
Energy-Efficient Non-Von Neumann Computing Architecture Supporting Multiple Computing Paradigms for Logic and Binarized Neural Networks


Abstract
:1. Introduction
2. Results
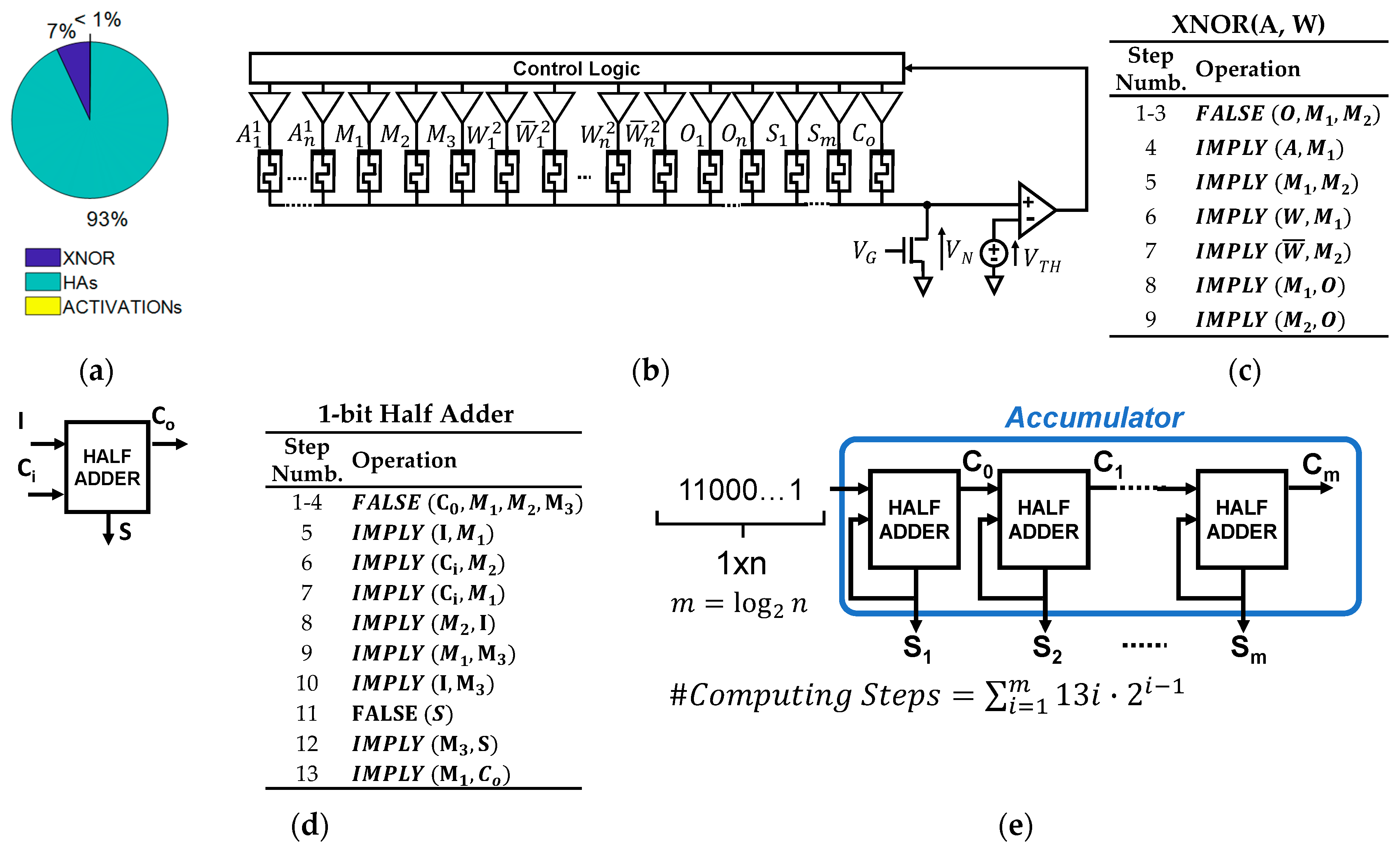
2.1. Logic-in-Memory and the SIMPLY Architecture
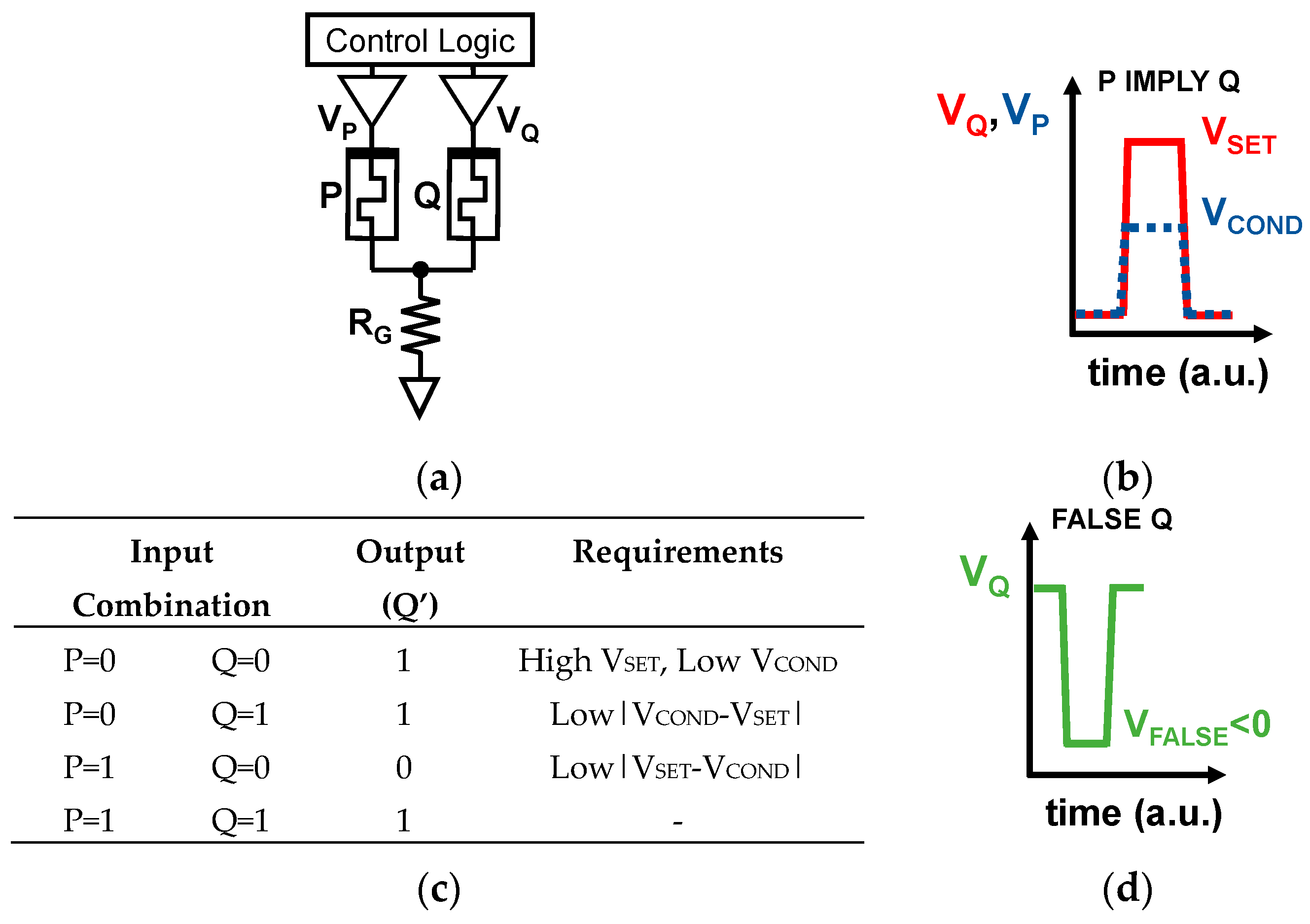
2.1.1. Material Implication Logic
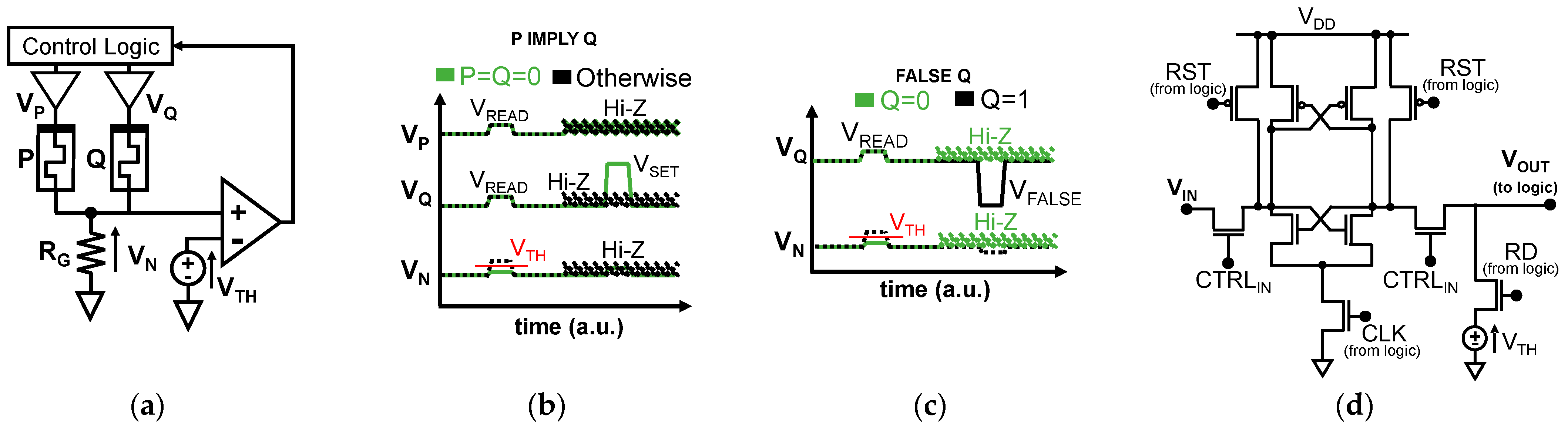
2.1.2. SIMPLY
2.2. Binarized Neural Networks (BNNs) Hardware Accelerator Architectures
2.2.1. Binarized Neural Networks with SIMPLY
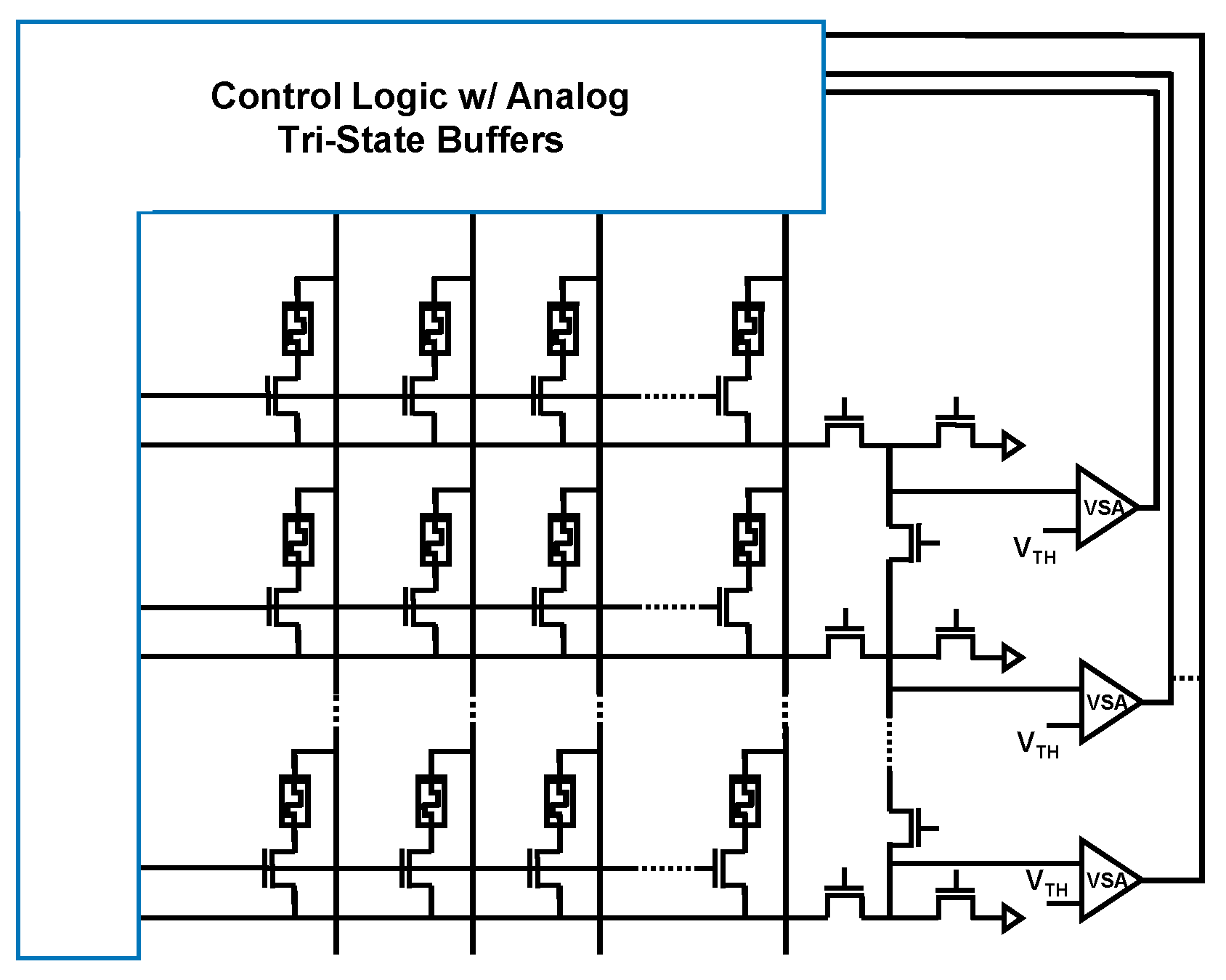
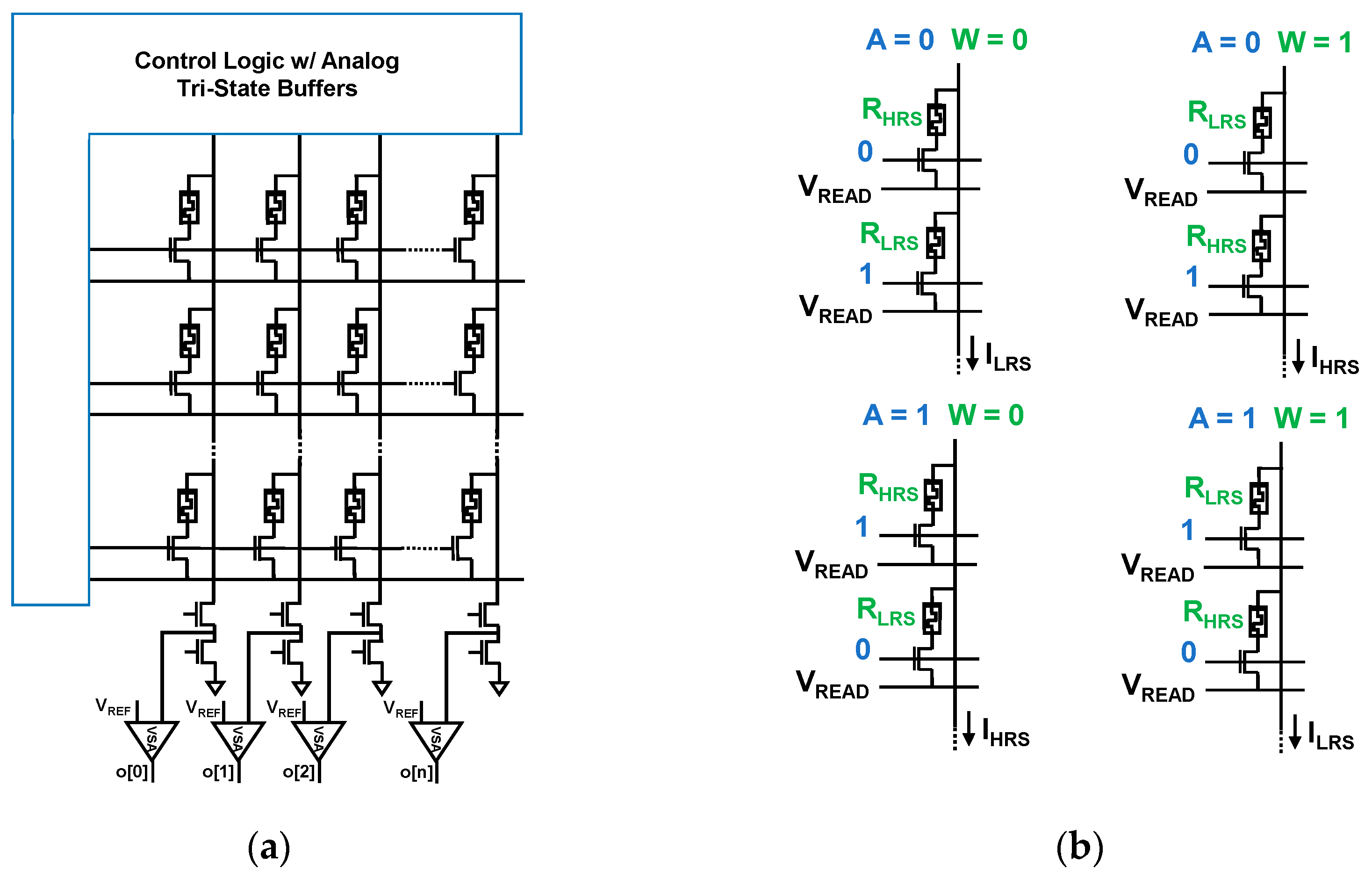
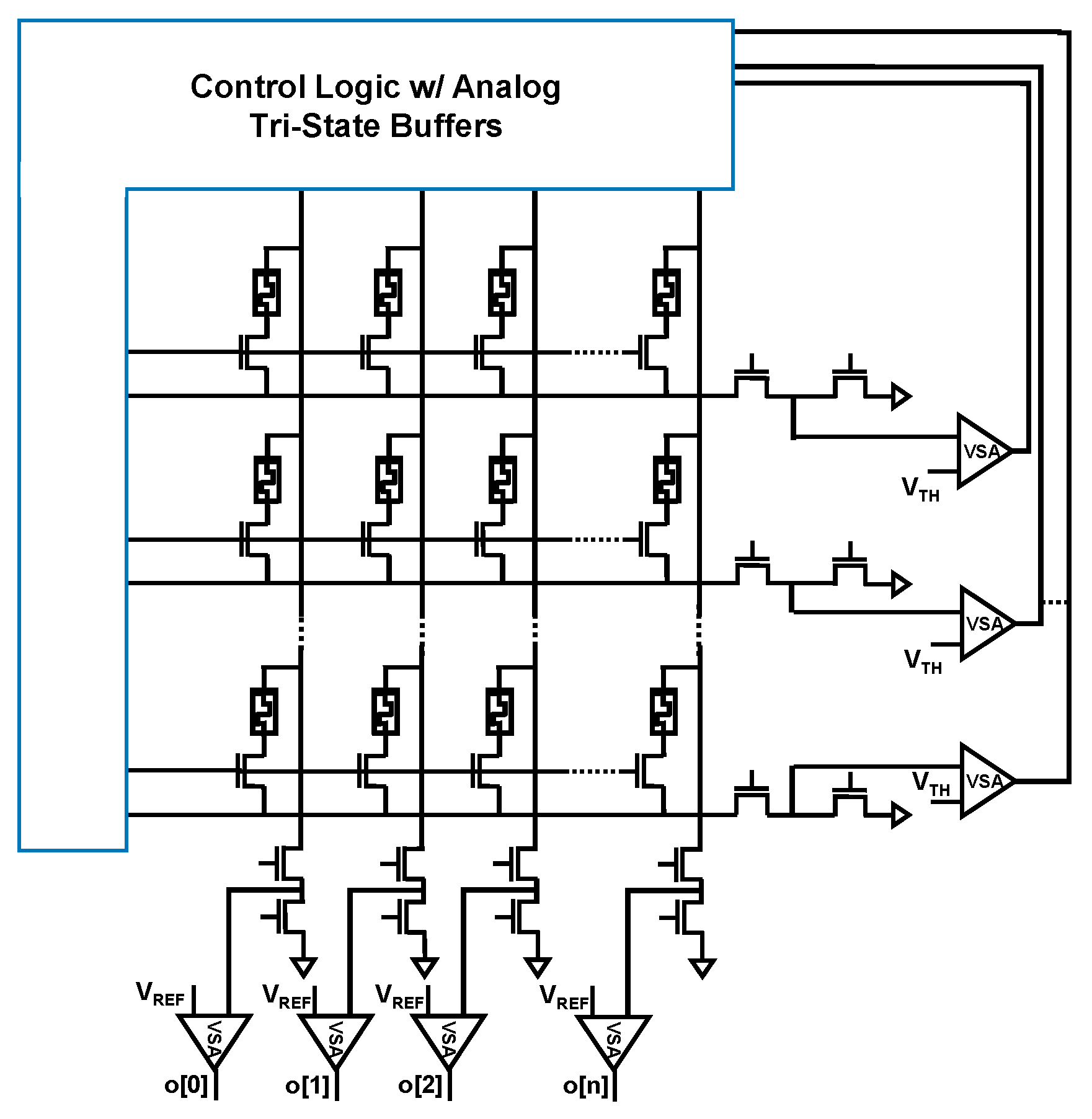
2.2.2. Binarized Neural Networks with Analog Vector Matrix Multiplication
2.3. Merging SIMPLY and BNN Analog Vector Matrix Multiplication Accelerator
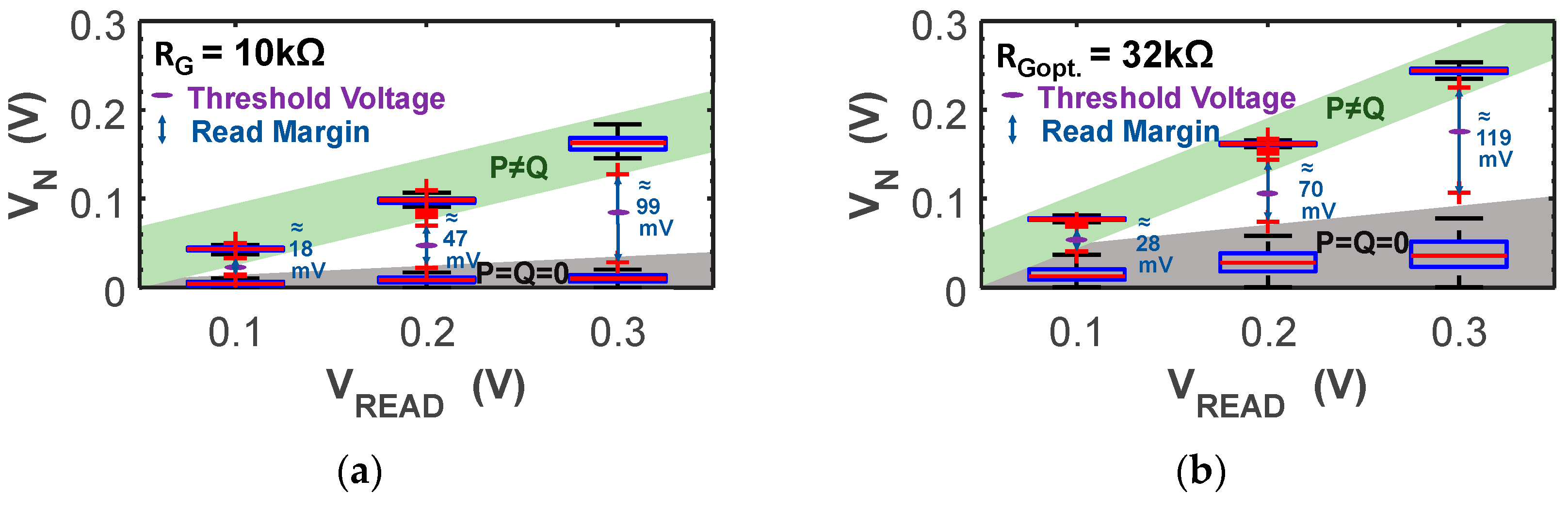
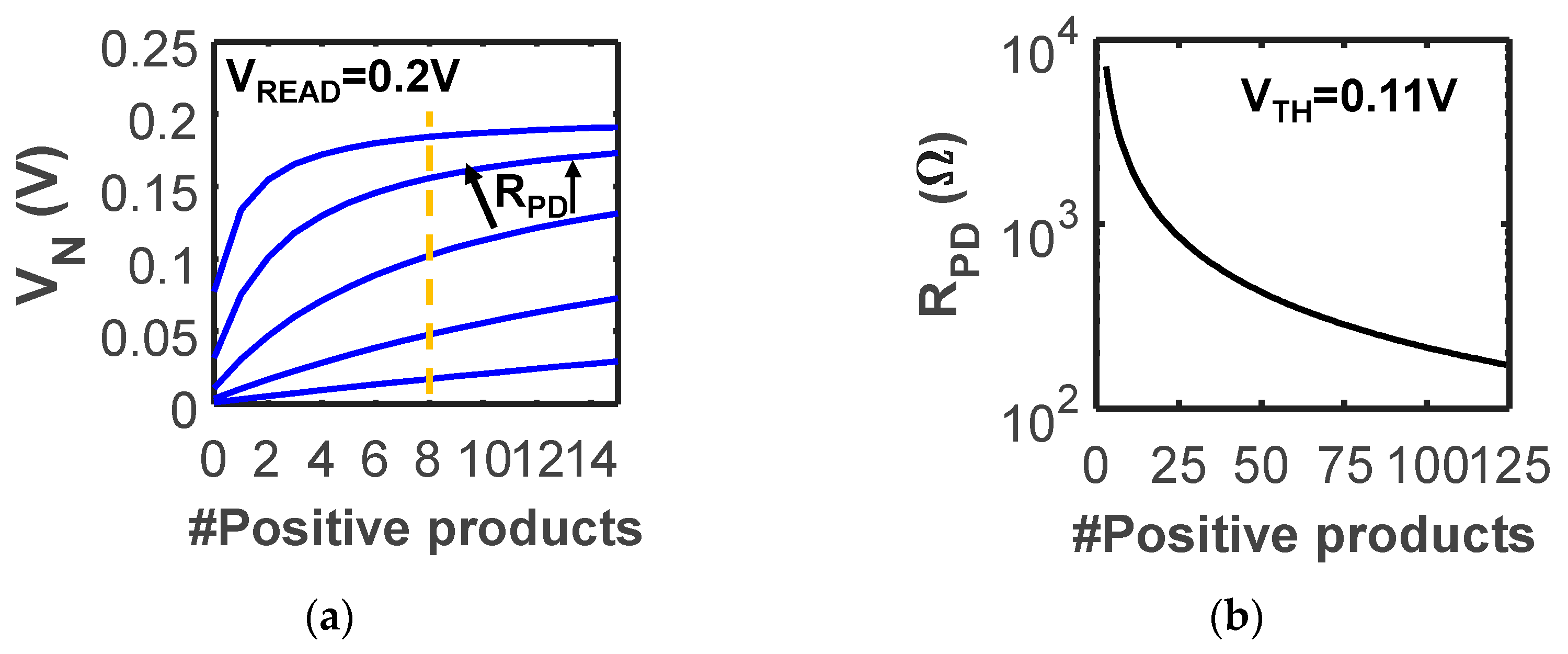
2.4. Circuit Design Tradeoffs for Performance and Reliability
3. Discussion
4. Materials and Methods
4.1. Circuit Simulations
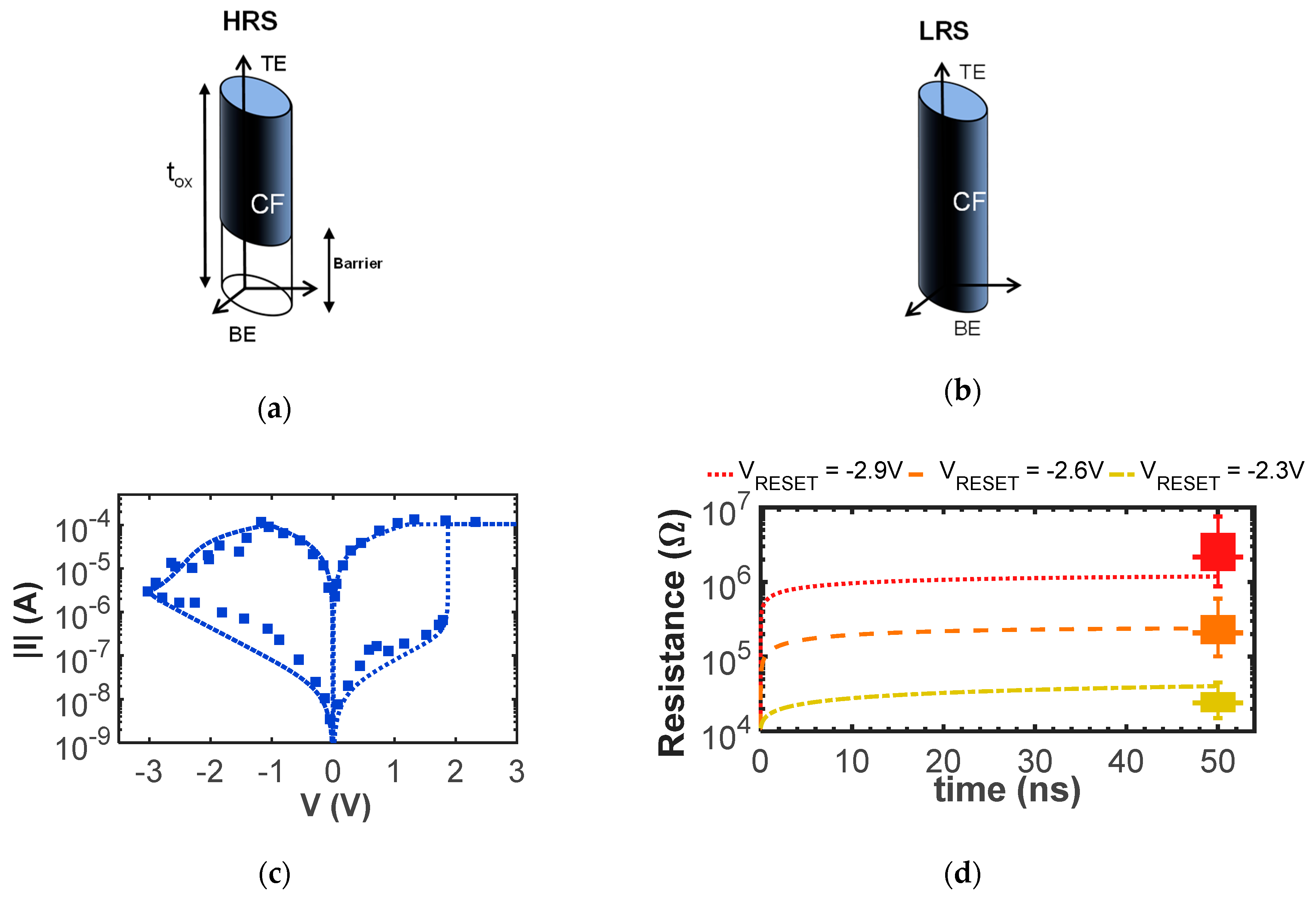
4.1.1. RRAM Physics-Based Compact Model
4.1.2. SIMPLY Simulations
4.2. Implemented Neural Network
4.3. BNN Performance Estimates
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, W.; Gao, B.; Tang, J.; Yao, P.; Yu, S.; Chang, M.-F.; Yoo, H.-J.; Qian, H.; Wu, H. Neuro-Inspired Computing Chips. Nat. Electron. 2020, 3, 371–382. [Google Scholar] [CrossRef]
- Deng, S.; Zhao, H.; Fang, W.; Yin, J.; Dustdar, S.; Zomaya, A.Y. Edge Intelligence: The Confluence of Edge Computing and Artificial Intelligence. IEEE Internet Things J. 2020, 7, 7457–7469. [Google Scholar] [CrossRef] [Green Version]
- Pedretti, G.; Ielmini, D. In-Memory Computing with Resistive Memory Circuits: Status and Outlook. Electronics 2021, 10, 1063. [Google Scholar] [CrossRef]
- Kvatinsky, S.; Belousov, D.; Liman, S.; Satat, G.; Wald, N.; Friedman, E.G.; Kolodny, A.; Weiser, U.C. MAGIC—Memristor-Aided Logic. IEEE Trans. Circuits Syst. II: Express Briefs 2014, 61, 895–899. [Google Scholar] [CrossRef]
- Ziegler, T.; Waser, R.; Wouters, D.J.; Menzel, S. In-Memory Binary Vector–Matrix Multiplication Based on Complementary Resistive Switches. Adv. Intell. Syst. 2020, 2, 2000134. [Google Scholar] [CrossRef]
