
Machine-Learning-Based Semiparametric Time Series Conditional Variance: Estimation and Forecasting

Department of Economics, University of California, Riverside, CA 92521, USA
*
Author to whom correspondence should be addressed.
J. Risk Financial Manag. 2022, 15(1), 38; https://0-doi-org.brum.beds.ac.uk/10.3390/jrfm15010038
Submission received: 1 December 2021
/
Revised: 12 January 2022
/
Accepted: 14 January 2022
/
Published: 17 January 2022
(This article belongs to the Special Issue Predictive Modeling for Economic and Financial Data)
Abstract
:This paper proposes a new combined semiparametric estimator of the conditional variance that takes the product of a parametric estimator and a nonparametric estimator based on machine learning. A popular kernel-based machine learning algorithm, known as the kernel-regularized least squares estimator, is used to estimate the nonparametric component. We discuss how to estimate the semiparametric estimator using real data and how to use this estimator to make forecasts for the conditional variance. Simulations are conducted to show the dominance of the proposed estimator in terms of mean squared error. An empirical application using S&P 500 daily returns is analyzed, and the semiparametric estimator effectively forecasts future volatility.
Keywords:
conditional variance; nonparametric estimator; semiparametric models; forecasting; machine learning; kernel-regularized least squaresJEL Classification:
C01; C14; C51; C53; C581. Introduction
It is well known that financial time series data, especially stock returns, are not predictable. On the other hand, volatility (risk) or the conditional variance of the returns is easier to predict since autocorrelations are shown to be significant in various time series data. There are a plethora of models that try and capture the dynamics of the volatility of a series, including both parametric and nonparametric models. In this paper, both a parametric and nonparametric model of the conditional variance are combined in a multiplicative way, resulting in a semiparametric estimator of the conditional variance. The semiparametric estimator is shown to dominate both fully parametric and nonparametric counterparts in forecasting ability and can successfully capture the asymmetric volatility effect of return.
To model the conditional variance of a series, one can specify a parametric model, but this can lead to misspecification issues of the volatility function. One can also specify a nonparametric model, where the explicit specification of the form of the conditional variance function is not needed. However, this may be harder to estimate when, for example, some of the conditioning set of variables are unobserved lagged conditional variances. The proposed semiparametric estimator of the conditional variance uses a parametric component as a basis. This basis is then multiplied by an adjustment factor based on the nonparametric modeling of parametric squared residuals using estimated lagged conditional variances, if present, in the conditioning set. Thus, such a semiparametric estimator combines a parametric conditional variance estimator with a nonparametric estimator of the conditional variance. The parametric component of the conditional variance is used mainly to capture the overall dynamics whereas the nonparametric part analyzes the residual variance and catches the nonlinearities in the data that the parametric component fails to capture. The generalized autoregressive conditional heteroskedasticity (GARCH) family of models are considered for the parametric estimation. For the nonparametric estimation, a popular machine learning (ML) algorithm is used, known as Kernel Regularized Least Squares (KRLS), which does not rely on linearity or additivity assumptions (Hainmueller and Hazlett 2014).
The GARCH family of models is a common method to modeling volatility as the conditional variance, , for a stocastic process . The first among these started with Engle (1982) for the autoregressive conditional heteroskedasticity (ARCH) model and Bollerslev (1986) for the GARCH model of the conditional variance. Later, many papers following their work paved the way for other GARCH-type models that capture many stylized facts including being able to capture volatility dynamics and incorporating leverage effects (Glosten et al. (1993); Nelson (1991) and Ding et al. (1993)). All of these models are considered to be parametric and are subject to misspecification. If a GARCH model, or any other parametric model, is correctly specified, then it can be shown that the model can consistently estimate the conditional variance. However, when a parametric model is misspecified, then the volatility estimator is often inconsistent for . In this paper, we will use and models to estimate the parametric conditional variance and use a ML based nonparametric method to enhance the conditional variance estimates.
Nonparametric and semiparametric estimation of the conditional variance have also proven to capture dynamics in the volatility well. To estimate the conditional variance, Ziegelmann (2002) models the squared residuals, from the conditional mean equation, nonparametrically via the local exponential estimator. However, this procedure may not be applicable for the GARCH-type conditional variation. In this paper, however, the conditional variance function is considered to be semiparametric as the product of a parametric part and nonparametric part similar to Mishra et al. (2010). This framework stems from the seminal work by Glad (1998) where a multiplicative semiparametric model of the conditional mean function is formulated. In this paper, the framework is based on Glad (1998) and Mishra et al. (2010) for the conditional variance by multiplying the parametric component by the nonparametric component. However, instead of using local exponential (or polynomial) smoothing for estimating the nonparametric component as they do, we will use another nonparametric technique known as KRLS based ML.
