
Reconstructing Sessions from Data Discovery and Access Logs to Build a Semantic Knowledge Base for Improving Data Discovery

 , , ,
, , ,
Abstract
:1. Introduction and Literature Review
- h1: Total session duration may not exceed a threshold α. Given t0, the timestamp for the first request in a constructed session S, the request with timestamp t is assigned to S, if t − t0 ≤ α.
- h2: Total time spent on a page may not exceed a threshold α. Given t1, the timestamp for request assigned to constructed session S, the next request with timestamp t2 is assigned to S, if t2 − t1 ≤ α.
- href: Given two consecutive requests p and q, with p belonging to constructed session S. Then q is assigned to S, if the referrer for q was previously invoked in S.
2. Data Format and Preparation
2.1. Web Log Format
2.2. Data Source
2.3. User Identification
2.4. Data Cleansing
- Well-known search engine crawlers are the easiest to detect, because they usually write their identities in the user-agent field. Therefore, they could be identified and removed by maintaining a list of known crawlers.
- Other “well-behaved” crawlers, which abide by standard robot exclusion protocols, begin their site crawl by first accessing exclusion file “robots.txt” in the server root directory. Such crawlers, can therefore, be identified by checking whether a request to the robots.txt file was made.
- Unfortunately a lot of crawlers neither identify themselves explicitly; nor deliberately masquerade as legitimate users. In this case, we examine other two important features: maximum sustained request rate and the number of request types. The rationale behind this is that there is an upper bound on the maximum number of clicks that a human can make within a specific time frame. Also, after looking into many crawler requests, we found that requests generated by humans are more diverse during their single visit.
3. Methodology for Session Identification
3.1. Threshold Selection in Time-Based Heuristics
3.2. Clustering-Based Heuristics
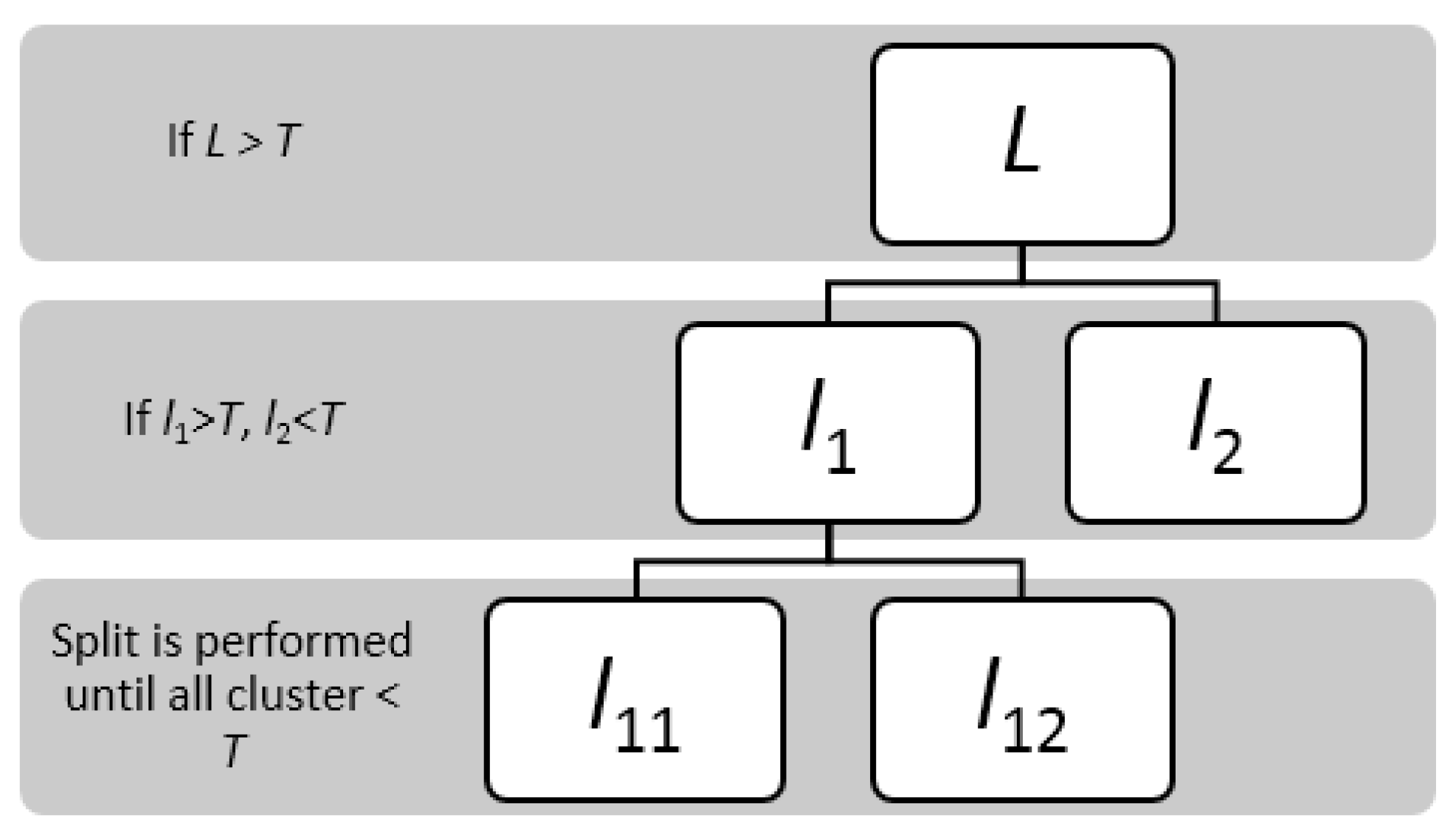
- For a given user, his or her visit is thought of as an entire cluster L. If the length of his or her visit is longer than T, all the access logs (sorted by time, including both HTTP and FTP) would be split into two clusters: l1 and l2. Threshold T could be considered as the study scale.
