Crowdsourcing without Data Bias: Building a Quality Assurance System for Air Pollution Symptom Mapping

 , , , , and
, , , , and 
Abstract
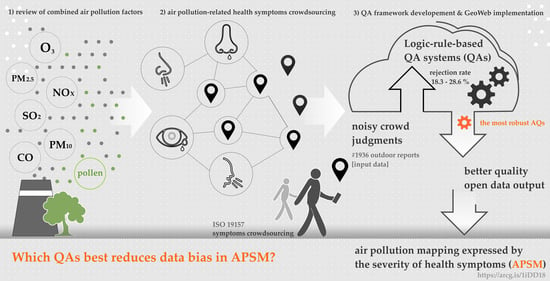
:
1. Introduction
1.1. Extending the Paradigm of Urban Air Pollution
1.2. Contribution of Citizen Science to Improvements in Air Pollution Mapping
1.3. Importance of Data Quality in Crowdsourced Air Pollution
2. Materials and Methods
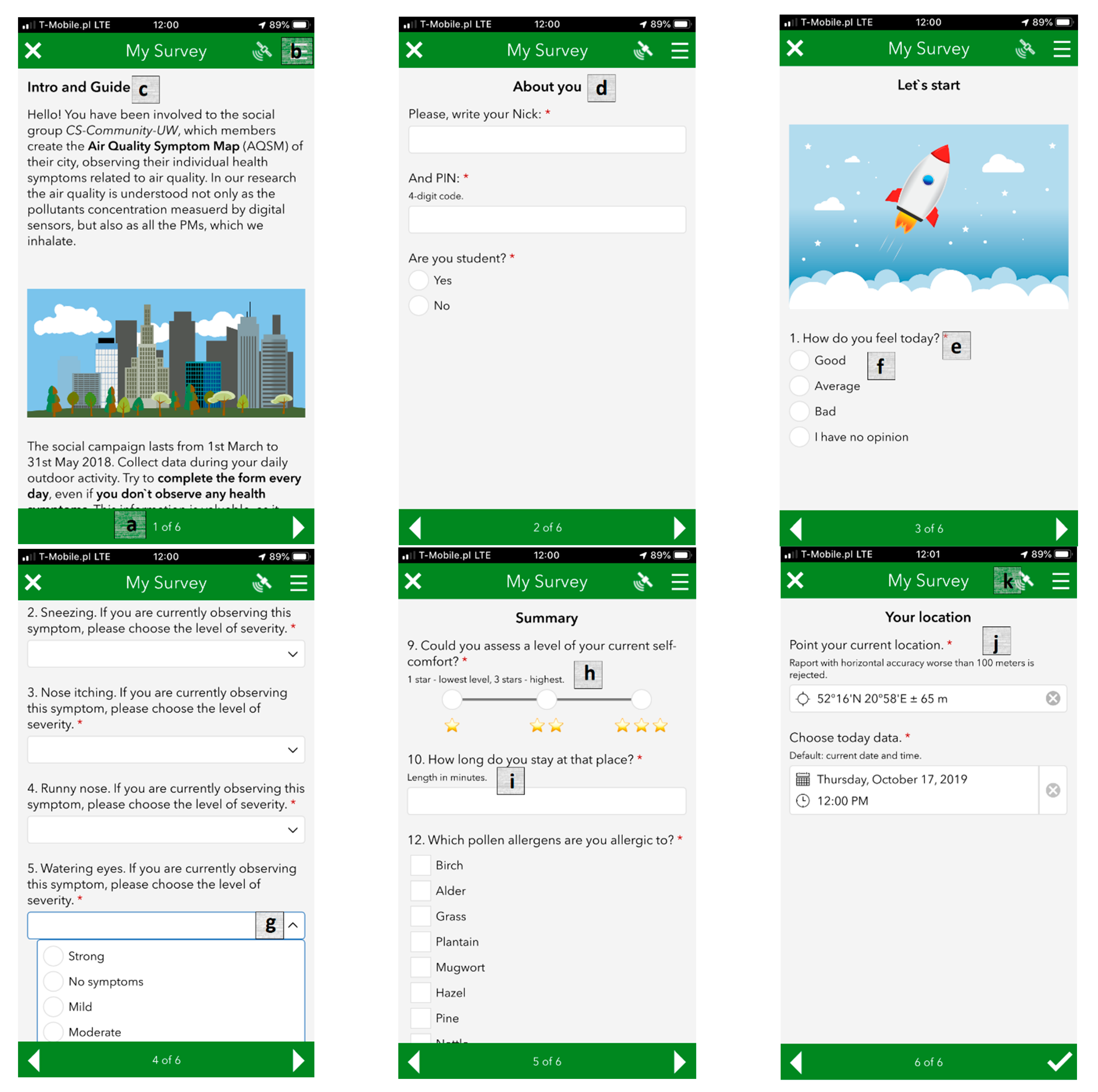
2.1. Building a Field Data Collection Strategy
2.2. Data Quality Assurance Methods for APSM
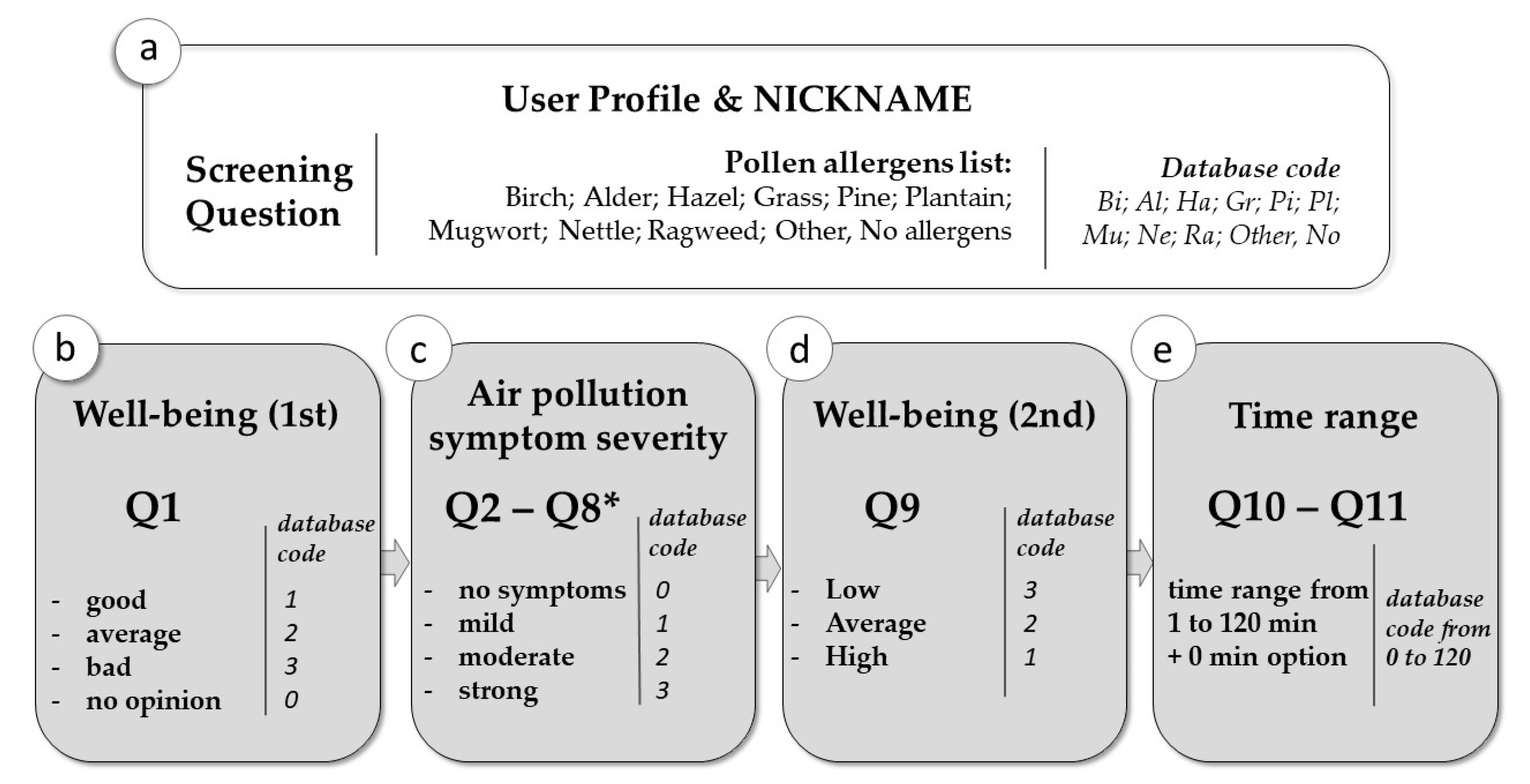
- Q1.
- How do you feel today?
- Q2.
