue, Paul Samuelson wrote a letter to Stanford information theorist Thomas Cover. Samuelson had been sent one of Cover’s papers on portfolio theory for review. “If I did use some of your procedures,” Samuelson wrote, “I would not let that … bias my portfolio choice toward choices my alien cousin with log utility would make”. He chides Kelly, Latané, Markowitz, and “various Ph.D’s who appear with Poisson-distribution probabilities most Junes”.—William Poundstone, Fortune’s Formula, 2005
With four parameters I can fit an elephant, and with five I can make him wiggle his trunk.—John von Neumann
1. Introduction; Literature Review
This note contains a nice application and extension of the elegant universal portfolio theory that was established by Thomas Cover (1991); Cover and Ordentlich (1996); and Ordentlich and Cover (1998).
Universal portfolio theory is the on-line analogue of the log-optimal portfolio theory (that is, the theory of asymptotic capital growth), whose brilliant simplicity came down to us from such illustrative thinkers as John Kelly (1956), Henry Latané (1959), Leo Breiman (1961), and card-counter Edward O. Thorp (1969). Under laboratory conditions where the investor or gambler knows in advance the precise distribution of the profit-and-loss outcomes on which he is betting, the tea leaves say (cf. with MacLean et al. (2011)) that log-optimal portfolios (or growth-optimal portfolios) enjoy tremendous optimality properties, quite apart from the fact that they saturate a very specific type of expected utility, as pointed out so many times by Samuelson (1963, 1969, 1979).
Leo Breiman (1961) gave the first substantial results in this direction, namely, that the so-called Kelly gambler will, under general conditions, asymptotically outperform any “essentially different strategy” almost surely by an exponential factor. He also demonstrated that, for the sake of goal-based investing, the Kelly criterion minimizes the expected waiting time with respect to hitting a distant high-water mark.
In a pair of beautiful articles, Bell and Cover(1980, 1988) established that, actually, the Kelly rule also possesses very strong short-term competitive optimality properties, even for a single period’s fluctuation of a betting or investment market. They considered a static, zero-sum investment ϕ-game whose payoff kernel is equal to the expected value of an arbitrary increasing function of the ratio of one trader’s wealth to that of another. Subject to the proviso that, prior to the actual portfolio choice, each contestant is permitted to make a fair randomization of his initial dollar (by exchanging it for any random capital whose mean is at most 1), the saddle point of the game amounts to each player using the log-optimal portfolio, together with fair randomizations that depend only on the criterion , and not on any particular characteristic of the underlying investment opportunities.
Garivaltis (2018a) showed that the Bell-Cover theorem holds equally well for stochastic differential investment -games in continuous time that exhibit state-dependent drift and diffusion; Garivaltis (2019a) generalized this result even further, so as to cover levered investment -games over continuous time markets whereby the asset prices follow jump-diffusion processes with compactly-supported jump returns. Some recent work by Curatola (2019) investigates the strategic interaction of two large traders whose transactions affect not just each other, but also the expected returns of the entire stock market. For an illuminating discussion of competitive optimality as it relates to evolutionary contingencies in mathematical biology, consult with Tal and Tran (2020).
Cover’s universal portfolio theory, which began in earnest with his empirical Bayes stock portfolio (Cover and Gluss (1986)), takes its cue from the fact that for stock markets with iid returns, the log-optimal portfolio amounts to a certain constant-rebalanced portfolio (CRP); this consists in fixing the correct (growth-optimal) target percentages of wealth for each asset, and continuously executing rebalancing trades so as to counteract allocation drift. However, in the presence of model uncertainty (e.g., for actual stock markets), this particular CRP is completely unknown to the practitioner.
Inspired by the analogies with information theory, Thomas Cover had the brilliant insight that one should benchmark his on-line investment performance relative to that of the best constant-rebalanced portfolio determined in hindsight for the actual (realized) sequence of asset prices. The hindsight-optimized wealth can be interpreted as a financial derivative that is susceptible of exact pricing and replication in the (complete) continuous time market of Black and Scholes (1973). On that score, Ordentlich and Cover (1998) priced the rebalancing option at time-0 for unlevered hindsight optimization over a single risk asset; their work sat unfinished for twenty years, until it was completed by Garivaltis (2019b), who demonstrated how to price and replicate Cover’s (levered) rebalancing option at any time t, for any number of correlated stocks in geometric Brownian motion.
In discrete time, the empirical Bayes stock portfolio (Cover and Gluss (1986)), the Dirichlet-weighted universal portfolio (Cover and Ordentlich (1996)), and the minimax universal portfolio (Ordentlich and Cover (1998)) are all notable in that they guarantee to achieve a high percentage of the final wealth of the best constant-rebalanced portfolio in hindsight, uniformly for all possible sequences of asset prices. On account of the fact that this percentage (or competitive ratio) converges to zero at a slow (polynomial) rate, the excess compound (logarithmic) growth rate of the best CRP in hindsight (over and above that of the on-line portfolio) converges uniformly to zero. Thus, universal portfolios succeed in matching the performance of the best CRP in hindsight “to first order in the exponent”.
