Lung Segmentation on High-Resolution Computerized Tomography Images Using Deep Learning: A Preliminary Step for Radiomics Studies

 ,
,  ,
,  ,
, 
 , ,
, , 
Abstract
:1. Introduction
- For radiomics analysis, accurate and user-independent segmentations are mandatory to correctly identify the texture-based prediction model.
- Artificial intelligence approaches are still far from being widely applied in clinical practice, mainly due to the requirement of large amounts of labelled training data.
2. Materials and Methods
2.1. Data and Hardware Setup
- 11 studies obtained using the Philips CT scanner have a matrix resolution of 720 × 720
- 31 studies obtained using the GE CT scanner have a matrix resolution of 672 × 672.
2.2. U-Net and E-Net
2.3. Loss Function
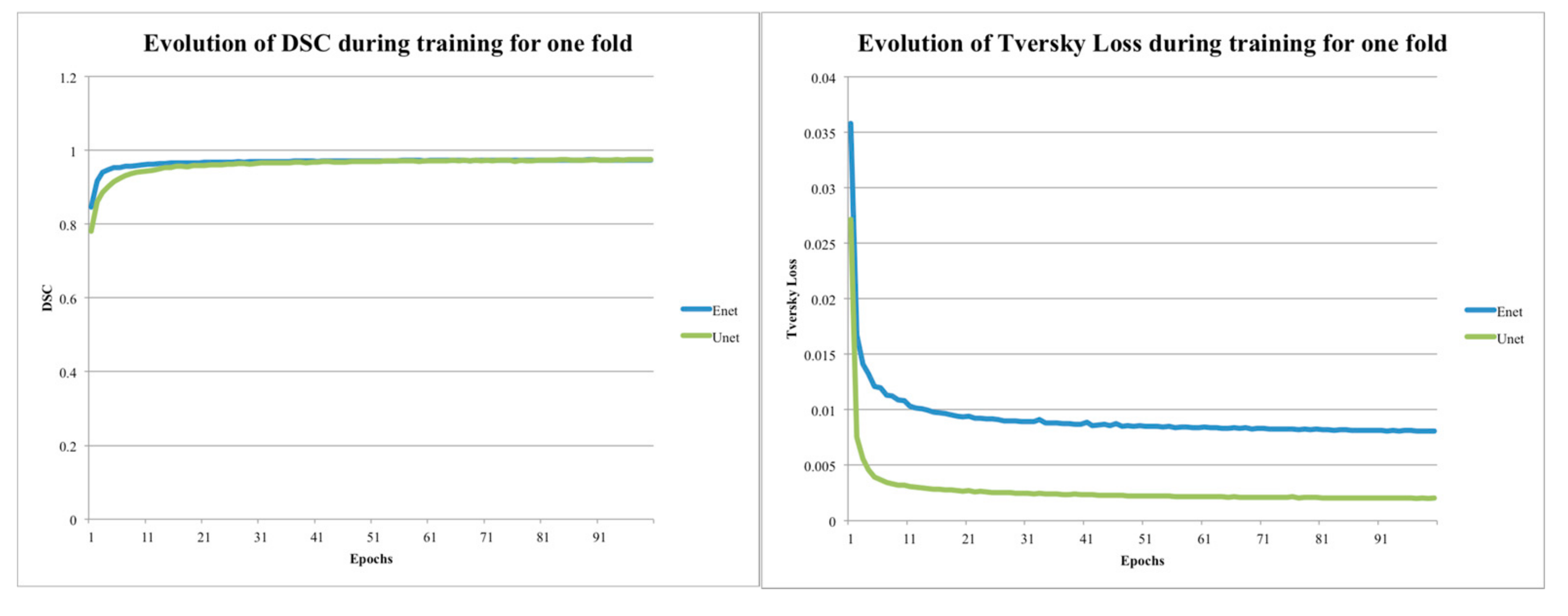
2.4. Data Training
2.5. Data Analysis
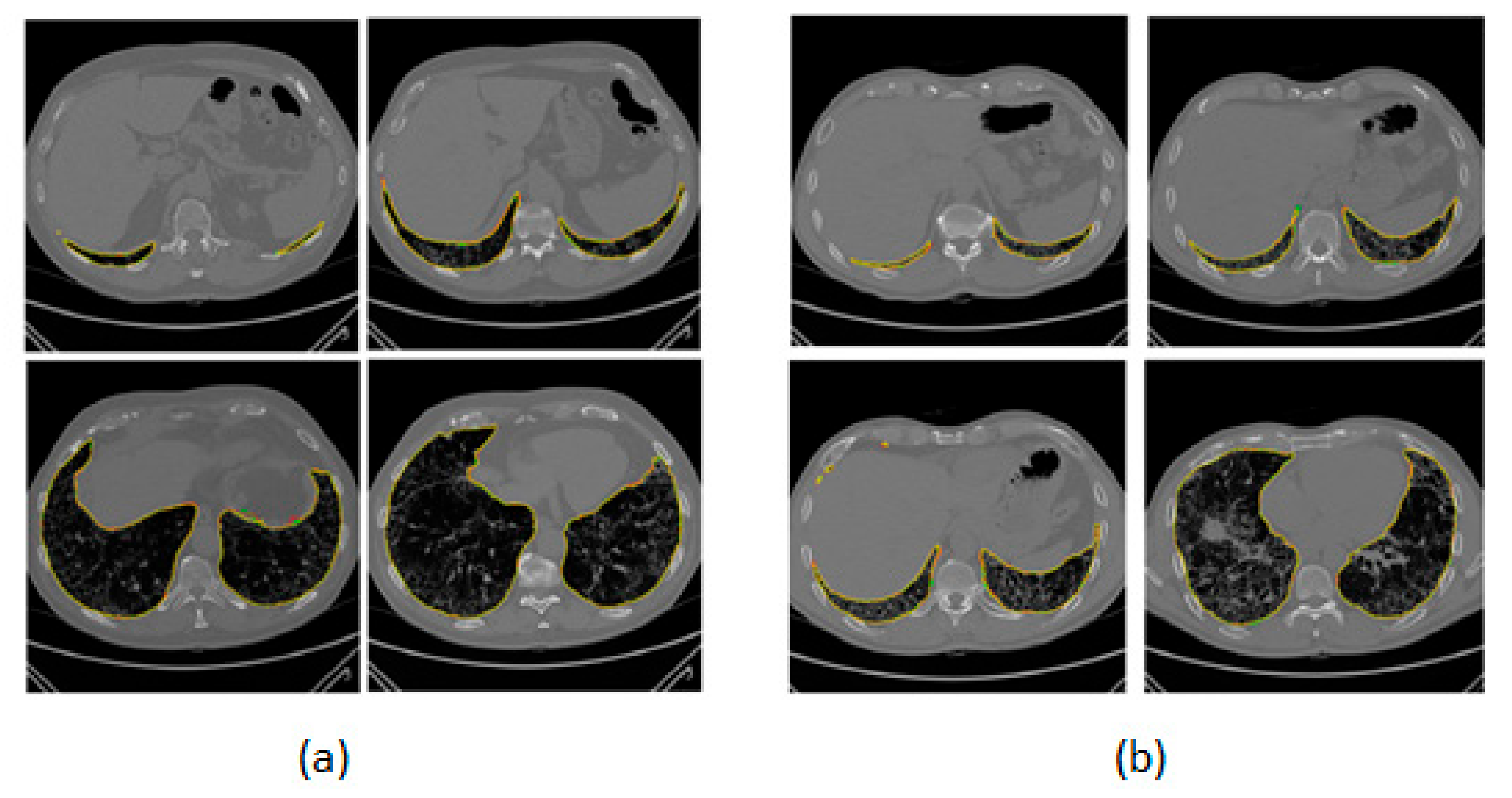
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Stefano, A.; Comelli, A.; Bravata, V.; Barone, S.; Daskalovski, I.; Savoca, G.; Sabini, M.G.; Ipplito, M.; Russo, G. A preliminary PET radiomics study of brain metastases using a fully automatic segmentation method. BMC Bioinform. 2020, 21, 325. [Google Scholar] [CrossRef] [PubMed]
- Cuocolo, R.; Stanzione, A.; Ponsiglione, A.; Romeo, V.; Verde, F.; Creta, M.; La Rocca, R.; Longo, N.; Pace, L.; Imbriaco, M. Clinically significant prostate cancer detection on MRI: A radiomic shape features study. Eur. J. Radiol. 2019, 116, 144–149. [Google Scholar] [CrossRef] [PubMed]
- Comelli, A.; Stefano, A.; Coronnello, C.; Russo, G.; Vernuccio, F.; Cannella, R.; Salvaggio, G.; Lagalla, R.; Barone, S. Radiomics: A New Biomedical Workflow to Create a Predictive Model. In Annual Conference on Medical Image Understanding and Analysis; Springer: Berlin/Heidelberg, Germany, 2020; pp. 280–293. [Google Scholar]
- Comelli, A.; Bignardi, S.; Stefano, A.; Russo, G.; Sabini, M.G.; Ippolito, M.; Yezzi, A. Development of a new fully three-dimensional methodology for tumours delineation in functional images. Comput. Biol. Med. 2020, 120, 103701. [Google Scholar] [CrossRef] [PubMed]
- Comelli, A. Fully 3D Active Surface with Machine Learning for PET Image Segmentation. J. Imaging 2020, 6, 113. [Google Scholar] [CrossRef]
- Christe, A.; Peters, A.A.; Drakopoulos, D.; Heverhagen, J.T.; Geiser, T.; Stathopoulou, T.; Christodoulidis, S.; Anthimopoulos, M.; Mougiakakou, S.G.; Ebner, L. Computer-Aided Diagnosis of Pulmonary Fibrosis Using Deep Learning and CT Images. Invest. Radiol. 2019, 54, 627–632. [Google Scholar] [CrossRef] [Green Version]
