An Adaptive Construction Method of Hierarchical Spatio-Temporal Index for Vector Data under Peer-to-Peer Networks

Abstract
:1. Introduction
- Studies focused on improving or expanding traditional spatial index (QuadTree, R-Tree, Grid index, etc.) for distributed environments [7,8,9,10]. For example, as an extended MapReduce framework, SpatialHadoop provides a generic global indexing algorithm which was used to implement Grid, R-tree, R+-tree, Quad-tree, and k-dimensional (KD) tree based partitioning [11]. Spatio-temporal (ST) Hadoop, which is a comprehensive extension to Hadoop and SpatialHadoop, takes the advantages of applying the aforementioned spatial bulk loading techniques that are already implemented in SpatialHadoop and spatiotemporally loads and divides data across computation nodes, which result in achieving orders of magnitude better performance than Hadoop and SpatialHadoop [4]. GeoSpark also provides uniform grid, R-tree, Quad-Tree, and KDB-Tree (the combination of KD-tree and B-tree) spatial data indexing algorithm and it builds local spatial indexes on each Spark data partition to speed up the local computation [12]. Such index structure always need long constructing time, high updating cost and the index consistency is difficult to maintain, hence it is not suitable for the spatio-temporal data which updated frequently in distributed environments.
- Studies focused on constructing an index based on space-filling curves (SFCs; Z-Order, Hilbert, Google S2, etc.). Fox et al. [13] proposed a spatio-temporal index structure that uses a GeoHash string to identify the spatial information and interleaves the time attribute string to form the index key value. Le et al. [14] proposed a spatial index method by combining R-Tree and Geohash. Google implemented a spatial index called S2 by combining a quadtree and Hilbert curve, enabling the expression of multi-level spatial elements [15,16]. GeoMesa [17], a popular open source project, involves implementing an extended Z-ordering (XZ-ordering) spatio-temporal indexing method based on Z-order [18]. In this approach, XZ sorting is utilized to express spatial information at arbitrary resolution, and the query performance does not deteriorate with increasing resolution [19,20]. Moreover, Eldawy et al. [21] extend the traditional spatial index by introducing Z-curve and Hilbert curve partitioning techniques in SpatialHadoop. The SFC-based strategy can better describe the spatial continuity characteristics of spatio-temporal data due to its spatial agglomeration characteristics [22,23]. Therefore, this approach has been widely used in spatio-temporal index studies in recent years. However, in the existing SFC index-based research, the spatial and temporal attributes have generally been separated, which has made it difficult to take into account the efficiencies of temporal and spatial queries simultaneously. In addition, for line and polygon elements with different geographic ranges, the efficiencies and accuracies of queries are closely related to the index level used, and a means of achieving a reasonable spatio-temporal expression and determining a practical index level has not yet been identified.
2. Related Work
2.1. XZ3 Spatio-Temporal Index
- (1)
- The algorithm uses a Z-order curve as an SFC, which has a hopping problem when expressing two-dimensional space. Consequently, the data expressed by proximity coding are not spatially adjacent and leading to a large number of ineffective queries when querying hopping regions.
- (2)
- When dividing spatial hierarchy, the XZ3 algorithm decides whether to divide further by judging whether the number of cells divided in a hierarchy meets a certain threshold. However, the threshold setting does not fully consider the spatial distribution and density of all the elements in the same layer.
2.2. S2 Spatial Index
- Step 1
- Assume a cube surrounding the Earth with radius 1, [−1,1] × [−1,1] × [−1,1], and the center of the earth as the origin. For a certain point or region on the Earth, transform the longitude and latitude coordinates of point p on the minimum bounding rectangle (MBR) surrounding the point or region into three-dimensional coordinates of a cube, p = (lat, lng) => (x, y, z).
- Step 2
- Project point p onto a certain surface of the cube by following the radial direction, (x, y, z) => (face, u, v), where face represents the number of the surface of the cube, face = {0, 1, 2, 3, 4, 5}, u and v represent the projection coordinates of each surface. Then normalize the projected coordinates u and v to the interval [0, 1].
- Step 3
- Discrete normalized u and v into i and j, respectively, (face, u, v) => (face, i, j), where i, j ∈ [0, 2n − 1] denotes the maximum effective bit of the quadtree cell, and n ∈ [0, 30] denotes the depth of the quadtree, which is a hierarchical series.
- Step 4
- Map the quadtree cell identified by face, i, and j to a Hilbert curve of a certain level, and calculate the corresponding cell ID, (face, i, j) => CellId, where CellId is a 64-bit integer and can uniquely represent a point or region.
- (1)
- Regarding the joint expression of spatio-temporal information, S2 only expresses the spatial information. For spatial geometric elements with multiple time series, an effective means of combining temporal and spatial information has not yet been determined.
- (2)
- The expression of non-point elements. For line and polygon elements, the spatial scale varies greatly, and for geographic element queries, the spatial span and spatial query mode are both random. It is necessary to take into account both accurate and fast queries in a small range and scanning operation on a large scale. A reasonable method of spatio-temporal expressions is the second limitations.
- (3)
- The determination of time granularity and optimal hierarchy. In the research on traditional spatial index including regular grid, Quadtree-based grid and R-tree based grid, Belussi et al. [28] pointed out that the efficiencies and accuracies of queries are closely related to spatio-temporal dataset distribution characteristic. Therefore, the lack of a reasonable means of achieving spatio-temporal expression and determining a practical index level according to the spatial and temporal characteristics of elements for the SFC-based index is the third limitation.