The original universal portfolios (inspired as they were by iid stock markets) suffer from the defect that they fail to recognize and exploit even very simple types of serial dependence in the individual sequence of asset returns. For example, consider a two-asset market whereby asset 2 is cash (that pays no interest), and asset 1 is a “hot stock” whose price alternately doubles in odd periods and gets cut in half in even periods. Naturally, one should hope that his portfolio selection algorithm is capable of detecting such a trivial pattern, thereby learning to (asymptotically) double its capital every two periods. But the original universal portfolios, when applied to this particular sequence of asset prices, merely learn to use the constant-rebalanced portfolio that puts of its wealth into the stock and holds the rest in cash at the start of each investment period; this generates asymptotic capital growth at a rate of every two periods, compounded continuously—a far cry from the that accrues to perfect trading.
One way out of this conundrum is the use the universal portfolio with side information (Cover and Ordentlich (1996)) along with a “signal” that indicates, say, whether or not the current period is odd. The obvious objection here is that the efficacy of this particular signal (as opposed to any other piece of side information) will only ever become apparent in hindsight. Accordingly, this paper tackles the problem differently: we consider an expanded parametric family of mini 2-period active trading strategies called bilinear portfolios, which explicitly generalize the constant-rebalanced portfolios (here called 1-linear portfolios). Accordingly, we apply the Ordentlich-Cover techniques to design a universal bilinear portfolio that compounds its money at the same asymptotic rate as the best bilinear trading strategy in hindsight (thereby learning to trade perfectly in the motivating example). Thus, the universal bilinear portfolio will be shown to asymptotically dominate the universal 1-linear portfolio in the same technical sense (cf. with Cover and Thomas (2006)) that the universal 1-linear portfolio asymptotically dominates all constant-rebalanced portfolios and all buy-and-hold strategies. Once this is done, it will become readily apparent just how one can go about constructing an endless hierarchy of ever more dominant universal H-linear portfolios, for all possible mini-horizons .
2. Bilinear Trading Strategies
We start by defining the concept of a bilinear trading strategy (or bilinear portfolio), which is a simple 2-period active strategy that generalizes the notion of a constant-rebalanced portfolio (CRP). To this end, we assume that there are m assets called ; we let denote the gross return1 of a investment in asset i in period 1, and similarly we let denote the gross return of asset j in period 2. We let denote the gross return vector in period 1, and in the same vein, is the gross return vector in period 2.
Definition 1.
A bilinear trading strategy is a square matrix of non-negative weights that sum to one. After two investment periods, the bilinear trading strategy B multiplies the initial dollar by a factor of
The set of all bilinear trading strategies is denoted
where is an vector of ones.
Proposition 1.
The bilinear2 final wealth is uniquely replicated by the following 2-period active trading strategy: in period 1, we use the initial portfolio , where is the initial fraction of wealth that will be invested in asset i; in period 2, we must use the portfolio
e.g.,
Proof.
We start with the functional equation
e.g., the two-period growth factor is equal to the product of the individual growth factors that were achieved in periods 1 and 2. To start, we substitute and which is the unit basis vector for . There lies , as promised. Next, in the identity
we put . This leaves us with
which is the desired result. In order to be logically complete, we must substitute our expressions for p and into Equation (5) so as to verify that they turn it into an identity. Here you go:
□
Example 1.
Every constant-rebalanced portfolio (cf. with Thomas Cover (1991)) amounts to a bilinear trading strategy that is represented by the outer product , e.g., for all . Here, the constant-rebalanced portfolio c resolves to maintain the constant fraction of wealth in each asset i at all times3, where and .
Example 2.
More generally, consider the trading strategy that always uses the portfolio in period 1 and then always uses the portfolio in period 2 (regardless of the observed value of x), where denotes the unit portfolio simplex in . This scheme is a bilinear trading strategy that corresponds to the outer product , e.g., for all .
Example 3.
Every buy-and-hold strategy (that buys some initial portfolio and holds it for two periods, without rebalancing) amounts to a bilinear trading strategy that is represented by the diagonal matrix .
