Identification of Urban Functional Regions in Chengdu Based on Taxi Trajectory Time Series Data


Abstract
:1. Introduction
2. Materials and Methods
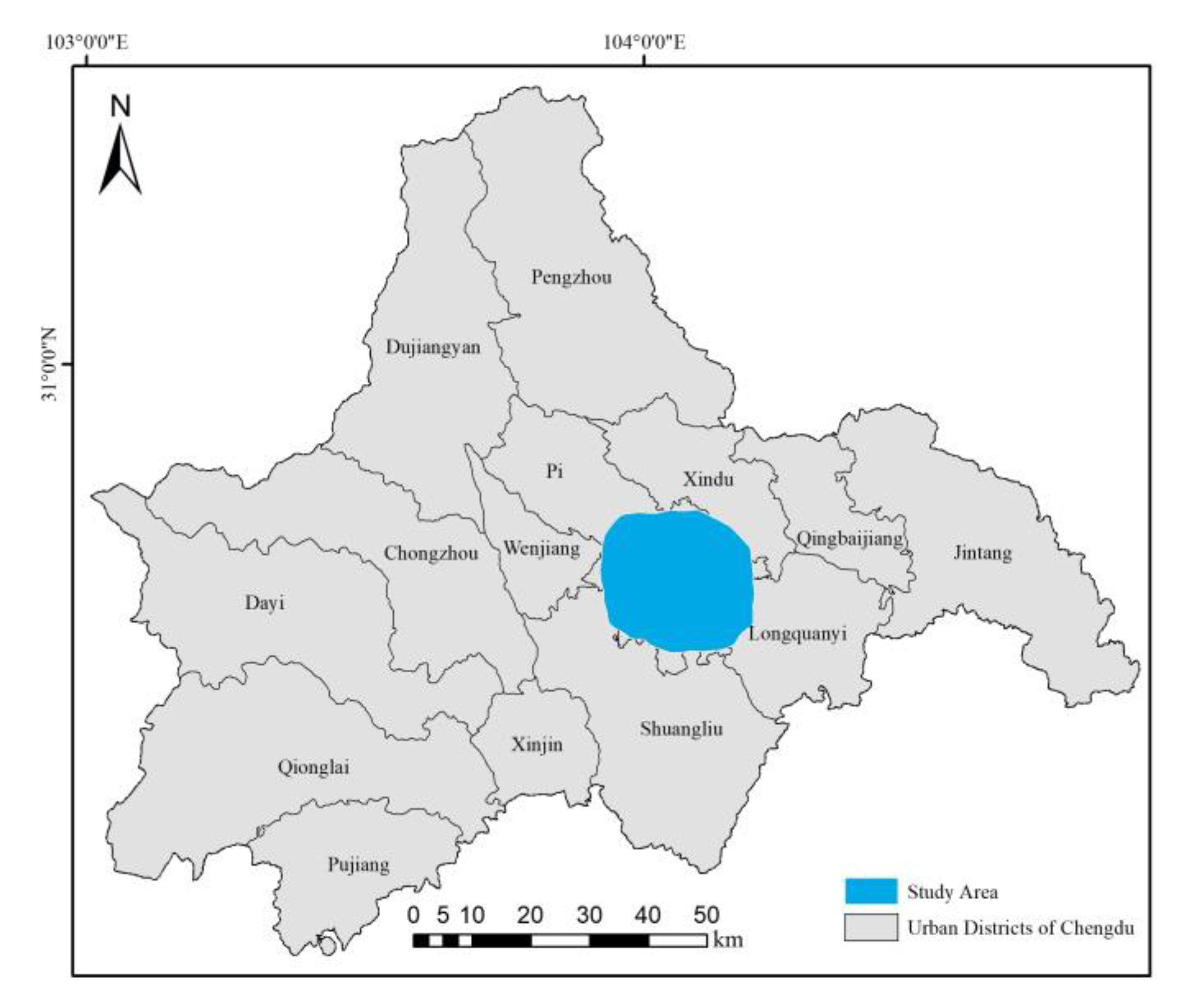
2.1. Study Area
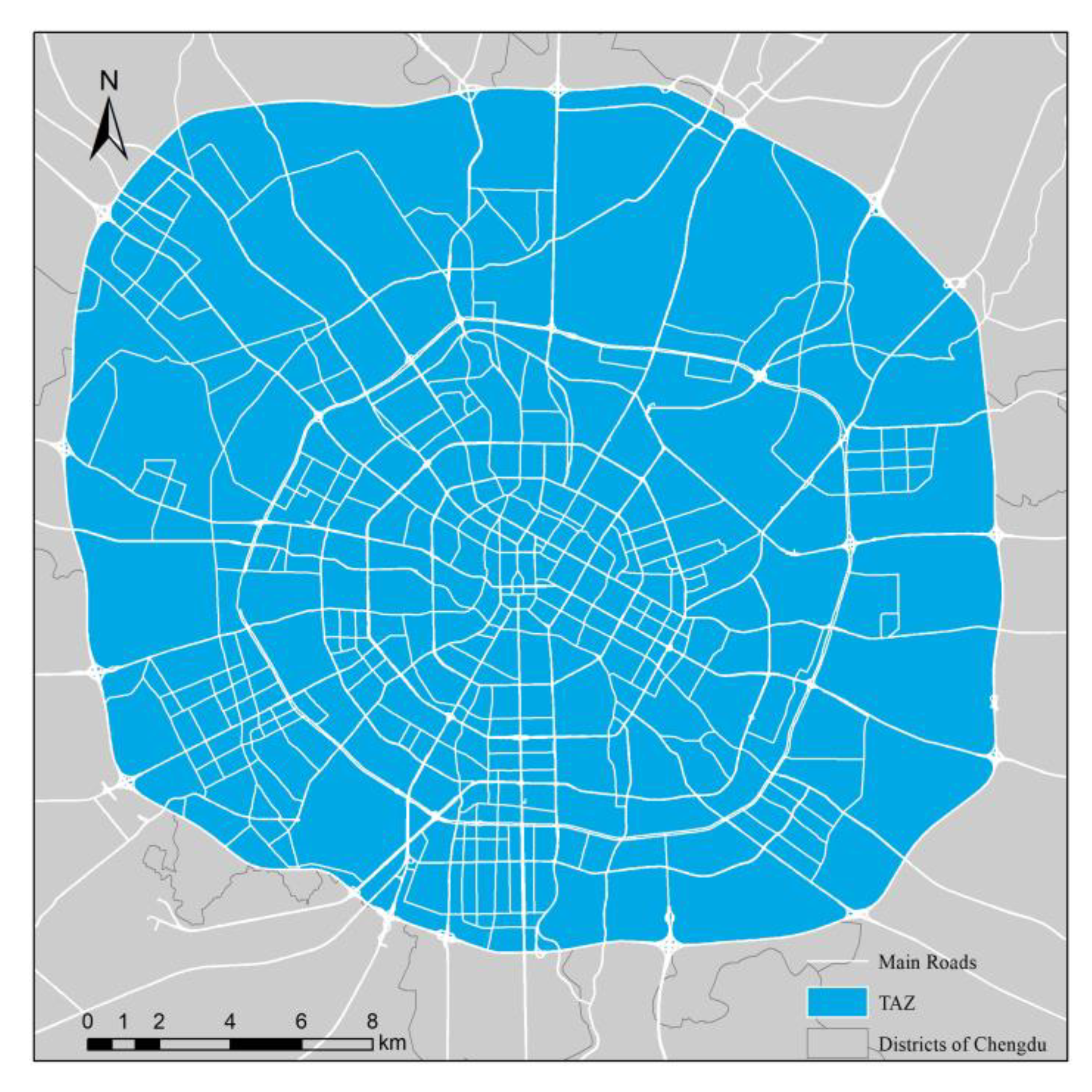
2.2. Study Data and Preprocessing
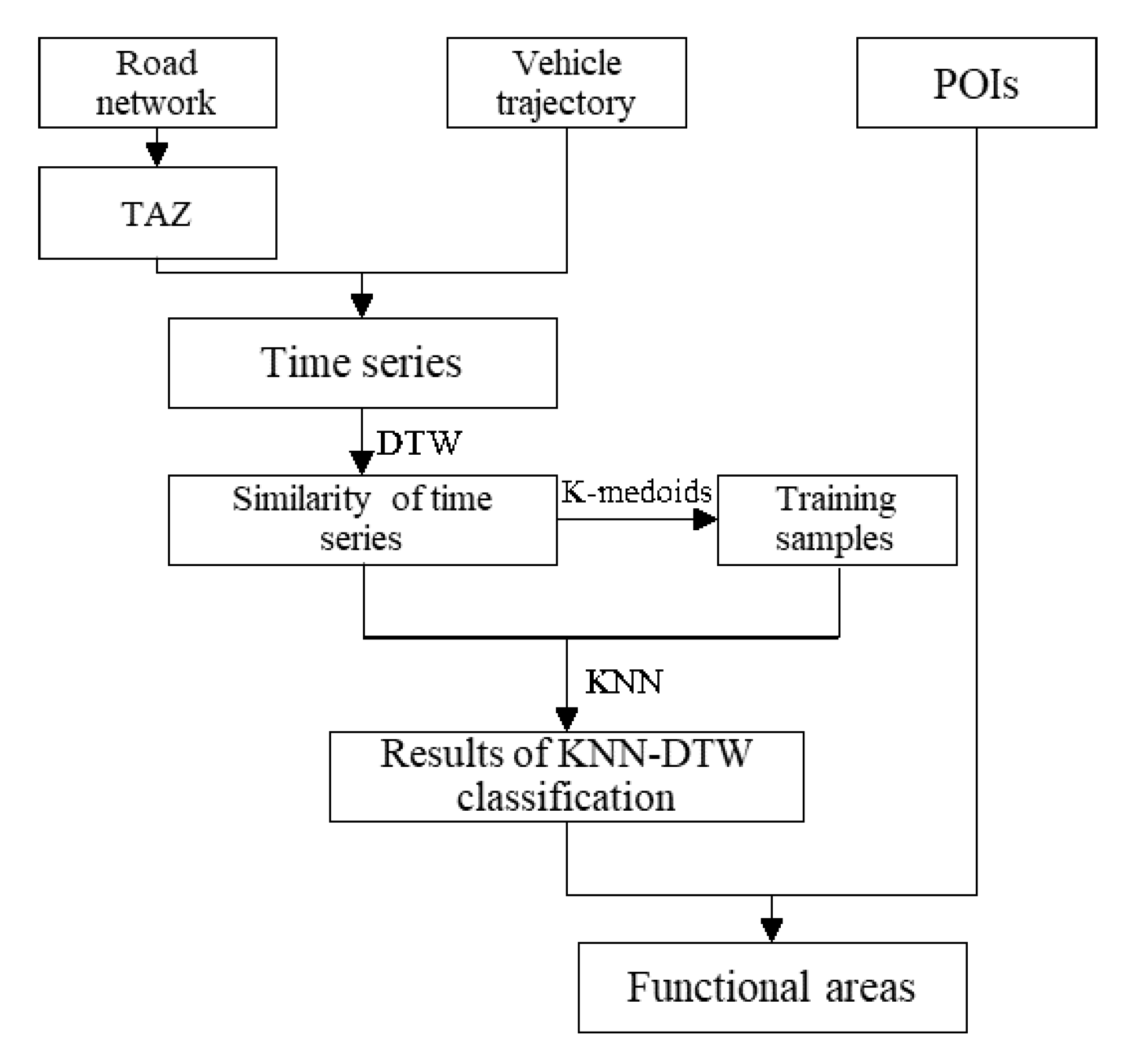
2.3. Methods
2.3.1. Methods of Time Series Generation
2.3.2. Dynamic Time Warping
2.3.3. K-Medoids
2.3.4. K-Nearest Neighbour
2.3.5. POI Auxiliary Analysis
3. Results
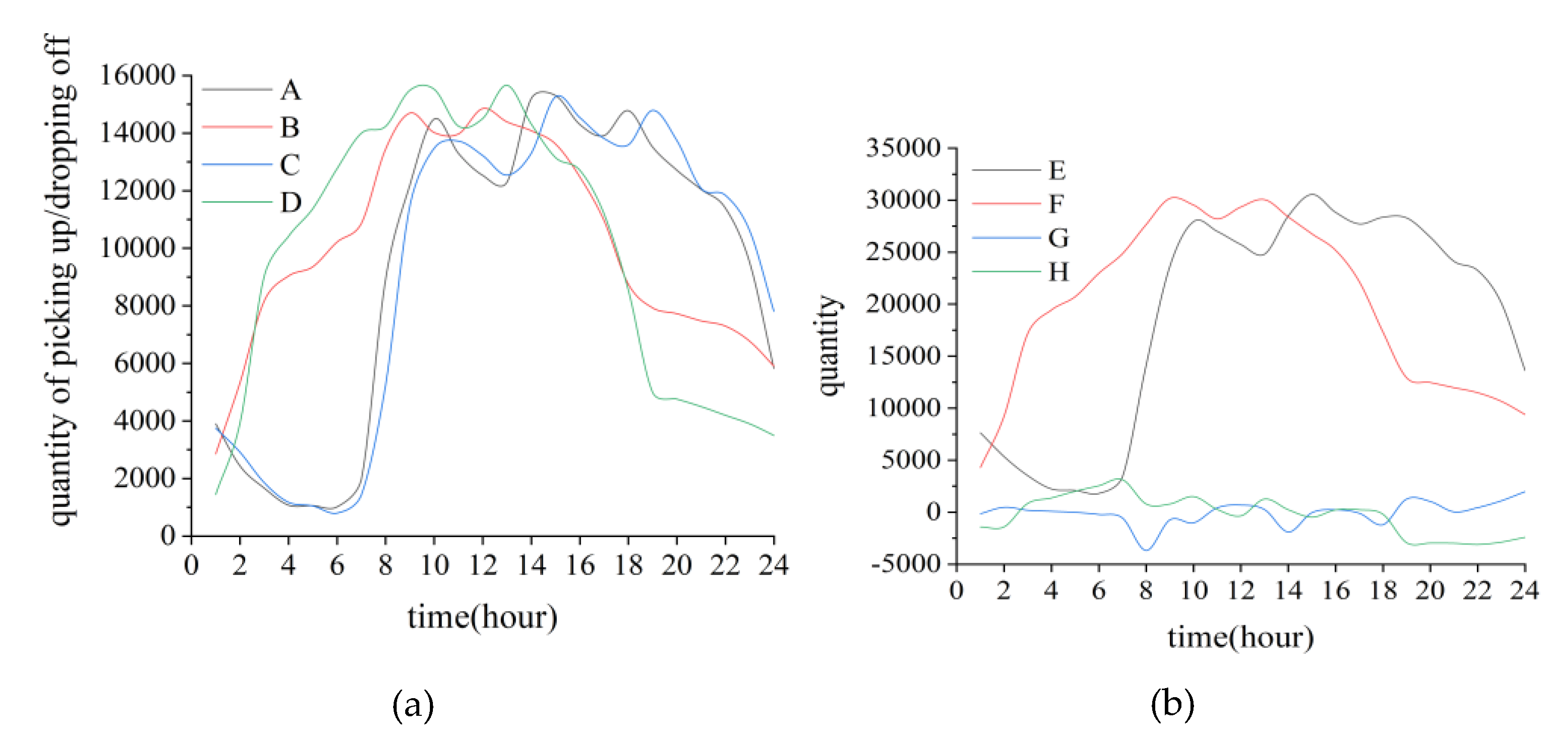
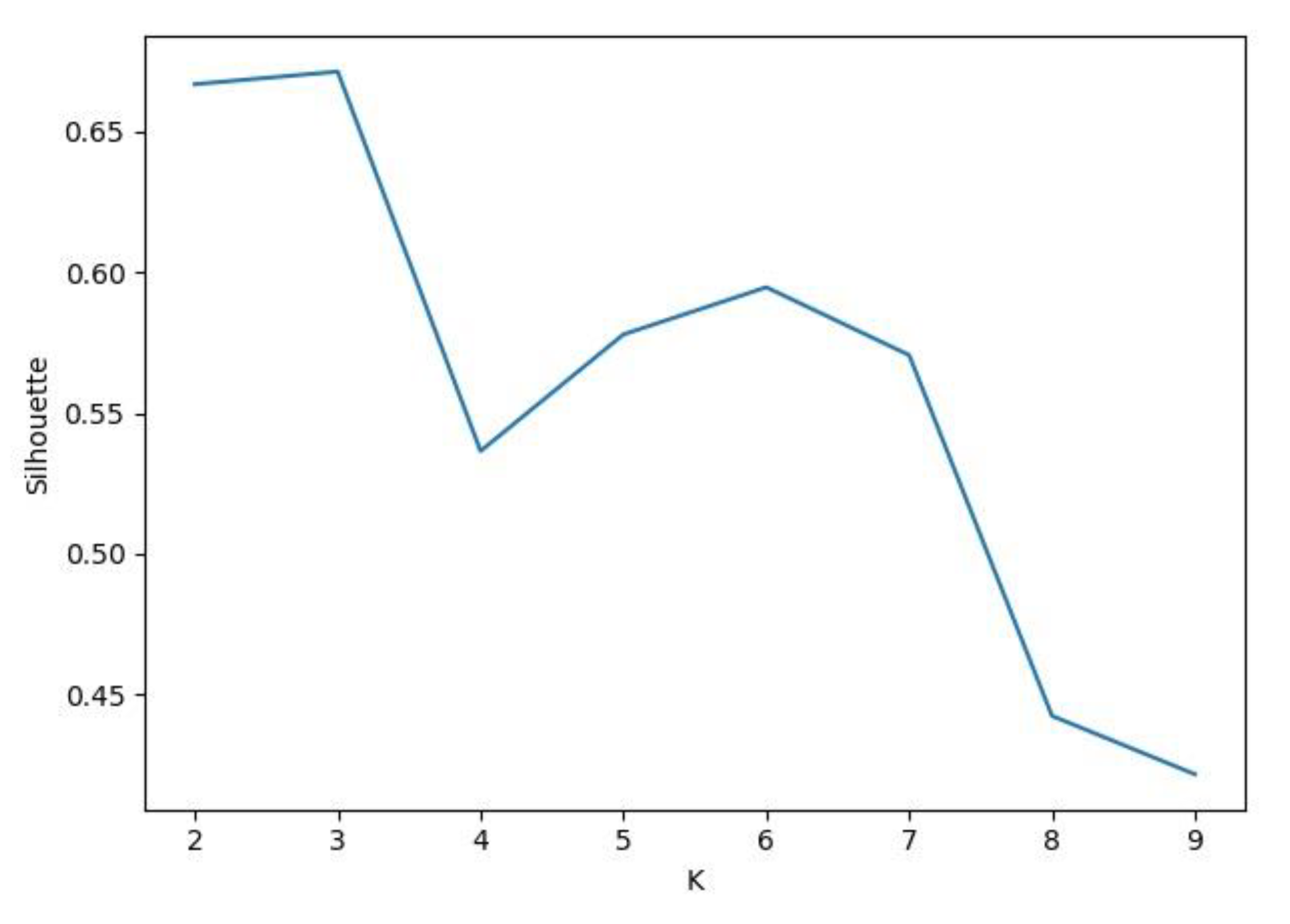
3.1. Generation of the Training Sample
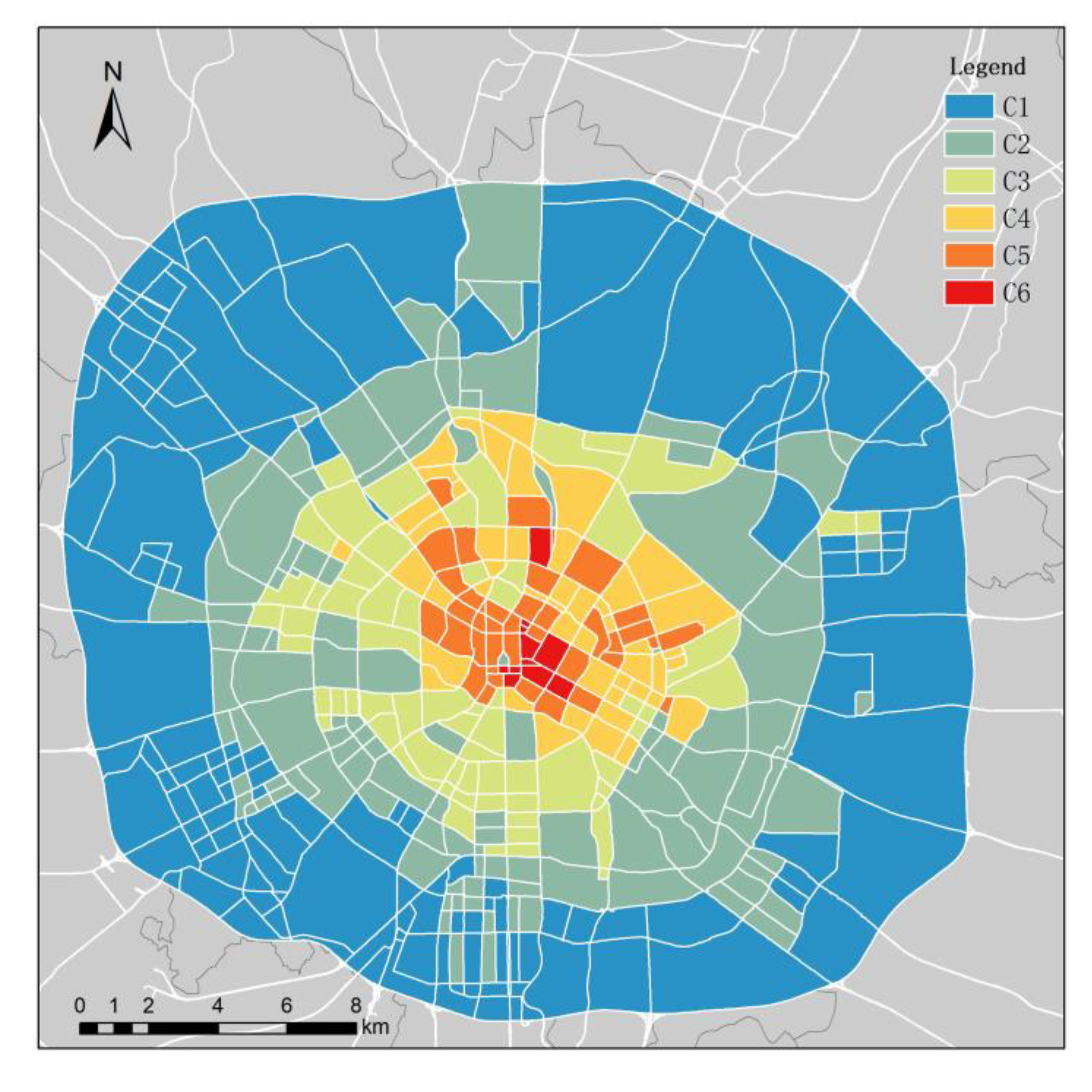
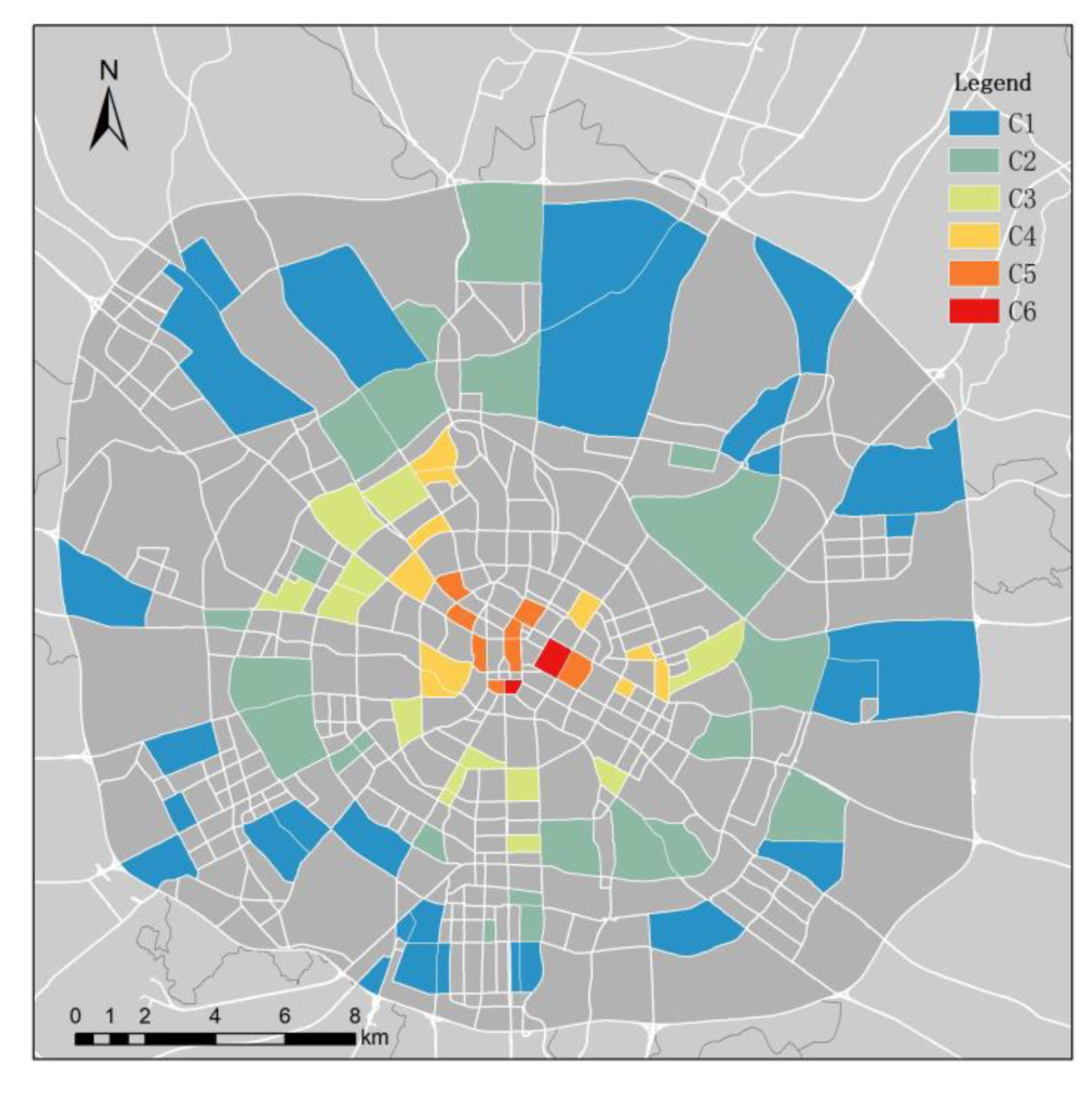
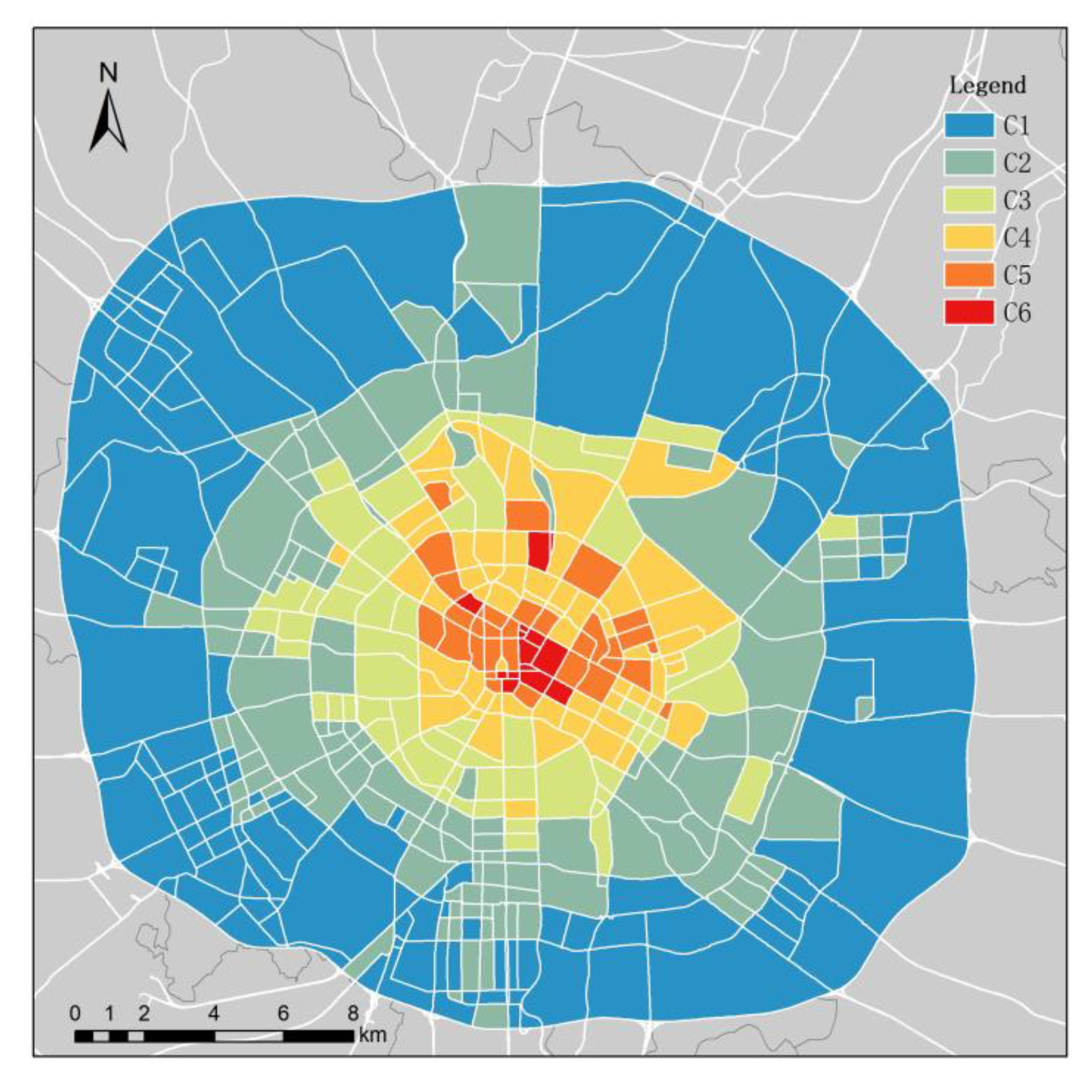
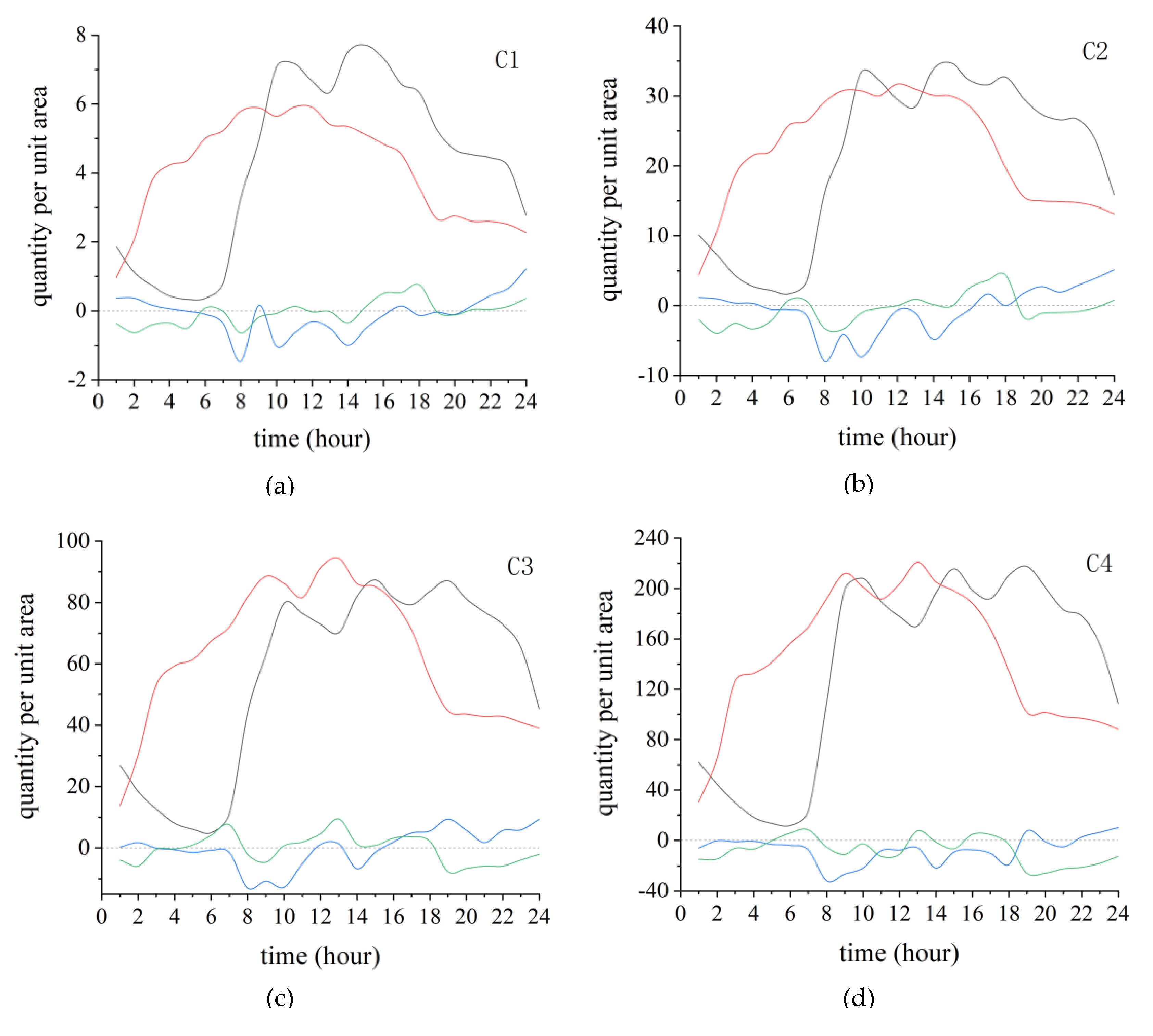
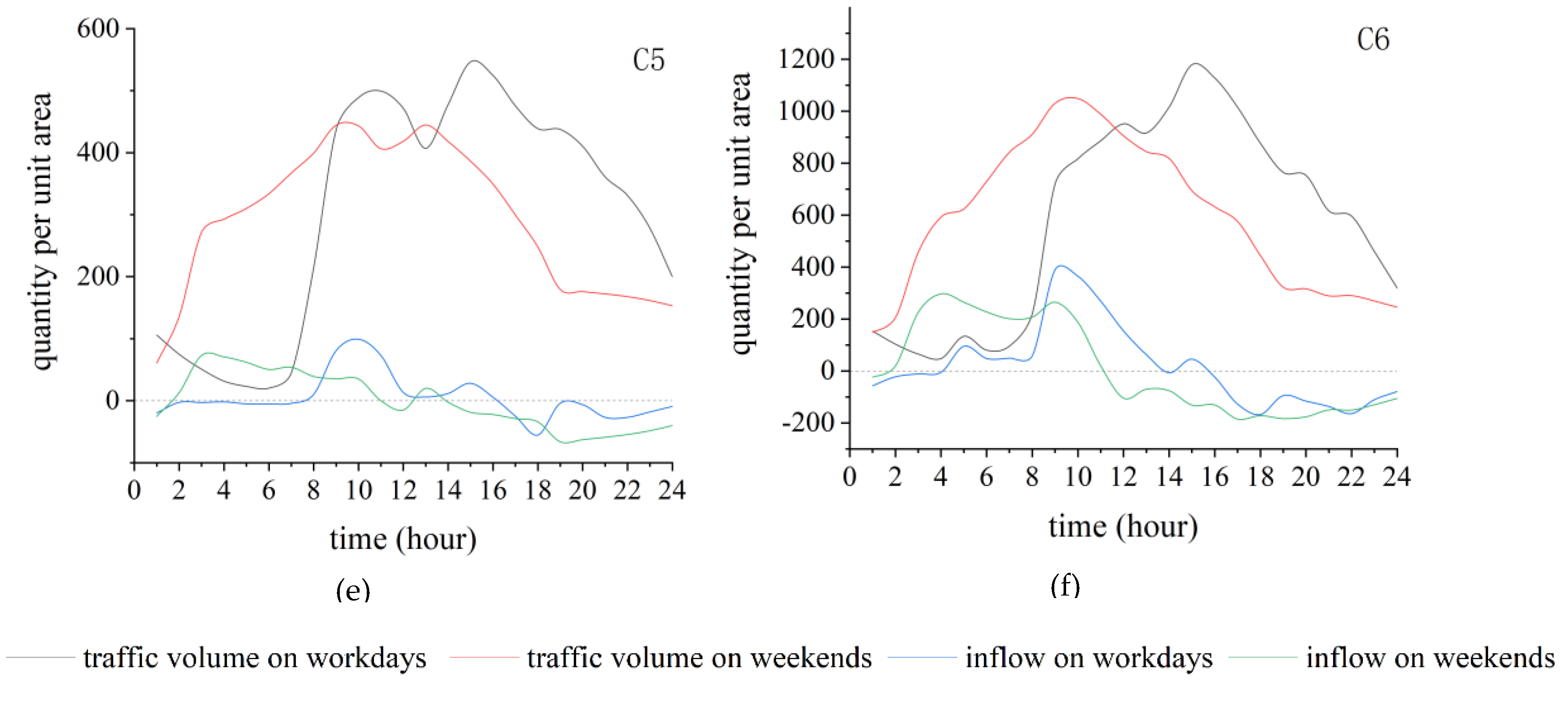
3.2. Results of KN–-DTW Classification
3.3. Results of POI Auxiliary Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gao, S.; Janowicz, K.; Couclelis, H. Extracting urban functional regions from points of interest and human activities on location-based social networks. Trans. GIS 2017, 21, 446–467. [Google Scholar] [CrossRef]
- Wang, H.; Pingping, T.; Liu, H. Spatial structuring of the ‘new economies’ in xi’an and its mechanisms. Geogr. Res. 2006, 3, 173–184. [Google Scholar]
- Herold, M.; Couclelis, H.; Clarke, K.C. The role of spatial metrics in the analysis and modeling of urban land use change. Comput. Environ. Urban Syst. 2005, 29, 369–399. [Google Scholar] [CrossRef]
- Banzhaf, E.; Netzband, M. Monitoring urban land use changes with remote sensing techniques. In Applied Urban Ecology: A Global Framework; John Wiley & Sons, Ltd: Hoboken, NJ, USA, 2011. [Google Scholar]
