
A Multi-Component Framework for the Analysis and Design of Explainable Artificial Intelligence

 , , ,
, , ,  , , ,
, , ,
Abstract
:1. Introduction
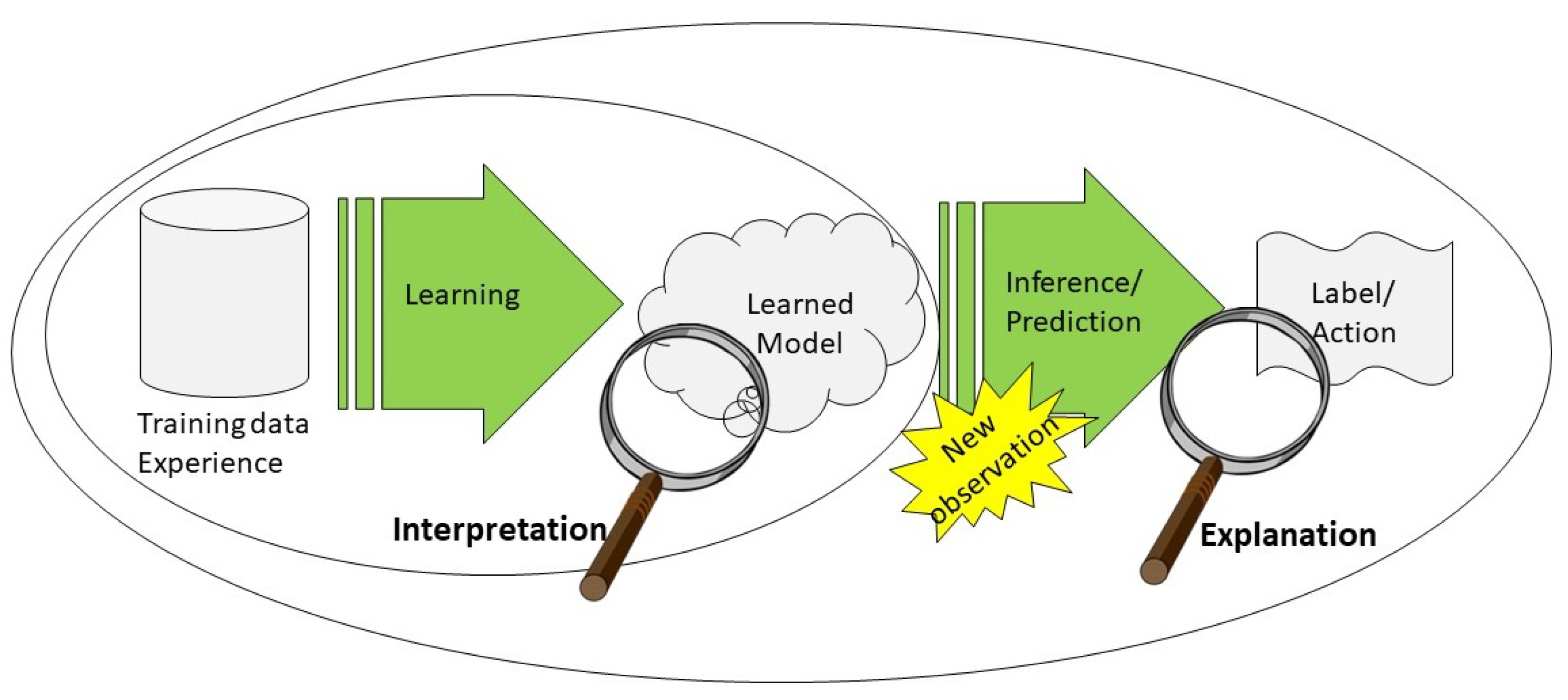
2. Principal Components at the Foundations of XAI
2.1. Explainability and Interpretability
2.2. Alternative Explanations: Who Are Explanations for?
2.3. Debugging Versus Explanation
