
An Innovative Intelligent System with Integrated CNN and SVM: Considering Various Crops through Hyperspectral Image Data

Abstract
:1. Introduction
2. Materials
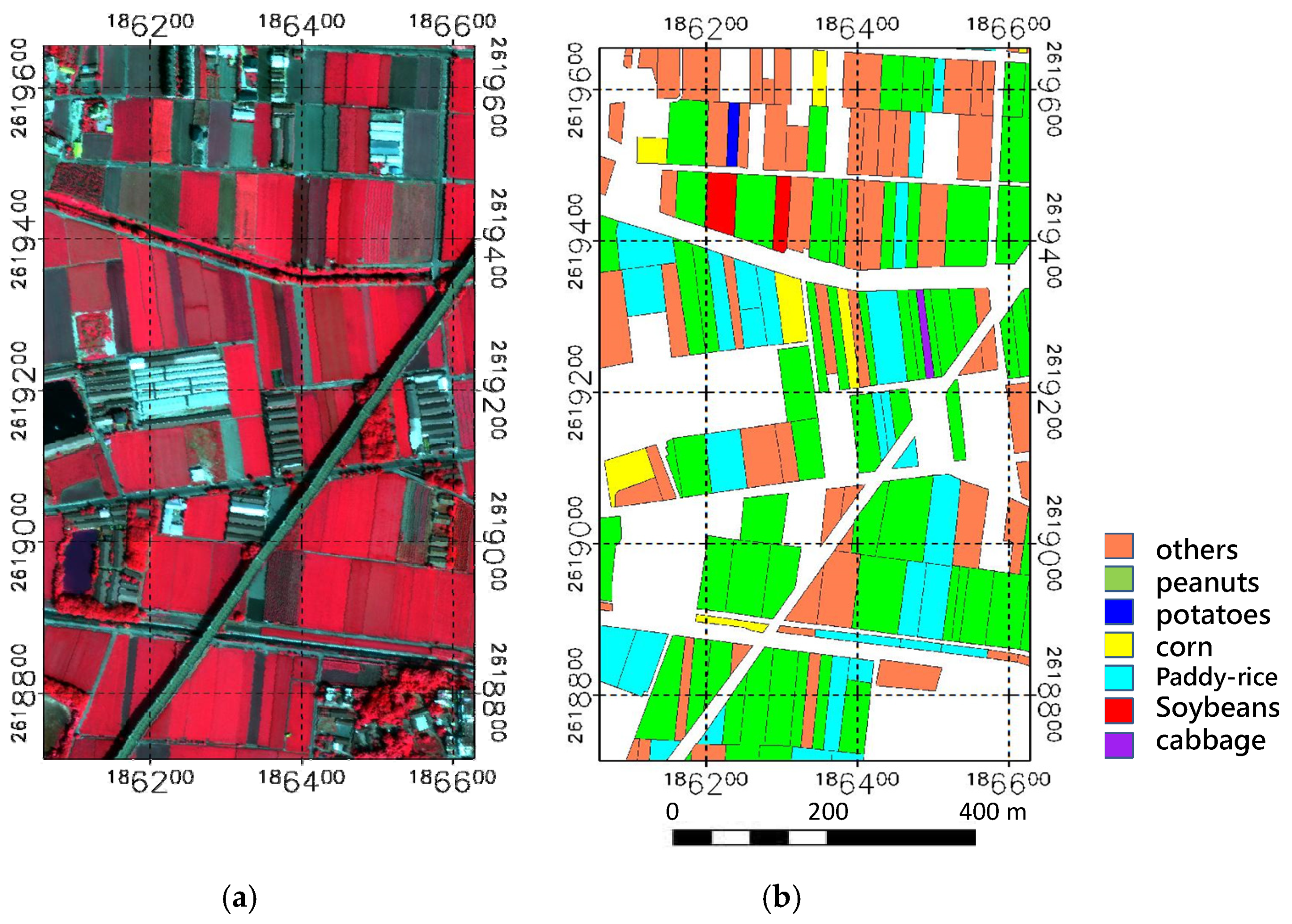
2.1. Brief Introduction on Study Area
2.2. Brief Introduction on Image Format
