
High-Efficiency Parallel Cryptographic Accelerator for Real-Time Guaranteeing Dynamic Data Security in Embedded Systems


Abstract
:1. Introduction
- An optimal four-parallel AES-GCM hardware architecture is constructed to provide confidentiality and integrity protections for the data at run-time, any unauthorized changes of ciphertext and signature in memory will be detected by authenticating the integrity Tag.
- The dynamic encryption mechanism is achieved according to the D-Cache hit status for the purpose of significantly reducing the system performance overhead induced by cryptographic accelerator.
- Evaluation experiments of four-parallel cryptographic accelerator in terms of performance overhead, security capability, processing efficiency, and resource consumption confirm the SoC effectiveness against external physical attacks and reaches a good trade-off between security capability and hardware overhead.
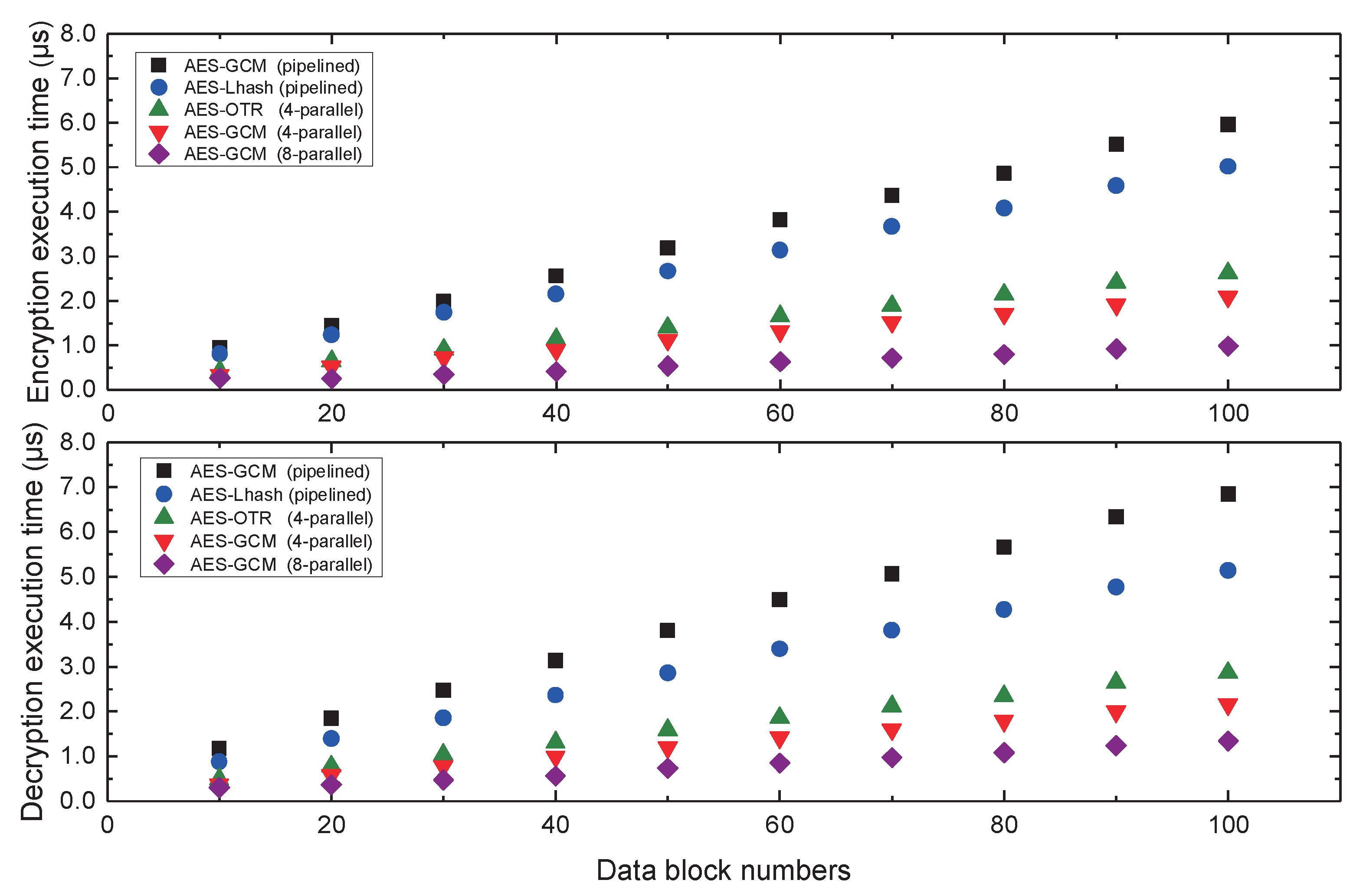
- The four-parallel hardware accelerator is around 3 times as the pipelined AES-GCM contruction in data encryption efficiency, which will further help reducing performance overhead in encryption and integrity authentication.
