
Opti-nQL: An Optimized, Versatile and Sensitive Nano-LC Method for MS-Based Lipidomics Analysis

 , , and
, , and
Abstract
:1. Introduction
2. Results and Discussion
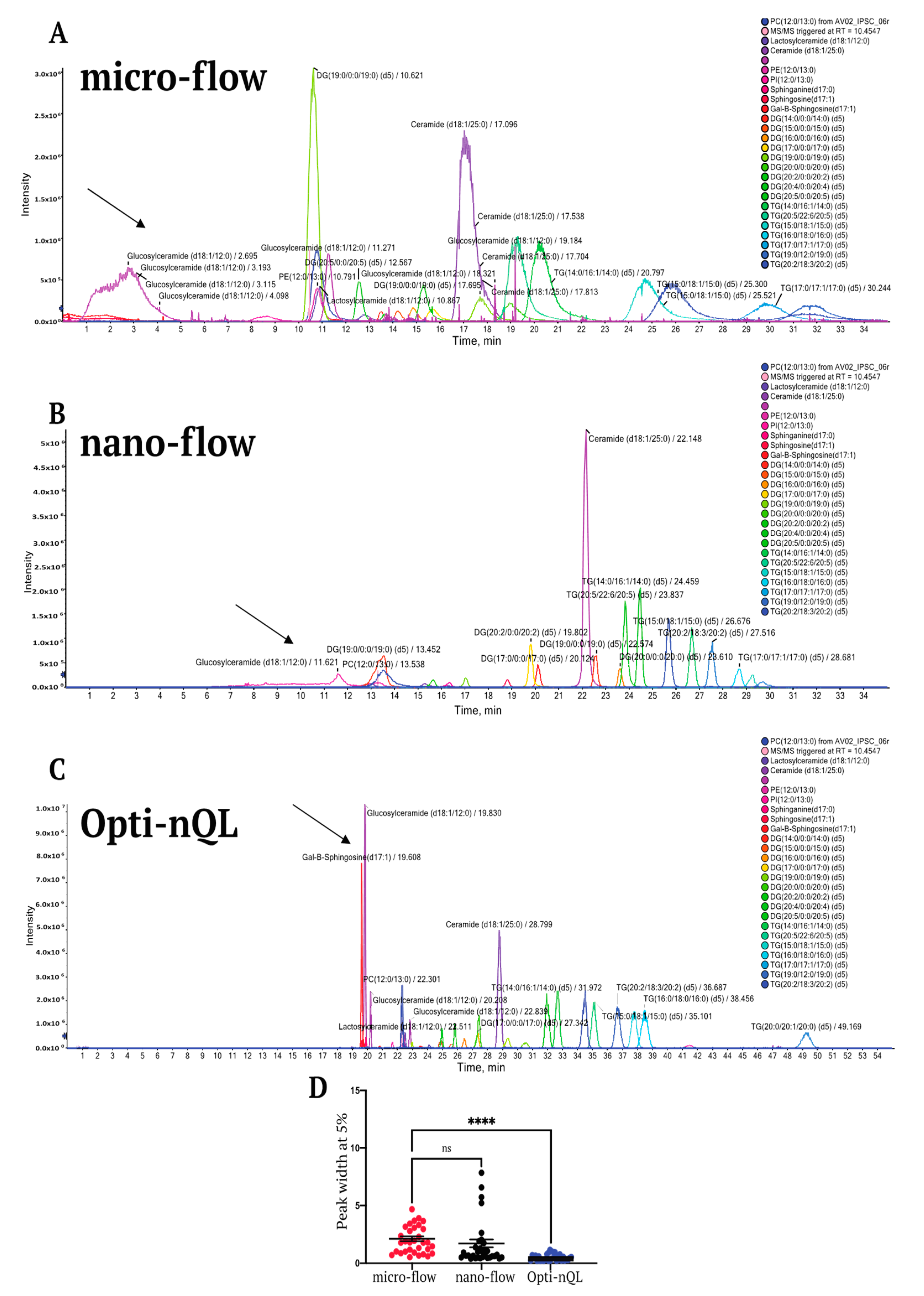
2.1. Method Development
Lipid Extraction and LC Optimization
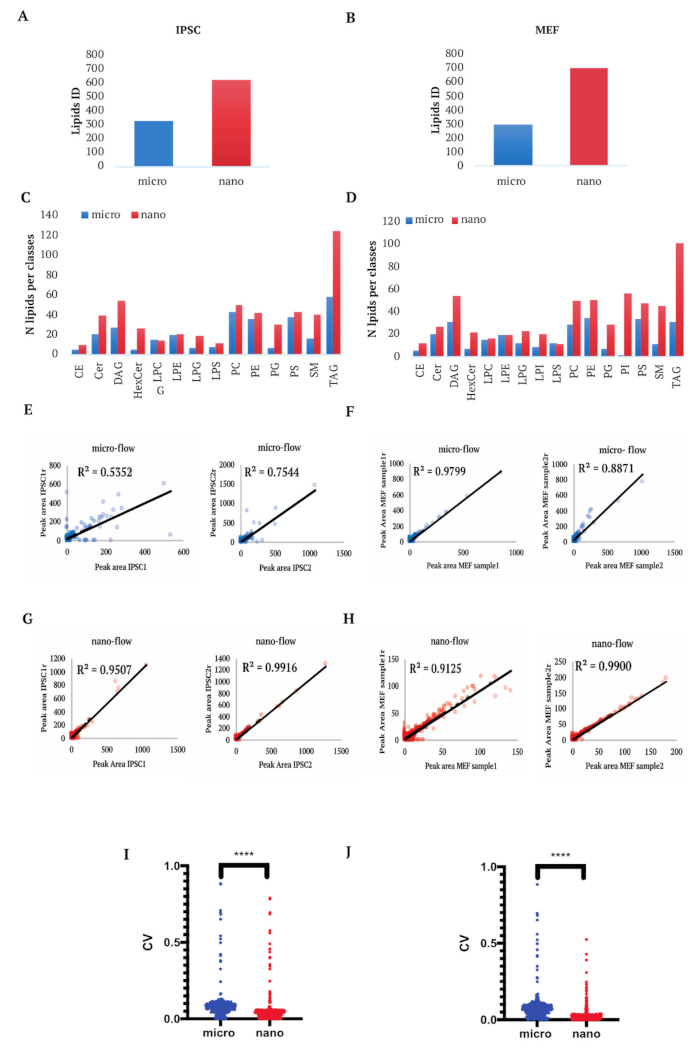
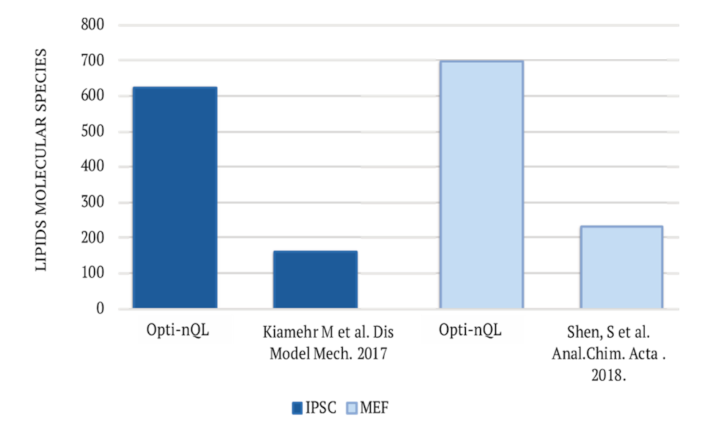
2.2. Lipidomics Analysis of Mammalian Cells
2.2.1. Semi-Targeted Lipidomics Analysis
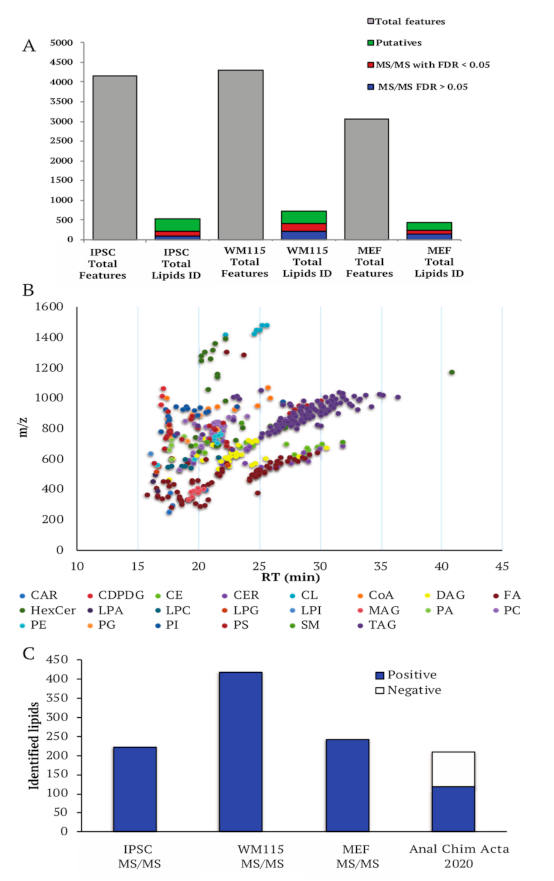
2.2.2. Untargeted Lipidomics Analysis
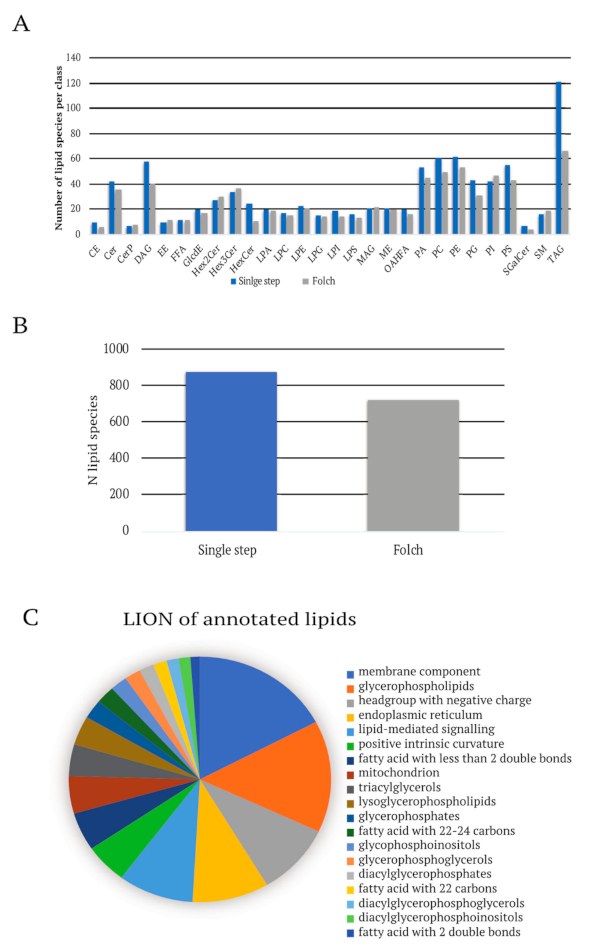
2.3. Opti-nQL Is Compatible with Alternative Lipid Extraction Methods
3. Materials and Methods
3.1. Materials
3.2. Biological Sample Collection and Cell Lysis
3.3. Proteins Extraction and Quantification
3.4. Lipids Extraction
3.5. Liquid Chromatography
3.6. Mass Spectrometry Analysis
3.7. Data Processing and Analysis
3.8. Statistics
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Finkelstein, J.; Heemels, M.T.; Shadan, S.; Weiss, U. Lipids in health and disease. Nature 2014, 510, 47. [Google Scholar] [CrossRef]