- Sneezing. If you are currently experiencing this symptom, please choose the level of severity.
- Q3.
- Nose itching. If you are currently experiencing this symptom, please choose the level of severity.
- Q4.
- Runny nose. If you are currently experiencing this symptom, please choose the level of severity.
- Q5.
- Watering eyes. If you are currently experiencing this symptom, please choose the level of severity.
- Q6.
- Scratchy throat. If you are currently experiencing this symptom, please choose the level of severity.
- Q7.
- Breathing problems. If you are currently experiencing this symptom, please choose the level of severity.
- Q8.
- Do you rub your eyes?
- Q9.
- Could you assess the level of your current self-comfort?
- Q10.
- How long have you been in this location?
- Q11.
- For how long have you felt your symptoms?
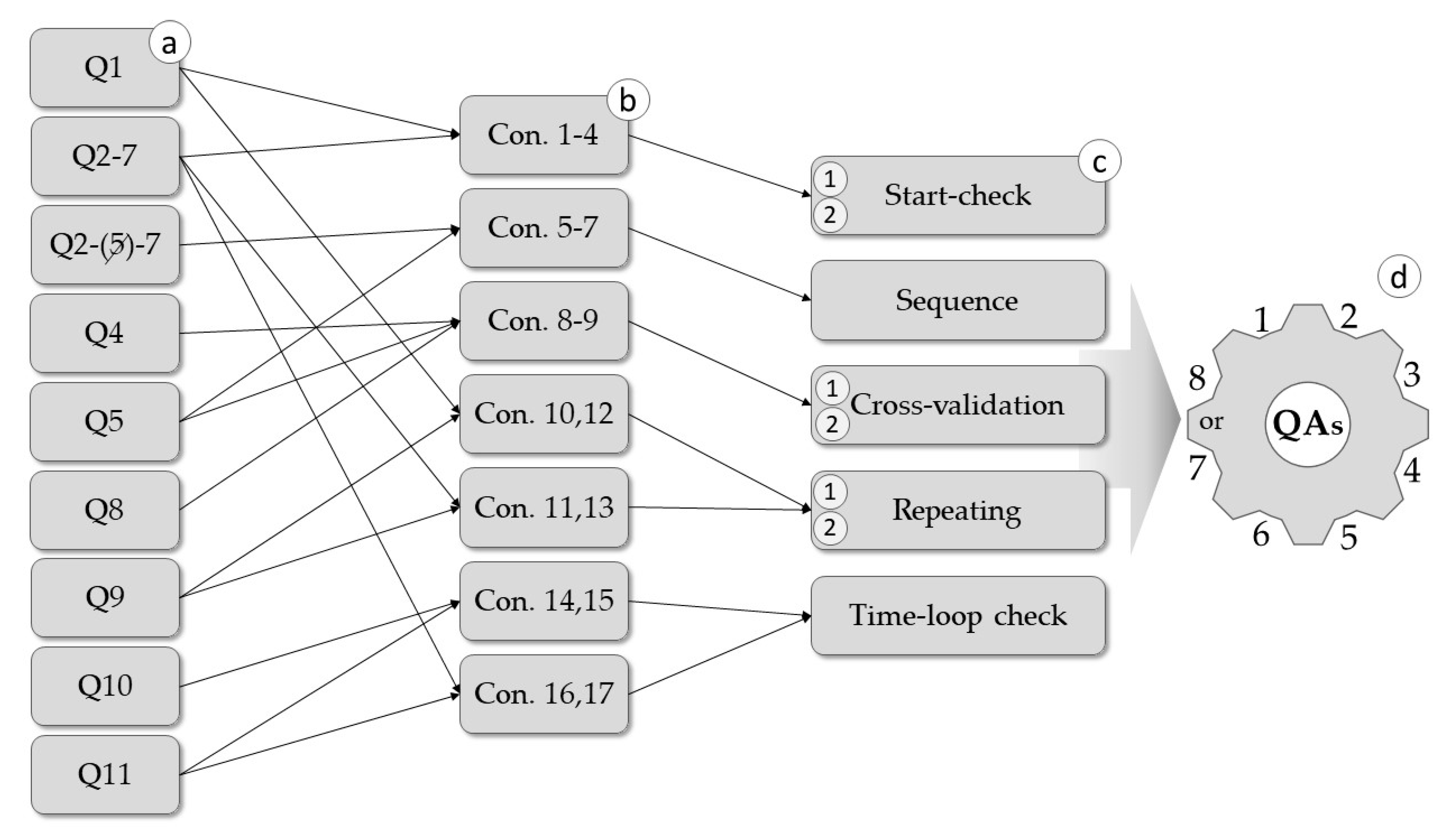
2.2.1. QA Methods Applied during the Data Collection Process
2.2.2. Logic-Based QA Mechanisms Implemented after the Data Collection Process
2.3. GeoWeb Method Supporting Data Quality Assurance
3. Results
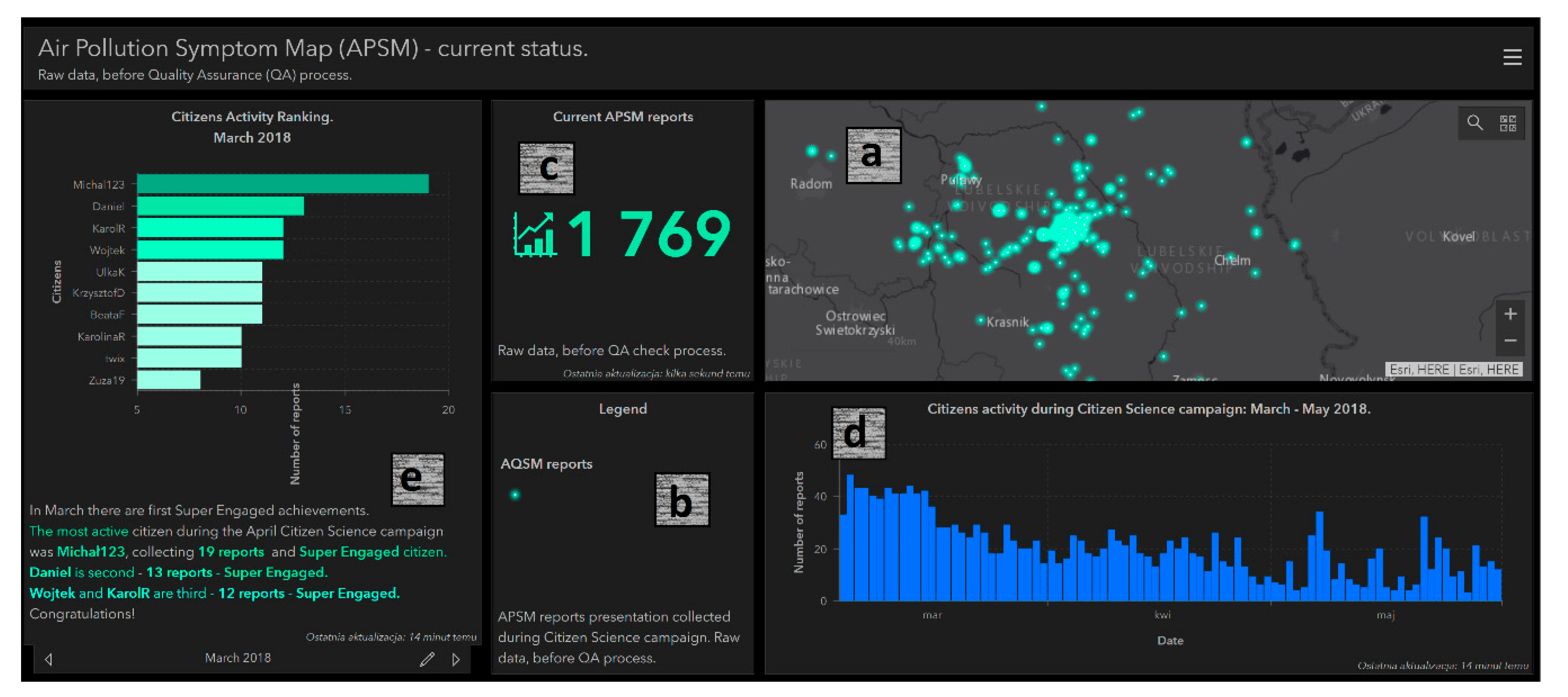
3.1. Data Collection Campaign Outcomes
3.2. Robustness of QA Mechanisms
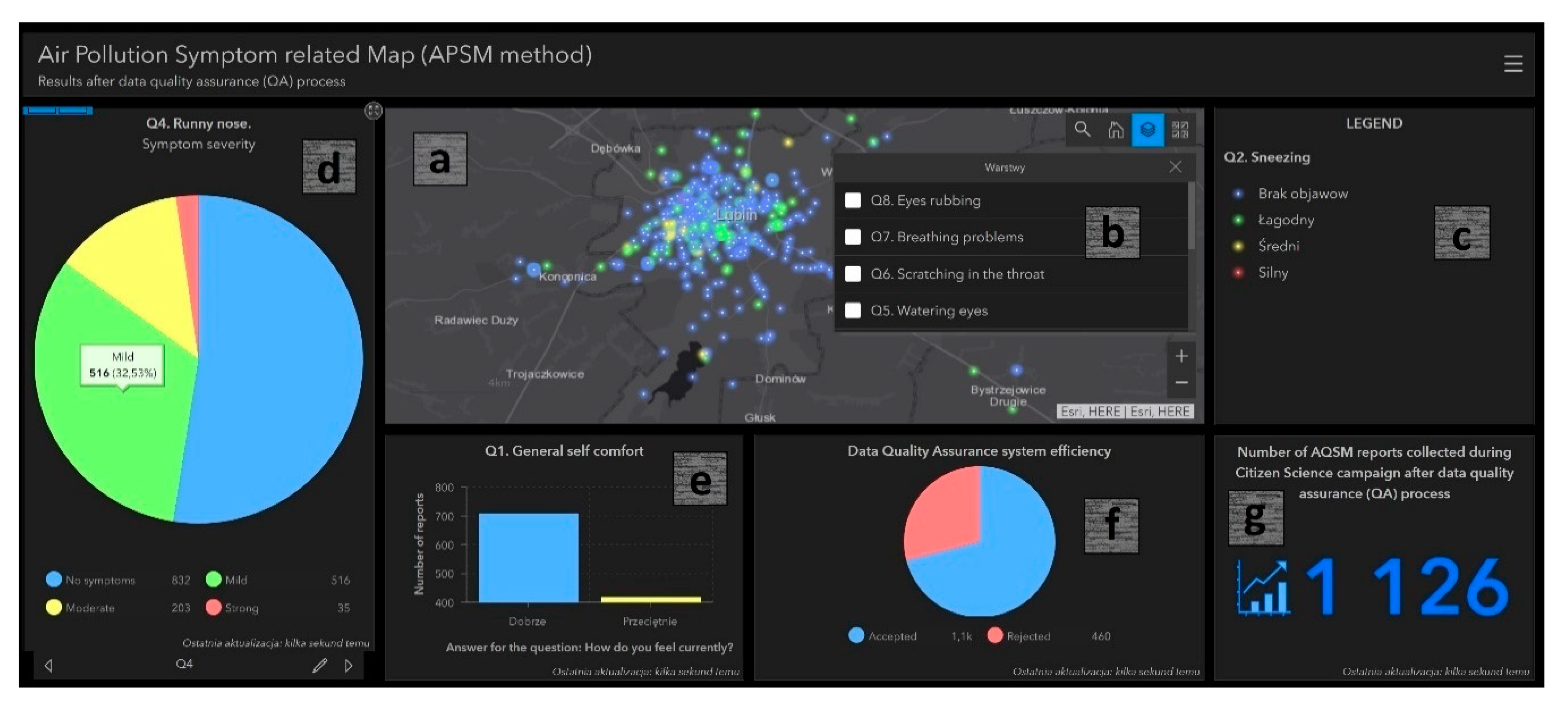
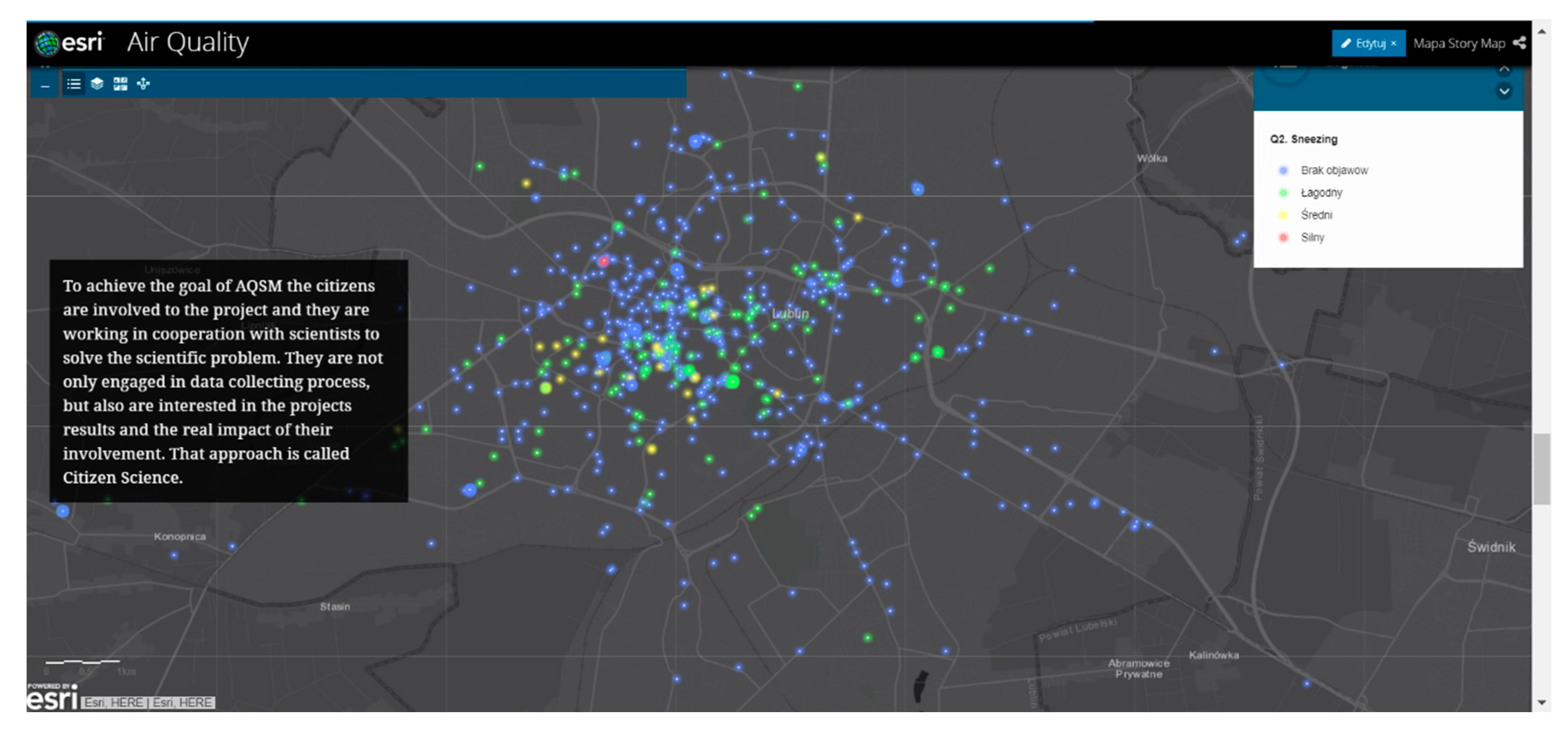
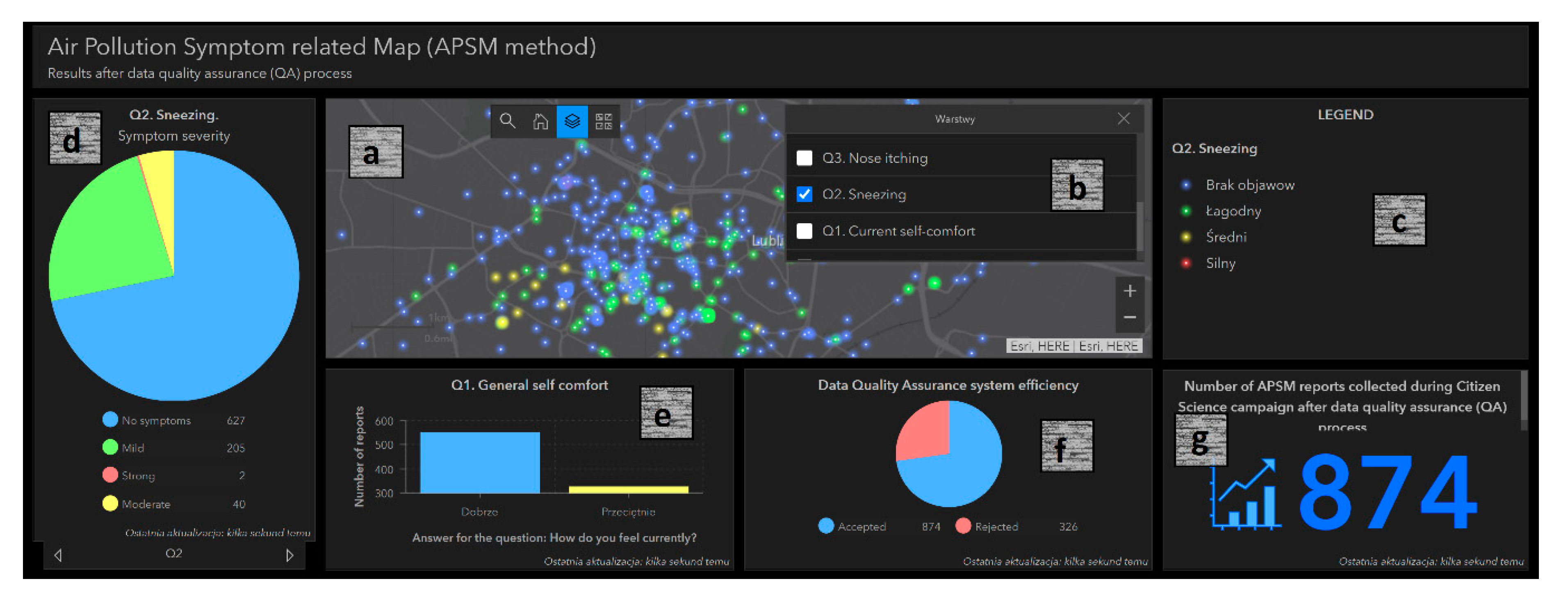
3.3. APSM Results after QA System Implementation
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Acronym | Defined in Section | Meaning (Section) |
| CS | citizen science | Citizen-driven research that citizens (non-experts) participate in by cooperating with researchers (Introduction, Section 1.2). |
| QAm | quality assurance mechanism | Conditional-statement-based mechanism for data bias controlling. Five data quality assurance mechanisms are proposed in this study (Introduction, Section 1.3; Section Materials and Methods, Section 2.2). |
| QAs | quality assurance system | Combinations of data quality assurance mechanisms. In the study, we studied and analyzed eight QAs variants, depending on their robustness levels, QAs1–QAs8 (Materials and Methods, Section 2.2). |
| GeoWeb | geospatial web | Geographically related tools and web services for individuals and groups (Abstract, Introduction, Materials and Methods Section 2.3). |
| SC (SC1, SC2) | start-check mechanism in variant 1 and variant 2 | The start-check mechanism is used to verify the report quality at the beginning of the survey and controls the report quality during the analysis of each symptom severity answer.The mechanism studied and proposed in two variants of robustness (variant 1: less robust; variant 2: more robust) (Materials and Methods, Section 2.2). |
| Rp (Rp1, Rp2) | repeating mechanism in variant 1 and variant 2 | The repeating mechanism determines the quality of the report, according to other previously asked questions, by asking the same question but in a different way.The mechanism studied and proposed in two variants of robustness (variant 1: less robust; variant 2: more robust) (Materials and Methods, Section 2.2). |
| Sq | sequence mechanism | The sequence mechanism was applied to exclude user automatism in providing answers (Materials and Methods, Section 2.2). |
| CV (CV1, CV2) | cross-validation mechanism in variant 1 and variant 2 | The cross-validation mechanism was used to reject responses using three essentially related questions.The mechanism studied and proposed in two variants of robustness (variant 1: less robust; variant 2: more robust) (Materials and Methods, Section 2.2). |
| TC | time-loop check mechanism | The time-loop check mechanism was used to eliminate reports that did not align with the geolocation of the citizens, according to the length of their stay in the place, in comparison to the duration of their symptoms (Materials and Methods, Section 2.2). |
| SWB | subjective well-being | Reflects the philosophical notion of people’s good life, a proxy of their life satisfaction, momentary experiences, and stress (Introduction). |
| sCS | human-sensed CS | Citizen science measurement relying on one of the human senses (Introduction). |
| APSM | air pollution symptom mapping | Air pollution monitoring, expressed on the map as the severity of human health symptoms caused by combined factors of anthropogenic and biophysical ambient air pollutants (Introduction). |