- Stefano, A.; Gioè, M.; Russo, G.; Palmucci, S.; Torrisi, S.E.; Bignardi, S.; Basile, A.; Comelli, A.; Benfante, V.; Sambataro, G.; et al. Performance of Radiomics Features in the Quantification of Idiopathic Pulmonary Fibrosis from HRCT. Diagnostics 2020, 10, 306. [Google Scholar] [CrossRef]
- Palmucci, S.; Torrisi, S.E.; Falsaperla, D.; Stefano, A.; Torcitto, A.G.; Russo, G.; Pavone, M.; Vancheri, A.; Mauro, L.A.; Grassedonio, E.; et al. Assessment of Lung Cancer Development in Idiopathic Pulmonary Fibrosis Patients Using Quantitative High-Resolution Computed Tomography: A Retrospective Analysis. J. Thorac. Imaging 2019, 35, 115–122. [Google Scholar] [CrossRef]
- Torrisi, S.E.; Palmucci, S.; Stefano, A.; Russo, G.; Torcitto, A.G.; Falsaperla, D.; Gioè, M.; Pavone, M.; Vancheri, A.; Sambataro, G.; et al. Assessment of survival in patients with idiopathic pulmonary fibrosis using quantitative HRCT indexes. Multidiscip. Respir. Med. 2018, 13, 1–8. [Google Scholar] [CrossRef]
- Laudicella, R.; Comelli, A.; Stefano, A.; Szostek, M.; Crocè, L.; Vento, A.; Spataro, A.; Comis, A.D.; La Torre, F.; Gaeta, M.; et al. Artificial Neural Networks in Cardiovascular Diseases and its Potential for Clinical Application in Molecular Imaging. Curr. Radiopharm. 2020. [Google Scholar] [CrossRef]
- Gerard, S.E.; Herrmann, J.; Kaczka, D.W.; Musch, G.; Fernandez-Bustamante, A.; Reinhardt, J.M. Multi-resolution convolutional neural networks for fully automated segmentation of acutely injured lungs in multiple species. Med. Image Anal. 2020, 60, 101592. [Google Scholar] [CrossRef]
- Jia, H.; Xia, Y.; Song, Y.; Cai, W.; Fulham, M.; Feng, D.D. Atlas registration and ensemble deep convolutional neural network-based prostate segmentation using magnetic resonance imaging. Neurocomputing 2018, 275, 1358–1369. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5686–5696. [Google Scholar]
- Cuocolo, R.; Cipullo, M.B.; Stanzione, A.; Ugga, L.; Romeo, V.; Radice, L.; Brunetti, A.; Imbriaco, M. Machine learning applications in prostate cancer magnetic resonance imaging. Eur. Radiol. Exp. 2019, 3, 35. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked denoising autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ghiasi, G.; Fowlkes, C.C. Laplacian pyramid reconstruction and refinement for semantic segmentation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 519–534. [Google Scholar]