2. Assumptions and Threat Model
3. Preliminaries
3.1. Security Policies against Sensitive Information Leakages
3.1.1. Confidentiality Protection Scheme
3.1.2. Integrity Protection Scheme
3.1.3. Authentication of Data Signature
3.2. Data Tampering Attacks on External Main Memory
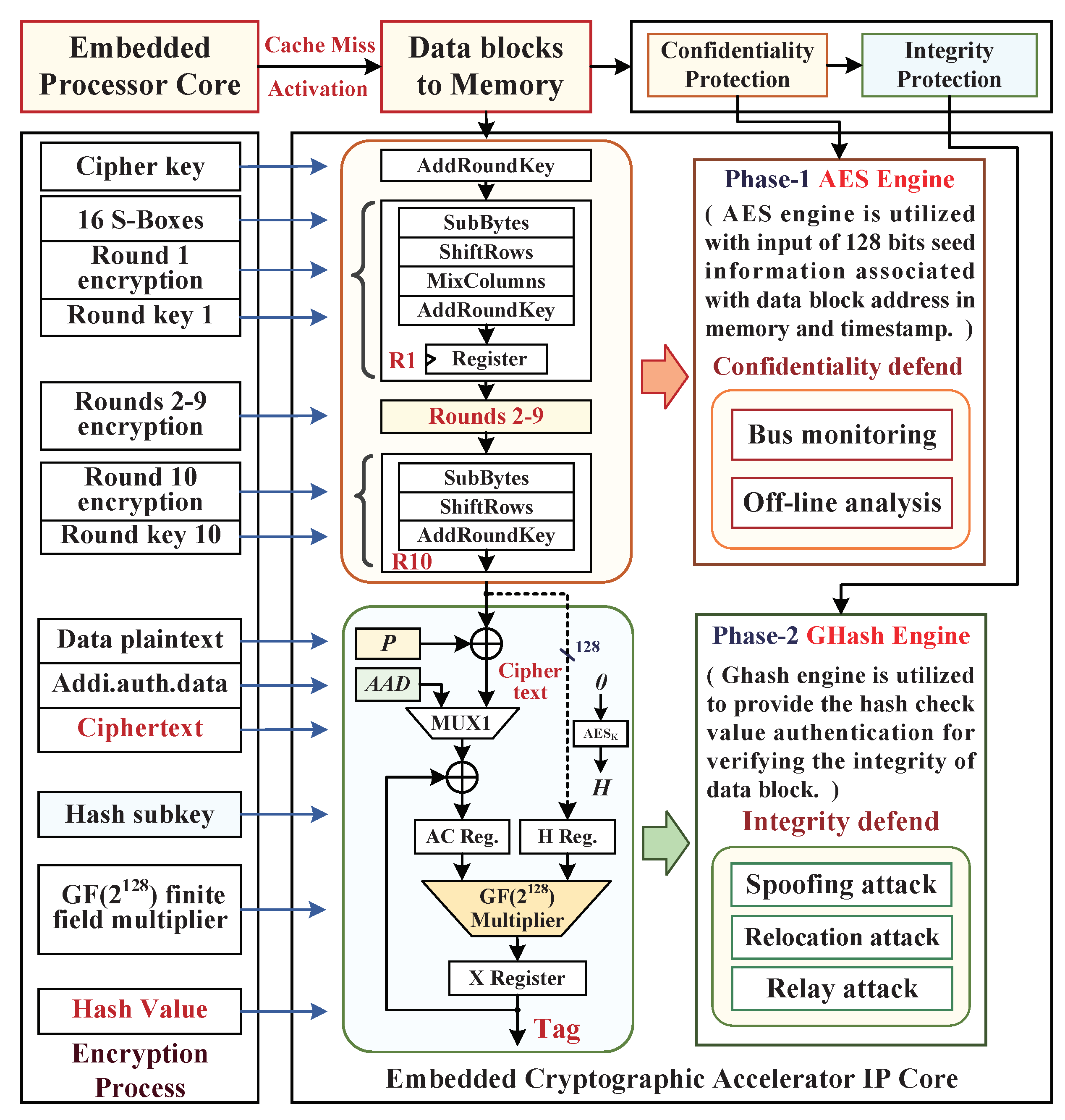
3.3. AES-GCM Model and Activated Mechanism
4. Parallel Hardware Architecture Based on AES-GCM
4.1. Hardware Multiplexing Structure of AES Encryption
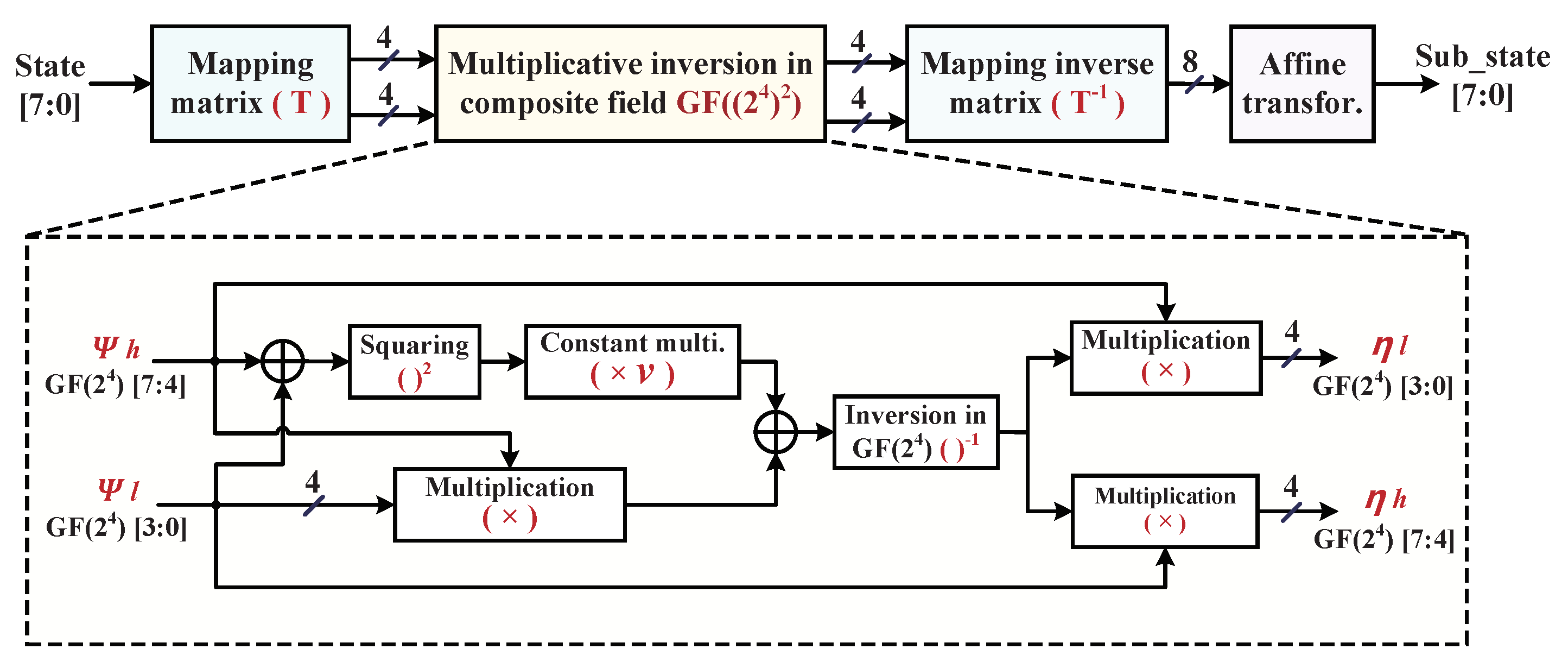
4.2. Optimized Composite Field Implementation of S-Boxes
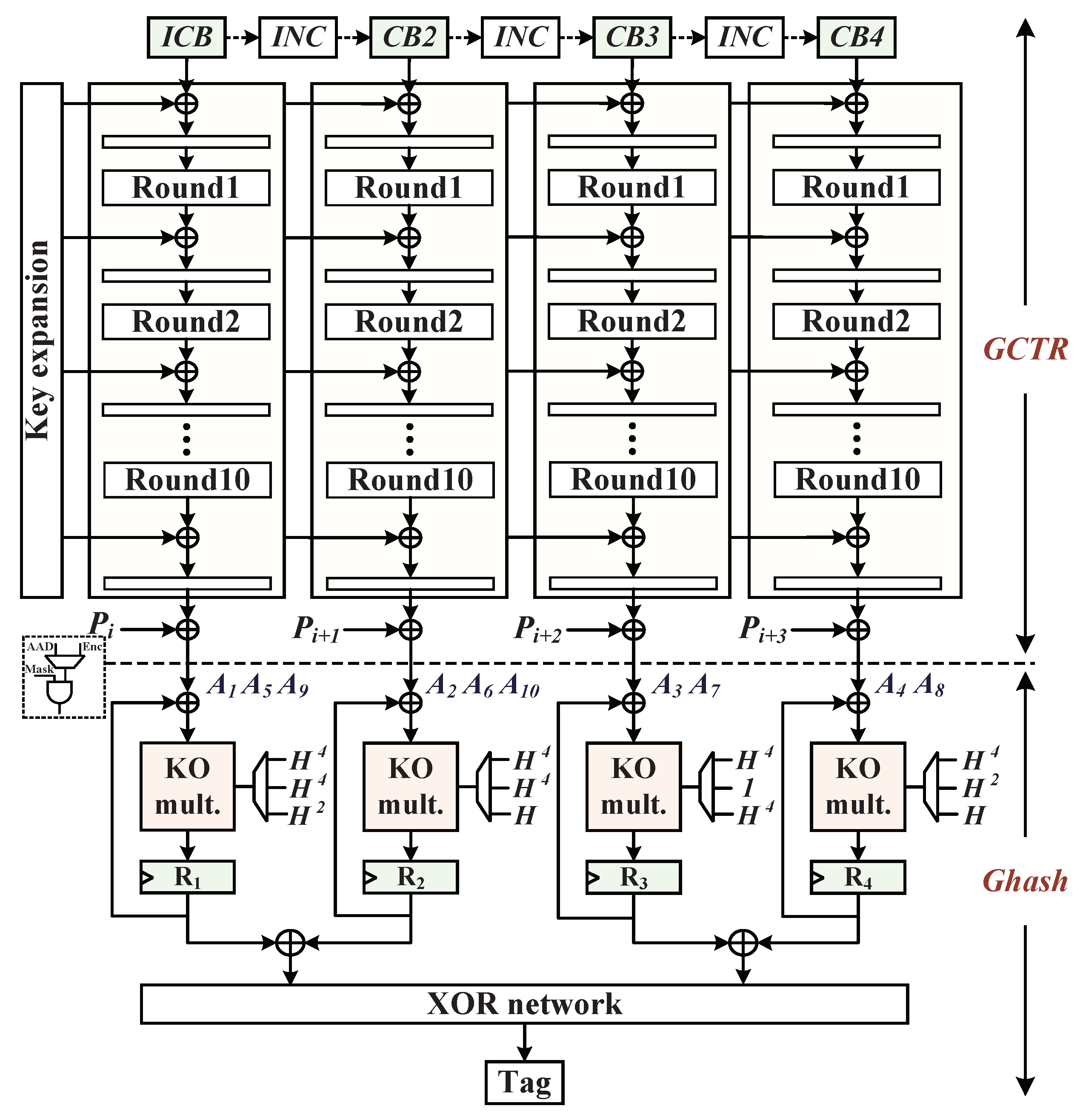
4.3. Multiplier Implementation of Galois Hash
4.4. AES-GCM Parallel Architecture Mechanism
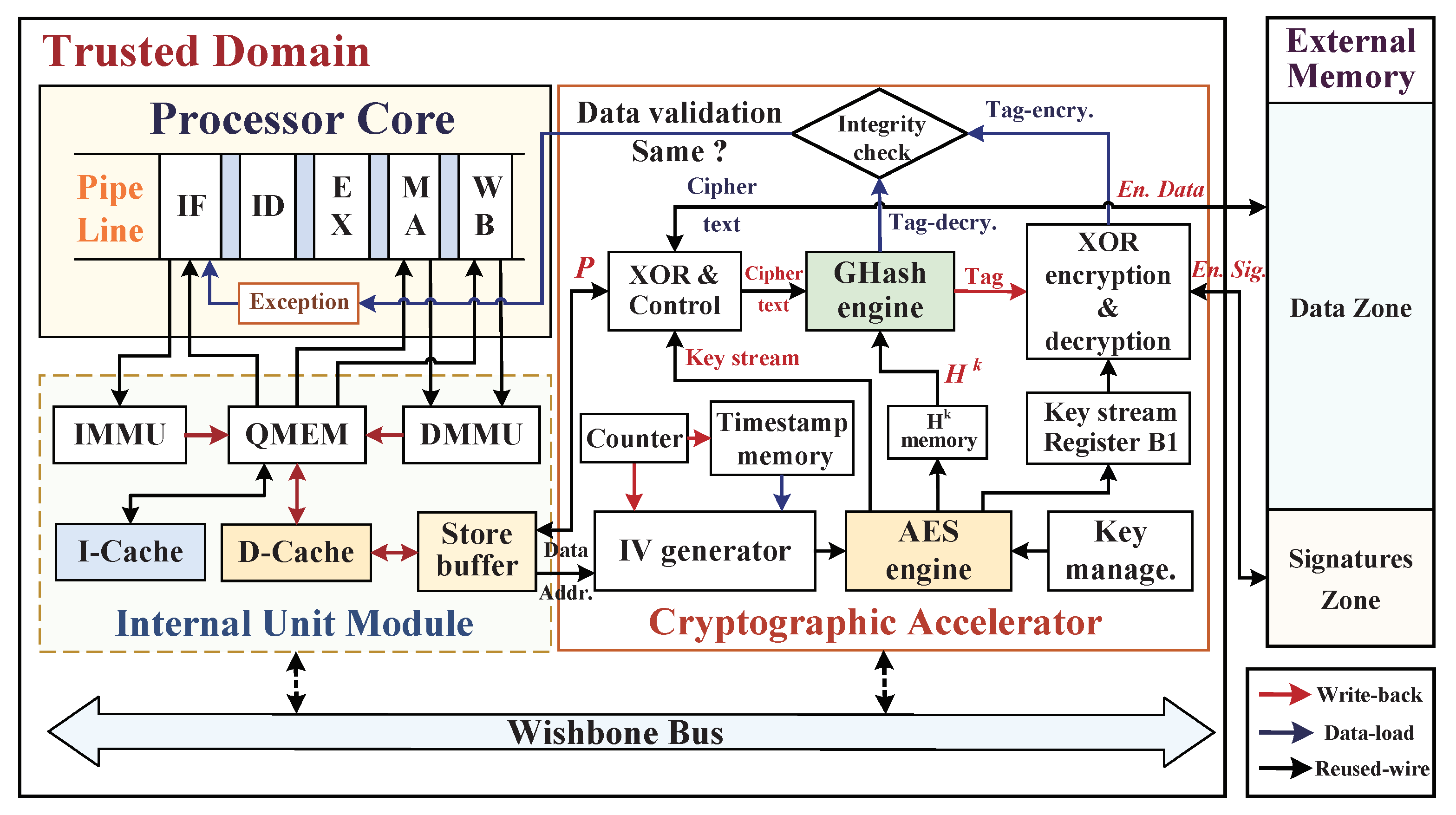
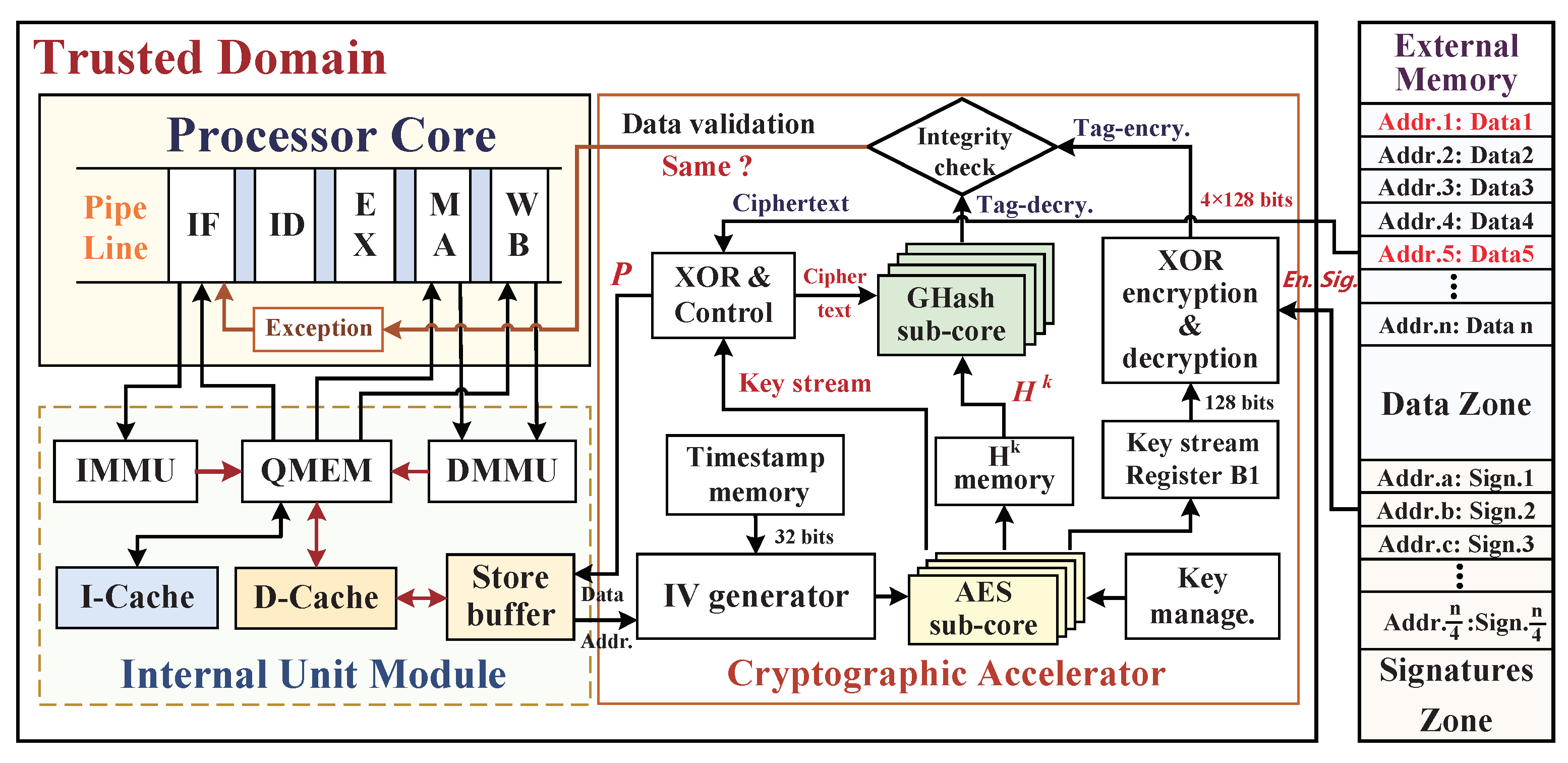
5. SoC Architecture against External Physical Attacks
5.1. Embedded System Architecture for Security Monitoring
5.2. Data Blocks Write-Back Procedure of Memory Access
5.2.1. Hash Subkey Pre-Calculation
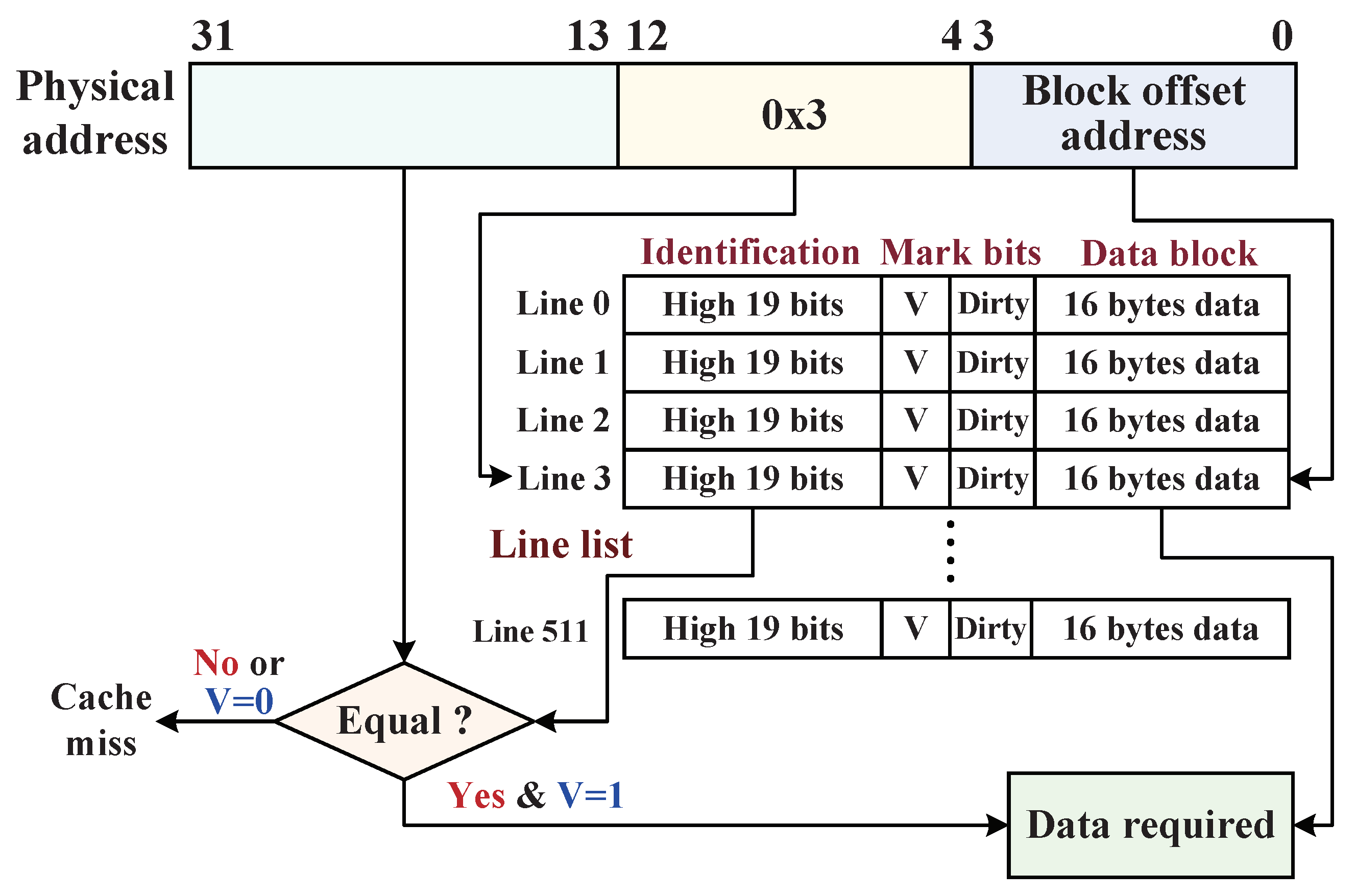
5.2.2. Dynamic Monitoring Mechanism with D-Cache
5.2.3. Write-Back Procedure of D-Cache Data Blocks
| Algorithm 1 Write-back operation of data blocks being stored into external main memory |
| Inputs:Data, Address |
| Outputs:Timestamps, Ciphertext, Signature |
| 1: Data ← set of data blocks to write back , . |
| 2: address ← set of memory physical , . |
| 3: pre-calculation H = , squaring operations, hash subkeys 1, H, , are pre-stored in memory; |
| 4: D-Cache miss, mapping address to physical address; |
| 5: begin inputting four physical address blocks, counter generates timestamps (Ts), Ts++, are stored in Ts memory; |
| 6: IV_seed = {address [127:96], , timestamp [31:0]}; |
| 7: repeat: the four IV seed blocks are generated; |
| 8: Using AES engine to generate key_stream, and storing the first block key_stream_B1 in register B1; |
| 9: Ciphertext = Data XOR key_stream, then input ciphertext blocks to the GHash engine; |
| 10: output: ciphertext blocks at another branch path are stored into the data zone of external memory; |
| 11: until ciphertext blocks are computed in the GHash engine, signature = Tag XOR key_stream_B1; |