| APS | air pollution symptoms | Human health symptoms related to air pollution, caused by combined factors of anthropogenic and biophysical ambient air pollutants (Introduction). |
| AP | air pollution | Air pollution refers to six major air pollutants: inhalable particulate matter (PM10), fine particulate matter (PM2.5), ozone (O3), sulfur dioxide (SO2), nitrogen dioxide (NO2), and carbon monoxide (CO) (Introduction). |
| AQ | air quality | Air quality refers to the AQI as well as to classifications, opinions, and feelings (including citizens’ experiences) of air- and air-quality-related SWB. However, a consensus about urban air quality terminology has not been reached, and researchers distinguish air pollution through pollen exposure [49] (Introduction). |
| AQI | air quality index | The AQI tracks six major air pollutants—inhalable particulate matter (PM10), fine particulate matter (PM2.5), ozone (O3), sulfur dioxide (SO2), nitrogen dioxide (NO2), and carbon monoxide (CO)—to describe the air quality with the use of an objective scale (Introduction). |
| AGOL | ArcGIS Online | WebGIS platform by Esri Inc. (Materials and Methods). |
| Q1–Q12 | question 1–question 12 | The 12 questions about air-pollution-related symptoms and factors related to APS, but also additional information about subjective well-being, asked to citizens in the mobile survey (Materials and Methods, Section 2.2). |
| Con.1–Con.17 | conditional statement 1–conditional statement 17 | The 17 conditional statements that, in specific combinations, are the basis of the developed data quality assurance mechanisms (QAm) (Materials and Methods, Section 2.2). |
| Survey123, cascade, time slider | Survey123 for ArcGIS mobile app, Esri Story Map Cascade app template, Esri Time Aware app template | Configurable mobile apps and web app templates based on ArcGIS. |
| PM | particulate matter | A mixture of particle pollution, both solid and liquid droplets found in the ambient air. PM is characterized by particle size and chemical composition. A PM fraction of 2.5 µm or less (PM2.5) is especially important for evaluating health as well as environmental risks (Introduction). |
Appendix A. APSM-Dedicated GeoWeb Tools Supporting Quality Assurance
Appendix A.1. Mobile App for Crowdsourcing

Appendix A.2. APSM: Result Sharing through Web Apps






References
- Laffan, K. Every breath you take, every move you make: Visits to the outdoors and physical activity help to explain the relationship between air pollution and subjective wellbeing. Ecol. Econ. 2018, 147, 96–113. [Google Scholar] [CrossRef]
- Kim-Prieto, C.; Diener, E.; Tamir, M.; Scollon, C.; Diener, M. Integrating the Diverse Definitions of Happiness: A Time-Sequential Framework of Subjective Well-Being. J. Happiness Stud. 2005, 6, 261–300. [Google Scholar] [CrossRef]
- Ferreira, S.; Akay, A.; Brereton, F.; Cuñado, J.; Martinsson, P.; Moro, M.; Ningal, T.F. Life satisfaction and air quality in Europe. Ecol. Econ. 2013, 88, 1–10. [Google Scholar] [CrossRef]
- Signoretta, P.E.; Buffel, V.; Bracke, P. Mental wellbeing, air pollution and the ecological state. Health Place 2019, 57, 82–91. [Google Scholar] [CrossRef]
- Yigitcanlar, T.; Kamruzzaman, M.; Foth, M.; Sabatini-Marques, J.; da Costa, E.; Ioppolo, G. Can cities become smart without being sustainable? A systematic review of the literature. Sustain. Cities Soc. 2019, 45, 348–365. [Google Scholar] [CrossRef]
- Giffinger, R.; Fertner, C.; Kramar, H.; Meijers, E. City-Ranking of European Medium-Sized Cities; Centre of Regional Science: Vienna, Austria, 2007; p. 28. [Google Scholar]
- Arias, R.; Capelli, L.; Díaz, C. A new methodology based on citizen science to improve environmental odour management. Chem. Eng. Trans. 2018, 68, 7–12. [Google Scholar] [CrossRef]
- Bastl, K.; Kmenta, M.; Geller-Bernstein, C.; Berger, U.; Jäger, S. Can we improve pollen season definitions by using the symptom load index in addition to pollen counts? Environ. Pollut. 2015, 204, 109–116. [Google Scholar] [CrossRef]
- Dutta, J.; Chowdhury, C.; Roy, S.; Middya, A.I.; Gazi, F. Towards Smart City. In Proceedings of the 18th International Conference on Distributed Computing and Networking—ICDCN’17, Hyderabad, India, 4–7 January 2017; ACM Press: New York, NY, USA, 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Feng, C.; Tian, Y.; Gong, X.; Que, X.; Wang, W. MCS-RF: Mobile crowdsensing–based air quality estimation with random forest. Int. J. Distrib. Sens. Netw. 2018, 14. [Google Scholar] [CrossRef] [Green Version]
