
Ontology-Guided Image Interpretation for GEOBIA of High Spatial Resolution Remote Sense Imagery: A Coastal Area Case Study

Abstract
:1. Introduction
2. Methodology
2.1. Ontology-Guided Image Interpretation for Image Object
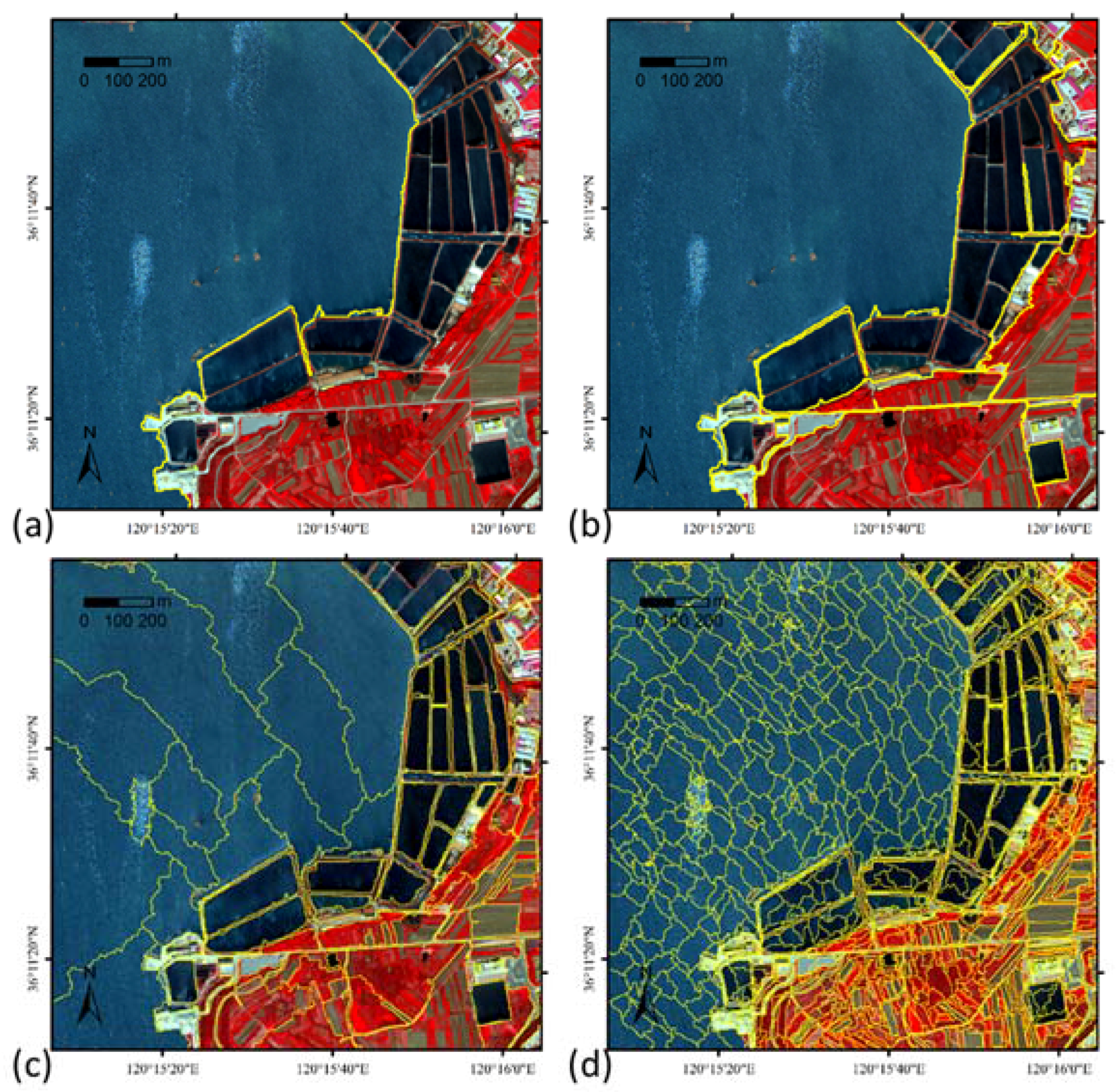
2.2. Multi-Scaled Segmentation and Evaluation
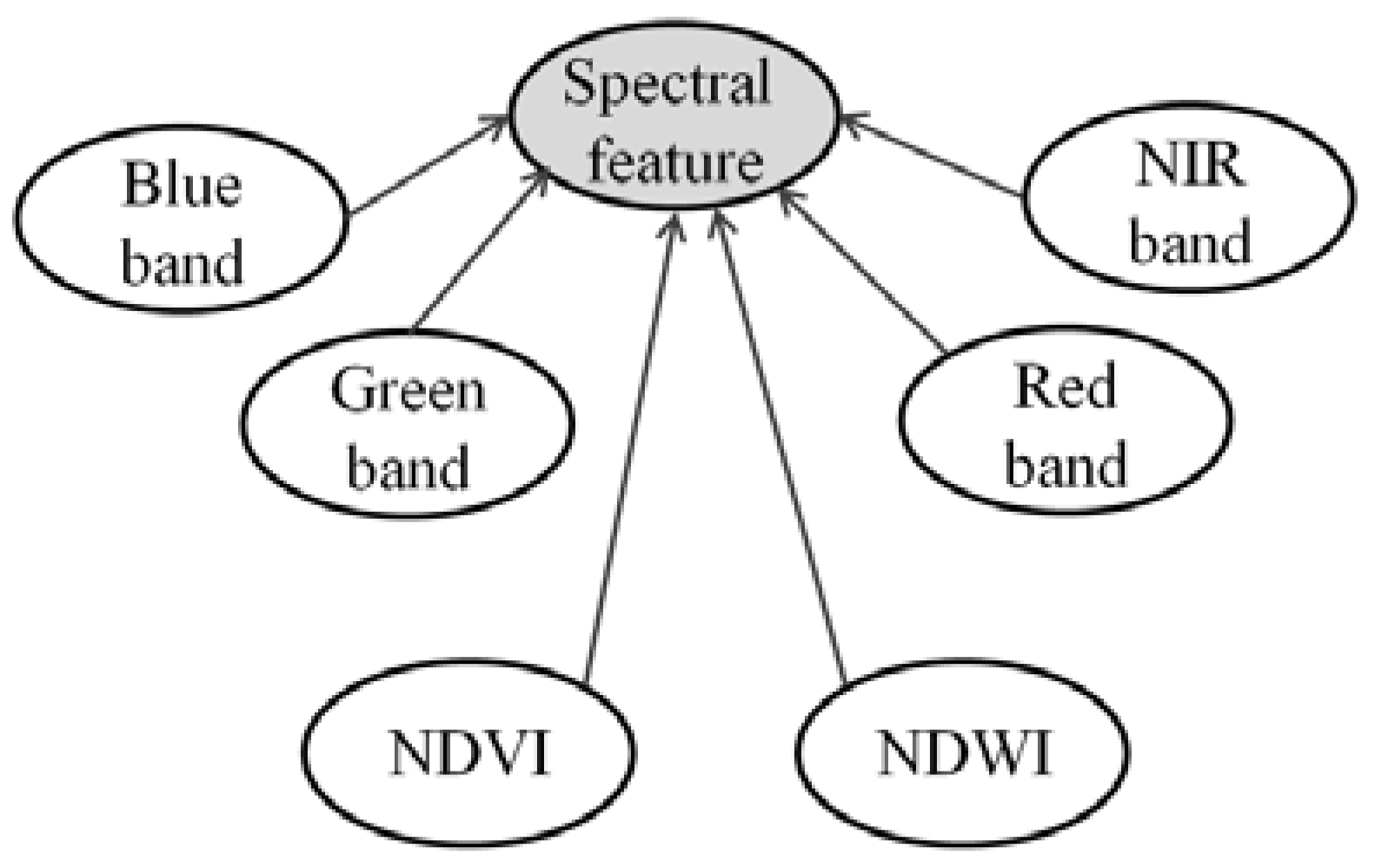
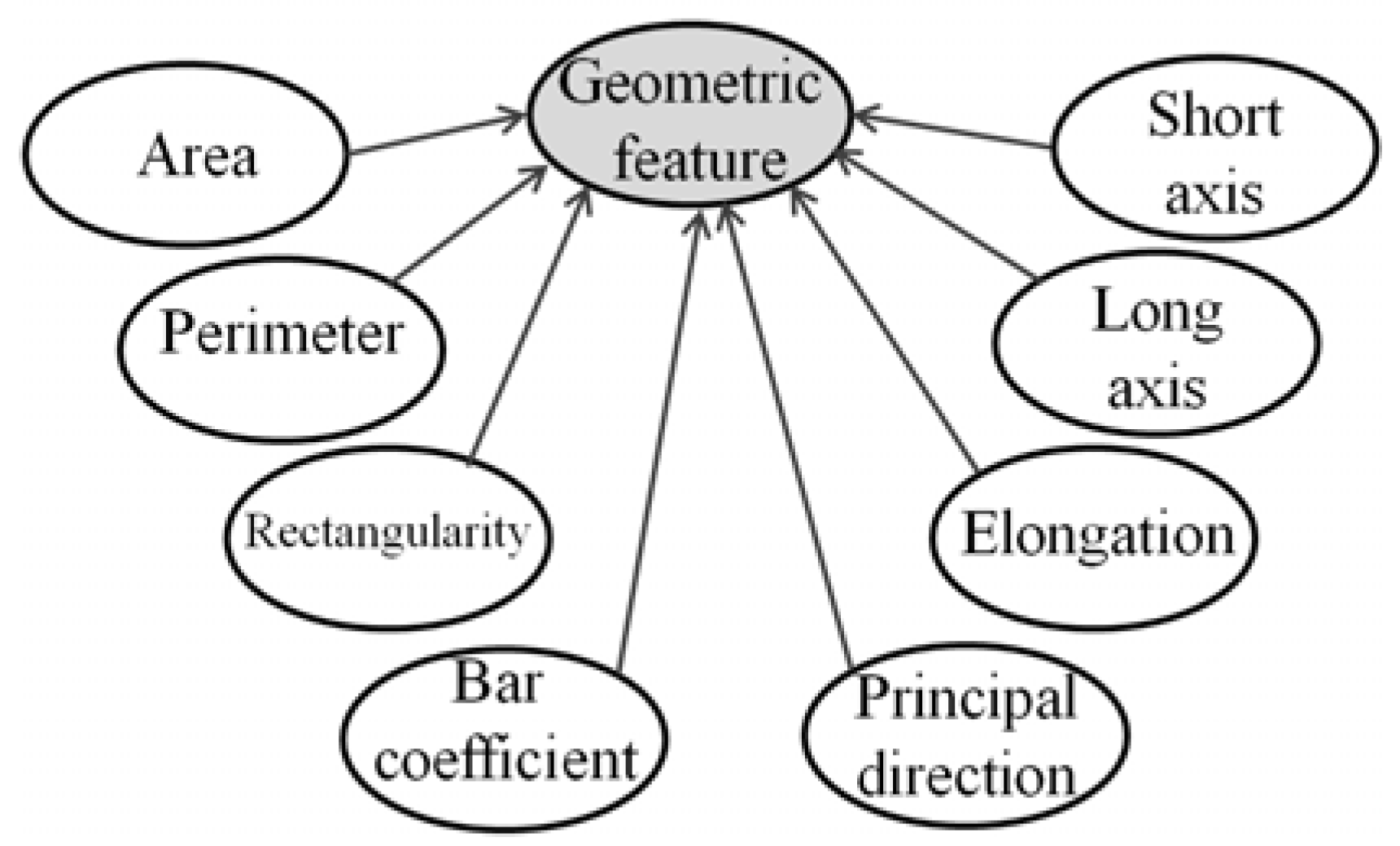