- If the length of l1 or l2 is longer than T, they would be split into two clusters again.
- The split process is performed recursively until all the cluster length is shorter than T.
- Calculate the sum of squared deviations between classes (SDBC).
- Calculate the sum of squared deviations from the array mean (SDAM).
- Subtract the SDBC from the SDAM (SDAM-SDBC). This equals the sum of the squared deviations from the class means (SDCM).
- After inspecting each of the SDBC, a decision is made to move one unit from the class with the largest SDBC toward the class with the lowest SDBC.
- New class deviations are then calculated, and the process is repeated until the sum of the within class deviations reaches a minimal value. Based on Jenks natural breaks optimization, the best break in step two of our clustering-based heuristic could be identified.
3.3. Time-Referrer-Based Heuristics
- If the referrer of log q is “-“, URL from other websites (e.g., commercial search engine) or the first page of website, a new session S starts.
- If the referrer r is none of the three cases in step 1, we would look for the most recent page p whose request is identical to r. Instead of simply assigning log q to session S as they do in traditional referrer-based heuristic, we calculate the time interval Tpq between p and q. Then the time interval is compared with T * N. Note that N is the number of logs between p and q, and T is the time threshold in the first section.
- If Tpq < T * N, log q is assigned to session S. Otherwise, if Tpq > T * N, or previous page is not found, a new session starts.
- After all the logs are visited, close sessions are merged together if the time interval between the ending time of one session and the starting time of the other is less than T.
- 5.
- If the time interval from the last log, either HTTP or FTP, is less than T, the FTP log is assigned to the same session and the last log. Otherwise, a new session starts.
4. Implementation and Workflow
4.1. Implementation
4.2. Workflow
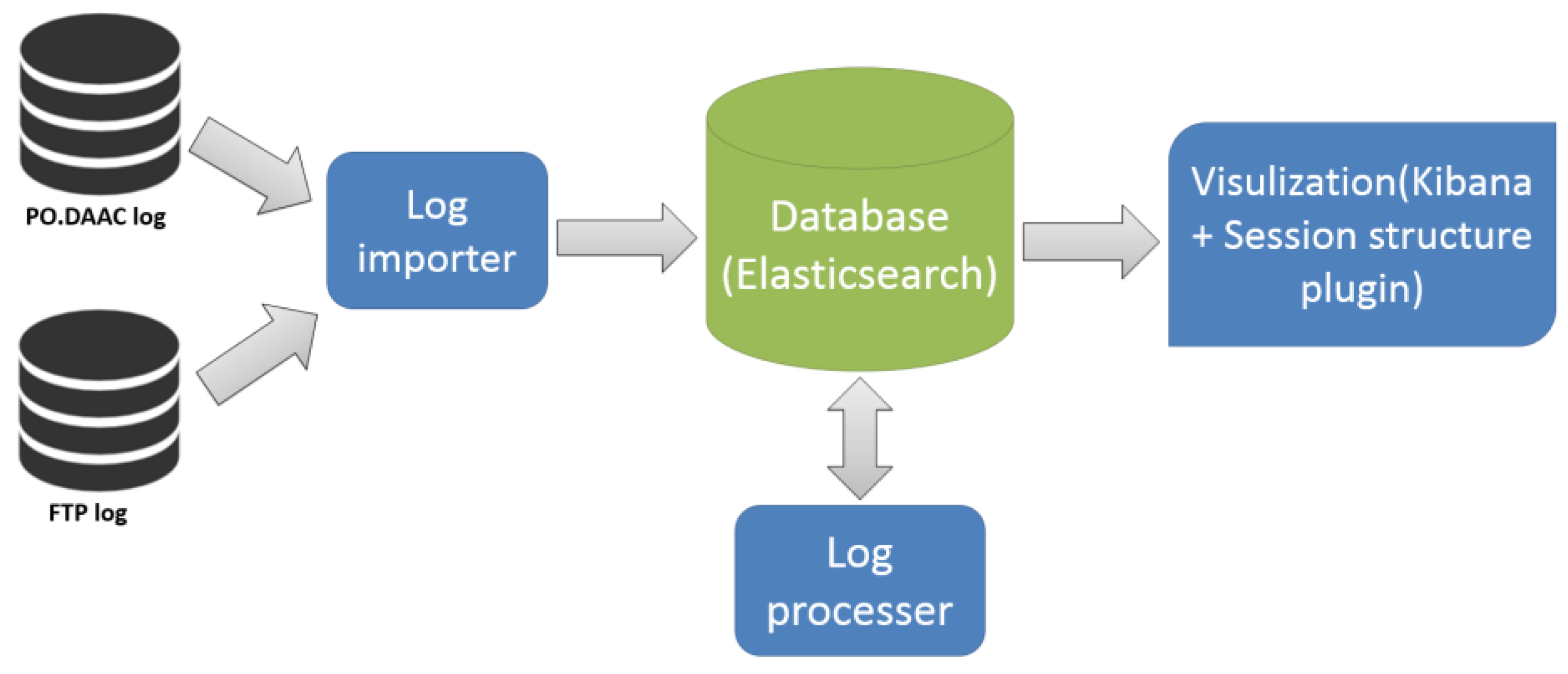
- Import HTTP logs: The first step is to import HTTP logs of PO.DAAC website into Elasticsearch. All the redundant requests (.img, .js, etc.) and part of the crawler requests are removed based on the known crawler list. Only HTML requests are parsed and imported into database for further processing. The input is 4, 191, 741 raw HTTP logs, and the output is 297, 569 HTML requests in JSON format.
- Import FTP logs: Since there is no user-agent information which is used to compare with crawler list, all the FTP logs (3, 174, 458 logs) are imported into Elasticsearch.