KRLS is a common ML technique in the nonparametric ML literature. The method uses kernels to find the best fit surface in a flexible hypothesis space by minimizing a penalized least squares problem, see Hainmueller and Hazlett (2014). De Brebanter et al. (2011) refer to the same method as Least Squares Support Vector Machines (LSSVM) and propose bias corrected confidence intervals for the estimator. However, these papers study the conditional mean function, and not the conditonal variance function. This paper differs by estimating the conditional variance function with the help of ML. That is, standardized squared residuals, obtained from the conditional mean equation, are used in a ML regression to estimate the nonparametric component of the conditional variance. With the help of ML, the nonparametric component can hopefully capture the nonlinearites in the true volatility function, where the parametric component failed to do so.
Overall, this paper proposes a semiparametric estimator based on the ML technique KRLS. The proposed estimator is capable of handling in and out of sample data, where forecasting the future conditional variance based on a conditioning set is achieved. We show in simulation that the semiparametric estimator beats the parametric counterpart in terms of mean squared error. An empirical example with real data from S&P 500 daily returns is also given to illustrate the advantage of using the semiparametric ML estimator of the conditional variance, where news impact curves and out of sample forecasts are evaluated. In the empirical example, the semiparametric estimator is shown to be superior to the parametric estimators when evaluating out of sample forecasts.
The structure of this paper is as follows: Section 2 discusses the model framework of the conditional variance, Section 3 proposes the semiparametric estimator using ML to estimate the nonparametric component, Section 4 shows how forecasts are made via the semiparametric estimator, Section 5 runs through a simulation example, Section 6 illustrates an empirical example using S&P 500 daily returns, and Section 7 concludes the paper.
2. The Model
Consider the following model:
where satisfies and and represents a vector of regressors, and represents the vector of parametric parameters for the mean regression. The function can be any parametric function of the data and parameter vector , such as an Autoregressive Moving Average (ARMA) function or a constant function for the conditional mean function. Note that since , .
Similar to Glad (1998) and Mishra et al. (2010), we can redefine the conditional variance, as
where is found by a parametric specification of the conditional variance. Let denote the nonparametric specification of the conditional variance. We can think of as a new dependent variable in the nonparametric estimation stage. Then, the final semiparametric estimator of the conditional variance is
The idea is that if the parametric form of the conditional variance fails to capture some feature of the true conditional variance, the nonparametric form of the conditional variance will have a multiplicative correction factor that will hopefully be easier to estimate. If the parametric conditional variance underestimates the true conditional variance, in which the parametric model will be subject to misspecification, the nonparametric component, , will be greater than one and vice versa. In the extreme case, where the parametric form of the conditional variance is correctly specified, the nonparametric component, , will hopefully be constant over time.
3. The Semiparametric ML Estimator
Since is unobservable, the first step is to obtain the residuals of the estimated regression equation.
where is the estimated regression function, e.g., ARMA process and T is the total number of observations in the sample. We will then use the residuals in Equation (5) to estimate both the parametric and nonparametric components of the conditional variance.
3.1. Estimating the Parametric Component
Let denote the paramatric conditional variance, which depends on regressors . We can estimate the parametric conditional variance, , by using the squared residuals obtained from Equation (5), with any parametric form, such as an model, where and . Any GARCH type model may also be used, which is often estimated by the quasi maximum likelihood approach. Note that the parametric form may be misspecified. The idea is that even if the parametric form is misspecified, the nonparametric component will hopefully pick up the parts of the conditional variance that the parametric part failed to estimate correctly. Once the parametric conditional variance is estimated, predictions can be made by for some test observation .
3.2. Estimating the Nonparametric Component via ML
To get the new dependent variable to be used in the nonparametric estimation of the conditional variance, we can estimate the standardized residuals as , using the estimated residuals and the estimated parametric conditional variance evaluated at each data point in the sample. Let depend on regressors . Note that the regressors, for , are considered past information. Then, we can regress on to get the nonparametric component of the conditional variance.
For KRLS based ML, the function can be approximated by some function in the space of functions constituted by
where is the vector of regressors considered for the nonparametric estimation for some test observation and where are the parameters of interest, which can be thought of as the weights of the kernel functions . The subscript of the kernel function, , indicates that the kernel depends on the bandwidth parameter, . We will use the Radial Basis Function (RBF) kernel,
Notice that the RBF kernel is very similar to the Gaussian kernel, in that it does not have the normalizing term out in front and that is proportional to the bandwidth h in the Gaussian kernel often used in nonparametric local polynomial regression. This functional form is justified by a regularized least squares problem with a feature mapping function that maps x into a higher dimension, see Hainmueller and Hazlett (2014), where this derivation of KRLS is also known as Kernel Ridge Regression (KRR). Overall, KRLS uses a quadratic loss with a weighted -regularization. Then, in matrix notation, the minimization problem is
where is the vector of the standardized squared residuals to be used as the responses in this regression and is the kernel matrix, with for and is the vector of coefficients that is optimized over. The solution to this minimization problem is
The kernel function and its parameters are user specified but can be found via cross validation along with the regularization parameter . In simulation and in the empirical application, leave one out cross validation is used to find the hyperparameters, and . Finally, predictions for the nonparametric ML conditional variance estimator can be made by
for some test observation .