- Barnsley, M.J.; Barr, S.L. Inferring urban land use from satellite sensor images using kernel-based spatial reclassification. Photogramm. Eng. Remote Sens. 1996, 62, 949–958. [Google Scholar]
- Ahas, R.; Mark, Ü. Location based services—New challenges for planning and public administration? Futures 2005, 37, 547–561. [Google Scholar] [CrossRef]
- Ratti, C.; Pulselli, R.M.; Williams, S.; Frenchman, D. Mobile landscapes: Using location data from cell phones for urban analysis. Environ. Plan. B Plan. Des. 2006, 33, 727–748. [Google Scholar] [CrossRef]
- Joh, C.; Hwang, C. A time-geographic analysis of trip trajectories and land use characteristics in seoul metropolitan area by using multidimensional sequence alignment and spatial analysis. In Proceedings of the AAG Annual Meeting, Washington, DC, USA, 14–17 April 2010. [Google Scholar]
- Kling, F.; Pozdnoukhov, A. When a city tells a story:Urban topic analysis. In Proceedings of the International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 6–9 November 2012. [Google Scholar]
- Steiger, E.; Westerholt, R.; Zipf, A. Research on social media feeds–A giscience perspective. In European Handbook of Crowdsourced Geographic Information; Ubiquity Press: London, UK, 2016; Volume 99, pp. 237–254. [Google Scholar]
- Dong, M. Research on Identifying Urban Regions of Different Functions from Wechat Data and Pois. Master’s Thesis, Zhejiang Normal University, Jinhua, China, 2017. [Google Scholar]
