Robust Learning with Implicit Residual Networks



1
Data Analysis and Machine Learning, Oak Ridge National Laboratory, Oak Ridge, TN 37831, USA
2
Department of Mathematics, University of Tennessee at Knoxville, Knoxville, TN 37996, USA
3
Behavioral Reinforcement Learning Lab (BReLL), Lirio LLC, Knoxville, TN 37923, USA
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Mach. Learn. Knowl. Extr. 2021, 3(1), 34-55; https://0-doi-org.brum.beds.ac.uk/10.3390/make3010003
Submission received: 16 November 2020
/
Revised: 22 December 2020
/
Accepted: 25 December 2020
/
Published: 31 December 2020
(This article belongs to the Special Issue Explainable Machine Learning)
Abstract
:In this effort, we propose a new deep architecture utilizing residual blocks inspired by implicit discretization schemes. As opposed to the standard feed-forward networks, the outputs of the proposed implicit residual blocks are defined as the fixed points of the appropriately chosen nonlinear transformations. We show that this choice leads to the improved stability of both forward and backward propagations, has a favorable impact on the generalization power, and allows for control the robustness of the network with only a few hyperparameters. In addition, the proposed reformulation of ResNet does not introduce new parameters and can potentially lead to a reduction in the number of required layers due to improved forward stability. Finally, we derive the memory-efficient training algorithm, propose a stochastic regularization technique, and provide numerical results in support of our findings.
1. Introduction and Related Works
A large volume of empirical results has been collected in recent years illustrating the striking success of deep neural networks (DNNs) in approximating complicated maps by a mere composition of relatively simple functions [1]. Universal approximation property of DNNs with a relatively small number of parameters has also been shown for a large class of functions [2,3]. The training of deep networks nevertheless remains a notoriously difficult task due to the issues of exploding and vanishing gradients, which become more apparent and noticeable with increasing depth [4]. These issues accelerated efforts of the research community in an attempt to explain this behavior and gain new insights into the design of better architectures and faster algorithms. A promising approach in this direction was obtained by casting evolution of the hidden states of a DNN as a dynamical system [5], i.e.,
where for each layer t, is a nonlinear transformation parameterized by the weights , and , are the appropriately chosen spaces. In the case of a very deep network, when , it is convenient to consider the continuous time limit of the above expression such that
where the parametric evolution function defines a continuous flow through the input data . Parameter estimation for such continuous evolution can be viewed as an optimal controlling problem [6], given by
where is a terminal loss function, is a regularizer, and is a probability distribution of the input–target data pairs . More general models additionally consider continuity in the “patial” dimension as well by using differential [7] or integral formulations [8]. A continuous time formulation based on ordinary differential equations (ODEs) was proposed in [9] with the state Equation (2) of the form
In the work [9], the authors relied on the black-box ODE solvers and used adjoint sensitivity analysis to derive equations for the backpropagation of errors through the continuous system.
The authors of [10] concentrated on the well-posedness of the learning problem for ODE-constrained control and emphasized the importance of stability in the design of deep architectures. For instance, the solution of a homogeneous linear ODE with constant coefficients
is given by
where is the eigendecomposition of a matrix A, and is the diagonal matrix with the corresponding eigenvalues. The similar equation holds for the backpropagation of gradients. To guarantee the efficient propagation of information through the network, one must ensure that the elements of have magnitudes close to one. This condition, of course, is satisfied when all eigenvalues of the matrix A are imaginary with real parts close to zero. In order to preserve this property, the authors of [10] proposed several time continuous architectures of the form
When , , the equations above provide an example of a conservative Hamiltonian system with the total energy H.
In the discrete setting of the ordinary feed forward networks, the necessary conditions for the optimal solution of (1) and (2) recover the well-known equations for the forward propagation (state Equation (2)), backward gradient propagation (co-state equation), and the optimality condition, to compute the weights (gradient descent algorithm); see, e.g, [11]. The continuous setting offers additional flexibility in the construction of discrete networks with the desired properties and efficient learning algorithms. Classical feed forward networks (Figure 1, left) is just the particular and the simplest example of such discretization, which is prone to all the issues of deep learning. In order to facilitate the training process, a skip-connection is often added to the network (Figure 1, middle) yielding
where h is a positive hyperparameter. Equation (5) can be viewed as a forward Euler scheme to solve the ODE in (3) numerically on the time grid with step size h. While it was shown that such residual layers help to mitigate the problem of vanishing gradients and speed-up the training process [12], the scheme has very restrictive stability properties [13]. This can result in the uncontrolled accumulation of errors at the inference stage reducing the generalization ability of the trained network. Moreover, the Euler scheme is not capable of preserving geometric structure of conservative flows and is thus a bad choice for the long time integration of such ODEs [14].
Memory efficient explicit reversible architectures can be obtained by considering time discretization of the partitioned system of ODEs in (4). The reversibility property allows for recovering the internal states of the system by propagating through the network in both directions and thus does not require one to cache these values for the evaluation of the gradients. First, such architecture (RevNet) was proposed in [15], and, without using a connection to discrete solutions of ODEs, it has the form
It was later recognized as the Verlet method applied to the particular form of the system in (4), see [10,16]. The leapfrog and midpoint networks are two other examples of reversible architectures proposed in [16].
Other residual architectures can be also found in the literature including Resnet in Resnet (RiR) [17], Dense Convolutional Network (DenseNet) [18] and linearly implicit network (IMEXNet) [19]. For some problems, all of these networks show a substantial improvement over the classical ResNet but still have an explicit structure, which has limited robustness to the perturbations of the input data and parameters of the network. Instead, in this effort, we propose new fully implicit residual architecture, which, unlike the above mentioned examples, is unconditionally stable and robust.
As opposed to the standard feed-forward networks, the outputs of the proposed implicit residual blocks are defined as the fixed points of the appropriately chosen nonlinear transformations as follows:
The right part of Figure 1 provides a graphical illustration of the proposed layer. One can immediately recognize the feedback loop which is typical for recurrent neural networks (RNN). The standard approach to train RNNs is by backpropagation through time, the algorithm which requires substantial memory resources for deep unrolled recurrent networks. The authors of [20,21] utilized related to our idea of implicit layers to cope with this issue by directly learning the equilibrium points of “infinite” depth recurrent models with a constant memory complexity. The main difference of our approach is that we design the feedback loop with a specific goal of driving the output of the implicit layer to the stable fixed point. We will discuss the choice of the nonlinear transformation in (6) and the design of the training algorithm in the next section. It is also worth noting that the idea of learning fixed points is not quite new and is rooting way back to the Hopfield networks and content-addressable (“associative”) memory [22,23].
After the first version of this manuscript has appeared, another work proposed the similar idea of implicit Euler skip connections to enhance the adversarial robustness of residual networks [24]. The authors of [24] modified the original residual block by complementing it with a fixed number of steps of the gradient descent algorithm and applied adversarial training to the modified architecture. While both efforts are inspired by implicit numerical schemes for integrating ODEs, our approach is more general as we ensure the convergence of the proposed implicit layer to the stable fixed point. As discussed above and unlike the work in [24], in addition to the enhanced stability properties, this approach does not increase the memory complexity of the original residual networks. We also propose an initialization and regularization strategies which allow for training the network efficiently and admit simple interpretation.
The preliminary results for the work proposed in the current manuscript have been presented at the Second Symposium on Machine Learning and Dynamical Systems in the Fields Institute [25]. Here, we provide a completely revised version of this work including an in-depth description of the method, a new regularization approach, and much extended numerical results.
2. Description of the Method
We first motivate the necessity for our new method by letting the continuous model of a network be given by the ordinary differential equations in (4) that is:
An s-stage Runge–Kutta (RK) method for the approximate solution of the above equations is given by
The order conditions for the coefficients , , , , , and , which guarantee that convergence of the numerical solution is well known and can be found in any topical text, see, e.g., [13]. Note that, when or for at least some , the scheme is implicit and a system of nonlinear equations has to be solved at each iteration which obviously increases the complexity of the solver. Nevertheless, the following example illustrates the benefits of using implicit approximations.