3.3. The Semiparametric ML Estimator
Now that we have both the estimated parametric, , and nonparametric, , components of the conditional variance, we can estimate the final semiparametric conditional variance in a multiplicative way and predictions can be made by
for some test observation point .
Notice that both and can be unobservable. To illustrate, we will discuss the model of the conditional variance, . Here, . The estimate for can be obtained by any parametric model based on quasi maximum likelihood estimation (QMLE), which is standard for ARCH and GARCH models. Now, suppose that we estimate the nonparametric component in a similar fashion but instead of imposing a parametric form of the conditional variance, we will use ML. That is, we estimate nonparametrically via ML, where . In this case, we estimate the lagged residuals by Equation (5) and we will use the parametric conditional variance estimates for . Therefore, we use as regressors for the nonparametric estimation. Then, Equation (11) can be used to obtain the final conditional variance estimate. This estimator will be denoted as SPMLGARCH estimator for using a GARCH model for the parametric component and ML for the nonparametric component. Without loss of generality, the procedure can be extended to higher order lags.
4. Forecasting
To forecast the conditional variance, we can use Equations (10) and (11). Let denote the number of periods ahead we wish to forecast, e.g., for a one-step-ahead forecast. First, we use the training sample to fit a parametric model of the conditional variance, , and forecast h periods ahead using standard techniques, . Then, we use the standardized residuals to fit a nonparametric model of the conditional variance via ML, , and forecast h periods ahead using Equation (10), . Finally combining the two components gives the h period ahead forecast for the semiparametric conditional variance,
where .
In the case of the model, parametric forecasts can be made in the standard way. However, for the nonparametric case, the forecasts may depend on regressors that include future residuals and conditional variances that are unobservable. Recall that a possile vector of regressors for the nonparametric regression of can be as in the SPMLGARCH example discussed previously. To deal with this, we estimate future residuals, , to be 0 for . When , i.e., one-step-ahead forecast, can be estimated by the T-th residual from the estimated regression function. To be consistent with the estimation procedure, the parametric conditional variance forecasts will be used for future predictions of in when forecasting the nonparametric component of the conditional variance. That is, let denote the test observation point, or the conditioning set, to be used in forecasting the nonparametric component of the conditional variance in Equation (12).
5. Simulation
This section evaluates the semiparametric ML estimator in a simulation setting. The data-generating process will come from GJR’s model of conditional variance, which takes the leverage effect into consideration, see Glosten et al. (1993). Consider the following data-generating process (DGP):
where we assume that the mean function , , , , and .1 We also assume that , where , , and . The leverage effect comes from the indicator function, , which makes the effect of negative shocks different; a positive shock is captured by and a negative shock is captured by . The simulated data and GARCH models are estimated by the R package rugarch from Ghalanos (2020).2
We evaluate five models: , see Engle (1982), denoted by ARCH, GARCH(1, 1), see Bollerslev (1986), denoted by GARCH, their semiparametric ML counterparts, denoted by SPMLARCH and SPMLGARCH, where ARCH and GARCH models are estimated in the first stage, and the fully nonparametric ML using KRLS, denoted as NPML. For NPML, the estimation procedure is similar to the procedure detailed in Section 3.2; the residuals , instead of the standardized residuals , are used in constructing the dependent variable. For the second stage in SPMLARCH and for NPML, we let and in SPMLGARCH, we let , where is the fitted parametric conditional variance estimates in the first stage. To avoid the starting-out effect, we discard the first 500 observations and use a sample size of . The number of replications is . To evaluate these five models, we will use the mean squared error (MSE) criteria.
where is the estimated conditional variance at time t for replication m and is the true condtional variance at time t. The lowest MSE suggests the best model.
Table 1 displays the MSEs for each of the five estimators considered. For this DGP, both the parametric and the semiparametric ARCH models, compared to the GARCH models, perform the worst. Although the parametric GARCH model performs adequately well, SPMLGARCH improves upon the parametric GARCH and outperforms all other models in terms of MSE. Since the ARCH models only consider lagged values of the residuals, these models fail to pick up the importance of the GARCH effects in the true conditional variance. The SPMLARCH model actually is the least preferred, comparing models with parametric estimation, and shows that the nonparametric estimation stage may not help if GARCH effects are not considered when these effects are actually present. Notice that the semiparametric estimators, SPMLARCH and SPMLGARCH, dominate the NPML estimator in terms of MSE. A possible explanation is that as long as the parametric conditional variance, estimated in the first stage, can capture some shape features of the true conditional variance function, the semiparametric estimator can outperform the fully nonparametric estimator. Regardless, the SPMLGARCH model, where GARCH effects are considered in both the parametric and nonparametric estimation stages, is deemed the most appropriate model in this scenario, which has the lowest MSE compared to the parametric GARCH model as well as compared to the others.