- Phithakkitnukoon, S.; Horanont, T.; Lorenzo, G.D.; Shibasaki, R.; Ratti, C. Activity-aware map: Identifying human daily activity pattern using mobile phone data. In Human Behavior Understanding, First International Workshop; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Soto, V.; Frías-Martínez, E. Automated land use identification using cell-phone records. In Proceedings of the Acm International Workshop on Mobiarch, Washington, DC, USA, 28 June–1 July 2011. [Google Scholar]
- Becker, R.A.; Cáceres, R.; Hanson, K.; Ji, M.L.; Volinsky, C. A tale of one city: Using cellular network data for urban planning. IEEE Pervasive Comput. 2011, 10, 18–26. [Google Scholar] [CrossRef]
- Brockmann, D.; Theis, F.J. Money circulation, trackable items, and the emergence of universal human mobility patterns. IEEE Pervasive Comput. 2008, 7, 28–35. [Google Scholar] [CrossRef]
- Doyle, J.; Hung, P.; Farrell, R.; McLoone, S. Population mobility dynamics estimated from mobile telephony data. J. Urban Technol. 2014, 21, 109–132. [Google Scholar] [CrossRef]
- Yuan, J.; Zheng, Y.; Xie, X. Discovering regions of different functions in a city using human mobility and pois. In Proceedings of the Acm Sigkdd International Conference on Knowledge Discovery & Data Mining, Beijing, China, 12–16 August 2012. [Google Scholar]
- Sun, L.; Lee, D.H.; Erath, A.; Huang, X. Using smart card data to extract passenger′s spatio-temporal density and train′s trajectory of mrt system. In Proceedings of the Acm Sigkdd International Workshop on Urban Computing, Beijing, China, 12 August 2012. [Google Scholar]
- Zhong, C.; Huang, X.; Arisona, S.M.; Schmitt, G.; Batty, M. Inferring building functions from a probabilistic model using public transportation data. Comput. Environ. Urban Syst. 2014, 48, 124–137. [Google Scholar] [CrossRef]