3. Methodology
3.1. Joint Coding of Spatio-Temporal Information
3.1.1. Time Information Coding
3.1.2. Spatial Information Coding
3.1.3. Feature Identification Information Coding
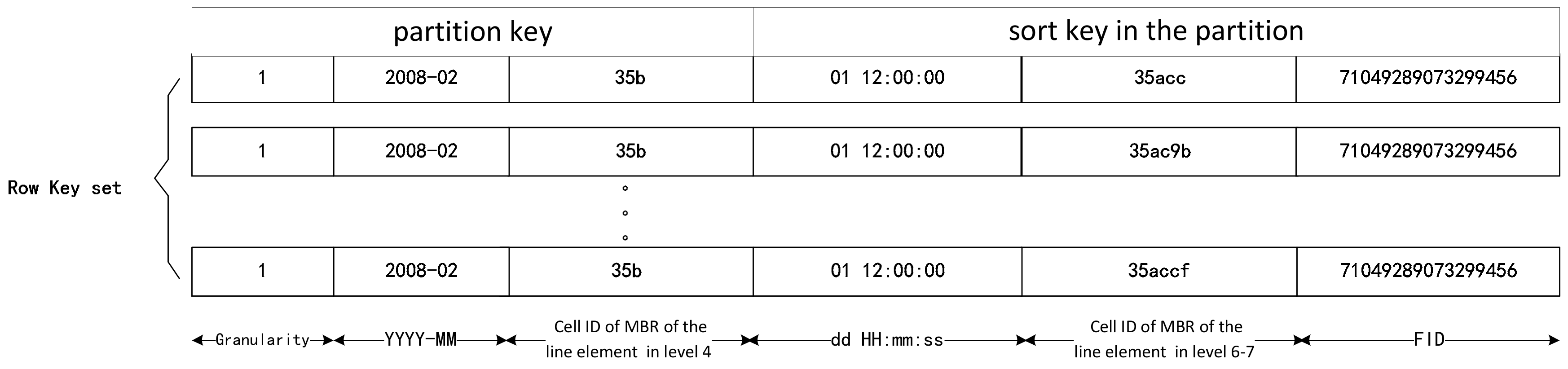
3.1.4. Organization of Row Key Coding
3.2. Expression of Spatio-Temporal Elements
3.2.1. Spatio-Temporal Expression of Point Elements
3.2.2. Spatio-Temporal Expression of Non-Point Elements
3.3. Spatio-Temporal Index Construction Algorithm in Peer-to-Peer (P2P) Network
3.3.1. Determination of Time Granularity
3.3.2. Determination of the Spatial Grid Hierarchy
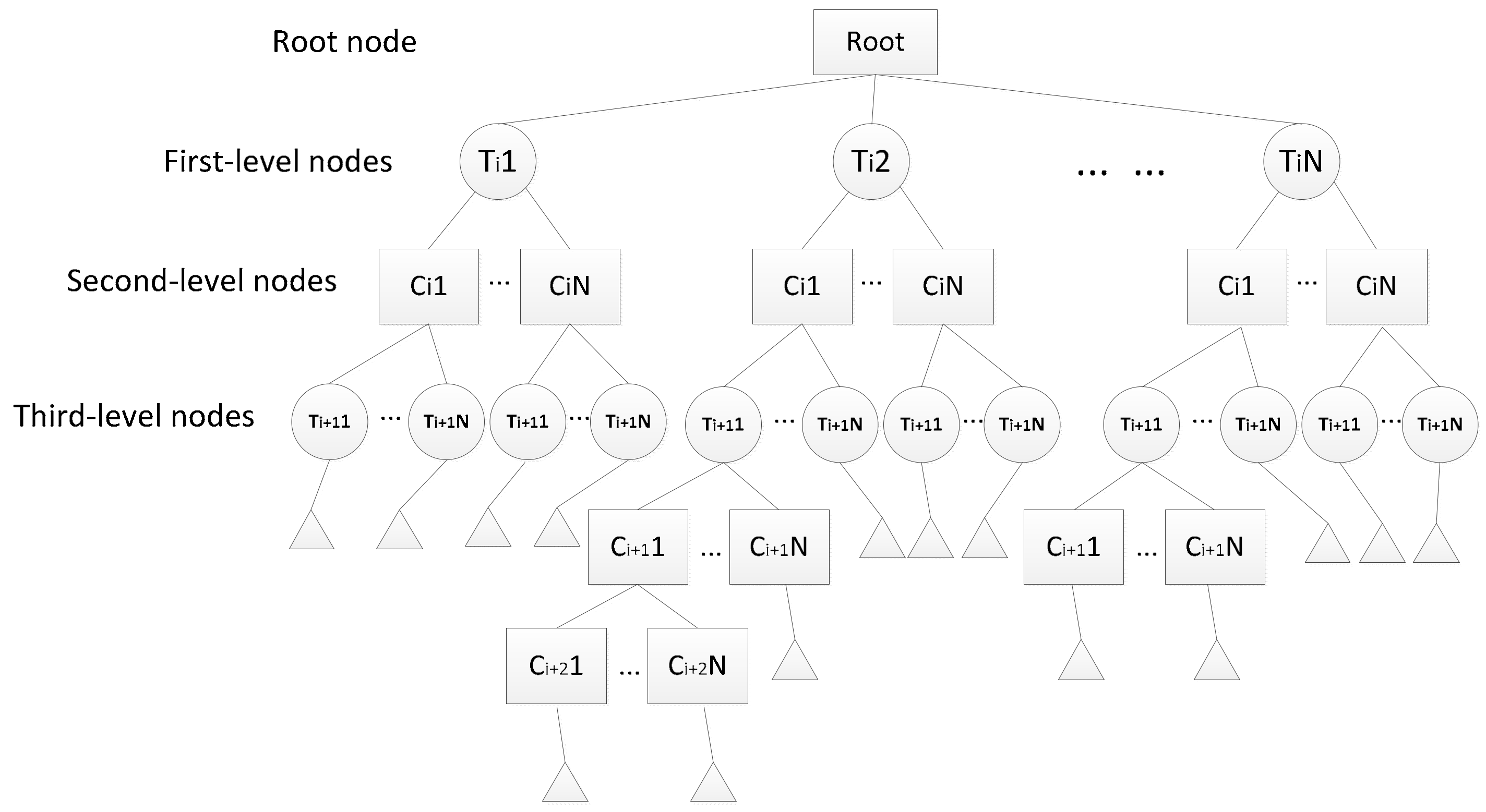
3.3.3. Multi-Level Spatio-Temporal Index Tree
- Step 1
- Determine the time granularity Tpartition(gi) used in the partition key and construct a first-level node, as shown by Ti in Figure 9.