- He, J.; Deng, Z.; Qiao, Y. Dynamic multi-scale filters for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Chen, L.C.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A.L. Attention to Scale: Scale-Aware Semantic Image Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016—Conference Track Proceedings, San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets Mehdi. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Park, B.; Park, H.; Lee, S.M.; Seo, J.B.; Kim, N. Lung Segmentation on HRCT and Volumetric CT for Diffuse Interstitial Lung Disease Using Deep Convolutional Neural Networks. J. Digit. Imaging 2019, 32, 1019–1026. [Google Scholar] [CrossRef]
- Ait Skourt, B.; El Hassani, A.; Majda, A. Lung CT image segmentation using deep neural networks. Proc. Comput. Sci. 2018, 127, 109–113. [Google Scholar] [CrossRef]
- Chassagnon, G.; Vakalopoulou, M.; Régent, A.; Zacharaki, E.I.; Aviram, G.; Martin, C.; Marini, R.; Bus, N.; Jerjir, N.; Mekinian, A.; et al. Deep Learning–based Approach for Automated Assessment of Interstitial Lung Disease in Systemic Sclerosis on CT Images. Radiol. Artif. Intell. 2020, 2, e190006. [Google Scholar] [CrossRef]
- Ma, J.; Song, Y.; Tian, X.; Hua, Y.; Zhang, R.; Wu, J. Survey on deep learning for pulmonary medical imaging. Front. Med. 2019, 14, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Kido, S.; Hirano, Y.; Mabu, S. Deep Learning for Pulmonary Image Analysis: Classification, Detection, and Segmentation. In Deep Learning in Medical Image Analysis; Springer: Berlin/Heidelberg, Germany, 2020; Volume 1213, pp. 47–58. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Lecture Notes in Computer Science; including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Salehi, S.S.M.; Erdogmus, D.; Gholipour, A. Tversky loss function for image segmentation using 3D fully convolutional deep networks. In Proceedings of the Lecture Notes in Computer Science; including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Raghu, G.; Collard, H.R.; Egan, J.J.; Martinez, F.J.; Behr, J.; Brown, K.K.; Colby, T.V.; Cordier, J.F.; Flaherty, K.R.; Lasky, J.A.; et al. An Official ATS/ERS/JRS/ALAT Statement: Idiopathic pulmonary fibrosis: Evidence-based guidelines for diagnosis and management. Am. J. Respir. Crit. Care Med. 2011, 183, 788–824. [Google Scholar] [CrossRef] [PubMed]
- Rosset, A.; Spadola, L.; Ratib, O. OsiriX: An open-source software for navigating in multidimensional DICOM images. J. Digit. Imaging 2004, 17, 205–216. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tversky, A. Features of similarity. Psychol. Rev. 1977, 84, 327. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Taha, A.A.; Hanbury, A. Metrics for evaluating 3D medical image segmentation: Analysis, selection, and tool. BMC Med. Imaging 2015, 15, 29. [Google Scholar] [CrossRef] [Green Version]