- Synchronize HTTP and FTP logs: Although the combination of user-agent and IP address is preferable, unique user is identified only through IP address since there is no user-agent in FTP log. IPs with maximum sustained request rate greater than two requests are removed from the database. After this step, we found 7536 unique users with 901, 945 logs.
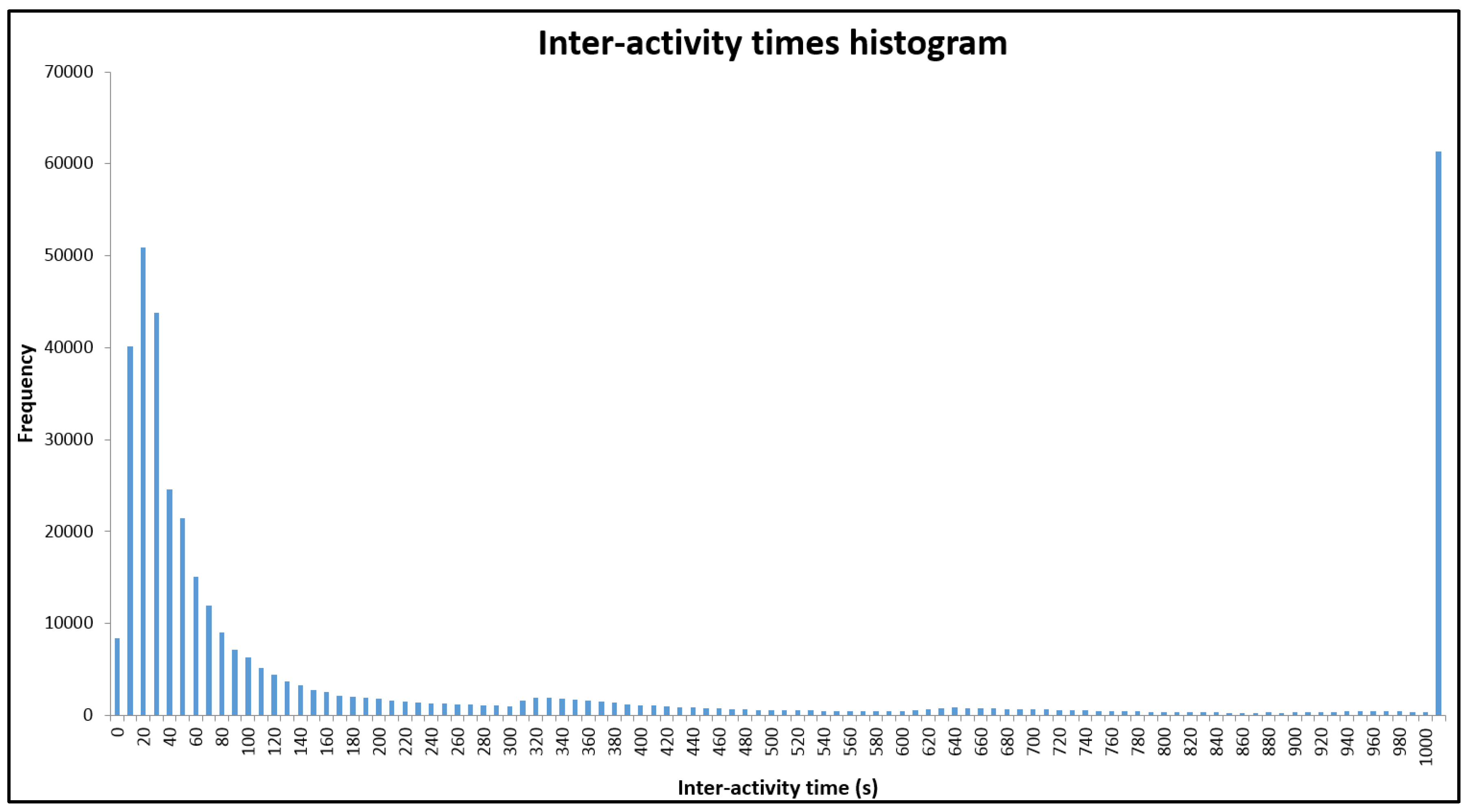
- Time threshold selection: After user identification, we plot the inter-activity histogram based on what we described in the methodology part. Because the expected value of the second curve is several days, we left it out and only focus on the first normal distribution curve. After calculation, we found that the critical value at 97.5% confidence level is around 10 min (596.73 s) (Figure 3).
- Session identification: Both session identification methods are experimented in this step. 15,783 user sessions are found. Based on this result, we further filter session by using the number of request types. Specifically, the numbers of searching, viewing, and downloading requests are required to be no less than 1. When one of the requests is missing (less than 1), the session will not provide valid knowledge as needed for data discovery. In this way, the actual user session that only contains one or two of them, and the remaining sessions that were generated by crawlers, are finally removed. In the end, 414 sessions are identified after this step.
- Similarly, 34,604 user sessions are identified with time-clustering-based heuristics when T is set 30 min, and they are narrowed down to 471 user sessions that contain all three types of requests.
- Structure reconstruction: The last step is to reconstruct the session based on referrer. Note that FTP logs are attached to the nearest viewing request in this process.