6. Application
In this section, we fit the semiparametric ML model to real data, obtained from Federal Reserve Economic Data (FRED).3 The data contain S&P 500 daily returns from 5 August 2016 to 5 August 2021 (1305 observations). Missing oversations due to non-trading days are imputed as means of the previous and following daily returns. We allow for the mean component to be an ARMA process. For the conditional variance, we evaluate five models ARCH, GARCH, SPMLARCH, SPMLGARCH, and NPML. That is, in the first-stage parametric estimation, we estimate by an ARMA model, and estimate the parametric conditional variance models and by using the Gaussian QMLE method. In the second-stage nonparametric modeling, we estimate by using the conditioning set for SPMLARCH and for SPMLGARCH. To evaluate out of sample predictions, we split the full sample into a training data set where and the testing data set where . The data are split in this way so that the volatility can be forecasted for a time period in which there is high volatility. The date corresponds to 20 Febuary 2020, which is right when COVID-19 started to have a huge impact on the U.S. as well as its financial markets. A rolling window scheme with the window size of is used for one and five steps ahead forecasts.
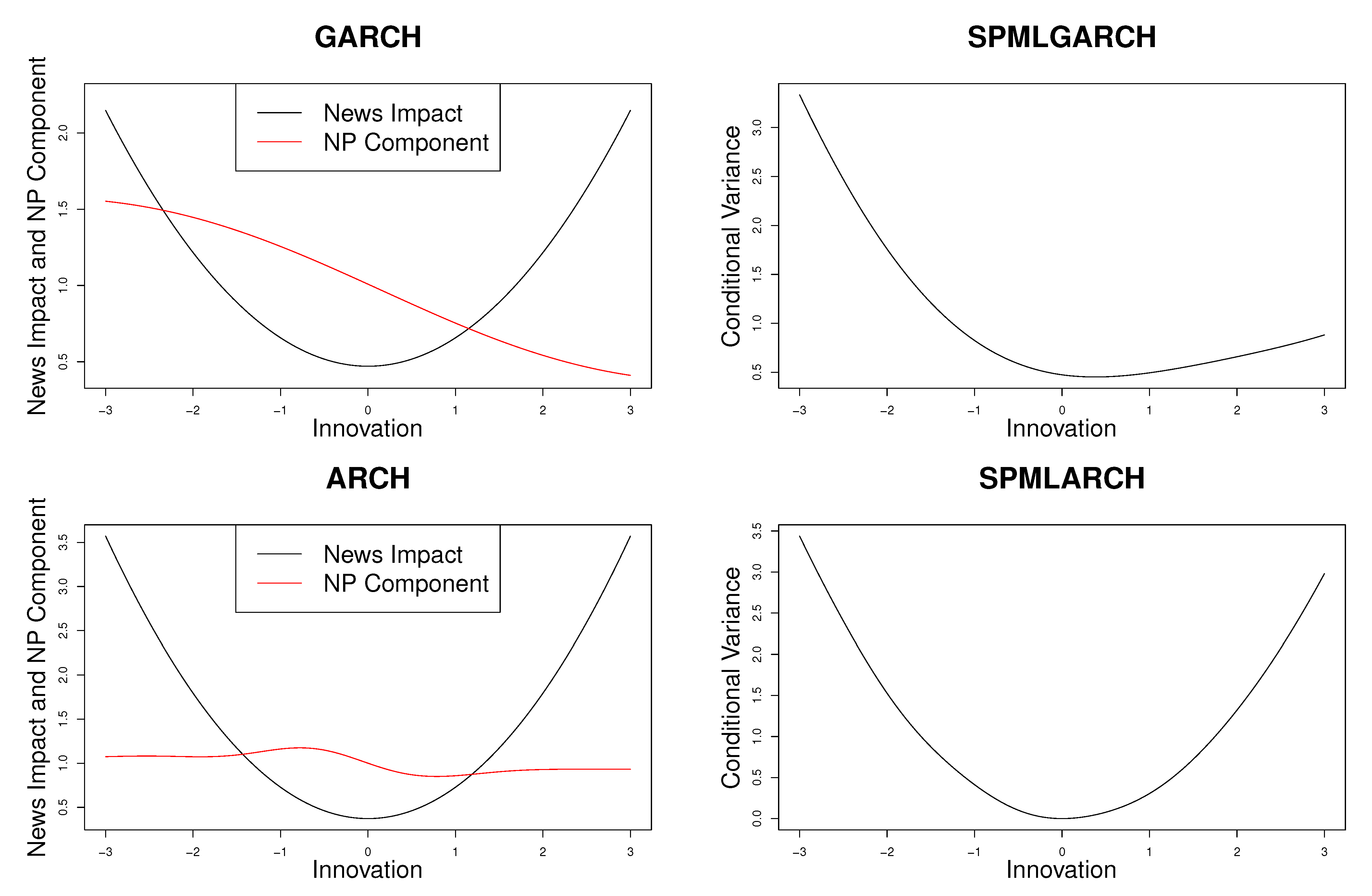
It is common practice to study the impact of the innovation, on the current conditional variance, holding all other factors fixed, which is known as the news impact curve, see Engle and Ng (1993). Due to the nature of ARCH and GARCH models, these parametric models often have symmetric news impact curves where both negative and positive shocks in absolute value have the same effect on the conditional variance, which is uncommon in financial data. The goal of estimating the nonparametric component is to pick up the asymmetry, and other nonlinearities, in the data. To see this, we can plot the nonparametric component of the conditional variance evaluated across different values of . In the extreme case where the parametric model is correctly specified, the nonparametric component will be a constant and the curve will be a horizontal line at one.
