1. Introduction
The mobility behavior of users is the key factor for understanding the spatiotemporal characteristics of human activity, transportation conditions, and environment. Massive travels by users can be categorized into different modes, such as transportation modes (subway, bike, taxi, and bus, etc.) [
1] and different frequent route patterns [
2]. Distinguishing different mobility modes and understanding the character of them play a key role in location-based services such as destination and route prediction [
3,
4] and analysis of travel behavior [
5], etc. Traditional ways of investigating mobility modes rely on household interviews and manual labelling, which are inefficient and costly.
With the rapid development of navigation and positioning technology, it has become feasible to acquire users’ trajectory data in real-time and in a consecutive manner. Valuable knowledge about the mobility behavior of users and the spatiotemporal characteristics of environment are contained in these data [
6]. Ubiquitous trajectory data and great demand of decision support lead to the increasing advent of data-driven techniques for trajectory mining [
7]. The recent literature on trajectory mining mainly focused on significant locations discovery, anomaly detection, location-based activity recognition, and mobility modes identification [
1,
8]. Trajectory mining also provides an opportunity to enhance the awareness of mobility modes. Our work considers the information of both travel activity types and route patterns to categorize different mobility modes. For example, a person travels from
location A to
location B by
bus/taxi, or a vessel travels from
port A to
port B for
tugging/carrying cargo.
The mobility modes introduced above are worth exploring since different modes contain abundant knowledge about not only the significant places [
9] and route patterns [
10], but also semantic information such as the travel activity types. Mobility modes awareness in this work involves two issues: mobility modes discovery and mobility modes identification. The former aims to mine different mobility modes existing in a large amount of history trajectories. This knowledge facilitates the intelligent management of both environment and travel behavior of users, such as land use classification [
11] and anomalous trajectory detection [
12]. The latter focuses on predicting the mobility mode of a newly emerging trajectory in real-time manner. Mobility modes identification is the basis of customized location-based service [
13] and activity surveillance [
14].
In order to mine valuable knowledge from history trajectory data and generate massive labeled data for the training of the identification model automatically, we propose an approach to integrate the issues of mobility modes discovery and identification together. This approach includes three successive components: trajectory preprocessing, clustering, and identification model training and evaluation. Firstly, we perform trajectory preprocessing to obtain clean data and prepare trajectories well for subsequent study. Then, we categorize history trajectories into different mobility modes in an unsupervised manner and tag them with labels. Further, in the phase of mobility modes identification, we construct and train an identification model offline by leveraging history trajectory data labeled before. The mobility mode of a newly emerging trajectory will be identified in real-time manner by this well-trained identification model. Although lots of previous literatures [
15,
16] have paid attention to the issues about mobility modes awareness, there still exists much space to explore. In this paper, we make an effort to efficiently discover distinguishable mobility modes and improve the performance of identification.
The crucial issue of mobility modes discovery is route pattern extraction. The most widely used way to mine route patterns is utilizing clustering-based approaches due to the similarity among trajectories in the same route pattern [
17,
18,
19]. Ordering points to identify the clustering structure (OPTICS) algorithm is insensitive to parameters and more robust compared to other clustering algorithms [
20]. In this work, we propose to extract route patterns by means of origin and destination (OD) points clustering based on OPTICS. One of the most prominent advantages of this method is the adaptive ability against density imbalance condition. Moreover, it can efficiently deal with the complicated trajectory behavior.
Accomplishing the identification task involves two key points. The first one is preparing trajectories for representative feature extraction. These features are supposed to be capable of adequately interpreting different modes. The second is constructing and training an identification model for feature learning and result prediction. This model is expected to identify different modes accurately on the basis of extracted representative features. In this work, we propose a deep learning approach to identify mobility modes based on a convolutional neural network (CNN). We introduce mobility-based structure for individual trajectories. Compared to an ordinary time-series trajectory structure, the superiority of a mobility-based structure is the simultaneous expression of comprehensive knowledge including the spatial and kinematic characteristics. A CNN, which is outstanding in the field of pattern identification, is also capable of extracting distinguishable features from mobility-based trajectory.
The principal contributions of our work are: (1) We propose a method aiming to integrate the issues of mobility modes discovery and identification together. It enhances the awareness of mobility behavior, which will be contributive in plenty of practical fields. (2) We put forward an efficient OD points clustering method based on OPTICS for mobility modes discovery. The discovered modes contain abundant knowledge about both spatial and semantic characteristics of moving objects. (3) We propose a deep learning approach for mobility modes identification, which automatically learns high-level features from trajectory data. This approach does not need any domain knowledge to develop sophisticated feature extractor and is easy to be transplanted to different situation. The introduction of mobility-based trajectory structure is also progressive. (4) Our work provides a typical way to convert trajectory big data into knowledge and decision support.
We employed real-world vessel trajectory data collected by an Automatic Identification System (AIS) [
21] for the evaluation of the proposed method. The mobility modes defined above were composed of vessel route patterns and different maritime activity types in this specific case. The remainder of this paper is organized as follows.
Section 2 reviews the related work on the investigation of mobility modes. In
Section 3, the proposed methodology on mobility modes awareness is elaborated. Experiments and evaluation are presented in
Section 4. This section also brings a visualization of extracted deep features. Ultimately, we discuss and conclude this work and also present future prospects in
Section 5.
2. Related Work
Destination prediction from trajectories is a widely discussed issue which is usually derived from mobility modes awareness. In Reference [
22], three steps were involved in the destination prediction issue: (1) obtain trajectory clusters and traffic pattern models, (2) assign the new trajectory to a particular cluster, and (3) predict the destination based on history information and current state. The first two steps can also be regarded as mobility modes awareness.
A specific mobility mode is formed by the behavior of a group of similar trajectories. Thus, clustering algorithms are the most widely used techniques for mobility modes discovery in previous studies. A comprehensive review on trajectory clustering categorized these algorithms into three groups [
23]: unsupervised, supervised, and semi-supervised. The most intuitional way is taking the trajectory itself as clustering object [
17,
24,
25]. A framework called hierarchical graph-based similarity measurement (HGSM) was proposed to mine the similarity between user trajectories geographically. The advantages of this framework lie in taking both the sequence property of people’s behavior and the hierarchy property of geographic space into consideration [
24]. A trajectory clustering algorithm called TRACLUS was put forward to discover sub-trajectories groups based on partition-and-group framework [
25]. The prominent advantage of TRACLUS is the capability of mining the fine-grained trajectory similarity.
However, the approaches mentioned above which apply clustering algorithms to whole and partial trajectories are vulnerable to complex mobility situations. On the one hand, it is difficult to determine an optimal similarity function among line elements like trajectories. On the other hand, similarity computation is very time-consuming when lots of positioning points are involved. Hence, there emerges another branch of approaches which extract route patterns based on preliminary clustering of waypoints or OD points [
19,
26,
27,
28,
29]. Within a specific study region, waypoints consist of stationary points, entry points, and exit points. Frequent route patterns could be extracted by clustering these waypoints [
19]. In Reference [
29], a density-based clustering algorithm was applied to OD points collected by smart card data. These points indicate the boarding and alighting stops of regular bus passengers. In this way, the potential locations where passengers on a customized commuter bus may aggregate were detected. To sum up, the light-weight computational burden and adaptive ability for complicated trajectory behavior are the remarkable superiority of these OD points clustering approaches.
In order to infer the mobility mode of a certain individual trajectory, it is crucial to extract representative features. Previous studies employed machine learning tools to identify mobility modes by carefully selecting low-level features such as statistics of length and velocity [
30]. Whereas it is hard for these features to accurately interpret different modes due to the diversity of travel behavior. To handle this problem, more sophisticated handcrafted features were introduced and enhanced the identification accuracy, e.g., heading change rate, stop rate, and velocity change rate [
31]. In Reference [
31], a group of machine learning techniques including support vector machine (SVM), decision tree (DT), Bayesian net (BN), and conditional random field (CRF) were evaluated. In addition, the approach proposed by Reference [
32] built an ensemble of probabilistic classifiers to infer mobility modes. These classifiers were integrated with a discrete hidden Markov model (DHMM). In Reference [
32], representative features included both raw statistical features and the power spectrum of the accelerometer signal.
However, the handcrafted features employed in the literature mentioned above still have evident bottlenecks. Firstly, it is difficult to define distinguishable features for various mobility modes. Domain knowledge is required to comprehend the representative discrepancy among different modes. Secondly, these extrinsic features are not adaptive enough to complicated situations. To deal with these challenges, recent literature has made an effort to directly extract high-level deep features from trajectory by means of deep learning [
16,
33,
34]. Different from handcrafted features, deep features containing the intrinsic properties of trajectory are obtained automatically. Moreover, deep learning algorithms are also superior to traditional machine learning algorithms in the aspect of learning these features [
33]. The approach proposed by Reference [
34] transformed trajectory into two-dimensional image architecture, then extracted the deep features utilizing a fully-connected deep neural network (FCDNN). This approach evenly resampled the positioning points of trajectories. The value of each image pixel is equal to the number of resampled points in it. In this way, the geometrical information of trajectories can be reserved. However, it is essential to point out that the resample operation may destroy the kinematic characteristics of trajectory. Since the original sample frequency of positioning devices is associated with the moving state.