5. Results
5.1. Comparison of Session Identification Heuristics
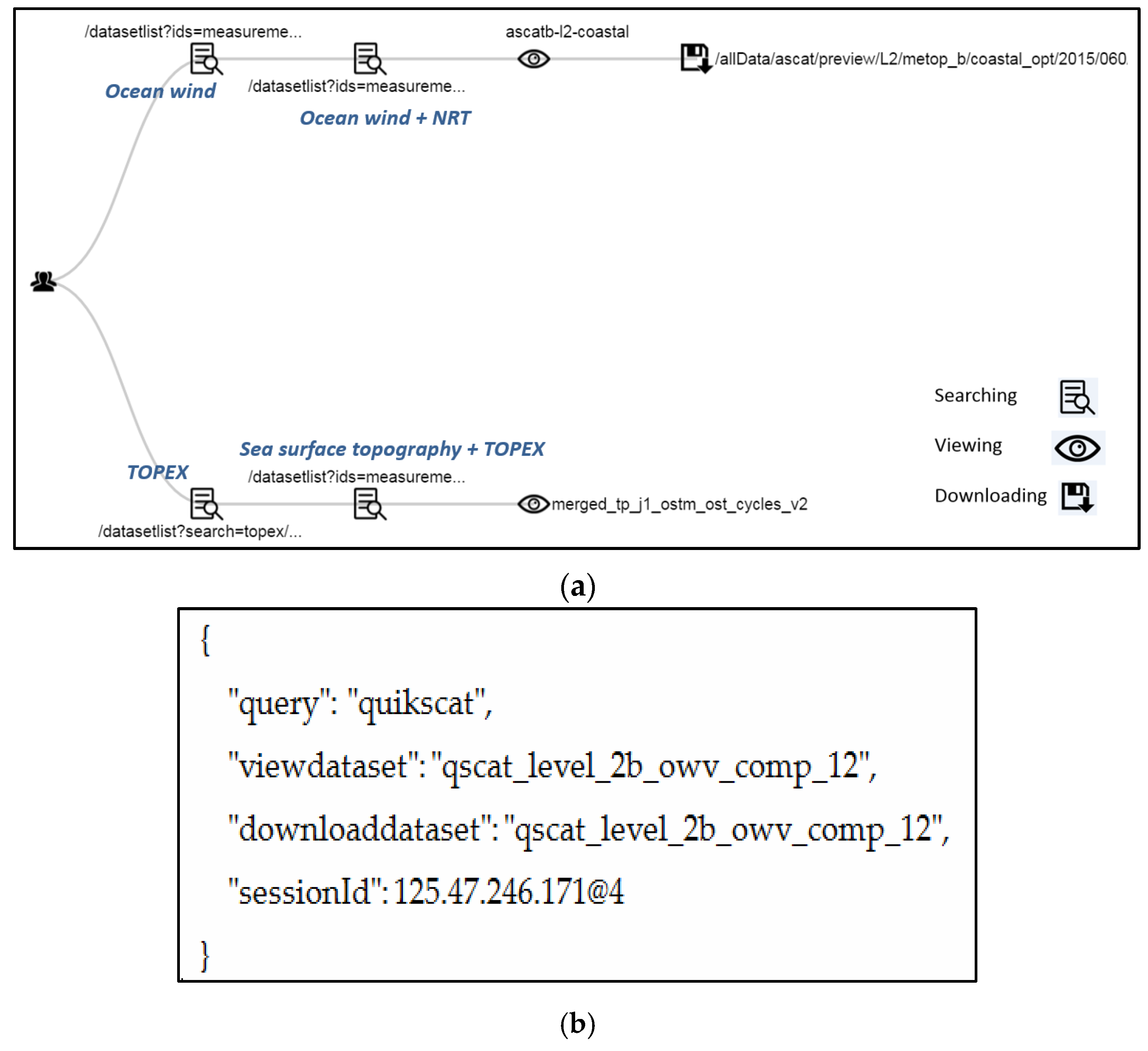
5.2. Session Structure
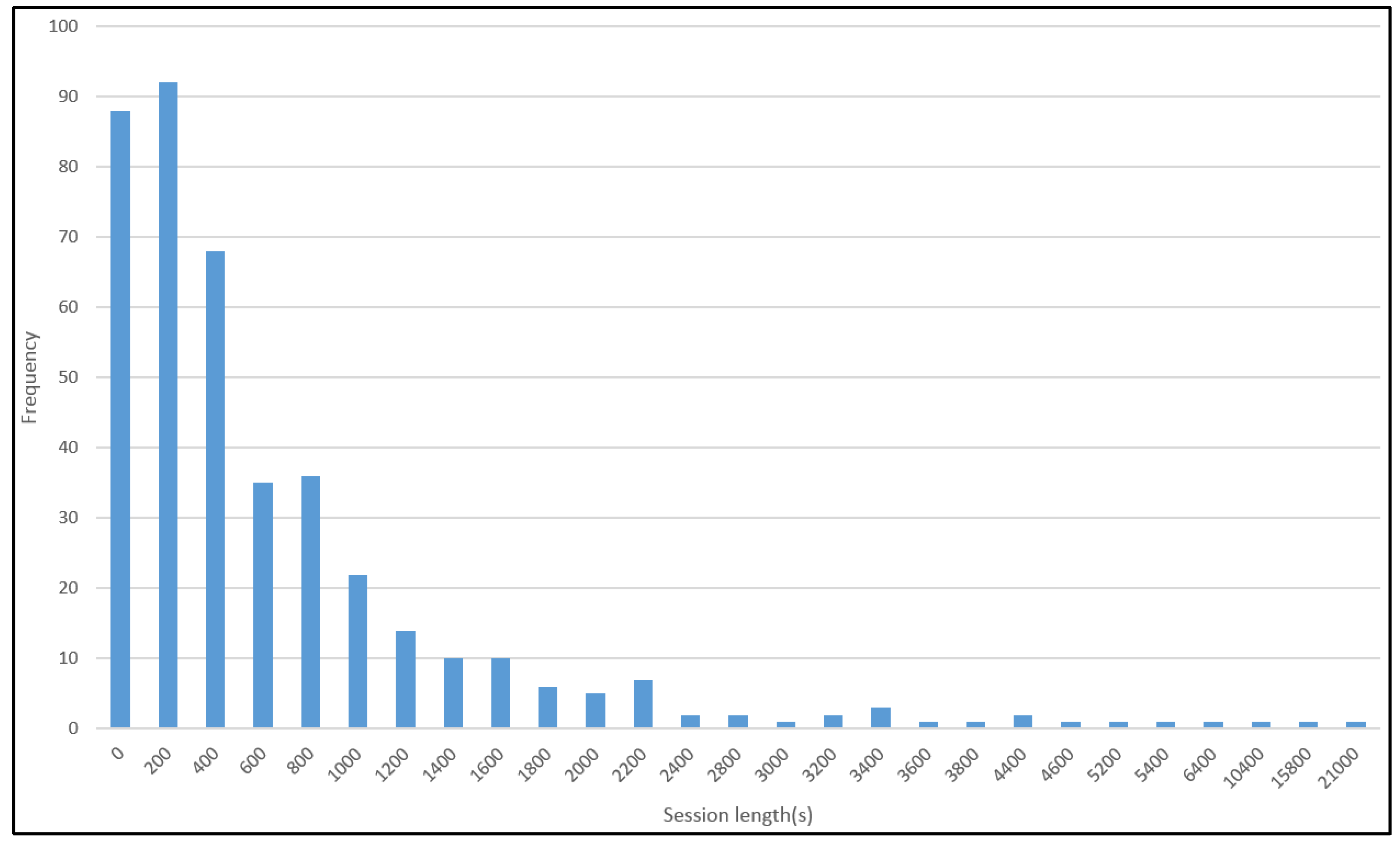
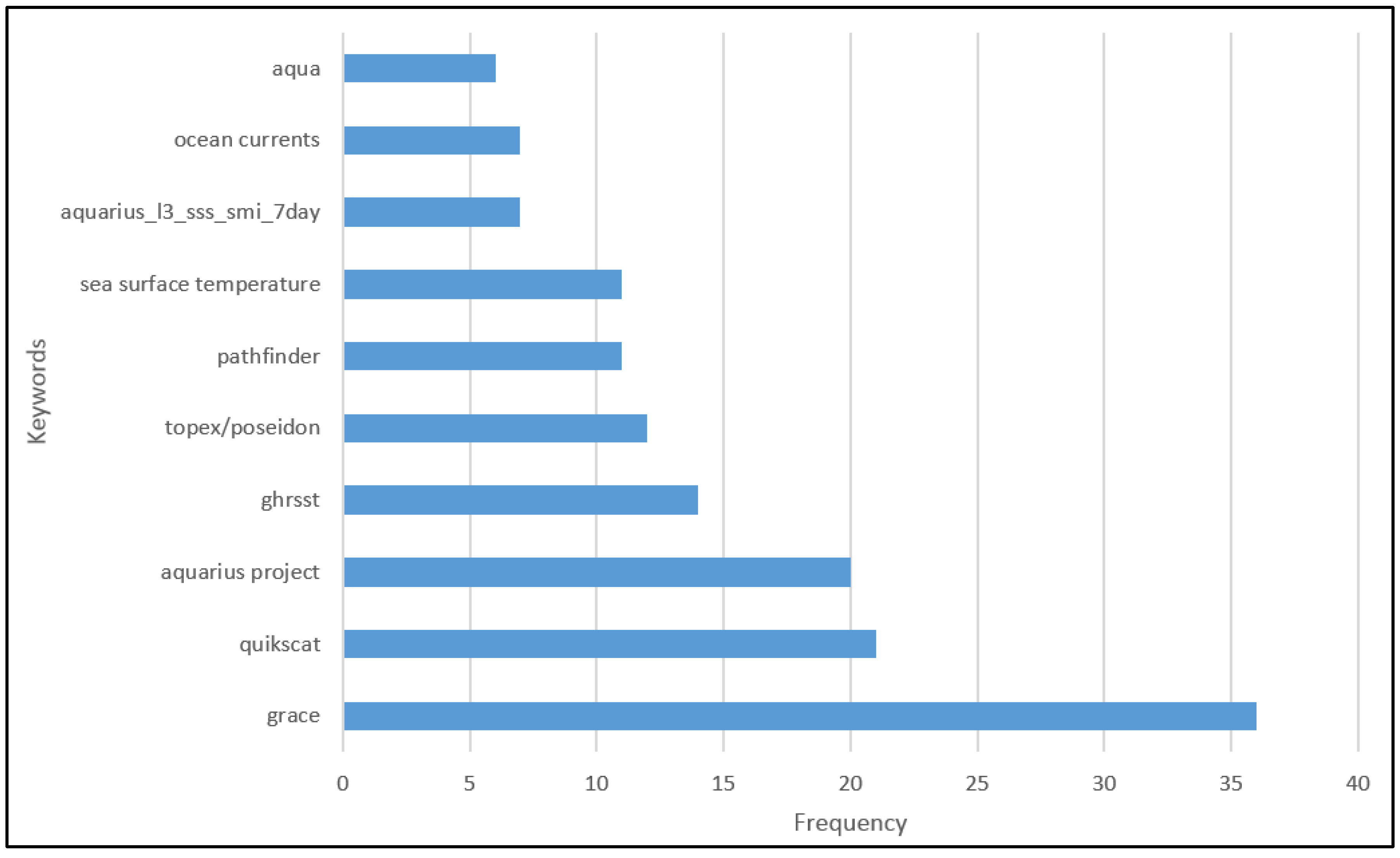
5.3. Session Length Histogram and Keywords Popularity
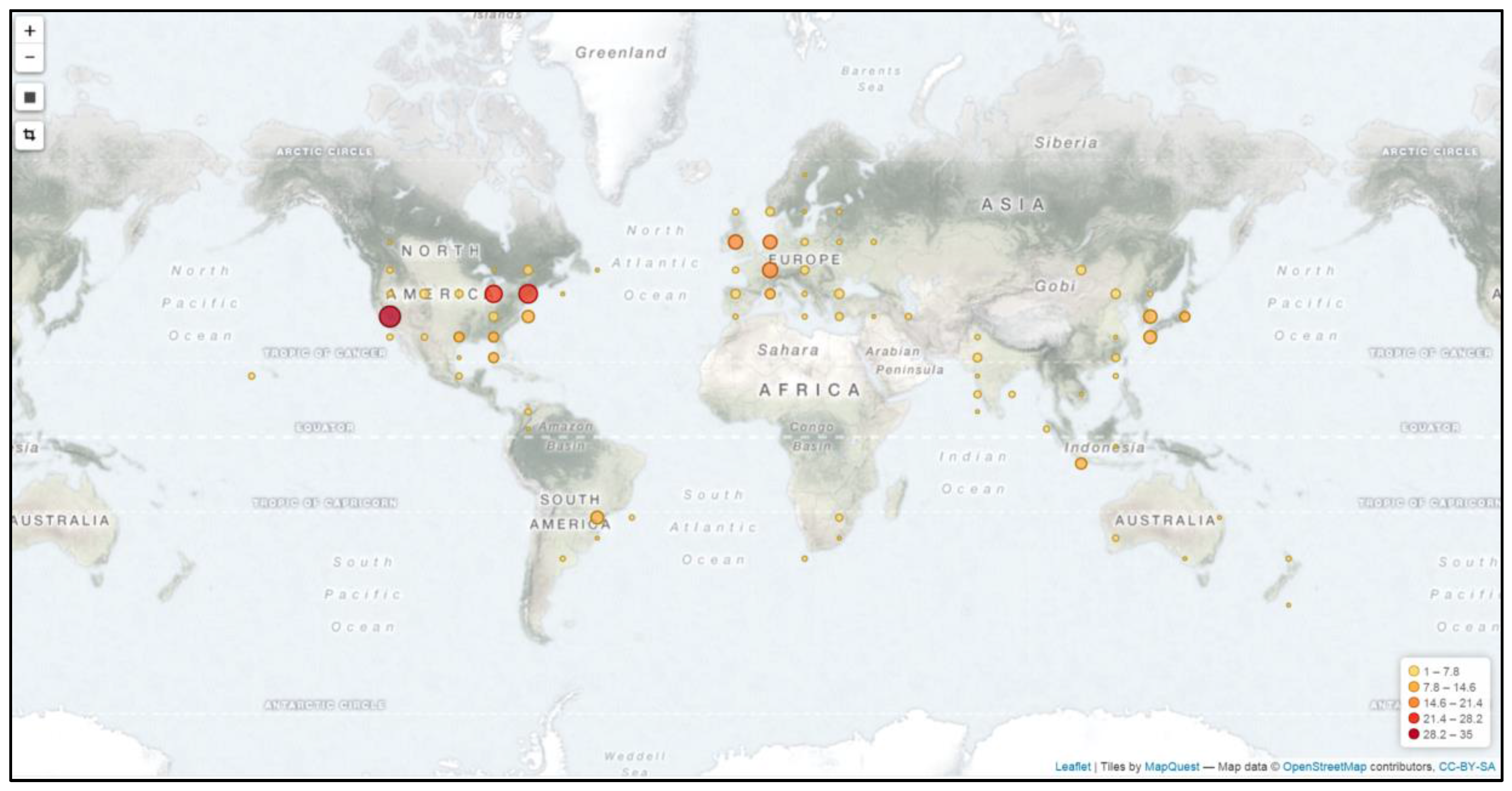
5.4. Website Traffic and User Location (Heatmap)
6. Discussion and Conclusions
- The proposed selection method based on inter-activity statistical threshold provides more confidence for further analysis in contrast to the empirical time threshold.
- In comparison to the standard referrer-based heuristic, the time-referrer-based heuristic improves the performance from two aspects by introducing a time component: First, close referrer-based tasks are connected to form an actual session, which means the connections among these close tasks are kept this way. Second, a time component adds