- Zupančič, E.; Žalik, B. Data Trustworthiness Evaluation in Mobile Crowdsensing Systems with Users’ Trust Dispositions’ Consideration. Sensors 2019, 19, 1326. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Castell, N.; Kobernus, M.; Liu, H.-Y.; Schneider, P.; Lahoz, W.; Berre, A.J.; Noll, J. Mobile technologies and services for environmental monitoring: The Citi-Sense-MOB approach. Urban Clim. 2015, 14, 370–382. [Google Scholar] [CrossRef]
- Komarkova, J.; Novak, M.; Bilkova, R.; Visek, O.; Valenta, Z. Usability of GeoWeb Sites: Case Study of Czech Regional Authorities Web Sites. In Business Information Systems; Springer: Berlin/Heidelberg, Germany, 2007; pp. 411–423. ISBN 9783540720348. [Google Scholar] [CrossRef]
- Haklay, M. Citizen Science and Volunteered Geographic Information: Overview and Typology of Participation. In Crowdsourcing Geographic Knowledge; Sui, D., Elwood, S., Goodchild, M., Eds.; Springer: Dordrecht, The Netherlands, 2013; pp. 105–122. ISBN 9789400745872. [Google Scholar] [CrossRef]
- Jankowski, P.; Czepkiewicz, M.; Zwoliński, Z.; Kaczmarek, T.; Młodkowski, M.; Bąkowska-Waldmann, E.; Mikuła, Ł.; Brudka, C.; Walczak, D. Geoweb Methods for Public Participation in Urban Planning: Selected Cases from Poland. In Geospatial Challenges in the 21st Century; Koutsopoulos, K., de Miguel González, R., Donert, K., Eds.; Springer Nature: Cham, Switzerland, 2019; pp. 249–269. [Google Scholar] [CrossRef]
- Goodchild, M.F. Citizens as Voluntary Sensors: Spatial Data Infrastructure in the World of Web 2.0. Int. J. Spatial Data Infrastruct. Res. 2007, 2, 24–32. [Google Scholar]
- Moreri, K.K.; Fairbairn, D.; James, P. Volunteered geographic information quality assessment using trust and reputation modelling in land administration systems in developing countries. Int. J. Geogr. Inf. Sci. 2018, 32, 931–959. [Google Scholar] [CrossRef] [Green Version]
- Capineri, C.; Haklay, M.; Huang, H.; Antoniou, V.; Kettunen, J.; Ostermann, F.; Purves, R. (Eds.) European Handbook of Crowdsourced Geographic Information; Ubiquity Press: London, UK, 2016; p. 474. ISBN 9781909188792. [Google Scholar]
- Kamp, J.; Oppel, S.; Heldbjerg, H.; Nyegaard, T.; Donald, P.F. Unstructured citizen science data fail to detect long-term population declines of common birds in Denmark. Divers. Distrib. 2016, 22, 1024–1035. [Google Scholar] [CrossRef]
- Kosmala, M.; Wiggins, A.; Swanson, A.; Simmons, B. Assessing data quality in citizen science. Front. Ecol. Environ. 2016, 14, 551–560. [Google Scholar] [CrossRef] [Green Version]
- Wiggins, A.; Newman, G.; Stevenson, R.D.; Crowston, K. Mechanisms for Data Quality and Validation in Citizen Science. In Proceedings of the 2011 IEEE Seventh International Conference on e-Science Workshops, Stockholm, Sweden, 5–8 December 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 14–19. [Google Scholar] [CrossRef]
- Bishr, M.; Mantelas, L. A trust and reputation model for filtering and classifying knowledge about urban growth. GeoJournal 2008, 72, 229–237. [Google Scholar] [CrossRef]
- Grewling, Ł.; Frątczak, A.; Kostecki, Ł.; Nowak, M.; Szymańska, A.; Bogawski, P. Biological and Chemical Air Pollutants in an Urban Area of Central Europe: Co-exposure Assessment. Aerosol Air Qual. Res. 2019, 19, 1526–1537. [Google Scholar] [CrossRef] [Green Version]
- Sheng, N.; Tang, U.W. The first official city ranking by air quality in China—A review and analysis. Cities 2016, 51, 139–149. [Google Scholar] [CrossRef]
- WHO. Air Quality Guidelines—Particulate Matter, Ozone, Nitrogen Dioxide and Sulphur Dioxide; WHO Europe Publication: Geneva, Switzerland, 2005; pp. 67–105. [Google Scholar]
- Enemark, S.; Rajabifard, A. Spatially Enabled Society. Geoforum Perspekt. 2011, 10, 1–8. [Google Scholar] [CrossRef]
- Ionita, A.; Visan, M.; Niculescu, C.; Popa, A. Smart Collaborative Platform for eLearning with Application in Spatial Enabled Society. Procedia Soc. Behav. Sci. 2015, 191, 2097–2107. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Li, Q.; Yu, D.; Gu, Y. Air Quality Index and Air Pollutant Concentration Prediction Based on Machine Learning Algorithms. Appl. Sci. 2019, 9, 4069. [Google Scholar] [CrossRef] [Green Version]