- Step 2
- According to the idea of the S2 index, define the MBR of a certain spatial range as Rect and convert its four-corner latitude and longitude coordinates (Rectk, k = 0, 1, 2, 3) into three-dimensional coordinates. The rectangular spatial range Rect is used as the root node of index tree.
- Step 3
- Divide the projected four-corner coordinate into different levels n, n ∈ [0, 30]. The value range of n is determined by the spatial range of cell in each level of S2 index, as shown in Table 2 [15], the minimum area that a single grid can describe in level 30 is 0.43 cm2, which means every cm2 can be represented using a 64-bit integer and this is fine enough for the common spatial data management scenarios [30,31]. Starting from level n = 0, the current Region(face, ik, jk) can be covered by m cells, if m > threshold (N1), the current level is the desired level and it is used as the second-level node Ci.
- Step 4
- Construct the time granularity information in the sort key, i.e., Tsort(gi), as a third-level node, as shown by Ti+1 in Figure 9.
- Step 5
- Sample the elements in the entire layer and count the number of elements in the cell. If the number is larger than the threshold Splitthresh, Ci is split further. The threshold Splitthresh is an empirical value, which we obtained through a large number of actual data experiments. In this paper, we set it as 30% of the total elements. Different from the quadtree split of four cells, the only sub-cell that is split is that covering the element as sub-tree nodes of the third-level node Ti+1, and the maximum number of sub-cells is 4. Step 5 is then repeated for the sub-cells until the number of elements is less than the threshold or the depth of the sub-tree reaches the depth threshold Heightthresh(thresh). The level is set as sublevel, and the splitting is stopped.
- Step 6
- By mapping the m-th quadtree unit cells identified by (face, ik, jk) to the Hilbert curve of sublevel, the corresponding cell ID set Scell is calculated. Scell can uniquely represent the query area, where each cell ID of Scell represents a sub-area of a query. All the cell IDs in Scell are used as the level nodes and serve as the encoding of the spatial information in the sort key.
- Step 7
- According to the first- and second-level nodes, the Murmur Hash function is substituted to calculate the corresponding partition location, and the locations of the third-level node and its sub-tree leaf node are determined according to the cell ID.
3.3.4. Dynamic Update and Maintenance of Multi-Level Sphere 3 (MLS3)
- Insert operation: for the new added data, the cell ID will be calculated first. If the time information does not belong to the current index tree, a new first-level node and a new index tree branch will be