2.4. Is There a Trade-off between Explanatory Models and Classification Accuracy?
2.5. Assessing the Quality of Explanations
3. A Brief History of Explanation
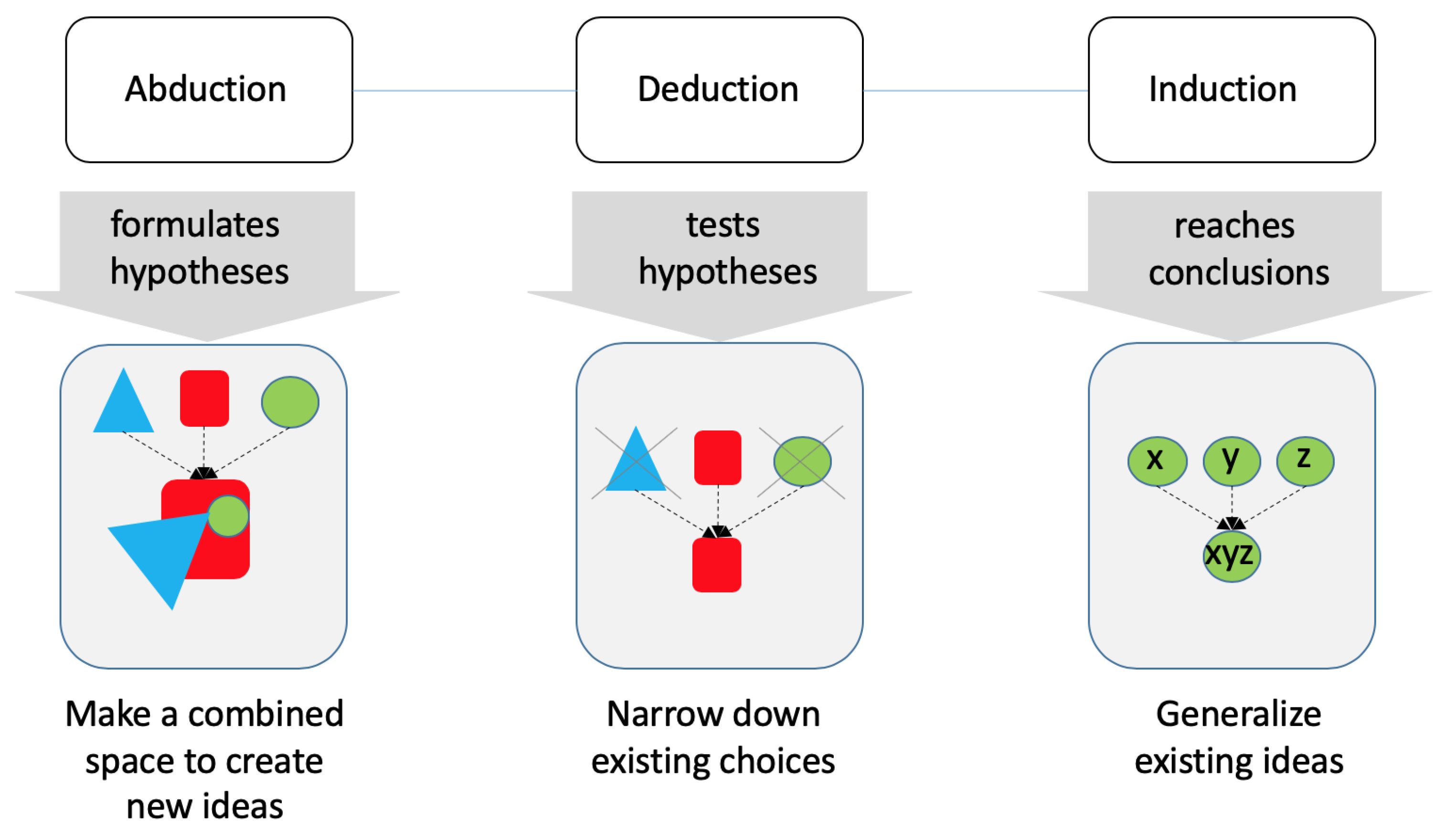
3.1. Expert Systems and Abduction
3.2. Scientific Explanation
3.3. Causality
3.4. Explaining Mechanism/Syntax Versus Semantics
- All men are mortal.