- Kingra, S.K.; Parmar, V.; Chang, C.-C.; Hudec, B.; Hou, T.-H.; Suri, M. SLIM: Simultaneous Logic-in-Memory Computing Exploiting Bilayer Analog OxRAM Devices. Sci. Rep. 2020, 10. [Google Scholar] [CrossRef] [Green Version]
- Pei, J.; Deng, L.; Song, S.; Zhao, M.; Zhang, Y.; Wu, S.; Wang, G.; Zou, Z.; Wu, Z.; He, W.; et al. Towards Artificial General Intelligence with Hybrid Tianjic Chip Architecture. Nature 2019, 572, 106–111. [Google Scholar] [CrossRef] [PubMed]
- Xiao, T.P.; Bennett, C.H.; Feinberg, B.; Agarwal, S.; Marinella, M.J. Analog Architectures for Neural Network Acceleration Based on Non-Volatile Memory. Appl. Phys. Rev. 2020, 7, 031301. [Google Scholar] [CrossRef]
- Saxena, V. Neuromorphic Computing: From Devices to Integrated Circuits. J. Vac. Sci. Technol. B 2021, 39, 010801. [Google Scholar] [CrossRef]
- Berggren, K.; Xia, Q.; Likharev, K.K.; Strukov, D.B.; Jiang, H.; Mikolajick, T.; Querlioz, D.; Salinga, M.; Erickson, J.R.; Pi, S.; et al. Roadmap on Emerging Hardware and Technology for Machine Learning. Nanotechnology 2020, 32, 012002. [Google Scholar] [CrossRef]
- Benoit, P.; Dalmasso, L.; Patrigeon, G.; Gil, T.; Bruguier, F.; Torres, L. Edge-Computing Perspectives with Reconfigurable Hardware. In Proceedings of the 2019 14th International Symposium on Reconfigurable Communication-centric Systems-on-Chip (ReCoSoC); York, UK, 1–3 July 2019; pp. 51–58. [Google Scholar]
- Yu, J.; Du Nguyen, H.A.; Abu Lebdeh, M.; Taouil, M.; Hamdioui, S. Enhanced Scouting Logic: A Robust Memristive Logic Design Scheme. In Proceedings of the 2019 IEEE/ACM International Symposium on Nanoscale Architectures (NANOARCH), Qingdao, China, 17−19 July 2019; pp. 1–6. [Google Scholar]
- Borghetti, J.; Snider, G.S.; Kuekes, P.J.; Yang, J.J.; Stewart, D.R.; Williams, R.S. ‘Memristive’ Switches Enable ‘Stateful’ Logic Operations via Material Implication. Nature 2010, 464, 873–876. [Google Scholar] [CrossRef]
- Siemon, A.; Menzel, S.; Waser, R.; Linn, E. A Complementary Resistive Switch-Based Crossbar Array Adder. IEEE J. Emerg. Sel. Top. Circuits Syst. 2015, 5, 64–74. [Google Scholar] [CrossRef] [Green Version]