Inspired by Ordentlich and Cover (1998) and Cover and Thomas (2006), we note that the concept of a bilinear trading strategy admits the following simple and lucid interpretation. Let an extremal strategy4 be defined by the simple trading scheme: in period 1, we put of wealth into asset i, and then in period 2, we take all the proceeds and roll them over into asset j. Hence, there are different extremal strategies ; since the extremal strategy yields a capital growth factor of , it therefore amounts to the bilinear trading strategy , which is an extreme point of . The general bilinear portfolio is uniquely representable as a convex combination
of extremal strategies; this means that the practitioner of B has elected to invest the fraction of his initial dollar into each extremal strategy . Thus, after the elapse of two periods, the investor’s total wealth will be equal to
3. Universal Bilinear Portfolios
We now consider the on-line learning of the asymptotically dominant (or growth-optimal) bilinear portfolio. To this end, we assume that there are T basic investment periods , each of which is divided into a “first half” (during which the gross return vector is ) and a “second half” (during which the gross return vector is .) We let denote the history of returns in the first halves of periods , and, likewise, we let denote the return history for the latter halves of periods . Thus, we have the transition laws and , where and denote empty histories. We let
denote the final wealth function5 of the bilinear trading strategy B against the return history ; similarly, we write
if period t has only been half-completed. We will consider sequential investment strategies that, at the start of each period t, select some bilinear portfolio that is conditioned on the observed return history ; this bilinear portfolio will be used for the entire duration of period t. The capital growth factor achieved by an investment scheme against the history is equal to
and, if period t is only half-finished, we write
Within a given period t, the on-line behavior of amounts to the portfolio vectors and
In order to have a practical benchmark for the on-line performance of after the elapse of t complete investment periods, we will consider the best bilinear trading strategy in hindsight for the individual sequence :
and
The final wealth that accrues to is a path-dependent financial derivative, with payoff
and
Proposition 2.
The final wealth function is a multilinear form in the vectors , e.g., it is linear separately in each vector and also in each vector , for Consequently, the hindsight-optimized final wealth is convex and positively homogeneous separately in each and also in each .
Proof.
The multi-linearity of follows easily from the definition, e.g., is clearly additive and homogeneous in and also in . If we write and view as a function of alone, then the convexity and homogeneity with respect to (or with respect to ) follow from the fact that the mapping is a pointwise maximum of a family of linear functions, namely, . □
For obvious reasons, the hindsight-optimized payoff is not achievable by any causal (or non-anticipating) investment strategy ; however, it is possible to achieve6 any average
where is a continuous density function over . That is, inspired by Thomas Cover (1991) and Cover and Ordentlich (1996), we make the following definition.
Definition 2.
Theuniversal bilinear portfolio(that corresponds to the prior density ) is a performance-weighted average of all bilinear-trading strategies:
So-defined, the matrix is indeed a valid bilinear portfolio, on account of the fact that and . The initial bilinear portfolio is equal to the center of mass that is induced by the prior density .
Proposition 3.
After T complete investment periods, the universal wealth is equal to the average value
Proof.
The gross return of the universal bilinear portfolio in period t is given by
Taking the (telescopic) product of both sides of Equation (22) for , and bearing in mind that , we arrive at the desired result: . □
Following Cover (1991) and Cover and Thomas (2006), the intuition behind the universal bilinear portfolio is just this: we distribute the initial dollar (according to ) among all the bilinear trading strategies , whereby the bilinear portfolios in the neighborhood of a given B receive dollars to manage (from now until kingdom come). After the elapse of t complete investment periods, the bilinear strategies in this locale have grown their bankroll to ; the investor’s aggregate wealth is thereby equal to With this intuition in hand, the formula for can be written down immediately, on account of the fact that the locale of a given B is responsible for managing the fraction of the aggregate wealth.
Hence, the overall bilinear portfolio is just the convex combination . Over long periods of time, the bilinear trading strategies in the neighborhood of will come to control an ever-greater share of the aggregate wealth, on account of their superior exponential growth rate, namely . Thus, the aggregate bankroll will (asymptotically) compound itself at this same rate; that is, we have the relation
regardless7 of the individual return sequence . The remainder of the paper is concerned with fleshing out the necessary details. On that score, we make the definition:
Definition 3.
The competitive ratio measures the percentage of hindsight-optimized bilinear wealth that was actually achieved by the universal bilinear portfolio, e.g.,
Lemma 1.
The competitive ratio is always ; it is homogeneous of degree 0 and quasi-concave separately in each vector and also in each vector .
Proof.
The fact that follows immediately from the fact that any convex combination (or weighted average) of the numbers cannot exceed their maximum. The homogeneity of degree 0 follows from the fact that and are both linearly homogeneous (of degree 1) in each vector or . The multi-quasi-concavity obtains from the fact that, when viewed as a function of alone (or of alone), we are dealing with the ratio of a positive linear function (namely, ) to a positive convex function (viz., ). That is, if we consider the upper contour sets
then we see that is a convex set for all . For, if , then , which is convex; if , then is convex because it is an upper contour set of the concave function . □
On account of the (multi-) homogeneity of degree 0, the competitive ratio only cares about the directions of the vectors or —their lengths do not affect the relative performance of the universal bilinear portfolio. Thus, we are free to scale each (resp. ) by a factor of (resp. ), so that the coordinates of (resp. ) sum to one, e.g., we may assume that each or belongs to the unit simplex . Hence, we have the relation
e.g., the worst-case8 relative performance is achieved over the product of simplices . Even better, since is multi-quasi-concave, its minimum value must in fact be realized at some extreme point , e.g., a return history whereby all are unit basis vectors. This happens on account of the fact that when is viewed as a function solely of (or solely of ), we have
so that the competitive ratio can always be reduced by replacing any or by an appropriate unit basis vector .