- Socrates is a man.
- Socrates is mortal.
4. Classification of Research Trends Based on Levels of Explanation
4.1. Concurrently Constructed Explanations
4.2. Post-Hoc Explanations
4.2.1. Model-Dependent Explanations
4.2.2. Model-Independent Explanations
4.3. Application Dependent vs. Generic Explanations
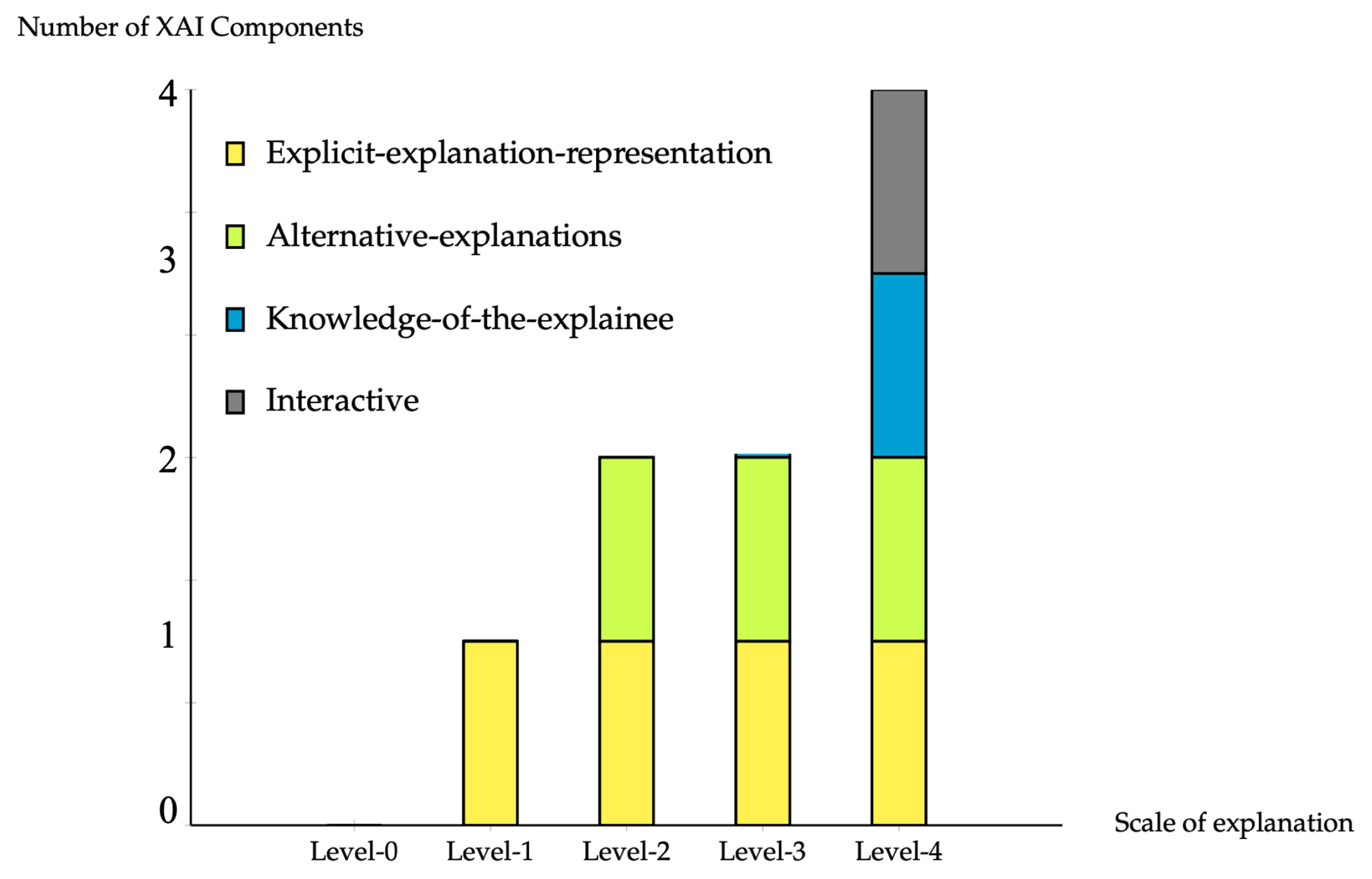
4.4. Classification Based on Levels of Explanation
4.4.1. Level 0: XAI Application Provides No Explanation
4.4.2. Level 1: XAI Application Provides Explicit Explanations
4.4.3. Level 2: XAI Application Provides Alternative Explanations
4.4.4. Level 3: AI Application Provides Explainee-Aware Alternative Explanations
4.4.5. Level 4: XAI Application Interactively Provides Explainee-Aware Alternative Explanations
5. Priority Components for a Synthesis of an XAI Architecture
5.1. XAI Architecture
5.2. User-Guided Explanation
5.3. Measuring the Value of Explanations
6. Summary and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| XAI | Explainable Artificial Intelligence |
| CNN | Convolutional Neural Network |
| BBC | British Broadcasting Corporation |
| ILP | Inductive Logic Programming |
| SSA | Sensibleness and Specificity Average |
| GPS | Global Positioning System |
| DN | Deductive Nomological |
| NLP | Natural Language Processing |
| LIME | Local Interpretable Model-Agnostic Explanations |
| MD | Model Dependent |
| MI | Model Independent |
| CC | Concurrently Constructed |
| PH | Post Hoc |
References
- Chollet, F. Deep Learning with Python; (See Especially Section 2, Chapter 9, The Limitations of Deep Learning); Manning: New York, NY, USA, 2017. [Google Scholar]
- Rudin, C. Please stop explaining black box models for high stakes decisions. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NIPS 2018), Workshop on Critiquing and Correcting Trends in Machine Learning, Montreal, QC, Canada, 7 December 2018. [Google Scholar]
- Molchanov, P.; Mallya, A.; Tyree, S.; Frosio, I.; Kautz, J. Importance Estimation for Neural Network Pruning. arXiv 2019, arXiv:1906.10771. [Google Scholar]
- Cohen, N. Can Increasing Depth Serve to Accelerate Optimization? 2018. BLOG: “Off the Convex Path”. Available online: https://www.offconvex.org/2018/03/02/acceleration-overparameterization/ (accessed on 2 March 2018).