- Han, X. Lipidomics for studying metabolism. Nat. Rev. Endocrinol. 2016, 12, 668–679. [Google Scholar] [CrossRef]
- Rustam, Y.H.; Reid, G.E. Analytical Challenges and Recent Advances in Mass Spectrometry Based Lipidomics. Anal. Chem. 2018, 90, 374–397. [Google Scholar] [CrossRef]
- Fahy, E.; Subramaniam, S.; Brown, H.A.; Glass, C.K.; Merrill, A.H., Jr.; Murphy, R.C.; Raetz, C.R.; Russell, D.W.; Seyama, Y.; Shaw, W.; et al. A comprehensive classification system for lipids. J. Lipid Res. 2005, 46, 839–861. [Google Scholar] [CrossRef] [Green Version]
- Zullig, T.; Kofeler, H.C. High Resolution Mass Spectrometry in Lipidomics. Mass Spectrom. Rev. 2020, 40, 162–176. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Griffiths, W.J.; Yutuc, E.; Davies, D.; Dickson, A.; Angelini, R.; El Assad, D.; Frache, G.; Wang, Y. Chapter 1 Lipidomics Basics. In Lipidomics: Current and Emerging Techniques; The Royal Society of Chemistry: London, UK, 2020; pp. 1–24. [Google Scholar]
- Sales, S.; Knittelfelder, O.; Shevchenko, A. Lipidomics of Human Blood Plasma by High-Resolution Shotgun Mass Spectrometry. Methods Mol. Biol. 2017, 1619, 203–212. [Google Scholar] [CrossRef] [PubMed]