| 12: output: integrity digital signature is stored into the signatures zone of external memory; |
5.3. Data Blocks Read-Load Procedure of Memory Access
| Algorithm 2 Data-load operation with hardware security checking from external memory |
| Inputs:Address, Ciphertext, Signature |
| Outputs:Data, Exception |
| 1: Data ← set of data blocks to write back , . |
| 2: signature ← Integrity set of data blocks and corresponding addresses, . |
| 3: assert the target address, map address to physical address; |
| 4: assign ← , i = 1, i++, , |
| signature ← , where ; |
| 5: Input four physical address blocks and a corresponding signature to cryptographic accelerator; |
| 6: begin timestamps memory pops four timestamps, Ts++; |
| 7: IV_seed = {address [127:96], , timestamp [31:0]}; |
| 8: repeat: the four IV seed blocks are generated; |
| 9: Using AES engine to generate key_stream, and storing the first block key_stream_B1 in register B1; |
| 10: Data = Ciphertext XOR key_stream, then Ciphertext = Data XOR key_stream input to the GHash engine; |
| 11: until ciphertext blocks are computed in the GHash engine, the authenticated Tag of Tag-decry. is output; |
| 12: Tag-encry. = Signature XOR key_stream_B1 |
| 13: if Tag-decry. = Tag-encry. then |
| Exception = NULL /* integrity valid */ |
| else Exception = assertion; /* integrity invalid */ |
6. Experiments and Results
6.1. Experimental Setup
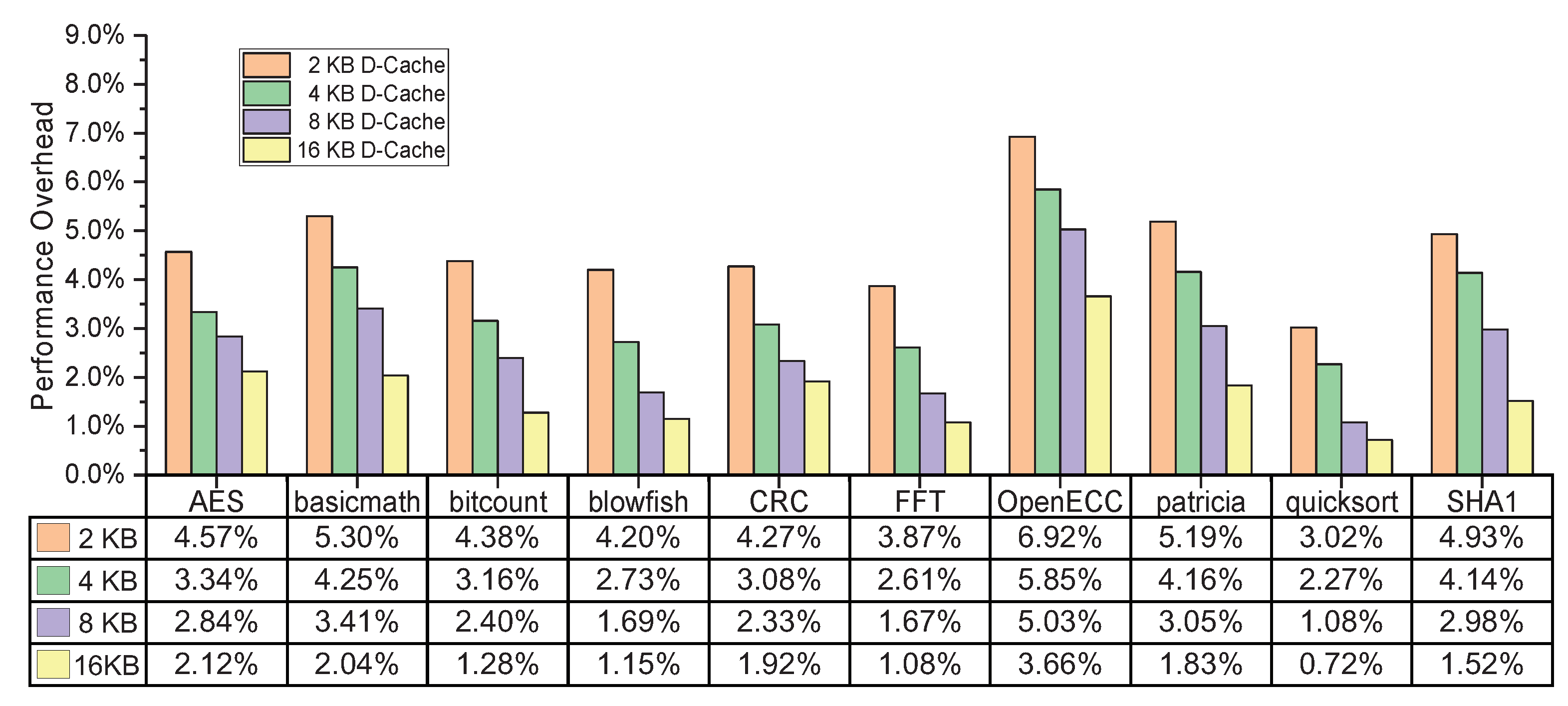
6.2. Performance Overhead Evaluation
6.3. Security Capability Evaluation
6.4. Efficiency Evaluation of Encryption and Decryption
6.5. Hardware Implementation Overhead
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ray, S.; Peeters, E.; Tehranipoor, M.M.; Bhunia, S. System-on-chip platform security assurance: Architecture and validation. Proc. IEEE 2018, 106, 21–37. [Google Scholar] [CrossRef]
- Basak, A.; Bhunia, S.; Tkacik, T.; Ray, S. Security assurance for system-on-chip designs with untrusted IPs. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1515–1528. [Google Scholar] [CrossRef]
- Das, S.; Liu, Y.; Zhang, W.; Chandramohan, M. Semantics-based online malware detection: Towards efficient real–time protection against malware. IEEE Trans. Inf. Forensics Secur. 2016, 11, 289–302. [Google Scholar] [CrossRef]
