1. Introduction
The importance of developing high-performance video codecs for the audiovisual entertainment industry is widely recognized. Rising consumption of more immersive video content with higher resolutions, from video games to video streaming delivery services, is pushing both industry and academy towards seeking new video codecs with the best possible coding performance. However, the varied and not-always-compatible facets of coding performance must be taken into account, such as higher video resolutions, higher frame rates, real-time response for 360
video, and AR/VR immersive platforms. The High-Efficiency Video Coding (HEVC) standard [
1] was initially intended to be the successor of AVC/H.264 [
2]. However, it did not penetrate the industry as successfully (mainly due to licensing costs), and other alternatives promising better performance or royalty-free usage emerged [
3,
4]. A set of new video coding technologies is thus being proposed by the Joint Video Exploration Team (JVET), a joint ISO/IEC MPEG and ITU-VCEG initiative created to explore tools that offer video coding capabilities beyond HEVC.
The JVET team started its exploration process by implementing new coding enhancements in a software package known as the Joint Exploration Test Model (JEM) [
5,
6]. Its main purpose was to investigate the benefits of adding coding tools to the video coding layer. It is worth noting that JEM’s main purpose was not to establish a new standard but to identify modifications beyond HEVC that would be worthy of interest in terms of compression performance. The main goal was to achieve bit rate savings of 25–30% compared to HEVC [
7]. Experimental results using the All Intra (AI) configuration [
8] showed that the new model (JEM 3.0) achieved an 18% reduction in bit rate, although at the expense of a major increase in computational complexity (60x) with respect to HEVC. On the other hand, by applying a Random Access (RA) configuration, JEM obtained an average bit rate reduction of 26% with a computational complexity increment of 11x.
JEM’s increase in computational complexity with respect to HEVC was so huge that a complexity-reduction strategy had to be undertaken to compete with other emerging coding proposals. The JVET team thus decided to change the exploration process to the new Versatile Video Coding (VVC) [
9,
10] standard project. The main objective of VVC is to significantly improve compression performance compared to the existing HEVC, supporting the deployment of higher-quality video services and emerging applications such as 360
omnidirectional immersive multimedia and high-dynamic-range (HDR) video.
Following JVET’s exploration to find a successor to HEVC, we need to build a deeper understanding of the key factors involved in this evolution: the Rate/Distortion (R/D) performance of new coding tools and the increase in coding complexity. Therefore, a detailed evaluation of HEVC, JEM, and VVC proposals was performed in the present study to analyze the results of this evolution.
To begin, in
Section 2, we conduct a comparative analysis of the new JEM and VVC coding approaches using the HEVC as a reference. In
Section 3, we present a set of experimental tests that were performed, with a detailed analysis of JEM and VVC improvements to R/D performance compared to the HEVC coding standard. The impact of new coding tools on coding complexity is also described. Conclusions are drawn in
Section 4.
2. Overview and Comparison of Video Coding Techniques
As the JEM codec is based on the HEVC reference software (called HEVC Test Model (HM)) and the VVC standard is based on JEM, the overall architecture of the three evaluated codecs is quite similar to that of the HEVC HM codec. The three codecs thus share the hybrid video codec design. The coding stages, however, were modified in each encoder; they included modification or removal of techniques in order to improve the previous standard [
9,
11,
12]. For example, the three codecs use closed-loop prediction with motion compensation from previously decoded reference frames or intra prediction from previously decoded areas of the current frame, but the picture partitioning schema vary for each encoder. Furthermore, the VVC standard is currently in the stage of evaluation of proposals, that is, in the “CfP results” stage, implying that the final architecture has not been definitely defined, and therefore some of the following VVC descriptions are based on currently accepted proposals [
9,
13]. The VVC encoder seeks a trade-off between computational complexity and R/D performance, and therefore many of the techniques included in JEM have been optimized to reduce complexity. Some have even been fully removed, specifically: mode dependent transform (DST-VII), mode dependent scanning, strong intra smoothing, hiding of sign data in transform coding, unnecessary high-level syntax (e.g., VPS), tiles and wavefronts, and finally, quantization weighting. The most relevant techniques used by the three under evaluation will be described below. They are evaluated mainly focusing in the trade-off between computational complexity and the R/D performance. Detailed information about the encoders can be found in [
10,
12,
14] for HEVC, JEM and VVC, respectively.
2.1. Picture Partitioning
Picture partitioning is the way in which encoders divide each video sequence frame into a set of non-overlapping blocks. In HEVC, this partitioning is based on a quad tree structure called Coding Tree Units (CTUs) [
1]. A CTU can be further partitioned into Coding Units (CUs), Prediction Units (PUs), and Transform Units (TUs). PUs store the prediction information in the form of Motion Vectors (MVs), and PU sizes range from
to
using either symmetrical or asymmetrical partitions. HEVC uses eight possible partitions for each CU size: 2Nx2N, 2NxN, Nx2N, NxN, 2NxnU, 2NxnD, nLx2N and nRx2N.