2.1. Linear Stability Analysis
Consider the following linear differential system:
and four simple discretization schemes [13]:
| Forward Euler: | |
| Backward Euler: | |
| Trapezoidal: | |
| Verlet: |
Due to linearity of the system in (8), the numerical solution after n steps can be written as
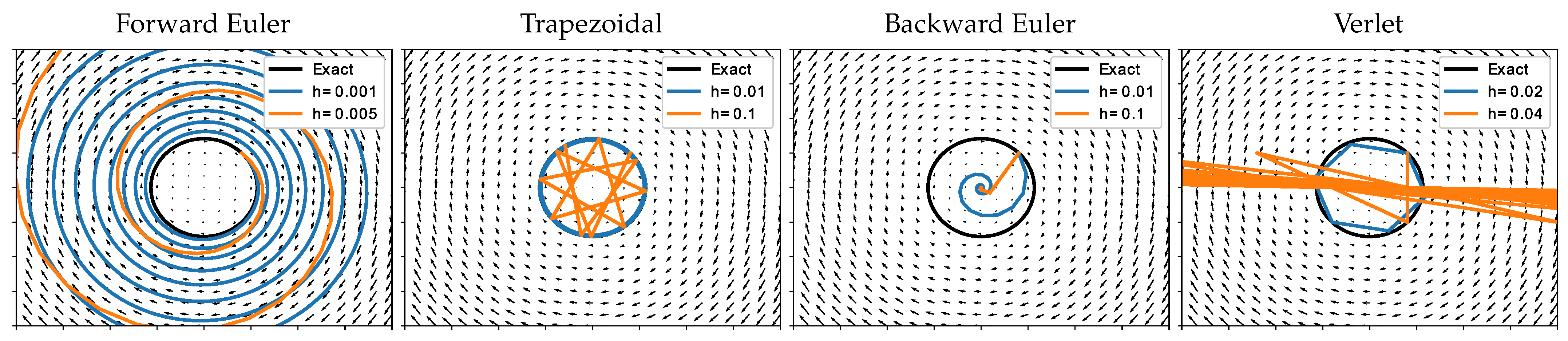
The long time behavior of the discrete dynamics is hence determined by the spectral radius of the matrix (called the stability matrix), which needs to be less than or equal to one for the sake of stability. For example, we have for the forward Euler scheme, and the method is unconditionally unstable. The Backward Euler scheme gives and the method is unconditionally stable. The corresponding eigenvalues of the trapezoidal scheme have a magnitude equal to one for all and h. Finally, the characteristic polynomial for the matrix of the Verlet scheme is given by , i.e., the method is only conditionally stable when .
Figure 2 illustrates this behavior for the particular case of . Notice that the flows of the forward and backward Euler schemes are strictly expanding and contracting; if one had to fit the exact flow of the system in (8) using either of these methods, this would result in an inherently ill-posed problem. On the contrary, the implicit trapezoidal and explicit Verlet schemes seem to reproduce the original flow very well, but the latter is conditional on the size of the step h. Another nice property of the trapezoidal and Verlet schemes is their symmetry with respect to the exchanging and . Such methods play a central role in the geometric integration of reversible differential flows and are handy in the construction of the memory efficient reversible network architectures. Conditions for the reversibility of general Runge–Kutta schemes can be found in [14].
The discussion above highlights the importance of the appropriate choice for both the structure of a dynamical system (DS) and the corresponding time integrator. The stability of a general Runge–Kutta method is often studied in application to the simpler scalar test equation
and by analogy with (9) its stability function is given by
where and , are the parameters of the RK method in (7) with the remaining parameters set to zero for the scalar test equation. From this expression, one can see that the stability function of any explicit Runge–Kutta method is a polynomial and hence is bounded only for z in a finite region of the complex plane. The set of all such z with is called the stability region of the method.
2.2. Implicit ResNet
Motivated by the discussion above, we propose an implicit residual layer in (6) with a nonlinear map given by
where x, y, are the input, output, and parameters of the layer, and is a vector field to be estimated. Table 1 shows the derivatives of the nonlinear maps in (11) and (12) with respect to their arguments.
The stability function of the layers in (11) and (12) is given by
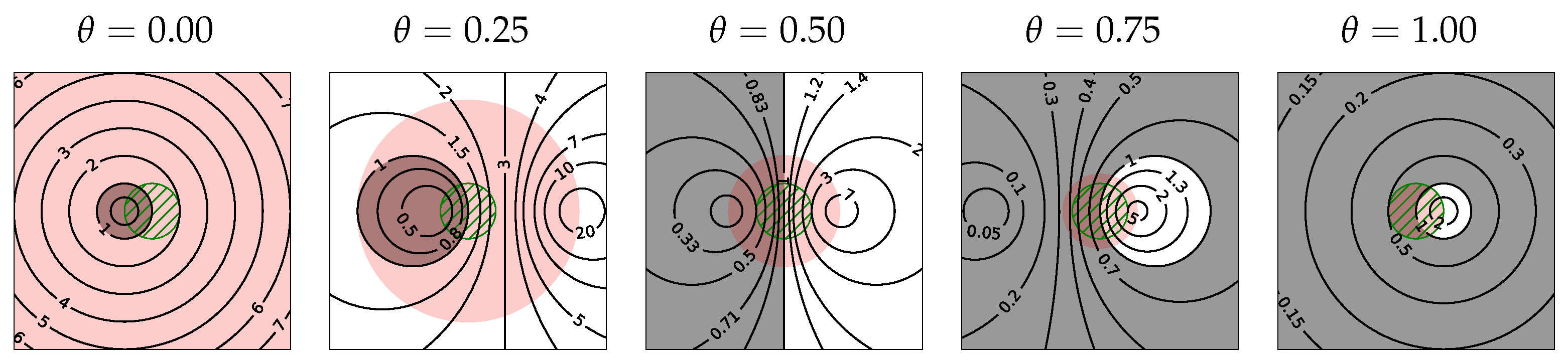
The corresponding stability regions are illustrated in Figure 3 indicating the improved stability of implicit layers for increasing .
Additionally, instead of a single layer in (6), one might consider a block of implicit layers on a given “time interval”
Note that, by viewing (14) as a numerical ODE integrator and to get the above expressions, we have assumed that the ODE coefficients are piecewise constant cádlág functions, see Figure 4.
We will use (12) as the definition of implicit layers in the rest of this work.
2.2.1. Forward Propagation
Assume that the fixed point in (6) exists and can be computed. To solve the corresponding nonlinear equation, consider the equivalent minimization problem
One way to construct the required solution is by applying the descent algorithm
where is the descent direction and is the corresponding step size. Several common choices are summarized in Table 2.
The required gradient of the residual norm can be computed as
where the Jacobian of the residual vector is given by (c.f. Table 1)
The expression in (16) can be efficiently computed with the automatic differentiation capabilities of any standard deep learning framework making it possible to interface existing iterative solvers. However, optimized implementations of the gradient descent algorithms are readily provided by any such framework. Hence, the forward propagation for implicit layers can be easily implemented using built-in tools native to each framework and without interfacing external solvers. Listing 1 shows the PyTorch pseudocode of the implicit layer and the left part of Figure 5 illustrates its corresponding computational graph.
Listing 1. PyTorch pseudocode of the implicit residual block.
import torch
class fpmap (torch.Function):
@staticmethod
def forward (ctx, γ, x, ŷ):
y = x + Φ(γ, x, ŷ)
ctx.save_for_backward (y, ŷ)
return y
@staticmethod
def backward (ctx, ∇yL):
y, ŷ = ctx.saved_tensors
return (I − ∂y/∂ŷ)−T∇yL
def ImplicitResidualBlock (x):
nsolve = lambda γ, x: argminz ||z − fpmap (γ, x, z)||2
ŷ = nsolve (γ.detach(), x.detach())
return fpmap.apply (γ, x, ŷ)
2.2.2. Backpropagation
We now show that, even though the nonlinearity in (6) adds to the complexity of the forward propagation, the direct backpropagation through the nonlinear solver is not required. Firstly, using the chain rule, we can easily find the Jacobian matrices of the implicit residual layer as follows:
and
The backpropagation formulas then follow immediately:
where is the solution to the linear system
Note that the custom backpropagation for the function in Listing 1 is responsible for the linear solve in (17). The gradients of the loss with respect to the parameters and the input are then computed automatically by the deep learning framework. Finally, DL frameworks allow for the cheap computation of the vector-Jacobian products in (17) and hence for the efficient implementation of iterative linear solvers. For example, we utilize restarted GMRES as a linear solver in our implementation.
2.3. fpResNet
Sophisticated solvers are not required for the nonlinear and linear systems in (15) and (17) when is a contractive mapping, i.e., when
where is the spectral norm of the matrix equal to its largest singular value. The red color in Figure 3 is used to highlight the part of the complex plane , where the above condition is satisfied for the Dahlquist test equation in (10). In this case, the Banach fixed-point theorem ensures the convergence of the recurrence relation
during the forward propagation. The same condition guarantees the validity of the Neumann series expansion for the matrix inverse required for the backpropagation; one gets
with
Similarly to (17), each has a form of the vector-Jacobian product which can be efficiently evaluated with any deep learning framework. In practice, however, such simple iterations converge linearly with the rate proportional to the Lipschitz constant which can be rather inefficient when .
2.4. Regularization
One way to ensure the stability of the neural network when viewed as a nonlinear DS is by imposing a hard constraint on its parameters to make it globally dissipative or conservative. This approach has been utilized, for instance, in [7,10] and applied to several explicit, and hence only conditionally stable, residual network architectures. Another approach that we employ here is by imposing the structure by regularization. In this section, we review some common regularization techniques and propose a new one that suits the presented implicit architecture.
