
Fast Hyperparameter Calibration of Sparsity Enforcing Penalties in Total Generalised Variation Penalised Reconstruction Methods for XCT Using a Planted Virtual Reference Image


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Motivations
1.2. The Hyperparameter Tuning Problem
1.3. Our Contribution
2. Total Variation and Total Generalised Variation
3. Estimating the Reconstruction Error Using a Planted Virtual Image Approach
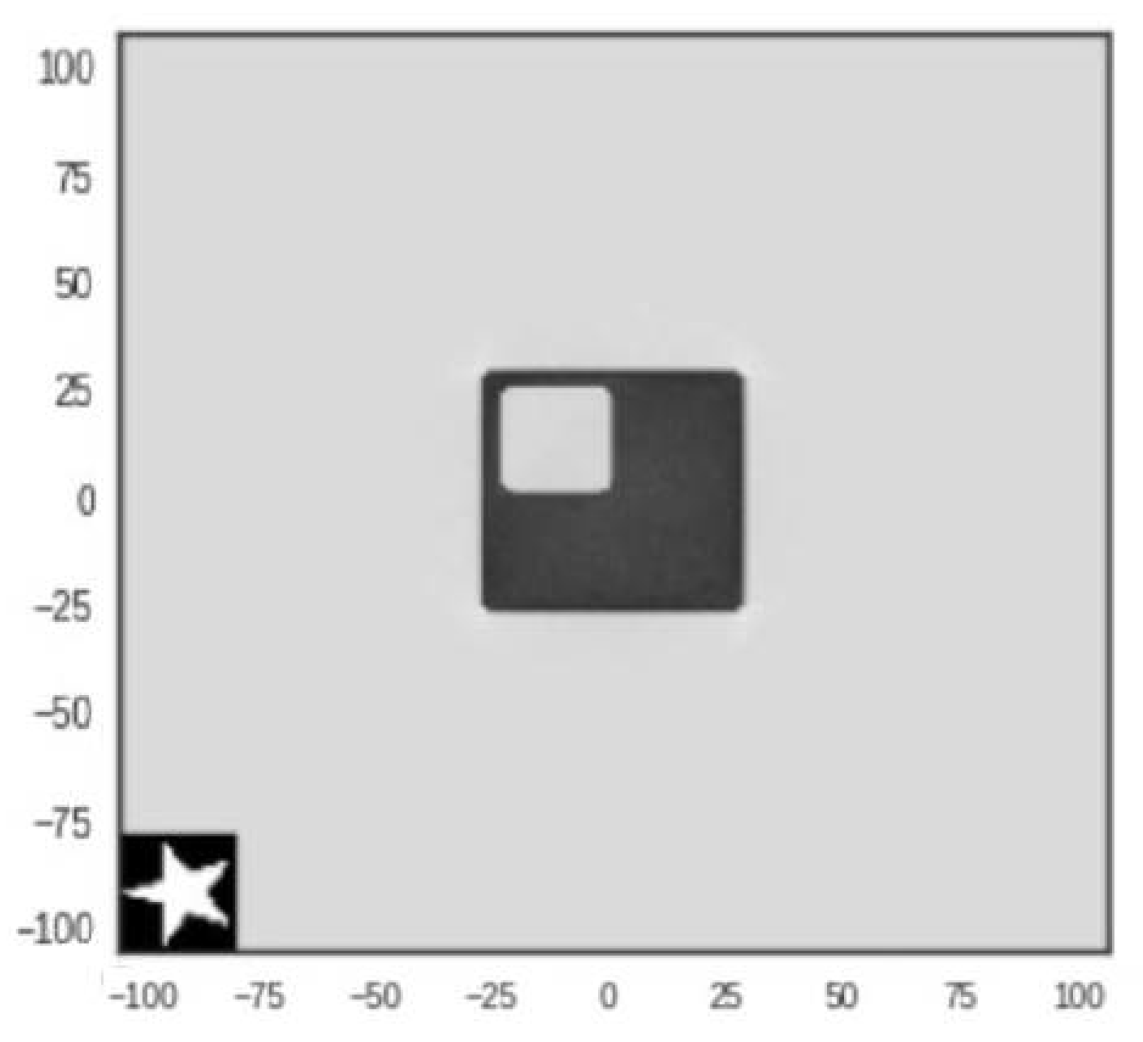
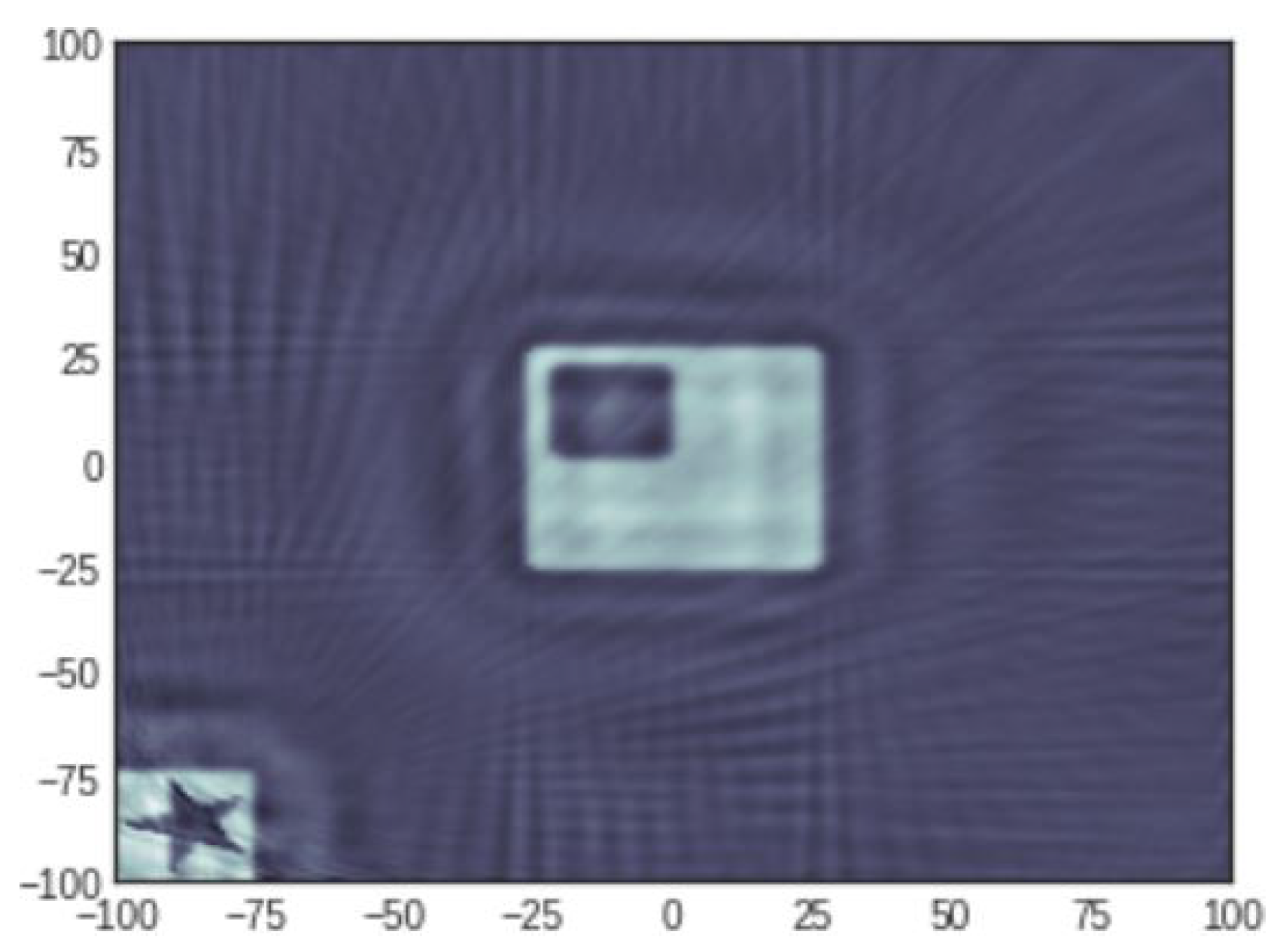
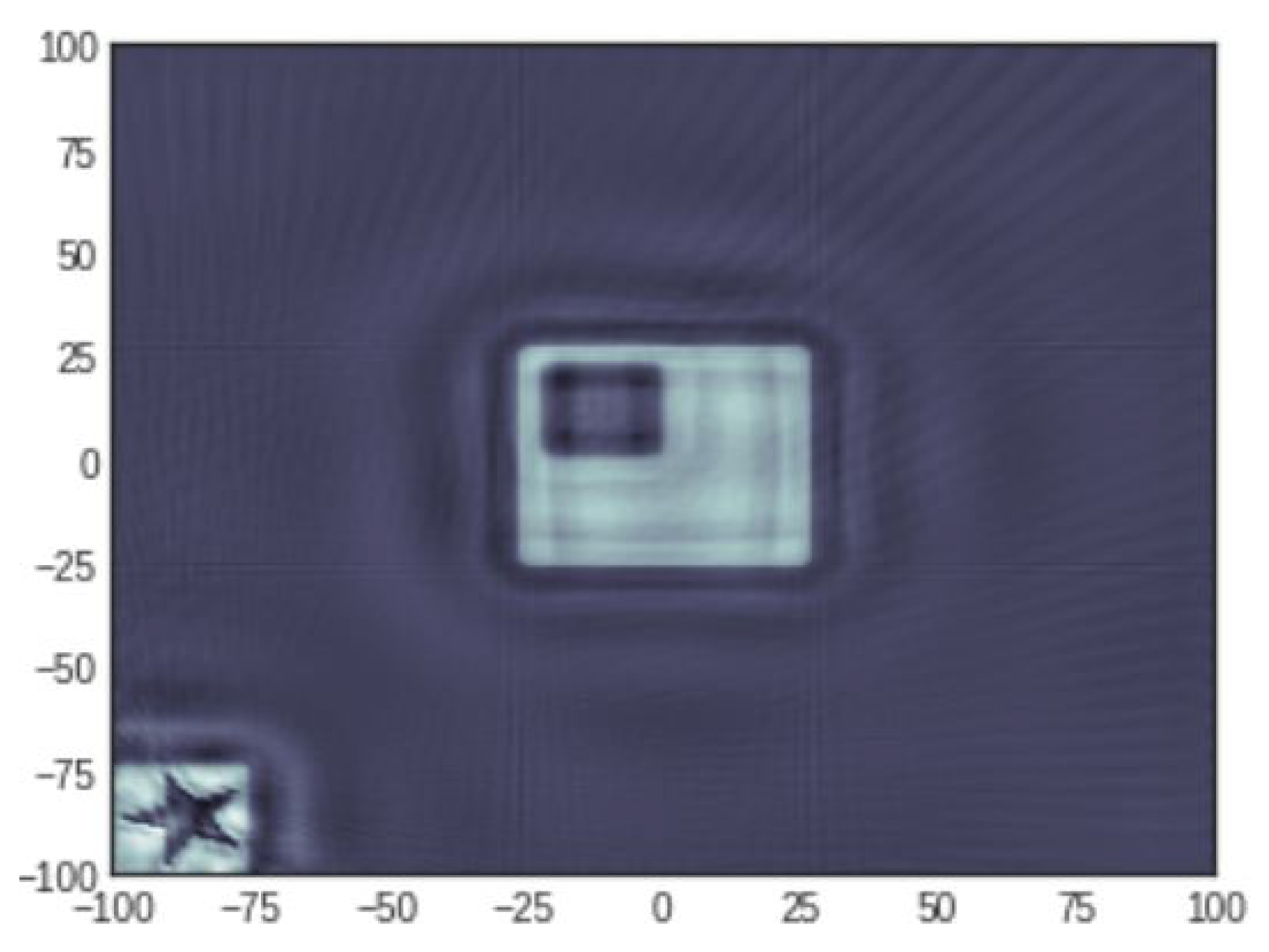
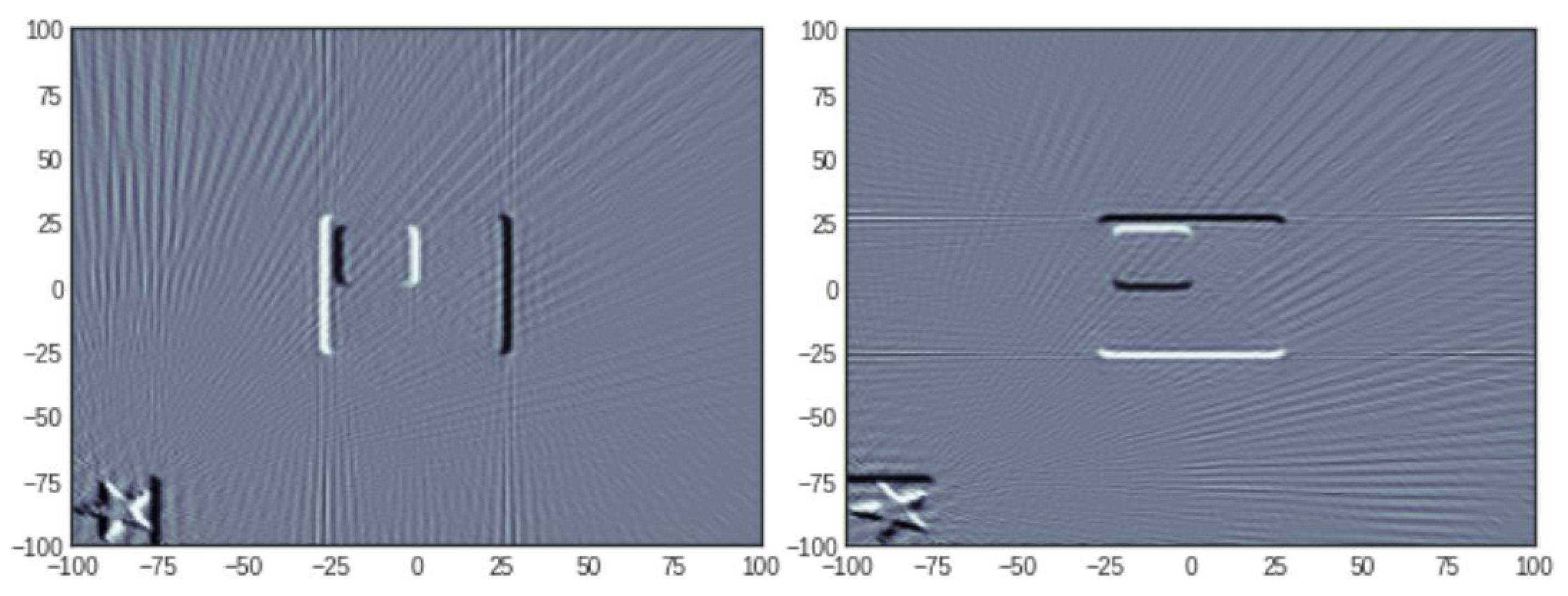
3.1. Main Idea: Planting Known Shapes in the Image
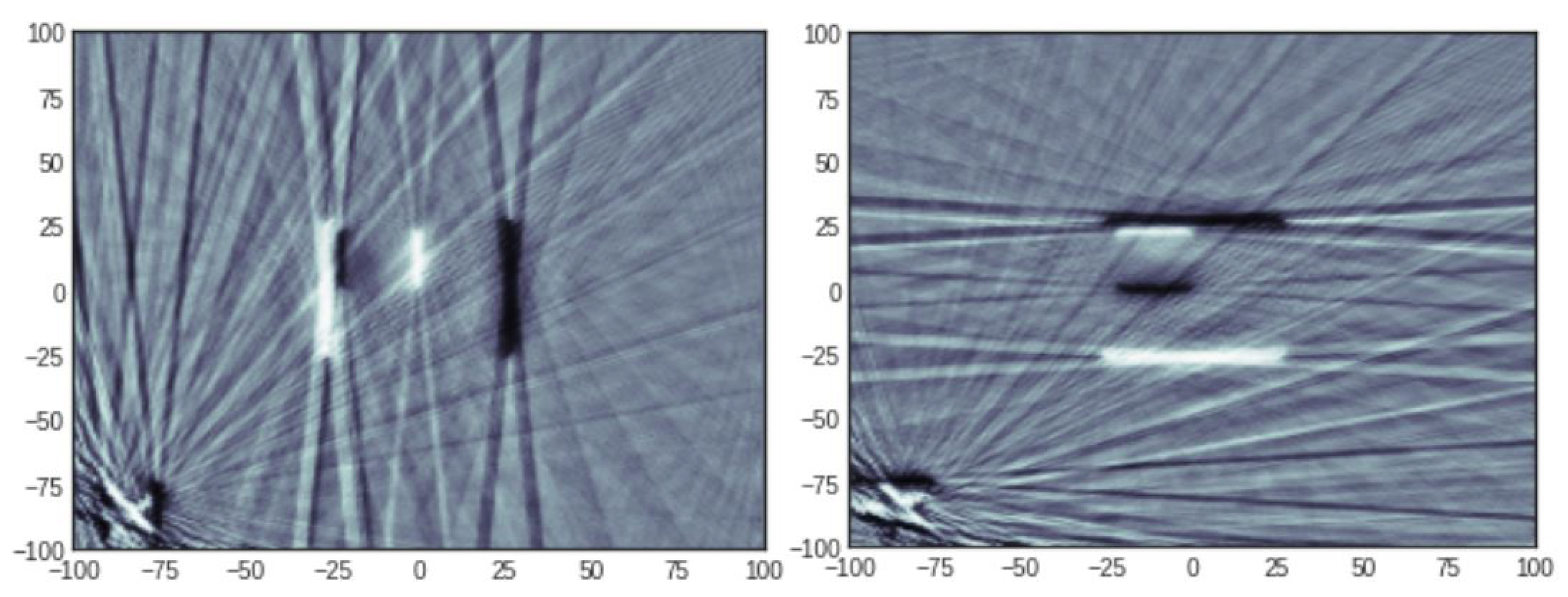
3.2. Numerical Validation
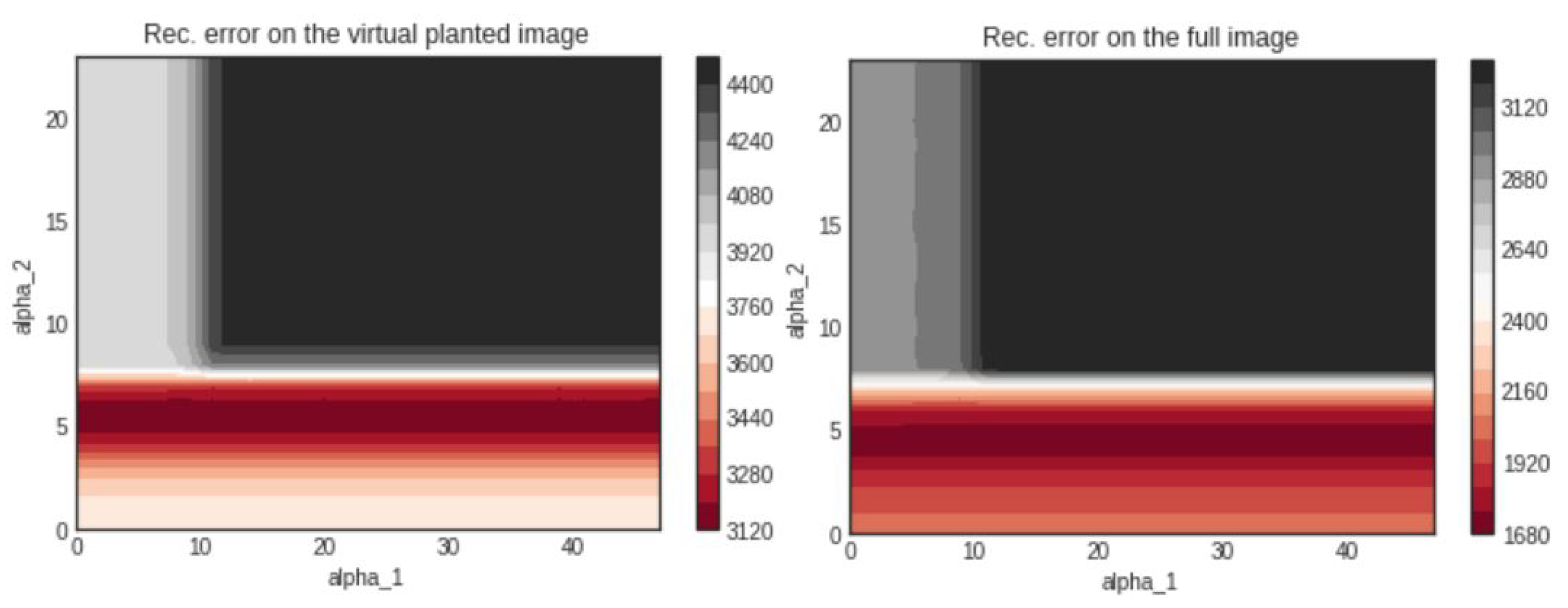
3.2.1. Comparison of the Reconstruction Errors: 20 Projections
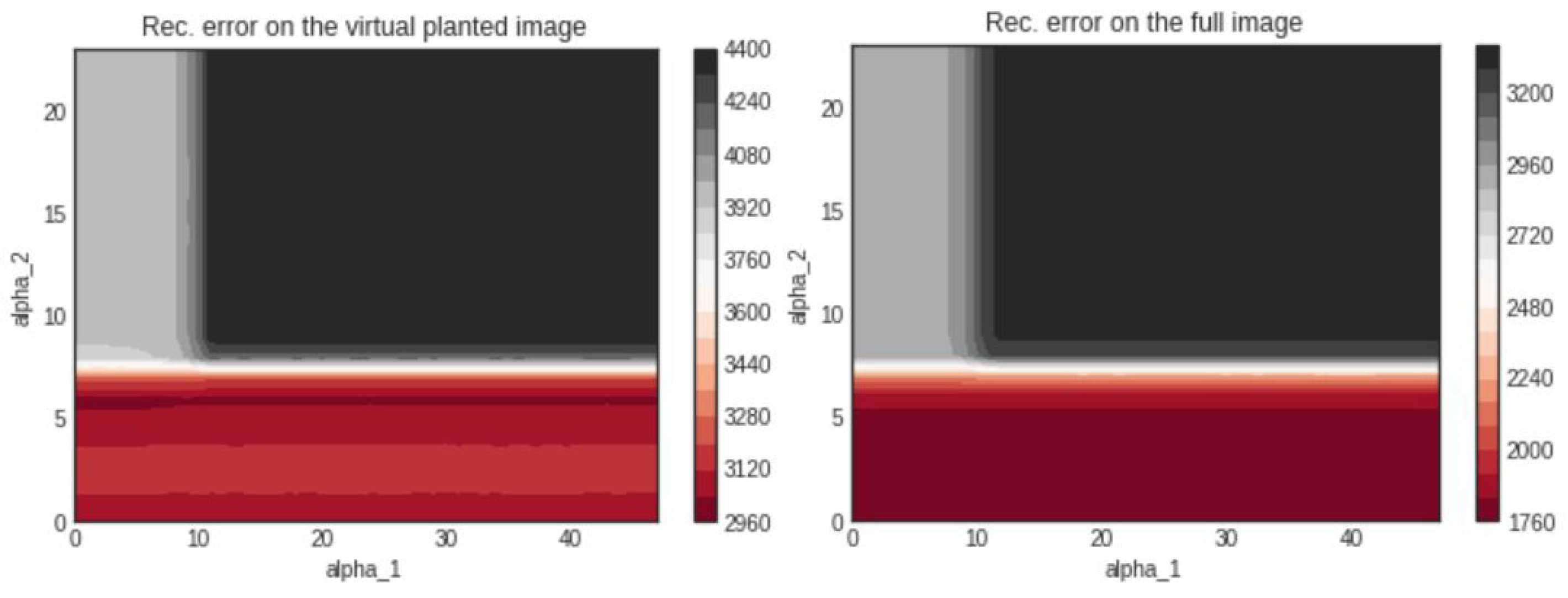
3.2.2. Comparison of the Reconstruction Errors: 50 Projections
3.2.3. Comparison of the Reconstruction Errors: 100 Projections