The picture partitioning schema is modified in JEM in order to simplify the prediction and transform stages; it should not be partitioned further, since the main partitioning schema encompasses the desired sizes for prediction and transform. The highest level is also called a CTU, as in HEVC, but the main change is that block splitting below the CTU level is performed first using a quad tree as in HEVC, and for each branch, a binary partition is made at a desired level to obtain the leaves. This partition method is called Quad Tree plus Binary Tree (QTBT). This partitioning schema offers a better match with the local characteristics of each video sequence frame so the organization in CUs, PUs, and TUs is no longer needed [
15]. The leaves are considered as CUs and can have either square or rectangular shapes. The CTU can reach up to
pixels and only the first partition should be set into four square blocks. For lower partitions, the quad tree or binary tree can be used in this order.
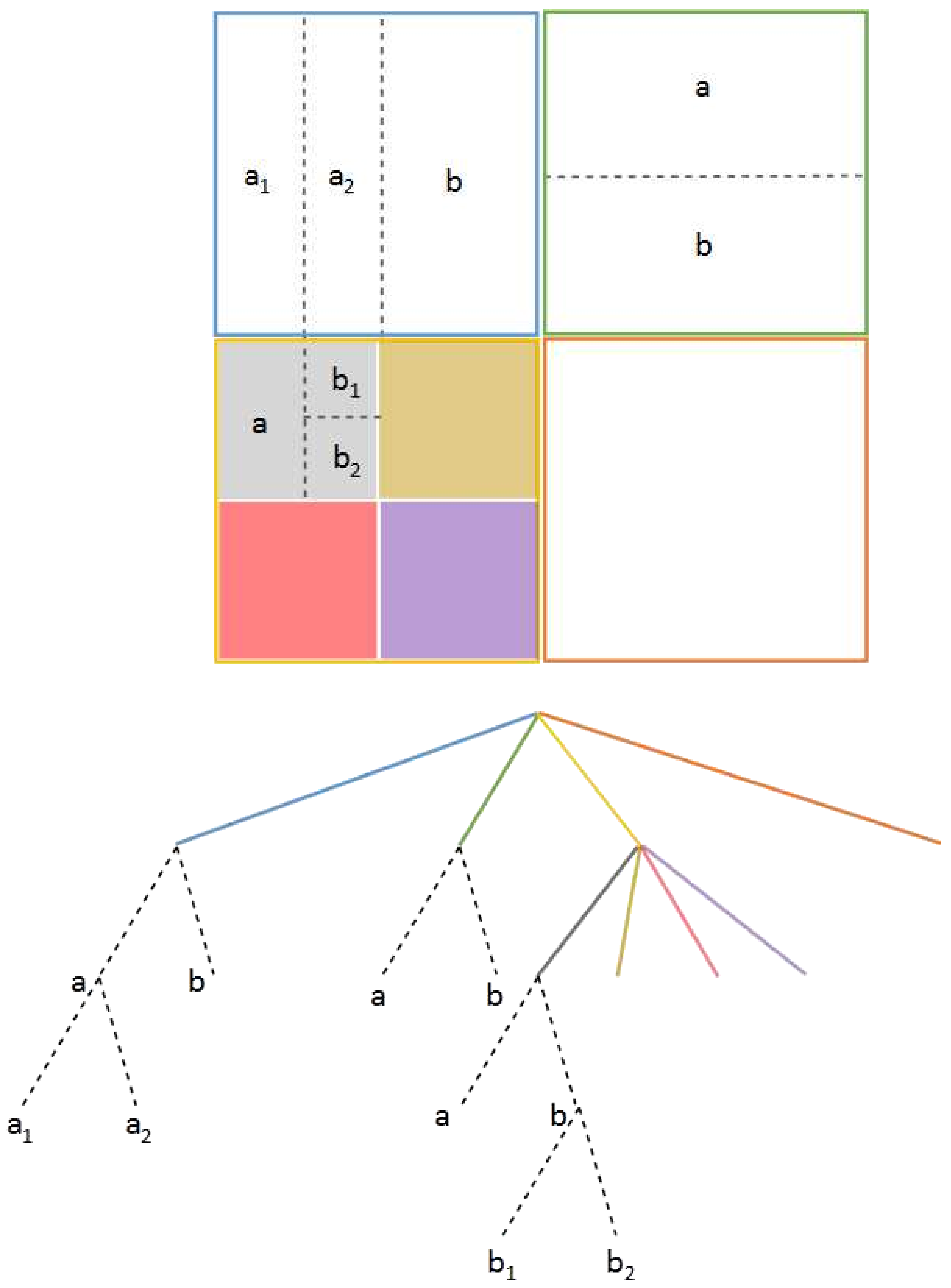
Figure 1 shows an example of a CTU partition and its quad tree plus binary tree graphical representation, where the quad tree reaches two levels (continuous colored lines), after which the binary tree starts (dotted lines labeled as a and b).