2.3. Feature Extraction
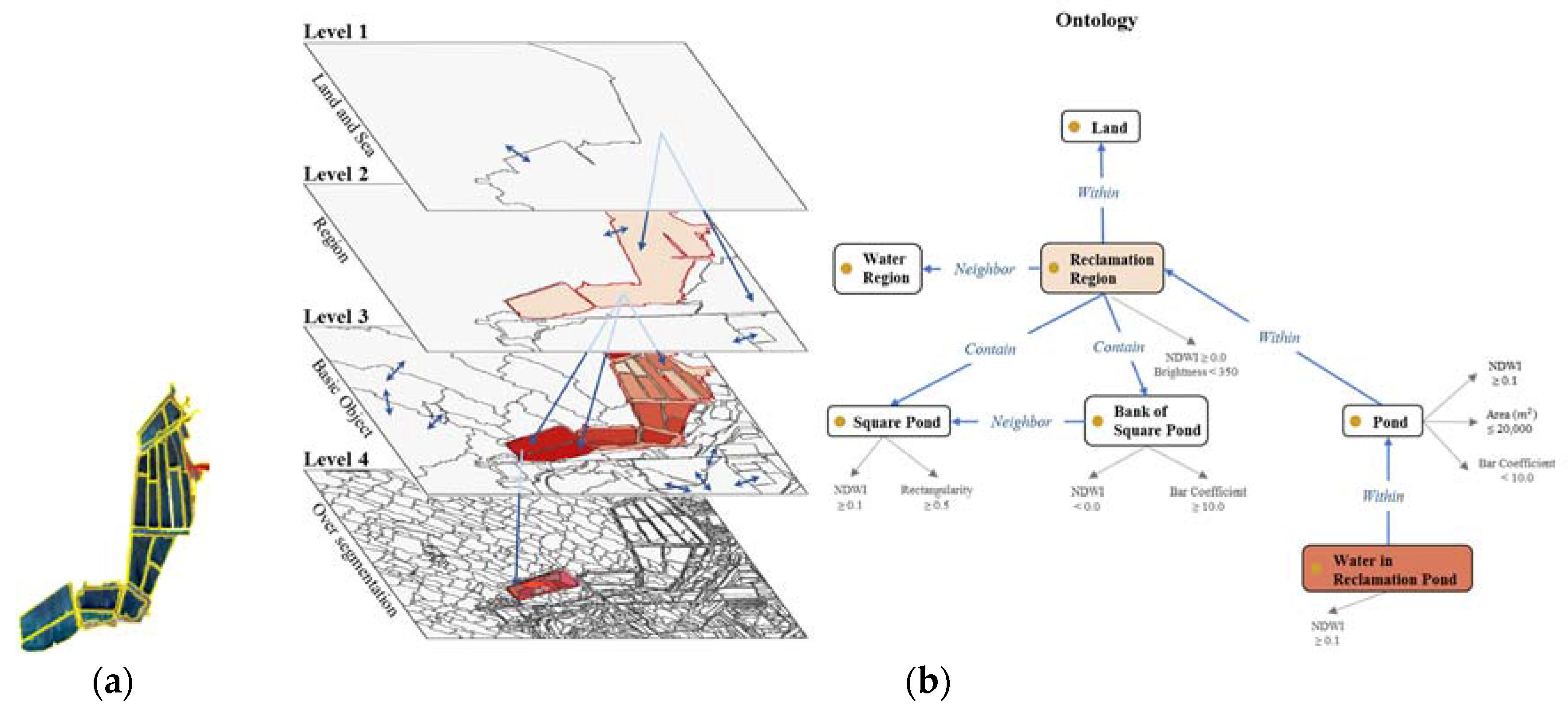
2.4. Geographical Ontology for a Coastal Area
2.4.1. Ontology
2.4.2. Concept Definition Working with Multi-Scaled Image Objects
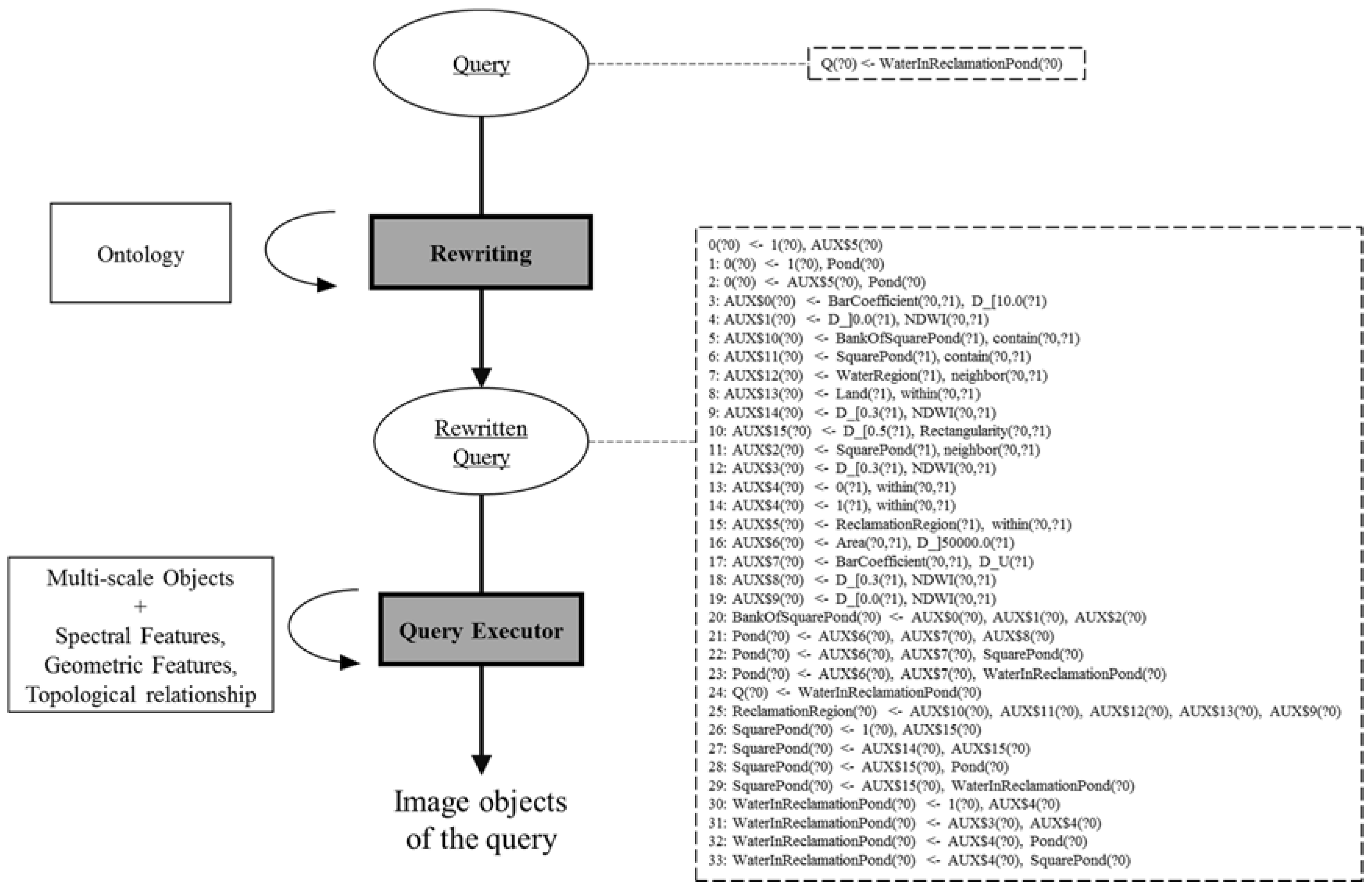
2.5. OWL-QL Query and Anwser
- The user specifies a query in the form of a conjunctive query, for instance, the query WaterInReclamationPond(x) to retrieve this kind of image objects.
- Using ontology that only contains concept descriptions, the query is rewritten into a set of queries still in the form of a conjunctive query, which means the query is extended by the ontology according to inference rules. This process is called rewriting-based reasoning.
- Rewritten queries are answered using the database or ontology that only stores the instances and its properties.