- Siemon, A.; Drabinski, R.; Schultis, M.J.; Hu, X.; Linn, E.; Heittmann, A.; Waser, R.; Querlioz, D.; Menzel, S.; Friedman, J.S. Stateful Three-Input Logic with Memristive Switches. Sci. Rep. 2019, 9, 1–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hu, S.-Y.; Li, Y.; Cheng, L.; Wang, Z.-R.; Chang, T.-C.; Sze, S.M.; Miao, X. Reconfigurable Boolean Logic in Memristive Crossbar: The Principle and Implementation. IEEE Electron Device Lett. 2019, 40, 200–203. [Google Scholar] [CrossRef]
- Puglisi, F.M.; Zanotti, T.; Pavan, P. SIMPLY: Design of a RRAM-Based Smart Logic-in-Memory Architecture Using RRAM Compact Model. In Proceedings of the ESSDERC 2019—49th European Solid-State Device Research Conference (ESSDERC), Krakow, Poland, 23−26 September 2019; pp. 130–133. [Google Scholar]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained To+ 1 or-1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Zanotti, T.; Puglisi, F.M.; Pavan, P. Reliability and Performance Analysis of Logic-in-Memory Based Binarized Neural Networks. IEEE Trans. Device Mater. Reliab. 2021, 1. [Google Scholar] [CrossRef]
- Zanotti, T.; Puglisi, F.M.; Pavan, P. Reconfigurable Smart In-Memory Computing Platform Supporting Logic and Binarized Neural Networks for Low-Power Edge Devices. IEEE J. Emerg. Sel. Top. Circuits Syst. 2020, 1. [Google Scholar] [CrossRef]
- He, W.; Yin, S.; Kim, Y.; Sun, X.; Kim, J.-J.; Yu, S.; Seo, J.-S. 2-Bit-Per-Cell RRAM-Based In-Memory Computing for Area-/Energy-Efficient Deep Learning. IEEE Solid State Circuits Lett. 2020, 3, 194–197. [Google Scholar] [CrossRef]
- Sun, X.; Peng, X.; Chen, P.; Liu, R.; Seo, J.; Yu, S. Fully Parallel RRAM Synaptic Array for Implementing Binary Neural Network with (+1, −1) Weights and (+1, 0) Neurons. In Proceedings of the 2018 23rd Asia and South Pacific Design Automation Conference (ASP-DAC), Jeju, Korea, 22−25 January 2018; pp. 574–579. [Google Scholar]
- Vieira, J.; Giacomin, E.; Qureshi, Y.; Zapater, M.; Tang, X.; Kvatinsky, S.; Atienza, D.; Gaillardon, P.-E. A Product Engine for Energy-Efficient Execution of Binary Neural Networks Using Resistive Memories. In Proceedings of the 2019 IFIP/IEEE 27th International Conference on Very Large Scale Integration (VLSI-SoC), Cuzco, Peru, 6−9 October 2019; pp. 160–165. [Google Scholar]