3.2.4. Comments on the Numerical Results
4. Minimising the Reconstruction Error on the Planted Virtual Image Using Bayesian Optimisation
4.1. Description of the Method
| Algorithm 1: Basic pseudo-code for Bayesian optimisation. |
 |
4.2. Computational Results
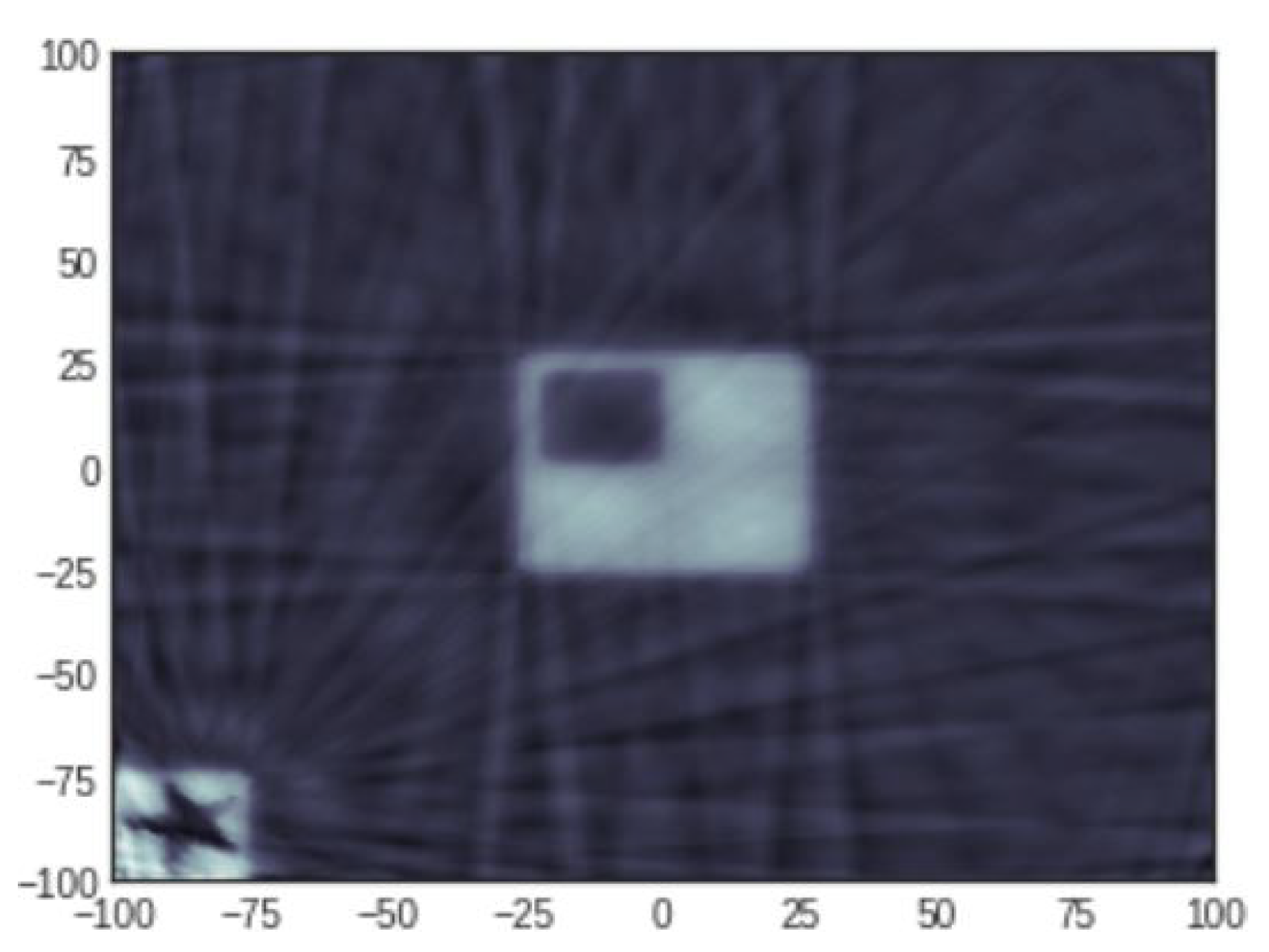
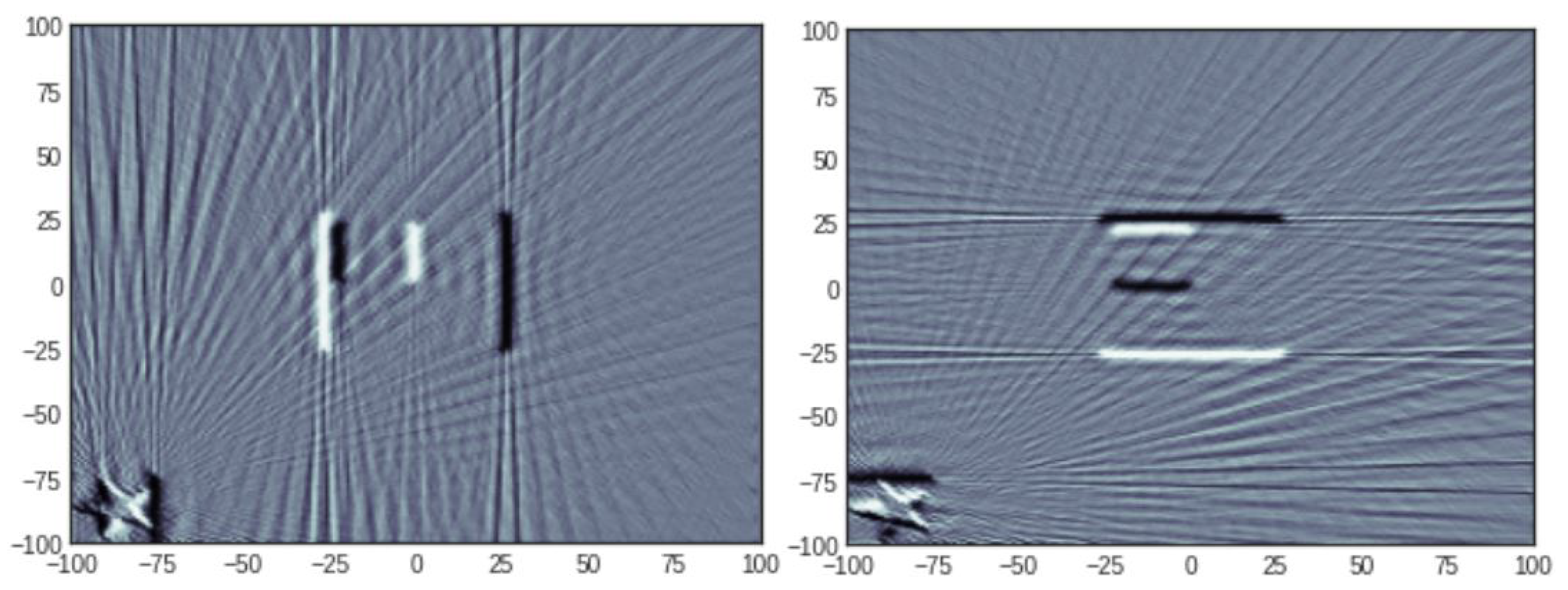
4.2.1. Reconstruction Results: 20 Projections
4.2.2. Reconstruction Results: 50 Projections
4.2.3. Reconstruction Results: 100 Projections
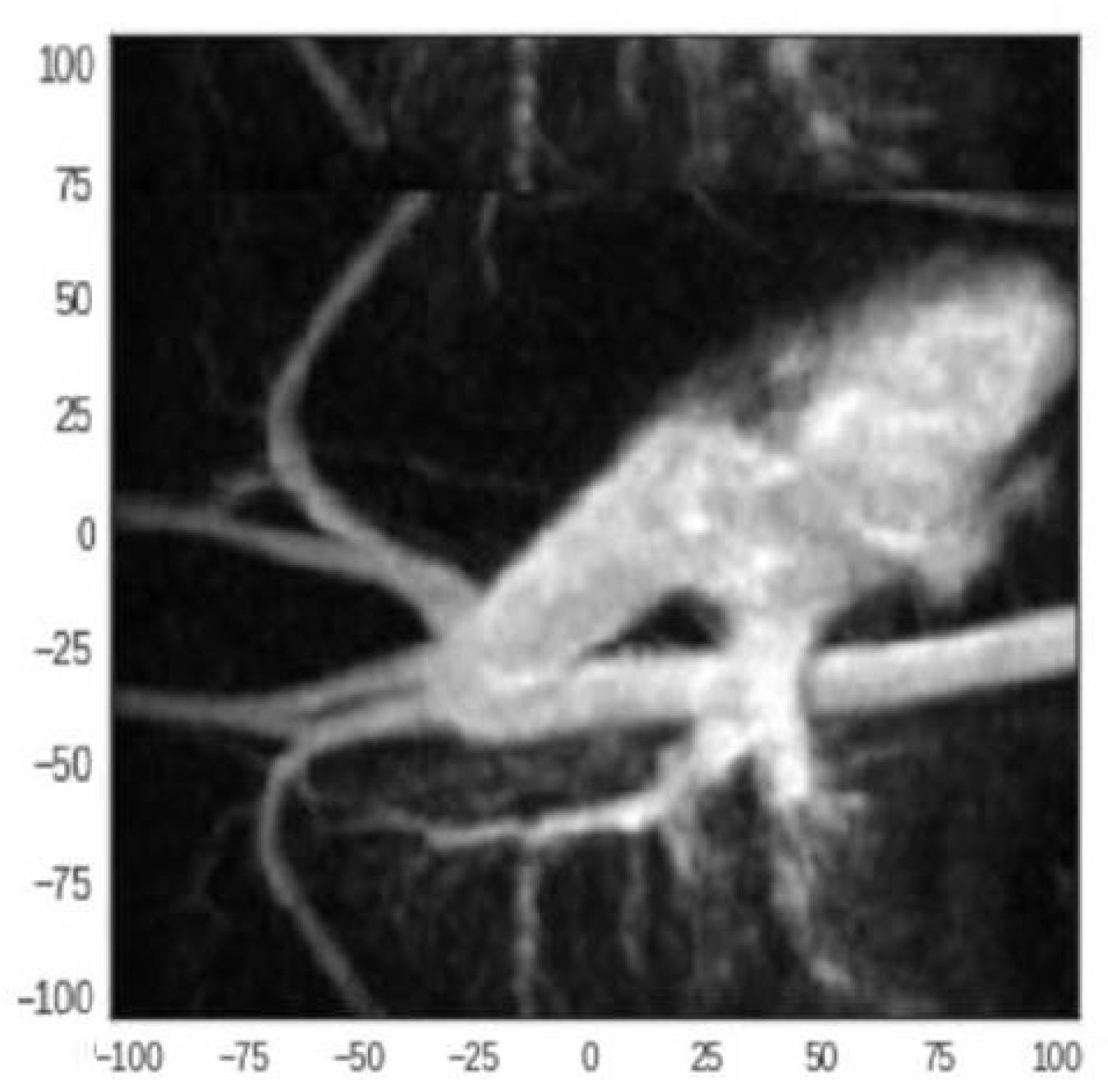
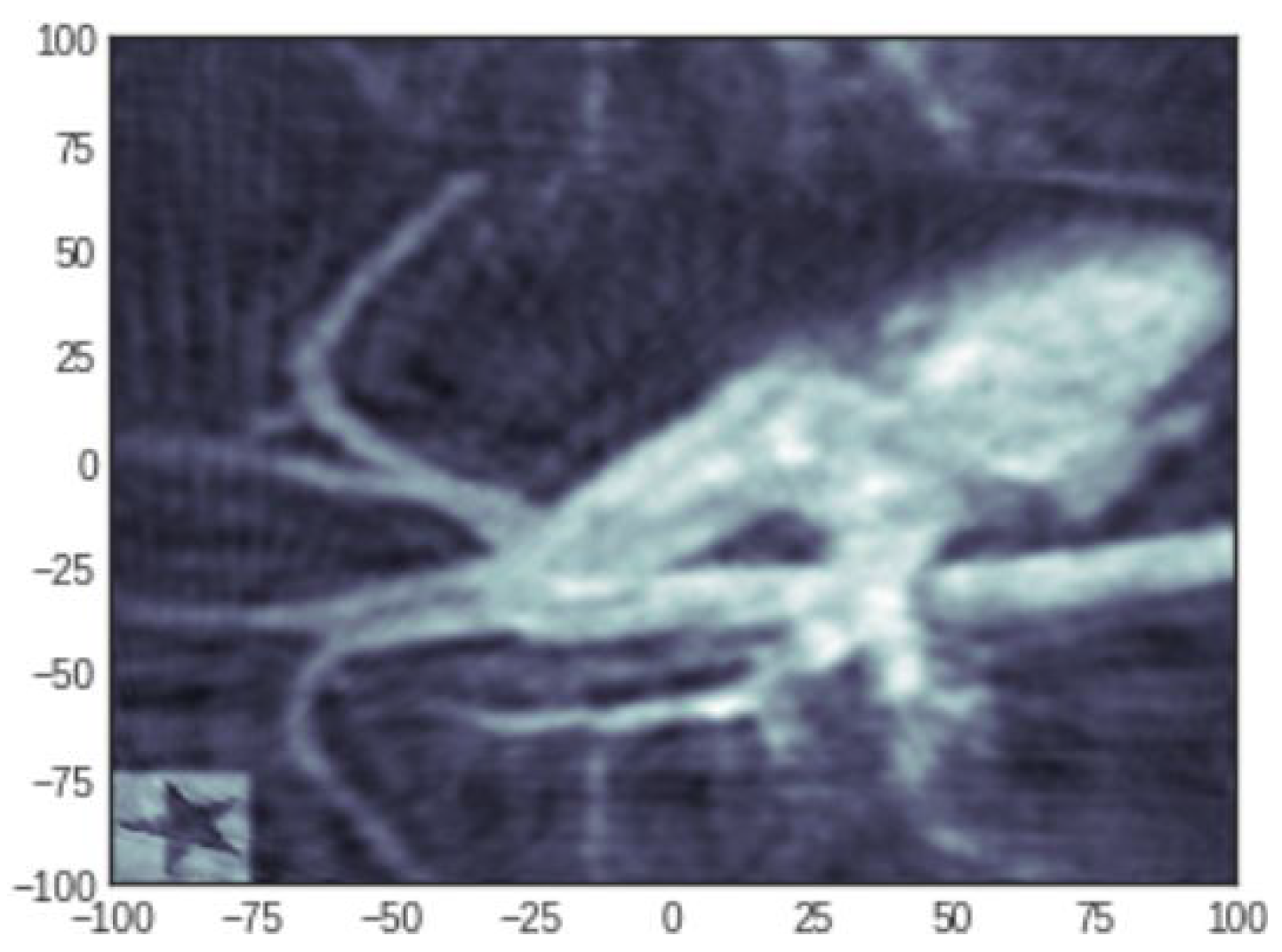
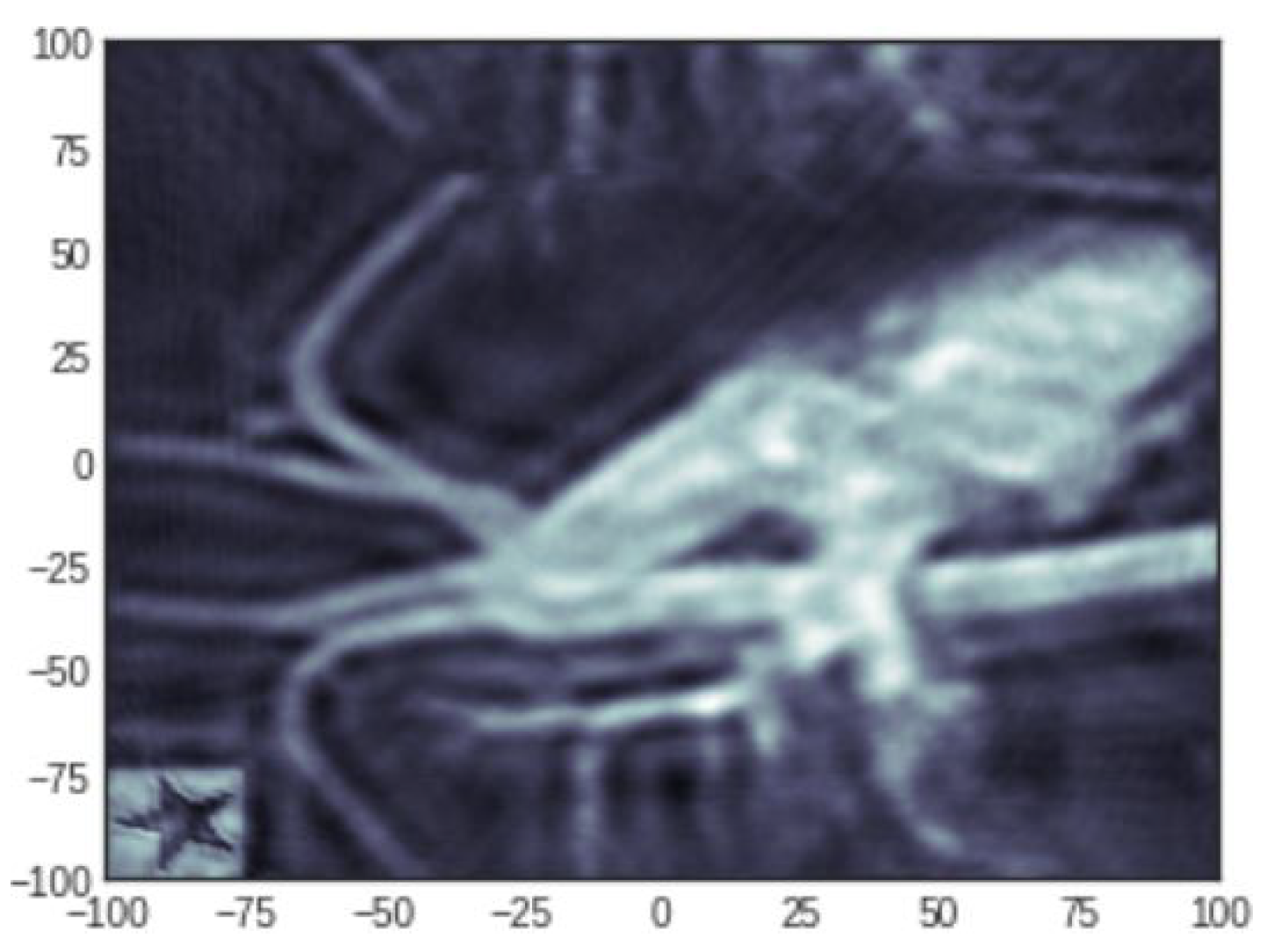
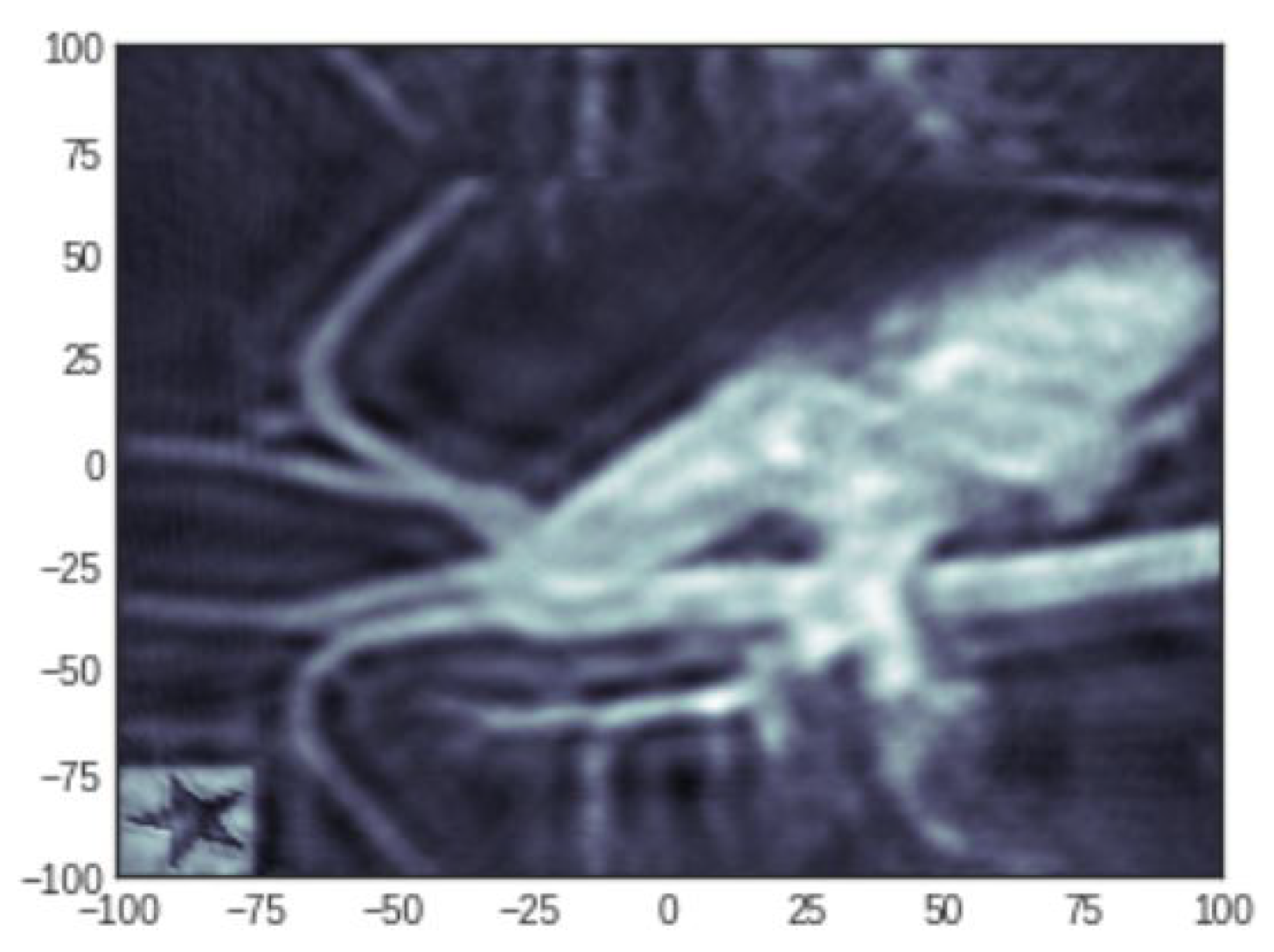
4.3. Reconstruction of a Medical Image
4.3.1. Reconstruction with 50 Projections
4.3.2. Reconstruction with 100 Projections
4.3.3. Reconstruction with 100 Projections and Four Parameters
4.4. Discussion of the Benefits as Compared with the Other Approaches
5. Conclusions
Author Contributions