3. Case Study
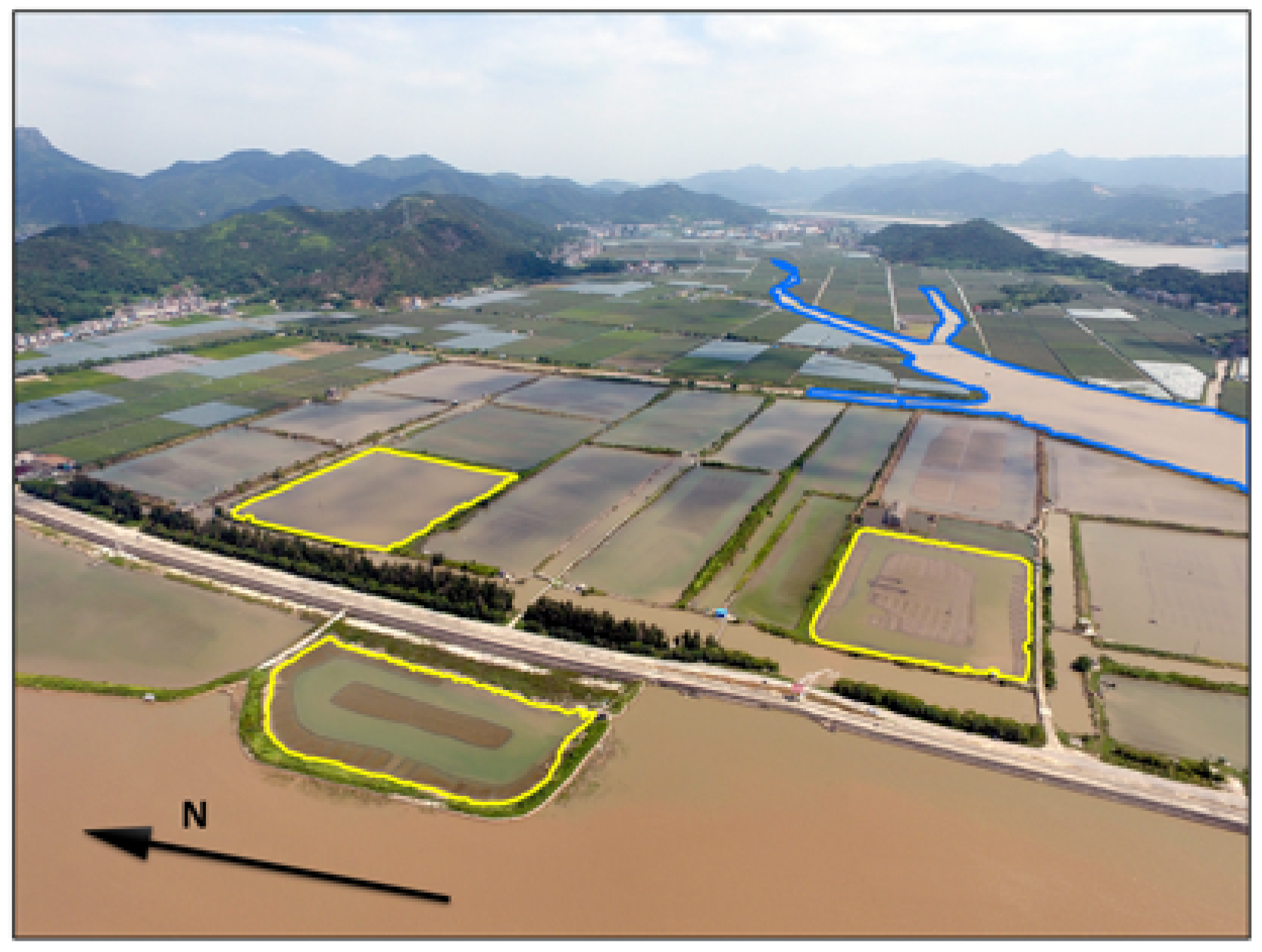
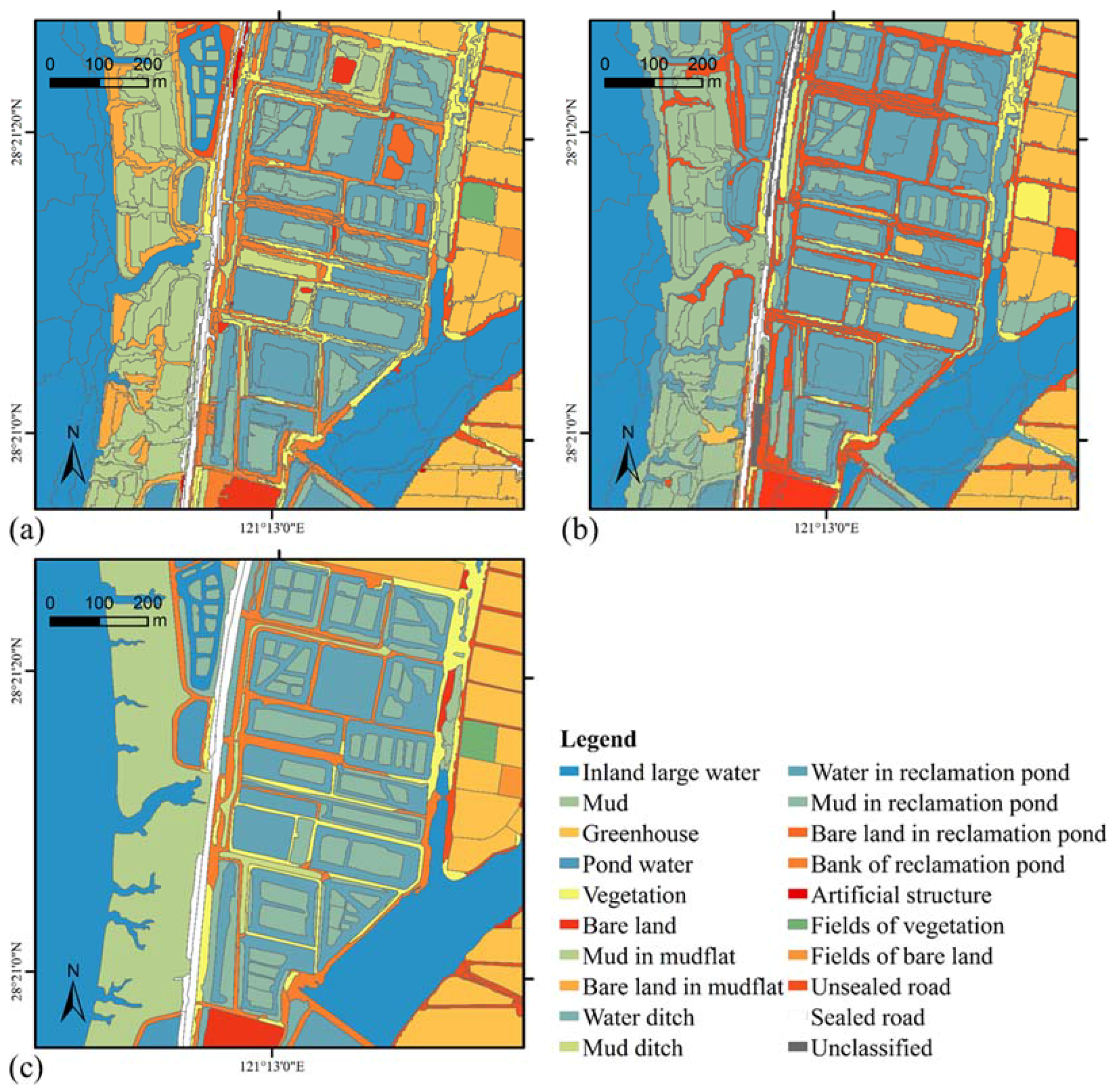
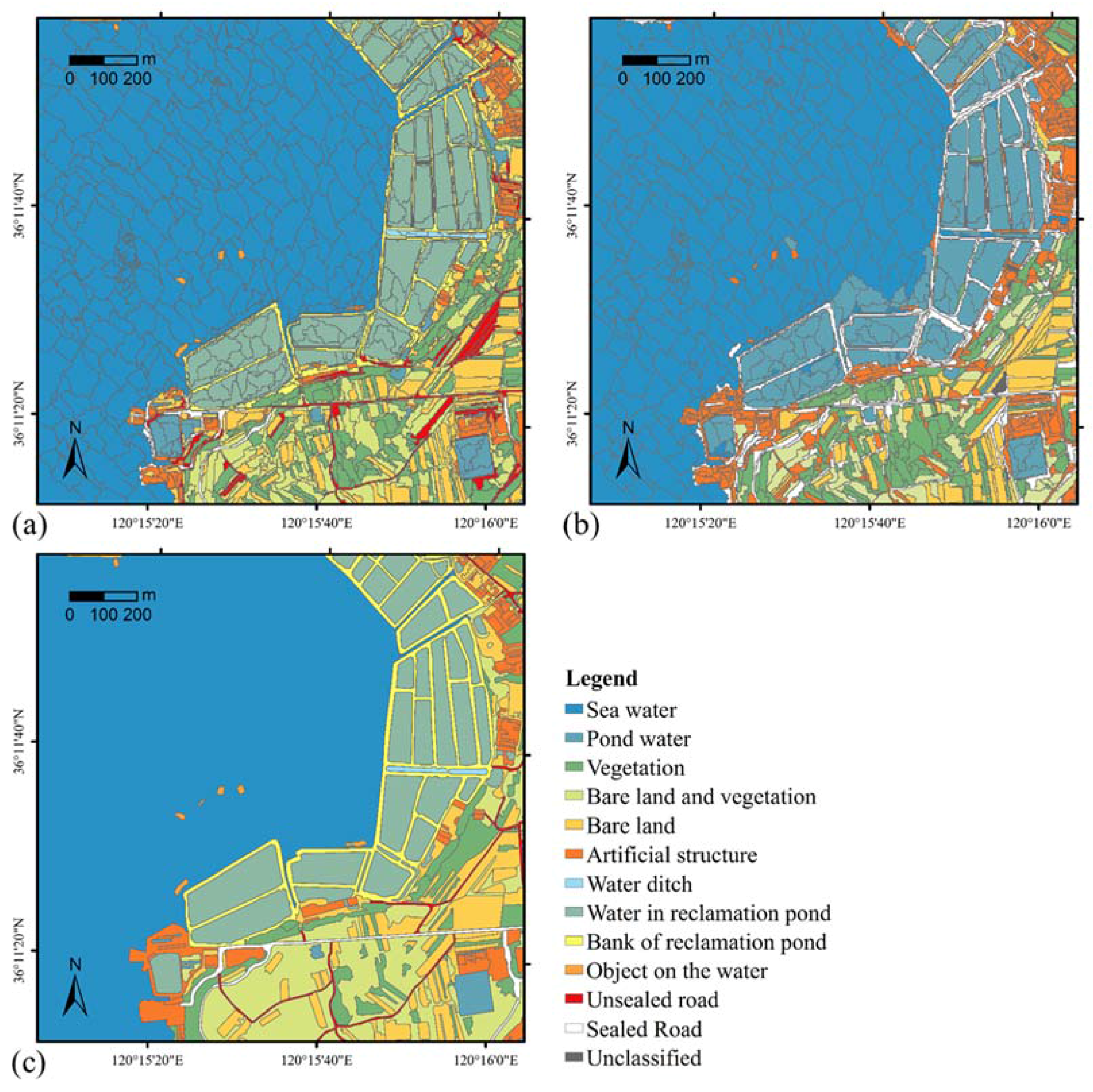
3.1. Data
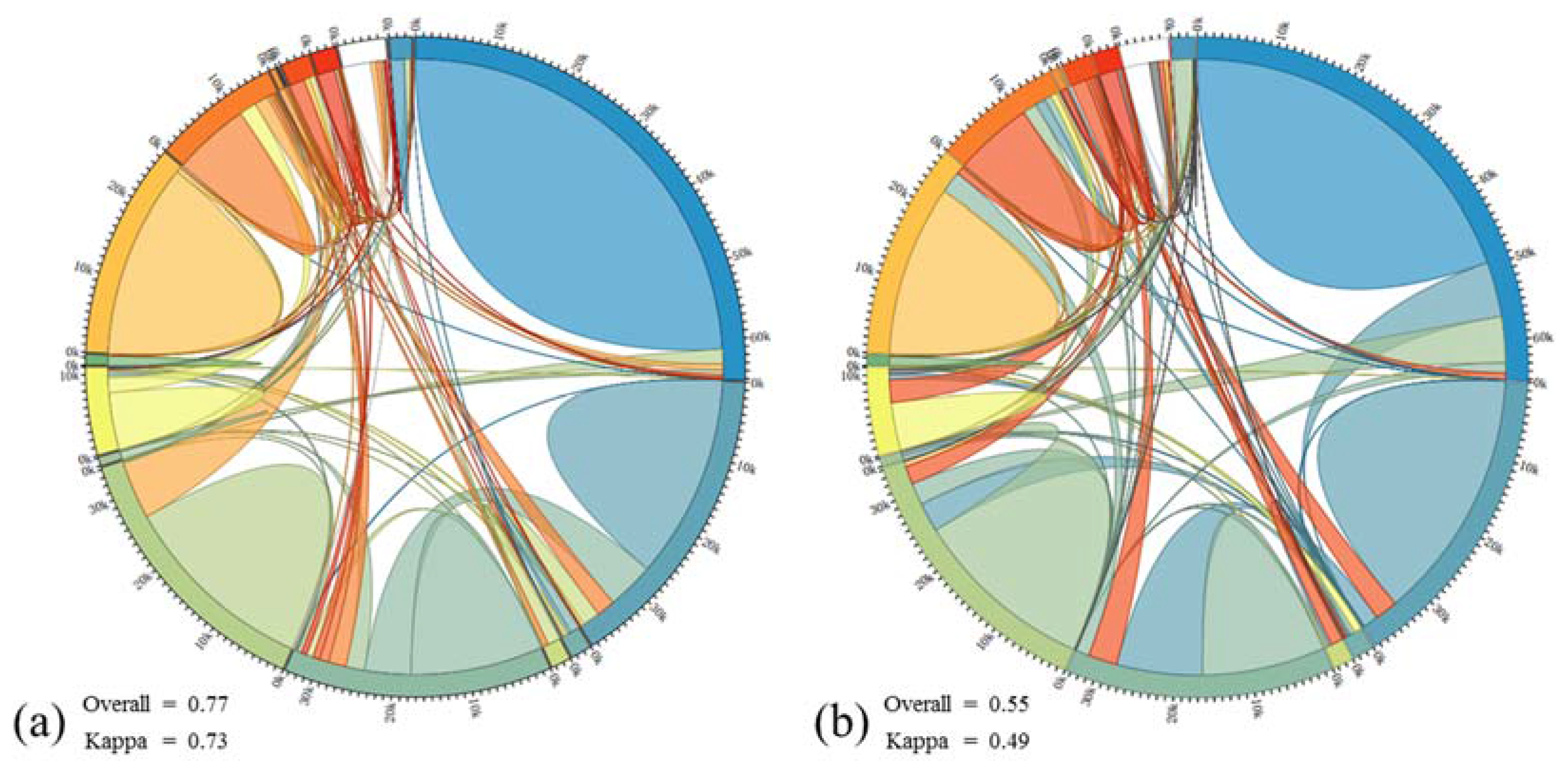
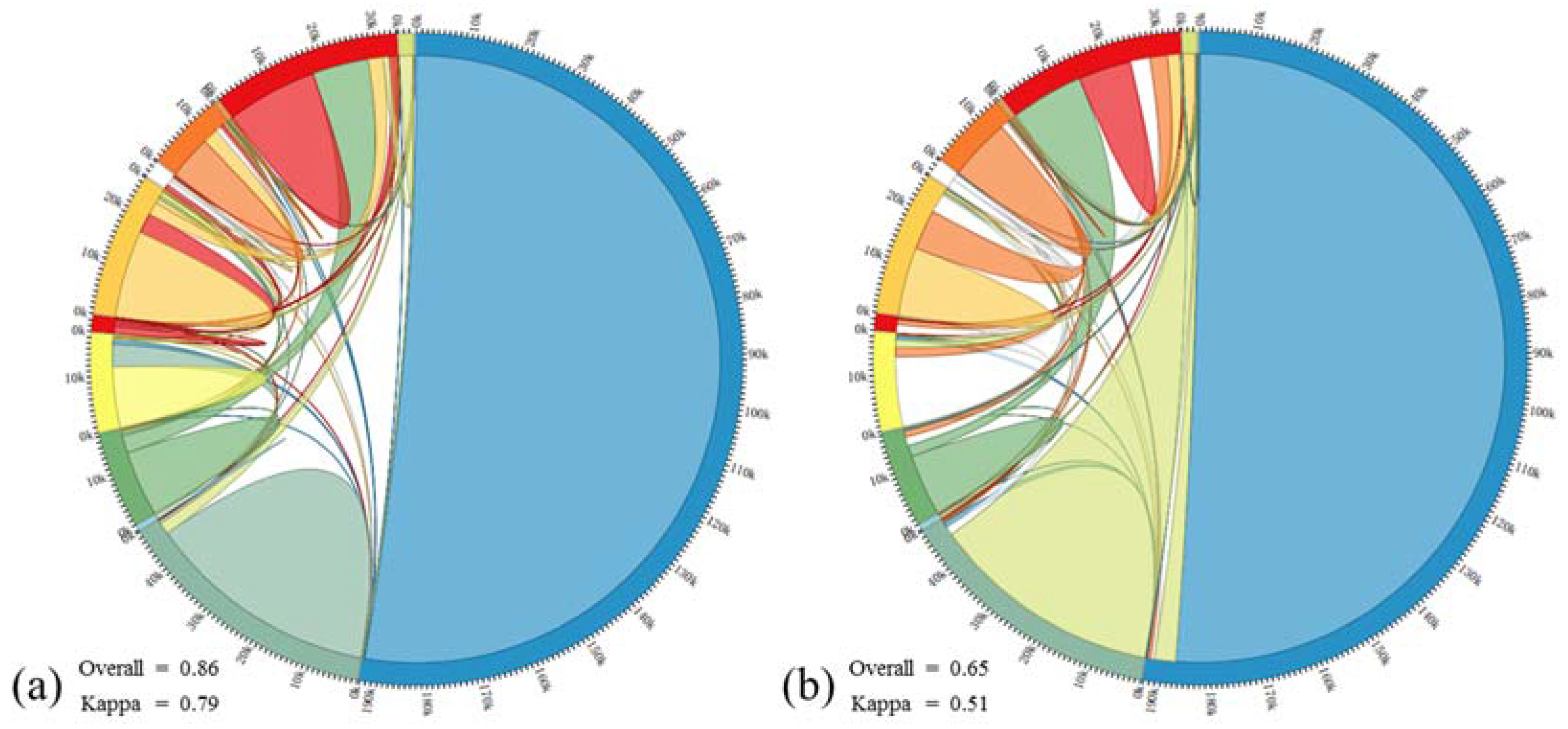
3.2. Experiments and Discussion
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Queiroz Feitosa, R.; van der Meer, F.; van der Werff, H.; van Coillie, F.; et al. Geographic object-based image analysis—Towards a new paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef] [PubMed]
- Baatz, M.; Schäpe, A. Multiresolution Segmentation: An optimization approach for high quality multi-scale image segmentation. J. Photogramm. Remote Sens. 2000, 58, 12–23. [Google Scholar]
- Chen, J.; Pan, D.; Mao, Z. Image-object detectable in multiscale analysis on high-resolution remotely sensed imagery. Int. J. Remote Sens. 2009, 30, 3585–3602. [Google Scholar] [CrossRef]
- Chen, G.; Hay, G.J.; St-Onge, B. A GEOBIA framework to estimate forest parameters from lidar transects, Quickbird imagery and machine learning: A case study in Quebec, Canada. Int. J. Appl. Earth Obs. Geo-inf. 2012, 15, 28–37. [Google Scholar] [CrossRef]
- Benz, U.C.; Hofmann, P.; Willhauck, G.; Lingenfelder, I.; Heynen, M. Multi-resolution, object-oriented fuzzy analysis of remote sensing data for GIS-ready information. ISPRS J. Photogramm. Remote Sens. 2004, 58, 239–258. [Google Scholar] [CrossRef]
- eCoginition Professional User Guide. Available online: http://www.definiens-imaging.com/ (accessed on 19 January 2017).
- Hajj, E.M.; Bégué, A.; Guillaume, S.; Martiné, J.F. Integrating SPOT-5 time series, crop growth modeling and expert knowledge for monitoring agricultural practices—The case of sugarcane harvest on Reunion Island. Remote Sens. Environ. 2011, 113, 2052–2061. [Google Scholar] [CrossRef]