- Yi, W.; Kim, Y.; Kim, J.-J. Effect of Device Variation on Mapping Binary Neural Network to Memristor Crossbar Array. In Proceedings of the 2019 Design, Automation Test in Europe Conference Exhibition (DATE), Florence, Italy, 25−29 March 2019; pp. 320–323. [Google Scholar]
- Qin, Y.-F.; Kuang, R.; Huang, X.-D.; Li, Y.; Chen, J.; Miao, X.-S. Design of High Robustness BNN Inference Accelerator Based on Binary Memristors. IEEE Trans. Electron Devices 2020, 67, 3435–3441. [Google Scholar] [CrossRef]
- Yu, S.; Wu, Y.; Chai, Y.; Provine, J.; Wong, H.-S.P. Characterization of Switching Parameters and Multilevel Capability in HfOx/AlOx Bi-Layer RRAM Devices. In Proceedings of the 2011 International Symposium on VLSI Technology, Systems and Applications, Hsinchu, Taiwan, 25−27 April 2011; pp. 1–2. [Google Scholar]
- Lehtonen, E.; Poikonen, J.H.; Laiho, M. Two Memristors Suffice to Compute All Boolean Functions. Electron. Lett. 2010, 46, 239–240. [Google Scholar] [CrossRef]
- Zanotti, T.; Puglisi, F.M.; Pavan, P. Reliability-Aware Design Strategies for Stateful Logic-in-Memory Architectures. IEEE Trans. Device Mater. Reliab. 2020, 20, 278–285. [Google Scholar] [CrossRef]
- Kvatinsky, S.; Satat, G.; Wald, N.; Friedman, E.G.; Kolodny, A.; Weiser, U.C. Memristor-Based Material Implication (IMPLY) Logic: Design Principles and Methodologies. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2014, 22, 2054–2066. [Google Scholar] [CrossRef]
- Stine, J.E.; Castellanos, I.; Wood, M.; Henson, J.; Love, F.; Davis, W.R.; Franzon, P.D.; Bucher, M.; Basavarajaiah, S.; Oh, J.; et al. FreePDK: An Open-Source Variation-Aware Design Kit. In Proceedings of the 2007 IEEE International Conference on Microelectronic Systems Education (MSE’07), San Diego, CA, USA, 3−4 June 2007; pp. 173–174. [Google Scholar]
- Zanotti, T.; Zambelli, C.; Puglisi, F.M.; Milo, V.; Pérez, E.; Mahadevaiah, M.K.; Ossorio, O.G.; Wenger, C.; Pavan, P.; Olivo, P.; et al. Reliability of Logic-in-Memory Circuits in Resistive Memory Arrays. IEEE Trans. Electron Devices 2020, 67, 4611–4615. [Google Scholar] [CrossRef]