- Liang, J. Chemical Modeling for Air Resources; Academic Press, Elsevier: Oxford, UK, 2013; p. 298. ISBN 9780124081352. [Google Scholar] [CrossRef]
- Kelly, F.J.; Fussell, J.C. Air pollution and public health: Emerging hazards and improved understanding of risk. Environ. Geochem. Health 2015, 37, 631–649. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zwozdziak, A.; Sówka, I.; Willak-Janc, E.; Zwozdziak, J.; Kwiecińska, K.; Balińska-Miśkiewicz, W. Influence of PM1 and PM2.5 on lung function parameters in healthy schoolchildren—A panel study. Environ. Sci. Pollut. Res. 2016, 23, 23892–23901. [Google Scholar] [CrossRef] [PubMed]
- Bastl, K.; Berger, M.; Bergmann, K.-C.; Kmenta, M.; Berger, U. The medical and scientific responsibility of pollen information services. Wien. Klin. Wochenschr. 2017, 129, 70–74. [Google Scholar] [CrossRef] [PubMed]
- Joseph, E.P.; Jackson, V.B.; Beckles, D.M.; Cox, L.; Edwards, S. A citizen science approach for monitoring volcanic emissions and promoting volcanic hazard awareness at Sulphur Springs, Saint Lucia in the Lesser Antilles arc. J. Volcanol. Geotherm. Res. 2019, 369, 50–63. [Google Scholar] [CrossRef]
- Baldacci, S.; Maio, S.; Cerrai, S.; Sarno, G.; Baïz, N.; Simoni, M.; Annesi-Maesano, I.; Viegi, G. Allergy and asthma: Effects of the exposure to particulate matter and biological allergens. Respir. Med. 2015, 109, 1089–1104. [Google Scholar] [CrossRef] [Green Version]
- Di Menno di Bucchianico, A.; Brighetti, M.A.; Cattani, G.; Costa, C.; Cusano, M.; De Gironimo, V.; Froio, F.; Gaddi, R.; Pelosi, S.; Sfika, I.; et al. Combined effects of air pollution and allergens in the city of Rome. Urban For. Urban Green. 2019, 37, 13–23. [Google Scholar] [CrossRef]
- McInnes, R.N.; Hemming, D.; Burgess, P.; Lyndsay, D.; Osborne, N.J.; Skjøth, C.A.; Thomas, S.; Vardoulakis, S. Mapping allergenic pollen vegetation in UK to study environmental exposure and human health. Sci. Total Environ. 2017, 599–600, 483–499. [Google Scholar] [CrossRef] [Green Version]
- Robichaud, A.; Comtois, P. Environmental factors and asthma hospitalization in Montreal, Canada, during spring 2006–2008: A synergy perspective. Air Qual. Atmos. Health 2019, 12, 1495–1509. [Google Scholar] [CrossRef] [Green Version]
- Werchan, B.; Werchan, M.; Mücke, H.-G.; Gauger, U.; Simoleit, A.; Zuberbier, T.; Bergmann, K.-C. Spatial distribution of allergenic pollen through a large metropolitan area. Environ. Monit. Assess. 2017, 189, 169. [Google Scholar] [CrossRef]
- Bédard, A.; Sofiev, M.; Arnavielhe, S.; Antó, J.M.; Garcia-Aymerich, J.; Thibaudon, M.; Bergmann, K.C.; Dubakiene, R.; Bedbrook, A.; Onorato, G.; et al. Interactions between air pollution and pollen season for rhinitis using mobile technology: A MASK-POLLAR study. J. Allerg. Clin. Immun. 2020, 8, 1063–1073.e4. [Google Scholar] [CrossRef]
- Connors, J.P.; Lei, S.; Kelly, M. Citizen Science in the Age of Neogeography: Utilizing Volunteered Geographic Information for Environmental Monitoring. Ann. Assoc. Am. Geogr. 2012, 102, 1267–1289. [Google Scholar] [CrossRef]
- Eitzel, M.V.; Cappadonna, J.L.; Santos-Lang, C.; Duerr, R.E.; Virapongse, A.; West, S.E.; Kyba, C.C.M.; Bowser, A.; Cooper, C.B.; Sforzi, A.; et al. Citizen Science Terminology Matters: Exploring Key Terms. Citiz. Sci. Theory Pract. 2017, 2, 1. [Google Scholar] [CrossRef] [Green Version]
- Silvertown, J. A new dawn for citizen science. Trends Ecol. Evol. 2009, 24, 467–471. [Google Scholar] [CrossRef] [PubMed]
- Dickinson, J.L.; Zuckerberg, B.; Bonter, D.N. Citizen Science as an Ecological Research Tool: Challenges and Benefits. Annu. Rev. Ecol. Evol. Syst. 2010, 41, 149–172. [Google Scholar] [CrossRef] [Green Version]
- Kar, B.; Sieber, R.; Haklay, M.; Ghose, R. Public Participation GIS and Participatory GIS in the Era of GeoWeb. Cartogr. J. 2016, 53, 296–299. [Google Scholar] [CrossRef] [Green Version]
- Bonney, R.; Balard, H.; Jordan, R.; McCallie, E.; Phillips, T.; Shirk, J.; Wilderman, C.C. Public Participation in Scientific Research: Defining the Field and Assessing Its Potential for Informal Science Education; A CAISE Inquiry Group Report; Center for Advancement of Informal Science Education (CAISE): Washington, DC, USA, 2009; p. 58. Available online: http://www.birds.cornell.edu/citscitoolkit/publications/CAISE-PPSR-report-2009.pdf (accessed on 14 August 2019).