2.4.1. Lipschitz Continuous Architectures
Enforcing Lipschitz continuity of neural networks has been recognized as an important component in many applications. For instance, explicit bounds on the Lipschitz constants of the loss function have been utilized to improve the robustness and establish the generalization error of large margin classifiers and GAN discriminators in [27,28,29,30], respectively. Lipschitz continuity has also been considered implicitly in [31,32] to improve the adversarial robustness of DNNs and in [33] for the design of contractive auto-encoders. In all these works, bounding the Lipschitz constants was implemented by penalizing the norm of the Jacobian matrix of the network on the training dataset.
Spectral normalization of weight matrices can be used to provide the uniform bound on the Lipschitz constant of the network. It has been applied to improve the stability of deep networks in [34,35,36] and to construct invertible normalizing flows of probability distributions in [37]. To justify the method, consider the common choice of in (11) as a composition of affine maps and contractive nonlinear activations, i.e.,
The Lipschitz constant of as a function of x can be bounded from above by
where is the spectral norm and denotes the spectral radius of a linear map A. Hence, to ensure that , it is enough to take
The exact calculation of the operator norm is expensive and one usually appeals to approximate techniques such as the power iteration method [38]. According to this method, the dominant singular vector v and the singular value of a linear operator A are estimated iteratively as
In practice, it is enough to take a fixed number (usually 1) of iterations at each weight evaluation during the training stage since the parameters are not expected to change much close to the convergence of the training loop. By observing that
Algorithm 1 provides a simple implementation of this approach.
| Algorithm 1 Power iteration method |
|
More generally, spectral normalization allows for controlling the spread of the Jacobian matrix , i.e., the largest distance between its eigenvalues
By definition of the spectral radius, one has
Hence, by denoting , we obtain
so that all eigenvalues of the Jacobian are located in the disc with radius centered at . In practice, we use the more flexible form of this definition
where ⊙ is the Hadamard product, are additional learnable parameters, has the same dimensionality as , and each is the sigmoid function.
2.4.2. Trajectory Regularization
The Lipschitz constant of the proposed residual block in (6) is defined as
and, for the linear scalar test equation in (10), it is given by the stability function (13) of the method. The hatched circle in Figure 3 contains the spectrum of the 1-Lipschitz function and shows that the Lipschitz constant of a residual block can fall outside of its stability region. Moreover, the pole of (13) is located at and the stability of implicit layers might actually degrade with increasing if no additional precautions are taken to isolate the spectrum of the layers from its vicinity. This can be achieved, for instance, by setting for some .
Previous works have focused on improving the efficiency of residual and neural ODE architectures by regularizing their vector fields in a way that leads to a simpler dynamical behavior. For example, the authors of [39] considered the following regularizer
The first term encourages the trajectories with origin in the training dataset to follow straight lines, while the second term reduces overfitting by restricting the vector field to be nearly constant in the vicinity of each trajectory. A more general approach has been taken in [40] by directly penalizing the K-th order total derivative of the vector field along the solution trajectories. It has been shown that, by matching K to the order of numerical integrator, it is possible to significantly reduce the cost of solving the learned dynamics without sacrificing the resulting accuracy.
Instead, we consider “discrete-time” regularization of the form
where is the trapezoidal quadrature rule, d is the dimension of the vector field , is some fixed number, and is the divergence of .
The total variation (TV) like term in (20) is responsible for the temporal regularity of the vector field . Similarly to the approach of [39,40], the second term penalizes the Jacobian matrix of the layer producing vector fields which tend to be constant in the vicinity of the learned trajectories; this results in simpler dynamics and faster convergence. Finally, the first term in (20) promotes the negative divergence of along the trajectories. By definition of the divergence of the vector field, one has
i.e., it is equal to the sum of eigenvalues of the Jacobian matrix. By minimizing this term, we attempt to push the spectrum of the Jacobian matrix to the negative part of the complex plane so that we can take advantage of the enhanced stability of implicit layers in this region. In addition, note that, by definition, the squared Frobenius norm of a matrix is equal to the sum of its squared singular values
Hence, the first two terms in (20) are competing with each other, and the coefficient is used to balance these two components by increasing the level of dissipation along the trajectories. The divergence term, however, does not impact the off-diagonal part of the Jacobian matricies, and, for large enough , this will promote their diagonal dominance.
According to the Gershgorin circle theorem, every eigenvalue of a matrix A lies within at least one of the Gershgorin discs with . This means that the optimal solution of the optimization problem with the proposed regularizer in (20) will result in the dynamics that are strongly dissipative in the directions irrelevant for the accurate representation of the training data effectively reducing the dimension of the state space. The behavior of the dynamical system in the remaining directions along the so-obtained low-dimensional state manifold can potentially be arbitrary and, with a proper balance between the loss and regularization, should not decrease the expressive power of the network.
For the efficient evaluation of the divergence and Jacobian regularizers in (20), we utilize the unbiased stochastic Hutchinson trace estimator [41] to obtain
This approach has also been applied in [39,42]. Algorithm 2 provides a more general variant of Hutchinson algorithm which allows for estimating the diagonal of a matrix [43]. This can be convenient when one needs to control the magnitude of the diagonal elements rather than just their sum.
| Algorithm 2 Stochastic diagonal estimator |
|
3. Results
The source code used to generate all examples below can be found at https://github.com/vreshniak/ImplicitResNet.
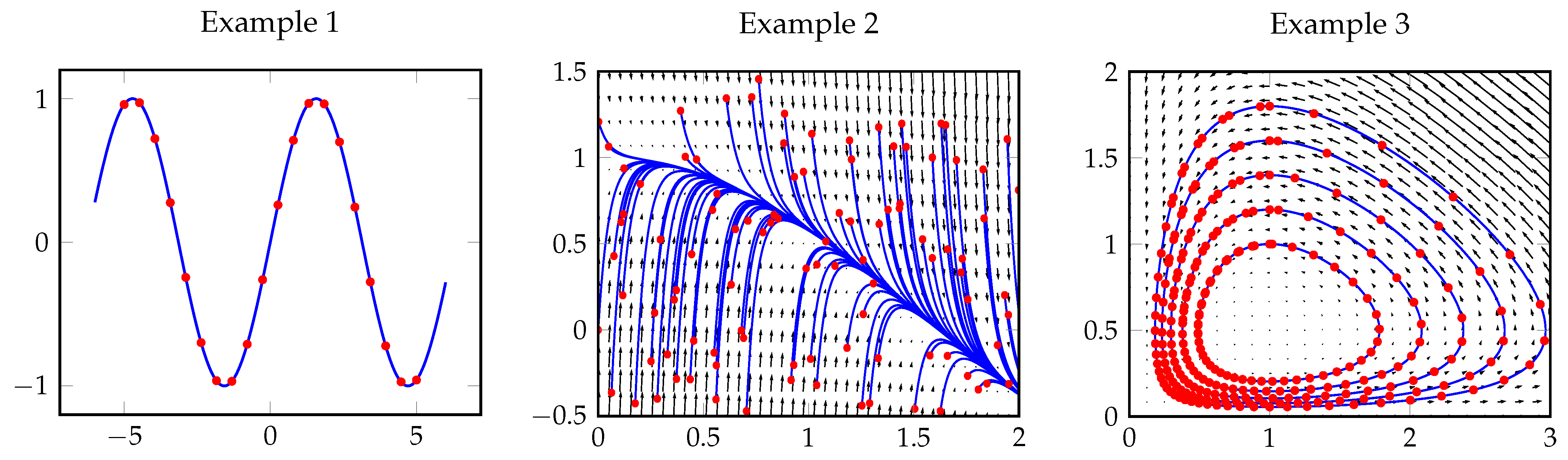
3.1. Example 1. (Regression)
For the first example, we consider the simple problem that can be easily visualized. The goal is to approximate the one-dimensional sine function in Figure 6 given data points evenly distributed on the interval . Following the approach of [44], we augment the original one-dimensional data with an additional dimension initialized with zero. The resulting two-dimensional vector field is approximated by a multilayer perceptron using three hidden layers of width 10 and GeLU activation function, i.e.,
where , , and .
We used residual layers with shared parameters initialized with a Xavier uniform initializer and trained the network for 3000 epochs using Adam optimizer and the regularized loss given by
where is the dimension of the hidden state space and gives the last component of . The initial learning rate was set to and reduced dynamically using ReduceLROnPlateau PyTorch scheduler with patience and cooldown parameters set to 50 epochs.