- Zhou, S.; Wu, Y.; Ni, Z.; Zhou, X.; Wen, H.; Zou, Y. DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients. arXiv 2018, arXiv:1606.06160. [Google Scholar]
- Krestinskaya, O.; Otaniyozov, O.; James, A.P. Binarized Neural Network with Stochastic Memristors. In Proceedings of the 2019 IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS), Hsinchu, Taiwan, 18−20 March 2019; pp. 274–275. [Google Scholar]
- Chen, W.-H.; Dou, C.; Li, K.-X.; Lin, W.-Y.; Li, P.-Y.; Huang, J.-H.; Wang, J.-H.; Wei, W.-C.; Xue, C.-X.; Chiu, Y.-C.; et al. CMOS-Integrated Memristive Non-Volatile Computing-in-Memory for AI Edge Processors. Nat. Electron 2019, 2, 420–428. [Google Scholar] [CrossRef]
- Wan, W.; Kubendran, R.; Gao, B.; Joshi, S.; Raina, P.; Wu, H.; Cauwenberghs, G.; Wong, H.S.P. A Voltage-Mode Sensing Scheme with Differential-Row Weight Mapping for Energy-Efficient RRAM-Based In-Memory Computing. In Proceedings of the 2020 IEEE Symposium on VLSI Technology, Honolulu, HI, USA, 16–19 June 2020; pp. 1–2. [Google Scholar]
- Yin, S.; Kim, Y.; Han, X.; Barnaby, H.; Yu, S.; Luo, Y.; He, W.; Sun, X.; Kim, J.-J.; Seo, J. Monolithically Integrated RRAM- and CMOS-Based In-Memory Computing Optimizations for Efficient Deep Learning. IEEE Micro. 2019, 39, 54–63. [Google Scholar] [CrossRef]
- Grossi, A.; Nowak, E.; Zambelli, C.; Pellissier, C.; Bernasconi, S.; Cibrario, G.; El Hajjam, K.; Crochemore, R.; Nodin, J.F.; Olivo, P.; et al. Fundamental Variability Limits of Filament-Based RRAM. In Proceedings of the 2016 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 3−7 December 2016. [Google Scholar]
- Mahmoodi, M.R.; Vincent, A.F.; Nili, H.; Strukov, D.B. Intrinsic Bounds for Computing Precision in Memristor-Based Vector-by-Matrix Multipliers. IEEE Trans. Nanotechnol. 2020, 19, 429–435. [Google Scholar] [CrossRef]
- Xia, Q.; Yang, J.J. Memristive Crossbar Arrays for Brain-Inspired Computing. Nat. Mater. 2019, 18, 309–323. [Google Scholar] [CrossRef]
- Yu, M.; Cai, Y.; Wang, Z.; Fang, Y.; Liu, Y.; Yu, Z.; Pan, Y.; Zhang, Z.; Tan, J.; Yang, X.; et al. Novel Vertical 3D Structure of TaOx-Based RRAM with Self-Localized Switching Region by Sidewall Electrode Oxidation. Sci. Rep. 2016, 6, 21020. [Google Scholar] [CrossRef] [Green Version]