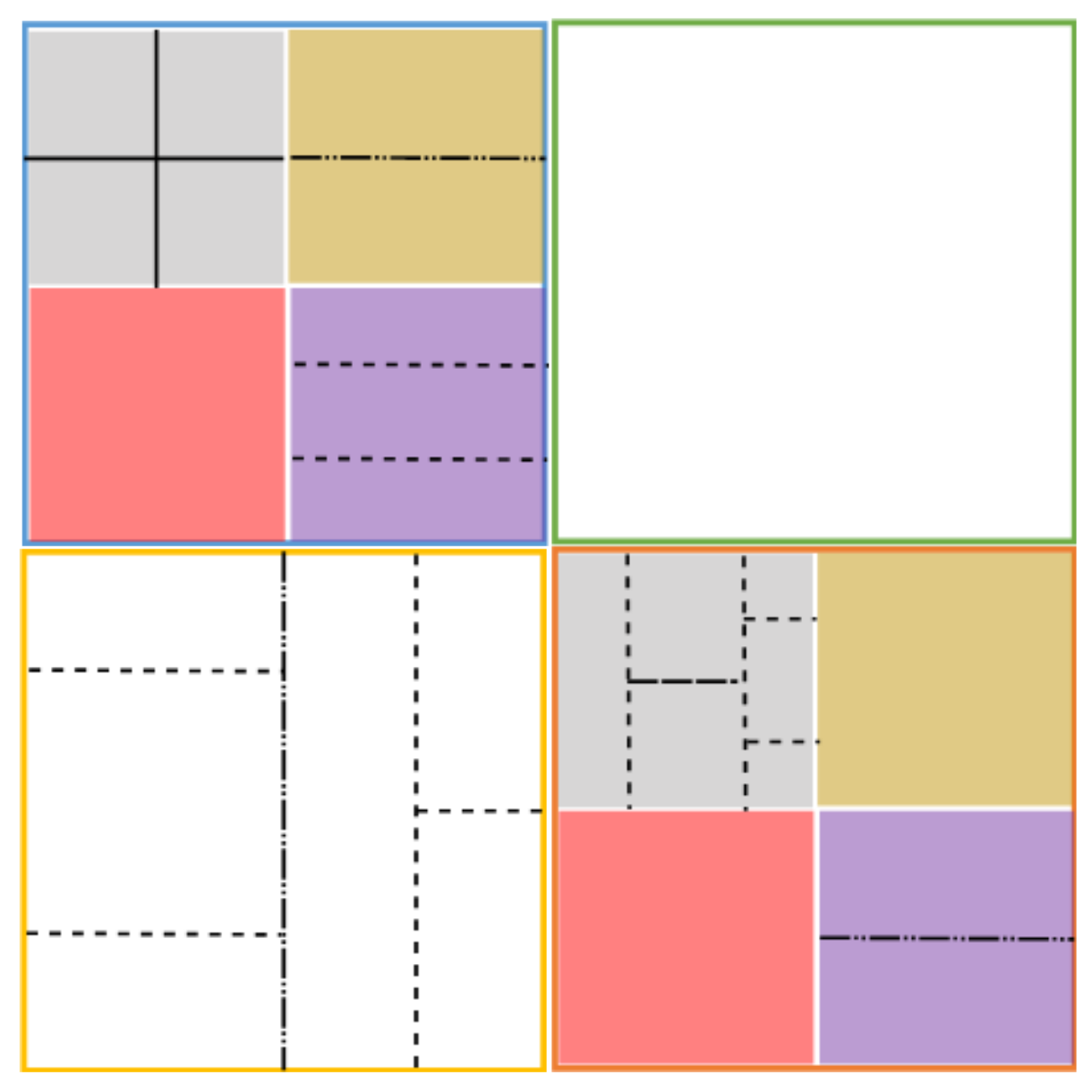
The same QTBT partitioning schema is also used in VVC, but some of the proposed partitioning schemes are also of interest. For example, nested recursive Multi-Type Tree (MTT) partitioning is proposed: after an original quad-tree partition, a ternary or binary split can be chosen alternatively at any desired level. This new partition schema is called Quad-Tree plus Multi-Type Tree (QT + MTT) block partitioning. In
Figure 2, we can see how some nodes have a ternary partition first and then a binary partition, or vice versa. The maximum CTU size is fixed at 128 × 128 pixels with variable sizes for the resulting CUs. As in the JEM encoder, these CUs are not partitioned further for transform or prediction unless the CU is too large for the maximum transform size (
). This means that in most cases, the CU, PU, and TU have the same size. Based on the Benchmark Set Results [
16], rate savings of up to 12% on average are obtained only when using the QT-MTT instead of the QTBT, with significantly reduced encoding time. Several interesting proposals can also be found to use asymmetric rectangular binary modes and even diagonal (wedge-shaped) binary split modes.