In what follows, we will consider sequences of unit basis vectors and , where and . For the sake of simplicity, we will abuse notation by writing the (self-evident) expressions , , and . Sequences of unit basis vectors will hereby be referred to as extremal sequences, or Kelly horse race sequences, on account of the fact that they correspond to betting markets (say, horse races or prediction markets) whereby only one of the m assets has a positive gross return. For a given Kelly sequence , we will require the counts, or relative frequencies
so that and .
Lemma 2.
For any Kelly sequence , the final wealth of the best bilinear trading strategy in hindsight is equal to ; the universal wealth admits the minorant
where is the minimum weight assigned to any bilinear portfolio by the prior density .
Proof.
Against the Kelly sequence , the final wealth of the bilinear trading strategy B is given by
Maximization of this quantity with respect to B amounts to a standard Cobb-Douglas optimization problem over the unit simplex in . Lagrange’s multipliers yield the solution , so that .
The stated minorant for will be gotten by direct integration of over the set of bilinear trading strategies. To this end, we will identify with the solid region
where is not a free variable. Thus, we must evaluate the -fold integral
Using the fact that , and recalling the general identity9
where is the gamma function, we put and obtain
as promised. □
Corollary 1.
The competitive ratio has the following (uniform) bounds, for all :
10 means that The relation ∼ signifies that the two sequences are asymptotically equivalent, e.g., means that .
Hence, the excess continuously-compounded per-period growth rate10 of the best bilinear portfolio in hindsight (namely, ) is sandwiched by
That is, at worst, the excess growth rate is asymptotically equivalent to the quantity .
Proof.
For any Kelly sequence , Lemma 1 implies that
where the right-hand side makes use of the convention that . Now, note that the integer program
is solved by setting any entry of the matrix to T and setting all the other entries to zero, e.g., we have the well-known inequality (cf. with Cover and Ordentlich (1996))
Hence, there lies
□
Theorem 1.
The universal bilinear portfolio asymptotically dominates the original (1-linear) universal portfolio in precisely the same technical sense that the universal 1-linear portfolio asymptotically dominates all constant-rebalanced portfolios and all buy-and-hold strategies.
If it turns out that the best bilinear trading strategy in hindsight sustains a higher asymptotic capital growth rate than the best constant-rebalanced portfolio in hindsight, then the universal bilinear portfolio will asymptotically outperform the universal 1-linear portfolio by an exponential factor.