- Fouda, M.E.; Eltawil, A.M.; Kurdahi, F. Modeling and Analysis of Passive Switching Crossbar Arrays. IEEE Trans. Circuits Syst. I: Regul. Pap. 2018, 65, 270–282. [Google Scholar] [CrossRef]
- McDanel, B.; Teerapittayanon, S.; Kung, H.T. Embedded Binarized Neural Networks. In Proceedings of the 2017 International Conference on Embedded Wireless Systems and Networks, Uppsala, Sweden, 20−22 February 2017; pp. 168–173. [Google Scholar]
- Kim, C.-H.; Lim, S.; Woo, S.Y.; Kang, W.-M.; Seo, Y.-T.; Lee, S.-T.; Lee, S.; Kwon, D.; Oh, S.; Noh, Y.; et al. Emerging Memory Technologies for Neuromorphic Computing. Nanotechnology 2019, 30, 032001. [Google Scholar] [CrossRef]
- Gao, S.; Chen, B.; Qu, Y.; Zhao, Y. MRAM Acceleration Core for Vector Matrix Multiplication and XNOR-Binarized Neural Network Inference. In Proceedings of the 2020 International Symposium on VLSI Technology, Systems and Applications (VLSI-TSA), Hsinchu, Taiwan, 10−13 August 2020; pp. 153–154. [Google Scholar]
- Slesazeck, S.; Mikolajick, T. Nanoscale Resistive Switching Memory Devices: A Review. Nanotechnology 2019, 30, 352003. [Google Scholar] [CrossRef] [PubMed]
- Ielmini, D.; Wong, H.-S.P. In-Memory Computing with Resistive Switching Devices. Nat. Electron. 2018, 1, 333–343. [Google Scholar] [CrossRef]
- Chen, A. A Review of Emerging Non-Volatile Memory (NVM) Technologies and Applications. Solid State Electron. 2016, 125, 25–38. [Google Scholar] [CrossRef]
- Nail, C.; Molas, G.; Blaise, P.; Piccolboni, G.; Sklenard, B.; Cagli, C.; Bernard, M.; Roule, A.; Azzaz, M.; Vianello, E.; et al. Understanding RRAM Endurance, Retention and Window Margin Trade-off Using Experimental Results and Simulations. In Proceedings of the 2016 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 3−7 December 2016. [Google Scholar]
- Shi, L.; Zheng, G.; Tian, B.; Dkhil, B.; Duan, C. Research Progress on Solutions to the Sneak Path Issue in Memristor Crossbar Arrays. Nanoscale Adv. 2020, 2, 1811–1827. [Google Scholar] [CrossRef]
