
Context-Specific Point-of-Interest Recommendation Based on Popularity-Weighted Random Sampling and Factorization Machine

Abstract
:1. Introduction
2. Related Work
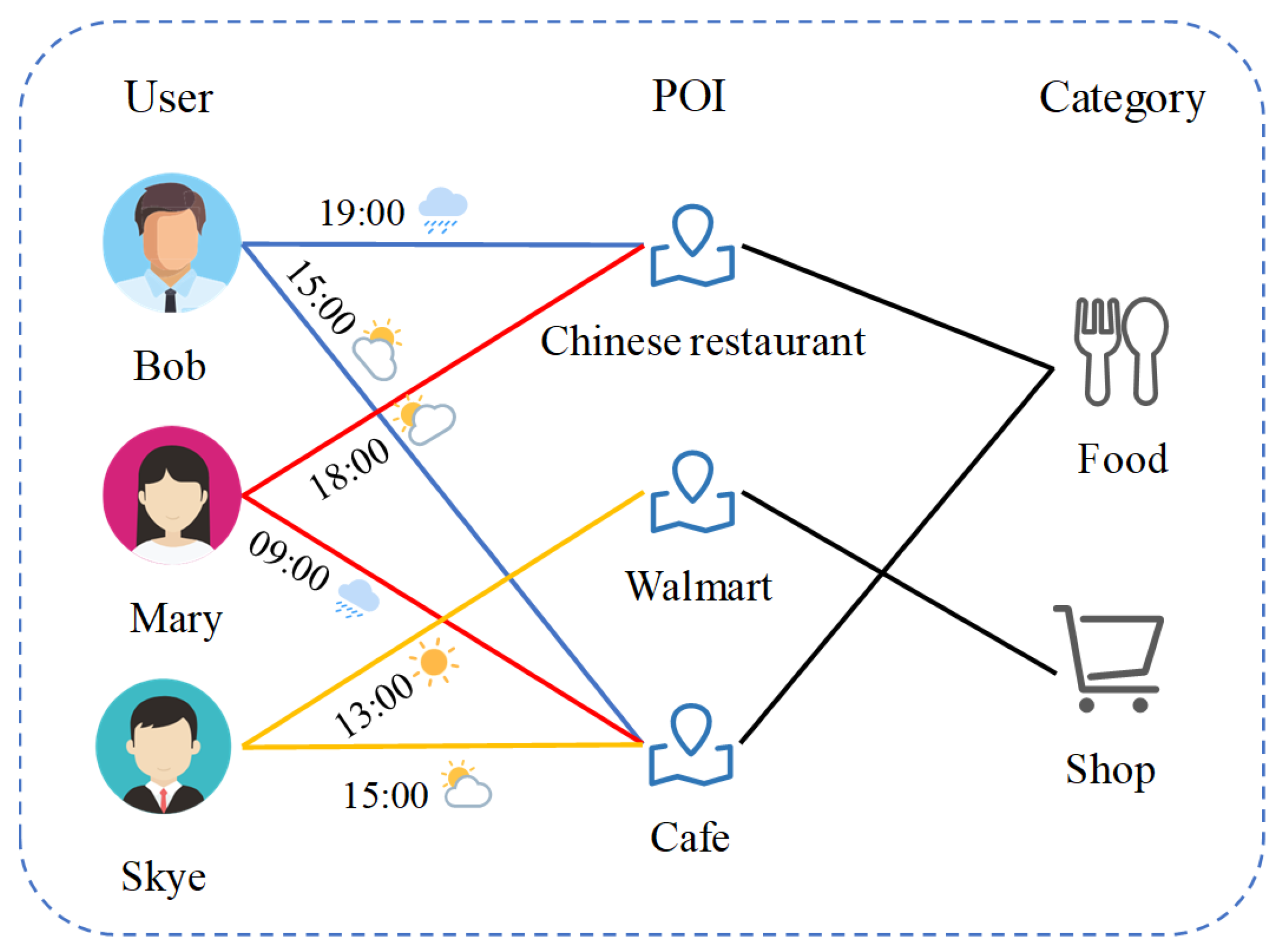
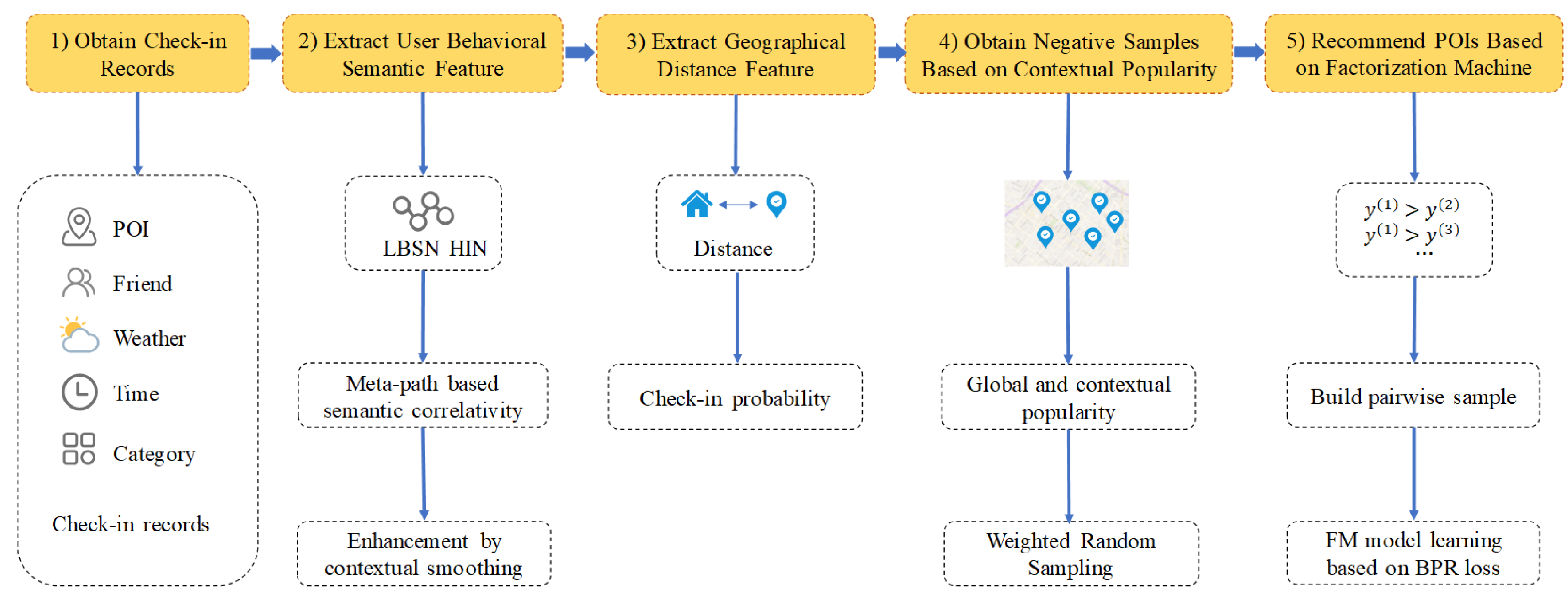
3. User Behavioral Semantic Feature Based on Check-in Contexts
3.1. Semantic Correlativity Based on Meta-Path
3.2. Enhancement by Contextual Smoothing
4. The Distances and Check-In Probabilities
5. Recommendation Model
5.1. Weighted Random Sampling Based on Contextual Popularity
5.2. Model Learning Based on Bayesian Personalized Ranking
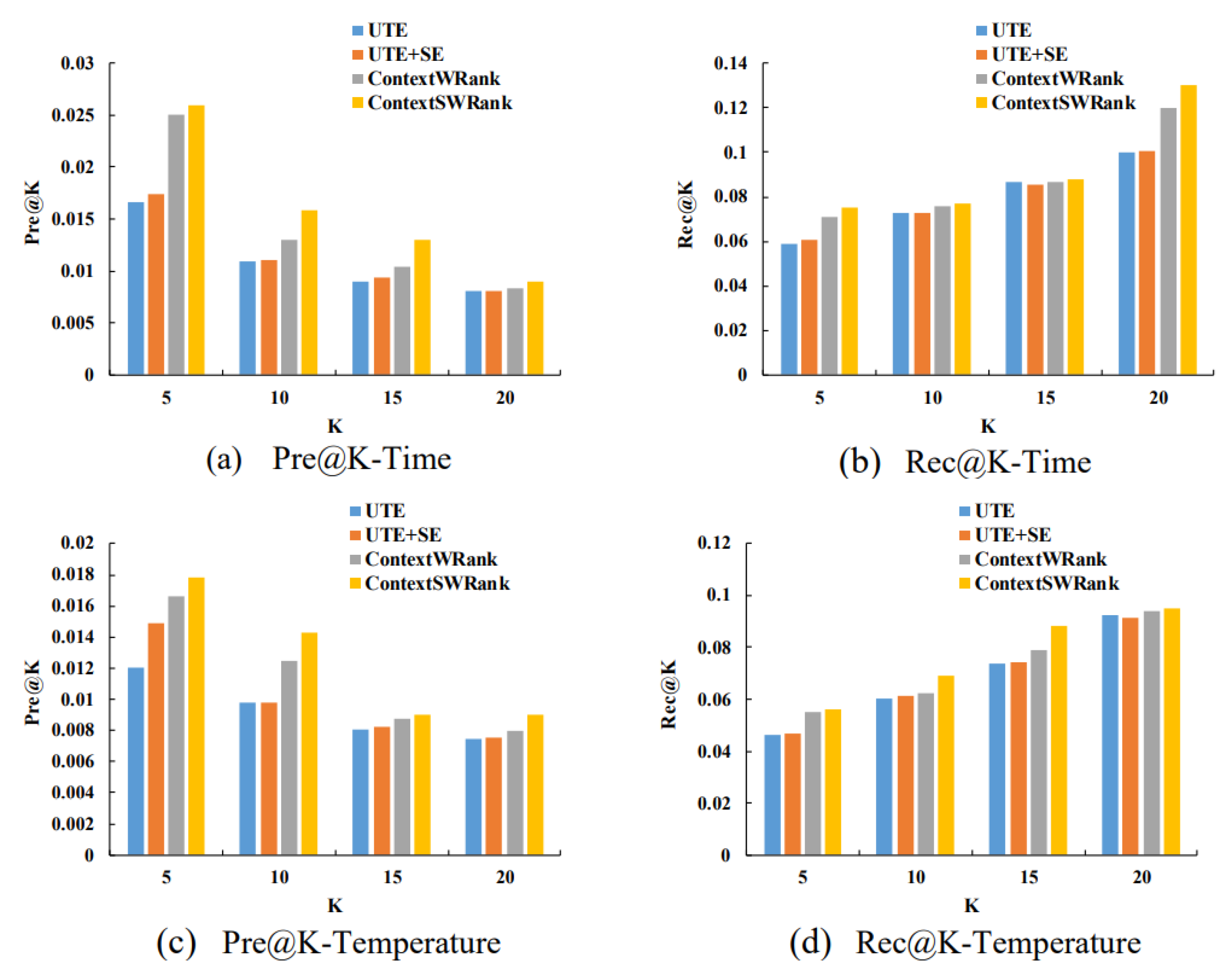
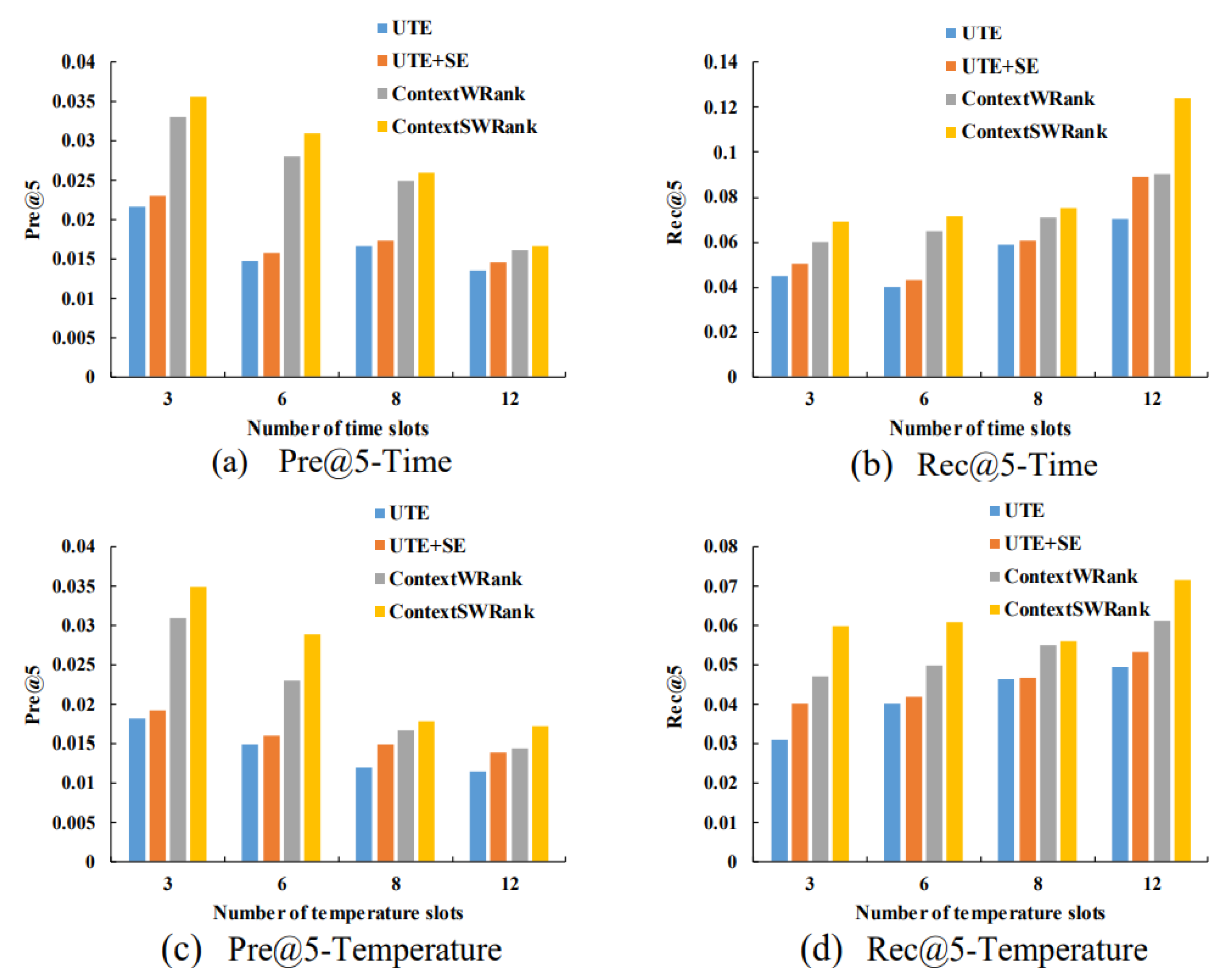
6. Experiments
- UTE [12]: A collaborative recommendation model which incorporates temporal influence for time-specific POI recommendation;
- UTE+SE [12]: A collaborative recommendation model which incorporates both temporal and geographical influence for time-specific POI recommendation;
- ContextWRank: The proposed model in this paper, but does not employ contextual smoothing method given in Section 3.2;
- ContextSWRank: The proposed model in this paper, which employ contextual smoothing method in Section 3.2.
7. Threats to Validity
8. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gao, H.; Tang, J.; Hu, X.; Liu, H. Exploring temporal effects for location recommendation on location-based social networks. In Proceedings of the Seventh ACM Conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; pp. 93–100. [Google Scholar] [CrossRef]