- Loreto, V.; Haklay, M.; Hotho, A.; Servedio, V.D.P.; Stumme, G.; Theunis, J.; Tria, F. Participatory Sensing, Opinions and Collective Awareness; Springer: Cham, Switzerland, 2017; p. 405. [Google Scholar] [CrossRef]
- Grey, F. The Age of Citizen Cyberscience; CERN Courier, IOP Publishing: Bristol, UK, 2009; Available online: http://cerncourier.com/cws/article/cern/38718 (accessed on 31 May 2017).
- Guo, B.; Wang, Z.; Yu, Z.; Wang, Y.; Yen, N.Y.; Huang, R.; Zhou, X. Mobile Crowd Sensing and Computing. ACM Comput. Surv. 2015, 48, 1–31. [Google Scholar] [CrossRef]
- Capponi, A.; Fiandrino, C.; Kantarci, B.; Foschini, L.; Kliazovich, D.; Bouvry, P. A Survey on Mobile Crowdsensing Systems: Challenges, Solutions, and Opportunities. IEEE Commun. Surv. Tutor. 2019, 21, 2419–2465. [Google Scholar] [CrossRef] [Green Version]
- Haklay, M.; Basiouka, S.; Antoniou, V.; Ather, A. How Many Volunteers Does it Take to Map an Area Well? The Validity of Linus’ Law to Volunteered Geographic Information. Cartogr. J. 2010, 47, 315–322. [Google Scholar] [CrossRef] [Green Version]
- English, P.B.; Richardson, M.J.; Garzón-Galvis, C. From Crowdsourcing to Extreme Citizen Science: Participatory Research for Environmental Health. Annu. Rev. Public Health 2018, 39, 335–350. [Google Scholar] [CrossRef] [Green Version]
- Nimbalkar, P.M.; Tripathi, N.K. Space-time epidemiology and effect of meteorological parameters on influenza-like illness in Phitsanulok, a northern province in Thailand. Geospat. Health 2016, 11. [Google Scholar] [CrossRef] [Green Version]
- Sheppard, S.A.; Terveen, L. Quality is a verb. In Proceedings of the 7th International Symposium on Wikis and Open Collaboration—WikiSym ’11, Mountain View, CA, USA, 3–5 October 2011; ACM Press: New York, NY, USA, 2011; p. 29. [Google Scholar] [CrossRef]
- Lin, Y.-P.; Deng, D.; Lin, W.-C.; Lemmens, R.; Crossman, N.D.; Henle, K.; Schmeller, D.S. Uncertainty analysis of crowd-sourced and professionally collected field data used in species distribution models of Taiwanese moths. Biol. Conserv. 2015, 181, 102–110. [Google Scholar] [CrossRef]
- Parrish, J.K.; Burgess, H.; Weltzin, J.F.; Fortson, L.; Wiggins, A.; Simmons, B. Exposing the Science in Citizen Science: Fitness to Purpose and Intentional Design. Integr. Comp. Biol. 2018, 58, 150–160. [Google Scholar] [CrossRef] [PubMed]
- Fritz, S.; Fonte, C.; See, L. The Role of Citizen Science in Earth Observation. Remote Sens. 2017, 9, 357. [Google Scholar] [CrossRef] [Green Version]
- Maantay, J. Asthma and air pollution in the Bronx: Methodological and data considerations in using GIS for environmental justice and health research. Health Place 2007, 13, 32–56. [Google Scholar] [CrossRef]
- Keddem, S.; Barg, F.K.; Glanz, K.; Jackson, T.; Green, S.; George, M. Mapping the urban asthma experience: Using qualitative GIS to understand contextual factors affecting asthma control. Soc. Sci. Med. 2015, 140, 9–17. [Google Scholar] [CrossRef]
- Palmer, J.R.B.; Oltra, A.; Collantes, F.; Delgado, J.A.; Lucientes, J.; Delacour, S.; Bengoa, M.; Eritja, R.; Bartumeus, F. Citizen science provides a reliable and scalable tool to track disease-carrying mosquitoes. Nat. Commun. 2017, 8, 916. [Google Scholar] [CrossRef] [Green Version]
- Penza, M.; Suriano, D.; Pfister, V.; Prato, M.; Cassano, G. Urban Air Quality Monitoring with Networked Low-Cost Sensor-Systems. Proceedings 2017, 1, 573. [Google Scholar] [CrossRef] [Green Version]
- Kankanamge, N.; Yigitcanlar, T.; Goonetilleke, A.; Kamruzzaman, M. Can volunteer crowdsourcing reduce disaster risk? A systematic review of the literature. Int. J. Disaster Risk Reduct. 2019, 35, 101097. [Google Scholar] [CrossRef]
- Choi, J.; Hwang, M.; Kim, G.; Seong, J.; Ahn, J. Supporting the measurement of the United Nations’ sustainable development goal 11 through the use of national urban information systems and open geospatial technologies: A case study of south Korea. Open Geospatial Data Softw. Stand. 2016, 1, 1. [Google Scholar] [CrossRef] [Green Version]
- Chmielewski, S.; Samulowska, M.; Lupa, M.; Lee, D.; Zagajewski, B. Citizen science and WebGIS for outdoor advertisement visual pollution assessment. Comput. Environ. Urban Syst. 2018, 67, 97–109. [Google Scholar] [CrossRef]
- Flanagin, A.J.; Metzger, M.J. The credibility of volunteered geographic information. GeoJournal 2008, 72, 137–148. [Google Scholar] [CrossRef]
- Antoniou, V.; Skopeliti, A. Measures and indicators of VGI quality: An overview. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, II-3/W5, 345–351. [Google Scholar] [CrossRef] [Green Version]
- Wu, P.; Ngai, E.W.T.; Wu, Y. Toward a real-time and budget-aware task package allocation in spatial crowdsourcing. Decis. Support Syst. 2018, 110, 107–117. [Google Scholar] [CrossRef]
- Foody, G.; See, L.; Fritz, S.; Moorthy, I.; Perger, C.; Schill, C.; Boyd, D. Increasing the Accuracy of Crowdsourced Information on Land Cover via a Voting Procedure Weighted by Information Inferred from the Contributed Data. ISPRS Int. J. Geo-Inf. 2018, 7, 80. [Google Scholar] [CrossRef] [Green Version]
- Gillooly, S.E.; Zhou, Y.; Vallarino, J.; Chu, M.T.; Michanowicz, D.R.; Levy, J.I.; Adamkiewicz, G. Development of an in-home, real-time air pollutant sensor platform and implications for community use. Environ. Pollut. 2019, 244, 440–450. [Google Scholar] [CrossRef] [PubMed]
- Kosmidis, E.; Syropoulou, P.; Tekes, S.; Schneider, P.; Spyromitros-Xioufis, E.; Riga, M.; Charitidis, P.; Moumtzidou, A.; Papadopoulos, S.; Vrochidis, S.; et al. hackAIR: Towards Raising Awareness about Air Quality in Europe by Developing a Collective Online Platform. ISPRS Int. J. Geo-Inf. 2018, 7, 187. [Google Scholar] [CrossRef] [Green Version]
- Commodore, A.; Wilson, S.; Muhammad, O.; Svendsen, E.; Pearce, J. Community-based participatory research for the study of air pollution: A review of motivations, approaches, and outcomes. Environ. Monit. Assess. 2017, 189, 378. [Google Scholar] [CrossRef]
- International Organization for Standardization. ISO 19157: Geographic Information—Data Quality; International Organization for Standardization: Geneva, Switzerland, 2013. [Google Scholar]
- Fonte, C.C.; Antoniou, V.; Bastin, L.; Estima, J.; Arsanjani, J.J.; Bayas, J.-C.L.; See, L.; Vatseva, R. Assessing VGI Data Quality. In Mapping and the Citizen Sensor; Foody, G., See, L., Fritz, S., Mooney, P., Olteanu-Raimond, A.-M., Fonte, C.C., Antoniou, V., Eds.; Ubiquity Press: London, UK, 2017; pp. 137–163. [Google Scholar] [CrossRef] [Green Version]