Using the training data set from , the estimated news impact curve and second-stage nonlinearities are shown in the left two plots of Figure 1. Since the GARCH model has two variables in the conditioning set , we evaluate the curves at 100 evenly spaced points from −3 to 3 for while holding fixed at the mean of the estimated lagged parametric conditional variances. For the ARCH model, the conditioning set only contains one variable, , where we evaluate the ARCH model at 100 evenly spaced points from −3 to 3. As expected, the news impact curve for both the ARCH and GARCH models seem to be symmetric. However, the nonparametric curve is not constant at one and in fact is somewhat downwards sloping. This implies that the nonparamtric component is able to detect the nonlinearity in the data and shows that the leverage effect is present in these data, which is common in various financial data.
The right two plots of Figure 1 show the conditional variance estimates for innovations spanning −3 to 3, holding other factors fixed. Visually, these plots are found by multiplying the nonparametric component and the news impact curve in the left two plots. Using Equation (11), the final conditional variance estimates do in fact show an asymmetry effect where negative shocks appear to correspond with higher conditional variances and positive shocks appear to correspond with lower conditional variances. In addition, we also estimate the semiparametric conditional variance on the entire sample using all 1305 observations, where the news impact curves are also symmetric, the nonparametric components are all downwards sloping, and the final semiparametric conditional variance estimates all exhibit the existence of the leverage effect. On the other hand, if a parametric model is estimated, the model would fail to pick up the inherent leverage effect present in the data.
To investigate the first stage estimation step, Table 2 reports the coefficients and standard errors of the and models. We have estimated these models based on the training data set as well as the full data set and the results are similar. A key takeaway from this table is that, the coefficient, of the GARCH term is around 0.7 and is statistically significant at the 5% level in both sample sizes, indicating that there is a GARCH effect present in the data. In addition, all ARCH effects are significant at the 5% level.
Now, to have a better understanding of how estimating the nonparametric component can help estimate the conditional variance, we evaluate the mean absolute percentage change in the semiparametric conditional variance due to the nonparametric component by the following
The idea here is to see what percentage change is present of the semiparamtric estimate relative to the parametric estimate, and using the identity in Equation (4), this percentage change can be thought of as the amount that we need to adjust the parametric component by. The absolute percentage change is used to take into consideration that the nonparametric component may in fact increase or decrease the parametric conditional variance. These mean percentage changes are reported in the last column of Table 2. For example, the model of the conditional variance, under the sample using observations, is on average changed by 12% via the multiplicative adjustment from the nonparametric component. The model is on average affected by a 9% change. Furthermore, in the full sample these estimates are even larger, indicating that the estimation of the nonparametric component is vital in picking up nonlinearities or other signals from the conditional variance that the parametric models failed to pick up. Lastly, the estimate for the model is the largest at around 28%. A possible explanation is that, under the full sample, which includes the highly volatile time period due to COVID-19, the parametric ARCH model may fail to pick up the these highly volatile peaks in the data, so the nonparametric part may have to uncover more of the signal from the data, and as a result the parametric component may change drastically.
Now, to evaluate forecasts, the validation set is used with a rolling window scheme. A window width of 925 observations is used to re-estimate a model and to forecast and periods ahead. First, we train a model, both parametric and nonparametric components, from the first 925 observations and forecast h periods ahead. For the nonparametric component, the hyperparameters, and , are found via leave one out cross validation (LOOCV). Then, we roll the window h periods forward and re-estimate the parametric component using the new data set. For the nonparametric component, is re-estimated using the new data; however, instead of performing cross validation repeatedly to estimate the hyperparameters, and , these hyperparameters will be the ones found in the original sample using observations, i.e., observations in the first window.