- Trattner, C.; Oberegger, A.; Eberhard, L.; Parra, D.; Marinho, L.B. Understanding the Impact of Weather for POI Recommendations. In CEUR Workshop Proceedings, Proceedings of the Workshop on Recommenders in Tourism Co-Located with 10th ACM Conference on Recommender Systems (RecSys 2016), Boston, MA, USA, 15 September 2016; CEUR-WS.org; Fesenmaier, D.R., Kuflik, T., Neidhardt, J., Eds.; ACM: New York, NY, USA, 2016; Volume 1685, pp. 16–23. [Google Scholar]
- Ye, M.; Yin, P.; Lee, W.; Lee, D.L. Exploiting geographical influence for collaborative point-of-interest recommendation. In SIGIR 2011, Proceeding of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, China, 25–29 July 2011; Ma, W., Nie, J., Baeza-Yates, R., Chua, T., Croft, W.B., Eds.; ACM: New York, NY, USA, 2011; pp. 325–334. [Google Scholar] [CrossRef]
- Lian, D.; Zhao, C.; Xie, X.; Sun, G.; Chen, E.; Rui, Y. GeoMF: Joint geographical modeling and matrix factorization for point-of-interest recommendation. In KDD’14, Proceeding of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24– 27 August 2014; Macskassy, S.A., Perlich, C., Leskovec, J., Wang, W., Ghani, R., Eds.; ACM: New York, NY, USA, 2014; pp. 831–840. [Google Scholar] [CrossRef]
- Liu, Y.; Pham, T.; Cong, G.; Yuan, Q. An Experimental Evaluation of Point-of-interest Recommendation in Location-based Social Networks. Proc. VLDB Endow. 2017, 10, 1010–1021. [Google Scholar] [CrossRef]
- Bao, J.; Zheng, Y.; Wilkie, D.; Mokbel, M.F. Recommendations in location-based social networks: A survey. GeoInformatica 2015, 19, 525–565. [Google Scholar] [CrossRef]
- Kulkarni, S.; Rodd, S.F. Context Aware Recommendation Systems: A review of the state of the art techniques. Comput. Sci. Rev. 2020, 37, 100255. [Google Scholar] [CrossRef]