- Chen, Y.; Sun, W.; Zhang, N.; Zheng, Q.; Lou, W.; Hou, Y.T. Towards efficient fine-grained access control and trustworthy data processing for remote monitoring services in IoT. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1830–1842. [Google Scholar] [CrossRef]
- De, A.; Nasim Imtiaz Khan, M.; Nagarajan, K.; Ghosh, S. HarTBleed: Using hardware Trojans for data leakage exploits. IEEE Trans. Very Large Scale Integr. VLSI Syst. 2020, 28, 968–979. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, X.; Hao, Q.; Zhang, Z.; Xu, B.; Dong, H.; Xia, T.; Wang, X. Hardware-enhanced protection for the runtime data security in embedded systems. Electronics 2019, 8, 52. [Google Scholar] [CrossRef] [Green Version]
- Kaji, S.; Kinugawa, M.; Fujimoto, D.; Hayashi, Y. Data injection attack against electronic devices with locally weakened immunity using a hardware Trojan. IEEE Trans. Electromagn. Compat. 2019, 61, 1115–1121. [Google Scholar] [CrossRef]
- Fiskiran, A.M.; Lee, R.B. Runtime execution monitoring (REM) to detect and prevent malicious code execution. In Proceedings of the IEEE International Conference on Computer Design: VLSI in Computers and Processors, San Jose, CA, USA, 11–13 October 2004; pp. 452–457. [Google Scholar]
- Ahn, Y.; Lee, Y.; Choi, J.; Lee, G.; Ahn, D. Monitoring translation lookahead buffers to detect code injection attacks. Computer 2013, 47, 66–72. [Google Scholar] [CrossRef]
- Kanuparthi, A.K.; Karri, R.; Ormazabal, G.; Addepalli, S.K. A high-performance, low-overhead microarchitecture for secure program execution. In Proceedings of the IEEE 30th International Conference on Computer Design (ICCD), Montreal, QC, Canada, 30 September–3 October 2012; pp. 102–107. [Google Scholar]
- Shehab, D.A.; Batarfi, O.A. RCR for preventing stack smashing attacks bypass stack canaries. In Proceedings of the Computing Conference, London, UK, 18–20 July 2017; pp. 795–800. [Google Scholar]
- Lin, H.; Fei, Y.; Guan, X.; Shi, Z.J. Architectural enhancement and system software support for program code integrity monitoring in application-specific instruction-set processors. IEEE Trans. Very Large Scale Integr. VLSI Syst. 2010, 18, 1519–1532. [Google Scholar] [CrossRef]