- Puglisi, F.M.; Zanotti, T.; Pavan, P. Unimore Resistive Random Access Memory (RRAM) Verilog-A Model. nanoHUB 2019. [Google Scholar] [CrossRef]
- Yakopcic, C.; Taha, T.M.; Subramanyam, G.; Pino, R.E.; Rogers, S. A Memristor Device Model. IEEE Electron Device Lett. 2011, 32, 1436–1438. [Google Scholar] [CrossRef]
- Kvatinsky, S.; Friedman, E.G.; Kolodny, A.; Weiser, U.C. TEAM: ThrEshold Adaptive Memristor Model. IEEE Trans. Circuits Syst. I: Regul. Pap. 2013, 60, 211–221. [Google Scholar] [CrossRef]
- Kvatinsky, S.; Ramadan, M.; Friedman, E.G.; Kolodny, A. VTEAM: A General Model for Voltage-Controlled Memristors. IEEE Trans. Circuits Syst. II: Express Briefs 2015, 62, 786–790. [Google Scholar] [CrossRef]
- Messaris, I.; Serb, A.; Stathopoulos, S.; Khiat, A.; Nikolaidis, S.; Prodromakis, T. A Data-Driven Verilog-A ReRAM Model. IEEE Trans. Comput-Aided Des. Integr. Circuits Syst. 2018, 37, 3151–3162. [Google Scholar] [CrossRef]
- La Torre, C.; Zurhelle, A.F.; Breuer, T.; Waser, R.; Menzel, S. Compact Modeling of Complementary Switching in Oxide-Based ReRAM Devices. IEEE Trans. Electron Devices 2019, 66, 1268–1275. [Google Scholar] [CrossRef]
- Wiefels, S.; Bengel, C.; Kopperberg, N.; Zhang, K.; Waser, R.; Menzel, S. HRS Instability in Oxide-Based Bipolar Resistive Switching Cells. IEEE Trans. Electron Devices 2020, 67, 4208–4215. [Google Scholar] [CrossRef]
- González-Cordero, G.; González, M.B.; Campabadal, F.; Jiménez-Molinos, F.; Roldán, J.B. A Physically Based SPICE Model for RRAMs Including RTN. In Proceedings of the 2020 XXXV Conference on Design of Circuits and Integrated Systems (DCIS), Segovia, Spain, 18−20 November 2020; pp. 1–6. [Google Scholar]
- Yu, S.; Gao, B.; Fang, Z.; Yu, H.; Kang, J.; Wong, H.-P. A Neuromorphic Visual System Using RRAM Synaptic Devices with Sub-PJ Energy and Tolerance to Variability: Experimental Characterization and Large-Scale Modeling. In Proceedings of the 2012 International Electron Devices Meeting, San Francisco, CA, USA, 10−13 December 2012. [Google Scholar]
- Jiang, Z.; Yu, S.; Wu, Y.; Engel, J.H.; Guan, X.; Wong, H.-P. Verilog-A Compact Model for Oxide-Based Resistive Random Access Memory (RRAM). In Proceedings of the 2014 International Conference on Simulation of Semiconductor Processes and Devices (SISPAD), Yokohama, Japan, 9−11 September 2014; pp. 41–44. [Google Scholar]