- Ye, M.; Yin, P.; Lee, W. Location recommendation for location-based social networks. In Proceedings of the 18th ACM SIGSPATIAL International Symposium on Advances in Geographic Information Systems, San Jose, CA, USA, 3–5 November 2010; pp. 458–461. [Google Scholar] [CrossRef]
- Li, H.; Ge, Y.; Hong, R.; Zhu, H. Point-of-Interest Recommendations: Learning Potential Check-ins from Friends. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 975–984. [Google Scholar] [CrossRef]
- Cai, L.; Wen, W.; Wu, B.; Yang, X. A coarse-to-fine user preferences prediction method for point-of-interest recommendation. Neurocomputing 2021, 422, 1–11. [Google Scholar] [CrossRef]
- Aliannejadi, M.; Rafailidis, D.; Crestani, F. A Joint Two-Phase Time-Sensitive Regularized Collaborative Ranking Model for Point of Interest Recommendation. IEEE Trans. Knowl. Data Eng. 2020, 32, 1050–1063. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Q.; Cong, G.; Ma, Z.; Sun, A.; Magnenat-Thalmann, N. Time-aware point-of-interest recommendation. In Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 28 July–1 August 2013; pp. 363–372. [Google Scholar] [CrossRef]
- Yuan, Q.; Cong, G.; Sun, A. Graph-based Point-of-interest Recommendation with Geographical and Temporal Influences. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 659–668. [Google Scholar] [CrossRef]
- Si, Y.; Zhang, F.; Liu, W. An adaptive point-of-interest recommendation method for location-based social networks based on user activity and spatial features. Knowl. Based Syst. 2019, 163, 267–282. [Google Scholar] [CrossRef]
- Zhao, H.; Yao, Q.; Li, J.; Song, Y.; Lee, D.L. Meta-Graph Based Recommendation Fusion over Heterogeneous Information Networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 635–644. [Google Scholar] [CrossRef]