- Woodward, J. Scientific explanation. In Stanford Encyclopedia of Philosophy; Stanford University: Palo Alto, CA, USA, 2003; Available online: https://plato.stanford.edu/entries/scientific-explanation/ (accessed on 9 May 2003).
- Pearl, J.; Mackenzie, D. The Book of Why: The New Science of Cause and Effect; Basic Books: New York, NY, USA, 2018. [Google Scholar]
- Newell, A.; Simon, H.A. Computer science as empirical inquiry: Symbols and search. Commun. ACM 1976, 19, 113–146. [Google Scholar] [CrossRef] [Green Version]
- Bashier, H.K.; Kim, M.Y.; Goebel, R. DISK-CSV: Distilling Interpretable Semantic Knowledge with a Class Semantic Vector. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics, online, 21 April 2021; pp. 3021–3030. [Google Scholar]
- Miller, T. Explanation in Artificial Intelligence: Insights from the Social Sciences. Artif. Intell. 2019, 267, 1–38. [Google Scholar] [CrossRef]
- Bex, F.; Walton, D. Combining explanation and argumentation in dialogue. Argum. Comput. 2016, 7, 55–68. [Google Scholar] [CrossRef] [Green Version]
- Amarasinghe, K.; Kenney, K.; Manic, M. Toward explainable deep neural network based anomaly detection. In Proceedings of the 2018 11th International Conference on Human System Interaction (HSI), Gdansk, Poland, 4–6 July 2018; pp. 311–317. [Google Scholar]
- Nascita, A.; Montieri, A.; Aceto, G.; Ciuonzo, D.; Persico, V.; Pescapé, A. XAI meets mobile traffic classification: Understanding and improving multimodal deep learning architectures. IEEE Trans. Netw. Serv. Manag. 2021. [Google Scholar] [CrossRef]
- Meng, Z.; Wang, M.; Bai, J.; Xu, M.; Mao, H.; Hu, H. Interpreting deep learning-based networking systems. In Proceedings of the Annual Conference of the ACM Special Interest Group on Data Communication on the Applications, Technologies, Architectures, and Protocols for Computer Communication, online, 10–14 August 2020; pp. 154–171. [Google Scholar]
- Morichetta, A.; Casas, P.; Mellia, M. EXPLAIN-IT: Towards explainable AI for unsupervised network traffic analysis. In Proceedings of the 3rd ACM CoNEXT Workshop on Big DAta, Machine Learning and Artificial Intelligence for Data Communication Networks, Orlando, FL, USA, 9 December 2019; pp. 22–28. [Google Scholar]
- Koh, P.W.; Liang, P. Understanding Black-box Predictions via Influence Functions. arXiv 2017, arXiv:1703.04730. [Google Scholar]