- Hsu, F.F. Mass spectrometry-based shotgun lipidomics—A critical review from the technical point of view. Anal. Bioanal. Chem. 2018, 410, 6387–6409. [Google Scholar] [CrossRef] [PubMed]
- Holcapek, M.; Liebisch, G.; Ekroos, K. Lipidomic Analysis. Anal. Chem. 2018, 90, 4249–4257. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liebisch, G.; Vizcaino, J.A.; Kofeler, H.; Trotzmuller, M.; Griffiths, W.J.; Schmitz, G.; Spener, F.; Wakelam, M.J. Shorthand notation for lipid structures derived from mass spectrometry. J. Lipid Res. 2013, 54, 1523–1530. [Google Scholar] [CrossRef] [Green Version]
- Paglia, G.; Astarita, G. Metabolomics and lipidomics using traveling-wave ion mobility mass spectrometry. Nat. Protoc. 2017, 12, 797–813. [Google Scholar] [CrossRef]
- Danne-Rasche, N.; Coman, C.; Ahrends, R. Nano-LC/NSI MS Refines Lipidomics by Enhancing Lipid Coverage, Measurement Sensitivity, and Linear Dynamic Range. Anal. Chem. 2018, 90, 8093–8101. [Google Scholar] [CrossRef]
- Bang, D.Y.; Jeong Ahn, E.; Moon, M.H. Shotgun analysis of phospholipids from mouse liver and brain by nanoflow liquid chromatography/tandem mass spectrometry. J. Chromatogr. B 2007, 852, 268–277. [Google Scholar] [CrossRef] [PubMed]