The CNN, a kind of deep learning technique, has achieved remarkable performance in computer vision and image recognition fields [
35]. The methodology of Reference [
16] utilized a CNN architecture to infer mobility modes. A four-channel input composed of four kinematic features was fed into the input layer of CNN, including speed, acceleration, jerk, and bearing rate. In Reference [
36], a light-weight and energy-efficient transportation mode detection application was designed, which only uses the accelerometer sensor data of smartphones. Acceleration magnitude of a size-fixed window was selected as a representative feature to be fed into the CNN. These CNN-based methods achieved high inference accuracy without involving any handcrafted features. However, the advantage of a CNN in processing multi-dimensional input has not been exploited sufficiently.
In this work, OD points clustering was performed to discover route patterns. The route patterns discovered in this way are more reliable and distinguishable than those obtained by clustering trajectories directly. We employed the OPTICS algorithm to cluster points, instead of density-based spatial clustering of applications with noise (DBSCAN) utilized in Reference [
15], since OPTICS is superior in detecting the intrinsic density structure of objects when faced with density imbalance issues. In the phase of mobility modes identification, we propose an advanced mobility-based trajectory structure. It retains not only geometrical information, but also the geographical and kinematic information of trajectory. Furthermore, the CNN model designed in our work is more competent for coping with this kind of trajectory structure than the fully connected network proposed in Reference [
34] and other machine learning algorithms. It is worth mentioning that learning features automatically from trajectory in a deep learning manner is more efficient than designing sophisticated handcrafted features.
3. Methods
The methodology we propose in this section aims to mine valuable knowledge from the raw trajectory data and enhance mobility modes awareness. It integrates two issues together: mobility modes discovery and identification. Consequently, it contains three successive steps overall: (1) trajectory preprocessing, (2) OD points clustering for route patterns discovery, and (3) a CNN-based method for mobility modes identification. The framework of this method is illustrated in
Figure 1. The purpose of trajectory preprocessing is obtaining clean and well-prepared data for the following investigation. The mobility modes categories that are useful for obtaining knowledge about trajectory behavior are generated after the OD points clustering step. These categories are also used as ground truth for training and evaluating the mobility modes identification model which identifies the mode of a newly emerging trajectory in a real-time manner.
Raw trajectories are formed by a series of consecutive sampling points with a certain time interval, which contains gross errors and missing data. Therefore, we discard outliers and complement the missing portion in the trajectory preprocessing step. Then, we extract OD points and divide these consecutive points into individual trajectories. The most important part of trajectory preprocessing is transforming the trajectory sequence into a well-designed mobility-based structure.
In the mobility modes discovery phase, the OD points clustering method based on OPTICS is applied to excavate latent route patterns of history trajectory data. After the integration of route patterns and travel activity types, each individual trajectory is labeled with a definite mobility mode annotation.
Ultimately, mobility modes identification consists of two steps: (1) an offline training process on the basis of labeled history data, and (2) real-time identification for test data. A CNN-based method is proposed to learn deep features from the mobility-based structure of trajectories.
3.1. Trajectory Preprocessing
Raw positioning data collected by multiple devices contain multi-dimensional attributes such as longitude, latitude, timestamp, status, etc. Trajectory data stored in the database are formed by positioning data as the structure of the time sequence. Before subsequent processing, raw trajectory data are preprocessed to eliminate the invalid and gross error caused by devices in collection and storage process.
The most significant feature points of trajectories are OD points defined as:
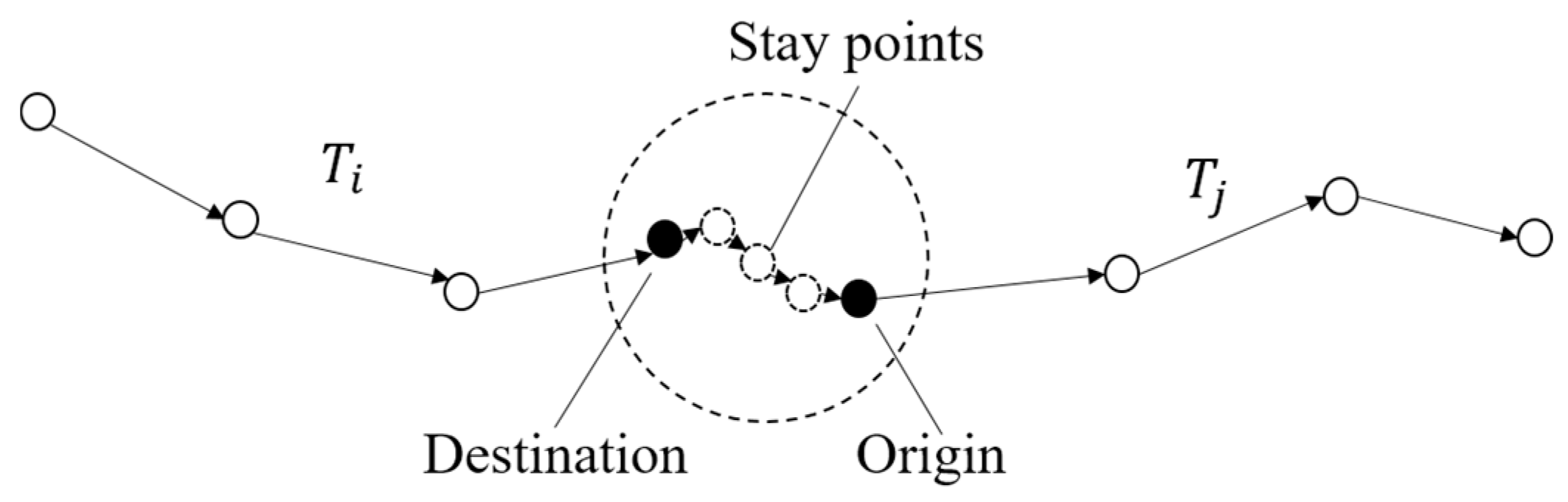
Definition 1. OD points: OD points of trajectories represent the origin and destination of individual trajectories, including the entrance and exit points of a specific study region and stay points [26]. Definition 2. Stay points: If the transition duration between adjacent points is greater than a specific threshold while the transition distance is shorter than the distance threshold, these points will be recognized as stay points [37]. Stay points depicted in
Figure 2 stand for important geographical locations where moving objects stay for a significant amount of time. Thus, they contain the start and termination of different individual travels. To reduce data redundancy, in the group of stay points, only the endpoints are remained, as depicted in
Figure 2.
The distance between two points is given by the Haversine formula:
where
is the distance between point
and point
,
denotes the radius of the earth,
and
denote the longitude and latitude of points, respectively. Following the OD points extraction, an individual trajectory is expressed as:
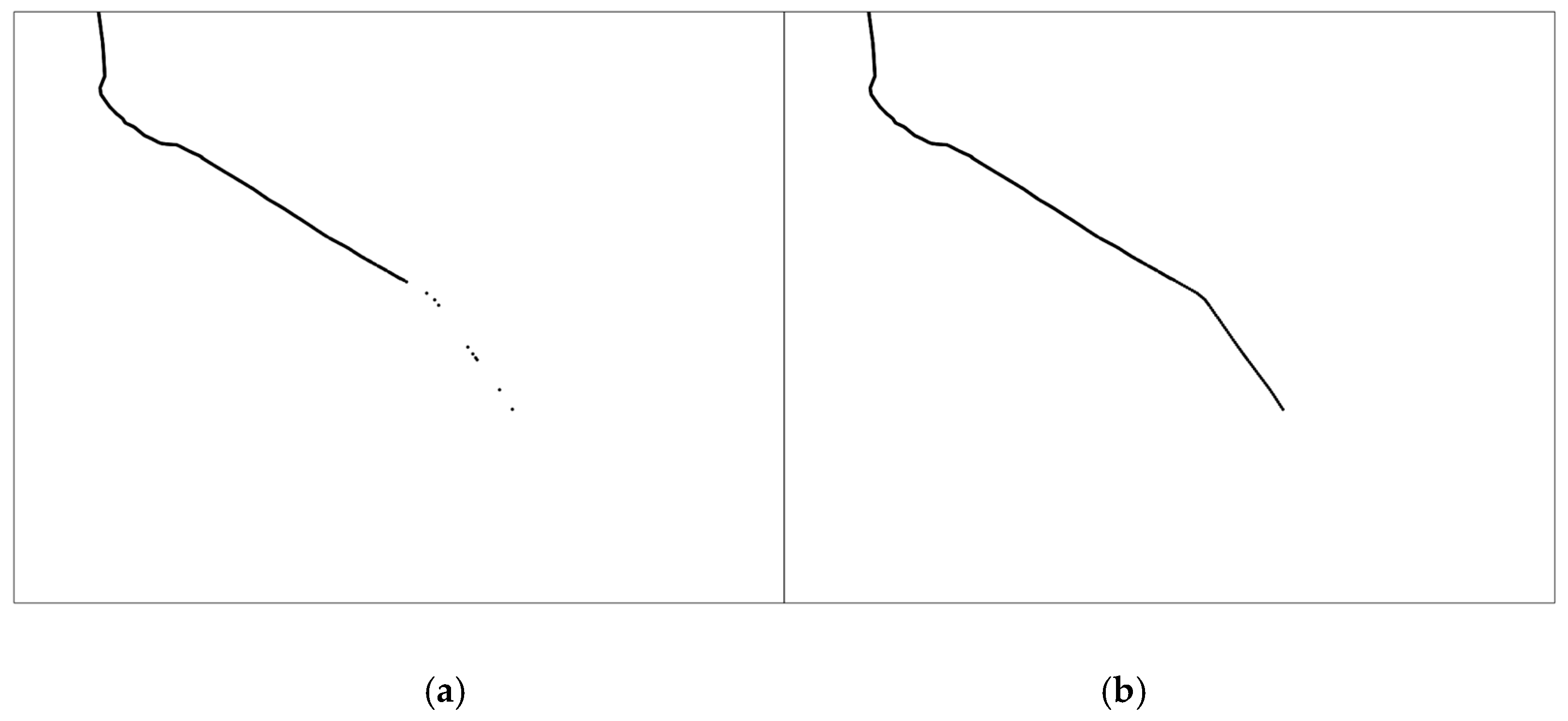
Missing data generated by interruption of the signal or data cleaning could cause information loss, which further lead to poor performance in the following trajectory mining. Thus, it is essential to add interpolation between two points when the interval between them is greater than the predefined threshold. Linear interpolation technique is employed to complement trajectories, as represented in
Figure 3. The interval of interpolation is adjustable to guarantee the continuity of trajectory between adjacent grids introduced in the following spatial discretization process.