- Chehregani, A.; Majde, A.; Moin, M.; Gholami, M.; Ali Shariatzadeh, M.; Nassiri, H. Increasing allergy potency of Zinnia pollen grains in polluted areas. Ecotoxicol. Environ. Saf. 2004, 58, 267–272. [Google Scholar] [CrossRef]
- D’Amato, G.; Holgate, S.T.; Pawankar, R.; Ledford, D.K.; Cecchi, L.; Al-Ahmad, M.; Al-Enezi, F.; Al-Muhsen, S.; Ansotegui, I.; Baena-Cagnani, C.E.; et al. Meteorological conditions, climate change, new emerging factors, and asthma and related allergic disorders. A statement of the World Allergy Organization. World Allergy Organ. J. 2015, 8, 25. [Google Scholar] [CrossRef] [Green Version]
- Karatzas, K.D. Informing the public about atmospheric quality: Air pollution and pollen. Allergo J. 2009, 18, 212–217. [Google Scholar] [CrossRef]
- Sofiev, M.; Bergmann, K.C. Allergenic Pollen; Sofiev, M., Bergmann, K.-C., Eds.; Springer: Dordrecht, The Netherlands, 2013; ISBN 978-94-007-4880-4. [Google Scholar] [CrossRef]
- Bonney, R.; Cooper, C.B.; Dickinson, J.; Kelling, S.; Phillips, T.; Rosenberg, K.V.; Shirk, J. Citizen Science: A Developing Tool for Expanding Science Knowledge and Scientific Literacy. Bioscience 2009, 59, 977–984. [Google Scholar] [CrossRef]
- Ring, J.; Krämer, U.; Schäfer, T.; Behrendt, H. Why are allergies increasing? Curr. Opin. Immunol. 2001, 13, 701–708. [Google Scholar] [CrossRef]
- Harlin, J.; Kloetzer, L.; Patton, D.; Leonhard, C. Turning students into citizen scientists. In Citizen Science; UCL Press: London, UK, 2018; pp. 410–428. [Google Scholar] [CrossRef]
- Seymour, V.; Haklay, M. Exploring Engagement Characteristics and Behaviours of Environmental Volunteers. Citiz. Sci. Theory Pract. 2017, 2, 5. [Google Scholar] [CrossRef]
- Kmenta, M.; Bastl, K.; Jäger, S.; Berger, U. Development of personal pollen information—the next generation of pollen information and a step forward for hay fever sufferers. Int. J. Biometeorol. 2014, 58, 1721–1726. [Google Scholar] [CrossRef] [PubMed]
- Samoliński, B.; Raciborski, F.; Lipiec, A.; Tomaszewska, A.; Krzych-Fałta, E.; Samel-Kowalik, P.; Walkiewicz, A.; Lusawa, A.; Borowicz, J.; Komorowski, J.; et al. Epidemiologia Chorób Alergicznych w Polsce (ECAP). Alergol. Pol. Polish J. Allergol. 2014, 1, 10–18. [Google Scholar] [CrossRef]
- Galesic, M.; Bosnjak, M. Effects of Questionnaire Length on Participation and Indicators of Response Quality in a Web Survey. Public Opin. Q. 2009, 73, 349–360. [Google Scholar] [CrossRef]
- Malhotra, N.K. Questionnaire design and scale development. In The Handbook of Marketing Research: Uses, Misuses, and Future Advances; Grover, R., Vriens, M., Eds.; SAGE Publications Inc.: Thousand Oaks, CA, USA, 2006; p. 720. ISBN 1-4129-0997-X. [Google Scholar] [CrossRef] [Green Version]
- Krosnick, J.A.; Presser, S. Question and Questionnaire Design. In Handbook of Survey Research, 2nd ed.; Wright, J.D., Marsden, P.V., Eds.; Elsevier: San Diego, CA, USA, 2009; p. 81. [Google Scholar]
- Weijters, B.; Baumgartner, H.; Schillewaert, N. Reversed item bias: An integrative model. Psychol. Methods 2013, 18, 320–334. [Google Scholar] [CrossRef] [Green Version]
- Bousquet, J.; Bewick, M.; Arnavielhe, S.; Mathieu-Dupas, E.; Murray, R.; Bedbrook, A.; Caimmi, D.P.; Vandenplas, O.; Hellings, P.W.; Bachert, C.; et al. Work productivity in rhinitis using cell phones: The MASK pilot study. Allergy 2017, 72, 1475–1484. [Google Scholar] [CrossRef]
- Albuam, G.; Oppenheim, A.N. Questionnaire Design, Interviewing and Attitude Measurement. J. Mark. Res. 1993, 30, 393. [Google Scholar] [CrossRef]
- Garbarski, D.; Schaeffer, N.C.; Dykema, J. The effects of response option order and question order on self-rated health. Qual. Life Res. 2015, 24, 1443–1453. [Google Scholar] [CrossRef] [Green Version]
- Schaeffer, N.C.; Presser, S. The Science of Asking Questions. Annu. Rev. Soc. 2003, 29, 65–88. [Google Scholar] [CrossRef] [Green Version]
- Boynton, P.M.; Greenhalgh, T. Selecting, designing, and developing your questionnaire. BMJ 2004, 328, 1312–1315. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Arvidsson, M.B.; Lowhagen, O.; Rak, S. Allergen specific immunotherapy attenuates early and late phase reactions in lower airways of birch pollen asthmatic patients: A double blind placebo-controlled study. Allergy 2004, 59, 74–80. [Google Scholar] [CrossRef] [PubMed]
- Galli, S.J.; Tsai, M.; Piliponsky, A.M. The development of allergic inflammation. Nature 2008, 454, 445–454. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gauvreau, G.M.; El-Gammal, A.I.; O’Byrne, P.M. Allergen-induced airway responses. Eur. Respir. J. 2015, 46, 819–831. [Google Scholar] [CrossRef] [Green Version]
- Skoner, D.P. Allergic rhinitis: Definition, epidemiology, pathophysiology, detection, and diagnosis. J. Allergy Clin. Immunol. 2001, 108, S2–S8. [Google Scholar] [CrossRef]
- Ferguson, B.J. Influences of Allergic Rhinitis on Sleep. Otolaryngol. Neck Surg. 2004, 130, 617–629. [Google Scholar] [CrossRef]
- Kampa, M.; Castanas, E. Human health effects of air pollution. Environ. Pollut. 2008, 151, 362–367. [Google Scholar] [CrossRef]
- D’Amato, G.; Liccardi, G.; D’Amato, M.; Cazzola, M. Outdoor air pollution, climatic changes and allergic bronchial asthma. Eur. Respir. J. 2002, 20, 763–776. [Google Scholar] [CrossRef]
- Couper, M.P.; Traugott, M.W.; Lamias, M.J. Web Survey Design and Administration. Public Opin. Q. 2001, 65, 230–253. [Google Scholar] [CrossRef]
- Ganassali, S. The influence of the design of web survey questionnaires on the quality of responses. Surv. Res. Methods 2008, 2, 21–32. [Google Scholar] [CrossRef]
- Lupa, M.; Samulowska, M.; Chmielewski, S.; Myszkowska, D.; Czarnobilska, E. A concept of webgis pollen allergy mapping. In Proceedings of the 17th International Multidisciplinary Scientific GeoConference Surveying Geology and Mining Ecology Management, Albena, Bulgaria, 29 June–5 July 2017; SGEM: Sofia, Bulgaria, 2017; pp. 1141–1148. [Google Scholar] [CrossRef]
- Kubik-Komar, A.; Piotrowska-Weryszko, K.; Weryszko-Chmielewska, E.; Kuna-Broniowska, I.; Chłopek, K.; Myszkowska, D.; Puc, M.; Rapiejko, P.; Ziemianin, M.; Dąbrowska-Zapart, K.; et al. A study on the spatial and temporal variability in airborne Betula pollen concentration in five cities in Poland using multivariate analyses. Sci. Total Environ. 2019, 660, 1070–1078. [Google Scholar] [CrossRef] [PubMed]
- Caspari, G.; Donato, S.; Jendryke, M. Remote sensing and citizen science for assessing land use change in the Musandam (Oman). J. Arid Environ. 2019, 171, 104003. [Google Scholar] [CrossRef]