- Han, H.; Yu, X.; Long, Y. Discovering functional zones using bus smart card data and points of interest in beijing. In City Planning Review; Springer: Cham, Germany, 2015. [Google Scholar]
- Mckenzie, G.; Janowicz, K.; Gao, S.; Gong, L. How where is when? On the regional variability and resolution of geosocial temporal signatures for points of interest. Comput. Environ. Urban Syst. 2015, 54, 336–346. [Google Scholar] [CrossRef]
- Yu, L.; Wang, F.; Xiao, Y.; Gao, S. Urban land uses and traffic ‘source-sink areas’: Evidence from gps-enabled taxi data in shanghai. Landsc. Urban Plan. 2012, 106, 73–87. [Google Scholar]
- Pan, G.; Qi, G.; Wu, Z.; Zhang, D.; Li, S. Land-use classification using taxi gps traces. Intell. Transp. Syst. IEEE Trans. 2013, 14, 113–123. [Google Scholar] [CrossRef]
- Chen, S.; Tao, H.; Li, X.; Zhuo, L. Discovering urban functional regions using latent semantic information: Spatiotemporal data mining of floating cars gps data of guangzhou. Acta Geogr. Sin. 2016, 71, 471–483. [Google Scholar]
- Cheng, J.; Liu, J.; Gao, Y. Analyzing the spatio-temporal characteristics of beijing′s od trip volume based on time series clustering method. J. Geo Inf. Sci. 2016, 18, 1227–1239. [Google Scholar]
- Mori, U.; Mendiburu, A.; Lozano, J.A. Similarity measure selection for clustering time series databases. IEEE Trans. Knowl. Data Eng. 2015, 28, 181–195. [Google Scholar] [CrossRef]
- Li, Z.; Zhao, Y.; Liu, R.; Pei, D. Robust and rapid clustering of kpis for large-scale anomaly detection. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service, IWQoS, Banff, AB, Canada, 4–6 June 2018; pp. 1–10. [Google Scholar]