2.2. Spatial Prediction
In the intra prediction stage, the JEM and VVC encoders increase the number of directional intra-modes to capture the finer edge direction presented in natural videos. The 33 directional intra-modes of the HEVC are thus increased to 65 while the planar and DC modes remain equal. All directional modes are also applied to chroma intra-prediction. To adapt to the greater number of directional intra-modes, the intra-coding method uses the six Most Probable Modes (MPMs) in JEM, while only three MPMs with additional processing and a pruning process that removes duplicated modes to be included in the MPM list are used in VVC.
Furthermore, several new coding proposals are included in both JEM and VVC with respect to HEVC to improve the intra prediction stage. Some of these proposals are improved in VVC with respect to JEM but rely on the same concepts. For example, for entropy coding of the 64 non-MPM modes, a six-bit Fixed Length Code (FLC) is used in JEM and VVC. The interpolation filter is increased from a three-tap filter (used in HEVC) to a four-tap filter. A new Cross-Component Linear Model (CCLM) prediction is also included to reduce cross-component redundancy in chroma samples. The prediction is based on the reconstructed luma samples of the same CU by using a proposed linear model. A Position Dependent Prediction Combination (PDPC) method is included. It uses unfiltered and filtered boundary reference samples, which are applied depending on the prediction mode and block size. PDPC tries to adapt to the different smoothing needed for pixels close to and far from the block borders and statistical variability when increasing the size of blocks. VVC also adaptively replaces several conventional angular intra prediction modes with wide-angle intra prediction modes for non-square blocks where the replacement depends on the blocks’ aspect ratio.
2.3. Temporal Prediction
In H.265/HEVC, one PU is always associated with only one set of motion information (motion vectors and reference indices). When facing inter-prediction with the new QTBT partition schema in JEM, each CU will have a maximum of one set of motion information. Two sub-CU-level motion-vector-prediction methods are included, however, that split a large CU into sub-CUs with related motion information. With the Alternative Temporal Motion Vector Prediction (ATMVP) method, each CU is split into four square sub-CUs for which motion information is obtained. In the Spatial-Temporal Motion Vector Prediction (STMVP) method, motion vectors of the sub-CUs are derived recursively by using the temporal motion vector predictor and a neighbouring spatial motion vector. In JEM, accuracy increases to 1/16 of a pixel for the internal motion vector storage and the Merge candidate, whereas one-quarter of a pixel is used for motion estimation as in HEVC. The highest level of motion vector accuracy is used in motion compensation inter-prediction for the CU coded with Skip/Merge mode.
In HEVC, only a translation motion model is applied for Motion Compensation Prediction (MCP), while in the real world, there are many kinds of motions, for example, zoom in/out, rotation, perspective motions, and other irregular motions. In order to improve motion compensation, JEM and VVC include an advanced MCP mode that uses affine transformation. The affine-transform-based motion model was adopted to improve MCP for more complicated motions such as rotation and zoom. Affine-motion estimation for the encoder uses an iterative method based on optical flow and is quite different from conventional motion estimation for translational motion models. The model builds an affine motion field composed of sub-CUs’ motion vectors, obtained by using the affine transform for the centre pixel of each sub-CU block with a precision of one-sixteenth of a pixel. The smallest CU partition is , so an CU should be used to apply the affine model. Some proposals increase this precision up to 1/64 pixel for VVC.
Furthermore, to reduce the blocking artifacts produced by motion compensation, JEM (also inherited in VVC) uses Overlapped Block Motion Compensation (OBMC), which performs a weighted average of overlapped block segments during motion prediction. OBMC can be switched on and off using syntax at the CU level. Both encoders also include Local Illumination Compensation (LIC), which is adaptively switched on and off for each inter-mode coded CU in order to compensate local luminance variations between current and reference blocks in the motion compensation process. It is based on a linear model for luminance changes that obtains its parameters from current CU luminance values and referenced CU samples.
2.4. Transform Coding
For transform coding, the HEVC uses Discrete Cosine Transform (DCT-II) for block sizes over pixels and the Discrete Sine Transform (DST-VII) for block sizes. JEM includes a new Adaptive Multiple Transform (AMT) that uses different DCT and DST families from those used in HEVC. The specific DCT finally used for each block, whose size is below or equal to 64, is signalled by a CU-level flag. Different transforms can be applied to the rows and columns in a block. In intra mode, different sets of transforms are applied depending on the selected intra prediction mode, whereas for inter prediction, the same transforms (both vertical and horizontal) are always applied. AMT complexity is relatively high on the encoder side, since different transform candidates need to be evaluated. Several optimization methods are included in JEM to lighten this complexity.