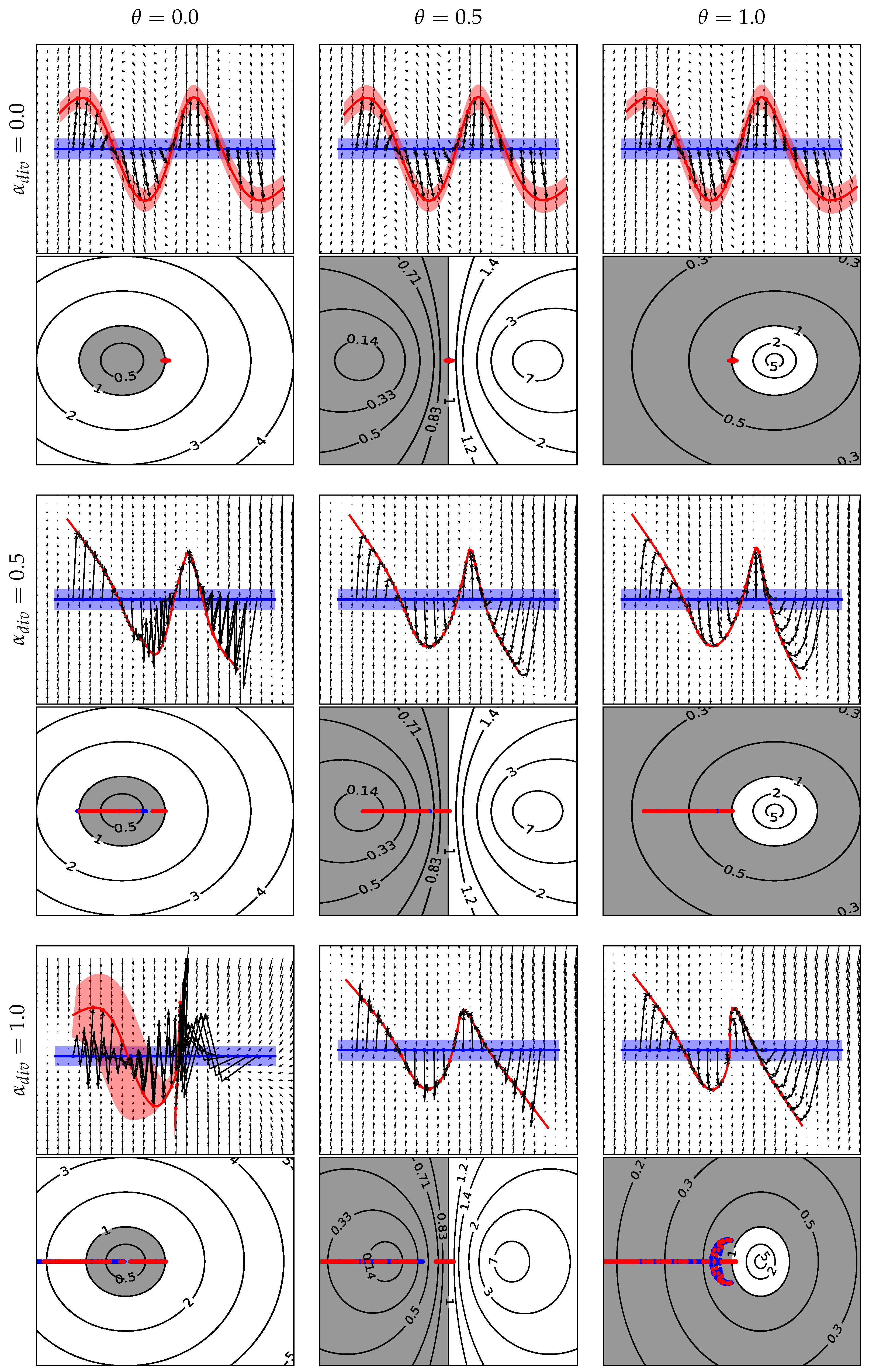
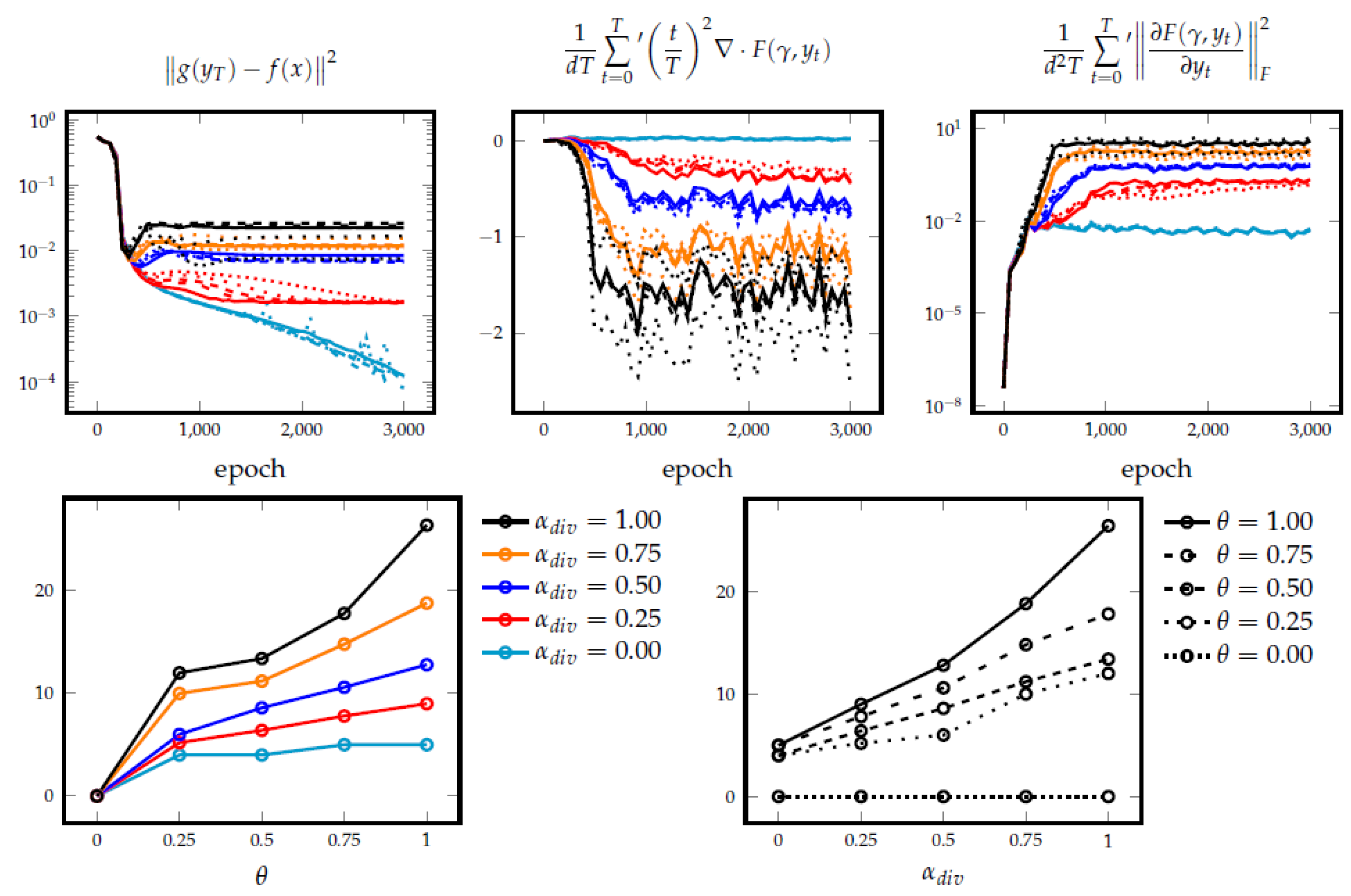
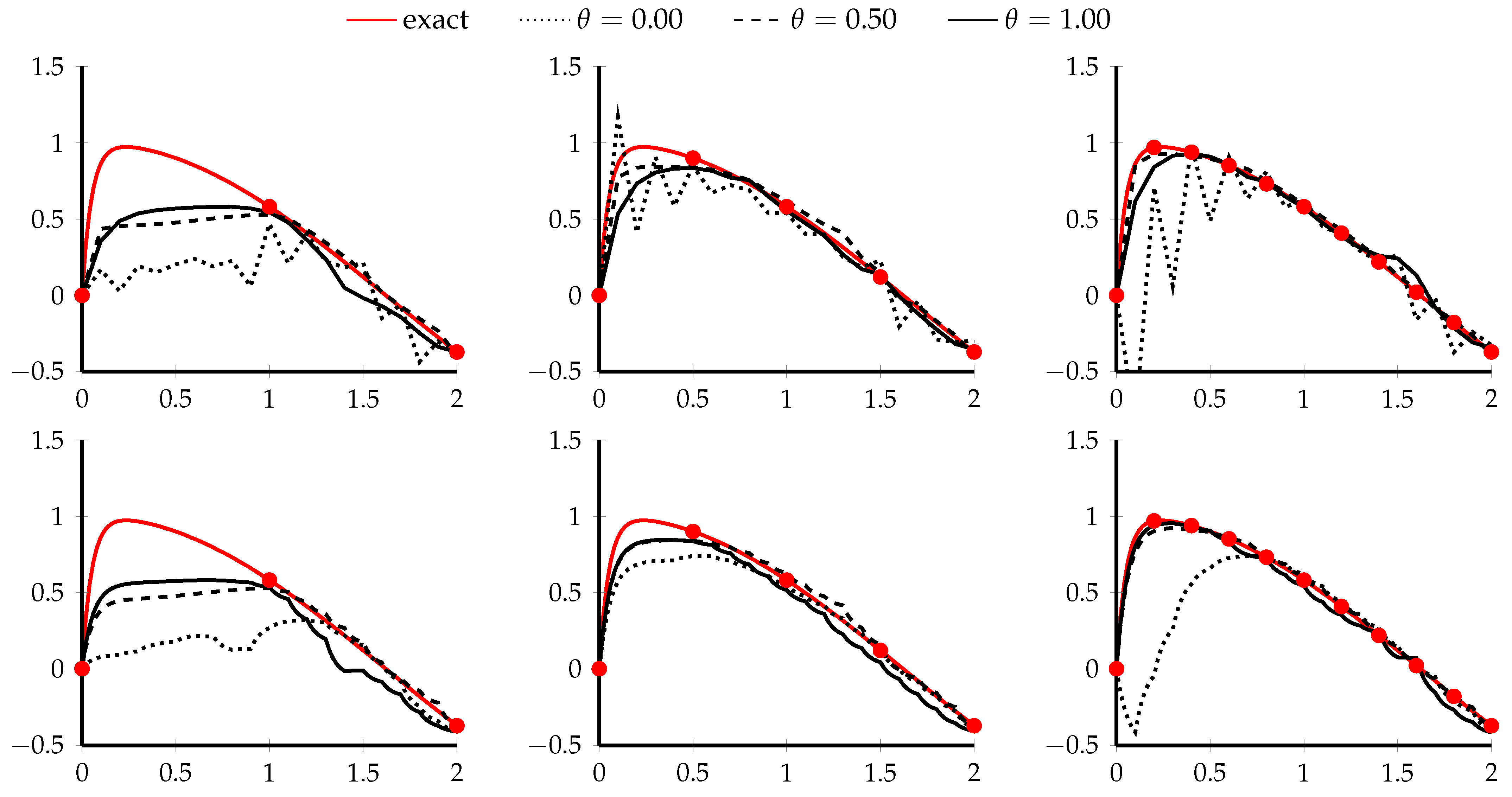
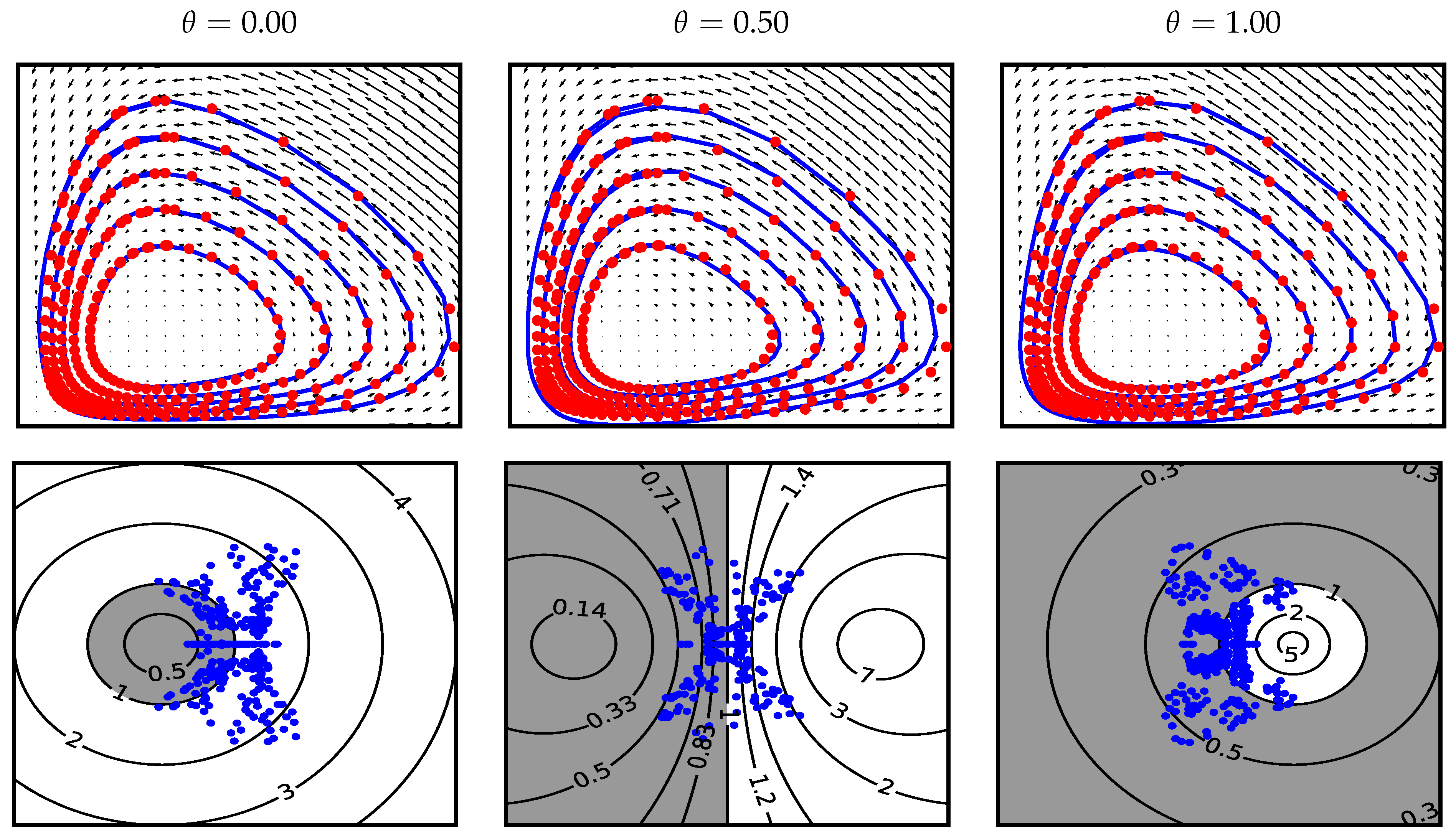
Figure 7 shows the learned vector fields and eigenvalues of the Jacobian along the learned trajectories for several values of and . Additionally, the top row of Figure 8 depicts the evolution of the loss components in (21), and the number of nonlinear iterations of the trained network for the selected parameter values. One can see that, with the Jacobian regularization alone (, ), implicit methods demonstrate similar dynamical behavior for all considered values of : (1) the learned vector fields take full advantage of all two available dimensions and tend to be expansive, note the increasing divergence in Figure 8, (2) the learned trajectories mostly follow straight lines, and (3) aside from the fully explicit scheme (), the costs of all the methods are nearly identical, see the bottom row of Figure 8. By increasing , one starts observing the formation of a lower dimensional invariant manifold with increasingly dissipative orthogonal dynamics indicated by the negative part of the spectrum of and the evolution of the filled regions in Figure 7. As the resulting dynamics becomes more restricted and less trivial, the following observations can be made: (1) the model tends to be less flexible and more difficult to fit the data, (2) the cost of the model is increasing with and , and (3) the explicit method demonstrates unstable oscillatory behavior when the level of dissipation exceeds its stability threshold.
3.2. Example 2. (Stiff ODE)
In our second example, we aim to fit the model to the given stiff ODE