Proof.
We let
denote the wealth of the universal 1-linear portfolio (cf. with Thomas Cover (1991) and Cover and Ordentlich (1996)) after the elapse of t complete investment periods, where is the unit portfolio simplex in and is a prior density over . The final wealth of the best constant-rebalanced portfolio in hindsight will be denoted
On account of the lower bound
we can minorize the asymptotic excess growth rate (of the universal bilinear portfolio relative to the universal 1-linear portfolio) as follows:
where we have made use of the fact that the relations and hold for all and all .
Thus, we have shown that even the smallest subsequential limit of the excess growth rate is non-negative; if the best bilinear trading strategy in hindsight happens to achieve a higher asymptotic growth rate than the best constant-rebalanced portfolio in hindsight11 (in the sense that the smallest subsequential limit of is strictly positive), then the universal bilinear portfolio will asymptotically outperform the universal 1-linear portfolio by an exponential factor. □
Resolution of the Motivating Example
To close out the paper, this subsection provides exact formulas for the behavior of the universal bilinear portfolio in the context of our original motivating example (as discussed in the introduction) for the case of assets. Accordingly, we will assume that asset 2 is cash (which pays no interest) and that asset 1 is a “hot stock” that always doubles in the first half of each investment period and then loses of its value in the latter half of each investment period. Thus, we have the individual return sequence defined by and . The set of all bilinear trading strategies is now a family of matrices
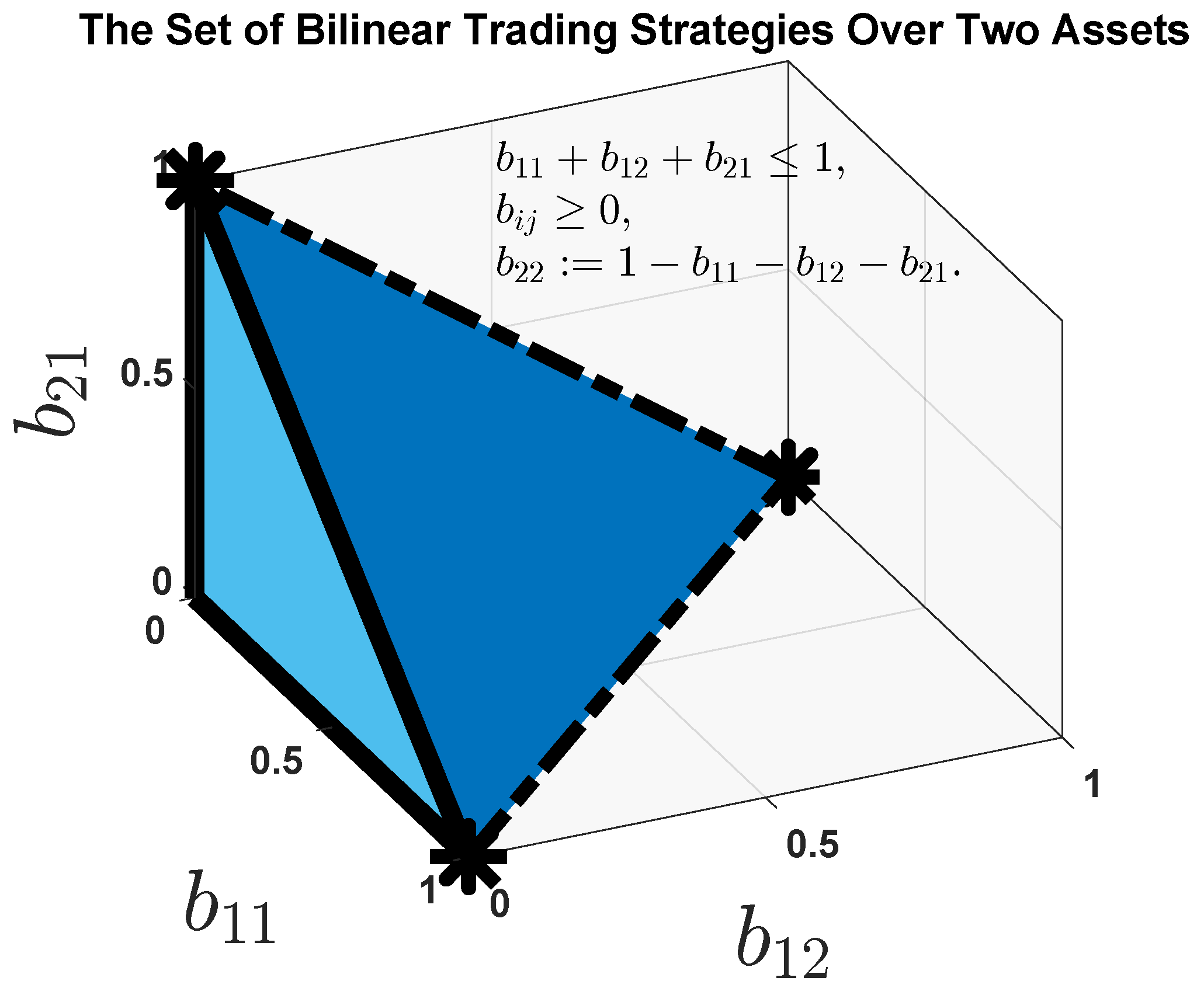
where the variable is bound by the relation . As depicted in Figure 1, this set of matrices amounts to a tetrahedron in .
Analogous to Thomas Cover (1991), we will use the uniform prior density , e.g., the volume of the tetrahedron is given by
During each (complete) investment period, the (intra-period) capital growth factor achieved by the bilinear trading strategy B amounts to
so that . Thus, the universal wealth that obtains after the elapse of t complete investment periods is found by evaluating the triple integral
The best bilinear trading strategy in hindsight is obviously
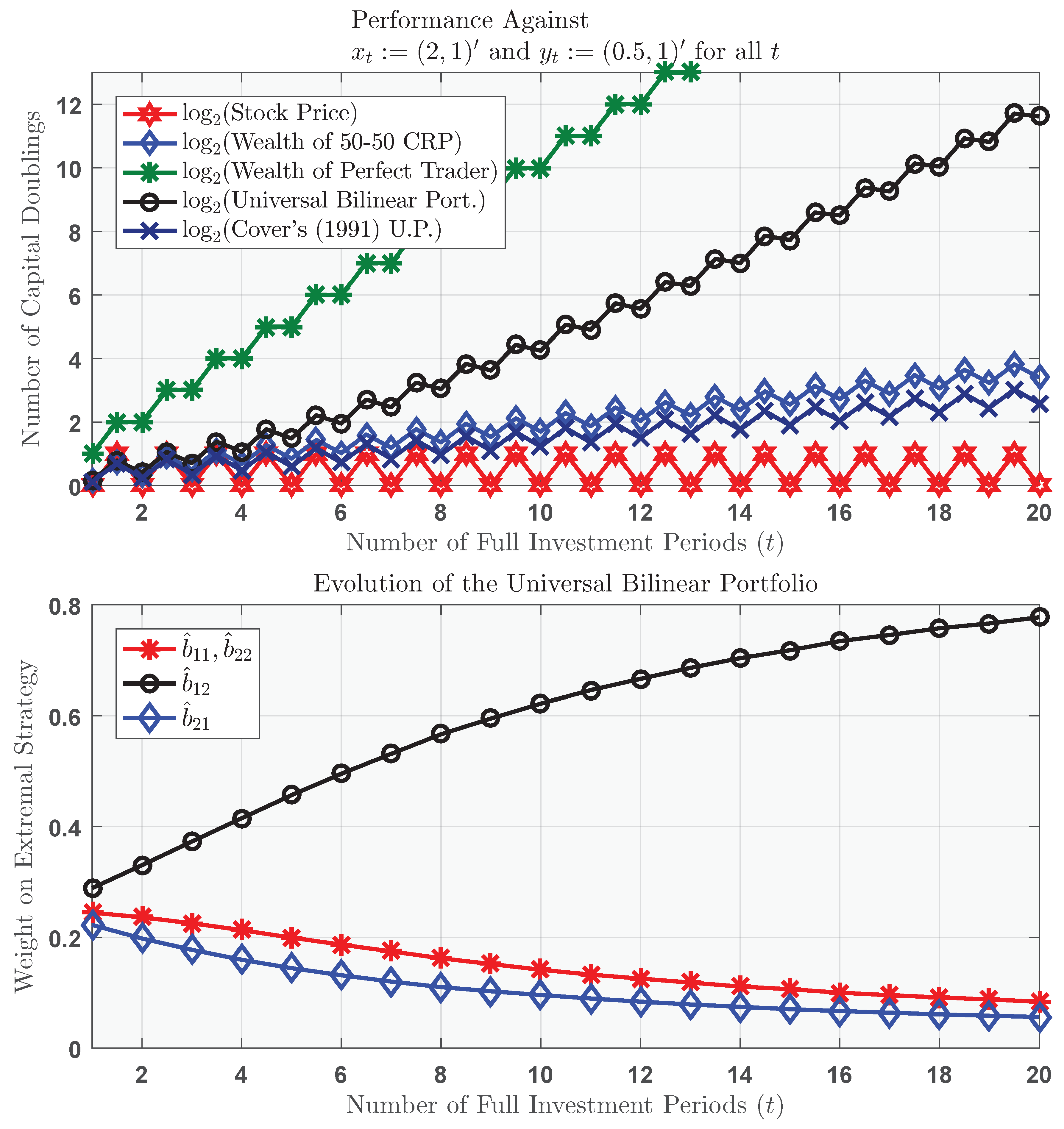
e.g., the extremal strategy that bets the ranch on the stock in the first half of each investment period, and then cashes out completely in the latter half of each investment period. This (perfect trading) yields the hindsight-optimized wealth , which corresponds to the asymptotic growth rate per complete investment period, compounded continuously. The competitive ratio after t full periods is equal to