Characteristics of trajectory will not be expressed sufficiently if it is considered as a one-dimensional time-series and a two-dimensional evenly sampled geometric curve. Thus, we construct a mobility-based structure to represent trajectory. This kind of trajectory structure is three-dimensional containing not only geometrical characteristics, but also geographical and kinematic information. In Reference [
33], a certain area just covering each individual trajectory was clipped and discretized. This operation will lose the information on the geographical characteristics and outside the defined area. Instead, we discretize the whole study region into grids, as shown in
Figure 4a. Then we define the mobility-based structure of trajectories as follows:
Definition 3. Mobility-based structure trajectory: The mobility-based structure trajectory refers to an expression of a certain trajectory where . Grid is a three-dimensional vector, where and refer to the row and column index of grids. The third attribute is the pixel value of each grid, which present the mobility characteristics of trajectories.
The pixel value
of each grid shown in
Figure 4b is determined as follows:
where
denotes the number of points located in
,
is the speed information of each point
. Given that the raw speed information provided by devices collection are not reliable enough,
is recalculated by the transition duration and distance between adjacent points.
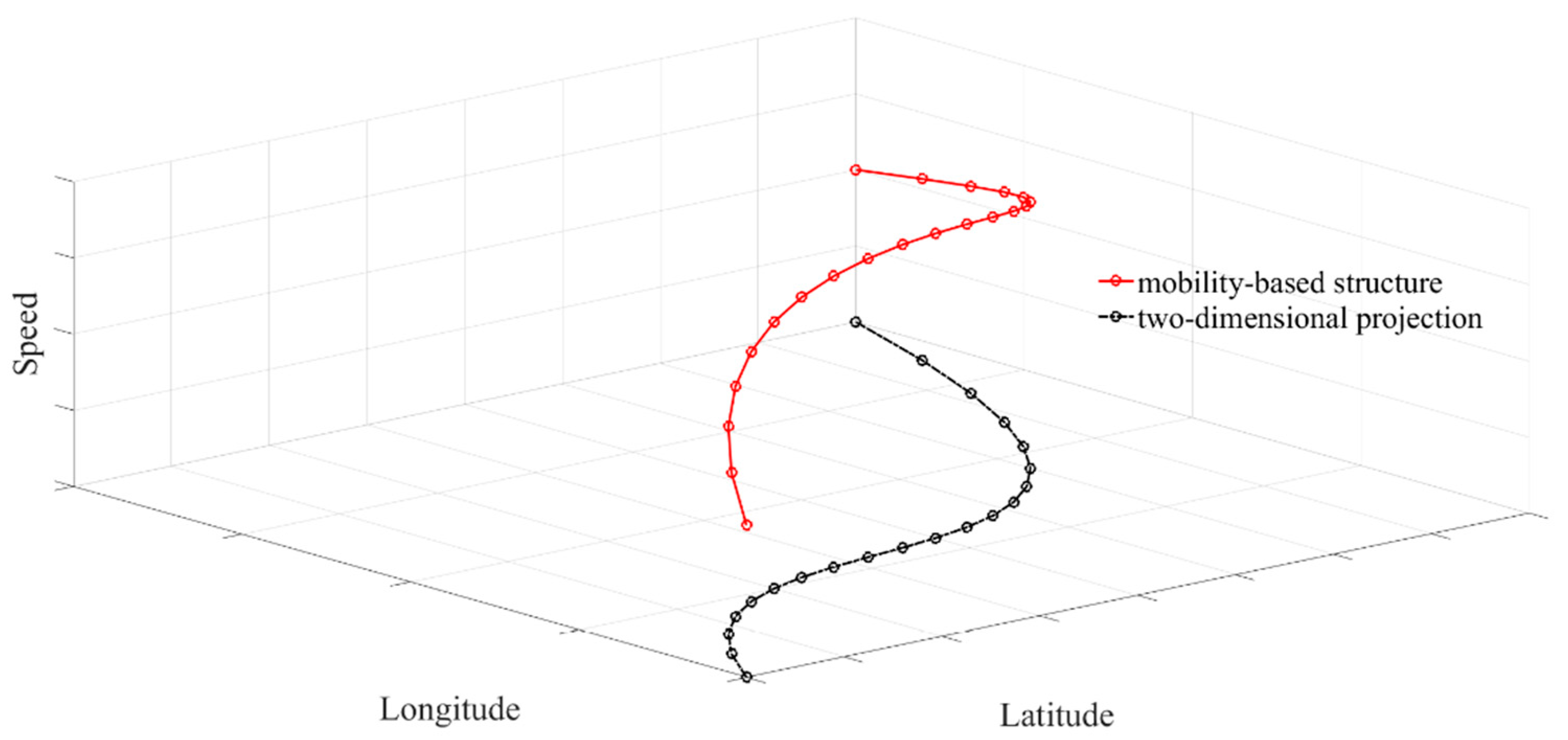
Figure 5 presents a schematic diagram of this kind of mobility-based structure trajectory and its projection in a two-dimensional spatial plane. It is three-dimensional comprising three attributes of longitude, latitude, and speed, respectively. The spatial distribution of the non-zero pixels simultaneously reveal the geographical and geometrical characteristics, as well as the moving direction information. Meanwhile, the value of the pixels also reflects the kinematic characteristics of moving objects.
3.2. OD Points Clustering for Route Patterns Discovery
As mentioned in
Section 1 and
Section 2, the advantages of OD points clustering can be summarized as: (1) the distance function between points is easier to be determined and calculated, and (2) trajectories connecting the same group of origin and destination regions share more similarity and generate more representative frequent route patterns than those that only resemble each other in some partial segments.
The OPTICS algorithm is employed to accomplish points clustering task [
20]. The OPTICS algorithm is a density-based algorithm deriving from DBSCAN, which is superior in dealing with the problems of parameter sensitivity and density unbalance [
38]. This algorithm generates an order of points which reveals the intrinsic density structure of a points dataset, instead of generating clustering results directly. Subsequently, concrete clustering results can be obtained based on this order. Compared to DBSCAN, which adopts invariable scale parameters to obtain size-fixed clustering results, OPTICS can easily cope with the unbalanced density issue and generate clusters of any size. Euler distance, the most widely used geometric distance function, is calculated by Equation (1) as the similarity measure among points. There are three vital definitions of this method [
38]:
Definition 4. Core-object: Let be a point in dataset , be the distance threshold, be the ε-neighborhood of , where is the distance between point and . is regarded as core-object on condition that , where is the point number threshold.