- Zheng, H.; Yang, L.; Chen, J.; Han, J.; Zhang, Y.; Liang, P.; Zhao, Z.; Wang, C.; Chen, D.Z. Biomedical image segmentation via representative annotation. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, AAAI 2019, 31st Innovative Applications of Artificial Intelligence Conference, IAAI 2019 and the 9th AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2019, Honolulu, HI, USA, 27 January–1 February 2019; pp. 5901–5908. [Google Scholar]
- Zhou, Y.; Yen, G.G.; Yi, Z. Evolutionary compression of deep neural networks for biomedical image segmentation. IEEE Trans. Neural Networks Learn. Syst. 2020, 31, 2916–2929. [Google Scholar] [CrossRef]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef] [Green Version]
- Luís, L.F.; Holanda, G.B.; Alves, S.S.A.; Francisco, F.H.; Filho, P.P.R. Automatic lung segmentation in CT images using mask R-CNN for mapping the feature extraction in supervised methods of machine learning. In Proceedings of the Advances in Intelligent Systems and Computing, 2021; AISC: Chicago, IL, USA, 2020; Volume 1181, pp. 140–149. [Google Scholar]
- Liu, C.; Zhao, R.; Xie, W.; Pang, M. Pathological lung segmentation based on random forest combined with deep model and multi-scale superpixels. Neural Process. Lett. 2020, 52, 1631–1649. [Google Scholar] [CrossRef]
- Depeursinge, A.; Vargas, A.; Platon, A.; Geissbuhler, A.; Poletti, P.A.; Müller, H. Building a reference multimedia database for interstitial lung diseases. Comput. Med. Imaging Graph. 2012, 36, 227–238. [Google Scholar] [CrossRef]
- Khanna, A.; Londhe, N.D.; Gupta, S.; Semwal, A. A deep Residual U-Net convolutional neural network for automated lung segmentation in computed tomography images. Biocybern. Biomed. Eng. 2020, 40, 1314–1327. [Google Scholar] [CrossRef]
- Sun, S.; Tian, D.; Wu, W.; Kang, Y.; Zhao, H. Lung segmentation by active shape model approach based on low rank theory. J. Image Graph. 2020, 25, 759–767. [Google Scholar]
- Zhao, H.; Zhou, B.L.; Zhu, H.B.; Dou, S.C. Fast Segmentation Algorithm of 3D Lung Parenchyma Based on Continuous Max-Flow. Dongbei Daxue Xuebao/J. Northeast. Univ. 2020, 41, 470–474. [Google Scholar]
- Kumar, S.P.; Latte, M.V. Lung Parenchyma Segmentation: Fully Automated and Accurate Approach for Thoracic CT Scan Images. IETE J. Res. 2020, 66, 370–383. [Google Scholar] [CrossRef]
- Mongan, J.; Moy, L.; Kahn, C.E. Checklist for Artificial Intelligence in Medical Imaging (CLAIM): A Guide for Authors and Reviewers. Radiol. Artif. Intell. 2020, 2, e200029. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Validation Dataset (32 Patient 5-Fold) | ||||||
|---|---|---|---|---|---|---|
| E-Net | U-Net | |||||
| Mean | ±std | ±CI (95%) | Mean | ±std | ±CI (95%) | |
| Sensitivity | 98.97% | 2.09% | 0.72% | 97.67% | 3.44% | 2.76% |