JEM and VVC also include an intra Mode-Dependent Non-Separable Secondary Transform (MDNSST), which is defined and applied only to the low-frequency coefficients between the core transform and quantization at the encoder and between dequantization and the core inverse transform at the decoder. The idea behind the MDNSST is to improve intra prediction performance with transforms adapted to each angular prediction mode. Furthermore, JEM includes a Signal Dependent Transform (SDT) intended to enhance coding performance, taking advantage of the fact that there are many similar patches within a frame and across frames. Furthermore, such correlations are exploited by the Karhunen-Loève Transform (KLT) up to block sizes of 16.
VVC increases the TU size up to 64, which is essential for higher video resolution, for example, 1080p and 4K sequences. However, for large transform blocks (), high-frequency coefficients are zeroed out so only low frequencies are retained. For example, in an M × N block, if M or N is 64, only the first 32 coefficients (left and top, respectively) are retained.
2.5. Loop Filter
JEM includes two new filters in addition to the deblocking filter and the sample adaptive offset present in the HEVC encoder, which remain the same but with slight configuration modifications when the Adaptive Loop Filter (ALF) is enabled. These new filters consist in the ALF with block-based filter adaptation and a Bilateral Filter (BF). The filtering process in the JEM first applies the deblocking filter followed by the Sample Adaptive Offset (SAO) and finally the ALF. Intra prediction is performed after the bilateral filtering, and the rest of the filters are applied after intra prediction. The BF is a non-linear, edge-reserving, noise-reducing smoothing filter applied by replacing the intensity of all pixels with a weighted average of intensity values from nearby pixels; it has been designed using a lookup table to minimize the number of calculations [
17].
The ALF in JEM software is designed to support up to 25 filter coefficient sets that are decided after gradient calculation, that is, according to the direction and activity of local textures. A filter is selected for each block among the 25 available filters. This aims to reduce visible artefacts such as ringing and blurring by reducing the mean absolute error between the original and the reconstructed images. In VVC, the ALF is improved with some new variants: classification-based blocks (gradient strength and orientation) are used for luma, while the filter sizes are for luma and for chroma filters. A signaling flag is also included in the CTU.
2.6. Entropy Coding
Three improvements to the Context-based Adaptive Binary Arithmetic Coding (CABAC), the arithmetic encoder used in HEVC, are included in JEM. The first improvement is a modified model to set the context for the transform coefficients. To select the context, a transform block is split in three areas where coefficients in each area are processed in different scan passes as explained in [
18]. The final selection of the context, among those assigned to each area, is determined for each coefficient depending on the values of previously scanned neighbouring coefficients. The second improvement is a multi-hypothesis probability estimation, which uses two probability estimates associated with each context model updated independently, based on the probabilities obtained before and after decoding each specific bin. The final probability used in the interval subdivision of the arithmetic encoder is the average of these two estimations. Finally, the third improvement relies on the models’ adaptive initialization, where instead of using fixed tables for context model initialization as in HEVC, initial probability states for inter-coded slices can be initialized by inheriting the statistics from previously coded pictures.
3. Comparative Analysis between HEVC, JEM and VVC
In this section, we present a comparative analysis of R/D (following guidelines stated in documents [
19,
20]) and encoding time overhead between HEVC, JEM, and VVC encoding standards using the AI, Low Delay (LD), Low Delay P (LDP), and RA coding modes. Under the AI coding mode, each frame in the sequence is coded as an independent (I) frame, so no temporal prediction is used, i.e., no frame use information from other frames. When LD and LDP coding modes are used, only the first frame is encoded as an I frame, and all subsequent frames are split into multiple image groups (Group Of Pictures, GOP), coded as B (LD coding mode) or P (LDP coding mode) frames, in both modes information from other frames are used, but a P frame has only one reference list of frames while a B frame has two reference lists. Under RA coding mode the frames are also divided into GOPs, but an I-frame is inserted for an integer number of GOPs and the coding order of the frames differs from the playing order, coding order preserved in the rest of coding modes.
The platform was an HP Proliant SL390 G7 of which only one of the Intel Xeon X5660 processors was used and the compiler was GCC v.4.8.5 [
21]. Thirty-three video sequences with different resolutions were used in our study and are listed in
Table 1. Detailed information about the test video sequences can be found, for example, in [
22], and they can be downloaded from
ftp://ftp.tnt.uni-hannover.de/pub/svc/testsequences (accessed on 23 March 2015). The reference software for the encoders was HM 16.3 [
23] for HEVC and JEM 7.0 [
12] for JEM and VTM 1.1 for VVC [
9,
10], using their default configurations except for the HEVC encoder, where the Main10 Profile was chosen in order to work with the same colour depth as the rest of the encoders.
The Bjontegaard-Delta rate (BD-rate) metric [
24] represents the percentage bit-rate variation between two sequences encoded with different encoding proposals with the same objective quality. A negative value implies an improvement in coding efficiency, that is, a lower rate required to encode with the same quality, between one proposal and another.