2.3. Image Take Place on Study Area
3. Research Method
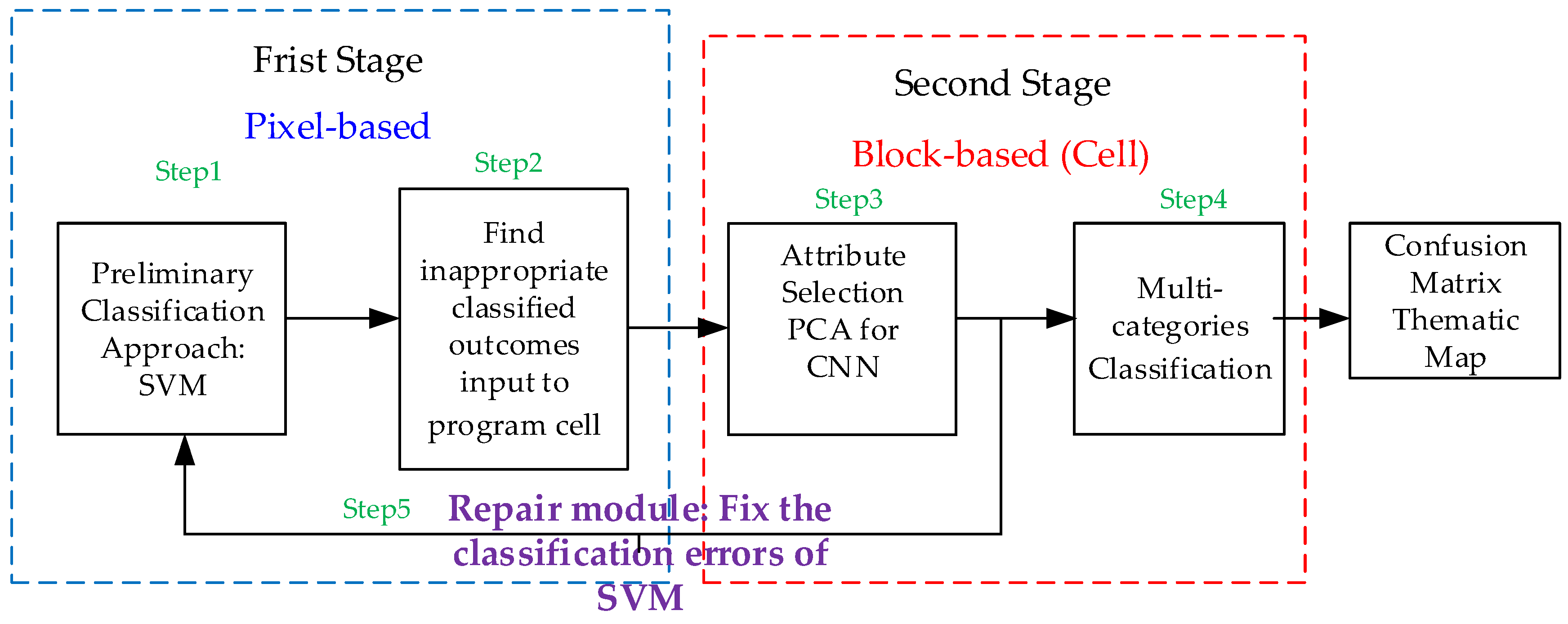
3.1. Study Plan
3.2. Support Vector Machine
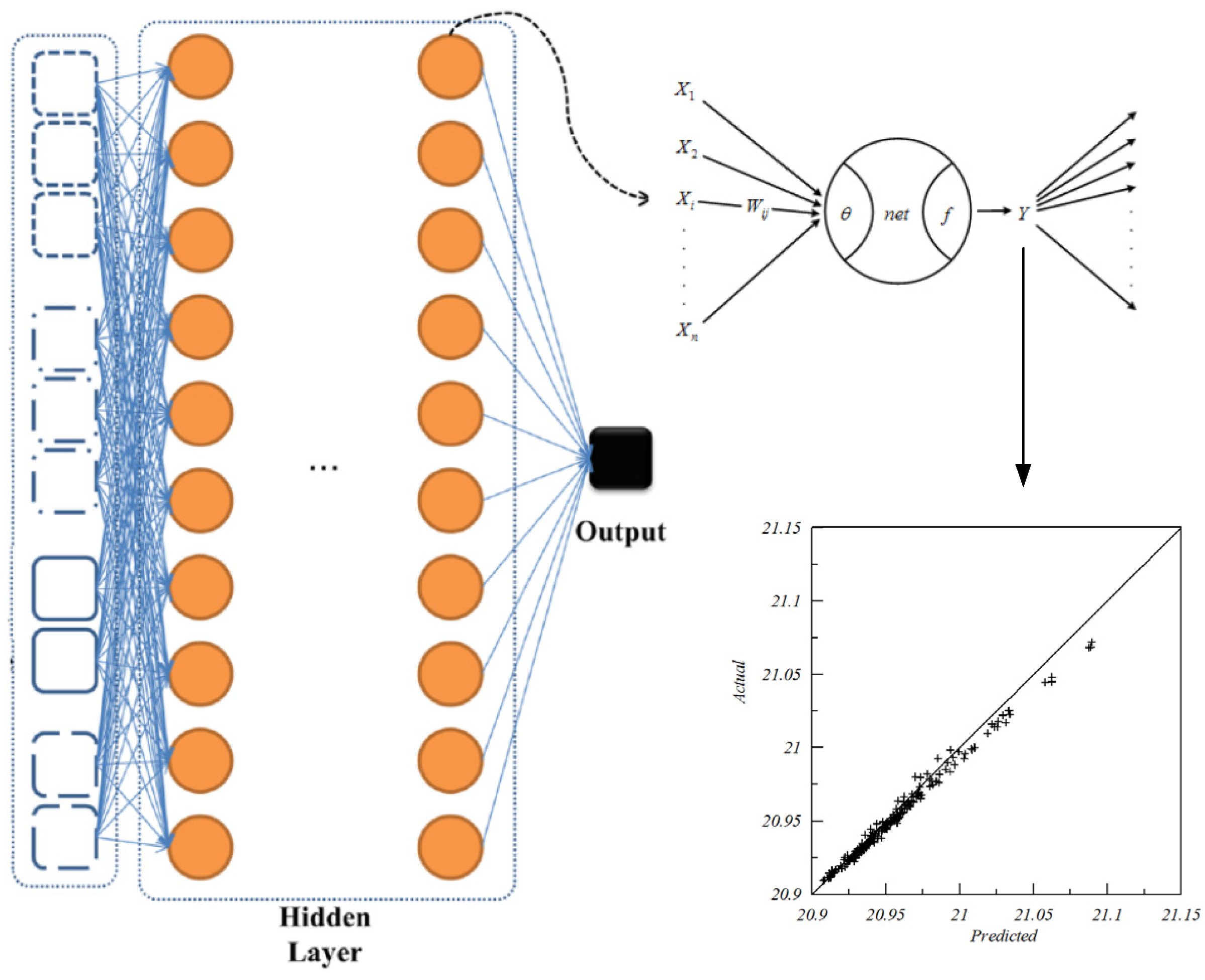
3.3. Deep Learning for Regional Image Classification
3.3.1. Convolution