- Wang, X.; Zhao, Z.; Xu, D.; Zhang, Z.; Hao, Q.; Liu, M. An M-Cachebased security monitoring and fault recovery architecture for embedded processor. IEEE Trans. Very Large Scale Integr. VLSI Syst. 2020, 28, 2314–2327. [Google Scholar] [CrossRef]
- Arora, D.; Ravi, S.; Raghunathan, A.; Jha, N.K. Hardware-assisted run-time monitoring for secure program execution on embedded processors. IEEE Trans. Very Large Scale Integr. VLSI Syst. 2006, 14, 1295–1308. [Google Scholar] [CrossRef]
- Wang, X.; Zhao, Z.; Xu, D.; Zhang, Z.; Hao, Q.; Liu, M.; Si, Y. Two-Stage Checkpoint Based Security Monitoring and Fault Recovery Architecture for Embedded Processor. Electronics 2020, 9, 1165. [Google Scholar] [CrossRef]
- Sen Gupta, S.; Chattopadhyay, A.; Sinha, K.; Maitra, S.; Sinha, B.P. High-performance hardware implementation for RC4 stream cipher. IEEE Trans. Comput. 2013, 62, 730–743. [Google Scholar] [CrossRef]
- Nagar, S.A.; Alshamma, S. High speed implementation of RSA algorithm with modified keys exchange. In Proceedings of the 6th International Conference on Sciences of Electronics, Technologies of Information and Telecommunications (SETIT), Sousse, Tunisia, 21–24 March 2012; pp. 639–642. [Google Scholar]
- Wu, W.; Wu, S.; Zhang, L.; Zou, J.; Dong, L. Lhash: A lightweight hash function. In International Conference on Information Security and Cryptology; Springer: Cham, Switzerland, 2013; pp. 291–308. [Google Scholar]
- Mozaffari-Kermani, M.; Reyhani-Masoleh, A. Efficient and high-performance parallel hardware architectures for the AES-GCM. IEEE Trans. Comput. 2012, 61, 1165–1178. [Google Scholar] [CrossRef]
- Gupta, H.; Mondal, S.; Majumdar, R.; Ghosh, N.S.; Suvra, K.S.; Kwanyu, N.E.; Mishra, V.P. Impact of side channel attack in information security. In Proceedings of the International Conference on Computational Intelligence and Knowledge Economy (ICCIKE), Dubai, United Arab Emirates, 11–12 December 2019; pp. 291–295. [Google Scholar]
- Shan, W.; Fu, X.; Xu, Z. A secure reconfigurable crypto IC with countermeasures against SPA, DPA, and EMA. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2015, 34, 1201–1205. [Google Scholar] [CrossRef]