Note well that Corollary 1 promised us the minorant
which is indeed correct; we of course have , so that the universal bilinear portfolio compounds its money at the same asymptotic rate as the best bilinear trading strategy in hindsight.
Against this individual return sequence, the universal bilinear portfolio finds its expression in the triple integral
With some effort, one can explicitly evaluate the on-line bilinear weights, as follows:
Notice that the and extremal strategies (which both amount to buy-and-hold strategies) are assigned equal weights by the universal bilinear portfolio (in the sense that ); this happens on account of the fact that both assets produce identical results for a buy-and-hold investor over any complete investment period.
Thus, the universal bilinear portfolio learns to trade perfectly in as much as
The same cannot be said for the universal 1-linear portfolio, which achieves the capital growth factor12
After t complete investment periods, the best constant-rebalanced portfolio in hindsight is equal to , which corresponds to the (sub-optimal) bilinear trading strategy The final wealth of the best constant-rebalanced portfolio in hindsight is thereby . Thus, the excess asymptotic growth rate of the universal bilinear portfolio (over and above that of the universal 1-linear portfolio) is per (complete) investment period, compounded continuously.
For the sake of visualization, Figure 2 plots the bankroll of the universal bilinear portfolio in comparison to that of the universal 1-linear portfolio and the wealth achieved by a perfect trader. The lower panel illustrates the parameter learning that obtains from the performance-weighted average of all bilinear trading strategies.
4. Summary and Conclusions
In this note, we constructed a neat application and extension of the brilliantly lucid Ordentlich-Cover theory of “universal portfolios”. The original (1-linear) universal portfolios guarantee to achieve a high percentage of the final wealth that would have accrued to the best constant-rebalanced portfolio in hindsight for the actual (realized) sequence of asset prices.
The constant-rebalanced portfolios constitute a very simple parametric family of active trading strategies, where the “activity” amounts to continuously executing rebalancing trades so as to restore the portfolio to a given target allocation. Inspired by the fact that a constant-rebalanced portfolio is a (horizon-1) trading strategy whose capital growth factor in any given period is a linear function of the market’s gross return vector, we decided to consider the wider class of bilinear trading strategies (or bilinear portfolios), which are mini 2-period active strategies whose capital growth factors are linear separately in the two gross return vectors.