3.3.2. Max-Pooling
3.3.3. Colorful Image
3.3.4. Determination of Layers
3.4. Study Plan
4. Discussion of the Results
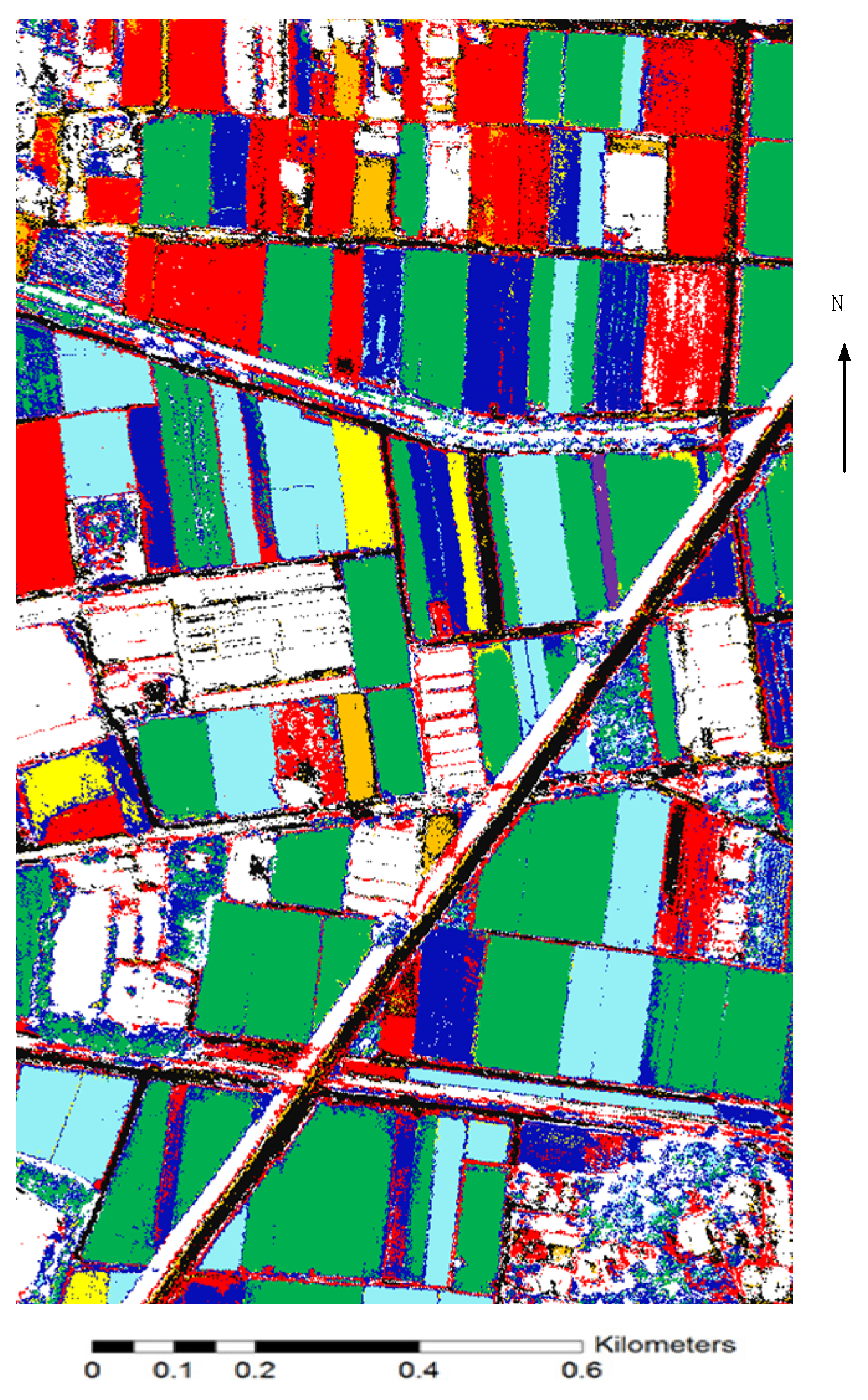
4.1. First Stage Analysis of Support Vector Machine (SVM)
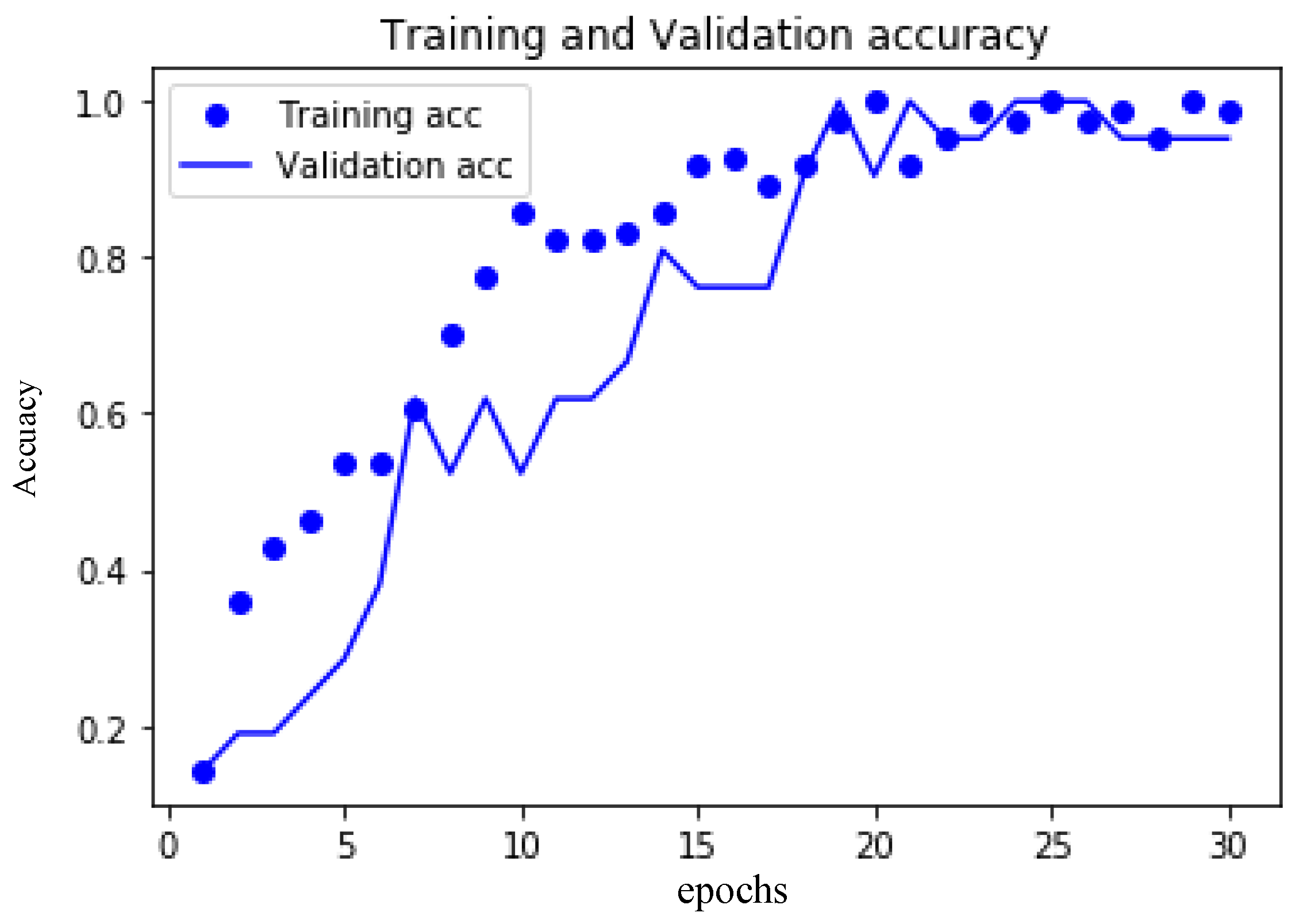