- Forestier, G.; Puissant, A.; Gancarski, P.; Wemmert, C.; Ganarski, P. Knowledge-based Region Labeling for Remote Sensing Image Interpretation. Comput. Environ. Urban Syst. 2012, 36, 470–480. [Google Scholar] [CrossRef]
- Moller-Jensen, L. Classification of urban land cover based on expert systems, object models and texture. Comput. Environ. Urban Syst. 1997, 21, 291–302. [Google Scholar] [CrossRef]
- Lillesand, T.M.; Kiefer, R.W.; Chipman, J.W. Remote Sensing and Image Interpretation, 7th ed.; Wiley: Hoboken, NJ, USA, 2003. [Google Scholar]
- Gruber, T.R. A translation approach to portable ontology specifications. Knowl. Acquis. 1993, 5, 199–220. [Google Scholar] [CrossRef]
- Andres, S.; Arvor, D.; Pierkot, C. Towards an ontological approach for classifying remote sensing images. In Proceedings of the 2012 Eighth International Conference on Signal Image Technology and Internet Based Systems (SITIS), Naples, Italy, 25–29 November 2012. [Google Scholar]
- Forestier, G.; Wemmert, C.; Puissant, A. Coastal image interpretation using background knowledge and semantics. Comput. Geosci. 2013, 54, 88–96. [Google Scholar] [CrossRef]
- Luo, H.; Li, L.; Zhu, H.; Kuai, X.; Zhang, Z.; Liu, Y. Land Cover Extraction from High Resolution ZY-3 Satellite Imagery Using Ontology-Based Method. ISPRS Int. J. Geo Inf. 2016, 5, 31. [Google Scholar] [CrossRef]
- Durand, N.; Derivaux, S.; Forestier, G.; Wemmert, C.; Gancarski, P.; Boussaid, O.; Puissant, A.; Ganc, P.; Boussa, O.; Puissant, A. Ontology-based Object Recognition for Remote Sensing Image Interpretation. In Proceedings of the 19th IEEE International Conference on Tools with Artificial Intelligence (ICTAI 2007), Washington, DC, USA, 29–31 October 2007; Volume 1, pp. 472–479. [Google Scholar]
- Puissant, A.; Sheeren, D.; Durand, D. Urban ontology for semantic intergretation of muti-source images. In Proceedings of the 2nd Workshop on Ontologies for Urban Development: Conceptual Models for Practitioners, Turin, Italy, 17–18 October 2007; pp. 1–17. [Google Scholar]