Accordingly, we hit upon the more powerful benchmark of the best bilinear trading strategy in hindsight for the actual sequence of asset prices. This led us to apply Cover’s ingenious (Cover 1991) performance-weighted averaging technique to this new situation, e.g., the universal bilinear portfolio is a performance-weighted average of all possible bilinear trading strategies.
Applying Cover and Ordentlich’s elegant (Cover and Ordentlich 1996) methodology, we showed that for any financial market with m assets13, at worst, the percentage of hindsight-optimized wealth achieved by the universal bilinear portfolio will tend to zero like the quantity as , where T denotes the number of complete (bipartite) investment periods. Consequently, the universal bilinear portfolio succeeds in matching the performance of the best bilinear trading strategy in hindsight to “first order in the exponent,” e.g., the excess continuously-compounded per-period capital growth rate of the best bilinear trading strategy in hindsight converges (uniformly) to zero, regardless of the individual sequence of asset prices.
Thus, we showed that the universal bilinear portfolio asymptotically dominates the universal 1-linear portfolio in the same technical sense that the universal 1-linear portfolio asymptotically dominates all constant-rebalanced portfolios and all buy-and-hold strategies. The universal bilinear portfolio will beat the universal 1-linear portfolio by an exponential factor, provided that the individual sequence of asset prices enjoys the property that the best bilinear trading strategy in hindsight achieves an asymptotic growth rate that is strictly greater than that of the best constant-rebalanced portfolio in hindsight.
Analogously, we can get carried away and define the concept of a trilinear trading strategy , whose (horizon-3) capital growth factor in any (tripartite) period t is equal to the trilinear form
where and . This leads to a universal trilinear portfolio whose worst-case competitive ratio behaves like as . In general, an H-linear trading strategy (cf. with Garivaltis (2018b)) divides each period t into H sub-periods, wherein the gross return vectors are denoted . Intra-period capital growth is now generated by the H-linear form (cf. with Serge Lang (1987))
where and ; the attendant universal H-linear portfolio asymptotically achieves, at worst, the fraction of the final wealth of the best H-linear trading strategy in hindsight.
Hence, one can use this method to construct an endless hierarchy of ever more dominant universal portfolios. If the horizon is an integer multiple of the horizon , say , then the act of repeating a given -linear portfolio B for q times in succession constitutes a special type of -linear portfolio; the universal -linear portfolio thereby asymptotically outperforms the universal -linear portfolio “to first order in the exponent,” á la Cover.
Disclosures
This paper is solely the work of the author, who declares that he has no conflicts of interest; the work was funded entirely through his regular academic appointment at Northern Illinois University.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The author declares that he has no conflicts of interest.
References
- Bell, R. M., and T. M. Cover. 1980. Competitive Optimality of Logarithmic Investment. Mathematics of Operations Research 5: 161–66. [Google Scholar] [CrossRef]
- Bell, R. M., and T. M. Cover. 1988. Game-Theoretic Optimal Portfolios. Management Science 34: 724–33. [Google Scholar] [CrossRef] [Green Version]
- Black, Fischer, and Myron Scholes. 1973. The pricing of options and corporate liabilities. Journal of Political Economy 81: 637–54. [Google Scholar] [CrossRef] [Green Version]
- Breiman, Leo. 1961. Optimal Gambling Systems for Favorable Games. Paper presented at the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, June 20–July 30; vol. 1, pp. 63–68. [Google Scholar]
- Cover, Thomas M. 1991. Universal Portfolios. Mathematical Finance 1: 1–29. [Google Scholar] [CrossRef]
- Cover, Thomas M., and David H. Gluss. 1986. Empirical Bayes Stock Market Portfolios. Advances in Applied Mathematics 7: 170–81. [Google Scholar] [CrossRef] [Green Version]
- Cover, Thomas M., and Erik Ordentlich. 1996. Universal Portfolios With Side Information. IEEE Transactions on Information Theory 42: 348–63. [Google Scholar] [CrossRef] [Green Version]
- Cover, Thomas M., and Joy A. Thomas. 2006. Elements of Information Theory. Hoboken: John Wiley & Sons. [Google Scholar]
- Curatola, Giuliano. 2019. Portfolio Choice of Large Investors Who Interact Strategically. Working Paper. Siena: University of Siena. [Google Scholar]
- Garivaltis, Alex. 2018a. Game-Theoretic Optimal Portfolios in Continuous Time. Economic Theory Bulletin 7: 235–43. [Google Scholar] [CrossRef] [Green Version]
- Garivaltis, Alex. 2018b. Multilinear Superhedging of Lookback Options. Working Paper. DeKalb: Northern Illinois University. [Google Scholar]
- Garivaltis, Alex. 2019a. Game-Theoretic Optimal Portfolios for Jump Diffusions. Games 10: 8. [Google Scholar] [CrossRef] [Green Version]