- Shokoohi-Yekta, M.; Hu, B.; Jin, H.; Wang, J.; Keogh, E. Generalizing dtw to the multi-dimensional case requires an adaptive approach. Data Min. Knowl. Discov. 2017, 31, 1–31. [Google Scholar] [CrossRef] [Green Version]
- Ma, C.H.; Weng, X.Q.; Shan, Z.N. Early classification of multivariate time series based on piecewise aggregate approximation. In Computer Science; Springer: Cham, Germany, 2017. [Google Scholar]
- Cheng, W.; Zou, P.; Jia, Y.; Yang, Y. Anomaly detection over pseudo period data streams based on dtw distance. J. Comput. Res. Dev. 2010, 47, 893–902. [Google Scholar]
- Zhu, X.; Goldberg, A.B. Introduction to Semi-Supervised Learning; Morgan & Claypool: Williston, VT, USA, 2009. [Google Scholar]
- Chen, Y.; Liu, X.; Li, X.; Liu, X.; Yao, Y.; Hu, G.; Xu, X.; Pei, F. Delineating urban functional areas with building-level social media data: A dynamic time warping (dtw) distance based k -medoids method. Landsc. Urban Plan. 2017, 160, 48–60. [Google Scholar] [CrossRef]
- Zhu, C.; Cheng, G.; Wang, K. Big data analytics for program popularity prediction in broadcast tv industries. IEEE Access 2017. [Google Scholar] [CrossRef]
- Costa, B.G.; Freire, J.C.A.; Cavalcante, H.S.; Homci, M.; Castro, A.R.G.; Viegas, R.; Meiguins, B.S.; Morais, J.M. Fault classification on transmission lines using knn-dtw. In Proceedings of the International Conference on Computational Science & Its Applications, Trieste, Italy, 3–6 July 2017. [Google Scholar]
- Hsu, H.-H.; Yang, A.C.; Lu, M.-D. Knn-dtw based missing value imputation for microarray time series data. J. Comput. 2011, 6, 418–425. [Google Scholar] [CrossRef]