- Kosicek, M.; Kirsch, S.; Bene, R.; Trkanjec, Z.; Titlic, M.; Bindila, L.; Katalinic, J.P.; Hecimovic, S. Nano-HPLC–MS analysis of phospholipids in cerebrospinal fluid of Alzheimer’s disease patients—A pilot study. Anal. Bioanal. Chem. 2010, 398, 2929–2937. [Google Scholar] [CrossRef] [PubMed]
- Kappler, L.; Lehmann, R. Mass-spectrometric multi-omics linked to function -State-of-the-art investigations of mitochondria in systems medicine. TrAC Trends Anal Chem. 2019, 119, 115635. [Google Scholar] [CrossRef]
- Folch, J.; Lees, M.; Sloane Stanley, G.H. A simple method for the isolation and purification of total lipides from animal tissues. J. Biol. Chem. 1957, 226, 497–509. [Google Scholar] [CrossRef]
- Zardini Buzatto, A.; Kwon, B.K.; Li, L. Development of a NanoLC-MS workflow for high-sensitivity global lipidomic analysis. Anal. Chim. Acta 2020, 1139, 88–99. [Google Scholar] [CrossRef]
- Lipidomics Standards Initiative. Available online: https://lipidomics-standards-initiative.org/ (accessed on 18 August 2021).