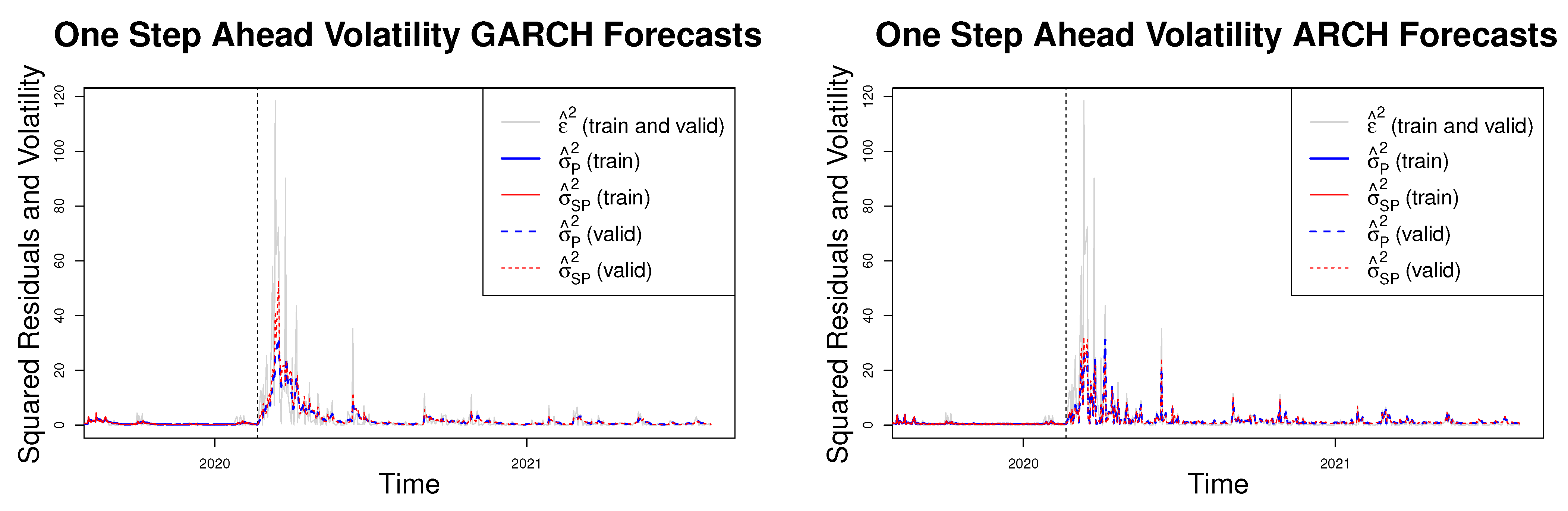
The one-step-ahead, , forecasts are plotted in Figure 2. The left plot contains the GARCH and SPMLGARCH forecasts and the right plot contains the ARCH and SPMLARCH forecasts. Note that the last 506 observations are plotted to save space in the figures but the rolling window procedure uses the entire sample of 1305 observations. Since the true conditional variance is unknown we will use the squared residuals as a proxy. In order to do so, we estimate a parametric model, e.g., ARMA process, of the mean and obtain the residuals for the entire sample using Equation (5) and square them as an estimate of the conditional variance.4 This will be used for reference when comparing the conditional variance estimates obtained from the five models.
As we can see from the data, the conditional variance is very high during March of 2020, depicted by the grey curves indicating the squared residuals. The red and blue curves indicate the semiparametric and parametric estimates of the conditional variance. All four models appear to pick up the peaks of the conditional variances especially around March of 2020, the most volatile period of the series. However, looking closely at the figures, both SPMLGARCH and SPMLARCH pick up more of the volatility peaks around this time, indicating that the semiparametric ML models may be better suited for forecasting the volatility of S&P 500 returns.
As mentioned previously, the true conditional variance is unknown, and as a proxy we will use the squared residuals estimated from an ARMA process of the entire sample. For this data set, we found to follow an , under the full sample. To assess forecasting ability, we will use the root-mean-squared forecast error (RMSFE) as
where are the estimated residuals under the full sample. Table 3 reports the RMSFE’s of the one and five steps ahead forecasts. For both and , SPMLGARCH outperforms all other models in terms of having the lowest MSFE. In addition both the parametric and semiparametric GARCH models outperform the ARCH models, implying that GARCH effects may be present in the data, as we have seen from Table 2. In both ARCH and GARCH cases, the semiparametric counterparts perform better than the parametric ones. In addition, both semiparametric estimators exhibit superior foecasting ability relative to the nonparametric estimator, implying that the parametric components play a role in detecting some features of the true volatility function. Overall, SPMLGARCH appears to be the best model for forecasting the volatility of S&P 500 daily returns.
7. Conclusions
This paper proposes a semiparametric estimator for the conditional variance of a stochastic series. The estimator combines a parametric component and a nonparametric component via ML in a multiplicative way. The estimator is able to pick up asymmetric effects even when the parametric component can not. The ability to find asymmetric effects is directly due to the nonparametric ML estimation stage, where nonlinearities can be estimated via a kernel-based machine learning algorithm. A metric is also created to show the importance of the nonparametric component by providing on average how much the parametric component is changed by. We show that the semiparametric estimator performs better in simulations, and in the empirical application, the proposed estimator is superior to the other considered models and is able to forecast future volatility given a conditioning set.
Author Contributions
Conceptualization, J.D. and A.U.; methodology, J.D. and A.U.; software, J.D.; validation, J.D. and A.U.; formal analysis, J.D. and A.U.; investigation, J.D. and A.U.; resources, J.D. and A.U.; data curation, J.D.; writing—original draft preparation, J.D.; writing—review and editing, J.D. and A.U.; visualization, J.D.; supervision, A.U.; project administration, A.U.; All authors have read and agreed to the published version of the manuscript.
Funding
This research received no funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: https://fred.stlouisfed.org/series/SP500# (accessed on 5 August 2021).
Acknowledgments
We are grateful to the two anonymous referees for helpful comments and suggestions.