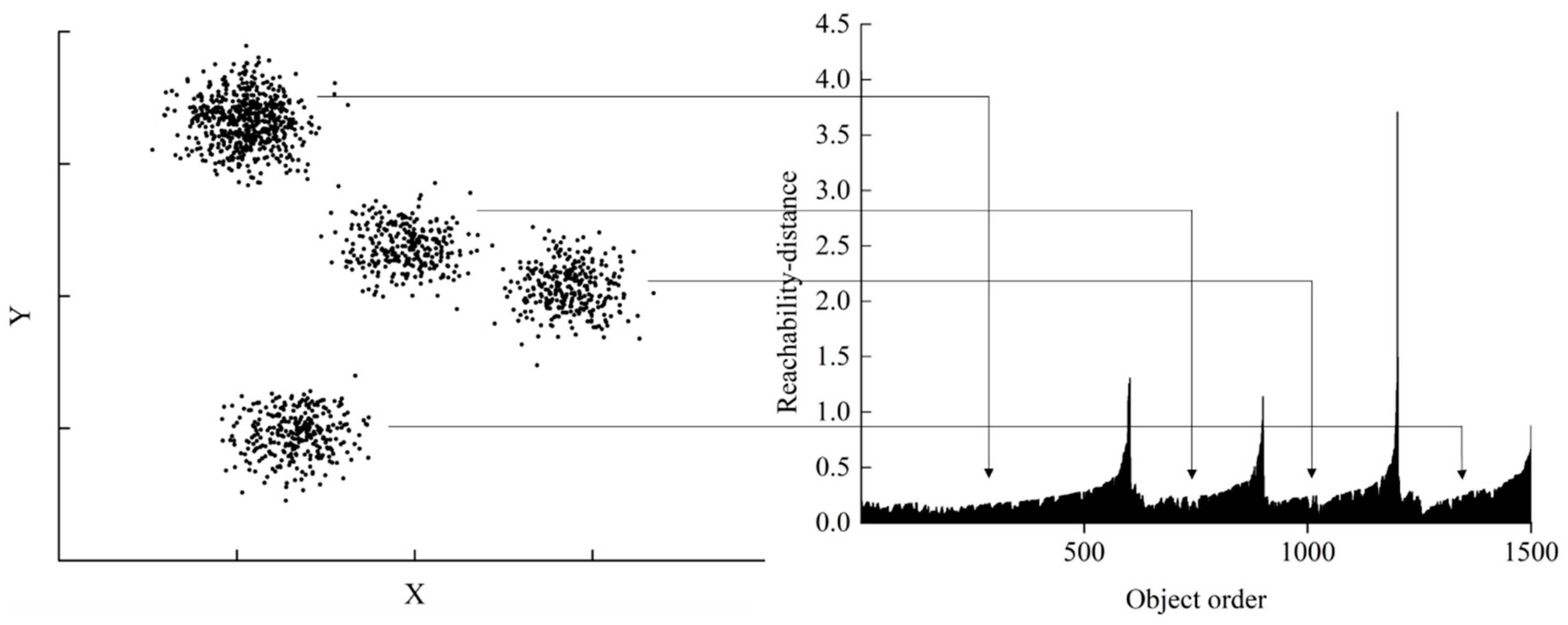
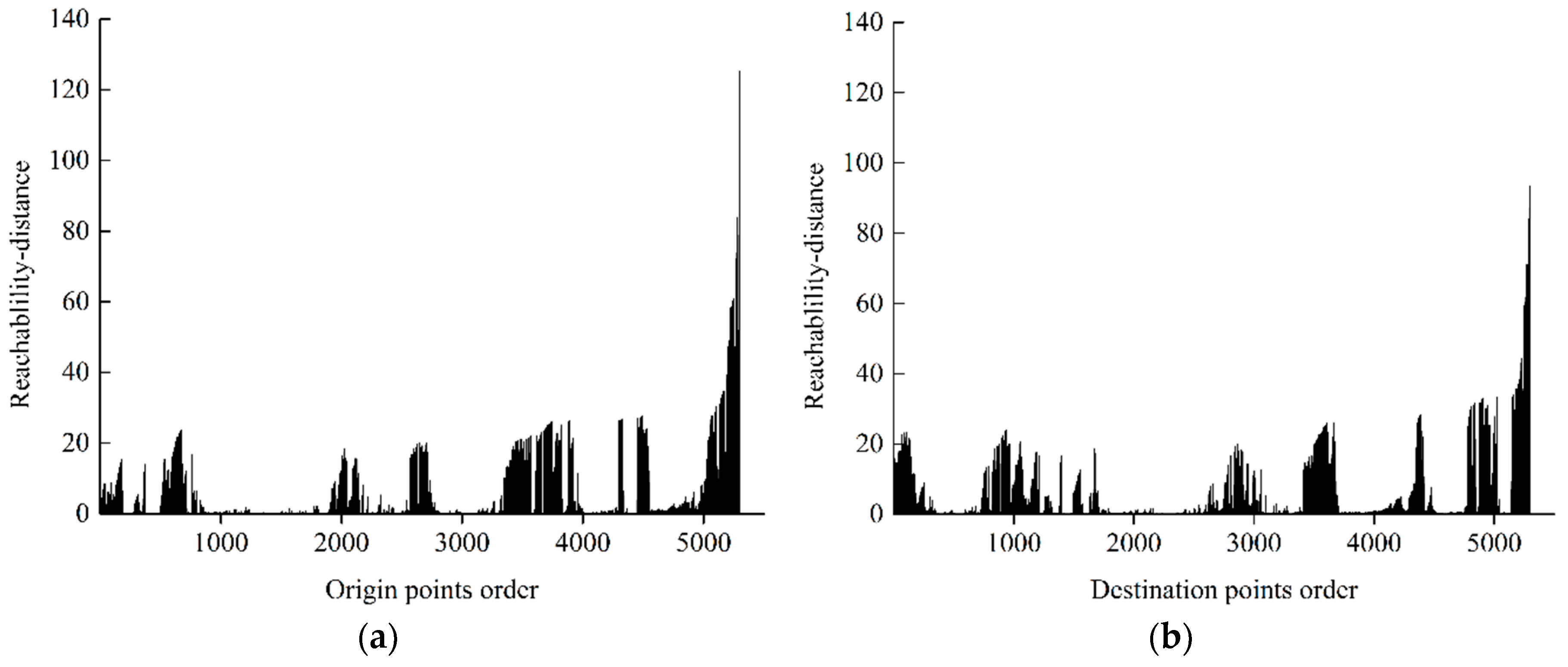
Definition 5. Core-distance: Core-distance is the smallest distance that makes become a core-object:where is the -th nearest point to in the ε-neighborhood set . It is remarkable to note that . Definition 6. Reachability-distance: For both , the reachability-distance from to is defined as: The output of the OPTICS algorithm is an order of points with the attributes of core-distance and reachability-distance. Based on this order, reachability-distance of all objects are presented in a reachability plot which intuitively reveals the intrinsic density structure of a dataset, as illustrated in
Figure 6. The horizontal axis denotes the objects order and the vertical axis denotes the reachability-distance. The large reachability-distance indicates that this point belongs to a sparse region instead of any possible clusters. On the contrary, a small reachability-distance means a small distance from other points. As a consequence, it is obvious to recognize cluster structures corresponding to the valleys in reachability plot. Clusters with any scale could be obtained automatically from this plot after a concrete steep parameter is determined. This parameter determines the edge of clusters by measuring the variation amplitude of reachability-distance [
20].
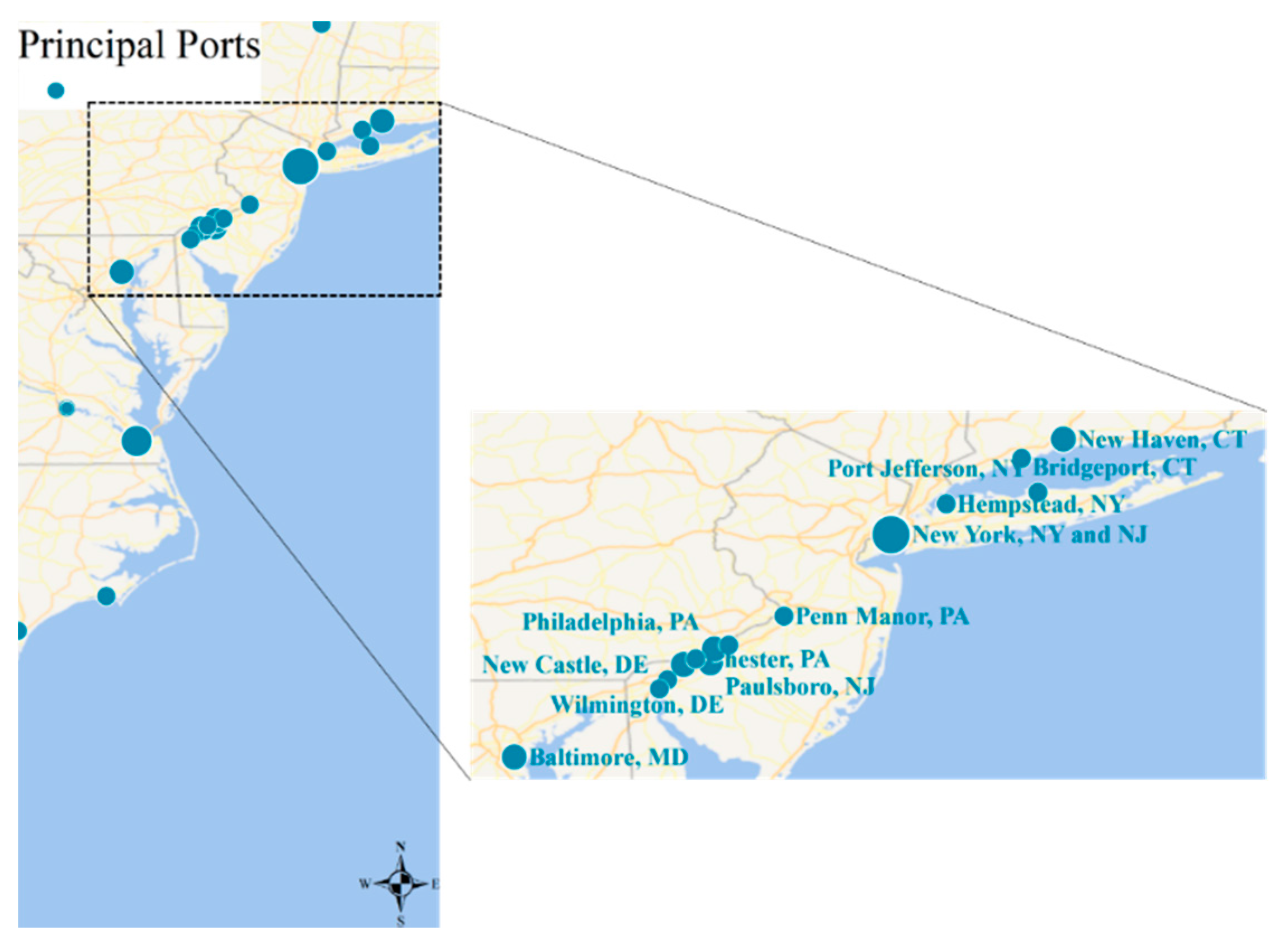
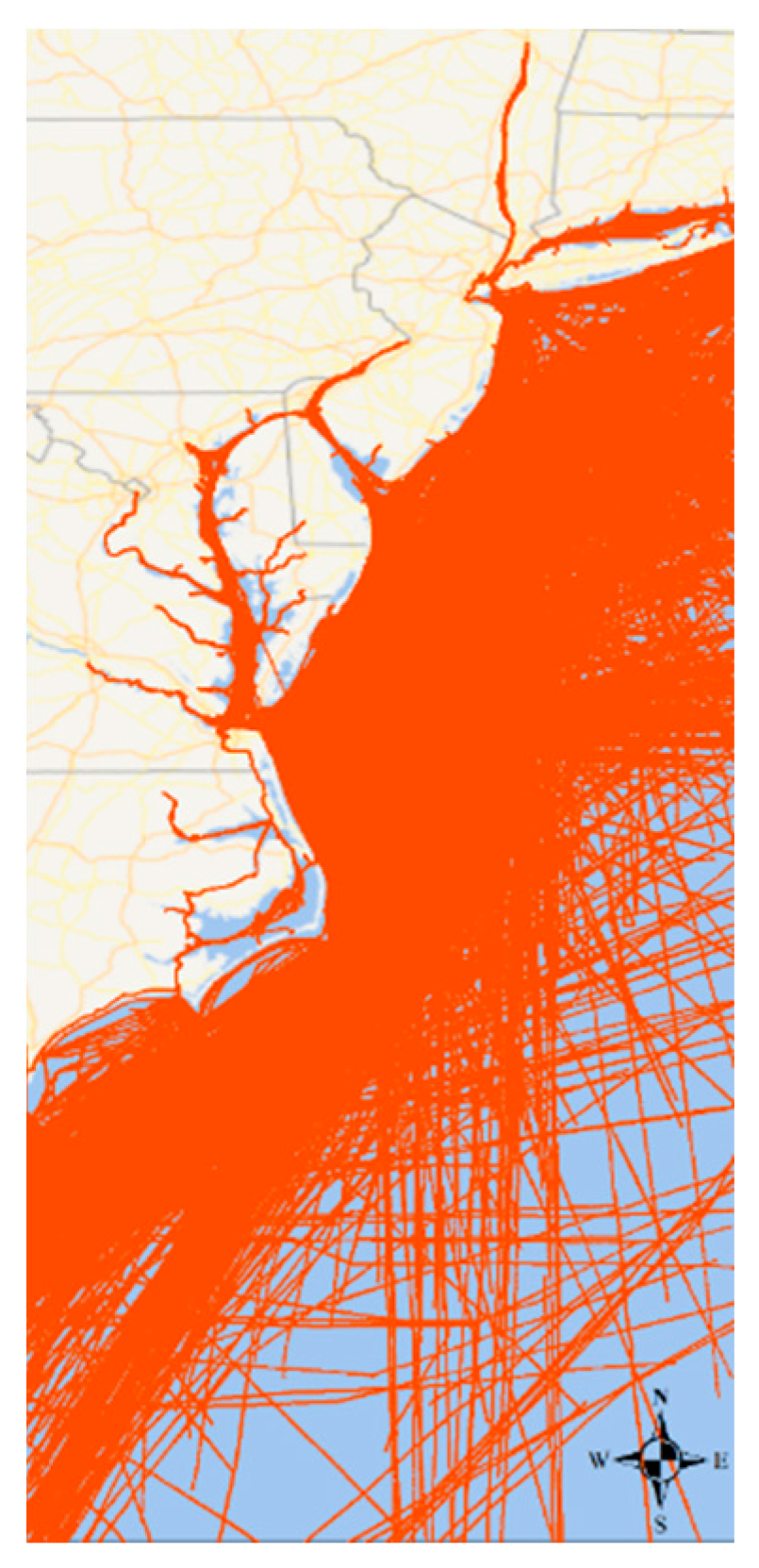
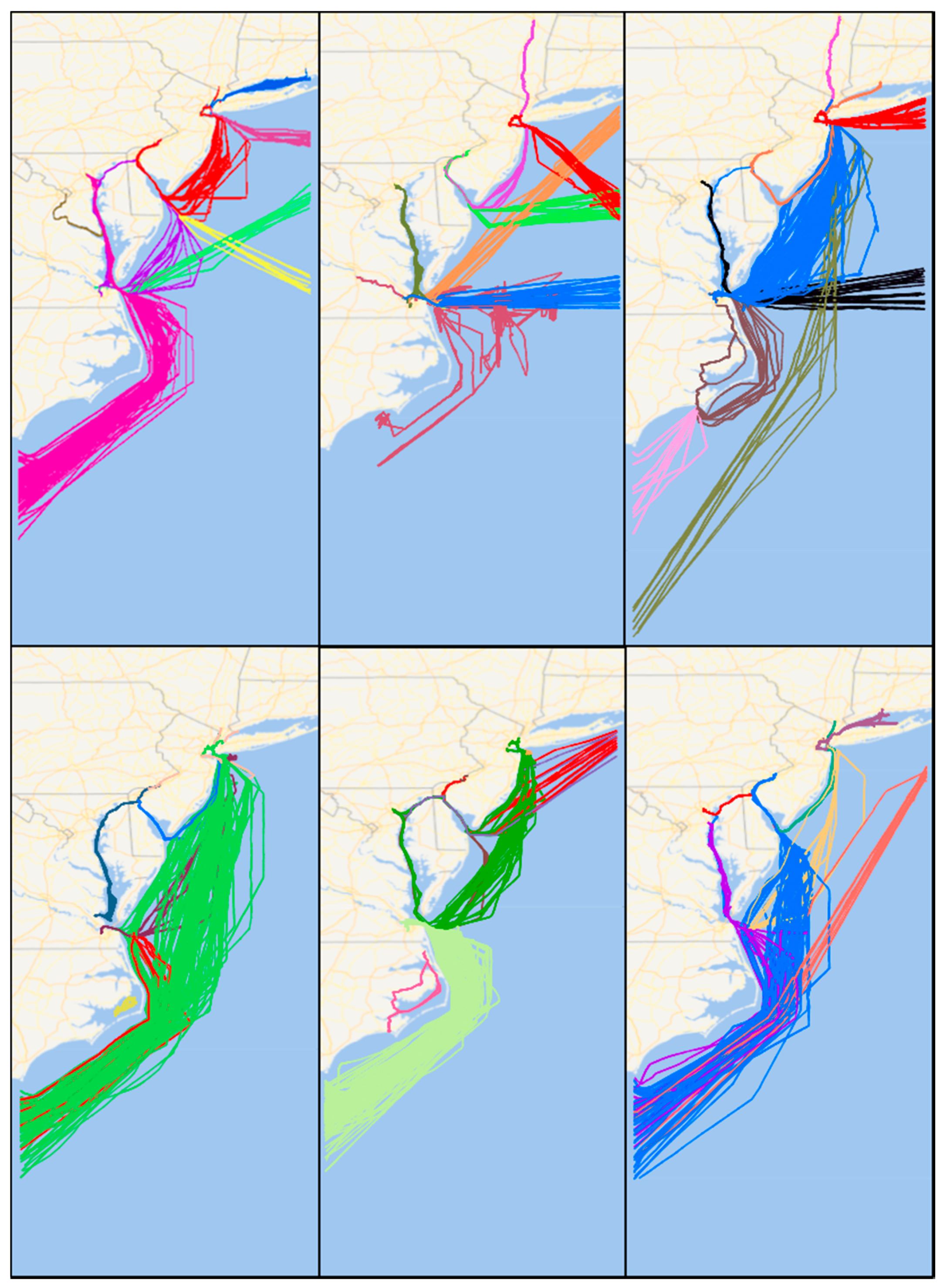
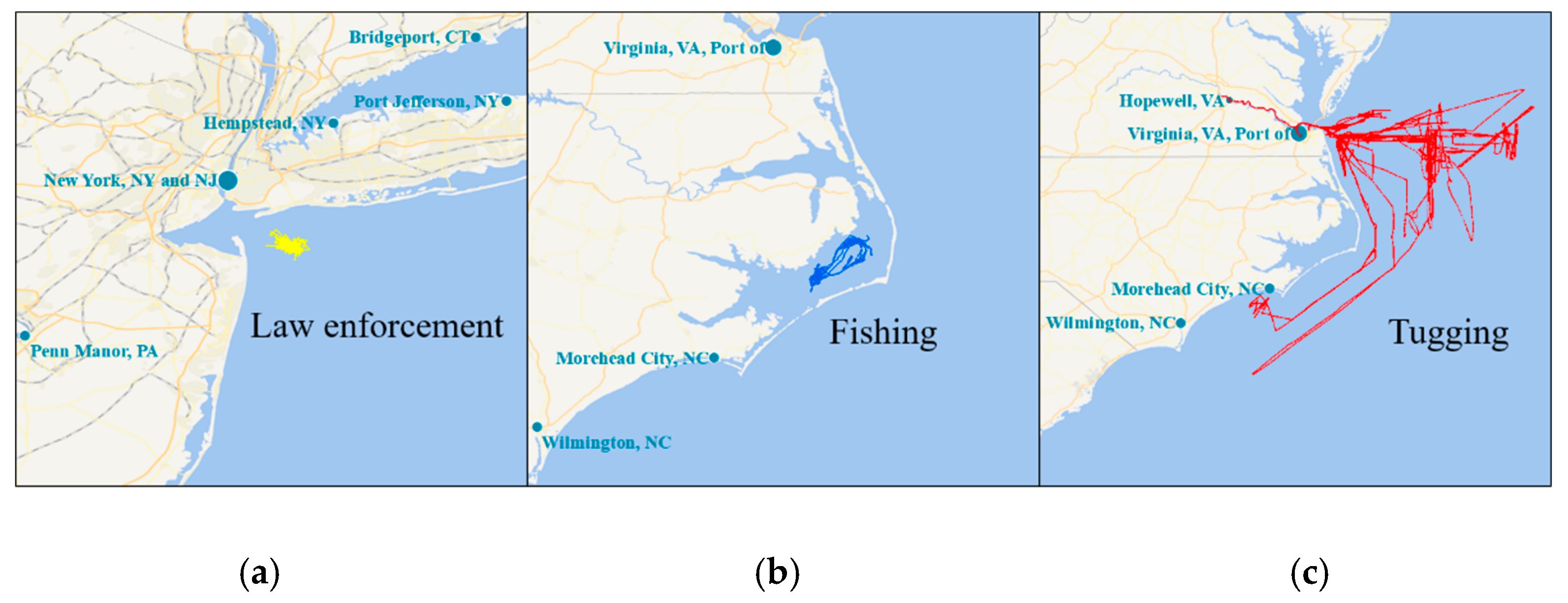