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Sun, W.; Brown, S.; Leach, R. An Overview of Industrial X-ray Computed Tomography; National Physical Laboratory: Teddington, UK, 2012. [Google Scholar]
- Candes, E.J.; Tao, T. Near-optimal signal recovery from random projections: Universal encoding strategies? IEEE Trans. Inf. Theory 2006, 52, 5406–5425. [Google Scholar] [CrossRef] [Green Version]
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Candès, E.J. Compressive sampling. In Proceedings of the International Congress of Mathematicians, Madrid, Spain, 22–30 August 2006; pp. 1433–1452. [Google Scholar]
- Baraniuk, R.G. Compressive sensing. IEEE Signal Process. Mag. 2007, 24, 1–9. [Google Scholar] [CrossRef]
- Candès, E.J.; Wakin, M.B. An introduction to compressive sampling [a sensing/sampling paradigm that goes against the common knowledge in data acquisition]. IEEE Signal Process. Mag. 2008, 25, 21–30. [Google Scholar]
- Chretien, S. An alternating l_1 approach to the compressed sensing problem. IEEE Signal Process. Lett. 2009, 17, 181–184. [Google Scholar] [CrossRef] [Green Version]
- Giraud, C.; Huet, S.; Verzelen, N. High-dimensional regression with unknown variance. Stat. Sci. 2012, 27, 500–518. [Google Scholar] [CrossRef]
- Chrétien, S.; Darses, S. Sparse recovery with unknown variance: A LASSO-type approach. IEEE Trans. Inf. Theory 2014, 60, 3970–3988. [Google Scholar] [CrossRef]
- Tillmann, A.M.; Pfetsch, M.E. The computational complexity of the restricted isometry property, the nullspace property, and related concepts in compressed sensing. IEEE Trans. Inf. Theory 2013, 60, 1248–1259. [Google Scholar] [CrossRef] [Green Version]
- Wu, T.T.; Lange, K. Coordinate descent algorithms for lasso penalized regression. Ann. Appl. Stat. 2008, 2, 224–244. [Google Scholar] [CrossRef]
- Beck, A.; Teboulle, M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef] [Green Version]
- Sra, S.; Nowozin, S.; Wright, S.J. Optimization for Machine Learning; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Arlot, S.; Celisse, A. A survey of cross-validation procedures for model selection. Stat. Surv. 2010, 4, 40–79. [Google Scholar] [CrossRef]