- Vaughan, J.; Sudjianto, A.; Brahimi, E.; Chen, J.; Nair, V.N. Explainable Neural Networks based on Additive Index Models. arXiv 2018, arXiv:1806.01933. [Google Scholar]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining Explanations: An Overview of Interpretability of Machine Learning. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1 October 2018; pp. 80–89. [Google Scholar]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef] [Green Version]
- Mendelson, E. Introduction to Mathematical Logic, 6th ed.; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- d’Avila Garcez, A.; Lamb, L.C. Neurosymbolic AI: The 3rd Wave. arXiv 2020, arXiv:2012.05876. [Google Scholar]
- Babiker, H.; Goebel, R. An Introduction to Deep Visual Explanation. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Lent, R.C. Overcoming Textbook Fatigue: 21st Century Tools to Revitalize Teaching and Learning; Association for Supervision and Curriculum Development: Alexandria, VA, USA, 2012. [Google Scholar]
- British Broadcasting Corporation. Richard Feynman: Magnets and Why Questions. 1983. Available online: https://www.youtube.com/watch?v=Dp4dpeJVDxs (accessed on 11 November 2019).
- Lécué, F.; Pommellet, T. Feeding Machine Learning with Knowledge Graphs for Explainable Object Detection. In Proceedings of the ISWC 2019 Satellite Tracks (Posters & Demonstrations, Industry, and Outrageous Ideas) co-located with 18th International Semantic Web Conference (ISWC 2019), Auckland, New Zealand, 26–30 October 2019; pp. 277–280. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Evans, R.; Greffenstette, E. Learning Explanatory Rules from Noisy Data. J. Artif. Intell. Res. 2018, 61, 1–64. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Povolny, S.; Trivedi, S. Model Hacking ADAS to Pave Safer Roads for Autonomous Vehicles. 2020. Available online: https://www.mcafee.com/blogs/other-blogs/mcafee-labs/model-hacking-adas-to-pave-safer-roads-for-autonomous-vehicles/ (accessed on 15 November 2021).
- Adiwardana, D.; Luong, M.T.; So, D.R.; Hall, J.; Fiedel, N.; Thoppilan, R.; Yang, Z.; Kulshreshtha, A.; Nemade, G.; Lu, Y.; et al. Towards a Human-like Open-Domain Chatbot. arXiv 2020, arXiv:2001.09977. [Google Scholar]
- Dickson, B. Artificial Intelligence: Does Another Huge Language Model Prove Anything? 2020. Available online: https://bdtechtalks.com/2020/02/03/google-meena-chatbot-ai-language-model/ (accessed on 14 April 2020).