The OD clusters stand for the regions frequently visited by moving objects. They are usually regions of interest ( ROIs ) like shop centers, transportation hubs in city or principal ports in maritime industry. Since plenty of activities emerge in ROIs, there are also a mass of moving objects traveling back and forth among them. Plenty of repeated similar trajectories connecting different ROIs form the active routes (ARs), also called frequent route patterns [
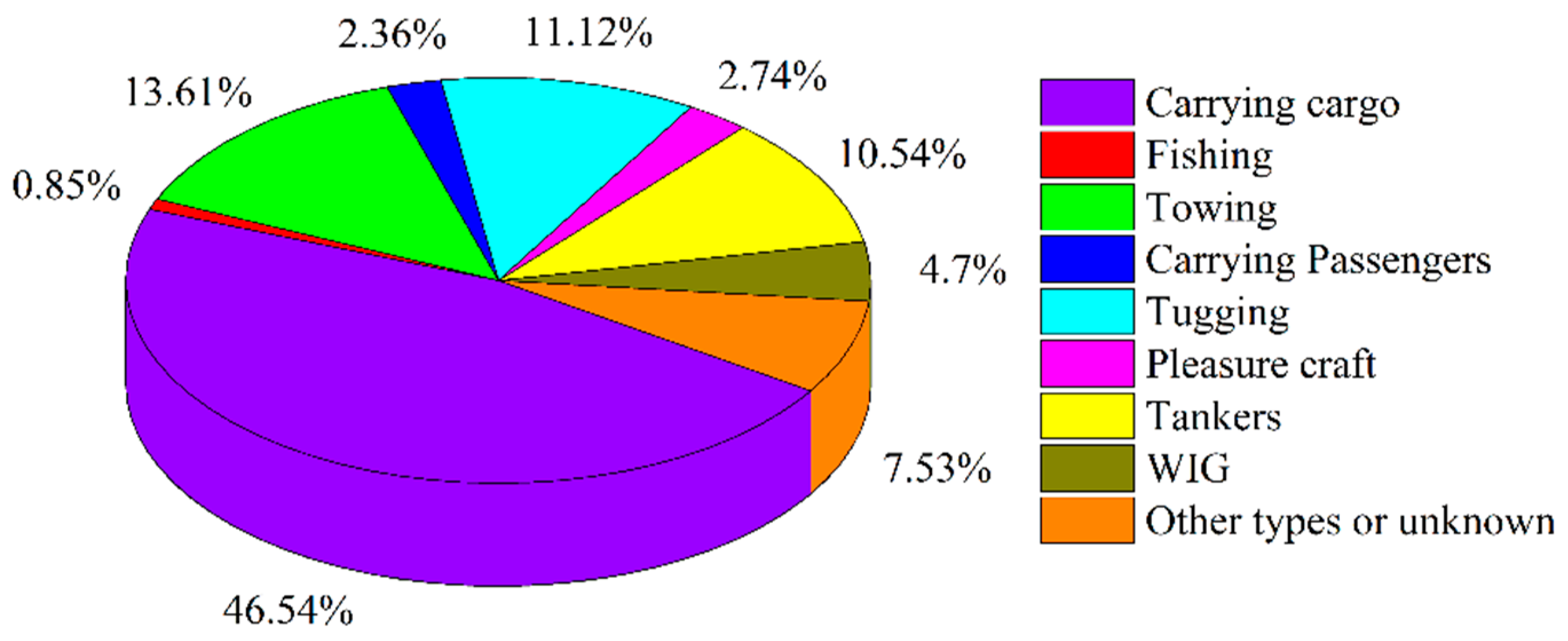
39]. Trajectories connecting these ROIs are then picked out to form route patterns after OD points clustering. Additionally, trajectories in the same route pattern also share similar semantic information such as geographical and geometrical characteristics. However, trajectories in active routes connecting the same group of OD clusters may still differ from each other due to the diversity of travel activities. For example, between region A and region B, trajectories of taking the subway are probably different from that of taking taxi. Thus, as explained in
Section 1, we take both travel activity types and route patterns into account when investigating mobility modes.
3.3. CNN-Based Method for Mobility Modes Identification
We introduce a mobility modes identification method in a deep learning manner. On the basis of mobility modes discovery method elaborated in
Section 3.2, massive history trajectories can be labeled with concrete mobility modes annotation. Then, these trajectories are able to be utilized as training data to train the identification model. The mobility modes identification process consists of two phases: offline model training and real-time identification. Feature extraction and representative learning from trajectory data are crucial issues for training this identification model.