- Singh, A.; Kar, M.; Mathew, S.; Rajan, A.; De, V.; Mukhopadhyay, S. 25.3 A 128b AES engine with higher resistance to power and electromagnetic side-channel attacks enabled by a security-aware integrated all-digital low-dropout regulator. In Proceedings of the IEEE International Solid- State Circuits Conference—(ISSCC), San Francisco, CA, USA, 17–21 February 2019; pp. 404–406. [Google Scholar]
- Wong, M.M.; Wong, M.L.D.; Nandi, A.K.; Hijazin, I. Construction of optimum composite field architecture for compact high-throughput AES S-Boxes. IEEE Trans. Very Large Scale Integr. VLSI Syst. 2012, 20, 1151–1155. [Google Scholar] [CrossRef]
- Hsiao, S.-F.; Chen, M.-C.; Tu, C.-S. Memory-free low-cost designs of advanced encryption standard using common subexpression elimination for subfunctions in transformations. IEEE Trans. Circuits Syst. I Reg. Pap. 2006, 53, 615–626. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, N.; Zhou, F.; Ge, F. Optimization of area and delay for implementation of the composite field advanced encryption standard S-Box. J. Circuits Syst. Comput. 2016, 25, 1–29. [Google Scholar] [CrossRef]
- Canright, D. A very compact S-Box for AES. In Proceedings of the Int’l Workshop Cryptographic Hardware and Embedded Systems (CHES’05), Edinburgh, UK, 29 August–1 September 2005; pp. 441–455. [Google Scholar]
- Abdulrahman, E.A.H.; Reyhani-Masoleh, A. High-speed hybrid-double multiplication architectures using new serial-out bit-level Mastrovito multipliers. IEEE Trans. Comput. 2016, 65, 1734–1747. [Google Scholar] [CrossRef]
- Zhou, G.; Michalik, H.; Hinsenkamp, L. Complexity analysis and efficient implementations of bit parallel finite field multipliers based on Karatsuba-Ofman algorithm on FPGAs. IEEE Trans. Very Large Scale Integr. VLSI Syst. 2010, 18, 1057–1066. [Google Scholar] [CrossRef]
- Machhout, M.; Zeghid, M.; Bouallegue, B.; Tourki, R. Efficient hardware architecture of recursive Karatsuba-Ofman multiplier. In Proceedings of the 3rd International Conference on Design and Technology of Integrated Systems in Nanoscale Era, Tozeur, Tunisia, 25–27 March 2008; pp. 1–6. [Google Scholar]