added. Otherwise, determine the first-level node of the new data according to the cell ID, and then traverse the sub-tree layer by layer from the first-level node to the leaf node to find whether the node containing the new data exists. If not, insert the new data as a new leaf node; if it exists, the node is no longer need to insert [4,6].
- Delete operation: if the deleted node is a leaf node, it can be deleted directly; otherwise it cannot be deleted. If the deleted leaf node has the same level node, the delete operation is terminated and if there are no other nodes in the same level of the leaf node, the parent node is deleted. Traverse the sub-tree in turn and repeat the above step [4,6].
- Split operation: if the number of elements in a cell is larger than the threshold Splitthresh, this cell is split further. Different from the quadtree split of four cells, only the sub-cell that covering the element as sub-tree nodes of the third-level node Ti+1 is split, and the maximum number of sub-cells is 4. The split operation is repeated for the sub-cells until the number of elements is less than the threshold or the depth of sub-tree reaches the depth threshold Heightthresh(thresh).
4. Results and Discussion
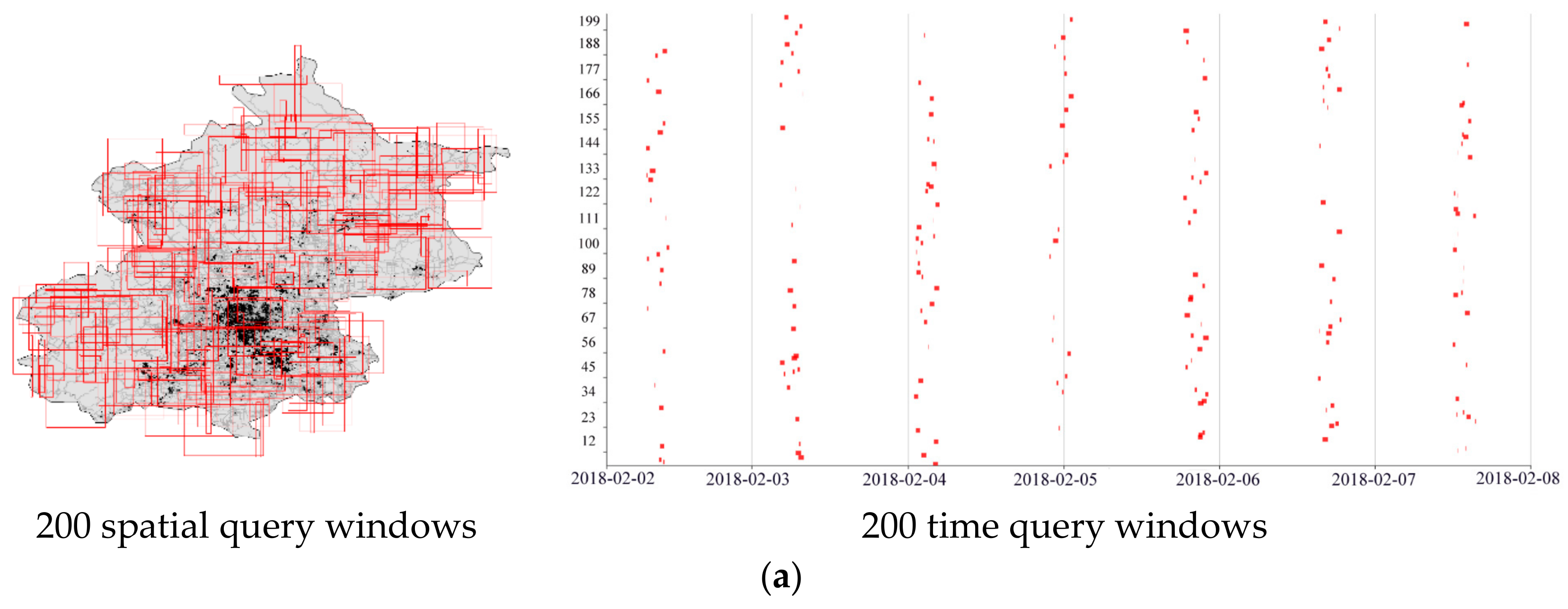
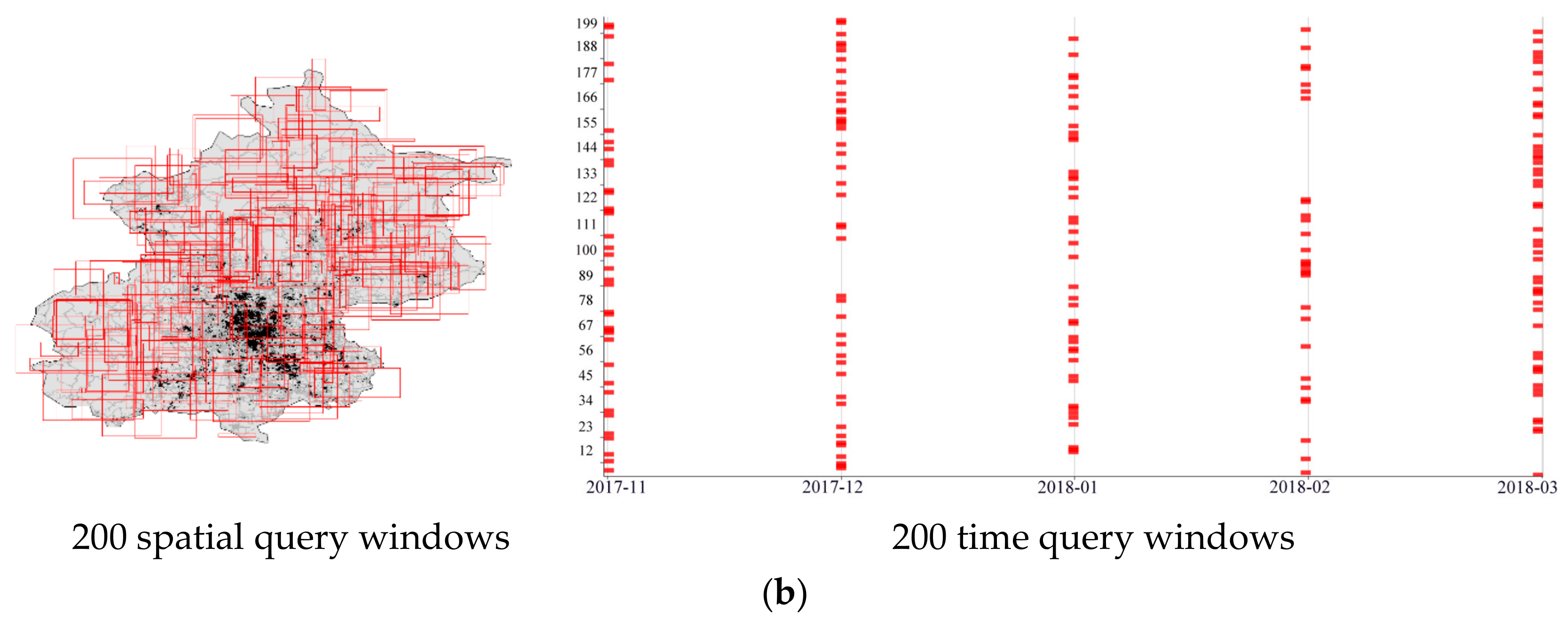
4.1. Experimental Data and Environment
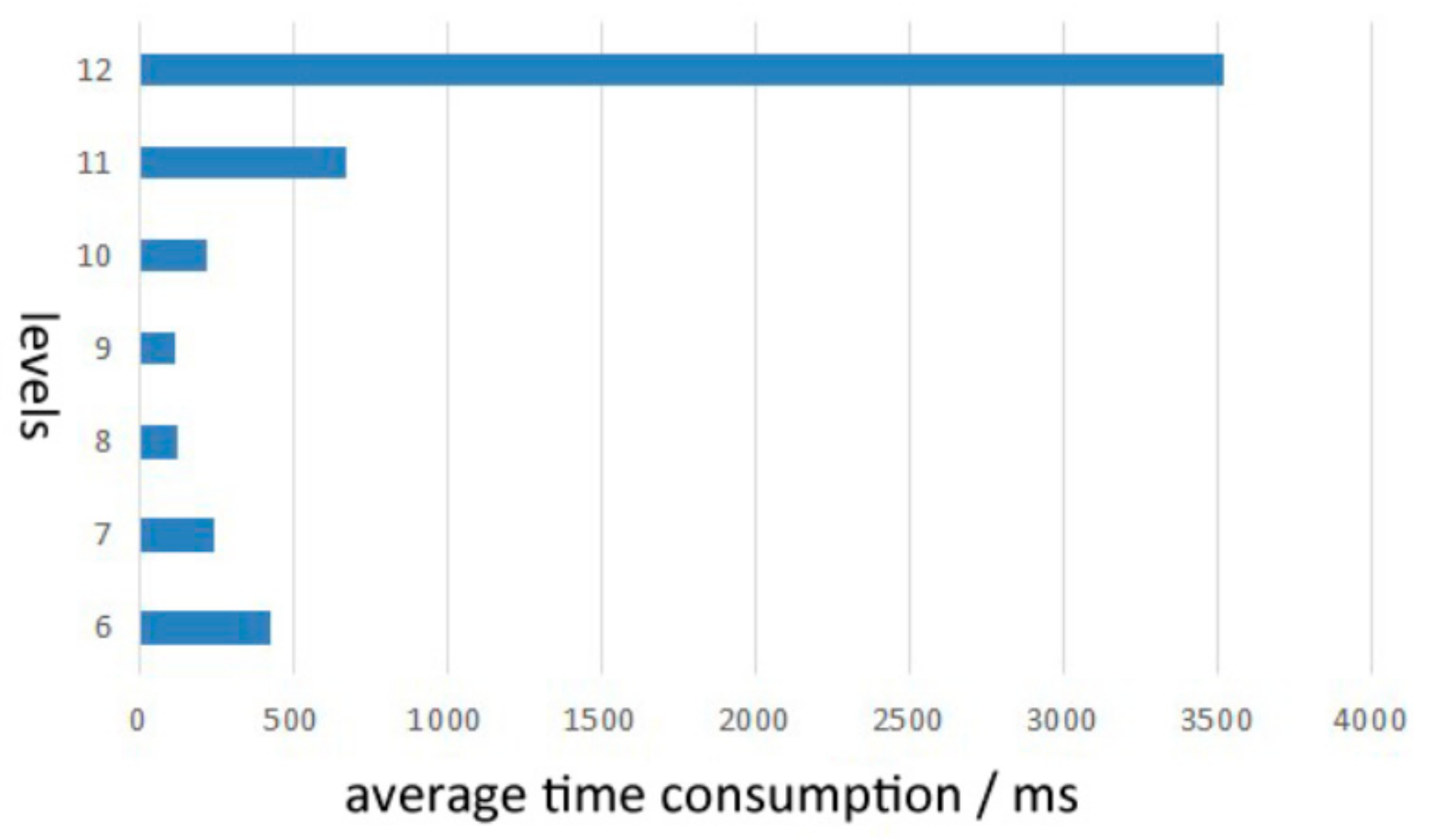