The training data in Figure 6 consist of 100 trajectories with randomly sampled initial conditions and the given number of uniformly distributed points along each trajectory as shown in Figure 9.
Since the exact Lipschitz constant of the forcing term is equal to , we use in (19) with the one-dimensional vector field given by the multilayer perceptron with 2 hidden layers of width 4 and ReLU activation function, i.e,
where , , and .
We took residual layers initialized with Xavier uniform initializer and trained the network for 50 epochs using Adam optimizer, batch of size 1, and the regularized loss given by
The top row of Figure 9 illustrates the evolution of the single trajectory generated by three residual models with and . Each model was trained using the loss function in (23) with 2, 4 and 10 points taken along the trajectories of the training dataset. One can see that the explicit ResNet is unstable as was expected for the stiff system in (22), and the generated solution becomes increasingly oscillatory along the transient part of the trajectory as we increase the number of the training points from 2 to 10. This is due to the model attempting to be increasingly expressive for the data it cannot potentially fit. Once the dynamical system relaxes to the slow manifold, the accuracy of the model improves slightly but remains susceptible to the orthogonal perturbations. In order to stabilize the model, more layers need to be taken which will lead to the increased memory footprint and computational complexity. At the same time, both implicit residual networks with and are unconditionally stable and improve their accuracy with increasing number of the training points as expected.