- Wang, M.; Wang, C.; Han, X. Selection of internal standards for accurate quantification of complex lipid species in biological extracts by electrospray ionization mass spectrometry-What, how and why? Mass Spectrom. Rev. 2017, 36, 693–714. [Google Scholar] [CrossRef] [Green Version]
- Laaksonen, R.; Katajamaa, M.; Paiva, H.; Sysi-Aho, M.; Saarinen, L.; Junni, P.; Lutjohann, D.; Smet, J.; Van Coster, R.; Seppanen-Laakso, T.; et al. A systems biology strategy reveals biological pathways and plasma biomarker candidates for potentially toxic statin-induced changes in muscle. PLoS ONE 2006, 1, e97. [Google Scholar] [CrossRef]
- Cajka, T.; Fiehn, O. Increasing lipidomic coverage by selecting optimal mobile-phase modifiers in LC–MS of blood plasma. Metabolomics 2016, 12, 34. [Google Scholar] [CrossRef]
- Züllig, T.; Trötzmüller, M.; Köfeler, H.C. Lipidomics from sample preparation to data analysis: A primer. Anal. Bioanal. Chem. 2020, 412, 2191–2209. [Google Scholar] [CrossRef] [Green Version]
- Surma, M.A.; Gerl, M.J.; Herzog, R.; Helppi, J.; Simons, K.; Klose, C. Flexibility of a mammalian lipidome—insights from mouse lipid omics. BioRxiv 2021. [Google Scholar] [CrossRef]
- Grzybek, M.; Palladini, A.; Alexaki, V.I.; Surma, M.A.; Simons, K.; Chavakis, T.; Klose, C.; Coskun, Ü. Comprehensive and quantitative analysis of white and brown adipose tissue by shotgun lipidomics. Mol. Metab. 2019, 22, 12–20. [Google Scholar] [CrossRef]
- Eggers, L.F.; Schwudke, D. Liquid Extraction: Folch. In Encyclopedia of Lipidomics; Wenk, M.R., Ed.; Springer: Dordrecht, The Netherlands, 2016; pp. 1–6. [Google Scholar]
- Matafora, V.; Corno, A.; Ciliberto, A.; Bachi, A. Missing Value Monitoring Enhances the Robustness in Proteomics Quantitation. J. Proteome Res. 2017, 16, 1719–1727. [Google Scholar] [CrossRef] [PubMed]
- Martano, G.; Leone, M.; D’Oro, P.; Matafora, V.; Cattaneo, A.; Masseroli, M.; Bachi, A. SMfinder: Small Molecules Finder for Metabolomics and Lipidomics Analysis. Anal. Chem. 2020, 92, 8874–8882. [Google Scholar] [CrossRef]
- Kidiyoor, G.R.; Li, Q.; Bastianello, G.; Bruhn, C.; Giovannetti, I.; Mohamood, A.; Beznoussenko, G.V.; Mironov, A.; Raab, M.; Piel, M.; et al. ATR is essential for preservation of cell mechanics and nuclear integrity during interstitial migration. Nat. Commun. 2020, 11, 4828. [Google Scholar] [CrossRef]
- Mangiameli, E.; Cecchele, A.; Morena, F.; Sanvito, F.; Matafora, V.; Cattaneo, A.; Volpe, L.D.; Gnani, D.; Paulis, M.; Susani, L.; et al. Human iPSC-based neurodevelopmental models of globoid cell leukodystrophy uncover patient- and cell type-specific disease phenotypes. Stem. Cell Rep. 2021, 16, 1478–1495. [Google Scholar] [CrossRef] [PubMed]
- Shen, S.; Yang, L.; Li, L.; Bai, Y.; Liu, H. Lipid metabolism in mouse embryonic fibroblast cells in response to autophagy induced by nutrient stress. Anal. Chim. Acta 2018, 1037, 75–86. [Google Scholar] [CrossRef]
- Kiamehr, M.; Viiri, L.E.; Vihervaara, T.; Koistinen, K.M.; Hilvo, M.; Ekroos, K.; Kakela, R.; Aalto-Setala, K. Lipidomic profiling of patient-specific iPSC-derived hepatocyte-like cells. Dis. Models Mech. 2017, 10, 1141–1153. [Google Scholar] [CrossRef] [Green Version]
- Astarita, G.; Ollero, M. Lipidomics: An Evolving Discipline in Molecular Sciences. Int. J. Mol. Sci. 2015, 16, 7748–7752. [Google Scholar] [CrossRef] [Green Version]
- Aldana, J.; Romero-Otero, A.; Cala, M.P. Exploring the Lipidome: Current Lipid Extraction Techniques for Mass Spectrometry Analysis. Metabolites 2020, 10, 231. [Google Scholar] [CrossRef]
- Vasilopoulou, C.G.; Sulek, K.; Brunner, A.D.; Meitei, N.S.; Schweiger-Hufnagel, U.; Meyer, S.W.; Barsch, A.; Mann, M.; Meier, F. Trapped ion mobility spectrometry and PASEF enable in-depth lipidomics from minimal sample amounts. Nat. Commun. 2020, 11, 331. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- LION/Web|Lipid Ontology Enrichment Analysis. Available online: http://www.lipidontology.com/ (accessed on 15 June 2021).