a dynamic time frame as a restriction to the searching of the previous page, which avoids the generation of an unreasonably long session.
- When compared with the standard time-based heuristics, clustering-based heuristic addresses the limitation of a fixed threshold by building a hierarchy of clusters on the time dimension.
- The workflow of session reconstruction from multiple servers has proven to be able to extract and visualize valuable information from raw log data, which has laid the foundation of discovering keyword and dataset relationships. Furthermore, this information is easy to generalize and reuse in other web usage mining research.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Vatsavai, R.R.; Ganguly, A.; Chandola, V.; Stefanidis, A.; Klasky, S.; Shekhar, S. Spatiotemporal data mining in the era of big spatial data: Algorithms and applications. In Proceedings of the 1st ACM SIGSPATIAL International Workshop on Analytics for Big Geospatial Data, Redondo Beach, CA, USA, 7–9 November 2012.
- Gui, Z.; Yang, C.; Xia, J.; Liu, K.; Xu, C.; Li, J.; Lostritto, P. A performance, semantic and service quality-enhanced distributed search engine for improving geospatial resource discovery. Int. J. Geograph. Inf. Sci. 2013, 27, 1109–1132. [Google Scholar] [CrossRef]
- Yang, C.; Sun, M.; Liu, K.; Huang, Q.; Li, Z.; Gui, Z.; Jiang, Y.; Xia, J.; Yu, M.; Xu, C.; Lostritto, P. Contemporary computing technologies for processing big spatiotemporal data. In Space-Time Integration in Geography and GIScience; Springer Netherlands, 2015; pp. 327–351. [Google Scholar]
- Langille, A.N.; Meyer, C.D. Google’s PageRank and Beyond: The Science of Search Engine Rankings. Available online: http://geza.kzoo.edu/~erdi/patent/langvillebook.pdf (accessed on 3 January 2016).