- Wang, Z.; Juang, J.; Teng, W. Predicting POI visits with a heterogeneous information network. In Proceedings of the Conference on Technologies and Applications of Artificial Intelligence, TAAI 2015, Tainan, Taiwan, 20–22 November 2015; pp. 388–395. [Google Scholar] [CrossRef]
- Unger, M.; Bar, A.; Shapira, B.; Rokach, L. Towards latent context-aware recommendation systems. Knowl. Based Syst. 2016, 104, 165–178. [Google Scholar] [CrossRef]
- Chang, B.; Jang, G.; Kim, S.; Kang, J. Learning Graph-Based Geographical Latent Representation for Point-of-Interest Recommendation. In Proceedings of the 29th ACM International Conference on Information and Knowledge Management, Virtual Event, Ireland, 19–23 October 2020; pp. 135–144. [Google Scholar] [CrossRef]
- Ma, Y.; Gan, M. Exploring multiple spatio-temporal information for point-of-interest recommendation. Soft Comput. 2020, 24, 18733–18747. [Google Scholar] [CrossRef]
- Yu, F.; Cui, L.; Guo, W.; Lu, X.; Li, Q.; Lu, H. A Category-Aware Deep Model for Successive POI Recommendation on Sparse Check-in Data. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 1264–1274. [Google Scholar] [CrossRef]
- Kang, W.; McAuley, J. Self-Attentive Sequential Recommendation. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 197–206. [Google Scholar] [CrossRef] [Green Version]
- Shi, C.; Li, Y.; Zhang, J.; Sun, Y.; Yu, P.S. A survey of heterogeneous information network analysis. IEEE Trans. Knowl. Data Eng. 2017, 29, 17–37. [Google Scholar] [CrossRef]
- Sun, Y.; Han, J.; Yan, X.; Yu, P.S.; Wu, T. PathSim: Meta Path-Based Top-K Similarity Search in Heterogeneous Information Networks. Proc. VLDB Endow. 2011, 4, 992–1003. [Google Scholar] [CrossRef]