We propose to utilize CNN to accomplish the tasks of feature extraction and identification. Deep features of trajectories, which are recognizable for different mobility modes, can be learned by CNN automatically. The remarkable advantage of CNN compared with ordinary neural network is the character of local connection and weight sharing. In ordinary neural network, every neuron is connected to every neuron in adjacent layers. Instead, neurons in CNN only receive signals from neurons in the local area in the preceding layer. Local connections behave like the receptive field in animals’ brain. This character allows the CNN to capture more local spatial correlations. The weight sharing character in the connection of adjacent layers significantly reduces the number of variables. Both overfitting degree and computation consumption are further alleviated in this way.
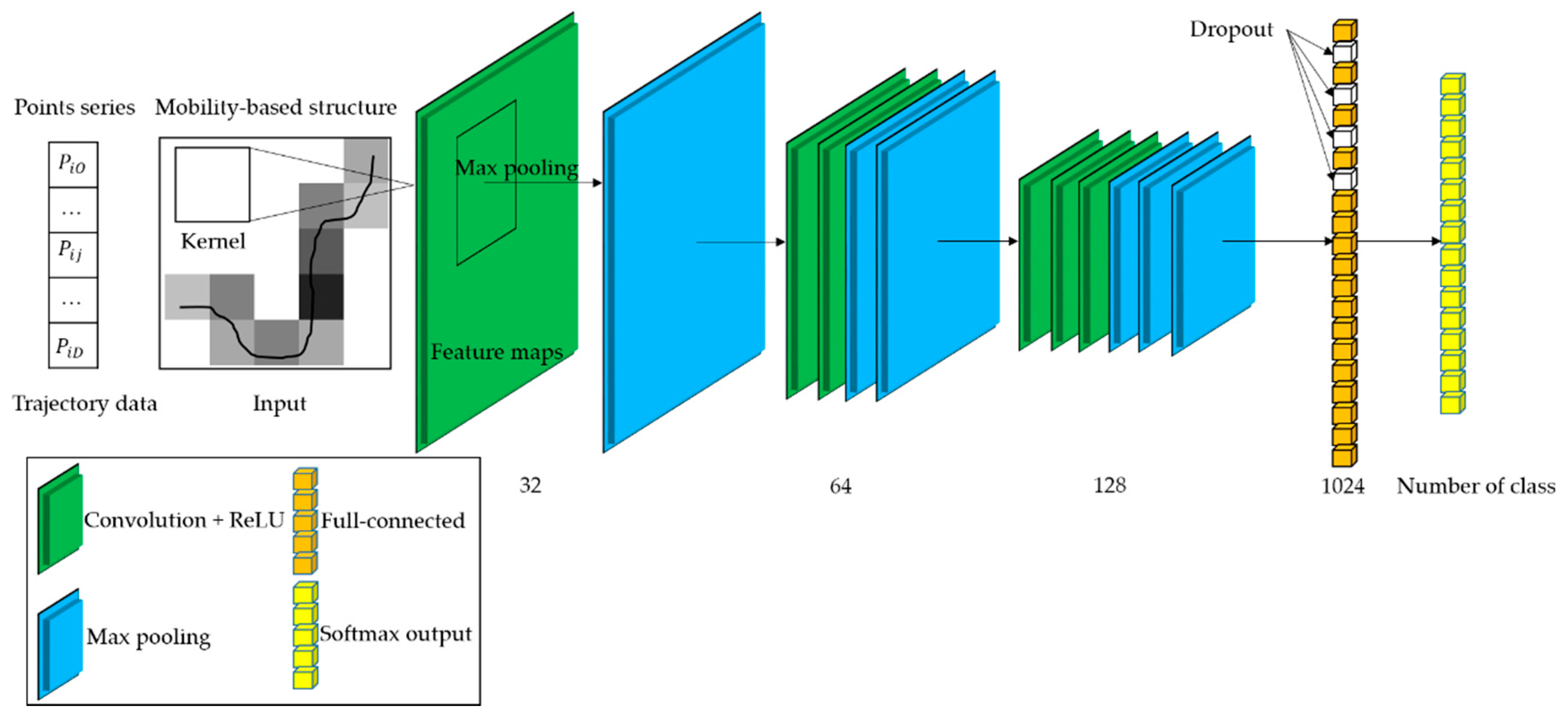
Figure 7 presents the schematic of our proposed identification model. The deep architecture of this model is capable of extracting high-level features from trajectory and also light-weight for training and fine tuning. Trajectory data are transformed into the mobility-based structure described in
Section 3.1 and then fed into the CNN. Mobility mode labels of these trajectories are encoded into one-hot vectors and serve as desired output. This identification model is trained through a back-propagation operation. The training process is completed until the optimization process of the objective function converges.