- Li, H.; Jiang, Z.; Huang, P.; Wu, Y.; Chen, H.-; Gao, B.; Liu, X.Y.; Kang, J.F.; Wong, H.-P. Variation-Aware, Reliability-Emphasized Design and Optimization of RRAM Using SPICE Model. In Proceedings of the 2015 Design, Automation Test in Europe Conference Exhibition (DATE), Grenoble, France, 9−13 March 2015; pp. 1425–1430. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Implementation 1 | Average Energy | Latency | Average EDP | EDP Improvement |
|---|---|---|---|---|
| Embedded system [42] | 5.37 mJ | 17.35 ms | 9.3 × 10−5 Js | 1 |
| SIMPLY parallel 1, 2 [19] | 11.4 µJ | 663 µs | 7.6 × 10−9 Js | 1.2 × 104 |
| SIMPLY parallel 1 w RG, Opt | 78.9 µJ | 663 µs | 5.2 × 10−9 Js | 1.8 × 104 |
| This work 1 w RG, Opt | 231 nJ | 31.6 µs | 7.3 × 10−12 Js | 1.3 × 107 |
| Input Configuration | Energy 1 (min-avg-max) | |
|---|---|---|
| 0 | 0 | 139 – 429 – 509 fJ |
| 0 | 1 | 6.18 – 6.183 – 6.185 fJ |
| 1 | 0 | 6.18 – 6.183 – 6.185 fJ |
| 1 | 1 | 6.184 – 6.184 – 6.185 fJ |
| Input Configuration | Energy 1 (min-avg-max) |
|---|---|
| 0 | 9.6 – 11.2 – 12 fJ |
| 1 | 100 – 145 – 190 fJ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zanotti, T.; Puglisi, F.M.; Pavan, P. Energy-Efficient Non-Von Neumann Computing Architecture Supporting Multiple Computing Paradigms for Logic and Binarized Neural Networks. J. Low Power Electron. Appl. 2021, 11, 29. https://0-doi-org.brum.beds.ac.uk/10.3390/jlpea11030029
Zanotti T, Puglisi FM, Pavan P. Energy-Efficient Non-Von Neumann Computing Architecture Supporting Multiple Computing Paradigms for Logic and Binarized Neural Networks. Journal of Low Power Electronics and Applications. 2021; 11(3):29. https://0-doi-org.brum.beds.ac.uk/10.3390/jlpea11030029
Chicago/Turabian StyleZanotti, Tommaso, Francesco Maria Puglisi, and Paolo Pavan. 2021. "Energy-Efficient Non-Von Neumann Computing Architecture Supporting Multiple Computing Paradigms for Logic and Binarized Neural Networks" Journal of Low Power Electronics and Applications 11, no. 3: 29. https://0-doi-org.brum.beds.ac.uk/10.3390/jlpea11030029