The bottom row of Figure 9 shows the continuous dynamics generated by the vector fields learned by three considered implicit models. In this case, the discrete-time stability is not an issue anymore. However, the corruption caused by the instability of the explicit method transfers to the inaccurate behavior of the continuous system as well. On the contrary, both implicit methods lead to the satisfactory approximation of the original vector field with the midpoint scheme () being observably more accurate, likely due to its higher order of convergence. This suggests the proposed implicit networks as a means for learning stiff continuous-time ODE systems.
3.3. Example 3. (Periodic ODE)
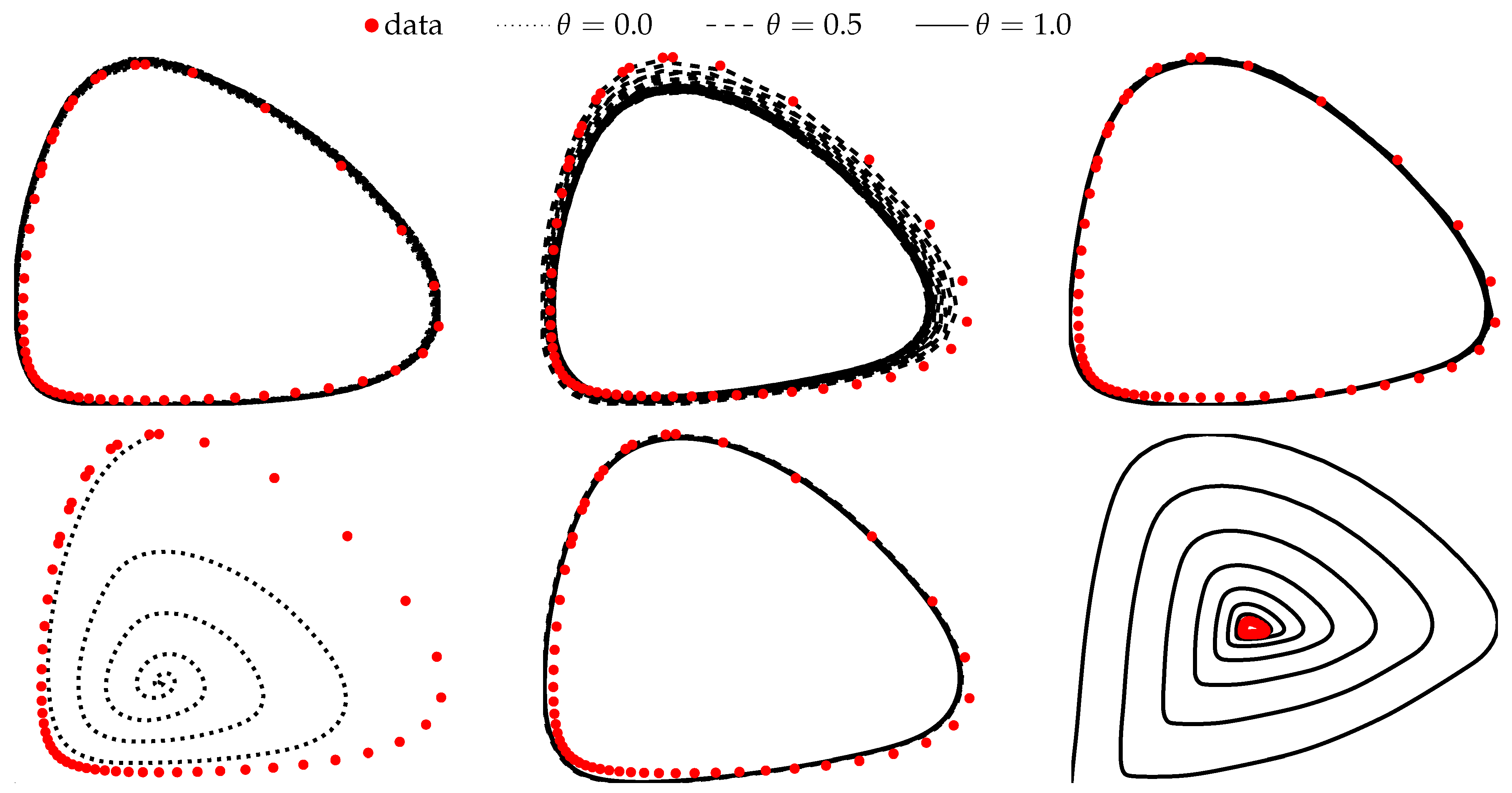
In this example, we consider the Lotka–Volterra system given by
with , , and . These equations are used to model the time evolution of the biological systems with two interacting species one being the prey and the other being the predator. The model has two equilibrium points when neither of the two interacting populations is changing. The first equilibrium is at and the non-trivial one is at , . Other solutions are periodic and lie on the closed curves in the phase space. Figure 6 shows five such curves; each curve contains 51 points which are distributed uniformly on the time interval and used as the training data for our example.
To fit this data, we utilized implicit residual networks with layers and the two-dimensional vector field approximated by the multilayer perceptron with four hidden layers of width 20 and ReLU activation functions, i.e.,
where , , and . We initialized the network with Xavier uniform initializer and trained it for 3000 epochs using Adam optimizer, full batch size, and the loss given by
Note that we did not use any form of weight normalization or regularization.
Figure 10 shows the learned trajectories and eigenvalues of the vector field along these trajectories for three implicit networks with and on the time interval . At a first glance, all three networks learn very similar vector fields and can accurately fit the data on the time interval of the training dataset. Moreover, the top row of Figure 11 shows that all three methods are also successful at extrapolating the dynamics to the time interval . However, the bottom row of the same figure shows that the midpoint scheme () is the only one which produces the vector field accurate for the long-time integration of the continuous dynamics. This behavior is indeed expected since the method is a geometrical integrator for this type of system, recall Figure 2 and the discussion in Section 2. The explicit residual network () is strictly expanding for such conservative systems, and the learned vector field tends to compensate for this behavior resulting in the dissipative continuous dynamics. The situation is reverse for the backward Euler integrator () since the method is strictly dissipative and hence the learned vector field is overly expanding.
3.4. Example 4. (MNIST Classification)
For the last example, consider the problem of classifying images of handwritten digits from the subset of MNIST dataset of size 1000. For this purpose, we adopt the standard preactivation ResNet-18 architecture with eight initial channels and train the network using the Adam optimizer for 100 epochs with learning rate of . We used the cross entropy loss function
and normalized the forcing terms of all residual layers as using (19). Additionally, the divergence regularization in (20) with was applied to each residual layer.
To test the robustness of the trained network, we corrupted the original dataset with the Gaussian noise of varying standard deviation. Table 3 illustrates the classification accuracy for different levels of noise intensity and five different implicit residual networks. The results show that the implicit architectures with a proper regularization can significantly improve the robustness properties of trained networks.
4. Conclusions and Future Work
In this work, we presented a novel implicit residual layer and provided a memory-efficient algorithm to evaluate and train deep neural networks composed of such layers. We also proposed a regularization technique to control the spectral properties of the presented layer and showed that it leads to improved stability and robustness of the trained networks. The obtained numerical results support our findings.
We see several opportunities for potential improvements to the presented architecture. For example, implementations of the forward and backward propagation algorithms can be further optimized to account for the repetitive nature of the training process. This includes the better estimation of initial guesses for nonlinear solvers and preconditioners for linear solvers and other ways to reuse available information from previous runs. It is also interesting to study other, possibly multistep, types of implicit residual layers and their combinations. In this regard and in addition to the provided examples, we plan to identify the best use cases and applications for deep residual networks containing implicit layers. In particular, we are interested in exploring the impact of adversarial training and the proposed spectral regularization on the properties of the trained implicit networks. Other applications of interest include the identification of physical systems with known properties such as energy dissipation/conservation, large horizon time series forecasting, applications with corrupted and noisy data, etc. Finally, as the proper regularization is essential for the good performance of implicit layers, new regularization approaches tailored to specific applications should also be analyzed. We intend to study these questions in our future works.
Author Contributions
Conceptualization, V.R. and C.G.W.; methodology, V.R. and C.G.W.; software, V.R.; writing, V.R. and C.G.W.; funding acquisition, C.G.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the U.S. Department of Energy, Office of Science, Early Career Research Program under award number ERKJ314; U.S. Department of Energy, Office of Advanced Scientific Computing Research under award numbers ERKJ331 and ERKJ345; the National Science Foundation, Division of Mathematical Sciences, Computational Mathematics program under contract number DMS1620280; and the Behavioral Reinforcement Learning Lab at Lirio LLC.
Conflicts of Interest
The authors declare no conflict of interest.