- Satoh, A.; Sugawara, T.; Aoki, T. High-performance hardware architectures for Galois Counter Mode. IEEE Trans. Comput. 2009, 58, 917–930. [Google Scholar] [CrossRef]
- Guthaus, M.R.; Ringenberg, J.S.; Ernst, D.; Austin, T.M.; Mudge, T.; Brown, R.B. MiBench: A free, commercially representative embedded benchmark suite. In Proceedings of the 4th Annual IEEE International Workshop Workload Characterization, WWC-4, Austin, TX, USA, 2 December 2001; pp. 3–14. [Google Scholar]
- Bakiri, M.; Titri, S.; Izeboudjen, N.; Abid, F.; Louiz, F.; Lazib, D. Embedded system with Linux Kernel based on OpenRISC 1200-V3. In Proceedings of the International Conference on Sciences of Electronics, Sousse, Tunisia, 21–24 March 2012; pp. 177–182. [Google Scholar]
- Kermani, M.M.; Azarderakhsh, R. Reliable architecture-oblivious error detection schemes for secure cryptographic GCM structures. IEEE Trans. Reliab. 2019, 68, 1347–1355. [Google Scholar] [CrossRef]
- Sung, B.; Kim, K.; Shin, K. An AES-GCM authenticated encryption crypto-core for IoT security. In Proceedings of the 2018 International Conference on Electronics, Information, and Communication (ICEIC), Honolulu, HI, USA, 24–27 January 2018; pp. 1–3. [Google Scholar]
- Wang, X.; Zhou, C.; Pang, S.; Li, M. Hardware assisted protection for data validation at run-time on embedded processors. DEStech Trans. Eng. Technol. Res. 2016, 680–685. [Google Scholar] [CrossRef]
- Ueno, R.; Homma, N.; Iida, T.; Minematsu, K. High throughput/gate FN-based hardware architectures for AES-OTR. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Sapporo, Japan, 26–29 May 2019; pp. 1–4. [Google Scholar]
- Abdellatif, K.M.; Chotin-Avot, R.; Mehrez, H. Improved method for parallel AES-GCM cores using FPGAs. In Proceedings of the 2013 International Conference on Reconfigurable Computing and FPGAs (ReConFig), Cancun, Mexico, 9–11 December 2013; pp. 1–4. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Benchmark | Total Instructions | I-Cache Hit | D-Cache Read Hit | D-Cache Write Hit | CPI without AES-GCM | CPI with AES-GCM | Performance Overhead |
|---|---|---|---|---|---|---|---|
| AES | 22,170 | 98.97% | 99.84% | 99.65% | 3.52 | 3.62 | 2.84% |
| basicmath | 26,515 | 98.08% | 98.63% | 98.57% | 2.64 | 2.73 | 3.41% |