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting on Association for Computational Linguistics (ACL), Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries; Text Summarization Branches Out; Association for Computational Linguistics: Barcelona, Spain, 2004; pp. 74–81. [Google Scholar]
- Liu, C.W.; Lowe, R.; Serban, I.V.; Noseworthy, M.; Charlin, L.; Pineau, J. How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 2122–2132. [Google Scholar]
- Spence, R. Information Visualization, 3rd ed.; Springer: New York, NY, USA, 2014. [Google Scholar]
- Lam, H.; Bertini, E.; Isenberg, P.; Plaisant, C.; Carpendale, S. Empirical Studies in Information Visualization: Seven Scenarios. IEEE Trans. Graph. Vis. Comput. 2012, 18, 1520–1536. [Google Scholar] [CrossRef] [Green Version]
- Goebel, R.; Shi, W.; Tanaka, Y. The role of direct manipulation of visualizations in the development and use of multi-level knowledge models. In Proceedings of the 17th International Conference on Information Visualisation, IV’13, London, UK, 16–18 July 2013; pp. 325–332. [Google Scholar]
- Ramsey, C.L.; Reggia, J.A.; Nau, D.S.; Ferrentino, A. A comparative analysis of methods for expert systems. Int. J. Man-Mach. Stud. 1986, 24, 475–499. [Google Scholar] [CrossRef]
- Lucas, P.; Van Der Gaag, L. Principles of Expert Systems; Addison-Wesley: Boston, MA, USA, 1991. [Google Scholar]
- Peirce, C.S. The architecture of theories. Monist 1891, 1, 161–176. [Google Scholar] [CrossRef]
- Pople, H. On the mechanization of abductive logic. In Proceedings of the IJCAI’73: Proceedings of the 3rd International Joint Conference on Artificial Intelligence, Stanford, CA, USA, 20–23 August 1973; pp. 147–152. [Google Scholar]
- Poole, D.; Goebel, R.; Aleliunas, R. Theorist: A Logical Reasoning System for Defaults and Diagnosis. Knowl. Front. Symb. Comput. (Artif. Intell.) 1987, 331–352. [Google Scholar] [CrossRef]
- Muggleton, S. Inductive Logic Programming. In New Generation Computing; Springer: New York, NY, USA, 1991; pp. 295–318. [Google Scholar]
- Thagard, P. Explanatory coherence. Behav. Brain Sci. 1989, 12, 435–467. [Google Scholar] [CrossRef]
- Eriksson, K.; Lindström, U.Å. Abduction—A way to deeper understanding of the world of caring. Scand. J. Caring Sci. 1997, 11, 195–198. [Google Scholar] [CrossRef]
- Jokhio, I.; Chalmers, I. Using Your Logical Powers: Abductive Reasoning for Business Success. 2015. Available online: https://uxpamagazine.org/using-your-logical-powers/ (accessed on 2 October 2021).
- Falcon, A.; Aristotle on Causality. Stanford Encyclopedia of Philosophy. 2006. Available online: https://plato.stanford.edu/entries/aristotle-causality/ (accessed on 11 January 2006).
- Hempel, C.G. The function of general laws in history. J. Philos. 1942, 39, 35–48. [Google Scholar] [CrossRef]
- Hempel, C.G. The Theoretician’s Dilemma: A Study in the Logic of Theory Construction. Minn. Stud. Philos. Sci. 1958, 2, 173–226. [Google Scholar]
- Hempel, C.G. Aspects of Scientific Explanation; Free Press: New York, NY, USA, 1965. [Google Scholar]
- Hempel, C.G.; Oppenheim, P. Studies in the Logic of Explanation. Philos. Sci. 1948, 15, 135–175. [Google Scholar] [CrossRef]
- McGrew, T.; Alspector-Kelly, M.; Allhoff, F. Philosophy of Science: An Historical Anthology; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 14. [Google Scholar]
- Bunzl, M. The Context of Explanation; Boston Studies in the Philosophy and History of Science; Springer Science and Business Media: Berlin/Heidelberg, Germany, 1993; Volume 149. [Google Scholar]
- Janssen, T. Montague Semantics. 2016. Available online: https://plato.stanford.edu/entries/montague-semantics/ (accessed on 24 February 2020).