- Mitsa, T. Temporal Data Mining; CRC: Boca Raton, FL, USA, 2010. [Google Scholar]
- Qingke, G.; Jianhong, F.; Yang, Y.; Xuehua, T. Identification of urban regions’ functions in Chengdu, China, based on vehicle trajectory data. PLoS ONE 2019, 14. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Xu, J.; Cai, L.; Meng, B.; Pei, T. Identifying functional regions based on the spatio-temporal pattern of taxi trajectories. J. Geo Inf. Sci. 2018, 20, 1550–1561. [Google Scholar]
- Chen, Z.; Qiao, B.; Zhang, J. Identification and spatial interaction of urban functional regions in beijing based on the characteristics of residents’ traveling. J. Geo Inf. Sci. 2018, 20, 291–301. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category of POIs | C1 | C2 | C3 | ||||||
| Catering | 25.41 | 0.00 | - | 75.82 | 0.12 | 9.99% | 138.49 | 0.27 | 9.04% |
| Shopping services | 21.78 | 0.00 | - | 54.68 | 0.24 | 20.57% | 64.31 | 0.32 | 10.72% |
| Leisure services | 20.75 | 0.00 | - | 56.50 | 0.12 | 10.09% | 109.16 | 0.30 | 10.06% |
| Accommodation | 3.85 | 0.00 | - | 15.25 | 0.05 | 4.15% | 26.75 | 0.10 | 3.36% |
| Science & Education | 8.26 | 0.00 | - | 26.39 | 0.14 | 11.46% | 59.72 | 0.39 | 13.12% |
| Healthcare services | 9.75 | 0.00 | - | 25.02 | 0.16 | 13.45% | 56.46 | 0.49 | 16.58% |
| Dwellings | 6.33 | 0.00 | - | 20.34 | 0.09 | 7.29% | 59.84 | 0.33 | 11.22% |
| Companies | 27.41 | 0.00 | - | 64.91 | 0.10 | 8.25% | 98.52 | 0.19 | 6.30% |
| Government agencies | 6.05 | 0.00 | - | 14.16 | 0.09 | 7.70% | 33.45 | 0.31 | 10.50% |
| Tourist attractions | 0.73 | 0.00 | - | 1.51 | 0.08 | 7.04% | 3.24 | 0.27 | 9.10% |
| Category of POIs | C4 | C5 | C6 | ||||||