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Hanin, B. Universal function approximation by deep neural nets with bounded width and ReLU activations. Mathematics 2019, 7, 992. [Google Scholar] [CrossRef] [Green Version]
- Lu, Z.; Pu, H.; Wang, F.; Hu, Z.; Wang, L. The Expressive Power of Neural Networks: A View from the Width. In Advances in Neural Information Processing Systems 30: 31st Annual Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 6231–6239. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Weinan, E. A Proposal on Machine Learning via Dynamical Systems. Commun. Math. Stat. 2017, 5, 1–11. [Google Scholar] [CrossRef]
- Weinan, E.; Han, J.; Li, Q. A mean-field optimal control formulation of deep learning. Res. Math. Sci. 2018, 6, 10. [Google Scholar] [CrossRef] [Green Version]
- Ruthotto, L.; Haber, E. Deep Neural Networks Motivated by Partial Differential Equations. J. Math. Imaging Vis. 2020, 62, 352–364. [Google Scholar] [CrossRef] [Green Version]
- Sonoda, S.; Murata, N. Double continuum limit of deep neural networks. In Proceedings of the ICML Workshop on Principled Approaches to Deep Learning (ICML 2017), Sydney, Australia, 10 August 2017. [Google Scholar]
- Chen, T.Q.; Rubanova, Y.; Bettencourt, J.; Duvenaud, D.K. Neural Ordinary Differential Equations. In Advances in Neural Information Processing Systems 31: 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montreal, QC, Canada, 3–8 December 2018; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 6571–6583. [Google Scholar]
- Haber, E.; Ruthotto, L. Stable architectures for deep neural networks. Inverse Probl. 2017, 34, 014004. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y. A theoretical framework for back-propagation. In Proceedings of the 1988 Connectionist Models Summer School; Touretzky, D., Hinton, G., Sejnowsky, T., Eds.; Morgan Kaufmann, CMU: Pittsburgh, PA, USA, 1988; pp. 21–28. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the 14th European Conference on Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 11–14 October 2016; Lecture Notes in Computer Science. Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; Volume 9908, pp. 630–645. [Google Scholar] [CrossRef] [Green Version]
- Hairer, E.; Nørsett, S.P.; Wanner, G. Solving Ordinary Differential Equations I, Nonstiff Problems; Springer Series in Computational Mathematics; Springer: Berlin/Heidelberg, Germany, 1993; Volume 8. [Google Scholar]
- Hairer, E.; Lubich, C.; Wanner, G. Geometric Numerical Integration: Structure-Preserving Algorithms for Ordinary Differential Equations; Springer Series in Computational Mathematics; Springer: Berlin/Heidelberg, Germany, 2006; Volume 31. [Google Scholar]
- Gomez, A.N.; Ren, M.; Urtasun, R.; Grosse, R.B. The Reversible Residual Network: Backpropagation Without Storing Activations. In Advances in Neural Information Processing Systems 30: 31st Annual Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 2214–2224. [Google Scholar]
- Chang, B.; Meng, L.; Haber, E.; Ruthotto, L.; Begert, D.; Holtham, E. Reversible architectures for arbitrarily deep residual neural networks. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, LA, USA, 2–7 February 2018; AAAI Press: Palo Alto, CA, USA, 2018. [Google Scholar]
- Targ, S.; Almeida, D.; Lyman, K. Resnet in resnet: Generalizing residual architectures. arXiv 2016, arXiv:1603.08029. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 2261–2269. [Google Scholar] [CrossRef] [Green Version]
- Haber, E.; Lensink, K.; Treister, E.; Ruthotto, L. IMEXnet A Forward Stable Deep Neural Network. In Proceedings of the 36th International Conference on Machine Learning (ICML 2019), Long Beach, CA, USA, 9–15 June 2019; Chaudhuri, K., Salakhutdinov, R., Eds.; Volume 97, pp. 2525–2534. [Google Scholar]
- El Ghaoui, L.; Gu, F.; Travacca, B.; Askari, A. Implicit deep learning. arXiv 2019, arXiv:1908.06315. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. Deep Equilibrium Models. In Advances in Neural Information Processing Systems 32: 32nd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; pp. 690–701. [Google Scholar]
- Pineda, F.J. Generalization of back-propagation to recurrent neural networks. Phys. Rev. Lett. 1987, 59, 2229. [Google Scholar] [CrossRef]
- Hunt, K.J.; Sbarbaro, D.; Żbikowski, R.; Gawthrop, P.J. Neural networks for control systems—A survey. Automatica 1992, 28, 1083–1112. [Google Scholar] [CrossRef]
- Li, M.; He, L.; Lin, Z. Implicit Euler Skip Connections: Enhancing Adversarial Robustness via Numerical Stability. In Proceedings of the 37th International Conference on Machine Learning (ICML 2020), Vienna, Austria, 12–18 July 2020; Volume 119, pp. 5874–5883. [Google Scholar]
- Reshniak, V.; Webster, C. Robust Learning with Implicit Residual Networks. Unpublished work. 2020. [Google Scholar]
- Nocedal, J.; Wright, S. Numerical Optimization, 2nd ed.; Springer Series in Operations Research and Financial Engineering; Springer: New York, NY, USA, 2006. [Google Scholar]
- Sokolić, J.; Giryes, R.; Sapiro, G.; Rodrigues, M.R. Robust large margin deep neural networks. IEEE Trans. Signal Process. 2017, 65, 4265–4280. [Google Scholar] [CrossRef]
- Tsuzuku, Y.; Sato, I.; Sugiyama, M. Lipschitz-margin training: Scalable certification of perturbation invariance for deep neural networks. In Advances in Neural Information Processing Systems 31: 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montreal, QC, Canada, 3–8 December 2018; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 6541–6550. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved Training of Wasserstein GANs. In Advances in Neural Information Processing Systems 30: 31st Annual Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 5767–5777. [Google Scholar]
- Qi, G.J. Loss-Sensitive Generative Adversarial Networks on Lipschitz Densities. Int. J. Comput. Vis. 2020, 128, 1118–1140. [Google Scholar] [CrossRef] [Green Version]
- Jakubovitz, D.; Giryes, R. Improving DNN robustness to adversarial attacks using Jacobian regularization. In Proceedings of the 15th European Conference on Computer Vision (ECCV 2018), Munich, Germany, 8–14 September 2018; Lecture Notes in Computer Science. Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; pp. 514–529. [Google Scholar] [CrossRef] [Green Version]
- Hoffman, J.; Roberts, D.A.; Yaida, S. Robust learning with Jacobian regularization. arXiv 2019, arXiv:1908.02729. [Google Scholar]
- Alain, G.; Bengio, Y. What regularized auto-encoders learn from the data-generating distribution. J. Mach. Learn. Res. 2014, 15, 3563–3593. [Google Scholar]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral normalization for generative adversarial networks. In Proceedings of the Sixth International Conference on Learning Representations (ICLR 2018), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Gouk, H.; Frank, E.; Pfahringer, B.; Cree, M. Regularisation of neural networks by enforcing Lipschitz continuity. Mach. Learn. 2020. [Google Scholar] [CrossRef]
- Yoshida, Y.; Miyato, T. Spectral norm regularization for improving the generalizability of deep learning. arXiv 2017, arXiv:1705.10941. [Google Scholar]
- Behrmann, J.; Grathwohl, W.; Chen, R.T.; Duvenaud, D.; Jacobsen, J.H. Invertible Residual Networks. In Proceedings of the 36th International Conference on Machine Learning (ICML 2019), Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 573–582. [Google Scholar]
- Golub, G.H.; Van Loan, C.F. Matrix computations, 4 ed.; The Johns Hopkins University Press: Baltimore, MD, USA, 2013. [Google Scholar]
- Finlay, C.; Jacobsen, J.H.; Nurbekyan, L.; Oberman, A.M. How to train your neural ODE: The world of Jacobian and kinetic regularization. In Proceedings of the 37th International Conference on Machine Learning (ICML 2020), Vienna, Austria, 12–18 July 2020; Volume 119, pp. 3154–3164. [Google Scholar]
- Kelly, J.; Bettencourt, J.; Johnson, M.J.; Duvenaud, D. Learning Differential Equations that are Easy to Solve. In Proceedings of the 34st Annual Conference on Neural Information Processing Systems (NIPS 2020), Vancouver, BC, Canada, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H.T., Eds.; [Google Scholar]
- Hutchinson, M. A Stochastic Estimator of the Trace of the Influence Matrix for Laplacian Smoothing Splines. Commun. Stat. Simul. Comput. 1989, 18, 1059–1076. [Google Scholar] [CrossRef]
- Grathwohl, W.; Chen, R.T.; Bettencourt, J.; Sutskever, I.; Duvenaud, D. Ffjord: Free-form continuous dynamics for scalable reversible generative models. In Proceedings of the Seventh International Conference on Learning Representations (ICLR 2019), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Bekas, C.; Kokiopoulou, E.; Saad, Y. An estimator for the diagonal of a matrix. Appl. Numer. Math. 2007, 57, 1214–1229. [Google Scholar] [CrossRef] [Green Version]
- Dupont, E.; Doucet, A.; Teh, Y.W. Augmented neural ODEs. In Advances in Neural Information Processing Systems 32: 32nd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; pp. 3140–3150. [Google Scholar]
Figure 1.