- Assoweh, M.; Chrétien, S.; Tamadazte, B. Low tubal rank tensor recovery using the Burer-Monteiro factorisation approach. Application to optical coherence tomography. J. Appl. Comput. Math. (under review).
- Maron, O.; Moore, A.W. Hoeffding races: Accelerating model selection search for classification and function approximation. In Advances in Neural Information Processing Systems; Carnegie Mellon University: Pittsburgh, PA, USA, 1994; pp. 59–66. [Google Scholar]
- Chretien, S.; Gibberd, A.; Roy, S. Hedging parameter selection for basis pursuit. arXiv 2018, arXiv:1805.01870. [Google Scholar]
- Li, L.; Jamieson, K.; DeSalvo, G.; Rostamizadeh, A.; Talwalkar, A. Hyperband: A novel bandit-based approach to hyperparameter optimization. J. Mach. Learn. Res. 2017, 18, 6765–6816. [Google Scholar]
- Donoho, D.L.; Johnstone, I.M. Adapting to unknown smoothness via wavelet shrinkage. J. Am. Stat. Assoc. 1995, 90, 1200–1224. [Google Scholar] [CrossRef]
- Stein, C.M. Estimation of the mean of a multivariate normal distribution. Ann. Stat. 1981, 9, 1135–1151. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T.; Tibshirani, R. On the “degrees of freedom” of the lasso. Ann. Stat. 2007, 35, 2173–2192. [Google Scholar] [CrossRef]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical bayesian optimization of machine learning algorithms. In Advances in Neural Information Processing Systems; NeurIPS: Toronto, ON, Canada, 2012; Volume 25. [Google Scholar]
- Eggensperger, K.; Feurer, M.; Hutter, F.; Bergstra, J.; Snoek, J.; Hoos, H.; Leyton-Brown, K. Towards an empirical foundation for assessing bayesian optimization of hyperparameters. In Proceedings of the NIPS workshop on Bayesian Optimization in Theory and Practice, SEMANTIC SCHOLAR, Lake Tahoe, NV, USA, 5–8 December 2013; Volume 10. [Google Scholar]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; De Freitas, N. Taking the human out of the loop: A review of Bayesian optimization. Proc. IEEE 2015, 104, 148–175. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Chen, X.Y.; Zhang, H.; Xiong, L.D.; Lei, H.; Deng, S.H. Hyperparameter optimization for machine learning models based on Bayesian optimization. J. Electron. Sci. Technol. 2019, 17, 26–40. [Google Scholar]
- MacKay, M.; Vicol, P.; Lorraine, J.; Duvenaud, D.; Grosse, R. Self-tuning networks: Bilevel optimization of hyperparameters using structured best-response functions. arXiv 2019, arXiv:1903.03088. [Google Scholar]
- Bredies, K.; Kunisch, K.; Pock, T. Total generalized variation. SIAM J. Imaging Sci. 2010, 3, 492–526. [Google Scholar] [CrossRef]
- Zhang, C.H.; Zhang, S.S. Confidence intervals for low dimensional parameters in high dimensional linear models. J. R. Stat. Soc. Ser. B Stat. Methodol. 2014, 76, 217–242. [Google Scholar] [CrossRef] [Green Version]

















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chrétien, S.; Giampiccolo, C.; Sun, W.; Talbott, J. Fast Hyperparameter Calibration of Sparsity Enforcing Penalties in Total Generalised Variation Penalised Reconstruction Methods for XCT Using a Planted Virtual Reference Image. Mathematics 2021, 9, 2960. https://0-doi-org.brum.beds.ac.uk/10.3390/math9222960
Chrétien S, Giampiccolo C, Sun W, Talbott J. Fast Hyperparameter Calibration of Sparsity Enforcing Penalties in Total Generalised Variation Penalised Reconstruction Methods for XCT Using a Planted Virtual Reference Image. Mathematics. 2021; 9(22):2960. https://0-doi-org.brum.beds.ac.uk/10.3390/math9222960
Chicago/Turabian StyleChrétien, Stéphane, Camille Giampiccolo, Wenjuan Sun, and Jessica Talbott. 2021. "Fast Hyperparameter Calibration of Sparsity Enforcing Penalties in Total Generalised Variation Penalised Reconstruction Methods for XCT Using a Planted Virtual Reference Image" Mathematics 9, no. 22: 2960. https://0-doi-org.brum.beds.ac.uk/10.3390/math9222960