- Lei, Y.; Uren, V.; Motta, E. Semsearch: A Search Engine for the Semantic Web. Available online: http://kmi.open.ac.uk/publications/pdf/semsearch_paper.pdf (accessed on 3 January 2016).
- Srivastava, J.; Cooley, R.; Deshpande, M.; Tan, P.-N. Web Usage Mining: Discovery and Applications of Usage Patterns from Web Data. Available online: http://nlp.uned.es/WebMining/Tema5.Uso/srivastava2000.pdf (accessed on 3 January 2016).
- Romero, C.; Espejo, P.G.; Zafra, A.; Romeroand, J.R.; Ventura, S. Web usage mining for predicting final marks of students that use Moodle courses. Comput. Appl. Eng. Educ. 2013, 21, 135–146. [Google Scholar] [CrossRef]
- Berendt, B.; Mobasher, B.; Nakagawa, M.; Spiliopoulou, M. The impact of site structure and user environment on session reconstruction in web usage analysis. In WEBKDD 2002-Mining Web Data for Discovering Usage Patterns and Profiles; Springer: Berlin, Germany, 2003; pp. 159–179. [Google Scholar]
- Zhang, J.; Ghorbani, A. The reconstruction of user sessions from a server log using improved time-oriented heuristics. In Proceedings of the Second Annual Conference on Communication Networks and Services Research, Fredericton, NB, Canada, 19–21 May 2004.
- Sharma, N.; Makhija, P. Web Usage Mining: A Novel Approach for Web User Session Construction. Glob. J. Comput. Sci. Technol. 2015, 15, 23–27. [Google Scholar]
- Jones, R.; Klinkner, K.L. Beyond the session timeout: Automatic hierarchical segmentation of search topics in query logs. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008.
- Cooley, R.; Mobasher, B.; Srivastava, J. Data preparation for mining world wide web browsing patterns. Knowl. Inf. Syst. 1999, 1, 5–32. [Google Scholar] [CrossRef]
- Halfaker, A.; Keyes, O.; Kluver, D.; Thebault-Spieker, J.; Nguyen, T.; Shores, K.; Uduwage, A.; Warncke-Wang, M. User session identification based on strong regularities in inter-activity time. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015.
- Pei, J.; Han, J.; Mortazavi-asl, B.; Zhu, H. Mining Access Patterns Efficiently from Web Logs. Available online: http://www.cse.msu.edu/~cse960/Papers/usagemining/pei00mining.pdf (accessed on 3 January 2016).
- Zaiane, O.R.; Xin, M.; Han, J. Discovering web access patterns and trends by applying OLAP and data mining technology on web logs. In Proceedings of the IEEE International Forum on Research and Technology Advances in Digital Libraries, ADL 98, Santa Barbara, CA, USA, 22–24 April 1998.
- Spiliopoulou, M.; Mobasher, B.; Berendt, B.; Nakagawa, M. A framework for the evaluation of session reconstruction heuristics in web-usage analysis. Inf. J. Comput. 2003, 15, 171–190. [Google Scholar] [CrossRef]
- Liu, B. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data; Springer Science & Business Media: Berlin, Germany, 2007. [Google Scholar]
- Tanasa, D.; Trousse, B. Advanced data preprocessing for intersites web usage mining. IEEE Intell. Syst. 2004, 19, 59–65. [Google Scholar] [CrossRef]
- Tanasa, D. Web Usage Mining: Contributions to Intersites Logs Preprocessing and Sequential Pattern Extraction with Low Support. Available online: https://tel.archives-ouvertes.fr/tel-00178870/document (accessed on 1 January 2016).
- Apache. Apache HTTP Server Version 2.4. Available online: http://httpd.apache.org/docs/current/logs.html#combined (accessed on 1 January 2016).
- Castaglia. ProFTPD Server Logfile. 2009. Available online: http://www.castaglia.org/proftpd/doc/xferlog.html (accessed on 1 January 2016).
- Romero, C.; Ventura, S.; García, E. Data mining in course management systems: Moodle case study and tutorial. Comput. Educ. 2008, 51, 368–384. [Google Scholar] [CrossRef]
- Doran, D.; Gokhale, S.S. Web robot detection techniques: Overview and limitations. Data Min. Knowl. Discov. 2011, 22, 183–210. [Google Scholar] [CrossRef]
- Benaglia, T.; Chauveau, D.; Hunter, D.R.; Young, D.S. Mixtools: An R package for analyzing finite mixture models. J. Stat. Softw. 2009, 32, 1–29. [Google Scholar] [CrossRef]
- Jenks, G.F. The data model concept in statistical mapping. Int. Yearb. Cartogr. 1967, 7, 186–190. [Google Scholar]
- ESRI. What Is the JENKS Optimization Method? 2012. Available online: http://support.esri.com/en/knowledgebase/techarticles/detail/26442 (accessed on 3 January 2016).