| PPV | 97.97% | 1.86% | 0.64% | 99.00% | 1.10% | 0.88% |
| DSC | 98.34% | 1.44% | 0.50% | 98.26% | 1.97% | 1.57% |
| VOE | 3.23% | 2.73% | 0.95% | 3.35% | 3.73% | 2.98% |
| VD | 0.87% | 2.62% | 0.91% | 3.35% | 3.73% | 2.98% |
| ASSD | 1.42 | 1.68 | 1.34 | 1.29 | 1.81 | 1.45 |
| Testing Dataset (10 Patients’ Studies) | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| E-Net | U-Net | Region Growing | |||||||
| Mean | ±std | ±CI (95%) | Mean | ±std | ±CI (95%) | Mean | ±std | ±CI (95%) | |
| Sensitivity | 93.56% | 3.41% | 0.95% | 92.40% | 4.20% | 2.60% | 98.58% | 11.18% | 2.57% |
| PPV | 98.44% | 0.95% | 0.26% | 99.00% | 0.82% | 0.51% | 77.71% | 9.47% | 2.21% |
| DSC | 95.90% | 1.56% | 0.43% | 95.61% | 1.82% | 1.13% | 86.91% | 8.94% | 2.03% |
| VOE | 7.84% | 2.91% | 0.81% | 8.36% | 3.40% | 2.11% | 23.15% | 11.55% | 2.67% |
| VD | −4.89% | 3.82% | 1.06% | −6.71% | 4.43% | 2.75% | 26.85% | 14.42% | 3.33% |
| ASSD | 2.31 | 0.70 | 0.43 | 2.26 | 0.60 | 0.37 | 9.72 | 4.51 | 1.07 |
| ANOVA | F Value | F Critic Value | p-Value |
|---|---|---|---|
| E-Net vs U-Net | 0.18392749 | 4.964602744 | 0.677111335 |
| Model Name | Number of Parameters | Size on Disk | Inference Times/Dataset | ||
|---|---|---|---|---|---|
| Trainable | Non-Trainable | CPU | GPU | ||
| E-Net | 362,992 | 8352 | 5.8 MB | 115.08 s | 20.32 s |
| U-Net (3 × 3) | 1,946,338 | 0 | 23.5 MB | 1211.99 s | 39.53 s |
| U-Net (5 × 5) | 5,403,874 | 0 | 65.0 MB | 1411.69 s | 46.21 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Comelli, A.; Coronnello, C.; Dahiya, N.; Benfante, V.; Palmucci, S.; Basile, A.; Vancheri, C.; Russo, G.; Yezzi, A.; Stefano, A. Lung Segmentation on High-Resolution Computerized Tomography Images Using Deep Learning: A Preliminary Step for Radiomics Studies. J. Imaging 2020, 6, 125. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging6110125
Comelli A, Coronnello C, Dahiya N, Benfante V, Palmucci S, Basile A, Vancheri C, Russo G, Yezzi A, Stefano A. Lung Segmentation on High-Resolution Computerized Tomography Images Using Deep Learning: A Preliminary Step for Radiomics Studies. Journal of Imaging. 2020; 6(11):125. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging6110125
Chicago/Turabian StyleComelli, Albert, Claudia Coronnello, Navdeep Dahiya, Viviana Benfante, Stefano Palmucci, Antonio Basile, Carlo Vancheri, Giorgio Russo, Anthony Yezzi, and Alessandro Stefano. 2020. "Lung Segmentation on High-Resolution Computerized Tomography Images Using Deep Learning: A Preliminary Step for Radiomics Studies" Journal of Imaging 6, no. 11: 125. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging6110125