Our CNN architecture was composed of multiple successive layers, as depicted in
Figure 7, including: input layer, convolutional layer, pooling layer, fully connected layer, and output layer [
16]. The input layer was designed as the mobility-based trajectory structure. The output of each neuron in this layer was equal to the
attribute of the mobility-based trajectory. Convolutional layers consist of several feature maps. Each feature map connects to the preceding layer via a kernel, i.e., a fixed-size weight matrix. In each iteration, this kernel performs a convolution operation on a group of neighboring neurons within a local area of preceding layer. Then the kernel slid with a fixed stride until this operation was performed on all neurons. After adding a bias to convolution item, the output of convolutional layer was activated by a non-linear activation function like rectified linear unit (ReLU) [
34], Sigmoid, tanh, etc. Because of the ability of avoiding a vanishing gradient and the fast converge speed, the ReLU function was chosen to be the activation function in our convolutional layer:
where
and
denote the output of two successive convolutional layers, respectively,
denotes the connection weight matrix between them,
represents the operation of convolution, and
refers to the bias. Reducing the resolution of the convolutional layer can preserve scale-steady features. Hence, the pooling layer was introduced to carry out down-sample operation after the convolutional layer, as shown in
Figure 7. In the pooling layer, down-sample operation aims to derive a unique statistic from the local region of the convolutional layer by taking a pooling strategy. Since the discretization processing was performed on the whole study region, the sparsity problem must be stressed. Therefore, we adopted a max pooling strategy [
36] instead of other strategies since it always performs well in the process of separating sparse features. The pooling layer also alleviates the computational burden due to the reduction of variables. Moreover, the function of a fully connected layer includes: (1) converting the stimulation signal from hidden convolutional layers into one-dimensional form for the output layer, and (2) extracting higher-level features. Ultimately, the output layer generates a probability distribution over the classification labels by resorting to logistic regression function Softmax:
where
is a set including all the received stimulation
of the output layer.
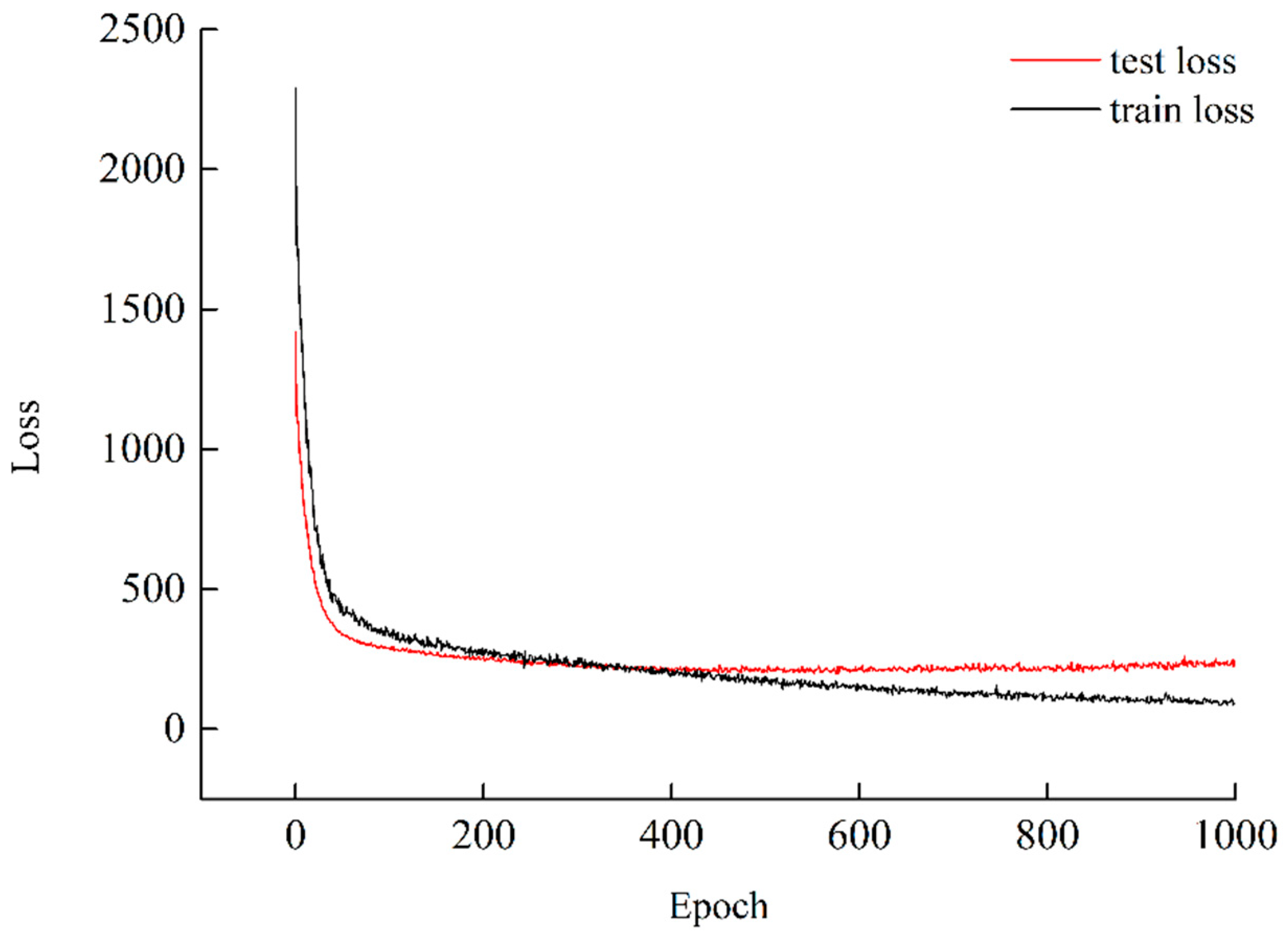
Limited by the volume of the dataset and the complexity of the CNN architecture, overfitting was an inevitable issue of our model. Overfitting means the trained identification model is short of generalization ability. Thus, we introduced L2 regularization [
36] and the dropout technique [
35] to deal with this issue. The prediction error between the actual output and desired output is called loss function. Loss function is the objective function decreased in the back-propagation process of each iteration by means of gradient descend optimizer such as adaptive moment estimation (Adam) optimizer [
40]. However, this operation may produce large weights and further leads to instability of prediction results. The L2 regularization aims to add the quadratic sum of weights to loss function. There is a tradeoff between the decrease of weights and prediction error in loss function after adding L2 regularization. Cross-entropy function with L2 regularization was chosen to be the objective function in the training process:
where
and
denote the loss function with and without L2 regularization, respectively. In Equation (10),
is calculated by cross-entropy function where
is the input,
and
are the desired output and actual output, respectively.
is the weight decay parameter measuring the proportion of regularization item in loss function,
refers to the quadratic sum of all weight variables in Equation (7). Dropout technique stochastically removes a portion of hidden neurons with a certain probability, as shown in
Figure 7. In this way, different architecture is trained in each iteration of the training process. Dropout alleviates the complexity and co-adaption of neurons and consequently enhances the generalization ability of our identification model.