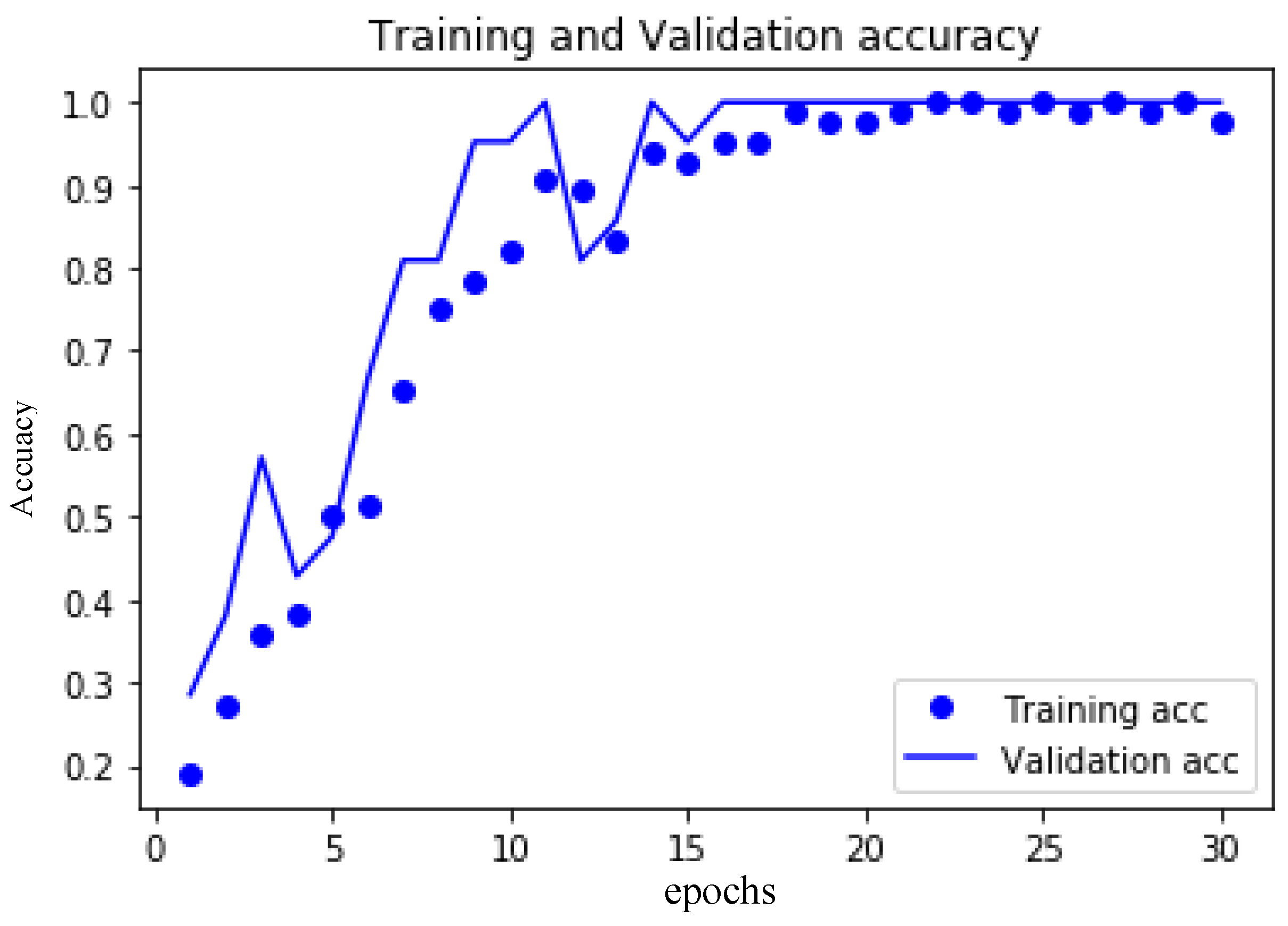
4.2. Second Stage: Improvement Classification of CNN
5. Summary and Conclusions
- (a)
- The first stage: The SVM approach was carried out for the roughly pixel-based results. The accuracy rate was about 95.85%.
- (b)
- The second stage: The deep learning method was carried out for cell-based results. Three different cases were considered: PCA = 8, epoch = 30, the accuracy was 97.1%; PCA = 16, epoch = 30, where the accuracy was 98%; and PCA = 24, epoch = 30, where the accuracy was 98.6%.