- Fikes, R.; Hayes, P.; Horrocks, I. OWL-QL—A language for deductive query answering on the Semantic Web. Web Semant. Sci. Serv. Agents World Wide Web 2004, 2, 19–29. [Google Scholar] [CrossRef]
- Addink, E.A.; Van Coillie, F.M.B.; de Jong, S.M. Introduction to the GEOBIA 2010 special issue: From pixels to geographic objects in remote sensing image analysis. Int. J. Appl. Earth Obs. Geoinf. 2012, 15, 1–6. [Google Scholar] [CrossRef]
- Arvor, D.; Durieux, L.; Andrés, S.; Laporte, M.-A. Advances in Geographic Object-Based Image Analysis with ontologies: A review of main contributions and limitations from a remote sensing perspective. ISPRS J. Photogramm. Remote Sens. 2013, 82, 125–137. [Google Scholar] [CrossRef]
- Cheng, J.; Bo, Y.; Zhu, Y.; Ji, X. A novel method for assessing the segmentation quality of high-spatial resolution remote-sensing images. Int. J. Remote Sens. 2014, 35, 3816–3839. [Google Scholar] [CrossRef]
- Schöpfer, E.; Lang, S. Object fate analysis—A virtual overlay method for the categorisation of object transition and object-based accuracy assessment. In Proceedings of the 1st International Conference on Object-Based Image Analysis, Salzburg, Austria, 4–5 July 2006. [Google Scholar]
- Lucieer, A.; Stein, A. Existential uncertainty of spatial objects segmented from satellite sensor imagery. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2518–2521. [Google Scholar] [CrossRef]
- Navulur, K. Multispectral Image Analysis Using the Object-Oriented Paradigm; CRC Press: Boca Raton, FL, USA, 2006. [Google Scholar]
- OWL Working Group OWL 2 Web Ontology Language Document Overview (Second Edition). Available online: https://www.w3.org/TR/owl-overview/ (accessed on 6 March 2017).