- Yang, C.; Xu, Y.; Nebert, D. Redefining the possibility of digital Earth and geosciences with spatial cloud computing. Int. J. Digit. Earth 2013, 6, 297–312. [Google Scholar] [CrossRef]
- Liu, K.; Yang, C.; Li, W.; Gui, Z.; Xu, C.; Xia, J. Using semantic search and knowledge reasoning to improve the discovery of earth science records: An example with the ESIP semantic testbed. Int. J. Appl. Geos. Res. 2014, 5, 44–58. [Google Scholar] [CrossRef]
- Yang, C.; Li, W.; Xie, J.; Zhou, B. Distributed geospatial information processing: Sharing distributed geospatial resources to support Digital Earth. Int. J. Digit. Earth 2008, 1, 259–278. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| <IP> - - <Date> <Method> <Request> <Protocol> <Code> <Bytes> <Referrer> <User-agent> |
|---|
| 68.180.228.99 - - [31/Jan/2015:23:59:13 -0800] "GET /datasetlist/... HTTP/1.1" 200 84779 "-" "Mozilla/5.0 ..." |
| 185.10.104.195 - - [31/Jan/2015:23:59:19 -0800] "GET /datasetlist/... HTTP/1.1" 200 83486 "-" "Mozilla/5.0 ..." |
| 185.10.104.196 - - [31/Jan/2015:23:59:25 -0800] "GET /datasetlist... HTTP/1.1" 200 84357 "-" "Mozilla/5.0 ..." |
| 198.118.243.101 - - [31/Jan/2015:23:59:37 -0800] "GET /dataset/... HTTP/1.0" 200 117223 "-" "gsa-crawler..." |
| <Date > <Transfer-time > <IP > <File-size > <File-name > <Transfer-type >_< Transfer-direction > < Access-mode > < User-name >< Service > < Authentication-method >*< Completion-status > |
|---|
| Mon Feb 16 23:43:29 2015 1 66.249.65.134 698872 /allData/... b _ o a lftp@ ftp 0 * c |
| Mon Feb 16 23:43:29 2015 1 130.54.59.5 103307 /allData/... b _ o a lftp@ ftp 0 * c |
| Mon Feb 16 23:43:30 2015 1 130.54.59.5 103455 /allData/... b _ o a lftp@ ftp 0 * c |
| Mon Feb 16 23:43:30 2015 1 66.249.65.142 168421 /allData/... b _ o a lftp@ ftp 0 * c |
| No. | Time | URL | Referrer | Traditional Referrer-Based | Intermediate Result of Proposed Method | Final Result of Proposed Method |
|---|---|---|---|---|---|---|
| 1 | 2015-12-30 12:00:00 | A | - | 1 | 1 | 1 |
| 2 | 2015-12-30 12:01:00 | B | A | 1 | 1 | 1 |
| 3 | 2015-12-30 12:03:00 | C | B | 1 | 1 | 1 |
| 4 | 2015-12-30 12:05:00 | D | B | 1 | 1 | 1 |
| 5 | 2015-12-30 12:53:00 | E | F | 2 | 2 | 2 |
| 6 | 2015-12-30 12:55:00 | G | E | 2 | 2 | 2 |
| 7 | 2015-12-30 13:06:00 | H | D | 1 | 3 | 2 |
| 8 | 2015-12-30 13:43:00 | A | - | 3 | 4 | 3 |
| 9 | 2015-12-30 13:45:00 | B | - | 4 | 5 | 3 |
| 10 | 2015-12-31 02:06:00 | I | D | 1 | 6 | 4 |
| Time | Request | Referrer | Type | Time-Clustering | Time-Referrer |
|---|---|---|---|---|---|
| 07:19:33 | /ghrsst/ | - | HTTP | 1 | 1 |
| 07:20:04 | /datasetlist?search=ghrsst | /ghrsst/ | HTTP | 1 | 1 |
| 07:20:30 | /datasetlist?ids=processinglevel&values=*4*&search=ghrsst&view=list | /datasetlist?search=GHRSST | HTTP | 1 | 1 |
| 07:20:34 | /datasetlist?ids=processinglevel&values=*3*&search=ghrsst&view=list | /datasetlist?search=GHRSST | HTTP | 1 | 1 |
| 07:20:52 | /dataset/jpl_ourocean-l4uhfnd-glob-g1sst?ids=processinglevel&values=*4*&search=ghrsst | /datasetlist?ids=ProcessingLevel&values=*4*&search=GHRSST&view=list | HTTP | 1 | 1 |
| 07:20:21 | /allData/aquarius/L3/mapped/V3/annual/SCI | - | FTP | 1 | 1 |
| 07:51:43 | /avhrr-pathfinder | /ghrsst/ | HTTP | 2 | 1 |
| 07:57:00 | /seasurfacetemperature | /AVHRR-Pathfinder | HTTP | 2 | 1 |
| Session ID | Keyword 1 | Keyword 2 | Keyword 3 | Keyword 4 |
|---|---|---|---|---|
| 1 | qscat | Ascat | ||
| 2 | pathfinder | Modis | ostia | |
| 3 | ghrsst | Pathfinder | ||
| 4 | pathfinder | Ghrsst | ||
| 5 | quickscat | Qscat | rapidscat | ascat |
| 6 | salinity | aquarius project | ||
| 7 | geos-3 | topex/poseidon | jason-1 | |
| 8 | long | Ascat | ||
| 9 | sea level | wind data | climatology sst | sst |
| 10 | orumieh | aquarius project | ||
| 11 | ocean wind | wind speed | quikscat | |
| 12 | Quikscat | Ascat |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Y.; Li, Y.; Yang, C.; Armstrong, E.M.; Huang, T.; Moroni, D. Reconstructing Sessions from Data Discovery and Access Logs to Build a Semantic Knowledge Base for Improving Data Discovery. ISPRS Int. J. Geo-Inf. 2016, 5, 54. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5050054
Jiang Y, Li Y, Yang C, Armstrong EM, Huang T, Moroni D. Reconstructing Sessions from Data Discovery and Access Logs to Build a Semantic Knowledge Base for Improving Data Discovery. ISPRS International Journal of Geo-Information. 2016; 5(5):54. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5050054
Chicago/Turabian StyleJiang, Yongyao, Yun Li, Chaowei Yang, Edward M. Armstrong, Thomas Huang, and David Moroni. 2016. "Reconstructing Sessions from Data Discovery and Access Logs to Build a Semantic Knowledge Base for Improving Data Discovery" ISPRS International Journal of Geo-Information 5, no. 5: 54. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5050054