From left to right: feed forward layer, residual layer, proposed implicit residual layer.

Figure 2.
Phase diagrams of different numerical solutions of the system in (8).
Figure 2.
Phase diagrams of different numerical solutions of the system in (8).

Figure 3.
Stability regions (grey) and the contours of the stability function of implicit residual layers; the corresponding regions where layers are contractive are shown in red while the hatched circles contain the spectrum of the spectrally normalized 1-Lipschitz function .
Figure 3.
Stability regions (grey) and the contours of the stability function of implicit residual layers; the corresponding regions where layers are contractive are shown in red while the hatched circles contain the spectrum of the spectrally normalized 1-Lipschitz function .

Figure 4.
Cádlág function.

Figure 5.
Forward and backward computational graphs of the implicit layer.

Figure 6.
Training data in Examples 1–3.

Figure 7.
(Top) Learned vector fields in Example 1. Blue line is the initial state, red curve is the final state after steps, solid black lines are the trajectories of the training data. (Bottom) Eigenvalues of evaluated along the learned trajectories at times . Red and blue dots are used for the train and test datasets, respectively. Stability regions of implicit layers are highlighted with grey color and the contours depict the values of the stability function.
Figure 7.
(Top) Learned vector fields in Example 1. Blue line is the initial state, red curve is the final state after steps, solid black lines are the trajectories of the training data. (Bottom) Eigenvalues of evaluated along the learned trajectories at times . Red and blue dots are used for the train and test datasets, respectively. Stability regions of implicit layers are highlighted with grey color and the contours depict the values of the stability function.

Figure 8.
(Top) Evolution of the training loss components in (21) for Example 1. (Bottom) Nonlinear iterations per residual layer of the trained network.
Figure 8.
(Top) Evolution of the training loss components in (21) for Example 1. (Bottom) Nonlinear iterations per residual layer of the trained network.

Figure 9.
(Top) A single trajectory generated by three trained implicit residual networks for the problem in Example 2. (Bottom) Continuous-time trajectory generated by the learned vector fields of these residual networks.
Figure 9.
(Top) A single trajectory generated by three trained implicit residual networks for the problem in Example 2. (Bottom) Continuous-time trajectory generated by the learned vector fields of these residual networks.

Figure 10.
(Top) Learned vector fields and trajectories for the system in Example 3 on the time interval . (Bottom) Eigenvalues of the vector fields along these trajectories.
Figure 10.
(Top) Learned vector fields and trajectories for the system in Example 3 on the time interval . (Bottom) Eigenvalues of the vector fields along these trajectories.

Figure 11.
(Top) A single trajectory generated by three trained implicit residual networks for the problem in Example 3 on the time interval ; (Bottom) continuous-time trajectory generated by the learned vector fields of these residual networks on the same time interval.
Figure 11.
(Top) A single trajectory generated by three trained implicit residual networks for the problem in Example 3 on the time interval ; (Bottom) continuous-time trajectory generated by the learned vector fields of these residual networks on the same time interval.


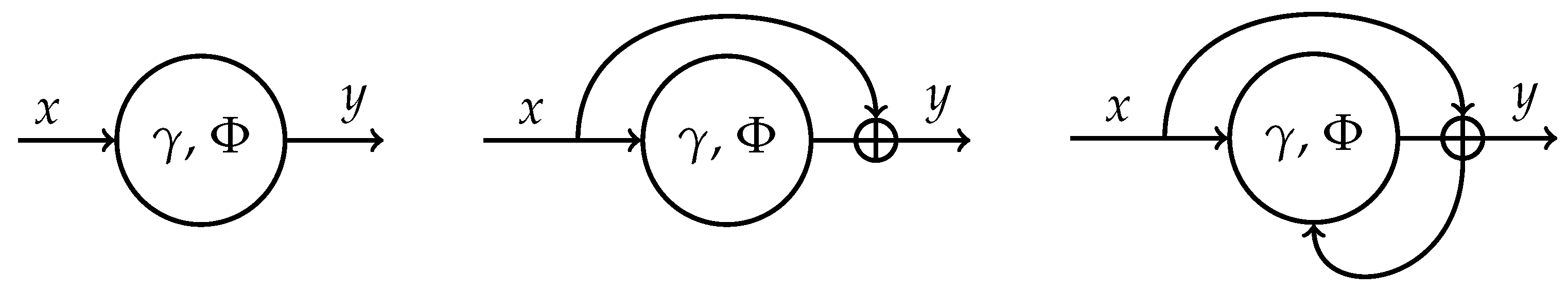{kind=link}
{kind=link}
{kind=link}
{kind=link}
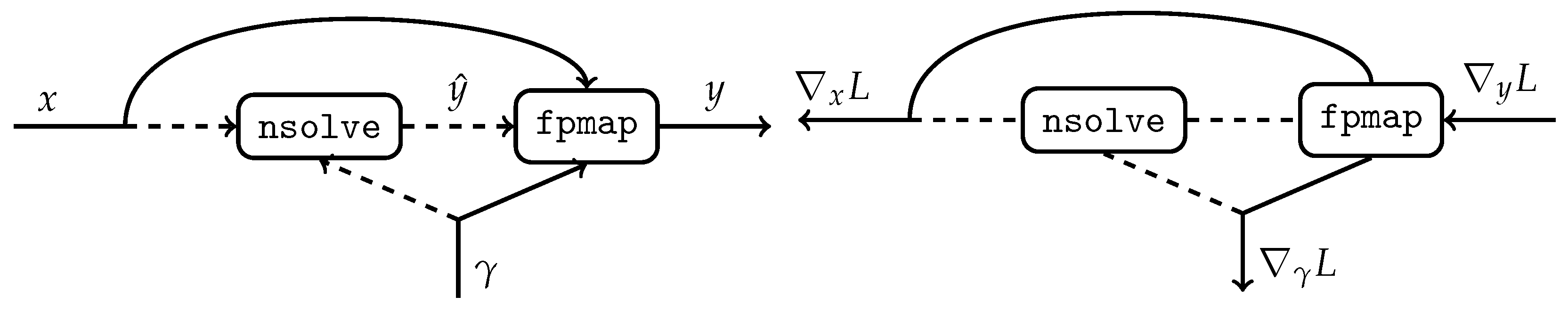{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 2.
Common descent algorithms [26].
Table 2.
Common descent algorithms [26].
| Method | Parameters | ||
|---|---|---|---|
| gradient descent | Wolfe conditions | scaling matrix momentum vector | |
| quasi-Newton | Wolfe conditions | approximate Hessian | |
| conjugate gradient | conjugate direction parameters |
Table 3.
Classification accuracy in Example 4 for different levels of Gaussian noise corruption.
| Noise | Top-1 Accuracy | Top-2 Accuracy | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Intensity | 0.25 | 0.50 | 0.75 | 1.00 | 0.25 | 0.50 | 0.75 | 1.00 | ||
| 0.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
| 0.1 | 98.2 | 99.6 | 99.9 | 99.9 | 99.9 | 99.7 | 100.0 | 100.0 | 100.0 | 100.0 |
| 0.2 | 89.2 | 95.7 | 96.3 | 98.3 | 98.4 | 96.7 | 99.3 | 99.8 | 100.0 | 100.0 |
| 0.3 | 74.7 | 86.0 | 89.3 | 93.2 | 93.6 | 89.0 | 95.2 | 97.8 | 99.0 | 98.8 |
| 0.4 | 59.3 | 74.1 | 77.2 | 81.8 | 84.7 | 75.5 | 89.1 | 91.1 | 94.4 | 95.0 |
| 0.5 | 47.2 | 60.4 | 64.7 | 69.8 | 73.0 | 65.7 | 79.6 | 83.4 | 87.1 | 87.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Reshniak, V.; Webster, C.G. Robust Learning with Implicit Residual Networks. Mach. Learn. Knowl. Extr. 2021, 3, 34-55. https://0-doi-org.brum.beds.ac.uk/10.3390/make3010003
AMA Style
Reshniak V, Webster CG. Robust Learning with Implicit Residual Networks. Machine Learning and Knowledge Extraction. 2021; 3(1):34-55. https://0-doi-org.brum.beds.ac.uk/10.3390/make3010003
Chicago/Turabian StyleReshniak, Viktor, and Clayton G. Webster. 2021. "Robust Learning with Implicit Residual Networks" Machine Learning and Knowledge Extraction 3, no. 1: 34-55. https://0-doi-org.brum.beds.ac.uk/10.3390/make3010003