- Morton, G.M. A Computer Oriented Geodetic Data Base and a New Technique in File Sequencing; Technical Report; IBM Ltd.: Ottawa, ON, Canada, 1966. [Google Scholar]
- Rendle, S. Factorization Machines. In Proceedings of the 10th IEEE International Conference on Data Mining, Sydney, Australia, 14–17 December 2010; pp. 995–1000. [Google Scholar] [CrossRef] [Green Version]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian Personalized Ranking from Implicit Feedback. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–21 June 2009; pp. 452–461. [Google Scholar]
- Harris, D.; Harris, S. Digital Design and Computer Architecture, 2nd ed.; Morgan Kaufmann: Waltham, MA, USA, 2012; p. 129. [Google Scholar]
- Efraimidis, P.S.; Spirakis, P.G. Weighted Random Sampling. In Encyclopedia of Algorithms—2008 Edition; Kao, M., Ed.; Springer: Berlin, Germany, 2008; pp. 1024–1027. [Google Scholar] [CrossRef]
- Lukacs, E. A Characterization of the Normal Distribution. Ann. Math. Stat. 1942, 13, 91–93. [Google Scholar] [CrossRef]
- Bottou, L. Stochastic Gradient Descent Tricks. In Neural Networks: Tricks of the Trade, 2nd ed.; Montavon, G., Orr, G.B., Müller, K.R., Eds.; Springer: Berlin, Germany, 2012; pp. 421–436. [Google Scholar] [CrossRef] [Green Version]
- Su, Y.; Zhang, J.D.; Li, X.; Zha, D.; Xiang, J.; Tang, W.; Gao, N. FGRec: A Fine-Grained Point-of-Interest Recommendation Framework by Capturing Intrinsic Influences. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–9. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meta-Path | Semantics |
|---|---|---|
| Users prefer locations they have | ||
| checked in | ||