- (c)
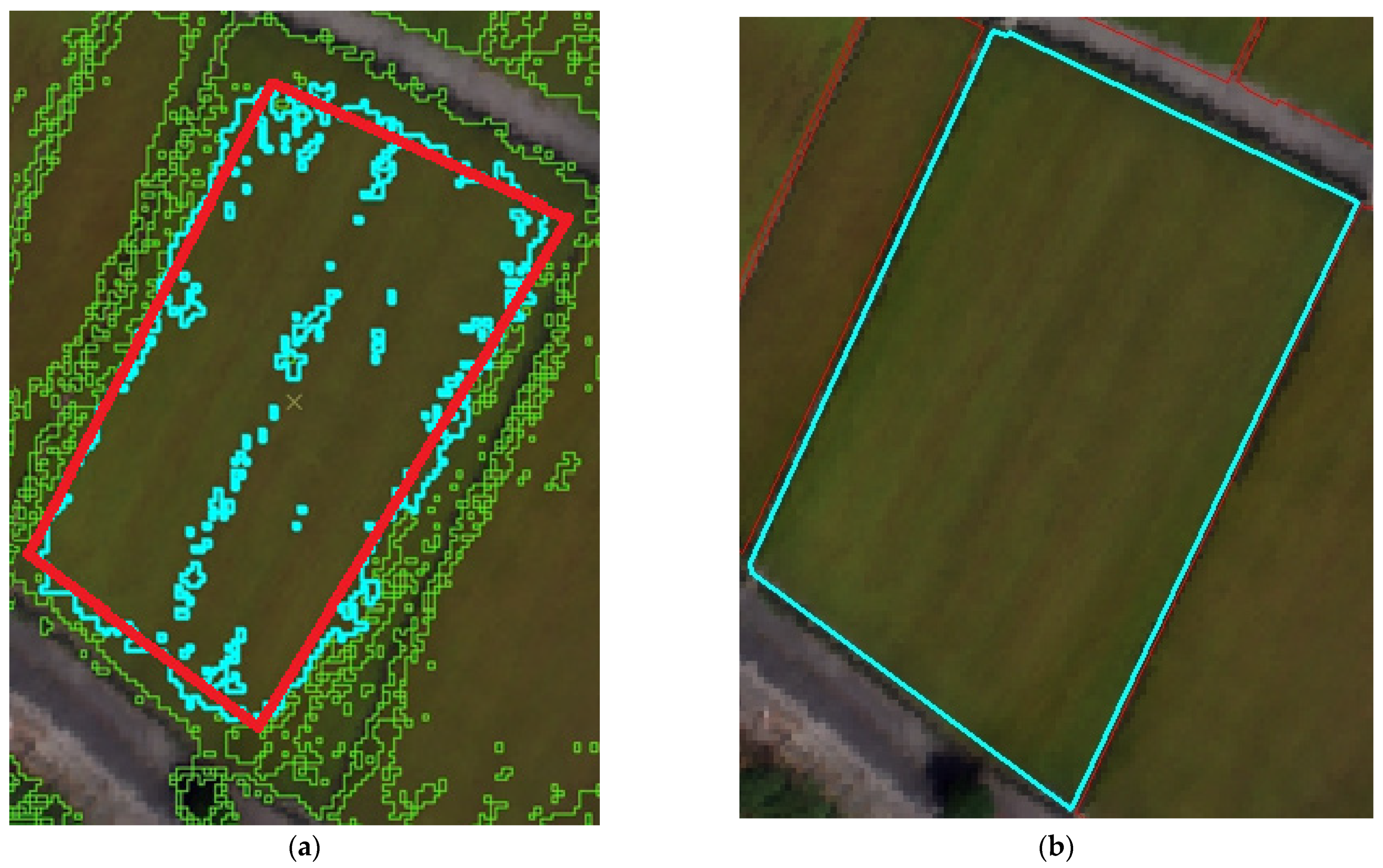
- The repair module was designed to use the CNN classification outcomes to fix the pixel-based model of SVM classification errors. The target cell also successfully eliminated the salt and pepper effect.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wan, S.; Wang, Y.P. The comparison of density-based clustering approach among different machine learning models on paddy rice image classification of multispectral and hyperspectral image data. Agriculture 2020, 10, 465. [Google Scholar] [CrossRef]
- Lu, D.; Mausel, P.; Batistella, M. Land-Cover binary change detection methods for use in the moist tropical region of the Amazon: A comparative study. Int. J. Remote Sens. 2005, 26, 101–114. [Google Scholar] [CrossRef]
- Cao, J.; Leng, W.; Liu, K.; Liu, L.; He, Z.; Zhu, Y. Object-Based mangrove species classification using unmanned aerial vehicle hyperspectral images and digital surface models. Remote Sens. 2018, 10, 89. [Google Scholar] [CrossRef] [Green Version]
- Cheriyadat, A.; Bruce, L.M. Why principal component analysis is not an appropriate feature extraction method for hyperspectral data. Geosci. Remote Sens. Symp. 2003, 104, 3420–3422. [Google Scholar]
- Muhammed, H.H. Hyperspectral crop reflectance data for characterising and estimating fungal disease severity in wheat. Biosyst. Eng. 2005, 91, 9–20. [Google Scholar] [CrossRef]
- Lei, T.C.; Wan, S.; Wu, S.C.; Wang, H.P. A new approach of ensemble learning technique to resolve the uncertainties of paddy area through image classification. Remote Sens. 2020, 12, 3666. [Google Scholar] [CrossRef]
- Bertels, L.; Vanderstraete, T.; Van Coillie, S. Mapping of coral reefs using hyperspectral CASI data; a case study: Fordata, Tanimbar, Indonesia. Int. J. Remote Sens. 2008, 29, 2359–2391. [Google Scholar] [CrossRef]
- Nguyen, A.; Yosinski, J.; Clune, J. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 427–436. [Google Scholar]
- Rodarmel, C.; Shan, J. Principal component analysis for hyperspectral image classification. Surv. Land Inf. Sci. 2002, 62, 115–122. [Google Scholar]
- Tuia, D.; Pasolli, E.; Emery, W.J. Using active learning to adapt remote sensing image classifiers. Remote Sens. Environ. 2011, 115, 2232–2242. [Google Scholar] [CrossRef]
- Wan, S.; Chang, S.H. Crop classification with WorldView-2 imagery using support vector machine comparing texture analysis approaches and grey relational analysis in Jianan Plain, Taiwan. Int. J. Remote Sens. 2019, 40, 8076–8092. [Google Scholar] [CrossRef]
- Du, P.J.; Tan, K.; Xing, X.S. A novel binary tree support vector machine for hyperspectral remote sensing image classification. Opt. Commun. 2012, 285, 3054–3060. [Google Scholar] [CrossRef]
- Chapelle, O.; Haffner, P. Support vector machines for histogram-based image classification. VN Vapnik—IEEE Trans. Neural Netw. 1999, 10, 1055–1064. [Google Scholar] [CrossRef]
- Wan, S.; Lei, T.C.; Ma, H.L.; Cheng, R.W. The analysis on similarity of spectrum analysis of landslide and bareland through hyper-spectrum image bands. Water 2019, 11, 2414. [Google Scholar] [CrossRef] [Green Version]
- Pradhan, B. A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using GIS. Comput. Geosci. 2013, 51, 350–365. [Google Scholar] [CrossRef]