Conflicts of Interest
The authors declare no conflict of interest.
| 1 | The parameters and capture how shocks will affect future volatility and the high persistence in volatility. The parameter captures the small leverage effect. Since is positive, negative shocks will correspond to larger values of volatility, which is commonly seen in financial data. |
| 2 | All other packages used include Wickham et al. (2021); Hyndman et al. (2020); Warnes et al. (2017); Borchers (2021) and Zeileis and Grothendieck (2005). |
| 3 | The data can be obtained from https://fred.stlouisfed.org/series/SP500# (accessed on 5 August 2021). |
| 4 | The squared daily returns or squared demeaned daily returns can also be used as proxies of the unknown conditional variance. In all cases, the results are similar and SPMLGARCH is the superior model in terms of RMSFE. |
References
- Bollerslev, Tim. 1986. Generalized Autoregressive Conditional Heteroskedasticity. Journal of Econometrics 31: 307–27. [Google Scholar] [CrossRef] [Green Version]
- Borchers, Hans W. 2021. Pracma: Practical Numerical Math Functions, R Package Version 2.3.3; Available online: https://cran.r-project.org/web/packages/pracma/index.html (accessed on 5 August 2021).
- De Brabanter, Kris, Jos De Brabanter, Johan A. K. Suykens, and Bart De Moor. 2011. Approximate Confidence and Prediction Intervals for Least Squares Support Vector Regression. IEEE Transactions on Neural Networks 22: 110–20. [Google Scholar] [CrossRef] [PubMed]
- Ding, Zhuanxin, Clive W. J. Granger, and Robert F. Engle. 1993. A Long Memory Property of Stock Market Returns and a New Model. Journal of Empirical Finance 1: 83–106. [Google Scholar] [CrossRef]
- Engle, Robert F. 1982. Autoregressive Conditional Heteroskedasticity with Estimates of the Variance of UK Inflation. Econometrica 50: 987–1008. [Google Scholar] [CrossRef]
- Engle, Robert F., and Victor K. Ng. 1993. Measuring and Testing the Impact of News on Volatility. The Journal of Finance 48: 1749–78. [Google Scholar] [CrossRef]
- Ghalanos, Alexios. 2020. Rugarch: Univariate GARCH Models, R Package Version 1.4-4; Available online: https://cran.r-project.org/web/packages/rugarch/index.html (accessed on 5 August 2021).
- Glad, Ingrid K. 1998. Parametrically Guided Non-parametric Regression. Scandinavian Journal of Statistics 25: 649–68. [Google Scholar] [CrossRef]
- Glosten, Lawrence R., Ravi Jagannathan, and David E. Runkle. 1993. On the Relationship Between the Expected Value and the Volatility of the Nominal Excess Return on Stocks. The Journal of Finance 48: 1779–801. [Google Scholar] [CrossRef]
- Hainmueller, Jens, and Chad Hazlett. 2014. Kernel Regularized Least Squares: Reducing Misspecification Bias with a Flexible and Interpretable Machine Learning Approach. Political Analysis 22: 143–68. [Google Scholar] [CrossRef]
- Hyndman, Rob J., George Athanasopoulos, Christoph Bergmeir, Gabriel Caceres, Leanne Chhay, Mitchell O’Hara-Wild, Fotios Petropoulos, Slava Razbash, Earo Wang, and Farah Yasmeen. 2020. Forecast: Forecasting Functions for Time Series and Linear Models, R Package Version 8.13; Available online: https://cran.r-project.org/web/packages/forecast/index.html (accessed on 5 August 2021).
- Mishra, Santosh, Liangjun Su, and Aman Ullah. 2010. Semiparametric Estimator of Time Series Conditional Variance. Journal of Business & Economic Statistics 28: 256–74, Research Collection School Of Economics. [Google Scholar]
- Nelson, Daniel B. 1991. Conditional Heteroskedasticity in Asset Returns: A New Approach. Econometrica 59: 347–70. [Google Scholar] [CrossRef]
- Warnes, Gregory R., Ben Bolker, Gregor Gorjanc, Gabor Grothendieck, Ales Korosec, Thomas Lumley, Don MacQueen, Arni Magnusson, and Jim Rogers. 2017. gdata: Various R Programming Tools for Data Manipulation, R package Version 2.18.0; Available online: https://cran.r-project.org/web/packages/gdata/index.html (accessed on 5 August 2021).
- Wickham, Hadley, Romain François, Lionel Henry, and Kirill Müller. 2021. dplyr: A Grammar of Data Manipulation, R Package Version 1.0.7; Available online: https://cran.r-project.org/web/packages/dplyr/index.html (accessed on 5 August 2021).
- Zeileis, Achim, and Gabor Grothendieck. 2005. zoo: S3 Infrastructure for Regular and Irregular Time Series. Journal of Statistical Software 14: 1–27. [Google Scholar] [CrossRef] [Green Version]
- Ziegelmann, Flavio A. 2002. Nonparametric Estimation of Volatility Functions: The Local Exponential Estimator. Econometric Theory 18: 985–91. [Google Scholar] [CrossRef]
Figure 1.