- Krötzsch, M. OWL 2 Profiles: An introduction to lightweight ontology languages. In Reasoning Web International Summer School; Springer: Berlin/Heidelberg, Germany, 2012; pp. 112–183. [Google Scholar]
- REQUIEM: REsolution-Based QUery Rewriting for Expressive Models. Available online: http://www.cs.ox.ac.uk/projects/requiem/ (accessed on 12 December 2016).
- Pérez-Urbina, H.; Motik, B.; Horrocks, I. Tractable query answering and rewriting under description logic constraints. J. Appl. Log. 2010, 8, 186–209. [Google Scholar] [CrossRef]
- Ji, X. Research on the Method of Accuracy Assessment of the Object-Based Classification from Remotely Sensed Data. Master’s Thesis, Beijing Normal University, Beijing, China, 2012. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Measurement | Definition | Description |
|---|---|---|
| Area Fitness Index (AFI) | When AFI > 0, over segmentation; When AFI < 0, under segmentation | |
| Omission Error (OE) | Describes the over-segmentation. An OE closer to zero means less over-segmentation. | |
| Commission Error (CE) | Describes the under-segmentation. A CE closer to zero means less under-segmentation. | |
| OEoverall | The weighted average of OE. | |
| CEoverall | The weighted average of CE. | |
| Overall Area Discrepancy Index (ADIoverall) | The overall of over- and under- segmentation. When ADI is zero, the segmentation is exactly the objects of interest. |
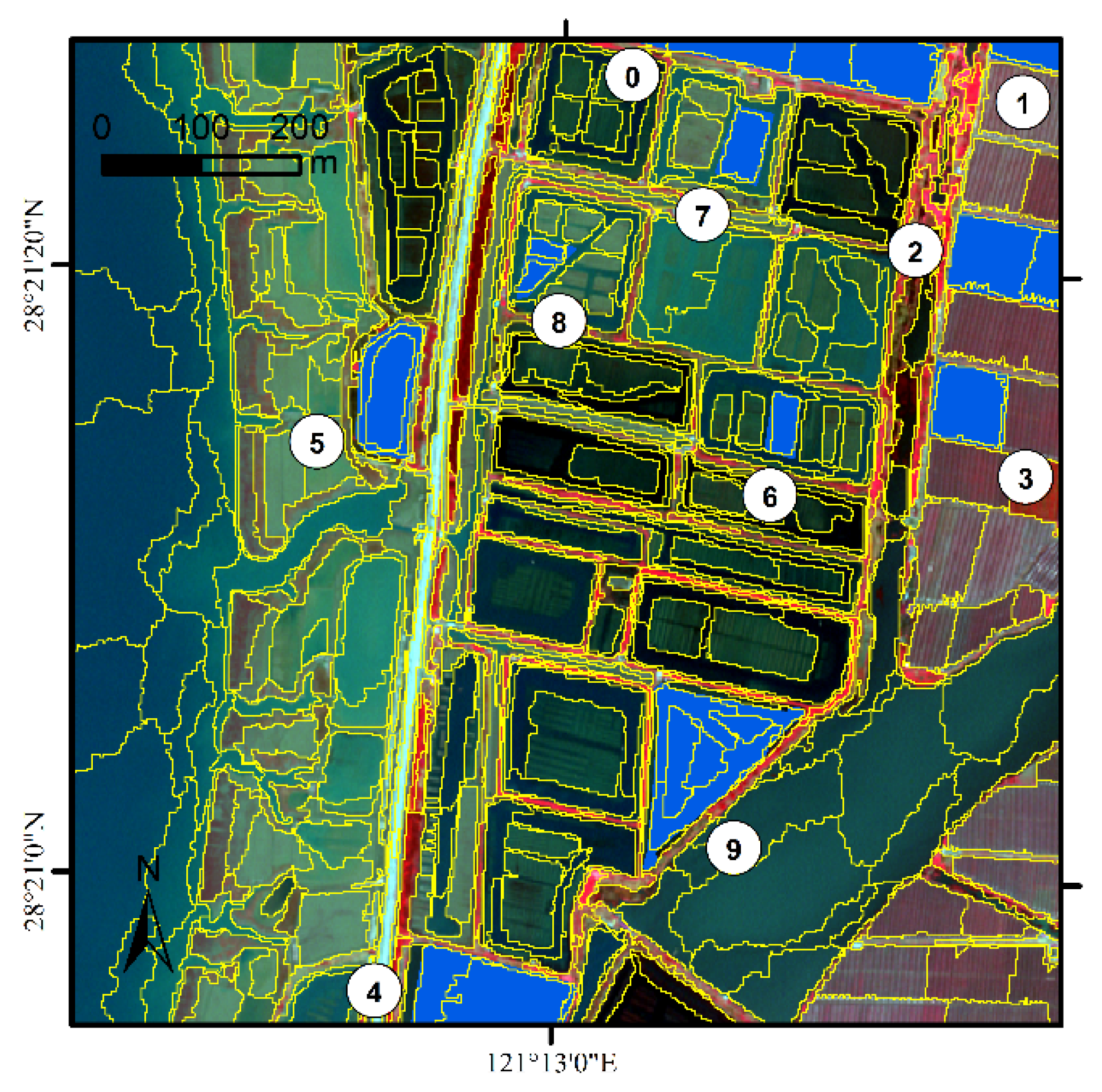
| Reference Object | Description | ngood | nexpanding | ninvading | OL | I | AFI | OE | CE | PDI |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Greenhouse | 0 | 3 | 5 | 0 | 0.63 | 0.56 | 0.04 | 0.02 | 105.70 |
| 1 | Greenhouse | 0 | 1 | 1 | 0 | 0.50 | 0.05 | 0.05 | 0.01 | 18.19 |
| 2 | Greenhouse | 1 | 1 | 3 | 0.50 | 0.60 | 0.31 | 0.04 | 0.03 | 37.36 |
| 3 | Vegetation | 0 | 2 | 2 | 0 | 0.50 | 0.09 | 0.03 | 0.06 | 26.46 |
| 4 | Bare land | 0 | 3 | 3 | 0 | 0.50 | 0.33 | 0.01 | 0.02 | 83.15 |
| 5 | Water | 1 | 1 | 4 | 0.50 | 0.67 | 0.38 | 0.05 | 0.02 | 42.61 |
| 6 | Mud | 0 | 1 | 2 | 0 | 0.67 | 0.10 | 0.10 | 0.04 | 27.11 |