- Foody, M.G.; Mathur, A. A relative evaluation of multiclass image classification by support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1335–1343. [Google Scholar] [CrossRef] [Green Version]
- Furey, T.; Cristianini, N.; Duffy, N.; Bednarski, D.; Schummer, M.; Haussler, D. Support vector machine classification and validation of cancer tissue samples using microarray expression data. Bioinformatics 2000, 16, 906–914. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.; Song, W.J.; Kim, S.H. Infrared variation optimized deep convolutional neural network for robust automatic ground target recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 195–202. [Google Scholar]
- Acharya, U.R.; Oh, S.L.; Hagiwara, Y.; Tan, J.H.; Adeli, H. Deep convolutional neural network for the automated detection and diagnosis of seizure using EEG signals. Comput. Biol. Med. 2018, 100, 270–278. [Google Scholar] [CrossRef]
- Zhou, Q.; Flores, A.; Glenn, N.F.; Walters, R.; Han, B. A machine learning approach to estimation of downward solar radiation from satellite-derived data products: An application over a semi-arid ecosystem in the U.S. PLoS ONE 2017, 12, e0180239. [Google Scholar] [CrossRef] [Green Version]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Senthilnath, J.; Omkar, S.N.; Mani, V. Crop Stage Classification of Hyperspectral Data Using Unsupervised Techniques. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 861–866. [Google Scholar] [CrossRef]
- Pang, Y.; Sun, M.; Jiang, X. Convolution in convolution for network in network. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 1587–1597. [Google Scholar] [CrossRef] [Green Version]
- Yu, S.; Jia, S.; Xu, C. Convolutional neural networks for hyperspectral image classification. Neurocomputing 2017, 219, 88–98. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. An object-based convolutional neural network (OCNN) for urban land use classification. Remote Sens. Environ. 2018, 216, 57–70. [Google Scholar] [CrossRef] [Green Version]
- Wu, Q.; Gao, T.; Lai, Z.; Li, D. Hybrid SVM-CNN classification technique for human–vehicle targets in an automotive LFMCW radar. Sensors 2020, 20, 3504. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.; Kwon, H. Going deeper with contextual CNN for hyperspectral image classification. IEEE Trans. Image Process. 2017, 26, 4843–4855. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Espindola, G.M.; Camara, G.; Reis, I.A.; Bins, L.S.; Monteiro, A.M. Parameter selection for region-growing image segmentation algorithms using spatial autocorrelation. Int. J. Remote Sens. 2006, 27, 3035–3040. [Google Scholar] [CrossRef]
- Gong, Y.H. Advancing content-based image retrieval by exploiting image color and region features. Multimed. Syst. 1999, 7, 449–457. [Google Scholar] [CrossRef]
- Wan, S.; Lei, T.C.; Chou, T.Y. Optimized object-based image classification: A development of landslide knowledge decision support system. Arab. J. Geosci. 2014, 7, 2059–2070. [Google Scholar] [CrossRef]
- Lu, H.; Ma, L.; Fu, X.; Liu, C.; Wang, Z.; Tang, M.; Li, N. Landslides information extraction using object-oriented image analysis paradigm based on deep learning and transfer learning. Remote Sens. 2020, 12, 752. [Google Scholar] [CrossRef] [Green Version]
- Narendra, G.; Sivakumar, D. Deep learning based hyperspectral image analysis-a survey. J. Comput. Theor. Nanosci. 2019, 16, 1528–1535. [Google Scholar] [CrossRef]