- Garivaltis, Alex. 2019b. Exact Replication of the Best Rebalancing Rule in Hindsight. The Journal of Derivatives 26: 35–53. [Google Scholar] [CrossRef]
- Kelly, John L. 1956. A New Interpretation of Information Rate. The Bell System Technical Journal 35: 917–26. [Google Scholar] [CrossRef]
- Lang, Serge. 1987. Linear Algebra. New York: Springer. [Google Scholar]
- Latané, Henry Allen. 1959. Criteria for Choice Among Risky Ventures. Journal of Political Economy 67: 144–55. [Google Scholar] [CrossRef]
- MacLean, Leonard C., Edward O. Thorp, and William T. Ziemba. 2011. The Kelly Capital Growth Investment Criterion: Theory and Practice. Hackensack: World Scientific Publishing Company. [Google Scholar]
- Ordentlich, Erik, and Thomas M. Cover. 1998. The Cost of Achieving the Best Portfolio in Hindsight. Mathematics of Operations Research 23: 960–82. [Google Scholar] [CrossRef] [Green Version]
- Samuelson, Paul A. 1963. Risk and Uncertainty: A Fallacy of Large Numbers. Scientia 6: 153–58. [Google Scholar]
- Samuelson, Paul A. 1969. Lifetime Portfolio Selection by Dynamic Stochastic Programming. Review of Economics and Statistics 51: 239–46. [Google Scholar] [CrossRef]
- Samuelson, Paul A. 1979. Why We Should not Make Mean Log of Wealth Big Though Years to Act are Long. Journal of Banking and Finance 2: 305–7. [Google Scholar] [CrossRef]
- Tal, O., and T. D. Tran. 2020. Adaptive Bet-Hedging Revisited: Considerations of Risk and Time Horizon. Bulletin of Mathematical Biology 82: 1–32. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thorp, Edward O. 1969. Optimal Gambling Systems for Favorable Games. Revue de l’Institut International de Statistique 37: 273–93. [Google Scholar] [CrossRef]
- Widder, David Vernon. 1989. Advanced Calculus. New York: Dover Publications. [Google Scholar]
| 1. | e.g., if then asset i appreciated in period 1; if , then asset i lost of its value in period 1, etc. |
| 2. | Bilinearity (cf. with Serge Lang (1987)) refers to the fact that the capital growth factor is linear separately in each of the vectors x and y. When viewed jointly as a function of , the bilinear form is a homogeneous quadratic polynomial in the variables . |
| 3. | On account of allocation drift, e.g., the fact that some constituent assets will outperform the portfolio each period (and some assets will underperform), a CRP must generally trade each period so as to restore the target allocation . |
| 4. | Literally, an extreme point of . |
| 5. | The initial monetary deposit into B is equal to the empty product . |
| 6. | By the way, if a discrete-time payoff can be exactly replicated (or hedged) by some causal (non-anticipating) trading strategy, then that strategy is necessarily be unique. We have encountered this phenomenon already vis-á-vis the bilinear payoff . |
| 7. | Not just almost everywhere; but everywhere, for all possible . |
| 8. | Come what may—for all possible market behavior . |
| 9. | This identity follows by direct evaluation of the iterated integral (33). In order to accomplish this, one must repeatedly invoke the special case , e.g., which is the beta function, or Euler integral of the first kind (cf. with David Widder (1989)). |
| 10. | That is, per complete investment period (both halves). |
| 11. | The practitioner of the universal bilinear portfolio must hope against hope that the individual return sequence has this pleasant feature. |
| 12. | Here, we have used the uniform prior density over the unit interval . |
| 13. | One of which can be cash, or a risk-free bond. |
Figure 1.
Geometric depiction of the set of all possible bilinear trading strategies over two assets. The defining relations are The volume of this tetrahedron is .
Figure 1.
Geometric depiction of the set of all possible bilinear trading strategies over two assets. The defining relations are The volume of this tetrahedron is .

Figure 2.
Superior performance of the universal bilinear portfolio against the individual return sequence and . Asset 2 is cash (that pays no interest); asset 1 is a “hot stock” that doubles in the first half of each investment period and loses of its value in the latter half of each investment period. Note that in the bottom plot, we have and .
Figure 2.
Superior performance of the universal bilinear portfolio against the individual return sequence and . Asset 2 is cash (that pays no interest); asset 1 is a “hot stock” that doubles in the first half of each investment period and loses of its value in the latter half of each investment period. Note that in the bottom plot, we have and .

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Garivaltis, A. A Note on Universal Bilinear Portfolios. Int. J. Financial Stud. 2021, 9, 11. https://0-doi-org.brum.beds.ac.uk/10.3390/ijfs9010011
AMA Style
Garivaltis A. A Note on Universal Bilinear Portfolios. International Journal of Financial Studies. 2021; 9(1):11. https://0-doi-org.brum.beds.ac.uk/10.3390/ijfs9010011
Chicago/Turabian StyleGarivaltis, Alex. 2021. "A Note on Universal Bilinear Portfolios" International Journal of Financial Studies 9, no. 1: 11. https://0-doi-org.brum.beds.ac.uk/10.3390/ijfs9010011
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.