4.2. Rationality Verification of Hierarchy Determination
4.3. Comparison of Index Performance
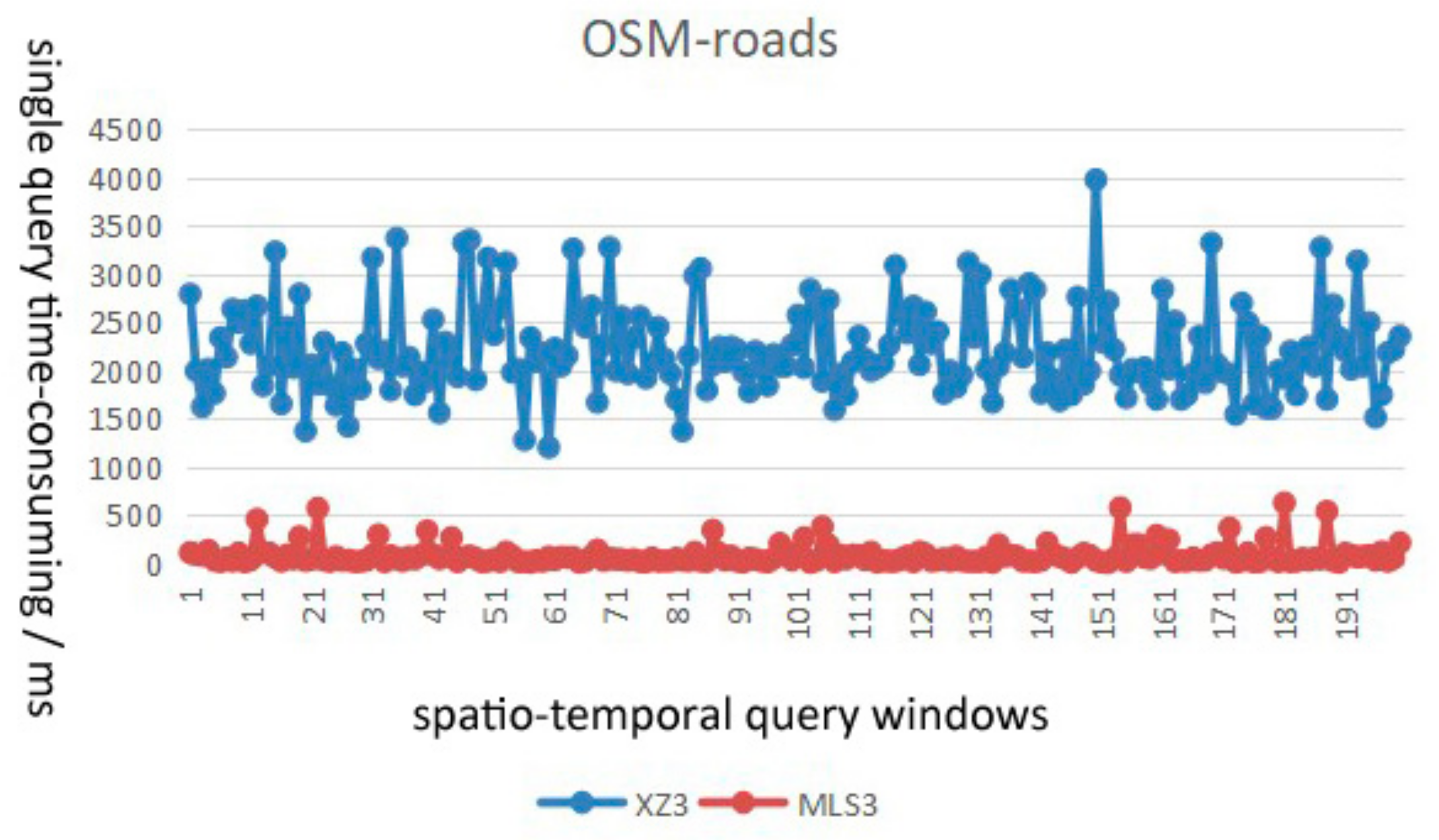
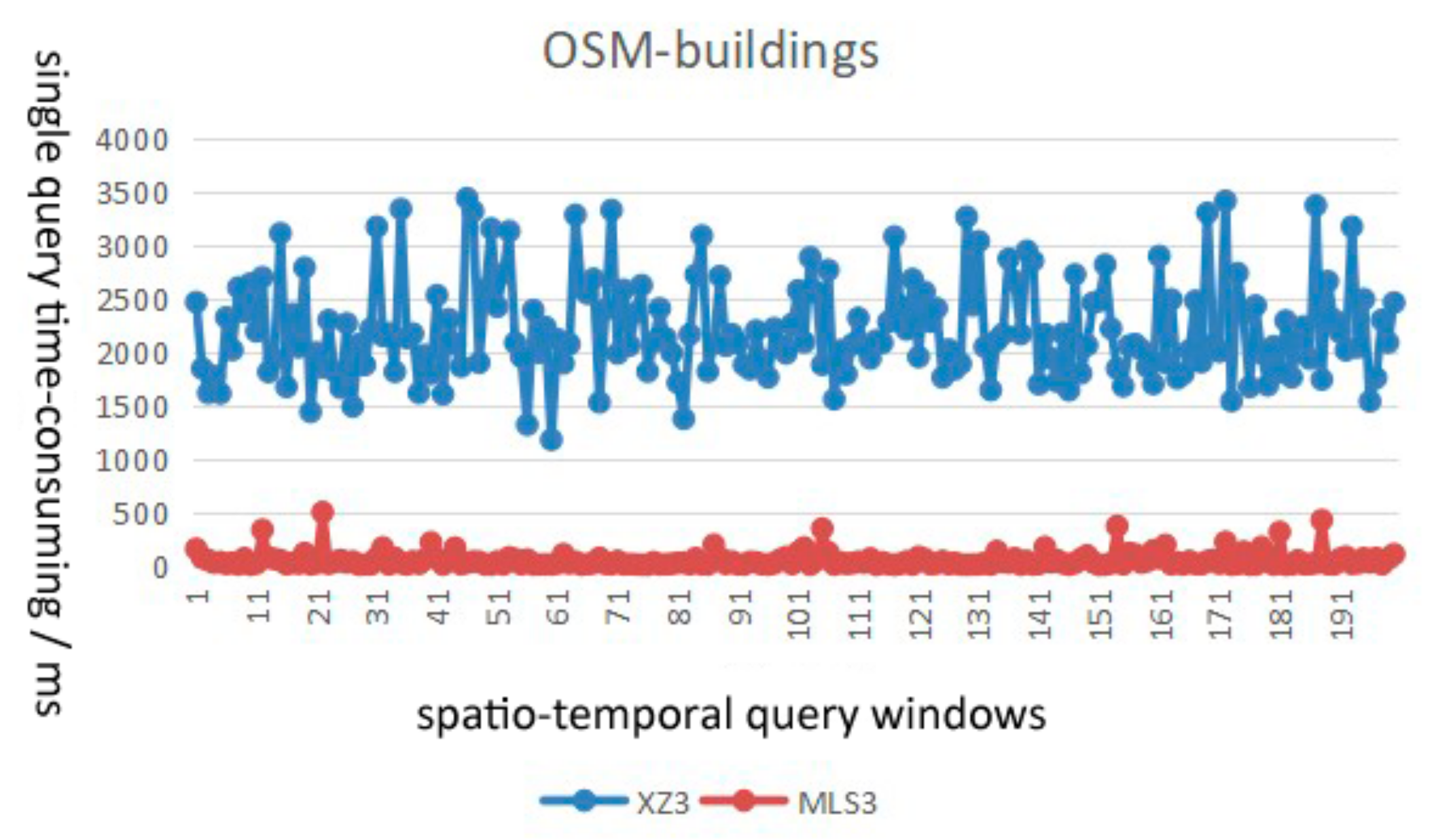
4.3.1. Index Query Efficiency
4.3.2. Construction Efficiency and Space Consumption Ratio
5. Conclusions
- (1)
- To determine the optimal hierarchy, the spatial distribution and density of the entire layer of elements were considered. The most suitable level for the national layer is 4–5, for the provincial layer 7–8, and for the city layer 9–10.
- (2)
- In terms of query efficiency, the average time consumption of the proposed MLS3 algorithm is about 1/7–1/2 of that of the XZ3 algorithm with the same parameters, and the query efficiency of the MLS3 index can be improved by 4–7 times after parameter optimization.
- (3)
- In terms of query stability, the MLS3 index with a Hilbert filling curve can better describe the continuity of spatio-temporal data than the XZ3 index with a Z-order filling curve. The MLS3 index shows more stable query performance and is more suitable for distributed storage management of massive multi-scale data.
- (4)
- In terms of space consumption ratio, our method sacrifices part of the storage space for an efficient query; however, the storage space of the index accounts for about 0.5% of total hardware storage space, which is acceptable for the spatio-temporal big data storage and management.