- Lei, T.; Barzilay, R.; Jaakkola, T. Rationalizing Neural Predictions. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 107–117. [Google Scholar] [CrossRef]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Serrano, S.; Smith, N.A. Is Attention Interpretable? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2931–2951. [Google Scholar] [CrossRef] [Green Version]
- Jain, S.; Wallace, B.C. Attention is not explanation. arXiv 2019, arXiv:1902.10186. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why should i trust you? Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4765–4774. [Google Scholar]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Pedreschi, D.; Turini, F.; Giannotti, F. Local rule-based explanations of black box decision systems. arXiv 2018, arXiv:1805.10820. [Google Scholar]
- Hendricks, L.A.; Hu, R.; Darrell, T.; Akata, Z. Grounding visual explanations. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 269–286. [Google Scholar]
- Bastings, J.; Aziz, W.; Titov, I. Interpretable Neural Predictions with Differentiable Binary Variables. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July 28–2 August 2019; pp. 2963–2977. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Kasirzadeh, A. Mathematical Decisions & Non-causal Elements of Explainable AI. arXiv 2019, arXiv:1910.13607. [Google Scholar]
- Madumal, P.; Miller, T.; Vetere, F.; Sonenberg, L. Towards a Grounded Dialog Model for Explainable Artificial Intelligence. arXiv 2018, arXiv:1806.08055. [Google Scholar]
- Bear, A.; Knobe, J. Normality: Part descriptive, Part prescriptive. Cognition 2017, 167, 25–37. [Google Scholar] [CrossRef] [Green Version]
- Gunning, D. Explainable Artificial Intelligence. November 2017. Available online: https://www.darpa.mil/attachments/XAIIndustryDay_Final.pptx (accessed on 11 August 2016).




{kind=link}
{kind=link}
{kind=link}
| Attributes | Level 0 | Level 1 | Level 2 | Level 3 | Level 4 |
|---|---|---|---|---|---|
| Explicit explanation representation | ✓ | ✓ | ✓ | ✓ | |
| Alternative Explanations | ✓ | ✓ | ✓ | ||
| Knowledge of the explainee | ✓ | ✓ | |||
| Interactive | ✓ |
| Method | Level | MD/MI | CC/PH |
|---|---|---|---|
| LIME [60] | 1 | MI | PH |
| Grad-CAM [59] | 1 | MD | PH |
| SHAP [61] | 1 | MI | PH |
| Rationalizing predictions [55] | 1 | MD | CC |
| Grounding visual explanations [63] | 2 | MD | PH |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M.-Y.; Atakishiyev, S.; Babiker, H.K.B.; Farruque, N.; Goebel, R.; Zaïane, O.R.; Motallebi, M.-H.; Rabelo, J.; Syed, T.; Yao, H.; et al. A Multi-Component Framework for the Analysis and Design of Explainable Artificial Intelligence. Mach. Learn. Knowl. Extr. 2021, 3, 900-921. https://0-doi-org.brum.beds.ac.uk/10.3390/make3040045
Kim M-Y, Atakishiyev S, Babiker HKB, Farruque N, Goebel R, Zaïane OR, Motallebi M-H, Rabelo J, Syed T, Yao H, et al. A Multi-Component Framework for the Analysis and Design of Explainable Artificial Intelligence. Machine Learning and Knowledge Extraction. 2021; 3(4):900-921. https://0-doi-org.brum.beds.ac.uk/10.3390/make3040045
Chicago/Turabian StyleKim, Mi-Young, Shahin Atakishiyev, Housam Khalifa Bashier Babiker, Nawshad Farruque, Randy Goebel, Osmar R. Zaïane, Mohammad-Hossein Motallebi, Juliano Rabelo, Talat Syed, Hengshuai Yao, and et al. 2021. "A Multi-Component Framework for the Analysis and Design of Explainable Artificial Intelligence" Machine Learning and Knowledge Extraction 3, no. 4: 900-921. https://0-doi-org.brum.beds.ac.uk/10.3390/make3040045