- The Human Metabolome Database. Available online: https://hmdb.ca/ (accessed on 10 October 2020).
- MoNA-MassBank of North America. Available online: https://mona.fiehnlab.ucdavis.edu/ (accessed on 10 October 2020).
- UCDAVIS Fienh Lab. Available online: https://fiehnlab.ucdavis.edu/projects/LipidBlast (accessed on 10 October 2020).
- Metlin-Scripps Research. Available online: http://metlin.scripps.edu (accessed on 10 October 2020).
- SMfinder-IFOM. Available online: https://www.ifom.eu/SMfinder/library.php (accessed on 15 September 2021).
- Danne-Rasche, N.; Rubenzucker, S.; Ahrends, R. Uncovering the complexity of the yeast lipidome by means of nLC/NSI-MS/MS. Anal. Chim. Acta 2020, 1140, 199–209. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Subclass | Species | Concentration |
|---|---|---|---|
| Glycero-Phospholipids | PG | PG 12:0/13:0 | 7.5 pmol |
| PI | PI 12:0/13:0 | 54 pmol | |
| PE | PE 12:0/13:0 | 52 pmol | |
| PS | PS 12:0/13:0 | 43 pmol | |
| PC | PC 12:0/13:0, | 40 pmol | |
| Sphingolipids | CER | Ceramide d18:1/25:0 | 100 pmol |
| GlcCer | GalCer d18:1/12:0 | 50 pmol | |
| LacCer | LacCer d18:1/12:0 | 50 pmol | |
| Sa | Sphinganine (d17:0) | 50 pmol | |
| S | Sphingosine (d17:1) | 50 pmol | |
| S1P | Sphingosine-1-P (d17:1) | 100 pmol | |
| GalSph | Galactosyl(s) Sphingosine-d5 | 20 pmol | |
| Glycerolipids | DAG | D5-DAG ISTD Mix I | 20 pmol |
| TAG | D5-TAG ISTD Mix I | 20 pmol | |
| Sterol Lipids | Chol | Chol-d7 | 800 pmol |
| CE | CE (19:0) | 100 pmol |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cattaneo, A.; Martano, G.; Restuccia, U.; Tronci, L.; Bianchi, M.; Bachi, A.; Matafora, V. Opti-nQL: An Optimized, Versatile and Sensitive Nano-LC Method for MS-Based Lipidomics Analysis. Metabolites 2021, 11, 720. https://0-doi-org.brum.beds.ac.uk/10.3390/metabo11110720
Cattaneo A, Martano G, Restuccia U, Tronci L, Bianchi M, Bachi A, Matafora V. Opti-nQL: An Optimized, Versatile and Sensitive Nano-LC Method for MS-Based Lipidomics Analysis. Metabolites. 2021; 11(11):720. https://0-doi-org.brum.beds.ac.uk/10.3390/metabo11110720
Chicago/Turabian StyleCattaneo, Angela, Giuseppe Martano, Umberto Restuccia, Laura Tronci, Michele Bianchi, Angela Bachi, and Vittoria Matafora. 2021. "Opti-nQL: An Optimized, Versatile and Sensitive Nano-LC Method for MS-Based Lipidomics Analysis" Metabolites 11, no. 11: 720. https://0-doi-org.brum.beds.ac.uk/10.3390/metabo11110720