- Prasad, S.; Bruce, L.M. Limitations of principal components analysis for hyperspectral target recognition. IEEE Geosci. Remote Sens. Lett. 2008, 5, 625–629. [Google Scholar] [CrossRef]
- Ball, J.E.; Anderson, D.T.; Chan, C.S. Comprehensive survey of deep learning in remote sensing: Theories, tools, and challenges for the community. J. Appl. Remote Sens. 2017, 11, 1. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Training Samples | Testing Samples | Color |
|---|---|---|---|
| Cabbage | 25 | 75 | |
| Empty ground | 55 | 94 | |
| Corn | 45 | 132 | |
| Road | 149 | 435 | |
| Building | 152 | 408 | |
| Uncultivated land | 114 | 325 | |
| Potatoes | 119 | 273 | |
| Paddy rice | 143 | 404 | |
| Peanuts | 251 | 725 |

| Layer | Output Feature Map | Kernel Size | Output Size |
|---|---|---|---|
| Conv1 | 150 | 3 × 3 | 28 × 28 |
| Max pool 2 × 2 | 14 × 14 | ||
| Conv2 | 100 | 3 × 3 | 12 × 12 |
| Max pool 2 × 2 | 6 × 6 | ||
| Conv3 | 150 | 3 × 3 | 4 × 4 |
| softmax | 7 × 1 | ||
| Class | Training Samples | Testing Samples | Size | Conv. Resize |
|---|---|---|---|---|
| Cabbage | 15 | 10 | 5 × 5 | 30 × 30 |
| Corn | 15 | 10 | 10 × 10 | 30 × 30 |
| Road | 15 | 10 | 20 × 20 | 30 × 30 |
| Building | 15 | 10 | 5 × 5 | 30 × 30 |
| Potatoes | 15 | 10 | 15 × 15 | 30 × 30 |
| Paddy rice | 15 | 10 | 30 × 30 | 30 × 30 |
| Peanuts | 15 | 10 | 30 × 30 | 30 × 30 |
| Paddy | Peanuts | Potatoes | Corn | Cabbage | Road | Building | ||
|---|---|---|---|---|---|---|---|---|
| Paddy | 10 | 0 | 0 | 0 | 0 | 0 | 0 | 100% |
| Peanuts | 0 | 10 | 0 | 0 | 0 | 0 | 0 | 100% |
| Potatoes | 0 | 2 | 8 | 0 | 0 | 0 | 0 | 80% |
| Corn | 0 | 0 | 0 | 10 | 0 | 0 | 0 | 100% |
| Cabbage | 0 | 0 | 0 | 0 | 10 | 0 | 0 | 100% |
| Road | 0 | 0 | 0 | 0 | 0 | 10 | 0 | 100% |
| Building | 0 | 0 | 0 | 0 | 0 | 0 | 10 | 100% |
| 100% | 83.3% | 100% | 100% | 100% | 100% | 100% |

| Categories | PCA = 8 | PCA = 16 | PCA = 24 | Full-Band (Bands = 72) |
|---|---|---|---|---|
| SVM with RBF | 94.95% | 95.16% | 95.51% | 95.85% |
| CNN Accuracy | Epoch = 30 97.1% | Epoch = 30 98% | Epoch = 30 98.6% | Epoch = 100 100% |
| * SVM + CNN Repair module | 100% | 100% | 100% |
| Categories | PCA = 8 | PCA = 16 | PCA = 24 | Full-Band (Bands = 72) |
|---|---|---|---|---|
| SVM with RBF | 0.5 min | 1.7 min | 3.4 min | 1.3 h |
| CNN Accuracy | 3.1 min | 8.2 min | 15.2 min | 4 h |
| * SVM + CNN Repair module | 3.6 min | 10 min | 18.7 min | 5.3 h |
| Accuracy | 100% | 100% | 100% | 100% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wan, S.; Yeh, M.-L.; Ma, H.-L. An Innovative Intelligent System with Integrated CNN and SVM: Considering Various Crops through Hyperspectral Image Data. ISPRS Int. J. Geo-Inf. 2021, 10, 242. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10040242
Wan S, Yeh M-L, Ma H-L. An Innovative Intelligent System with Integrated CNN and SVM: Considering Various Crops through Hyperspectral Image Data. ISPRS International Journal of Geo-Information. 2021; 10(4):242. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10040242
Chicago/Turabian StyleWan, Shiuan, Mei-Ling Yeh, and Hong-Lin Ma. 2021. "An Innovative Intelligent System with Integrated CNN and SVM: Considering Various Crops through Hyperspectral Image Data" ISPRS International Journal of Geo-Information 10, no. 4: 242. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10040242