| Catering | 165.72 | 0.33 | 8.94% | 274.55 | 0.59 | 9.22% | 450.62 | 1.00 | 10.36% |
| Shopping services | 58.16 | 0.27 | 7.31% | 88.19 | 0.49 | 7.75% | 156.60 | 1.00 | 10.36% |
| Leisure services | 122.73 | 0.34 | 9.25% | 184.30 | 0.55 | 8.62% | 319.49 | 1.00 | 10.36% |
| Accommodation | 42.91 | 0.17 | 4.58% | 92.83 | 0.38 | 6.05% | 235.17 | 1.00 | 10.36% |
| Science & Education | 61.63 | 0.40 | 10.85% | 107.27 | 0.74 | 11.69% | 141.54 | 1.00 | 10.36% |
| Healthcare services | 71.84 | 0.65 | 17.58% | 105.46 | 1.00 | 15.74% | 72.55 | 0.66 | 6.79% |
| Dwellings | 67.59 | 0.38 | 10.25% | 126.73 | 0.74 | 11.70% | 168.37 | 1.00 | 10.36% |
| Companies | 124.85 | 0.25 | 6.89% | 188.30 | 0.42 | 6.61% | 410.65 | 1.00 | 10.36% |
| Government agencies | 43.30 | 0.42 | 11.38% | 89.86 | 0.95 | 14.88% | 94.72 | 1.00 | 10.36% |
| Tourist attractions | 5.23 | 0.48 | 12.97% | 5.35 | 0.49 | 7.74% | 10.13 | 1.00 | 10.36% |
| Functional Area | No. | Results of Identification | Google Earth Image | Gaode Map (English Edition) | Real Photos of Landmark Site |
|---|---|---|---|---|---|
| C1: Suburban Tourism Area | 1 |  |  Lat.: 30.637492 Lon.: 104.178509 |  Lat.: 30.634418 Lon.: 104.181086 |  Date: 2018/9/6 |
| 2 |  |  Lat.: 30.751676 Lon.: 104.137462 |  Lat.: 30.746165 Lon.: 104.136454 |  Date: 2017/12/30 | |
| C2: Residential/Tourism Mixed Area | 3 |  |  Lat.: 30.729891 Lon.: 104.031037 |  Lat.: 30.729678 Lon.: 104.035385 |  Date: 2019/6/21 |
| 4 |  |  Lat.: 30.616207 Lon.: 104.083512 |  Lat.: 30.614217 Lon.: 104.086004 |  Date: 2017/8/31 | |
| C3: Urban Residential Area | 5 |  |  Lat.: 30.636909 Lon.: 104.039137 |  Lat.: 30.634067 Lon.: 104.042427 |  Date: 2016/5/23 |