Table 2,
Table 3,
Table 4,
Table 5 and
Table 6 show the BD rate obtained when comparing the coding efficiencies of JEM and VVC with respect to HEVC for each of the coding modes. Each table corresponds to video sequences that share the same frame resolution.
After analyzing the results provided in
Table 2,
Table 3,
Table 4,
Table 5 and
Table 6, we can observe rate savings (negative BD-rate values) for each frame resolution and that both the JEM and the VVC encoder outperform the HEVC encoder. Rate savings with respect to HEVC amount to an average of 32.81% for JEM but only 16.08%, on average, for VVC. Maximum rate savings in our tests were obtained when using the RA coding mode: up to 39.04% for JEM and 22.87% for VVC.
The results provided in
Table 2,
Table 3,
Table 4,
Table 5 and
Table 6 and the average values for each frame resolution, shown in
Table 7, lead us to conclude that frame resolution does not affect the results for rate savings. Therefore, the average for all sequences, regardless of their resolution, is also presented in
Table 7. Regarding the coding mode, different coding modes can be observed to provide different rate savings. Performance decreased as expected in this order: RA, LDP, LD, and AI; that is, the best rate savings were obtained when using RA and lower rate savings were obtained when using the AI coding mode. These results were also obtained independently for the frame resolution.
As shown, JEM provided better performance than VVC in all cases. The average values in
Table 7 (for all images) allow us to obtain the relative performances of JEM and VVC shown in
Table 8, where the third column represents the number of times that JEM improves VVC in terms of R/D performance (BD-Rate). As mentioned earlier, JEM outperformed VVC in terms of rate savings in all encoding modes, but not to the same extent for each one. As shown in
Table 8, JEM is on average almost four times better than VVC in AI coding mode, while it is only two times better in RA coding mode. These results should be compared with those obtained for the computational time needed to process the sequences in each mode.
Table 9 shows as the computational time, in seconds, for one video sequence per resolution. As can be seen, the computational cost increase of both JEM and VVC with respect to HEVC is really significant.
Table 10,
Table 11,
Table 12,
Table 13,
Table 14, show the computational time increase, expressed as a percentage, with respect to HEVC for each Quantization Parameter (QP) value and coding mode. As expected, less computational time is required in all coding modes as the QP parameter increases. The increase in computational time depends on the scene content and not on the scene resolution.
The JEM encoder requires considerably more time to encode in any coding mode, but this increase is extremely high in the AI coding mode. For some sequences in our test, up to 6,419% more time is required than with HEVC. In the LP, LDP, and RA modes, the increase was also very high. These results show that all the techniques included in JEM to provide better R/D results actually bring about much more computational complexity.
In the VVC encoder, some of these techniques were removed from the reference software as a trade-off between computational complexity and R/D performance, and many others were improved to reduce the time overhead. This can be seen in
Table 10,
Table 11,
Table 12,
Table 13,
Table 14 when comparing the results for the JEM and VVC columns. In all cases, the time overhead of VVC with respect to HEVC is lower than that of JEM. As the negative values show for many sequences, VVC needs even less time to encode than the HEVC, especially in the case of higher QP values. This reduction achieved by VVC reaches up to 76% compared to HEVC when using the LD coding mode for the SlideEditing (1280 × 720) sequence for a QP value of 37.
Regarding the time results obtained in the LP, LDP, and RA coding modes, we analysed which mode had statistically less time overhead with respect to HEVC. We could thus compare the time overheads of LD, LDP, and RA by conducting Friedman’s rank test [
25], making it possible to determine which coding mode leads to statistically less computing overhead. The test’s output includes the
p-value, a scalar value in the [0…1] range, which, when below 0.05, indicates that the results are statistically relevant, and the
value, which expresses the variance of the mean ranks. Friedman’s rank test was applied to data in the columns LD, LDP, and RA for VVC in
Table 10,
Table 11 and
Table 12, obtaining a mean rank of 1.18 for LD, 2.13 for LDP, and 2.69 for RA, with a p-value of
and
= 135.29. The AI mode undoubtedly introduces the highest computational overhead, note that considering the rest of the modes (LD, LDP and RA) and as the results were statistically significant, it can be concluded that the LD coding mode introduces, statistically, less overhead for VVC when using the default software configuration, while RA generates the highest overhead for VVC.