| Users prefer locations where their | ||
| friends have checked in | ||
| Users prefer locations where people | ||
| with common check-in records have checked in | ||
| Users prefer the same category of locations | ||
| they have checked in | ||
| Users prefer locations where people have same | ||
| category of check-in records have checked in |
| # Users | # POIS | # Categories | # Check_ins | # Social Links | Sparsity |
|---|---|---|---|---|---|
| 2792 | 8414 | 127 | 234,049 | 14,932 | 99.61% |
| Parameter | Values |
|---|---|
| the number of context slots | 3, 6, 8, 12 |
| the adjustive parameter | 0.4 |
| the number of latent factors f | 6 |
| regularization parameters | 0.01 |
| the range of distance k when sampling | 2 |
| the number of negative samples m | 5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, D.; Shen, Y.; Xu, K.; Xu, Y. Context-Specific Point-of-Interest Recommendation Based on Popularity-Weighted Random Sampling and Factorization Machine. ISPRS Int. J. Geo-Inf. 2021, 10, 258. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10040258
Yu D, Shen Y, Xu K, Xu Y. Context-Specific Point-of-Interest Recommendation Based on Popularity-Weighted Random Sampling and Factorization Machine. ISPRS International Journal of Geo-Information. 2021; 10(4):258. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10040258
Chicago/Turabian StyleYu, Dongjin, Yi Shen, Kaihui Xu, and Yihang Xu. 2021. "Context-Specific Point-of-Interest Recommendation Based on Popularity-Weighted Random Sampling and Factorization Machine" ISPRS International Journal of Geo-Information 10, no. 4: 258. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10040258