| 6 |  |  Lat.: 30.650295 Lon.: 104.025001 |  Lat.: 30.648028 Lon.: 104.027046 |  Date: 2016/9/16 | |
| C4: Residential/Commercial Mixed Area | 7 |  |  Lat.: 30.656678 Lon.: 104.053936 |  Lat.: 30.648305 Lon.: 104.047764 |  Date: 2017/4/17 |
| 8 |  |  Lat.: 30.656678 Lon.: 104.053936 |  Lat.: 30.655058 Lon.: 104.056887 |  Date: 2017/2/12 | |
| C5: Office Area | 9 |  |  Lat.: 30.654412 Lon.: 104.070917 |  Lat.: 30.652455 Lon.: 104.073602 |  Date: 2018/7/6 |
| 10 |  |  Lat.: 30.669699 Lon.: 104.090741 |  Lat.: 30.667969 Lon.: 104.092903 |  Date: 2017/4/17 | |
| C6: Mature Business Area | 11 |  |  Lat.:30.658748 Lon.:104.072673 |  Lat.: 30.656309 Lon.: 104.075811 |  Date: 2017/1/20 |
| 12 |  |  Lat.:30.659761 Lon.:104.063428 |  Lat.: 30.657511 Lon.: 104.065741 |  Date: 2018/2/9 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Tian, Y.; Zhang, X.; Wan, Z. Identification of Urban Functional Regions in Chengdu Based on Taxi Trajectory Time Series Data. ISPRS Int. J. Geo-Inf. 2020, 9, 158. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9030158
Liu X, Tian Y, Zhang X, Wan Z. Identification of Urban Functional Regions in Chengdu Based on Taxi Trajectory Time Series Data. ISPRS International Journal of Geo-Information. 2020; 9(3):158. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9030158
Chicago/Turabian StyleLiu, Xudong, Yongzhong Tian, Xueqian Zhang, and Zuyi Wan. 2020. "Identification of Urban Functional Regions in Chengdu Based on Taxi Trajectory Time Series Data" ISPRS International Journal of Geo-Information 9, no. 3: 158. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9030158