Author Contributions
Funding
Conflicts of Interest
References
- Cornelli, F.; Damiani, E.; Di Vimercati, S.D.C.; Paraboschi, S.; Samarati, P. Choosing reputable servents in a P2P network. In Proceedings of the 11th International Conference on World Wide Web, Honolulu, HI, USA, 7–11 May 2002; pp. 376–386. [Google Scholar]
- Kostakis, V.; Bauwens, M.; Niaros, V. Urban Reconfiguration after the emergence of peer-to-peer infrastructure: Four future scenarios with an impact on smart cities. In Smart Cities as Democratic Ecologies; Palgrave Macmillan: London, UK, 2015; pp. 116–124. [Google Scholar]
- Santos, J.; Wauters, T.; Volckaert, B.; De Turck, F. Fog computing: Enabling the management and orchestration of smart city applications in 5g networks. Entropy 2018, 20, 4. [Google Scholar] [CrossRef]
- Alarabi, L.; Mokbel, M.F.; Musleh, M. St-hadoop: A mapreduce framework for spatio-temporal data. GeoInformatica 2018, 22, 785–813. [Google Scholar] [CrossRef]
- Shen, D.; Yu, G.; Wang, X.; Nie, T.; Kou, Y. Survey on NoSQL for management of big data. J. Softw. 2013, 24, 1786–1803. (In Chinese) [Google Scholar] [CrossRef]
- John, A.; Sugumaran, M.; Rajesh, R.S. Indexing and query processing techniques in spatio-temporal data. ICTACT J. Soft Comput. 2016, 6. [Google Scholar] [CrossRef]
- Aguilera, M.K.; Golab, W.; Shah, M.A. A practical scalable distributed B-tree. In Proceedings of the VLDB. Morgan Kaufmann, Auckland, New Zealand, 24–30 August 2008. [Google Scholar]
- Cary, A.; Sun, Z.; Hristidis, V.; Rishe, N. Experiences on processing spatial data with MapReduce. In Proceedings of the Scientific and Statistical Database Management, International Conference (SSDBM 2009), New Orleans, LA, USA, 2–4 June 2009; pp. 302–319. [Google Scholar]
- Mouza, C.; Litwin, W.; Rigaux, P. Large-scale indexing of spatial data in distributed repositories: The SD-Rtree. VLDB J. 2009, 18, 933–958. [Google Scholar] [CrossRef]
- Wu, S.; Jiang, D.W.; Ooi, B.C.; Wu, K.L. Efficient B-tree based indexing for cloud data processing. Proc. VLDB Endow. 2010, 3, 1207–1218. [Google Scholar] [CrossRef]
- Eldawy, A.; Mokbel, M.F. Spatialhadoop: A mapreduce framework for spatial data. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, Korea, 13–17 April 2015; pp. 1352–1363. [Google Scholar]
- Yu, J.; Zhang, Z.; Sarwat, M. Spatial data management in apache spark: The geospark perspective and beyond. Geoinformatica 2019, 23, 37–78. [Google Scholar] [CrossRef]
- Fox, A.; Eichelberger, C.; Hughes, J.; Lyon, S. Spatio-temporal indexing in non-relational distributed databases. In Proceedings of the IEEE International Conference on Big Data, Silicon Valley, CA, USA, 6–9 October 2013; pp. 291–299. [Google Scholar]
- Le, H.V.; Atsuhiro, T. An efficient distributed index for geospatial databases. In Database and Expert Systems Applications; Springer: Cham, Switzerland, 2015; pp. 28–42. [Google Scholar]
- Google Corporation. S2 Geometry Library. 2015. Available online: http://s2geometry.io/ (accessed on 6 April 2019).
- Procopiuc, O. Geometry on the Sphere: Google’s S2 Library. 2011. Available online: https://docs.google.com/presentation/d/1Hl4KapfAENAOf4gv-pSngKwvS_jwNVHRPZTTDzXXn6Q/view#slide=id.i22 (accessed on 7 April 2019).
- Hughes, J.N.; Annex, A.; Eichelberger, C.N.; Fox, A.; Hulbert, A.; Ronquest, M. GeoMesa: A Distributed Architecture for Spatio-Temporal Fusion. In Geospatial Informatics, Fusion, and Motion Video Analytics V; International Society for Optics and Photonics: Baltimore, MD, USA, 20 April 2015. [Google Scholar]
- Böxhm, C.; Klump, G.; Kriegel, H.P. XZ-Ordering: A space-filling curve for objects with spatial extension. In International Symposium on Advances in Spatial Databases; Springer: Berlin, Germany, 1999. [Google Scholar]
- Zhang, R.; Qi, J.; Stradling, M.; Huang, J. Towards a painless index for spatial objects. ACM Trans. Database Syst. 2014, 39, 19. [Google Scholar] [CrossRef]
- Fecher, R.; Whitby, M.A. Optimizing Spatiotemporal Analysis Using Multidimensional Indexing with GeoWave. Free Open Source Softw. Geospat. Conf. Proc. 2017, 17, 12. [Google Scholar]
- Eldawy, A.; Alarabi, L.; Mokbel, M.F. Spatial partitioning techniques in SpatialHadoop. Proc. VLDB Endow. 2015, 8, 1602–1605. [Google Scholar] [CrossRef]
- Eldawy, A. SpatialHadoop: Towards flexible and scalable spatial processing using MapReduce. In Proceedings of the Sigmod PhD Symposium, Snowbird, UT, USA, 22 June 2014; pp. 46–50. [Google Scholar]
- Whitman, R.T.; Park, M.B.; Ambrose, S.M.; Hoel, E.G. Spatial indexing and analytics on Hadoop. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas, TX, USA, 4–7 November 2014; pp. 73–82. [Google Scholar]
- Lakshman, A.; Malik, P. Cassandra: A structured storage system on a P2P network. In Proceedings of the ACM Symposium on Parallelism in Algorithms and Architectures, Calgary, AB, Canada, 10–12 August 2009; p. 47. [Google Scholar]
- Lakshman, A.; Malik, P. Cassandra: A decentralized structured storage system. ACM SIGOPS Oper. Syst. Rev. 2010, 44, 35–40. [Google Scholar] [CrossRef]
- Brahim, M.B.; Drira, W.; Filali, F.; Hamdi, N. Spatial data extension for Cassandra NoSQL database. J. Big Data 2016, 3, 1–16. [Google Scholar] [CrossRef]