| bitcount | 19,684 | 97.95% | 96.47% | 95.92% | 1.67 | 1.71 | 2.40% |
| blowfish | 19,128 | 97.67% | 97.70% | 97.44% | 3.54 | 3.60 | 1.69% |
| CRC | 18,941 | 99.49% | 98.38% | 97.65% | 1.72 | 1.76 | 2.33% |
| FFT | 13,506 | 95.62% | 98.45% | 98.16% | 2.39 | 2.43 | 1.67% |
| OpenECC | 56,313 | 99.14% | 99.12% | 98.58% | 3.18 | 3.34 | 5.03% |
| patricia | 23,130 | 97.68% | 97.06% | 96.39% | 1.64 | 1.69 | 3.05% |
| quicksort | 6707 | 99.12% | 98.89% | 98.67% | 1.86 | 1.88 | 1.08% |
| SHA1 | 20,455 | 98.65% | 99.32% | 99.21% | 2.35 | 2.42 | 2.98% |
| Average | - | 98.24% | 98.39% | 98.02% | 2.45 | 2.52 | 2.65% |
| Tampering Attacks | Spoofing Attack | Relocation Attack | Replay Attack |
|---|---|---|---|
| Approaches | Write addr.: 0x00002016 Read addr.: 0x00002016 | Write addr.: 0x00002016 Read addr.: 0x00002012 | T8: 32’h2c9340b4 T4: 32’h4f5c1a08 |
| Data Tampering | 32’h68e5a4c5 32’h68e50000 | 32’h364c91f8 32’hf10d4a12 | 32’h2c9340b4 32’h4f5c1a08 |
| Exception | Integrity Error | Integrity Error | Integrity Error |
| Slice Logic Utilization | SoC | Processor Core | AES-GCM |
|---|---|---|---|
| Slice registers | 6518 | 1864 | 4923 |
| Slice LUTs | 16,610 | 5547 | 11,956 |
| Occupied slices | 10,637 | 3262 | 7512 |
| BlockRAM/FIFO | 58 | 13 | 42 |
| BUFG/BUFGCTRLs | 7 | 1 | 3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Wang, X.; Hao, Q.; Xu, D.; Zhang, J.; Liu, J.; Ma, J. High-Efficiency Parallel Cryptographic Accelerator for Real-Time Guaranteeing Dynamic Data Security in Embedded Systems. Micromachines 2021, 12, 560. https://0-doi-org.brum.beds.ac.uk/10.3390/mi12050560
Zhang Z, Wang X, Hao Q, Xu D, Zhang J, Liu J, Ma J. High-Efficiency Parallel Cryptographic Accelerator for Real-Time Guaranteeing Dynamic Data Security in Embedded Systems. Micromachines. 2021; 12(5):560. https://0-doi-org.brum.beds.ac.uk/10.3390/mi12050560
Chicago/Turabian StyleZhang, Zhun, Xiang Wang, Qiang Hao, Dongdong Xu, Jinlei Zhang, Jiakang Liu, and Jinhui Ma. 2021. "High-Efficiency Parallel Cryptographic Accelerator for Real-Time Guaranteeing Dynamic Data Security in Embedded Systems" Micromachines 12, no. 5: 560. https://0-doi-org.brum.beds.ac.uk/10.3390/mi12050560