The left two plots show the news impact curves in black and second-stage nonlinearities in red for S&P 500 daily returns. The right two plots show the conditional variance estimates for SPMLGARCH and SPMLGARCH.
Figure 1.
The left two plots show the news impact curves in black and second-stage nonlinearities in red for S&P 500 daily returns. The right two plots show the conditional variance estimates for SPMLGARCH and SPMLGARCH.

Figure 2.
The left plot shows the one-step-ahead GARCH and SPMLGARCH forecasts and the right plot shows the one-step-ahead ARCH and SPMLARCH forecast. The forecast period is from , or 21 Febuary 2021 to 5 August 2021. The vertical black dashed line indicates the start of the forecasting period. The red and blue curves indicate the semiparametric and parametric models, respectively. The solid curves represent fitted values of the conditional variance based on the training data set and the dashed curves denote the forecasts based on the validation data set. The forecasts were calculated using a rolling window scheme of window size 925.
Figure 2.
The left plot shows the one-step-ahead GARCH and SPMLGARCH forecasts and the right plot shows the one-step-ahead ARCH and SPMLARCH forecast. The forecast period is from , or 21 Febuary 2021 to 5 August 2021. The vertical black dashed line indicates the start of the forecasting period. The red and blue curves indicate the semiparametric and parametric models, respectively. The solid curves represent fitted values of the conditional variance based on the training data set and the dashed curves denote the forecasts based on the validation data set. The forecasts were calculated using a rolling window scheme of window size 925.


{kind=link}
{kind=link}
Table 1.
The table shows MSEs calculated by Equation (14) for the ARCH, GARCH, NPML, SPMLARCH, and SPMLGARCH models under the DGP specified in Equation (13). The sample size for each estimation is and the number of replications is .
| MSEs of Estimators for Conditional Variance | ||||
|---|---|---|---|---|
| ARCH | GARCH | NPML | SPMLARCH | SPMLGARCH |
Table 2.
The table reports coefficients of the and models with standard errors in parentheses. The results from the top panel are based on estimates obtained from the training data set, , whereas the results from the bottom panel are based on estimates obtained from the entire data set . is the intercept of the conditional variance, is the coefficient of the ARCH term, and is the coefficient of the GARCH term. The last column contains the estimates of the mean absolute percentage change of the conditional variance due to the nonparametric component, calculated by Equation (15).
Table 2.
The table reports coefficients of the and models with standard errors in parentheses. The results from the top panel are based on estimates obtained from the training data set, , whereas the results from the bottom panel are based on estimates obtained from the entire data set . is the intercept of the conditional variance, is the coefficient of the ARCH term, and is the coefficient of the GARCH term. The last column contains the estimates of the mean absolute percentage change of the conditional variance due to the nonparametric component, calculated by Equation (15).
| Estimated Parameters in the First Stage Estimation and Absolute Percentage Change in the Variance | ||||
|---|---|---|---|---|
| Due to NP | ||||
| GARCH(1, 1) | 0.0382 | 0.1864 | 0.7481 | 12.06 |
| (0.0076) | (0.0328) | (0.0352) | ||
| ARCH(1) | 0.3725 | 0.3554 | 9.02 | |
| (0.0229) | (0.0611) | |||
| GARCH(1, 1) | 0.0407 | 0.2779 | 0.7032 | 15.8 |
| (FULL) | (0.0069) | (0.0354) | (0.0284) | |
| ARCH(1) | 0.4986 | 0.7443 | 27.53 | |
| (FULL) | (0.0296) | (0.0822) | ||
Table 3.
The table reports RMSFE’s for and steps ahead forecasts and for the following estimators: SPMLGARCH, SPMLARCH, GARCH, ARCH, and NPML.
Table 3.
The table reports RMSFE’s for and steps ahead forecasts and for the following estimators: SPMLGARCH, SPMLARCH, GARCH, ARCH, and NPML.
| RMSFE’s of Estimators for Forecasting Conditional Variance | |||||
|---|---|---|---|---|---|
| SPMLGARCH | GARCH | SPMLARCH | ARCH | NPML | |
| One Step Ahead | |||||
| Five Steps Ahead | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Dang, J.; Ullah, A. Machine-Learning-Based Semiparametric Time Series Conditional Variance: Estimation and Forecasting. J. Risk Financial Manag. 2022, 15, 38. https://0-doi-org.brum.beds.ac.uk/10.3390/jrfm15010038
AMA Style
Dang J, Ullah A. Machine-Learning-Based Semiparametric Time Series Conditional Variance: Estimation and Forecasting. Journal of Risk and Financial Management. 2022; 15(1):38. https://0-doi-org.brum.beds.ac.uk/10.3390/jrfm15010038
Chicago/Turabian StyleDang, Justin, and Aman Ullah. 2022. "Machine-Learning-Based Semiparametric Time Series Conditional Variance: Estimation and Forecasting" Journal of Risk and Financial Management 15, no. 1: 38. https://0-doi-org.brum.beds.ac.uk/10.3390/jrfm15010038