| 7 | Mud | 0 | 1 | 2 | 0 | 0.67 | 0.13 | 0.13 | 0.00 | 0.40 |
| 8 | Mud | 0 | 2 | 2 | 0 | 0.50 | 0.62 | 0.30 | 0.04 | 8.62 |
| 9 | Water | 0 | 6 | 6 | 0 | 0.50 | 0.71 | 0.02 | 0.06 | 45.17 |
| Overall | 0.04 | 0.03 | 39.48 | |||||||
| Overall ADI | 0.05 |
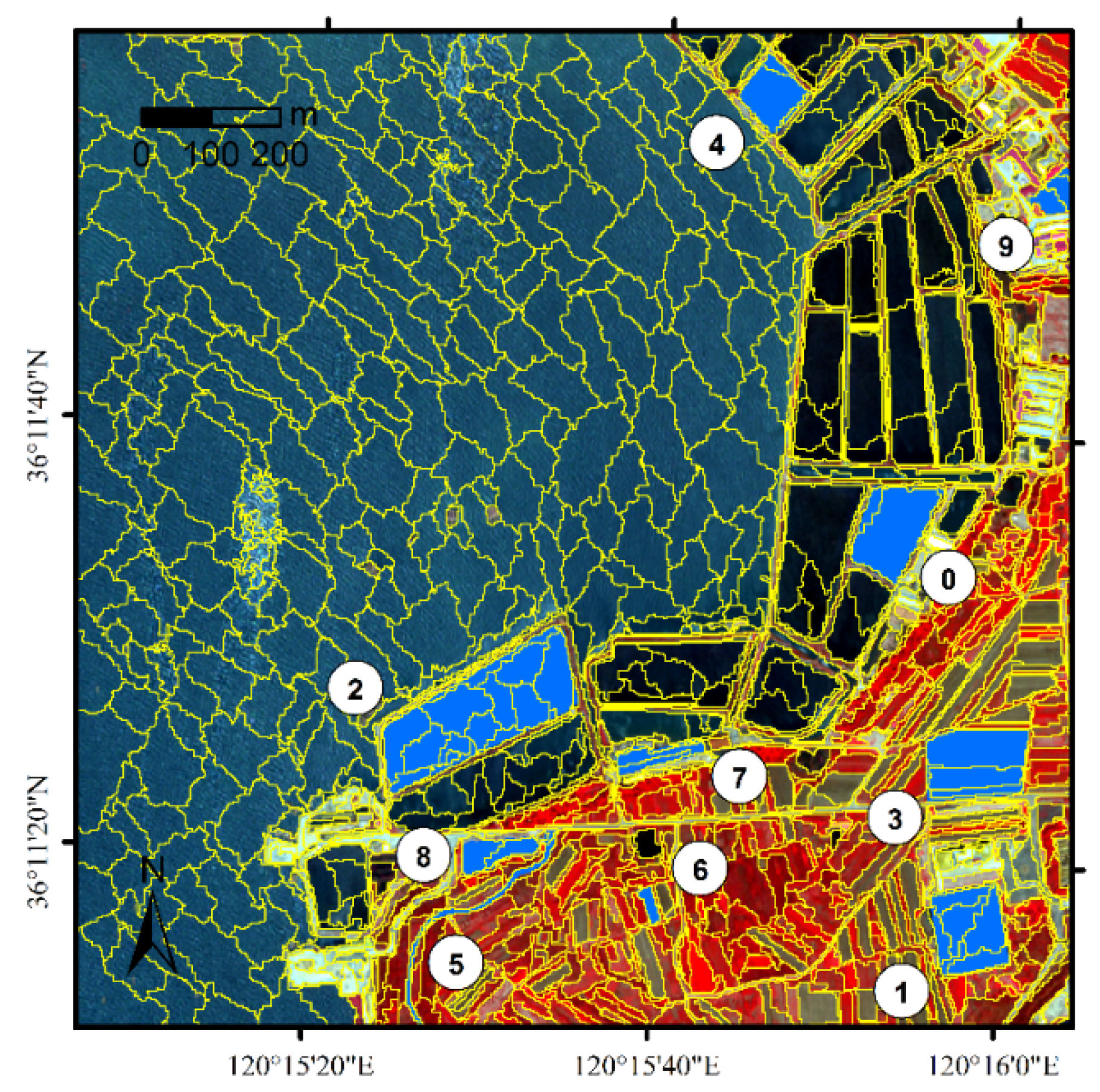
| Reference Object | Description | ngood | nexpanding | ninvading | OL | I | AFI | OE | CE | PDI |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Water | 0 | 2 | 7 | 0 | 0.78 | 0.12 | 0.03 | 0.02 | 112.07 |
| 1 | Water | 0 | 6 | 8 | 0 | 0.57 | 0.71 | 0.02 | 0.03 | 62.56 |
| 2 | Water | 4 | 12 | 8 | 0.25 | 0.33 | 0.86 | 0.02 | 0.02 | 88.15 |
| 3 | Bare land | 0 | 3 | 8 | 0 | 0.73 | 0.47 | 0.08 | 0.00 | 39.97 |
| 4 | Water | 0 | 3 | 5 | 0 | 0.63 | 0.17 | 0.02 | 0.03 | 66.58 |
| 5 | Bare land | 0 | 1 | 19 | 0 | 0.95 | 0.19 | 0.95 | 0.04 | 176.97 |
| 6 | Bare land | 0 | 1 | 4 | 0 | 0.80 | 0.08 | 0.08 | 0.05 | 18.79 |
| 7 | Structure | 0 | 2 | 10 | 0 | 0.83 | 0.50 | 0.21 | 0.10 | 51.25 |
| 8 | Bare land | 0 | 2 | 7 | 0 | 0.78 | 0.47 | 0.04 | 0.11 | 27.39 |
| 9 | Vegetation | 0 | 3 | 5 | 0 | 0.63 | 0.53 | 0.03 | 0.11 | 35.73 |
| Overall | 0.07 | 0.03 | 67.94 | |||||||
| Overall ADI | 0.08 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, H.; Chen, J.; Li, Z.; Gong, F.; Chen, N. Ontology-Guided Image Interpretation for GEOBIA of High Spatial Resolution Remote Sense Imagery: A Coastal Area Case Study. ISPRS Int. J. Geo-Inf. 2017, 6, 105. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi6040105
Huang H, Chen J, Li Z, Gong F, Chen N. Ontology-Guided Image Interpretation for GEOBIA of High Spatial Resolution Remote Sense Imagery: A Coastal Area Case Study. ISPRS International Journal of Geo-Information. 2017; 6(4):105. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi6040105
Chicago/Turabian StyleHuang, Helingjie, Jianyu Chen, Zhu Li, Fang Gong, and Ninghua Chen. 2017. "Ontology-Guided Image Interpretation for GEOBIA of High Spatial Resolution Remote Sense Imagery: A Coastal Area Case Study" ISPRS International Journal of Geo-Information 6, no. 4: 105. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi6040105