- Nov, O.; Arazy, O.; Anderson, D. Dusting for science. In Proceedings of the 2011 iConference on iConference’11, Seattle, WA, USA, 8–11 February 2011; ACM Press: New York, NY, USA, 2011; pp. 68–74. [Google Scholar] [CrossRef]
- McCrory, G.; Veeckman, C.; Claeys, L. Citizen Science Is in the Air—Engagement Mechanisms from Technology-Mediated Citizen Science Projects Addressing Air Pollution. In Lecture Notes in Computer Science, 10673; Springer: Cham, Switzerland, 2017; pp. 28–38. [Google Scholar] [CrossRef]
- Farman, J. Infrastructures of Mobile Social Media. Soc. Media Soc. 2015, 1. [Google Scholar] [CrossRef] [Green Version]
- Hube, C.; Fetahu, B.; Gadiraju, U. Understanding and Mitigating Worker Biases in the Crowdsourced Collection of Subjective Judgments. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems—CHI ’19, Glasgow, UK, 4–9 May 2019; ACM Press: New York, NY, USA, 2019; pp. 1–12. [Google Scholar] [CrossRef]
- Eickhoff, C. Cognitive Biases in Crowdsourcing. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining—WSDM ’18, Los Angeles, CA, USA, 5–9 February 2018; ACM Press: New York, NY, USA, 2018; pp. 162–170. [Google Scholar] [CrossRef]
- Alabri, A.; Hunter, J. Enhancing the Quality and Trust of Citizen Science Data. In Proceedings of the 2010 IEEE Sixth International Conference on e-Science, Brisbane, Australia, 7–10 December 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 81–88. [Google Scholar] [CrossRef]
- Langley, S.A.; Messina, J.P.; Moore, N. Using meta-quality to assess the utility of volunteered geographic information for science. Int. J. Health Geogr. 2017, 16, 40. [Google Scholar] [CrossRef] [Green Version]
- Nowak, M.M.; Dziób, K.; Ludwisiak, Ł.; Chmiel, J. Mobile GIS applications for environmental field surveys: A state of the art. Glob. Ecol. Conserv. 2020, 23, e01089. [Google Scholar] [CrossRef]
- Geoghegan, H.; Dyke, A.; Pateman, R.; West, S.; Everett, G. Understanding Motivations for Citizen Science; Final Report on Behalf of the UK Environmental Observation Framework; University of Reading, Stockholm Environment Institute (University of York) and University of the West of England; UK Centre for Ecology & Hydrology, Lancaster Environment Centre: Lancaster, UK, May 2016; pp. 1–4. Available online: http://www.ukeof.org.uk/resources/citizen-science-resources/citizenscienceSUMMARYReportFINAL19052.pdf (accessed on 12 November 2018).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Conditional Statement Number | Logic Formula |
|---|---|
| Con.1 | , |
| Con.2 | |
| Con.3 | , |
| Con.4 | |
| Con.5 | |
| Con.6 | |
| Con.7 | |
| Con.8 | |
| Con.9 | |
| Con.10 | |
| Con.11 | |
| Con.12 | |
| Con.13 | |
| Con.14 | |
| Con.15 | |
| Con.16 | |
| Con.17 |
| QA Mechanism | QA Mechanism Code | QA Mechanism Components: Conditional Statement Combination |
|---|---|---|
| Start-check (SC) | SC1 | Con.1 or Con.2 |
| SC2 | Con.3 or Con.4 | |
| Sequence (Sq) | Sq | Con.5 or Con.6 or Con.7 |
| Cross-validation (CV) | CV1 | Con.8 |
| CV2 | Con.9 | |
| Repeating (Rp) | Rp1 | Con.10 or Con.11 |
| Rp2 | Con.12 or Con.13 | |
| Time-loop check (TC) | TC | Con.14 or Con.15 or Con.16 or Con.17 |
| QA System (QAs) Variant | QA System Components: QA Mechanism Combination |
|---|---|
| QAs1 | SC1 or Sq or CV1 or Rp1 or TC |
| QAs2 | SC1 or Sq or CV1 or Rp2 or TC |
| QAs3 | SC1 or Sq or CV2 or Rp1 or TC |
| QAs4 | SC2 or Sq or CV1 or Rp1 or TC |
| QAs5 | SC2 or Sq or CV1 or Rp2 or TC |
| QAs6 | SC2 or Sq or CV2 or Rp1 or TC |
| QAs7 | SC1 or Sq or CV2 or Rp2 or TC |
| QAs8 | SC2 or Sq or CV2 or Rp2 or TC |
| QA Mechanism | Reports | QA Mechanism Robustness Rank | ||||
|---|---|---|---|---|---|---|
| Name | Code | Accepted | Rejected | Total | Rejected (% of Total) | |
| Start-check | SC1 | 1752 | 71 | 1823 | 3.9 | 5 |
| SC2 | 1698 | 125 | 1823 | 6.9 | 3 | |
| Sequence | Sq | 1806 | 17 | 1823 | 0.9 | 8 |
| Cross-validation | CV1 | 1769 | 54 | 1823 | 3.0 | 6 |
| CV2 | 1716 | 107 | 1823 | 5.9 | 4 | |
| Repeating | Rp1 | 1629 | 194 | 1823 | 10.6 | 2 |
| Rp2 | 1401 | 422 | 1823 | 23.1 | 1 | |
| Time-loop check | TC | 1771 | 52 | 1823 | 2.9 | 7 |
| Start-Check2 | Cross-Validation2 | Repeating2 | |||||
|---|---|---|---|---|---|---|---|
| Accepted | Rejected | Accepted | Rejected | Accepted | Rejected | ||
| Start-check1 | Accepted | 1698 | 54 | ||||
| Rejected | 0 | 71 | |||||
| Cross-validation1 | Accepted | 1716 | 53 | ||||
| Rejected | 0 | 54 | |||||
| Repeating1 | Accepted | 1401 | 228 | ||||
| Rejected | 0 | 194 | |||||
| QA System Variant | QA Mechanisms Combination | Reports | QA System Robustness Rank | |||
|---|---|---|---|---|---|---|
| Accepted | Rejected | Total | Rejected (% of total) | |||
| QAs1 | SC1 or Sq or CV1 or Rp1 or TC | 1490 | 333 | 1823 | 18.3 | 6 |
| QAs2 | SC1 or Sq or CV1 or Rp2 or TC | 1325 | 498 | 1823 | 27.3 | 2 |
| QAs3 | SC1 or Sq or CV2 or Rp1 or TC | 1459 | 364 | 1823 | 20.0 | 5 |
| QAs4 | SC2 or Sq or CV1 or Rp1 or TC | 1445 | 378 | 1823 | 20.7 | 4 |
| QAs5 | SC2 or Sq or CV1 or Rp2 or TC | 1325 | 498 | 1823 | 27.3 | 2 |
| QAs6 | SC2 or Sq or CV2 or Rp1 or TC | 1422 | 401 | 1823 | 22.0 | 3 |
| QAs7 | SC1 or Sq or CV2 or Rp2 or TC | 1302 | 521 | 1823 | 28.6 | 1 |
| QAs8 | SC2 or Sq or CV2 or Rp2 or TC | 1302 | 521 | 1823 | 28.6 | 1 |
| % of Surveys with Reported Symptoms | QAs8 Impact on the Results | ||
|---|---|---|---|
| Raw Data | QAs8-Checked Data | ||
| Sneezing | 29.98 | 25.52 | −0.149 |
| Nose itching | 30.27 | 21.98 | −0.274 |
| Runny nose | 46.58 | 46.98 | 0.009 |
| Watering eyes | 26.77 | 21.52 | −0.196 |
| Scratching in the throat | 22.73 | 14.68 | −0.542 |
| Breathing problems | 13.14 | 6.92 | −0.473 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Samulowska, M.; Chmielewski, S.; Raczko, E.; Lupa, M.; Myszkowska, D.; Zagajewski, B. Crowdsourcing without Data Bias: Building a Quality Assurance System for Air Pollution Symptom Mapping. ISPRS Int. J. Geo-Inf. 2021, 10, 46. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10020046
Samulowska M, Chmielewski S, Raczko E, Lupa M, Myszkowska D, Zagajewski B. Crowdsourcing without Data Bias: Building a Quality Assurance System for Air Pollution Symptom Mapping. ISPRS International Journal of Geo-Information. 2021; 10(2):46. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10020046
Chicago/Turabian StyleSamulowska, Marta, Szymon Chmielewski, Edwin Raczko, Michał Lupa, Dorota Myszkowska, and Bogdan Zagajewski. 2021. "Crowdsourcing without Data Bias: Building a Quality Assurance System for Air Pollution Symptom Mapping" ISPRS International Journal of Geo-Information 10, no. 2: 46. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10020046