5. Discussion and Conclusions
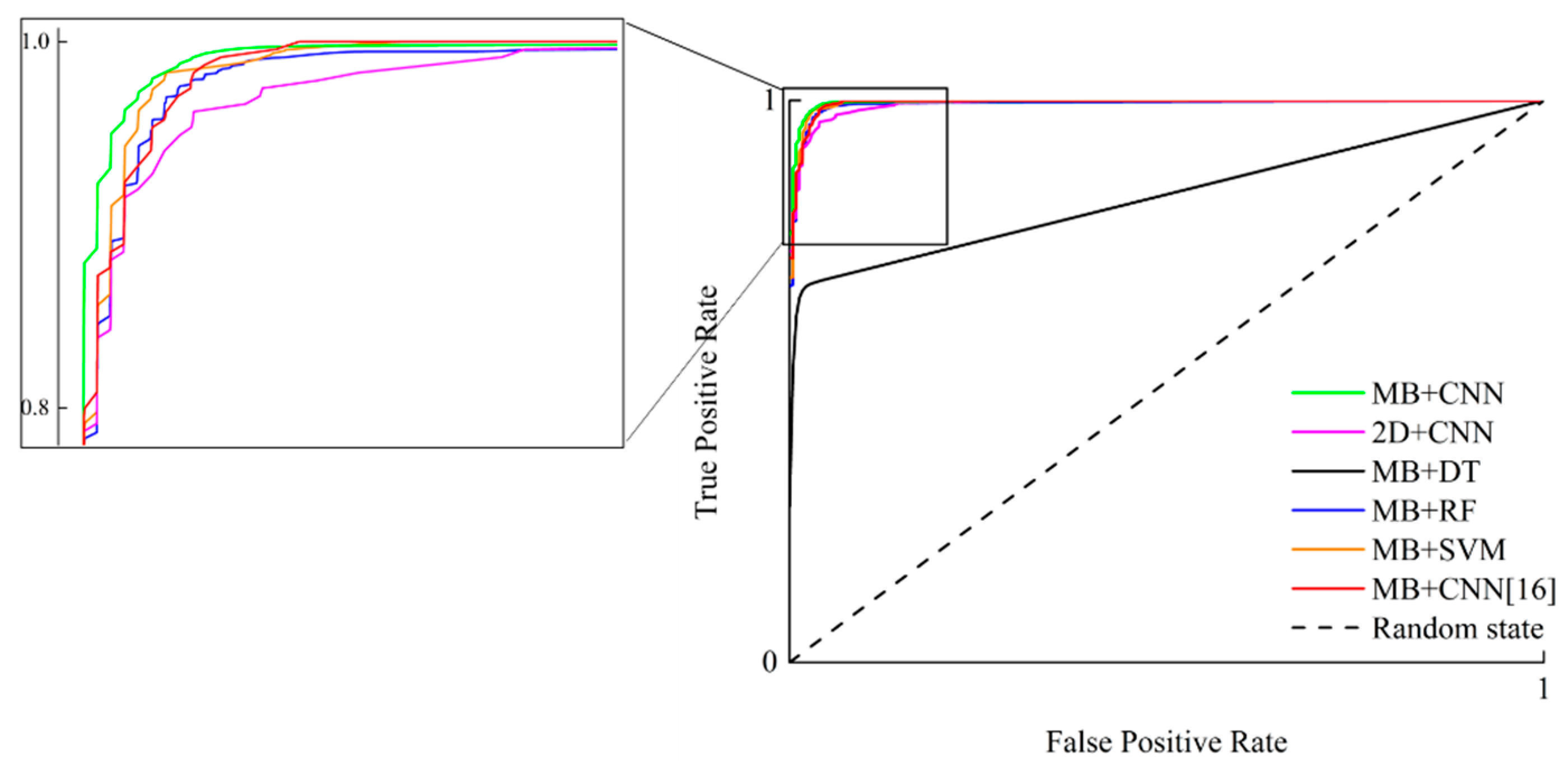
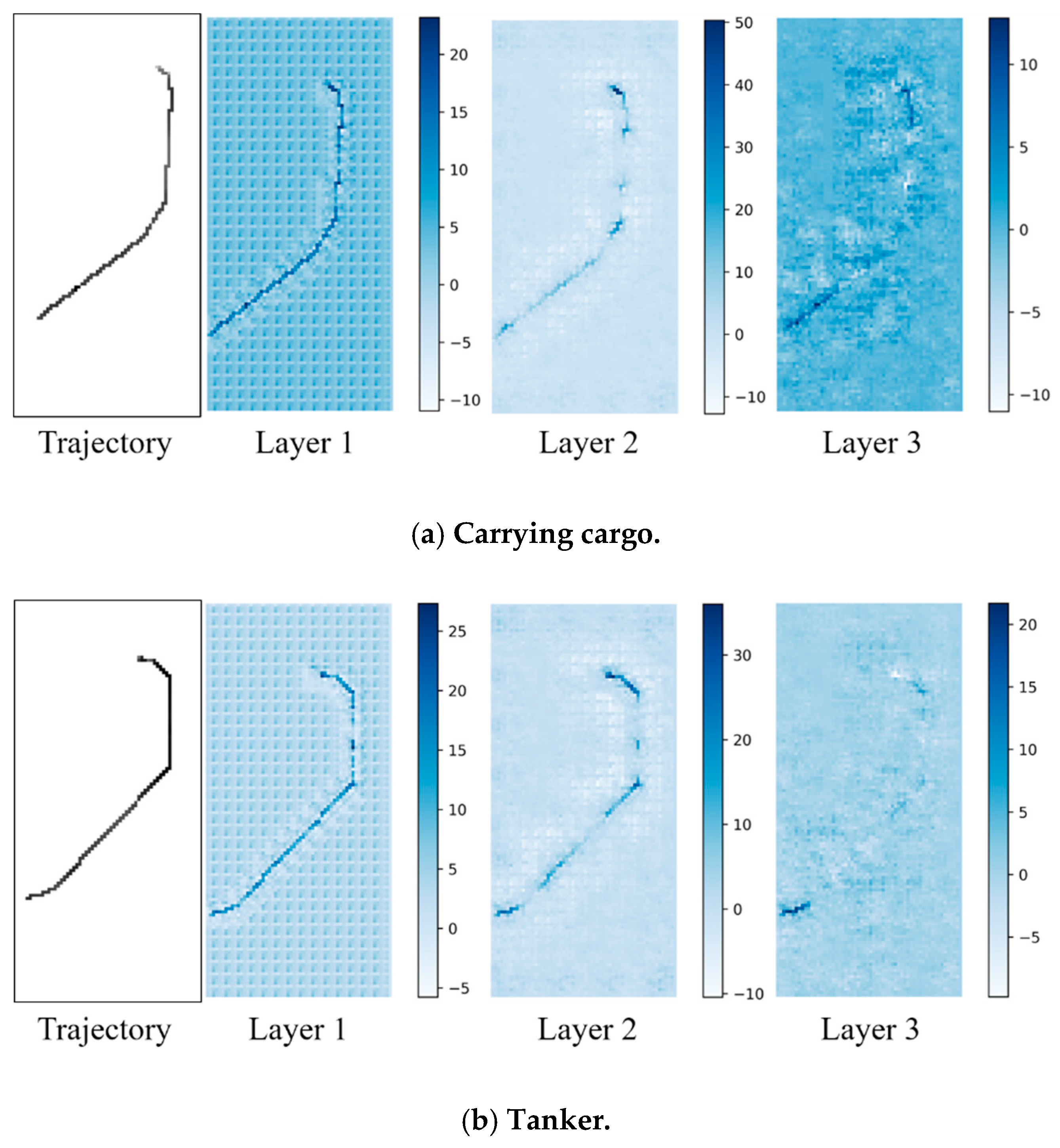
In this work, we proposed a data-driven method to mine the potential knowledge about mobility modes from raw trajectory data. The concerned issues consisted of two aspects: (1) mobility modes discovery and (2) mobility modes identification. Our method aimed to integrate these two issues together. To achieve this goal, we presented an unsupervised approach, i.e., OD points clustering, to discover route patterns from massive history trajectories. Then, we built a CNN-based identification model by taking advantage of the labeled history trajectory data. Experimental results on real data indicate the reasonable superiority of our method as expected. Further, visualization of deep features was also inspiring for understanding the mechanism of deep learning.
The conclusion of this work can be summarized as follows. (1) In the phase of mobility modes discovery, the proposed OD points clustering method performed excellently in discovering different route patterns. The uncovered mobility modes containing abundant geographical and semantic information were useful knowledge hidden in massive history trajectory data. This method and the corresponding results were valuable for land use planning and traffic management. (2) We put forward an advanced mobility-based structure of trajectory which integrated geometrical, geographical, and kinematic information comprehensively. This well-designed structure is preferable for capturing representative features directly from trajectories. (3) Moreover, we proposed a deep learning model leveraging a CNN to identify mobility modes. This model achieved good performance in capturing the deep features without any domain knowledge. This approach could be used to provide real-time identification result for traffic surveillance.
This work presents a typical way to transform the raw trajectory data into knowledge and decision support. This way is expected to be applied to many other trajectory mining investigation and various practical application fields. There still exist future fields to be explored over this work. Firstly, we will try to synthesize more useful attributes to construct a multi-dimensional trajectory structure, such as semantic and temporal information. We believe that more knowledge contained in multi-attributes can make different mobility modes more recognizable. In addition, we plan to perform further study on routes and destination prediction and abnormal behavior detection based on mobility modes awareness.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}