- Chebotko, A.; Kashlev, A.; Lu, S. A big data modeling methodology for Apache Cassandra. In Proceedings of the IEEE International Congress on Big Data, New York, NY, USA, 27 June–2 July 2015; pp. 238–245. [Google Scholar]
- Belussi, A.; Migliorini, S.; Eldawy, A. Detecting skewness of big spatial data in SpatialHadoop. In Proceedings of the 26th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 6–9 November 2018; pp. 432–435. [Google Scholar]
- González, R.; Munoz, A.; Hernández, J.A.; Cuevas, R. On the tweet arrival process at Twitter: Analysis and applications. Trans. Emerg. Telecommun. Technol. 2014, 25, 273–282. [Google Scholar] [CrossRef]
- Shaw, B.; Shea, J.; Sinha, S.; Hogue, A. Learning to rank for spatiotemporal search. In Proceedings of the Sixth ACM International Conference on Web Search and Data Mining, Rome, Italy, 4–8 February 2013; pp. 717–726. [Google Scholar]
- Weyand, T.; Kostrikov, I.; Philbin, J. PlaNet—Photo Geolocation with Convolutional Neural Networks. In European Conference on Computer Vision; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Yuan, J.; Zheng, Y.; Zhang, C.; Xie, W.; Xie, X.; Sun, G.; Huang, Y. Tdrive: Driving directions based on taxi trajectories. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, GIS’10, San Jose, CA, USA, 2–5 November 2010; pp. 99–108. [Google Scholar]
- Yuan, J.; Zheng, Y.; Xie, X.; Sun, G. Driving with knowledge from the physical world. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD’11, San Diego, CA, USA, 21–24 August 2011; pp. 316–324. [Google Scholar]
- Curran, K.; Fisher, G.; Crumlish, J. OpenStreetMap. Int. J. Interact. Commun. Syst. Technol. 2012, 2, 69–78. [Google Scholar] [CrossRef]
- Haklay, M.; Weber, P. OpenStreetMap: User-generated street maps. IEEE Pervasive Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef]
- Shao, J.; Liu, X.; Li, Y.; Liu, J. Database performance optimization for SQL Server based on hierarchical queuing network model. Int. J. Database Theory Appl. 2015, 8, 187–196. [Google Scholar] [CrossRef]
- Cao, Y.; Ritz, C.; Raad, R. How much longer to go? The influence of waiting time and progress indicators on quality of experience for mobile visual search applied to print media. In Proceedings of the 2013 Fifth International Workshop on Quality of Multimedia Experience (QoMEX), Klagenfurt am Wo¿rthersee, Austria, 3–5 July 2013; pp. 112–117. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time Granularity | Partition Key | Partition Key Time Format | Sort Key | Sort Key Time Format |
|---|---|---|---|---|
| 0 | Year | yyyy | Month-Day Hour-Minute | MMdd hh:mm:ss |
| 1 | Year-Month | yyyyMM | Day Hour-Minute | dd hh:mm:ss |
| 2 | Year-Month-Day | yyyyMMdd | Hour-Minute-Second | hh:mm:ss |
| 3 | Year-Month-Day Hour | yyyyMMdd hh | Minute-Second | mm:ss |
| 4 | Year-Month-Day Hour-Minute | yyyyMMdd hh:mm | Second | ss |
| 5 | Year-Month-Day Hour-Minute-Second | yyyyMMdd hh:mm:ss | — | — |
| Level | Min Area | Max Area | Avg. Area |
|---|---|---|---|
| 0 | 85,011,012.00 km2 | 85,011,012.00 km2 | 85,011,012.00 km2 |
| 1 | 21,252,753.00 km2 | 21,252,753.00 km2 | 21,252,753.00 km2 |
| 2 | 5,313,188.25 km2 | 5,313,188.25 km2 | 5,313,188.25 km2 |
| … | … | … | … |
| 29 | 1.77 cm2 | 3.71 cm2 | 2.95 cm2 |
| 30 | 0.43 cm2 | 0.93 cm2 | 0.74 cm2 |
| Number of Concurrent Tasks | 1 | 5 | 10 | 15 | 20 | 25 | 30 | 35 | 40 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Average time consumption (ms) | TDrive Taxi (Point) | XZ3 | 1623 | 1628 | 2165 | 2285 | 2317 | 2401 | 2245 | 2606 | 2373 |
| MLS3 | 526 | 625 | 642 | 788 | 676 | 981 | 1011 | 1461 | 1216 | ||
| OSM Roads (line) | XZ3 | 2213 | 1931 | 2632 | 4177 | 4948 | 5106 | 5422 | 4036 | 5729 | |
| MLS3 | 520 | 626 | 694 | 836 | 872 | 1953 | 2861 | 3365 | 3958 | ||
| OSM Buildings (polygon) | XZ3 | 2215 | 1869 | 2365 | 3239 | 3662 | 4477 | 4270 | 4417 | 4430 | |
| MLS3 | 374 | 446 | 459 | 521 | 523 | 622 | 595 | 993 | 969 | ||
| Indicator | Index Method | TDrive Taxi (Point) | OSM Roads (Line) | OSM Buildings (Polygon) |
|---|---|---|---|---|
| Space consumption ratio | XZ3 | 31.14% | 7.37% | 10.68% |
| MLS3 | 38.63% | 8.91% | 13.70% | |
| Construction efficiency (s) | XZ3 | 63 | 2 | 2 |
| MLS3 | 147 | 23 | 19 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Wu, Z.; Wu, P.; Zhao, Z. An Adaptive Construction Method of Hierarchical Spatio-Temporal Index for Vector Data under Peer-to-Peer Networks. ISPRS Int. J. Geo-Inf. 2019, 8, 512. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8110512
Li C, Wu Z, Wu P, Zhao Z. An Adaptive Construction Method of Hierarchical Spatio-Temporal Index for Vector Data under Peer-to-Peer Networks. ISPRS International Journal of Geo-Information. 2019; 8(11):512. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8110512
Chicago/Turabian StyleLi, Chengming, Zheng Wu, Pengda Wu, and Zhanjie Zhao. 2019. "An Adaptive Construction Method of Hierarchical Spatio-Temporal Index for Vector Data under Peer-to-Peer Networks" ISPRS International Journal of Geo-Information 8, no. 11: 512. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8110512