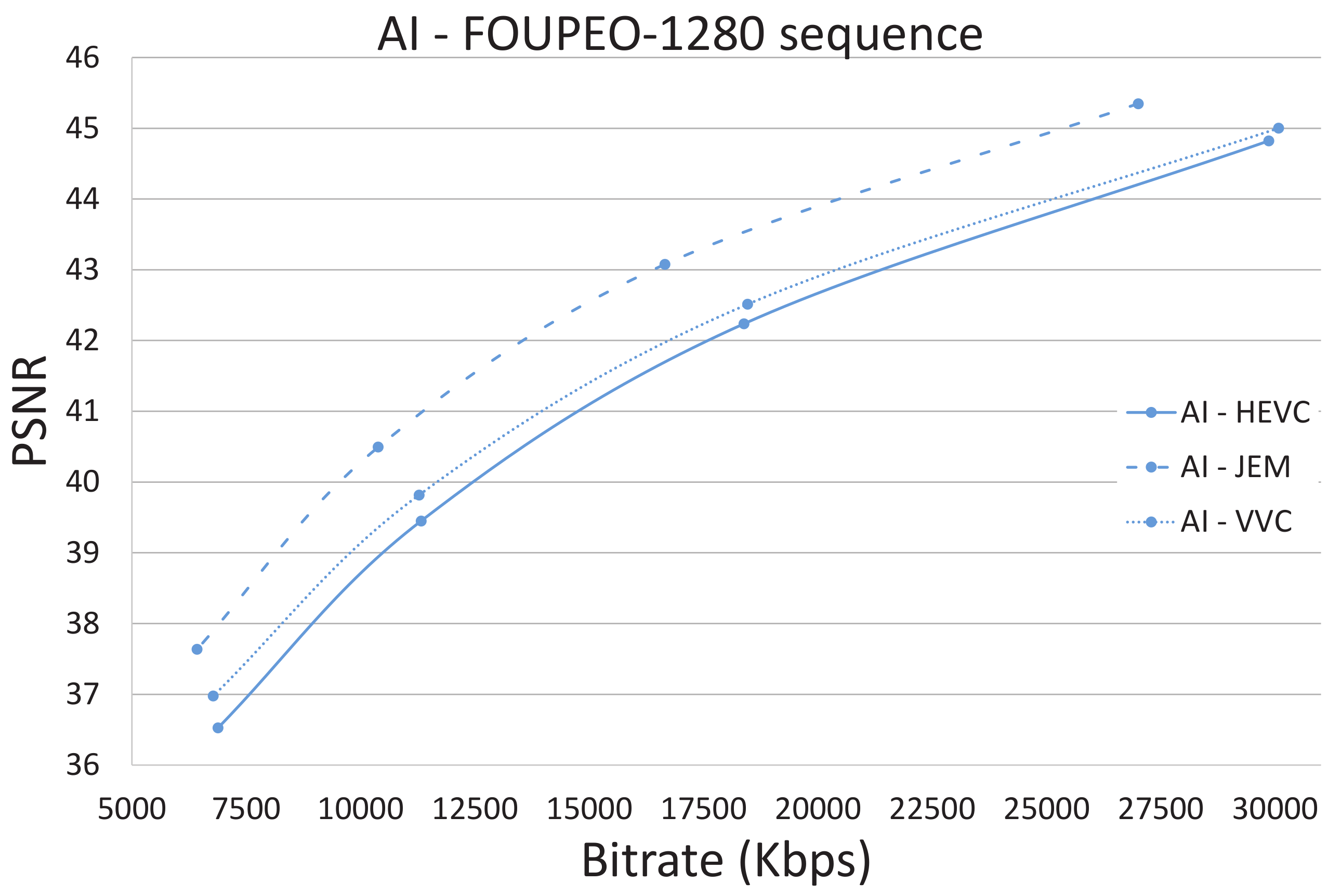
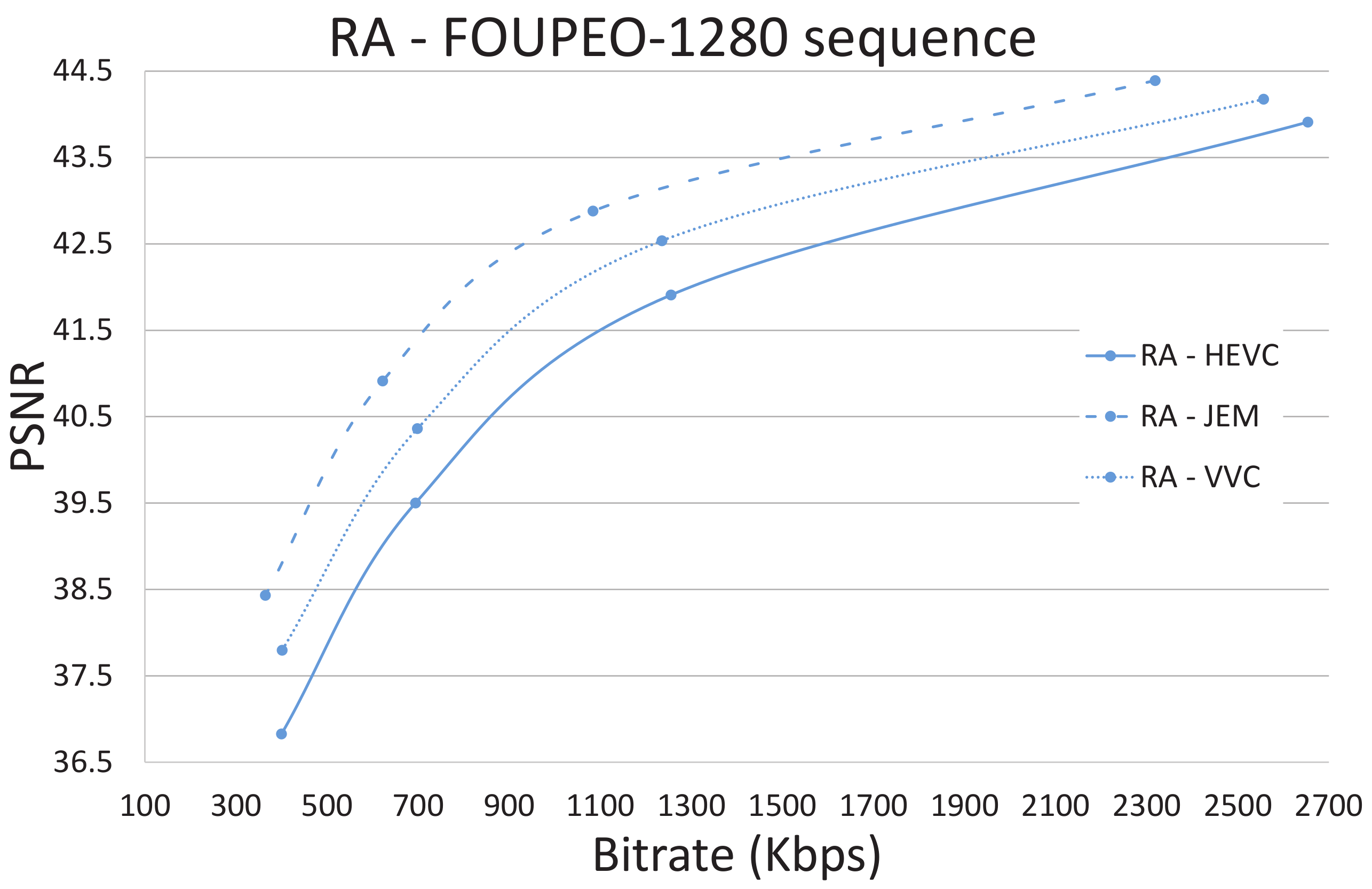
Figure 3,
Figure 4 and
Figure 5 show the R/D performance obtained using the three encoders HEVC, JEM, and VVC for the FourPeople 1280 × 720 sequence.
Figure 3 shows the results for the AI coding mode,
Figure 4 shows those for the LD and LDP coding modes, and
Figure 5 shows those for the RA coding mode. The figures illustrate how the JEM encoder clearly outperforms HEVC and VVC in terms of R/D, as revealed in
Table 2,
Table 3,
Table 4,
Table 5 and
Table 6 above; that is, the R/D curve for JEM is clearly better than the two other curves for all the coding modes and sequences. However, this improvement comes at the expense of a much greater amount of computational time. In the same way, VVC also outperforms HEVC in terms of R/D in all scenarios and even, as observable in
Table 10,
Table 11 and
Table 12, in terms of computational time for many sequences.
For example, in the case of the FourPeople 1280 × 720 sequence (see
Figure 5 and
Table 13), if we focus on the LD mode and on the lowest QP value (highest rate), VVC needs 15% less computational time than HEVC, although it obtains a lower rate and better Peak Signal-to-Noise Ratio (PSNR). JEM obtains a better R/D curve with these settings but at the cost of a 238% increase in computational time compared to HEVC.
4. Conclusions
In this paper, we summarized the evolution of the JVET exploration process to propose a new video coding standard that significantly improves the performance of HEVC. We took into account, however, further design factors such as coding complexity. We performed an exhaustive experimental study to analyze the behavior of JEM and VVC video coding projects in terms of coding performance and complexity.
The results showed that VVC achieves a better trade-off between R/D performance and computational effort, and as shown for many sequences, takes even less coding time than HEVC when using the LD, LDP, and RA coding modes.
Nevertheless, in the AI coding mode, the increase in complexity was still too high in the case of VVC and overwhelming in the case of JEM. VVC needs to improve its coding tools to achieve a better trade-off between coding performance and complexity in the AI mode. The standard is currently not closed and some proposals may come forward in this direction. Efforts should be made to define coding tools that are effective in terms of performance while offering a low-complexity design or at least a straightforward parallelization process.
Given the rise in video resolutions and low-latency video (VR/AR, 360, etc.) demands, future coding standards should be cleverly designed to broadly support different application requirements and to better use available hardware resources.
The experimental study presented made it possible to discern which techniques to improve coding standards can be definitively applied, with the improvement of R/D not the only factor to be taken into account. In addition, the increase in bandwidth of current networks is not sufficient for the increases in bit rates due to the increase in video resolutions, quality, and different flavours (360, AR/VR, etc.).


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}